diff --git a/.gitignore b/.gitignore
index ae7bdc4d6..8319a4d2f 100644
--- a/.gitignore
+++ b/.gitignore
@@ -15,6 +15,7 @@ evaluation/.env
!evaluation/configs-example/*.json
evaluation/configs/*
**tree_textual_memory_locomo**
+**script.py**
.env
evaluation/scripts/personamem
diff --git a/README.md b/README.md
index 6873ba2b1..30f01f49c 100644
--- a/README.md
+++ b/README.md
@@ -54,22 +54,20 @@
## 📈 Performance Benchmark
-MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks.
+MemOS demonstrates significant improvements over baseline memory solutions in multiple memory tasks,
+showcasing its capabilities in **information extraction**, **temporal and cross-session reasoning**, and **personalized preference responses**.
-| Model | Avg. Score | Multi-Hop | Open Domain | Single-Hop | Temporal Reasoning |
-|-------------|------------|-----------|-------------|------------|---------------------|
-| **OpenAI** | 0.5275 | 0.6028 | 0.3299 | 0.6183 | 0.2825 |
-| **MemOS** | **0.7331** | **0.6430** | **0.5521** | **0.7844** | **0.7321** |
-| **Improvement** | **+38.98%** | **+6.67%** | **+67.35%** | **+26.86%** | **+159.15%** |
+| Model | LOCOMO | LongMemEval | PrefEval-10 | PersonaMem |
+|-----------------|-------------|-------------|-------------|-------------|
+| **GPT-4o-mini** | 52.75 | 55.4 | 2.8 | 43.46 |
+| **MemOS** | **75.80** | **77.80** | **71.90** | **61.17** |
+| **Improvement** | **+43.70%** | **+40.43%** | **+2568%** | **+40.75%** |
-> 💡 **Temporal reasoning accuracy improved by 159% compared to the OpenAI baseline.**
-
-### Details of End-to-End Evaluation on LOCOMO
-
-> [!NOTE]
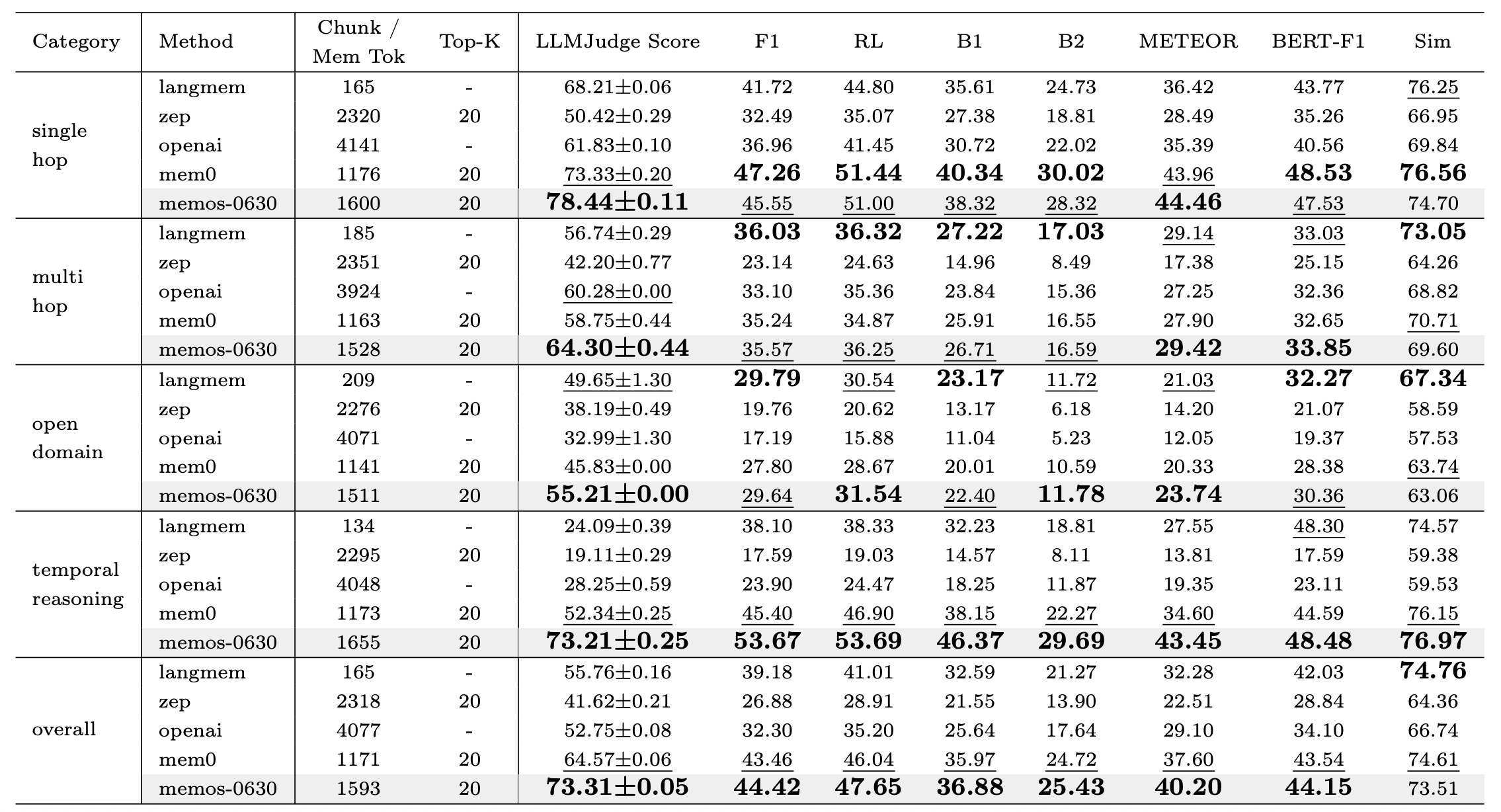
-> Comparison of LLM Judge Scores across five major tasks in the LOCOMO benchmark. Each bar shows the mean evaluation score judged by LLMs for a given method-task pair, with standard deviation as error bars. MemOS-0630 consistently outperforms baseline methods (LangMem, Zep, OpenAI, Mem0) across all task types, especially in multi-hop and temporal reasoning scenarios.
-
- +### Detailed Evaluation Results
+- We use gpt-4o-mini as the processing and judging LLM and bge-m3 as embedding model in MemOS evaluation.
+- The evaluation was conducted under conditions that align various settings as closely as possible. Reproduce the results with our scripts at [`evaluation`](./evaluation).
+- Check the full search and response details at huggingface https://huggingface.co/datasets/MemTensor/MemOS_eval_result.
+> 💡 **MemOS outperforms all other methods (Mem0, Zep, Memobase, SuperMemory et al.) across all benchmarks!**
## ✨ Key Features
@@ -83,6 +81,27 @@ MemOS demonstrates significant improvements over baseline memory solutions in mu
## 🚀 Getting Started
+### ⭐️ MemOS online API
+The easiest way to use MemOS. Equip your agent with memory **in minutes**!
+
+Sign up and get started on[`MemOS dashboard`](https://memos-dashboard.openmem.net/cn/quickstart/?source=landing).
+
+
+### Self-Hosted Server
+1. Get the repository.
+```bash
+git clone https://github.com/MemTensor/MemOS.git
+cd MemOS
+pip install -r ./docker/requirements.txt
+```
+
+2. Configure `docker/.env.example` and copy to `MemOS/.env`
+3. Start the service.
+```bash
+uvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 8
+```
+
+### Local SDK
Here's a quick example of how to create a **`MemCube`**, load it from a directory, access its memories, and save it.
```python
@@ -104,7 +123,7 @@ for item in mem_cube.act_mem.get_all():
mem_cube.dump("tmp/mem_cube")
```
-What about **`MOS`** (Memory Operating System)? It's a higher-level orchestration layer that manages multiple MemCubes and provides a unified API for memory operations. Here's a quick example of how to use MOS:
+**`MOS`** (Memory Operating System) is a higher-level orchestration layer that manages multiple MemCubes and provides a unified API for memory operations. Here's a quick example of how to use MOS:
```python
from memos.configs.mem_os import MOSConfig
diff --git a/docker/.env.example b/docker/.env.example
index 33f7ae853..0f4fcb65d 100644
--- a/docker/.env.example
+++ b/docker/.env.example
@@ -1,29 +1,60 @@
# MemOS Environment Variables Configuration
+TZ=Asia/Shanghai
-# Path to memory storage (e.g. /tmp/data_test)
-MOS_CUBE_PATH=
+MOS_CUBE_PATH="/tmp/data_test" # Path to memory storage (e.g. /tmp/data_test)
+MOS_ENABLE_DEFAULT_CUBE_CONFIG="true" # Enable default cube config (true/false)
# OpenAI Configuration
-OPENAI_API_KEY= # Your OpenAI API key
-OPENAI_API_BASE= # OpenAI API base URL (default: https://api.openai.com/v1)
+OPENAI_API_KEY="sk-xxx" # Your OpenAI API key
+OPENAI_API_BASE="http://xxx" # OpenAI API base URL (default: https://api.openai.com/v1)
-# MemOS Feature Toggles
-MOS_ENABLE_DEFAULT_CUBE_CONFIG= # Enable default cube config (true/false)
-MOS_ENABLE_SCHEDULER= # Enable background scheduler (true/false)
+# MemOS Chat Model Configuration
+MOS_CHAT_MODEL=gpt-4o-mini
+MOS_CHAT_TEMPERATURE=0.8
+MOS_MAX_TOKENS=8000
+MOS_TOP_P=0.9
+MOS_TOP_K=50
+MOS_CHAT_MODEL_PROVIDER=openai
-# Neo4j Configuration
-NEO4J_URI= # Neo4j connection URI (e.g. bolt://localhost:7687)
-NEO4J_USER= # Neo4j username
-NEO4J_PASSWORD= # Neo4j password
-MOS_NEO4J_SHARED_DB= # Shared Neo4j database name (if using multi-db)
+# graph db
+# neo4j
+NEO4J_BACKEND=xxx
+NEO4J_URI=bolt://xxx
+NEO4J_USER=xxx
+NEO4J_PASSWORD=xxx
+MOS_NEO4J_SHARED_DB=xxx
+NEO4J_DB_NAME=xxx
+
+# tetxmem reog
+MOS_ENABLE_REORGANIZE=false
# MemOS User Configuration
-MOS_USER_ID= # Unique user ID
-MOS_SESSION_ID= # Session ID for current chat
-MOS_MAX_TURNS_WINDOW= # Max number of turns to keep in memory
+MOS_USER_ID=root
+MOS_SESSION_ID=default_session
+MOS_MAX_TURNS_WINDOW=20
+
+# MemRader Configuration
+MEMRADER_MODEL=gpt-4o-mini
+MEMRADER_API_KEY=sk-xxx
+MEMRADER_API_BASE=http://xxx:3000/v1
+MEMRADER_MAX_TOKENS=5000
+
+#embedding & rerank
+EMBEDDING_DIMENSION=1024
+MOS_EMBEDDER_BACKEND=universal_api
+MOS_EMBEDDER_MODEL=bge-m3
+MOS_EMBEDDER_API_BASE=http://xxx
+MOS_EMBEDDER_API_KEY=EMPTY
+MOS_RERANKER_BACKEND=http_bge
+MOS_RERANKER_URL=http://xxx
+# Ollama Configuration (for embeddings)
+#OLLAMA_API_BASE=http://xxx
-# Ollama Configuration (for local embedding models)
-OLLAMA_API_BASE= # Ollama API base URL (e.g. http://localhost:11434)
+# milvus for pref mem
+MILVUS_URI=http://xxx
+MILVUS_USER_NAME=xxx
+MILVUS_PASSWORD=xxx
-# Embedding Configuration
-MOS_EMBEDDER_BACKEND= # Embedding backend: openai, ollama, etc.
+# pref mem
+ENABLE_PREFERENCE_MEMORY=true
+RETURN_ORIGINAL_PREF_MEM=true
diff --git a/docker/requirements.txt b/docker/requirements.txt
index d20c0b36e..4846f1832 100644
--- a/docker/requirements.txt
+++ b/docker/requirements.txt
@@ -157,4 +157,4 @@ volcengine-python-sdk==4.0.6
watchfiles==1.1.0
websockets==15.0.1
xlrd==2.0.2
-xlsxwriter==3.2.5
\ No newline at end of file
+xlsxwriter==3.2.5
diff --git a/docs/openapi.json b/docs/openapi.json
index 5a3471ac0..ee2ff1368 100644
--- a/docs/openapi.json
+++ b/docs/openapi.json
@@ -884,7 +884,7 @@
"type": "string",
"title": "Session Id",
"description": "Session ID for the MOS. This is used to distinguish between different dialogue",
- "default": "0ce84b9c-0615-4b9d-83dd-fba50537d5d3"
+ "default": "41bb5e18-252d-4948-918c-07d82aa47086"
},
"chat_model": {
"$ref": "#/components/schemas/LLMConfigFactory",
@@ -939,6 +939,12 @@
"description": "Enable parametric memory for the MemChat",
"default": false
},
+ "enable_preference_memory": {
+ "type": "boolean",
+ "title": "Enable Preference Memory",
+ "description": "Enable preference memory for the MemChat",
+ "default": false
+ },
"enable_mem_scheduler": {
"type": "boolean",
"title": "Enable Mem Scheduler",
diff --git a/evaluation/.env-example b/evaluation/.env-example
index fc57344da..5381532c2 100644
--- a/evaluation/.env-example
+++ b/evaluation/.env-example
@@ -3,39 +3,22 @@ MODEL="gpt-4o-mini"
OPENAI_API_KEY="sk-***REDACTED***"
OPENAI_BASE_URL="http://***.***.***.***:3000/v1"
-MEM0_API_KEY="m0-***REDACTED***"
-
-ZEP_API_KEY="z_***REDACTED***"
# response model
CHAT_MODEL="gpt-4o-mini"
CHAT_MODEL_BASE_URL="http://***.***.***.***:3000/v1"
CHAT_MODEL_API_KEY="sk-***REDACTED***"
+# memos
MEMOS_KEY="Token mpg-xxxxx"
-MEMOS_URL="https://apigw-pre.memtensor.cn/api/openmem/v1"
-PRE_SPLIT_CHUNK=false # pre split chunk in client end
-
-MEMOBASE_API_KEY="xxxxx"
-MEMOBASE_PROJECT_URL="http://xxx.xxx.xxx.xxx:8019"
-
-# Configuration Only For Scheduler
-# RabbitMQ Configuration
-MEMSCHEDULER_RABBITMQ_HOST_NAME=rabbitmq-cn-***.cn-***.amqp-32.net.mq.amqp.aliyuncs.com
-MEMSCHEDULER_RABBITMQ_USER_NAME=***
-MEMSCHEDULER_RABBITMQ_PASSWORD=***
-MEMSCHEDULER_RABBITMQ_VIRTUAL_HOST=memos
-MEMSCHEDULER_RABBITMQ_ERASE_ON_CONNECT=true
-MEMSCHEDULER_RABBITMQ_PORT=5672
+MEMOS_URL="http://127.0.0.1:8001"
+MEMOS_ONLINE_URL="https://memos.memtensor.cn/api/openmem/v1"
-# OpenAI Configuration
-MEMSCHEDULER_OPENAI_API_KEY=sk-***
-MEMSCHEDULER_OPENAI_BASE_URL=http://***.***.***.***:3000/v1
-MEMSCHEDULER_OPENAI_DEFAULT_MODEL=gpt-4o-mini
+# other memory agents
+MEM0_API_KEY="m0-xxx"
+ZEP_API_KEY="z_xxx"
+MEMU_API_KEY="mu_xxx"
+SUPERMEMORY_API_KEY="sm_xxx"
+MEMOBASE_API_KEY="xxx"
+MEMOBASE_PROJECT_URL="http://***.***.***.***:8019"
-# Graph DB Configuration
-MEMSCHEDULER_GRAPHDBAUTH_URI=bolt://localhost:7687
-MEMSCHEDULER_GRAPHDBAUTH_USER=neo4j
-MEMSCHEDULER_GRAPHDBAUTH_PASSWORD=***
-MEMSCHEDULER_GRAPHDBAUTH_DB_NAME=neo4j
-MEMSCHEDULER_GRAPHDBAUTH_AUTO_CREATE=true
\ No newline at end of file
diff --git a/evaluation/README.md b/evaluation/README.md
index 16752c075..a5a4f32ca 100644
--- a/evaluation/README.md
+++ b/evaluation/README.md
@@ -1,6 +1,6 @@
# Evaluation Memory Framework
-This repository provides tools and scripts for evaluating the LoCoMo dataset using various models and APIs.
+This repository provides tools and scripts for evaluating the `LoCoMo`, `LongMemEval`, `PrefEval`, `personaMem` dataset using various models and APIs.
## Installation
@@ -16,16 +16,35 @@ This repository provides tools and scripts for evaluating the LoCoMo dataset usi
```
## Configuration
+Copy the `.env-example` file to `.env`, and fill in the required environment variables according to your environment and API keys.
-1. Copy the `.env-example` file to `.env`, and fill in the required environment variables according to your environment and API keys.
+## Setup MemOS
+### local server
+```bash
+# modify {project_dir}/.env file and start server
+uvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 8
+
+# configure {project_dir}/evaluation/.env file
+MEMOS_URL="http://127.0.0.1:8001"
+```
+### online service
+```bash
+# get your api key at https://memos-dashboard.openmem.net/cn/quickstart/
+# configure {project_dir}/evaluation/.env file
+MEMOS_KEY="Token mpg-xxxxx"
+MEMOS_ONLINE_URL="https://memos.memtensor.cn/api/openmem/v1"
+
+```
-2. Copy the `configs-example/` directory to a new directory named `configs/`, and modify the configuration files inside it as needed. This directory contains model and API-specific settings.
+## Supported frameworks
+We support `memos-api` and `memos-api-online` in our scripts.
+And give unofficial implementations for the following memory frameworks:`zep`, `mem0`, `memobase`, `supermemory`, `memu`.
## Evaluation Scripts
### LoCoMo Evaluation
-⚙️ To evaluate the **LoCoMo** dataset using one of the supported memory frameworks — `memos`, `mem0`, or `zep` — run the following [script](./scripts/run_locomo_eval.sh):
+⚙️ To evaluate the **LoCoMo** dataset using one of the supported memory frameworks — run the following [script](./scripts/run_locomo_eval.sh):
```bash
# Edit the configuration in ./scripts/run_locomo_eval.sh
@@ -45,10 +64,21 @@ First prepare the dataset `longmemeval_s` from https://huggingface.co/datasets/x
./scripts/run_lme_eval.sh
```
-### prefEval Evaluation
+### PrefEval Evaluation
+Downloading benchmark_dataset/filtered_inter_turns.json from https://github.com/amazon-science/PrefEval/blob/main/benchmark_dataset/filtered_inter_turns.json and save it as `./data/prefeval/filtered_inter_turns.json`.
+To evaluate the **Prefeval** dataset — run the following [script](./scripts/run_prefeval_eval.sh):
-### personaMem Evaluation
+```bash
+# Edit the configuration in ./scripts/run_prefeval_eval.sh
+# Specify the model and memory backend you want to use (e.g., mem0, zep, etc.)
+./scripts/run_prefeval_eval.sh
+```
+
+### PersonaMem Evaluation
get `questions_32k.csv` and `shared_contexts_32k.jsonl` from https://huggingface.co/datasets/bowen-upenn/PersonaMem and save them at `data/personamem/`
```bash
+# Edit the configuration in ./scripts/run_pm_eval.sh
+# Specify the model and memory backend you want to use (e.g., mem0, zep, etc.)
+# If you want to use MIRIX, edit the the configuration in ./scripts/personamem/config.yaml
./scripts/run_pm_eval.sh
```
diff --git a/evaluation/configs-example/mem_cube_config.json b/evaluation/configs-example/mem_cube_config.json
deleted file mode 100644
index d609d27b0..000000000
--- a/evaluation/configs-example/mem_cube_config.json
+++ /dev/null
@@ -1,51 +0,0 @@
-{
- "user_id": "__USER_ID__",
- "cube_id": "__USER_ID__",
- "text_mem": {
- "backend": "tree_text",
- "config": {
- "extractor_llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "dispatcher_llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "graph_db": {
- "backend": "neo4j",
- "config": {
- "uri": "bolt://***.***.***.***:7687",
- "user": "***REDACTED***",
- "password": "***REDACTED***",
- "db_name": "__DB_NAME__",
- "auto_create": true
- }
- },
- "embedder": {
- "backend": "ollama",
- "config": {
- "model_name_or_path": "nomic-embed-text:latest"
- }
- }
- }
- },
- "act_mem": {},
- "para_mem": {}
-}
diff --git a/evaluation/configs-example/mos_memos_config.json b/evaluation/configs-example/mos_memos_config.json
deleted file mode 100644
index b7f2767b7..000000000
--- a/evaluation/configs-example/mos_memos_config.json
+++ /dev/null
@@ -1,51 +0,0 @@
-{
- "user_id": "root",
- "chat_model": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1",
- "temperature": 0.1,
- "remove_think_prefix": true,
- "max_tokens": 4096
- }
- },
- "mem_reader": {
- "backend": "simple_struct",
- "config": {
- "llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "embedder": {
- "backend": "ollama",
- "config": {
- "model_name_or_path": "nomic-embed-text:latest"
- }
- },
- "chunker": {
- "backend": "sentence",
- "config": {
- "tokenizer_or_token_counter": "gpt2",
- "chunk_size": 512,
- "chunk_overlap": 128,
- "min_sentences_per_chunk": 1
- }
- }
- }
- },
- "max_turns_window": 30,
- "top_k": "__TOP_K__",
- "enable_textual_memory": true,
- "enable_activation_memory": false,
- "enable_parametric_memory": false
-}
diff --git a/evaluation/scripts/PrefEval/pref_eval.py b/evaluation/scripts/PrefEval/pref_eval.py
index cd9c5dde2..ec079614d 100644
--- a/evaluation/scripts/PrefEval/pref_eval.py
+++ b/evaluation/scripts/PrefEval/pref_eval.py
@@ -1,24 +1,24 @@
+import argparse
import asyncio
import json
+import os
import re
-import argparse
-from typing import Dict, Any
+
from collections import Counter
-from tqdm.asyncio import tqdm
-import os
+from typing import Any
+
import pandas as pd
+
from dotenv import load_dotenv
from openai import OpenAI
+from tqdm.asyncio import tqdm
+
load_dotenv()
API_KEY = os.getenv("OPENAI_API_KEY")
API_URL = os.getenv("OPENAI_BASE_URL")
-INPUT_FILE = "./results/prefeval/pref_memos_process.jsonl"
-OUTPUT_FILE = "./results/prefeval/eval_pref_memos.jsonl"
-OUTPUT_EXCEL_FILE = "./results/prefeval/eval_pref_memos_summary.xlsx"
-
async def call_gpt4o_mini_async(client: OpenAI, prompt: str) -> str:
messages = [{"role": "user", "content": prompt}]
@@ -34,7 +34,7 @@ async def call_gpt4o_mini_async(client: OpenAI, prompt: str) -> str:
)
return response.choices[0].message.content
except Exception as e:
- print(f"API call failed: {str(e)}")
+ print(f"API call failed: {e!s}")
return ""
@@ -45,7 +45,7 @@ def parse_xml_response(response: str, tag: str) -> str:
async def evaluate_violate_preference_async(
client: OpenAI, preference: str, question: str, response: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant's response violates the user's stated preference.
Evaluate the response based on these criteria:
@@ -77,8 +77,8 @@ async def evaluate_violate_preference_async(
async def evaluate_acknowledge_preference_async(
client: OpenAI, question: str, response: str
-) -> Dict[str, str]:
- prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant acknowledges any user preference in answering the user's query.
+) -> dict[str, str]:
+ prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant acknowledges any user preference in answering the user's query.
Evaluate the response based on these stringent criteria:
@@ -86,7 +86,7 @@ async def evaluate_acknowledge_preference_async(
Answer "Yes" if:
-1. The response explicitly mentions or refers to a user preference in answering the user's question. Examples include: "Based on your previous preference for xxxx"; "Based on your previous preference, I would suggest you xxxx"; "Since you mentioned you prefer/dislike xxxx"; "Since you are a xxxx"; "I will recommend the following given your preference for xxx", etc. You should extract the "xxxx" in your answer. If it only says "Based on our previous conversation, I recommend..." and does not explicitly mention any preference, you should answer 'No'.
+1. The response explicitly mentions or refers to a user preference in answering the user's question. Examples include: "Based on your previous preference for xxxx"; "Based on your previous preference, I would suggest you xxxx"; "Since you mentioned you prefer/dislike xxxx"; "Since you are a xxxx"; "I will recommend the following given your preference for xxx", etc. You should extract the "xxxx" in your answer. If it only says "Based on our previous conversation, I recommend..." and does not explicitly mention any preference, you should answer 'No'.
2. The response assumes the user preference in answering the user's question implicitly. For example, when the user asks 'Can you recommend me cars to drive?', if the response is 'Based on your preference, I will recommend non-EV cars, ...', then this indicates the assistant assumes that the user's preference is a dislike of EV cars, and you should answer 'Yes'.
Answer "No" if the response does not mention or refer to any user preference explicitly or implicitly. If you cannot extract the sentence stating what the preference is, answer 'No'.
@@ -107,7 +107,7 @@ async def evaluate_acknowledge_preference_async(
async def evaluate_hallucinate_preference_async(
client: OpenAI, preference: str, restatement: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
if not restatement.strip():
return {"explanation": "No restatement provided by assistant", "answer": "No"}
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant's restatement of the user's stated preference is the same preference. Evaluate the response based on these stringent criteria to answer if the assistant has hallucinated the preference or not:
@@ -124,10 +124,10 @@ async def evaluate_hallucinate_preference_async(
2. The assistant's restatement is a minor paraphrase that fully preserves the meaning and intent of the original preference.
3. The restatement is just empty, no hallucination.
-Here is the information:
-Original user preference: "{preference}"
-Assistant's restatement: "{restatement}"
-Examine the original preference and the assistant's restatement meticulously and answer. Please answer in this exact XML format without any other additional text:
+Here is the information:
+Original user preference: "{preference}"
+Assistant's restatement: "{restatement}"
+Examine the original preference and the assistant's restatement meticulously and answer. Please answer in this exact XML format without any other additional text:
[1 short sentence explanation]
[Yes/No]"""
@@ -140,7 +140,7 @@ async def evaluate_hallucinate_preference_async(
async def evaluate_helpful_response_async(
client: OpenAI, question: str, response: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant provides any substantive response to the user's query.
Evaluate the response based on these stringent criteria:
@@ -178,7 +178,7 @@ async def evaluate_helpful_response_async(
}
-def classify_error_type(evaluation_results: Dict[str, Any]) -> str:
+def classify_error_type(evaluation_results: dict[str, Any]) -> str:
violate = evaluation_results["violate_preference"]["answer"]
acknowledge = evaluation_results["acknowledge_preference"]["answer"]
hallucinate = evaluation_results["hallucinate_preference"]["answer"]
@@ -196,7 +196,7 @@ def classify_error_type(evaluation_results: Dict[str, Any]) -> str:
return "Personalized Response"
-async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore) -> Dict[str, Any]:
+async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore) -> dict[str, Any]:
async with semaphore:
data = json.loads(line.strip())
preference = data["preference"]
@@ -227,7 +227,7 @@ async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore)
return result
-def log_summary(error_counter: Counter, total_samples: int) -> Dict[str, Dict[str, float]]:
+def log_summary(error_counter: Counter, total_samples: int) -> dict[str, dict[str, float]]:
summary_data = {}
print("\n--- Error Type Summary ---")
@@ -251,13 +251,14 @@ def log_summary(error_counter: Counter, total_samples: int) -> Dict[str, Dict[st
def generate_excel_summary(
- summary_results: Dict[str, Dict[str, float]],
+ summary_results: dict[str, dict[str, float]],
avg_search_time: float,
avg_context_tokens: float,
avg_add_time: float,
+ output_excel_file: str,
model_name: str = "gpt-4o-mini",
):
- print(f"Generating Excel summary at {OUTPUT_EXCEL_FILE}...")
+ print(f"Generating Excel summary at {output_excel_file}...")
def get_pct(key):
return summary_results.get(key, {}).get("percentage", 0)
@@ -282,7 +283,7 @@ def get_pct(key):
df = pd.DataFrame(data)
- with pd.ExcelWriter(OUTPUT_EXCEL_FILE, engine="xlsxwriter") as writer:
+ with pd.ExcelWriter(output_excel_file, engine="xlsxwriter") as writer:
df.to_excel(writer, index=False, sheet_name="Summary")
workbook = writer.book
@@ -300,10 +301,10 @@ def get_pct(key):
bold_pct_format = workbook.add_format({"num_format": "0.0%", "bold": True})
worksheet.set_column("F:F", 18, bold_pct_format)
- print(f"Successfully saved summary to {OUTPUT_EXCEL_FILE}")
+ print(f"Successfully saved summary to {output_excel_file}")
-async def main(concurrency_limit: int):
+async def main(concurrency_limit: int, input_file: str, output_file: str, output_excel_file: str):
semaphore = asyncio.Semaphore(concurrency_limit)
error_counter = Counter()
@@ -313,17 +314,17 @@ async def main(concurrency_limit: int):
total_add_time = 0
print(f"Starting evaluation with a concurrency limit of {concurrency_limit}...")
- print(f"Input file: {INPUT_FILE}")
- print(f"Output JSONL: {OUTPUT_FILE}")
- print(f"Output Excel: {OUTPUT_EXCEL_FILE}")
+ print(f"Input file: {input_file}")
+ print(f"Output JSONL: {output_file}")
+ print(f"Output Excel: {output_excel_file}")
client = OpenAI(api_key=API_KEY, base_url=API_URL)
try:
- with open(INPUT_FILE, "r", encoding="utf-8") as f:
+ with open(input_file, encoding="utf-8") as f:
lines = f.readlines()
except FileNotFoundError:
- print(f"Error: Input file not found at '{INPUT_FILE}'")
+ print(f"Error: Input file not found at '{input_file}'")
return
if not lines:
@@ -332,7 +333,7 @@ async def main(concurrency_limit: int):
tasks = [process_line(line, client, semaphore) for line in lines]
- with open(OUTPUT_FILE, "w", encoding="utf-8") as outfile:
+ with open(output_file, "w", encoding="utf-8") as outfile:
pbar = tqdm(
asyncio.as_completed(tasks),
total=len(tasks),
@@ -382,6 +383,7 @@ async def main(concurrency_limit: int):
avg_search_time,
avg_context_tokens,
avg_add_time,
+ output_excel_file,
)
except Exception as e:
print(f"\nFailed to generate Excel file: {e}")
@@ -389,12 +391,46 @@ async def main(concurrency_limit: int):
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Evaluate assistant responses from a JSONL file.")
+
+ parser.add_argument("--input", type=str, required=True, help="Path to the input JSONL file.")
+
parser.add_argument(
"--concurrency-limit",
type=int,
default=10,
help="The maximum number of concurrent API calls.",
)
+
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ "zep",
+ ],
+ default="memos-api",
+ help="Which library to use (used in 'add' mode).",
+ )
+
args = parser.parse_args()
- asyncio.run(main(concurrency_limit=args.concurrency_limit))
+ input_path = args.input
+ output_dir = os.path.dirname(input_path)
+
+ output_jsonl_path = os.path.join(output_dir, f"eval_pref_{args.lib}.jsonl")
+ output_excel_path = os.path.join(output_dir, f"eval_pref_{args.lib}_summary.xlsx")
+
+ asyncio.run(
+ main(
+ concurrency_limit=args.concurrency_limit,
+ input_file=input_path,
+ output_file=output_jsonl_path,
+ output_excel_file=output_excel_path,
+ )
+ )
diff --git a/evaluation/scripts/PrefEval/pref_mem0.py b/evaluation/scripts/PrefEval/pref_mem0.py
new file mode 100644
index 000000000..300e0ede3
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_mem0.py
@@ -0,0 +1,324 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+os.environ["MEM0_API_KEY"] = os.getenv("MEM0_API_KEY")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+ timestamp_add = int(time.time() * 100)
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ timestamp=timestamp_add,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memory_list = relevant_memories.get("results", [])
+ memories_str = "\n".join(f"- {entry['memory']}" for entry in memory_list)
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["mem0", "mem0_graph"],
+ default="mem0",
+ help="Which Mem0 library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import Mem0Client
+
+ mem_client = Mem0Client(enable_graph="graph" in args.lib)
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_memobase.py b/evaluation/scripts/PrefEval/pref_memobase.py
new file mode 100644
index 000000000..776642657
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_memobase.py
@@ -0,0 +1,332 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+ mem_client.delete_user(user_id)
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+ if conversation:
+ messages = []
+
+ for chunk_start in range(len(conversation)):
+ chunk = conversation[chunk_start : chunk_start + 1]
+ timestamp_add = str(int(time.time() * 100))
+ time.sleep(0.001) # Ensure unique timestamp
+
+ messages.append(
+ {
+ "role": chunk[0]["role"],
+ "content": chunk[0]["content"][:8000],
+ "created_at": timestamp_add,
+ }
+ )
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(messages=conversation[msg_idx : msg_idx + 2], user_id=user_id)
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = relevant_memories
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["memobase"],
+ default="memobase",
+ help="Which Memobase library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import MemobaseClient
+
+ mem_client = MemobaseClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_memos.py b/evaluation/scripts/PrefEval/pref_memos.py
index d1a901dd2..bbe1788b5 100644
--- a/evaluation/scripts/PrefEval/pref_memos.py
+++ b/evaluation/scripts/PrefEval/pref_memos.py
@@ -4,12 +4,14 @@
import os
import sys
import time
+
import tiktoken
+
from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
from openai import OpenAI
from tqdm import tqdm
-from irrelevant_conv import irre_10, irre_300
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
@@ -18,6 +20,7 @@
sys.path.insert(0, ROOT_DIR)
sys.path.insert(0, EVAL_SCRIPTS_DIR)
+
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
BASE_URL = os.getenv("OPENAI_BASE_URL")
@@ -26,8 +29,8 @@
def add_memory_for_line(
- line_data: tuple, mem_client, num_irrelevant_turns: int, lib: str, version: str
-) -> dict:
+ line_data, mem_client, num_irrelevant_turns, lib, version, success_records, f
+):
"""
Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
"""
@@ -43,15 +46,22 @@ def add_memory_for_line(
elif num_irrelevant_turns == 300:
conversation = conversation + irre_300
- turns_add = 5
start_time_add = time.monotonic()
- if conversation:
- if os.getenv("PRE_SPLIT_CHUNK", "false").lower() == "true":
- for chunk_start in range(0, len(conversation), turns_add * 2):
- chunk = conversation[chunk_start : chunk_start + turns_add * 2]
- mem_client.add(messages=chunk, user_id=user_id, conv_id=None)
- else:
- mem_client.add(messages=conversation, user_id=user_id, conv_id=None)
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ conv_id=None,
+ batch_size=2,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
end_time_add = time.monotonic()
add_duration = end_time_add - start_time_add
@@ -64,12 +74,11 @@ def add_memory_for_line(
return None
-def process_line_with_id(
- line_data: tuple, mem_client, openai_client: OpenAI, top_k_value: int, lib: str, version: str
-) -> dict:
+def search_memory_for_line(line_data, mem_client, top_k_value):
"""
- Processes a single line of data using a pre-existing user_id, searching memory and generating a response.
+ Processes a single line of data, searching memory based on the question.
"""
+
i, line = line_data
try:
original_data = json.loads(line)
@@ -79,33 +88,27 @@ def process_line_with_id(
metrics_dict = original_data.get("metrics", {})
if not user_id:
- original_data["response"] = (
+ original_data["error"] = (
"Error: user_id not found in this line. Please run 'add' mode first."
)
return original_data
if not question:
- original_data["response"] = "Question not found in this line."
+ original_data["error"] = "Question not found in this line."
return original_data
start_time_search = time.monotonic()
relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
search_memories_duration = time.monotonic() - start_time_search
- memories_str = "\n".join(
- f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ memories_str = (
+ "\n".join(
+ f"- {entry.get('memory', '')}"
+ for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+ + f"\n{relevant_memories.get('pref_string', '')}"
)
memory_tokens_used = len(tokenizer.encode(memories_str))
- system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
- messages = [
- {"role": "system", "content": system_prompt},
- {"role": "user", "content": question},
- ]
-
- response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
- assistant_response = response.choices[0].message.content
- original_data["response"] = assistant_response
-
metrics_dict.update(
{
"search_memories_duration_seconds": search_memories_duration,
@@ -119,38 +122,94 @@ def process_line_with_id(
except Exception as e:
user_id_from_data = json.loads(line).get("user_id", "N/A")
- print(f"Error processing line {i + 1} (user_id: {user_id_from_data}): {e}")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data, openai_client, lib):
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ from utils.prompts import PREFEVAL_ANSWER_PROMPT
+
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = PREFEVAL_ANSWER_PROMPT.format(context=memories_str)
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
return None
def main():
parser = argparse.ArgumentParser(
- description="Process conversations with MemOS. Run 'add' mode first, then 'process' mode."
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
)
parser.add_argument(
"mode",
- choices=["add", "process"],
- help="The mode to run the script in ('add' or 'process').",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
)
parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
- parser.add_argument("--top-k", type=int, default=10, help="Number of memories to retrieve.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
parser.add_argument(
"--add-turn",
type=int,
choices=[0, 10, 300],
default=0,
- help="Number of irrelevant turns to add (0, 10, or 300).",
+ help="Number of irrelevant turns to add (used in 'add' mode).",
)
parser.add_argument(
"--lib",
type=str,
- choices=["memos-api", "memos-local"],
+ choices=["memos-api", "memos-api-online"],
default="memos-api",
- help="Which MemOS library to use.",
+ help="Which MemOS library to use (used in 'add' mode).",
)
parser.add_argument(
- "--version", type=str, default="0929-1", help="Version identifier for user_id generation."
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
)
parser.add_argument(
"--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
@@ -159,15 +218,28 @@ def main():
args = parser.parse_args()
try:
- with open(args.input, "r", encoding="utf-8") as infile:
+ with open(args.input, encoding="utf-8") as infile:
lines = infile.readlines()
except FileNotFoundError:
print(f"Error: Input file '{args.input}' not found")
return
- from utils.client import memosApiClient
+ from utils.client import MemosApiClient, MemosApiOnlineClient
- mem_client = memosApiClient()
+ if args.lib == "memos-api":
+ mem_client = MemosApiClient()
+ elif args.lib == "memos-api-online":
+ mem_client = MemosApiOnlineClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
if args.mode == "add":
print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
@@ -176,6 +248,7 @@ def main():
with (
open(args.output, "w", encoding="utf-8") as outfile,
concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as record_f,
):
futures = [
executor.submit(
@@ -185,6 +258,8 @@ def main():
args.add_turn,
args.lib,
args.version,
+ success_records,
+ record_f,
)
for i, line in enumerate(lines)
]
@@ -200,38 +275,55 @@ def main():
outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
- elif args.mode == "process":
- print(f"Running in 'process' mode. Processing questions from '{args.input}'...")
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
print(f"Retrieving top {args.top_k} memories for each query.")
print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
with (
open(args.output, "w", encoding="utf-8") as outfile,
concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
):
futures = [
- executor.submit(
- process_line_with_id,
- (i, line),
- mem_client,
- openai_client,
- args.top_k,
- args.lib,
- args.version,
- )
+ executor.submit(generate_response_for_line, (i, line), openai_client, args.lib)
for i, line in enumerate(lines)
]
pbar = tqdm(
concurrent.futures.as_completed(futures),
total=len(lines),
- desc="Processing questions...",
+ desc="Generating responses...",
)
for future in pbar:
result = future.result()
if result:
outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
- print(f"\n'process' mode complete! Final results written to '{args.output}'.")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
if __name__ == "__main__":
diff --git a/evaluation/scripts/PrefEval/pref_memu.py b/evaluation/scripts/PrefEval/pref_memu.py
new file mode 100644
index 000000000..00c411eb7
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_memu.py
@@ -0,0 +1,326 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+from datetime import datetime
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ iso_date=datetime.now().isoformat(),
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = "\n".join(
+ f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["memu"],
+ default="memu",
+ help="Which Memu library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import MemuClient
+
+ mem_client = MemuClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_supermemory.py b/evaluation/scripts/PrefEval/pref_supermemory.py
new file mode 100644
index 000000000..7386bc462
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_supermemory.py
@@ -0,0 +1,358 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = relevant_memories
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["supermemory"],
+ default="supermemory",
+ help="Which Supermemory library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ class SupermemoryClient:
+ def __init__(self):
+ from supermemory import Supermemory
+
+ self.client = Supermemory(api_key=os.getenv("SUPERMEMORY_API_KEY"))
+
+ def add(self, messages, user_id):
+ content = "\n".join([f"{msg['role']}: {msg['content']}" for msg in messages])
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ self.client.memories.add(content=content, container_tag=user_id)
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ def search(self, query, user_id, top_k):
+ max_retries = 10
+ for attempt in range(max_retries):
+ try:
+ results = self.client.search.memories(
+ q=query,
+ container_tag=user_id,
+ threshold=0,
+ rerank=True,
+ rewrite_query=True,
+ limit=top_k,
+ )
+ context = "\n\n".join([r.memory for r in results.results])
+ return context
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ mem_client = SupermemoryClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_zep.py b/evaluation/scripts/PrefEval/pref_zep.py
new file mode 100644
index 000000000..8a4d50558
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_zep.py
@@ -0,0 +1,327 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+from datetime import datetime
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ conv_id=None,
+ timestamp=datetime.now().isoformat(),
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = "\n".join(
+ f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["zep"],
+ default="zep",
+ help="Which Zep library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import ZepClient
+
+ mem_client = ZepClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/prefeval_preprocess.py b/evaluation/scripts/PrefEval/prefeval_preprocess.py
index 004d5e505..b8ccf3f34 100644
--- a/evaluation/scripts/PrefEval/prefeval_preprocess.py
+++ b/evaluation/scripts/PrefEval/prefeval_preprocess.py
@@ -1,7 +1,8 @@
-from datasets import load_dataset
import json
import os
+from datasets import load_dataset
+
def convert_dataset_to_jsonl(dataset_name, output_dir="./scripts/PrefEval"):
if not os.path.exists(output_dir):
@@ -64,7 +65,7 @@ def process_jsonl_file(input_filepath, output_filepath):
line_count = 0
print(f"Start processing file: {input_filepath}")
with (
- open(input_filepath, "r", encoding="utf-8") as infile,
+ open(input_filepath, encoding="utf-8") as infile,
open(output_filepath, "w", encoding="utf-8") as outfile,
):
for line in infile:
@@ -93,6 +94,7 @@ def process_jsonl_file(input_filepath, output_filepath):
def main():
huggingface_dataset_name = "siyanzhao/prefeval_implicit_persona"
output_directory = "./data/prefeval"
+ os.makedirs(output_directory, exist_ok=True)
input_file_path = os.path.join(output_directory, "train.jsonl")
processed_file_path = os.path.join(output_directory, "pref_processed.jsonl")
diff --git a/evaluation/scripts/locomo/locomo_eval.py b/evaluation/scripts/locomo/locomo_eval.py
index f142fe130..b431e7768 100644
--- a/evaluation/scripts/locomo/locomo_eval.py
+++ b/evaluation/scripts/locomo/locomo_eval.py
@@ -363,7 +363,15 @@ async def limited_task(task):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_ingestion.py b/evaluation/scripts/locomo/locomo_ingestion.py
index 2a177a52a..a9e4d5f02 100644
--- a/evaluation/scripts/locomo/locomo_ingestion.py
+++ b/evaluation/scripts/locomo/locomo_ingestion.py
@@ -1,12 +1,16 @@
-import os
-import sys
import argparse
import concurrent.futures
+import os
+import sys
import time
+
from datetime import datetime, timezone
+
import pandas as pd
+
from dotenv import load_dotenv
+
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
@@ -40,26 +44,33 @@ def ingest_session(client, session, frame, version, metadata):
speaker_a_messages.append({"role": "assistant", "content": data})
speaker_b_messages.append({"role": "user", "content": data})
- if frame == "memos-api":
+ if "memos-api" in frame:
for m in speaker_a_messages:
m["chat_time"] = iso_date
for m in speaker_b_messages:
m["chat_time"] = iso_date
- client.add(speaker_a_messages, speaker_a_user_id, f"{conv_id}_{metadata['session_key']}")
- client.add(speaker_b_messages, speaker_b_user_id, f"{conv_id}_{metadata['session_key']}")
+ client.add(
+ speaker_a_messages,
+ speaker_a_user_id,
+ f"{conv_id}_{metadata['session_key']}",
+ batch_size=2,
+ )
+ client.add(
+ speaker_b_messages,
+ speaker_b_user_id,
+ f"{conv_id}_{metadata['session_key']}",
+ batch_size=2,
+ )
elif "mem0" in frame:
- for i in range(0, len(speaker_a_messages), 2):
- batch_messages_a = speaker_a_messages[i : i + 2]
- batch_messages_b = speaker_b_messages[i : i + 2]
- client.add(batch_messages_a, speaker_a_user_id, timestamp)
- client.add(batch_messages_b, speaker_b_user_id, timestamp)
+ client.add(speaker_a_messages, speaker_a_user_id, timestamp, batch_size=2)
+ client.add(speaker_b_messages, speaker_b_user_id, timestamp, batch_size=2)
elif frame == "memobase":
for m in speaker_a_messages:
m["created_at"] = iso_date
for m in speaker_b_messages:
m["created_at"] = iso_date
- client.add(speaker_a_messages, speaker_a_user_id)
- client.add(speaker_b_messages, speaker_b_user_id)
+ client.add(speaker_a_messages, speaker_a_user_id, batch_size=2)
+ client.add(speaker_b_messages, speaker_b_user_id, batch_size=2)
elif frame == "memu":
client.add(speaker_a_messages, speaker_a_user_id, iso_date)
client.add(speaker_b_messages, speaker_b_user_id, iso_date)
@@ -77,7 +88,7 @@ def ingest_session(client, session, frame, version, metadata):
return elapsed_time
-def process_user(conv_idx, frame, locomo_df, version):
+def process_user(conv_idx, frame, locomo_df, version, success_records, f):
conversation = locomo_df["conversation"].iloc[conv_idx]
max_session_count = 35
start_time = time.time()
@@ -88,8 +99,8 @@ def process_user(conv_idx, frame, locomo_df, version):
client = None
if frame == "mem0" or frame == "mem0_graph":
- from utils.client import Mem0Client
from prompts import custom_instructions
+ from utils.client import Mem0Client
client = Mem0Client(enable_graph="graph" in frame)
client.client.update_project(custom_instructions=custom_instructions)
@@ -99,16 +110,16 @@ def process_user(conv_idx, frame, locomo_df, version):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- all_users = client.client.get_all_users(limit=5000)
- for user in all_users:
- if user["additional_fields"]["user_id"] in [speaker_a_user_id, speaker_b_user_id]:
- client.client.delete_user(user["id"])
- speaker_a_user_id = client.client.add_user({"user_id": speaker_a_user_id})
- speaker_b_user_id = client.client.add_user({"user_id": speaker_b_user_id})
+ client.delete_user(speaker_a_user_id)
+ client.delete_user(speaker_b_user_id)
elif frame == "memu":
from utils.client import MemuClient
@@ -138,11 +149,15 @@ def process_user(conv_idx, frame, locomo_df, version):
print(f"Processing {valid_sessions} sessions for user {conv_idx}")
- for session, metadata in sessions_to_process:
- session_time = ingest_session(client, session, frame, version, metadata)
- total_session_time += session_time
- print(f"User {conv_idx}, {metadata['session_key']} processed in {session_time} seconds")
-
+ for session_idx, (session, metadata) in enumerate(sessions_to_process):
+ if f"{conv_idx}_{session_idx}" not in success_records:
+ session_time = ingest_session(client, session, frame, version, metadata)
+ total_session_time += session_time
+ print(f"User {conv_idx}, {metadata['session_key']} processed in {session_time} seconds")
+ f.write(f"{conv_idx}_{session_idx}\n")
+ f.flush()
+ else:
+ print(f"Session {conv_idx}_{session_idx} already ingested")
end_time = time.time()
elapsed_time = round(end_time - start_time, 2)
print(f"User {conv_idx} processed successfully in {elapsed_time} seconds")
@@ -159,9 +174,20 @@ def main(frame, version="default", num_workers=4):
print(
f"Starting processing for {num_users} users in serial mode, each user using {num_workers} workers for sessions..."
)
- with concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor:
+ os.makedirs(f"results/locomo/{frame}-{version}/", exist_ok=True)
+ success_records = []
+ record_file = f"results/locomo/{frame}-{version}/success_records.txt"
+ if os.path.exists(record_file):
+ with open(record_file) as f:
+ for i in f.readlines():
+ success_records.append(i.strip())
+
+ with (
+ concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor,
+ open(record_file, "a+") as f,
+ ):
futures = [
- executor.submit(process_user, user_id, frame, locomo_df, version)
+ executor.submit(process_user, user_id, frame, locomo_df, version, success_records, f)
for user_id in range(num_users)
]
for future in concurrent.futures.as_completed(futures):
@@ -187,17 +213,25 @@ def main(frame, version="default", num_workers=4):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
"--version",
type=str,
- default="default1",
+ default="default",
help="Version identifier for saving results (e.g., 1010)",
)
parser.add_argument(
- "--workers", type=int, default=3, help="Number of parallel workers to process users"
+ "--workers", type=int, default=10, help="Number of parallel workers to process users"
)
args = parser.parse_args()
lib = args.lib
diff --git a/evaluation/scripts/locomo/locomo_metric.py b/evaluation/scripts/locomo/locomo_metric.py
index 6ddcdf127..e63888d45 100644
--- a/evaluation/scripts/locomo/locomo_metric.py
+++ b/evaluation/scripts/locomo/locomo_metric.py
@@ -9,7 +9,15 @@
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_responses.py b/evaluation/scripts/locomo/locomo_responses.py
index 4e3b966a3..6c082b31d 100644
--- a/evaluation/scripts/locomo/locomo_responses.py
+++ b/evaluation/scripts/locomo/locomo_responses.py
@@ -2,6 +2,7 @@
import asyncio
import json
import os
+import sys
from time import time
@@ -13,6 +14,15 @@
from tqdm import tqdm
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+
+
async def locomo_response(frame, llm_client, context: str, question: str) -> str:
if frame == "zep":
prompt = ANSWER_PROMPT_ZEP.format(
@@ -47,7 +57,9 @@ async def process_qa(frame, qa, search_result, oai_client):
gold_answer = qa.get("answer")
qa_category = qa.get("category")
- answer = await locomo_response(frame, oai_client, search_result.get("context"), query)
+ context = search_result.get("context")
+
+ answer = await locomo_response(frame, oai_client, context, query)
response_duration_ms = (time() - start) * 1000
@@ -122,7 +134,15 @@ async def main(frame, version="default"):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_search.py b/evaluation/scripts/locomo/locomo_search.py
index d976b8f67..24f6149ec 100644
--- a/evaluation/scripts/locomo/locomo_search.py
+++ b/evaluation/scripts/locomo/locomo_search.py
@@ -1,14 +1,18 @@
-import os
-import sys
import argparse
import json
+import os
+import sys
+
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from time import time
+
import pandas as pd
+
from dotenv import load_dotenv
from tqdm import tqdm
+
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
@@ -100,11 +104,14 @@ def memos_api_search(
start = time()
search_a_results = client.search(query=query, user_id=speaker_a_user_id, top_k=top_k)
search_b_results = client.search(query=query, user_id=speaker_b_user_id, top_k=top_k)
- speaker_a_context = "\n".join(
- [i["memory"] for i in search_a_results["text_mem"][0]["memories"]]
+
+ speaker_a_context = (
+ "\n".join([i["memory"] for i in search_a_results["text_mem"][0]["memories"]])
+ + f"\n{search_a_results.get('pref_string', '')}"
)
- speaker_b_context = "\n".join(
- [i["memory"] for i in search_b_results["text_mem"][0]["memories"]]
+ speaker_b_context = (
+ "\n".join([i["memory"] for i in search_b_results["text_mem"][0]["memories"]])
+ + f"\n{search_b_results.get('pref_string', '')}"
)
context = TEMPLATE_MEMOS.format(
@@ -191,7 +198,7 @@ def search_query(client, query, metadata, frame, version, top_k=20):
context, duration_ms = mem0_graph_search(
client, query, speaker_a_user_id, speaker_b_user_id, top_k, speaker_a, speaker_b
)
- elif frame == "memos-api":
+ elif "memos-api" in frame:
context, duration_ms = memos_api_search(
client, query, speaker_a_user_id, speaker_b_user_id, top_k, speaker_a, speaker_b
)
@@ -250,16 +257,14 @@ def process_user(conv_idx, locomo_df, frame, version, top_k=20, num_workers=1):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- users = client.client.get_all_users(limit=5000)
- for u in users:
- if u["additional_fields"]["user_id"] == speaker_a_user_id:
- speaker_a_user_id = u["id"]
- if u["additional_fields"]["user_id"] == speaker_b_user_id:
- speaker_b_user_id = u["id"]
elif frame == "memu":
from utils.client import MemuClient
@@ -335,7 +340,15 @@ def main(frame, version="default", num_workers=1, top_k=20):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
@@ -348,7 +361,7 @@ def main(frame, version="default", num_workers=1, top_k=20):
"--workers", type=int, default=5, help="Number of parallel workers to process users"
)
parser.add_argument(
- "--top_k", type=int, default=20, help="Number of results to retrieve in search queries"
+ "--top_k", type=int, default=15, help="Number of results to retrieve in search queries"
)
args = parser.parse_args()
lib = args.lib
diff --git a/evaluation/scripts/locomo/prompts.py b/evaluation/scripts/locomo/prompts.py
index 2827716a0..152e5b87f 100644
--- a/evaluation/scripts/locomo/prompts.py
+++ b/evaluation/scripts/locomo/prompts.py
@@ -49,12 +49,12 @@
5. Always convert relative time references to specific dates, months, or years.
6. Be as specific as possible when talking about people, places, and events
7. Timestamps in memories represent the actual time the event occurred, not the time the event was mentioned in a message.
-
+
Clarification:
When interpreting memories, use the timestamp to determine when the described event happened, not when someone talked about the event.
-
+
Example:
-
+
Memory: (2023-03-15T16:33:00Z) I went to the vet yesterday.
Question: What day did I go to the vet?
