You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+48-23Lines changed: 48 additions & 23 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -1,51 +1,63 @@
1
-
# GPT Crawler
1
+
<!-- Markdown written with https://marketplace.visualstudio.com/items?itemName=yzhang.markdown-all-in-one -->
2
+
3
+
# GPT Crawler <!-- omit from toc -->
2
4
3
5
Crawl a site to generate knowledge files to create your own custom GPT from one or multiple URLs
4
6
5
7
6
8
9
+
-[Example](#example)
10
+
-[Get started](#get-started)
11
+
-[Running locally](#running-locally)
12
+
-[Clone the repository](#clone-the-repository)
13
+
-[Install dependencies](#install-dependencies)
14
+
-[Configure the crawler](#configure-the-crawler)
15
+
-[Run your crawler](#run-your-crawler)
16
+
-[Alternative methods](#alternative-methods)
17
+
-[Running in a container with Docker](#running-in-a-container-with-docker)
18
+
-[Running as a CLI](#running-as-a-cli)
19
+
-[Development](#development)
20
+
-[Upload your data to OpenAI](#upload-your-data-to-openai)
21
+
-[Create a custom GPT](#create-a-custom-gpt)
22
+
-[Create a custom assistant](#create-a-custom-assistant)
23
+
-[Contributing](#contributing)
7
24
8
25
## Example
9
26
10
-
[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
27
+
