| timezone |
|---|
Asia/Shanghai |
- 自我介绍 hi,我是henryleo,生物信息工程师,开放科学/DeSci爱好者,同时也对代币经济学、隐私和区块链在社会治理中的作用很感兴趣。目前专注合成生物学工作。
- 你认为你会完成本次残酷学习吗? 我想我可以!
EPF全称是Ethereum Protocol Fellowship, 是一个以学徒制的形式招募、筛选和培养以太坊核心开发者的活动。可想而知EPF是小规模且深入的活动,为了吸引更多开发者加入以太坊生态, EPF Study Group(EPFsg)被提出,以相对浅显的形式介绍以太坊,从开发哲学到路线图均有涉及,更方便广大开发者、研究员, 甚至爱好者了解以太坊的核心组织架构、开发进展以及目前面临的技术问题。
残酷共学是ETHPanda主办,以中文社群为主,基于EPFsg的材料的共学获得,每日打卡但并不限制学习进度(无需许可的进展2333),旨在为中文社群更好地连接至EPFsg
Encryption 加密 是将一个被称为Plaintext 明文的信息,对其进行一种操作,称为Cipher 密码。这样,你就会收到一个混乱的、不可读的信息作为输出,称为Ciphertext 密码文本。而将密码文本转会为可读的明文的过程称为Decryption 解密
由两部分组成的:
- Encryption algorithm 加密算法 用于将明文转换为密文的基本逻辑或过程
- Key 密钥 为你的密码引入了一些独特的东西。如果没有密钥,任何使用相同算法的人都能解码你的信息,而你实际上不会有任何保密性
- 是保护你的数据的独特部分,对称密钥必须保密以确保被保护数据的机密性。Key size 密钥大小,以bit为单位,是组成加密密钥的比特或数据的总数。可以把密钥大小看作是一个给定加密算法可能的密钥总数的上限。Key length 密钥长度在密码学中超级重要,因为它本质上定义了系统的最大潜在强度
又名"the enemy knows the system" “敌人了解系统“, Shannon's maxim 香农箴言
该原则指出,一个Cryptosystem 密码系统,或一个用于Key generation 密钥生成和Encryption 加密及Decryption 解密操作的算法集合,构成了一个密码服务,应该保持安全,即使关于该系统的一切都被知道,除了密钥。这意味着,即使你的敌人知道你用来保护数据的确切加密算法,他们仍然无法从截获的密码文本中恢复明文。
定义了加密,但涵盖编码和隐藏信息不被第三方发现的做法的总体学科。与此相反,寻找隐藏信息或试图破译编码信息被称为Cryptanalysis 密码分析
- Frequency analysis 频率分析 是研究字母在密码文本中出现的频率的做法 最早记录是来自一个九世纪的阿拉伯数学家
Symmetric-key algorithm 对称密钥算法,这类型的加密算法被称为symmetric 对称算法,因为它们使用相同的密钥来加密和解密信息。对称加密的最大缺陷是假设密钥可以传达给预期的接收者,而不会将其暴露给不需要的一方。换句话说,无论是单个数字、秘密词还是具有特定配置的机器,密钥都必须以受信任的设置从发送方传递到接收方。所有后续消息的安全性取决于维护密钥的安全传输。
- Substitution cipher 替换密码 是一种加密机制,用密码文本替换部分明文。Caesar cipher 凯撒密码 是一种替换加密技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文,如:当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。另一种例子,Vigenère cipher 此密码不是使用常量值来交换消息中的每个字母,而是根据秘密词(secret code word,也称为key 密钥)中字母的字母顺序来改变每个字符的偏移量。 如:密钥 abc 会将编码单词的第一个字母按字母顺序移动一个字母,将第二个字母移动 2 个字母,将第三个字母移动 3 个字母
- Block ciphers 区块密码,它将明文分成多个等长的模块(block),使用确定的算法和对称密钥对每个区块分别加密解密。
- Stream ciphers 流密码,加密和解密双方使用相同pseudo-random stream 伪随机加密数据流作为密钥,明文数据每次与密钥数据流顺次对应加密(Simple XOR cipher 简单异或密码),得到密文数据流。
一些实例:
- DES Data Encryption Standard 数据加密标准:使用128位区块密码
- AES Advanced Encryption Standard 高级加密标准:对称的区块密码
- RC4 Rivest Cipher 4:一种串流加密法,密钥长度可变。
