diff --git a/AWS_DeepRacer_Presentation.pdf b/AWS_DeepRacer_Presentation.pdf
new file mode 100644
index 0000000..917d445
Binary files /dev/null and b/AWS_DeepRacer_Presentation.pdf differ
diff --git a/DesignDoc.md b/DesignDoc.md
new file mode 100644
index 0000000..22b4ad5
--- /dev/null
+++ b/DesignDoc.md
@@ -0,0 +1,153 @@
+## Contributing members
+
+- **Ahmed Moustafa** - Model (training & testing), Physical track & model, Notebook (README), Design Doc, Presentation
+
+- **Ramiro Gonzalez** - Notebook (README), Model (reward function), Design Doc, Presentation
+
+- **Cristopher Torres** - Ethical Considerations Worksheet, Design Doc
+
+- **Jaydyn Odor** - Design Doc, Track
+
+## Abstract
+
+Train a 1/18th scale AWS car to race autonomously using a Reinforcement Learning model.
+
+## Background
+
+
+ +
+
+
+#### What is **Reinforcement Learning**?
+Reinforcement Learning is a subset of Machine learning yet it differs from the other 2 basic Machine Learning paradigms (Supervised & Unsupervised). A specific difference we can point to between Reinforcement Learning and Supervised Learning is the unecessary input/output labellings as RL algorithms typically use dynamic programming techniques with the goal of automatically improving through reward maximization.
+
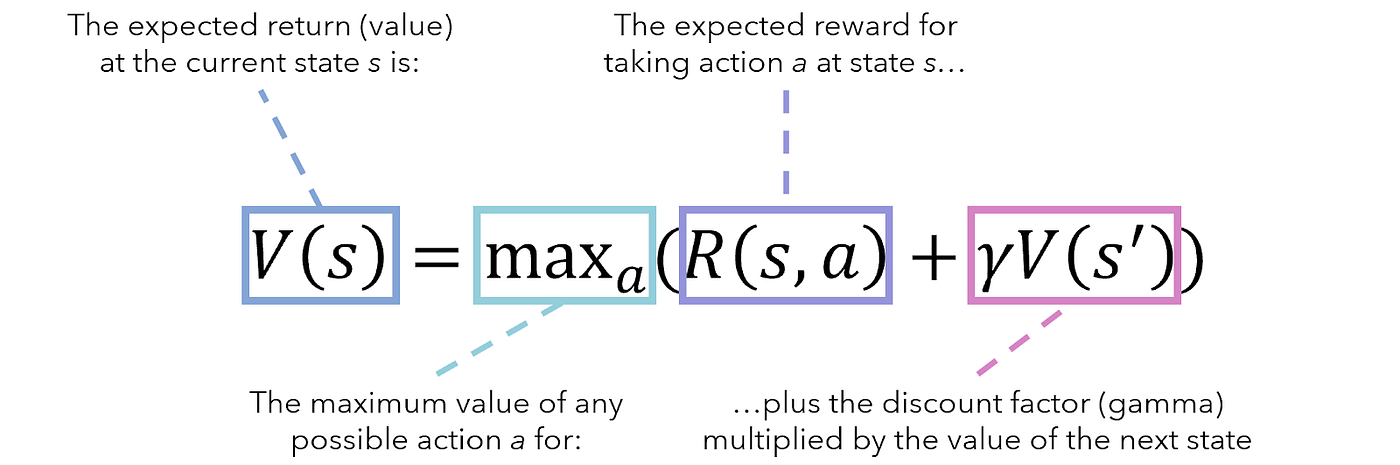
+The formal definition of RL is "*an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.*" The basis of most Reinforcement Learning algorithms is the Markov Decision Process which is an extension of Markov Chains. Below is a labelled value iteration function which is the mathematical formula that is occuring behind the scenes for how our agent determines which actions are "better" than others at any given moment.
+
+
+ +
+
+
+MDP and RL can get very complicated and this basic/relevant information is only the surface of those topics so if you'd like to read more about it, checkout the links under the `Resources` header. On the note of Reinforcement Learning, it's important to understand how the AWS DeepRacer works [behind the scenes](https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-how-it-works-solution-workflow.html) to apply these concepts.
+
+- The AWS DeepRacer service initializes the simulation with a virtual track, an agent representing the vehicle, and the background.
+
+
+ +
+
+
+- The agent embodies a policy neural network that can be tuned with hyper-parameters. The agent acts (as specified with a steering angle and a speed) based on a given state (represented by an image from the front camera).