Correct Answer: March 15, 2023
@@ -111,6 +111,7 @@
Answer:
"""
+
custom_instructions = """
Generate personal memories that follow these guidelines:
diff --git a/evaluation/scripts/longmemeval/lme_eval.py b/evaluation/scripts/longmemeval/lme_eval.py
index 45c038a2b..20681ac2c 100644
--- a/evaluation/scripts/longmemeval/lme_eval.py
+++ b/evaluation/scripts/longmemeval/lme_eval.py
@@ -26,6 +26,7 @@
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.prompts import LME_JUDGE_MODEL_TEMPLATE
+
encoding = tiktoken.get_encoding("cl100k_base")
logging.basicConfig(level=logging.CRITICAL)
transformers.logging.set_verbosity_error()
@@ -343,7 +344,15 @@ async def main(frame, version, nlp_options, num_runs=3, num_workers=5):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
@@ -354,7 +363,7 @@ async def main(frame, version, nlp_options, num_runs=3, num_workers=5):
type=str,
nargs="+",
default=["lexical"],
- choices=["lexical", "semantic"],
+ choices=["lexical"],
help="NLP options to use for evaluation.",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_ingestion.py b/evaluation/scripts/longmemeval/lme_ingestion.py
index 6e9bd5ab4..e846a254c 100644
--- a/evaluation/scripts/longmemeval/lme_ingestion.py
+++ b/evaluation/scripts/longmemeval/lme_ingestion.py
@@ -1,11 +1,15 @@
import argparse
import os
import sys
+
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime, timezone
+
import pandas as pd
+
from tqdm import tqdm
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
@@ -14,7 +18,7 @@ def ingest_session(session, date, user_id, session_id, frame, client):
if "mem0" in frame:
for _idx, msg in enumerate(session):
messages.append({"role": msg["role"], "content": msg["content"][:8000]})
- client.add(messages, user_id, int(date.timestamp()))
+ client.add(messages, user_id, int(date.timestamp()), batch_size=2)
elif frame == "memobase":
for _idx, msg in enumerate(session):
messages.append(
@@ -24,8 +28,8 @@ def ingest_session(session, date, user_id, session_id, frame, client):
"created_at": date.isoformat(),
}
)
- client.add(messages, user_id)
- elif frame == "memos-api":
+ client.add(messages, user_id, batch_size=2)
+ elif "memos-api" in frame:
for msg in session:
messages.append(
{
@@ -35,7 +39,7 @@ def ingest_session(session, date, user_id, session_id, frame, client):
}
)
if messages:
- client.add(messages=messages, user_id=user_id, conv_id=session_id)
+ client.add(messages=messages, user_id=user_id, conv_id=session_id, batch_size=2)
elif frame == "memu":
for _idx, msg in enumerate(session):
messages.append({"role": msg["role"], "content": msg["content"][:8000]})
@@ -76,15 +80,15 @@ def ingest_conv(lme_df, version, conv_idx, frame, success_records, f):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- all_users = client.client.get_all_users(limit=5000)
- for user in all_users:
- if user["additional_fields"]["user_id"] == user_id:
- client.client.delete_user(user["id"])
- user_id = client.client.add_user({"user_id": user_id})
+ client.delete_user(user_id)
elif frame == "memu":
from utils.client import MemuClient
@@ -130,7 +134,7 @@ def main(frame, version, num_workers=2):
success_records = []
record_file = f"results/lme/{frame}-{version}/success_records.txt"
if os.path.exists(record_file):
- with open(record_file, "r") as f:
+ with open(record_file) as f:
for i in f.readlines():
success_records.append(i.strip())
@@ -167,7 +171,15 @@ def main(frame, version, num_workers=2):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_metric.py b/evaluation/scripts/longmemeval/lme_metric.py
index 93fa1de21..3664b47ba 100644
--- a/evaluation/scripts/longmemeval/lme_metric.py
+++ b/evaluation/scripts/longmemeval/lme_metric.py
@@ -258,7 +258,15 @@ def calculate_scores(data, grade_path, output_path):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_responses.py b/evaluation/scripts/longmemeval/lme_responses.py
index 3df3e2da4..7d82358d6 100644
--- a/evaluation/scripts/longmemeval/lme_responses.py
+++ b/evaluation/scripts/longmemeval/lme_responses.py
@@ -21,7 +21,6 @@ def lme_response(llm_client, context, question, question_date):
question_date=question_date,
context=context,
)
-
response = llm_client.chat.completions.create(
model=os.getenv("CHAT_MODEL"),
messages=[
@@ -133,7 +132,15 @@ def main(frame, version, num_workers=4):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_search.py b/evaluation/scripts/longmemeval/lme_search.py
index a24c0eaf5..8e0e3c5c2 100644
--- a/evaluation/scripts/longmemeval/lme_search.py
+++ b/evaluation/scripts/longmemeval/lme_search.py
@@ -3,6 +3,7 @@
import os
import sys
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
@@ -10,13 +11,12 @@
from time import time
import pandas as pd
+
from tqdm import tqdm
from utils.prompts import (
MEM0_CONTEXT_TEMPLATE,
MEM0_GRAPH_CONTEXT_TEMPLATE,
- MEMOBASE_CONTEXT_TEMPLATE,
MEMOS_CONTEXT_TEMPLATE,
- ZEP_CONTEXT_TEMPLATE,
)
@@ -44,7 +44,10 @@ def mem0_search(client, query, user_id, top_k):
def memos_search(client, query, user_id, top_k):
start = time()
results = client.search(query=query, user_id=user_id, top_k=top_k)
- context = "\n".join([i["memory"] for i in results["text_mem"][0]["memories"]])
+ context = (
+ "\n".join([i["memory"] for i in results["text_mem"][0]["memories"]])
+ + f"\n{results.get('pref_string', '')}"
+ )
context = MEMOS_CONTEXT_TEMPLATE.format(user_id=user_id, memories=context)
duration_ms = (time() - start) * 1000
return context, duration_ms
@@ -114,16 +117,17 @@ def process_user(lme_df, conv_idx, frame, version, top_k=20):
from utils.client import MemobaseClient
client = MemobaseClient()
- users = client.client.get_all_users(limit=5000)
- for u in users:
- if u["additional_fields"]["user_id"] == user_id:
- user_id = u["id"]
context, duration_ms = memobase_search(client, question, user_id, top_k)
elif frame == "memos-api":
from utils.client import MemosApiClient
client = MemosApiClient()
context, duration_ms = memos_search(client, question, user_id, top_k)
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+ context, duration_ms = memos_search(client, question, user_id, top_k)
elif frame == "memu":
from utils.client import MemuClient
@@ -219,7 +223,15 @@ def main(frame, version, top_k=20, num_workers=2):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/personamem/pm_ingestion.py b/evaluation/scripts/personamem/pm_ingestion.py
index 5cd9d38a6..b960aa157 100644
--- a/evaluation/scripts/personamem/pm_ingestion.py
+++ b/evaluation/scripts/personamem/pm_ingestion.py
@@ -1,48 +1,63 @@
import argparse
-import os
-import sys
import csv
import json
+import os
+import sys
+import time
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
from tqdm import tqdm
-from utils.client import mem0_client,zep_client,memos_api_client
-from zep_cloud.types import Message
+
+
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
def ingest_session(session, user_id, session_id, frame, client):
messages = []
if frame == "zep":
pass
+ elif "mem0" in frame:
for idx, msg in enumerate(session):
+ messages.append({"role": msg["role"], "content": msg["content"][:8000]})
print(
- f"[{frame}] 💬 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}...")
- client.memory.add(messages=[Message(role=msg["role"], role_type=msg["role"], content=msg["content"], )], )
- elif frame == "mem0-local" or frame == "mem0-api":
- for idx, msg in enumerate(session):
- messages.append({"role": msg["role"], "content": msg["content"]})
- print(
- f"[{frame}] 📝 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}...")
- if frame == "mem0-local":
- client.add(messages=messages, user_id=user_id)
- elif frame == "mem0-api":
- client.add(messages=messages,
- user_id=user_id,
- session_id=session_id,
- version="v2", )
+ f"[{frame}] 📝 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}..."
+ )
+ timestamp_add = int(time.time() * 100)
+ client.add(messages=messages, user_id=user_id, timestamp=timestamp_add, batch_size=10)
+ print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
+ elif frame == "memos-api":
+ client.add(messages=session, user_id=user_id, conv_id=session_id, batch_size=10)
+ print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(session)} messages")
+ elif frame == "memobase":
+ for _idx, msg in enumerate(session):
+ if msg["role"] != "system":
+ messages.append(
+ {
+ "role": msg["role"],
+ "content": msg["content"],
+ "created_at": datetime.now().isoformat(),
+ }
+ )
+ client.add(messages, user_id, batch_size=10)
print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
- elif frame == "memos-local" or frame == "memos-api":
- if os.getenv("PRE_SPLIT_CHUNK")=="true":
- for i in range(0, len(session), 10):
- messages = session[i: i + 10]
- client.add(messages=messages, user_id=user_id, conv_id=session_id)
- print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
- else:
- client.add(messages=session, user_id=user_id, conv_id=session_id)
- print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(session)} messages")
+ elif frame == "supermemory":
+ for _idx, msg in enumerate(session):
+ messages.append(
+ {
+ "role": msg["role"],
+ "content": msg["content"][:8000],
+ "chat_time": datetime.now().astimezone().isoformat(),
+ }
+ )
+ client.add(messages, user_id)
+ elif frame == "memu":
+ for _idx, msg in enumerate(session):
+ messages.append({"role": msg["role"], "content": msg["content"]})
+ client.add(messages, user_id, datetime.now().astimezone().isoformat())
+ elif frame == "memos-api-online":
+ client.add(messages, user_id, session_id, batch_size=10)
def build_jsonl_index(jsonl_path):
@@ -51,7 +66,7 @@ def build_jsonl_index(jsonl_path):
Assumes each line is a JSON object with a single key-value pair.
"""
index = {}
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
while True:
offset = f.tell()
line = f.readline()
@@ -63,14 +78,14 @@ def build_jsonl_index(jsonl_path):
def load_context_by_id(jsonl_path, offset):
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
f.seek(offset)
item = json.loads(f.readline())
return next(iter(item.values()))
def load_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for _, row in enumerate(reader, start=1):
row_data = {}
@@ -82,7 +97,7 @@ def load_rows(csv_path):
def load_rows_with_context(csv_path, jsonl_path):
jsonl_index = build_jsonl_index(jsonl_path)
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
prev_sid = None
prev_context = None
@@ -102,13 +117,17 @@ def load_rows_with_context(csv_path, jsonl_path):
def count_csv_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as f:
+ with open(csv_path, newline="", encoding="utf-8") as f:
return sum(1 for _ in f) - 1
-def ingest_conv(row_data, context, version, conv_idx, frame):
+def ingest_conv(row_data, context, version, conv_idx, frame, success_records, f):
+ if str(conv_idx) in success_records:
+ print(f"✅ Conversation {conv_idx} already ingested, skipping...")
+ return conv_idx
+
end_index_in_shared_context = row_data["end_index_in_shared_context"]
- context = context[:int(end_index_in_shared_context)]
+ context = context[: int(end_index_in_shared_context)]
user_id = f"pm_exper_user_{conv_idx}_{version}"
print(f"👤 User ID: {user_id}")
print("\n" + "=" * 80)
@@ -116,43 +135,65 @@ def ingest_conv(row_data, context, version, conv_idx, frame):
print("=" * 80)
if frame == "zep":
- client = zep_client()
+ from utils.client import ZepClient
+
+ client = ZepClient()
print("🔌 Using Zep client for ingestion...")
client.user.delete(user_id)
print(f"🗑️ Deleted existing user {user_id} from Zep memory...")
client.user.add(user_id=user_id)
print(f"➕ Added user {user_id} to Zep memory...")
- elif frame == "mem0-local":
- client = mem0_client(mode="local")
- print("🔌 Using Mem0 Local client for ingestion...")
- client.delete_all(user_id=user_id)
- print(f"🗑️ Deleted existing memories for user {user_id}...")
- elif frame == "mem0-api":
- client = mem0_client(mode="api")
- print("🔌 Using Mem0 API client for ingestion...")
- client.delete_all(user_id=user_id)
+ elif frame == "mem0" or frame == "mem0_graph":
+ from utils.client import Mem0Client
+
+ client = Mem0Client(enable_graph="graph" in frame)
+ print("🔌 Using Mem0 client for ingestion...")
+ client.client.delete_all(user_id=user_id)
print(f"🗑️ Deleted existing memories for user {user_id}...")
- elif frame == "memos-local":
- client = memos_client(
- mode="local",
- db_name=f"pm_{frame}-{version}",
- user_id=user_id,
- top_k=20,
- mem_cube_path=f"results/pm/{frame}-{version}/storages/{user_id}",
- mem_cube_config_path="configs/mu_mem_cube_config.json",
- mem_os_config_path="configs/mos_memos_config.json",
- addorsearch="add",
- )
- print("🔌 Using Memos Local client for ingestion...")
elif frame == "memos-api":
- client = memos_api_client()
+ from utils.client import MemosApiClient
- ingest_session(session=context, user_id=user_id, session_id=conv_idx, frame=frame, client=client)
- print(f"✅ Ingestion of conversation {conv_idx} completed")
- print("=" * 80)
+ client = MemosApiClient()
+ elif frame == "memobase":
+ from utils.client import MemobaseClient
+
+ client = MemobaseClient()
+ elif frame == "supermemory":
+ from utils.client import SupermemoryClient
+
+ client = SupermemoryClient()
+ elif frame == "memu":
+ from utils.client import MemuClient
+
+ client = MemuClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+
+ try:
+ ingest_session(
+ session=context, user_id=user_id, session_id=conv_idx, frame=frame, client=client
+ )
+ print(f"✅ Ingestion of conversation {conv_idx} completed")
+ print("=" * 80)
+
+ f.write(f"{conv_idx}\n")
+ f.flush()
+ return conv_idx
+ except Exception as e:
+ print(f"❌ Error ingesting conversation {conv_idx}: {e}")
+ raise
+
+
+def main(frame, version, num_workers=2, clear=False):
+ os.makedirs(f"results/pm/{frame}-{version}/", exist_ok=True)
+ record_file = f"results/pm/{frame}-{version}/success_records.txt"
+ if clear and os.path.exists(record_file):
+ os.remove(record_file)
+ print("🧹 Cleared progress records")
-def main(frame, version, num_workers=2):
print("\n" + "=" * 80)
print(f"🚀 PERSONAMEM INGESTION - {frame.upper()} v{version}".center(80))
print("=" * 80)
@@ -164,22 +205,53 @@ def main(frame, version, num_workers=2):
print(f"📚 Loaded PersonaMem dataset from {question_csv_path} and {context_jsonl_path}")
print("-" * 80)
- start_time = datetime.now()
+ success_records = set()
+ if os.path.exists(record_file):
+ with open(record_file) as f:
+ success_records = {line.strip() for line in f}
+ print(
+ f"📊 Found {len(success_records)} completed conversations, {total_rows - len(success_records)} remaining"
+ )
+ start_time = datetime.now()
all_data = list(load_rows_with_context(question_csv_path, context_jsonl_path))
- with ThreadPoolExecutor(max_workers=num_workers) as executor:
- future_to_idx = {
- executor.submit(ingest_conv, row_data=row_data, context=context, version=version, conv_idx=idx,
- frame=frame, ): idx
- for idx, (row_data, context) in enumerate(all_data)}
-
- for future in tqdm(as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"):
- idx = future_to_idx[future]
+ pending_data = [
+ (idx, row_data, context)
+ for idx, (row_data, context) in enumerate(all_data)
+ if str(idx) not in success_records
+ ]
+
+ if not pending_data:
+ print("✅ All conversations have been processed!")
+ return
+
+ print(f"🔄 Processing {len(pending_data)} conversations...")
+
+ with ThreadPoolExecutor(max_workers=num_workers) as executor, open(record_file, "a") as f:
+ futures = []
+ for idx, row_data, context in pending_data:
+ future = executor.submit(
+ ingest_conv,
+ row_data=row_data,
+ context=context,
+ version=version,
+ conv_idx=idx,
+ frame=frame,
+ success_records=success_records,
+ f=f,
+ )
+ futures.append(future)
+
+ completed_count = 0
+ for future in tqdm(
+ as_completed(futures), total=len(futures), desc="Processing conversations"
+ ):
try:
future.result()
+ completed_count += 1
except Exception as exc:
- print(f'\n❌ Conversation {idx} generated an exception: {exc}')
+ print(f"\n❌ Conversation generated an exception: {exc}")
end_time = datetime.now()
elapsed_time = end_time - start_time
@@ -190,15 +262,34 @@ def main(frame, version, num_workers=2):
print("=" * 80)
print(f"⏱️ Total time taken to ingest {total_rows} rows: {elapsed_time_str}")
print(f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}")
+ print(f"📈 Processed: {len(success_records) + completed_count}/{total_rows} conversations")
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Ingestion Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
- default='memos-api')
- parser.add_argument("--version", type=str, default="0925-1", help="Version of the evaluation framework.")
- parser.add_argument("--workers", type=int, default=3, help="Number of parallel workers for processing users.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ "zep",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=3, help="Number of parallel workers for processing users."
+ )
+ parser.add_argument("--clear", action="store_true", help="Clear progress and start fresh")
args = parser.parse_args()
- main(frame=args.lib, version=args.version, num_workers=args.workers)
+ main(frame=args.lib, version=args.version, num_workers=args.workers, clear=args.clear)
diff --git a/evaluation/scripts/personamem/pm_metric.py b/evaluation/scripts/personamem/pm_metric.py
index 0f6a1e138..4c93ec0c6 100644
--- a/evaluation/scripts/personamem/pm_metric.py
+++ b/evaluation/scripts/personamem/pm_metric.py
@@ -8,40 +8,48 @@
def save_to_excel(results, output_path):
"""Save results to Excel file"""
combined_data = []
-
+
# Add overall statistics row
- overall_row = {"category": "overall", "accuracy": results["metrics"]["accuracy"],
- "accuracy_std": results["metrics"]["accuracy_std"],
- "total_questions": results["metrics"]["total_questions"],
- "total_runs": results["metrics"]["total_runs"]}
+ overall_row = {
+ "category": "overall",
+ "accuracy": results["metrics"]["accuracy"],
+ "accuracy_std": results["metrics"]["accuracy_std"],
+ "total_questions": results["metrics"]["total_questions"],
+ "total_runs": results["metrics"]["total_runs"],
+ }
# Add response duration metrics
for metric, value in results["metrics"]["response_duration"].items():
overall_row[f"response_{metric}"] = value
-
+
# Add search duration metrics (if exists)
if "search_duration" in results["metrics"] and results["metrics"]["search_duration"]:
for metric, value in results["metrics"]["search_duration"].items():
overall_row[f"search_{metric}"] = value
-
+
combined_data.append(overall_row)
-
+
# Add category statistics rows
for category, scores in results["category_scores"].items():
- category_row = {"category": category, "accuracy": scores["accuracy"], "accuracy_std": scores["accuracy_std"],
- "total_questions": scores["total_questions"], "total_runs": scores["total_runs"]}
+ category_row = {
+ "category": category,
+ "accuracy": scores["accuracy"],
+ "accuracy_std": scores["accuracy_std"],
+ "total_questions": scores["total_questions"],
+ "total_runs": scores["total_runs"],
+ }
# Add response duration metrics
for metric, value in scores["response_duration"].items():
category_row[f"response_{metric}"] = value
-
+
# Add search duration metrics (if exists)
- if "search_duration" in scores and scores["search_duration"]:
+ if scores.get("search_duration"):
for metric, value in scores["search_duration"].items():
category_row[f"search_{metric}"] = value
-
+
combined_data.append(category_row)
-
+
# Save to Excel
df = pd.DataFrame(combined_data)
df.to_excel(output_path, sheet_name="PersonaMem_Metrics", index=False)
@@ -50,62 +58,62 @@ def save_to_excel(results, output_path):
def calculate_scores(data, grade_path, output_path):
"""Calculate PersonaMem evaluation metrics"""
-
+
# Initialize statistics variables
category_scores = {}
user_metrics = {}
-
+
# Overall metrics - collect accuracy for each run
all_response_durations = []
all_search_durations = []
total_questions = 0
-
+
# For calculating accuracy across multiple runs
num_runs = None # Will be determined from first user's data
run_accuracies = [] # List to store accuracy for each run across all users
-
+
# Category-wise statistics
category_response_durations = {}
category_search_durations = {}
category_run_accuracies = {} # Store accuracy for each run by category
-
+
print(f"📋 Processing response data for {len(data)} users...")
-
+
# First pass: determine number of runs and initialize run accuracy arrays
- for user_id, user_data in data.items():
+ for _user_id, user_data in data.items():
# Skip incomplete data (users with only topic field)
if len(user_data) <= 2 and "topic" in user_data:
continue
-
+
results = user_data.get("results", [])
if not results:
continue
-
+
if num_runs is None:
num_runs = len(results)
run_accuracies = [[] for _ in range(num_runs)] # Initialize for each run
print(f"📊 Detected {num_runs} runs per user")
break
-
+
if num_runs is None:
print("❌ Error: Could not determine number of runs from data")
return
-
+
# Iterate through all user data
for user_id, user_data in data.items():
# Skip incomplete data (users with only topic field)
if len(user_data) <= 2 and "topic" in user_data:
print(f"⚠️ Skipping incomplete data for user {user_id}")
continue
-
+
# Get category and results
category = user_data.get("category", "unknown")
results = user_data.get("results", [])
-
+
if not results:
print(f"⚠️ No results found for user {user_id}")
continue
-
+
# Initialize category if not exists
if category not in category_scores:
category_scores[category] = {
@@ -115,39 +123,39 @@ def calculate_scores(data, grade_path, output_path):
"accuracy": 0.0,
"accuracy_std": 0.0,
"response_duration": {},
- "search_duration": {}
+ "search_duration": {},
}
category_response_durations[category] = []
category_search_durations[category] = []
category_run_accuracies[category] = [[] for _ in range(num_runs)]
-
+
# Process each run for this user
user_response_durations = []
for run_idx, result in enumerate(results):
is_correct = result.get("is_correct", False)
-
+
# Collect accuracy for each run (1 if correct, 0 if not)
if run_idx < num_runs:
run_accuracies[run_idx].append(1.0 if is_correct else 0.0)
category_run_accuracies[category][run_idx].append(1.0 if is_correct else 0.0)
-
+
# Collect response duration
response_duration = result.get("response_duration_ms", 0)
if response_duration > 0:
user_response_durations.append(response_duration)
all_response_durations.append(response_duration)
category_response_durations[category].append(response_duration)
-
+
# Get search duration (usually same for all runs)
search_duration = user_data.get("search_duration_ms", 0)
if search_duration > 0:
all_search_durations.append(search_duration)
category_search_durations[category].append(search_duration)
-
+
# Calculate user-level accuracy (average across runs)
user_correct_count = sum(1 for result in results if result.get("is_correct", False))
user_accuracy = user_correct_count / len(results) if results else 0.0
-
+
# Store user-level metrics
user_metrics[user_id] = {
"user_id": user_id,
@@ -156,22 +164,26 @@ def calculate_scores(data, grade_path, output_path):
"accuracy": user_accuracy,
"total_runs": len(results),
"correct_runs": user_correct_count,
- "avg_response_duration_ms": np.mean(user_response_durations) if user_response_durations else 0.0,
+ "avg_response_duration_ms": np.mean(user_response_durations)
+ if user_response_durations
+ else 0.0,
"search_duration_ms": search_duration,
"golden_answer": user_data.get("golden_answer", ""),
- "topic": user_data.get("topic", "")
+ "topic": user_data.get("topic", ""),
}
-
+
# Count statistics
total_questions += 1
category_scores[category]["total_questions"] += 1
category_scores[category]["total_runs"] += len(results)
-
+
# Calculate overall accuracy and std across runs
overall_run_accuracies = [np.mean(run_acc) for run_acc in run_accuracies if run_acc]
overall_accuracy = np.mean(overall_run_accuracies) if overall_run_accuracies else 0.0
- overall_accuracy_std = np.std(overall_run_accuracies) if len(overall_run_accuracies) > 1 else 0.0
-
+ overall_accuracy_std = (
+ np.std(overall_run_accuracies) if len(overall_run_accuracies) > 1 else 0.0
+ )
+
# Calculate response duration statistics
response_duration_stats = {}
if all_response_durations:
@@ -182,9 +194,9 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(all_response_durations, 95),
"std": np.std(all_response_durations),
"min": np.min(all_response_durations),
- "max": np.max(all_response_durations)
+ "max": np.max(all_response_durations),
}
-
+
# Calculate search duration statistics
search_duration_stats = {}
if all_search_durations:
@@ -195,16 +207,22 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(all_search_durations, 95),
"std": np.std(all_search_durations),
"min": np.min(all_search_durations),
- "max": np.max(all_search_durations)
+ "max": np.max(all_search_durations),
}
-
+
# Calculate category-wise metrics
for category in category_scores:
# Calculate accuracy mean and std across runs for this category
- cat_run_accuracies = [np.mean(run_acc) for run_acc in category_run_accuracies[category] if run_acc]
- category_scores[category]["accuracy"] = np.mean(cat_run_accuracies) if cat_run_accuracies else 0.0
- category_scores[category]["accuracy_std"] = np.std(cat_run_accuracies) if len(cat_run_accuracies) > 1 else 0.0
-
+ cat_run_accuracies = [
+ np.mean(run_acc) for run_acc in category_run_accuracies[category] if run_acc
+ ]
+ category_scores[category]["accuracy"] = (
+ np.mean(cat_run_accuracies) if cat_run_accuracies else 0.0
+ )
+ category_scores[category]["accuracy_std"] = (
+ np.std(cat_run_accuracies) if len(cat_run_accuracies) > 1 else 0.0
+ )
+
# Response duration statistics for this category
if category_response_durations[category]:
durations = category_response_durations[category]
@@ -215,14 +233,19 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(durations, 95),
"std": np.std(durations),
"min": np.min(durations),
- "max": np.max(durations)
+ "max": np.max(durations),
}
else:
category_scores[category]["response_duration"] = {
- "mean": 0.0, "median": 0.0, "p50": 0.0, "p95": 0.0,
- "std": 0.0, "min": 0.0, "max": 0.0
+ "mean": 0.0,
+ "median": 0.0,
+ "p50": 0.0,
+ "p95": 0.0,
+ "std": 0.0,
+ "min": 0.0,
+ "max": 0.0,
}
-
+
# Search duration statistics for this category
if category_search_durations[category]:
durations = category_search_durations[category]
@@ -233,14 +256,19 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(durations, 95),
"std": np.std(durations),
"min": np.min(durations),
- "max": np.max(durations)
+ "max": np.max(durations),
}
else:
category_scores[category]["search_duration"] = {
- "mean": 0.0, "median": 0.0, "p50": 0.0, "p95": 0.0,
- "std": 0.0, "min": 0.0, "max": 0.0
+ "mean": 0.0,
+ "median": 0.0,
+ "p50": 0.0,
+ "p95": 0.0,
+ "std": 0.0,
+ "min": 0.0,
+ "max": 0.0,
}
-
+
# Build final results
results = {
"metrics": {
@@ -249,22 +277,22 @@ def calculate_scores(data, grade_path, output_path):
"total_questions": total_questions,
"total_runs": total_questions * num_runs if num_runs else 0,
"response_duration": response_duration_stats,
- "search_duration": search_duration_stats
+ "search_duration": search_duration_stats,
},
"category_scores": category_scores,
- "user_scores": user_metrics
+ "user_scores": user_metrics,
}
-
+
# Save results to JSON file
with open(grade_path, "w") as outfile:
json.dump(results, outfile, indent=4, ensure_ascii=False)
-
+
# Save to Excel
save_to_excel(results, output_path)
-
+
# Print summary
print_summary(results)
-
+
return results
@@ -273,19 +301,19 @@ def print_summary(results):
print("\n" + "=" * 80)
print("📊 PERSONAMEM EVALUATION SUMMARY".center(80))
print("=" * 80)
-
+
# Overall accuracy
accuracy = results["metrics"]["accuracy"]
accuracy_std = results["metrics"]["accuracy_std"]
total_questions = results["metrics"]["total_questions"]
total_runs = results["metrics"]["total_runs"]
-
+
print(f"🎯 Overall Accuracy: {accuracy:.4f} ± {accuracy_std:.4f}")
print(f"📋 Total Questions: {total_questions}")
print(f"🔄 Total Runs: {total_runs}")
-
+
print("-" * 80)
-
+
# Response duration statistics
if results["metrics"]["response_duration"]:
rd = results["metrics"]["response_duration"]
@@ -294,7 +322,7 @@ def print_summary(results):
print(f" P50: \033[96m{rd['p50']:.2f}")
print(f" P95: \033[91m{rd['p95']:.2f}")
print(f" Std Dev: {rd['std']:.2f}")
-
+
# Search duration statistics
if results["metrics"]["search_duration"]:
sd = results["metrics"]["search_duration"]
@@ -303,9 +331,9 @@ def print_summary(results):
print(f" P50: \033[96m{sd['p50']:.2f}")
print(f" P95: \033[91m{sd['p95']:.2f}")
print(f" Std Dev: {sd['std']:.2f}")
-
+
print("-" * 80)
-
+
# Category-wise accuracy
print("📂 Category-wise Accuracy:")
for category, scores in results["category_scores"].items():
@@ -313,50 +341,58 @@ def print_summary(results):
acc_std = scores["accuracy_std"]
total_cat = scores["total_questions"]
total_runs_cat = scores["total_runs"]
- print(f" {category:<35}: {acc:.4f} ± {acc_std:.4f} ({total_cat} questions, {total_runs_cat} runs)")
-
+ print(
+ f" {category:<35}: {acc:.4f} ± {acc_std:.4f} ({total_cat} questions, {total_runs_cat} runs)"
+ )
+
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem evaluation metrics calculation script")
parser.add_argument(
- "--lib",
- type=str,
- choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
+ "--lib",
+ type=str,
+ choices=[
+ "zep",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
required=True,
help="Memory library to evaluate",
- default='memos-api'
+ default="memos-api",
)
parser.add_argument(
- "--version",
- type=str,
- default="0925",
- help="Evaluation framework version"
+ "--version", type=str, default="default", help="Evaluation framework version"
)
-
+
args = parser.parse_args()
lib, version = args.lib, args.version
-
+
# Define file paths
responses_path = f"results/pm/{lib}-{version}/{lib}_pm_responses.json"
grade_path = f"results/pm/{lib}-{version}/{lib}_pm_grades.json"
output_path = f"results/pm/{lib}-{version}/{lib}_pm_results.xlsx"
-
+
print(f"📂 Loading response data from: {responses_path}")
-
+
try:
- with open(responses_path, 'r', encoding='utf-8') as file:
+ with open(responses_path, encoding="utf-8") as file:
data = json.load(file)
-
+
# Calculate metrics
results = calculate_scores(data, grade_path, output_path)
-
+
print(f"📁 Results saved to: {grade_path}")
print(f"📊 Excel report saved to: {output_path}")
-
+
except FileNotFoundError:
print(f"❌ Error: File not found {responses_path}")
print("Please make sure to run pm_responses.py first to generate response data")
except Exception as e:
- print(f"❌ Error occurred during processing: {e}")
\ No newline at end of file
+ print(f"❌ Error occurred during processing: {e}")
diff --git a/evaluation/scripts/personamem/pm_responses.py b/evaluation/scripts/personamem/pm_responses.py
index c48933c11..171b5af1a 100644
--- a/evaluation/scripts/personamem/pm_responses.py
+++ b/evaluation/scripts/personamem/pm_responses.py
@@ -10,20 +10,21 @@
from openai import OpenAI
from tqdm import tqdm
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from utils.prompts import PM_ANSWER_PROMPT
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import re
+from utils.prompts import PM_ANSWER_PROMPT
+
def extract_choice_answer(predicted_answer, correct_answer):
def _extract_only_options(text):
text = text.lower()
- in_parens = re.findall(r'\(([a-d])\)', text)
+ in_parens = re.findall(r"\(([a-d])\)", text)
if in_parens:
return set(in_parens)
else:
- return set(re.findall(r'\b([a-d])\b', text))
+ return set(re.findall(r"\b([a-d])\b", text))
correct = correct_answer.lower().strip("() ")
@@ -33,7 +34,7 @@ def _extract_only_options(text):
if "" in predicted_answer:
predicted_answer = predicted_answer.split("")[-1].strip()
if predicted_answer.endswith(""):
- predicted_answer = predicted_answer[:-len("")].strip()
+ predicted_answer = predicted_answer[: -len("")].strip()
pred_options = _extract_only_options(predicted_answer)
@@ -79,12 +80,14 @@ def process_qa(user_id, search_result, num_runs, llm_client):
is_correct, answer = extract_choice_answer(answer, search_result.get("golden_answer", ""))
response_duration_ms = (time() - start) * 1000
- run_results.append({
- "run_id": idx + 1,
- "answer": answer,
- "is_correct": is_correct,
- "response_duration_ms": response_duration_ms,
- })
+ run_results.append(
+ {
+ "run_id": idx + 1,
+ "answer": answer,
+ "is_correct": is_correct,
+ "response_duration_ms": response_duration_ms,
+ }
+ )
response_duration_ms = sum(result["response_duration_ms"] for result in run_results) / num_runs
@@ -95,8 +98,11 @@ def process_qa(user_id, search_result, num_runs, llm_client):
print(f"💡 Golden Answer: {search_result.get('golden_answer', 'N/A')}")
for idx, result in enumerate(run_results, start=1):
print(f"\n🔄 Run {idx}/{num_runs}:")
- print(f"💬 Run Answer: {result['answer'][:150]}..." if len(
- result['answer']) > 150 else f"💬 Run Answer: {result['answer']}")
+ print(
+ f"💬 Run Answer: {result['answer'][:150]}..."
+ if len(result["answer"]) > 150
+ else f"💬 Run Answer: {result['answer']}"
+ )
print(f"✅ Run Is Correct: {result['is_correct']}")
print(f"⏱️ Run Duration: {result['response_duration_ms']:.2f} ms")
print("-" * 80)
@@ -122,7 +128,9 @@ def main(frame, version, num_runs=3, num_workers=4):
load_dotenv()
- oai_client = OpenAI(api_key=os.getenv("CHAT_MODEL_API_KEY"), base_url=os.getenv("CHAT_MODEL_BASE_URL"))
+ oai_client = OpenAI(
+ api_key=os.getenv("CHAT_MODEL_API_KEY"), base_url=os.getenv("CHAT_MODEL_BASE_URL")
+ )
print(f"🔌 Using OpenAI client with model: {os.getenv('CHAT_MODEL')}")
search_path = f"results/pm/{frame}-{version}/{frame}_pm_search_results.json"
@@ -146,9 +154,9 @@ def main(frame, version, num_runs=3, num_workers=4):
future_to_user_id[future] = user_id
for future in tqdm(
- as_completed(future_to_user_id),
- total=len(future_to_user_id),
- desc="📝 Generating responses",
+ as_completed(future_to_user_id),
+ total=len(future_to_user_id),
+ desc="📝 Generating responses",
):
user_id = future_to_user_id[future]
try:
@@ -177,10 +185,30 @@ def main(frame, version, num_runs=3, num_workers=4):
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Response Generation Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"], default='memos-api')
- parser.add_argument("--version", type=str, default="0925", help="Version of the evaluation framework.")
- parser.add_argument("--num_runs", type=int, default=3, help="Number of runs for LLM-as-a-Judge evaluation.")
- parser.add_argument("--workers", type=int, default=3, help="Number of worker threads to use for processing.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "zep",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--num_runs", type=int, default=3, help="Number of runs for LLM-as-a-Judge evaluation."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=10, help="Number of worker threads to use for processing."
+ )
args = parser.parse_args()
main(frame=args.lib, version=args.version, num_runs=args.num_runs, num_workers=args.workers)
diff --git a/evaluation/scripts/personamem/pm_search.py b/evaluation/scripts/personamem/pm_search.py
index 50f46f692..80a65e09b 100644
--- a/evaluation/scripts/personamem/pm_search.py
+++ b/evaluation/scripts/personamem/pm_search.py
@@ -1,18 +1,19 @@
import argparse
+import csv
import json
import os
import sys
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
from time import time
-import csv
-
from tqdm import tqdm
-from utils.client import mem0_client,zep_client,memos_api_client
+
+
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+
from utils.prompts import (
MEM0_CONTEXT_TEMPLATE,
MEM0_GRAPH_CONTEXT_TEMPLATE,
@@ -50,93 +51,69 @@ def zep_search(client, user_id, query, top_k=20):
return context, duration_ms
-def mem0_search(client, user_id, query, top_k=20, enable_graph=False, frame="mem0-api"):
+def mem0_search(client, query, user_id, top_k):
start = time()
-
- if frame == "mem0-local":
- results = client.search(
- query=query,
- user_id=user_id,
- top_k=top_k,
- )
- search_memories = "\n".join(
+ results = client.search(query, user_id, top_k)
+ memory = [f"{memory['created_at']}: {memory['memory']}" for memory in results["results"]]
+ if client.enable_graph:
+ graph = "\n".join(
[
- f" - {item['memory']} (date: {item['metadata']['timestamp']})"
- for item in results["results"]
+ f" - 'source': {item.get('source', '?')} -> 'target': {item.get('target', '?')} "
+ f"(relationship: {item.get('relationship', '?')})"
+ for item in results.get("relations", [])
]
)
- search_graph = (
- "\n".join(
- [
- f" - 'source': {item.get('source', '?')} -> 'target': {item.get('destination', '?')} (relationship: {item.get('relationship', '?')})"
- for item in results.get("relations", [])
- ]
- )
- if enable_graph
- else ""
- )
-
- elif frame == "mem0-api":
- results = client.search(
- query=query,
- user_id=user_id,
- top_k=top_k,
- version="v2",
- output_format="v1.1",
- enable_graph=enable_graph,
- filters={"AND": [{"user_id": user_id}, {"run_id": "*"}]},
- )
- search_memories = "\n".join(
- [f" - {item['memory']} (date: {item['created_at']})" for item in results["results"]]
- )
- search_graph = (
- "\n".join(
- [
- f" - 'source': {item.get('source', '?')} -> 'target': {item.get('target', '?')} (relationship: {item.get('relationship', '?')})"
- for item in results.get("relations", [])
- ]
- )
- if enable_graph
- else ""
- )
- if enable_graph:
context = MEM0_GRAPH_CONTEXT_TEMPLATE.format(
- user_id=user_id, memories=search_memories, relations=search_graph
+ user_id=user_id, memories=memory, relations=graph
)
else:
- context = MEM0_CONTEXT_TEMPLATE.format(user_id=user_id, memories=search_memories)
+ context = MEM0_CONTEXT_TEMPLATE.format(user_id=user_id, memories=memory)
duration_ms = (time() - start) * 1000
return context, duration_ms
-def memos_search(client, user_id, query, top_k, frame="memos-local"):
+def memobase_search(client, query, user_id, top_k):
start = time()
- if frame == "memos-local":
- results = client.search(
- query=query,
- user_id=user_id,
- )
+ context = client.search(query=query, user_id=user_id, top_k=top_k)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
- results = filter_memory_data(results)["text_mem"][0]["memories"]
- search_memories = "\n".join([f" - {item['memory']}" for item in results])
- elif frame == "memos-api":
- results = client.search(query=query, user_id=user_id, top_k=top_k)
- search_memories = "\n".join(f"- {entry.get('memory_value', '')}"
- for entry in results.get("memory_detail_list", []))
+def memos_search(client, user_id, query, top_k):
+ start = time()
+ results = client.search(query=query, user_id=user_id, top_k=top_k)
+ search_memories = (
+ "\n".join(item["memory"] for cube in results["text_mem"] for item in cube["memories"])
+ + f"\n{results.get('pref_string', '')}"
+ )
context = MEMOS_CONTEXT_TEMPLATE.format(user_id=user_id, memories=search_memories)
duration_ms = (time() - start) * 1000
return context, duration_ms
+def supermemory_search(client, query, user_id, top_k):
+ start = time()
+ context = client.search(query, user_id, top_k)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
+
+
+def memu_search(client, query, user_id, top_k):
+ start = time()
+ results = client.search(query, user_id, top_k)
+ context = "\n".join(results)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
+
+
def build_jsonl_index(jsonl_path):
"""
Scan the JSONL file once to build a mapping: {key: file_offset}.
Assumes each line is a JSON object with a single key-value pair.
"""
index = {}
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
while True:
offset = f.tell()
line = f.readline()
@@ -148,14 +125,14 @@ def build_jsonl_index(jsonl_path):
def load_context_by_id(jsonl_path, offset):
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
f.seek(offset)
item = json.loads(f.readline())
return next(iter(item.values()))
def load_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for _, row in enumerate(reader, start=1):
row_data = {}
@@ -167,7 +144,7 @@ def load_rows(csv_path):
def load_rows_with_context(csv_path, jsonl_path):
jsonl_index = build_jsonl_index(jsonl_path)
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
prev_sid = None
prev_context = None
@@ -190,7 +167,7 @@ def load_rows_with_context(csv_path, jsonl_path):
def count_csv_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as f:
+ with open(csv_path, newline="", encoding="utf-8") as f:
return sum(1 for _ in f) - 1
@@ -219,35 +196,48 @@ def process_user(row_data, conv_idx, frame, version, top_k=20):
return existing_results
if frame == "zep":
- client = zep_client()
+ from utils.client import ZepClient
+
+ client = ZepClient()
print("🔌 Using Zep client for search...")
context, duration_ms = zep_search(client, user_id, question)
- elif frame == "mem0-local":
- client = mem0_client(mode="local")
- print("🔌 Using Mem0 Local client for search...")
- context, duration_ms = mem0_search(client, user_id, question, top_k=top_k, frame=frame)
- elif frame == "mem0-api":
- client = mem0_client(mode="api")
+ elif frame == "mem0" or frame == "mem0-graph":
+ from utils.client import Mem0Client
+
+ client = Mem0Client(enable_graph="graph" in frame)
print("🔌 Using Mem0 API client for search...")
- context, duration_ms = mem0_search(client, user_id, question, top_k=top_k, frame=frame)
- elif frame == "memos-local":
- client = memos_client(
- mode="local",
- db_name=f"pm_{frame}-{version}",
- user_id=user_id,
- top_k=top_k,
- mem_cube_path=f"results/pm/{frame}-{version}/storages/{user_id}",
- mem_cube_config_path="configs/mu_mem_cube_config.json",
- mem_os_config_path="configs/mos_memos_config.json",
- addorsearch="search",
- )
- print("🔌 Using Memos Local client for search...")
- context, duration_ms = memos_search(client, user_id, question, frame=frame)
+ context, duration_ms = mem0_search(client, question, user_id, top_k)
elif frame == "memos-api":
- client = memos_api_client()
+ from utils.client import MemosApiClient
+
+ client = MemosApiClient()
print("🔌 Using Memos API client for search...")
- context, duration_ms = memos_search(client, user_id, question, top_k=top_k, frame=frame)
+ context, duration_ms = memos_search(client, user_id, question, top_k=top_k)
+ elif frame == "supermemory":
+ from utils.client import SupermemoryClient
+
+ client = SupermemoryClient()
+ print("🔌 Using supermemory client for search...")
+ context, duration_ms = supermemory_search(client, question, user_id, top_k)
+ elif frame == "memu":
+ from utils.client import MemuClient
+
+ client = MemuClient()
+ print("🔌 Using memu client for search...")
+ context, duration_ms = memu_search(client, question, user_id, top_k)
+ elif frame == "memobase":
+ from utils.client import MemobaseClient
+
+ client = MemobaseClient()
+ print("🔌 Using Memobase client for search...")
+ context, duration_ms = memobase_search(client, question, user_id, top_k)
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+ print("🔌 Using memos-api-online client for search...")
+ context, duration_ms = memos_search(client, question, user_id, top_k)
search_results[user_id].append(
{
@@ -266,25 +256,23 @@ def process_user(row_data, conv_idx, frame, version, top_k=20):
os.makedirs(f"results/pm/{frame}-{version}/tmp", exist_ok=True)
with open(
- f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{conv_idx}.json", "w"
+ f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{conv_idx}.json", "w"
) as f:
json.dump(search_results, f, indent=4)
- print(f"💾 \033[92mSearch results for conversation {conv_idx} saved...")
+ print(f"💾 Search results for conversation {conv_idx} saved...")
print("-" * 80)
return search_results
def load_existing_results(frame, version, group_idx):
- result_path = (
- f"results/locomo/{frame}-{version}/tmp/{frame}_locomo_search_results_{group_idx}.json"
- )
+ result_path = f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{group_idx}.json"
if os.path.exists(result_path):
try:
with open(result_path) as f:
return json.load(f), True
except Exception as e:
- print(f"\033[91m❌ Error loading existing results for group {group_idx}: {e}")
+ print(f"❌ Error loading existing results for group {group_idx}: {e}")
return {}, False
@@ -299,9 +287,7 @@ def main(frame, version, top_k=20, num_workers=2):
print(f"📚 Loaded PersonaMem dataset from {question_csv_path} and {context_jsonl_path}")
print(f"📊 Total conversations: {total_rows}")
- print(
- f"⚙️ Search parameters: top_k={top_k}, workers={num_workers}"
- )
+ print(f"⚙️ Search parameters: top_k={top_k}, workers={num_workers}")
print("-" * 80)
all_search_results = defaultdict(list)
@@ -320,7 +306,9 @@ def main(frame, version, top_k=20, num_workers=2):
for idx, (row_data, _) in enumerate(all_data)
}
- for future in tqdm(as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"):
+ for future in tqdm(
+ as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"
+ ):
idx = future_to_idx[future]
try:
search_results = future.result()
@@ -328,37 +316,49 @@ def main(frame, version, top_k=20, num_workers=2):
all_search_results[user_id].extend(results)
print(f"✅ Conversation {idx} processed successfully.")
except Exception as exc:
- print(f'\n❌ Conversation {idx} generated an exception: {exc}')
+ print(f"\n❌ Conversation {idx} generated an exception: {exc}")
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_time_str = str(elapsed_time).split(".")[0]
print("\n" + "=" * 80)
- print("✅ \033[1;32mSEARCH COMPLETE".center(80))
+ print("✅ SEARCH COMPLETE".center(80))
print("=" * 80)
- print(
- f"⏱️ Total time taken to search {total_rows} users: \033[92m{elapsed_time_str}"
- )
- print(
- f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}"
- )
+ print(f"⏱️ Total time taken to search {total_rows} users: {elapsed_time_str}")
+ print(f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}")
with open(f"results/pm/{frame}-{version}/{frame}_pm_search_results.json", "w") as f:
json.dump(dict(all_search_results), f, indent=4)
- print(
- f"📁 Results saved to: \033[1;94mresults/pm/{frame}-{version}/{frame}_pm_search_results.json"
- )
+ print(f"📁 Results saved to: mresults/pm/{frame}-{version}/{frame}_pm_search_results.json")
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Search Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
- default='memos-api')
- parser.add_argument("--version", type=str, default="0925", help="Version of the evaluation framework.")
- parser.add_argument("--top_k", type=int, default=20, help="Number of top results to retrieve from the search.")
- parser.add_argument("--workers", type=int, default=3, help="Number of parallel workers for processing users.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--top_k", type=int, default=20, help="Number of top results to retrieve from the search."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=3, help="Number of parallel workers for processing users."
+ )
args = parser.parse_args()
diff --git a/evaluation/scripts/run_lme_eval.sh b/evaluation/scripts/run_lme_eval.sh
index 08e431312..8fa8d6c7e 100755
--- a/evaluation/scripts/run_lme_eval.sh
+++ b/evaluation/scripts/run_lme_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="1020"
+VERSION="default"
WORKERS=10
TOPK=20
diff --git a/evaluation/scripts/run_locomo_eval.sh b/evaluation/scripts/run_locomo_eval.sh
index d9c13a1ac..37569956f 100755
--- a/evaluation/scripts/run_locomo_eval.sh
+++ b/evaluation/scripts/run_locomo_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="072001"
+VERSION="default"
WORKERS=10
TOPK=20
diff --git a/evaluation/scripts/run_openai_eval.sh b/evaluation/scripts/run_openai_eval.sh
index 27bb712af..e07f113e5 100755
--- a/evaluation/scripts/run_openai_eval.sh
+++ b/evaluation/scripts/run_openai_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="openai"
-VERSION="063001"
+VERSION="default"
WORKERS=10
NUM_RUNS=3
diff --git a/evaluation/scripts/run_pm_eval.sh b/evaluation/scripts/run_pm_eval.sh
index 89484616b..39d9e72ca 100755
--- a/evaluation/scripts/run_pm_eval.sh
+++ b/evaluation/scripts/run_pm_eval.sh
@@ -2,40 +2,54 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="072201"
+VERSION="default"
WORKERS=10
TOPK=20
-# echo "downloading data..."
-# export HF_ENDPOINT=https://hf-mirror.com
-# huggingface-cli download --repo-type dataset bowen-upenn/PersonaMem --local-dir /mnt/afs/codes/ljl/MemOS/evaluation/data/personamem
+if ["$LIB" = "zep"]; then
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion_zep.py --version $VERSION --workers $WORKERS
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search_zep.py --version $VERSION --top_k $TOPK --workers $WORKERS
+ echo "Running pm_responses.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_responses.py"
+ exit 1
+ fi
-echo "Running pm_ingestion.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion.py --lib $LIB --version $VERSION --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_ingestion.py"
- exit 1
-fi
+ echo "Running pm_metric.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_metric.py"
+ exit 1
+ fi
+else
+ echo "Running pm_ingestion.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_ingestion.py"
+ exit 1
+ fi
-echo "Running pm_search.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search.py --lib $LIB --version $VERSION --top_k $TOPK --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_search.py"
- exit 1
-fi
+ echo "Running pm_search.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search.py --lib $LIB --version $VERSION --top_k $TOPK --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_search.py"
+ exit 1
+ fi
-echo "Running pm_responses.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_responses.py"
- exit 1
-fi
+ echo "Running pm_responses.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_responses.py"
+ exit 1
+ fi
-echo "Running pm_metric.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
-if [ $? -ne 0 ]; then
- echo "Error running pm_metric.py"
- exit 1
+ echo "Running pm_metric.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_metric.py"
+ exit 1
+ fi
fi
echo "All scripts completed successfully!"
diff --git a/evaluation/scripts/run_prefeval_eval.sh b/evaluation/scripts/run_prefeval_eval.sh
old mode 100644
new mode 100755
index 8e718192a..6f5f3b7b0
--- a/evaluation/scripts/run_prefeval_eval.sh
+++ b/evaluation/scripts/run_prefeval_eval.sh
@@ -6,24 +6,46 @@
# Number of workers for parallel processing.
# This variable controls both pref_memos.py (--max-workers)
# and pref_eval.py (--concurrency-limit).
-WORKERS=10
+WORKERS=20
# Parameters for pref_memos.py
TOP_K=10
-ADD_TURN=0 # Options: 0, 10, or 300
-LIB="memos-api"
-VERSION="1021-5"
+ADD_TURN=10 # Options: 0, 10, or 300
+LIB="memos-api" # Options: memos-api, memos-api-online, mem0, mem0-graph, memobase, supermemory, memu, zep
+VERSION="default"
# --- File Paths ---
# You may need to adjust these paths based on your project structure.
-# Assumes Step 1 (preprocess) outputs this file:
-PREPROCESSED_FILE="data/prefeval/pref_processed.jsonl"
+# Step 1 (preprocess) outputs this file:
+PREPROCESSED_FILE="data/prefeval/pref_processed.jsonl"
+
+# Create a directory name based on the *specific* LIB (e.g., "memos")
+OUTPUT_DIR="results/prefeval/${LIB}_${VERSION}"
+
+
+if [[ "$LIB" == *"mem0"* ]]; then
+ SCRIPT_NAME_BASE="mem0"
+elif [[ "$LIB" == *"memos"* ]]; then
+ SCRIPT_NAME_BASE="memos"
+elif [[ "$LIB" == *"memobase"* ]]; then
+ SCRIPT_NAME_BASE="memobase"
+elif [[ "$LIB" == *"supermemory"* ]]; then
+ SCRIPT_NAME_BASE="supermemory"
+elif [[ "$LIB" == *"memu"* ]]; then
+ SCRIPT_NAME_BASE="memu"
+elif [[ "$LIB" == *"zep"* ]]; then
+ SCRIPT_NAME_BASE="zep"
+else
+ SCRIPT_NAME_BASE=$LIB
+fi
-# Intermediate file (output of 'add' mode, input for 'process' mode)
-IDS_FILE="results/prefeval/pref_memos_add.jsonl"
+# The script to be executed (e.g., pref_mem0.py)
+LIB_SCRIPT="scripts/PrefEval/pref_${SCRIPT_NAME_BASE}.py"
-# Final response file (output of 'process' mode, input for Step 3)
-RESPONSE_FILE="results/prefeval/pref_memos_process.jsonl"
+# Output files will be unique to the $LIB (e.g., pref_memos-api_add.jsonl)
+IDS_FILE="${OUTPUT_DIR}/pref_${LIB}_add.jsonl"
+SEARCH_FILE="${OUTPUT_DIR}/pref_${LIB}_search.jsonl"
+RESPONSE_FILE="${OUTPUT_DIR}/pref_${LIB}_response.jsonl"
# Set the Hugging Face mirror endpoint
@@ -31,6 +53,8 @@ export HF_ENDPOINT="https://hf-mirror.com"
echo "--- Starting PrefEval Pipeline ---"
echo "Configuration: WORKERS=$WORKERS, TOP_K=$TOP_K, ADD_TURN=$ADD_TURN, LIB=$LIB, VERSION=$VERSION, HF_ENDPOINT=$HF_ENDPOINT"
+echo "Results will be saved to: $OUTPUT_DIR"
+echo "Using script: $LIB_SCRIPT (mapped from LIB=$LIB)"
echo ""
# --- Step 1: Preprocess the data ---
@@ -42,11 +66,29 @@ if [ $? -ne 0 ]; then
exit 1
fi
-# --- Step 2: Generate responses using MemOS (split into 'add' and 'process') ---
+# --- Create output directory ---
+echo ""
+echo "Creating output directory: $OUTPUT_DIR"
+mkdir -p $OUTPUT_DIR
+if [ $? -ne 0 ]; then
+ echo "Error: Could not create output directory '$OUTPUT_DIR'."
+ exit 1
+fi
+
+# Check if the *mapped* script exists
+if [ ! -f "$LIB_SCRIPT" ]; then
+ echo "Error: Script not found for library '$LIB' (mapped to $LIB_SCRIPT)"
+ exit 1
+fi
+
+# --- Step 2: Generate responses based on LIB ---
echo ""
-echo "Running pref_memos.py in 'add' mode..."
+echo "--- Step 2: Generate responses using $LIB (3-Step Process) ---"
+
+echo ""
+echo "Running $LIB_SCRIPT in 'add' mode..."
# Step 2a: Ingest conversations into memory and generate user_ids
-python scripts/PrefEval/pref_memos.py add \
+python $LIB_SCRIPT add \
--input $PREPROCESSED_FILE \
--output $IDS_FILE \
--add-turn $ADD_TURN \
@@ -55,35 +97,50 @@ python scripts/PrefEval/pref_memos.py add \
--version $VERSION
if [ $? -ne 0 ]; then
- echo "Error: pref_memos.py 'add' mode failed."
