Replies: 13 comments 43 replies
-
|
it is worth to try it? seems like a lot of steps to intall it... |
Beta Was this translation helpful? Give feedback.
-
|
I'm gonna make a zip people can just drop in their folder that should make it a lot easier. Mainly the important parts are the toolkit and python versions for now but I'll work on rebuilding one for 3.10.6 later. Still have a few hours to go here tho. |
Beta Was this translation helpful? Give feedback.
-
|
Awesome, thank you, waiting for that zip and the instructions.. I already have one of my venvs on the needed version... T1.31.1cu117 - Xformers 0.0.16 |
Beta Was this translation helpful? Give feedback.
-
|
What's the benefit of this? Or is this a gimmick? |
Beta Was this translation helpful? Give feedback.
-
|
To people just creating art with stable diffusion, none. It's more for people who do a lot of training and meant to help offload some of the less important tasks to CPU/RAM |
Beta Was this translation helpful? Give feedback.
-
|
I'm gonna start trying to train little stuff on my laptop, as I have just a 1660ti 6GB ram, it is difficult, and almost all of the time impossible for me to train something with my card... going to give it a try with this... |
Beta Was this translation helpful? Give feedback.
-
|
It still oomed me on 8gbs bc I don't have a ton of system memory but I suspect this is more an issue with some recent updates to either A1111 or Dreambooth extension bc even Lora modeling shoots past 8gb in seconds now. For 6gb cards, you may be able to use Lora training in Kohya still and I'm working on implementing this into that as well. I'm almost home now so I'll write up a quick guide and post the whl first then figure out what all needs to go in the zip and what needs to be deleted on the downloaders side first. |
Beta Was this translation helpful? Give feedback.
-
|
Awesome, that sounds great.. thank you for the effort |
Beta Was this translation helpful? Give feedback.
-
|
i've encountered a new error that wasn't there last night about torch.distributed.elastic training that has me hesitant to post it and risk breaking anybody else's models in the meantime... i've already found the right bit of code to insert to fix it bc it's still looking for a Linux backend. now I just need to figure out where to put it so torch looks for Windows "gloo" instead. it's gotta be either in accelerate or torch... |
Beta Was this translation helpful? Give feedback.
-
|
Take your time... |
Beta Was this translation helpful? Give feedback.
-
|
pretty sure I got it cleaned up hopefully. only warning I get now is one that can thankfully be ignored bc it's for a logging software that windows version doesnt currently support redirecting for anyway lol |

Beta Was this translation helpful? Give feedback.
-
|
nope... still there after remembering to actually enable it in the Deepspeed config. Ironically this build comes from a Microsoft guy on a totally unrelated forum that was like "uh yeah we don't guarantee this will work at all but you can still try to build it".... son of b... welp back to work on it lol |

Beta Was this translation helpful? Give feedback.
-
|
I have good news and bad news... The problem was never anything to do with my install at all bc I was able to recreate the same exact error without deepspeed installed at all from a zipped backup I made right before installing it... thats the good news... the bad news is I was able to recreate it simply enabling any sort of distributed training via accelerate config... so that means the likely culprit is either the Triton module, my primary suspect, or xformers, or both bc the 2 are tied together... |
Beta Was this translation helpful? Give feedback.
-
|
nope... its still throwing up the same error with distributed training on and both triton/xformers deleted entirely |
Beta Was this translation helpful? Give feedback.
-
|
the culprit has got to be accelerate... I just did a fresh install from zip with the only thing added being "--xformers" to launch.py line 178 in command args |
Beta Was this translation helpful? Give feedback.
