|
516 | 516 | "id": "qtHEYI9KNn0A" |
517 | 517 | }, |
518 | 518 | "source": [ |
519 | | - "## 2.5 Debiasing variational autoencoder (DB-VAE)\n", |
| 519 | + "## 2.5 Semi-supervised variational autoencoder (SS-VAE)\n", |
520 | 520 | "\n", |
521 | | - "Now, we'll use the general idea behind the VAE architecture to build a model, termed a [*debiasing variational autoencoder*](https://lmrt.mit.edu/sites/default/files/AIES-19_paper_220.pdf) or DB-VAE, to mitigate (potentially) unknown biases present within the training idea. We'll train our DB-VAE model on the facial detection task, run the debiasing operation during training, evaluate on the PPB dataset, and compare its accuracy to our original, biased CNN model. \n", |
522 | | - "\n", |
523 | | - "### Supervised VAEs\n", |
524 | | - "\n", |
525 | | - "In this lab, we'll start with developing a vanilla VAE, with a supervised component, in order to analyze where the biases in our model may be resulting from. From the classification accuracies above, we can see that skin tone and gender are two categories where we may be experiencing bias, but there may be other unlabeled features that also are biased, resulting in poorer classification performance.\n", |
526 | | - "\n", |
527 | | - "\n", |
528 | | - "A general schematic of the DB-VAE approach is shown here. In the next lab, we'll dive further into updating positive probabilities.\n", |
529 | | - "\n", |
530 | | - "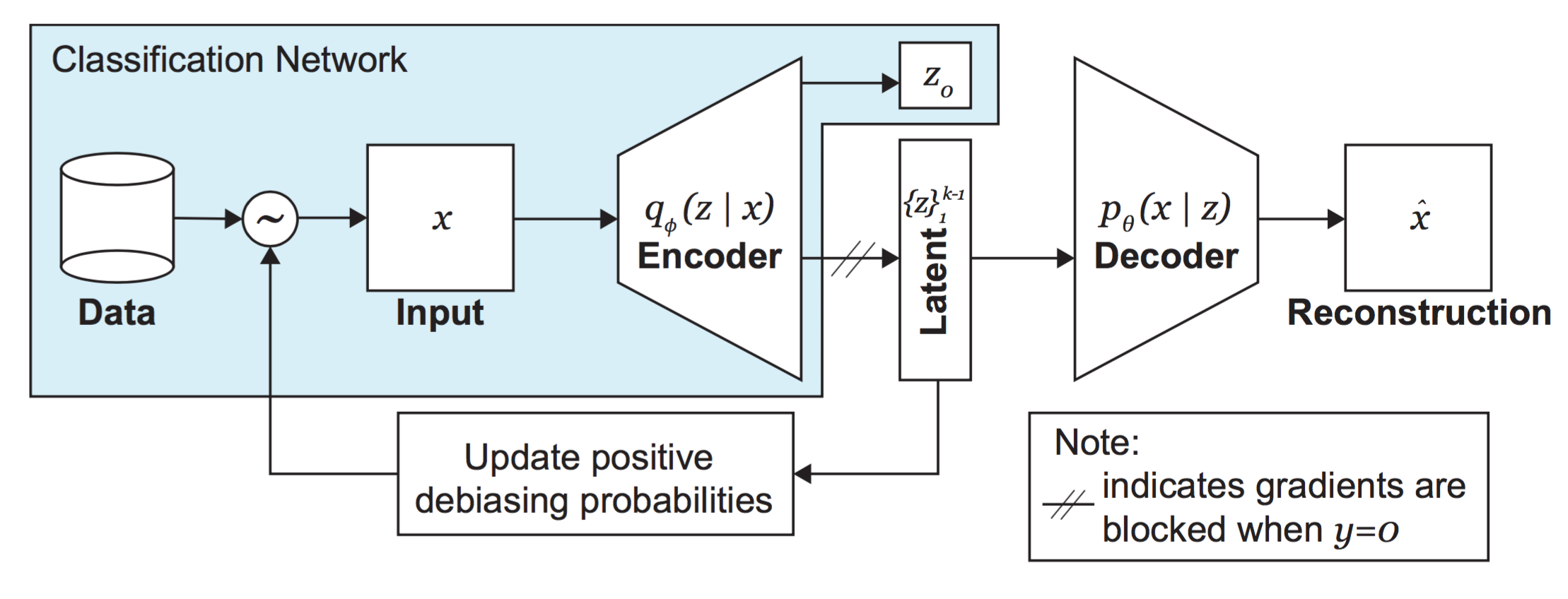\n" |
| 521 | + "Now, we will use the general idea behind the VAE architecture to build a model to automatically uncover (potentially) unknown biases present within the training data, while simultaneously learning the facial detection task. This draws direct inspiration from [a recent paper](http://introtodeeplearning.com/AAAI_MitigatingAlgorithmicBias.pdf) proposing this as a general approach for automatic bias detetion and mitigation.\n" |
531 | 522 | ] |
532 | 523 | }, |
533 | 524 | { |
534 | 525 | "cell_type": "markdown", |
535 | | - "metadata": { |
536 | | - "id": "ziA75SN-UxxO" |
537 | | - }, |
538 | 526 | "source": [ |
539 | | - "Recall that we want to apply our DB-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the DB-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is another key distinction between the DB-VAE and a traditional VAE. \n", |
| 527 | + "### Semi-supervised VAE architecture\n", |
540 | 528 | "\n", |
541 | | - "Keep in mind that we only want to learn the latent representation of *faces*, as that's what we're ultimately debiasing against, even though we are training a model on a binary classification problem. We'll need to ensure that, **for faces**, our DB-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$." |
