|
195 | 195 | "not_face_images = images[np.where(labels==0)[0]]\n", |
196 | 196 | "\n", |
197 | 197 | "idx_face = 23 #@param {type:\"slider\", min:0, max:50, step:1}\n", |
198 | | - "idx_not_face = 9 #@param {type:\"slider\", min:0, max:50, step:1}\n", |
| 198 | + "idx_not_face = 6 #@param {type:\"slider\", min:0, max:50, step:1}\n", |
199 | 199 | "\n", |
200 | 200 | "plt.figure(figsize=(5,5))\n", |
201 | 201 | "plt.subplot(1, 2, 1)\n", |
|
460 | 460 | "\n", |
461 | 461 | "Our goal is to train a *debiased* version of this classifier -- one that accounts for potential disparities in feature representation within the training data. Specifically, to build a debiased facial classifier, we'll train a model that **learns a representation of the underlying latent space** to the face training data. The model then uses this information to mitigate unwanted biases by sampling faces with rare features, like dark skin or hats, *more frequently* during training. The key design requirement for our model is that it can learn an *encoding* of the latent features in the face data in an entirely *unsupervised* way. To achieve this, we'll turn to variational autoencoders (VAEs).\n", |
462 | 462 | "\n", |
463 | | - "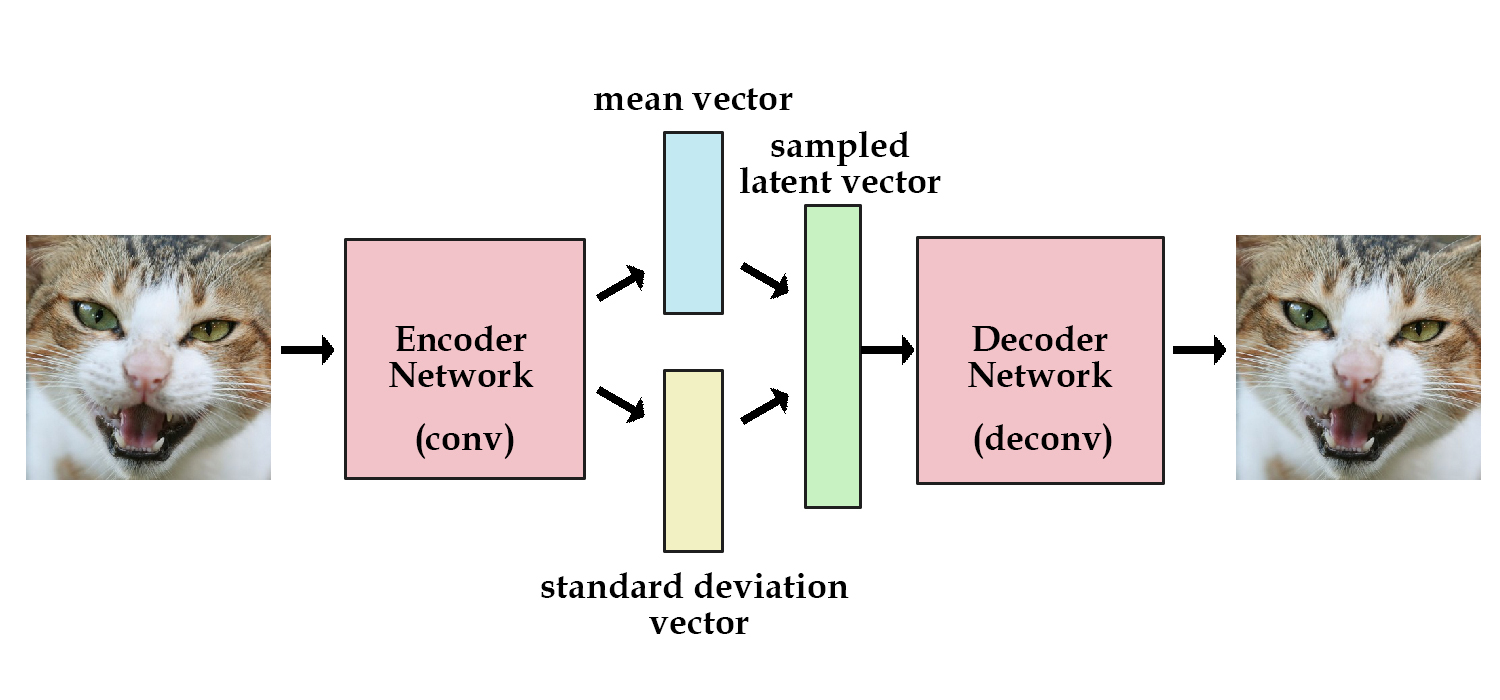\n", |
| 463 | + "\n", |
464 | 464 | "\n", |
465 | 465 | "As shown in the schematic above and in Lecture 4, VAEs rely on an encoder-decoder structure to learn a latent representation of the input data. In the context of computer vision, the encoder network takes in input images, encodes them into a series of variables defined by a mean and standard deviation, and then draws from the distributions defined by these parameters to generate a set of sampled latent variables. The decoder network then \"decodes\" these variables to generate a reconstruction of the original image, which is used during training to help the model identify which latent variables are important to learn. \n", |
466 | 466 | "\n", |
|
482 | 482 | "\n", |
483 | 483 | "The equations for both of these losses are provided below:\n", |
484 | 484 | "\n", |
485 | | - "$$ L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum\\limits_{j=0}^{k-1}\\small{(\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})} $$\n", |
