Replies: 98 comments 254 replies
-
|
Also just at a glance without seeing the current results, you're also going to want to change "style_filewords.txt" to "subject.txt" as TI is training your embedding on prompts such as "a cool painting of [filewords], art by [name]" instead of prompts like "a photo of the [name]" |
Beta Was this translation helpful? Give feedback.
-
|
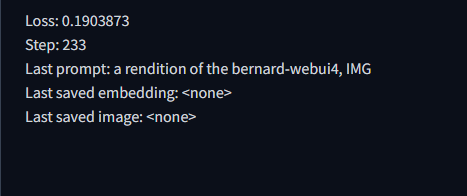
OK... I was noticing some weird "last prompt" that sort of indicate this:
I will try with the other file as you suggested. P.S.: There are no duplicate photos. |
Beta Was this translation helpful? Give feedback.
-
|
Let us know how you get on changing the template! P.S. There was a duplicate screenshot, I saw that you edited it to show the correct picture now though. All good. |
Beta Was this translation helpful? Give feedback.
-
|
After 1000 steps it does not look as bad. I did remove one of the picture that could have possibly induce the "dots". Here it is... maybe it picked the pattern from the background?
|

Beta Was this translation helpful? Give feedback.
-
|
OK... the dots are mostly gone with the subject.txt and the dot inducing photo removed... but not it produce "skeleton" looking image. Nightmare infusing:
I will let it train another 3000 steps and see it things improve |

Beta Was this translation helpful? Give feedback.
-
|
Here is 5000 steps... improving somewhat:
|

Beta Was this translation helpful? Give feedback.
-
|
The 6000 step was not much different from 5000... so TI did not produce a flattering result ;-) It sort of resemble me... but not really. More like what I might look like in 20 years... |
Beta Was this translation helpful? Give feedback.
-
|
Just for you know (if not already) this is not like Dreambooth, inversion is totally different. |
Beta Was this translation helpful? Give feedback.
-
Well, we have 1 already: #1536 The thing is how to get the CKPT... And Dreambooth takes a lot less time to train it with a few images. |
Beta Was this translation helpful? Give feedback.
-
This is the issue with those "Diffuser" based solution. They work with way less RAM... but produce gigantic 12Ggb diffuser models instead of tight 2gb ckpt models. |
Beta Was this translation helpful? Give feedback.
-
|
https://github.com/JoePenna/Dreambooth-Stable-Diffusion |
Beta Was this translation helpful? Give feedback.
-
that guy does everything. what the hell. so he made dreambooth locally that behaves just like the web version? |
Beta Was this translation helpful? Give feedback.
-
whats the difference actually? |
Beta Was this translation helpful? Give feedback.
-
|
Something I tried and that did not lead to success. I renamed all the pictures with a description of the scene hoping it would help with the learning... to the contrary... when using those it actually started to diverge... interesting... Names like:
|
Beta Was this translation helpful? Give feedback.
-
|
I had better luck using captions than not. But the thing is you should use the preprocess caption or use img2img interrogate so it can identify tokens that are prevalent in the image. Then just fix the text it gives you if it's wrong. A bit more work, but it quickly eliminated things that it wasn't supposed to learn from my dataset, like outfits, glasses, backgrounds, etc. |
Beta Was this translation helpful? Give feedback.
-
|
I can confirm what OP observed that TI makes me look at least 20 years older (also adding weird grey sweater and a glasses, none of which were present on the training photo set). HOWEVER it's possible to remediate this by using negative prompts! In my case something like: ((poorly drawn face)), ((ugly)), ((ugly face)), ((glasses)), (((old man))), (bald man) works very well immediately producing results of me looking much more like on the training set of photos. |
Beta Was this translation helpful? Give feedback.
-
|
I don't understand why it generates a second person? The test subject was cut from photos, and I tried photos where only he is visible, or I cut the other person out of the picture. Still it detects it, and after the training I can hardly generate a picture where he is alone, he always appears twice in the picture (sometimes where he is both male and female). |
Beta Was this translation helpful? Give feedback.
-
|
Because algorithm detected that there is another person even if you cropped from the photo - on some of my pics I had super blurry car in the background, yet both BLIP Interrogator (picture preparation) and textual-inversion (which uses CLIP I believe?) detected it and the subject in most cases had some car in the background as well. When I used some conference photo with super blurry people behind me (even if it was just a single picture in the batch of like 10 pics) - same behaviour - almost all generations had additional persons. And on another picture I had somebody's ear on the pic - and it still detected it as another subject. So it's pretty hard to select pics which won't introduce features that will cause the model to fixate on them. Also you can't really just crop your face from the pics because I find - all generated images will look bland then - you need to have some stuff going on in the background to generate a noise but ideally it shouldn't be recognizable by the algorithm. Also number of learning steps matters (too high doesn't mean better), learning rate (again, too low doesn't mean better) and especially number of vectors per token (again can't be too high - ideally under 10). |
Beta Was this translation helpful? Give feedback.
-
|
To my experience so far, that happens when the embedding is dead. I've been trying some aggressive learning rates to train characters and a lot of them ended showing copies of the character side by side. I had to ditch the embedding and start over with a lower learning rate. |
Beta Was this translation helpful? Give feedback.
-
|
I left it at the default learning rate, and by filtering out the extra people in the photos, I minimized the number of duplicates. However, it always generated two persons during training, so my guess is that a new textual inversion template list is needed to learn the persons. Could it be that the list is causing duplication? |
Beta Was this translation helpful? Give feedback.
-
|
Now I use the trick of ticking add caption first during the preprocess. Then I see what he sees textually. If I see something in the text that refers to something else (like two women or two men), I delete that source. After I clean up the sources, I regenerate the patterns and then edit, using only subject.txt. In principle, this should be fine. |
Beta Was this translation helpful? Give feedback.
-
|
Yes, that's a good method. |
Beta Was this translation helpful? Give feedback.
-
|
Frustrated - Have a training that looks (by the example output pics it makes while building) like it's going well - the pics its generating look very usable. Excited to try them I start some prompts - simple ones - a photo of embedname1 looking at the camera - Any help appreciated - feel like I'm so close! Thanks to everyone helping out here - amazing |
Beta Was this translation helpful? Give feedback.
-
|
My most effective way to train textual-inversion to reproduce people faces is (I learned it using the same set of images gradually removing the pics which screwed up the embedding and re-trained over and over again for like 20 times): 4-8 good photos of the HEAD - pics need to be evenly lit, no dramatic contrast, no over/under exposure, sharp, no unnecessary body parts (ie. hand touching face), no dramatic angle changes - ie. one pic of the side of the face, and one mugshot-like, different expressions are fine, no additional content in the background (even when it's very blurry) unless it's something pretty neutral like a landscape or plants (although I had some leaves on some of my pics and it liked to add a very nice although very unrealistic green wall on some generations). Vectors per token set to 6 OR LESS. Learning rate - default 0,005 (may be slightly lower, although it should need more steps I guess) Steps - 8000 Photos pre-prepared with description in the filename (I verify what the model recognized in the pics to remove pics which will potentially contain stuff which will skew the embedding, and correct them by hand if necessary). I use subject_filewords.txt or my own person_filewords.txt template (although I didn't observed dramatic changes in the embedding quality, nor when I was using subject.txt). This way the results are very satisfying with some 'meh' results from time to time. For me the biggest issue is that it's not clearly documented (or maybe it is but it's in some scientific paper which is simply TL;DR for most of us?) how the different parameters (beside the vectors per token which is pretty obvious) influence the final results - ie. what's more important - the template or the CLIP recognition during training? How learning rate should be scaled according to number of images and learning steps? And so on... Some of the images generated using an embedding trained on the pics of my ugly face (and I must say these are super accurate - 10/10 people instantly recognized that it's my face although they certainly went through a very uncanny valley looking at them): |
Beta Was this translation helpful? Give feedback.
-
|
I also miss the documentation (as well as the word list for SD, what words it knows), and it takes several days to figure out how to work it. The technical explanation doesn't tell me much, like reading a description of the screws and gears and belt drive of a washing machine to be able to do the washing. |
Beta Was this translation helpful? Give feedback.
-
|
This number of images may be simply to high. There is a reason why several guides tell that 3-5 images is optimal number and with higher number of pictures model may have a problem to converge. |
Beta Was this translation helpful? Give feedback.
-
|
Still in training, but the FaceSwap trick seems to have worked:
So far it really only generates unique images, and you can recognize the person at the 3000th step. Update 1: Apparently 10000 wasn't enough, because although it's very similar, it's not the right one, so I'll train up to 20000 |
Beta Was this translation helpful? Give feedback.
-
|
I finally stopped at 30,000, but took pictures with the same seed at 10, 20 and 30,000 saves. There were some interesting differences between them, sometimes the smaller model was better, sometimes the larger |
Beta Was this translation helpful? Give feedback.
-
|
Can you show some examples? |
Beta Was this translation helpful? Give feedback.
-
|
Now I see that the older model has been hardened up to 30000, the newer ones only up to 20. But I'll look at samples as soon as my machine is free :) |
Beta Was this translation helpful? Give feedback.
-
|
Here is a very interesting result. I used the same prompt and parameters. Although the face is of similar quality, the composition is different (apart from the double headshot).
|



Beta Was this translation helpful? Give feedback.
-
At 10000, it looks like it will reach a state where you can work with it. When mixing full shape and face models, this is how I use the prompt when generating: |
Beta Was this translation helpful? Give feedback.
-
|
In the new versions, you can train for more than just square image sizes! I am very curious to see what the final results will be! |
Beta Was this translation helpful? Give feedback.
