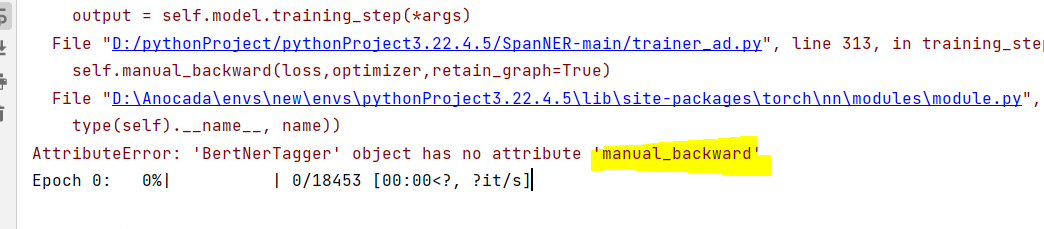
When I use the official sample to carry out back propagation manually, I make mistakes. First, there is no optimizer, and second, there is no attribute in the image #12683
-
|
import torch
from torch import Tensor
from pytorch_lightning import LightningModule
class Generator:
def __init__(self):
pass
def forward(self):
pass
class Discriminator:
def __init__(self):
pass
def forward(self):
pass
class SimpleGAN(LightningModule):
def __init__(self):
super().__init__()
self.G = Generator()
self.D = Discriminator()
# Important: This property activates manual optimization.
self.automatic_optimization = False
def sample_z(self, n) -> Tensor:
sample = self._Z.sample((n,))
return sample
def sample_G(self, n) -> Tensor:
z = self.sample_z(n)
return self.G(z)
def training_step(self, batch, batch_idx):
# Implementation follows the PyTorch tutorial:
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
g_opt, d_opt = self.optimizers()
X, _ = batch
batch_size = X.shape[0]
real_label = torch.ones((batch_size, 1), device=self.device)
fake_label = torch.zeros((batch_size, 1), device=self.device)
g_X = self.sample_G(batch_size)
##########################
# Optimize Discriminator #
##########################
d_x = self.D(X)
errD_real = self.criterion(d_x, real_label)
d_z = self.D(g_X.detach())
errD_fake = self.criterion(d_z, fake_label)
errD = errD_real + errD_fake
d_opt.zero_grad()
self.manual_backward(errD)
d_opt.step()
######################
# Optimize Generator #
######################
d_z = self.D(g_X)
errG = self.criterion(d_z, real_label)
g_opt.zero_grad()
self.manual_backward(errG)
g_opt.step()
self.log_dict({"g_loss": errG, "d_loss": errD}, prog_bar=True)
def configure_optimizers(self):
g_opt = torch.optim.Adam(self.G.parameters(), lr=1e-5)
d_opt = torch.optim.Adam(self.D.parameters(), lr=1e-5)
return g_opt, d_opt
batch=torch.randn(3,2)
batch_idx=torch.ones(3)
SimpleGAN().training_step(batch,batch_idx) |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 3 replies
-
|
Hi @Hou-jing!
|
Beta Was this translation helpful? Give feedback.
-
|
This example (adapted from the official examples) in my repo could be useful for you: https://github.com/akihironitta/gist/blob/master/pl_gan_manual_optimization/main.py |
Beta Was this translation helpful? Give feedback.
-
|
When I upgraded the version to the latest version, I solved this problem。 |
Beta Was this translation helpful? Give feedback.
-
|
@Hou-jing Cannot access to your Colab notebook... I'd suggest to profile your lightningmodule to identify the cause of the problem. |
Beta Was this translation helpful? Give feedback.
-
|
If you still have the issue, could you create another GitHub discussion? Each discussion/issue should be about only one topic. |
Beta Was this translation helpful? Give feedback.
-
|
I think ,Because the loss is calculated twice, the time is delayed |
Beta Was this translation helpful? Give feedback.
When I upgraded the version to the latest version, I solved this problem。
However, my running speed has been greatly affected. I used to have an epoch every 8 minutes, but now it has been delayed for a long time, and the data can't be loaded. I don't know why
And this is the code
[https://colab.research.google.com/drive/1dCP7-1xK48-PohGc8-RKx3Ne2HWd4Jkq#scrollTo=frTD9xWvBEUT]