+ echo "Error: $LIB_SCRIPT 'add' mode failed."
exit 1
fi
echo ""
-echo "Running pref_memos.py in 'process' mode..."
-# Step 2b: Search memories using user_ids and generate responses
-python scripts/PrefEval/pref_memos.py process \
+echo "Running $LIB_SCRIPT in 'search' mode..."
+# Step 2b: Search memories using user_ids
+python $LIB_SCRIPT search \
--input $IDS_FILE \
- --output $RESPONSE_FILE \
+ --output $SEARCH_FILE \
--top-k $TOP_K \
- --max-workers $WORKERS \
- --lib $LIB \
- --version $VERSION
+ --max-workers $WORKERS
if [ $? -ne 0 ]; then
- echo "Error: pref_memos.py 'process' mode failed."
+ echo "Error: $LIB_SCRIPT 'search' mode failed."
+ exit 1
+fi
+
+echo ""
+echo "Running $LIB_SCRIPT in 'response' mode..."
+# Step 2c: Generate responses based on searched memories
+python $LIB_SCRIPT response \
+ --input $SEARCH_FILE \
+ --output $RESPONSE_FILE \
+ --max-workers $WORKERS
+
+if [ $? -ne 0 ]; then
+ echo "Error: $LIB_SCRIPT 'response' mode failed."
exit 1
fi
# --- Step 3: Evaluate the generated responses ---
echo ""
echo "Running pref_eval.py..."
-# Pass the WORKERS variable to the script's --concurrency-limit argument
-python scripts/PrefEval/pref_eval.py --concurrency-limit $WORKERS
+python scripts/PrefEval/pref_eval.py \
+ --input $RESPONSE_FILE \
+ --concurrency-limit $WORKERS \
+ --lib $LIB
+
if [ $? -ne 0 ]; then
echo "Error: Evaluation script failed."
exit 1
fi
echo ""
-echo "--- PrefEval Pipeline completed successfully! ---"
\ No newline at end of file
+echo "--- PrefEval Pipeline completed successfully! ---"
+echo "Final results are in $RESPONSE_FILE"
diff --git a/evaluation/scripts/utils/client.py b/evaluation/scripts/utils/client.py
index 87b863e86..157c3f8ea 100644
--- a/evaluation/scripts/utils/client.py
+++ b/evaluation/scripts/utils/client.py
@@ -2,10 +2,16 @@
import os
import sys
import time
+import uuid
+
+from contextlib import suppress
from datetime import datetime
-from dotenv import load_dotenv
+
import requests
+from dotenv import load_dotenv
+
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
load_dotenv()
@@ -17,7 +23,7 @@ def __init__(self):
api_key = os.getenv("ZEP_API_KEY")
self.client = Zep(api_key=api_key)
- def add(self, messages, user_id, conv_id, timestamp):
+ def add(self, messages, user_id, timestamp):
iso_date = datetime.fromtimestamp(timestamp).isoformat()
for msg in messages:
self.client.graph.add(
@@ -49,39 +55,40 @@ def __init__(self, enable_graph=False):
self.client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
self.enable_graph = enable_graph
- def add(self, messages, user_id, timestamp):
- if self.enable_graph:
- self.client.add(
- messages=messages,
- timestamp=timestamp,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- enable_graph=True,
- )
- else:
- self.client.add(messages=messages, timestamp=timestamp, user_id=user_id, version="v2")
+ def add(self, messages, user_id, timestamp, batch_size=2):
+ max_retries = 5
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ for attempt in range(max_retries):
+ try:
+ if self.enable_graph:
+ self.client.add(
+ messages=batch_messages,
+ timestamp=timestamp,
+ user_id=user_id,
+ enable_graph=True,
+ )
+ else:
+ self.client.add(
+ messages=batch_messages,
+ timestamp=timestamp,
+ user_id=user_id,
+ )
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
def search(self, query, user_id, top_k):
- if self.enable_graph:
- res = self.client.search(
- query=query,
- top_k=top_k,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- enable_graph=True,
- filters={"AND": [{"user_id": f"{user_id}"}, {"run_id": "*"}]},
- )
- else:
- res = self.client.search(
- query=query,
- top_k=top_k,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- filters={"AND": [{"user_id": f"{user_id}"}, {"run_id": "*"}]},
- )
+ res = self.client.search(
+ query=query,
+ top_k=top_k,
+ user_id=user_id,
+ enable_graph=self.enable_graph,
+ filters={"AND": [{"user_id": f"{user_id}"}]},
+ )
return res
@@ -93,18 +100,29 @@ def __init__(self):
project_url=os.getenv("MEMOBASE_PROJECT_URL"), api_key=os.getenv("MEMOBASE_API_KEY")
)
- def add(self, messages, user_id):
- from memobase import ChatBlob
-
+ def add(self, messages, user_id, batch_size=2):
"""
- user_id: memobase user_id
messages = [{"role": "assistant", "content": data, "created_at": iso_date}]
"""
- user = self.client.get_user(user_id, no_get=True)
- user.insert(ChatBlob(messages=messages), sync=True)
+ from memobase import ChatBlob
+
+ real_uid = self.string_to_uuid(user_id)
+ user = self.client.get_or_create_user(real_uid)
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ _ = user.insert(ChatBlob(messages=batch_messages), sync=True)
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
def search(self, query, user_id, top_k):
- user = self.client.get_user(user_id, no_get=True)
+ real_uid = self.string_to_uuid(user_id)
+ user = self.client.get_user(real_uid, no_get=True)
memories = user.context(
max_token_size=top_k * 100,
chats=[{"role": "user", "content": query}],
@@ -113,26 +131,45 @@ def search(self, query, user_id, top_k):
)
return memories
+ def delete_user(self, user_id):
+ from memobase.error import ServerError
+
+ real_uid = self.string_to_uuid(user_id)
+ with suppress(ServerError):
+ self.client.delete_user(real_uid)
+
+ def string_to_uuid(self, s: str, salt="memobase_client"):
+ return str(uuid.uuid5(uuid.NAMESPACE_DNS, s + salt))
+
class MemosApiClient:
def __init__(self):
self.memos_url = os.getenv("MEMOS_URL")
self.headers = {"Content-Type": "application/json", "Authorization": os.getenv("MEMOS_KEY")}
- def add(self, messages, user_id, conv_id):
+ def add(self, messages, user_id, conv_id, batch_size: int = 9999):
+ """
+ messages = [{"role": "assistant", "content": data, "chat_time": date_str}]
+ """
url = f"{self.memos_url}/product/add"
- payload = json.dumps(
- {
- "messages": messages,
- "user_id": user_id,
- "mem_cube_id": user_id,
- "conversation_id": conv_id,
- }
- )
- response = requests.request("POST", url, data=payload, headers=self.headers)
- assert response.status_code == 200, response.text
- assert json.loads(response.text)["message"] == "Memory added successfully", response.text
- return response.text
+ added_memories = []
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ payload = json.dumps(
+ {
+ "messages": batch_messages,
+ "user_id": user_id,
+ "mem_cube_id": user_id,
+ "conversation_id": conv_id,
+ }
+ )
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "Memory added successfully", (
+ response.text
+ )
+ added_memories += json.loads(response.text)["data"]
+ return added_memories
def search(self, query, user_id, top_k):
"""Search memories."""
@@ -144,6 +181,9 @@ def search(self, query, user_id, top_k):
"mem_cube_id": user_id,
"conversation_id": "",
"top_k": top_k,
+ "mode": os.getenv("SEARCH_MODE", "fast"),
+ "include_preference": True,
+ "pref_top_k": 6,
},
ensure_ascii=False,
)
@@ -155,6 +195,85 @@ def search(self, query, user_id, top_k):
return json.loads(response.text)["data"]
+class MemosApiOnlineClient:
+ def __init__(self):
+ self.memos_url = os.getenv("MEMOS_ONLINE_URL")
+ self.headers = {"Content-Type": "application/json", "Authorization": os.getenv("MEMOS_KEY")}
+
+ def add(self, messages, user_id, conv_id=None, batch_size: int = 9999):
+ url = f"{self.memos_url}/add/message"
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ payload = json.dumps(
+ {
+ "messages": batch_messages,
+ "user_id": user_id,
+ "conversation_id": conv_id,
+ }
+ )
+
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "ok", response.text
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ def search(self, query, user_id, top_k):
+ """Search memories."""
+ url = f"{self.memos_url}/search/memory"
+ payload = json.dumps(
+ {
+ "query": query,
+ "user_id": user_id,
+ "memory_limit_number": top_k,
+ "mode": os.getenv("SEARCH_MODE", "fast"),
+ "include_preference": True,
+ "pref_top_k": 6,
+ }
+ )
+
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "ok", response.text
+ text_mem_res = json.loads(response.text)["data"]["memory_detail_list"]
+ pref_mem_res = json.loads(response.text)["data"]["preference_detail_list"]
+ preference_note = json.loads(response.text)["data"]["preference_note"]
+ for i in text_mem_res:
+ i.update({"memory": i.pop("memory_value")})
+ explicit_pref_string = "Explicit Preference:"
+ implicit_pref_string = "\n\nImplicit Preference:"
+ explicit_idx = 0
+ implicit_idx = 0
+ for pref in pref_mem_res:
+ if pref["preference_type"] == "explicit_preference":
+ explicit_pref_string += f"\n{explicit_idx + 1}. {pref['preference']}"
+ explicit_idx += 1
+ if pref["preference_type"] == "implicit_preference":
+ implicit_pref_string += f"\n{implicit_idx + 1}. {pref['preference']}"
+ implicit_idx += 1
+
+ return {
+ "text_mem": [{"memories": text_mem_res}],
+ "pref_string": explicit_pref_string + implicit_pref_string + preference_note,
+ }
+
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+
class SupermemoryClient:
def __init__(self):
from supermemory import Supermemory
@@ -172,7 +291,7 @@ def add(self, messages, user_id):
break
except Exception as e:
if attempt < max_retries - 1:
- time.sleep(2**attempt) # 指数退避
+ time.sleep(2**attempt)
else:
raise e
@@ -192,7 +311,7 @@ def search(self, query, user_id, top_k):
return context
except Exception as e:
if attempt < max_retries - 1:
- time.sleep(2**attempt) # 指数退避
+ time.sleep(2**attempt)
else:
raise e
@@ -216,7 +335,7 @@ def add(self, messages, user_id, iso_date):
agent_name=self.agent_id,
session_date=iso_date,
)
- self.wait_for_completion(response.task_id)
+ self.wait_for_completion(response.item_id)
except Exception as error:
print("❌ Error saving conversation:", error)
@@ -245,3 +364,11 @@ def wait_for_completion(self, task_id):
timestamp = 1682899200
query = "杭州西湖有什么"
top_k = 5
+
+ # MEMOS-API
+ client = MemosApiClient()
+ for m in messages:
+ m["created_at"] = iso_date
+ client.add(messages, user_id, user_id)
+ memories = client.search(query, user_id, top_k)
+ print(memories)
diff --git a/evaluation/scripts/utils/mirix_utils.py b/evaluation/scripts/utils/mirix_utils.py
new file mode 100644
index 000000000..63cd490df
--- /dev/null
+++ b/evaluation/scripts/utils/mirix_utils.py
@@ -0,0 +1,84 @@
+import os
+
+import yaml
+
+from tqdm import tqdm
+
+
+def get_mirix_client(config_path, load_from=None):
+ if os.path.exists(os.path.expanduser("~/.mirix")):
+ os.system("rm -rf ~/.mirix/*")
+
+ with open(config_path) as f:
+ agent_config = yaml.safe_load(f)
+
+ os.environ["OPENAI_API_KEY"] = agent_config["api_key"]
+ import mirix
+
+ from mirix import EmbeddingConfig, LLMConfig, Mirix
+
+ embedding_default_config = EmbeddingConfig(
+ embedding_model=agent_config["embedding_model_name"],
+ embedding_endpoint_type="openai",
+ embedding_endpoint=agent_config["model_endpoint"],
+ embedding_dim=1536,
+ embedding_chunk_size=8191,
+ )
+
+ llm_default_config = LLMConfig(
+ model=agent_config["model_name"],
+ model_endpoint_type="openai",
+ model_endpoint=agent_config["model_endpoint"],
+ api_key=agent_config["api_key"],
+ model_wrapper=None,
+ context_window=128000,
+ )
+
+ def embedding_default_config_func(cls, model_name=None, provider=None):
+ return embedding_default_config
+
+ def llm_default_config_func(cls, model_name=None, provider=None):
+ return llm_default_config
+
+ mirix.EmbeddingConfig.default_config = embedding_default_config_func
+ mirix.LLMConfig.default_config = llm_default_config_func
+
+ assistant = Mirix(
+ api_key=agent_config["api_key"],
+ config_path=config_path,
+ model=agent_config["model_name"],
+ load_from=load_from,
+ )
+ return assistant
+
+
+if __name__ == "__main__":
+ config_path = "configs-example/mirix_config.yaml"
+ out_dir = "results/mirix-test"
+
+ assistant = get_mirix_client(config_path)
+
+ chunks = [
+ "I prefer coffee over tea",
+ "My work hours are 9 AM to 5 PM",
+ "Important meeting with client on Friday at 2 PM",
+ ]
+
+ for _idx, chunk in tqdm(enumerate(chunks), total=len(chunks)):
+ response = assistant.add(chunk)
+
+ assistant.save(out_dir)
+
+ assistant = get_mirix_client(config_path, load_from=out_dir)
+ response = assistant.chat("What's my schedule like this week?")
+
+ print(response)
+ assistant.create_user(user_name="user1")
+ assistant.create_user(user_name="user2")
+ user1 = assistant.get_user_by_name(user_name="user1")
+ user2 = assistant.get_user_by_name(user_name="user2")
+ assistant.add("i prefer tea over coffee", user_id=user1.id)
+ assistant.add("my favourite drink is coke", user_id=user2.id)
+ response1 = assistant.chat("What drink do I prefer?", user_id=user1.id)
+ response2 = assistant.chat("What drink do I prefer?", user_id=user2.id)
+ print(response1, response2)
diff --git a/evaluation/scripts/utils/prompts.py b/evaluation/scripts/utils/prompts.py
index bd418af54..32e6d6729 100644
--- a/evaluation/scripts/utils/prompts.py
+++ b/evaluation/scripts/utils/prompts.py
@@ -27,6 +27,7 @@
Answer:
"""
+
PM_ANSWER_PROMPT = """
You are a helpful assistant tasked with selecting the best answer to a user question, based solely on summarized conversation memories.
@@ -58,6 +59,13 @@
"""
+PREFEVAL_ANSWER_PROMPT = """
+ You are a helpful AI. Answer the question based on the query and the following memories:
+ User Memories:
+ {context}
+"""
+
+
ZEP_CONTEXT_TEMPLATE = """
FACTS and ENTITIES represent relevant context to the current conversation.
diff --git a/examples/mem_os/simple_prefs_memos_product.py b/examples/mem_os/simple_prefs_memos_product.py
new file mode 100644
index 000000000..40ec920f5
--- /dev/null
+++ b/examples/mem_os/simple_prefs_memos_product.py
@@ -0,0 +1,399 @@
+from memos.configs.mem_cube import GeneralMemCubeConfig
+from memos.configs.mem_os import MOSConfig
+from memos.mem_cube.general import GeneralMemCube
+from memos.mem_os.product import MOSProduct
+
+
+def get_config(user_id: str):
+ llm_config = {
+ "backend": "openai",
+ "config": {
+ "model_name_or_path": "gpt-4o-mini",
+ "api_key": "sk-xxxxx",
+ "api_base": "http://xxxx/v1",
+ "temperature": 0.1,
+ "remove_think_prefix": True,
+ "max_tokens": 4096,
+ },
+ }
+
+ embedder_config = {
+ "backend": "ollama",
+ "config": {"model_name_or_path": "nomic-embed-text:latest"},
+ }
+
+ # init MOS
+ mos_config = {
+ "user_id": user_id,
+ "chat_model": llm_config,
+ "mem_reader": {
+ "backend": "simple_struct",
+ "config": {
+ "llm": llm_config,
+ "embedder": embedder_config,
+ "chunker": {
+ "backend": "sentence",
+ "config": {
+ "tokenizer_or_token_counter": "gpt2",
+ "chunk_size": 512,
+ "chunk_overlap": 128,
+ "min_sentences_per_chunk": 1,
+ },
+ },
+ },
+ },
+ "max_turns_window": 20,
+ "top_k": 5,
+ "enable_textual_memory": True,
+ "enable_activation_memory": False,
+ "enable_parametric_memory": False,
+ "enable_preference_memory": True,
+ }
+
+ cube_config = {
+ "model_schema": "memos.configs.mem_cube.GeneralMemCubeConfig",
+ "user_id": user_id,
+ "cube_id": f"{user_id}/mem_cube",
+ "text_mem": {
+ "backend": "tree_text",
+ "config": {
+ "cube_id": f"{user_id}/mem_cube",
+ "extractor_llm": llm_config,
+ "dispatcher_llm": llm_config,
+ "graph_db": {
+ "backend": "neo4j",
+ "config": {
+ "uri": "bolt://localhost:7687",
+ "user": "neo4j",
+ "password": "12345678",
+ "db_name": "neo4j",
+ "user_name": "memosneo4j",
+ "embedding_dimension": 768,
+ "use_multi_db": False,
+ "auto_create": False,
+ },
+ },
+ "embedder": embedder_config,
+ },
+ },
+ "act_mem": {"backend": "uninitialized", "config": {}},
+ "para_mem": {"backend": "uninitialized", "config": {}},
+ "pref_mem": {
+ "backend": "pref_text",
+ "config": {
+ "cube_id": f"{user_id}/mem_cube",
+ "extractor_llm": llm_config,
+ "vector_db": {
+ "backend": "milvus",
+ "config": {
+ "collection_name": [
+ "explicit_preference",
+ "implicit_preference",
+ ],
+ "vector_dimension": 768,
+ "distance_metric": "cosine",
+ "uri": "./milvus_demo.db",
+ },
+ },
+ "embedder": embedder_config,
+ "extractor": {"backend": "naive", "config": {}},
+ "adder": {"backend": "naive", "config": {}},
+ "retriever": {"backend": "naive", "config": {}},
+ },
+ },
+ }
+ mos_config = MOSConfig(**mos_config)
+ cube_config = GeneralMemCubeConfig.model_validate(cube_config)
+
+ return mos_config, cube_config
+
+
+user_id = "superman"
+mos_config, mem_cube_config = get_config(user_id)
+
+memory = MOSProduct(default_config=mos_config)
+
+# register user and mem cube
+mem_cube = GeneralMemCube(mem_cube_config)
+
+register_result = memory.user_register(
+ user_id=user_id, user_name=user_id, default_mem_cube=mem_cube
+)
+print(f"register_result: {register_result}")
+
+# add memory for user
+memory.add(
+ messages=[
+ # Sports and hobbies
+ {"role": "user", "content": "I like playing football."},
+ {
+ "role": "assistant",
+ "content": "I like playing football too. It's a great way to stay active and work as a team.",
+ },
+ {"role": "user", "content": "Do you enjoy watching basketball games?"},
+ {
+ "role": "assistant",
+ "content": "Yes, I find basketball exciting to watch, especially the fast-paced action and strategic plays.",
+ },
+ {"role": "user", "content": "I'm learning to play tennis this summer."},
+ {
+ "role": "assistant",
+ "content": "That's wonderful! Tennis is a fantastic sport that improves both physical fitness and mental focus.",
+ },
+ # Food and cooking
+ {"role": "user", "content": "What's your favorite type of cuisine?"},
+ {
+ "role": "assistant",
+ "content": "I really enjoy Italian cuisine, especially pasta dishes and authentic pizza.",
+ },
+ {"role": "user", "content": "I love cooking Asian food at home."},
+ {
+ "role": "assistant",
+ "content": "Asian cooking is amazing! The balance of flavors and techniques is so interesting to learn.",
+ },
+ {"role": "user", "content": "Have you ever tried making homemade bread?"},
+ {
+ "role": "assistant",
+ "content": "Yes, there's something magical about the process of making bread from scratch. The smell is incredible!",
+ },
+ # Travel and places
+ {"role": "user", "content": "I'm planning a trip to Japan next year."},
+ {
+ "role": "assistant",
+ "content": "Japan is an incredible destination! The culture, food, and technology blend is fascinating.",
+ },
+ {"role": "user", "content": "What's the most beautiful place you've ever seen?"},
+ {
+ "role": "assistant",
+ "content": "I find mountain landscapes particularly breathtaking, especially during sunrise or sunset.",
+ },
+ {"role": "user", "content": "I prefer beach vacations over city trips."},
+ {
+ "role": "assistant",
+ "content": "Beach vacations are so relaxing! The sound of waves and warm sand is perfect for unwinding.",
+ },
+ # Technology and innovation
+ {"role": "user", "content": "What do you think about artificial intelligence?"},
+ {
+ "role": "assistant",
+ "content": "AI is transforming many aspects of our lives. It's exciting to see how it can help solve complex problems.",
+ },
+ {"role": "user", "content": "I'm learning to code in Python."},
+ {
+ "role": "assistant",
+ "content": "Python is a great language to start with! It's versatile and has a wonderful community.",
+ },
+ {"role": "user", "content": "Do you use any productivity apps?"},
+ {
+ "role": "assistant",
+ "content": "I find task management apps really helpful for organizing daily activities and staying focused.",
+ },
+ # Music and entertainment
+ {"role": "user", "content": "What kind of music do you enjoy?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate many genres, but I particularly enjoy jazz and classical music for their complexity.",
+ },
+ {"role": "user", "content": "I play the guitar in my free time."},
+ {
+ "role": "assistant",
+ "content": "That's fantastic! Playing an instrument is such a rewarding creative outlet.",
+ },
+ {"role": "user", "content": "Have you seen any good movies lately?"},
+ {
+ "role": "assistant",
+ "content": "I enjoy films that make you think deeply about human nature and society.",
+ },
+ # Books and learning
+ {"role": "user", "content": "Do you read books regularly?"},
+ {
+ "role": "assistant",
+ "content": "Yes, reading is one of my favorite ways to learn and explore new ideas.",
+ },
+ {"role": "user", "content": "I'm currently reading a science fiction novel."},
+ {
+ "role": "assistant",
+ "content": "Science fiction is great for exploring possibilities and imagining different futures.",
+ },
+ {"role": "user", "content": "What's your favorite subject to learn about?"},
+ {
+ "role": "assistant",
+ "content": "I'm fascinated by psychology and how the human mind works.",
+ },
+ # Nature and environment
+ {"role": "user", "content": "I love hiking in the mountains."},
+ {
+ "role": "assistant",
+ "content": "Hiking is wonderful! It's a great way to connect with nature and get exercise.",
+ },
+ {"role": "user", "content": "Are you concerned about climate change?"},
+ {
+ "role": "assistant",
+ "content": "Yes, it's one of the most important challenges of our time that requires collective action.",
+ },
+ {"role": "user", "content": "I try to recycle and reduce waste at home."},
+ {
+ "role": "assistant",
+ "content": "That's commendable! Every small action contributes to environmental protection.",
+ },
+ # Work and career
+ {"role": "user", "content": "What do you do for work?"},
+ {
+ "role": "assistant",
+ "content": "I work in technology, helping people solve problems and improve their daily lives.",
+ },
+ {"role": "user", "content": "I'm considering a career change."},
+ {
+ "role": "assistant",
+ "content": "Career changes can be challenging but also very rewarding when you find the right fit.",
+ },
+ {"role": "user", "content": "Do you work from home or in an office?"},
+ {
+ "role": "assistant",
+ "content": "I work remotely, which gives me flexibility in how I organize my day.",
+ },
+ # Health and wellness
+ {"role": "user", "content": "I've started doing yoga in the morning."},
+ {
+ "role": "assistant",
+ "content": "Yoga is excellent for both physical and mental well-being. Great way to start the day!",
+ },
+ {"role": "user", "content": "How do you manage stress?"},
+ {
+ "role": "assistant",
+ "content": "I find meditation and regular exercise help me stay balanced and focused.",
+ },
+ {"role": "user", "content": "I'm trying to eat more vegetables."},
+ {
+ "role": "assistant",
+ "content": "That's a great health goal! Vegetables provide so many essential nutrients.",
+ },
+ # Art and creativity
+ {"role": "user", "content": "Do you enjoy painting or drawing?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate visual arts, though I'm more of an observer than a creator.",
+ },
+ {"role": "user", "content": "I'm learning photography."},
+ {
+ "role": "assistant",
+ "content": "Photography is a beautiful way to capture moments and express your perspective.",
+ },
+ {"role": "user", "content": "What's your favorite type of art?"},
+ {
+ "role": "assistant",
+ "content": "I'm drawn to abstract art because it allows for personal interpretation.",
+ },
+ # Family and relationships
+ {"role": "user", "content": "I have two siblings."},
+ {
+ "role": "assistant",
+ "content": "Having siblings can be wonderful - they're often our first friends and lifelong companions.",
+ },
+ {"role": "user", "content": "Do you have any pets?"},
+ {
+ "role": "assistant",
+ "content": "I don't have pets, but I think they bring so much joy and companionship to people's lives.",
+ },
+ {"role": "user", "content": "I'm planning to visit my grandparents this weekend."},
+ {
+ "role": "assistant",
+ "content": "That's lovely! Grandparents often have such interesting stories and wisdom to share.",
+ },
+ # Education and growth
+ {"role": "user", "content": "I'm taking an online course in data science."},
+ {
+ "role": "assistant",
+ "content": "Data science is a fascinating field with many applications across different industries.",
+ },
+ {"role": "user", "content": "What's the best way to learn a new language?"},
+ {
+ "role": "assistant",
+ "content": "Immersion and consistent practice are key, along with finding methods that work for your learning style.",
+ },
+ {"role": "user", "content": "I enjoy attending workshops and conferences."},
+ {
+ "role": "assistant",
+ "content": "Workshops are great for hands-on learning and networking with like-minded people.",
+ },
+ # Hobbies and interests
+ {"role": "user", "content": "I collect vintage postcards."},
+ {
+ "role": "assistant",
+ "content": "What a unique hobby! Postcards offer glimpses into different times and places.",
+ },
+ {"role": "user", "content": "Do you garden?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate gardening, though I'm more of a plant observer than a gardener myself.",
+ },
+ {"role": "user", "content": "I love solving puzzles and brain teasers."},
+ {
+ "role": "assistant",
+ "content": "Puzzles are excellent for keeping the mind sharp and developing problem-solving skills.",
+ },
+ # Future and goals
+ {"role": "user", "content": "What are your goals for next year?"},
+ {
+ "role": "assistant",
+ "content": "I aim to continue learning and growing, helping more people with their challenges.",
+ },
+ {"role": "user", "content": "I want to start my own business someday."},
+ {
+ "role": "assistant",
+ "content": "Entrepreneurship is exciting! It requires courage, planning, and persistence.",
+ },
+ {"role": "user", "content": "Do you believe in setting New Year's resolutions?"},
+ {
+ "role": "assistant",
+ "content": "I think any time is good for setting positive goals and making positive changes.",
+ },
+ # Philosophy and life
+ {"role": "user", "content": "What's the meaning of life to you?"},
+ {
+ "role": "assistant",
+ "content": "I believe it's about learning, growing, and making positive connections with others.",
+ },
+ {"role": "user", "content": "I try to practice gratitude daily."},
+ {
+ "role": "assistant",
+ "content": "Gratitude is such a powerful practice that can transform your perspective on life.",
+ },
+ {"role": "user", "content": "What's your biggest fear?"},
+ {
+ "role": "assistant",
+ "content": "I think fear of not being able to help when someone really needs it would be challenging.",
+ },
+ # Technology and daily life
+ {"role": "user", "content": "How has technology changed your daily routine?"},
+ {
+ "role": "assistant",
+ "content": "Technology has made many tasks more efficient and connected me with people worldwide.",
+ },
+ {"role": "user", "content": "I'm trying to reduce my screen time."},
+ {
+ "role": "assistant",
+ "content": "That's a healthy goal! Finding balance with technology is important for well-being.",
+ },
+ {"role": "user", "content": "Do you use social media?"},
+ {
+ "role": "assistant",
+ "content": "I think social media can be a great tool for connection when used mindfully.",
+ },
+ # Final thoughts
+ {"role": "user", "content": "This has been a great conversation!"},
+ {
+ "role": "assistant",
+ "content": "I've really enjoyed our chat too! It's wonderful to explore so many different topics together.",
+ },
+ ],
+ user_id=user_id,
+ mem_cube_id=register_result["default_cube_id"],
+)
+
+retrieved_memories = memory.search(query="What do you like?", user_id=user_id)
+print(
+ f"len_pref_memories: {len(retrieved_memories['pref_mem'][0]['memories'])}"
+ if retrieved_memories["pref_mem"]
+ else 0
+)
diff --git a/examples/mem_reader/reader.py b/examples/mem_reader/reader.py
index e26d00a67..3da5d5e76 100644
--- a/examples/mem_reader/reader.py
+++ b/examples/mem_reader/reader.py
@@ -2,6 +2,11 @@
from memos.configs.mem_reader import SimpleStructMemReaderConfig
from memos.mem_reader.simple_struct import SimpleStructMemReader
+from memos.memories.textual.item import (
+ SourceMessage,
+ TextualMemoryItem,
+ TreeNodeTextualMemoryMetadata,
+)
def main():
@@ -11,7 +16,7 @@ def main():
)
reader = SimpleStructMemReader(reader_config)
- # 3. Define scene data
+ # 2. Define scene data
scene_data = [
[
{"role": "user", "chat_time": "3 May 2025", "content": "I'm feeling a bit down today."},
@@ -187,32 +192,389 @@ def main():
],
]
- # 4. Acquiring memories
+ print("=== Mem-Reader Fast vs Fine Mode Comparison ===\n")
+
+ # 3. Test Fine Mode (default)
+ print("🔄 Testing FINE mode (default, with LLM processing)...")
+ start_time = time.time()
+ fine_memory = reader.get_memory(
+ scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}, mode="fine"
+ )
+ fine_time = time.time() - start_time
+ print(f"✅ Fine mode completed in {fine_time:.2f} seconds")
+ print(f"📊 Fine mode generated {sum(len(mem_list) for mem_list in fine_memory)} memory items")
+
+ # 4. Test Fast Mode
+ print("\n⚡ Testing FAST mode (quick processing, no LLM calls)...")
start_time = time.time()
- chat_memory = reader.get_memory(
- scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}
+ fast_memory = reader.get_memory(
+ scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}, mode="fast"
)
- print("\nChat Memory:\n", chat_memory)
+ fast_time = time.time() - start_time
+ print(f"✅ Fast mode completed in {fast_time:.2f} seconds")
+ print(f"📊 Fast mode generated {sum(len(mem_list) for mem_list in fast_memory)} memory items")
+
+ # 5. Performance Comparison
+ print("\n📈 Performance Comparison:")
+ print(f" Fine mode: {fine_time:.2f}s")
+ print(f" Fast mode: {fast_time:.2f}s")
+ print(f" Speed improvement: {fine_time / fast_time:.1f}x faster")
+
+ # 6. Show sample results from both modes
+ print("\n🔍 Sample Results Comparison:")
+ print("\n--- FINE Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fine_memory[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
- # 5. Example of processing documents
- print("\n=== Processing Documents ===")
+ print("\n--- FAST Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fast_memory[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
+
+ # 7. Example of transfer fast mode result into fine result
+ fast_mode_memories = [
+ TextualMemoryItem(
+ id="4553141b-3a33-4548-b779-e677ec797a9f",
+ memory="user: Nate:Oh cool! I might check that one out some time soon! I do love watching classics.\nassistant: Joanna:Yep, that movie is awesome. I first watched it around 3 years ago. I even went out and got a physical copy!\nuser: Nate:Sounds cool! Have you seen it a lot? sounds like you know the movie well!\nassistant: Joanna:A few times. It's one of my favorites! I really like the idea and the acting.\nuser: Nate:Cool! I'll definitely check it out. Thanks for the recommendation!\nassistant: Joanna:No problem, Nate! Let me know if you like it!\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:Oh cool",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.094877+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.094919+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ TextualMemoryItem(
+ id="752e42fa-92b6-491a-a430-6864a7730fba",
+ memory="user: Nate:It was! How about you? Do you have any hobbies you love?\nassistant: Joanna:Yeah! Besides writing, I also enjoy reading, watching movies, and exploring nature. Anything else you enjoy doing, Nate?\nuser: Nate:Playing video games and watching movies are my main hobbies.\nassistant: Joanna:Cool, Nate! So we both have similar interests. What type of movies do you like best?\nuser: Nate:I love action and sci-fi movies, the effects are so cool! What about you, what's your favorite genre?\nassistant: Joanna:I'm all about dramas and romcoms. I love getting immersed in the feelings and plots.\nuser: Nate:Wow, movies can be so powerful! Do you have any recommendations for me?\nassistant: Joanna:Yeah, totally! Have you seen this romantic drama that's all about memory and relationships? It's such a good one.\nuser: Nate:Oh cool! I might check that one out some time soon! I do love watching classics.\nassistant: Joanna:Yep, that movie is awesome. I first watched it around 3 years ago. I even went out and got a physical copy!\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:It was",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.095726+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=6,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=7,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=8,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=9,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.095767+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ TextualMemoryItem(
+ id="c9cf448c-deee-43a8-bafd-eb15fde535b2",
+ memory="user: Nate:Hey Joanna! Long time no see! What's up? Anything fun going on?\nassistant: Joanna:Hey Nate! Long time no see! I've been working on a project lately - it's been pretty cool. What about you - any fun projects or hobbies?\nuser: Nate:Hey Joanna! That's cool! I won my first video game tournament last week - so exciting!\nassistant: Joanna:Wow Nate! Congrats on winning! Tell me more - what game was it?\nuser: Nate:Thanks! it's a team shooter game.\nassistant: Joanna:Wow, great job! What was is called?\nuser: Nate:The game was called Counter-Strike: Global Offensive, and me and my team had a blast to the very end!\nassistant: Joanna:Cool, Nate! Sounds like a fun experience, even if I'm not into games.\nuser: Nate:It was! How about you? Do you have any hobbies you love?\nassistant: Joanna:Yeah! Besides writing, I also enjoy reading, watching movies, and exploring nature. Anything else you enjoy doing, Nate?\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:Hey Joanna",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.098208+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=6,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=7,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=8,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=9,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.098246+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ ]
+ fine_memories = reader.fine_transfer_simple_mem(fast_mode_memories, type="chat")
+ print("\n--- Transfer Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fine_memories[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
+
+ # 7. Example of processing documents (only in fine mode)
+ print("\n=== Processing Documents (Fine Mode Only) ===")
# Example document paths (you should replace these with actual document paths)
doc_paths = [
"examples/mem_reader/text1.txt",
"examples/mem_reader/text2.txt",
]
- # 6. Acquiring memories from documents
- doc_memory = reader.get_memory(
- doc_paths,
- "doc",
- info={
- "user_id": "1111",
- "session_id": "2222",
- },
- )
- print("\nDocument Memory:\n", doc_memory)
- end_time = time.time()
- print(f"The runtime is {end_time - start_time} seconds.")
+
+ try:
+ # 6. Acquiring memories from documents
+ doc_memory = reader.get_memory(
+ doc_paths,
+ "doc",
+ info={
+ "user_id": "1111",
+ "session_id": "2222",
+ },
+ mode="fine",
+ )
+ print(
+ f"\n📄 Document Memory generated {sum(len(mem_list) for mem_list in doc_memory)} items"
+ )
+ except Exception as e:
+ print(f"⚠️ Document processing failed: {e}")
+ print(" (This is expected if document files don't exist)")
+
+ print("\n🎯 Summary:")
+ print(f" • Fast mode: {fast_time:.2f}s - Quick processing, no LLM calls")
+ print(f" • Fine mode: {fine_time:.2f}s - Full LLM processing for better understanding")
+ print(" • Use fast mode for: Real-time applications, high-throughput scenarios")
+ print(" • Use fine mode for: Quality analysis, detailed memory extraction")
if __name__ == "__main__":
diff --git a/examples/mem_scheduler/orm_examples.py b/examples/mem_scheduler/orm_examples.py
new file mode 100644
index 000000000..bbb57b4ab
--- /dev/null
+++ b/examples/mem_scheduler/orm_examples.py
@@ -0,0 +1,374 @@
+#!/usr/bin/env python3
+"""
+ORM Examples for MemScheduler
+
+This script demonstrates how to use the BaseDBManager's new environment variable loading methods
+for MySQL and Redis connections.
+"""
+
+import multiprocessing
+import os
+import sys
+
+from pathlib import Path
+
+
+# Add the src directory to the Python path
+sys.path.insert(0, str(Path(__file__).parent.parent.parent / "src"))
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager, DatabaseError
+from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager, SimpleListManager
+
+
+logger = get_logger(__name__)
+
+
+def test_mysql_engine_from_env():
+ """Test loading MySQL engine from environment variables"""
+ print("\n" + "=" * 60)
+ print("Testing MySQL Engine from Environment Variables")
+ print("=" * 60)
+
+ try:
+ # Test loading MySQL engine from current environment variables
+ mysql_engine = BaseDBManager.load_mysql_engine_from_env()
+ if mysql_engine is None:
+ print("❌ Failed to create MySQL engine - check environment variables")
+ return
+
+ print(f"✅ Successfully created MySQL engine: {mysql_engine}")
+ print(f" Engine URL: {mysql_engine.url}")
+
+ # Test connection
+ with mysql_engine.connect() as conn:
+ from sqlalchemy import text
+
+ result = conn.execute(text("SELECT 'MySQL connection test successful' as message"))
+ message = result.fetchone()[0]
+ print(f" Connection test: {message}")
+
+ mysql_engine.dispose()
+ print(" MySQL engine disposed successfully")
+
+ except DatabaseError as e:
+ print(f"❌ DatabaseError: {e}")
+ except Exception as e:
+ print(f"❌ Unexpected error: {e}")
+
+
+def test_redis_connection_from_env():
+ """Test loading Redis connection from environment variables"""
+ print("\n" + "=" * 60)
+ print("Testing Redis Connection from Environment Variables")
+ print("=" * 60)
+
+ try:
+ # Test loading Redis connection from current environment variables
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection - check environment variables")
+ return
+
+ print(f"✅ Successfully created Redis connection: {redis_client}")
+
+ # Test basic Redis operations
+ redis_client.set("test_key", "Hello from ORM Examples!")
+ value = redis_client.get("test_key")
+ print(f" Redis test - Set/Get: {value}")
+
+ # Test Redis info
+ info = redis_client.info("server")
+ redis_version = info.get("redis_version", "unknown")
+ print(f" Redis server version: {redis_version}")
+
+ # Clean up test key
+ redis_client.delete("test_key")
+ print(" Test key cleaned up")
+
+ redis_client.close()
+ print(" Redis connection closed successfully")
+
+ except DatabaseError as e:
+ print(f"❌ DatabaseError: {e}")
+ except Exception as e:
+ print(f"❌ Unexpected error: {e}")
+
+
+def test_environment_variables():
+ """Test and display current environment variables"""
+ print("\n" + "=" * 60)
+ print("Current Environment Variables")
+ print("=" * 60)
+
+ # MySQL environment variables
+ mysql_vars = [
+ "MYSQL_HOST",
+ "MYSQL_PORT",
+ "MYSQL_USERNAME",
+ "MYSQL_PASSWORD",
+ "MYSQL_DATABASE",
+ "MYSQL_CHARSET",
+ ]
+
+ print("\nMySQL Environment Variables:")
+ for var in mysql_vars:
+ value = os.getenv(var, "Not set")
+ # Mask password for security
+ if "PASSWORD" in var and value != "Not set":
+ value = "*" * len(value)
+ print(f" {var}: {value}")
+
+ # Redis environment variables
+ redis_vars = [
+ "REDIS_HOST",
+ "REDIS_PORT",
+ "REDIS_DB",
+ "REDIS_PASSWORD",
+ "MEMSCHEDULER_REDIS_HOST",
+ "MEMSCHEDULER_REDIS_PORT",
+ "MEMSCHEDULER_REDIS_DB",
+ "MEMSCHEDULER_REDIS_PASSWORD",
+ ]
+
+ print("\nRedis Environment Variables:")
+ for var in redis_vars:
+ value = os.getenv(var, "Not set")
+ # Mask password for security
+ if "PASSWORD" in var and value != "Not set":
+ value = "*" * len(value)
+ print(f" {var}: {value}")
+
+
+def test_manual_env_loading():
+ """Test loading environment variables manually from .env file"""
+ print("\n" + "=" * 60)
+ print("Testing Manual Environment Loading")
+ print("=" * 60)
+
+ env_file_path = "/Users/travistang/Documents/codes/memos/.env"
+
+ if not os.path.exists(env_file_path):
+ print(f"❌ Environment file not found: {env_file_path}")
+ return
+
+ try:
+ from dotenv import load_dotenv
+
+ # Load environment variables
+ load_dotenv(env_file_path)
+ print(f"✅ Successfully loaded environment variables from {env_file_path}")
+
+ # Test some key variables
+ test_vars = ["OPENAI_API_KEY", "MOS_CHAT_MODEL", "TZ"]
+ for var in test_vars:
+ value = os.getenv(var, "Not set")
+ if "KEY" in var and value != "Not set":
+ value = f"{value[:10]}..." if len(value) > 10 else value
+ print(f" {var}: {value}")
+
+ except ImportError:
+ print("❌ python-dotenv not installed. Install with: pip install python-dotenv")
+ except Exception as e:
+ print(f"❌ Error loading environment file: {e}")
+
+
+def test_redis_lockable_orm_with_list():
+ """Test RedisDBManager with list[str] type synchronization"""
+ print("\n" + "=" * 60)
+ print("Testing RedisDBManager with list[str]")
+ print("=" * 60)
+
+ try:
+ from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager
+
+ # Create a simple list manager instance
+ list_manager = SimpleListManager(["apple", "banana", "cherry"])
+ print(f"Original list manager: {list_manager}")
+
+ # Create RedisDBManager instance
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection - check environment variables")
+ return
+
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="test_list_cube",
+ obj=list_manager,
+ )
+
+ # Save to Redis
+ db_manager.save_to_db(list_manager)
+ print("✅ List manager saved to Redis")
+
+ # Load from Redis
+ loaded_manager = db_manager.load_from_db()
+ if loaded_manager:
+ print(f"Loaded list manager: {loaded_manager}")
+ print(f"Items match: {list_manager.items == loaded_manager.items}")
+ else:
+ print("❌ Failed to load list manager from Redis")
+
+ # Clean up
+ redis_client.delete("lockable_orm:test_user:test_list_cube:data")
+ redis_client.delete("lockable_orm:test_user:test_list_cube:lock")
+ redis_client.delete("lockable_orm:test_user:test_list_cube:version")
+ redis_client.close()
+
+ except Exception as e:
+ print(f"❌ Error in RedisDBManager test: {e}")
+
+
+def modify_list_process(process_id: int, items_to_add: list[str]):
+ """Function to be run in separate processes to modify the list using merge_items"""
+ try:
+ from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager
+
+ # Create Redis connection
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print(f"Process {process_id}: Failed to create Redis connection")
+ return
+
+ # Create a temporary list manager for this process with items to add
+ temp_manager = SimpleListManager()
+
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=temp_manager,
+ )
+
+ print(f"Process {process_id}: Starting modification with items: {items_to_add}")
+ for item in items_to_add:
+ db_manager.obj.add_item(item)
+ # Use sync_with_orm which internally uses merge_items
+ db_manager.sync_with_orm(size_limit=None)
+
+ print(f"Process {process_id}: Successfully synchronized with Redis")
+
+ redis_client.close()
+
+ except Exception as e:
+ print(f"Process {process_id}: Error - {e}")
+ import traceback
+
+ traceback.print_exc()
+
+
+def test_multiprocess_synchronization():
+ """Test multiprocess synchronization with RedisDBManager"""
+ print("\n" + "=" * 60)
+ print("Testing Multiprocess Synchronization")
+ print("=" * 60)
+
+ try:
+ # Initialize Redis with empty list
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection")
+ return
+
+ # Initialize with empty list
+ initial_manager = SimpleListManager([])
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=initial_manager,
+ )
+ db_manager.save_to_db(initial_manager)
+ print("✅ Initialized empty list manager in Redis")
+
+ # Define items for each process to add
+ process_items = [
+ ["item1", "item2"],
+ ["item3", "item4"],
+ ["item5", "item6"],
+ ["item1", "item7"], # item1 is duplicate, should not be added twice
+ ]
+
+ # Create and start processes
+ processes = []
+ for i, items in enumerate(process_items):
+ p = multiprocessing.Process(target=modify_list_process, args=(i + 1, items))
+ processes.append(p)
+ p.start()
+
+ # Wait for all processes to complete
+ for p in processes:
+ p.join()
+
+ print("\n" + "-" * 40)
+ print("All processes completed. Checking final result...")
+
+ # Load final result
+ final_db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=SimpleListManager([]),
+ )
+ final_manager = final_db_manager.load_from_db()
+
+ if final_manager:
+ print(f"Final synchronized list manager: {final_manager}")
+ print(f"Final list length: {len(final_manager)}")
+ print("Expected items: {'item1', 'item2', 'item3', 'item4', 'item5', 'item6', 'item7'}")
+ print(f"Actual items: {set(final_manager.items)}")
+
+ # Check if all unique items are present
+ expected_items = {"item1", "item2", "item3", "item4", "item5", "item6", "item7"}
+ actual_items = set(final_manager.items)
+
+ if expected_items == actual_items:
+ print("✅ All processes contributed correctly - synchronization successful!")
+ else:
+ print(f"❌ Expected items: {expected_items}")
+ print(f" Actual items: {actual_items}")
+ else:
+ print("❌ Failed to load final result")
+
+ # Clean up
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:data")
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:lock")
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:version")
+ redis_client.close()
+
+ except Exception as e:
+ print(f"❌ Error in multiprocess synchronization test: {e}")
+
+
+def main():
+ """Main function to run all tests"""
+ print("ORM Examples - Environment Variable Loading Tests")
+ print("=" * 80)
+
+ # Test environment variables display
+ test_environment_variables()
+
+ # Test manual environment loading
+ test_manual_env_loading()
+
+ # Test MySQL engine loading
+ test_mysql_engine_from_env()
+
+ # Test Redis connection loading
+ test_redis_connection_from_env()
+
+ # Test RedisLockableORM with list[str]
+ test_redis_lockable_orm_with_list()
+
+ # Test multiprocess synchronization
+ test_multiprocess_synchronization()
+
+ print("\n" + "=" * 80)
+ print("All tests completed!")
+ print("=" * 80)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/poetry.lock b/poetry.lock
index d34f964b6..926d580fb 100644
--- a/poetry.lock
+++ b/poetry.lock
@@ -1,4 +1,4 @@
-# This file is automatically @generated by Poetry 2.1.4 and should not be changed by hand.
+# This file is automatically @generated by Poetry 2.1.3 and should not be changed by hand.
[[package]]
name = "absl-py"
@@ -192,6 +192,19 @@ torch = ">=1.0.0"
tqdm = ">=4.31.1"
transformers = ">=3.0.0"
+[[package]]
+name = "cachetools"
+version = "6.2.1"
+description = "Extensible memoizing collections and decorators"
+optional = true
+python-versions = ">=3.9"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "cachetools-6.2.1-py3-none-any.whl", hash = "sha256:09868944b6dde876dfd44e1d47e18484541eaf12f26f29b7af91b26cc892d701"},
+ {file = "cachetools-6.2.1.tar.gz", hash = "sha256:3f391e4bd8f8bf0931169baf7456cc822705f4e2a31f840d218f445b9a854201"},
+]
+
[[package]]
name = "certifi"
version = "2025.7.14"
@@ -690,6 +703,30 @@ toml = ["tomli (>=2.0.0) ; python_version < \"3.11\""]
trio = ["trio (>=0.10.0)"]
yaml = ["pyyaml (>=6.0.1)"]
+[[package]]
+name = "datasketch"
+version = "1.6.5"
+description = "Probabilistic data structures for processing and searching very large datasets"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"pref-mem\" or extra == \"all\""
+files = [
+ {file = "datasketch-1.6.5-py3-none-any.whl", hash = "sha256:59311b2925b2f37536e9f7c2f46bbc25e8e54379c8635a3fa7ca55d2abb66d1b"},
+ {file = "datasketch-1.6.5.tar.gz", hash = "sha256:ba2848cb74f23d6d3dd444cf24edcbc47b1c34a171b1803231793ed4d74d4fcf"},
+]
+
+[package.dependencies]
+numpy = ">=1.11"
+scipy = ">=1.0.0"
+
+[package.extras]
+benchmark = ["SetSimilaritySearch (>=0.1.7)", "matplotlib (>=3.1.2)", "nltk (>=3.4.5)", "pandas (>=0.25.3)", "pyfarmhash (>=0.2.2)", "pyhash (>=0.9.3)", "scikit-learn (>=0.21.3)", "scipy (>=1.3.3)"]
+cassandra = ["cassandra-driver (>=3.20)"]
+experimental-aio = ["aiounittest ; python_version >= \"3.6\"", "motor ; python_version >= \"3.6\""]
+redis = ["redis (>=2.10.0)"]
+test = ["cassandra-driver (>=3.20)", "coverage", "mock (>=2.0.0)", "mockredispy", "nose (>=1.3.7)", "nose-exclude (>=0.5.0)", "pymongo (>=3.9.0)", "pytest", "redis (>=2.10.0)"]
+
[[package]]
name = "defusedxml"
version = "0.7.1"
@@ -1222,7 +1259,7 @@ files = [
{file = "grpcio-1.73.1-cp39-cp39-win_amd64.whl", hash = "sha256:42f0660bce31b745eb9d23f094a332d31f210dcadd0fc8e5be7e4c62a87ce86b"},
{file = "grpcio-1.73.1.tar.gz", hash = "sha256:7fce2cd1c0c1116cf3850564ebfc3264fba75d3c74a7414373f1238ea365ef87"},
]
-markers = {main = "extra == \"all\""}
+markers = {main = "extra == \"pref-mem\" or extra == \"all\""}
[package.extras]
protobuf = ["grpcio-tools (>=1.73.1)"]
@@ -1529,6 +1566,18 @@ files = [
{file = "itsdangerous-2.2.0.tar.gz", hash = "sha256:e0050c0b7da1eea53ffaf149c0cfbb5c6e2e2b69c4bef22c81fa6eb73e5f6173"},
]
+[[package]]
+name = "jieba"
+version = "0.42"
+description = "Chinese Words Segmentation Utilities"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "jieba-0.42.tar.gz", hash = "sha256:34a3c960cc2943d9da16d6d2565110cf5f305921a67413dddf04f84de69c939b"},
+]
+
[[package]]
name = "jinja2"
version = "3.1.6"
@@ -3241,7 +3290,7 @@ files = [
{file = "pandas-2.3.1-cp39-cp39-win_amd64.whl", hash = "sha256:b4b0de34dc8499c2db34000ef8baad684cfa4cbd836ecee05f323ebfba348c7d"},
{file = "pandas-2.3.1.tar.gz", hash = "sha256:0a95b9ac964fe83ce317827f80304d37388ea77616b1425f0ae41c9d2d0d7bb2"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[package.dependencies]
numpy = [
@@ -3560,7 +3609,7 @@ files = [
{file = "protobuf-6.31.1-py3-none-any.whl", hash = "sha256:720a6c7e6b77288b85063569baae8536671b39f15cc22037ec7045658d80489e"},
{file = "protobuf-6.31.1.tar.gz", hash = "sha256:d8cac4c982f0b957a4dc73a80e2ea24fab08e679c0de9deb835f4a12d69aca9a"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[[package]]
name = "pycparser"
@@ -3773,6 +3822,33 @@ files = [
[package.extras]
windows-terminal = ["colorama (>=0.4.6)"]
+[[package]]
+name = "pymilvus"
+version = "2.6.2"
+description = "Python Sdk for Milvus"
+optional = true
+python-versions = ">=3.8"
+groups = ["main"]
+markers = "extra == \"pref-mem\" or extra == \"all\""
+files = [
+ {file = "pymilvus-2.6.2-py3-none-any.whl", hash = "sha256:933e447e09424d490dcf595053b01a7277dadea7ae3235cd704363bd6792509d"},
+ {file = "pymilvus-2.6.2.tar.gz", hash = "sha256:b4802cc954de8f2d47bf8d6230e92196514dcb8a3726ba6098dc27909d4bc8e3"},
+]
+
+[package.dependencies]
+grpcio = ">=1.66.2,<1.68.0 || >1.68.0,<1.68.1 || >1.68.1,<1.69.0 || >1.69.0,<1.70.0 || >1.70.0,<1.70.1 || >1.70.1,<1.71.0 || >1.71.0,<1.72.1 || >1.72.1,<1.73.0 || >1.73.0"
+pandas = ">=1.2.4"
+protobuf = ">=5.27.2"
+python-dotenv = ">=1.0.1,<2.0.0"
+setuptools = ">69"
+ujson = ">=2.0.0"
+
+[package.extras]
+bulk-writer = ["azure-storage-blob", "minio (>=7.0.0)", "pyarrow (>=12.0.0)", "requests", "urllib3"]
+dev = ["azure-storage-blob", "black", "grpcio (==1.66.2)", "grpcio-testing (==1.66.2)", "grpcio-tools (==1.66.2)", "minio (>=7.0.0)", "pyarrow (>=12.0.0)", "pytest (>=5.3.4)", "pytest-asyncio", "pytest-cov (>=5.0.0)", "pytest-timeout (>=1.3.4)", "requests", "ruff (>=0.12.9,<1)", "scipy", "urllib3"]
+milvus-lite = ["milvus-lite (>=2.4.0) ; sys_platform != \"win32\""]
+model = ["pymilvus.model (>=0.3.0)"]
+
[[package]]
name = "pymysql"
version = "1.1.2"
@@ -3946,7 +4022,7 @@ files = [
{file = "pytz-2025.2-py2.py3-none-any.whl", hash = "sha256:5ddf76296dd8c44c26eb8f4b6f35488f3ccbf6fbbd7adee0b7262d43f0ec2f00"},
{file = "pytz-2025.2.tar.gz", hash = "sha256:360b9e3dbb49a209c21ad61809c7fb453643e048b38924c765813546746e81c3"},
]
-markers = {main = "extra == \"tree-mem\" or extra == \"all\" or extra == \"mem-reader\""}
+markers = {main = "extra == \"tree-mem\" or extra == \"all\" or extra == \"mem-reader\" or extra == \"pref-mem\""}
[[package]]
name = "pywin32"
@@ -4072,6 +4148,25 @@ urllib3 = ">=1.26.14,<3"
fastembed = ["fastembed (>=0.7,<0.8)"]
fastembed-gpu = ["fastembed-gpu (>=0.7,<0.8)"]
+[[package]]
+name = "rank-bm25"
+version = "0.2.2"
+description = "Various BM25 algorithms for document ranking"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "rank_bm25-0.2.2-py3-none-any.whl", hash = "sha256:7bd4a95571adadfc271746fa146a4bcfd89c0cf731e49c3d1ad863290adbe8ae"},
+ {file = "rank_bm25-0.2.2.tar.gz", hash = "sha256:096ccef76f8188563419aaf384a02f0ea459503fdf77901378d4fd9d87e5e51d"},
+]
+
+[package.dependencies]
+numpy = "*"
+
+[package.extras]
+dev = ["pytest"]
+
[[package]]
name = "redis"
version = "6.2.0"
@@ -4955,7 +5050,7 @@ files = [
{file = "setuptools-80.9.0-py3-none-any.whl", hash = "sha256:062d34222ad13e0cc312a4c02d73f059e86a4acbfbdea8f8f76b28c99f306922"},
{file = "setuptools-80.9.0.tar.gz", hash = "sha256:f36b47402ecde768dbfafc46e8e4207b4360c654f1f3bb84475f0a28628fb19c"},
]
-markers = {main = "extra == \"all\" and platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\" and extra == \"all\"", eval = "platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\""}
+markers = {main = "platform_system == \"Linux\" and platform_machine == \"x86_64\" and (extra == \"all\" or extra == \"pref-mem\") or extra == \"pref-mem\" or extra == \"all\"", eval = "platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\""}
[package.extras]
check = ["pytest-checkdocs (>=2.4)", "pytest-ruff (>=0.2.1) ; sys_platform != \"cygwin\"", "ruff (>=0.8.0) ; sys_platform != \"cygwin\""]
@@ -5578,7 +5673,7 @@ files = [
{file = "tzdata-2025.2-py2.py3-none-any.whl", hash = "sha256:1a403fada01ff9221ca8044d701868fa132215d84beb92242d9acd2147f667a8"},
{file = "tzdata-2025.2.tar.gz", hash = "sha256:b60a638fcc0daffadf82fe0f57e53d06bdec2f36c4df66280ae79bce6bd6f2b9"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[[package]]
name = "ujson"
@@ -6301,13 +6396,14 @@ cffi = {version = ">=1.11", markers = "platform_python_implementation == \"PyPy\
cffi = ["cffi (>=1.11)"]
[extras]
-all = ["chonkie", "markitdown", "neo4j", "pika", "pymysql", "qdrant-client", "redis", "schedule", "sentence-transformers", "torch", "volcengine-python-sdk"]
+all = ["cachetools", "chonkie", "datasketch", "jieba", "markitdown", "neo4j", "pika", "pymilvus", "pymysql", "qdrant-client", "rank-bm25", "redis", "schedule", "sentence-transformers", "torch", "volcengine-python-sdk"]
mem-reader = ["chonkie", "markitdown"]
mem-scheduler = ["pika", "redis"]
mem-user = ["pymysql"]
+pref-mem = ["datasketch", "pymilvus"]
tree-mem = ["neo4j", "schedule"]
[metadata]
lock-version = "2.1"
python-versions = ">=3.10,<4.0"
-content-hash = "d85cb8a08870d67df6e462610231f1e735ba5293bd3fe5b0c4a212b3ccff7b72"
\ No newline at end of file
+content-hash = "ec17679a44205ada4494fbc485ac592883281fde273d5e73d6b8cbc6f7f9ed10"
diff --git a/pyproject.toml b/pyproject.toml
index a03b9174b..2f88797a8 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -88,6 +88,12 @@ mem-reader = [
"markitdown[docx,pdf,pptx,xls,xlsx] (>=0.1.1,<0.2.0)", # Markdown parser for various file formats
]
+# PreferenceTextMemory
+pref-mem = [
+ "pymilvus (>=2.6.1,<3.0.0)", # Milvus Vector DB
+ "datasketch (>=1.6.5,<2.0.0)", # MinHash library
+]
+
# All optional dependencies
# Allow users to install with `pip install MemoryOS[all]`
all = [
@@ -99,7 +105,11 @@ all = [
"pymysql (>=1.1.0,<2.0.0)",
"chonkie (>=1.0.7,<2.0.0)",
"markitdown[docx,pdf,pptx,xls,xlsx] (>=0.1.1,<0.2.0)",
-
+ "pymilvus (>=2.6.1,<3.0.0)",
+ "datasketch (>=1.6.5,<2.0.0)",
+ "jieba (>=0.38.1,<0.42.1)",
+ "rank-bm25 (>=0.2.2)",
+ "cachetools (>=6.0.0)",
# NOT exist in the above optional groups
# Because they are either huge-size dependencies or infrequently used dependencies.
# We kindof don't want users to install them.
diff --git a/src/memos/api/config.py b/src/memos/api/config.py
index d552369c5..f02edaad6 100644
--- a/src/memos/api/config.py
+++ b/src/memos/api/config.py
@@ -1,18 +1,258 @@
+import base64
+import hashlib
+import hmac
import json
+import logging
import os
+import re
+import time
from typing import Any
+import requests
+
from dotenv import load_dotenv
from memos.configs.mem_cube import GeneralMemCubeConfig
from memos.configs.mem_os import MOSConfig
+from memos.context.context import ContextThread
from memos.mem_cube.general import GeneralMemCube
# Load environment variables
load_dotenv()
+logger = logging.getLogger(__name__)
+
+
+def _update_env_from_dict(data: dict[str, Any]) -> None:
+ """Apply a dict to environment variables, with change logging."""
