Replies: 10 comments 34 replies
-
|
And the sequel is already here: I was happy cause there is a face at 48800.
But I died in hell
Cause my loss shot up. See? Overfitting and gradient explosions are two different things that both result in pretty colors. |

Beta Was this translation helpful? Give feedback.
-
|
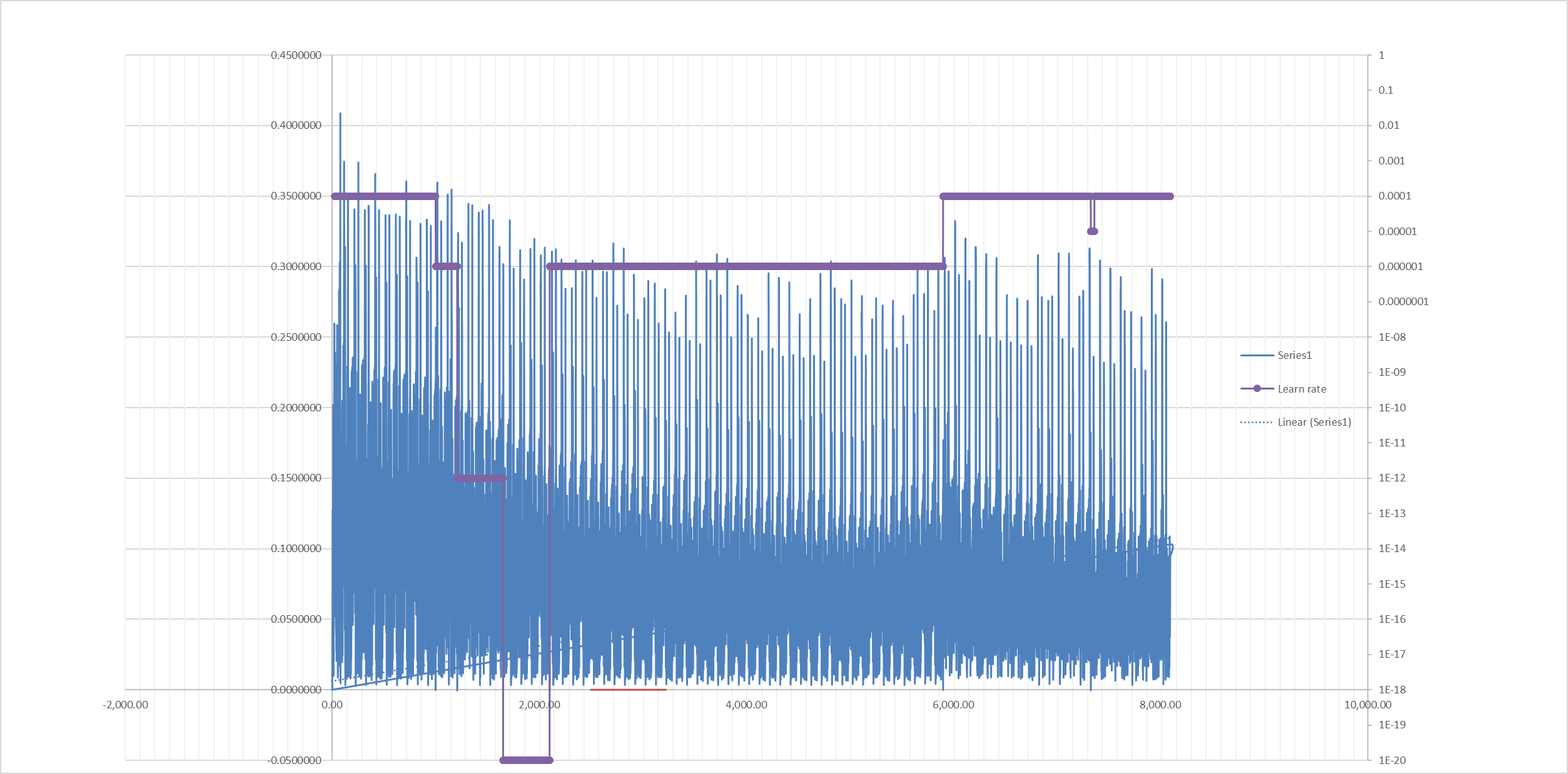
And I got out of hell:
Not gonna wait for it to stabilize and show perfect pictures again because the optimizer is still very sub par for this. But you can see that you can get back from blobs to actual shapes - weights are normalizing and overfitting becomes less severe to a point where you start seeing things again. This also confirmed what I thought about how this works and how current training worked - why training at high learn rate was better. Setting the low learn rate (1e-20 on my graph) gives the algorithm a lot of room to approach global minimum and get closer to training points which creates much bigger overfitting (hell pictures). Then setting the learn rate high makes it less likely to move closer to data points which made it that I got a picture again at 6000 when I upped the learn rate to 1e-4. At 7400 I removed optimizer data to make it harder for the algorithm to find result closer to training points and it probably helped. Next I will try to play around with beta parameters of adam to remove or even reverse the learn rate decrease it does when it is stuck. Because this makes it more likely to move and destroy normalization. |

