You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
feat(openai): add support for tagging by API key [backport #5757 to 1.13] (#5769)
This PR backports #5757 to 1.13.
Support tagging traces, logs and metrics with the API key. This enables
OpenAI admins and users to see usage per-API key. The API key is
obfuscated to include only the last 4 characters which is what OpenAI
displays in their UI.
Note: with this change, we no longer trace streamed responses and
instead include that in the initial openai request/response span. This
was done since having the stream captured in the request span itself is
likely more useful to users than having a disjointed trace. For example:
Previous behavior:
<img width="1141" alt="Screenshot 2023-05-04 at 10 02 39 PM"
src="https://user-images.githubusercontent.com/35776586/236363999-a61737e7-76a5-4a20-9e66-bea34ba9ccf1.png">
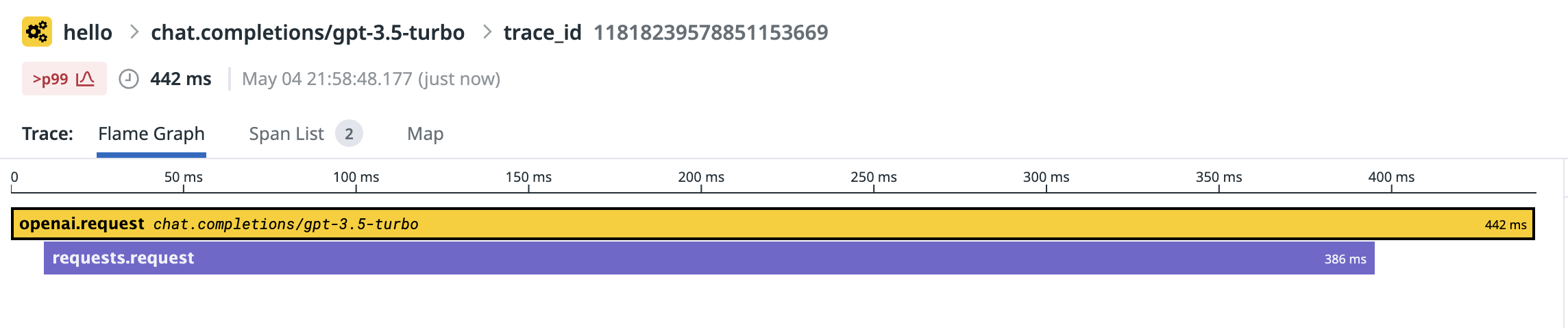
Trace behavior after this change:
<img width="1144" alt="Screenshot 2023-05-04 at 10 02 24 PM"
src="https://user-images.githubusercontent.com/35776586/236363976-aa34a907-8ad5-40d9-9533-e3706f88b9ed.png">
The one risk is if a user never consumers the stream generator, then
this span will never be finished. This is a low risk, but should be
addressed as a future step.
## Checklist
- [x] Change(s) are motivated and described in the PR description.
- [x] Testing strategy is described if automated tests are not included
in the PR.
- [x] Risk is outlined (performance impact, potential for breakage,
maintainability, etc).
- [x] Change is maintainable (easy to change, telemetry, documentation).
- [x] [Library release note
guidelines](https://ddtrace.readthedocs.io/en/stable/contributing.html#Release-Note-Guidelines)
are followed.
- [x] Documentation is included (in-code, generated user docs, [public
corp docs](https://github.com/DataDog/documentation/)).
- [x] PR description includes explicit acknowledgement/acceptance of the
performance implications of this PR as reported in the benchmarks PR
comment.
## Reviewer Checklist
- [x] Title is accurate.
- [x] No unnecessary changes are introduced.
- [x] Description motivates each change.
- [x] Avoids breaking
[API](https://ddtrace.readthedocs.io/en/stable/versioning.html#interfaces)
changes unless absolutely necessary.
- [x] Testing strategy adequately addresses listed risk(s).
- [x] Change is maintainable (easy to change, telemetry, documentation).
- [x] Release note makes sense to a user of the library.
- [x] Reviewer has explicitly acknowledged and discussed the performance
implications of this PR as reported in the benchmarks PR comment.
Co-authored-by: Kyle Verhoog <[email protected]>
{kind=link}
{kind=link}
0 commit comments