-
|
Is there any reason why there is not implemented the ability to increase batch size or set the gradient accumulation? |
Beta Was this translation helpful? Give feedback.
-
|
Batch size seems to be added now. I've been thinking about how to implement gradient accumulation since I had much better results with it in lstein's repo, and if I understand it correctly, it might be as simple as just averaging losses over the last n iterations (which would be easy with the last 32 losses already stored), and only calling loss.backward and optimizer.step every n steps (plus making sure it's called on the last iteration if the training data size doesn't neatly divide by the accumulation size). |
Beta Was this translation helpful? Give feedback.
-
|
How can I rename the initialization text? I seem to have run into a more familiar word, and txt2img doesn't generate what it should after loading. Or it has been fooled by deepbooru. It seems I should only teach with BLIP, or if I taught with deepbooru in addition to BLIP, I should generate the image with deepbooru. |
Beta Was this translation helpful? Give feedback.
-
|
I'm wondering how much of a problem it is to train for both BLIP and deepbooru text at the same time. So does it handle if both are included in the prompt or should only one be? I'm wondering because if I only train on deepbooru, could it be a problem for those who don't use it? Is subject_filewords.txt good for deepbooru training? I'm going to try it out on a train today. Update: I found this description on the wiki, and I'm starting the training with deepbooru only. What already seems like a good tip: replace underscores with spaces, skip the abc sequence and enable Unload VAE. Even though this is for hypernetwork, I already get better quality output with the settings in the pictures for TI. |
Beta Was this translation helpful? Give feedback.
-
|
What seems certain now is that you need to train for [name], [filewords], so you need to put that in the .txt template, in the first line. If this is left out, you can only get a good result for the word relations, otherwise the result will be a big mess. |
Beta Was this translation helpful? Give feedback.
-
|
Let's say I want to train on a new concept that wasn't in SD before (water polo, for example). I'll hyphenate it: water-polo |
Beta Was this translation helpful? Give feedback.
-
|
What I just noticed is that when switching epochs (number of frames x 100 /adjustable in settings/) it seems to restart the workout. |
Beta Was this translation helpful? Give feedback.
-
|
What I don't understand is where are the training steps stored? I mean the counter, because I wanted to go back from 5000 to 4000, and I put the save back in the embedding folder and then deleted the 4500 and 5000 saves, but the workout resumed after 5000. Which parameter did I not reset? |
Beta Was this translation helpful? Give feedback.
-
|
What I have experienced so far:
|
Beta Was this translation helpful? Give feedback.
-
|
Apparently I need the [name] too, because after 16000 steps just generating an image for the name creates some huge mess. I edited the previous post. |
Beta Was this translation helpful? Give feedback.
-
|
I found this trick on Reddit, and the manual learning rate tuning seems to work well. If you sample a lot of images at quite high values, you can set the limits quite well. I'm trying it now, going up to 500 steps first, and with high values: |
Beta Was this translation helpful? Give feedback.
-
|
There is a bigger problem with the training. It's useless to try to give you concepts and words to help you understand better if you don't know a word or two. For example, you certainly don't know the concept of alohomora, but surprisingly you don't know that the body leans forward. If I type in one of the key words on its own, it will tell you straight away whether we meant the same thing or not. So before training, every keyword should be checked in the txt2img sheet to see if it is even known by SD. |
Beta Was this translation helpful? Give feedback.
-
They are if you are using models specifically trained for this (with training set containing proper descriptions). While LAION contains some NSFW content I doubt it's descriptions are very detailed when it comes to stuff like this. |
Beta Was this translation helpful? Give feedback.
-
|
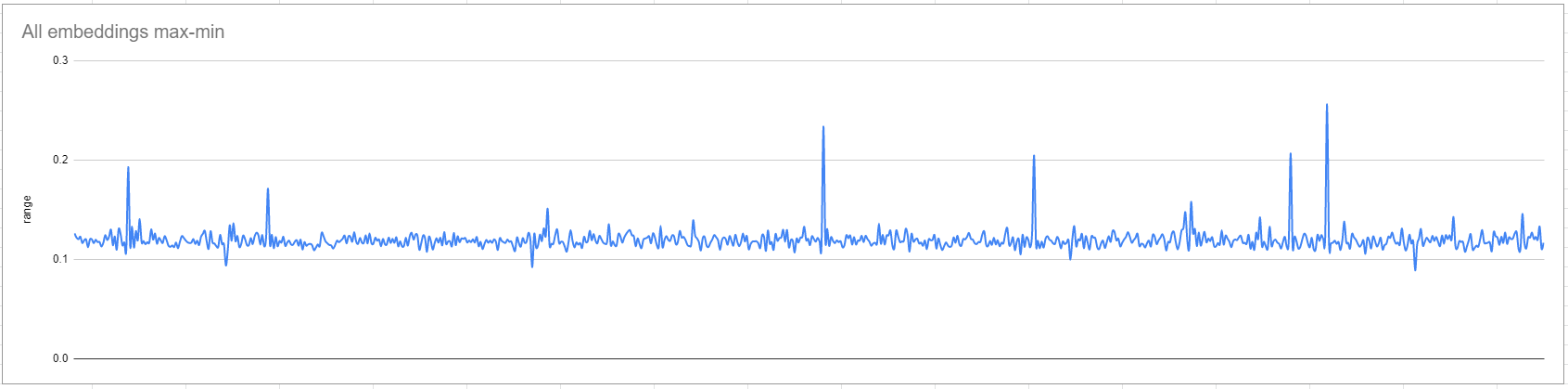
For what it's worth, I did a query on all the original embeddings for every CLIP token (0 to 49405 which I'm fairly sure is the range), and this is the max-min values range for the 768 weights in all the original embedding vectors. I'm not sure if it can be used to determine the best learning rate, but most of the original weight only vary by about 0.12 at the very most.
Automatic also helped me write some code on discord to increase the error the more that an embedding moves outside of the range of the original embeddings, since the author of the textual inversion paper mentioned that embeddings would be expected to be less editable and play less nicely with other parts of the prompt if they move outside of the original distribution which the model was trained on. I've implemented the changes in the latest 3 commits to this fork, and it looks like it should still be doable to just paste them into the most recent version: https://github.com/CodeExplode/stable-diffusion-webui-TI-Tests/commits/master The create_embedding method I added in the first commit was wrong and shouldn't be included (I took it out in the second commit) |
Beta Was this translation helpful? Give feedback.
-
|
I would love a graph like that for the loss rates during training. Per image, per step and median rate. |
Beta Was this translation helpful? Give feedback.
-
|
Following the previous measure of the original embedding weight ranges, I've printed out the largest weight change in an embedding each step, and it's pretty much exactly the learning rate (slightly smaller, 3.5 to 4.5e-08 for a LR of 5e-08). So at the very least you'd never want a learning rate as high as 0.1, or it would just be yo-yoing back and forth across the entire plausible range of values. Given that there's about 50k original embeddings, and presuming the range of a weight divides up equally into the number of embeddings to each define a unique point, a learning rate of 0.12/50000 would presumably be needed to land on individual existing embeddings. Dividing that by 10 again would let you do 10 steps between each embedding position (though I suspect the weights are more concentrated into clusters). So I think eventually you'd want your learning rate scheduler to drop to about 0.00000024 or even lower. |
Beta Was this translation helpful? Give feedback.
-
|
@CodeExplode It might be worth reading up on KL Divergence and VAEs if you haven't. There are particular loss functions that are used for regularization like this, making it fit a distribution. Using one of those may give even better results. |
Beta Was this translation helpful? Give feedback.
-
|
Okay, I have a fundamental question. I'm trying to train an embedding of a style. I specify "john_smith_artist" as the name of the embedding. If I want to use [filewords] during training, then I need to have caption files for each image in the dataset, correct? Exactly what should be in the caption file? For example, "image_001.jpg" file is an image of a house with a forest in the background with mountains in the distance with clear blue sky above it. What do I write in the "image_001.txt" caption file? And which prompt template should I use? |
Beta Was this translation helpful? Give feedback.
-
|
I haven't trained on style yet, but I would use this terms in the template:
The [filewords] should not contain commas, so use BLIP! or if you don't want to use [filewords]:
or similar. |
Beta Was this translation helpful? Give feedback.
-
Wait, what?! The caption text files should NOT contain commas? That is the first time I've ever heard of that. Here is a typical example of one of my caption text files: a high shot of a seductive 30 year old woman, with long brown hair in a polytail, wearing a black bikini and red round sunglasses, sitting on a wooden barcalounger with a towel hanging on it, while on a sandy beach, with blurry surf in the background My caption text files are FULL of commas. Is that somehow negating its effect on training? |
Beta Was this translation helpful? Give feedback.
-
|
Not if you train on SD 1.5. If you train on a model that is deepbooru based, you can use it there. However, in the structure I posted before, the comma breaks the prompt. If you use it with deepbooru, you should definitely put a check in Shuffle tags by ',' when creating prompts option and use droprout with 0,1. |
Beta Was this translation helpful? Give feedback.
-
|
I just created new caption text files for all 12 dataset images using BLIP. Not a single comma in any of them. No change. No decrease in loss rate. I'm using SDv2-1 which renders mangled hands and limbs far less often than SDv1-5. Yet with any embedding I train, almost all images generated with them look worse than the most horrific SDv1-4 atrocity. Everywhere I read about this problem says that it's because of overfitting. And the way to avoid overfitting is to traing quickly to a loss rate less than 0.10. And I can never get anywhere near that. I never get lower than 0.35. I see other people posting graphs of trainings that start at 0.10 and I have absolutely no idea how they do it! |
Beta Was this translation helpful? Give feedback.
