Replies: 26 comments
-
|
That's neat! Certainly not necessary but it might be useful to create some plots in the script too? |
Beta Was this translation helpful? Give feedback.
-
|
Plots are a good idea. My first throught is for the shallow water model, for example, is to have a plot with markers for the CPU and GPUs results. That is easy to do. Then we could have a plot of the speed up on the same figure but with the y axis on the right. We will talk about doing this using |
Beta Was this translation helpful? Give feedback.
-
|
I closed #1676 in favor of this. |
Beta Was this translation helpful? Give feedback.
-
|
This is a plot of the shallow water benchmark times: cpu vs gpu. What do you think? Absolute Times
Speed Up
In theory, it should be easy to include the code to create this image in the benchmark script. However, because the garbage collector does not clear the memory, we actually have to run the script separately for the high resolution runs. Any advice on how to resolve this issue? |
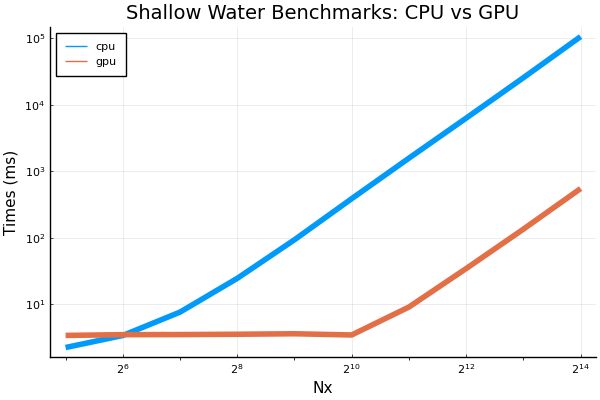
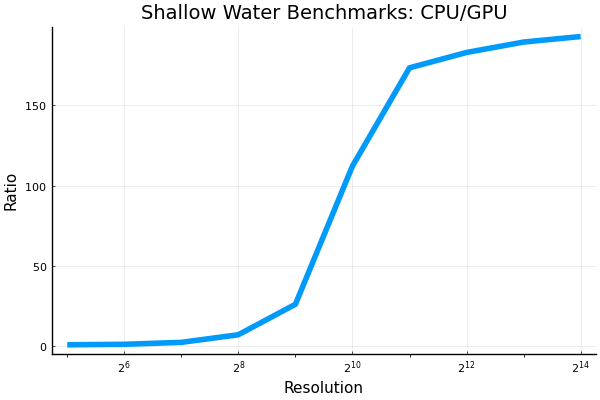
Beta Was this translation helpful? Give feedback.
-
|
That is an awesome plot. I would refer to using the GPU as "speed up" or "acceleration" (rather than a "slow down" incurred by using the CPU). Is the resolution the total resolution, or the resolution in a single direction in a two-dimensional grid? Quite enlightening to see how the GPU isn't fully utilized until the resolution is high enough. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks @glwagner and I agree, speed up is better. WIll fix that that. The x-axis is the number of points in each direction. We could square it to get the total degrees of freedom, and that might be nice, but I keep on thinking that looking at the number of points in each direction on a square grid would be easier for the user to learn what to expect. But both are easy enough to produce. But I will keep this in mind when we are doing the I agree about this being enlightening. It seems to me that for high resolutions, the cpus and gpus have pretty much the same slopes, it just takes a lot for the gpu to start to increase. I didn't know this before and am happy to have learned it. |
Beta Was this translation helpful? Give feedback.
-
|
Happy with any measure of resolution --- just asking for clarification. Perhaps instead of Resolution the plot can be labeled Nx (or some other word that indicates the meaning of the axis clearly. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks. We will change it to |
Beta Was this translation helpful? Give feedback.