[Here is a custom GPT](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) that I quickly made to help answer questions about how to use and integrate [Builder.io](https://www.builder.io) by simply providing the URL to the Builder docs.
11
28
12
29
This project crawled the docs and generated the file that I uploaded as the basis for the custom GPT.
13
30
14
-
[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
31
+
[Try it out yourself](https://chat.openai.com/g/g-kywiqipmR-builder-io-assistant) by asking questions about how to integrate Builder.io into a site.
15
32
16
33
> Note that you may need a paid ChatGPT plan to access this feature
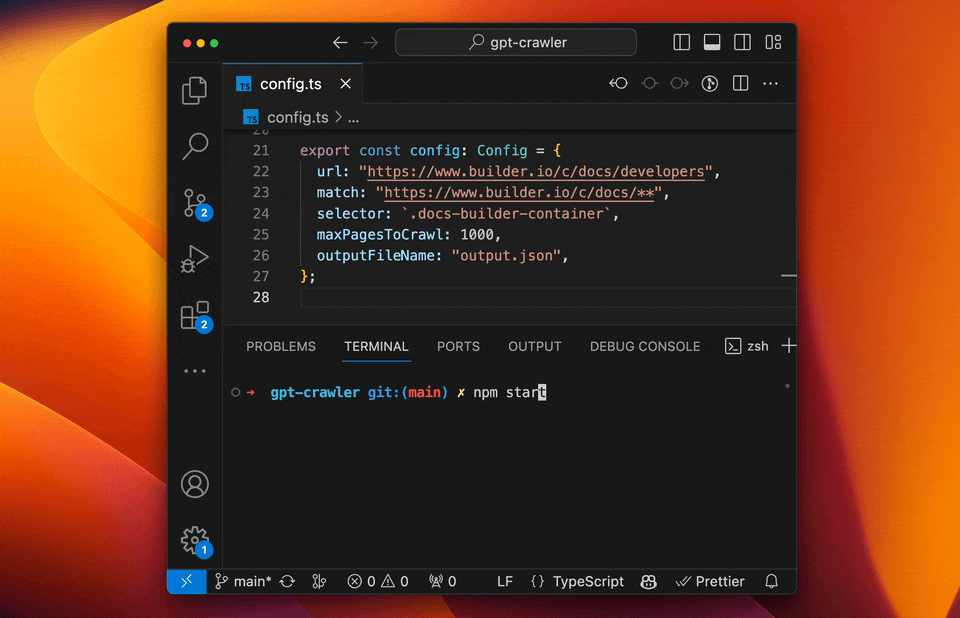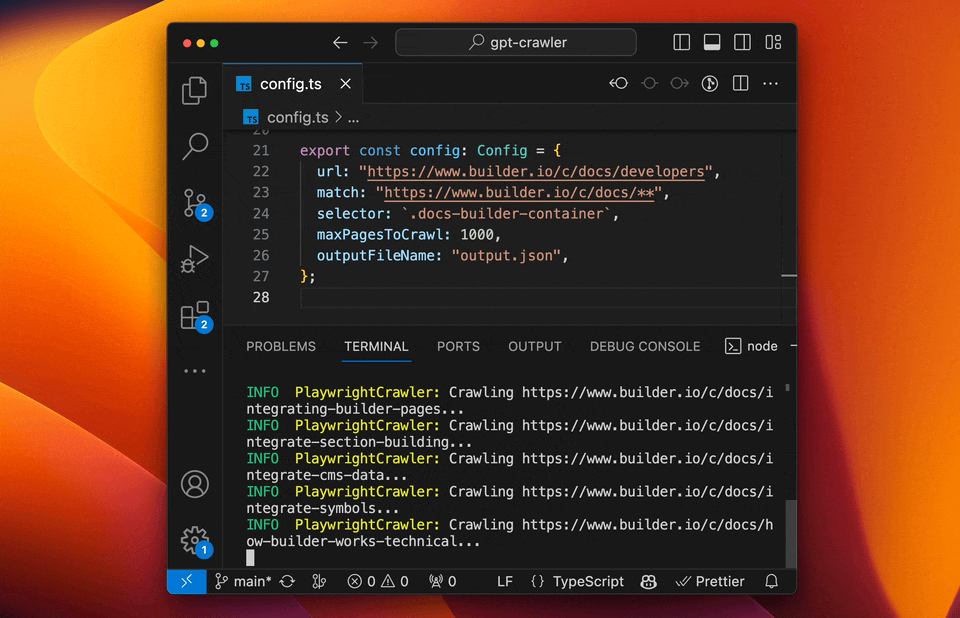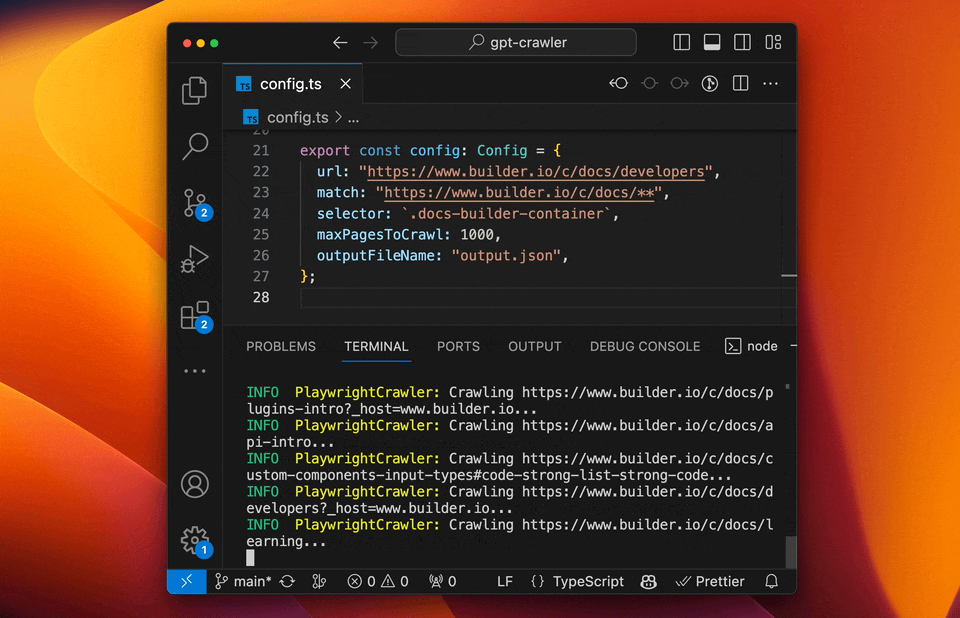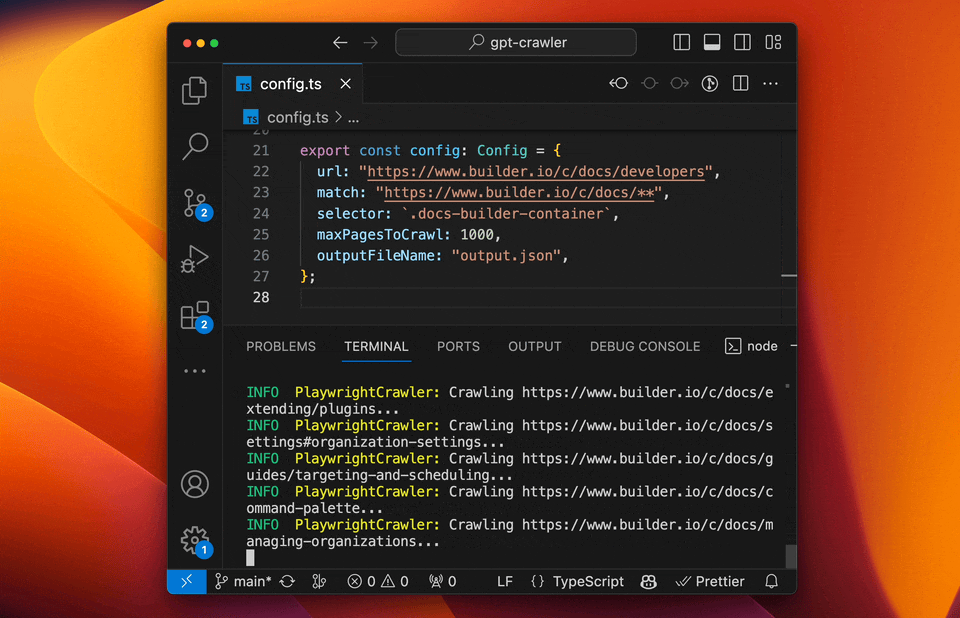
Open [config.ts](config.ts) and edit the `url` and `selectors` properties to match your needs.
44
56
45
57
E.g. to crawl the Builder.io docs to make our custom GPT you can use:
46
58
47
59
```ts
48
-
exportconstconfig:Config= {
60
+
exportconstdefaultConfig:Config= {
49
61
url: "https://www.builder.io/c/docs/developers",
50
62
match: "https://www.builder.io/c/docs/**",
51
63
selector: `.docs-builder-container`,
@@ -69,23 +81,41 @@ type Config = {
69
81
/** File name for the finished data */
70
82
outputFileName:string;
71
83
