|
1 | 1 | { |
2 | 2 | "cells": [ |
| 3 | + { |
| 4 | + "cell_type": "markdown", |
| 5 | + "source": [ |
| 6 | + "<table align=\"center\">\n", |
| 7 | + " <td align=\"center\"><a target=\"_blank\" href=\"http://introtodeeplearning.com\">\n", |
| 8 | + " <img src=\"https://i.ibb.co/Jr88sn2/mit.png\" style=\"padding-bottom:5px;\" />\n", |
| 9 | + " Visit MIT Deep Learning</a></td>\n", |
| 10 | + " <td align=\"center\"><a target=\"_blank\" href=\"https://colab.research.google.com/github/aamini/introtodeeplearning/blob/2023/lab3/solutions/Lab3_Part_1_Introduction_to_CAPSA.ipynb\">\n", |
| 11 | + " <img src=\"https://i.ibb.co/2P3SLwK/colab.png\" style=\"padding-bottom:5px;\" />Run in Google Colab</a></td>\n", |
| 12 | + " <td align=\"center\"><a target=\"_blank\" href=\"https://github.com/aamini/introtodeeplearning/blob/2023/lab3/solutions/Lab3_Part_1_Introduction_to_CAPSA.ipynb\">\n", |
| 13 | + " <img src=\"https://i.ibb.co/xfJbPmL/github.png\" height=\"70px\" style=\"padding-bottom:5px;\" />View Source on GitHub</a></td>\n", |
| 14 | + "</table>\n", |
| 15 | + "\n", |
| 16 | + "# Copyright Information" |
| 17 | + ], |
| 18 | + "metadata": { |
| 19 | + "id": "Kxl9-zNYhxlQ" |
| 20 | + } |
| 21 | + }, |
| 22 | + { |
| 23 | + "cell_type": "code", |
| 24 | + "source": [ |
| 25 | + "# Copyright 2023 MIT Introduction to Deep Learning. All Rights Reserved.\n", |
| 26 | + "# \n", |
| 27 | + "# Licensed under the MIT License. You may not use this file except in compliance\n", |
| 28 | + "# with the License. Use and/or modification of this code outside of MIT Introduction\n", |
| 29 | + "# to Deep Learning must reference:\n", |
| 30 | + "#\n", |
| 31 | + "# © MIT Introduction to Deep Learning\n", |
| 32 | + "# http://introtodeeplearning.com\n", |
| 33 | + "#" |
| 34 | + ], |
| 35 | + "metadata": { |
| 36 | + "id": "aAcJJN3Xh3S1" |
| 37 | + }, |
| 38 | + "execution_count": null, |
| 39 | + "outputs": [] |
| 40 | + }, |
3 | 41 | { |
4 | 42 | "cell_type": "markdown", |
5 | 43 | "metadata": { |
6 | 44 | "id": "IgYKebt871EK" |
7 | 45 | }, |
8 | 46 | "source": [ |
9 | | - "# Laboratory 3: Detecting and mitigating bias and uncertainty in Facial Detection Systems\n", |
10 | | - "In this lab, we'll continue to explore how to mitigate algorithmic bias in facial recognition systems. In addition, we'll explore the notion of *uncertainty* in datasets, and learn how to reduce both data-based and model-based uncertainty.\n", |
| 47 | + "# Laboratory 3: Debiasing, Uncertainty, and Robustness\n", |
11 | 48 | "\n", |
12 | | - "As we've seen in lecture 5, bias and uncertainty underlie many common issues with machine learning models today, and these are not just limited to classification tasks. Automatically detecting and mitigating uncertainty is crucial to deploying fair and safe models. \n", |
| 49 | + "# Part 2: Mitigating Bias and Uncertainty in Facial Detection Systems\n", |
13 | 50 | "\n", |
14 | | - "In this lab, we'll be using [CAPSA](https://github.com/themis-ai/capsa/), a software package developed by [Themis AI](https://themisai.io/), which automatically *wraps* models to make them risk-aware and plugs into training workflows. We'll explore how we can use CAPSA to diagnose uncertainties, and then develop methods for automatically mitigating them.\n", |