542 | | - ] |
| 529 | + "We will develop a VAE that has a supervised component in order to both output a classification decision for the facial detection task and analyze where the biases in our model may be resulting from. While previous works like that of Buolamwini and Gebru have focused on skin tone and gender as two categories where facial detection models may be experiencing bias, there may be other unlabeled features that also are biased, resulting in poorer classification performance. We will build our semi-supervised VAE (SS-VAE) to learn these underlying latent features.\n", |
| 530 | + "\n", |
| 531 | + "A general schematic of the SS-VAE architecture is shown here.\n", |
| 532 | + "\n", |
| 533 | + "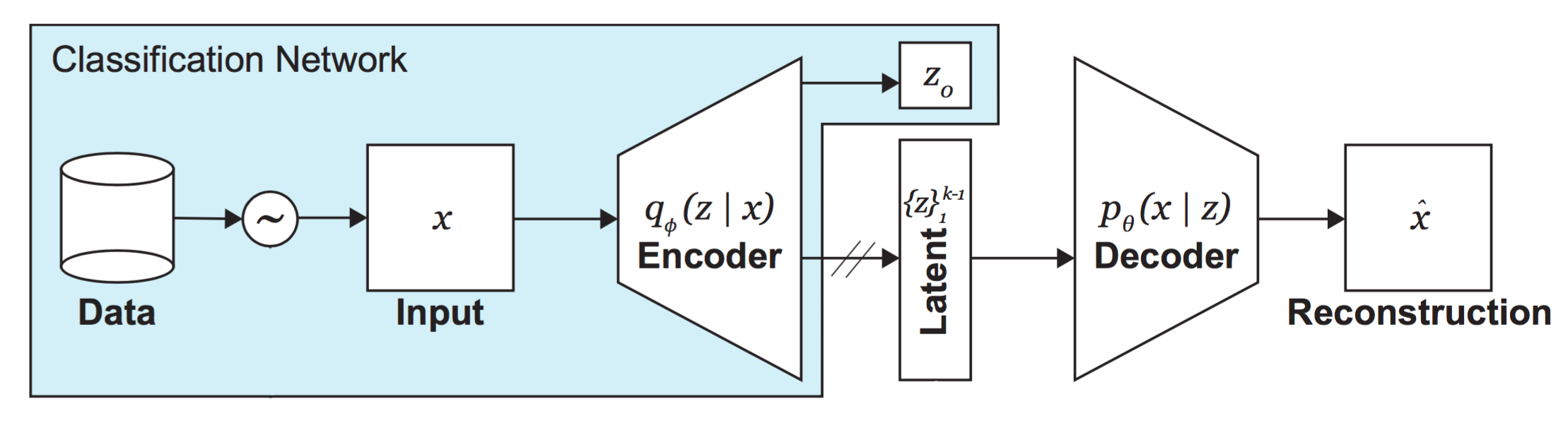\n", |
| 534 | + "\n", |
| 535 | + "We will apply our SS-VAE to a *supervised classification* problem -- the facial detection task. Importantly, note how the encoder portion in the SS-VAE architecture also outputs a single supervised variable, $z_o$, corresponding to the class prediction -- face or not face. Usually, VAEs are not trained to output any supervised variables (such as a class prediction)! This is the key distinction between the SS-VAE and a traditional VAE. \n", |
| 536 | + "\n", |
| 537 | + "Keep in mind that we only want to learn the latent representation of *faces*, as that is where we are interested in uncovering potential biases, even though we are training a model on a binary classification problem. So, we will need to ensure that, **for faces**, our SS-VAE model both learns a representation of the unsupervised latent variables, captured by the distribution $q_\\phi(z|x)$, **and** outputs a supervised class prediction $z_o$, but that, **for negative examples**, it only outputs a class prediction $z_o$." |
| 538 | + ], |
| 539 | + "metadata": { |
| 540 | + "id": "A3IOB3d61WSN" |
| 541 | + } |
543 | 542 | }, |
544 | 543 | { |
545 | 544 | "cell_type": "markdown", |
546 | 545 | "metadata": { |
547 | 546 | "id": "XggIKYPRtOZR" |
548 | 547 | }, |
549 | 548 | "source": [ |
550 | | - "### Defining the DB-VAE loss function\n", |
| 549 | + "### Defining the SS-VAE loss function\n", |
551 | 550 | "\n", |
552 | | - "This means we'll need to be a bit clever about the loss function for the DB-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered. \n", |
| 551 | + "This means we'll need to be a bit clever about the loss function for the SS-VAE. The form of the loss will depend on whether it's a face image or a non-face image that's being considered. \n", |
553 | 552 | "\n", |
554 | 553 | "For **face images**, our loss function will have two components:\n", |
555 | 554 | "\n", |
556 | | - "\n", |
