How to properly configure lr schedulers when using fine tuning and DDP? #8724
Unanswered
Scass0807
asked this question in
Lightning Trainer API: Trainer, LightningModule, LightningDataModule
Replies: 0 comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
Uh oh!
There was an error while loading. Please reload this page.
-
Hi I am currently trying to train an image classifier with ResNet Iam trying to use a ReduceLROnPlateau to improve training accuracy. I also have split the model and last layer into a backbone and classifier. My goal is to freeze the backbone for the first 10 or so epochs and then unfreeze and train the whole model. The problem I am having is that is scheduler does not seem to be behaving as expected and I am getting errors using DDP.
I am trying to lower the learning rate by a factor of 10 on both the backbone and classifier when Top 1 Validation Accuracy plateaus. My expectation is that the backbone and classifier learning rates will be equal at all times and they will decrease at the same time. However, this does not appear to be the case. It appears that as soon as the backbone unfreezes its learning rate is decreasing by a factor of 10 Even though there is no plateau in accuracy There is however a slight increase in loss and I read here that
scheduler.stepis always called on val_loss. However that appears to be an old thread and I then read here that this is no longer the case. Even then, the interval is set toepochand thepatienceshould be high enough that is has no effect.This happens both with and without DDP. However in DDP and am getting a warning when the backbone is unfroze:
This is occurring even though I am already using the filter and I have also tried setting
find_unused_parameters=TrueThe other thing that is happening is midway through training the scheduler tres to kick in and causes this error crashing the program.I have posted figures and limited code below to show what is happening:
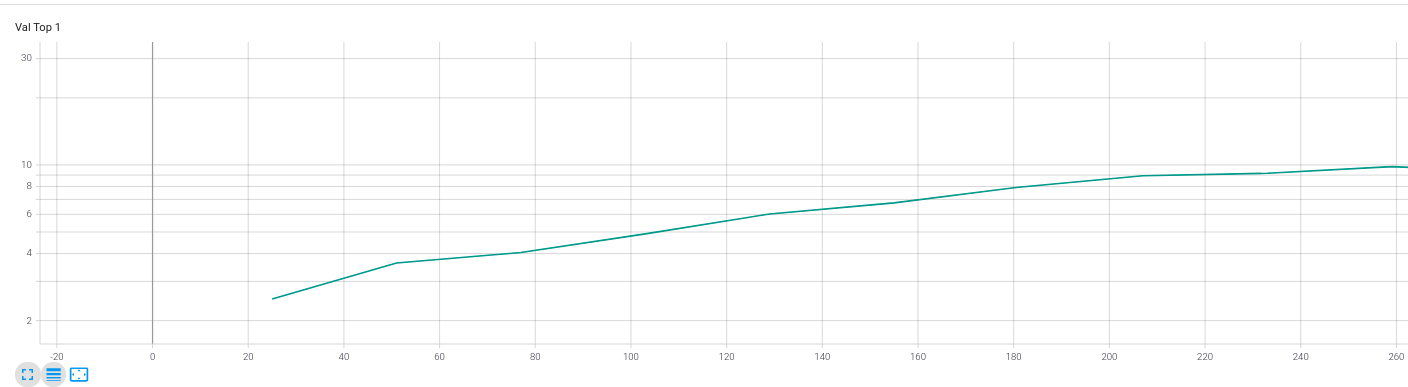
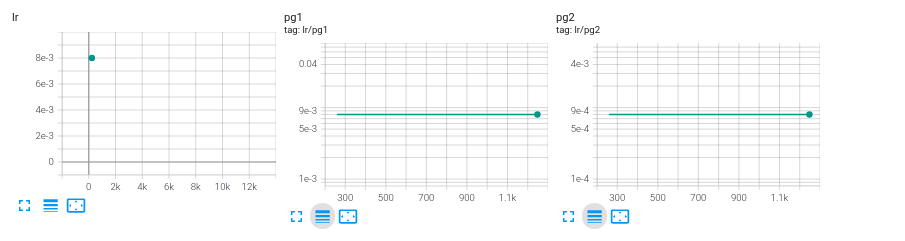
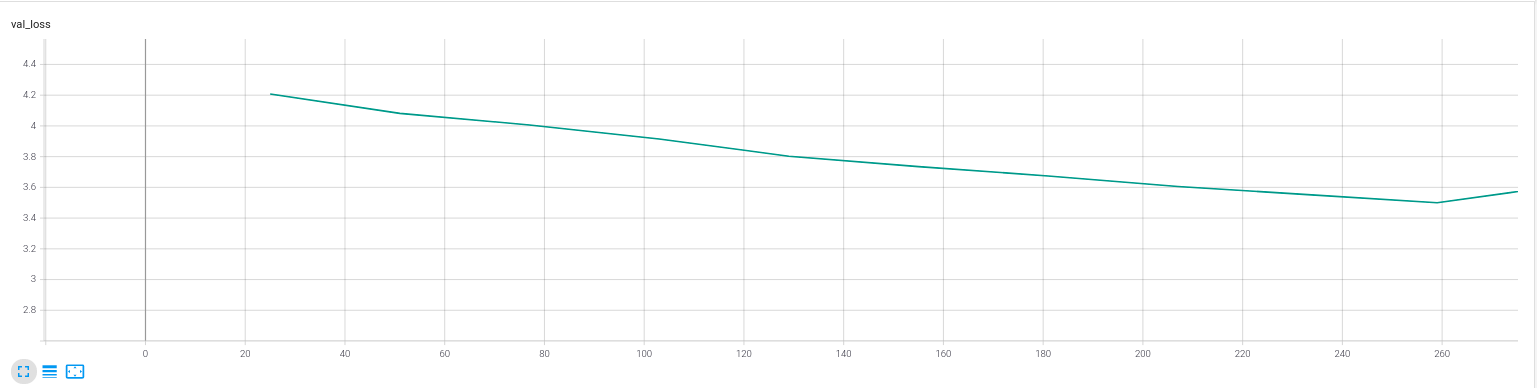
Both parameter groups should have a learning rate of 8e-3 not 8e-4.
I have already tried splitting the backbone and classifier into multiple optimizers, lr_schedulers with no success, I know this is really multiple issues not sure if this should be multiple threads. Any help would be appreciated.
Beta Was this translation helpful? Give feedback.
All reactions