- TLS 1.2 + AES GCM:是AES区块密码的一种特殊操作模式,基本上将其变成了流密码。
又称Public-key cryptography 公开密钥加密。它需要两个密钥,一个是公开密钥,另一个是私有密钥;公钥用作加密,私钥则用作解密。使用公钥把明文加密后所得的密文,只能用相对应的私钥才能解密并得到原本的明文,最初用来加密的公钥不能用作解密。
- 第一步,A、B交换公钥
- 第二步,A使用B的公钥加密信息并发送
- 第三步,B接受接受加密的信息,通过B的私钥将加密信息解密为明文
公钥/私钥的物理隐喻是个人锁定邮箱。任何人都可以在其中存放一封信,但只有邮箱的所有者才能打开它并阅读其中包含的消息。
对称与不对称密码系统的比较:
- 不对称密码系统在不受信任的信道上传输比较安全
- 对称密码系统的算法速度更快,效率更高,可以加密大量的数据
- 有时可以联合使用,通过不对称密码系统传输对称密码系统的密钥,通过对称密码系统的密钥解锁数据
非对称密码系统实例
- RSA:最早的非对称密码系统 以发明人首字母命名 密钥的生成过程取决于选择两个独特的、随机的、通常是非常大的素数
- DSA Digital Signature Algorithm 数字签名算法:这个系统的安全性取决于选择一个随机种子值,并将其纳入签署过程。如果这个值被泄露了,或者可以推断出质数不是真正的随机数,那么攻击者就有可能恢复私钥
- DH Diffie-Hellman 一种流行的密钥交换算法
- ECC** Elliptic curve cryptography 椭圆曲线密码学, 传统的公钥系统是利用大素数的因式分解,ECC使用有限域上的椭圆曲线的代数结构来生成安全密钥。
- 椭圆曲线是由一组符合等式的坐标组成的,类似于
$y^2=x^3+ax+b$ 。一个是水平对称性,这意味着在曲线的任何一点都可以沿X轴进行镜像,并且仍然构成相同的曲线。除此之外,任何非垂直的直线最多只能在三个地方与曲线相交。 -
正是这最后一个特性使得椭圆曲线可以被用于加密。基于椭圆曲线的加密系统的好处是,它们能够以较小的密钥规模实现与传统公钥系统类似的安全性
- 举例来说,一个256位的椭圆曲线密钥,将与一个3072位的RSA密钥相当。这确实很有利,因为它减少了处理密钥时需要存储和传输的数据量
- 椭圆曲线是由一组符合等式的坐标组成的,类似于
Cryptography Applications 密码学应用
- PKI Public Key Infrastructure system 公钥基础设施系统
- Web of Trust 信任之网
- Pretty Good Privacy (PGP) 优良保密协议
又名Hash function 散列函数,是一种函数或操作,它接收任意数据输入并将其映射到一个固定大小的输出,称为Hash 散列或digest 摘要。
哈希不同于加密,哈希是单向的、不可逆的,但运算速度快,一旦有微小的变化哈希函数就会发生改变
Hash collisions 哈希冲突
- 即两个不同的输入映射到同一个输出,这是不应该存在的、需要修正的
一些例子
- MD5:它在512bit的block 区块上运行,并产生128bit的哈希值。是一个流行和广泛使用的散列函数,设计于20世纪90年代初,是一个加密散列函数
- SHA-1:它操作一个512bit的区块并生成160bit的哈希值 是一个广泛使用的加密散列函数,用于流行的协议,如TLS/SSL、PGP SSH和IPsec。也用于像Git这样的版本控制系统,它使用哈希值来识别修订版,并通过检测损坏或篡改来确保数据的完整性。
- MIC Message Integrity check 信息完整性检查:是有关信息的哈希值。你可以把它看成是信息的一个校验和,确保信息的内容在传输过程中没有被修改。
比特币网络中交易记录的非对称加密
每个账户有一个公钥(pk)和一个私钥(sk),转账记录是一个明文的信息,其中唯一的交易编号,这个信息通过签名函数生成一个Digtal Signature电子签名(也许是一个哈希),并可以将其与信息和公钥以及另一个验证函数验证真伪。

Merkle tree
Merkle Tree是一种数据结构,将已有的交易记录通过哈希散列函数反复求值合并为一个Merkle root(这也是一个Hash),并将其记录在比特币网络的Block Header区块标头中,以确保区块无法被篡改。具体的计算方法如下:
- 假设已有的交易记录有4笔,为L1~L4,通过散列函数计算其哈希(分别为H0_0、H0_1、H1_0、H1-1)
- 其次,按交易的先后顺序将其哈希两两拼接,再次计算哈希,如
H0_0+H0_1=>H0、H1_0+H1_1=>H1,这样我们就把四笔交易的信息压缩为两个哈希 - 第三,将H0和H1拼接并计算哈希,得到一个Merkle root,完成压缩
- 最后,将Merkle root放入比特币网络的Block Header区块标头中

