Replies: 3 comments 3 replies
-
|
I only monitored the value of aux_loss at the beginning of training and finetuning, and did not observe aux_loss in the middle stage of training. And at the beginning of training, aux_loss can converge quickly . |
Beta Was this translation helpful? Give feedback.
-
|
The same phenomenon in my training, do you solve it? |
Beta Was this translation helpful? Give feedback.
-
|
@dq0309 |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Are you training from scratch or fine-tuning a pre-trained model ? |
Beta Was this translation helpful? Give feedback.
-
|
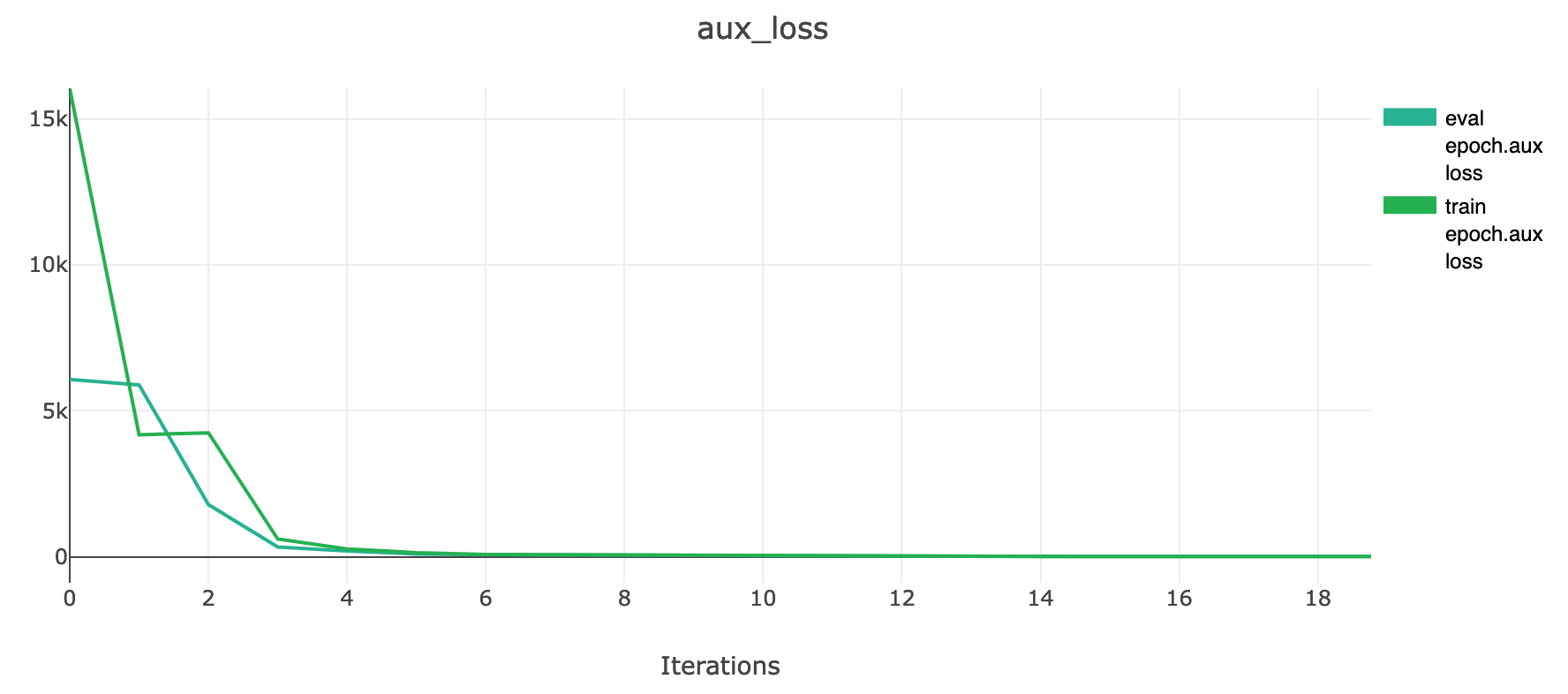
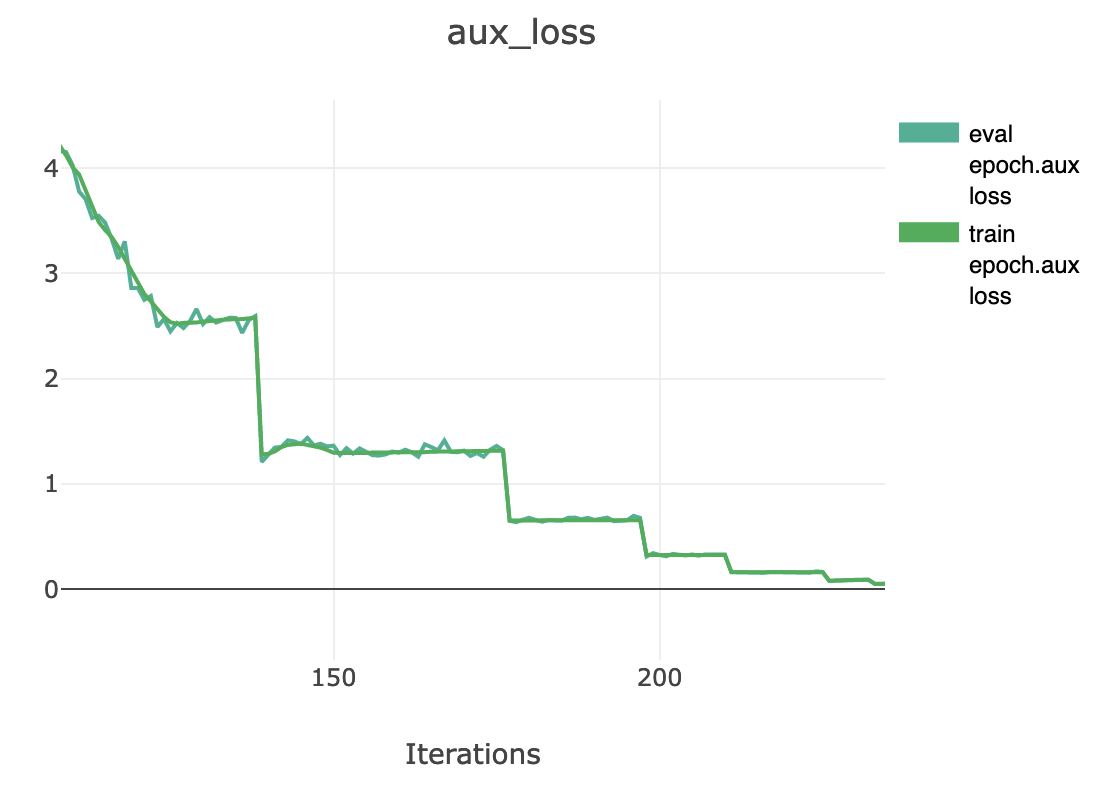
@fracape Hi! I only monitored the aux_loss at the beginning and end of training. At the beginning ,aux_loss converges rapidly from 12K to nearly 100.In the last few epochs, I found aux_loss rising slowly.But the increase is not too large,nearly from 30 to 38. In the picture you show, the vertical axis value is very large, so the change of aux in the later stage of training may not be obvious. I tried to adjust aux's LR,but it didn't work. In the next experiment, maybe I need to monitor the change of the aux_loss in the whole process |
Beta Was this translation helpful? Give feedback.
-
|
|
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi! @fracape
Recently i am reproducing a E2E video compression paper based on compressai. Folllow https://github.com/InterDigitalInc/CompressAI/blob/master/examples/train.py ,during traing i keep the learning rate of aux_optimizer the same. But i found the aux_loss keep rising when i finetune the model(which means reduce other parameters optimizer’s learning rate and don't change the learning rate of aux_optimizer). Even if I try to reduce the learning rate of aux_optimizer , aux loss will still keep rising. But when I encode it into an actual bitstream, the actual bpp does not differ much from the predicted bpp. Can I ignore the rise of aux_loss? Or how to solve it.
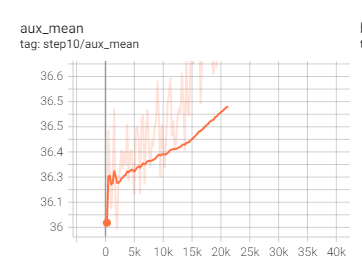
And this is the bpp and psnr difference between compress and forward. The difference of psnr is already talked in #41
Beta Was this translation helpful? Give feedback.
All reactions