-
|
found it... now... how to fix it... NCCL is linux |
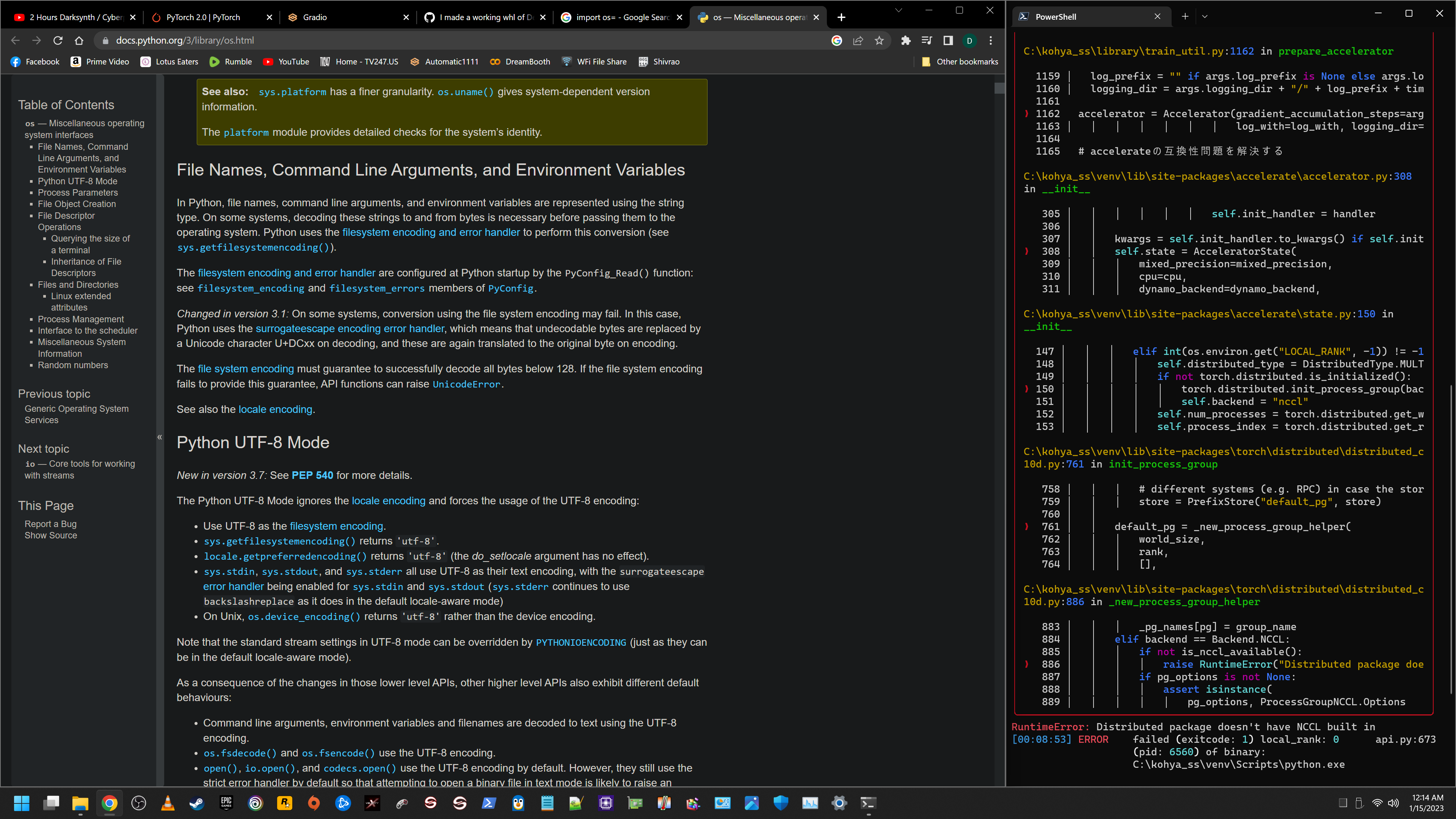
Beta Was this translation helpful? Give feedback.
-
|
this is from accelerate 0.15.0 you get with dreambooth extension that breaks while trying to install it in its own now from fresh zip extract... |
Beta Was this translation helpful? Give feedback.