557 | 555 | "1. **VAE loss ($L_{VAE}$)**: consists of the latent loss and the reconstruction loss.\n", |
558 | 556 | "2. **Classification loss ($L_y(y,\\hat{y})$)**: standard cross-entropy loss for a binary classification problem. \n", |
559 | 557 | "\n", |
|
563 | 561 | "\n", |
564 | 562 | "$$L_{total} = L_y(y,\\hat{y}) + {I}_f(y)\\Big[L_{VAE}\\Big]$$\n", |
565 | 563 | "\n", |
566 | | - "Let's write a function to define the DB-VAE loss function:\n" |
| 564 | + "Let's write a function to define the SS-VAE loss function:\n" |
567 | 565 | ] |
568 | 566 | }, |
569 | 567 | { |
|
574 | 572 | }, |
575 | 573 | "outputs": [], |
576 | 574 | "source": [ |
577 | | - "### Loss function for DB-VAE ###\n", |
| 575 | + "### Loss function for SS-VAE ###\n", |
578 | 576 | "\n", |
579 | | - "\"\"\"Loss function for DB-VAE.\n", |
| 577 | + "\"\"\"Loss function for SS-VAE.\n", |
580 | 578 | "# Arguments\n", |
581 | 579 | " x: true input x\n", |
582 | 580 | " x_pred: reconstructed x\n", |
|
585 | 583 | " mu: mean of latent distribution (Q(z|X))\n", |
586 | 584 | " logsigma: log of standard deviation of latent distribution (Q(z|X))\n", |
587 | 585 | "# Returns\n", |
588 | | - " total_loss: DB-VAE total loss\n", |
589 | | - " classification_loss = DB-VAE classification loss\n", |
| 586 | + " total_loss: SS-VAE total loss\n", |
| 587 | + " classification_loss: SS-VAE classification loss\n", |
590 | 588 | "\"\"\"\n", |
591 | | - "def debiasing_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n", |
| 589 | + "def ss_vae_loss_function(x, x_pred, y, y_logit, mu, logsigma):\n", |
592 | 590 | "\n", |
593 | | - " # TODO: call the relevant function to obtain VAE loss\n", |
| 591 | + " # TODO: call the relevant function to obtain VAE loss, defined earlier in the lab\n", |
594 | 592 | " vae_loss = vae_loss_function(x, x_pred, mu, logsigma)\n", |
595 | 593 | " # vae_loss = vae_loss_function('''TODO''') # TODO\n", |
596 | 594 | "\n", |
|
603 | 601 | " # indicator that reflects which training data are images of faces\n", |
604 | 602 | " face_indicator = tf.cast(tf.equal(y, 1), tf.float32)\n", |
605 | 603 | "\n", |
606 | | - " # TODO: define the DB-VAE total loss! Use tf.reduce_mean to average over all\n", |
| 604 | + " # TODO: define the SS-VAE total loss! Use tf.reduce_mean to average over all\n", |
607 | 605 | " # samples\n", |
608 | 606 | " total_loss = tf.reduce_mean(\n", |
609 | 607 | " classification_loss + \n", |
|
620 | 618 | "id": "YIu_2LzNWwWY" |
621 | 619 | }, |
622 | 620 | "source": [ |
623 | | - "### DB-VAE architecture\n", |
| 621 | + "### Defining the SS-VAE architecture\n", |
624 | 622 | "\n", |
625 | | - "Now we're ready to define the DB-VAE architecture. To build the DB-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the two models, and then construct the end-to-end VAE. We will use a latent space with 100 latent variables.\n", |