| 51 | + "In Lab 2, we defined a semi-supervised VAE (SS-VAE) to diagnose feature representation disparities and biases in facial detection systems. In Lab 3 Part 1, we gained experience with Capsa and its ability to build risk-aware models automatically through wrapping. Now in this lab, we will put these two together: using Capsa to build systems that can *automatically* uncover and mitigate bias and uncertainty in facial detection systems.\n", |
15 | 52 | "\n", |
| 53 | + "As we have seen, automatically detecting and mitigating bias and uncertainty is crucial to deploying fair and safe models. Building off our foundation with [Capsa](https://github.com/themis-ai/capsa/), developed by [Themis AI](https://themisai.io/), we will now use Capsa for the facial detection problem, in order to diagnose risks in facial detection models. You will then design and create strategies to mitigate these risks, with goal of improving model performance across the entire facial detection dataset.\n", |
16 | 54 | "\n", |
17 | | - "Run the next code block for a short video from Google that explores how and why it's important to consider bias when thinking about machine learning:" |
| 55 | + "**Your goal in this lab -- and the associated competition -- is to design a strategic solution for bias and uncertainty mitigation, using Capsa.** The approaches and solutions with oustanding performance will be recognized with outstanding prizes! Details on the submission process are at the end of this lab.\n", |
| 56 | + "\n", |
| 57 | + "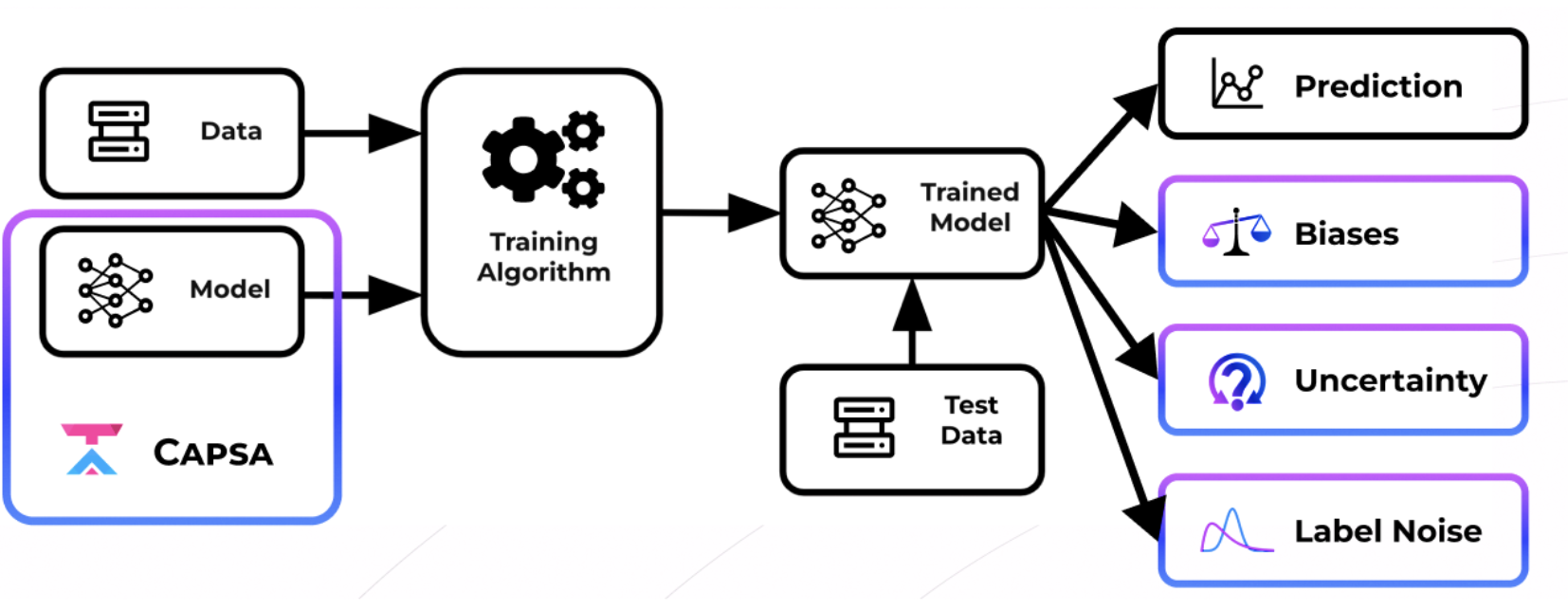" |
18 | 58 | ] |
19 | 59 | }, |
20 | 60 | { |
|
23 | 63 | "id": "6JTRoM7E71EU" |
24 | 64 | }, |
25 | 65 | "source": [ |
26 | | - "Let's get started by installing the relevant dependencies:" |
| 66 | + "Let's get started by installing the necessary dependencies:" |
27 | 67 | ] |
28 | 68 | }, |
29 | 69 | { |
|
40 | 80 | "base_uri": "https://localhost:8080/" |
41 | 81 | } |
42 | 82 | }, |
43 | | - "execution_count": 1, |
| 83 | + "execution_count": null, |
44 | 84 | "outputs": [ |
45 | 85 | { |
46 | 86 | "output_type": "stream", |
|
74 | 114 | }, |
75 | 115 | { |
76 | 116 | "cell_type": "code", |
77 | | - "execution_count": 17, |
| 117 | + "execution_count": null, |
78 | 118 | "metadata": { |
79 | 119 | "id": "2PdAhs1371EU", |
80 | 120 | "outputId": "dd327495-e85d-4849-9487-4f71535b6cae", |
|
118 | 158 | "id": "6VKVqLb371EV" |
119 | 159 | }, |
120 | 160 | "source": [ |
121 | | - "## 3.1 Datasets\n", |
| 161 | + "# 3.1 Datasets\n", |
122 | 162 | "\n", |
123 | | - "We'll be using the same datasets from lab 2 in this lab. Note that in this dataset, we've intentionally perturbed some of the samples in some ways (it's up to you to figure out how!) that are not necessarily present in the actual dataset. \n", |
| 163 | + "Since we are again focusing on the facial detection problem, we will use the same datasets from Lab 2. To remind you, we have a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces).\n", |
124 | 164 | "\n", |
125 | | - "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale (over 200K images) of celebrity faces. \n", |
126 | | - "2. **Negative training data**: [ImageNet](http://www.image-net.org/). Many images across many different categories. We'll take negative examples from a variety of non-human categories. \n", |
127 | | - "[Fitzpatrick Scale](https://en.wikipedia.org/wiki/Fitzpatrick_scale) skin type classification system, with each image labeled as \"Lighter'' or \"Darker''.\n", |
