|
161 | 161 | "As we can see the execution times printed by `tune_kernel` already vary quite dramatically between the different values for `block_size_x` and `block_size_y`. However, even with the best thread block dimensions our kernel is still not very efficient.\n", |
162 | 162 | "\n", |
163 | 163 | "Therefore, we'll have a look at the Nvidia Visual Profiler to find that the utilization of our kernel is actually pretty low:\n", |
164 | | - "\n", |
| 164 | + "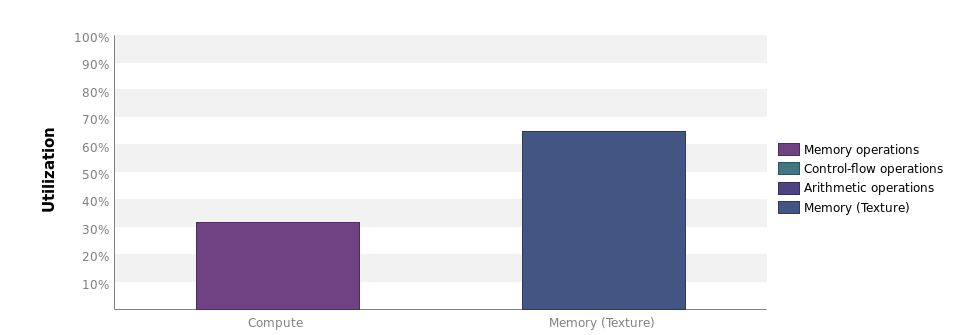\n", |
165 | 165 | "There is however, a lot of opportunity for data reuse, which is realized by making the threads in a thread block collaborate." |
166 | 166 | ] |
167 | 167 | }, |
|
270 | 270 | "source": [ |
271 | 271 | "This kernel drastically reduces memory bandwidth consumption. Compared to our naive kernel, it is about three times faster now, which comes from the highly increased memory utilization:\n", |
272 | 272 | "\n", |
273 | | - "\n", |
| 273 | + "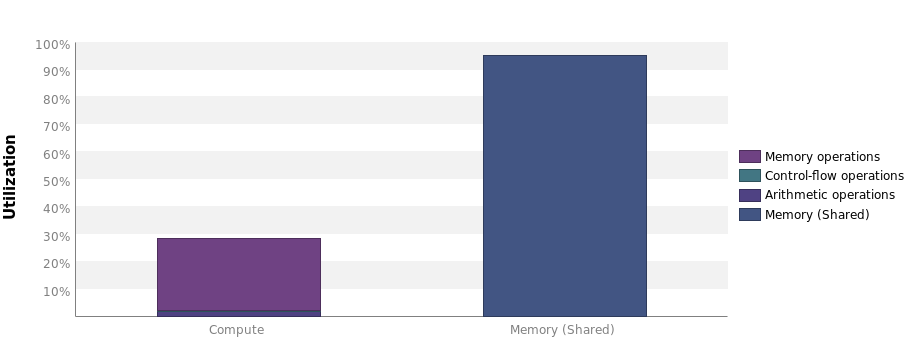\n", |
274 | 274 | "\n", |
275 | 275 | "The compute utilization has actually decreased slightly, which is due to the synchronization overhead, because ``__syncthread()`` is called frequently.\n", |
276 | 276 | "\n", |
|
422 | 422 | "source": [ |
423 | 423 | "As we can see the number of kernel configurations evaluated by the tuner has increased again. Also the performance has increased quite dramatically with roughly another factor 3. If we look at the Nvidia Visual Profiler output of our kernel we see the following:\n", |
424 | 424 | "\n", |
425 | | - "\n", |
| 425 | + "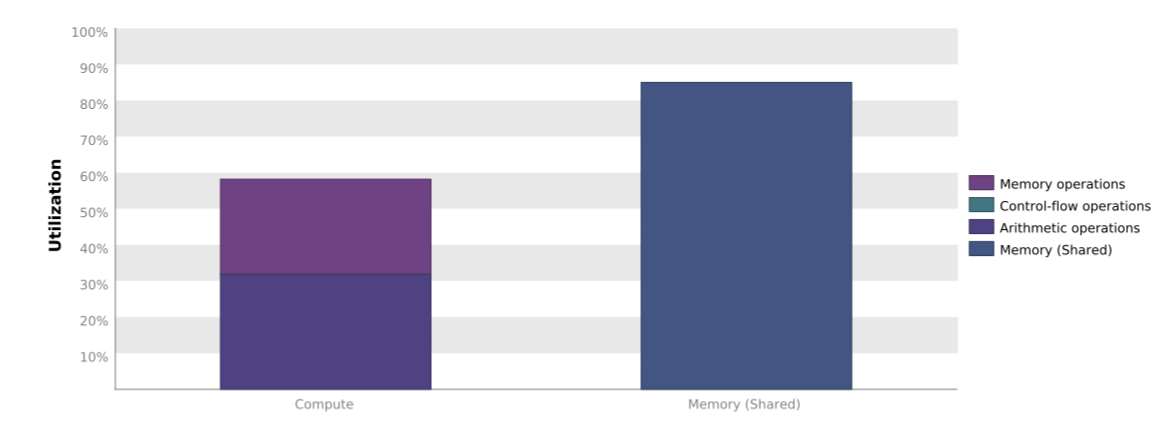\n", |
426 | 426 | "\n", |
427 | 427 | "As expected, the compute utilization of our kernel has improved. There may even be some more room for improvement, but our tutorial on how to use Kernel Tuner ends here. In this tutorial, we have seen how you can use Kernel Tuner to tune kernels with a small number of tunable parameters, how to impose restrictions on the parameter space, and how to use grid divisor lists to specify how grid dimensions are computed." |
428 | 428 | ] |
|
0 commit comments