| 623 | + "Now we're ready to define the SS-VAE architecture. To build the SS-VAE, we will use the standard CNN classifier from above as our encoder, and then define a decoder network. We will create and initialize the encoder and decoder networks, and then construct the end-to-end VAE. We will use a latent space with 32 latent variables.\n", |
626 | 624 | "\n", |
627 | 625 | "The decoder network will take as input the sampled latent variables, run them through a series of deconvolutional layers, and output a reconstruction of the original input image." |
628 | 626 | ] |
|
635 | 633 | }, |
636 | 634 | "outputs": [], |
637 | 635 | "source": [ |
638 | | - "### Define the decoder portion of the DB-VAE ###\n", |
| 636 | + "### Define the decoder portion of the SS-VAE ###\n", |
639 | 637 | "\n", |
640 | | - "n_filters = 12 # base number of convolutional filters, same as standard CNN\n", |
641 | | - "latent_dim = 100 # number of latent variables\n", |
| 638 | + "def make_face_decoder_network(n_filters=12):\n", |
642 | 639 | "\n", |
643 | | - "def make_face_decoder_network():\n", |
644 | 640 | " # Functionally define the different layer types we will use\n", |
645 | 641 | " Conv2DTranspose = functools.partial(tf.keras.layers.Conv2DTranspose, padding='same', activation='relu')\n", |
646 | 642 | " BatchNormalization = tf.keras.layers.BatchNormalization\n", |
|
670 | 666 | "id": "yWCMu12w1BuD" |
671 | 667 | }, |
672 | 668 | "source": [ |
673 | | - "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the DB-VAE. Note that at this point, there is nothing special about how we put the model together that makes it a \"debiasing\" model -- that will come when we modify the training operation, which we will do in the next lab. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, reparameterization, and decoding operations; and calling the network end-to-end." |
| 669 | + "Now, we will put this decoder together with the standard CNN classifier as our encoder to define the SS-VAE. Here, we will define the core VAE architecture by sublassing the `Model` class; defining encoding, sampling, and decoding operations; and calling the network end-to-end." |
674 | 670 | ] |
675 | 671 | }, |
676 | 672 | { |
|
681 | 677 | }, |
682 | 678 | "outputs": [], |
683 | 679 | "source": [ |
684 | | - "### Defining and creating the DB-VAE ###\n", |
| 680 | + "### Defining and creating the SS-VAE ###\n", |
685 | 681 | "\n", |
686 | | - "class DB_VAE(tf.keras.Model):\n", |
| 682 | + "class SS_VAE(tf.keras.Model):\n", |
687 | 683 | " def __init__(self, latent_dim):\n", |
688 | | - " super(DB_VAE, self).__init__()\n", |
| 684 | + " super(SS_VAE, self).__init__()\n", |
