|
| 1 | +<div align="center"> |
| 2 | + <h2 align="center"> |
| 3 | + TransferQueue: An asynchronous streaming data management module for efficient post-training |
| 4 | + </h2> |
| 5 | + <a href="https://arxiv.org/abs/2507.01663" target="_blank"><strong>Paper</strong></a> |
| 6 | +| <a href="https://zhuanlan.zhihu.com/p/1930244241625449814" target="_blank"><strong>Zhihu</strong></a> |
| 7 | + <br /> |
| 8 | + <br /> |
| 9 | + |
| 10 | +</div> |
| 11 | +<br/> |
| 12 | + |
| 13 | + |
| 14 | +<h2 id="overview">🎉 Overview</h2> |
| 15 | + |
| 16 | +TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows. |
| 17 | + |
| 18 | +<p align="center"> |
| 19 | + <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696193102-a5654375-65a1-4e06-9c63-142b59df90b8.png" width="70%"> |
| 20 | +</p> |
| 21 | + |
| 22 | + |
| 23 | +TransferQueue offers **fine-grained, sample-level** data management and **load-balancing** (on the way) capabilities, serving as a data gateway that decouples explicit data dependencies across computational tasks. This enables a divide-and-conquer approach, significantly simplifying the design of the algorithm controller. |
| 24 | + |
| 25 | + |
| 26 | +<p align="center"> |
| 27 | + <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696791245-fa7baf96-46af-4c19-8606-28ffadc4556c.png" width="70%"> |
| 28 | +</p> |
| 29 | + |
| 30 | + |
| 31 | + |
| 32 | + |
| 33 | + |
| 34 | + |
| 35 | +<h2 id="updates">🔄 Updates</h2> |
| 36 | + |
| 37 | + - **July 22, 2025**: We present a series of Chinese blogs on <a href="https://zhuanlan.zhihu.com/p/1930244241625449814">Zhihu 1</a>, <a href="https://zhuanlan.zhihu.com/p/1933259599953232589">2</a>. |
| 38 | + - **July 21, 2025**: We start an RFC on verl community [RFC#2662](https://github.com/volcengine/verl/discussions/2662). |
| 39 | + - **July 2, 2025**: We publish the paper [AsyncFlow](https://arxiv.org/abs/2507.01663). |
| 40 | + |
| 41 | + |
| 42 | + |
| 43 | +<h2 id="components">🧩 Components</h2> |
| 44 | + |
| 45 | + |
| 46 | + |
| 47 | +### Control Plane: Panoramic Data Management |
| 48 | + |
| 49 | +In the control plane, `TransferQueueController` tracks the **production status** and **consumption status** of each training sample as metadata. When all the required data fields are ready (i.e., written to the `TransferQueueStorage`), we know that this data sample can be consumed by downstream tasks. |
| 50 | + |
| 51 | +For consumption status, we record the consumption records for each computational task (e.g., `generate_sequences`, `compute_log_prob`, etc.). Therefore, even different computation tasks require the same data field, they can consume the data independently without interfering with each other. |
