doublet removal #967
Unanswered
pengxin2019
asked this question in
Questions / Documentation
doublet removal
#967
Replies: 0 comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
Hi there,
I have some questions about the doublet removal of ArchR.
If I understand correctly, ArchR is projecting the synthetic doublets to the UMAP embedding of my scATAC dataset. There would be a lot of synthetic doublets and 10 nearest neighbors of each synthetic doublet are predicted as nuclei doublets. ArchR would iterate this process for a lot of times, the consistent doublets among different iterations are reported as doublets?
I still can not understand the
filterRatiooffilterDoubletswell though you do provide an example as "if there are 5000 cells, the maximum would be filterRatio * 5000^2 / (100000) (which simplifies to filterRatio * 5000 * 0.05)" why we have 5000 square and 100000 here?I have 4 datasets and here are the violin plots for the doublet score and doublet enrichment:
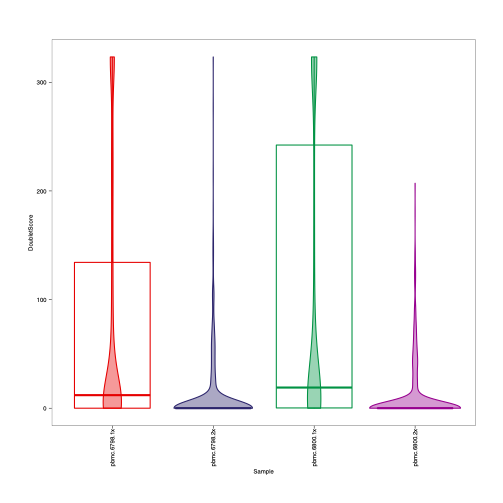
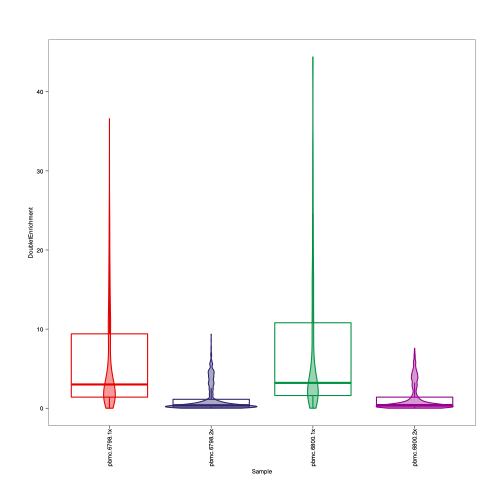
These two plots kind of does not make biologically sense to me since the cell number of 2x datasets is around ~4 time that of 1x dataset. Theoretically, there should be more doublet in the 2x datasets than the 1x datasets.
From the two violin plots, it seems like the doublet score in the 1x datasets is even larger than that of 2x datasets( the median doublet score and median enrichment, also the width of the 1x violin plot at the high density is even larger than that of 2x?) if my understanding is correct, then it does not make sense to me
However, after I run the

filterDoubletswith the default parameter. The versose is:It makes sense here since the percentage of the removed doublets of 2x is larger than that of 1x.
Can you give me some suggestions?
Thanks
Best
Beta Was this translation helpful? Give feedback.
All reactions