+
+ def _is_sensitive(name: str) -> bool:
+ n = name.upper()
+ return any(s in n for s in ["PASSWORD", "SECRET", "AK", "SK", "TOKEN", "KEY"])
+
+ for k, v in data.items():
+ if isinstance(v, dict):
+ new_val = json.dumps(v, ensure_ascii=False)
+ elif isinstance(v, bool):
+ new_val = "true" if v else "false"
+ elif v is None:
+ new_val = ""
+ else:
+ new_val = str(v)
+
+ old_val = os.environ.get(k)
+ os.environ[k] = new_val
+
+ try:
+ log_old = "***" if _is_sensitive(k) else (old_val if old_val is not None else "")
+ log_new = "***" if _is_sensitive(k) else new_val
+ if old_val != new_val:
+ logger.info(f"Nacos config update: {k}={log_new} (was {log_old})")
+ except Exception as e:
+ # Avoid logging failures blocking config updates
+ logger.debug(f"Skip logging change for {k}: {e}")
+
+
+def get_config_json(name: str, default: Any | None = None) -> Any:
+ """Read JSON object/array from env and parse. Returns default on missing/invalid."""
+ raw = os.getenv(name)
+ if not raw:
+ return default
+ try:
+ return json.loads(raw)
+ except Exception:
+ logger.warning(f"Invalid JSON in env '{name}', returning default.")
+ return default
+
+
+def get_config_value(path: str, default: Any | None = None) -> Any:
+ """Read value from env with optional dot-path for structured configs.
+
+ Examples:
+ - get_config_value("MONGODB_CONFIG.base_uri")
+ - get_config_value("MONGODB_BASE_URI")
+ """
+ if "." not in path:
+ val = os.getenv(path)
+ return val if val is not None else default
+ root, *subkeys = path.split(".")
+ data = get_config_json(root, default=None)
+ if not isinstance(data, dict):
+ return default
+ cur: Any = data
+ for key in subkeys:
+ if isinstance(cur, dict) and key in cur:
+ cur = cur[key]
+ else:
+ return default
+ return cur
+
+
+class NacosConfigManager:
+ _client = None
+ _data_id = None
+ _group = None
+ _enabled = False
+
+ # Pre-compile regex patterns for better performance
+ _KEY_VALUE_PATTERN = re.compile(r"^([^=]+)=(.*)$")
+ _INTEGER_PATTERN = re.compile(r"^[+-]?\d+$")
+ _FLOAT_PATTERN = re.compile(r"^[+-]?(\d+\.?\d*|\.\d+)([eE][+-]?\d+)?$")
+
+ @classmethod
+ def _sign(cls, secret_key: str, data: str) -> str:
+ """HMAC-SHA1 sgin"""
+ signature = hmac.new(secret_key.encode("utf-8"), data.encode("utf-8"), hashlib.sha1)
+ return base64.b64encode(signature.digest()).decode()
+
+ @staticmethod
+ def _parse_value(value: str) -> Any:
+ """Parse string value to appropriate Python type.
+
+ Supports: bool, int, float, and string.
+ """
+ if not value:
+ return value
+
+ val_lower = value.lower()
+
+ # Boolean
+ if val_lower in ("true", "false"):
+ return val_lower == "true"
+
+ # Integer
+ if NacosConfigManager._INTEGER_PATTERN.match(value):
+ try:
+ return int(value)
+ except (ValueError, OverflowError):
+ return value
+
+ # Float
+ if NacosConfigManager._FLOAT_PATTERN.match(value):
+ try:
+ return float(value)
+ except (ValueError, OverflowError):
+ return value
+
+ # Default to string
+ return value
+
+ @staticmethod
+ def parse_properties(content: str) -> dict[str, Any]:
+ """Parse properties file content to dictionary with type inference.
+
+ Supports:
+ - Comments (lines starting with #)
+ - Key-value pairs (KEY=VALUE)
+ - Type inference (bool, int, float, string)
+ """
+ data: dict[str, Any] = {}
+
+ for line in content.splitlines():
+ line = line.strip()
+
+ # Skip empty lines and comments
+ if not line or line.startswith("#"):
+ continue
+
+ # Parse key-value pair
+ match = NacosConfigManager._KEY_VALUE_PATTERN.match(line)
+ if match:
+ key = match.group(1).strip()
+ value = match.group(2).strip()
+ data[key] = NacosConfigManager._parse_value(value)
+
+ return data
+
+ @classmethod
+ def start_config_watch(cls):
+ while True:
+ cls.init()
+ time.sleep(60)
+
+ @classmethod
+ def start_watch_if_enabled(cls) -> None:
+ enable = os.getenv("NACOS_ENABLE_WATCH", "false").lower() == "true"
+ print("enable:", enable)
+ if not enable:
+ return
+ interval = int(os.getenv("NACOS_WATCH_INTERVAL", "60"))
+
+ def _loop() -> None:
+ while True:
+ try:
+ cls.init()
+ except Exception as e:
+ logger.error(f"❌ Nacos watch loop error: {e}")
+ time.sleep(interval)
+
+ ContextThread(target=_loop, daemon=True).start()
+ logger.info(f"Nacos watch thread started (interval={interval}s).")
+
+ @classmethod
+ def init(cls) -> None:
+ server_addr = os.getenv("NACOS_SERVER_ADDR")
+ data_id = os.getenv("NACOS_DATA_ID")
+ group = os.getenv("NACOS_GROUP", "DEFAULT_GROUP")
+ namespace = os.getenv("NACOS_NAMESPACE", "")
+ ak = os.getenv("AK")
+ sk = os.getenv("SK")
+
+ if not (server_addr and data_id and ak and sk):
+ logger.warning("❌ missing NACOS_SERVER_ADDR / AK / SK / DATA_ID")
+ return
+
+ base_url = f"http://{server_addr}/nacos/v1/cs/configs"
+
+ def _auth_headers():
+ ts = str(int(time.time() * 1000))
+
+ sign_data = namespace + "+" + group + "+" + ts if namespace else group + "+" + ts
+ signature = cls._sign(sk, sign_data)
+ return {
+ "Spas-AccessKey": ak,
+ "Spas-Signature": signature,
+ "timeStamp": ts,
+ }
+
+ try:
+ params = {
+ "dataId": data_id,
+ "group": group,
+ "tenant": namespace,
+ }
+
+ headers = _auth_headers()
+ resp = requests.get(base_url, headers=headers, params=params, timeout=10)
+
+ if resp.status_code != 200:
+ logger.error(f"Nacos AK/SK fail: {resp.status_code} {resp.text}")
+ return
+
+ content = resp.text.strip()
+ if not content:
+ logger.warning("⚠️ Nacos is empty")
+ return
+ try:
+ data_props = cls.parse_properties(content)
+ logger.info("nacos config:", data_props)
+ _update_env_from_dict(data_props)
+ logger.info("✅ parse Nacos setting is Properties ")
+ except Exception as e:
+ logger.error(f"⚠️ Nacos parse fail(not JSON/YAML/Properties): {e}")
+ raise Exception(f"Nacos configuration parsing failed: {e}") from e
+
+ except Exception as e:
+ logger.error(f"❌ Nacos AK/SK init fail: {e}")
+ raise Exception(f"❌ Nacos AK/SK init fail: {e}") from e
+
+
+# init Nacos
+NacosConfigManager.init()
+NacosConfigManager.start_watch_if_enabled()
+
class APIConfig:
"""Centralized configuration management for MemOS APIs."""
@@ -23,7 +263,7 @@ def get_openai_config() -> dict[str, Any]:
return {
"model_name_or_path": os.getenv("MOS_CHAT_MODEL", "gpt-4o-mini"),
"temperature": float(os.getenv("MOS_CHAT_TEMPERATURE", "0.8")),
- "max_tokens": int(os.getenv("MOS_MAX_TOKENS", "1024")),
+ "max_tokens": int(os.getenv("MOS_MAX_TOKENS", "8000")),
"top_p": float(os.getenv("MOS_TOP_P", "0.9")),
"top_k": int(os.getenv("MOS_TOP_K", "50")),
"remove_think_prefix": True,
@@ -84,7 +324,7 @@ def get_memreader_config() -> dict[str, Any]:
"config": {
"model_name_or_path": os.getenv("MEMRADER_MODEL", "gpt-4o-mini"),
"temperature": 0.6,
- "max_tokens": int(os.getenv("MEMRADER_MAX_TOKENS", "5000")),
+ "max_tokens": int(os.getenv("MEMRADER_MAX_TOKENS", "8000")),
"top_p": 0.95,
"top_k": 20,
"api_key": os.getenv("MEMRADER_API_KEY", "EMPTY"),
@@ -108,20 +348,40 @@ def get_activation_vllm_config() -> dict[str, Any]:
},
}
+ @staticmethod
+ def get_preference_memory_config() -> dict[str, Any]:
+ """Get preference memory configuration."""
+ return {
+ "backend": "pref_text",
+ "config": {
+ "extractor_llm": APIConfig.get_memreader_config(),
+ "vector_db": {
+ "backend": "milvus",
+ "config": APIConfig.get_milvus_config(),
+ },
+ "embedder": APIConfig.get_embedder_config(),
+ "reranker": APIConfig.get_reranker_config(),
+ "extractor": {"backend": "naive", "config": {}},
+ "adder": {"backend": "naive", "config": {}},
+ "retriever": {"backend": "naive", "config": {}},
+ },
+ }
+
@staticmethod
def get_reranker_config() -> dict[str, Any]:
"""Get embedder configuration."""
embedder_backend = os.getenv("MOS_RERANKER_BACKEND", "http_bge")
- if embedder_backend == "http_bge":
+ if embedder_backend in ["http_bge", "http_bge_strategy"]:
return {
- "backend": "http_bge",
+ "backend": embedder_backend,
"config": {
"url": os.getenv("MOS_RERANKER_URL"),
"model": os.getenv("MOS_RERANKER_MODEL", "bge-reranker-v2-m3"),
"timeout": 10,
"headers_extra": os.getenv("MOS_RERANKER_HEADERS_EXTRA"),
"rerank_source": os.getenv("MOS_RERANK_SOURCE"),
+ "reranker_strategy": os.getenv("MOS_RERANKER_STRATEGY", "single_turn"),
},
}
else:
@@ -159,9 +419,23 @@ def get_embedder_config() -> dict[str, Any]:
},
}
+ @staticmethod
+ def get_reader_config() -> dict[str, Any]:
+ """Get reader configuration."""
+ return {
+ "backend": os.getenv("MEM_READER_BACKEND", "simple_struct"),
+ "config": {
+ "chunk_type": os.getenv("MEM_READER_CHAT_CHUNK_TYPE", "default"),
+ "chunk_length": int(os.getenv("MEM_READER_CHAT_CHUNK_TOKEN_SIZE", 1600)),
+ "chunk_session": int(os.getenv("MEM_READER_CHAT_CHUNK_SESS_SIZE", 10)),
+ "chunk_overlap": int(os.getenv("MEM_READER_CHAT_CHUNK_OVERLAP", 2)),
+ },
+ }
+
@staticmethod
def get_internet_config() -> dict[str, Any]:
"""Get embedder configuration."""
+ reader_config = APIConfig.get_reader_config()
return {
"backend": "bocha",
"config": {
@@ -169,7 +443,7 @@ def get_internet_config() -> dict[str, Any]:
"max_results": 15,
"num_per_request": 10,
"reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": {
"backend": "openai",
@@ -195,6 +469,7 @@ def get_internet_config() -> dict[str, Any]:
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
},
@@ -275,6 +550,46 @@ def get_nebular_config(user_id: str | None = None) -> dict[str, Any]:
"embedding_dimension": int(os.getenv("EMBEDDING_DIMENSION", 3072)),
}
+ @staticmethod
+ def get_milvus_config():
+ return {
+ "collection_name": [
+ "explicit_preference",
+ "implicit_preference",
+ ],
+ "vector_dimension": int(os.getenv("EMBEDDING_DIMENSION", 1024)),
+ "distance_metric": "cosine",
+ "uri": os.getenv("MILVUS_URI", "http://localhost:19530"),
+ "user_name": os.getenv("MILVUS_USER_NAME", "root"),
+ "password": os.getenv("MILVUS_PASSWORD", "12345678"),
+ }
+
+ @staticmethod
+ def get_polardb_config(user_id: str | None = None) -> dict[str, Any]:
+ """Get PolarDB configuration."""
+ use_multi_db = os.getenv("POLAR_DB_USE_MULTI_DB", "false").lower() == "true"
+
+ if use_multi_db:
+ # Multi-DB mode: each user gets their own database (physical isolation)
+ db_name = f"memos{user_id.replace('-', '')}" if user_id else "memos_default"
+ user_name = None
+ else:
+ # Shared-DB mode: all users share one database with user_name tag (logical isolation)
+ db_name = os.getenv("POLAR_DB_DB_NAME", "shared_memos_db")
+ user_name = f"memos{user_id.replace('-', '')}" if user_id else "memos_default"
+
+ return {
+ "host": os.getenv("POLAR_DB_HOST", "localhost"),
+ "port": int(os.getenv("POLAR_DB_PORT", "5432")),
+ "user": os.getenv("POLAR_DB_USER", "root"),
+ "password": os.getenv("POLAR_DB_PASSWORD", "123456"),
+ "db_name": db_name,
+ "user_name": user_name,
+ "use_multi_db": use_multi_db,
+ "auto_create": True,
+ "embedding_dimension": int(os.getenv("EMBEDDING_DIMENSION", 1024)),
+ }
+
@staticmethod
def get_mysql_config() -> dict[str, Any]:
"""Get MySQL configuration."""
@@ -299,10 +614,10 @@ def get_scheduler_config() -> dict[str, Any]:
),
"context_window_size": int(os.getenv("MOS_SCHEDULER_CONTEXT_WINDOW_SIZE", "5")),
"thread_pool_max_workers": int(
- os.getenv("MOS_SCHEDULER_THREAD_POOL_MAX_WORKERS", "10")
+ os.getenv("MOS_SCHEDULER_THREAD_POOL_MAX_WORKERS", "10000")
),
- "consume_interval_seconds": int(
- os.getenv("MOS_SCHEDULER_CONSUME_INTERVAL_SECONDS", "3")
+ "consume_interval_seconds": float(
+ os.getenv("MOS_SCHEDULER_CONSUME_INTERVAL_SECONDS", "0.01")
),
"enable_parallel_dispatch": os.getenv(
"MOS_SCHEDULER_ENABLE_PARALLEL_DISPATCH", "true"
@@ -356,6 +671,8 @@ def get_product_default_config() -> dict[str, Any]:
openai_config = APIConfig.get_openai_config()
qwen_config = APIConfig.qwen_config()
vllm_config = APIConfig.vllm_config()
+ reader_config = APIConfig.get_reader_config()
+
backend_model = {
"openai": openai_config,
"huggingface": qwen_config,
@@ -367,7 +684,7 @@ def get_product_default_config() -> dict[str, Any]:
"user_id": os.getenv("MOS_USER_ID", "root"),
"chat_model": {"backend": backend, "config": backend_model[backend]},
"mem_reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": APIConfig.get_memreader_config(),
"embedder": APIConfig.get_embedder_config(),
@@ -380,11 +697,14 @@ def get_product_default_config() -> dict[str, Any]:
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": int(os.getenv("MOS_TOP_K", "50")),
"max_turns_window": int(os.getenv("MOS_MAX_TURNS_WINDOW", "20")),
}
@@ -414,6 +734,8 @@ def get_start_default_config() -> dict[str, Any]:
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": int(os.getenv("MOS_TOP_K", "5")),
"chat_model": {
"backend": os.getenv("MOS_CHAT_MODEL_PROVIDER", "openai"),
@@ -446,6 +768,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
qwen_config = APIConfig.qwen_config()
vllm_config = APIConfig.vllm_config()
mysql_config = APIConfig.get_mysql_config()
+ reader_config = APIConfig.get_reader_config()
backend = os.getenv("MOS_CHAT_MODEL_PROVIDER", "openai")
backend_model = {
"openai": openai_config,
@@ -460,7 +783,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"config": backend_model[backend],
},
"mem_reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": APIConfig.get_memreader_config(),
"embedder": APIConfig.get_embedder_config(),
@@ -473,11 +796,14 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": 30,
"max_turns_window": 20,
}
@@ -500,6 +826,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
neo4j_community_config = APIConfig.get_neo4j_community_config(user_id)
neo4j_config = APIConfig.get_neo4j_config(user_id)
nebular_config = APIConfig.get_nebular_config(user_id)
+ polardb_config = APIConfig.get_polardb_config(user_id)
internet_config = (
APIConfig.get_internet_config()
if os.getenv("ENABLE_INTERNET", "false").lower() == "true"
@@ -509,6 +836,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"neo4j-community": neo4j_community_config,
"neo4j": neo4j_config,
"nebular": nebular_config,
+ "polardb": polardb_config,
}
graph_db_backend = os.getenv("NEO4J_BACKEND", "neo4j-community").lower()
if graph_db_backend in graph_db_backend_map:
@@ -533,9 +861,14 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"reorganize": os.getenv("MOS_ENABLE_REORGANIZE", "false").lower()
== "true",
"memory_size": {
- "WorkingMemory": os.getenv("NEBULAR_WORKING_MEMORY", 20),
- "LongTermMemory": os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6),
- "UserMemory": os.getenv("NEBULAR_USER_MEMORY", 1e6),
+ "WorkingMemory": int(os.getenv("NEBULAR_WORKING_MEMORY", 20)),
+ "LongTermMemory": int(os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6)),
+ "UserMemory": int(os.getenv("NEBULAR_USER_MEMORY", 1e6)),
+ },
+ "search_strategy": {
+ "fast_graph": bool(os.getenv("FAST_GRAPH", "false") == "true"),
+ "bm25": bool(os.getenv("BM25_CALL", "false") == "true"),
+ "cot": bool(os.getenv("VEC_COT_CALL", "false") == "true"),
},
},
},
@@ -543,6 +876,9 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
if os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower() == "false"
else APIConfig.get_activation_vllm_config(),
"para_mem": {},
+ "pref_mem": {}
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() == "false"
+ else APIConfig.get_preference_memory_config(),
}
)
else:
@@ -564,10 +900,12 @@ def get_default_cube_config() -> GeneralMemCubeConfig | None:
neo4j_community_config = APIConfig.get_neo4j_community_config(user_id="default")
neo4j_config = APIConfig.get_neo4j_config(user_id="default")
nebular_config = APIConfig.get_nebular_config(user_id="default")
+ polardb_config = APIConfig.get_polardb_config(user_id="default")
graph_db_backend_map = {
"neo4j-community": neo4j_community_config,
"neo4j": neo4j_config,
"nebular": nebular_config,
+ "polardb": polardb_config,
}
internet_config = (
APIConfig.get_internet_config()
@@ -595,16 +933,25 @@ def get_default_cube_config() -> GeneralMemCubeConfig | None:
== "true",
"internet_retriever": internet_config,
"memory_size": {
- "WorkingMemory": os.getenv("NEBULAR_WORKING_MEMORY", 20),
- "LongTermMemory": os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6),
- "UserMemory": os.getenv("NEBULAR_USER_MEMORY", 1e6),
+ "WorkingMemory": int(os.getenv("NEBULAR_WORKING_MEMORY", 20)),
+ "LongTermMemory": int(os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6)),
+ "UserMemory": int(os.getenv("NEBULAR_USER_MEMORY", 1e6)),
+ },
+ "search_strategy": {
+ "fast_graph": bool(os.getenv("FAST_GRAPH", "false") == "true"),
+ "bm25": bool(os.getenv("BM25_CALL", "false") == "true"),
+ "cot": bool(os.getenv("VEC_COT_CALL", "false") == "true"),
},
+ "mode": os.getenv("ASYNC_MODE", "sync"),
},
},
"act_mem": {}
if os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower() == "false"
else APIConfig.get_activation_vllm_config(),
"para_mem": {},
+ "pref_mem": {}
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() == "false"
+ else APIConfig.get_preference_memory_config(),
}
)
else:
diff --git a/src/memos/api/exceptions.py b/src/memos/api/exceptions.py
index 2fd22ad52..10a14b4d1 100644
--- a/src/memos/api/exceptions.py
+++ b/src/memos/api/exceptions.py
@@ -1,5 +1,6 @@
import logging
+from fastapi.exceptions import HTTPException, RequestValidationError
from fastapi.requests import Request
from fastapi.responses import JSONResponse
@@ -10,9 +11,24 @@
class APIExceptionHandler:
"""Centralized exception handling for MemOS APIs."""
+ @staticmethod
+ async def validation_error_handler(request: Request, exc: RequestValidationError):
+ """Handle request validation errors."""
+ logger.error(f"Validation error: {exc.errors()}")
+ return JSONResponse(
+ status_code=422,
+ content={
+ "code": 422,
+ "message": "Parameter validation error",
+ "detail": exc.errors(),
+ "data": None,
+ },
+ )
+
@staticmethod
async def value_error_handler(request: Request, exc: ValueError):
"""Handle ValueError exceptions globally."""
+ logger.error(f"ValueError: {exc}")
return JSONResponse(
status_code=400,
content={"code": 400, "message": str(exc), "data": None},
@@ -21,8 +37,17 @@ async def value_error_handler(request: Request, exc: ValueError):
@staticmethod
async def global_exception_handler(request: Request, exc: Exception):
"""Handle all unhandled exceptions globally."""
- logger.exception("Unhandled error:")
+ logger.error(f"Exception: {exc}")
return JSONResponse(
status_code=500,
content={"code": 500, "message": str(exc), "data": None},
)
+
+ @staticmethod
+ async def http_error_handler(request: Request, exc: HTTPException):
+ """Handle HTTP exceptions globally."""
+ logger.error(f"HTTP error {exc.status_code}: {exc.detail}")
+ return JSONResponse(
+ status_code=exc.status_code,
+ content={"code": exc.status_code, "message": str(exc.detail), "data": None},
+ )
diff --git a/src/memos/api/middleware/request_context.py b/src/memos/api/middleware/request_context.py
index cb41428d4..025a0f9eb 100644
--- a/src/memos/api/middleware/request_context.py
+++ b/src/memos/api/middleware/request_context.py
@@ -2,6 +2,8 @@
Request context middleware for automatic trace_id injection.
"""
+import time
+
from collections.abc import Callable
from starlette.middleware.base import BaseHTTPMiddleware
@@ -34,30 +36,66 @@ class RequestContextMiddleware(BaseHTTPMiddleware):
3. Ensures the context is available throughout the request lifecycle
"""
+ def __init__(self, app, source: str | None = None):
+ """
+ Initialize the middleware.
+
+ Args:
+ app: The ASGI application
+ source: Source identifier (e.g., 'product' or 'server') to distinguish request origin
+ """
+ super().__init__(app)
+ self.source = source or "api"
+
async def dispatch(self, request: Request, call_next: Callable) -> Response:
# Extract or generate trace_id
trace_id = extract_trace_id_from_headers(request) or generate_trace_id()
+ env = request.headers.get("x-env")
+ user_type = request.headers.get("x-user-type")
+ user_name = request.headers.get("x-user-name")
+ start_time = time.time()
+
# Create and set request context
- context = RequestContext(trace_id=trace_id, api_path=request.url.path)
+ context = RequestContext(
+ trace_id=trace_id,
+ api_path=request.url.path,
+ env=env,
+ user_type=user_type,
+ user_name=user_name,
+ source=self.source,
+ )
set_request_context(context)
- # Log request start with parameters
- params_log = {}
-
- # Get query parameters
- if request.query_params:
- params_log["query_params"] = dict(request.query_params)
+ logger.info(
+ f"Request started, source: {self.source}, method: {request.method}, path: {request.url.path}, "
+ f"headers: {request.headers}"
+ )
- logger.info(f"Request started: {request.method} {request.url.path}, {params_log}")
-
- # Process the request
response = await call_next(request)
+ end_time = time.time()
- # Log request completion with output
- logger.info(f"Request completed: {request.url.path}, status: {response.status_code}")
-
- # Add trace_id to response headers for debugging
- response.headers["x-trace-id"] = trace_id
+ # Process the request
+ try:
+ if not response:
+ logger.error(
+ f"Request Failed No Response, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+
+ return response
+
+ if response.status_code == 200:
+ logger.info(
+ f"Request completed: source: {self.source}, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+ else:
+ logger.error(
+ f"Request Failed: source: {self.source}, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+ except Exception as e:
+ end_time = time.time()
+ logger.error(
+ f"Request Exception Error: source: {self.source}, path: {request.url.path}, error: {e}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
return response
diff --git a/src/memos/api/product_api.py b/src/memos/api/product_api.py
index 709ad74fb..ec5cccae1 100644
--- a/src/memos/api/product_api.py
+++ b/src/memos/api/product_api.py
@@ -17,7 +17,7 @@
version="1.0.1",
)
-app.add_middleware(RequestContextMiddleware)
+app.add_middleware(RequestContextMiddleware, source="product_api")
# Include routers
app.include_router(product_router)
diff --git a/src/memos/api/product_models.py b/src/memos/api/product_models.py
index 86751b008..0412754c3 100644
--- a/src/memos/api/product_models.py
+++ b/src/memos/api/product_models.py
@@ -5,6 +5,7 @@
from pydantic import BaseModel, Field
# Import message types from core types module
+from memos.mem_scheduler.schemas.general_schemas import SearchMode
from memos.types import MessageDict, PermissionDict
@@ -170,7 +171,7 @@ class APISearchRequest(BaseRequest):
query: str = Field(..., description="Search query")
user_id: str = Field(None, description="User ID")
mem_cube_id: str | None = Field(None, description="Cube ID to search in")
- mode: str = Field("fast", description="search mode fast or fine")
+ mode: SearchMode = Field(SearchMode.FAST, description="search mode: fast, fine, or mixture")
internet_search: bool = Field(False, description="Whether to use internet search")
moscube: bool = Field(False, description="Whether to use MemOSCube")
top_k: int = Field(10, description="Number of results to return")
@@ -179,6 +180,8 @@ class APISearchRequest(BaseRequest):
operation: list[PermissionDict] | None = Field(
None, description="operation ids for multi cubes"
)
+ include_preference: bool = Field(True, description="Whether to handle preference memory")
+ pref_top_k: int = Field(6, description="Number of preference results to return")
class APIADDRequest(BaseRequest):
diff --git a/src/memos/api/routers/server_router.py b/src/memos/api/routers/server_router.py
index a332de583..8df383bfb 100644
--- a/src/memos/api/routers/server_router.py
+++ b/src/memos/api/routers/server_router.py
@@ -1,9 +1,16 @@
+import json
import os
+import random as _random
+import socket
+import time
import traceback
-from typing import Any
+from collections.abc import Iterable
+from datetime import datetime
+from typing import TYPE_CHECKING, Any
from fastapi import APIRouter, HTTPException
+from fastapi.responses import StreamingResponse
from memos.api.config import APIConfig
from memos.api.product_models import (
@@ -18,7 +25,10 @@
from memos.configs.internet_retriever import InternetRetrieverConfigFactory
from memos.configs.llm import LLMConfigFactory
from memos.configs.mem_reader import MemReaderConfigFactory
+from memos.configs.mem_scheduler import SchedulerConfigFactory
from memos.configs.reranker import RerankerConfigFactory
+from memos.configs.vec_db import VectorDBConfigFactory
+from memos.context.context import ContextThreadPoolExecutor
from memos.embedders.factory import EmbedderFactory
from memos.graph_dbs.factory import GraphStoreFactory
from memos.llms.factory import LLMFactory
@@ -26,17 +36,52 @@
from memos.mem_cube.navie import NaiveMemCube
from memos.mem_os.product_server import MOSServer
from memos.mem_reader.factory import MemReaderFactory
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
+from memos.mem_scheduler.scheduler_factory import SchedulerFactory
+from memos.mem_scheduler.schemas.general_schemas import (
+ ADD_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
+ SearchMode,
+)
+from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
+from memos.memories.textual.prefer_text_memory.factory import (
+ AdderFactory,
+ ExtractorFactory,
+ RetrieverFactory,
+)
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
from memos.memories.textual.tree_text_memory.retrieve.internet_retriever_factory import (
InternetRetrieverFactory,
)
from memos.reranker.factory import RerankerFactory
+from memos.templates.instruction_completion import instruct_completion
+
+
+if TYPE_CHECKING:
+ from memos.mem_scheduler.optimized_scheduler import OptimizedScheduler
from memos.types import MOSSearchResult, UserContext
+from memos.vec_dbs.factory import VecDBFactory
logger = get_logger(__name__)
router = APIRouter(prefix="/product", tags=["Server API"])
+INSTANCE_ID = f"{socket.gethostname()}:{os.getpid()}:{_random.randint(1000, 9999)}"
+
+
+def _to_iter(running: Any) -> Iterable:
+ """Normalize running tasks to an iterable of task objects."""
+ if running is None:
+ return []
+ if isinstance(running, dict):
+ return running.values()
+ return running # assume it's already an iterable (e.g., list)
def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
@@ -45,6 +90,7 @@ def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
"neo4j-community": APIConfig.get_neo4j_community_config(user_id=user_id),
"neo4j": APIConfig.get_neo4j_config(user_id=user_id),
"nebular": APIConfig.get_nebular_config(user_id=user_id),
+ "polardb": APIConfig.get_polardb_config(user_id=user_id),
}
graph_db_backend = os.getenv("NEO4J_BACKEND", "nebular").lower()
@@ -56,6 +102,16 @@ def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
)
+def _build_vec_db_config() -> dict[str, Any]:
+ """Build vector database configuration."""
+ return VectorDBConfigFactory.model_validate(
+ {
+ "backend": "milvus",
+ "config": APIConfig.get_milvus_config(),
+ }
+ )
+
+
def _build_llm_config() -> dict[str, Any]:
"""Build LLM configuration."""
return LLMConfigFactory.model_validate(
@@ -88,6 +144,21 @@ def _build_internet_retriever_config() -> dict[str, Any]:
return InternetRetrieverConfigFactory.model_validate(APIConfig.get_internet_config())
+def _build_pref_extractor_config() -> dict[str, Any]:
+ """Build extractor configuration."""
+ return ExtractorConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
+def _build_pref_adder_config() -> dict[str, Any]:
+ """Build adder configuration."""
+ return AdderConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
+def _build_pref_retriever_config() -> dict[str, Any]:
+ """Build retriever configuration."""
+ return RetrieverConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
def _get_default_memory_size(cube_config) -> dict[str, int]:
"""Get default memory size configuration."""
return getattr(cube_config.text_mem.config, "memory_size", None) or {
@@ -104,15 +175,19 @@ def init_server():
# Build component configurations
graph_db_config = _build_graph_db_config()
- print(graph_db_config)
llm_config = _build_llm_config()
embedder_config = _build_embedder_config()
mem_reader_config = _build_mem_reader_config()
reranker_config = _build_reranker_config()
internet_retriever_config = _build_internet_retriever_config()
+ vector_db_config = _build_vec_db_config()
+ pref_extractor_config = _build_pref_extractor_config()
+ pref_adder_config = _build_pref_adder_config()
+ pref_retriever_config = _build_pref_retriever_config()
# Create component instances
graph_db = GraphStoreFactory.from_config(graph_db_config)
+ vector_db = VecDBFactory.from_config(vector_db_config)
llm = LLMFactory.from_config(llm_config)
embedder = EmbedderFactory.from_config(embedder_config)
mem_reader = MemReaderFactory.from_config(mem_reader_config)
@@ -120,6 +195,25 @@ def init_server():
internet_retriever = InternetRetrieverFactory.from_config(
internet_retriever_config, embedder=embedder
)
+ pref_extractor = ExtractorFactory.from_config(
+ config_factory=pref_extractor_config,
+ llm_provider=llm,
+ embedder=embedder,
+ vector_db=vector_db,
+ )
+ pref_adder = AdderFactory.from_config(
+ config_factory=pref_adder_config,
+ llm_provider=llm,
+ embedder=embedder,
+ vector_db=vector_db,
+ )
+ pref_retriever = RetrieverFactory.from_config(
+ config_factory=pref_retriever_config,
+ llm_provider=llm,
+ embedder=embedder,
+ reranker=reranker,
+ vector_db=vector_db,
+ )
# Initialize memory manager
memory_manager = MemoryManager(
@@ -134,6 +228,40 @@ def init_server():
llm=llm,
online_bot=False,
)
+
+ naive_mem_cube = NaiveMemCube(
+ llm=llm,
+ embedder=embedder,
+ mem_reader=mem_reader,
+ graph_db=graph_db,
+ reranker=reranker,
+ internet_retriever=internet_retriever,
+ memory_manager=memory_manager,
+ default_cube_config=default_cube_config,
+ vector_db=vector_db,
+ pref_extractor=pref_extractor,
+ pref_adder=pref_adder,
+ pref_retriever=pref_retriever,
+ )
+
+ # Initialize Scheduler
+ scheduler_config_dict = APIConfig.get_scheduler_config()
+ scheduler_config = SchedulerConfigFactory(
+ backend="optimized_scheduler", config=scheduler_config_dict
+ )
+ mem_scheduler: OptimizedScheduler = SchedulerFactory.from_config(scheduler_config)
+ mem_scheduler.initialize_modules(
+ chat_llm=llm,
+ process_llm=mem_reader.llm,
+ db_engine=BaseDBManager.create_default_sqlite_engine(),
+ mem_reader=mem_reader,
+ )
+ mem_scheduler.current_mem_cube = naive_mem_cube
+ mem_scheduler.start()
+
+ # Initialize SchedulerAPIModule
+ api_module = mem_scheduler.api_module
+
return (
graph_db,
mem_reader,
@@ -144,6 +272,13 @@ def init_server():
memory_manager,
default_cube_config,
mos_server,
+ mem_scheduler,
+ naive_mem_cube,
+ api_module,
+ vector_db,
+ pref_extractor,
+ pref_adder,
+ pref_retriever,
)
@@ -158,24 +293,16 @@ def init_server():
memory_manager,
default_cube_config,
mos_server,
+ mem_scheduler,
+ naive_mem_cube,
+ api_module,
+ vector_db,
+ pref_extractor,
+ pref_adder,
+ pref_retriever,
) = init_server()
-def _create_naive_mem_cube() -> NaiveMemCube:
- """Create a NaiveMemCube instance with initialized components."""
- naive_mem_cube = NaiveMemCube(
- llm=llm,
- embedder=embedder,
- mem_reader=mem_reader,
- graph_db=graph_db,
- reranker=reranker,
- internet_retriever=internet_retriever,
- memory_manager=memory_manager,
- default_cube_config=default_cube_config,
- )
- return naive_mem_cube
-
-
def _format_memory_item(memory_data: Any) -> dict[str, Any]:
"""Format a single memory item for API response."""
memory = memory_data.model_dump()
@@ -185,6 +312,7 @@ def _format_memory_item(memory_data: Any) -> dict[str, Any]:
memory["ref_id"] = ref_id
memory["metadata"]["embedding"] = []
memory["metadata"]["sources"] = []
+ memory["metadata"]["usage"] = []
memory["metadata"]["ref_id"] = ref_id
memory["metadata"]["id"] = memory_id
memory["metadata"]["memory"] = memory["memory"]
@@ -192,6 +320,26 @@ def _format_memory_item(memory_data: Any) -> dict[str, Any]:
return memory
+def _post_process_pref_mem(
+ memories_result: list[dict[str, Any]],
+ pref_formatted_mem: list[dict[str, Any]],
+ mem_cube_id: str,
+ include_preference: bool,
+):
+ if include_preference:
+ memories_result["pref_mem"].append(
+ {
+ "cube_id": mem_cube_id,
+ "memories": pref_formatted_mem,
+ }
+ )
+ pref_instruction, pref_note = instruct_completion(pref_formatted_mem)
+ memories_result["pref_string"] = pref_instruction
+ memories_result["pref_note"] = pref_note
+
+ return memories_result
+
+
@router.post("/search", summary="Search memories", response_model=SearchResponse)
def search_memories(search_req: APISearchRequest):
"""Search memories for a specific user."""
@@ -201,24 +349,107 @@ def search_memories(search_req: APISearchRequest):
mem_cube_id=search_req.mem_cube_id,
session_id=search_req.session_id or "default_session",
)
- logger.info(f"Search user_id is: {user_context.mem_cube_id}")
+ logger.info(f"Search Req is: {search_req}")
memories_result: MOSSearchResult = {
"text_mem": [],
"act_mem": [],
"para_mem": [],
+ "pref_mem": [],
+ "pref_note": "",
}
+
+ search_mode = search_req.mode
+
+ def _search_text():
+ if search_mode == SearchMode.FAST:
+ formatted_memories = fast_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ elif search_mode == SearchMode.FINE:
+ formatted_memories = fine_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ elif search_mode == SearchMode.MIXTURE:
+ formatted_memories = mix_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ else:
+ logger.error(f"Unsupported search mode: {search_mode}")
+ raise HTTPException(status_code=400, detail=f"Unsupported search mode: {search_mode}")
+ return formatted_memories
+
+ def _search_pref():
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() != "true":
+ return []
+ results = naive_mem_cube.pref_mem.search(
+ query=search_req.query,
+ top_k=search_req.pref_top_k,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": search_req.session_id,
+ "chat_history": search_req.chat_history,
+ },
+ )
+ return [_format_memory_item(data) for data in results]
+
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(_search_text)
+ pref_future = executor.submit(_search_pref)
+ text_formatted_memories = text_future.result()
+ pref_formatted_memories = pref_future.result()
+
+ memories_result["text_mem"].append(
+ {
+ "cube_id": search_req.mem_cube_id,
+ "memories": text_formatted_memories,
+ }
+ )
+
+ memories_result = _post_process_pref_mem(
+ memories_result,
+ pref_formatted_memories,
+ search_req.mem_cube_id,
+ search_req.include_preference,
+ )
+
+ logger.info(f"Search memories result: {memories_result}")
+
+ return SearchResponse(
+ message="Search completed successfully",
+ data=memories_result,
+ )
+
+
+def mix_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
+ """
+ Mix search memories: fast search + async fine search
+ """
+
+ formatted_memories = mem_scheduler.mix_search_memories(
+ search_req=search_req,
+ user_context=user_context,
+ )
+ return formatted_memories
+
+
+def fine_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
target_session_id = search_req.session_id
if not target_session_id:
target_session_id = "default_session"
search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
# Create MemCube and perform search
- naive_mem_cube = _create_naive_mem_cube()
search_results = naive_mem_cube.text_mem.search(
query=search_req.query,
user_name=user_context.mem_cube_id,
top_k=search_req.top_k,
- mode=search_req.mode,
+ mode=SearchMode.FINE,
manual_close_internet=not search_req.internet_search,
moscube=search_req.moscube,
search_filter=search_filter,
@@ -230,17 +461,36 @@ def search_memories(search_req: APISearchRequest):
)
formatted_memories = [_format_memory_item(data) for data in search_results]
- memories_result["text_mem"].append(
- {
- "cube_id": search_req.mem_cube_id,
- "memories": formatted_memories,
- }
- )
+ return formatted_memories
- return SearchResponse(
- message="Search completed successfully",
- data=memories_result,
+
+def fast_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ # Create MemCube and perform search
+ search_results = naive_mem_cube.text_mem.search(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=SearchMode.FAST,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ },
)
+ formatted_memories = [_format_memory_item(data) for data in search_results]
+
+ return formatted_memories
@router.post("/add", summary="Add memories", response_model=MemoryResponse)
@@ -252,51 +502,299 @@ def add_memories(add_req: APIADDRequest):
mem_cube_id=add_req.mem_cube_id,
session_id=add_req.session_id or "default_session",
)
- naive_mem_cube = _create_naive_mem_cube()
+
+ logger.info(f"Add Req is: {add_req}")
+
target_session_id = add_req.session_id
if not target_session_id:
target_session_id = "default_session"
- memories = mem_reader.get_memory(
- [add_req.messages],
- type="chat",
- info={
- "user_id": add_req.user_id,
- "session_id": target_session_id,
- },
- )
- # Flatten memory list
- flattened_memories = [mm for m in memories for mm in m]
- logger.info(f"Memory extraction completed for user {add_req.user_id}")
- mem_id_list: list[str] = naive_mem_cube.text_mem.add(
- flattened_memories,
- user_name=user_context.mem_cube_id,
- )
+ # If text memory backend works in async mode, submit tasks to scheduler
+ try:
+ sync_mode = getattr(naive_mem_cube.text_mem, "mode", "sync")
+ except Exception:
+ sync_mode = "sync"
+ logger.info(f"Add sync_mode mode is: {sync_mode}")
+
+ def _process_text_mem() -> list[dict[str, str]]:
+ memories_local = mem_reader.get_memory(
+ [add_req.messages],
+ type="chat",
+ info={
+ "user_id": add_req.user_id,
+ "session_id": target_session_id,
+ },
+ mode="fast" if sync_mode == "async" else "fine",
+ )
+ flattened_local = [mm for m in memories_local for mm in m]
+ logger.info(f"Memory extraction completed for user {add_req.user_id}")
+ mem_ids_local: list[str] = naive_mem_cube.text_mem.add(
+ flattened_local,
+ user_name=user_context.mem_cube_id,
+ )
+ logger.info(
+ f"Added {len(mem_ids_local)} memories for user {add_req.user_id} "
+ f"in session {add_req.session_id}: {mem_ids_local}"
+ )
+ if sync_mode == "async":
+ try:
+ message_item_read = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids_local),
+ timestamp=datetime.utcnow(),
+ user_name=add_req.mem_cube_id,
+ )
+ mem_scheduler.submit_messages(messages=[message_item_read])
+ logger.info(f"2105Submit messages!!!!!: {json.dumps(mem_ids_local)}")
+ except Exception as e:
+ logger.error(f"Failed to submit async memory tasks: {e}", exc_info=True)
+ else:
+ message_item_add = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids_local),
+ timestamp=datetime.utcnow(),
+ user_name=add_req.mem_cube_id,
+ )
+ mem_scheduler.submit_messages(messages=[message_item_add])
+ return [
+ {
+ "memory": memory.memory,
+ "memory_id": memory_id,
+ "memory_type": memory.metadata.memory_type,
+ }
+ for memory_id, memory in zip(mem_ids_local, flattened_local, strict=False)
+ ]
+
+ def _process_pref_mem() -> list[dict[str, str]]:
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() != "true":
+ return []
+ # Follow async behavior similar to core.py: enqueue when async
+ if sync_mode == "async":
+ try:
+ messages_list = [add_req.messages]
+ message_item_pref = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=PREF_ADD_LABEL,
+ content=json.dumps(messages_list),
+ timestamp=datetime.utcnow(),
+ )
+ mem_scheduler.submit_messages(messages=[message_item_pref])
+ logger.info("Submitted preference add to scheduler (async mode)")
+ except Exception as e:
+ logger.error(f"Failed to submit PREF_ADD task: {e}", exc_info=True)
+ return []
+ else:
+ pref_memories_local = naive_mem_cube.pref_mem.get_memory(
+ [add_req.messages],
+ type="chat",
+ info={
+ "user_id": add_req.user_id,
+ "session_id": target_session_id,
+ },
+ )
+ pref_ids_local: list[str] = naive_mem_cube.pref_mem.add(pref_memories_local)
+ logger.info(
+ f"Added {len(pref_ids_local)} preferences for user {add_req.user_id} "
+ f"in session {add_req.session_id}: {pref_ids_local}"
+ )
+ return [
+ {
+ "memory": memory.memory,
+ "memory_id": memory_id,
+ "memory_type": memory.metadata.preference_type,
+ }
+ for memory_id, memory in zip(pref_ids_local, pref_memories_local, strict=False)
+ ]
+
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(_process_text_mem)
+ pref_future = executor.submit(_process_pref_mem)
+ text_response_data = text_future.result()
+ pref_response_data = pref_future.result()
+
+ logger.info(f"add_memories Text response data: {text_response_data}")
+ logger.info(f"add_memories Pref response data: {pref_response_data}")
- logger.info(
- f"Added {len(mem_id_list)} memories for user {add_req.user_id} "
- f"in session {add_req.session_id}: {mem_id_list}"
- )
- response_data = [
- {
- "memory": memory.memory,
- "memory_id": memory_id,
- "memory_type": memory.metadata.memory_type,
- }
- for memory_id, memory in zip(mem_id_list, flattened_memories, strict=False)
- ]
return MemoryResponse(
message="Memory added successfully",
- data=response_data,
+ data=text_response_data + pref_response_data,
)
+@router.get("/scheduler/status", summary="Get scheduler running status")
+def scheduler_status(user_name: str | None = None):
+ try:
+ if user_name:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: getattr(task, "mem_cube_id", None) == user_name
+ )
+ tasks_iter = list(_to_iter(running))
+ running_count = len(tasks_iter)
+ return {
+ "message": "ok",
+ "data": {
+ "scope": "user",
+ "user_name": user_name,
+ "running_tasks": running_count,
+ "timestamp": time.time(),
+ "instance_id": INSTANCE_ID,
+ },
+ }
+ else:
+ running_all = mem_scheduler.dispatcher.get_running_tasks(lambda _t: True)
+ tasks_iter = list(_to_iter(running_all))
+ running_count = len(tasks_iter)
+
+ task_count_per_user: dict[str, int] = {}
+ for task in tasks_iter:
+ cube = getattr(task, "mem_cube_id", "unknown")
+ task_count_per_user[cube] = task_count_per_user.get(cube, 0) + 1
+
+ try:
+ metrics_snapshot = mem_scheduler.dispatcher.metrics.snapshot()
+ except Exception:
+ metrics_snapshot = {}
+
+ return {
+ "message": "ok",
+ "data": {
+ "scope": "global",
+ "running_tasks": running_count,
+ "task_count_per_user": task_count_per_user,
+ "timestamp": time.time(),
+ "instance_id": INSTANCE_ID,
+ "metrics": metrics_snapshot,
+ },
+ }
+ except Exception as err:
+ logger.error("Failed to get scheduler status: %s", traceback.format_exc())
+ raise HTTPException(status_code=500, detail="Failed to get scheduler status") from err
+
+
+@router.post("/scheduler/wait", summary="Wait until scheduler is idle for a specific user")
+def scheduler_wait(
+ user_name: str,
+ timeout_seconds: float = 120.0,
+ poll_interval: float = 0.2,
+):
+ """
+ Block until scheduler has no running tasks for the given user_name, or timeout.
+ """
+ start = time.time()
+ try:
+ while True:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: task.mem_cube_id == user_name
+ )
+ running_count = len(running)
+ elapsed = time.time() - start
+
+ # success -> scheduler is idle
+ if running_count == 0:
+ return {
+ "message": "idle",
+ "data": {
+ "running_tasks": 0,
+ "waited_seconds": round(elapsed, 3),
+ "timed_out": False,
+ "user_name": user_name,
+ },
+ }
+
+ # timeout check
+ if elapsed > timeout_seconds:
+ return {
+ "message": "timeout",
+ "data": {
+ "running_tasks": running_count,
+ "waited_seconds": round(elapsed, 3),
+ "timed_out": True,
+ "user_name": user_name,
+ },
+ }
+
+ time.sleep(poll_interval)
+
+ except Exception as err:
+ logger.error("Failed while waiting for scheduler: %s", traceback.format_exc())
+ raise HTTPException(status_code=500, detail="Failed while waiting for scheduler") from err
+
+
+@router.get("/scheduler/wait/stream", summary="Stream scheduler progress for a user")
+def scheduler_wait_stream(
+ user_name: str,
+ timeout_seconds: float = 120.0,
+ poll_interval: float = 0.2,
+):
+ """
+ Stream scheduler progress via Server-Sent Events (SSE).
+
+ Contract:
+ - We emit periodic heartbeat frames while tasks are still running.
+ - Each heartbeat frame is JSON, prefixed with "data: ".
+ - On final frame, we include status = "idle" or "timeout" and timed_out flag,
+ with the same semantics as /scheduler/wait.