| 165 | + "1. **Positive training data**: [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). A large-scale dataset (over 200K images) of celebrity faces. \n", |
| 166 | + "2. **Negative training data**: [ImageNet](http://www.image-net.org/). A large-scale dataset with many images across many different categories. We will take negative examples from a variety of non-human categories.\n", |
128 | 167 | "\n", |
129 | | - "Like before, let's begin by importing these datasets. We've written a class that does a bit of data pre-processing to import the training data in a usable format.\n", |
| 168 | + "We will evaluate trained models on an independent test dataset of face images to diagnose and mitigate potential issues with *bias, fairness, and confidence*. This will be a larger test dataset for evaluation purposes.\n", |
130 | 169 | "\n", |
131 | | - "Also note that in this lab, we'll be using a much larger test dataset for evaluation purposes." |
| 170 | + "We begin by importing these datasets. We have defined a `DatasetLoader` class that does a bit of data pre-processing to import the training data in a usable format." |
132 | 171 | ] |
133 | 172 | }, |
134 | 173 | { |
135 | 174 | "cell_type": "code", |
136 | | - "execution_count": 6, |
| 175 | + "execution_count": null, |
137 | 176 | "metadata": { |
138 | 177 | "id": "HIA6EA1D71EW", |
139 | 178 | "outputId": "162f7d36-81aa-4fb9-b265-af9a8fa9395d", |
|
173 | 212 | "source": [ |
174 | 213 | "### Recap: Thinking about bias and uncertainty\n", |
175 | 214 | "\n", |
176 | | - "Remember that we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics, and to thus show that this model does not suffer from any hidden bias. \n", |
177 | | - "\n", |
178 | | - "In addition to thinking about bias, we want to detect areas of high *aleatoric* uncertainty in the dataset, which is defined as data noise: in the context of facial detection, this means that we may have very similar inputs with different labels-- think about the scenario where one face is labeled correctly as a positive, and another face is labeled incorrectly as a negative. \n", |
| 215 | + "Remember that we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. Our goal is to build a model that trains on CelebA *and* achieves high classification accuracy on the the test dataset across all demographics. We want to mitigate the effects of unwanted bias and uncertainty on the model's predictions and performance. and to thus show that this model does not suffer from any hidden bias.\n", |
179 | 216 | "\n", |
180 | | - "Finally, we want to look at samples with high *epistemic*, or predictive, uncertainty. These may be samples that are anomalous or out of distribution, samples that contain adversarial noise, or samples that are \"harder\" to learn in some way. Importantly, epistemic uncertainty is not the same as bias! We may have well-represented samples that still have high epistemic uncertainty. " |
| 217 | + "You may consider the three metrics introduced with Capsa: (1) representation bias, (2) data or aleatoric uncertainty, and (3) model or epistemic uncertainty. Note that all three of these metrics are different! For example, we can have well-represented examples that still have high epistemic uncertainty. " |
181 | 218 | ] |
182 | 219 | }, |
183 | 220 | { |
|
202 | 239 | }, |
203 | 240 | { |
204 | 241 | "cell_type": "code", |
205 | | - "execution_count": 50, |