Beta Was this translation helpful? Give feedback.
-
|
I added what I said: Changed optimizer to:
(EPS probably not even necessary weight decay of 0.1 is nice and beta is default beta) And I am completely blown away by results. It finally works quickly and doesn't go into overfitting. I mean I probably need to fine tune it a bit from here but this is exactly what was lacking in the training.
|

Beta Was this translation helpful? Give feedback.
-
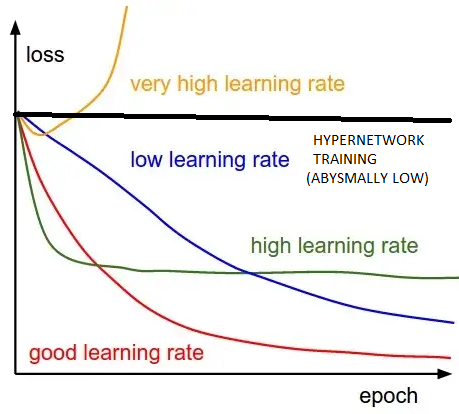
That looks amazing, bro, I've encountered the same problem as you before, I'd tried using the Learning Rate Generator to help me get a dynamic LR but didn't go too well if the curve goes like your red line, it'll only be able to generate an acceptable result with the green line LR...(but I didn't put any optimizer and loss.backward, do you think that's the issue? Or there's no need for those once we hit the perfect LR curve |
Beta Was this translation helpful? Give feedback.
-
|
I think a lot of people (me included when I started) pay way too much attention to training loss. I am still not exactly sure how the first few epochs look and where do you cross from undertrained to overtrained. But I am 100% sure that once you see cooking you are already pretty high in overtraining - low test accuracy. And you can hit that quickly with 1e-4 or with complex networks. If you use 1e-3 or higher you go into yellow curve on graph - too high learn rate and you get a blowout a different thing from overcooking which you can easily distinguish through loss jumping up or not. And it is visually different. If you lower learn rate you will overcook it further. Learn rate is kind of a red herring here as anything below and including 1e4 will be more than enough to reach overtraining. What you want to do after that is let the weight decay set in and filter out noise. Which is impossible in default settings because you keep getting further increases in training accuracy that undo the weight decay normalizing. I feel like I am restating the same thing over and over but maybe some people will finally get it. I mean reading that article I posted in OP should explain everything about what is happening in hypernetwork training. |
Beta Was this translation helpful? Give feedback.
-
|
Hmmm, after reading the OP, I think I know what you mean now, so the normal/default setting of current hypernetwork training will easily pass the perfect point and go into overtrained/overfitting because it's only applying with a dynamic downward training rate, nothing changed in weight of the dataset. That's why we manually choose the model we want with the picture it generates after x of steps, just to find the model nearest to the perfect point. And now with this loss.backward() and optimizer command, we're able to lower the weight of the dataset after each epoch during training..? |
Beta Was this translation helpful? Give feedback.
-
|
I have a chance to try with weight decay and lossbackward last night, but something bugs me, I tried with might, gelu and linear, the gelu initialization went pretty well, and after a certain point, the AI stop generating meaning pictures, it starts drawing cotton textures or something, and after I checked the csv that's being saved, the LR is constant at 1e-4, is that what it suppose to be? |
Beta Was this translation helpful? Give feedback.
-
I am sitting trying to answer this and I don't know how to word it. 1e-4 (and after playing around I realize that value is of course dynamic depending on layer size and number). Is sufficient to overcook. Smaller rates after 1e-4 will get you closer to the training data because this works like regular problem where smaller step lets you come closer to training data. It is just very hard to see when from the beginning you are already very accurately representing training data. And if you want to normalize weights at point where you are sufficiently close to training data (which you should want to do) static learn rate should do that over time provided decay is high enough and you train long enough for it to overcome regular steps. You can accelerate it with cosine annealing, or even as I have shown with my coming out of hell experiment - sudden changes to it. And about cotton pictures I have very hard time distinguishing between undertrained vs overtrained blobs. Overtrained blobs should be the ones that happen if your training loss is low and it doesn't go up. Undertrained blobs should be visible if your loss suddenly starts going up - you normalized parameters too far and now you are entering underfitting. If you had overtrained blobs than your decay wasn't high enough + possibly clamp isn't working as intended. If you had undertrained blobs your decay was too high and you should have stopped just before your training loss started shooting up - that was possibly (I think it is even more complicated than that but I am too stupid for now) the best degree of generalization possible for that training accuracy. |
Beta Was this translation helpful? Give feedback.
-
|
Here is a 1 picture no tag speedrun. Can we agree that this works? (Actually 1 picture learning is more complex than I thought...) |