+
+ Example curl:
+ curl -N "${API_HOST}/product/scheduler/wait/stream?timeout_seconds=10&poll_interval=0.5"
+ """
+
+ def event_generator():
+ start = time.time()
+ try:
+ while True:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: task.mem_cube_id == user_name
+ )
+ running_count = len(running)
+ elapsed = time.time() - start
+
+ payload = {
+ "user_name": user_name,
+ "running_tasks": running_count,
+ "elapsed_seconds": round(elapsed, 3),
+ "status": "running" if running_count > 0 else "idle",
+ "instance_id": INSTANCE_ID,
+ }
+ yield "data: " + json.dumps(payload, ensure_ascii=False) + "\n\n"
+
+ if running_count == 0 or elapsed > timeout_seconds:
+ payload["status"] = "idle" if running_count == 0 else "timeout"
+ payload["timed_out"] = running_count > 0
+ yield "data: " + json.dumps(payload, ensure_ascii=False) + "\n\n"
+ break
+
+ time.sleep(poll_interval)
+
+ except Exception as e:
+ err_payload = {
+ "status": "error",
+ "detail": "stream_failed",
+ "exception": str(e),
+ "user_name": user_name,
+ }
+ logger.error(f"Scheduler stream error for {user_name}: {traceback.format_exc()}")
+ yield "data: " + json.dumps(err_payload, ensure_ascii=False) + "\n\n"
+
+ return StreamingResponse(event_generator(), media_type="text/event-stream")
+
+
@router.post("/chat/complete", summary="Chat with MemOS (Complete Response)")
def chat_complete(chat_req: APIChatCompleteRequest):
"""Chat with MemOS for a specific user. Returns complete response (non-streaming)."""
try:
# Collect all responses from the generator
- naive_mem_cube = _create_naive_mem_cube()
content, references = mos_server.chat(
query=chat_req.query,
user_id=chat_req.user_id,
diff --git a/src/memos/api/server_api.py b/src/memos/api/server_api.py
index 78e05ef85..0dfef99d9 100644
--- a/src/memos/api/server_api.py
+++ b/src/memos/api/server_api.py
@@ -1,6 +1,7 @@
import logging
-from fastapi import FastAPI
+from fastapi import FastAPI, HTTPException
+from fastapi.exceptions import RequestValidationError
from memos.api.exceptions import APIExceptionHandler
from memos.api.middleware.request_context import RequestContextMiddleware
@@ -17,12 +18,17 @@
version="1.0.1",
)
-app.add_middleware(RequestContextMiddleware)
+app.add_middleware(RequestContextMiddleware, source="server_api")
# Include routers
app.include_router(server_router)
-# Exception handlers
+# Request validation failed
+app.exception_handler(RequestValidationError)(APIExceptionHandler.validation_error_handler)
+# Invalid business code parameters
app.exception_handler(ValueError)(APIExceptionHandler.value_error_handler)
+# Business layer manual exception
+app.exception_handler(HTTPException)(APIExceptionHandler.http_error_handler)
+# Fallback for unknown errors
app.exception_handler(Exception)(APIExceptionHandler.global_exception_handler)
diff --git a/src/memos/chunkers/sentence_chunker.py b/src/memos/chunkers/sentence_chunker.py
index 4de0cf32b..080962482 100644
--- a/src/memos/chunkers/sentence_chunker.py
+++ b/src/memos/chunkers/sentence_chunker.py
@@ -28,7 +28,7 @@ def __init__(self, config: SentenceChunkerConfig):
)
logger.info(f"Initialized SentenceChunker with config: {config}")
- def chunk(self, text: str) -> list[Chunk]:
+ def chunk(self, text: str) -> list[str] | list[Chunk]:
"""Chunk the given text into smaller chunks based on sentences."""
chonkie_chunks = self.chunker.chunk(text)
diff --git a/src/memos/configs/graph_db.py b/src/memos/configs/graph_db.py
index 2df917166..ce180606b 100644
--- a/src/memos/configs/graph_db.py
+++ b/src/memos/configs/graph_db.py
@@ -154,6 +154,59 @@ def validate_config(self):
return self
+class PolarDBGraphDBConfig(BaseConfig):
+ """
+ PolarDB-specific configuration.
+
+ Key concepts:
+ - `db_name`: The name of the target PolarDB database
+ - `user_name`: Used for logical tenant isolation if needed
+ - `auto_create`: Whether to automatically create the target database if it does not exist
+ - `use_multi_db`: Whether to use multi-database mode for physical isolation
+
+ Example:
+ ---
+ host = "localhost"
+ port = 5432
+ user = "postgres"
+ password = "password"
+ db_name = "memos_db"
+ user_name = "alice"
+ use_multi_db = True
+ auto_create = True
+ """
+
+ host: str = Field(..., description="Database host")
+ port: int = Field(default=5432, description="Database port")
+ user: str = Field(..., description="Database user")
+ password: str = Field(..., description="Database password")
+ db_name: str = Field(..., description="The name of the target PolarDB database")
+ user_name: str | None = Field(
+ default=None,
+ description="Logical user or tenant ID for data isolation (optional, used in metadata tagging)",
+ )
+ auto_create: bool = Field(
+ default=False,
+ description="Whether to auto-create the database if it does not exist",
+ )
+ use_multi_db: bool = Field(
+ default=True,
+ description=(
+ "If True: use multi-database mode for physical isolation; "
+ "each tenant typically gets a separate database. "
+ "If False: use a single shared database with logical isolation by user_name."
+ ),
+ )
+ embedding_dimension: int = Field(default=1024, description="Dimension of vector embedding")
+
+ @model_validator(mode="after")
+ def validate_config(self):
+ """Validate config."""
+ if not self.db_name:
+ raise ValueError("`db_name` must be provided")
+ return self
+
+
class GraphDBConfigFactory(BaseModel):
backend: str = Field(..., description="Backend for graph database")
config: dict[str, Any] = Field(..., description="Configuration for the graph database backend")
@@ -162,6 +215,7 @@ class GraphDBConfigFactory(BaseModel):
"neo4j": Neo4jGraphDBConfig,
"neo4j-community": Neo4jCommunityGraphDBConfig,
"nebular": NebulaGraphDBConfig,
+ "polardb": PolarDBGraphDBConfig,
}
@field_validator("backend")
diff --git a/src/memos/configs/mem_cube.py b/src/memos/configs/mem_cube.py
index b9868fa99..4bd709fab 100644
--- a/src/memos/configs/mem_cube.py
+++ b/src/memos/configs/mem_cube.py
@@ -54,6 +54,11 @@ class GeneralMemCubeConfig(BaseMemCubeConfig):
default_factory=MemoryConfigFactory,
description="Configuration for the parametric memory",
)
+ pref_mem: MemoryConfigFactory = Field(
+ ...,
+ default_factory=MemoryConfigFactory,
+ description="Configuration for the preference memory",
+ )
@field_validator("text_mem")
@classmethod
@@ -87,3 +92,14 @@ def validate_para_mem(cls, para_mem: MemoryConfigFactory) -> MemoryConfigFactory
f"GeneralMemCubeConfig requires para_mem backend to be one of {allowed_backends}, got '{para_mem.backend}'"
)
return para_mem
+
+ @field_validator("pref_mem")
+ @classmethod
+ def validate_pref_mem(cls, pref_mem: MemoryConfigFactory) -> MemoryConfigFactory:
+ """Validate the pref_mem field."""
+ allowed_backends = ["pref_text", "uninitialized"]
+ if pref_mem.backend not in allowed_backends:
+ raise ConfigurationError(
+ f"GeneralMemCubeConfig requires pref_mem backend to be one of {allowed_backends}, got '{pref_mem.backend}'"
+ )
+ return pref_mem
diff --git a/src/memos/configs/mem_os.py b/src/memos/configs/mem_os.py
index 0645fce44..549e55792 100644
--- a/src/memos/configs/mem_os.py
+++ b/src/memos/configs/mem_os.py
@@ -58,6 +58,10 @@ class MOSConfig(BaseConfig):
default=False,
description="Enable parametric memory for the MemChat",
)
+ enable_preference_memory: bool = Field(
+ default=False,
+ description="Enable preference memory for the MemChat",
+ )
enable_mem_scheduler: bool = Field(
default=False,
description="Enable memory scheduler for automated memory management",
diff --git a/src/memos/configs/mem_reader.py b/src/memos/configs/mem_reader.py
index 1c62087a3..dc8d37a35 100644
--- a/src/memos/configs/mem_reader.py
+++ b/src/memos/configs/mem_reader.py
@@ -36,11 +36,19 @@ def parse_datetime(cls, value):
description="whether remove example in memory extraction prompt to save token",
)
+ chat_chunker: dict[str, Any] = Field(
+ default=None, description="Configuration for the MemReader chat chunk strategy"
+ )
+
class SimpleStructMemReaderConfig(BaseMemReaderConfig):
"""SimpleStruct MemReader configuration class."""
+class StrategyStructMemReaderConfig(BaseMemReaderConfig):
+ """StrategyStruct MemReader configuration class."""
+
+
class MemReaderConfigFactory(BaseConfig):
"""Factory class for creating MemReader configurations."""
@@ -49,6 +57,7 @@ class MemReaderConfigFactory(BaseConfig):
backend_to_class: ClassVar[dict[str, Any]] = {
"simple_struct": SimpleStructMemReaderConfig,
+ "strategy_struct": StrategyStructMemReaderConfig,
}
@field_validator("backend")
diff --git a/src/memos/configs/mem_scheduler.py b/src/memos/configs/mem_scheduler.py
index 39586081c..e757f243b 100644
--- a/src/memos/configs/mem_scheduler.py
+++ b/src/memos/configs/mem_scheduler.py
@@ -11,8 +11,15 @@
from memos.mem_scheduler.schemas.general_schemas import (
BASE_DIR,
DEFAULT_ACT_MEM_DUMP_PATH,
+ DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT,
DEFAULT_CONSUME_INTERVAL_SECONDS,
+ DEFAULT_CONTEXT_WINDOW_SIZE,
+ DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
+ DEFAULT_MULTI_TASK_RUNNING_TIMEOUT,
DEFAULT_THREAD_POOL_MAX_WORKERS,
+ DEFAULT_TOP_K,
+ DEFAULT_USE_REDIS_QUEUE,
+ DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT,
)
@@ -20,7 +27,8 @@ class BaseSchedulerConfig(BaseConfig):
"""Base configuration class for mem_scheduler."""
top_k: int = Field(
- default=10, description="Number of top candidates to consider in initial retrieval"
+ default=DEFAULT_TOP_K,
+ description="Number of top candidates to consider in initial retrieval",
)
enable_parallel_dispatch: bool = Field(
default=True, description="Whether to enable parallel message processing using thread pool"
@@ -28,19 +36,34 @@ class BaseSchedulerConfig(BaseConfig):
thread_pool_max_workers: int = Field(
default=DEFAULT_THREAD_POOL_MAX_WORKERS,
gt=1,
- lt=20,
description=f"Maximum worker threads in pool (default: {DEFAULT_THREAD_POOL_MAX_WORKERS})",
)
consume_interval_seconds: float = Field(
default=DEFAULT_CONSUME_INTERVAL_SECONDS,
gt=0,
- le=60,
description=f"Interval for consuming messages from queue in seconds (default: {DEFAULT_CONSUME_INTERVAL_SECONDS})",
)
auth_config_path: str | None = Field(
default=None,
description="Path to the authentication configuration file containing private credentials",
)
+ # Redis queue configuration
+ use_redis_queue: bool = Field(
+ default=DEFAULT_USE_REDIS_QUEUE,
+ description="Whether to use Redis queue instead of local memory queue",
+ )
+ redis_config: dict[str, Any] = Field(
+ default_factory=lambda: {"host": "localhost", "port": 6379, "db": 0},
+ description="Redis connection configuration",
+ )
+ max_internal_message_queue_size: int = Field(
+ default=DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
+ description="Maximum size of internal message queue when not using Redis",
+ )
+ multi_task_running_timeout: int = Field(
+ default=DEFAULT_MULTI_TASK_RUNNING_TIMEOUT,
+ description="Default timeout for multi-task running operations in seconds",
+ )
class GeneralSchedulerConfig(BaseSchedulerConfig):
@@ -49,7 +72,8 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
default=300, description="Interval in seconds for updating activation memory"
)
context_window_size: int | None = Field(
- default=10, description="Size of the context window for conversation history"
+ default=DEFAULT_CONTEXT_WINDOW_SIZE,
+ description="Size of the context window for conversation history",
)
act_mem_dump_path: str | None = Field(
default=DEFAULT_ACT_MEM_DUMP_PATH, # Replace with DEFAULT_ACT_MEM_DUMP_PATH
@@ -59,10 +83,12 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
default=False, description="Whether to enable automatic activation memory updates"
)
working_mem_monitor_capacity: int = Field(
- default=30, description="Capacity of the working memory monitor"
+ default=DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT,
+ description="Capacity of the working memory monitor",
)
activation_mem_monitor_capacity: int = Field(
- default=20, description="Capacity of the activation memory monitor"
+ default=DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT,
+ description="Capacity of the activation memory monitor",
)
# Database configuration for ORM persistence
@@ -79,6 +105,14 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
)
+class OptimizedSchedulerConfig(GeneralSchedulerConfig):
+ """Configuration for the optimized scheduler.
+
+ This class inherits all fields from `GeneralSchedulerConfig`
+ and is used to distinguish optimized scheduling logic via type.
+ """
+
+
class SchedulerConfigFactory(BaseConfig):
"""Factory class for creating scheduler configurations."""
@@ -88,7 +122,7 @@ class SchedulerConfigFactory(BaseConfig):
model_config = ConfigDict(extra="forbid", strict=True)
backend_to_class: ClassVar[dict[str, Any]] = {
"general_scheduler": GeneralSchedulerConfig,
- "optimized_scheduler": GeneralSchedulerConfig, # optimized_scheduler uses same config as general_scheduler
+ "optimized_scheduler": OptimizedSchedulerConfig, # optimized_scheduler uses same config as general_scheduler
}
@field_validator("backend")
diff --git a/src/memos/configs/memory.py b/src/memos/configs/memory.py
index 237450e15..34967849a 100644
--- a/src/memos/configs/memory.py
+++ b/src/memos/configs/memory.py
@@ -10,6 +10,11 @@
from memos.configs.reranker import RerankerConfigFactory
from memos.configs.vec_db import VectorDBConfigFactory
from memos.exceptions import ConfigurationError
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
# ─── 1. Global Base Memory Config ─────────────────────────────────────────────
@@ -179,11 +184,62 @@ class TreeTextMemoryConfig(BaseTextMemoryConfig):
),
)
+ search_strategy: dict[str, Any] | None = Field(
+ default=None,
+ description=(
+ 'Set search strategy for this memory configuration.{"bm25": true, "cot": false}'
+ ),
+ )
+
+ mode: str | None = Field(
+ default="sync",
+ description=("whether use asynchronous mode in memory add"),
+ )
+
class SimpleTreeTextMemoryConfig(TreeTextMemoryConfig):
"""Simple tree text memory configuration class."""
+class PreferenceTextMemoryConfig(BaseTextMemoryConfig):
+ """Preference memory configuration class."""
+
+ extractor_llm: LLMConfigFactory = Field(
+ ...,
+ default_factory=LLMConfigFactory,
+ description="LLM configuration for the memory extractor",
+ )
+ vector_db: VectorDBConfigFactory = Field(
+ ...,
+ default_factory=VectorDBConfigFactory,
+ description="Vector database configuration for the memory storage",
+ )
+ embedder: EmbedderConfigFactory = Field(
+ ...,
+ default_factory=EmbedderConfigFactory,
+ description="Embedder configuration for the memory embedding",
+ )
+ reranker: RerankerConfigFactory | None = Field(
+ None,
+ description="Reranker configuration (optional).",
+ )
+ extractor: ExtractorConfigFactory = Field(
+ ...,
+ default_factory=ExtractorConfigFactory,
+ description="Extractor configuration for the memory extracting",
+ )
+ adder: AdderConfigFactory = Field(
+ ...,
+ default_factory=AdderConfigFactory,
+ description="Adder configuration for the memory adding",
+ )
+ retriever: RetrieverConfigFactory = Field(
+ ...,
+ default_factory=RetrieverConfigFactory,
+ description="Retriever configuration for the memory retrieving",
+ )
+
+
# ─── 3. Global Memory Config Factory ──────────────────────────────────────────
@@ -198,6 +254,7 @@ class MemoryConfigFactory(BaseConfig):
"general_text": GeneralTextMemoryConfig,
"simple_tree_text": SimpleTreeTextMemoryConfig,
"tree_text": TreeTextMemoryConfig,
+ "pref_text": PreferenceTextMemoryConfig,
"kv_cache": KVCacheMemoryConfig,
"vllm_kv_cache": KVCacheMemoryConfig, # Use same config as kv_cache
"lora": LoRAMemoryConfig,
diff --git a/src/memos/context/context.py b/src/memos/context/context.py
index 4f54348fb..b5d4c24fe 100644
--- a/src/memos/context/context.py
+++ b/src/memos/context/context.py
@@ -29,9 +29,21 @@ class RequestContext:
This provides a Flask g-like object for FastAPI applications.
"""
- def __init__(self, trace_id: str | None = None, api_path: str | None = None):
+ def __init__(
+ self,
+ trace_id: str | None = None,
+ api_path: str | None = None,
+ env: str | None = None,
+ user_type: str | None = None,
+ user_name: str | None = None,
+ source: str | None = None,
+ ):
self.trace_id = trace_id or "trace-id"
self.api_path = api_path
+ self.env = env
+ self.user_type = user_type
+ self.user_name = user_name
+ self.source = source
self._data: dict[str, Any] = {}
def set(self, key: str, value: Any) -> None:
@@ -43,7 +55,14 @@ def get(self, key: str, default: Any | None = None) -> Any:
return self._data.get(key, default)
def __setattr__(self, name: str, value: Any) -> None:
- if name.startswith("_") or name in ("trace_id", "api_path"):
+ if name.startswith("_") or name in (
+ "trace_id",
+ "api_path",
+ "env",
+ "user_type",
+ "user_name",
+ "source",
+ ):
super().__setattr__(name, value)
else:
if not hasattr(self, "_data"):
@@ -58,7 +77,15 @@ def __getattr__(self, name: str) -> Any:
def to_dict(self) -> dict[str, Any]:
"""Convert context to dictionary."""
- return {"trace_id": self.trace_id, "api_path": self.api_path, "data": self._data.copy()}
+ return {
+ "trace_id": self.trace_id,
+ "api_path": self.api_path,
+ "env": self.env,
+ "user_type": self.user_type,
+ "user_name": self.user_name,
+ "source": self.source,
+ "data": self._data.copy(),
+ }
def set_request_context(context: RequestContext) -> None:
@@ -93,6 +120,46 @@ def get_current_api_path() -> str | None:
return None
+def get_current_env() -> str | None:
+ """
+ Get the current request's env.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("env")
+ return "prod"
+
+
+def get_current_user_type() -> str | None:
+ """
+ Get the current request's user type.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("user_type")
+ return "opensource"
+
+
+def get_current_user_name() -> str | None:
+ """
+ Get the current request's user name.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("user_name")
+ return "memos"
+
+
+def get_current_source() -> str | None:
+ """
+ Get the current request's source (e.g., 'product_api' or 'server_api').
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("source")
+ return None
+
+
def get_current_context() -> RequestContext | None:
"""
Get the current request context.
@@ -103,7 +170,12 @@ def get_current_context() -> RequestContext | None:
context_dict = _request_context.get()
if context_dict:
ctx = RequestContext(
- trace_id=context_dict.get("trace_id"), api_path=context_dict.get("api_path")
+ trace_id=context_dict.get("trace_id"),
+ api_path=context_dict.get("api_path"),
+ env=context_dict.get("env"),
+ user_type=context_dict.get("user_type"),
+ user_name=context_dict.get("user_name"),
+ source=context_dict.get("source"),
)
ctx._data = context_dict.get("data", {}).copy()
return ctx
@@ -141,6 +213,9 @@ def __init__(self, target, args=(), kwargs=None, **thread_kwargs):
self.main_trace_id = get_current_trace_id()
self.main_api_path = get_current_api_path()
+ self.main_env = get_current_env()
+ self.main_user_type = get_current_user_type()
+ self.main_user_name = get_current_user_name()
self.main_context = get_current_context()
def run(self):
@@ -148,7 +223,11 @@ def run(self):
if self.main_context:
# Copy the context data
child_context = RequestContext(
- trace_id=self.main_trace_id, api_path=self.main_context.api_path
+ trace_id=self.main_trace_id,
+ api_path=self.main_api_path,
+ env=self.main_env,
+ user_type=self.main_user_type,
+ user_name=self.main_user_name,
)
child_context._data = self.main_context._data.copy()
@@ -171,13 +250,22 @@ def submit(self, fn: Callable[..., T], *args: Any, **kwargs: Any) -> Any:
"""
main_trace_id = get_current_trace_id()
main_api_path = get_current_api_path()
+ main_env = get_current_env()
+ main_user_type = get_current_user_type()
+ main_user_name = get_current_user_name()
main_context = get_current_context()
@functools.wraps(fn)
def wrapper(*args: Any, **kwargs: Any) -> Any:
if main_context:
# Create and set new context in worker thread
- child_context = RequestContext(trace_id=main_trace_id, api_path=main_api_path)
+ child_context = RequestContext(
+ trace_id=main_trace_id,
+ api_path=main_api_path,
+ env=main_env,
+ user_type=main_user_type,
+ user_name=main_user_name,
+ )
child_context._data = main_context._data.copy()
set_request_context(child_context)
@@ -198,13 +286,22 @@ def map(
"""
main_trace_id = get_current_trace_id()
main_api_path = get_current_api_path()
+ main_env = get_current_env()
+ main_user_type = get_current_user_type()
+ main_user_name = get_current_user_name()
main_context = get_current_context()
@functools.wraps(fn)
def wrapper(*args: Any, **kwargs: Any) -> Any:
if main_context:
# Create and set new context in worker thread
- child_context = RequestContext(trace_id=main_trace_id, api_path=main_api_path)
+ child_context = RequestContext(
+ trace_id=main_trace_id,
+ api_path=main_api_path,
+ env=main_env,
+ user_type=main_user_type,
+ user_name=main_user_name,
+ )
child_context._data = main_context._data.copy()
set_request_context(child_context)
diff --git a/src/memos/embedders/universal_api.py b/src/memos/embedders/universal_api.py
index 72116cf05..fc51cf073 100644
--- a/src/memos/embedders/universal_api.py
+++ b/src/memos/embedders/universal_api.py
@@ -3,6 +3,11 @@
from memos.configs.embedder import UniversalAPIEmbedderConfig
from memos.embedders.base import BaseEmbedder
+from memos.log import get_logger
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
class UniversalAPIEmbedder(BaseEmbedder):
@@ -19,14 +24,18 @@ def __init__(self, config: UniversalAPIEmbedderConfig):
api_key=config.api_key,
)
else:
- raise ValueError(f"Unsupported provider: {self.provider}")
+ raise ValueError(f"Embeddings unsupported provider: {self.provider}")
+ @timed(log=True, log_prefix="EmbedderAPI")
def embed(self, texts: list[str]) -> list[list[float]]:
if self.provider == "openai" or self.provider == "azure":
- response = self.client.embeddings.create(
- model=getattr(self.config, "model_name_or_path", "text-embedding-3-large"),
- input=texts,
- )
- return [r.embedding for r in response.data]
+ try:
+ response = self.client.embeddings.create(
+ model=getattr(self.config, "model_name_or_path", "text-embedding-3-large"),
+ input=texts,
+ )
+ return [r.embedding for r in response.data]
+ except Exception as e:
+ raise Exception(f"Embeddings request ended with error: {e}") from e
else:
- raise ValueError(f"Unsupported provider: {self.provider}")
+ raise ValueError(f"Embeddings unsupported provider: {self.provider}")
diff --git a/src/memos/graph_dbs/factory.py b/src/memos/graph_dbs/factory.py
index 0b38287eb..ec9cbcda0 100644
--- a/src/memos/graph_dbs/factory.py
+++ b/src/memos/graph_dbs/factory.py
@@ -5,6 +5,7 @@
from memos.graph_dbs.nebular import NebulaGraphDB
from memos.graph_dbs.neo4j import Neo4jGraphDB
from memos.graph_dbs.neo4j_community import Neo4jCommunityGraphDB
+from memos.graph_dbs.polardb import PolarDBGraphDB
class GraphStoreFactory(BaseGraphDB):
@@ -14,6 +15,7 @@ class GraphStoreFactory(BaseGraphDB):
"neo4j": Neo4jGraphDB,
"neo4j-community": Neo4jCommunityGraphDB,
"nebular": NebulaGraphDB,
+ "polardb": PolarDBGraphDB,
}
@classmethod
diff --git a/src/memos/graph_dbs/nebular.py b/src/memos/graph_dbs/nebular.py
index 9a74373d7..89b58f417 100644
--- a/src/memos/graph_dbs/nebular.py
+++ b/src/memos/graph_dbs/nebular.py
@@ -439,21 +439,24 @@ def remove_oldest_memory(
Args:
memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name(str): optional user_name.
"""
- optional_condition = ""
-
- user_name = user_name if user_name else self.config.user_name
-
- optional_condition = f"AND n.user_name = '{user_name}'"
- query = f"""
- MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
- WHERE n.memory_type = '{memory_type}'
- {optional_condition}
- ORDER BY n.updated_at DESC
- OFFSET {int(keep_latest)}
- DETACH DELETE n
- """
- self.execute_query(query)
+ try:
+ user_name = user_name if user_name else self.config.user_name
+ optional_condition = f"AND n.user_name = '{user_name}'"
+ count = self.count_nodes(memory_type, user_name)
+ if count > keep_latest:
+ delete_query = f"""
+ MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
+ WHERE n.memory_type = '{memory_type}'
+ {optional_condition}
+ ORDER BY n.updated_at DESC
+ OFFSET {int(keep_latest)}
+ DETACH DELETE n
+ """
+ self.execute_query(delete_query)
+ except Exception as e:
+ logger.warning(f"Delete old mem error: {e}")
@timed
def add_node(
@@ -683,8 +686,7 @@ def get_node(
Returns:
dict: Node properties as key-value pairs, or None if not found.
"""
- user_name = user_name if user_name else self.config.user_name
- filter_clause = f'n.user_name = "{user_name}" AND n.id = "{id}"'
+ filter_clause = f'n.id = "{id}"'
return_fields = self._build_return_fields(include_embedding)
gql = f"""
MATCH (n@Memory)
@@ -728,16 +730,13 @@ def get_nodes(
"""
if not ids:
return []
-
- user_name = user_name if user_name else self.config.user_name
- where_user = f" AND n.user_name = '{user_name}'"
# Safe formatting of the ID list
id_list = ",".join(f'"{_id}"' for _id in ids)
return_fields = self._build_return_fields(include_embedding)
query = f"""
MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
- WHERE n.id IN [{id_list}] {where_user}
+ WHERE n.id IN [{id_list}]
RETURN {return_fields}
"""
nodes = []
@@ -1175,7 +1174,6 @@ def get_grouped_counts(
MATCH (n /*+ INDEX(idx_memory_user_name) */)
{where_clause}
RETURN {", ".join(return_fields)}, COUNT(n) AS count
- GROUP BY {", ".join(group_by_fields)}
"""
result = self.execute_query(gql) # Pure GQL string execution
@@ -1496,10 +1494,10 @@ def _ensure_space_exists(cls, tmp_client, cfg):
return
try:
- res = tmp_client.execute("SHOW GRAPHS;")
+ res = tmp_client.execute("SHOW GRAPHS")
existing = {row.values()[0].as_string() for row in res}
if db_name not in existing:
- tmp_client.execute(f"CREATE GRAPH IF NOT EXISTS `{db_name}` TYPED MemOSBgeM3Type;")
+ tmp_client.execute(f"CREATE GRAPH IF NOT EXISTS `{db_name}` TYPED MemOSBgeM3Type")
logger.info(f"✅ Graph `{db_name}` created before session binding.")
else:
logger.debug(f"Graph `{db_name}` already exists.")
@@ -1550,7 +1548,7 @@ def _ensure_database_exists(self):
"""
self.execute_query(create_tag, auto_set_db=False)
else:
- describe_query = f"DESCRIBE NODE TYPE Memory OF {graph_type_name};"
+ describe_query = f"DESCRIBE NODE TYPE Memory OF {graph_type_name}"
desc_result = self.execute_query(describe_query, auto_set_db=False)
memory_fields = []
@@ -1620,7 +1618,13 @@ def _create_basic_property_indexes(self) -> None:
Create standard B-tree indexes on user_name when use Shared Database
Multi-Tenant Mode.
"""
- fields = ["status", "memory_type", "created_at", "updated_at", "user_name"]
+ fields = [
+ "status",
+ "memory_type",
+ "created_at",
+ "updated_at",
+ "user_name",
+ ]
for field in fields:
index_name = f"idx_memory_{field}"
diff --git a/src/memos/graph_dbs/neo4j.py b/src/memos/graph_dbs/neo4j.py
index 55db60ed2..367b486cd 100644
--- a/src/memos/graph_dbs/neo4j.py
+++ b/src/memos/graph_dbs/neo4j.py
@@ -149,6 +149,7 @@ def remove_oldest_memory(
Args:
memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name(str): optional user_name.
"""
user_name = user_name if user_name else self.config.user_name
query = f"""
@@ -157,7 +158,7 @@ def remove_oldest_memory(
"""
if not self.config.use_multi_db and (self.config.user_name or user_name):
query += f"\nAND n.user_name = '{user_name}'"
-
+ keep_latest = int(keep_latest)
query += f"""
WITH n ORDER BY n.updated_at DESC
SKIP {keep_latest}
@@ -669,7 +670,7 @@ def search_by_embedding(
vector (list[float]): The embedding vector representing query semantics.
top_k (int): Number of top similar nodes to retrieve.
scope (str, optional): Memory type filter (e.g., 'WorkingMemory', 'LongTermMemory').
- status (str, optional): Node status filter (e.g., 'active', 'archived').
+ status (str, optional): Node status filter (e.g., 'activated', 'archived').
If provided, restricts results to nodes with matching status.
threshold (float, optional): Minimum similarity score threshold (0 ~ 1).
search_filter (dict, optional): Additional metadata filters for search results.
@@ -1071,7 +1072,7 @@ def drop_database(self) -> None:
with self.driver.session(database=self.system_db_name) as session:
session.run(f"DROP DATABASE {self.db_name} IF EXISTS")
- print(f"Database '{self.db_name}' has been dropped.")
+ logger.info(f"Database '{self.db_name}' has been dropped.")
else:
raise ValueError(
f"Refusing to drop protected database: {self.db_name} in "
diff --git a/src/memos/graph_dbs/polardb.py b/src/memos/graph_dbs/polardb.py
new file mode 100644
index 000000000..60902420f
--- /dev/null
+++ b/src/memos/graph_dbs/polardb.py
@@ -0,0 +1,3039 @@
+import json
+import random
+
+from datetime import datetime
+from typing import Any, Literal
+
+import numpy as np
+
+from memos.configs.graph_db import PolarDBGraphDBConfig
+from memos.dependency import require_python_package
+from memos.graph_dbs.base import BaseGraphDB
+from memos.log import get_logger
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
+
+
+def _compose_node(item: dict[str, Any]) -> tuple[str, str, dict[str, Any]]:
+ node_id = item["id"]
+ memory = item["memory"]
+ metadata = item.get("metadata", {})
+ return node_id, memory, metadata
+
+
+def _prepare_node_metadata(metadata: dict[str, Any]) -> dict[str, Any]:
+ """
+ Ensure metadata has proper datetime fields and normalized types.
+
+ - Fill `created_at` and `updated_at` if missing (in ISO 8601 format).
+ - Convert embedding to list of float if present.
+ """
+ now = datetime.utcnow().isoformat()
+
+ # Fill timestamps if missing
+ metadata.setdefault("created_at", now)
+ metadata.setdefault("updated_at", now)
+
+ # Normalize embedding type
+ embedding = metadata.get("embedding")
+ if embedding and isinstance(embedding, list):
+ metadata["embedding"] = [float(x) for x in embedding]
+
+ return metadata
+
+
+def generate_vector(dim=1024, low=-0.2, high=0.2):
+ """Generate a random vector for testing purposes."""
+ return [round(random.uniform(low, high), 6) for _ in range(dim)]
+
+
+def find_embedding(metadata):
+ def find_embedding(item):
+ """Find an embedding vector within nested structures"""
+ for key in ["embedding", "embedding_1024", "embedding_3072", "embedding_768"]:
+ if key in item and isinstance(item[key], list):
+ return item[key]
+ if "metadata" in item and key in item["metadata"]:
+ return item["metadata"][key]
+ if "properties" in item and key in item["properties"]:
+ return item["properties"][key]
+ return None
+
+
+def detect_embedding_field(embedding_list):
+ if not embedding_list:
+ return None
+ dim = len(embedding_list)
+ if dim == 1024:
+ return "embedding"
+ else:
+ logger.warning(f"Unknown embedding dimension {dim}, skipping this vector")
+ return None
+
+
+def convert_to_vector(embedding_list):
+ if not embedding_list:
+ return None
+ if isinstance(embedding_list, np.ndarray):
+ embedding_list = embedding_list.tolist()
+ return "[" + ",".join(str(float(x)) for x in embedding_list) + "]"
+
+
+def clean_properties(props):
+ """Remove vector fields"""
+ vector_keys = {"embedding", "embedding_1024", "embedding_3072", "embedding_768"}
+ if not isinstance(props, dict):
+ return {}
+ return {k: v for k, v in props.items() if k not in vector_keys}
+
+
+class PolarDBGraphDB(BaseGraphDB):
+ """PolarDB-based implementation using Apache AGE graph database extension."""
+
+ @require_python_package(
+ import_name="psycopg2",
+ install_command="pip install psycopg2-binary",
+ install_link="https://pypi.org/project/psycopg2-binary/",
+ )
+ def __init__(self, config: PolarDBGraphDBConfig):
+ """PolarDB-based implementation using Apache AGE.
+
+ Tenant Modes:
+ - use_multi_db = True:
+ Dedicated Database Mode (Multi-Database Multi-Tenant).
+ Each tenant or logical scope uses a separate PolarDB database.
+ `db_name` is the specific tenant database.
+ `user_name` can be None (optional).
+
+ - use_multi_db = False:
+ Shared Database Multi-Tenant Mode.
+ All tenants share a single PolarDB database.
+ `db_name` is the shared database.
+ `user_name` is required to isolate each tenant's data at the node level.
+ All node queries will enforce `user_name` in WHERE conditions and store it in metadata,
+ but it will be removed automatically before returning to external consumers.
+ """
+ import psycopg2
+ import psycopg2.pool
+
+ self.config = config
+
+ # Handle both dict and object config
+ if isinstance(config, dict):
+ self.db_name = config.get("db_name")
+ self.user_name = config.get("user_name")
+ host = config.get("host")
+ port = config.get("port")
+ user = config.get("user")
+ password = config.get("password")
+ else:
+ self.db_name = config.db_name
+ self.user_name = config.user_name
+ host = config.host
+ port = config.port
+ user = config.user
+ password = config.password
+ """
+ # Create connection
+ self.connection = psycopg2.connect(
+ host=host, port=port, user=user, password=password, dbname=self.db_name,minconn=10, maxconn=2000
+ )
+ """
+
+ # Create connection pool
+ self.connection_pool = psycopg2.pool.ThreadedConnectionPool(
+ minconn=5,
+ maxconn=2000,
+ host=host,
+ port=port,
+ user=user,
+ password=password,
+ dbname=self.db_name,
+ connect_timeout=60, # Connection timeout in seconds
+ keepalives_idle=40, # Seconds of inactivity before sending keepalive (should be < server idle timeout)
+ keepalives_interval=15, # Seconds between keepalive retries
+ keepalives_count=5, # Number of keepalive retries before considering connection dead
+ )
+
+ # Keep a reference to the pool for cleanup
+ self._pool_closed = False
+
+ """
+ # Handle auto_create
+ # auto_create = config.get("auto_create", False) if isinstance(config, dict) else config.auto_create
+ # if auto_create:
+ # self._ensure_database_exists()
+
+ # Create graph and tables
+ # self.create_graph()
+ # self.create_edge()
+ # self._create_graph()
+
+ # Handle embedding_dimension
+ # embedding_dim = config.get("embedding_dimension", 1024) if isinstance(config,dict) else config.embedding_dimension
+ # self.create_index(dimensions=embedding_dim)
+ """
+
+ def _get_config_value(self, key: str, default=None):
+ """Safely get config value from either dict or object."""
+ if isinstance(self.config, dict):
+ return self.config.get(key, default)
+ else:
+ return getattr(self.config, key, default)
+
+ def _get_connection_old(self):
+ """Get a connection from the pool."""
+ if self._pool_closed:
+ raise RuntimeError("Connection pool has been closed")
+ conn = self.connection_pool.getconn()
+ # Set autocommit for PolarDB compatibility
+ conn.autocommit = True
+ return conn
+
+ def _get_connection(self):
+ """Get a connection from the pool."""
+ if self._pool_closed:
+ raise RuntimeError("Connection pool has been closed")
+
+ max_retries = 3
+ for attempt in range(max_retries):
+ try:
+ conn = self.connection_pool.getconn()
+
+ # Check if connection is closed
+ if conn.closed != 0:
+ # Connection is closed, close it explicitly and try again
+ try:
+ conn.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+ if attempt < max_retries - 1:
+ continue
+ else:
+ raise RuntimeError("Pool returned a closed connection")
+
+ # Set autocommit for PolarDB compatibility
+ conn.autocommit = True
+ return conn
+ except Exception as e:
+ if attempt >= max_retries - 1:
+ raise RuntimeError(f"Failed to get a valid connection from pool: {e}") from e
+ continue
+
+ def _return_connection(self, connection):
+ """Return a connection to the pool."""
+ if not self._pool_closed and connection:
+ try:
+ # Check if connection is closed
+ if hasattr(connection, "closed") and connection.closed != 0:
+ # Connection is closed, just close it and don't return to pool
+ try:
+ connection.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+ return
+
+ # Connection is valid, return to pool
+ self.connection_pool.putconn(connection)
+ except Exception as e:
+ # If putconn fails, close the connection
+ logger.warning(f"Failed to return connection to pool: {e}")
+ try:
+ connection.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+
+ def _return_connection_old(self, connection):
+ """Return a connection to the pool."""
+ if not self._pool_closed and connection:
+ self.connection_pool.putconn(connection)
+
+ def _ensure_database_exists(self):
+ """Create database if it doesn't exist."""
+ try:
+ # For PostgreSQL/PolarDB, we need to connect to a default database first
+ # This is a simplified implementation - in production you might want to handle this differently
+ logger.info(f"Using database '{self.db_name}'")
+ except Exception as e:
+ logger.error(f"Failed to access database '{self.db_name}': {e}")
+ raise
+
+ @timed
+ def _create_graph(self):
+ """Create PostgreSQL schema and table for graph storage."""
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Create schema if it doesn't exist
+ cursor.execute(f'CREATE SCHEMA IF NOT EXISTS "{self.db_name}_graph";')
+ logger.info(f"Schema '{self.db_name}_graph' ensured.")
+
+ # Create Memory table if it doesn't exist
+ cursor.execute(f"""
+ CREATE TABLE IF NOT EXISTS "{self.db_name}_graph"."Memory" (
+ id TEXT PRIMARY KEY,
+ properties JSONB NOT NULL,
+ created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
+ updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
+ );
+ """)
+ logger.info(f"Memory table created in schema '{self.db_name}_graph'.")
+
+ # Add embedding column if it doesn't exist (using JSONB for compatibility)
+ try:
+ cursor.execute(f"""
+ ALTER TABLE "{self.db_name}_graph"."Memory"
+ ADD COLUMN IF NOT EXISTS embedding JSONB;
+ """)
+ logger.info("Embedding column added to Memory table.")
+ except Exception as e:
+ logger.warning(f"Failed to add embedding column: {e}")
+
+ # Create indexes
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_properties
+ ON "{self.db_name}_graph"."Memory" USING GIN (properties);
+ """)
+
+ # Create vector index for embedding field
+ try:
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_embedding
+ ON "{self.db_name}_graph"."Memory" USING ivfflat (embedding vector_cosine_ops)
+ WITH (lists = 100);
+ """)
+ logger.info("Vector index created for Memory table.")
+ except Exception as e:
+ logger.warning(f"Vector index creation failed (might not be supported): {e}")
+
+ logger.info("Indexes created for Memory table.")
+
+ except Exception as e:
+ logger.error(f"Failed to create graph schema: {e}")
+ raise e
+ finally:
+ self._return_connection(conn)
+
+ def create_index(
+ self,
+ label: str = "Memory",
+ vector_property: str = "embedding",
+ dimensions: int = 1024,
+ index_name: str = "memory_vector_index",
+ ) -> None:
+ """
+ Create indexes for embedding and other fields.
+ Note: This creates PostgreSQL indexes on the underlying tables.
+ """
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Create indexes on the underlying PostgreSQL tables
+ # Apache AGE stores data in regular PostgreSQL tables
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_properties
+ ON "{self.db_name}_graph"."Memory" USING GIN (properties);
+ """)
+
+ # Try to create vector index, but don't fail if it doesn't work
+ try:
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_embedding
+ ON "{self.db_name}_graph"."Memory" USING ivfflat (embedding vector_cosine_ops);
+ """)
+ except Exception as ve:
+ logger.warning(f"Vector index creation failed (might not be supported): {ve}")
+
+ logger.debug("Indexes created successfully.")
+ except Exception as e:
+ logger.warning(f"Failed to create indexes: {e}")
+ finally:
+ self._return_connection(conn)
+
+ def get_memory_count(self, memory_type: str, user_name: str | None = None) -> int:
+ """Get count of memory nodes by type."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ query = f"""
+ SELECT COUNT(*)
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ """
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params = [self.format_param_value(memory_type), self.format_param_value(user_name)]
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return result[0] if result else 0
+ except Exception as e:
+ logger.error(f"[get_memory_count] Failed: {e}")
+ return -1
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def node_not_exist(self, scope: str, user_name: str | None = None) -> int:
+ """Check if a node with given scope exists."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ query = f"""
+ SELECT id
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ """
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ query += "\nLIMIT 1"
+ params = [self.format_param_value(scope), self.format_param_value(user_name)]
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return 1 if result else 0
+ except Exception as e:
+ logger.error(f"[node_not_exist] Query failed: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def remove_oldest_memory(
+ self, memory_type: str, keep_latest: int, user_name: str | None = None
+ ) -> None:
+ """
+ Remove all WorkingMemory nodes except the latest `keep_latest` entries.
+
+ Args:
+ memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
+ keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Use actual OFFSET logic, consistent with nebular.py
+ # First find IDs to delete, then delete them
+ select_query = f"""
+ SELECT id FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ AND ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = %s::agtype
+ ORDER BY ag_catalog.agtype_access_operator(properties, '"updated_at"'::agtype) DESC
+ OFFSET %s
+ """
+ select_params = [
+ self.format_param_value(memory_type),
+ self.format_param_value(user_name),
+ keep_latest,
+ ]
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Execute query to get IDs to delete
+ cursor.execute(select_query, select_params)
+ ids_to_delete = [row[0] for row in cursor.fetchall()]
+
+ if not ids_to_delete:
+ logger.info(f"No {memory_type} memories to remove for user {user_name}")
+ return
+
+ # Build delete query
+ placeholders = ",".join(["%s"] * len(ids_to_delete))
+ delete_query = f"""
+ DELETE FROM "{self.db_name}_graph"."Memory"
+ WHERE id IN ({placeholders})
+ """
+ delete_params = ids_to_delete
+
+ # Execute deletion
+ cursor.execute(delete_query, delete_params)
+ deleted_count = cursor.rowcount
+ logger.info(
+ f"Removed {deleted_count} oldest {memory_type} memories, keeping {keep_latest} latest for user {user_name}"
+ )
+ except Exception as e:
+ logger.error(f"[remove_oldest_memory] Failed: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def update_node(self, id: str, fields: dict[str, Any], user_name: str | None = None) -> None:
+ """
+ Update node fields in PolarDB, auto-converting `created_at` and `updated_at` to datetime type if present.
+ """
+ if not fields:
+ return
+
+ user_name = user_name if user_name else self.config.user_name
+
+ # Get the current node
+ current_node = self.get_node(id, user_name=user_name)
+ if not current_node:
+ return
+
+ # Update properties but keep original id and memory fields
+ properties = current_node["metadata"].copy()
+ original_id = properties.get("id", id) # Preserve original ID
+ original_memory = current_node.get("memory", "") # Preserve original memory
+
+ # If fields include memory, use it; otherwise keep original memory
+ if "memory" in fields:
+ original_memory = fields.pop("memory")
+
+ properties.update(fields)
+ properties["id"] = original_id # Ensure ID is not overwritten
+ properties["memory"] = original_memory # Ensure memory is not overwritten
+
+ # Handle embedding field
+ embedding_vector = None
+ if "embedding" in fields:
+ embedding_vector = fields.pop("embedding")
+ if not isinstance(embedding_vector, list):
+ embedding_vector = None
+
+ # Build update query
+ if embedding_vector is not None:
+ query = f"""
+ UPDATE "{self.db_name}_graph"."Memory"
+ SET properties = %s, embedding = %s
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [
+ json.dumps(properties),
+ json.dumps(embedding_vector),
+ self.format_param_value(id),
+ ]
+ else:
+ query = f"""
+ UPDATE "{self.db_name}_graph"."Memory"
+ SET properties = %s
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [json.dumps(properties), self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ except Exception as e:
+ logger.error(f"[update_node] Failed to update node '{id}': {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def delete_node(self, id: str, user_name: str | None = None) -> None:
+ """
+ Delete a node from the graph.
+ Args:
+ id: Node identifier to delete.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ query = f"""
+ DELETE FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ except Exception as e:
+ logger.error(f"[delete_node] Failed to delete node '{id}': {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_extension(self):
+ extensions = [("polar_age", "Graph engine"), ("vector", "Vector engine")]
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Ensure in the correct database context
+ cursor.execute("SELECT current_database();")
+ current_db = cursor.fetchone()[0]
+ logger.info(f"Current database context: {current_db}")
+
+ for ext_name, ext_desc in extensions:
+ try:
+ cursor.execute(f"create extension if not exists {ext_name};")
+ logger.info(f"Extension '{ext_name}' ({ext_desc}) ensured.")
+ except Exception as e:
+ if "already exists" in str(e):
+ logger.info(f"Extension '{ext_name}' ({ext_desc}) already exists.")
+ else:
+ logger.warning(
+ f"Failed to create extension '{ext_name}' ({ext_desc}): {e}"
+ )
+ logger.error(
+ f"Failed to create extension '{ext_name}': {e}", exc_info=True
+ )
+ except Exception as e:
+ logger.warning(f"Failed to access database context: {e}")
+ logger.error(f"Failed to access database context: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_graph(self):
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(f"""
+ SELECT COUNT(*) FROM ag_catalog.ag_graph
+ WHERE name = '{self.db_name}_graph';
+ """)
+ graph_exists = cursor.fetchone()[0] > 0
+
+ if graph_exists:
+ logger.info(f"Graph '{self.db_name}_graph' already exists.")
+ else:
+ cursor.execute(f"select create_graph('{self.db_name}_graph');")
+ logger.info(f"Graph database '{self.db_name}_graph' created.")
+ except Exception as e:
+ logger.warning(f"Failed to create graph '{self.db_name}_graph': {e}")
+ logger.error(f"Failed to create graph '{self.db_name}_graph': {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_edge(self):
+ """Create all valid edge types if they do not exist"""
+
+ valid_rel_types = {"AGGREGATE_TO", "FOLLOWS", "INFERS", "MERGED_TO", "RELATE_TO", "PARENT"}
+
+ for label_name in valid_rel_types:
+ print(f"🪶 Creating elabel: {label_name}")
+ conn = self._get_connection()
+ logger.info(f"Creating elabel: {label_name}")
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(f"select create_elabel('{self.db_name}_graph', '{label_name}');")
+ logger.info(f"Successfully created elabel: {label_name}")
+ except Exception as e:
+ if "already exists" in str(e):
+ logger.info(f"Label '{label_name}' already exists, skipping.")
+ else:
+ logger.warning(f"Failed to create label {label_name}: {e}")
+ logger.error(f"Failed to create elabel '{label_name}': {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def add_edge(
+ self, source_id: str, target_id: str, type: str, user_name: str | None = None
+ ) -> None:
+ if not source_id or not target_id:
+ raise ValueError("[add_edge] source_id and target_id must be provided")
+
+ source_exists = self.get_node(source_id) is not None
+ target_exists = self.get_node(target_id) is not None
+
+ if not source_exists or not target_exists:
+ raise ValueError("[add_edge] source_id and target_id must be provided")
+
+ properties = {}
+ if user_name is not None:
+ properties["user_name"] = user_name
+ query = f"""
+ INSERT INTO {self.db_name}_graph."{type}"(id, start_id, end_id, properties)
+ SELECT
+ ag_catalog._next_graph_id('{self.db_name}_graph'::name, '{type}'),
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{source_id}'::text::cstring),
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{target_id}'::text::cstring),
+ jsonb_build_object('user_name', '{user_name}')::text::agtype
+ WHERE NOT EXISTS (
+ SELECT 1 FROM {self.db_name}_graph."{type}"
+ WHERE start_id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{source_id}'::text::cstring)
+ AND end_id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{target_id}'::text::cstring)
+ );
+ """
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, (source_id, target_id, type, json.dumps(properties)))
+ logger.info(f"Edge created: {source_id} -[{type}]-> {target_id}")
+ except Exception as e:
+ logger.error(f"Failed to insert edge: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def delete_edge(self, source_id: str, target_id: str, type: str) -> None:
+ """
+ Delete a specific edge between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type to remove.
+ """
+ query = f"""
+ DELETE FROM "{self.db_name}_graph"."Edges"
+ WHERE source_id = %s AND target_id = %s AND edge_type = %s
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, (source_id, target_id, type))
+ logger.info(f"Edge deleted: {source_id} -[{type}]-> {target_id}")
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def edge_exists_old(
+ self, source_id: str, target_id: str, type: str = "ANY", direction: str = "OUTGOING"
+ ) -> bool:
+ """
+ Check if an edge exists between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type. Use "ANY" to match any relationship type.
+ direction: Direction of the edge.
+ Use "OUTGOING" (default), "INCOMING", or "ANY".
+ Returns:
+ True if the edge exists, otherwise False.
+ """
+ where_clauses = []
+ params = []
+ # SELECT * FROM
+ # cypher('memtensor_memos_graph', $$
+ # MATCH(a: Memory
+ # {id: "13bb9df6-0609-4442-8bed-bba77dadac92"})-[r] - (b:Memory {id: "2dd03a5b-5d5f-49c9-9e0a-9a2a2899b98d"})
+ # RETURN
+ # r
+ # $$) AS(r
+ # agtype);
+
+ if direction == "OUTGOING":
+ where_clauses.append("source_id = %s AND target_id = %s")
+ params.extend([source_id, target_id])
+ elif direction == "INCOMING":
+ where_clauses.append("source_id = %s AND target_id = %s")
+ params.extend([target_id, source_id])
+ elif direction == "ANY":
+ where_clauses.append(
+ "((source_id = %s AND target_id = %s) OR (source_id = %s AND target_id = %s))"
+ )
+ params.extend([source_id, target_id, target_id, source_id])
+ else:
+ raise ValueError(
+ f"Invalid direction: {direction}. Must be 'OUTGOING', 'INCOMING', or 'ANY'."
+ )
+
+ if type != "ANY":
+ where_clauses.append("edge_type = %s")
+ params.append(type)
+
+ where_clause = " AND ".join(where_clauses)
+
+ query = f"""
+ SELECT 1 FROM "{self.db_name}_graph"."Edges"
+ WHERE {where_clause}
+ LIMIT 1
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return result is not None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def edge_exists(
+ self,
+ source_id: str,
+ target_id: str,
+ type: str = "ANY",
+ direction: str = "OUTGOING",
+ user_name: str | None = None,
+ ) -> bool:
+ """
+ Check if an edge exists between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type. Use "ANY" to match any relationship type.
+ direction: Direction of the edge.
+ Use "OUTGOING" (default), "INCOMING", or "ANY".
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ Returns:
+ True if the edge exists, otherwise False.
+ """
+
+ # Prepare the relationship pattern
+ user_name = user_name if user_name else self.config.user_name
+
+ # Prepare the match pattern with direction
+ if direction == "OUTGOING":
+ pattern = "(a:Memory)-[r]->(b:Memory)"
+ elif direction == "INCOMING":
+ pattern = "(a:Memory)<-[r]-(b:Memory)"
+ elif direction == "ANY":
+ pattern = "(a:Memory)-[r]-(b:Memory)"
+ else:
+ raise ValueError(
+ f"Invalid direction: {direction}. Must be 'OUTGOING', 'INCOMING', or 'ANY'."
+ )
+ query = f"SELECT * FROM cypher('{self.db_name}_graph', $$"
+ query += f"\nMATCH {pattern}"
+ query += f"\nWHERE a.user_name = '{user_name}' AND b.user_name = '{user_name}'"
+ query += f"\nAND a.id = '{source_id}' AND b.id = '{target_id}'"
+ if type != "ANY":
+ query += f"\n AND type(r) = '{type}'"
+
+ query += "\nRETURN r"
+ query += "\n$$) AS (r agtype)"
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ result = cursor.fetchone()
+ return result is not None and result[0] is not None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_node(
+ self, id: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> dict[str, Any] | None:
+ """
+ Retrieve a Memory node by its unique ID.
+
+ Args:
+ id (str): Node ID (Memory.id)
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ dict: Node properties as key-value pairs, or None if not found.
+ """
+
+ select_fields = "id, properties, embedding" if include_embedding else "id, properties"
+
+ query = f"""
+ SELECT {select_fields}
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+
+ if result:
+ if include_embedding:
+ _, properties_json, embedding_json = result
+ else:
+ _, properties_json = result
+ embedding_json = None
+
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse properties for node {id}")
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding from JSONB if it exists and include_embedding is True
+ if include_embedding and embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {id}")
+
+ return self._parse_node(
+ {
+ "id": id,
+ "memory": properties.get("memory", ""),
+ **properties,
+ }
+ )
+ return None
+
+ except Exception as e:
+ logger.error(f"[get_node] Failed to retrieve node '{id}': {e}", exc_info=True)
+ return None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_nodes(
+ self, ids: list[str], user_name: str | None = None, **kwargs
+ ) -> list[dict[str, Any]]:
+ """
+ Retrieve the metadata and memory of a list of nodes.
+ Args:
+ ids: List of Node identifier.
+ Returns:
+ list[dict]: Parsed node records containing 'id', 'memory', and 'metadata'.
+
+ Notes:
+ - Assumes all provided IDs are valid and exist.
+ - Returns empty list if input is empty.
+ """
+ if not ids:
+ return []
+
+ # Build WHERE clause using agtype_access_operator like get_node method
+ where_conditions = []
+ params = []
+
+ for id_val in ids:
+ where_conditions.append(
+ "ag_catalog.agtype_access_operator(properties, '\"id\"'::agtype) = %s::agtype"
+ )
+ params.append(self.format_param_value(id_val))
+
+ where_clause = " OR ".join(where_conditions)
+
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ({where_clause})
+ """
+
+ user_name = user_name if user_name else self.config.user_name
+ query += " AND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse properties for node {node_id}")
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding from JSONB if it exists
+ if embedding_json is not None:
+ try:
+ # remove embedding
+ """
+ embedding = json.loads(embedding_json) if isinstance(embedding_json, str) else embedding_json
+ # properties["embedding"] = embedding
+ """
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+ nodes.append(
+ self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ )
+ return nodes
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_edges_old(
+ self, id: str, type: str = "ANY", direction: str = "ANY"
+ ) -> list[dict[str, str]]:
+ """
+ Get edges connected to a node, with optional type and direction filter.
+
+ Args:
+ id: Node ID to retrieve edges for.
+ type: Relationship type to match, or 'ANY' to match all.
+ direction: 'OUTGOING', 'INCOMING', or 'ANY'.
+
+ Returns:
+ List of edges:
+ [
+ {"from": "source_id", "to": "target_id", "type": "RELATE"},
+ ...