-
|
I haven't trained on 2.x model, because I think you can train on 1.5 with good hands (you just have to choose a good model trained on 1.5), on the other hand I don't look at the loss anymore, but rather the end result. Or train below SD1.5 and generate the final result on a better model with good limbs. Visually it's worth checking what you get. And the final problem was more under Dreambooth in principle. |
Beta Was this translation helpful? Give feedback.
-
|
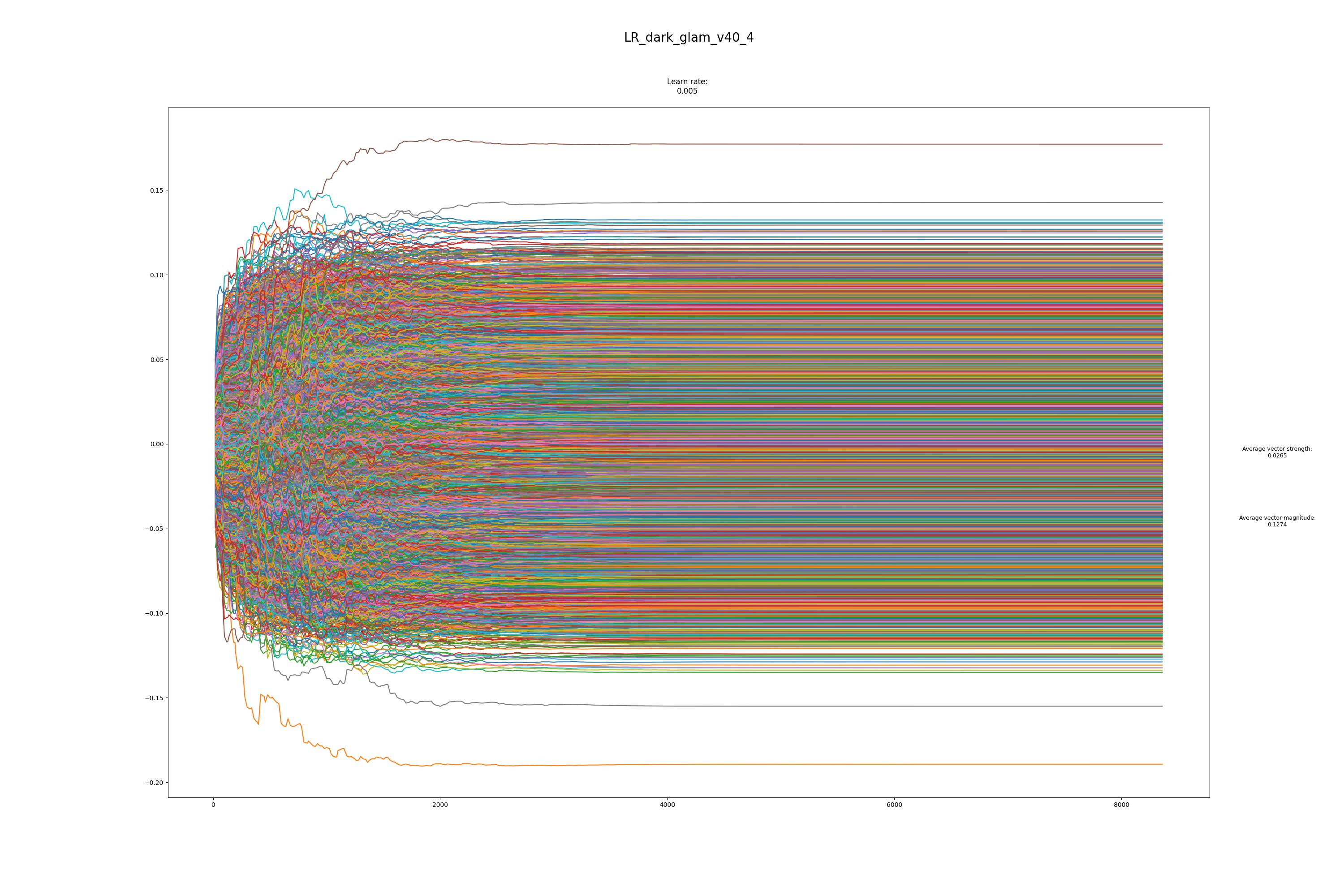
Wow nice script! @mykeehu |
Beta Was this translation helpful? Give feedback.
-
I'm not sure. The only hint that I have is on the repo page there is an example that I assume is an example of good training. And none of the squiggly lines go higher than 0.10 or lower than -0.10. So I scheduled trainings so they would increase quickly and then reduce the learning rate so it would level off. I'm assuming that once it levels off just below 0.10 you can stop training. I have nothing to back up what I say. My wisdom on this is entirely inferred from that one example image. Now if I could only figure out how to reduce the loss rate in any way, shape, or form. |
Beta Was this translation helpful? Give feedback.
-
|
Can you post the loss graph of the same training? |
Beta Was this translation helpful? Give feedback.
-
|
Can REALY help with that gradual Learning Rate |

Beta Was this translation helpful? Give feedback.
-
|
Thanks for the recommendation. It looks like it could be useful. I'm trying it right now but it's not affecting the loss rate in the slightest. I'm getting exactly the same results. |
Beta Was this translation helpful? Give feedback.
-
|
never got a loss rate decreasing with Textual inversion.
Le mar. 17 janv. 2023 à 17:21, GunnarQuist ***@***.***> a
écrit :
… But how this can help me? What it's trying to tell me?
I'm not sure. The only hint that I have is on the repo page there is an
example that I assume is an example of good training. And none of the
squiggly lines go higher than 0.10 or lower than -0.10. So I scheduled
trainings so they would increase quickly and then reduce the learning rate
so it would level off. I'm assuming that once it levels off just below 0.10
you can stop training. I have nothing to back up what I say. My wisdom on
this is entirely inferred from that one example image.
Now if I could only figure out how to reduce the loss rate in any way,
shape, or form.
—
Reply to this email directly, view it on GitHub
<#1528 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AODP7RF3ZP3UIUSVPMVBC4LWS3BIJANCNFSM6AAAAAAQ3AOWZ4>
.
You are receiving this because you were mentioned.Message ID:
<AUTOMATIC1111/stable-diffusion-webui/repo-discussions/1528/comments/4708566
@github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
I haven't kept any TI and TI data, all were bad. And my last one was like 1
or 2 months ago and so many things have changed with TI.
I have never seen anybody post any loss rate data or graph for Textual
inversion.
I am starting to think that either the calculation of loss rate is not
working with textual inversion or loss rate is different for textual
inversion compared to other types of training.
We just need to find someone that has a good training to do it again with
loss rate saved every step and we will see if it is relevant or not
Le mar. 17 janv. 2023 à 17:37, GunnarQuist ***@***.***> a
écrit :
… Can you post the loss graph of the same training?
—
Reply to this email directly, view it on GitHub
<#1528 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AODP7RF3V4EAK76N5JDRRFDWS3DFFANCNFSM6AAAAAAQ3AOWZ4>
.
You are receiving this because you were mentioned.Message ID:
<AUTOMATIC1111/stable-diffusion-webui/repo-discussions/1528/comments/4708719
@github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
Do people who posted loss rate also posted the graph from start to end of
only 1 value? Loss rate fluctuate a lot, at least from the output of
automatic 1111 WebUI, but does not mean that the trend is decreasing.
I am only using Thelastben google colab implementation of automatic 1111
webUI with a T4 GPU so maybe that is a reason for no change in loss rate?
(It is not clear which optimizations are done to run SD with this colab).
…On Tue, 17 Jan 2023, 17:49 GunnarQuist ***@***.***> wrote:
I just created new caption text files for all 12 dataset images using
BLIP. Not a single comma in any of them.
No change. No decrease in loss rate.
I'm using SDv2-1 which renders mangled hands and limbs far less often than
SDv1-5. Yet with any embedding I train, almost all images generated with
them look worse than the most horrific SDv1-4 atrocity. Everywhere I read
about this problem says that it's because of overfitting. And the way to
avoid overfitting is to traing quickly to a loss rate less than 0.10. And I
can never get anywhere near that. I never get lower than 0.35. I see other
people posting graphs of trainings that start at 0.10 and I have absolutely
no idea how they do it!
—
Reply to this email directly, view it on GitHub
<#1528 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AODP7RHEQEIWVQBGVUIUL2TWS3ERZANCNFSM6AAAAAAQ3AOWZ4>
.
You are receiving this because you were mentioned.Message ID:
<AUTOMATIC1111/stable-diffusion-webui/repo-discussions/1528/comments/4708834
@github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
I am using an A5000 on a PC using Ubuntu. I have never seen the loss rate decrease over the course of any embedding training. Never. |
Beta Was this translation helpful? Give feedback.
-
|
Im new to this TI training, I just have a 6gb vram 1660ti... Im trying to train a face, but I'm not getting good results... May I ask, how can I export a Loss graph to see these numbers? and also share them here to see if I can help with my poor tests... I have like "15 versions" of the same dataset, with different parameters, with n without xformers, fixed and variable learning rates, different prompt templates, datasets of 7 to 15 images... But results are always almost the same... |
Beta Was this translation helpful? Give feedback.