-
|
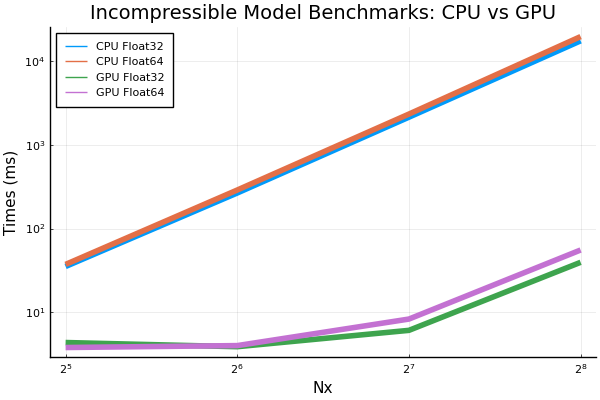
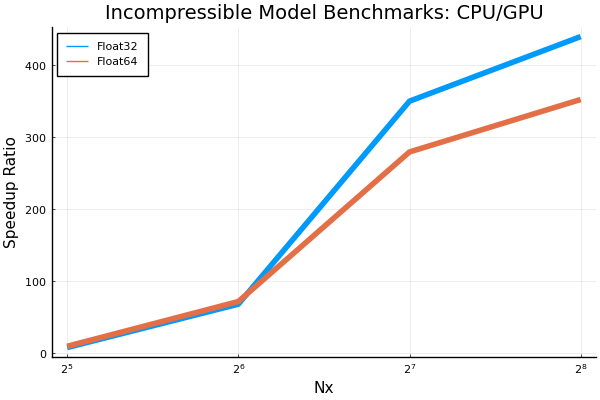
Here are some plots for the incompressible model's benchmarks. Note that I also added a benchmark for Nx=256 however, anything larger (e.g. Nx=512) resulted in an out of memory error even when ran by itself. times speedups going from cpu to gpu Also, a small change done to the shallow water graph above. The y-axis label has been changed to "Time (ms)" for more clarity. |
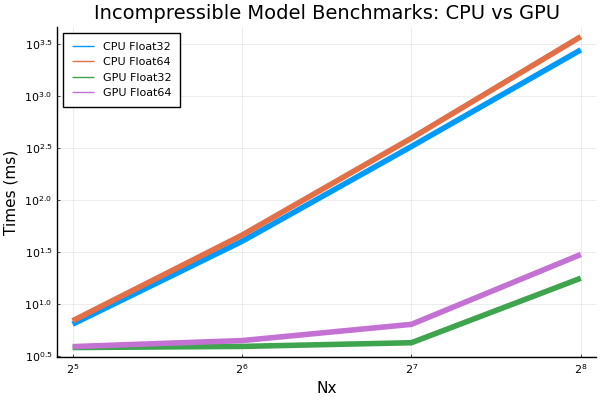
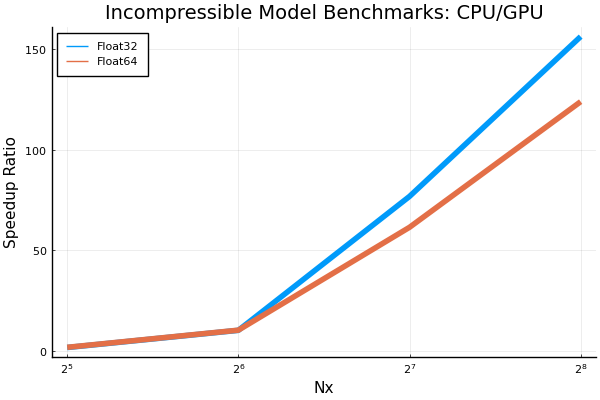
Beta Was this translation helpful? Give feedback.
-
Sure, I doubt that 512³ fits on a single GPU... |
Beta Was this translation helpful? Give feedback.
-
|
When @hennyg888 did benchmarks for shallow water with Probably not a major problem but any ideas what might have changed? Also, we can update as many of the benchmarks from above as people like, and add in some pictures where we have them. |
Beta Was this translation helpful? Give feedback.
