Confusion in training_step_end() API #9617
-
|
Hi! I am playing around with pytorch-lightning. Problem Question My code import torch
from torch import nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import torch.nn.functional as F
import pytorch_lightning as pl
class BaseImageClassificationSystem(pl.LightningModule):
def __init__(self):
super().__init__()
self.backbone = nn.Sequential(nn.Conv2d(1, 64, 3), nn.AdaptiveAvgPool2d((1, 1)))
self.fc = nn.Linear(64, 10)
def forward(self, x):
return self.fc(torch.flatten(self.backbone(x), 1))
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.fc(torch.flatten(self.backbone(x), 1))
loss = F.cross_entropy(y_hat, y)
self.log('train/loss', loss)
return loss
def training_step_end(self, losses):
print(losses)
return (losses[0] + losses[1]) / 2
def configure_optimizers(self):
return optim.SGD(self.parameters(), lr=0.01)
train_dl = DataLoader(datasets.MNIST(root='./', train=True, transform=transforms.ToTensor(), download=True),
batch_size=128)
model = BaseImageClassificationSystem()
trainer = pl.Trainer(num_processes=8, gpus='1, 2', accelerator='ddp', max_epochs=100)
trainer.fit(model, train_dl)Output tensor(2.3002, device='cuda:2', grad_fn=<NllLossBackward>)
tensor(2.2930, device='cuda:1', grad_fn=<NllLossBackward>) |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 2 replies
-
|
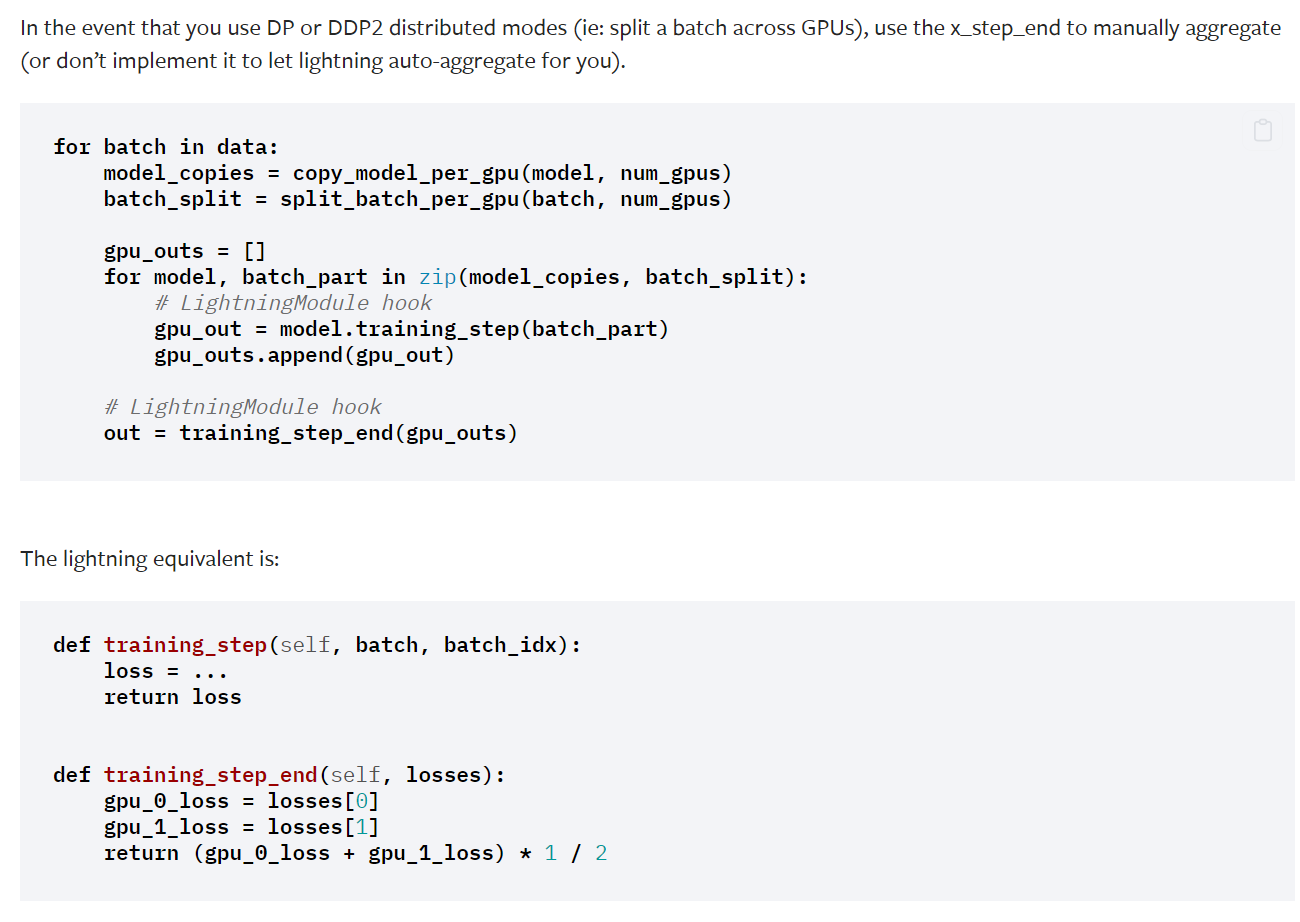
It's mentioned in the doc that this configuration works only for DP or DDP2, but in your code, you are using DDP so there will only be 1 loss item since gradient sync happens within DDP so each device has its own loss and backward call and won't require manual reduction of loss across devices. |
Beta Was this translation helpful? Give feedback.
-
|
@rohitgr7 I got it. Thank you!! |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the answer. Could you post a link to the doc you refer to, especially where the difference between DDP2 and DDP is discussed? I was confused by this behavior either since it is said in this section that
and I could not find any other docs discussing this different behavior. |
Beta Was this translation helpful? Give feedback.
It's mentioned in the doc that this configuration works only for DP or DDP2, but in your code, you are using DDP so there will only be 1 loss item since gradient sync happens within DDP so each device has its own loss and backward call and won't require manual reduction of loss across devices.