Beta Was this translation helpful? Give feedback.
-
|
That's pretty good. I always thought it was weird that hypernetworks take longer to train than full DreamBooth models. I'll give this a try later and report back. |
Beta Was this translation helpful? Give feedback.
-
|
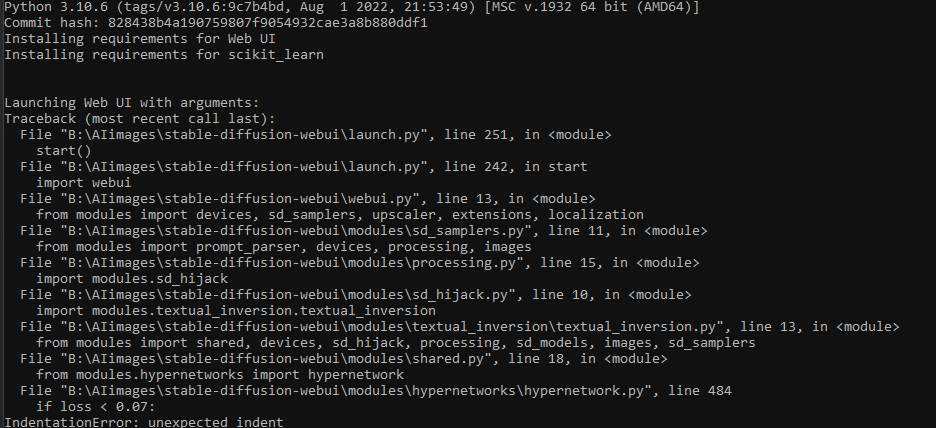
This is amazing stuff, though i am unable to replicate changes locally, what am i doing wrong adding |
Beta Was this translation helpful? Give feedback.
-
|
Had the same error arranging it like this fixed it |
Beta Was this translation helpful? Give feedback.
-
|
Loss clamping creates a new kind of death:
Death by oversimplification. On the other hand if you go the reverse route of decreasing the weight decay to 0.0001 with loss clamping:
Ok I got nothing. I was hoping that with a small weight decay I would get an inverse of current training where you go into overfitting and then hit eject before your network simplifies to nothing. But I don't have any idea what this is. I broke something. Some of this is nice. And it is only 50 steps. Possibly my patchwork implementation of it is wrong. Maybe it should be forced to do some steps to not kill itself like this. Maybe more playing around with weight decay and this limit + maybe adding dropout? I am gonna take a break because this is too complex for me. |


Beta Was this translation helpful? Give feedback.
-
|
Never mind. I had some derpy settings there.
Loss clamp can be stable. Now I am just hoping that this is still overfitting and not oversimplifying hard to tell. |

Beta Was this translation helpful? Give feedback.
-
|
After 9000 steps with loss clamped at 0.02 mean loss, 0.1 weight decay and low frequency highly aliased annealing (just me cycling around 4 learn rates) I got this:
It became a scanner that someone sat on. I mean yeah there are some differences there but I didn't expect you could actually make an almost perfect copy like this. Aside from the colors obviously, I have no idea if I would call this overfitting or perfection. |