-
|
Here are some results for weak and strong scaling of distributed shallow water model on one node with 32 cores. The efficiency for both goes down to 80% on 32 cores. This is comparable to what @ali-ramadhan found a while back, but not sure if that made it on an issue or a PR. I'm now trying to go to 64 cores on 2 nodes, and hope to have some results to show soon, after I figure out some weird behavour. |
Beta Was this translation helpful? Give feedback.
-
That is mysterious. Is this with The main thing that's changed is our update to julia 1.6 and CUDA 3.0. But I can't recall if there have been changes to the way that the |
Beta Was this translation helpful? Give feedback.
-
|
It's the shallow water model. |
Beta Was this translation helpful? Give feedback.
-
|
The advection equation for |
Beta Was this translation helpful? Give feedback.
-
|
I believe we also observed bigger speed ups for WENO when it was first implemented. This is plausible because WENO invokes the same memory access pattern as the UpwindBiasedFifthOrder scheme, but has much more compute, which gives the GPU more of an edge. |
Beta Was this translation helpful? Give feedback.
-
|
@francispoulin and I ran some of the strong and weak scaling scripts recently up to 128 CPU cores. An extra bit of code was added into the files that handled the plotting. Also added was a small but vital configuration adjustment for the @benchmark macro which allowed for more than 64 cores to be benchmarked without what is perceived as deadlocking from occurring. I will PR my all my changes made to the benchmarking scripts shortly. Here are the results: weak scaling shallow water model, with grid size being 8192 x 512R where R is the number of cores:
strong scaling shallow water, with grid size being 8192 x 8129:
|
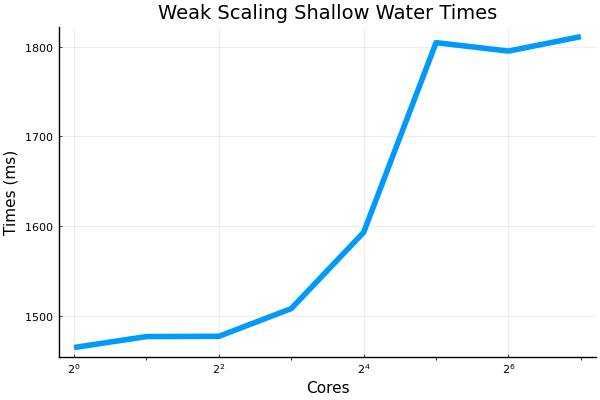
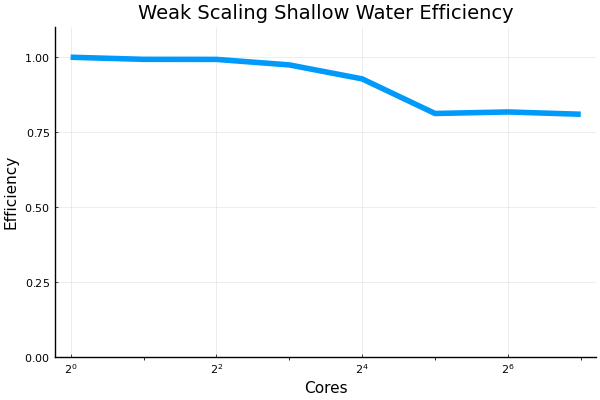
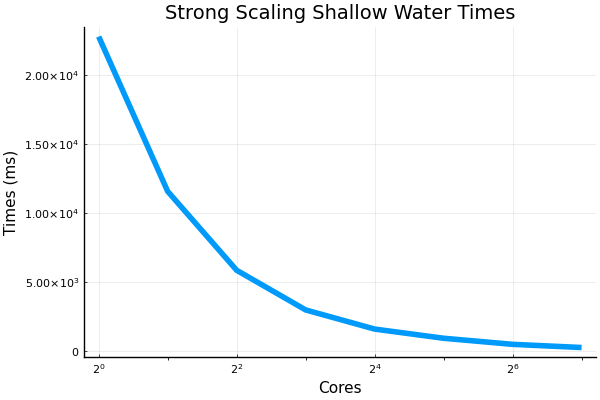
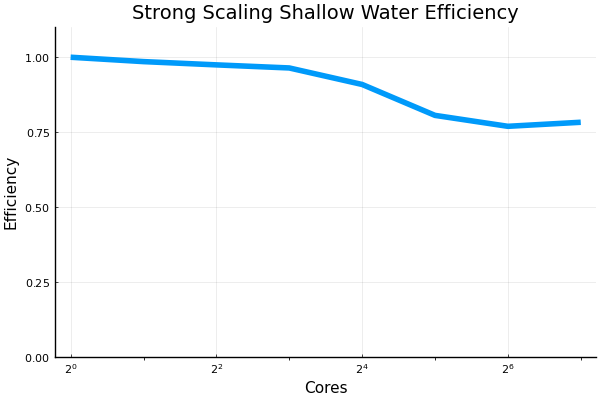
Beta Was this translation helpful? Give feedback.