比特币网络解决账本的中心化问题的方法——工作量证明
Proof of Work (PoW) 工作量证明是一种方法,其核心理念是**“信任最多工作量的结果”**,在区块链的世界里,这意味着矿工/参与者信任最长的那条区块链。

要解释这一点首先要介绍工作量的来源,也是散列函数计算哈希导致的。首先先介绍比特币区块标头的数据结构:前一个区块的哈希值(Prev Hash,又称哈希指针)+随机数(Nonce)+在上文中我们描述的由Merkle tree压缩的当前区块的交易记录+时间戳。比特币的工作量来源于这个随机数,这是因为网络鼓励矿工去找到一个随机数使得整个区块标头经过散列函数(SHA256)计算后的哈希值前若干位为0,例如0000000000000000000ec8769a995429b85e6301c97fa76de6fb9bc5162b27de
同时,比特币网络要求大约十分钟出一个块,这意味着随机数前导0的数量是动态的,当矿工算力变强,前导0的数量要求会更高,反之更少。
那么“信任最多工作量的结果”是什么意思呢?假设有恶意者试图使用假的交易记录蒙骗其他人,那他会构建一个假的Merkle tree和一个Nonce合并Prev Hash和时间戳发送给其他所有人,且大家一定会接受!这是因为它满足要求(前一个区块的哈希值正确、足够的前导0以及符合要求的时间戳);但有其他矿工同时在工作,他们大概率不是同谋,所以他们有真的交易记录也会生成一个符合要求的区块标头,其他人也会接受,这时,所有人拥有两份不同且同样长度的区块链,这也就是所谓“冲突”。随着下一个十分钟,新的区块出来,为了实现攻击恶意者必须超过其他所有人计算出正确的随机值,一旦有人抢先,那么其他矿工将会受到一个不同与恶意者发布的且长度更长的区块链,届时攻击将失败。因此,恶意者必须在随后N个区块内保持领先,但根据研究,若恶意者不拥有超过网络50%总算力将无法实现攻击,这就是著名的“51攻击”。

但十分钟出一个区块的限制导致了交易手续费昂贵且效能不足,这也就是以太坊和其他公链谈及的“Scaling 扩容”问题
挖矿奖励
当矿工计算出正确的随机数时,比特币网络将会在交易记录的最上方加入一行记录——xxx创造N个BTC,再构造Merkle tree。当区块被确认(被大家认可),该矿工则拥有N个BTC的记录,这也是所谓的挖矿奖励。
比特币网络每构造21万个区块后奖励会减半,初始值为50,这保证了BTC总量在2100万颗左右。
Refs
- What is the merkle tree in Bitcoin? | Keifer Kif
- Merkle tree | Wikipedia
- 你有疑惑過比特幣(與其他加密貨幣)的運作原理嗎?| 3Blue1Brown
- 比特币的区块 | 以太坊的指南针
P2P(peer to peer)区别于“服务器-客户端”模型,传统互联网需要一个中心机构储存、管理和分发数据,而P2P网络中的每一个计算机(被称为Node 节点)拥有数据的多个相同副本,这有助于防止数据操纵和控制行为的发生。
因此,P2P网络属于一种分布式网络,区块链也构筑在P2P网络的基础上。
BitTorrent 旨在解决依赖中心化服务器下载大文件导致的网络堵塞问题,通过将大文件切分成小块,每个用户理论上拥有一个小块,互相之间形成一个网络的全连接图,从而可以分享文件并减少网络负载。
另一个好处是对于家庭网络而言,上传带宽往往小于下载带宽,这称为“上传下载的不对称性”。因此当只有一位用户为另一位用户提供资源时速度是很慢的,这是由于上传带宽不足。而BitTorrent支持多个用户为一个用户提供资源,这使得上传带宽得以共享,在带宽资源有限的情况下提升了效能。
- What is BitTorrent? | internet-class
- What is a Peer to Peer Network? Blockchain P2P Networks Explained | Lisk
以太坊之所以创立是因为比特币网络的保守性,难以开发相对复杂的应用程序以支持现代金融和其他应用方式。
以太坊的愿景是“世界计算机”,我认为更好理解一点的说法是一个通用的计算平台,而不是可编程货币的平台,这在Vitalik的博客中“Gavin对以太坊的微妙愿景转变做出的贡献”有所提及。
以太坊坚持去中心化来实现无需许可、可信中立和抗审查,这并不意味着要求绝对的透明和排斥商业或其他组织,合约或者协议可以有不透明的部分,但规则和退出机制必须透明(个人理解)。要求和排斥是控制,以太坊不要控制,要通过技术构筑“无限花园”,这一点承接密码朋克的核心信念之一:“that the power of technology often creates new political realities.”。
- A Prehistory of the Ethereum Protocol | vitalik.eth.limo
- Inevitable Ethereum - World Computer