Beta Was this translation helpful? Give feedback.
-
|
Posting my results here. I'm not super into hypernetworks (because they take so long to train) so I don't have much to compare this to quality-wise, but this seems like a big win for quick hypernetwork training. Here's what I did:
Results: IMO it looks best after 1 epoch. |

Beta Was this translation helpful? Give feedback.
-
Wait, how does it even work? I thought that hypernetwork structure was supposed to represent an amount of neurons in Dense layers? |
Beta Was this translation helpful? Give feedback.
-
|
Yes the network is just very very small. I have spent a lot of hours on this now and I still have no idea what is the optimal size of network for classical regime training where you try to have a network with just enough capacity in it before it starts overfitting. But since people could easily get into overfitting with 1,2,1 even with potentially bugged training with resetting seed from previews I would guess it is less than 2. |
Beta Was this translation helpful? Give feedback.
-
|
I have no idea what any of this means, but i'm glad there are anime math nerds doing the good work so we dirt eating artists can make better trainings :D |
Beta Was this translation helpful? Give feedback.
-
|
I need to stop working on this but I can't... Here is how weight decay with loss clamp works (once again that 1 face picture as data set without tags): Weight decay 0.1
Weight decay 0.2
Weight decay 0.4 (I was expecting it to be too big already but it is still kind of good and probably better than 0.2)
Weight decay 2 (I really wanted to illustrate what happens when it is too big but I can't... It is still kind of good but I think it is starting to show)
Weight decay 10 (I was about to say finally it is too big but then step 500 happened and then it only kept getting better)
Weight decay 200( I just don't know anymore... I mean I was thinking 0.1 - 1 would be the optimal range for this.)
Weight decay 9001 (could have stopped at step 500)
Weight decay 1e20 (yes. actually that big)
Actually I got what I wanted 11 hours ago in the post "death by simplification" I simply wrote the loss clamp incorrectly and it never made a loss backward. What you see there is pure normalization from initial weights (at least I think so - I could be wrong but it looks like it to me)
I should also specify that while the same trend will carry over to all hypernetwork trainings the optimal value for weight decay will probably be different each time depending on size of network, number of pictures noise etc. Refer back to the article and section that starts with:
|