+
+ Hyperparameters for RL Optimization Algorithm
+
+ +
+
+
+ Example Action Space for Model to choose from
+
+ +
+
+
+- The simulated environment updates the agent's position based on the agent action and returns a reward and an updated camera image.
+- The experiences collected in the form of state, action, reward, and new state are used to update the neural network periodically. The updated network models are used to create more experiences.
+- The AWS DeepRacer service periodically saves the neural network model to persistent storage.
+
+
+## Problem Space
+ With companies like Tesla and Google paving the way for autonomous driving, machine learning has only continued to make strides towards a more automated future of
+travel. The reinforcement learning model for the AWS car was built to maximize accuracy in order for the vehicle to successfully complete a track autonomously. The
+autonomous model was operated under constant conditions for its tests, however what makes autonomous driving such a convoluted task is the required adaptability of a
+model under different conditions (i.e. visibility, road conditions, objects obstructing the road). It is fundamental to get a foundational, reinforced model that can
+make normal turns like the AWS car does prior to working with bigger vehicles in more rigorous environments.
+
+## Model Creation
+
+ To begin developing the model, we had to select values for the hyperparameters, action space, and a reward function. The hyperparameters of this project are gradient
+descent batch size, entropy, discount factor, loss type, learning rate, number of experience episodes between each policy-updating iteration, and number of epochs. The
+action space defines the limits of your vehicle. We choose the limits for steering angle and speed. There are many parameters that we are allowed to use when we are
+tuning the reward function. The ones that we used for the final model are distance_from_center, track_width, speed, waypoints, closest_waypoints, progress, and steps.
+
+
+ The AWS DeepRacer console allows us to choose when we want the training to stop. The range is from 5 to 1440 minutes. We usually kept this time unchanged, with the
+default being one hour. Each model was trained and evaluated on the re:Invent 2018 track.
+
+ For our first two models, we used built-in reward functions and used the default hyperparameters and action space. In the first model, the agent is incentivized to
+follow the center line. The second model uses a reward function that penalizes crooked driving. For the third model, we increased the entropy of the second model, but
+the performance was worse, so we didn’t change the hyperparameters afterwards. We explored other reward functions and their performances in order to determine which
+parameters we may want to introduce to our own reward function.
+
+ We added the speed parameter to the reward function, along with code to incentivize higher speed. Additionally, We changed the action space, increasing the max speed
+from 1 m/s to 2 m/s. We did not finish training this model because it was performing much worse than others. The speed incentive made it difficult for the agent to
+properly learn turning.
+
+ In our fifth model, we added the steering_angle parameter and created a threshold variable. Using absolute steering_angle, we only incentivized speed if the
+steering_angle was below the threshold. That way, the model would hopefully learn that it should only speed up when it is not turning at a high angle (such as at a
+corner). In the next model, we increased both the maximum speed to 3.5 m/s and the minimum speed to 0.8 m/s. Also, we replaced the center-line incentive and its
+associated parameters with waypoints, closest_waypoints, and heading. We modified the speed incentive rewards and threshold. We used code from the AWS DeepRacer
+Developer Guide to incentivize the agent to point in the right direction. However, once again, the model was performing poorly, so we stopped training early. We
+readjusted the speed range to [0.5: 3] m/s. We reintroduced the center-line incentive, with a modification to the reward weights. We also changed the way we used
+waypoints and closest_waypoints. We used code from the identify_corner() method written in this Github repository to determine if the agent was approaching a corner.
+We added a threshold for difference between current direction and future direction that we would use, along with speed, to penalize high speed near a turn and reward
+slow speed near a turn. Additionally, we penalized slow speed on straight track and rewarded high speed on straight track. The results of this model's evaluation were
+poor.
+
+ In the ninth model, we made changes to the previous model by adding the progress and speed parameters, changing the reward weights for all actions (instead of
+multiplying by different weights, we were now adding and subtracting) and we changed the way we used waypoints. We also increased the minimum speed to 0.6 m/s and
+added thresholds for speed and total steps. We learned that the agent performs roughly 15 steps per second. We learned how to incentivize the agent to make more
+progress more quickly using the Developer Guide. To do this, we checked the ratio of progress to 100% track completion and the ratio of current steps to the total
+steps threshold. The total steps threshold was just calculated by multiplying 15 by however many seconds we believed was a good average time, (20 seconds). We rewarded
+the agent based on how much faster it had gotten to a certain point that it would have if it went at a 20-second pace. The faster it went, the greater the reward.
+This model had an average performance.
