Multi-accumulator/lane summation #41
Description
Compensated summation [CS] is slow on modern CPUs partly because there's a loop-carried dependency all the way through. Dividing the input into several parts to run CS individually, followed by a CS step to sum the buckets together, is one solution. This also happens to work pretty well with SIMD, so it gets a lot faster. https://blog.zachbjornson.com/2019/08/11/fast-float-summation.html claims:
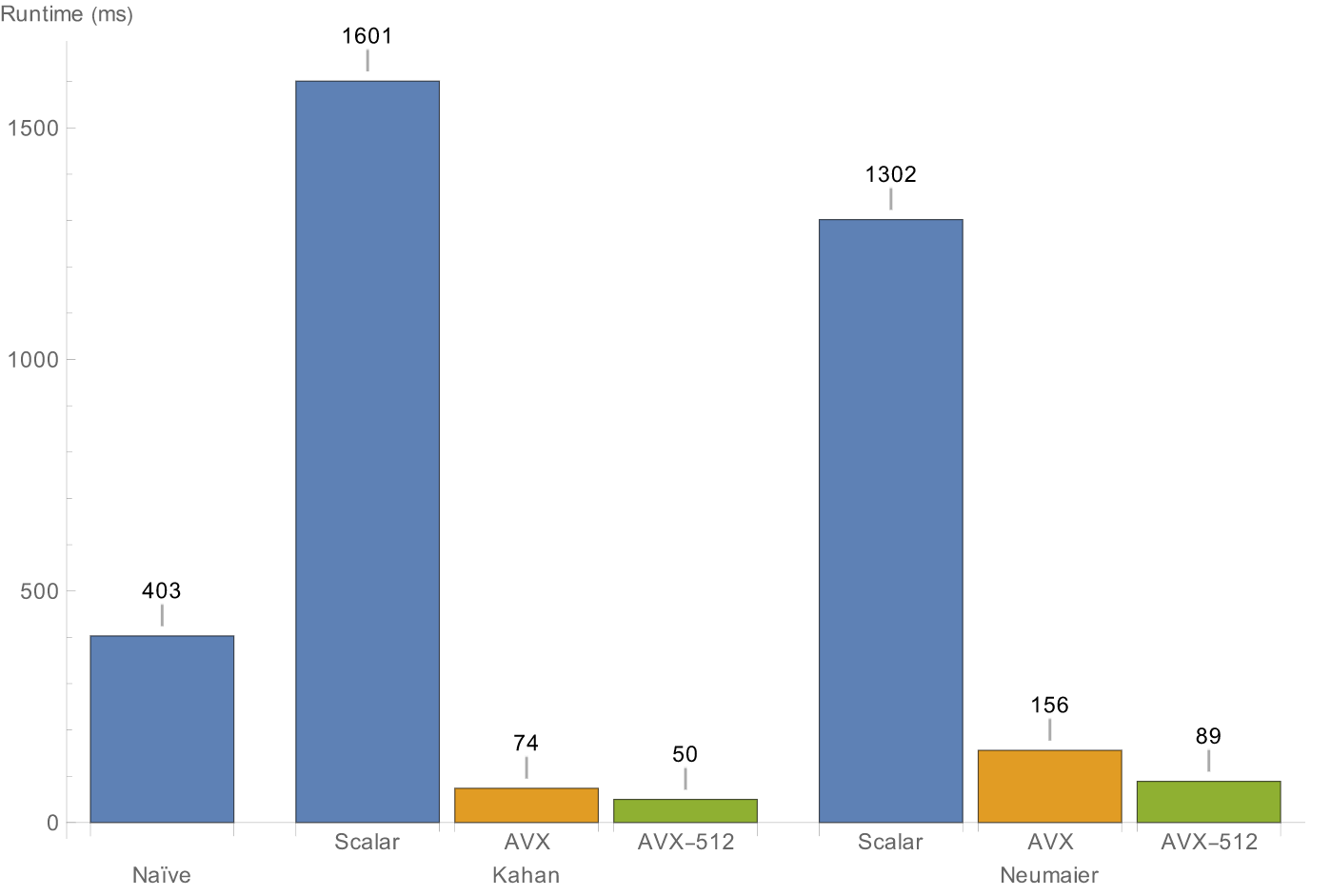
Now it's probably impossible to get that kind of numbers through the layers of abstraction Julia has... and there's not much sense to decide how many lanes to use for the user either. But some degree of autovectorization remains possible, so providing a way to pass in the desired # of lanes like sum_kbn(A; lanes) and cumsum_kbn(A; lanes) is probably good enough.