689 | 685 | " self.latent_dim = latent_dim\n", |
690 | 686 | "\n", |
691 | 687 | " # Define the number of outputs for the encoder. Recall that we have \n", |
|
737 | 733 | " y_logit, z_mean, z_logsigma = self.encode(x)\n", |
738 | 734 | " return y_logit\n", |
739 | 735 | "\n", |
740 | | - "dbvae = DB_VAE(latent_dim)" |
| 736 | + "ss_vae = SS_VAE(latent_dim=32)" |
741 | 737 | ] |
742 | 738 | }, |
743 | 739 | { |
|
746 | 742 | "id": "M-clbYAj2waY" |
747 | 743 | }, |
748 | 744 | "source": [ |
749 | | - "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed DB_VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n", |
| 745 | + "As stated, the encoder architecture is identical to the CNN from earlier in this lab. Note the outputs of our constructed SS-VAE model in the `call` function: `y_logit, z_mean, z_logsigma, z`. Think carefully about why each of these are outputted and their significance to the problem at hand.\n", |
750 | 746 | "\n" |
751 | 747 | ] |
752 | 748 | }, |
|
756 | 752 | "id": "nbDNlslgQc5A" |
757 | 753 | }, |
758 | 754 | "source": [ |
759 | | - "### Training the supervised VAE\n", |
760 | | - "\n", |
| 755 | + "### Training the SS-VAE\n", |
761 | 756 | "\n", |
762 | | - "At this point, we can now inspect the latent features learned by the VAE, and find biases in our dataset. Right now, the VAE will not *debias* these; we'll do this in the next lab! Complete the following training loop to train a standard VAE with a classifier: " |
| 757 | + "We are ready to train our SS-VAE model! Complete the `TODO`s in the following training loop to train the SS-VAE with face classification output." |
763 | 758 | ] |
764 | 759 | }, |
765 | 760 | { |
|
770 | 765 | }, |
771 | 766 | "outputs": [], |
772 | 767 | "source": [ |
773 | | - "### Training the DB-VAE ###\n", |
| 768 | + "### Training the SS-VAE ###\n", |
774 | 769 | "\n", |
775 | 770 | "# Hyperparameters\n", |
776 | 771 | "batch_size = 32\n", |
777 | 772 | "learning_rate = 5e-4\n", |
778 | 773 | "latent_dim = 32\n", |
779 | 774 | "\n", |
780 | | - "# DB-VAE needs slightly more epochs to train since its more complex than \n", |
| 775 | + "# SS-VAE needs slightly more epochs to train since its more complex than \n", |
781 | 776 | "# the standard classifier so we use 6 instead of 2\n", |
782 | 777 | "num_epochs = 6 \n", |
783 | 778 | "\n", |
784 | | - "# instantiate a new DB-VAE model and optimizer\n", |
785 | | - "dbvae = DB_VAE(latent_dim)\n", |
| 779 | + "# instantiate a new SS-VAE model and optimizer\n", |
| 780 | + "ss_vae = SS_VAE(latent_dim)\n", |
786 | 781 | "optimizer = tf.keras.optimizers.Adam(learning_rate)\n", |
787 | 782 | "\n", |
788 | 783 | "# To define the training operation, we will use tf.function which is a powerful tool \n", |