+
+ For the next model, we once again changed the reward weights and reduced the average time to 18 seconds. We also added a piece
+of code that rewarded the agent every time it made it past certain points of the track. However, we realized that this could lead to overfitting, and so we stopped
+the training of this model before it was completed to remove this piece of code.
+
+ The eleventh model was our final model. We changed the reward weights for the progress portion of the function and removed rewards for turning corners. After several
+evaluations, we determined that this is the best model. Although it doesn’t have the best evaluation or the fastest lap (the fastest lap was performed by model ten,
+though we quickly realized that this was a fluke), it is incredibly consistent, and within one second of the fastest overall evaluation. This was the model that we
+ended up using for the physical car. The values for the hyperparameters and action space for this model are shown below.
+
+
+ +
+
+
+## Results
+
+ We tested multiple models with different hyperparameters but we settled on our final model based on it's performance in the categories of both speed and consistency as both are important when transfering from a virtual to physical environment. For some additional information on our work throughout the project, ethical discussions, and results please check the `README.md`, `EthicalConsiderationsWksht.md`, and `AWS_DeepRacer_Presentation.pdf`.
+
+
+ +
+
+
+ Evaluation Results Table
+
+ +
+
+
+## Uses
+
+ Our model is used to train the AWS car to self-drive over a miniature track. More importantly, the AWS car helps simplify the initial steps for autonomous driving. Being able to test various training models virtually and then physically allows for many advantages. Overall, this led us to a more precise car in a fraction of the time. Furthermore, our 1/18th scale model was able to perform regular turns, at average speeds, using its reinforcement learning model. Furthermore, we have seen applications of models similar to but much more complex than ours in countless companies who are on the forefront of self-driving vehicles like Tesla, Canoo, etc.
+
+## Improvements
+
+### **Physical Limitations**
+- The **cost** of materials for a full track and **time** to construct it with the correct angles. Trying to make a subset of the re:Invent 2018 track with poster boards and tape was difficult because we lacked the tools and space. Since our model was trained on a virtual environment with no flaws in the track, all the small issues negatively affected the performance of our robot's real-life evaluation.
+- **WiFi** limitations were very frustating since it made connecting our laptop to the robot and streaming the camera's content sluggish and sometimes non-existent. The AWS DeepRacer logs also have no information on connecting to a network that is account secured like university WiFi. Our solution was to bring our own router to create a separate network that both the laptop and car could connect to.
+- The **AWS DeepRacer Compute Module** caused many issues that were nearly undiagnosable without previous knowledge. Alongside WiFi limitations were the challenges that were caused by a possibly corrupt ruleset for the compute module. The webserver would not open on our computers when connected to the car even after factory resetting by installing a fresh Ubuntu OS onto it and resetting the AWS credentials. The solution was to add an "http" rule to the compute module though that was nowhere to be found in any documentation or forums.
+
+### **Virtual Limitations**
+- Our free AWS accounts only had **10 hours for training & testing models** which made it hard to play around with all the combinations of hyperparameters as well as the fine-tuning for the reward function values which may have improved our time. Our approach to mitigate this was having each person test different models on separate accounts to get the most efficiency.
+
+ If we had more time in the future, some goals that we would love to accomplish are the optimization of our model to be faster than 10 seconds per lap as well as testing more on other tracks to avoid overfitting to one track. With regards to the physical environment, we'd hope to create a more permanent track using EVA foam pieces so that it is collapsable/transportable. Both virtually and physically, entering a competition is something that would allow us to compare and discuss our models and training environments to others who may have more experience or understanding in the field of Reinforcement Learning and Autonomous Driving.
+
+## Conclusion
+
+ The tested AWS model was able to successfully run the track virtually, and a segment of the track physically. Within the parameters of this project, the scaled-down model was precise enough to safely make it through the tracks without any major crashes. Our model was not perfect however, the speed of the physical model was lackluster during its few runs. This comes to no surprise since the main limiting factor was time. Given more time we could have worked with different tracks and models to see the adaptability of our vehicle. These results would have been interesting to study since different models could have been better on certain sets. Having a foundational code for autonomous driving like the AWS car provided could be used in larger projects and studies to help further self-driving.