| 52 | + |
| 53 | + |
| 54 | +<p align="center"> |
| 55 | + <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696820173-456c1784-42ba-40c8-a292-2ff1401f49c5.png" width="70%"> |
| 56 | +</p> |
| 57 | + |
| 58 | + |
| 59 | +> In the future, we plan to support **load-balancing** and **dynamic batching** capabilities in the control plane. Besides, we will support data management for disaggregated frameworks where each rank manages the data retrieval by itself, rather than coordinated by a single controller. |
| 60 | +
|
| 61 | +### Data Plane: Distributed Data Storage |
| 62 | + |
| 63 | +In the data plane, `TransferQueueStorageSimpleUnit` serves as a naive storage unit based on CPU memory, responsible for the actual storage and retrieval of data. Each storage unit can be deployed on a separate node, allowing for distributed data management. |
| 64 | + |
| 65 | +`TransferQueueStorageSimpleUnit` employs a 2D data structure as follows: |
| 66 | + |
| 67 | +- Each row corresponds to a training sample, assigned a unique index within the corresponding global batch. |
| 68 | +- Each column represents the input/output data fields for computational tasks. |
| 69 | + |
| 70 | +This data structure design is motivated by the computational characteristics of the post-training process, where each training sample is generated in a relayed manner across task pipelines. It provides an accurate addressing capability, which allows fine-grained, concurrent data read/write operations in a streaming manner. |
| 71 | + |
| 72 | +<p align="center"> |
| 73 | + <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696805154-3817011f-84e6-40d0-a80c-58b7e3e5f6a7.png" width="70%"> |
| 74 | +</p> |
| 75 | + |
| 76 | + |
| 77 | +> In the future, we plan to implement a **general storage abstraction layer** to support various storage backends. Through this abstraction, we hope to integrate high-performance storage solutions such as [MoonCakeStore](https://github.com/kvcache-ai/Mooncake) to support device-to-device data transfer through RDMA, further enhancing data transfer efficiency for large-scale data. |
| 78 | +
|
| 79 | + |
| 80 | +### User Interface: Asynchronous & Synchronous Client |
| 81 | + |
| 82 | + |
| 83 | +The interaction workflow of TransferQueue system is as follows: |
| 84 | + |
| 85 | +1. A process sends a read request to the `TransferQueueController`. |
| 86 | +2. `TransferQueueController` scans the production and consumption metadata for each sample (row), and dynamically assembles a micro-batch metadata according to the load-balancing policy. This mechanism enables sample-level data scheduling. |