-
|
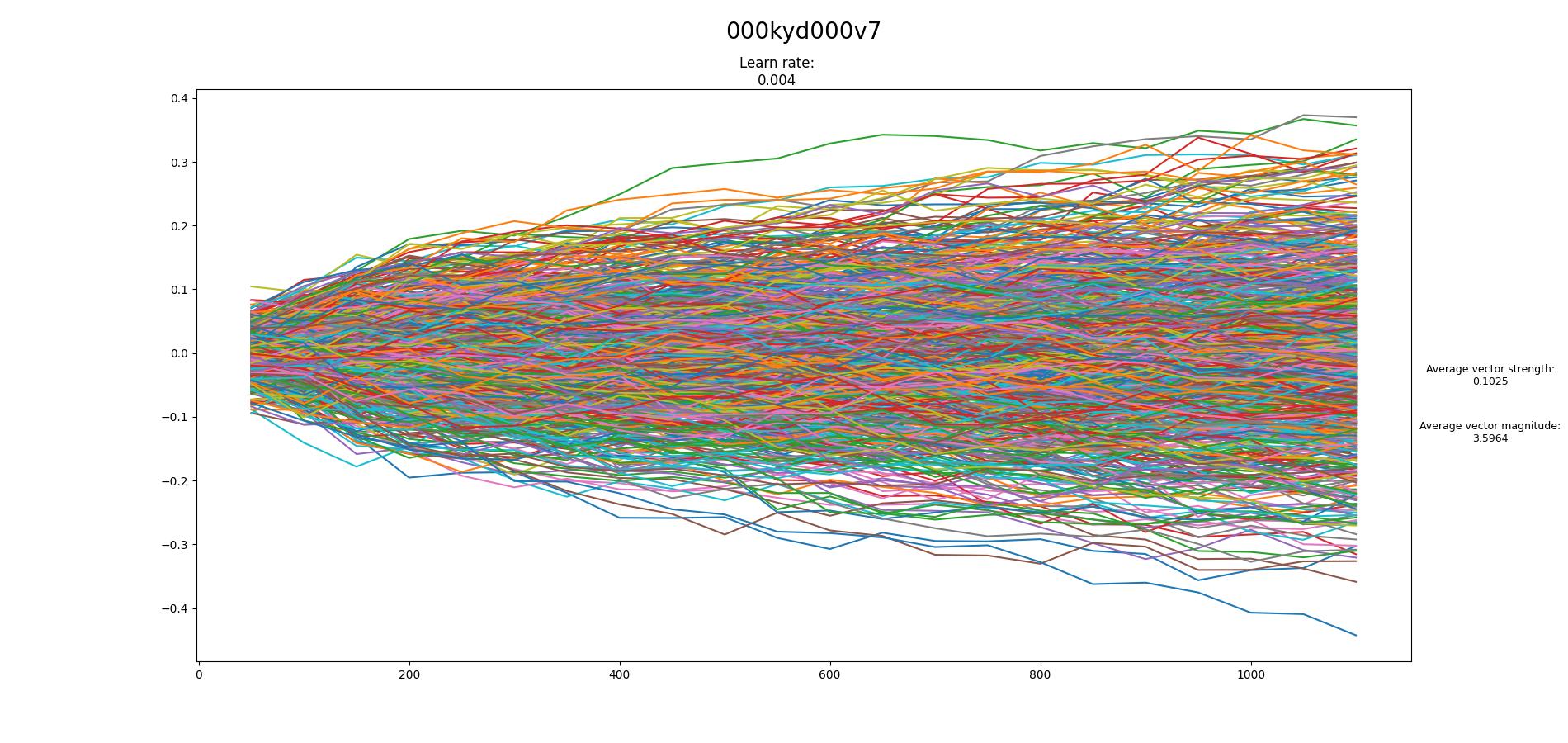
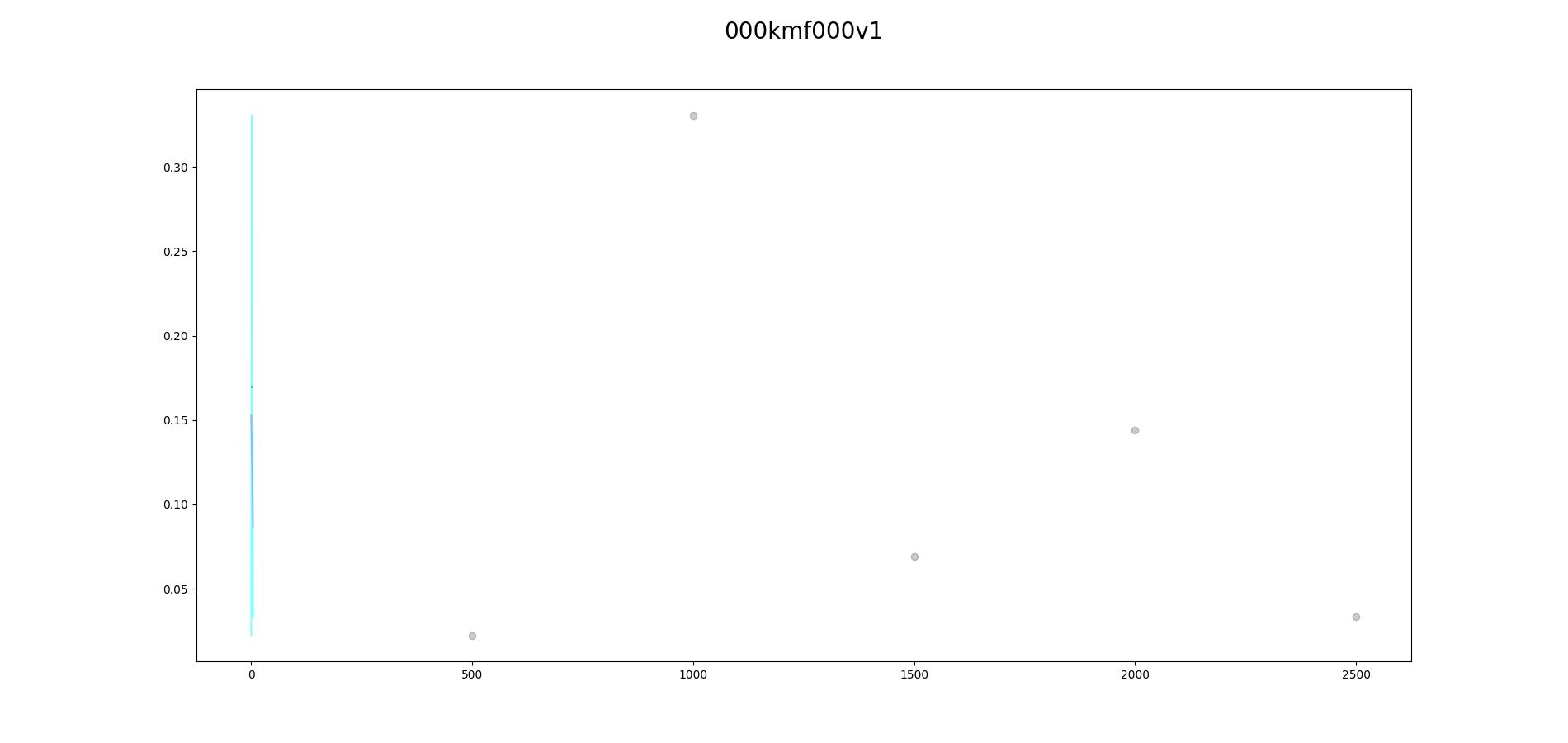
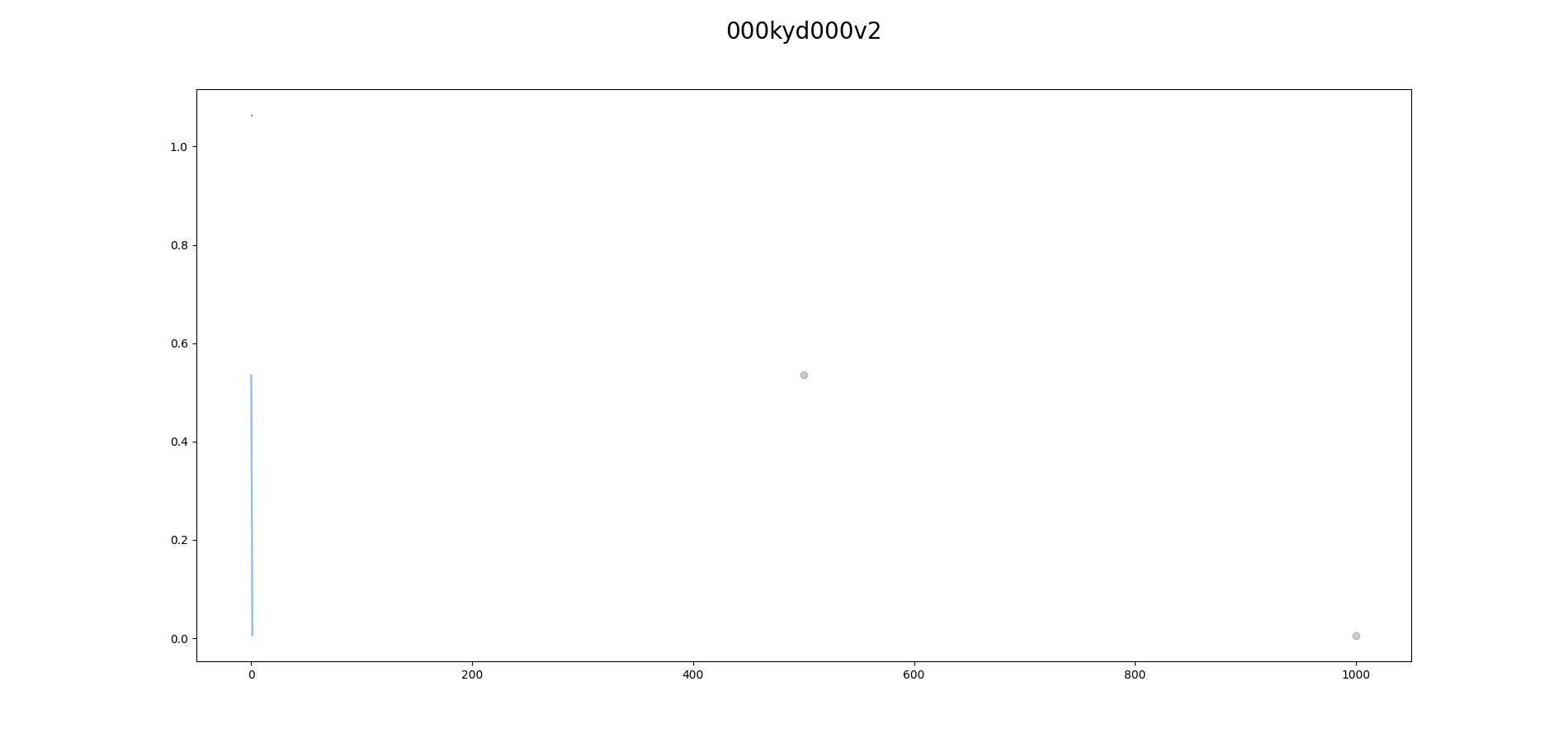
Found the tool to create the loss graph: Some of my results:
I don't know if they are good/bad.. I