+
+## Resources
+- https://www.baeldung.com/cs/mdp-value-iteration
+- https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292
+- https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-how-it-works-action-space.html
+- https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-how-it-works-solution-workflow.html
+
+
diff --git a/EthicalConsiderationsWksht.md b/EthicalConsiderationsWksht.md
new file mode 100644
index 0000000..3302e85
--- /dev/null
+++ b/EthicalConsiderationsWksht.md
@@ -0,0 +1,82 @@
+# AWS DeepRacer Ethical Considerations Worksheet
+
+**1. What is the importance of adaptability in a model, and what unprecedented issues may arise by allowing a car to drive itself with an inputted model only?**
+
+ Autonomous driving, a revolutionary idea within machine learning, has been improved at
+an exponential rate for the last few decades. A vast number of different models exist, however
+what most models retain in commonality is the training process they require. The reason for this
+being that the models must not only prioritize performance, but adaptability as well. A car can
+encounter many different styles of road’s, facing different conditions. A model only inputted and
+not trained will meet its limitations eventually, whether it be factors like the angle of a road, the
+speed limit on a road, or an object scattered on the road, this is why a trained and adaptable
+model is crucial.
+
+**2. How does variety in roads and their conditions create limitations on customers and the deployment of fully autonomous vehicles?**
+
+ Autonomous driving has made significant strides towards daily consumer usage. The
+greatest limitation with a self-driving vehicle however is variability and a model's ability to
+recognize different structures instantaneously. Machine reaction rates can be drastically better
+than a human's. A human's average reaction time to a visual stimulus is about ¼ of a second, and
+in most driving accidents fractions of a second can be the difference between evading an impact,
+or causing a crash. So why have autonomous vehicles not been implemented worldwide?
+Although the reliability of the vehicle may not be of main concern in these scenarios, being able
+to react to objects, animals, or people on the road at a similar reaction rate of a human is pivotal.
+Weather and geography can also play a crucial role in self-driving. A car's ability to correct
+hydroplaning, manage sliding on snow, and navigate tight corners is a prerequisite when
+distributing a new technology as important as this. Once all variables are accounted for and the
+car's adaptability is nearly identical to a human's then autonomous driving may become an
+ordinary part of travel.
+
+**3. What problem is the AWS Deep Racer trying to solve? Who will benefit if the problem is solved, and how will the model help?**
+
+ Ever since Karl Benz invented the Motorwagen in 1886 traveling was revolutionized and
+has remained unchanged for over a century. Although driving has never been safer with more
+safety regulations than ever in history, thousands of fatal crashes continue to occur on a yearly
+basis. What autonomous driving is trying to accomplish is the improvement of vehicles
+dependability, precision, and the diminishment of human-error accidents. Drivers provoke most
+of their mistakes when driving due to carelessness and distractions. With a computer automated
+driving system these obstacles could be mitigated. Unlike humans, machines do not become
+distracted changing the station on the radio, or become drowsy after driving extensive hours.
+That is why, in a world where we are on the move the majority of the day, autonomous driving is
+the solution we need for reduced accidents and overall safer travel.
+
+**4. Running an overfitted model can be problematic. What types of biases may arise when testing autonomous driving on different tracks/roads?**
+
+ Different obstacles require distinct, precise maneuvers to evade. A vehicle must be able
+to maintain composure and differentiate instantly amongst objects it has been trained with. For
+example, an animal may suddenly appear on a blind turn where the car’s visibility is reduced.
+When the animal comes into view the vehicle must be able to determine not only that an object is
+in the way but what it is. The main reason for this being that different animals may require
+different movements. A smaller animal many times can be run over in a worst case scenario.
+However, a larger animal like a deer must be evaded at all costs to ensure the passengers safety.
+This is why overfitting animals, or weather conditions can become dangerous. Another example
+of this can be seen during winter months. A car may be able to relate sunny weather to safe
+roads, this however changes when the temperature is below freezing and icy roads must be
+accounted for. Being able to accurately make decisions from many factors is what it takes for a
+vehicle to be able to drive itself better than any person.
+What might we do to mitigate future biases with autonomous driving performance.
+There are a plethora of things that can be done to mitigate any biases that may arise when
+training a vehicle model. What it really comes down to however is the model's accuracy when
+adapting to different situations. To mitigate bias we must increase the rate of recognition, an
+example of this can be seen when a vehicle encounters a person. Not all people look the same so
+the model must be able to differentiate what is a person. If the model encounters a child it must
+recognize it as a human although it may not look like an adult. This can only be done through
+extensive training points that the data can use to quickly make decisions on certain situations it
+encounters.