| 87 | +3. The process retrieves the actual data from distributed storage units using the metadata provided by the controller. |
| 88 | + |
| 89 | +To simplify the usage of TransferQueue, we have encapsulated this process into `AsyncTransferQueueClient` and `TransferQueueClient`. These clients provide both asynchronous and synchronous interfaces for data transfer, allowing users to easily integrate TransferQueue to their framework. |
| 90 | + |
| 91 | + |
| 92 | +> In the future, we will provide a `StreamingDataLoader` interface for disaggregated frameworks as discussed in [RFC#2662](https://github.com/volcengine/verl/discussions/2662). Leveraging this abstraction, each rank can automatically get its own data like `DataLoader` in PyTorch. The TransferQueue system will handle the underlying data scheduling and transfer logic caused by different parallelism strategies, significantly simplifying the design of disaggregated frameworks. |
| 93 | +
|
| 94 | + |
| 95 | +<h2 id="show-cases">🔥 Show Cases</h2> |
| 96 | + |
| 97 | +### General Usage |
| 98 | + |
| 99 | +The primary interaction points are `AsyncTransferQueueClient` and `TransferQueueClient`, serving as the communication interface with the TransferQueue system. |
| 100 | + |
| 101 | +Core interfaces: |
| 102 | + |
| 103 | +- (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta |
| 104 | +- (async_)get_data(metadata:BatchMeta) -> TensorDict |
| 105 | +- (async_)put(data:TensorDict, metadata:BatchMeta, global_step) |
| 106 | +- (async_)clear(global_step: int) |
| 107 | + |
| 108 | + |
| 109 | +We will soon release a detailed tutorial and API documentation. |
| 110 | + |
| 111 | + |
| 112 | +### Collocated Example |
| 113 | + |
| 114 | +#### verl |
| 115 | +The primary motivation for integrating TransferQueue to verl now is to **alleviate the data transfer bottleneck of the single controller `RayPPOTrainer`**. Currently, all `DataProto` objects must be routed through `RayPPOTrainer`, resulting in a single point bottleneck of the whole post-training system. |
| 116 | + |
| 117 | +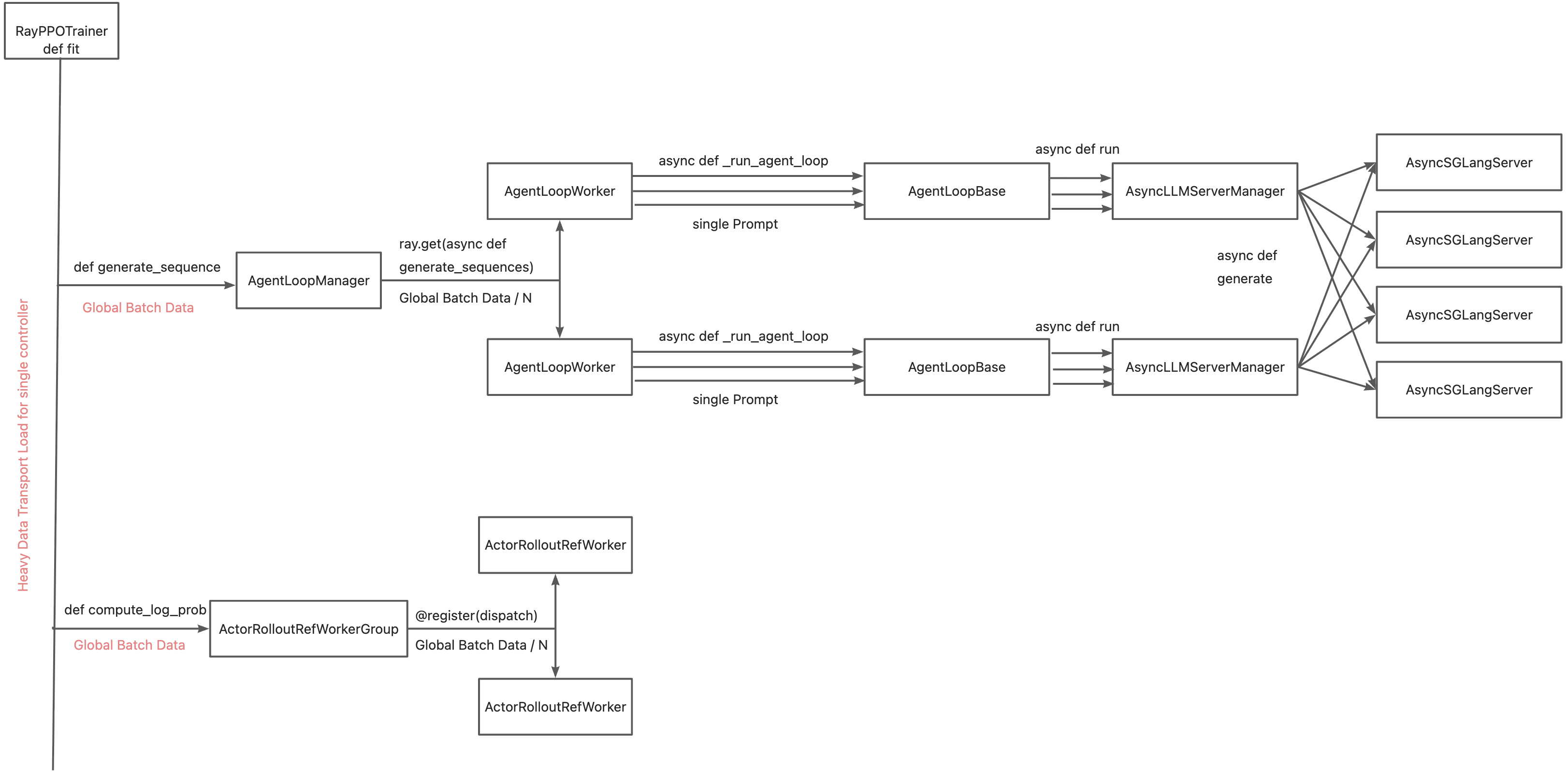 |
| 118 | + |
| 119 | +Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by |
| 120 | + |
| 121 | +- Replacing `DataProto` with `BatchMeta` (metadata) and `TensorDict` (actual data) structures |
| 122 | +- Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability) |
| 123 | +- Accelerating data transfer by TransferQueue's distributed storage units |
| 124 | + |
| 125 | +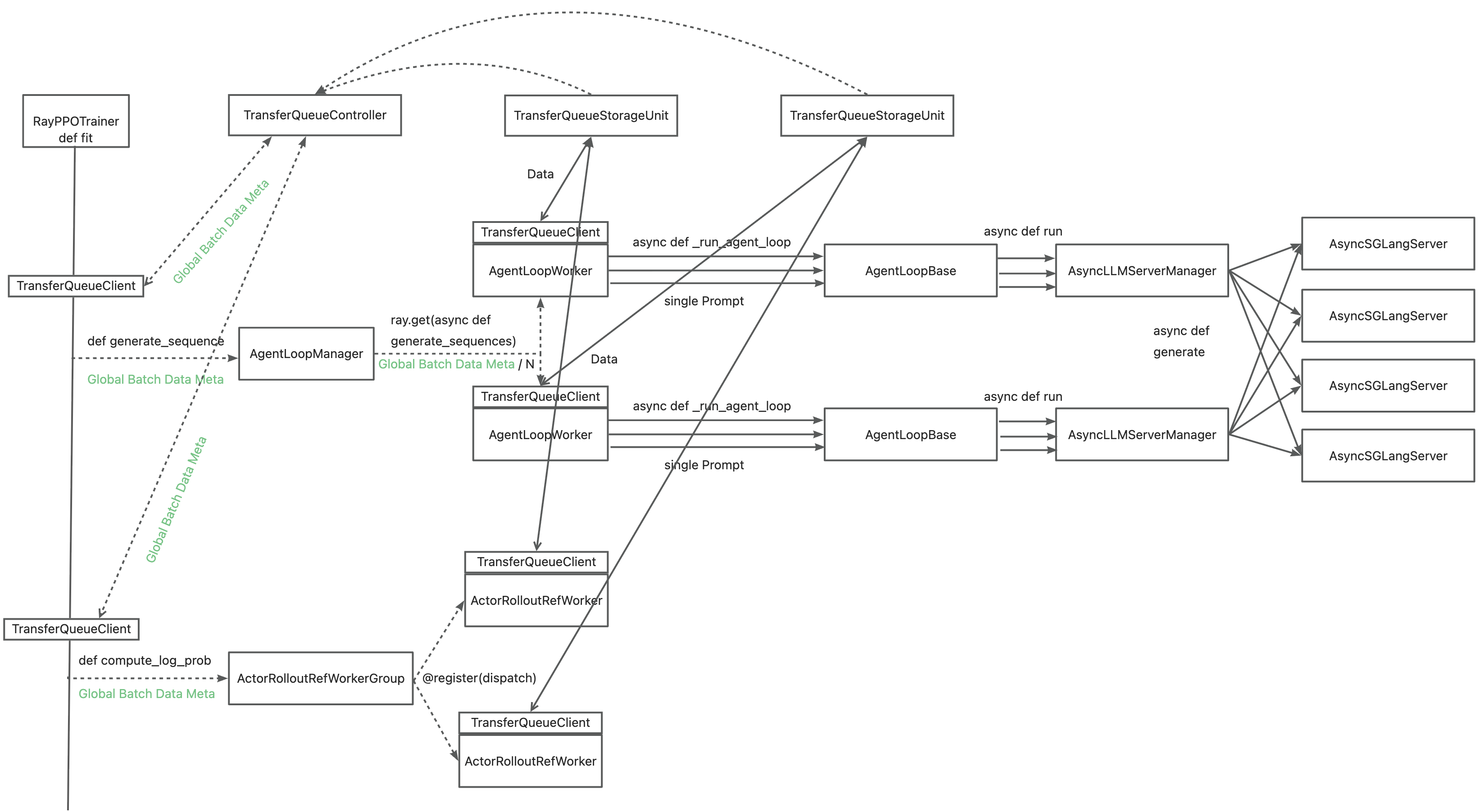 |
| 126 | + |