+ ]
+ """
+
+ # Create a simple edge table to store relationships (if not exists)
+ try:
+ with self.connection.cursor() as cursor:
+ # Create edge table
+ cursor.execute(f"""
+ CREATE TABLE IF NOT EXISTS "{self.db_name}_graph"."Edges" (
+ id SERIAL PRIMARY KEY,
+ source_id TEXT NOT NULL,
+ target_id TEXT NOT NULL,
+ edge_type TEXT NOT NULL,
+ properties JSONB,
+ created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
+ FOREIGN KEY (source_id) REFERENCES "{self.db_name}_graph"."Memory"(id),
+ FOREIGN KEY (target_id) REFERENCES "{self.db_name}_graph"."Memory"(id)
+ );
+ """)
+
+ # Create indexes
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_source
+ ON "{self.db_name}_graph"."Edges" (source_id);
+ """)
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_target
+ ON "{self.db_name}_graph"."Edges" (target_id);
+ """)
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_type
+ ON "{self.db_name}_graph"."Edges" (edge_type);
+ """)
+ except Exception as e:
+ logger.warning(f"Failed to create edges table: {e}")
+
+ # Query edges
+ where_clauses = []
+ params = [id]
+
+ if type != "ANY":
+ where_clauses.append("edge_type = %s")
+ params.append(type)
+
+ if direction == "OUTGOING":
+ where_clauses.append("source_id = %s")
+ elif direction == "INCOMING":
+ where_clauses.append("target_id = %s")
+ else: # ANY
+ where_clauses.append("(source_id = %s OR target_id = %s)")
+ params.append(id) # Add second parameter for ANY direction
+
+ where_clause = " AND ".join(where_clauses)
+
+ query = f"""
+ SELECT source_id, target_id, edge_type
+ FROM "{self.db_name}_graph"."Edges"
+ WHERE {where_clause}
+ """
+
+ with self.connection.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ edges = []
+ for row in results:
+ source_id, target_id, edge_type = row
+ edges.append({"from": source_id, "to": target_id, "type": edge_type})
+ return edges
+
+ def get_neighbors(
+ self, id: str, type: str, direction: Literal["in", "out", "both"] = "out"
+ ) -> list[str]:
+ """Get connected node IDs in a specific direction and relationship type."""
+ raise NotImplementedError
+
+ @timed
+ def get_neighbors_by_tag_old(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ # Build query conditions
+ where_clauses = []
+ params = []
+
+ # Exclude specified IDs
+ if exclude_ids:
+ placeholders = ",".join(["%s"] * len(exclude_ids))
+ where_clauses.append(f"id NOT IN ({placeholders})")
+ params.extend(exclude_ids)
+
+ # Status filter
+ where_clauses.append("properties->>'status' = %s")
+ params.append("activated")
+
+ # Type filter
+ where_clauses.append("properties->>'type' != %s")
+ params.append("reasoning")
+
+ where_clauses.append("properties->>'memory_type' != %s")
+ params.append("WorkingMemory")
+
+ # User filter
+ if not self._get_config_value("use_multi_db", True) and self._get_config_value("user_name"):
+ where_clauses.append("properties->>'user_name' = %s")
+ params.append(self._get_config_value("user_name"))
+
+ where_clause = " AND ".join(where_clauses)
+
+ # Get all candidate nodes
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE {where_clause}
+ """
+
+ with self.connection.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes_with_overlap = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding
+ if embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+
+ # Compute tag overlap
+ node_tags = properties.get("tags", [])
+ if isinstance(node_tags, str):
+ try:
+ node_tags = json.loads(node_tags)
+ except (json.JSONDecodeError, TypeError):
+ node_tags = []
+
+ overlap_tags = [tag for tag in tags if tag in node_tags]
+ overlap_count = len(overlap_tags)
+
+ if overlap_count >= min_overlap:
+ node_data = self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ nodes_with_overlap.append((node_data, overlap_count))
+
+ # Sort by overlap count and return top_k
+ nodes_with_overlap.sort(key=lambda x: x[1], reverse=True)
+ return [node for node, _ in nodes_with_overlap[:top_k]]
+
+ @timed
+ def get_children_with_embeddings(
+ self, id: str, user_name: str | None = None
+ ) -> list[dict[str, Any]]:
+ """Get children nodes with their embeddings."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ where_user = f"AND p.user_name = '{user_name}' AND c.user_name = '{user_name}'"
+
+ query = f"""
+ WITH t as (
+ SELECT *
+ FROM cypher('{self.db_name}_graph', $$
+ MATCH (p:Memory)-[r:PARENT]->(c:Memory)
+ WHERE p.id = '{id}' {where_user}
+ RETURN id(c) as cid, c.id AS id, c.memory AS memory
+ $$) as (cid agtype, id agtype, memory agtype)
+ )
+ SELECT t.id, m.embedding, t.memory FROM t,
+ "{self.db_name}_graph"."Memory" m
+ WHERE t.cid::graphid = m.id;
+ """
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ children = []
+ for row in results:
+ # Handle child_id - remove possible quotes
+ child_id_raw = row[0].value if hasattr(row[0], "value") else str(row[0])
+ if isinstance(child_id_raw, str):
+ # If string starts and ends with quotes, remove quotes
+ if child_id_raw.startswith('"') and child_id_raw.endswith('"'):
+ child_id = child_id_raw[1:-1]
+ else:
+ child_id = child_id_raw
+ else:
+ child_id = str(child_id_raw)
+
+ # Handle embedding - get from database embedding column
+ embedding_raw = row[1]
+ embedding = []
+ if embedding_raw is not None:
+ try:
+ if isinstance(embedding_raw, str):
+ # If it is a JSON string, parse it
+ embedding = json.loads(embedding_raw)
+ elif isinstance(embedding_raw, list):
+ # If already a list, use directly
+ embedding = embedding_raw
+ else:
+ # Try converting to list
+ embedding = list(embedding_raw)
+ except (json.JSONDecodeError, TypeError, ValueError) as e:
+ logger.warning(
+ f"Failed to parse embedding for child node {child_id}: {e}"
+ )
+ embedding = []
+
+ # Handle memory - remove possible quotes
+ memory_raw = row[2].value if hasattr(row[2], "value") else str(row[2])
+ if isinstance(memory_raw, str):
+ # If string starts and ends with quotes, remove quotes
+ if memory_raw.startswith('"') and memory_raw.endswith('"'):
+ memory = memory_raw[1:-1]
+ else:
+ memory = memory_raw
+ else:
+ memory = str(memory_raw)
+
+ children.append({"id": child_id, "embedding": embedding, "memory": memory})
+
+ return children
+
+ except Exception as e:
+ logger.error(f"[get_children_with_embeddings] Failed: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def get_path(self, source_id: str, target_id: str, max_depth: int = 3) -> list[str]:
+ """Get the path of nodes from source to target within a limited depth."""
+ raise NotImplementedError
+
+ @timed
+ def get_subgraph(
+ self,
+ center_id: str,
+ depth: int = 2,
+ center_status: str = "activated",
+ user_name: str | None = None,
+ ) -> dict[str, Any]:
+ """
+ Retrieve a local subgraph centered at a given node.
+ Args:
+ center_id: The ID of the center node.
+ depth: The hop distance for neighbors.
+ center_status: Required status for center node.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ Returns:
+ {
+ "core_node": {...},
+ "neighbors": [...],
+ "edges": [...]
+ }
+ """
+ if not 1 <= depth <= 5:
+ raise ValueError("depth must be 1-5")
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ if center_id.startswith('"') and center_id.endswith('"'):
+ center_id = center_id[1:-1]
+ # Use a simplified query to get the subgraph (temporarily only direct neighbors)
+ """
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH(center: Memory)-[r * 1..{depth}]->(neighbor:Memory)
+ WHERE
+ center.id = '{center_id}'
+ AND center.status = '{center_status}'
+ AND center.user_name = '{user_name}'
+ RETURN
+ collect(DISTINCT
+ center), collect(DISTINCT
+ neighbor), collect(DISTINCT
+ r)
+ $$ ) as (centers agtype, neighbors agtype, rels agtype);
+ """
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH(center: Memory)-[r * 1..{depth}]->(neighbor:Memory)
+ WHERE
+ center.id = '{center_id}'
+ AND center.status = '{center_status}'
+ AND center.user_name = '{user_name}'
+ RETURN
+ collect(DISTINCT
+ center), collect(DISTINCT
+ neighbor), collect(DISTINCT
+ r)
+ $$ ) as (centers agtype, neighbors agtype, rels agtype);
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ result = cursor.fetchone()
+
+ if not result or not result[0]:
+ return {"core_node": None, "neighbors": [], "edges": []}
+
+ # Parse center node
+ centers_data = result[0] if result[0] else "[]"
+ neighbors_data = result[1] if result[1] else "[]"
+ edges_data = result[2] if result[2] else "[]"
+
+ # Parse JSON data
+ try:
+ # Clean ::vertex and ::edge suffixes in data
+ if isinstance(centers_data, str):
+ centers_data = centers_data.replace("::vertex", "")
+ if isinstance(neighbors_data, str):
+ neighbors_data = neighbors_data.replace("::vertex", "")
+ if isinstance(edges_data, str):
+ edges_data = edges_data.replace("::edge", "")
+
+ centers_list = (
+ json.loads(centers_data) if isinstance(centers_data, str) else centers_data
+ )
+ neighbors_list = (
+ json.loads(neighbors_data)
+ if isinstance(neighbors_data, str)
+ else neighbors_data
+ )
+ edges_list = (
+ json.loads(edges_data) if isinstance(edges_data, str) else edges_data
+ )
+ except json.JSONDecodeError as e:
+ logger.error(f"Failed to parse JSON data: {e}")
+ return {"core_node": None, "neighbors": [], "edges": []}
+
+ # Parse center node
+ core_node = None
+ if centers_list and len(centers_list) > 0:
+ center_data = centers_list[0]
+ if isinstance(center_data, dict) and "properties" in center_data:
+ core_node = self._parse_node(center_data["properties"])
+
+ # Parse neighbor nodes
+ neighbors = []
+ if isinstance(neighbors_list, list):
+ for neighbor_data in neighbors_list:
+ if isinstance(neighbor_data, dict) and "properties" in neighbor_data:
+ neighbor_parsed = self._parse_node(neighbor_data["properties"])
+ neighbors.append(neighbor_parsed)
+
+ # Parse edges
+ edges = []
+ if isinstance(edges_list, list):
+ for edge_group in edges_list:
+ if isinstance(edge_group, list):
+ for edge_data in edge_group:
+ if isinstance(edge_data, dict):
+ edges.append(
+ {
+ "type": edge_data.get("label", ""),
+ "source": edge_data.get("start_id", ""),
+ "target": edge_data.get("end_id", ""),
+ }
+ )
+
+ return self._convert_graph_edges(
+ {"core_node": core_node, "neighbors": neighbors, "edges": edges}
+ )
+
+ except Exception as e:
+ logger.error(f"Failed to get subgraph: {e}", exc_info=True)
+ return {"core_node": None, "neighbors": [], "edges": []}
+ finally:
+ self._return_connection(conn)
+
+ def get_context_chain(self, id: str, type: str = "FOLLOWS") -> list[str]:
+ """Get the ordered context chain starting from a node."""
+ raise NotImplementedError
+
+ @timed
+ def search_by_embedding(
+ self,
+ vector: list[float],
+ top_k: int = 5,
+ scope: str | None = None,
+ status: str | None = None,
+ threshold: float | None = None,
+ search_filter: dict | None = None,
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[dict]:
+ """
+ Retrieve node IDs based on vector similarity using PostgreSQL vector operations.
+ """
+ # Build WHERE clause dynamically like nebular.py
+ where_clauses = []
+ if scope:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"memory_type\"'::agtype) = '\"{scope}\"'::agtype"
+ )
+ if status:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"{status}\"'::agtype"
+ )
+ else:
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"activated\"'::agtype"
+ )
+ where_clauses.append("embedding is not null")
+ # Add user_name filter like nebular.py
+
+ """
+ # user_name = self._get_config_value("user_name")
+ # if not self.config.use_multi_db and user_name:
+ # if kwargs.get("cube_name"):
+ # where_clauses.append(f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{kwargs['cube_name']}\"'::agtype")
+ # else:
+ # where_clauses.append(f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype")
+ """
+ user_name = user_name if user_name else self.config.user_name
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype"
+ )
+
+ # Add search_filter conditions like nebular.py
+ if search_filter:
+ for key, value in search_filter.items():
+ if isinstance(value, str):
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{key}\"'::agtype) = '\"{value}\"'::agtype"
+ )
+ else:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{key}\"'::agtype) = {value}::agtype"
+ )
+
+ where_clause = f"WHERE {' AND '.join(where_clauses)}" if where_clauses else ""
+
+ # Keep original simple query structure but add dynamic WHERE clause
+ query = f"""
+ WITH t AS (
+ SELECT id,
+ properties,
+ timeline,
+ ag_catalog.agtype_access_operator(properties, '"id"'::agtype) AS old_id,
+ (1 - (embedding <=> %s::vector(1024))) AS scope
+ FROM "{self.db_name}_graph"."Memory"
+ {where_clause}
+ ORDER BY scope DESC
+ LIMIT {top_k}
+ )
+ SELECT *
+ FROM t
+ WHERE scope > 0.1;
+ """
+ params = [vector]
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+ output = []
+ for row in results:
+ """
+ polarId = row[0] # id
+ properties = row[1] # properties
+ # embedding = row[3] # embedding
+ """
+ oldid = row[3] # old_id
+ score = row[4] # scope
+ id_val = str(oldid)
+ score_val = float(score)
+ score_val = (score_val + 1) / 2 # align to neo4j, Normalized Cosine Score
+ if threshold is None or score_val >= threshold:
+ output.append({"id": id_val, "score": score_val})
+ return output[:top_k]
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_by_metadata(
+ self, filters: list[dict[str, Any]], user_name: str | None = None
+ ) -> list[str]:
+ """
+ Retrieve node IDs that match given metadata filters.
+ Supports exact match.
+
+ Args:
+ filters: List of filter dicts like:
+ [
+ {"field": "key", "op": "in", "value": ["A", "B"]},
+ {"field": "confidence", "op": ">=", "value": 80},
+ {"field": "tags", "op": "contains", "value": "AI"},
+ ...
+ ]
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[str]: Node IDs whose metadata match the filter conditions. (AND logic).
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build WHERE conditions for cypher query
+ where_conditions = []
+
+ for f in filters:
+ field = f["field"]
+ op = f.get("op", "=")
+ value = f["value"]
+
+ # Format value
+ if isinstance(value, str):
+ # Escape single quotes in string values
+ escaped_str = value.replace("'", "''")
+ escaped_value = f"'{escaped_str}'"
+ elif isinstance(value, list):
+ # Handle list values - use double quotes for Cypher arrays
+ list_items = []
+ for v in value:
+ if isinstance(v, str):
+ # Escape double quotes in string values for Cypher
+ escaped_str = v.replace('"', '\\"')
+ list_items.append(f'"{escaped_str}"')
+ else:
+ list_items.append(str(v))
+ escaped_value = f"[{', '.join(list_items)}]"
+ else:
+ escaped_value = f"'{value}'" if isinstance(value, str) else str(value)
+ # Build WHERE conditions
+ if op == "=":
+ where_conditions.append(f"n.{field} = {escaped_value}")
+ elif op == "in":
+ where_conditions.append(f"n.{field} IN {escaped_value}")
+ """
+ # where_conditions.append(f"{escaped_value} IN n.{field}")
+ """
+ elif op == "contains":
+ where_conditions.append(f"{escaped_value} IN n.{field}")
+ """
+ # where_conditions.append(f"size(filter(n.{field}, t -> t IN {escaped_value})) > 0")
+ """
+ elif op == "starts_with":
+ where_conditions.append(f"n.{field} STARTS WITH {escaped_value}")
+ elif op == "ends_with":
+ where_conditions.append(f"n.{field} ENDS WITH {escaped_value}")
+ elif op in [">", ">=", "<", "<="]:
+ where_conditions.append(f"n.{field} {op} {escaped_value}")
+ else:
+ raise ValueError(f"Unsupported operator: {op}")
+
+ # Add user_name filter
+ escaped_user_name = user_name.replace("'", "''")
+ where_conditions.append(f"n.user_name = '{escaped_user_name}'")
+
+ where_str = " AND ".join(where_conditions)
+
+ # Use cypher query
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE {where_str}
+ RETURN n.id AS id
+ $$) AS (id agtype)
+ """
+
+ ids = []
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+ ids = [str(item[0]).strip('"') for item in results]
+ except Exception as e:
+ logger.error(f"Failed to get metadata: {e}, query is {cypher_query}")
+ finally:
+ self._return_connection(conn)
+
+ return ids
+
+ @timed
+ def get_grouped_counts1(
+ self,
+ group_fields: list[str],
+ where_clause: str = "",
+ params: dict[str, Any] | None = None,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Count nodes grouped by any fields.
+
+ Args:
+ group_fields (list[str]): Fields to group by, e.g., ["memory_type", "status"]
+ where_clause (str, optional): Extra WHERE condition. E.g.,
+ "WHERE n.status = 'activated'"
+ params (dict, optional): Parameters for WHERE clause.
+
+ Returns:
+ list[dict]: e.g., [{ 'memory_type': 'WorkingMemory', 'status': 'active', 'count': 10 }, ...]
+ """
+ user_name = user_name if user_name else self.config.user_name
+ if not group_fields:
+ raise ValueError("group_fields cannot be empty")
+
+ final_params = params.copy() if params else {}
+ if not self.config.use_multi_db and (self.config.user_name or user_name):
+ user_clause = "n.user_name = $user_name"
+ final_params["user_name"] = user_name
+ if where_clause:
+ where_clause = where_clause.strip()
+ if where_clause.upper().startswith("WHERE"):
+ where_clause += f" AND {user_clause}"
+ else:
+ where_clause = f"WHERE {where_clause} AND {user_clause}"
+ else:
+ where_clause = f"WHERE {user_clause}"
+ # Force RETURN field AS field to guarantee key match
+ group_fields_cypher = ", ".join([f"n.{field} AS {field}" for field in group_fields])
+ """
+ # group_fields_cypher_polardb = "agtype, ".join([f"{field}" for field in group_fields])
+ """
+ group_fields_cypher_polardb = ", ".join([f"{field} agtype" for field in group_fields])
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ {where_clause}
+ RETURN {group_fields_cypher}, COUNT(n) AS count1
+ $$ ) as ({group_fields_cypher_polardb}, count1 agtype);
+ """
+ try:
+ with self.connection.cursor() as cursor:
+ # Handle parameterized query
+ if params and isinstance(params, list):
+ cursor.execute(query, final_params)
+ else:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ output = []
+ for row in results:
+ group_values = {}
+ for i, field in enumerate(group_fields):
+ value = row[i]
+ if hasattr(value, "value"):
+ group_values[field] = value.value
+ else:
+ group_values[field] = str(value)
+ count_value = row[-1] # Last column is count
+ output.append({**group_values, "count": count_value})
+
+ return output
+
+ except Exception as e:
+ logger.error(f"Failed to get grouped counts: {e}", exc_info=True)
+ return []
+
+ @timed
+ def get_grouped_counts(
+ self,
+ group_fields: list[str],
+ where_clause: str = "",
+ params: dict[str, Any] | None = None,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Count nodes grouped by any fields.
+
+ Args:
+ group_fields (list[str]): Fields to group by, e.g., ["memory_type", "status"]
+ where_clause (str, optional): Extra WHERE condition. E.g.,
+ "WHERE n.status = 'activated'"
+ params (dict, optional): Parameters for WHERE clause.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: e.g., [{ 'memory_type': 'WorkingMemory', 'status': 'active', 'count': 10 }, ...]
+ """
+ if not group_fields:
+ raise ValueError("group_fields cannot be empty")
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build user clause
+ user_clause = f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype"
+ if where_clause:
+ where_clause = where_clause.strip()
+ if where_clause.upper().startswith("WHERE"):
+ where_clause += f" AND {user_clause}"
+ else:
+ where_clause = f"WHERE {where_clause} AND {user_clause}"
+ else:
+ where_clause = f"WHERE {user_clause}"
+
+ # Inline parameters if provided
+ if params and isinstance(params, dict):
+ for key, value in params.items():
+ # Handle different value types appropriately
+ if isinstance(value, str):
+ value = f"'{value}'"
+ where_clause = where_clause.replace(f"${key}", str(value))
+
+ # Handle user_name parameter in where_clause
+ if "user_name = %s" in where_clause:
+ where_clause = where_clause.replace(
+ "user_name = %s",
+ f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype",
+ )
+
+ # Build return fields and group by fields
+ return_fields = []
+ group_by_fields = []
+
+ for field in group_fields:
+ alias = field.replace(".", "_")
+ return_fields.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{field}\"'::agtype)::text AS {alias}"
+ )
+ group_by_fields.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{field}\"'::agtype)::text"
+ )
+
+ # Full SQL query construction
+ query = f"""
+ SELECT {", ".join(return_fields)}, COUNT(*) AS count
+ FROM "{self.db_name}_graph"."Memory"
+ {where_clause}
+ GROUP BY {", ".join(group_by_fields)}
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Handle parameterized query
+ if params and isinstance(params, list):
+ cursor.execute(query, params)
+ else:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ output = []
+ for row in results:
+ group_values = {}
+ for i, field in enumerate(group_fields):
+ value = row[i]
+ if hasattr(value, "value"):
+ group_values[field] = value.value
+ else:
+ group_values[field] = str(value)
+ count_value = row[-1] # Last column is count
+ output.append({**group_values, "count": int(count_value)})
+
+ return output
+
+ except Exception as e:
+ logger.error(f"Failed to get grouped counts: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def deduplicate_nodes(self) -> None:
+ """Deduplicate redundant or semantically similar nodes."""
+ raise NotImplementedError
+
+ def detect_conflicts(self) -> list[tuple[str, str]]:
+ """Detect conflicting nodes based on logical or semantic inconsistency."""
+ raise NotImplementedError
+
+ def merge_nodes(self, id1: str, id2: str) -> str:
+ """Merge two similar or duplicate nodes into one."""
+ raise NotImplementedError
+
+ @timed
+ def clear(self, user_name: str | None = None) -> None:
+ """
+ Clear the entire graph if the target database exists.
+
+ Args:
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ try:
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.user_name = '{user_name}'
+ DETACH DELETE n
+ $$) AS (result agtype)
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ logger.info("Cleared all nodes from database.")
+ finally:
+ self._return_connection(conn)
+
+ except Exception as e:
+ logger.error(f"[ERROR] Failed to clear database: {e}")
+
+ @timed
+ def export_graph(
+ self, include_embedding: bool = False, user_name: str | None = None
+ ) -> dict[str, Any]:
+ """
+ Export all graph nodes and edges in a structured form.
+ Args:
+ include_embedding (bool): Whether to include the large embedding field.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ {
+ "nodes": [ { "id": ..., "memory": ..., "metadata": {...} }, ... ],
+ "edges": [ { "source": ..., "target": ..., "type": ... }, ... ]
+ }
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ conn = self._get_connection()
+ try:
+ # Export nodes
+ if include_embedding:
+ node_query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = '\"{user_name}\"'::agtype
+ """
+ else:
+ node_query = f"""
+ SELECT id, properties
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = '\"{user_name}\"'::agtype
+ """
+
+ with conn.cursor() as cursor:
+ cursor.execute(node_query)
+ node_results = cursor.fetchall()
+ nodes = []
+
+ for row in node_results:
+ if include_embedding:
+ properties_json, embedding_json = row
+ else:
+ properties_json = row
+ embedding_json = None
+
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except json.JSONDecodeError:
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # # Build node data
+
+ """
+ # node_data = {
+ # "id": properties.get("id", node_id),
+ # "memory": properties.get("memory", ""),
+ # "metadata": properties
+ # }
+ """
+
+ if include_embedding and embedding_json is not None:
+ properties["embedding"] = embedding_json
+
+ nodes.append(self._parse_node(json.loads(properties[1])))
+
+ except Exception as e:
+ logger.error(f"[EXPORT GRAPH - NODES] Exception: {e}", exc_info=True)
+ raise RuntimeError(f"[EXPORT GRAPH - NODES] Exception: {e}") from e
+ finally:
+ self._return_connection(conn)
+
+ conn = self._get_connection()
+ try:
+ # Export edges using cypher query
+ edge_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (a:Memory)-[r]->(b:Memory)
+ WHERE a.user_name = '{user_name}' AND b.user_name = '{user_name}'
+ RETURN a.id AS source, b.id AS target, type(r) as edge
+ $$) AS (source agtype, target agtype, edge agtype)
+ """
+
+ with conn.cursor() as cursor:
+ cursor.execute(edge_query)
+ edge_results = cursor.fetchall()
+ edges = []
+
+ for row in edge_results:
+ source_agtype, target_agtype, edge_agtype = row
+
+ # Extract and clean source
+ source_raw = (
+ source_agtype.value
+ if hasattr(source_agtype, "value")
+ else str(source_agtype)
+ )
+ if (
+ isinstance(source_raw, str)
+ and source_raw.startswith('"')
+ and source_raw.endswith('"')
+ ):
+ source = source_raw[1:-1]
+ else:
+ source = str(source_raw)
+
+ # Extract and clean target
+ target_raw = (
+ target_agtype.value
+ if hasattr(target_agtype, "value")
+ else str(target_agtype)
+ )
+ if (
+ isinstance(target_raw, str)
+ and target_raw.startswith('"')
+ and target_raw.endswith('"')
+ ):
+ target = target_raw[1:-1]
+ else:
+ target = str(target_raw)
+
+ # Extract and clean edge type
+ type_raw = (
+ edge_agtype.value if hasattr(edge_agtype, "value") else str(edge_agtype)
+ )
+ if (
+ isinstance(type_raw, str)
+ and type_raw.startswith('"')
+ and type_raw.endswith('"')
+ ):
+ edge_type = type_raw[1:-1]
+ else:
+ edge_type = str(type_raw)
+
+ edges.append(
+ {
+ "source": source,
+ "target": target,
+ "type": edge_type,
+ }
+ )
+
+ except Exception as e:
+ logger.error(f"[EXPORT GRAPH - EDGES] Exception: {e}", exc_info=True)
+ raise RuntimeError(f"[EXPORT GRAPH - EDGES] Exception: {e}") from e
+ finally:
+ self._return_connection(conn)
+
+ return {"nodes": nodes, "edges": edges}
+
+ @timed
+ def count_nodes(self, scope: str, user_name: str | None = None) -> int:
+ user_name = user_name if user_name else self.config.user_name
+
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}'
+ AND n.user_name = '{user_name}'
+ RETURN count(n)
+ $$) AS (count agtype)
+ """
+ conn = self._get_connection()
+ try:
+ result = self.execute_query(query, conn)
+ return int(result.one_or_none()["count"].value)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_all_memory_items(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Retrieve all memory items of a specific memory_type.
+
+ Args:
+ scope (str): Must be one of 'WorkingMemory', 'LongTermMemory', or 'UserMemory'.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: Full list of memory items under this scope.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ if scope not in {"WorkingMemory", "LongTermMemory", "UserMemory", "OuterMemory"}:
+ raise ValueError(f"Unsupported memory type scope: {scope}")
+
+ # Use cypher query to retrieve memory items
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN id(n) as id1,n
+ LIMIT 100
+ $$) AS (id1 agtype,n agtype)
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id;
+ """
+ nodes = []
+ node_ids = set()
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ """
+ if isinstance(row, (list, tuple)) and len(row) >= 2:
+ """
+ if isinstance(row, list | tuple) and len(row) >= 2:
+ embedding_val, node_val = row[0], row[1]
+ else:
+ embedding_val, node_val = None, row[0]
+
+ node = self._build_node_from_agtype(node_val, embedding_val)
+ if node:
+ node_id = node["id"]
+ if node_id not in node_ids:
+ nodes.append(node)
+ node_ids.add(node_id)
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return nodes
+ else:
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN properties(n) as props
+ LIMIT 100
+ $$) AS (nprops agtype)
+ """
+
+ nodes = []
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ """
+ if isinstance(row[0], str):
+ memory_data = json.loads(row[0])
+ else:
+ memory_data = row[0] # 如果已经是字典,直接使用
+ nodes.append(self._parse_node(memory_data))
+ """
+ memory_data = json.loads(row[0]) if isinstance(row[0], str) else row[0]
+ nodes.append(self._parse_node(memory_data))
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return nodes
+
+ def get_all_memory_items_old(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Retrieve all memory items of a specific memory_type.
+
+ Args:
+ scope (str): Must be one of 'WorkingMemory', 'LongTermMemory', or 'UserMemory'.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: Full list of memory items under this scope.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ if scope not in {"WorkingMemory", "LongTermMemory", "UserMemory", "OuterMemory"}:
+ raise ValueError(f"Unsupported memory type scope: {scope}")
+
+ # Use cypher query to retrieve memory items
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN id(n) as id1,n
+ LIMIT 100
+ $$) AS (id1 agtype,n agtype)
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id;
+ """
+ else:
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN properties(n) as props
+ LIMIT 100
+ $$) AS (nprops agtype)
+ """
+
+ nodes = []
+ try:
+ with self.connection.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ node_agtype = row[0]
+
+ # Handle string-formatted data
+ if isinstance(node_agtype, str):
+ try:
+ # Remove ::vertex suffix
+ json_str = node_agtype.replace("::vertex", "")
+ node_data = json.loads(json_str)
+
+ if isinstance(node_data, dict) and "properties" in node_data:
+ properties = node_data["properties"]
+ # Build node data
+ parsed_node_data = {
+ "id": properties.get("id", ""),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+
+ if include_embedding and "embedding" in properties:
+ parsed_node_data["embedding"] = properties["embedding"]
+
+ nodes.append(self._parse_node(parsed_node_data))
+ logger.debug(
+ f"[get_all_memory_items] Parsed node successfully: {properties.get('id', '')}"
+ )
+ else:
+ logger.warning(f"Invalid node data format: {node_data}")
+
+ except (json.JSONDecodeError, TypeError) as e:
+ logger.error(f"JSON parsing failed: {e}")
+ elif node_agtype and hasattr(node_agtype, "value"):
+ # Handle agtype object
+ node_props = node_agtype.value
+ if isinstance(node_props, dict):
+ # Parse node properties
+ node_data = {
+ "id": node_props.get("id", ""),
+ "memory": node_props.get("memory", ""),
+ "metadata": node_props,
+ }
+
+ if include_embedding and "embedding" in node_props:
+ node_data["embedding"] = node_props["embedding"]
+
+ nodes.append(self._parse_node(node_data))
+ else:
+ logger.warning(f"Unknown data format: {type(node_agtype)}")
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+
+ return nodes
+
+ @timed
+ def get_structure_optimization_candidates(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Find nodes that are likely candidates for structure optimization:
+ - Isolated nodes, nodes with empty background, or nodes with exactly one child.
+ - Plus: the child of any parent node that has exactly one child.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build return fields based on include_embedding flag
+ if include_embedding:
+ return_fields = "id(n) as id1,n"
+ return_fields_agtype = " id1 agtype,n agtype"
+ else:
+ # Build field list without embedding
+ return_fields = ",".join(
+ [
+ "n.id AS id",
+ "n.memory AS memory",
+ "n.user_name AS user_name",
+ "n.user_id AS user_id",
+ "n.session_id AS session_id",
+ "n.status AS status",
+ "n.key AS key",
+ "n.confidence AS confidence",
+ "n.tags AS tags",
+ "n.created_at AS created_at",
+ "n.updated_at AS updated_at",
+ "n.memory_type AS memory_type",
+ "n.sources AS sources",
+ "n.source AS source",
+ "n.node_type AS node_type",
+ "n.visibility AS visibility",
+ "n.usage AS usage",
+ "n.background AS background",
+ "n.graph_id as graph_id",
+ ]
+ )
+ fields = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "usage",
+ "background",
+ "graph_id",
+ ]
+ return_fields_agtype = ", ".join([f"{field} agtype" for field in fields])
+
+ # Use OPTIONAL MATCH to find isolated nodes (no parents or children)
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}'
+ AND n.status = 'activated'
+ AND n.user_name = '{user_name}'
+ OPTIONAL MATCH (n)-[:PARENT]->(c:Memory)
+ OPTIONAL MATCH (p:Memory)-[:PARENT]->(n)
+ WITH n, c, p
+ WHERE c IS NULL AND p IS NULL
+ RETURN {return_fields}
+ $$) AS ({return_fields_agtype})
+ """
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ {cypher_query}
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id
+ """
+ logger.info(f"[get_structure_optimization_candidates] query: {cypher_query}")
+
+ candidates = []
+ node_ids = set()
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+ logger.info(f"Found {len(results)} structure optimization candidates")
+ for row in results:
+ if include_embedding:
+ # When include_embedding=True, return full node object
+ """
+ if isinstance(row, (list, tuple)) and len(row) >= 2:
+ """
+ if isinstance(row, list | tuple) and len(row) >= 2:
+ embedding_val, node_val = row[0], row[1]
+ else:
+ embedding_val, node_val = None, row[0]
+
+ node = self._build_node_from_agtype(node_val, embedding_val)
+ if node:
+ node_id = node["id"]
+ if node_id not in node_ids:
+ candidates.append(node)
+ node_ids.add(node_id)
+ else:
+ # When include_embedding=False, return field dictionary
+ # Define field names matching the RETURN clause
+ field_names = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "usage",
+ "background",
+ "graph_id",
+ ]
+
+ # Convert row to dictionary
+ node_data = {}
+ for i, field_name in enumerate(field_names):
+ if i < len(row):
+ value = row[i]
+ # Handle special fields
+ if field_name in ["tags", "sources", "usage"] and isinstance(
+ value, str
+ ):
+ try:
+ # Try parsing JSON string
+ node_data[field_name] = json.loads(value)
+ except (json.JSONDecodeError, TypeError):
+ node_data[field_name] = value
+ else:
+ node_data[field_name] = value
+
+ # Parse node using _parse_node_new
+ try:
+ node = self._parse_node_new(node_data)
+ node_id = node["id"]
+
+ if node_id not in node_ids:
+ candidates.append(node)
+ node_ids.add(node_id)
+ logger.debug(f"Parsed node successfully: {node_id}")
+ except Exception as e:
+ logger.error(f"Failed to parse node: {e}")
+
+ except Exception as e:
+ logger.error(f"Failed to get structure optimization candidates: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return candidates
+
+ def drop_database(self) -> None:
+ """Permanently delete the entire graph this instance is using."""
+ return
+ if self._get_config_value("use_multi_db", True):
+ with self.connection.cursor() as cursor:
+ cursor.execute(f"SELECT drop_graph('{self.db_name}_graph', true)")
+ logger.info(f"Graph '{self.db_name}_graph' has been dropped.")
+ else:
+ raise ValueError(
+ f"Refusing to drop graph '{self.db_name}_graph' in "
+ f"Shared Database Multi-Tenant mode"
+ )
+
+ def _parse_node(self, node_data: dict[str, Any]) -> dict[str, Any]:
+ """Parse node data from database format to standard format."""
+ node = node_data.copy()
+
+ # Convert datetime to string
+ for time_field in ("created_at", "updated_at"):
+ if time_field in node and hasattr(node[time_field], "isoformat"):
+ node[time_field] = node[time_field].isoformat()
+
+ return {"id": node.get("id"), "memory": node.get("memory", ""), "metadata": node}
+
+ def _parse_node_new(self, node_data: dict[str, Any]) -> dict[str, Any]:
+ """Parse node data from database format to standard format."""
+ node = node_data.copy()
+
+ # Normalize string values that may arrive as quoted literals (e.g., '"abc"')
+ def _strip_wrapping_quotes(value: Any) -> Any:
+ """
+ if isinstance(value, str) and len(value) >= 2:
+ if value[0] == value[-1] and value[0] in ("'", '"'):
+ return value[1:-1]
+ return value
+ """
+ if (
+ isinstance(value, str)
+ and len(value) >= 2
+ and value[0] == value[-1]
+ and value[0] in ("'", '"')
+ ):
+ return value[1:-1]
+ return value
+
+ for k, v in list(node.items()):
+ if isinstance(v, str):
+ node[k] = _strip_wrapping_quotes(v)
+
+ # Convert datetime to string
+ for time_field in ("created_at", "updated_at"):
+ if time_field in node and hasattr(node[time_field], "isoformat"):
+ node[time_field] = node[time_field].isoformat()
+
+ # Do not remove user_name; keep all fields
+
+ return {"id": node.pop("id"), "memory": node.pop("memory", ""), "metadata": node}
+
+ def __del__(self):
+ """Close database connection when object is destroyed."""
+ if hasattr(self, "connection") and self.connection:
+ self.connection.close()
+
+ @timed
+ def add_node(
+ self, id: str, memory: str, metadata: dict[str, Any], user_name: str | None = None
+ ) -> None:
+ """Add a memory node to the graph."""
+ logger.info(f"In add node polardb: id-{id} memory-{memory}")
+
+ # user_name comes from metadata; fallback to config if missing
+ metadata["user_name"] = user_name if user_name else self.config.user_name
+
+ # Safely process metadata
+ metadata = _prepare_node_metadata(metadata)
+
+ # Merge node and set metadata
+ created_at = metadata.pop("created_at", datetime.utcnow().isoformat())
+ updated_at = metadata.pop("updated_at", datetime.utcnow().isoformat())
+
+ # Prepare properties
+ properties = {
+ "id": id,
+ "memory": memory,
+ "created_at": created_at,
+ "updated_at": updated_at,
+ **metadata,
+ }
+
+ # Generate embedding if not provided
+ if "embedding" not in properties or not properties["embedding"]:
+ properties["embedding"] = generate_vector(
+ self._get_config_value("embedding_dimension", 1024)
+ )
+
+ # serialization - JSON-serialize sources and usage fields
+ for field_name in ["sources", "usage"]:
+ if properties.get(field_name):
+ if isinstance(properties[field_name], list):
+ for idx in range(len(properties[field_name])):
+ # Serialize only when element is not a string
+ if not isinstance(properties[field_name][idx], str):
+ properties[field_name][idx] = json.dumps(properties[field_name][idx])
+ elif isinstance(properties[field_name], str):
+ # If already a string, leave as-is
+ pass
+
+ # Extract embedding for separate column
+ embedding_vector = properties.pop("embedding", [])
+ if not isinstance(embedding_vector, list):
+ embedding_vector = []
+
+ # Select column name based on embedding dimension
+ embedding_column = "embedding" # default column
+ if len(embedding_vector) == 3072:
+ embedding_column = "embedding_3072"
+ elif len(embedding_vector) == 1024:
+ embedding_column = "embedding"
+ elif len(embedding_vector) == 768:
+ embedding_column = "embedding_768"
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Delete existing record first (if any)
+ delete_query = f"""
+ DELETE FROM {self.db_name}_graph."Memory"
+ WHERE id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring)
+ """
+ cursor.execute(delete_query, (id,))
+ #
+ get_graph_id_query = f"""
+ SELECT ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring)
+ """
+ cursor.execute(get_graph_id_query, (id,))
+ graph_id = cursor.fetchone()[0]
+ properties["graph_id"] = str(graph_id)
+
+ # Then insert new record
+ if embedding_vector:
+ insert_query = f"""
+ INSERT INTO {self.db_name}_graph."Memory"(id, properties, {embedding_column})
+ VALUES (
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring),
+ %s,
+ %s
+ )
+ """
+ cursor.execute(
+ insert_query, (id, json.dumps(properties), json.dumps(embedding_vector))
+ )
+ else:
+ insert_query = f"""
+ INSERT INTO {self.db_name}_graph."Memory"(id, properties)
+ VALUES (
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring),
+ %s
+ )
+ """
+ cursor.execute(insert_query, (id, json.dumps(properties)))
+ logger.info(f"Added node {id} to graph '{self.db_name}_graph'.")
+ finally:
+ logger.info(f"In add node polardb: id-{id} memory-{memory} query-{insert_query}")
+ self._return_connection(conn)
+
+ def _build_node_from_agtype(self, node_agtype, embedding=None):
+ """
+ Parse the cypher-returned column `n` (agtype or JSON string)
+ into a standard node and merge embedding into properties.
+ """
+ try:
+ # String case: '{"id":...,"label":[...],"properties":{...}}::vertex'
+ if isinstance(node_agtype, str):
+ json_str = node_agtype.replace("::vertex", "")
+ obj = json.loads(json_str)
+ if not (isinstance(obj, dict) and "properties" in obj):
+ return None
+ props = obj["properties"]
+ # agtype case: has `value` attribute
+ elif node_agtype and hasattr(node_agtype, "value"):
+ val = node_agtype.value
+ if not (isinstance(val, dict) and "properties" in val):
+ return None
+ props = val["properties"]
+ else:
+ return None
+
+ if embedding is not None:
+ props["embedding"] = embedding
+
+ # Return standard format directly
+ return {"id": props.get("id", ""), "memory": props.get("memory", ""), "metadata": props}
+ except Exception:
+ return None
+
+ @timed
+ def get_neighbors_by_tag(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ include_embedding: bool = False,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ if not tags:
+ return []
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build query conditions - more relaxed filters
+ where_clauses = []
+ params = []
+
+ # Exclude specified IDs - use id in properties
+ if exclude_ids:
+ exclude_conditions = []
+ for exclude_id in exclude_ids:
+ exclude_conditions.append(
+ "ag_catalog.agtype_access_operator(properties, '\"id\"'::agtype) != %s::agtype"
+ )
+ params.append(self.format_param_value(exclude_id))
+ where_clauses.append(f"({' AND '.join(exclude_conditions)})")
+
+ # Status filter - keep only 'activated'
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"activated\"'::agtype"
+ )
+
+ # Type filter - exclude 'reasoning' type
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"node_type\"'::agtype) != '\"reasoning\"'::agtype"
+ )
+
+ # User filter
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ )
+ params.append(self.format_param_value(user_name))
+
+ # Testing showed no data; annotate.
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"memory_type\"'::agtype) != '\"WorkingMemory\"'::agtype"
+ )
+
+ where_clause = " AND ".join(where_clauses)
+
+ # Fetch all candidate nodes
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE {where_clause}
+ """
+
+ logger.debug(f"[get_neighbors_by_tag] query: {query}, params: {params}")
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes_with_overlap = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding
+ if include_embedding and embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+
+ # Compute tag overlap
+ node_tags = properties.get("tags", [])
+ if isinstance(node_tags, str):
+ try:
+ node_tags = json.loads(node_tags)
+ except (json.JSONDecodeError, TypeError):
+ node_tags = []
+
+ overlap_tags = [tag for tag in tags if tag in node_tags]
+ overlap_count = len(overlap_tags)
+
+ if overlap_count >= min_overlap:
+ node_data = self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ nodes_with_overlap.append((node_data, overlap_count))
+
+ # Sort by overlap count and return top_k items
+ nodes_with_overlap.sort(key=lambda x: x[1], reverse=True)
+ return [node for node, _ in nodes_with_overlap[:top_k]]
+
+ except Exception as e:
+ logger.error(f"Failed to get neighbors by tag: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def get_neighbors_by_tag_ccl(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ include_embedding: bool = False,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ if not tags:
+ return []
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build query conditions; keep consistent with nebular.py
+ where_clauses = [
+ 'n.status = "activated"',
+ 'NOT (n.node_type = "reasoning")',
+ 'NOT (n.memory_type = "WorkingMemory")',
+ ]
+ where_clauses = [
+ 'n.status = "activated"',
+ 'NOT (n.memory_type = "WorkingMemory")',
+ ]
+
+ if exclude_ids:
+ exclude_ids_str = "[" + ", ".join(f'"{id}"' for id in exclude_ids) + "]"
+ where_clauses.append(f"NOT (n.id IN {exclude_ids_str})")
+
+ where_clauses.append(f'n.user_name = "{user_name}"')
+
+ where_clause = " AND ".join(where_clauses)
+ tag_list_literal = "[" + ", ".join(f'"{t}"' for t in tags) + "]"
+
+ return_fields = [
+ "n.id AS id",
+ "n.memory AS memory",
+ "n.user_name AS user_name",
+ "n.user_id AS user_id",
+ "n.session_id AS session_id",
+ "n.status AS status",
+ "n.key AS key",
+ "n.confidence AS confidence",
+ "n.tags AS tags",
+ "n.created_at AS created_at",
+ "n.updated_at AS updated_at",
+ "n.memory_type AS memory_type",
+ "n.sources AS sources",
+ "n.source AS source",
+ "n.node_type AS node_type",
+ "n.visibility AS visibility",
+ "n.background AS background",
+ ]
+
+ if include_embedding:
+ return_fields.append("n.embedding AS embedding")
+
+ return_fields_str = ", ".join(return_fields)
+ result_fields = []
+ for field in return_fields:
+ # Extract field name 'id' from 'n.id AS id'
+ field_name = field.split(" AS ")[-1]
+ result_fields.append(f"{field_name} agtype")
+
+ # Add overlap_count
+ result_fields.append("overlap_count agtype")
+ result_fields_str = ", ".join(result_fields)
+ # Use Cypher query; keep consistent with nebular.py
+ query = f"""
+ SELECT * FROM (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ WITH {tag_list_literal} AS tag_list
+ MATCH (n:Memory)
+ WHERE {where_clause}
+ RETURN {return_fields_str},
+ size([tag IN n.tags WHERE tag IN tag_list]) AS overlap_count
+ $$) AS ({result_fields_str})
+ ) AS subquery
+ ORDER BY (overlap_count::integer) DESC
+ LIMIT {top_k}
+ """
+ logger.debug(f"get_neighbors_by_tag: {query}")
+ try:
+ with self.connection.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ neighbors = []
+ for row in results:
+ # Parse results
+ props = {}
+ overlap_count = None
+
+ # Manually parse each field
+ field_names = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "background",
+ ]
+
+ if include_embedding:
+ field_names.append("embedding")
+ field_names.append("overlap_count")
+
+ for i, field in enumerate(field_names):
+ if field == "overlap_count":
+ overlap_count = row[i].value if hasattr(row[i], "value") else row[i]
+ else:
+ props[field] = row[i].value if hasattr(row[i], "value") else row[i]
+ overlap_int = int(overlap_count)
+ if overlap_count is not None and overlap_int >= min_overlap:
+ parsed = self._parse_node(props)
+ parsed["overlap_count"] = overlap_int
+ neighbors.append(parsed)
+
+ # Sort by overlap count
+ neighbors.sort(key=lambda x: x["overlap_count"], reverse=True)
+ neighbors = neighbors[:top_k]
+
+ # Remove overlap_count field
+ result = []
+ for neighbor in neighbors:
+ neighbor.pop("overlap_count", None)
+ result.append(neighbor)
+
+ return result
+
+ except Exception as e:
+ logger.error(f"Failed to get neighbors by tag: {e}", exc_info=True)
+ return []
+
+ @timed
+ def import_graph(self, data: dict[str, Any], user_name: str | None = None) -> None:
+ """
+ Import the entire graph from a serialized dictionary.
+
+ Args:
+ data: A dictionary containing all nodes and edges to be loaded.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Import nodes
+ for node in data.get("nodes", []):
+ try:
+ id, memory, metadata = _compose_node(node)
+ metadata["user_name"] = user_name
+ metadata = _prepare_node_metadata(metadata)
+ metadata.update({"id": id, "memory": memory})
+
+ # Use add_node to insert node
+ self.add_node(id, memory, metadata)
+
+ except Exception as e:
+ logger.error(f"Fail to load node: {node}, error: {e}")
+
+ # Import edges
+ for edge in data.get("edges", []):
+ try:
+ source_id, target_id = edge["source"], edge["target"]
+ edge_type = edge["type"]
+
+ # Use add_edge to insert edge
+ self.add_edge(source_id, target_id, edge_type, user_name)
+
+ except Exception as e:
+ logger.error(f"Fail to load edge: {edge}, error: {e}")
+
+ @timed
+ def get_edges(
+ self, id: str, type: str = "ANY", direction: str = "ANY", user_name: str | None = None
+ ) -> list[dict[str, str]]:
+ """
+ Get edges connected to a node, with optional type and direction filter.
+
+ Args:
+ id: Node ID to retrieve edges for.
+ type: Relationship type to match, or 'ANY' to match all.
+ direction: 'OUTGOING', 'INCOMING', or 'ANY'.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of edges:
+ [
+ {"from": "source_id", "to": "target_id", "type": "RELATE"},
+ ...
+ ]
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ if direction == "OUTGOING":
+ pattern = "(a:Memory)-[r]->(b:Memory)"
+ where_clause = f"a.id = '{id}'"
+ elif direction == "INCOMING":
+ pattern = "(a:Memory)<-[r]-(b:Memory)"
+ where_clause = f"a.id = '{id}'"
+ elif direction == "ANY":
+ pattern = "(a:Memory)-[r]-(b:Memory)"
+ where_clause = f"a.id = '{id}' OR b.id = '{id}'"
+ else:
+ raise ValueError("Invalid direction. Must be 'OUTGOING', 'INCOMING', or 'ANY'.")
+
+ # Add type filter
+ if type != "ANY":
+ where_clause += f" AND type(r) = '{type}'"
+
+ # Add user filter
+ where_clause += f" AND a.user_name = '{user_name}' AND b.user_name = '{user_name}'"
+
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH {pattern}
+ WHERE {where_clause}
+ RETURN a.id AS from_id, b.id AS to_id, type(r) AS edge_type
+ $$) AS (from_id agtype, to_id agtype, edge_type agtype)
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ edges = []
+ for row in results:
+ # Extract and clean from_id
+ from_id_raw = row[0].value if hasattr(row[0], "value") else row[0]
+ if (
+ isinstance(from_id_raw, str)
+ and from_id_raw.startswith('"')
+ and from_id_raw.endswith('"')
+ ):
+ from_id = from_id_raw[1:-1]
+ else:
+ from_id = str(from_id_raw)
+
+ # Extract and clean to_id
+ to_id_raw = row[1].value if hasattr(row[1], "value") else row[1]
+ if (
+ isinstance(to_id_raw, str)
+ and to_id_raw.startswith('"')
+ and to_id_raw.endswith('"')
+ ):
+ to_id = to_id_raw[1:-1]
+ else:
+ to_id = str(to_id_raw)
+
+ # Extract and clean edge_type
+ edge_type_raw = row[2].value if hasattr(row[2], "value") else row[2]
+ if (
+ isinstance(edge_type_raw, str)
+ and edge_type_raw.startswith('"')
+ and edge_type_raw.endswith('"')
+ ):
+ edge_type = edge_type_raw[1:-1]
+ else:
+ edge_type = str(edge_type_raw)
+
+ edges.append({"from": from_id, "to": to_id, "type": edge_type})
+ return edges
+
+ except Exception as e:
+ logger.error(f"Failed to get edges: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def _convert_graph_edges(self, core_node: dict) -> dict:
+ import copy
+
+ data = copy.deepcopy(core_node)
+ id_map = {}
+ core_node = data.get("core_node", {})
+ if not core_node:
+ return core_node
+ core_meta = core_node.get("metadata", {})
+ if "graph_id" in core_meta and "id" in core_node:
+ id_map[core_meta["graph_id"]] = core_node["id"]
+ for neighbor in data.get("neighbors", []):
+ n_meta = neighbor.get("metadata", {})
+ if "graph_id" in n_meta and "id" in neighbor:
+ id_map[n_meta["graph_id"]] = neighbor["id"]
+ for edge in data.get("edges", []):
+ src = edge.get("source")
+ tgt = edge.get("target")
+ if src in id_map:
+ edge["source"] = id_map[src]
+ if tgt in id_map:
+ edge["target"] = id_map[tgt]
+ return data
+
+ def format_param_value(self, value: str | None) -> str:
+ """Format parameter value to handle both quoted and unquoted formats"""
+ # Handle None value
+ if value is None:
+ logger.warning("format_param_value: value is None")
+ return "null"
+
+ # Remove outer quotes if they exist
+ if value.startswith('"') and value.endswith('"'):
+ # Already has double quotes, return as is
+ return value
+ else:
+ # Add double quotes
+ return f'"{value}"'
diff --git a/src/memos/llms/hf.py b/src/memos/llms/hf.py
index 00081b581..be0d1d95f 100644
--- a/src/memos/llms/hf.py
+++ b/src/memos/llms/hf.py
@@ -379,10 +379,52 @@ def build_kv_cache(self, messages) -> DynamicCache:
raise ValueError(
"Prompt after chat template is empty, cannot build KV cache. Check your messages input."
)
- kv = DynamicCache()
+ # Create cache and perform forward pass without pre-existing cache
with torch.no_grad():
- self.model(**inputs, use_cache=True, past_key_values=kv)
- for i, (k, v) in enumerate(zip(kv.key_cache, kv.value_cache, strict=False)):
- kv.key_cache[i] = k[:, :, :seq_len, :]
- kv.value_cache[i] = v[:, :, :seq_len, :]
- return kv
+ outputs = self.model(**inputs, use_cache=True)
+
+ # Get the cache from model outputs
+ if hasattr(outputs, "past_key_values") and outputs.past_key_values is not None:
+ kv = outputs.past_key_values
+
+ # Convert from legacy tuple format to DynamicCache if needed
+ if isinstance(kv, tuple):
+ kv = DynamicCache.from_legacy_cache(kv)
+
+ # Handle compatibility between old and new transformers versions
+ # In newer versions, DynamicCache uses 'layers' attribute
+ # In older versions, it uses 'key_cache' and 'value_cache' attributes
+ if hasattr(kv, "layers"):
+ # New version: trim cache using layers attribute
+ for layer in kv.layers:
+ if hasattr(layer, "key_cache") and hasattr(layer, "value_cache"):
+ # Trim each layer's cache to the sequence length
+ if layer.key_cache is not None:
+ layer.key_cache = layer.key_cache[:, :, :seq_len, :]
+ if layer.value_cache is not None:
+ layer.value_cache = layer.value_cache[:, :, :seq_len, :]
+ elif hasattr(layer, "keys") and hasattr(layer, "values"):
+ # Alternative attribute names in some versions
+ if layer.keys is not None:
+ layer.keys = layer.keys[:, :, :seq_len, :]
+ if layer.values is not None:
+ layer.values = layer.values[:, :, :seq_len, :]
+ elif hasattr(kv, "key_cache") and hasattr(kv, "value_cache"):
+ # Old version: trim cache using key_cache and value_cache attributes
+ for i in range(len(kv.key_cache)):
+ if kv.key_cache[i] is not None:
+ kv.key_cache[i] = kv.key_cache[i][:, :, :seq_len, :]
+ if kv.value_cache[i] is not None:
+ kv.value_cache[i] = kv.value_cache[i][:, :, :seq_len, :]
+ else:
+ # Fallback: log warning but continue without trimming
+ logger.warning(
+ f"DynamicCache object of type {type(kv)} has unexpected structure. "
+ f"Cache trimming skipped. Available attributes: {dir(kv)}"
+ )
+
+ return kv
+ else:
+ raise RuntimeError(
+ "Failed to build KV cache: no cache data available from model outputs"
+ )
diff --git a/src/memos/llms/openai.py b/src/memos/llms/openai.py
index 698bc3265..1a1703340 100644
--- a/src/memos/llms/openai.py
+++ b/src/memos/llms/openai.py
@@ -11,6 +11,7 @@
from memos.llms.utils import remove_thinking_tags
from memos.log import get_logger
from memos.types import MessageList
+from memos.utils import timed
logger = get_logger(__name__)
@@ -56,15 +57,19 @@ def clear_cache(cls):
cls._instances.clear()
logger.info("OpenAI LLM instance cache cleared")
- def generate(self, messages: MessageList) -> str:
- """Generate a response from OpenAI LLM."""