+
+**5. Who might be negatively impacted by your analysis? This person or persons might not be directly considered in the analysis, but they might be impacted indirectly.**
+
+ New technologies implemented to the public do not always have only positive impacts
+for everyone. Even when Henry Ford increased the accessibility of the motorized vehicle for
+common consumers to enjoy, fatal motorized crashes only grew exponentially. Just like a new
+technology, automated cars can not positively impact every potential party at stake. A potential
+risk when incorporating self-driving vehicles is job loss, specifically occupations as simple as
+delivery services or trailer drivers. Ever since companies like Amazon have taken control,
+delivery has become part of our everyday lives. What most people do not realize however is that
+these companies employ millions to keep their distribution running smoothly. With access to
+self-delivery vehicles that do not require a person to conduct, many companies will turn to
+saving more profits by cutting workers. Although examples like this may appear to be an issue
+that is a century away it is important to keep in mind there are a lot more people at stake when it
+comes to innovation. Being able to control interactions between people-driven cars and
+autonomous vehicles can also lead to negative impacts. Taking these things into consideration is
+needed in order to transition into a new technology.
\ No newline at end of file
diff --git a/README.md b/README.md
index 4b882f3..c75ff23 100644
--- a/README.md
+++ b/README.md
@@ -2,29 +2,239 @@
-# final-project
-## [National Action Council for Minorities in Engineering(NACME)](https://www.nacme.org) Google Applied Machine Learning Intensive (AMLI) at the `PARTICIPATING_UNIVERSITY`
+# AWS DeepRacer Final Project
+## [National Action Council for Minorities in Engineering (NACME)](https://www.nacme.org) Google Applied Machine Learning Intensive (AMLI) at the `University of Arkansas`
Developed by:
-- [member1](https://github.com/cbaker6) - `STUDENTS_UNIVERSITY`
-- [member2](https://github.com/cbaker6) - `STUDENTS_UNIVERSITY`
-- [member3](https://github.com/cbaker6) - `STUDENTS_UNIVERSITY`
-- [member4](https://github.com/cbaker6) - `STUDENTS_UNIVERSITY`
+- [Ahmed Moustafa](https://github.com/a-mufasa) - `University of Arkansas`
+- [Ramiro Gonzalez](https://github.com/ramirog034) - `University of Arkansas`
+- [Jaydyn Odor](https://github.com/Jodor101) - `University of Arkansas`
+- [Cris Torres](https://github.com/CristopherTorres1) - `Penn State University`
-## Description
-
+## Project Description
+According to the "Capstone Projects" pdf, which introduced us to the possible final projects, the goal for the AWS DeepRacer Project is to "**train a 1/18th scale car to race autonomously using Reinforcement Learning.**"
+
+## Intro to Reinforcement Learning
+Reinforcement Learning differs from the other 2 basic Machine Learning paradigms (Supervised & Unsupervised). A specific difference we can point to between Reinforcement Learning and Supervised Learning is the unnecessary input/output labelings as RL algorithms typically use dynamic programming techniques with the goal of automatically improving through reward maximization.
+
+
+
+
+
+## Dataset
+The dataset our autonomous vehicle will use is the live sensor data it extracts which is used to train our model to determine the correct (highest reward) action via our reward function. This automatic *trial-and-error* process will give us a model that can respond to similar environments as our training with the same actions deemed correct by the algorithm.
## Usage instructions
-1. Fork this repo
-2. Change directories into your project
-3. On the command line, type `pip3 install requirements.txt`
-4. ....
+1. Make sure you have access to the [AWS Console](https://aws.amazon.com/deepracer/getting-started/) for training & evaluating the model
+2. Follow the AWS DeepRacer instruction on how to 'Create a Model' and use the default hyperparameters on the 're:Invent 2018' track.
+3. Copy the code in `final_reward.py`
+4. Paste the reward function code into AWS and train & evaluate the model
+
+## Final Model: Training Configuration
+ re:Invent 2018 track
+
+ +
+
+
+Training happens through an iterative process of simulation to gather experience, followed by training on the experience to update your model, followed by simulation using the new model to get new experience, followed by training on the new experience to update your model and so forth. Initially your model does not have any knowledge of which actions will lead to good outcomes. It will choose actions at random as it explores the environment. Over time it will learn which actions are better and start to exploit these. How quickly it exploits or how long it explores is a trade-off that you have to make.
+
+ Hyperparameters for RL Optimization Algorithm
+
+
+
+
+The screenshot below shows the training configuration for the final model. This includes the action space, which is where we set the maximum and minimum speeds for the agent, as well as the maximum and minimum steering angles. Additionally, the screenshot shows the settings for the hyperparameters, which were not altered for the final model. A separate model, using the same reward function but an increased gradient descent batch size, number of experience episodes between each policy-updating iteration, and decreased learning rate led to much more consistent training, but slower peformance upon evaluation.