don't understand what I should look for on these graphs... If you can explain a little bit about this, maybe I can help more in the near future. I want to learn how to train TI... thanks in advance... |
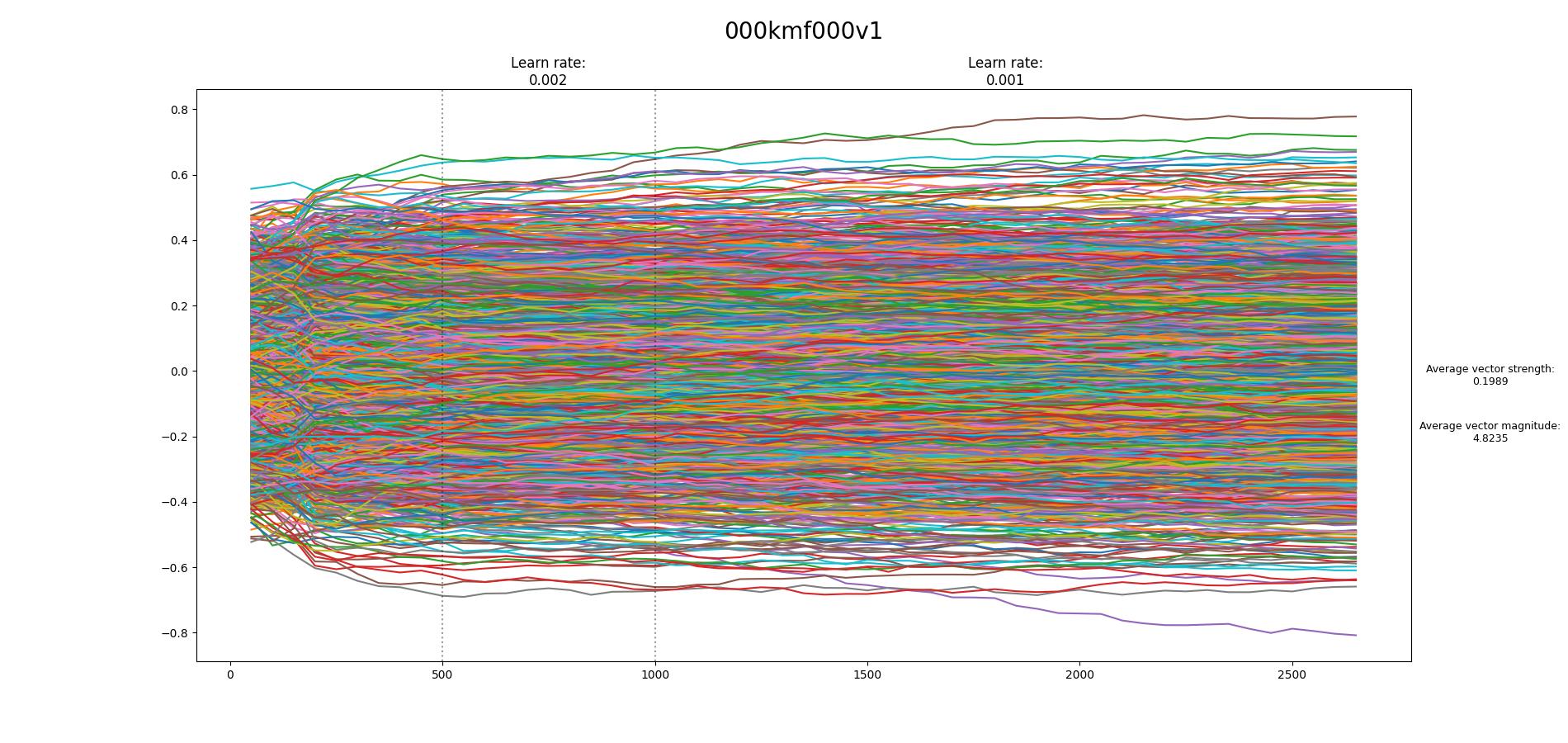