| 127 | + |
| 128 | +You may refer to the [recipe](https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case), where we mimic the verl usage in both async & sync scenarios. Official integration to verl is on the way. |
| 129 | + |
| 130 | + |
| 131 | +### Disaggregated Example |
| 132 | + |
| 133 | +Work in progress :) |
| 134 | + |
| 135 | + |
| 136 | +<p align="center"> |
| 137 | + <img src="https://cdn.nlark.com/yuque/0/2025/png/23208217/1758696840817-14ba4c3b-b96e-4390-ac7c-4ecf7b8c0ac3.png" width="70%"> |
| 138 | +</p> |
| 139 | + |
| 140 | + |
| 141 | +<h2 id="quick-start">🚀 Quick Start</h2> |
| 142 | + |
| 143 | + |
| 144 | +### Use Python package |
| 145 | +We will soon release the Python package on PyPI. |
| 146 | + |
| 147 | +### Build wheel package from source code |
| 148 | + |
| 149 | +The building and installation steps are the following: |
| 150 | +1. Retrieve source code from GitHub repo |
| 151 | + ```bash |
| 152 | + git clone https://github.com/TransferQueue/TransferQueue/ |
| 153 | + cd TransferQueue |
| 154 | + ``` |
| 155 | + |
| 156 | +2. Install dependencies |
| 157 | + ```bash |
| 158 | + pip install -r requirements.txt |
| 159 | + ``` |
| 160 | + |
| 161 | +3. Build and install |
| 162 | + ```bash |
| 163 | + python -m build --wheel |
| 164 | + pip install dist/*.whl |
| 165 | + ``` |
| 166 | + |
| 167 | + |
| 168 | +<h2 id="milestones"> 🛣️ RoadMap</h2> |
| 169 | + |
| 170 | +- [ ] Release the first stable version through PyPI |
| 171 | +- [ ] Support disaggregated framework (each rank retrieves its own data without going through a centralized node) |
| 172 | +- [ ] Provide a `StreamingDataLoader` interface for disaggregated framework |
| 173 | +- [ ] Support load-balancing and dynamic batching |
| 174 | +- [ ] Provide a general storage abstraction layer for different backends (e.g., [MoonCakeStore](https://github.com/kvcache-ai/Mooncake)) |
| 175 | +- [ ] High-performance serialization and deserialization |
| 176 | +- [ ] More documentation, examples and tutorials |
| 177 | + |
| 178 | +<h2 id="citation">📑 Citation</h2> |
| 179 | +Please kindly cite our paper if you find this repo is useful: |
| 180 | + |
| 181 | +```bibtex |
| 182 | +@article{han2025asyncflow, |
| 183 | + title={AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training}, |
| 184 | + author={Han, Zhenyu and You, Ansheng and Wang, Haibo and Luo, Kui and Yang, Guang and Shi, Wenqi and Chen, Menglong and Zhang, Sicheng and Lan, Zeshun and Deng, Chunshi and others}, |
| 185 | + journal={arXiv preprint arXiv:2507.01663}, |
| 186 | + year={2025} |
| 187 | +} |
| 188 | +``` |
0 commit comments