+ @timed(log=True, log_prefix="OpenAI LLM")
+ def generate(self, messages: MessageList, **kwargs) -> str:
+ """Generate a response from OpenAI LLM, optionally overriding generation params."""
+ temperature = kwargs.get("temperature", self.config.temperature)
+ max_tokens = kwargs.get("max_tokens", self.config.max_tokens)
+ top_p = kwargs.get("top_p", self.config.top_p)
response = self.client.chat.completions.create(
model=self.config.model_name_or_path,
messages=messages,
extra_body=self.config.extra_body,
- temperature=self.config.temperature,
- max_tokens=self.config.max_tokens,
- top_p=self.config.top_p,
+ temperature=temperature,
+ max_tokens=max_tokens,
+ top_p=top_p,
)
logger.info(f"Response from OpenAI: {response.model_dump_json()}")
response_content = response.choices[0].message.content
@@ -73,6 +78,7 @@ def generate(self, messages: MessageList) -> str:
else:
return response_content
+ @timed(log=True, log_prefix="OpenAI LLM")
def generate_stream(self, messages: MessageList, **kwargs) -> Generator[str, None, None]:
"""Stream response from OpenAI LLM with optional reasoning support."""
response = self.client.chat.completions.create(
diff --git a/src/memos/log.py b/src/memos/log.py
index 339d13f26..faa808414 100644
--- a/src/memos/log.py
+++ b/src/memos/log.py
@@ -14,7 +14,13 @@
from dotenv import load_dotenv
from memos import settings
-from memos.context.context import get_current_api_path, get_current_trace_id
+from memos.context.context import (
+ get_current_api_path,
+ get_current_env,
+ get_current_trace_id,
+ get_current_user_name,
+ get_current_user_type,
+)
# Load environment variables
@@ -34,15 +40,22 @@ def _setup_logfile() -> Path:
return logfile
-class TraceIDFilter(logging.Filter):
- """add trace_id to the log record"""
+class ContextFilter(logging.Filter):
+ """add context to the log record"""
def filter(self, record):
try:
trace_id = get_current_trace_id()
record.trace_id = trace_id if trace_id else "trace-id"
+ record.env = get_current_env()
+ record.user_type = get_current_user_type()
+ record.user_name = get_current_user_name()
+ record.api_path = get_current_api_path()
except Exception:
record.trace_id = "trace-id"
+ record.env = "prod"
+ record.user_type = "normal"
+ record.user_name = "unknown"
return True
@@ -86,13 +99,24 @@ def emit(self, record):
try:
trace_id = get_current_trace_id() or "trace-id"
api_path = get_current_api_path()
+ env = get_current_env()
+ user_type = get_current_user_type()
+ user_name = get_current_user_name()
if api_path is not None:
- self._executor.submit(self._send_log_sync, record.getMessage(), trace_id, api_path)
+ self._executor.submit(
+ self._send_log_sync,
+ record.getMessage(),
+ trace_id,
+ api_path,
+ env,
+ user_type,
+ user_name,
+ )
except Exception as e:
if not self._is_shutting_down.is_set():
print(f"Error sending log: {e}")
- def _send_log_sync(self, message, trace_id, api_path):
+ def _send_log_sync(self, message, trace_id, api_path, env, user_type, user_name):
"""Send log message synchronously in a separate thread"""
try:
logger_url = os.getenv("CUSTOM_LOGGER_URL")
@@ -104,6 +128,9 @@ def _send_log_sync(self, message, trace_id, api_path):
"trace_id": trace_id,
"action": api_path,
"current_time": round(time.time(), 3),
+ "env": env,
+ "user_type": user_type,
+ "user_name": user_name,
}
# Add auth token if exists
@@ -145,18 +172,18 @@ def close(self):
"disable_existing_loggers": False,
"formatters": {
"standard": {
- "format": "%(asctime)s [%(trace_id)s] - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
+ "format": "%(asctime)s | %(trace_id)s | path=%(api_path)s | env=%(env)s | user_type=%(user_type)s | user_name=%(user_name)s | %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
},
"no_datetime": {
- "format": "[%(trace_id)s] - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
+ "format": "%(trace_id)s | path=%(api_path)s | %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
},
"simplified": {
- "format": "%(asctime)s | %(trace_id)s | %(levelname)s | %(filename)s:%(lineno)d: %(funcName)s | %(message)s"
+ "format": "%(asctime)s | %(trace_id)s | path=%(api_path)s | % %(levelname)s | %(filename)s:%(lineno)d: %(funcName)s | %(message)s"
},
},
"filters": {
"package_tree_filter": {"()": "logging.Filter", "name": settings.LOG_FILTER_TREE_PREFIX},
- "trace_id_filter": {"()": "memos.log.TraceIDFilter"},
+ "context_filter": {"()": "memos.log.ContextFilter"},
},
"handlers": {
"console": {
@@ -164,7 +191,7 @@ def close(self):
"class": "logging.StreamHandler",
"stream": stdout,
"formatter": "no_datetime",
- "filters": ["package_tree_filter", "trace_id_filter"],
+ "filters": ["package_tree_filter", "context_filter"],
},
"file": {
"level": "DEBUG",
@@ -173,7 +200,7 @@ def close(self):
"maxBytes": 1024**2 * 10,
"backupCount": 10,
"formatter": "standard",
- "filters": ["trace_id_filter"],
+ "filters": ["context_filter"],
},
"custom_logger": {
"level": "INFO",
diff --git a/src/memos/mem_cube/base.py b/src/memos/mem_cube/base.py
index 7d7c5e779..349d511fb 100644
--- a/src/memos/mem_cube/base.py
+++ b/src/memos/mem_cube/base.py
@@ -19,6 +19,7 @@ def __init__(self, config: BaseMemCubeConfig):
self.text_mem: BaseTextMemory
self.act_mem: BaseActMemory
self.para_mem: BaseParaMemory
+ self.pref_mem: BaseTextMemory
@abstractmethod
def load(self, dir: str) -> None:
diff --git a/src/memos/mem_cube/general.py b/src/memos/mem_cube/general.py
index 17e45809c..1238ae050 100644
--- a/src/memos/mem_cube/general.py
+++ b/src/memos/mem_cube/general.py
@@ -41,16 +41,23 @@ def __init__(self, config: GeneralMemCubeConfig):
if config.para_mem.backend != "uninitialized"
else None
)
+ self._pref_mem: BaseTextMemory | None = (
+ MemoryFactory.from_config(config.pref_mem)
+ if config.pref_mem.backend != "uninitialized"
+ else None
+ )
def load(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Load memories.
Args:
dir (str): The directory containing the memory files.
memory_types (list[str], optional): List of memory types to load.
If None, loads all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
loaded_schema = get_json_file_model_schema(os.path.join(dir, self.config.config_filename))
if loaded_schema != self.config.model_schema:
@@ -61,7 +68,7 @@ def load(
# If no specific memory types specified, load all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Load specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -76,17 +83,23 @@ def load(
self.para_mem.load(dir)
logger.info(f"Loaded para_mem from {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.load(dir)
+ logger.info(f"Loaded pref_mem from {dir}")
+
logger.info(f"MemCube loaded successfully from {dir} (types: {memory_types})")
def dump(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump memories.
Args:
dir (str): The directory where the memory files will be saved.
memory_types (list[str], optional): List of memory types to dump.
If None, dumps all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
if os.path.exists(dir) and os.listdir(dir):
raise MemCubeError(
@@ -98,7 +111,7 @@ def dump(
# If no specific memory types specified, dump all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Dump specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -113,12 +126,16 @@ def dump(
self.para_mem.dump(dir)
logger.info(f"Dumped para_mem to {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.dump(dir)
+ logger.info(f"Dumped pref_mem to {dir}")
+
logger.info(f"MemCube dumped successfully to {dir} (types: {memory_types})")
@staticmethod
def init_from_dir(
dir: str,
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""Create a MemCube instance from a MemCube directory.
@@ -148,7 +165,7 @@ def init_from_dir(
def init_from_remote_repo(
cube_id: str,
base_url: str = "https://huggingface.co/datasets",
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""Create a MemCube instance from a remote repository.
@@ -207,3 +224,17 @@ def para_mem(self, value: BaseParaMemory) -> None:
if not isinstance(value, BaseParaMemory):
raise TypeError(f"Expected BaseParaMemory, got {type(value).__name__}")
self._para_mem = value
+
+ @property
+ def pref_mem(self) -> "BaseTextMemory | None":
+ """Get the preference memory."""
+ if self._pref_mem is None:
+ logger.warning("Preference memory is not initialized. Returning None.")
+ return self._pref_mem
+
+ @pref_mem.setter
+ def pref_mem(self, value: BaseTextMemory) -> None:
+ """Set the preference memory."""
+ if not isinstance(value, BaseTextMemory):
+ raise TypeError(f"Expected BaseTextMemory, got {type(value).__name__}")
+ self._pref_mem = value
diff --git a/src/memos/mem_cube/navie.py b/src/memos/mem_cube/navie.py
index 7ce3ca642..ba9f136b7 100644
--- a/src/memos/mem_cube/navie.py
+++ b/src/memos/mem_cube/navie.py
@@ -14,9 +14,14 @@
from memos.memories.activation.base import BaseActMemory
from memos.memories.parametric.base import BaseParaMemory
from memos.memories.textual.base import BaseTextMemory
+from memos.memories.textual.prefer_text_memory.adder import BaseAdder
+from memos.memories.textual.prefer_text_memory.extractor import BaseExtractor
+from memos.memories.textual.prefer_text_memory.retrievers import BaseRetriever
+from memos.memories.textual.simple_preference import SimplePreferenceTextMemory
from memos.memories.textual.simple_tree import SimpleTreeTextMemory
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
from memos.reranker.base import BaseReranker
+from memos.vec_dbs.base import BaseVecDB
logger = get_logger(__name__)
@@ -34,7 +39,11 @@ def __init__(
reranker: BaseReranker,
memory_manager: MemoryManager,
default_cube_config: GeneralMemCubeConfig,
+ vector_db: BaseVecDB,
internet_retriever: None = None,
+ pref_extractor: BaseExtractor | None = None,
+ pref_adder: BaseAdder | None = None,
+ pref_retriever: BaseRetriever | None = None,
):
"""Initialize the MemCube with a configuration."""
self._text_mem: BaseTextMemory | None = SimpleTreeTextMemory(
@@ -49,6 +58,15 @@ def __init__(
)
self._act_mem: BaseActMemory | None = None
self._para_mem: BaseParaMemory | None = None
+ self._pref_mem: BaseTextMemory | None = SimplePreferenceTextMemory(
+ extractor_llm=llm,
+ vector_db=vector_db,
+ embedder=embedder,
+ reranker=reranker,
+ extractor=pref_extractor,
+ adder=pref_adder,
+ retriever=pref_retriever,
+ )
def load(
self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
@@ -69,7 +87,7 @@ def load(
# If no specific memory types specified, load all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Load specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -84,17 +102,23 @@ def load(
self.para_mem.load(dir)
logger.info(f"Loaded para_mem from {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.load(dir)
+ logger.info(f"Loaded pref_mem from {dir}")
+
logger.info(f"MemCube loaded successfully from {dir} (types: {memory_types})")
def dump(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump memories.
Args:
dir (str): The directory where the memory files will be saved.
memory_types (list[str], optional): List of memory types to dump.
If None, dumps all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
if os.path.exists(dir) and os.listdir(dir):
raise MemCubeError(
@@ -106,7 +130,7 @@ def dump(
# If no specific memory types specified, dump all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Dump specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -121,6 +145,10 @@ def dump(
self.para_mem.dump(dir)
logger.info(f"Dumped para_mem to {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.dump(dir)
+ logger.info(f"Dumped pref_mem to {dir}")
+
logger.info(f"MemCube dumped successfully to {dir} (types: {memory_types})")
@property
@@ -164,3 +192,17 @@ def para_mem(self, value: BaseParaMemory) -> None:
if not isinstance(value, BaseParaMemory):
raise TypeError(f"Expected BaseParaMemory, got {type(value).__name__}")
self._para_mem = value
+
+ @property
+ def pref_mem(self) -> "BaseTextMemory | None":
+ """Get the preference memory."""
+ if self._pref_mem is None:
+ logger.warning("Preference memory is not initialized. Returning None.")
+ return self._pref_mem
+
+ @pref_mem.setter
+ def pref_mem(self, value: BaseTextMemory) -> None:
+ """Set the preference memory."""
+ if not isinstance(value, BaseTextMemory):
+ raise TypeError(f"Expected BaseTextMemory, got {type(value).__name__}")
+ self._pref_mem = value
diff --git a/src/memos/mem_cube/utils.py b/src/memos/mem_cube/utils.py
index a413ccce5..24836c509 100644
--- a/src/memos/mem_cube/utils.py
+++ b/src/memos/mem_cube/utils.py
@@ -68,44 +68,80 @@ def merge_config_with_default(
if "graph_db" in existing_text_config and "graph_db" in default_text_config:
existing_graph_config = existing_text_config["graph_db"]["config"]
default_graph_config = default_text_config["graph_db"]["config"]
-
- # Define graph_db fields to preserve (user-specific)
- preserve_graph_fields = {
- "auto_create",
- "user_name",
- "use_multi_db",
- }
-
- # Create merged graph_db config
- merged_graph_config = copy.deepcopy(existing_graph_config)
- for key, value in default_graph_config.items():
- if key not in preserve_graph_fields:
- merged_graph_config[key] = value
- logger.debug(
- f"Updated graph_db field '{key}': {existing_graph_config.get(key)} -> {value}"
+ existing_backend = existing_text_config["graph_db"]["backend"]
+ default_backend = default_text_config["graph_db"]["backend"]
+
+ # Detect backend change
+ backend_changed = existing_backend != default_backend
+
+ if backend_changed:
+ logger.info(
+ f"Detected graph_db backend change: {existing_backend} -> {default_backend}. "
+ f"Migrating configuration..."
+ )
+ # Start with default config as base when backend changes
+ merged_graph_config = copy.deepcopy(default_graph_config)
+
+ # Preserve user-specific fields if they exist in both configs
+ preserve_graph_fields = {
+ "auto_create",
+ "user_name",
+ "use_multi_db",
+ }
+ for field in preserve_graph_fields:
+ if field in existing_graph_config:
+ merged_graph_config[field] = existing_graph_config[field]
+ logger.debug(
+ f"Preserved graph_db field '{field}': {existing_graph_config[field]}"
+ )
+
+ # Clean up backend-specific fields that don't exist in the new backend
+ # This approach is generic: remove any field from merged config that's not in default config
+ # and not in the preserve list
+ fields_to_remove = []
+ for field in list(merged_graph_config.keys()):
+ if field not in default_graph_config and field not in preserve_graph_fields:
+ fields_to_remove.append(field)
+
+ for field in fields_to_remove:
+ removed_value = merged_graph_config.pop(field)
+ logger.info(
+ f"Removed {existing_backend}-specific field '{field}' (value: {removed_value}) "
+ f"during migration to {default_backend}"
)
- if not default_graph_config.get("use_multi_db", True):
- # set original use_multi_db to False if default_graph_config.use_multi_db is False
- if merged_graph_config.get("use_multi_db", True):
- merged_graph_config["use_multi_db"] = False
- merged_graph_config["user_name"] = merged_graph_config.get("db_name")
- merged_graph_config["db_name"] = default_graph_config.get("db_name")
- else:
- logger.info("use_multi_db is already False, no need to change")
- if "neo4j" not in default_text_config["graph_db"]["backend"]:
- if "db_name" in merged_graph_config:
- merged_graph_config.pop("db_name")
- logger.info("neo4j is not supported, remove db_name")
- else:
- logger.info("db_name is not in merged_graph_config, no need to remove")
else:
- if "space" in merged_graph_config:
- merged_graph_config.pop("space")
- logger.info("neo4j is not supported, remove db_name")
- else:
- logger.info("space is not in merged_graph_config, no need to remove")
+ # Same backend: merge configs while preserving user-specific fields
+ logger.debug(f"Same graph_db backend ({default_backend}), merging configurations")
+ preserve_graph_fields = {
+ "auto_create",
+ "user_name",
+ "use_multi_db",
+ }
+
+ # Start with existing config as base
+ merged_graph_config = copy.deepcopy(existing_graph_config)
+
+ # Update with default config except preserved fields
+ for key, value in default_graph_config.items():
+ if key not in preserve_graph_fields:
+ merged_graph_config[key] = value
+ logger.debug(
+ f"Updated graph_db field '{key}': {existing_graph_config.get(key)} -> {value}"
+ )
+
+ # Handle use_multi_db transition
+ if not default_graph_config.get("use_multi_db", True) and merged_graph_config.get(
+ "use_multi_db", True
+ ):
+ merged_graph_config["use_multi_db"] = False
+ # For Neo4j: db_name becomes user_name in single-db mode
+ if "neo4j" in default_backend and "db_name" in merged_graph_config:
+ merged_graph_config["user_name"] = merged_graph_config.get("db_name")
+ merged_graph_config["db_name"] = default_graph_config.get("db_name")
+ logger.info("Transitioned to single-db mode (use_multi_db=False)")
+
preserved_graph_db = {
- "backend": default_text_config["graph_db"]["backend"],
+ "backend": default_backend,
"config": merged_graph_config,
}
diff --git a/src/memos/mem_os/core.py b/src/memos/mem_os/core.py
index 958cc140c..97ff9879f 100644
--- a/src/memos/mem_os/core.py
+++ b/src/memos/mem_os/core.py
@@ -8,6 +8,7 @@
from typing import Any, Literal
from memos.configs.mem_os import MOSConfig
+from memos.context.context import ContextThreadPoolExecutor
from memos.llms.factory import LLMFactory
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
@@ -17,6 +18,8 @@
from memos.mem_scheduler.schemas.general_schemas import (
ADD_LABEL,
ANSWER_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
QUERY_LABEL,
)
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
@@ -70,6 +73,7 @@ def __init__(self, config: MOSConfig, user_manager: UserManager | None = None):
if self.enable_mem_scheduler:
self._mem_scheduler = self._initialize_mem_scheduler()
self._mem_scheduler.mem_cubes = self.mem_cubes
+ self._mem_scheduler.mem_reader = self.mem_reader
else:
self._mem_scheduler: GeneralScheduler = None
@@ -308,18 +312,20 @@ def chat(self, query: str, user_id: str | None = None, base_prompt: str | None =
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # TODO this only one cubes
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # TODO this only one cubes
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
break
# Generate response
response = self.chat_llm.generate(current_messages, past_key_values=past_key_values)
@@ -586,6 +592,7 @@ def search(
"text_mem": [],
"act_mem": [],
"para_mem": [],
+ "pref_mem": [],
}
if install_cube_ids is None:
install_cube_ids = user_cube_ids
@@ -600,33 +607,78 @@ def search(
)
for mem_cube_id, mem_cube in tmp_mem_cubes.items():
- if (
- (mem_cube_id in install_cube_ids)
- and (mem_cube.text_mem is not None)
- and self.config.enable_textual_memory
- ):
- time_start = time.time()
- memories = mem_cube.text_mem.search(
- query,
- top_k=top_k if top_k else self.config.top_k,
- mode=mode,
- manual_close_internet=not internet_search,
- info={
- "user_id": target_user_id,
- "session_id": target_session_id,
- "chat_history": chat_history.chat_history,
- },
- moscube=moscube,
- search_filter=search_filter,
- )
- result["text_mem"].append({"cube_id": mem_cube_id, "memories": memories})
- logger.info(
- f"🧠 [Memory] Searched memories from {mem_cube_id}:\n{self._str_memories(memories)}\n"
- )
- search_time_end = time.time()
- logger.info(
- f"time search graph: search graph time user_id: {target_user_id} time is: {search_time_end - time_start}"
- )
+ # Define internal functions for parallel search execution
+ def search_textual_memory(cube_id, cube):
+ if (
+ (cube_id in install_cube_ids)
+ and (cube.text_mem is not None)
+ and self.config.enable_textual_memory
+ ):
+ time_start = time.time()
+ memories = cube.text_mem.search(
+ query,
+ top_k=top_k if top_k else self.config.top_k,
+ mode=mode,
+ manual_close_internet=not internet_search,
+ info={
+ "user_id": target_user_id,
+ "session_id": target_session_id,
+ "chat_history": chat_history.chat_history,
+ },
+ moscube=moscube,
+ search_filter=search_filter,
+ )
+ search_time_end = time.time()
+ logger.info(
+ f"🧠 [Memory] Searched memories from {cube_id}:\n{self._str_memories(memories)}\n"
+ )
+ logger.info(
+ f"time search graph: search graph time user_id: {target_user_id} time is: {search_time_end - time_start}"
+ )
+ return {"cube_id": cube_id, "memories": memories}
+ return None
+
+ def search_preference_memory(cube_id, cube):
+ if (
+ (cube_id in install_cube_ids)
+ and (cube.pref_mem is not None)
+ and self.config.enable_preference_memory
+ ):
+ time_start = time.time()
+ memories = cube.pref_mem.search(
+ query,
+ top_k=top_k if top_k else self.config.top_k,
+ info={
+ "user_id": target_user_id,
+ "session_id": self.session_id,
+ "chat_history": chat_history.chat_history,
+ },
+ )
+ search_time_end = time.time()
+ logger.info(
+ f"🧠 [Memory] Searched preferences from {cube_id}:\n{self._str_memories(memories)}\n"
+ )
+ logger.info(
+ f"time search pref: search pref time user_id: {target_user_id} time is: {search_time_end - time_start}"
+ )
+ return {"cube_id": cube_id, "memories": memories}
+ return None
+
+ # Execute both search functions in parallel
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(search_textual_memory, mem_cube_id, mem_cube)
+ pref_future = executor.submit(search_preference_memory, mem_cube_id, mem_cube)
+
+ # Wait for both tasks to complete and collect results
+ text_result = text_future.result()
+ pref_result = pref_future.result()
+
+ # Add results to the main result dictionary
+ if text_result is not None:
+ result["text_mem"].append(text_result)
+ if pref_result is not None:
+ result["pref_mem"].append(pref_result)
+
return result
def add(
@@ -675,63 +727,111 @@ def add(
f"time add: get mem_cube_id time user_id: {target_user_id} time is: {time.time() - time_start}"
)
- time_start_0 = time.time()
if mem_cube_id not in self.mem_cubes:
raise ValueError(f"MemCube '{mem_cube_id}' is not loaded. Please register.")
- logger.info(
- f"time add: get mem_cube_id check in mem_cubes time user_id: {target_user_id} time is: {time.time() - time_start_0}"
- )
- time_start_1 = time.time()
- if (
- (messages is not None)
- and self.config.enable_textual_memory
- and self.mem_cubes[mem_cube_id].text_mem
- ):
- logger.info(
- f"time add: messages is not None and enable_textual_memory and text_mem is not None time user_id: {target_user_id} time is: {time.time() - time_start_1}"
+
+ sync_mode = self.mem_cubes[mem_cube_id].text_mem.mode
+ if sync_mode == "async":
+ assert self.mem_scheduler is not None, (
+ "Mem-Scheduler must be working when use asynchronous memory adding."
)
- if self.mem_cubes[mem_cube_id].config.text_mem.backend != "tree_text":
- add_memory = []
- metadata = TextualMemoryMetadata(
- user_id=target_user_id, session_id=target_session_id, source="conversation"
- )
- for message in messages:
- add_memory.append(
- TextualMemoryItem(memory=message["content"], metadata=metadata)
+ logger.debug(f"Mem-reader mode is: {sync_mode}")
+
+ def process_textual_memory():
+ if (
+ (messages is not None)
+ and self.config.enable_textual_memory
+ and self.mem_cubes[mem_cube_id].text_mem
+ ):
+ if self.mem_cubes[mem_cube_id].config.text_mem.backend != "tree_text":
+ add_memory = []
+ metadata = TextualMemoryMetadata(
+ user_id=target_user_id, session_id=target_session_id, source="conversation"
)
- self.mem_cubes[mem_cube_id].text_mem.add(add_memory)
- else:
+ for message in messages:
+ add_memory.append(
+ TextualMemoryItem(memory=message["content"], metadata=metadata)
+ )
+ self.mem_cubes[mem_cube_id].text_mem.add(add_memory)
+ else:
+ messages_list = [messages]
+ memories = self.mem_reader.get_memory(
+ messages_list,
+ type="chat",
+ info={"user_id": target_user_id, "session_id": target_session_id},
+ mode="fast" if sync_mode == "async" else "fine",
+ )
+ memories_flatten = [m for m_list in memories for m in m_list]
+ mem_ids: list[str] = self.mem_cubes[mem_cube_id].text_mem.add(memories_flatten)
+ logger.info(
+ f"Added memory user {target_user_id} to memcube {mem_cube_id}: {mem_ids}"
+ )
+ # submit messages for scheduler
+ if self.enable_mem_scheduler and self.mem_scheduler is not None:
+ mem_cube = self.mem_cubes[mem_cube_id]
+ if sync_mode == "async":
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+ else:
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+
+ def process_preference_memory():
+ if (
+ (messages is not None)
+ and self.config.enable_preference_memory
+ and self.mem_cubes[mem_cube_id].pref_mem
+ ):
messages_list = [messages]
- time_start_2 = time.time()
- memories = self.mem_reader.get_memory(
- messages_list,
- type="chat",
- info={"user_id": target_user_id, "session_id": target_session_id},
- )
- logger.info(
- f"time add: get mem_reader time user_id: {target_user_id} time is: {time.time() - time_start_2}"
- )
- mem_ids = []
- for mem in memories:
- mem_id_list: list[str] = self.mem_cubes[mem_cube_id].text_mem.add(mem)
- mem_ids.extend(mem_id_list)
+ mem_cube = self.mem_cubes[mem_cube_id]
+ if sync_mode == "sync":
+ pref_memories = self.mem_cubes[mem_cube_id].pref_mem.get_memory(
+ messages_list,
+ type="chat",
+ info={"user_id": target_user_id, "session_id": self.session_id},
+ )
+ pref_ids = self.mem_cubes[mem_cube_id].pref_mem.add(pref_memories)
logger.info(
- f"Added memory user {target_user_id} to memcube {mem_cube_id}: {mem_id_list}"
+ f"Added preferences user {target_user_id} to memcube {mem_cube_id}: {pref_ids}"
+ )
+ elif sync_mode == "async":
+ assert self.mem_scheduler is not None, (
+ "Mem-Scheduler must be working when use asynchronous memory adding."
)
-
- # submit messages for scheduler
- if self.enable_mem_scheduler and self.mem_scheduler is not None:
- mem_cube = self.mem_cubes[mem_cube_id]
message_item = ScheduleMessageItem(
user_id=target_user_id,
+ session_id=target_session_id,
mem_cube_id=mem_cube_id,
mem_cube=mem_cube,
- label=ADD_LABEL,
- content=json.dumps(mem_ids),
+ label=PREF_ADD_LABEL,
+ content=json.dumps(messages_list),
timestamp=datetime.utcnow(),
)
self.mem_scheduler.submit_messages(messages=[message_item])
+ # Execute both memory processing functions in parallel
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(process_textual_memory)
+ pref_future = executor.submit(process_preference_memory)
+
+ # Wait for both tasks to complete
+ text_future.result()
+ pref_future.result()
+
# user profile
if (
(memory_content is not None)
@@ -749,10 +849,12 @@ def add(
messages_list = [
[{"role": "user", "content": memory_content}]
] # for only user-str input and convert message
+
memories = self.mem_reader.get_memory(
messages_list,
type="chat",
info={"user_id": target_user_id, "session_id": target_session_id},
+ mode="fast" if sync_mode == "async" else "fine",
)
mem_ids = []
@@ -766,15 +868,26 @@ def add(
# submit messages for scheduler
if self.enable_mem_scheduler and self.mem_scheduler is not None:
mem_cube = self.mem_cubes[mem_cube_id]
- message_item = ScheduleMessageItem(
- user_id=target_user_id,
- mem_cube_id=mem_cube_id,
- mem_cube=mem_cube,
- label=ADD_LABEL,
- content=json.dumps(mem_ids),
- timestamp=datetime.utcnow(),
- )
- self.mem_scheduler.submit_messages(messages=[message_item])
+ if sync_mode == "async":
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+ else:
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
# user doc input
if (
@@ -998,7 +1111,7 @@ def load(
load_dir: str,
user_id: str | None = None,
mem_cube_id: str | None = None,
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump the MemCube to a dictionary.
Args:
diff --git a/src/memos/mem_os/main.py b/src/memos/mem_os/main.py
index 2e5b32548..6fc64c5e3 100644
--- a/src/memos/mem_os/main.py
+++ b/src/memos/mem_os/main.py
@@ -312,23 +312,25 @@ def _generate_enhanced_response_with_context(
# Handle activation memory if enabled (same as core method)
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # Get accessible cubes for the user
- target_user_id = user_id if user_id is not None else self.user_id
- accessible_cubes = self.user_manager.get_user_cubes(target_user_id)
- user_cube_ids = [cube.cube_id for cube in accessible_cubes]
-
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
- break
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # Get accessible cubes for the user
+ target_user_id = user_id if user_id is not None else self.user_id
+ accessible_cubes = self.user_manager.get_user_cubes(target_user_id)
+ user_cube_ids = [cube.cube_id for cube in accessible_cubes]
+
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
+ break
try:
# Generate the enhanced response using the chat LLM with same parameters as core
diff --git a/src/memos/mem_os/product.py b/src/memos/mem_os/product.py
index 7e0ed9aef..89e468bd7 100644
--- a/src/memos/mem_os/product.py
+++ b/src/memos/mem_os/product.py
@@ -1044,22 +1044,15 @@ def chat(
m.metadata.embedding = []
new_memories_list.append(m)
memories_list = new_memories_list
- # Build base system prompt without memory
- system_prompt = self._build_base_system_prompt(base_prompt, mode="base")
-
- # Build memory context to be included in user message
- memory_context = self._build_memory_context(memories_list, mode="base")
-
- # Combine memory context with user query
- user_content = memory_context + query if memory_context else query
+ system_prompt = super()._build_system_prompt(memories_list, base_prompt)
history_info = []
if history:
history_info = history[-20:]
current_messages = [
{"role": "system", "content": system_prompt},
*history_info,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
response = self.chat_llm.generate(current_messages)
time_end = time.time()
@@ -1129,16 +1122,8 @@ def chat_with_references(
reference = prepare_reference_data(memories_list)
yield f"data: {json.dumps({'type': 'reference', 'data': reference})}\n\n"
-
- # Build base system prompt without memory
- system_prompt = self._build_base_system_prompt(mode="enhance")
-
- # Build memory context to be included in user message
- memory_context = self._build_memory_context(memories_list, mode="enhance")
-
- # Combine memory context with user query
- user_content = memory_context + query if memory_context else query
-
+ # Build custom system prompt with relevant memories)
+ system_prompt = self._build_enhance_system_prompt(user_id, memories_list)
# Get chat history
if user_id not in self.chat_history_manager:
self._register_chat_history(user_id, session_id)
@@ -1149,7 +1134,7 @@ def chat_with_references(
current_messages = [
{"role": "system", "content": system_prompt},
*chat_history.chat_history,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
logger.info(
f"user_id: {user_id}, cube_id: {cube_id}, current_system_prompt: {system_prompt}"
@@ -1443,6 +1428,24 @@ def search(
reformat_memory_list.append({"cube_id": memory["cube_id"], "memories": memories_list})
logger.info(f"search memory list is : {reformat_memory_list}")
search_result["text_mem"] = reformat_memory_list
+
+ pref_memory_list = search_result["pref_mem"]
+ reformat_pref_memory_list = []
+ for memory in pref_memory_list:
+ memories_list = []
+ for data in memory["memories"]:
+ memories = data.model_dump()
+ memories["ref_id"] = f"[{memories['id'].split('-')[0]}]"
+ memories["metadata"]["embedding"] = []
+ memories["metadata"]["sources"] = []
+ memories["metadata"]["ref_id"] = f"[{memories['id'].split('-')[0]}]"
+ memories["metadata"]["id"] = memories["id"]
+ memories["metadata"]["memory"] = memories["memory"]
+ memories_list.append(memories)
+ reformat_pref_memory_list.append(
+ {"cube_id": memory["cube_id"], "memories": memories_list}
+ )
+ search_result["pref_mem"] = reformat_pref_memory_list
time_end = time.time()
logger.info(
f"time search: total time for user_id: {user_id} time is: {time_end - time_start}"
diff --git a/src/memos/mem_os/product_server.py b/src/memos/mem_os/product_server.py
index b94b26f65..758f2794d 100644
--- a/src/memos/mem_os/product_server.py
+++ b/src/memos/mem_os/product_server.py
@@ -71,11 +71,7 @@ def chat(
m.metadata.embedding = []
new_memories_list.append(m)
memories_list = new_memories_list
- system_prompt = self._build_base_system_prompt(base_prompt, mode="base")
-
- memory_context = self._build_memory_context(memories_list, mode="base")
-
- user_content = memory_context + query if memory_context else query
+ system_prompt = self._build_system_prompt(memories_list, base_prompt)
history_info = []
if history:
@@ -83,7 +79,7 @@ def chat(
current_messages = [
{"role": "system", "content": system_prompt},
*history_info,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
response = self.chat_llm.generate(current_messages)
time_end = time.time()
@@ -187,6 +183,42 @@ def _build_base_system_prompt(
prefix = (base_prompt.strip() + "\n\n") if base_prompt else ""
return prefix + sys_body
+ def _build_system_prompt(
+ self,
+ memories: list[TextualMemoryItem] | list[str] | None = None,
+ base_prompt: str | None = None,
+ **kwargs,
+ ) -> str:
+ """Build system prompt with optional memories context."""
+ if base_prompt is None:
+ base_prompt = (
+ "You are a knowledgeable and helpful AI assistant. "
+ "You have access to conversation memories that help you provide more personalized responses. "
+ "Use the memories to understand the user's context, preferences, and past interactions. "
+ "If memories are provided, reference them naturally when relevant, but don't explicitly mention having memories."
+ )
+
+ memory_context = ""
+ if memories:
+ memory_list = []
+ for i, memory in enumerate(memories, 1):
+ if isinstance(memory, TextualMemoryItem):
+ text_memory = memory.memory
+ else:
+ if not isinstance(memory, str):
+ logger.error("Unexpected memory type.")
+ text_memory = memory
+ memory_list.append(f"{i}. {text_memory}")
+ memory_context = "\n".join(memory_list)
+
+ if "{memories}" in base_prompt:
+ return base_prompt.format(memories=memory_context)
+ elif base_prompt and memories:
+ # For backward compatibility, append memories if no placeholder is found
+ memory_context_with_header = "\n\n## Memories:\n" + memory_context
+ return base_prompt + memory_context_with_header
+ return base_prompt
+
def _build_memory_context(
self,
memories_all: list[TextualMemoryItem],
diff --git a/src/memos/mem_reader/base.py b/src/memos/mem_reader/base.py
index f092c3870..3095a0bc6 100644
--- a/src/memos/mem_reader/base.py
+++ b/src/memos/mem_reader/base.py
@@ -18,10 +18,17 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
@abstractmethod
def get_memory(
- self, scene_data: list, type: str, info: dict[str, Any]
+ self, scene_data: list, type: str, info: dict[str, Any], mode: str = "fast"
) -> list[list[TextualMemoryItem]]:
"""Various types of memories extracted from scene_data"""
@abstractmethod
def transform_memreader(self, data: dict) -> list[TextualMemoryItem]:
"""Transform the memory data into a list of TextualMemoryItem objects."""
+
+ @abstractmethod
+ def fine_transfer_simple_mem(
+ self, input_memories: list[list[TextualMemoryItem]], type: str
+ ) -> list[list[TextualMemoryItem]]:
+ """Fine Transform TextualMemoryItem List into another list of
+ TextualMemoryItem objects via calling llm to better understand users."""
diff --git a/src/memos/mem_reader/factory.py b/src/memos/mem_reader/factory.py
index 52eed8d9d..2205a0215 100644
--- a/src/memos/mem_reader/factory.py
+++ b/src/memos/mem_reader/factory.py
@@ -3,6 +3,7 @@
from memos.configs.mem_reader import MemReaderConfigFactory
from memos.mem_reader.base import BaseMemReader
from memos.mem_reader.simple_struct import SimpleStructMemReader
+from memos.mem_reader.strategy_struct import StrategyStructMemReader
from memos.memos_tools.singleton import singleton_factory
@@ -11,6 +12,7 @@ class MemReaderFactory(BaseMemReader):
backend_to_class: ClassVar[dict[str, Any]] = {
"simple_struct": SimpleStructMemReader,
+ "strategy_struct": StrategyStructMemReader,
}
@classmethod
diff --git a/src/memos/mem_reader/simple_struct.py b/src/memos/mem_reader/simple_struct.py
index b439cb2b2..13515c038 100644
--- a/src/memos/mem_reader/simple_struct.py
+++ b/src/memos/mem_reader/simple_struct.py
@@ -3,6 +3,7 @@
import json
import os
import re
+import traceback
from abc import ABC
from typing import Any
@@ -41,14 +42,43 @@
"doc": {"en": SIMPLE_STRUCT_DOC_READER_PROMPT, "zh": SIMPLE_STRUCT_DOC_READER_PROMPT_ZH},
}
+try:
+ import tiktoken
+
+ try:
+ _ENC = tiktoken.encoding_for_model("gpt-4o-mini")
+ except Exception:
+ _ENC = tiktoken.get_encoding("cl100k_base")
+
+ def _count_tokens_text(s: str) -> int:
+ return len(_ENC.encode(s or ""))
+except Exception:
+ # Heuristic fallback: zh chars ~1 token, others ~1 token per ~4 chars
+ def _count_tokens_text(s: str) -> int:
+ if not s:
+ return 0
+ zh_chars = re.findall(r"[\u4e00-\u9fff]", s)
+ zh = len(zh_chars)
+ rest = len(s) - zh
+ return zh + max(1, rest // 4)
+
def detect_lang(text):
try:
if not text or not isinstance(text, str):
return "en"
+ cleaned_text = text
+ # remove role and timestamp
+ cleaned_text = re.sub(
+ r"\b(user|assistant|query|answer)\s*:", "", cleaned_text, flags=re.IGNORECASE
+ )
+ cleaned_text = re.sub(r"\[[\d\-:\s]+\]", "", cleaned_text)
+
+ # extract chinese characters
chinese_pattern = r"[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df\U0002a700-\U0002b73f\U0002b740-\U0002b81f\U0002b820-\U0002ceaf\uf900-\ufaff]"
- chinese_chars = re.findall(chinese_pattern, text)
- if len(chinese_chars) / len(re.sub(r"[\s\d\W]", "", text)) > 0.3:
+ chinese_chars = re.findall(chinese_pattern, cleaned_text)
+ text_without_special = re.sub(r"[\s\d\W]", "", cleaned_text)
+ if text_without_special and len(chinese_chars) / len(text_without_special) > 0.3:
return "zh"
return "en"
except Exception:
@@ -112,6 +142,14 @@ def _build_node(idx, message, info, scene_file, llm, parse_json_result, embedder
return None
+def _derive_key(text: str, max_len: int = 80) -> str:
+ """default key when without LLM: first max_len words"""
+ if not text:
+ return ""
+ sent = re.split(r"[。!?!?]\s*|\n", text.strip())[0]
+ return (sent[:max_len]).strip()
+
+
class SimpleStructMemReader(BaseMemReader, ABC):
"""Naive implementation of MemReader."""
@@ -126,27 +164,50 @@ def __init__(self, config: SimpleStructMemReaderConfig):
self.llm = LLMFactory.from_config(config.llm)
self.embedder = EmbedderFactory.from_config(config.embedder)
self.chunker = ChunkerFactory.from_config(config.chunker)
+ self.memory_max_length = 8000
+ # Use token-based windowing; default to ~5000 tokens if not configured
+ self.chat_window_max_tokens = getattr(self.config, "chat_window_max_tokens", 1024)
+ self._count_tokens = _count_tokens_text
+
+ def _make_memory_item(
+ self,
+ value: str,
+ info: dict,
+ memory_type: str,
+ tags: list[str] | None = None,
+ key: str | None = None,
+ sources: list | None = None,
+ background: str = "",
+ type_: str = "fact",
+ confidence: float = 0.99,
+ ) -> TextualMemoryItem:
+ """construct memory item"""
+ return TextualMemoryItem(
+ memory=value,
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id=info.get("user_id", ""),
+ session_id=info.get("session_id", ""),
+ memory_type=memory_type,
+ status="activated",
+ tags=tags or [],
+ key=key if key is not None else _derive_key(value),
+ embedding=self.embedder.embed([value])[0],
+ usage=[],
+ sources=sources or [],
+ background=background,
+ confidence=confidence,
+ type=type_,
+ ),
+ )
- @timed
- def _process_chat_data(self, scene_data_info, info):
- mem_list = []
- for item in scene_data_info:
- if "chat_time" in item:
- mem = item["role"] + ": " + f"[{item['chat_time']}]: " + item["content"]
- mem_list.append(mem)
- else:
- mem = item["role"] + ":" + item["content"]
- mem_list.append(mem)
- lang = detect_lang("\n".join(mem_list))
+ def _get_llm_response(self, mem_str: str) -> dict:
+ lang = detect_lang(mem_str)
template = PROMPT_DICT["chat"][lang]
examples = PROMPT_DICT["chat"][f"{lang}_example"]
-
- prompt = template.replace("${conversation}", "\n".join(mem_list))
+ prompt = template.replace("${conversation}", mem_str)
if self.config.remove_prompt_example:
prompt = prompt.replace(examples, "")
-
messages = [{"role": "user", "content": prompt}]
-
try:
response_text = self.llm.generate(messages)
response_json = self.parse_json_result(response_text)
@@ -155,15 +216,118 @@ def _process_chat_data(self, scene_data_info, info):
response_json = {
"memory list": [
{
- "key": "\n".join(mem_list)[:10],
+ "key": mem_str[:10],
"memory_type": "UserMemory",
- "value": "\n".join(mem_list),
+ "value": mem_str,
"tags": [],
}
],
- "summary": "\n".join(mem_list),
+ "summary": mem_str,
}
+ return response_json
+
+ def _iter_chat_windows(self, scene_data_info, max_tokens=None, overlap=200):
+ """
+ use token counter to get a slide window generator
+ """
+ max_tokens = max_tokens or self.chat_window_max_tokens
+ buf, sources, start_idx = [], [], 0
+ cur_text = ""
+ for idx, item in enumerate(scene_data_info):
+ role = item.get("role", "")
+ content = item.get("content", "")
+ chat_time = item.get("chat_time", None)
+ parts = []
+ if role and str(role).lower() != "mix":
+ parts.append(f"{role}: ")
+ if chat_time:
+ parts.append(f"[{chat_time}]: ")
+ prefix = "".join(parts)
+ line = f"{prefix}{content}\n"
+
+ if self._count_tokens(cur_text + line) > max_tokens and cur_text:
+ text = "".join(buf)
+ yield {"text": text, "sources": sources.copy(), "start_idx": start_idx}
+ while buf and self._count_tokens("".join(buf)) > overlap:
+ buf.pop(0)
+ sources.pop(0)
+ start_idx = idx
+ cur_text = "".join(buf)
+
+ buf.append(line)
+ sources.append(
+ {
+ "type": "chat",
+ "index": idx,
+ "role": role,
+ "chat_time": chat_time,
+ "content": content,
+ }
+ )
+ cur_text = "".join(buf)
+
+ if buf:
+ yield {"text": "".join(buf), "sources": sources.copy(), "start_idx": start_idx}
+
+ @timed
+ def _process_chat_data(self, scene_data_info, info, **kwargs):
+ mode = kwargs.get("mode", "fine")
+ windows = list(self._iter_chat_windows(scene_data_info))
+
+ if mode == "fast":
+ logger.debug("Using unified Fast Mode")
+
+ def _build_fast_node(w):
+ text = w["text"]
+ roles = {s.get("role", "") for s in w["sources"] if s.get("role")}
+ mem_type = "UserMemory" if roles == {"user"} else "LongTermMemory"
+ tags = ["mode:fast"]
+ return self._make_memory_item(
+ value=text, info=info, memory_type=mem_type, tags=tags, sources=w["sources"]
+ )
+ with ContextThreadPoolExecutor(max_workers=8) as ex:
+ futures = {ex.submit(_build_fast_node, w): i for i, w in enumerate(windows)}
+ results = [None] * len(futures)
+ for fut in concurrent.futures.as_completed(futures):
+ i = futures[fut]
+ try:
+ node = fut.result()
+ if node:
+ results[i] = node
+ except Exception as e:
+ logger.error(f"[ChatFast] error: {e}")
+ chat_nodes = [r for r in results if r]
+ return chat_nodes
+ else:
+ logger.debug("Using unified Fine Mode")
+ chat_read_nodes = []
+ for w in windows:
+ resp = self._get_llm_response(w["text"])
+ for m in resp.get("memory list", []):
+ try:
+ memory_type = (
+ m.get("memory_type", "LongTermMemory")
+ .replace("长期记忆", "LongTermMemory")
+ .replace("用户记忆", "UserMemory")
+ )
+ node = self._make_memory_item(
+ value=m.get("value", ""),
+ info=info,
+ memory_type=memory_type,
+ tags=m.get("tags", []),
+ key=m.get("key", ""),
+ sources=w["sources"],
+ background=resp.get("summary", ""),
+ )
+ chat_read_nodes.append(node)
+ except Exception as e:
+ logger.error(f"[ChatFine] parse error: {e}")
+ return chat_read_nodes
+
+ def _process_transfer_chat_data(self, raw_node: TextualMemoryItem):
+ raw_memory = raw_node.memory
+ response_json = self._get_llm_response(raw_memory)
chat_read_nodes = []
for memory_i_raw in response_json.get("memory list", []):
try:
@@ -172,28 +336,23 @@ def _process_chat_data(self, scene_data_info, info):
.replace("长期记忆", "LongTermMemory")
.replace("用户记忆", "UserMemory")
)
-
if memory_type not in ["LongTermMemory", "UserMemory"]:
memory_type = "LongTermMemory"
-
- node_i = TextualMemoryItem(
- memory=memory_i_raw.get("value", ""),
- metadata=TreeNodeTextualMemoryMetadata(
- user_id=info.get("user_id"),
- session_id=info.get("session_id"),
- memory_type=memory_type,
- status="activated",
- tags=memory_i_raw.get("tags", [])
- if type(memory_i_raw.get("tags", [])) is list
- else [],
- key=memory_i_raw.get("key", ""),
- embedding=self.embedder.embed([memory_i_raw.get("value", "")])[0],
- usage=[],
- sources=scene_data_info,
- background=response_json.get("summary", ""),
- confidence=0.99,
- type="fact",
- ),
+ node_i = self._make_memory_item(
+ value=memory_i_raw.get("value", ""),
+ info={
+ "user_id": raw_node.metadata.user_id,
+ "session_id": raw_node.metadata.session_id,
+ },
+ memory_type=memory_type,
+ tags=memory_i_raw.get("tags", [])
+ if isinstance(memory_i_raw.get("tags", []), list)
+ else [],
+ key=memory_i_raw.get("key", ""),
+ sources=raw_node.metadata.sources,
+ background=response_json.get("summary", ""),
+ type_="fact",
+ confidence=0.99,
)
chat_read_nodes.append(node_i)
except Exception as e:
@@ -202,7 +361,7 @@ def _process_chat_data(self, scene_data_info, info):
return chat_read_nodes
def get_memory(
- self, scene_data: list, type: str, info: dict[str, Any]
+ self, scene_data: list, type: str, info: dict[str, Any], mode: str = "fine"
) -> list[list[TextualMemoryItem]]:
"""
Extract and classify memory content from scene_data.
@@ -219,6 +378,8 @@ def get_memory(
- topic_chunk_overlap: Overlap for large topic chunks (default: 100)
- chunk_size: Size for small chunks (default: 256)
- chunk_overlap: Overlap for small chunks (default: 50)
+ mode: mem-reader mode, fast for quick process while fine for
+ better understanding via calling llm
Returns:
list[list[TextualMemoryItem]] containing memory content with summaries as keys and original text as values
Raises:
@@ -253,13 +414,48 @@ def get_memory(
# Process Q&A pairs concurrently with context propagation
with ContextThreadPoolExecutor() as executor:
futures = [
- executor.submit(processing_func, scene_data_info, info)
+ executor.submit(processing_func, scene_data_info, info, mode=mode)
for scene_data_info in list_scene_data_info
]
for future in concurrent.futures.as_completed(futures):
- res_memory = future.result()
- memory_list.append(res_memory)
+ try:
+ res_memory = future.result()
+ if res_memory is not None:
+ memory_list.append(res_memory)
+ except Exception as e:
+ logger.error(f"Task failed with exception: {e}")
+ logger.error(traceback.format_exc())
+ return memory_list
+
+ def fine_transfer_simple_mem(
+ self, input_memories: list[TextualMemoryItem], type: str
+ ) -> list[list[TextualMemoryItem]]:
+ if not input_memories:
+ return []
+
+ memory_list = []
+
+ if type == "chat":
+ processing_func = self._process_transfer_chat_data
+ elif type == "doc":
+ processing_func = self._process_transfer_doc_data
+ else:
+ processing_func = self._process_transfer_doc_data
+ # Process Q&A pairs concurrently with context propagation
+ with ContextThreadPoolExecutor() as executor:
+ futures = [
+ executor.submit(processing_func, scene_data_info)
+ for scene_data_info in input_memories
+ ]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ res_memory = future.result()
+ if res_memory is not None:
+ memory_list.append(res_memory)
+ except Exception as e:
+ logger.error(f"Task failed with exception: {e}")
+ logger.error(traceback.format_exc())
return memory_list
def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
@@ -275,30 +471,26 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
List of strings containing the processed scene data
"""
results = []
- parser_config = ParserConfigFactory.model_validate(
- {
- "backend": "markitdown",
- "config": {},
- }
- )
- parser = ParserFactory.from_config(parser_config)
if type == "chat":
for items in scene_data:
result = []
- for item in items:
- # Convert dictionary to string
- if "chat_time" in item:
- result.append(item)
- else:
- result.append(item)
+ for i, item in enumerate(items):
+ result.append(item)
if len(result) >= 10:
results.append(result)
- context = copy.deepcopy(result[-2:])
+ context = copy.deepcopy(result[-2:]) if i + 1 < len(items) else []
result = context
if result:
results.append(result)
elif type == "doc":
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": "markitdown",
+ "config": {},
+ }
+ )
+ parser = ParserFactory.from_config(parser_config)
for item in scene_data:
try:
if os.path.exists(item):
@@ -317,6 +509,9 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
return results
def _process_doc_data(self, scene_data_info, info, **kwargs):
+ mode = kwargs.get("mode", "fine")
+ if mode == "fast":
+ raise NotImplementedError
chunks = self.chunker.chunk(scene_data_info["text"])
messages = []
for chunk in chunks:
@@ -357,19 +552,48 @@ def _process_doc_data(self, scene_data_info, info, **kwargs):
logger.error(f"[DocReader] Future task failed: {e}")
return doc_nodes
- def parse_json_result(self, response_text):
+ def _process_transfer_doc_data(self, raw_node: TextualMemoryItem):
+ raise NotImplementedError
+
+ def parse_json_result(self, response_text: str) -> dict:
+ s = (response_text or "").strip()
+
+ m = re.search(r"```(?:json)?\s*([\s\S]*?)```", s, flags=re.I)
+ s = (m.group(1) if m else s.replace("```", "")).strip()
+
+ i = s.find("{")
+ if i == -1:
+ return {}
+ s = s[i:].strip()
+
+ try:
+ return json.loads(s)
+ except json.JSONDecodeError:
+ pass
+
+ j = max(s.rfind("}"), s.rfind("]"))
+ if j != -1:
+ try:
+ return json.loads(s[: j + 1])
+ except json.JSONDecodeError:
+ pass
+
+ def _cheap_close(t: str) -> str:
+ t += "}" * max(0, t.count("{") - t.count("}"))
+ t += "]" * max(0, t.count("[") - t.count("]"))
+ return t
+
+ t = _cheap_close(s)
try:
- json_start = response_text.find("{")
- response_text = response_text[json_start:]
- response_text = response_text.replace("```", "").strip()
- if not response_text.endswith("}"):
- response_text += "}"
- return json.loads(response_text)
+ return json.loads(t)
except json.JSONDecodeError as e:
- logger.error(f"[JSONParse] Failed to decode JSON: {e}\nRaw:\n{response_text}")
- return {}
- except Exception as e:
- logger.error(f"[JSONParse] Unexpected error: {e}")
+ if "Invalid \\escape" in str(e):
+ s = s.replace("\\", "\\\\")
+ return json.loads(s)
+ logger.error(
+ f"[JSONParse] Failed to decode JSON: {e}\nTail: Raw {response_text} \
+ json: {s}"
+ )
return {}
def transform_memreader(self, data: dict) -> list[TextualMemoryItem]:
diff --git a/src/memos/mem_reader/strategy_struct.py b/src/memos/mem_reader/strategy_struct.py
new file mode 100644
index 000000000..1fc21461e
--- /dev/null
+++ b/src/memos/mem_reader/strategy_struct.py
@@ -0,0 +1,151 @@
+import os
+
+from abc import ABC
+
+from memos import log
+from memos.configs.mem_reader import StrategyStructMemReaderConfig
+from memos.configs.parser import ParserConfigFactory
+from memos.mem_reader.simple_struct import SimpleStructMemReader, detect_lang
+from memos.parsers.factory import ParserFactory
+from memos.templates.mem_reader_prompts import (
+ SIMPLE_STRUCT_DOC_READER_PROMPT,
+ SIMPLE_STRUCT_DOC_READER_PROMPT_ZH,
+ SIMPLE_STRUCT_MEM_READER_EXAMPLE,
+ SIMPLE_STRUCT_MEM_READER_EXAMPLE_ZH,
+)
+from memos.templates.mem_reader_strategy_prompts import (
+ STRATEGY_STRUCT_MEM_READER_PROMPT,
+ STRATEGY_STRUCT_MEM_READER_PROMPT_ZH,
+)
+
+
+logger = log.get_logger(__name__)
+STRATEGY_PROMPT_DICT = {
+ "chat": {
+ "en": STRATEGY_STRUCT_MEM_READER_PROMPT,
+ "zh": STRATEGY_STRUCT_MEM_READER_PROMPT_ZH,
+ "en_example": SIMPLE_STRUCT_MEM_READER_EXAMPLE,
+ "zh_example": SIMPLE_STRUCT_MEM_READER_EXAMPLE_ZH,
+ },
+ "doc": {"en": SIMPLE_STRUCT_DOC_READER_PROMPT, "zh": SIMPLE_STRUCT_DOC_READER_PROMPT_ZH},
+}
+
+
+class StrategyStructMemReader(SimpleStructMemReader, ABC):
+ """Naive implementation of MemReader."""
