Drastic training slowdown after ~10 epochs #12544
erikfurevik
started this conversation in
General
Replies: 1 comment
-
|
I did some changes that were very effective:
In total these changes reduced time per epoch from ~30s to ~8s, at least for the smaller models that I tested on so far. |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
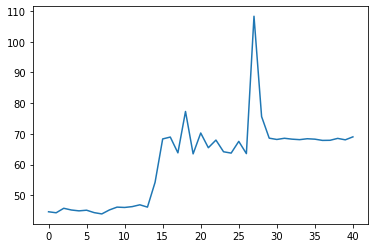
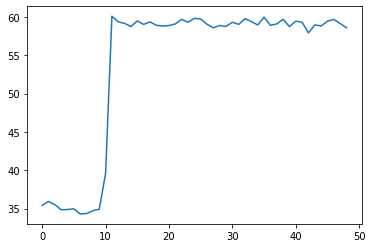
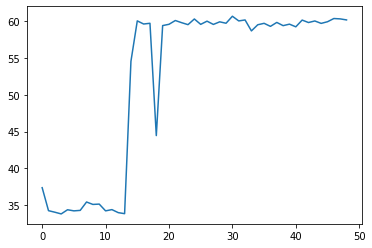
Hi, for most of my runs and models the training time per epoch at some point increases drastically as shown below (click to see axis).
This data is from a custom logging setup like this, but is verified with built-in tensorboard logging system as well.
This is a 30 million param model,
this one has 50K parameters,
and this has only 400 parameters.
Is there a natural explanation for this behaviour, or is it a bug?
As the models are very different size, and still get very similar behaviour and speed, this leads me to assume it must have to do with dataloading. My best guess is that data is pre-cached during the start of training with model validation/sanity check, then the trainer runs out of pre-cached data and must slow down?
Is there anything I can do to improve this and speed things up?
My setup:
I train with a GPU on Google Colab. I have 4 workers per dataloader, which I've seen recommended for a GPU (even though pl warns me I should use only 2). I have a custom dataset module that just stores a list of filenames, one per input and target example. Each file is a pickled numpy array of size 51x128x128, 3.2MB for input and 8x128x128, 0.5 MB for target. Here's my getitem.
Beta Was this translation helpful? Give feedback.
All reactions