- 密码朋克 | 以太坊协议的史前史
以太坊通过三个Part 组件致力于实现通用计算平台:
- EVM Ethereum Virtual Machine 以太坊虚拟机
- Ethereum Blockchain 以太坊区块链
- Ethereum Network 以太坊网络
三个组件并非相互独立,而是嵌套的,EVM是一个安装在物理设备(节点)上的一个程序,其中包含以太坊区块链,而全世界的节点组成以太坊网络。
要理解以太坊这个平台不能以“服务器-客户端”的模型去理解,而是每一个节点都是一个完整的副本,即每个参与以太坊的物理世界的计算机都拥有一个可信的计算平台也就是EVM,在EVM中更新区块链。
以太坊有两种账户:
- Externally-owned account 外部所有的帐户 (EOA)
- Smart contract account 智能合约帐户
举个例子,我们在Metamask创建的账户、我们自己拥有私钥的账户就是EOA,而拥有的USDT就是智能合约账户,所以USDT有CA(Contract Address 合约地址)。
在以太坊中,EOA只能进行ETH和代币交易,假设我在我的EOA中转移USDT,实际上它并不保存在我的账户中,而是EOA和USDT的智能合约进行交互,在合约中更新了token ID
重放攻击是跨链或者跨时间复制一笔交易,而双花攻击是一笔交易同一时间广播多次。
对于比特币网络,任何一个矿工都可以从一个区块读取某一笔交易的信息,假设没有时间戳, 一笔交易虽然被签名了,恶意的矿工虽然没有私钥,但它只需要将这个签名后的信息广播到新的区块就可以反复执行该笔交易, 因为签名是真的,验证函数会回传True。假设A想要攻击B,就会反复广播B的交易,这是双花攻击。
有了时间戳,这时A广播他获得的签名会发生什么?答案是会被矿工拒绝,因为时间戳显示该区块已经被打包了,不过这需要一些时间。因此最好的方案是等待交易确认多次后信任。
对于重放攻击,UTXO这种类似于纸币的性质天然就可以抵抗重放。
而以太坊通过Nonce防止重放攻击。以太坊中Nonce是一个账户的交易计数, 执行层会优先执行同一个账户Nonce较小的交易(TX2会在TX1被接受或取消之后才会进行处理), 且同一Nonce的交易只会执行一次(优先费高的)
先让我们忽略Gas fee的问题,假设发送者想做坏事,他有一个ETH,先发送一个ETH(TX1),
后又发送一个ETH(TX2),TX2会被拒绝,因为他账户余额不足;
他不服气,复制了一份TX1再广播一次(记为TX1',假设此时TX1还没被接受),
但TX1或TX1'会直接被拒绝,因为只会接受一次Nonce等于1的交易。
这下他十分生气,决定做接收者并且再做坏事,当他母亲给他打生活费时,他复制了这笔交易企图获得更多, 但也被拒绝了,因为Nonce被使用过了,防御重放成功。
简而言之,执行层相当于比特币区块链去除PoW的部分,仅起到验证区块和更新区块的作用。
客户端需要:
- 上一个区块
- 当前区块
- StateDB 状态数据库:账户信息 一旦发生错误将会唤起错误,简单代码体现:
def stf(parent_block: Block, current_block: Block, state: StateDB) -> StateDB:
# something validations
try:
verify_headers(parent_block, current_block)
except Error as error:
return (state, error) # the state no updated
state, error = verify_transactions(current_block, state)
if error:
return (state, error) # the state no updated
return statedef verify_headers(parent_block: Block, current_block: Block) -> Optional[error]:
# something validations
# error = None or others
if error:
raise Error("...")一个有意思的错误是gas超过上限,而gas上限是被硬编码的,这也制约了智能合约的复杂性。
def verify_transactions(current_block: Block, state: StateDB) -> Tuple[state, Optional[error]]:
origin_state = state.copy()
updated_state = state.copy()
good_tx = []
for n, tx in enumerate(current_block):
try:
# some validations
except Error as error:
return origin_state, error
else:
good_tx.append(tx)
updated_state = update_state(updated_state, good_tx)
return (updated_state, None)错了就返回原状态和错误原因,正确就更新。
这个东东负责告诉信标链当前区块是否验证成功
def new_payload(exec_payload: ExecutionPaylaod) -> bool:
_, error = stf(exec_payload.parent_block, exec_payload.current_block, exec_payload.state)
if error:
return False
return True构建区块需要:
- Environment 环境:包括一些信息,比如标头(时间戳、gas多少)、共识层的信息等
- TxPool 交易池:一个包含交易的列表,通过其价值降序排列。这个池也是根据广播中优先费最高的组成的。换句话说这些Gas信息没加密
- StateDB 状态数据库
def build(env: Environment, pool: TxPool, state: StateDB) -> Tuple[Block, StateDB, error]:
gas_used = 0 # 确定gas用量
txs = []
# Gas达到上限或池是非空
while gas_used < env.gas_limit or not pool.empty():
tx = pool.pop()
updated_state, gas, err = vm.run(env, tx, state)
if err is not None:
# tx invalid
continue
gas_used += gas
txs.append(tx)
state = updated_state
# 通过一个外包的函数回传,用于计算生产完整的块,比如一些数据压缩计算
return finalize(env, txs, state)共识层旨在协调分布式系统的同步问题,即基于区块链的分布式系统旨在就单一交易历史达成一致,包括抵抗不可靠的节点和恶意节点。
工作量证明 PoW和权益证明 PoS是共识机制,共识机制是用来确保能够实现Consensus protocol 共识协议的。 以太坊实际上采用两种不同的共识协议,并把它们结合在一起。一种称为LMD GHOST, 另一种称为Casper FFG。这种组合被称为Gasper。
区块链是一组不断延长的账本、不可串改的证明。每次延长时需要一个节点为此负责,在比特币网络中采用工作量证明——算力最强的矿工——作为负责人, 而以太坊是从质押者中随机挑选一位作为新区块的提议者。他负责将区块添加到链中,选择并排序其内容。
以太坊在巴黎升级中通过Beacon Chain 信标链替代原以太链的PoW机制,从原来的以太链上获得交易记录并验证。
信标链负责监督提出和证明新区块的验证者。验证者是根据一系列标准选出的,其中之一是他们质押的 ETH 数量,这也作为防止恶意行为的抵押品,也就是网络的安全经费。
验证者的工作:
- 质押 ETH:验证者必须质押至少 32 ETH 才能参与。
- 提议区块:随机选择一个验证者来提议新区块。他们必须构建有效的区块并将其广播到网络
- 参与委员会 Committees:验证者被分成多个委员会,负责区块提议和证明。每个委员会负责验证和证明区块,确保验证过程的去中心化和安全。
- 证明区块:验证者证明其他人提出的区块的有效性。证明本质上是对区块有效性的投票,以确保达成共识。
- 参与共识:验证者通过定期对区块链的状态进行投票来参与共识,帮助最终确定区块链的状态。
选拔过程通过加密随机性,通过RANDAO 和 VDF(可验证延迟函数)机制实现
12秒是一个Slot 时隙,一个时隙出一个区块,但也可以不出(没有交易);32个时隙为一个Epoch 时期。时隙和时期的计数都是从0开始的。
某一个验证者被随机选为区块提议者(伪随机过程 RANDAO),这个选择的过程是以Epoch为单位的,一次选32个提议者,然后委员会的其他验证者验证该区块。验证者通过投票进行区块验证,并将投票记录放在信标链的区块标头上。验证者的投票权重与其质押量相关。
信标链的内容主要是验证者地址的registry 注册表、每个验证者的状态和证明。
质押者与其质押的ETH数量相关联,而每个验证者的最大余额为32 ETH。每质押32 ETH,即可激活一个验证者。验证者由验证者客户端运行,这些客户端通过信标节点来跟踪并读取信标链。一个验证者客户端能够管理多个验证者。
当以太坊网络超过
当验证者小于