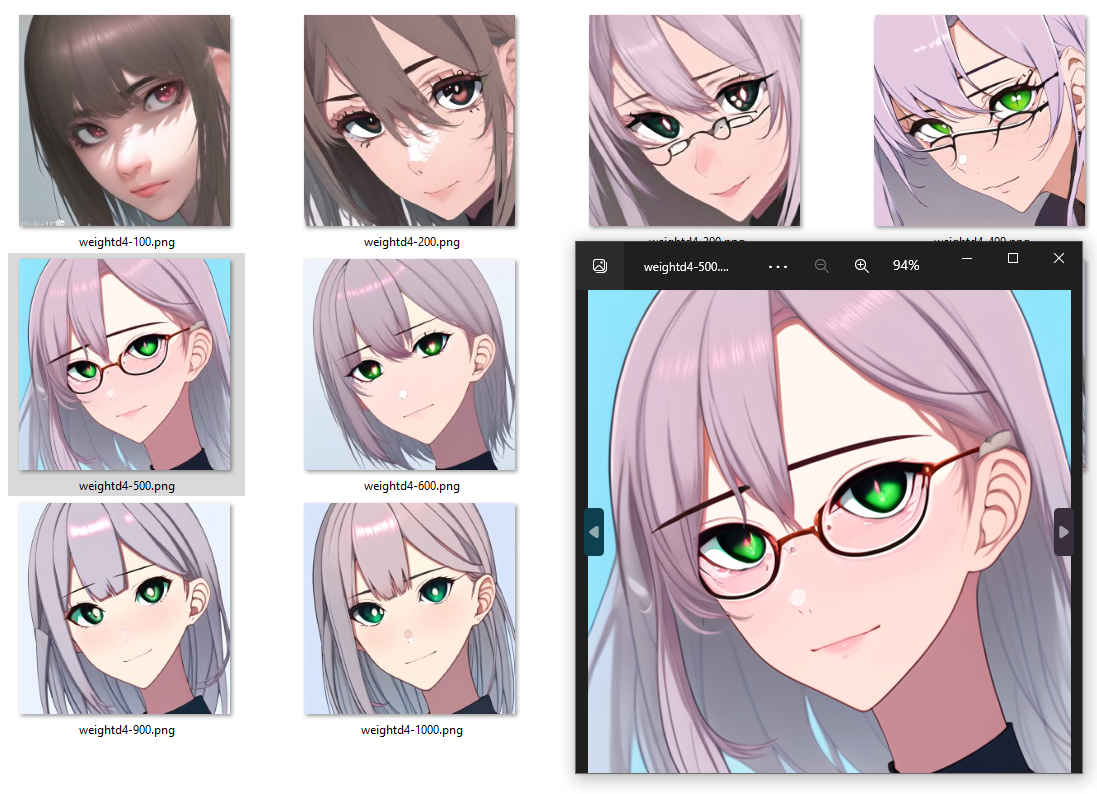
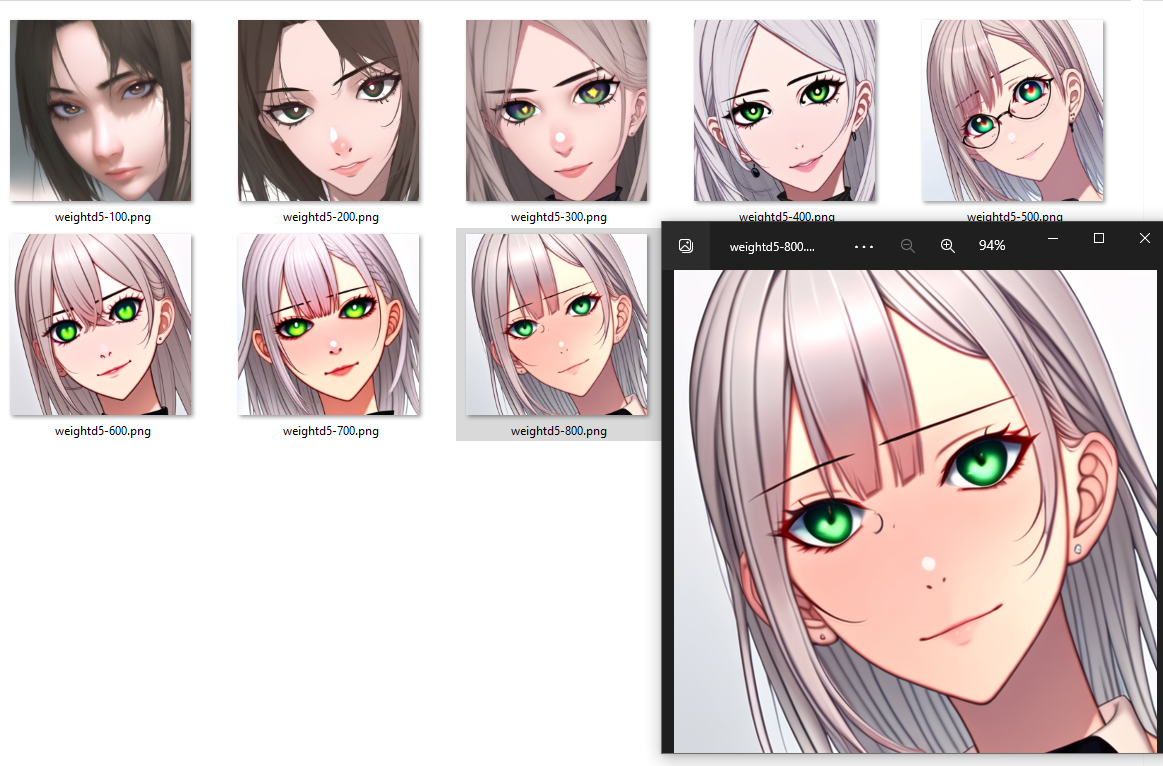


Beta Was this translation helpful? Give feedback.
-
|
Untagged 548 images with mirrors (cause why not). 1,1.5,1.5,1.5,1.5,1 softsign Weight decay 2. Only problem I have with those is that the colors are bland but I guess my prompt was also bland and non-descript. Curious thing is I got it exploding shortly after that and that was a gradient explosion and not overfitting (even when I added gradient clipping). Which could be because of weight decay above 1. |