-
|
@francispoulin and I also tried to increase the grid size to see if that would saturate the CPUs more and thus improve efficiency. Grid size was doubled, and the strong scaling shallow water model benchmarking script ran into some problems. However, the results from the weak scaling benchmark is sufficient enough to show that doubling grid size did indeed improve the larger ranked efficiencies from around 75% to above 80%. weak scaling shallow water model, with grid size 16384 x 1024R where R is the number of cores:
We also ran the incompressible model's strong scaling script. No weak scaling script existed for this model. The grid size was 256 x 256 x 256.
The overall trend looks like that efficiency plateaus off at around 75% when using 32 or more cores. We'll be trying to benchmark the GPUs' scaling performance next. |
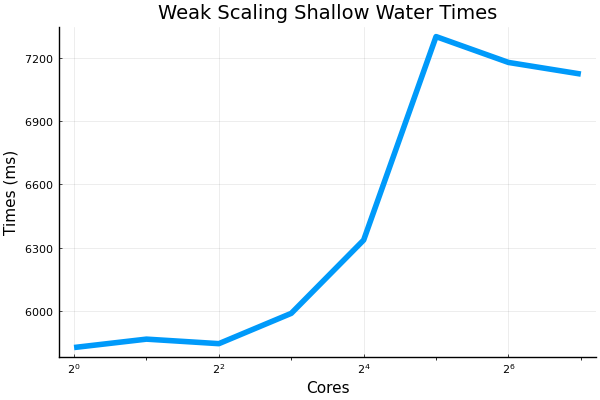
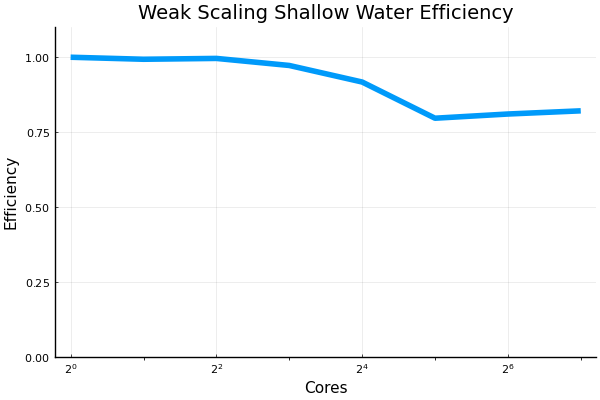
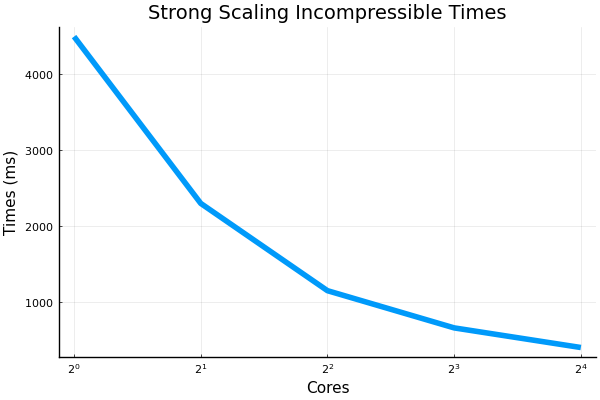
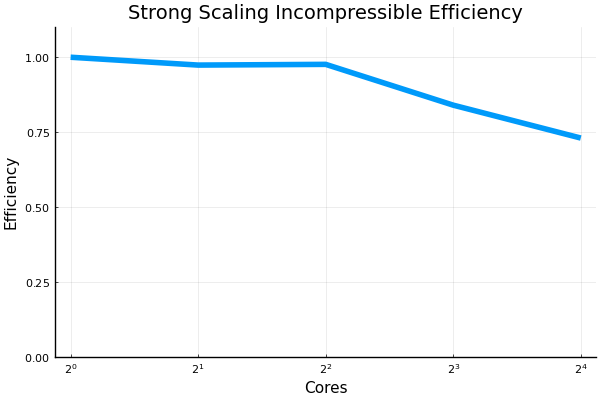
Beta Was this translation helpful? Give feedback.
-
|
Ran However, it should be noted that though there is a notable increase in speedup, it is actually caused by the cases using CPU architecture taking more time. Similarly, the cases with GPU architecture take more time as well, but not at as large a percentage as the additional time incurred by the CPU architecture cases. Please see #1722 (comment) for benchmark results without WENO5. |
Beta Was this translation helpful? Give feedback.
-
|
That is great @hennyg888 , thank you for doing this. It occurs to me it would be of interest to see how |
Beta Was this translation helpful? Give feedback.
-
|
Thanks to @glwagner's #1821 fix,
|
Beta Was this translation helpful? Give feedback.
-
|
Do these numbers get automatically ported in the Docs? |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the reminder @navidcy. I don't think the .md's in Docs are automatically updated. I will update https://github.com/CliMA/Oceananigans.jl/blob/master/docs/src/appendix/benchmarks.md with the latest benchmark results. On a second note, do we want to show the benchmark results with WENO5 or with no specified advection scheme? |