EIP-4844,又称proto-danksharding,是Deneb/Cancun硬分叉的一部分。它为以太坊引入了数据可用性层,使得在区块链上临时存储任意数据成为可能。这种数据结构被称为 Blob,每个区块可包含3至 6个 Blob sidecars(即Blob的封装)。这使得L2可以将交易打包送回L1验证,使得Gas费大减。
Blob这种临时数据存放4096个Epochs, 约18天。
储存要求:
$$
131,928 \space ssz \space bytes / blob * 4096 \space blobs \space retention \space period * 32 \space potential \space blocks/epoch * 36 \space blob \space sidecars / block = 52104 \space GB
$$
Byzantine Generals Problem 拜占庭将军问题,描述的是一组分布式计算机如何通过交换信息保持协作的难题。
一组拜占庭将军分别各率领一支军队共同围困一座城市。为了简化问题,将各支军队的行动策略限定为进攻或撤离两种。因为部分军队进攻部分军队撤离可能会造成灾难性后果,因此各位将军必须通过投票来达成一致策略,即所有军队一起进攻或所有军队一起撤离。
因为各位将军分处城市不同方向,他们只能通过信使互相联系。在投票过程中每位将军都将自己投票给进攻还是撤退的信息通过信使分别通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以知道共同的投票结果而决定行动策略。
这个问题的难点在于这些分布式电脑中可能有恶意用户,假设有9台电脑,4比4平票的时候,恶意电脑就选择反向投票,就会破坏系统。
注意:这个问题的关键不在于答案是什么,而在于大家能不能有一致的答案。
拜占庭容错是一个系统的特性,定义为:在一个拜占庭将军问题中,有一个解法,满足即使若干个将军都是叛徒系统都不会发生问题。
结论是:只要三分之二的节点同意一个答案,就能达成拜占庭容错。
推导过程略。
比特币网络通过其工作量证明实现拜占庭容错,即选择算力消耗最高的结果,实现共识机制。
工作量证明 PoW和权益证明 PoS是共识机制,共识机制是用来确保能够实现Consensus protocol 共识协议的。拜占庭将军问题是共识问题的一种描述形式,共识协议是实现拜占庭容错的途径。
以上这些的概念容易混淆!
- 共识机制 --实现--> 共识协议 --实现--> 拜占庭容错
- 拜占庭容错 --克服--> 拜占庭将军问题(分布式网络通信)
每个时期都有一个Checkpoints 检查点,也被称为Epoch boundary blocks (EBB,时期边界区块),它们在时期结束后被创建,一般为该时期第一个时隙区块,如果第一个时隙没有区块,则选择前一个时期最近的一个区块作为检查点。如图,时期2的第一个时隙没有区块,且时期1也只有一个区块,故:时期1的区块64成为时期2的检查点。
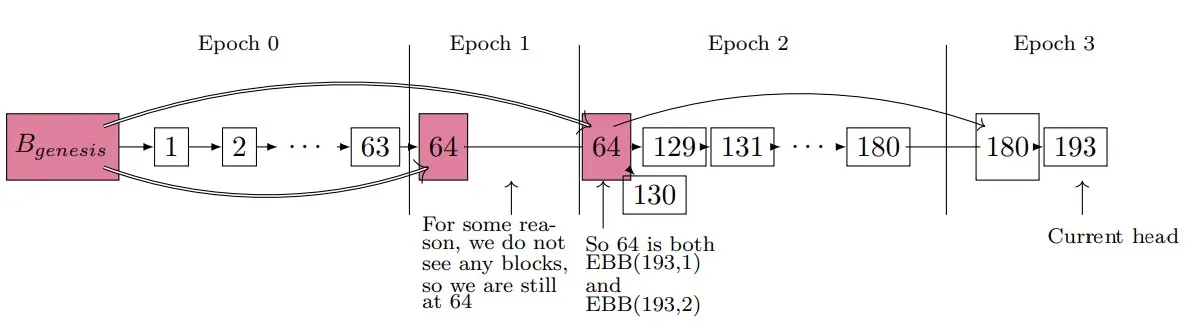
为了实现拜占庭容错,只有当超过质押余额的三分之二的验证者验证某一个检查点,该检查点才能成立(justified 合理)。但合理不意味着不能回滚,因此有一个概念叫做Finality 最终确认,一旦被最终确认则区块不能回滚。
最终确认的条件是达成两次合理,那么一个区块如何达成两次合理呢?我们知道每一个区块都会被包含在下一个区块中,即当它被包含在未来被合理化的区块中时,它将达成最终确认。
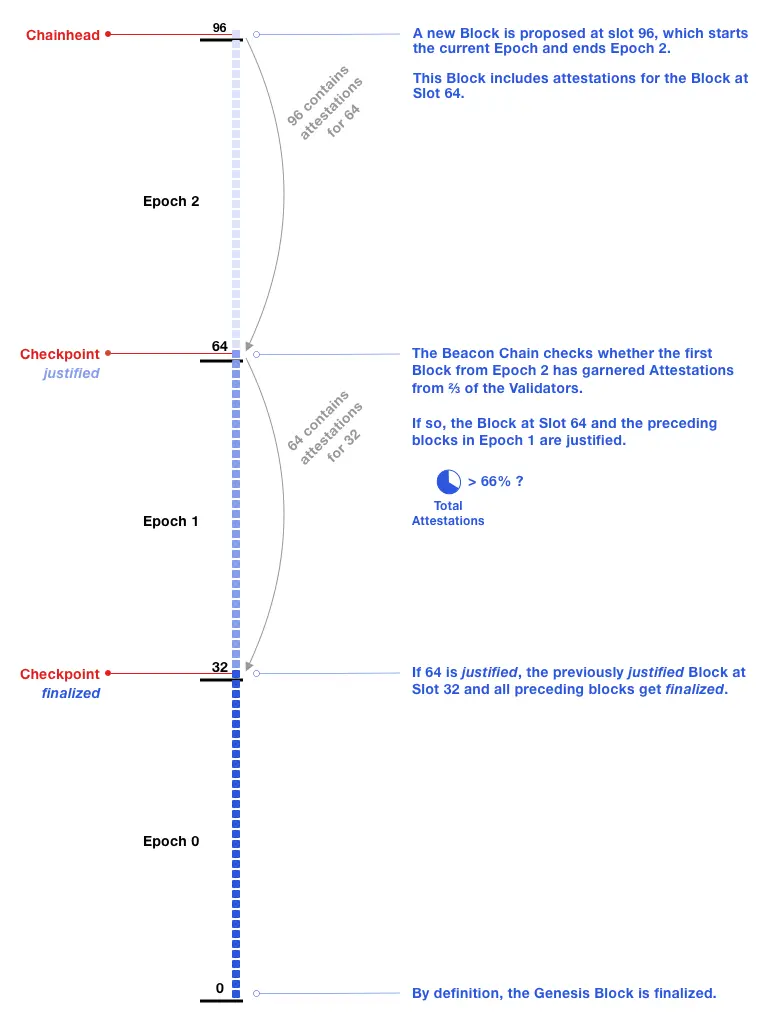
检查点的作用是便于计算。我们之前提到当一个时期开始时,RANDAO将会分配若干个委员会和32个区块提议者,这时,第一个区块成为检查点,该检查点的前两个时期的检查点即被最终确认。如下图,当区块96被选为检查点,这时从区块65~96一定包含超过三分之二的验证者,区块64被包含在区块96中,即被合理化;同理,区块32被及被包含在区块64和区块96中,即被最终确认。当检查点被最终确认时,最终确认会向前传播,前一个时期的所有区块都会被最终确认。
Gasper 是一种定义验证者如何受到奖惩的机制,决定要接受和拒绝哪个区块,以及将区块建在哪个区块链分叉上。
被选为区块提议者的验证者需要投出LMD票,而其他验证者需要投出FFG票。LMD用于提议区块,FFG用于创立检查点。
基于给定Block Tree 区块树和节点对于以太坊网络的本地视图,Fork Choice Rule 分叉选择机制被用于选择最有可能成为最终的 Linear & Canonical 线性规范链的区块链分支。
首先,分叉选择的首要条件是区块有效,在无效区块上构建的下游区块均无效。以太坊主要通过以下两个共识协议选择分支:
- Casper FFG协议有两个选择条件:
- 选择包含最大高度的合理化检查点的链
- 永远不会回退被最终确定的区块
- LMD GHOST协议:
- 采用“最贪婪最重的观察子树”,它涉及计算验证者对区块及其后续区块的累积投票
- 应用与 Casper FFG 相同的规则
以下就是一个区块树,即有分支的区块链,理论上越上游分支越少,源头为创世区块。分支最下游的为Head Block 带头区块。

假设节点α本地视图现在有区块A~F,其中C为分支、F为Head Block 带头区块。这时,区块G被广播至节点α,节点发现其被构建在区块C上。

假设区块G被分叉选择规则认为是带头区块,那么区块D~F将被裁剪。此时区块树如下:

这时,区块H来也,它被构建在区块F上,分叉选择机制认为区块H是更好的带头区块(闹麻了),那么区块C、G将被裁剪,区块链将被恢复为A->B->D->E->F->H
由于网络延迟,一两个区块的短重组很常见。较长的重组应该很少见,除非该链受到攻击或分叉选择规则或其实现存在错误。
又回到执行层的内容
Transaction Trie 交易字典树是用于存储特定区块内的交易的数据结构。Trie 字典树,是一种键-值型树状数据结构。在以太坊中,键是交易索引,值是交易内容。
另外,不论是交易索引还是交易内容均为 RLP(Recursive Length Prefix) 递归长度前缀编码。
Recursive Length Prefix PLP 递归长度前缀编码,是以太坊中最常使用的序列化格式方法,不定义数据的类型,是以嵌套数组形式存储结构型数据,由上层协议来确定数组的含义。该编码方式的特色就是可以用同一个编码函数递归地正向编码,直到不能再编码为止。 同样的过程也适用于解码,仅需将解码成果向同一个解码函数代入,直到彻底变为明文为止。
但“不定义数据的类型”并不代表可以编码任何类型的数据,它仅能用于序列化三种类型的数据:字符、字符串和数组。接下来将分别介绍RLP对这三种数据类型的处理方式。
根据密码学行业的惯例,字符往往是以16进制进行处理,16进制对于10进制更加紧凑,处理较大的数值比较节省空间。RLP也是以16进制并根据ASCII表处理字符串,以下是ASCII表的对照表:

可见ASCII表的覆盖范围是0127,即255($2^8$,0或1的8次幂),即0x00至0x7F,而一个Byte 字节(8个bit 比特)表达00x00至0xff。
对于单个字符而言,RLP根据条件语句编码:
- 如果该字符在ASCII表中,则直接返回字符编码。例如
a会被编码为0x61 - 如果不在,则在其编码前加上
0x81。例如0xef会被编码为:0x81, 0xef
这个方法很有趣,程序只需要读第一个字节即可判断其字符编码是否在ASCII表中。
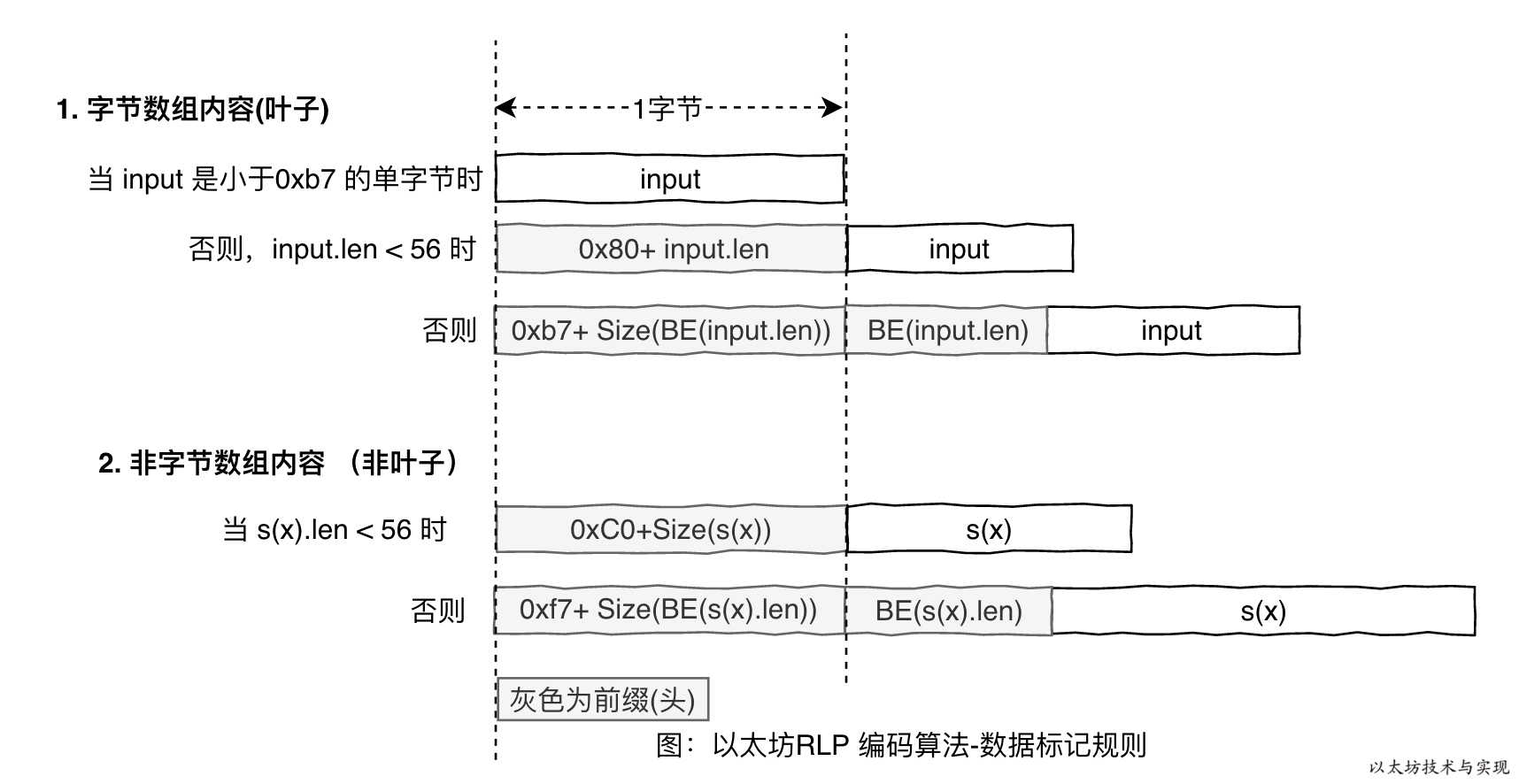
对于字符串而言:
- 字符串长度小于等于55,则返回“
0x80+ 字符串长度”和字符串编码- 例如"hello",转为16进制为:
0x68, 0x65, 0x6c, 0x6c, 0x6f - 将
0x80加上长度5,为0x80 + 5 = 0x85 - 返回 0x85 `, 0x68, 0x65, 0x6c, 0x6c, 0x6f
- 例如"hello",转为16进制为:
- 字符串长度大于55,返回“
0xb7+字符串总长度占的字节数”、字符串长度和字符串编码- 例如"aaaa, ..., a",两千个a,
0x61, ..., 0x61 - 两千为:
0x07,0xd0 - 两千占两位,加上
0xb7为:0xb7 + 2 = 0xb9,这个数值有限制:0xb8~0xbf,即字符串占位不能大于7 - 返回 0xb9, 0x07, 0xd0
,0x61, ..., 0x61
- 例如"aaaa, ..., a",两千个a,
注意:所谓加法是指数值运算,而不是ASCII表的字符运算:
- “
0x80+ 5的长度”是0x80 + 5,而不是0x80 + 0x35,5的16进制为0x35
对于数组:
- 空数组编码为
0xc0 - 数组中的每个值需要根据上述方法进行编码,例如["hello"],为[ `0x85, 0x68, 0x65, 0x6c, 0x6c, 0x6f]
- 如果数组中的每个值编码结果之和小于等于55,返回
0xc0、编码结果之和以及数组值编码。如["hello", "world"],这两个单词编码后的长度均为6,即12 = 0x0c,最后回传 0xc0, 0x0c, 这两个单词的编码 - 如果和大于55,同字符串编码方法差不多,“
0xf7+编码长度”,长度的16进制编码,数组值编码。“0xc0+编码长度”的限制为0xf8~0xff
综上,解码时仅需要根据开头的第一个字节即可确定解码方法。对于流式解码很有好处。
| 字符串开头 | 代表的含义 |
|---|---|
| 0x00~0x7f | 按照ASCII直接翻译该字符 |
| 0x81 | 会紧跟一个特殊的字符 |
| 0x82~0xb7 | 会紧跟一条不大于55个的字符串 |