+
+
+
+
+
+## Elements of Reward Function
+
+### **Initializing parameters**
+ List of Variables for the Reward Function
+
+ +
+
+
+The following code block shows the first few lines for the reward function. Here, we give a brief summary of the reward function's incentives and penalties. We also read the input parameters to memory in order to use them throughout the rest of the function. After we read in the parameters, we create three variables that hold values that we will later use to incentivize staying near center line of the track. We created thresholds and initialized the reward value in the final part of this code block.
+
+```python
+# Read input parameters
+distance_from_center = params['distance_from_center']
+track_width = params['track_width']
+speed = params['speed']
+waypoints = params['waypoints']
+closest_waypoints = params['closest_waypoints']
+progress = params['progress']
+steps = params['steps']
+
+# Calculate 3 marks that are increasingly farther away from the center line
+marker_1 = 0.1 * track_width
+marker_2 = 0.25 * track_width
+marker_3 = 0.5 * track_width
+
+# initialize thresholds and reward
+DIFF_HEADING_THRESHOLD = 6
+SPEED_THRESHOLD = 1.8
+TOTAL_STEPS = 270 # roughly 15 steps per second, 18 sec default lap
+reward = 5
+```
+
+### **Progress Incentive**
+After some research, we learned that the agent performs roughly 15 steps per second. The AWS DeepRacer Developer Guide (https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-input.html) provides information regarding all of the parameters that we can modify in the reward function. The guide also provides code that shows examples of the paramaters in use. One of these examples uses the "progress" and "steps" parameters in order to code a reward function that incentivizes the agent to make more progress more quickly. To write the code block below, we used the same logic, but modified the specific numbers.
+
+```python
+############################
+# Steps and progress, check every 30 steps. The less steps it takes to reach 100% progress means finished faster
+############################
+
+# reward less steps with greater progress if faster than 18 sec
+if (steps % 20) == 0 and progress/100 > (steps/TOTAL_STEPS):
+ reward += progress - (steps/TOTAL_STEPS)*100
+```
+
+Essentially, the "TOTAL_STEPS" variable is calculated using 15 steps per second * 18 seconds. 18 is an arbitrary value that we decided on based on the performance of the model using a default reward function. Since the agent performs 15 steps per second, it should complete 270 steps in 18 seconds. If the agent has made more progress around the track than it would have if it was driving at a constant 18 second pace, the agent is rewarded. This reward is calculated based on how much further ahead it is than it would've been if driving at an 18 second pace. We check every 20 steps.
+### **Waypoints Incentive**
+The waypoints parameter is an ordered list of milestones along the track center. Each track has its own unique list of waypoints. Each milestone is described as a coordinate of (xw,i, yw,i). The image below helps to visualize the manner in which waypoints are placed along a track. It is possible to retrieve the coordinates of any desired milestone at any point. This fact can be used to determine a corner in the future.
+
+
+ +
+
+
+In the code block below, we find the previous milestone, next milestone, and a milestone 6 points in the future. We then calculate the measure (in degrees) of the current direction we are facing, and the direction we will face 6 points in the future. We find the difference between these two variables. If this difference is greater than a certain value (stored in DIFF_HEADING_THRESHOLD), it indicates that a corner exists close ahead of the agent at the time. If the difference is greater than the threshold and the agent is going faster than the speed threshold (stored in SPEED_THRESHOLD), we penalize the agent. This works to incentivize the agent to take corners more slowly.
+
+```python
+#############################
+# Waypoints: referenced code from https://github.com/MatthewSuntup/DeepRacer/blob/master/reward/reward_final.py
+#############################
+
+# finding previous point, next point, and future point
+prev_point = waypoints[closest_waypoints[0]]
+next_point = waypoints[closest_waypoints[1]]
+future_point = waypoints[min(len(waypoints) - 1, closest_waypoints[1]+6)]
+
+# calculate headings to waypoints
+heading_current = math.degrees(math.atan2(prev_point[1]-next_point[1], prev_point[0]-next_point[0]))
+heading_future = math.degrees(math.atan2(prev_point[1]-future_point[1], prev_point[0]-future_point[0]))
+
+# calculate difference between headings
+# check we didn't choose reflex angle
+diff_heading = abs(heading_current-heading_future)
+if diff_heading > 180:
+ diff_heading = 360 - diff_heading
+
+# if diff_heading > than threshold indicates turn
+# so when a turn is ahead (high diff_heading)
+# penalize high speed, reward slow speed
+if (diff_heading > DIFF_HEADING_THRESHOLD) and speed >= SPEED_THRESHOLD:
+ reward -= 4
+```
+### **Centerline Incentive**
+The final part of the reward function was to incentivize the agent to stay near the centerline of the track. The following code is a modified version of the first default reward function given by the AWS DeepRacer console.
