One gpu 50% higher memory utilization than others? #12634
Unanswered
exnx
asked this question in
Lightning Trainer API: Trainer, LightningModule, LightningDataModule
Replies: 1 comment
-
|
Duplicate of #12651. Let's track in the issue to avoid scattering information. |
Beta Was this translation helpful? Give feedback.
0 replies
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
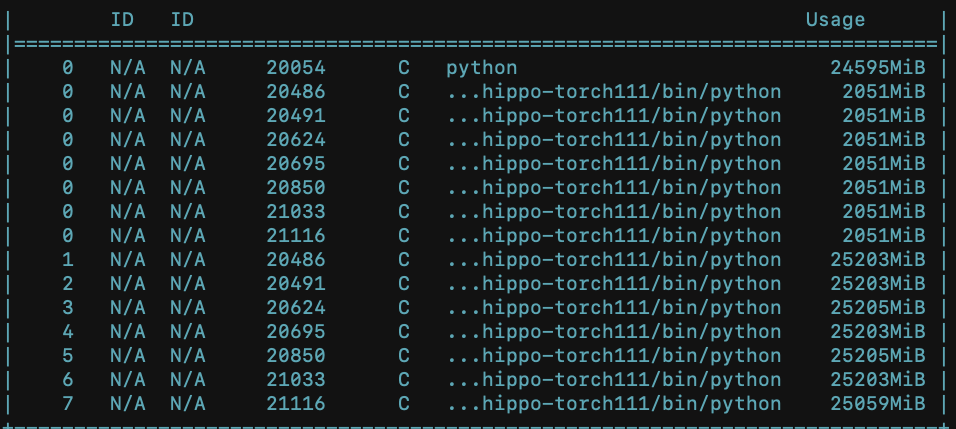
Hi, I am training ConvNext with 8 A100 gpus on GCP. When I am training with standard ConvNext-base, all 8 GPUs are utilized pretty evenly. However, I have this new layer (from the S4 paper) that I am swapping in for the group convolution in ConvNext. It runs, but then 1 gpu is at 39/40 GB, while the other 7 gpus are at 25/40 gpus, greatly limiting my training batch size :( And in turn, much slower, and costly with cloud credits.
As I was trying to investigate, here is something I found. The first gpu has 6 processes with ~2gb each memory each that were presumably supposed to be distributed to the other gpus, but for whatever reason, stuck to the first gpu.
Other than that, I have no idea even how to go about finding the source of the issue.
I was wondering if anyone had any hint on how to go about finding the problem? Any tips at all, ANY!, would be sooooo helpful. Thanks for your help.
I am using:
PTL 1.6, Python 3.8, Torch 1.11 cuda 11.3.2.
Best,
Eric
Beta Was this translation helpful? Give feedback.
All reactions