| 0xb8~0xbf | 会紧跟一条大于55个的字符串 |
| 0xc0 | 空数组 |
| 0xc1~0xf7 | 会紧跟一个不大于55个字符的数组 |
| 0xf8~0xff | 会紧跟一条大于55个字符的数组 |
图示版:
Geth 是一个执行客户端,运行Geth需要空出8545端口。文档中通过以下命令生成EOA:
clef newaccount --keystore geth-tutorial/keystore密钥将被保存在geth-tutorial/keystore中
Vitalik在博客中总结的以太坊路线图:
对于权益证明而言,区块提议者是公开的,包括他们的IP,那么攻击者就可以提前向他们发动DDoS攻击,使得他们错过区块提议。这对于恶意验证者来说是有利可图的。
例如,为时隙
n+1选择的区块提议者可以对时隙n中的提议者进行拒绝服务攻击,使其错过提出区块的机会。 这样可以让发起攻击的区块提议者提取两个时隙的最大可提取价值,或者获取本应分配到两个区块的所有交易,并将它们全部添加到一个区块,从而获得所有相关费用。这对家庭验证者的影响可能比先进的机构验证者更大,机构验证者可以使用更先进的方法来保护自己免受拒绝服务攻击,因此可能推动中心化。—— 秘密领袖选举 | EF
为了克服这个缺陷,需要Secret Leader Election SLE 秘密领袖选举,具体又有几种实现方式。
Single SLE 单一秘密领袖选举希望每一个验证者提交一个盲id(Commitment),然后网络打乱后发布该id,除了被选为领袖的验证者,其他人没办法从签名知道是谁被选中了。
这个算法的实现名叫Whisk:
- 验证者提交盲id
- 在某一个Epoch时,会通过RANDAO随机选择一组验证者从16384个盲id中随机抽样
- 接下来的 8182 个时隙(1 天),区块提议者使用自己的私有熵打乱盲id的子集使其随机化。
- 之后,使用 RANDAO 创建有序的盲id列表。 该列表映射到一系列Slot
- 被选为领袖的验证者看到他们的盲id被分配到特定时隙,于是他们就知道自己被选中了
这是一个循环,之后再重复
今天在周会上了解到一些很有趣的东东,我记录在这里:
- Trin 一个可以限制硬盘使用空间的客户端
- @parithosh_j详细Pectra升级出现问题的原因
- Ben用Python注释的CL协议
- Pyspec 教程
ZKP Zero-Knowledge Proof 零知识证明 是让你在不泄露秘密本身的情况下,就能让别人确信你知道这个秘密。
Zero-Knowledge Succinct Non-Interactive Argument of Knowledge
字词拆解:
- zk 零知识证明
- Succinct 简洁 证明的过程和结果都非常小巧和快速。验证起来也非常快
- Non-Interactive 非交互式 证明过程不需要证明者和验证者之间进行多次对话。 证明者一次性生成证明,验证者可以直接验证
- Argument of Knowledge 知识论证: 证明的目的是为了证明你确实拥有某种知识(比如知道秘密、知道答案等等)
Zero-Knowledge Scalable Transparent Argument of Knowledg 字词拆解:
- zk 零知识证明
- Succinct 可扩展: ZK-STARKs 在证明生成和验证方面都具有更好的扩展性。 这意味着,随着需要证明的计算变得越来越复杂,ZK-STARKs 的性能下降幅度相对较小,仍然能保持高效。
- Transparent 透明: ZK-STARKs 的 "透明性" 是它与 zk-SNARKs 的一个重要区别。 "透明" 主要指的是 ZK-STARKs 在设置过程中不需要 "可信设置" (Trusted Setup)。
- Argument of Knowledge 知识论证: 证明的目的是为了证明你确实拥有某种知识(比如知道秘密、知道答案等等)
为了让 zk-SNARKs 正常工作,通常需要一个初始的 "可信设置" 阶段。这个阶段会生成一些公开的参数,这些参数是证明和验证过程的基础。 但是,"可信设置" 的问题在于,如果设置过程中存在任何作弊行为,可能会导致整个系统的安全性受到威胁。 “可信” 的含义就是需要信任设置过程的参与者不会作恶。
ZK-STARKs 的透明性: ZK-STARKs 使用公开随机性来生成必要的参数,而不是依赖于 "可信设置"。 这意味着,任何人都可以验证参数的生成过程,不需要信任任何特定的参与者。 这种 "透明" 的设置方式,大大提高了 ZK-STARKs 的安全性,降低了潜在的风险。
zk-STARK的证明和验证在复杂计算中更具优势,且无需可信设置,而zk-SNARK验证速度非常快
Aggregate 聚合 是把多个 zk-SNARK 证明聚合成一个单一的、更小的证明
因为ZK当交易很多的时候会很重,所以聚合起来效率更高,可以提升吞吐量、降低Gas费