| 485 | + "$ L_{KL}(\\mu, \\sigma) = \\frac{1}{2}\\sum\\limits_{j=0}^{k-1}\\small{(\\sigma_j + \\mu_j^2 - 1 - \\log{\\sigma_j})} $\n", |
486 | 486 | "\n", |
487 | | - "$$ L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1 $$ \n", |
| 487 | + "$ L_{x}{(x,\\hat{x})} = ||x-\\hat{x}||_1 $ \n", |
488 | 488 | "\n", |
489 | 489 | "Thus for the VAE loss we have: \n", |
490 | 490 | "\n", |
491 | | - "$$ L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})} $$\n", |
| 491 | + "$ L_{VAE} = c\\cdot L_{KL} + L_{x}{(x,\\hat{x})} $\n", |
492 | 492 | "\n", |
493 | 493 | "where $c$ is a weighting coefficient used for regularization. \n", |
494 | 494 | "\n", |
|
551 | 551 | "\n", |
552 | 552 | "As you may recall from lecture, VAEs use a \"reparameterization trick\" for sampling learned latent variables. Instead of the VAE encoder generating a single vector of real numbers for each latent variable, it generates a vector of means and a vector of standard deviations that are constrained to roughly follow Gaussian distributions. We then sample from the standard deviations and add back the mean to output this as our sampled latent vector. Formalizing this for a latent variable $z$ where we sample $\\epsilon \\sim \\mathcal{N}(0,(I))$ we have: \n", |
553 | 553 | "\n", |
554 | | - "$$ z = \\mathbb{\\mu} + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon $$\n", |
| 554 | + "$ z = \\mathbb{\\mu} + e^{\\left(\\frac{1}{2} \\cdot \\log{\\Sigma}\\right)}\\circ \\epsilon $\n", |
555 | 555 | "\n", |
556 | 556 | "where $\\mu$ is the mean and $\\Sigma$ is the covariance matrix. This is useful because it will let us neatly define the loss function for the VAE, generate randomly sampled latent variables, achieve improved network generalization, **and** make our complete VAE network differentiable so that it can be trained via backpropagation. Quite powerful!\n", |
557 | 557 | "\n", |
|
1067 | 1067 | "\n", |
1068 | 1068 | "Hopefully this lab has shed some light on a few concepts, from vision based tasks, to VAEs, to algorithmic bias. We like to think it has, but we're biased ;). \n", |
1069 | 1069 | "\n", |
1070 | | - "" |
| 1070 | + "" |
1071 | 1071 | ] |
1072 | 1072 | } |
1073 | 1073 | ] |
|
0 commit comments