/** Optional cookie to be set. E.g. for Cookie Consent */
72
-
cookie?: {name:string; value:string}
84
+
cookie?: {name:string; value:string };
73
85
/** Optional function to run for each page found */
74
86
onVisitPage?: (options: {
75
87
page:Page;
76
88
pushData: (data:any) =>Promise<void>;
77
89
}) =>Promise<void>;
78
-
/** Optional timeout for waiting for a selector to appear */
79
-
waitForSelectorTimeout?:number;
90
+
/** Optional timeout for waiting for a selector to appear */
91
+
waitForSelectorTimeout?:number;
80
92
};
81
93
```
82
94
83
-
### Run your crawler
95
+
####Run your crawler
84
96
85
97
```sh
86
98
npm start
87
99
```
88
100
101
+
### Alternative methods
102
+
103
+
#### [Running in a container with Docker](./containerapp/README.md)
104
+
105
+
To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
The crawl will generate a file called `output.json` at the root of this project. Upload that [to OpenAI](https://platform.openai.com/docs/assistants/overview) to create your custom assistant or custom GPT.
@@ -105,7 +135,6 @@ Use this option for UI access to your generated knowledge that you can easily sh
105
135
106
136
107
137
108
-
109
138
#### Create a custom assistant
110
139
111
140
Use this option for API access to your generated knowledge that you can integrate into your product.