+
+```python
+############################
+# Center line incentives
+############################
+
+# give higher reward if the car is closer to center line and vice versa
+if distance_from_center <= marker_1:
+ reward += 5
+elif distance_from_center <= marker_2:
+ reward += 4
+elif distance_from_center <= marker_3:
+ reward += 3
+else:
+ reward -= 4
+```
+
+## Reward Graph
+The reward graph shows the model's progress as it trains. It is a line graph with three lines: Average reward (training), Average percentage completion (training), and Average percentage completion (evaluating). The final reward graph is shown below.
+
+
+
+
+
+## Testing Evaluation
+After the training had completed, we evaluated the model using the same track that it trained on. The AWS Console allows us to perform multiple evaluations. Below, we show the result and a video of our best evaluation that we performed, where the agent drove three laps around the track during each evaluation.
+
+ Evaluation Video
+
+
+
+ Evaluation Results Table
+
+
+
+
+## Physical Testing
+The entire goal of the AWS DeepRacer project is the train a Reinforcement Learning model that can be inputted into a vehicle in the real-world. To truly test our model we built the vehicle with all the necessary sensors to collect data and extract the parameters for running our trained model from earlier.
+
+### **Building the Robot**
+ Unboxed AWS DeepRacer Kit
+
+ +
+
+
+ Assembled Car
+
+  +
+
+
+We completed the assembly of our AWS DeepRacer Car using the instructions on [Amazon's Guide](https://aws.amazon.com/deepracer/getting-started/). After building the car we had to connect and calibrate it using a WiFi network to access the car's control panel for uploading and running our model. Below is a screenshot of the control panel for the robot.
+
+  +
+
+
+
+### **Building the Track**
+ re:Invent 2018 Track Template
+
+ +
+
+
+With our time constraints and the high price and lack of availability of materials, we were not able to construct a full track but rather completed a subset of the track which was the left hand side (boxed in green above).
+
+ Final Track Subset
+
+ +
+
+
+### **Evaluating the Model**
+Through the AWS DeepRacer control panel, we imported our best trained model that we had previously evaluated virtually (as shown earlier). Due to wifi limitations as well as the imperfect track conditions, we had to limit our vehicle's speed to ~50% which is why the run is not nearly as fast as the virtual. We can see in this video that the model seemed to be able to handle 110° and 78° turns as well as speed up on a straight-away.
+
+ Successful Physical Run
+
+
+
+
+## Discussion
+Throughout the development of our AWS DeepRacer, we experienced many challenges and moments of learning with relation to both the creation of a Reinforcement Learning model as well as the physical implementation and execution of projects. A huge consideration for the AWS DeepRacer project is that the 2 components (virtual and physical) can take months alone to set up and fine-tune for competitions so the limitation on time we had resulted in a lot less training and testing than ideal.
+
+### **Physical Limitations**
+- The **cost** of materials for a full track and **time** to construct it with the correct angles. Trying to make a subset of the re:Invent 2018 track with poster boards and tape was difficult because we lacked the tools and space. Since our model was trained on a virtual environment with no flaws in the track, all the small issues negatively affected the performance of our robot's real-life evaluation.
+- **WiFi** limitations were very frustating since it made connecting our laptop to the robot and streaming the camera's content sluggish and sometimes non-existent. The AWS DeepRacer logs also have no information on connecting to a network that is account secured like university WiFi. Our solution was to bring our own router to create a separate network that both the laptop and car could connect to.
+- The **AWS DeepRacer Compute Module** caused many issues that were nearly undiagnosable without previous knowledge. Alongside WiFi limitations were the challenges that were caused by a possibly corrupt ruleset for the compute module. The webserver would not open on our computers when connected to the car even after factory resetting by installing a fresh Ubuntu OS onto it and resetting the AWS credentials. The solution was to add an "http" rule to the compute module though that was nowhere to be found in any documentation or forums.
+
+### **Virtual Limitations**
+- Our free AWS accounts only had **10 hours for training & testing models** which made it hard to play around with all the combinations of hyperparameters as well as the fine-tuning for the reward function values which may have improved our time. Our approach to mitigate this was having each person test different models on separate accounts to get the most efficiency.
+
+### **Results**
+By the end of this project we successfully created a reward function for a Reinforcement Learning model and trained it to drive the AWS DeepRacer car around a track autonomously. Our virtual times of ~13 seconds for the 2018 competition track were not perfectly translated to physical testing for reasons as mentioned above but we still were able to get the model loaded onto the actual car and working.