Beta Was this translation helpful? Give feedback.
-
|
Yeap. Perhaps we can point out which version of Oceananigans was used for these numbers (ideally a tagged version). |
Beta Was this translation helpful? Give feedback.
-
Oh now I saw that. I think anything is good, but just make sure you clarify how these results were made and on what machines and point to the script that produced them. |
Beta Was this translation helpful? Give feedback.
-
|
In case people don't know, @hennyg888 ran all the benchmark scrips and I beileve he has posted the results here. Thank you Henry! I think the scripts have evolved in that some of the outputs are formatted different than what currently appears. I'm not sure if people want to change everything to the current benchmark scripts that we have? |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
@francispoulin and I recently ran some of the benchmark scripts with Julia 1.6.0 and Oceananigans v0.58.1.
If these benchmarks differ enough from the ones currently shown on
benchmarks.mdthen I'll make a PR to update them. The hardware these new benchmarks were run on are mostly the exact as the old benchmarks save for a few that were ran on Titan V GPUs but are now run on Tesla V100 GPUs.The shallow water model benchmarks were run without problems. With CPU, when the grid size exceeded 2048 x 2048, only one sample could be benchmarked. Trying to get more samples benchmarked by increasing the sampling time limit resulted in out of memory exceptions.
Benchmarkable incompressible model:
Tracers, with grid size being 256 x 256 x 128:
Some errors were encountered running the turbulence closure benchmark script with grid size 256 x 256 x 128.
There was an issue with the Nothing closure which was avoided by removing that type of closure from the closure array.
Beta Was this translation helpful? Give feedback.
All reactions