789 | 784 | "# that lets us turn a Python function into a TensorFlow computation graph.\n", |
790 | 785 | "@tf.function\n", |
791 | | - "def debiasing_train_step(x, y):\n", |
| 786 | + "def ss_vae_train_step(x, y):\n", |
792 | 787 | "\n", |
793 | 788 | " with tf.GradientTape() as tape:\n", |
794 | | - " # Feed input x into dbvae. Note that this is using the DB_VAE call function!\n", |
795 | | - " y_logit, z_mean, z_logsigma, x_recon = dbvae(x)\n", |
| 789 | + " # Feed input x into ss_vae. Note that this is using the SS_VAE call function!\n", |
| 790 | + " y_logit, z_mean, z_logsigma, x_recon = ss_vae(x)\n", |
796 | 791 | "\n", |
797 | | - " '''TODO: call the DB_VAE loss function to compute the loss'''\n", |
798 | | - " loss, class_loss, _ = debiasing_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n", |
799 | | - " # loss, class_loss = debiasing_loss_function('''TODO arguments''') # TODO\n", |
| 792 | + " '''TODO: call the SS_VAE loss function to compute the loss'''\n", |
| 793 | + " loss, class_loss, _ = ss_vae_loss_function(x, x_recon, y, y_logit, z_mean, z_logsigma)\n", |
| 794 | + " # loss, class_loss = ss_vae_loss_function('''TODO arguments''') # TODO\n", |
800 | 795 | " \n", |
801 | 796 | " '''TODO: use the GradientTape.gradient method to compute the gradients.\n", |
802 | 797 | " Hint: this is with respect to the trainable_variables of the dbvae.'''\n", |
803 | | - " grads = tape.gradient(loss, dbvae.trainable_variables)\n", |
| 798 | + " grads = tape.gradient(loss, ss_vae.trainable_variables)\n", |
804 | 799 | " # grads = tape.gradient('''TODO''', '''TODO''') # TODO\n", |
805 | 800 | "\n", |
806 | 801 | " # apply gradients to variables\n", |
807 | | - " optimizer.apply_gradients(zip(grads, dbvae.trainable_variables))\n", |
| 802 | + " optimizer.apply_gradients(zip(grads, ss_vae.trainable_variables))\n", |
808 | 803 | " return loss\n", |
809 | 804 | "\n", |
810 | 805 | "# get training faces from data loader\n", |
|
823 | 818 | " # load a batch of data\n", |
824 | 819 | " (x, y) = loader.get_batch(batch_size)\n", |
825 | 820 | " # loss optimization\n", |
826 | | - " loss = debiasing_train_step(x, y)\n", |
| 821 | + " loss = ss_vae_train_step(x, y)\n", |
827 | 822 | " \n", |
828 | 823 | " # plot the progress every 200 steps\n", |
829 | 824 | " if j % 500 == 0: \n", |
|
836 | 831 | "id": "uZBlWDPOVcHg" |
837 | 832 | }, |
838 | 833 | "source": [ |
839 | | - "Wonderful! Now we should have a trained (but not yet debiaed) facial classification model, ready for evaluation!" |
| 834 | + "Wonderful! Now we should have a trained SS-VAE facial classification model, ready for evaluation!" |
840 | 835 | ] |
841 | 836 | }, |
842 | 837 | { |
|
0 commit comments