| 242 | + "execution_count": null, |
206 | 243 | "metadata": { |
207 | 244 | "id": "5hQb75Vm71EZ" |
208 | 245 | }, |
|
261 | 298 | }, |
262 | 299 | { |
263 | 300 | "cell_type": "code", |
264 | | - "execution_count": 51, |
| 301 | + "execution_count": null, |
265 | 302 | "metadata": { |
266 | 303 | "id": "zTat3K8E71Eb" |
267 | 304 | }, |
|
294 | 331 | }, |
295 | 332 | { |
296 | 333 | "cell_type": "code", |
297 | | - "execution_count": 52, |
| 334 | + "execution_count": null, |
298 | 335 | "metadata": { |
299 | 336 | "id": "i4JmvmMA71Ec" |
300 | 337 | }, |
|
315 | 352 | }, |
316 | 353 | { |
317 | 354 | "cell_type": "code", |
318 | | - "execution_count": 53, |
| 355 | + "execution_count": null, |
319 | 356 | "metadata": { |
320 | 357 | "id": "NmshVdLM71Ed", |
321 | 358 | "outputId": "873a0931-c1ae-43cc-f8f0-53b11f30ae4a", |
|
387 | 424 | }, |
388 | 425 | { |
389 | 426 | "cell_type": "code", |
390 | | - "execution_count": 55, |
| 427 | + "execution_count": null, |
391 | 428 | "metadata": { |
392 | 429 | "id": "1dCqvPFH71Ed", |
393 | 430 | "outputId": "a3a19ee7-5c8e-4563-d6df-709f39dd357d", |
|
420 | 457 | }, |
421 | 458 | { |
422 | 459 | "cell_type": "code", |
423 | | - "execution_count": 14, |
| 460 | + "execution_count": null, |
424 | 461 | "metadata": { |
425 | 462 | "id": "OYMRqq5E71Ee" |
426 | 463 | }, |
|
434 | 471 | }, |
435 | 472 | { |
436 | 473 | "cell_type": "code", |
437 | | - "execution_count": 56, |
| 474 | + "execution_count": null, |
438 | 475 | "metadata": { |
439 | 476 | "id": "UAYaFUj-71Ee", |
440 | 477 | "outputId": "39f4fe7d-ca14-47f4-d229-97d868dcc182", |
|
473 | 510 | }, |
474 | 511 | { |
475 | 512 | "cell_type": "code", |
476 | | - "execution_count": 57, |
| 513 | + "execution_count": null, |
477 | 514 | "metadata": { |
478 | 515 | "id": "CnbR3qAF71Ef", |
479 | 516 | "outputId": "6a84a235-88b6-41e1-b616-17c3f9a0096b", |
|
521 | 558 | }, |
522 | 559 | { |
523 | 560 | "cell_type": "code", |
524 | | - "execution_count": 58, |
| 561 | + "execution_count": null, |
525 | 562 | "metadata": { |
526 | 563 | "id": "DfzlOhWi71Ef", |
527 | 564 | "outputId": "65e20e7a-5e3e-4452-ae49-559a33a063ba", |
|
580 | 617 | "height": 153 |
581 | 618 | } |
582 | 619 | }, |
583 | | - "execution_count": 33, |
| 620 | + "execution_count": null, |
584 | 621 | "outputs": [ |
585 | 622 | { |
586 | 623 | "output_type": "execute_result", |
|
632 | 669 | }, |
633 | 670 | { |
634 | 671 | "cell_type": "code", |
635 | | - "execution_count": 59, |
| 672 | + "execution_count": null, |
636 | 673 | "metadata": { |
637 | 674 | "id": "AwGPvdZm71Eg" |
638 | 675 | }, |
|
646 | 683 | }, |
647 | 684 | { |
648 | 685 | "cell_type": "code", |
649 | | - "execution_count": 60, |
| 686 | + "execution_count": null, |
650 | 687 | "metadata": { |
651 | 688 | "id": "kB8Iqrfb71Eg", |
652 | 689 | "outputId": "dc16b7d3-a6f1-4542-dcf2-135e0737e80e", |
|
685 | 722 | }, |
686 | 723 | { |
687 | 724 | "cell_type": "code", |
688 | | - "execution_count": 62, |
| 725 | + "execution_count": null, |
689 | 726 | "metadata": { |
690 | 727 | "id": "miu5h2Pc71Eh", |
691 | 728 | "outputId": "00442875-f1bb-4160-d11c-8cfdfb5765ac", |
|
733 | 770 | }, |
734 | 771 | { |
735 | 772 | "cell_type": "code", |
736 | | - "execution_count": 63, |
| 773 | + "execution_count": null, |
737 | 774 | "metadata": { |
738 | 775 | "id": "rzQwvSvA71Eh", |
739 | 776 | "outputId": "4299761d-22b3-4f44-b9b3-d9194d04a6f2", |
|
0 commit comments