Beta Was this translation helpful? Give feedback.
-
|
In the original thread I started with I mentioned wanting to try 0.49 or 0.99 because yes I saw that equation. I have a very slowly exploding gradient even with clipping after some iterations. Again I stress the difference between exploding gradient and not overcooking hell colors. On the other hand... I also have results? |
Beta Was this translation helpful? Give feedback.
-
It would have to be |
Beta Was this translation helpful? Give feedback.
-
|
I didn't really look deep into the equations and I can't say I understand them. But my impression was that with weight decay scales with learn rate and at each step it is subtracted from weights. Then in the next step the algorithm can compensate for it and undo this move. That would also make sense with annealing where changing the learn rate along the cosine curve reduces the capacity to correct. So 0.99 means that you are undoing almost all the work of previous step of constant rate. |
Beta Was this translation helpful? Give feedback.
-
I see why you'd think that, but that's not quite right. That would be the case if this was gradient decay, but weight decay is applied to total parameter values, rather than the gradients. So imagine you have parameter Then, weight decay of 0.99 is applied, giving you Now, if your parameter values are very low (which they will probably be if your weight decay is high) the gradients will probably be pushing them further away from 0 rather than towards it, but it's not as clear cut as it seems at first. |
Beta Was this translation helpful? Give feedback.
-
|
Yup that was my understanding of it too, just worded it a bit poorly. It is better to think of it as capacity for adam to escape from 0. At 0.49 it has a capacity to always escape but it is unlikely to ever do it and it is unlikely to ever explode or kill a neuron.
On that I am quite sure it depends on how much of an overkill your network is. If it can easily fit training data then there shouldn't be much need for high values. And it should lead to smooth functions... kinda hinting at what I am trying to do now but I will post when I get a good result. The point is a bit moot cause after one more day experimenting the run on top of this thread was tragic when used outside of this lucky preview. But it was very educational for me. 1.5,1.5,1.5,1.5 softsign even with a smaller weight decay is nowhere near enough to contain 500 pictures and leads to undertraining that is visible when you use the network. The preview also hints at it but I didn't see it. The network has caught onto the most prominent features and approximates them very well, but it ignored details and they never appeared in further steps. Instead I got a very gentle training loss explosion when oversimplification took the function away from approximating even the training set. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
#2670 (comment)
I started discussion there, but it is a bit chaotic as I was still trying to figure it out. Now I have a much more firm grasp and I will demonstrate everything on a run I am doing right now.First of all mandatory reading I posted in that thread:https://towardsdatascience.com/weight-decay-and-its-peculiar-effects-66e0aee3e7b8
What is described there is happening during hypernetwork training, but it is happening very very poorly and it is clear to me that the results are very random, just because of how ADAMW is unintentionally mishandling the training which may be very specific to how training is working right now.There was some truth to what I wrote but I needed to do more runs and I still need to do more runs. I will rewrite it again after I get the result I want.
For now the most important takeaways I got from sitting on this:
You can both undertrain and overtrain network. Overtraining will happen quickly for a complex network, default weight decay and small picture dataset (20). Undertraining will happen quickly for a simple network, high weight decay parameter and a big picture dataset (what was happening in my trainings - too big dataset (150 or so) for too small network even when I was using 300Mb sometimes).
Alternative way of training to the one posted in main hypernetwork style training set and people + me got working:
Make a picture or two in the middle of first epoch. Run training for up to 3000-5000 steps (the whole point of this method is that it is quick and should give fairly nice results) with... whatever learn rate you want, it doesn't matter that much to be honest, as long as it is slightly below the rate where you see the loss increased from the start . See if you like the first pictures in the middle of first epoch more. If you do then you need to increase the size of the network further but it may make the training take longer. Training this way should never lead to overcooking. What you should see is at one point the training loss will start to increase. But before that happens you will probably see the quality of previews drop. So you need to stop before quality of pictures starts to decay.
All of the above is directly tied to the weight norm of parameters - how smooth the functions of your network are. So what I said before this rewrite about it being useful stays. It would be great to be able to see it during training as it tells you if network is headed for simplification of not.
I want to believe that neither this method nor the one in original hypernetwork styles thread is the absolute best and I am going to keep trying to get that best method I have in mind to work.
Beta Was this translation helpful? Give feedback.
All reactions