+
+The most valuable part of this was being able to get hands-on experience with Applied Reinforcement Learning with the autonomous driving in this project. The ability to take the theoretical concept of Markov Decision Process and dynamically programmed trial-and-error and create something practical provided insight into the real-world use cases of Machine Learning.
+
+### **Considerations and Future Goals**
+While the learning process is crucial, it's even more important to question the implications of what you're doing. This is especially true as the project you are working on is more applied/practical. We dove deeper into the history of driving and the possible biases and impacts of our project in the real world. An example of the considerations that should be taken into account is how our project and trained models wouldn't be able to be applied in many real-world scenarios as roads are very different depending on where you are. This can cause a disparity in access to this new technology. For more in-depth discussion on these questions feel free to read the `EthicalConsiderationsWksht.md` within this repo.
+
+If we had more time in the future, some goals that we would love to accomplish are the optimization of our model to be faster than 10 seconds per lap as well as testing more on other tracks to avoid overfitting to one track. With regards to the physical environment, we'd hope to create a more permanent track using EVA foam pieces so that it is collapsable/transportable. Both virtually and physically, entering a competition is something that would allow us to compare and discuss our models and training environments to others who may have more experience or understanding in the field of Reinforcement Learning and Autonomous Driving.
diff --git a/final_reward.py b/final_reward.py
new file mode 100644
index 0000000..f1dba79
--- /dev/null
+++ b/final_reward.py
@@ -0,0 +1,78 @@
+import math
+
+'''
+ Reward function that incentivizes more progress at a fast pace,
+ penalizes fast driving at corners, incentivizes staying near
+ center line of track, and penalizes driving away from center line
+'''
+
+def reward_function(params):
+
+ # Read input parameters
+ distance_from_center = params['distance_from_center']
+ track_width = params['track_width']
+ speed = params['speed']
+ waypoints = params['waypoints']
+ closest_waypoints = params['closest_waypoints']
+ progress = params['progress']
+ steps = params['steps']
+
+ # Calculate 3 marks that are increasingly farther away from the center line
+ marker_1 = 0.1 * track_width
+ marker_2 = 0.25 * track_width
+ marker_3 = 0.5 * track_width
+
+ # initialize thresholds and reward
+ DIFF_HEADING_THRESHOLD = 6
+ SPEED_THRESHOLD = 1.8
+ TOTAL_STEPS = 270 # roughly 15 steps per second, 18 sec default lap
+ reward = 5
+
+ ############################
+ # Steps and progress, check every 30 steps. The less steps it takes to reach 100% progress means finished faster
+ ############################
+
+ # reward less steps with greater progress if faster than 18 sec
+ if (steps % 20) == 0 and progress/100 > (steps/TOTAL_STEPS):
+ reward += progress - (steps/TOTAL_STEPS)*100
+
+ #############################
+ # Waypoints: referenced code from https://github.com/MatthewSuntup/DeepRacer/blob/master/reward/reward_final.py
+ #############################
+
+ # finding previous point, next point, and future point
+ prev_point = waypoints[closest_waypoints[0]]
+ next_point = waypoints[closest_waypoints[1]]
+ future_point = waypoints[min(len(waypoints) - 1, closest_waypoints[1]+6)]
+
+ # calculate headings to waypoints
+ heading_current = math.degrees(math.atan2(prev_point[1]-next_point[1], prev_point[0]-next_point[0]))
+ heading_future = math.degrees(math.atan2(prev_point[1]-future_point[1], prev_point[0]-future_point[0]))
+
+ # calculate difference between headings
+ # check we didn't choose reflex angle
+ diff_heading = abs(heading_current-heading_future)
+ if diff_heading > 180:
+ diff_heading = 360 - diff_heading
+
+ # if diff_heading > than threshold indicates turn
+ # so when a turn is ahead (high diff_heading)
+ # penalize high speed, reward slow speed
+ if (diff_heading > DIFF_HEADING_THRESHOLD) and speed >= SPEED_THRESHOLD:
+ reward -= 4
+
+ ############################
+ # Center line incentives
+ ############################
+
+ # give higher reward if the car is closer to center line and vice versa
+ if distance_from_center <= marker_1:
+ reward += 5
+ elif distance_from_center <= marker_2:
+ reward += 4
+ elif distance_from_center <= marker_3:
+ reward += 3
+ else:
+ reward -= 4
+
+ return float(reward)
\ No newline at end of file