|
248 | 248 | " loss=tf.keras.losses.MeanSquaredError(), # MSE loss for the regression task\n", |
249 | 249 | ")\n", |
250 | 250 | "\n", |
251 | | - "# TODO: Train the model for 30 epochs. Use model.fit().\n", |
252 | | - "loss_history = dense_NN.fit(x_train, y_train, epochs=30) \n", |
253 | | - "# loss_history = # TODO" |
| 251 | + "# Train the model for 30 epochs using model.fit().\n", |
| 252 | + "loss_history = dense_NN.fit(x_train, y_train, epochs=30)" |
254 | 253 | ] |
255 | 254 | }, |
256 | 255 | { |
|
789 | 788 | "\n", |
790 | 789 | "You've just analyzed the bias, aleatoric uncertainty, and epistemic uncertainty for your first risk-aware model! This is a task that data scientists do constantly to determine methods of improving their models and datasets.\n", |
791 | 790 | "\n", |
792 | | - "## NOTE TO ADDRESS: THIS CAN BE ELIMINATED COMPLETELY IF IT IS TOO MUCH FOR COMPETITION!\n", |
793 | | - "### 1.6.1 Submission information\n", |
794 | | - "To be eligible for the Debiasing Faces Lab prize, you must submit a document of your answers to the short-answer `TODO`s with your complete lab submission. **Name your file in the following format: `[FirstName]_[LastName]_Debiasing_Report.pdf`.**\n", |
795 | | - "\n", |
796 | | - "Upload your document write-up as part of your complete lab submission for the Debiasing Faces Lab ([submission upload link](https://www.dropbox.com/request/TTYz3Ikx5wIgOITmm5i2)).\n", |
797 | | - "\n", |
798 | | - "Please see the short-answer `TODO`s replicated again here:\n", |
799 | | - "\n", |
800 | | - "#### **TODO: Inspecting the 2D regression dataset**\n", |
801 | | - "\n", |
802 | | - "1. What are your observations about where the train data and test data lie relative to each other?\n", |
803 | | - "2. What, if any, areas do you expect to have high/low aleatoric (data) uncertainty?\n", |
804 | | - "3. What, if any, areas do you expect to have high/low epistemic (model) uncertainty?\n", |
805 | | - "\n", |
806 | | - "#### **TODO: Analyzing the performance of standard regression model**\n", |
807 | | - "\n", |
808 | | - "1. Where does the model perform well?\n", |
809 | | - "2. Where does the model perform poorly?\n", |
810 | | - "\n", |
811 | | - "#### **TODO: Evaluating bias**\n", |
812 | | - "\n", |
813 | | - "1. How does the bias score relate to the train/test data density from the first plot?\n", |
814 | | - "2. What is one limitation of the Histogram approach that simply bins the data based on frequency?\n", |
815 | | - "\n", |
816 | | - "#### **TODO: Estimating aleatoric uncertainty**\n", |
817 | | - "\n", |
818 | | - "1. For what values of $x$ is the aleatoric uncertainty high or increasing suddenly?\n", |
819 | | - "2. How does your answer in (1) relate to how the $x$ values are distributed?\n", |
820 | | - "\n", |
821 | | - "#### **TODO: Estimating epistemic uncertainty**\n", |
822 | | - "\n", |
823 | | - "1. For what values of $x$ is the epistemic uncertainty high or increasing suddenly?\n", |
824 | | - "2. How does your answer in (1) relate to how the $x$ values are distributed (refer back to original plot)? Think about both the train and test data.\n", |
825 | | - "3. How could you reduce the epistemic uncertainty in regions where it is high?\n", |
826 | | - "\n", |
827 | | - "### 1.6.2 Moving forward\n", |
828 | | - "\n", |
829 | | - "In the next part of the lab, you'll continue to build off of these concepts to *mitigate* these risks, in addition to diagnosing them!\n", |
| 791 | + "In the next part of the lab, you'll continue to build off of these concepts to study them in the context of facial detection systems: not only diagnosing issues of bias and uncertainty, but also developing solutions to *mitigate* these risks.\n", |
830 | 792 | "\n", |
831 | 793 | "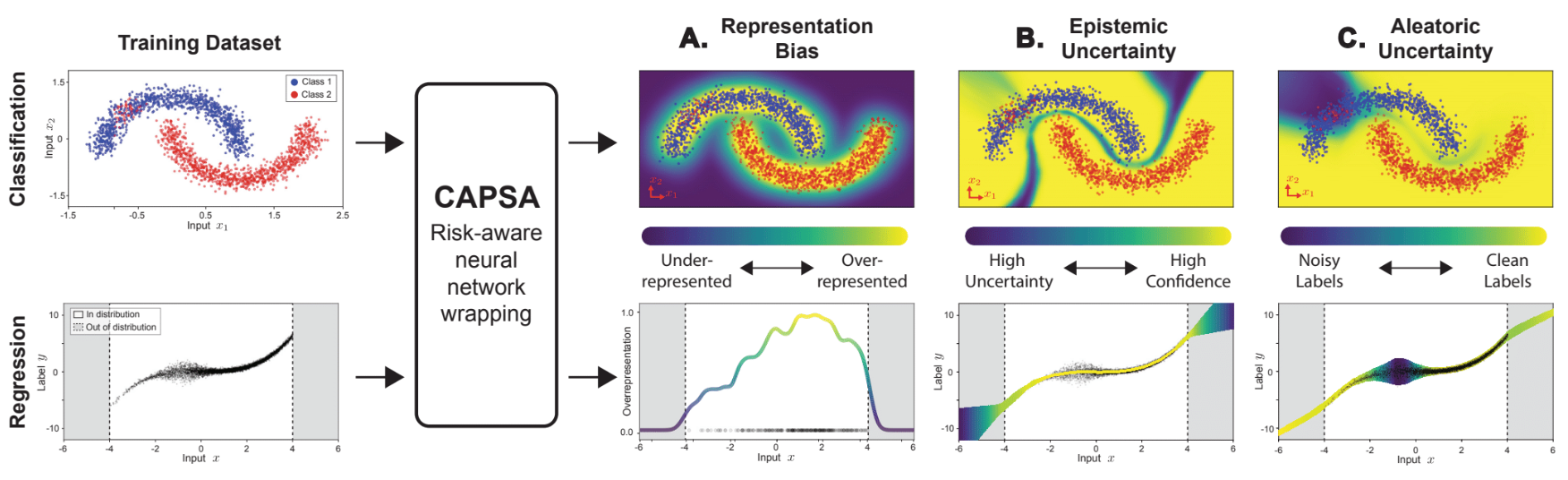" |
832 | 794 | ] |
|
0 commit comments