Replies: 5 comments 11 replies
-
|
I agree with changing hyperparameters of Adam can help training. But where did multiplying 10 come from? |
Beta Was this translation helpful? Give feedback.
-
|
Like I said - no idea what is optimal. From what I have read higher EPS means longer learning but also you can set a higher learning rate before it blows up. As for loss multiplication from limited runs I did so far I found that at same learn rate I did get a linear meltdown after 2000 steps. With loss times 10 I didn't. I am getting the feeling that maybe the default loss function is too low already and that is why you have float problems you wanted to fix with autocast. |
Beta Was this translation helpful? Give feedback.
-
|
As I understood f.e. from https://stats.stackexchange.com/a/395443, multiplying the loss is the same as multiplying learning rate, but it changes some "trade-off" for Adam optimizer. So we can set formal learning rate ten times smaller (*0.1), but counter that by increasing loss ten times instead (*10). This way we'll get the same actual learning rate, but optimizer gradients would be affected (for good or for bad). I think that making explicit option named like "loss pre-multiplier" (default to 1) to divide learning rate and multiply loss to – is better than just multiplying loss (by constant or by variable), since the latter will affect the "perceived" learning rate magnitude. |
Beta Was this translation helpful? Give feedback.
-
|
I would say that new tradeoff works because I got 4000 steps without melting with learn scheduler 1e-4 which means it was 1e-3 actually. VS meltdown at 2000 steps with 1e-4. You can tell me if that is because I indirectly changed the weight decay or because I somehow avoided float point rounding issues that are present with default parameters. It could well be the decay weight being too small (which I fixed through this) as well as the EPS because default assumes you will be running textbook problems around 1k iterations instead of 10-100k like we usually do for hypernetworks. I didn't want to get a migraine exactly understanding the equations under all this but I will probably have to sit down and do it. |
Beta Was this translation helpful? Give feedback.
-
|
Multiplying loss can help lead training but isn't really a standard way to go, nor does it solve the core problem of gradient explosion. |
Beta Was this translation helpful? Give feedback.
-
|
Can we export |
Beta Was this translation helpful? Give feedback.
-
|
I finally found something really promising. Fair warning I did it with: loss=loss*20 Linearly increasing learn rate on right axis which is as discussed above equivalent to 20 times learn rate of default settings.
Finally it is just gradually lowering and converging so the learn rate is finally high enough. |
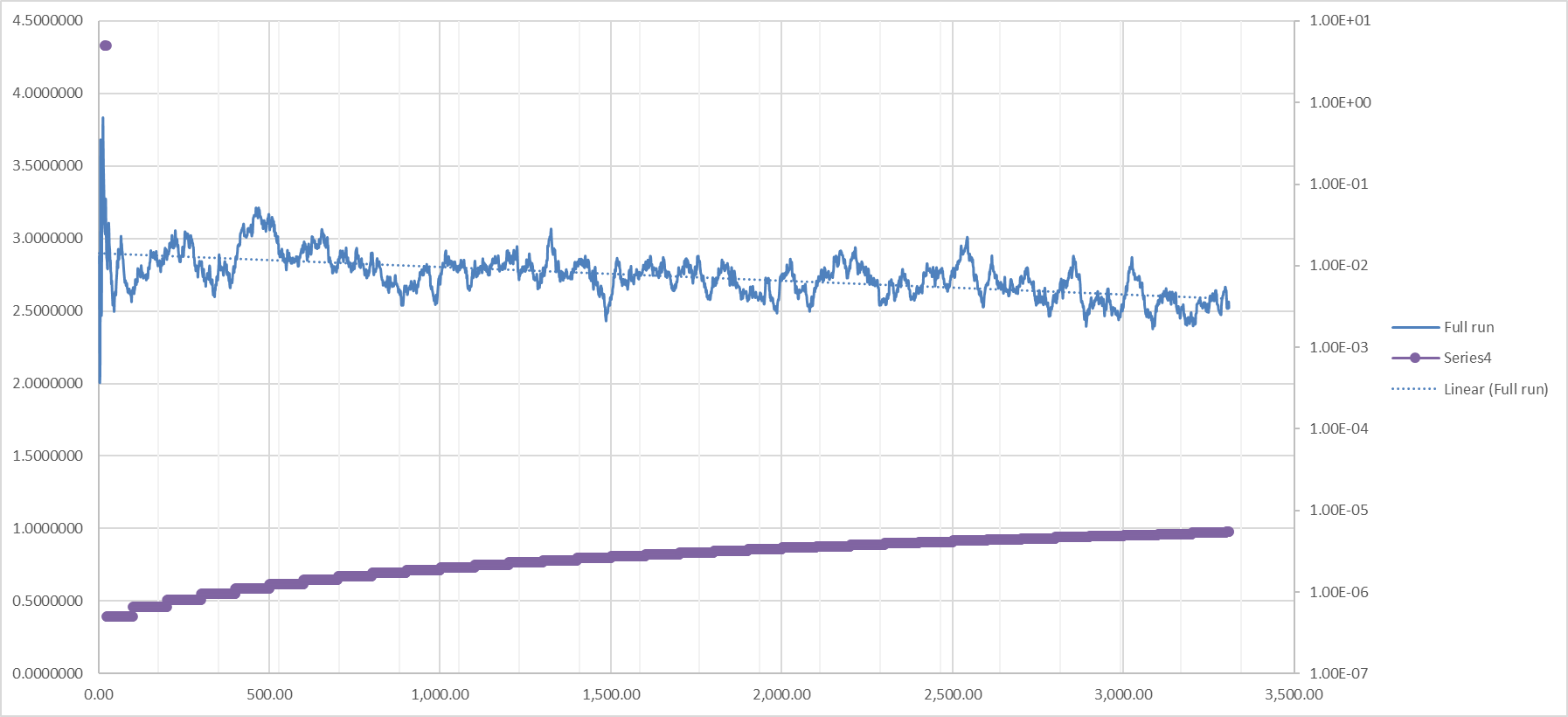
Beta Was this translation helpful? Give feedback.