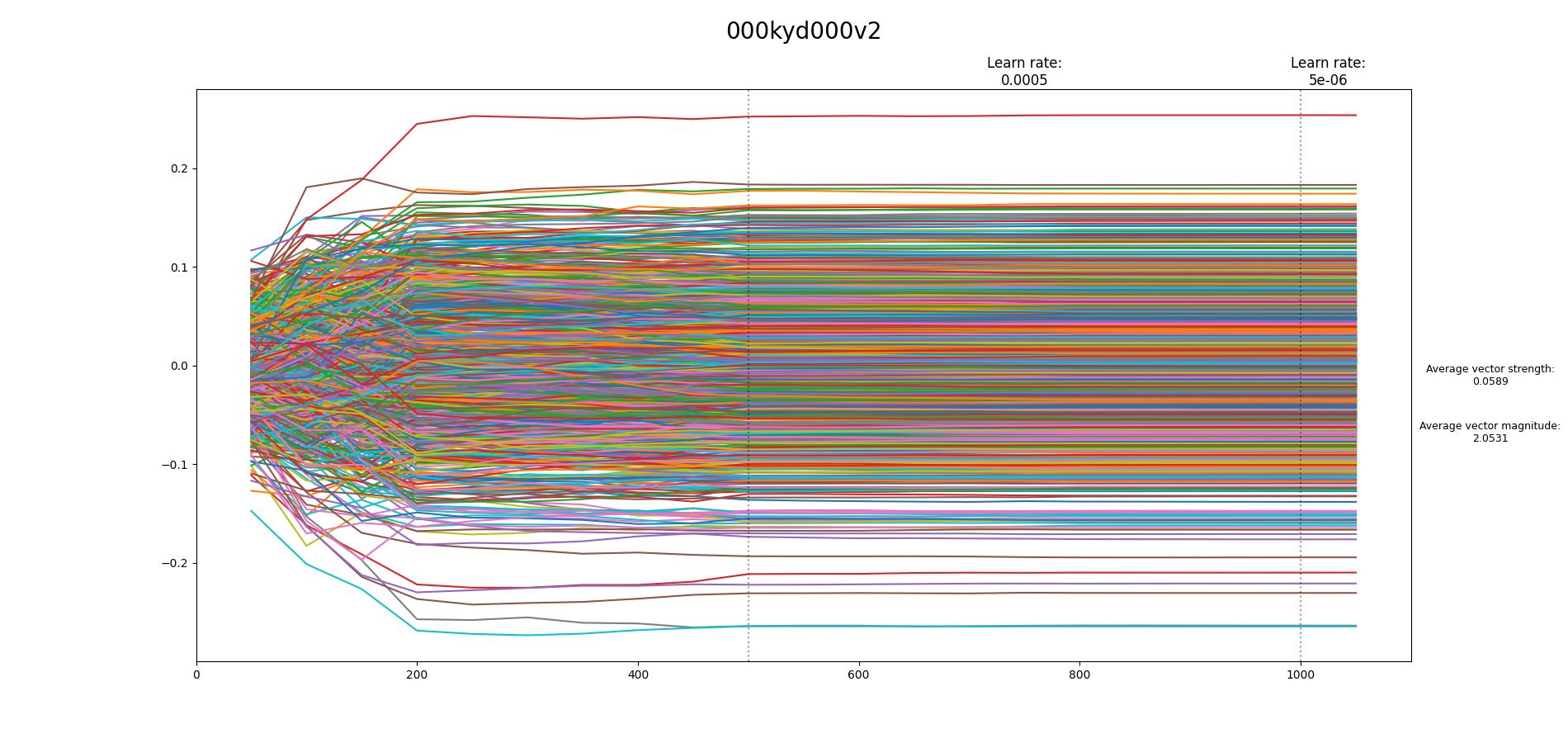
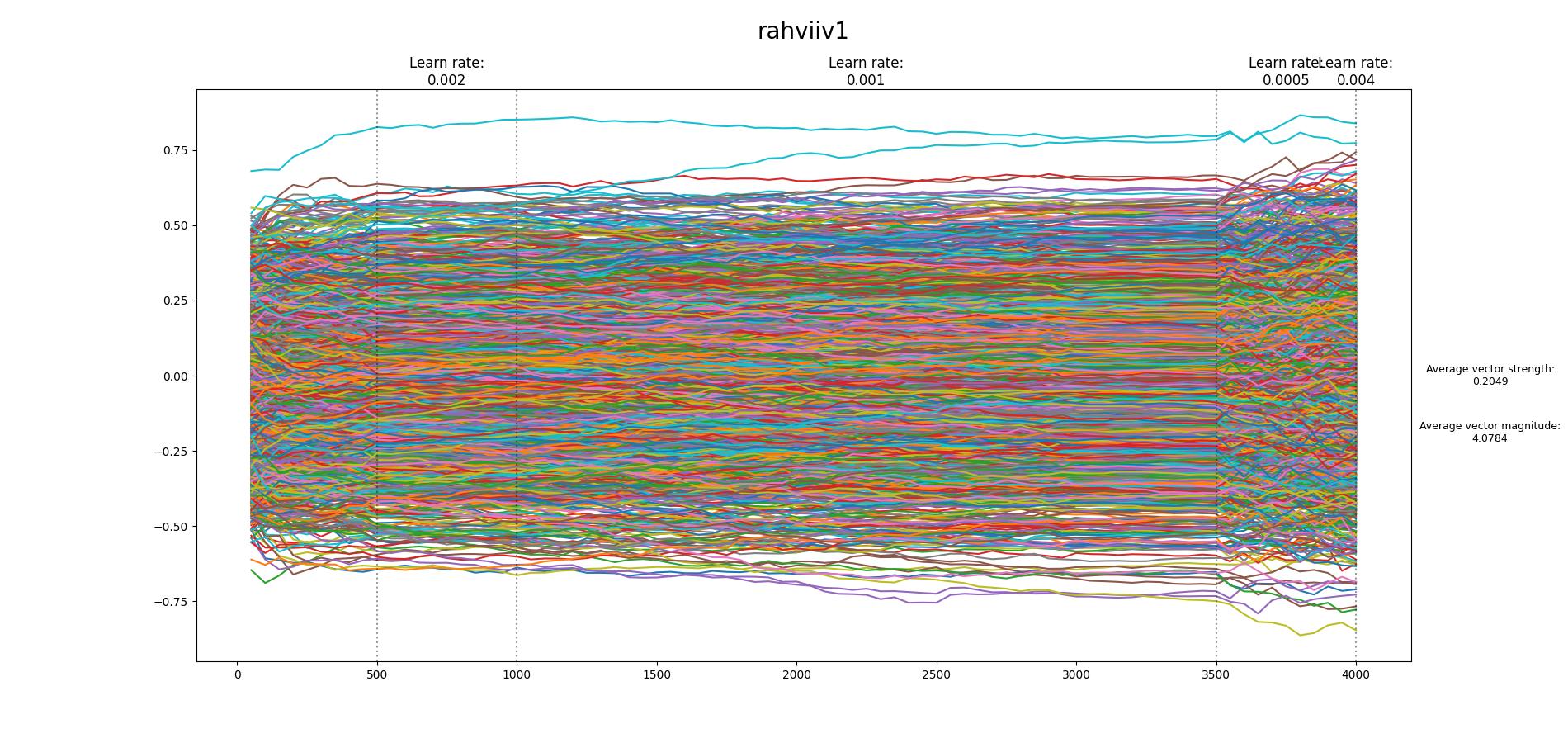
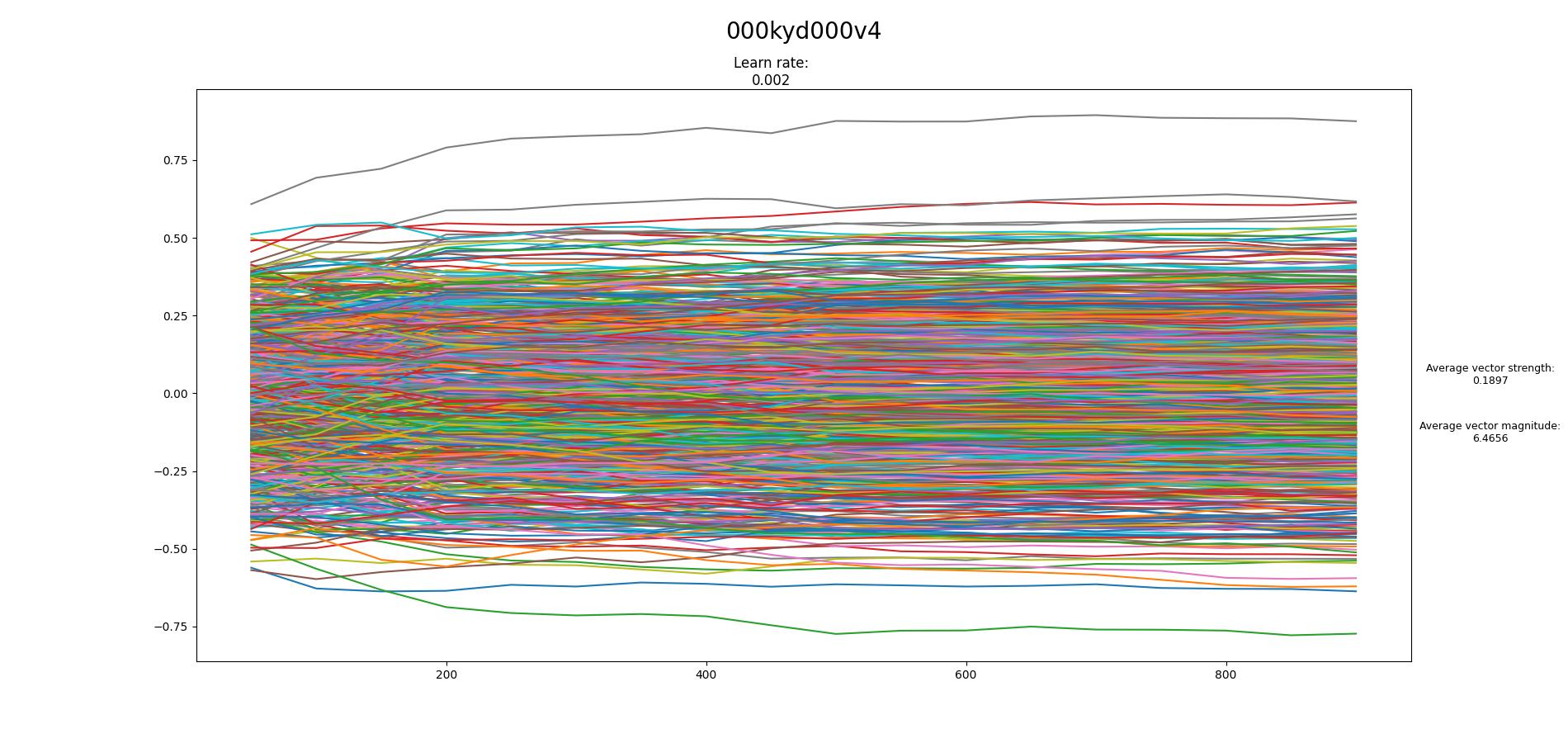
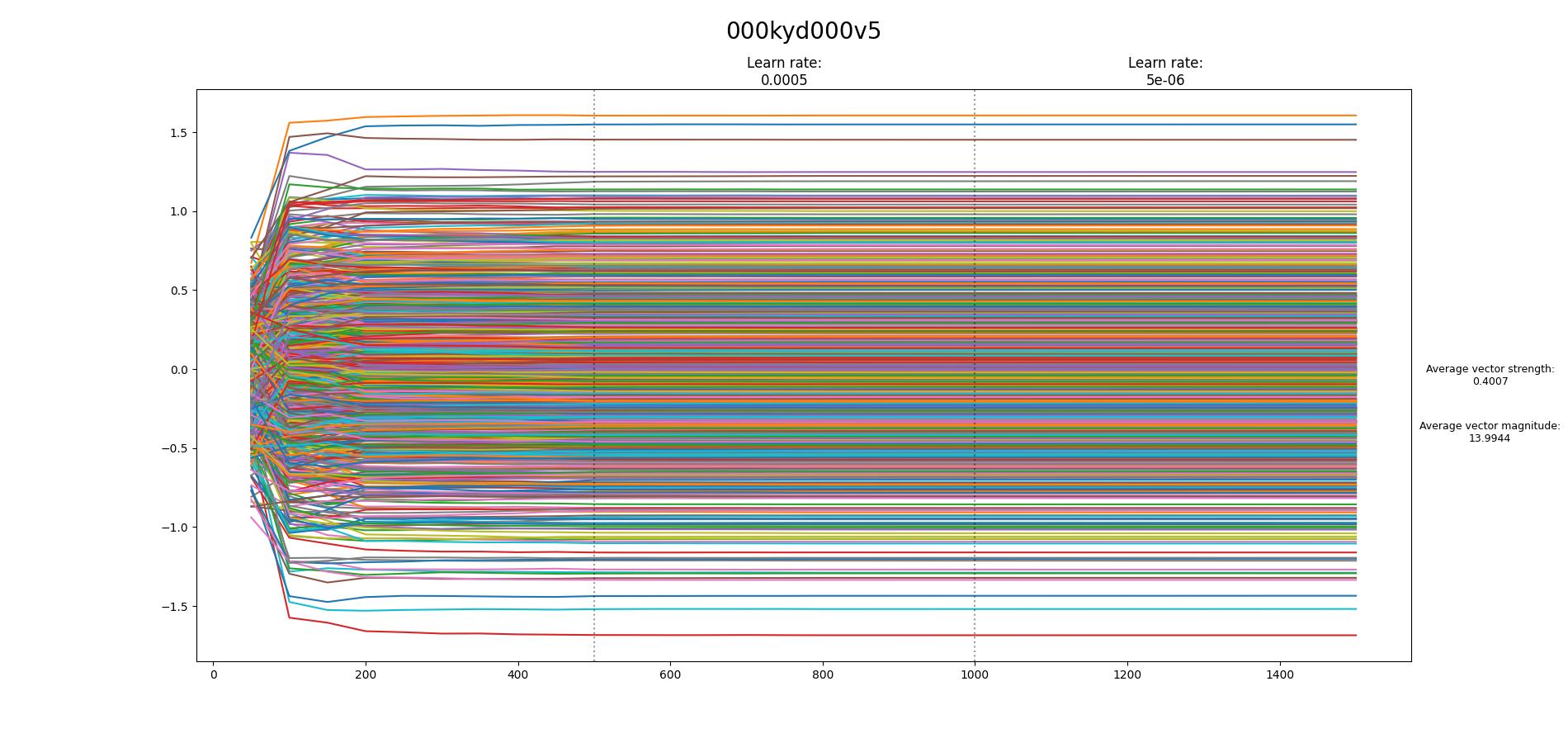
Beta Was this translation helpful? Give feedback.