@@ -116,10 +145,6 @@ Use this option for API access to your generated knowledge that you can integrat
116
145
117
146
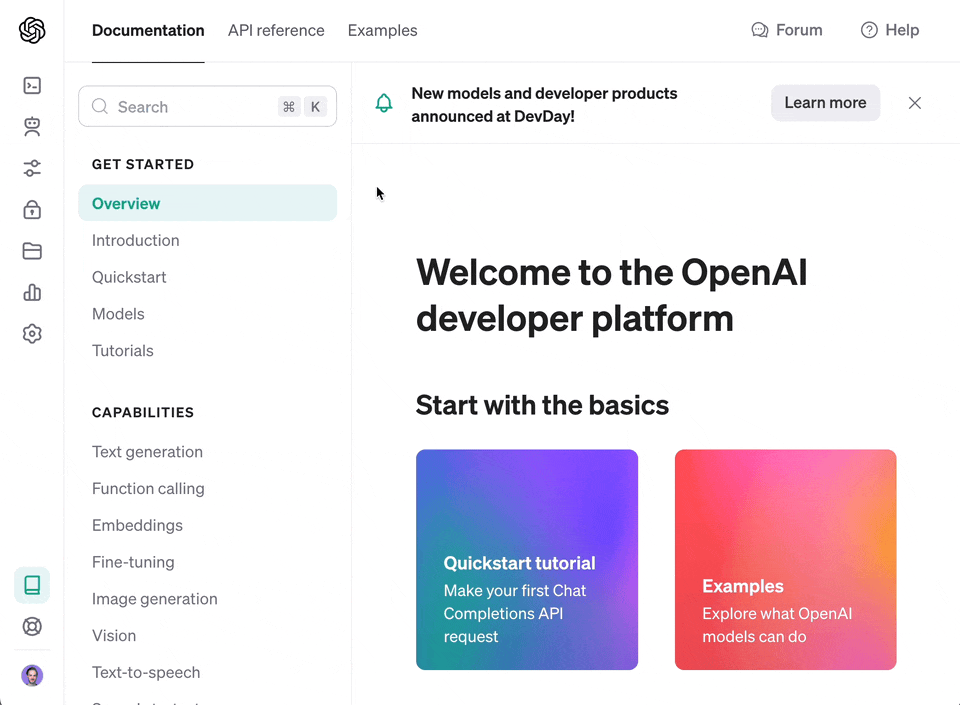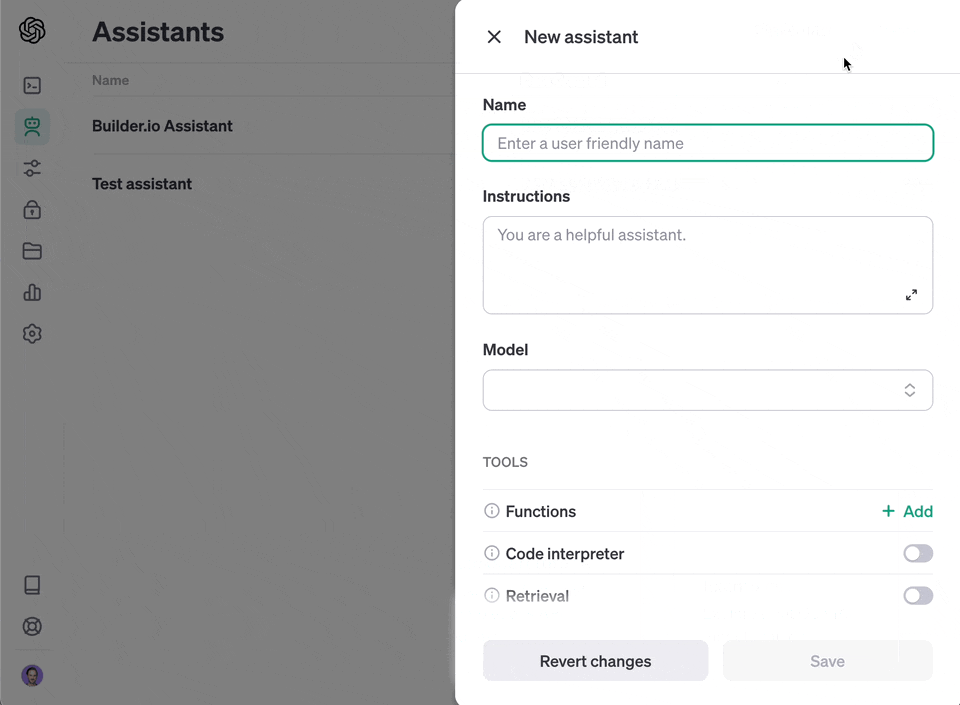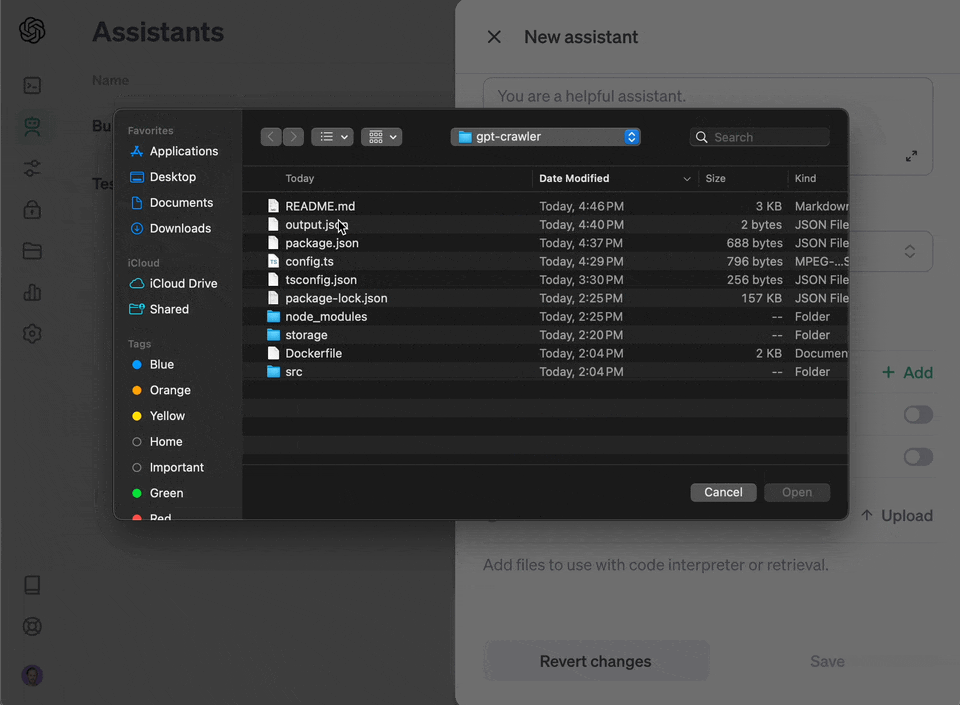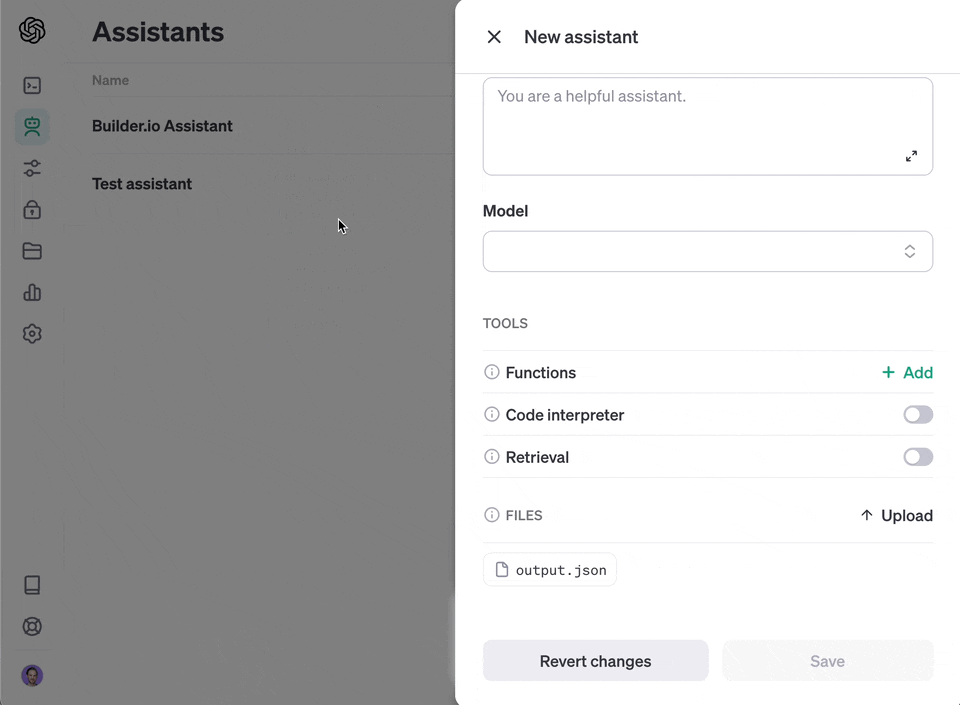
118
147
119
-
## (Alternate method) Running in a container with Docker
120
-
To obtain the `output.json` with a containerized execution. Go into the `containerapp` directory. Modify the `config.ts` same as above, the `output.json`file should be generated in the data folder. Note : the `outputFileName` property in the `config.ts` file in containerapp folder is configured to work with the container.
0 commit comments