-
|
im friggin exhausted but here's the whl file for anyone else who wants to give it a go: |
Beta Was this translation helpful? Give feedback.
-
|
Python working fine now... Still having the issue with "Accelerate"... |
Beta Was this translation helpful? Give feedback.
-
|
Search python from start menu, then right click the version you're looking for if you have multiple versions installed and click open file location. When it pops up, right click and tap open file location again. Right click and choose "copy as path" and paste that next to the set PYTHON= towards the top in webui-user.bat. no space between = and the file location still in quotes |
Beta Was this translation helpful? Give feedback.
-
|
set PYTHON="C:\program files\python 3.10.9\python.exe" Or wherever it points to on your computer when you paste it in |
Beta Was this translation helpful? Give feedback.
-
|
Glad you got that sorted but this should help find it next time and you can switch between versions this way pretty easily bc the full version name is given from start menu |
Beta Was this translation helpful? Give feedback.
-
|
thanks a lot..! |
Beta Was this translation helpful? Give feedback.
-
Beta Was this translation helpful? Give feedback.
-
|
Cool, waiting for the final fixes to get the most benefit of this.. thanks! Let us know your advances. |
Beta Was this translation helpful? Give feedback.
-
|
Looking forward to the final fixes too! Thanks |
Beta Was this translation helpful? Give feedback.
-
|
I'm pretty sure i've done everything I can on this from my end until Windows has better support for distibuted training baked into it bc everything is trying to look for a linux only backend nvidia has no plans on ever migrating over while torch distributed only really supports NCCL for GPU and gloo for CPU with little to no support for the one type of distributed windows supports called MPI... I hate Linux and WSL linux is even more of a headache... Oh well for now I guess |
Beta Was this translation helpful? Give feedback.
-
|
Are the steps in your previous comments working? I only have a single GPU, should I try them? |
Beta Was this translation helpful? Give feedback.
-
|
Right now this is a project on hold. Windows won't support Dreambooth training on more than 1 card with any less than 10GB of vram bc it has no language like NCCL to distribute the training process that's supported by pytorch. Nvidia has no plans to ever migrate NCCL to Windows either. Outside of doing it for them using something like codeGPT or codebert, which is no easy task, the only choice is Linux. Not subsystem linux either bc that's a headache and a half with all the errors that pop up from not knowing where libraries that were literally just installed are located all the time, full fledge linux. Need a minimum 8gb vram and 32gb (48gb minimum on WSL2, preferably 64gb) of system RAM but it's at least possible. I'm making up to date guides for both BC all the current ones I've found are broken... |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for your work bro, appreciate it. |
Beta Was this translation helpful? Give feedback.
-
|
Hi @PleezDeez |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
With the recent triton build for windows I was able to get deepspeed to build with proper sparse attention support from it on windows and integrated it into my 1111. I have a whl for it I'm going to be uploading tonight after a family gathering when I have more time to make a proper install guide but for now I'll leave the requirements I was working with. CUDA Toolkit 11.7, python 3.10.8, xformers most recent 0.0.16dev424 build, Deepspeed 0.8.0, torch 1.31cu117, py_cpuinfo, Triton 2.0.0 with any meta data in it and the dist.info folder saying it's 1.0.0, the contents of venv/lib/site-packages/triton copied into and over the contents of the triton folder in xformers it conflicts with, a few other metadata edits to numba, tensorflow_intel, and open_clip_torch to make them accept numby 1.23.3, had to change line 176 of launch.py and replace the torch it asks for there with the pip install command for torch 1.13cu117, and I had to make the accelerate config file in WSL then copy it over to windows to avoid a ton of errors that pop up after enabling deepspeed in the the config menu but it accepted the wsl parameters without issue. CPU offload is working now with triton as well but still no NVMe offload bc I have no way to get it to address the drives.
Beta Was this translation helpful? Give feedback.
All reactions