-
|
|
Beta Was this translation helpful? Give feedback.
-
|
These are not loss graph I think.
You need to select in the webui settings at which frequency to save the
loss rate. It then will be saved during training in a text file in the
folder of your embedding.
You need to plot yourself with excel or other spreadsheet software.
…On Tue, 17 Jan 2023, 22:31 Nacu ***@***.***> wrote:
Found the tool to create the loss graph:
Some of my results:
[image: 000kmf000v1-2650-vector]
<https://user-images.githubusercontent.com/18109442/213015866-37c3ff3c-c45d-445c-9802-0c3a1d695c00.jpg>
[image: 000kyd000v2-1050-vector]
<https://user-images.githubusercontent.com/18109442/213015896-1781c5c7-9b95-4525-b56d-05884454db8d.jpg>
[image: rahviiv1-4000-vector]
<https://user-images.githubusercontent.com/18109442/213015946-9fe5744f-88fa-4598-9f3a-d54f23a14b8b.jpg>
[image: 000kyd000v4-900-vector]
<https://user-images.githubusercontent.com/18109442/213015978-c0e73c4c-191e-4103-848f-02601b20bfde.jpg>
[image: 000kyd000v5-1500-vector]
<https://user-images.githubusercontent.com/18109442/213015997-6359e351-1aec-4283-ac52-6ad7d020abc4.jpg>
[image: 000kyd000v7-1100-vector]
<https://user-images.githubusercontent.com/18109442/213016020-dbf293d3-b268-47db-a432-69ab4f5f276f.jpg>
I don't know if they are good/bad.. I don't understand what I should look
for on these graphs...
If you can explain a little bit about this, maybe I can help more in the
near future.
I want to learn how to train TI... thanks in advance...
—
Reply to this email directly, view it on GitHub
<#1528 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AODP7RFZ7WOP6OMVFAGX7D3WS4FR5ANCNFSM6AAAAAAQ3AOWZ4>
.
You are receiving this because you were mentioned.Message ID:
<AUTOMATIC1111/stable-diffusion-webui/repo-discussions/1528/comments/4711258
@github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
added loss graphs |
Beta Was this translation helpful? Give feedback.
-
|
hopefully My upcoming video content : https://www.youtube.com/@SECourses The Topics Covered In This Tutorial / Guide Video – |
Beta Was this translation helpful? Give feedback.
-
|
@FurkanGozukara I really liked your video and congratulations, it was really well done! |
Beta Was this translation helpful? Give feedback.
-
|
@mykeehu thank you so much for the comment I am planning to do 2 more videos 1 teaching object and doing in painting Second teaching a style I still didn't have time to work on them yet If you have experience please let me know |
Beta Was this translation helpful? Give feedback.
-
|
Unfortunately, the training of style is absolutely vague to me. If you look at the style templates, they don't include keywords, which I don't understand. You could probably rely on extracting objects in filewords, leaving the style. That's just a guess. I looked at the TI models in civitai to find out, but I couldn't steal either the pose or the style, or DreamArtist could be used better for style (with "style" as initial word), because it generates negative embedding as well. It also contains a solution for capturing the pose, but I have a method for that on the way for TI here. So I saw several useful things in your video that I can use (like the parser, or that TI creates a new token, which was not clear to me before). What is not clear is if I train a specially trained DB model with TI. Because the DB already has the weight that I want to train TI to transfer to another model, but it hasn't done it. On one of my DB models it was already producing the pose well, but as soon as I switched to the basic SD model, it was producing something completely different. So I'm still trying to figure out how to train a TI that performs well on multiple models with the same base. |
Beta Was this translation helpful? Give feedback.
-
|
@mykeehu I think you have to do training for every model individually because TI generates new vector weights by using the existing vector weights of the model So when the underlying weights changes, the result of the calculations also changes. Therefore your previously trained TI will not work same on a new model It is all about machine learning and how weights are used |
Beta Was this translation helpful? Give feedback.
-
|
Then that's why it works for faces on other models when you train on the base model, because the weights you create for the human face will call for the same weights on the other model, but when it comes to style or pose, it mixes with the other model's abilities. At least I think so. Many people think LORA will be the solution because it stores more data, and although it doesn't create a new token (as you said in your video), it will be usable with more models because it changes their weights and fits in a small space. The LORA development is going well at d8, I'm curious to see how it ends. As for hypernetworks, there are a few that change the style dramatically, so maybe the style is worth training for HN. This is one of my favourites, where you can absolutely see the effects of strength adjustment, whatever model is loaded: But I've just found a pretty spectacular style from TI: |
Beta Was this translation helpful? Give feedback.
-
|
I have created two pose templates, and I suggest you type the word "pose" in the Initialization text. It works pretty much fine for me, except that it distorts the body parts in a strange way, which I don't understand, although it might be just me. Update: replaced the pose files and created one for blip and one for danbooru |
Beta Was this translation helpful? Give feedback.
-
|
I have prepared the literally most comprehensive video of text embedding / textual inversion If you are interested in check it out How To Do Stable Diffusion Textual Inversion (TI) / Text Embeddings By Automatic1111 Web UI Tutorial |