-
|
It booms worse. And the image previews were changing quicker and more chaotically. I would guess this will come back as a negative influence when I start approaching 0 but hey I would love to have those problems since I never approached 0 in the first place with a data set of 140 pictures. |
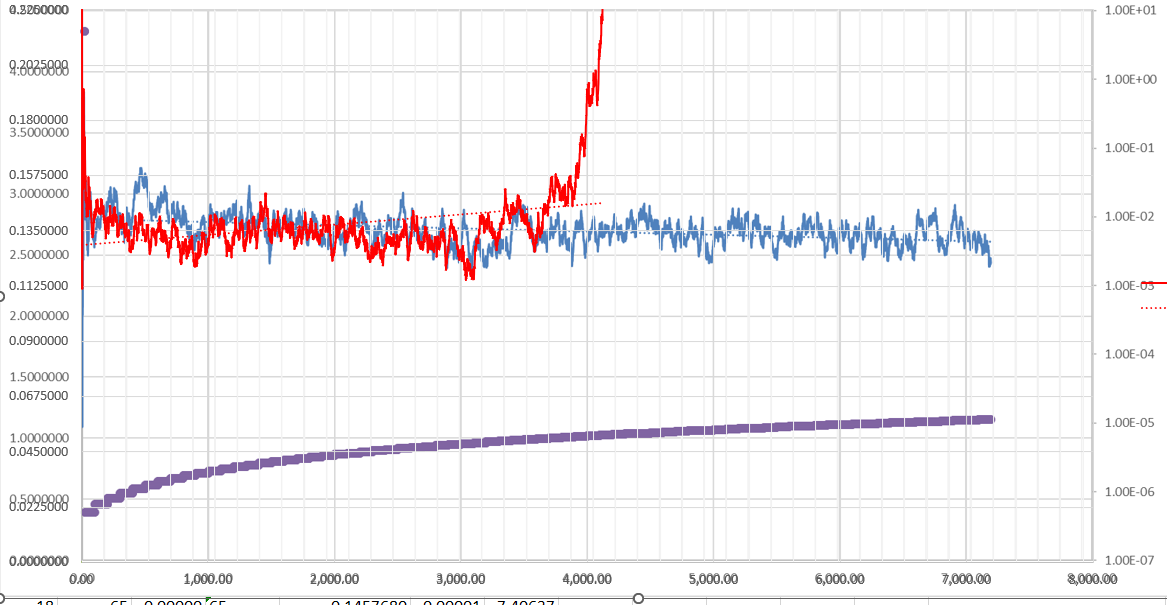
Beta Was this translation helpful? Give feedback.
-
|
Hm-m, very promising! And what if we use your method of loss multiplying, but like 200 or 500 instead of 20? (Lowering the learning rate accordingly to accommodate) |
Beta Was this translation helpful? Give feedback.
-
|
This. Floor it OP. Loss by 9,000. |
Beta Was this translation helpful? Give feedback.
-
|
In the end it is not viable. I tried 100 times higher and 100 times lower. In both cases loss starts diverging regardless of learn rate. Initially I used it as means to escape exploding. But now I have gradient clipping added since it is just one line of code: And for now I am trying to find a setup which works and converges "quickly" then I will play around with all the parameters more carefully. |
Beta Was this translation helpful? Give feedback.
-
|
And I got nothing. Only valuable info I got is that instead of static clip I think: torch.nn.utils.clip_grad_norm_(weights, max_norm=1, norm_type=2) makes more sense. But the default value you will see in library of 2 is too big and you still have explosions. Maybe 0.5 would be even better assuming people will be using higher learn rates. Or 2 combined with high EPS value. Otherwise I found no remarkable improvement to convergence with any parameters. (Also tried lower weight_decay which does make the loss curve smoother for what it is worth while setting it higher makes zero convergence happen so default 1e-2 may be too big). One thing that I found somewhat interesting but would need a lot more steps is plain SGD optimizer without momentum - seems to be jumping around the place much better than adam at initial stages but I wasn't lucky for it to end me in any nice place. |
Beta Was this translation helpful? Give feedback.
-
|
And I did find something but now I have no frame of reference to say if it is remarkable or not since all my previous attempts at making hypernetworks didn't create any results I would find as good enough. Result at step 1400 with 143 training pictures.
Closest training picture:
My guess is if I continued from there with a much lower rate I would get some details in and it would be nice but:
|


Beta Was this translation helpful? Give feedback.
-
|
eps=1 sounds crazy to me. Even 0.1 is. The default is 1e-8, and it should be a very small number, because the purpose for eps is really just to prevent division by zero so you get a very large number but not infinity. |
Beta Was this translation helpful? Give feedback.
-
|
Quoting linked StackOverflow page comment:
|
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
I was absolutely wrong about everything here but I found the real issue in the newer thread.
Beta Was this translation helpful? Give feedback.
All reactions