Beta Was this translation helpful? Give feedback.
-
|
Did you see today's innovation? One click to use all embeddings, hypernetwork and Lora. They're searchable, and if you want a preview image, put the PNG image you generated with the same name + ".preview.png" and next to the model and it will appear. You can find it here: The preview image works automatically for hypernetwork and Lora, not yet for TI/embedding, I reported it. This is how beautiful the gallery will be (these are The Ally's TI styles): |
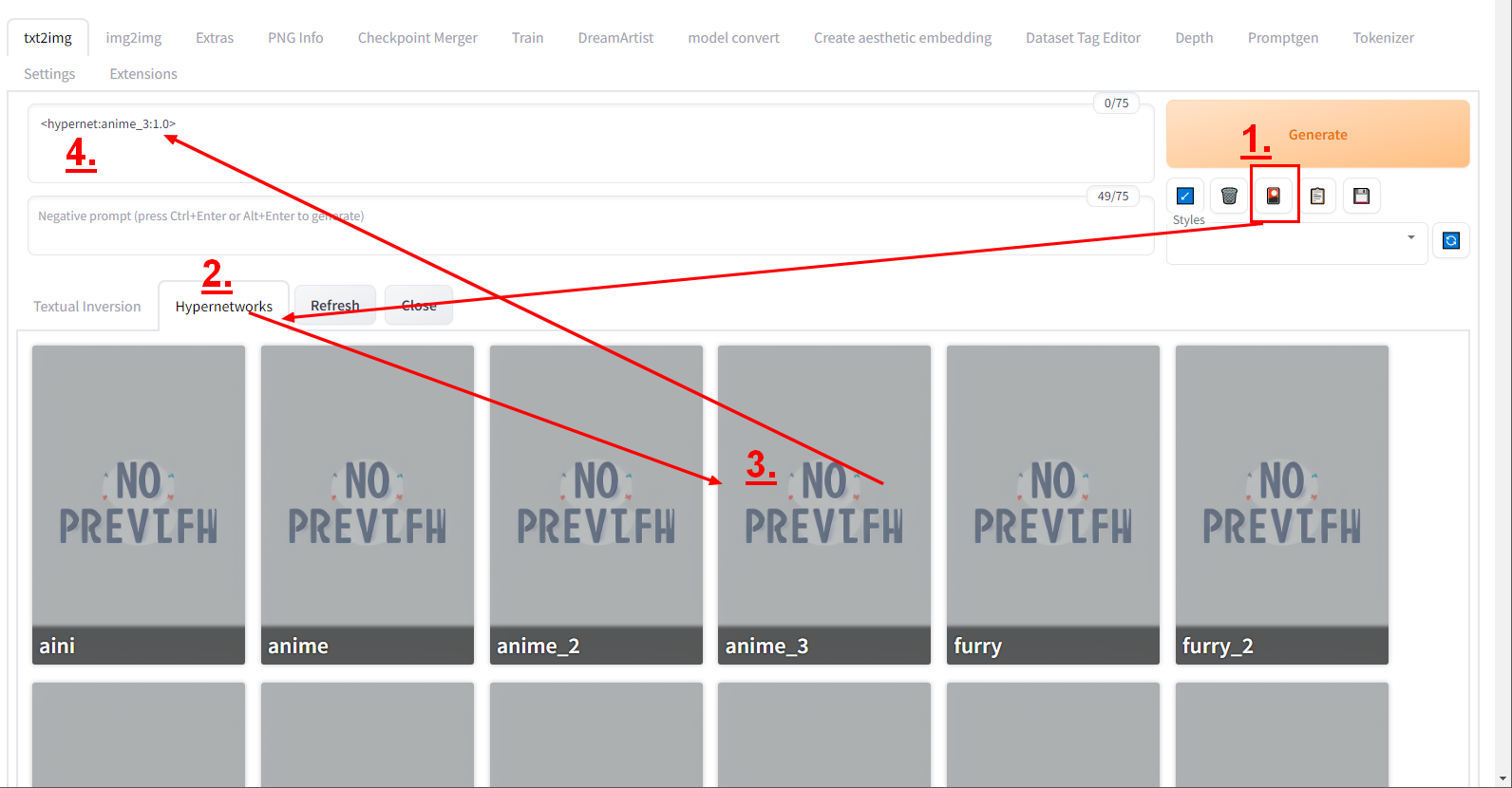
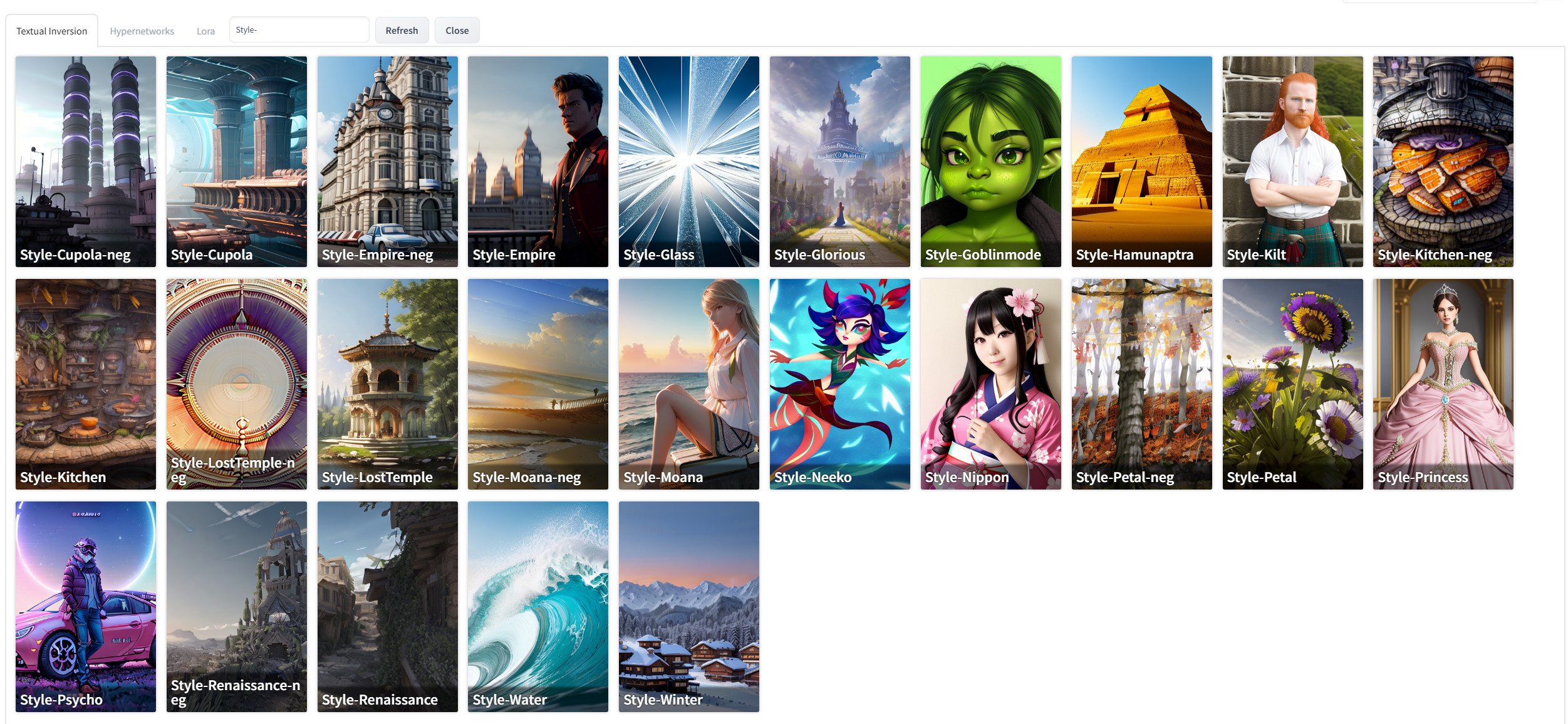
Beta Was this translation helpful? Give feedback.
-
|
@Heathen thanks for the tip, it works perfectly and is a perfect solution! |
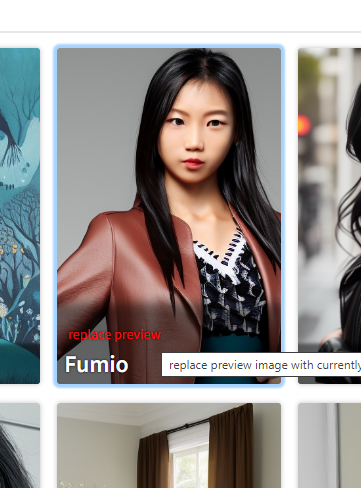
Beta Was this translation helpful? Give feedback.
-
|
If you have your embeddings folder outside the webUI root folder, the images don't load. I had to use again the normal embeddings folder in order to get the previews to work. |
Beta Was this translation helpful? Give feedback.
-
|
I have also looked on colab, and unfortunately the image does not appear there either, even though I copied it. This needs some polishing. |
Beta Was this translation helpful? Give feedback.
-
|
yep, also PNG images, if you use jpeg it doesn't work :p |
Beta Was this translation helpful? Give feedback.
-
|
Yes, I saw from the source code that it can only have PNG extension. |
Beta Was this translation helpful? Give feedback.
-
|
Are people generally training without cropping/resizing images now that it's an option? Are people finding it working better? Wondering if I should go back and redo my old TIs or not bother. |
Beta Was this translation helpful? Give feedback.
-
|
Training has changed a lot in the last few months, and will continue to do so as I look at the PRs. Fortunately, as the technology changes, the end result gets better and better.
Suddenly that's it, I'm still testing the vectors, which is the set that already likes the other networks.
|
Beta Was this translation helpful? Give feedback.
-
|
What is NAI model |
Beta Was this translation helpful? Give feedback.
-
|
I remember your video, but I modified these little things. |
Beta Was this translation helpful? Give feedback.
-
|
I have also seen some discussions about bad interactions between |
Beta Was this translation helpful? Give feedback.
-
|
@atensity yes not using it better. @mykeehu yes coma is another token and it also have same size vector and strength so i think same |
Beta Was this translation helpful? Give feedback.
-
|
Today I took out the TI again and followed this guide. I trained a person with 12 images, used vector 1 and set "woman" as Initialization text. With the LR there (0.05:10, 0.02:20, 0.01:60, 0.005:200, 0.002:500, 0.001:3000, 0.0005) I got a very nice result with no burn-in, with deterministic mode, and the attached personal-min.txt file. I stopped at 2000 steps, and although I could train for a long time, the result looked to me to be of nice quality, and no burn-in! I had previously tried [filewords] to extract the background, or generate a sample prompt like the ones I had created for the images (e.g. [name] [filewords] template with the description of what the image depicted), but it seems I really need to train for minimal composition, [filewords] can screw things up. So I can only recommend the above website, the methods described there are really effective, and on 1 vector! |
Beta Was this translation helpful? Give feedback.
-
|
Something must have happened to TI. I don't know if it's a memory leak or something else, but I noticed a strange phenomenon. I tried one guy's description on Discord, which is to generate sample images with a model, which I then "name" with the TI. Here, about 300 images are trained in 5000 steps, in the "classic" way, i.e. 1 batch and 1 gradient parameters and 0.005 LR. Interestingly, all images are generated with a grey background, and during the training, the sample prompt is generated in txt2img. I set a fixed seed and followed the description here, for example "a ohwx in the forest". To filter out the grey background, so that all [filewords] have "grey background" in them. I also tried the training in [name], [filewords] and [name] [filewords] (without comma). After about 3000 steps it started generating things that had nothing to do with the sample images. For example, it would generate a car or lose the pose and generate a generic image. At the end of the training, it also happened that if I unlocked the seed, it would just generate a forest without a person (even though I specified it was a woman in the training). It completely lost the meaning of the keyword. Then for the same embedding I started adding more keywords like smile, dress, sitting, it suddenly came back to itself and on other models it was already producing the person correctly. However, on some models it keeps the grey background and on other models it brings the embedded person well (e.g. office). What could be causing this weirdness of the embedding falling apart? |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
1st, thank you @AUTOMATIC1111 for addinf this to the webui. Awesome work.
I have been trying to add myself by using about 12 photos of myself and using the following TI config in webui:
I am getting strange results with pictures produced containing a lot of "dots" or noise. They are sprinkled all over the pictures. Here is an example:
I am using this prompt to generate it:
This is after about 3000 steps. Any idea what is happening?
Beta Was this translation helpful? Give feedback.
All reactions