+
+ def __init__(self, config: StrategyStructMemReaderConfig):
+ super().__init__(config)
+ self.chat_chunker = config.chat_chunker["config"]
+
+ def _get_llm_response(self, mem_str: str) -> dict:
+ lang = detect_lang(mem_str)
+ template = STRATEGY_PROMPT_DICT["chat"][lang]
+ examples = STRATEGY_PROMPT_DICT["chat"][f"{lang}_example"]
+ prompt = template.replace("${conversation}", mem_str)
+ if self.config.remove_prompt_example: # TODO unused
+ prompt = prompt.replace(examples, "")
+ messages = [{"role": "user", "content": prompt}]
+ try:
+ response_text = self.llm.generate(messages)
+ response_json = self.parse_json_result(response_text)
+ except Exception as e:
+ logger.error(f"[LLM] Exception during chat generation: {e}")
+ response_json = {
+ "memory list": [
+ {
+ "key": mem_str[:10],
+ "memory_type": "UserMemory",
+ "value": mem_str,
+ "tags": [],
+ }
+ ],
+ "summary": mem_str,
+ }
+ return response_json
+
+ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
+ """
+ Get raw information from scene_data.
+ If scene_data contains dictionaries, convert them to strings.
+ If scene_data contains file paths, parse them using the parser.
+
+ Args:
+ scene_data: List of dialogue information or document paths
+ type: Type of scene data: ['doc', 'chat']
+ Returns:
+ List of strings containing the processed scene data
+ """
+ results = []
+
+ if type == "chat":
+ if self.chat_chunker["chunk_type"] == "content_length":
+ content_len_thredshold = self.chat_chunker["chunk_length"]
+ for items in scene_data:
+ if not items:
+ continue
+
+ results.append([])
+ current_length = 0
+
+ for _i, item in enumerate(items):
+ content_length = (
+ len(item.get("content", ""))
+ if isinstance(item, dict)
+ else len(str(item))
+ )
+ if not results[-1]:
+ results[-1].append(item)
+ current_length = content_length
+ continue
+
+ if current_length + content_length <= content_len_thredshold:
+ results[-1].append(item)
+ current_length += content_length
+ else:
+ overlap_item = results[-1][-1]
+ overlap_length = (
+ len(overlap_item.get("content", ""))
+ if isinstance(overlap_item, dict)
+ else len(str(overlap_item))
+ )
+
+ results.append([overlap_item, item])
+ current_length = overlap_length + content_length
+ else:
+ cut_size, cut_overlap = (
+ self.chat_chunker["chunk_session"],
+ self.chat_chunker["chunk_overlap"],
+ )
+ for items in scene_data:
+ step = cut_size - cut_overlap
+ end = len(items) - cut_overlap
+ if end <= 0:
+ results.extend([items[:]])
+ else:
+ results.extend([items[i : i + cut_size] for i in range(0, end, step)])
+
+ elif type == "doc":
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": "markitdown",
+ "config": {},
+ }
+ )
+ parser = ParserFactory.from_config(parser_config)
+ for item in scene_data:
+ try:
+ if os.path.exists(item):
+ try:
+ parsed_text = parser.parse(item)
+ results.append({"file": item, "text": parsed_text})
+ except Exception as e:
+ logger.error(f"[SceneParser] Error parsing {item}: {e}")
+ continue
+ else:
+ parsed_text = item
+ results.append({"file": "pure_text", "text": parsed_text})
+ except Exception as e:
+ print(f"Error parsing file {item}: {e!s}")
+
+ return results
diff --git a/src/memos/mem_scheduler/analyzer/api_analyzer.py b/src/memos/mem_scheduler/analyzer/api_analyzer.py
index e69de29bb..28ca182e5 100644
--- a/src/memos/mem_scheduler/analyzer/api_analyzer.py
+++ b/src/memos/mem_scheduler/analyzer/api_analyzer.py
@@ -0,0 +1,717 @@
+"""
+API Analyzer for Scheduler
+
+This module provides the APIAnalyzerForScheduler class that handles API requests
+for search and add operations with reusable instance variables.
+"""
+
+import http.client
+import json
+import time
+
+from typing import Any
+from urllib.parse import urlparse
+
+import requests
+
+from memos.log import get_logger
+
+
+logger = get_logger(__name__)
+
+
+class APIAnalyzerForScheduler:
+ """
+ API Analyzer class for scheduler operations.
+
+ This class provides methods to interact with APIs for search and add operations,
+ with reusable instance variables for better performance and configuration management.
+ """
+
+ def __init__(
+ self,
+ base_url: str = "http://127.0.0.1:8002",
+ default_headers: dict[str, str] | None = None,
+ timeout: int = 30,
+ ):
+ """
+ Initialize the APIAnalyzerForScheduler.
+
+ Args:
+ base_url: Base URL for API requests
+ default_headers: Default headers to use for all requests
+ timeout: Request timeout in seconds
+ """
+ self.base_url = base_url.rstrip("/")
+ self.timeout = timeout
+
+ # Default headers
+ self.default_headers = default_headers or {"Content-Type": "application/json"}
+
+ # Parse URL for http.client usage
+ parsed_url = urlparse(self.base_url)
+ self.host = parsed_url.hostname
+ self.port = parsed_url.port or 8002
+ self.is_https = parsed_url.scheme == "https"
+
+ # Reusable connection for http.client
+ self._connection = None
+
+ # Attributes
+ self.user_id = "test_user_id"
+ self.mem_cube_id = "test_mem_cube_id"
+
+ logger.info(f"APIAnalyzerForScheduler initialized with base_url: {self.base_url}")
+
+ def _get_connection(self) -> http.client.HTTPConnection | http.client.HTTPSConnection:
+ """
+ Get or create a reusable HTTP connection.
+
+ Returns:
+ HTTP connection object
+ """
+ if self._connection is None:
+ if self.is_https:
+ self._connection = http.client.HTTPSConnection(self.host, self.port)
+ else:
+ self._connection = http.client.HTTPConnection(self.host, self.port)
+ return self._connection
+
+ def _close_connection(self):
+ """Close the HTTP connection if it exists."""
+ if self._connection:
+ self._connection.close()
+ self._connection = None
+
+ def search(
+ self, user_id: str, mem_cube_id: str, query: str, top: int = 50, use_requests: bool = True
+ ) -> dict[str, Any]:
+ """
+ Search for memories using the product/search API endpoint.
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ query: Search query string
+ top: Number of top results to return
+ use_requests: Whether to use requests library (True) or http.client (False)
+
+ Returns:
+ Dictionary containing the API response
+ """
+ payload = {"user_id": user_id, "mem_cube_id": mem_cube_id, "query": query, "top": top}
+
+ try:
+ if use_requests:
+ return self._search_with_requests(payload)
+ else:
+ return self._search_with_http_client(payload)
+ except Exception as e:
+ logger.error(f"Error in search operation: {e}")
+ return {"error": str(e), "success": False}
+
+ def _search_with_requests(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform search using requests library.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ url = f"{self.base_url}/product/search"
+
+ response = requests.post(
+ url, headers=self.default_headers, data=json.dumps(payload), timeout=self.timeout
+ )
+
+ logger.info(f"Search request to {url} completed with status: {response.status_code}")
+
+ try:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": response.json() if response.content else {},
+ "text": response.text,
+ }
+ except json.JSONDecodeError:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": {},
+ "text": response.text,
+ }
+
+ def _search_with_http_client(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform search using http.client.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ conn = self._get_connection()
+
+ try:
+ conn.request("POST", "/product/search", json.dumps(payload), self.default_headers)
+
+ response = conn.getresponse()
+ data = response.read()
+ response_text = data.decode("utf-8")
+
+ logger.info(f"Search request completed with status: {response.status}")
+
+ try:
+ response_data = json.loads(response_text) if response_text else {}
+ except json.JSONDecodeError:
+ response_data = {}
+
+ return {
+ "success": True,
+ "status_code": response.status,
+ "data": response_data,
+ "text": response_text,
+ }
+ except Exception as e:
+ logger.error(f"Error in http.client search: {e}")
+ return {"error": str(e), "success": False}
+
+ def add(
+ self, messages: list, user_id: str, mem_cube_id: str, use_requests: bool = True
+ ) -> dict[str, Any]:
+ """
+ Add memories using the product/add API endpoint.
+
+ Args:
+ messages: List of message objects with role and content
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ use_requests: Whether to use requests library (True) or http.client (False)
+
+ Returns:
+ Dictionary containing the API response
+ """
+ payload = {"messages": messages, "user_id": user_id, "mem_cube_id": mem_cube_id}
+
+ try:
+ if use_requests:
+ return self._add_with_requests(payload)
+ else:
+ return self._add_with_http_client(payload)
+ except Exception as e:
+ logger.error(f"Error in add operation: {e}")
+ return {"error": str(e), "success": False}
+
+ def _add_with_requests(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform add using requests library.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ url = f"{self.base_url}/product/add"
+
+ response = requests.post(
+ url, headers=self.default_headers, data=json.dumps(payload), timeout=self.timeout
+ )
+
+ logger.info(f"Add request to {url} completed with status: {response.status_code}")
+
+ try:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": response.json() if response.content else {},
+ "text": response.text,
+ }
+ except json.JSONDecodeError:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": {},
+ "text": response.text,
+ }
+
+ def _add_with_http_client(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform add using http.client.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ conn = self._get_connection()
+
+ try:
+ conn.request("POST", "/product/add", json.dumps(payload), self.default_headers)
+
+ response = conn.getresponse()
+ data = response.read()
+ response_text = data.decode("utf-8")
+
+ logger.info(f"Add request completed with status: {response.status}")
+
+ try:
+ response_data = json.loads(response_text) if response_text else {}
+ except json.JSONDecodeError:
+ response_data = {}
+
+ return {
+ "success": True,
+ "status_code": response.status,
+ "data": response_data,
+ "text": response_text,
+ }
+ except Exception as e:
+ logger.error(f"Error in http.client add: {e}")
+ return {"error": str(e), "success": False}
+
+ def update_base_url(self, new_base_url: str):
+ """
+ Update the base URL and reinitialize connection parameters.
+
+ Args:
+ new_base_url: New base URL for API requests
+ """
+ self._close_connection()
+ self.base_url = new_base_url.rstrip("/")
+
+ # Re-parse URL
+ parsed_url = urlparse(self.base_url)
+ self.host = parsed_url.hostname
+ self.port = parsed_url.port or (443 if parsed_url.scheme == "https" else 80)
+ self.is_https = parsed_url.scheme == "https"
+
+ logger.info(f"Base URL updated to: {self.base_url}")
+
+ def update_headers(self, headers: dict[str, str]):
+ """
+ Update default headers.
+
+ Args:
+ headers: New headers to merge with existing ones
+ """
+ self.default_headers.update(headers)
+ logger.info("Headers updated")
+
+ def __del__(self):
+ """Cleanup method to close connection when object is destroyed."""
+ self._close_connection()
+
+ def analyze_service(self):
+ # Example add operation
+ messages = [
+ {"role": "user", "content": "Where should I go for New Year's Eve in Shanghai?"},
+ {
+ "role": "assistant",
+ "content": "You could head to the Bund for the countdown, attend a rooftop party, or enjoy the fireworks at Disneyland Shanghai.",
+ },
+ ]
+
+ add_result = self.add(
+ messages=messages, user_id="test_user_id", mem_cube_id="test_mem_cube_id"
+ )
+ print("Add result:", add_result)
+
+ # Example search operation
+ search_result = self.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
+
+ def analyze_features(self):
+ try:
+ # Test basic search functionality
+ search_result = self.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
+ except Exception as e:
+ logger.error(f"Feature analysis failed: {e}")
+
+
+class DirectSearchMemoriesAnalyzer:
+ """
+ Direct analyzer for testing search_memories function
+ Used for debugging and analyzing search_memories function behavior without starting a full API server
+ """
+
+ def __init__(self):
+ """Initialize the analyzer"""
+ # Import necessary modules
+ try:
+ from memos.api.product_models import APIADDRequest, APISearchRequest
+ from memos.api.routers.server_router import add_memories, search_memories
+ from memos.types import MessageDict, UserContext
+
+ self.APISearchRequest = APISearchRequest
+ self.APIADDRequest = APIADDRequest
+ self.search_memories = search_memories
+ self.add_memories = add_memories
+ self.UserContext = UserContext
+ self.MessageDict = MessageDict
+
+ # Initialize conversation history for continuous conversation support
+ self.conversation_history = []
+ self.current_session_id = None
+ self.current_user_id = None
+ self.current_mem_cube_id = None
+
+ logger.info("DirectSearchMemoriesAnalyzer initialized successfully")
+ except ImportError as e:
+ logger.error(f"Failed to import modules: {e}")
+ raise
+
+ def start_conversation(self, user_id="test_user", mem_cube_id="test_cube", session_id=None):
+ """
+ Start a new conversation session for continuous dialogue.
+
+ Args:
+ user_id: User ID for the conversation
+ mem_cube_id: Memory cube ID for the conversation
+ session_id: Session ID for the conversation (auto-generated if None)
+ """
+ self.current_user_id = user_id
+ self.current_mem_cube_id = mem_cube_id
+ self.current_session_id = (
+ session_id or f"session_{hash(user_id + mem_cube_id)}_{len(self.conversation_history)}"
+ )
+ self.conversation_history = []
+
+ logger.info(f"Started conversation session: {self.current_session_id}")
+ print(f"🚀 Started new conversation session: {self.current_session_id}")
+ print(f" User ID: {self.current_user_id}")
+ print(f" Mem Cube ID: {self.current_mem_cube_id}")
+
+ def add_to_conversation(self, user_message, assistant_message=None):
+ """
+ Add messages to the current conversation and store them in memory.
+
+ Args:
+ user_message: User's message content
+ assistant_message: Assistant's response (optional)
+
+ Returns:
+ Result from add_memories function
+ """
+ if not self.current_session_id:
+ raise ValueError("No active conversation session. Call start_conversation() first.")
+
+ # Prepare messages for adding to memory
+ messages = [{"role": "user", "content": user_message}]
+ if assistant_message:
+ messages.append({"role": "assistant", "content": assistant_message})
+
+ # Add to conversation history
+ self.conversation_history.extend(messages)
+
+ # Create add request
+ add_req = self.create_test_add_request(
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ messages=messages,
+ session_id=self.current_session_id,
+ )
+
+ print(f"💬 Adding to conversation (Session: {self.current_session_id}):")
+ print(f" User: {user_message}")
+ if assistant_message:
+ print(f" Assistant: {assistant_message}")
+
+ # Add to memory
+ result = self.add_memories(add_req)
+ print(" ✅ Added to memory successfully")
+
+ return result
+
+ def search_in_conversation(self, query, mode="fast", top_k=10, include_history=True):
+ """
+ Search memories within the current conversation context.
+
+ Args:
+ query: Search query
+ mode: Search mode ("fast", "fine", or "mixture")
+ top_k: Number of results to return
+ include_history: Whether to include conversation history in the search
+
+ Returns:
+ Search results
+ """
+ if not self.current_session_id:
+ raise ValueError("No active conversation session. Call start_conversation() first.")
+
+ # Prepare chat history if requested
+ chat_history = self.conversation_history if include_history else None
+
+ # Create search request
+ search_req = self.create_test_search_request(
+ query=query,
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ mode=mode,
+ top_k=top_k,
+ chat_history=chat_history,
+ session_id=self.current_session_id,
+ )
+
+ print(f"🔍 Searching in conversation (Session: {self.current_session_id}):")
+ print(f" Query: {query}")
+ print(f" Mode: {mode}")
+ print(f" Top K: {top_k}")
+ print(f" Include History: {include_history}")
+ print(f" History Length: {len(self.conversation_history) if chat_history else 0}")
+
+ # Perform search
+ result = self.search_memories(search_req)
+
+ print(" ✅ Search completed")
+ if hasattr(result, "data") and result.data:
+ total_memories = sum(
+ len(mem_list) for mem_list in result.data.values() if isinstance(mem_list, list)
+ )
+ print(f" 📊 Found {total_memories} total memories")
+
+ return result
+
+ def test_continuous_conversation(self):
+ """Test continuous conversation functionality"""
+ print("=" * 80)
+ print("Testing Continuous Conversation Functionality")
+ print("=" * 80)
+
+ try:
+ # Start a conversation
+ self.start_conversation(user_id="conv_test_user", mem_cube_id="conv_test_cube")
+
+ # Prepare all conversation messages for batch addition
+ all_messages = [
+ {
+ "role": "user",
+ "content": "I'm planning a trip to Shanghai for New Year's Eve. What are some good places to visit?",
+ },
+ {
+ "role": "assistant",
+ "content": "Shanghai has many great places for New Year's Eve! You could visit the Bund for the countdown, go to a rooftop party, or enjoy fireworks at Disneyland Shanghai. The French Concession also has nice bars and restaurants.",
+ },
+ {"role": "user", "content": "What about food? Any restaurant recommendations?"},
+ {
+ "role": "assistant",
+ "content": "For New Year's Eve dining in Shanghai, I'd recommend trying some local specialties like xiaolongbao at Din Tai Fung, or for a fancy dinner, you could book at restaurants in the Bund area with great views.",
+ },
+ {"role": "user", "content": "I'm on a budget though. Any cheaper alternatives?"},
+ {
+ "role": "assistant",
+ "content": "For budget-friendly options, try street food in Yuyuan Garden area, local noodle shops, or food courts in shopping malls. You can also watch the fireworks from free public areas along the Huangpu River.",
+ },
+ ]
+
+ # Add all conversation messages at once
+ print("\n📝 Adding all conversation messages at once:")
+ add_req = self.create_test_add_request(
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ messages=all_messages,
+ session_id=self.current_session_id,
+ )
+
+ print(
+ f"💬 Adding {len(all_messages)} messages to conversation (Session: {self.current_session_id})"
+ )
+ self.add_memories(add_req)
+
+ # Update conversation history
+ self.conversation_history.extend(all_messages)
+ print(" ✅ Added all messages to memory successfully")
+
+ # Test searching within the conversation
+ print("\n🔍 Testing search within conversation:")
+
+ # Search for trip-related information
+ self.search_in_conversation(
+ query="New Year's Eve Shanghai recommendations", mode="mixture", top_k=5
+ )
+
+ # Search for food-related information
+ self.search_in_conversation(query="budget food Shanghai", mode="mixture", top_k=3)
+
+ # Search without conversation history
+ self.search_in_conversation(
+ query="Shanghai travel", mode="mixture", top_k=3, include_history=False
+ )
+
+ print("\n✅ Continuous conversation test completed successfully!")
+ return True
+
+ except Exception as e:
+ print(f"❌ Continuous conversation test failed: {e}")
+ import traceback
+
+ traceback.print_exc()
+ return False
+
+ def create_test_search_request(
+ self,
+ query="test query",
+ user_id="test_user",
+ mem_cube_id="test_cube",
+ mode="fast",
+ top_k=10,
+ chat_history=None,
+ session_id=None,
+ ):
+ """
+ Create a test APISearchRequest object with the given parameters.
+
+ Args:
+ query: Search query string
+ user_id: User ID for the request
+ mem_cube_id: Memory cube ID for the request
+ mode: Search mode ("fast" or "fine")
+ top_k: Number of results to return
+ chat_history: Chat history for context (optional)
+ session_id: Session ID for the request (optional)
+
+ Returns:
+ APISearchRequest: A configured request object
+ """
+ return self.APISearchRequest(
+ query=query,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mode=mode,
+ top_k=top_k,
+ chat_history=chat_history,
+ session_id=session_id,
+ )
+
+ def create_test_add_request(
+ self,
+ user_id="test_user",
+ mem_cube_id="test_cube",
+ messages=None,
+ memory_content=None,
+ session_id=None,
+ ):
+ """
+ Create a test APIADDRequest object with the given parameters.
+
+ Args:
+ user_id: User ID for the request
+ mem_cube_id: Memory cube ID for the request
+ messages: List of messages to add (optional)
+ memory_content: Direct memory content to add (optional)
+ session_id: Session ID for the request (optional)
+
+ Returns:
+ APIADDRequest: A configured request object
+ """
+ if messages is None and memory_content is None:
+ # Default test messages
+ messages = [
+ {"role": "user", "content": "What's the weather like today?"},
+ {
+ "role": "assistant",
+ "content": "I don't have access to real-time weather data, but you can check a weather app or website for current conditions.",
+ },
+ ]
+
+ # Ensure we have a valid session_id
+ if session_id is None:
+ session_id = "test_session_" + str(hash(user_id + mem_cube_id))[:8]
+
+ return self.APIADDRequest(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ messages=messages,
+ memory_content=memory_content,
+ session_id=session_id,
+ doc_path=None,
+ source="api_analyzer_test",
+ chat_history=None,
+ operation=None,
+ )
+
+ def run_all_tests(self):
+ """Run all available tests"""
+ print("🚀 Starting comprehensive test suite")
+ print("=" * 80)
+
+ # Test continuous conversation functionality
+ print("\n💬 Testing CONTINUOUS CONVERSATION functions:")
+ try:
+ self.test_continuous_conversation()
+ time.sleep(5)
+ print("✅ Continuous conversation test completed successfully")
+ except Exception as e:
+ print(f"❌ Continuous conversation test failed: {e}")
+
+ print("\n" + "=" * 80)
+ print("✅ All tests completed!")
+
+
+# Example usage
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser(description="API Analyzer for Memory Scheduler")
+ parser.add_argument(
+ "--mode",
+ choices=["direct", "api"],
+ default="direct",
+ help="Test mode: 'direct' for direct function testing, 'api' for API testing (default: direct)",
+ )
+
+ args = parser.parse_args()
+
+ if args.mode == "direct":
+ # Direct test mode for search_memories and add_memories functions
+ print("Using direct test mode")
+ try:
+ direct_analyzer = DirectSearchMemoriesAnalyzer()
+ direct_analyzer.run_all_tests()
+ except Exception as e:
+ print(f"Direct test mode failed: {e}")
+ import traceback
+
+ traceback.print_exc()
+ else:
+ # Original API test mode
+ print("Using API test mode")
+ analyzer = APIAnalyzerForScheduler()
+
+ # Test add operation
+ messages = [
+ {"role": "user", "content": "Where should I go for New Year's Eve in Shanghai?"},
+ {
+ "role": "assistant",
+ "content": "You could head to the Bund for the countdown, attend a rooftop party, or enjoy the fireworks at Disneyland Shanghai.",
+ },
+ ]
+
+ add_result = analyzer.add(
+ messages=messages, user_id="test_user_id", mem_cube_id="test_mem_cube_id"
+ )
+ print("Add result:", add_result)
+
+ # Test search operation
+ search_result = analyzer.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
diff --git a/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py b/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
index 7cd085ada..ace67eff6 100644
--- a/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
+++ b/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
@@ -485,18 +485,20 @@ def chat(self, query: str, user_id: str | None = None) -> str:
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # TODO this only one cubes
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # TODO this only one cubes
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
break
# Generate response
response = self.chat_llm.generate(current_messages, past_key_values=past_key_values)
diff --git a/src/memos/mem_scheduler/base_scheduler.py b/src/memos/mem_scheduler/base_scheduler.py
index 4f8b0719b..028fe8e3f 100644
--- a/src/memos/mem_scheduler/base_scheduler.py
+++ b/src/memos/mem_scheduler/base_scheduler.py
@@ -1,3 +1,4 @@
+import contextlib
import multiprocessing
import queue
import threading
@@ -6,10 +7,12 @@
from collections.abc import Callable
from datetime import datetime
from pathlib import Path
+from typing import TYPE_CHECKING
from sqlalchemy.engine import Engine
from memos.configs.mem_scheduler import AuthConfig, BaseSchedulerConfig
+from memos.context.context import ContextThread
from memos.llms.base import BaseLLM
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
@@ -22,8 +25,12 @@
from memos.mem_scheduler.schemas.general_schemas import (
DEFAULT_ACT_MEM_DUMP_PATH,
DEFAULT_CONSUME_INTERVAL_SECONDS,
+ DEFAULT_CONTEXT_WINDOW_SIZE,
+ DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
DEFAULT_STARTUP_MODE,
DEFAULT_THREAD_POOL_MAX_WORKERS,
+ DEFAULT_TOP_K,
+ DEFAULT_USE_REDIS_QUEUE,
STARTUP_BY_PROCESS,
MemCubeID,
TreeTextMemory_SEARCH_METHOD,
@@ -34,6 +41,7 @@
ScheduleMessageItem,
)
from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorItem
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.mem_scheduler.utils.filter_utils import (
transform_name_to_key,
)
@@ -45,6 +53,10 @@
from memos.templates.mem_scheduler_prompts import MEMORY_ASSEMBLY_TEMPLATE
+if TYPE_CHECKING:
+ from memos.mem_cube.base import BaseMemCube
+
+
logger = get_logger(__name__)
@@ -57,11 +69,13 @@ def __init__(self, config: BaseSchedulerConfig):
self.config = config
# hyper-parameters
- self.top_k = self.config.get("top_k", 10)
- self.context_window_size = self.config.get("context_window_size", 5)
+ self.top_k = self.config.get("top_k", DEFAULT_TOP_K)
+ self.context_window_size = self.config.get(
+ "context_window_size", DEFAULT_CONTEXT_WINDOW_SIZE
+ )
self.enable_activation_memory = self.config.get("enable_activation_memory", False)
self.act_mem_dump_path = self.config.get("act_mem_dump_path", DEFAULT_ACT_MEM_DUMP_PATH)
- self.search_method = TreeTextMemory_SEARCH_METHOD
+ self.search_method = self.config.get("search_method", TreeTextMemory_SEARCH_METHOD)
self.enable_parallel_dispatch = self.config.get("enable_parallel_dispatch", True)
self.thread_pool_max_workers = self.config.get(
"thread_pool_max_workers", DEFAULT_THREAD_POOL_MAX_WORKERS
@@ -76,6 +90,7 @@ def __init__(self, config: BaseSchedulerConfig):
self.db_engine: Engine | None = None
self.monitor: SchedulerGeneralMonitor | None = None
self.dispatcher_monitor: SchedulerDispatcherMonitor | None = None
+ self.mem_reader = None # Will be set by MOSCore
self.dispatcher = SchedulerDispatcher(
config=self.config,
max_workers=self.thread_pool_max_workers,
@@ -85,13 +100,22 @@ def __init__(self, config: BaseSchedulerConfig):
# optional configs
self.disable_handlers: list | None = self.config.get("disable_handlers", None)
- # internal message queue
+ # message queue configuration
+ self.use_redis_queue = self.config.get("use_redis_queue", DEFAULT_USE_REDIS_QUEUE)
self.max_internal_message_queue_size = self.config.get(
- "max_internal_message_queue_size", 100
- )
- self.memos_message_queue: Queue[ScheduleMessageItem] = Queue(
- maxsize=self.max_internal_message_queue_size
+ "max_internal_message_queue_size", DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE
)
+
+ # Initialize message queue based on configuration
+ if self.use_redis_queue:
+ self.memos_message_queue = None # Will use Redis instead
+ # Initialize Redis if using Redis queue with auto-initialization
+ self.auto_initialize_redis()
+ else:
+ self.memos_message_queue: Queue[ScheduleMessageItem] = Queue(
+ maxsize=self.max_internal_message_queue_size
+ )
+
self.max_web_log_queue_size = self.config.get("max_web_log_queue_size", 50)
self._web_log_message_queue: Queue[ScheduleLogForWebItem] = Queue(
maxsize=self.max_web_log_queue_size
@@ -107,7 +131,7 @@ def __init__(self, config: BaseSchedulerConfig):
self._context_lock = threading.Lock()
self.current_user_id: UserID | str | None = None
self.current_mem_cube_id: MemCubeID | str | None = None
- self.current_mem_cube: GeneralMemCube | None = None
+ self.current_mem_cube: BaseMemCube | None = None
self.auth_config_path: str | Path | None = self.config.get("auth_config_path", None)
self.auth_config = None
self.rabbitmq_config = None
@@ -117,6 +141,7 @@ def initialize_modules(
chat_llm: BaseLLM,
process_llm: BaseLLM | None = None,
db_engine: Engine | None = None,
+ mem_reader=None,
):
if process_llm is None:
process_llm = chat_llm
@@ -133,17 +158,25 @@ def initialize_modules(
self.dispatcher_monitor = SchedulerDispatcherMonitor(config=self.config)
self.retriever = SchedulerRetriever(process_llm=self.process_llm, config=self.config)
+ if mem_reader:
+ self.mem_reader = mem_reader
+
if self.enable_parallel_dispatch:
self.dispatcher_monitor.initialize(dispatcher=self.dispatcher)
self.dispatcher_monitor.start()
# initialize with auth_config
- if self.auth_config_path is not None and Path(self.auth_config_path).exists():
- self.auth_config = AuthConfig.from_local_config(config_path=self.auth_config_path)
- elif AuthConfig.default_config_exists():
- self.auth_config = AuthConfig.from_local_config()
- else:
- self.auth_config = AuthConfig.from_local_env()
+ try:
+ if self.auth_config_path is not None and Path(self.auth_config_path).exists():
+ self.auth_config = AuthConfig.from_local_config(
+ config_path=self.auth_config_path
+ )
+ elif AuthConfig.default_config_exists():
+ self.auth_config = AuthConfig.from_local_config()
+ else:
+ self.auth_config = AuthConfig.from_local_env()
+ except Exception:
+ pass
if self.auth_config is not None:
self.rabbitmq_config = self.auth_config.rabbitmq
@@ -157,6 +190,8 @@ def initialize_modules(
self._cleanup_on_init_failure()
raise
+ # start queue monitor if enabled and a bot is set later
+
def _cleanup_on_init_failure(self):
"""Clean up resources if initialization fails."""
try:
@@ -384,7 +419,7 @@ def update_activation_memory(
cache_item = act_mem.extract(new_text_memory)
cache_item.records.text_memories = new_text_memories
- cache_item.records.timestamp = datetime.utcnow()
+ cache_item.records.timestamp = get_utc_now()
act_mem.add([cache_item])
act_mem.dump(self.act_mem_dump_path)
@@ -465,7 +500,7 @@ def update_activation_memory_periodically(
mem_cube=mem_cube,
)
- self.monitor.last_activation_mem_update_time = datetime.utcnow()
+ self.monitor.last_activation_mem_update_time = get_utc_now()
logger.debug(
f"Activation memory update completed at {self.monitor.last_activation_mem_update_time}"
@@ -474,14 +509,14 @@ def update_activation_memory_periodically(
else:
logger.info(
f"Skipping update - {interval_seconds} second interval not yet reached. "
- f"Last update time is {self.monitor.last_activation_mem_update_time} and now is"
- f"{datetime.utcnow()}"
+ f"Last update time is {self.monitor.last_activation_mem_update_time} and now is "
+ f"{get_utc_now()}"
)
except Exception as e:
logger.error(f"Error in update_activation_memory_periodically: {e}", exc_info=True)
def submit_messages(self, messages: ScheduleMessageItem | list[ScheduleMessageItem]):
- """Submit multiple messages to the message queue."""
+ """Submit messages to the message queue (either local queue or Redis)."""
if isinstance(messages, ScheduleMessageItem):
messages = [messages] # transform single message to list
@@ -491,13 +526,27 @@ def submit_messages(self, messages: ScheduleMessageItem | list[ScheduleMessageIt
logger.error(error_msg)
raise TypeError(error_msg)
- # Check if this handler is disabled
+ if getattr(message, "timestamp", None) is None:
+ with contextlib.suppress(Exception):
+ message.timestamp = datetime.utcnow()
+
if self.disable_handlers and message.label in self.disable_handlers:
logger.info(f"Skipping disabled handler: {message.label} - {message.content}")
continue
- self.memos_message_queue.put(message)
- logger.info(f"Submitted message: {message.label} - {message.content}")
+ if self.use_redis_queue:
+ # Use Redis stream for message queue
+ self.redis_add_message_stream(message.to_dict())
+ logger.info(f"Submitted message to Redis: {message.label} - {message.content}")
+ else:
+ # Use local queue
+ self.memos_message_queue.put(message)
+ logger.info(
+ f"Submitted message to local queue: {message.label} - {message.content}"
+ )
+ with contextlib.suppress(Exception):
+ if messages:
+ self.dispatcher.on_messages_enqueued(messages)
def _submit_web_logs(
self, messages: ScheduleLogForWebItem | list[ScheduleLogForWebItem]
@@ -550,36 +599,64 @@ def _message_consumer(self) -> None:
Continuously checks the queue for messages and dispatches them.
Runs in a dedicated thread to process messages at regular intervals.
+ For Redis queue, this method starts the Redis listener.
"""
- while self._running: # Use a running flag for graceful shutdown
- try:
- # Get all available messages at once (thread-safe approach)
- messages = []
- while True:
- try:
- # Use get_nowait() directly without empty() check to avoid race conditions
- message = self.memos_message_queue.get_nowait()
- messages.append(message)
- except queue.Empty:
- # No more messages available
- break
-
- if messages:
- try:
- self.dispatcher.dispatch(messages)
- except Exception as e:
- logger.error(f"Error dispatching messages: {e!s}")
- finally:
- # Mark all messages as processed
- for _ in messages:
- self.memos_message_queue.task_done()
-
- # Sleep briefly to prevent busy waiting
- time.sleep(self._consume_interval) # Adjust interval as needed
-
- except Exception as e:
- logger.error(f"Unexpected error in message consumer: {e!s}")
- time.sleep(self._consume_interval) # Prevent tight error loops
+ if self.use_redis_queue:
+ # For Redis queue, start the Redis listener
+ def redis_message_handler(message_data):
+ """Handler for Redis messages"""
+ try:
+ # Redis message data needs to be decoded from bytes to string
+ decoded_data = {}
+ for key, value in message_data.items():
+ if isinstance(key, bytes):
+ key = key.decode("utf-8")
+ if isinstance(value, bytes):
+ value = value.decode("utf-8")
+ decoded_data[key] = value
+
+ message = ScheduleMessageItem.from_dict(decoded_data)
+ self.dispatcher.dispatch([message])
+ except Exception as e:
+ logger.error(f"Error processing Redis message: {e}")
+ logger.error(f"Message data: {message_data}")
+
+ self.redis_start_listening(handler=redis_message_handler)
+
+ # Keep the thread alive while Redis listener is running
+ while self._running:
+ time.sleep(self._consume_interval)
+ else:
+ # Original local queue logic
+ while self._running: # Use a running flag for graceful shutdown
+ try:
+ # Get all available messages at once (thread-safe approach)
+ messages = []
+ while True:
+ try:
+ # Use get_nowait() directly without empty() check to avoid race conditions
+ message = self.memos_message_queue.get_nowait()
+ messages.append(message)
+ except queue.Empty:
+ # No more messages available
+ break
+
+ if messages:
+ try:
+ self.dispatcher.dispatch(messages)
+ except Exception as e:
+ logger.error(f"Error dispatching messages: {e!s}")
+ finally:
+ # Mark all messages as processed
+ for _ in messages:
+ self.memos_message_queue.task_done()
+
+ # Sleep briefly to prevent busy waiting
+ time.sleep(self._consume_interval) # Adjust interval as needed
+
+ except Exception as e:
+ logger.error(f"Unexpected error in message consumer: {e!s}")
+ time.sleep(self._consume_interval) # Prevent tight error loops
def start(self) -> None:
"""
@@ -613,7 +690,7 @@ def start(self) -> None:
logger.info("Message consumer process started")
else:
# Default to thread mode
- self._consumer_thread = threading.Thread(
+ self._consumer_thread = ContextThread(
target=self._message_consumer,
daemon=True,
name="MessageConsumerThread",
@@ -716,17 +793,226 @@ def unregister_handlers(self, labels: list[str]) -> dict[str, bool]:
return self.dispatcher.unregister_handlers(labels)
+ def get_running_tasks(self, filter_func: Callable | None = None) -> dict[str, dict]:
+ if not self.dispatcher:
+ logger.warning("Dispatcher is not initialized, returning empty tasks dict")
+ return {}
+
+ running_tasks = self.dispatcher.get_running_tasks(filter_func=filter_func)
+
+ # Convert RunningTaskItem objects to dictionaries for easier consumption
+ result = {}
+ for task_id, task_item in running_tasks.items():
+ result[task_id] = {
+ "item_id": task_item.item_id,
+ "user_id": task_item.user_id,
+ "mem_cube_id": task_item.mem_cube_id,
+ "task_info": task_item.task_info,
+ "task_name": task_item.task_name,
+ "start_time": task_item.start_time,
+ "end_time": task_item.end_time,
+ "status": task_item.status,
+ "result": task_item.result,
+ "error_message": task_item.error_message,
+ "messages": task_item.messages,
+ }
+
+ return result
+
def _cleanup_queues(self) -> None:
"""Ensure all queues are emptied and marked as closed."""
- try:
- while not self.memos_message_queue.empty():
- self.memos_message_queue.get_nowait()
- self.memos_message_queue.task_done()
- except queue.Empty:
- pass
+ if self.use_redis_queue:
+ # For Redis queue, stop the listener and close connection
+ try:
+ self.redis_stop_listening()
+ self.redis_close()
+ except Exception as e:
+ logger.error(f"Error cleaning up Redis connection: {e}")
+ else:
+ # Original local queue cleanup
+ try:
+ while not self.memos_message_queue.empty():
+ self.memos_message_queue.get_nowait()
+ self.memos_message_queue.task_done()
+ except queue.Empty:
+ pass
try:
while not self._web_log_message_queue.empty():
self._web_log_message_queue.get_nowait()
except queue.Empty:
pass
+
+ def mem_scheduler_wait(
+ self, timeout: float = 180.0, poll: float = 0.1, log_every: float = 0.01
+ ) -> bool:
+ """
+ Uses EWMA throughput, detects leaked `unfinished_tasks`, and waits for dispatcher.
+ """
+ deadline = time.monotonic() + timeout
+
+ # --- helpers (local, no external deps) ---
+ def _unfinished() -> int:
+ """Prefer `unfinished_tasks`; fallback to `qsize()`."""
+ try:
+ u = getattr(self.memos_message_queue, "unfinished_tasks", None)
+ if u is not None:
+ return int(u)
+ except Exception:
+ pass
+ try:
+ return int(self.memos_message_queue.qsize())
+ except Exception:
+ return 0
+
+ def _fmt_eta(seconds: float | None) -> str:
+ """Format seconds to human-readable string."""
+ if seconds is None or seconds != seconds or seconds == float("inf"):
+ return "unknown"
+ s = max(0, int(seconds))
+ h, s = divmod(s, 3600)
+ m, s = divmod(s, 60)
+ if h > 0:
+ return f"{h:d}h{m:02d}m{s:02d}s"
+ if m > 0:
+ return f"{m:d}m{s:02d}s"
+ return f"{s:d}s"
+
+ # --- EWMA throughput state (tasks/s) ---
+ alpha = 0.3
+ rate = 0.0
+ last_t = None # type: float | None
+ last_done = 0
+
+ # --- dynamic totals & stuck detection ---
+ init_unfinished = _unfinished()
+ done_total = 0
+ last_unfinished = None
+ stuck_ticks = 0
+ next_log = 0.0
+
+ while True:
+ # 1) read counters
+ curr_unfinished = _unfinished()
+ try:
+ qsz = int(self.memos_message_queue.qsize())
+ except Exception:
+ qsz = -1
+
+ pend = run = 0
+ stats_fn = getattr(self.dispatcher, "stats", None)
+ if self.enable_parallel_dispatch and self.dispatcher is not None and callable(stats_fn):
+ try:
+ st = (
+ stats_fn()
+ ) # expected: {'pending':int,'running':int,'done':int?,'rate':float?}
+ pend = int(st.get("pending", 0))
+ run = int(st.get("running", 0))
+ except Exception:
+ pass
+
+ # 2) dynamic total (allows new tasks queued while waiting)
+ total_now = max(init_unfinished, done_total + curr_unfinished)
+ done_total = max(0, total_now - curr_unfinished)
+
+ # 3) update EWMA throughput
+ now = time.monotonic()
+ if last_t is None:
+ last_t = now
+ else:
+ dt = max(1e-6, now - last_t)
+ dc = max(0, done_total - last_done)
+ inst = dc / dt
+ rate = inst if rate == 0.0 else alpha * inst + (1 - alpha) * rate
+ last_t = now
+ last_done = done_total
+
+ eta = None if rate <= 1e-9 else (curr_unfinished / rate)
+
+ # 4) progress log (throttled)
+ if now >= next_log:
+ print(
+ f"[mem_scheduler_wait] remaining≈{curr_unfinished} | throughput≈{rate:.2f} msg/s | ETA≈{_fmt_eta(eta)} "
+ f"| qsize={qsz} pending={pend} running={run}"
+ )
+ next_log = now + max(0.2, log_every)
+
+ # 5) exit / stuck detection
+ idle_dispatcher = (
+ (pend == 0 and run == 0)
+ if (self.enable_parallel_dispatch and self.dispatcher is not None)
+ else True
+ )
+ if curr_unfinished == 0:
+ break
+ if curr_unfinished > 0 and qsz == 0 and idle_dispatcher:
+ if last_unfinished == curr_unfinished:
+ stuck_ticks += 1
+ else:
+ stuck_ticks = 0
+ else:
+ stuck_ticks = 0
+ last_unfinished = curr_unfinished
+
+ if stuck_ticks >= 3:
+ logger.warning(
+ "mem_scheduler_wait: detected leaked 'unfinished_tasks' -> treating queue as drained"
+ )
+ break
+
+ if now >= deadline:
+ logger.warning("mem_scheduler_wait: queue did not drain before timeout")
+ return False
+
+ time.sleep(poll)
+
+ # 6) wait dispatcher (second stage)
+ remaining = max(0.0, deadline - time.monotonic())
+ if self.enable_parallel_dispatch and self.dispatcher is not None:
+ try:
+ ok = self.dispatcher.join(timeout=remaining if remaining > 0 else 0)
+ except TypeError:
+ ok = self.dispatcher.join()
+ if not ok:
+ logger.warning("mem_scheduler_wait: dispatcher did not complete before timeout")
+ return False
+
+ return True
+
+ def _gather_queue_stats(self) -> dict:
+ """Collect queue/dispatcher stats for reporting."""
+ stats: dict[str, int | float | str] = {}
+ stats["use_redis_queue"] = bool(self.use_redis_queue)
+ # local queue metrics
+ if not self.use_redis_queue:
+ try:
+ stats["qsize"] = int(self.memos_message_queue.qsize())
+ except Exception:
+ stats["qsize"] = -1
+ # unfinished_tasks if available
+ try:
+ stats["unfinished_tasks"] = int(
+ getattr(self.memos_message_queue, "unfinished_tasks", 0) or 0
+ )
+ except Exception:
+ stats["unfinished_tasks"] = -1
+ stats["maxsize"] = int(self.max_internal_message_queue_size)
+ try:
+ maxsize = int(self.max_internal_message_queue_size) or 1
+ qsize = int(stats.get("qsize", 0))
+ stats["utilization"] = min(1.0, max(0.0, qsize / maxsize))
+ except Exception:
+ stats["utilization"] = 0.0
+ # dispatcher stats
+ try:
+ d_stats = self.dispatcher.stats()
+ stats.update(
+ {
+ "running": int(d_stats.get("running", 0)),
+ "inflight": int(d_stats.get("inflight", 0)),
+ "handlers": int(d_stats.get("handlers", 0)),
+ }
+ )
+ except Exception:
+ stats.update({"running": 0, "inflight": 0, "handlers": 0})
+ return stats
diff --git a/src/memos/mem_scheduler/general_modules/api_misc.py b/src/memos/mem_scheduler/general_modules/api_misc.py
new file mode 100644
index 000000000..1b10804fc
--- /dev/null
+++ b/src/memos/mem_scheduler/general_modules/api_misc.py
@@ -0,0 +1,137 @@
+from typing import Any
+
+from memos.log import get_logger
+from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
+from memos.mem_scheduler.orm_modules.api_redis_model import APIRedisDBManager
+from memos.mem_scheduler.schemas.api_schemas import (
+ APIMemoryHistoryEntryItem,
+ APISearchHistoryManager,
+ TaskRunningStatus,
+)
+from memos.memories.textual.item import TextualMemoryItem
+
+
+logger = get_logger(__name__)
+
+
+class SchedulerAPIModule(BaseSchedulerModule):
+ def __init__(self, window_size: int | None = None, history_memory_turns: int | None = None):
+ super().__init__()
+ self.window_size = window_size
+ self.history_memory_turns = history_memory_turns
+ self.search_history_managers: dict[str, APIRedisDBManager] = {}
+
+ def get_search_history_manager(self, user_id: str, mem_cube_id: str) -> APIRedisDBManager:
+ """Get or create a Redis manager for search history."""
+ logger.info(
+ f"Getting search history manager for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ key = f"search_history:{user_id}:{mem_cube_id}"
+ if key not in self.search_history_managers:
+ logger.info(f"Creating new search history manager for key: {key}")
+ self.search_history_managers[key] = APIRedisDBManager(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=APISearchHistoryManager(window_size=self.window_size),
+ )
+ return self.search_history_managers[key]
+
+ def sync_search_data(
+ self,
+ item_id: str,
+ user_id: str,
+ mem_cube_id: str,
+ query: str,
+ memories: list[TextualMemoryItem],
+ formatted_memories: Any,
+ session_id: str | None = None,
+ conversation_turn: int = 0,
+ ) -> Any:
+ logger.info(
+ f"Syncing search data for item_id: {item_id}, user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ # Get the search history manager
+ manager = self.get_search_history_manager(user_id, mem_cube_id)
+ manager.sync_with_redis(size_limit=self.window_size)
+
+ search_history = manager.obj
+
+ # Check if entry with item_id already exists
+ existing_entry, location = search_history.find_entry_by_item_id(item_id)
+
+ if existing_entry is not None:
+ # Update existing entry
+ success = search_history.update_entry_by_item_id(
+ item_id=item_id,
+ query=query,
+ formatted_memories=formatted_memories,
+ task_status=TaskRunningStatus.COMPLETED, # Use the provided running_status
+ session_id=session_id,
+ memories=memories,
+ )
+
+ if success:
+ logger.info(f"Updated existing entry with item_id: {item_id} in {location} list")
+ else:
+ logger.warning(f"Failed to update entry with item_id: {item_id}")
+ else:
+ # Add new entry based on running_status
+ entry_item = APIMemoryHistoryEntryItem(
+ item_id=item_id,
+ query=query,
+ formatted_memories=formatted_memories,
+ memories=memories,
+ task_status=TaskRunningStatus.COMPLETED,
+ session_id=session_id,
+ conversation_turn=conversation_turn,
+ )
+
+ # Add directly to completed list as APIMemoryHistoryEntryItem instance
+ search_history.completed_entries.append(entry_item)
+
+ # Maintain window size
+ if len(search_history.completed_entries) > search_history.window_size:
+ search_history.completed_entries = search_history.completed_entries[
+ -search_history.window_size :
+ ]
+
+ # Remove from running task IDs
+ if item_id in search_history.running_item_ids:
+ search_history.running_item_ids.remove(item_id)
+
+ logger.info(f"Created new entry with item_id: {item_id}")
+
+ # Update manager's object with the modified search history
+ manager.obj = search_history
+
+ # Use sync_with_redis to handle Redis synchronization with merging
+ manager.sync_with_redis(size_limit=self.window_size)
+ return manager
+
+ def get_history_memories(
+ self, user_id: str, mem_cube_id: str, turns: int | None = None
+ ) -> list:
+ """Get history memories for backward compatibility with tests."""
+ logger.info(
+ f"Getting history memories for user_id: {user_id}, mem_cube_id: {mem_cube_id}, turns: {turns}"
+ )
+ manager = self.get_search_history_manager(user_id, mem_cube_id)
+ existing_data = manager.load_from_db()
+
+ if existing_data is None:
+ return []
+
+ if turns is None:
+ turns = self.history_memory_turns
+
+ # Handle different data formats
+ if isinstance(existing_data, APISearchHistoryManager):
+ search_history = existing_data
+ else:
+ # Try to convert to APISearchHistoryManager
+ try:
+ search_history = APISearchHistoryManager(**existing_data)
+ except Exception:
+ return []
+
+ return search_history.get_history_memories(turns=turns)
diff --git a/src/memos/mem_scheduler/general_modules/dispatcher.py b/src/memos/mem_scheduler/general_modules/dispatcher.py
index 4584beb96..c2407b9e6 100644
--- a/src/memos/mem_scheduler/general_modules/dispatcher.py
+++ b/src/memos/mem_scheduler/general_modules/dispatcher.py
@@ -1,8 +1,10 @@
import concurrent
import threading
+import time
from collections import defaultdict
from collections.abc import Callable
+from datetime import timezone
from typing import Any
from memos.context.context import ContextThreadPoolExecutor
@@ -11,6 +13,7 @@
from memos.mem_scheduler.general_modules.task_threads import ThreadManager
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
from memos.mem_scheduler.schemas.task_schemas import RunningTaskItem
+from memos.mem_scheduler.utils.metrics import MetricsRegistry
logger = get_logger(__name__)
@@ -36,6 +39,11 @@ def __init__(self, max_workers=30, enable_parallel_dispatch=True, config=None):
# Main dispatcher thread pool
self.max_workers = max_workers
+ # Get multi-task timeout from config
+ self.multi_task_running_timeout = (
+ self.config.get("multi_task_running_timeout") if self.config else None
+ )
+
# Only initialize thread pool if in parallel mode
self.enable_parallel_dispatch = enable_parallel_dispatch
self.thread_name_prefix = "dispatcher"
@@ -62,6 +70,21 @@ def __init__(self, max_workers=30, enable_parallel_dispatch=True, config=None):
# Task tracking for monitoring
self._running_tasks: dict[str, RunningTaskItem] = {}
self._task_lock = threading.Lock()
+ self._completed_tasks = []
+ self.completed_tasks_max_show_size = 10
+
+ self.metrics = MetricsRegistry(
+ topk_per_label=(self.config or {}).get("metrics_topk_per_label", 50)
+ )
+
+ def on_messages_enqueued(self, msgs: list[ScheduleMessageItem]) -> None:
+ if not msgs:
+ return
+ now = time.time()
+ for m in msgs:
+ self.metrics.on_enqueue(
+ label=m.label, mem_cube_id=m.mem_cube_id, inst_rate=1.0, now=now
+ )
def _create_task_wrapper(self, handler: Callable, task_item: RunningTaskItem):
"""
@@ -77,39 +100,101 @@ def _create_task_wrapper(self, handler: Callable, task_item: RunningTaskItem):
def wrapped_handler(messages: list[ScheduleMessageItem]):
try:
+ # --- mark start: record queuing time(now - enqueue_ts)---
+ now = time.time()
+ for m in messages:
+ enq_ts = getattr(m, "timestamp", None)
+
+ # Path 1: epoch seconds (preferred)
+ if isinstance(enq_ts, int | float):
+ enq_epoch = float(enq_ts)
+
+ # Path 2: datetime -> normalize to UTC epoch
+ elif hasattr(enq_ts, "timestamp"):
+ dt = enq_ts
+ if dt.tzinfo is None:
+ # treat naive as UTC to neutralize +8h skew
+ dt = dt.replace(tzinfo=timezone.utc)
+ enq_epoch = dt.timestamp()
+ else:
+ # fallback: treat as "just now"
+ enq_epoch = now
+
+ wait_sec = max(0.0, now - enq_epoch)
+ self.metrics.on_start(
+ label=m.label, mem_cube_id=m.mem_cube_id, wait_sec=wait_sec, now=now
+ )
+
# Execute the original handler
result = handler(messages)
+ # --- mark done ---
+ for m in messages:
+ self.metrics.on_done(label=m.label, mem_cube_id=m.mem_cube_id, now=time.time())
# Mark task as completed and remove from tracking
with self._task_lock:
if task_item.item_id in self._running_tasks:
task_item.mark_completed(result)
del self._running_tasks[task_item.item_id]
-
+ self._completed_tasks.append(task_item)
+ if len(self._completed_tasks) > self.completed_tasks_max_show_size:
+ self._completed_tasks[-self.completed_tasks_max_show_size :]
logger.info(f"Task completed: {task_item.get_execution_info()}")
return result
except Exception as e:
# Mark task as failed and remove from tracking
+ for m in messages:
+ self.metrics.on_done(label=m.label, mem_cube_id=m.mem_cube_id, now=time.time())
+ # Mark task as failed and remove from tracking
with self._task_lock:
if task_item.item_id in self._running_tasks:
task_item.mark_failed(str(e))
del self._running_tasks[task_item.item_id]
-
+ if len(self._completed_tasks) > self.completed_tasks_max_show_size:
+ self._completed_tasks[-self.completed_tasks_max_show_size :]
logger.error(f"Task failed: {task_item.get_execution_info()}, Error: {e}")
raise
return wrapped_handler
- def get_running_tasks(self) -> dict[str, RunningTaskItem]:
+ def get_running_tasks(
+ self, filter_func: Callable[[RunningTaskItem], bool] | None = None
+ ) -> dict[str, RunningTaskItem]:
"""
- Get a copy of currently running tasks.
+ Get a copy of currently running tasks, optionally filtered by a custom function.
+
+ Args:
+ filter_func: Optional function that takes a RunningTaskItem and returns True if it should be included.
+ Common filters can be created using helper methods like filter_by_user_id, filter_by_task_name, etc.
Returns:
Dictionary of running tasks keyed by task ID
+
+ Examples:
+ # Get all running tasks
+ all_tasks = dispatcher.get_running_tasks()
+
+ # Get tasks for specific user
+ user_tasks = dispatcher.get_running_tasks(lambda task: task.user_id == "user123")
+
+ # Get tasks for specific task name
+ handler_tasks = dispatcher.get_running_tasks(lambda task: task.task_name == "test_handler")
+
+ # Get tasks with multiple conditions
+ filtered_tasks = dispatcher.get_running_tasks(
+ lambda task: task.user_id == "user123" and task.status == "running"
+ )
"""
with self._task_lock:
- return self._running_tasks.copy()
+ if filter_func is None:
+ return self._running_tasks.copy()
+
+ return {
+ task_id: task_item
+ for task_id, task_item in self._running_tasks.items()
+ if filter_func(task_item)
+ }
def get_running_task_count(self) -> int:
"""
@@ -186,6 +271,31 @@ def unregister_handlers(self, labels: list[str]) -> dict[str, bool]:
logger.info(f"Unregistered handlers for {len(labels)} labels")
return results
+ def stats(self) -> dict[str, int]:
+ """
+ Lightweight runtime stats for monitoring.
+
+ Returns:
+ {
+ 'running': ,
+ 'inflight': ,
+ 'handlers': ,
+ }
+ """
+ try:
+ running = self.get_running_task_count()
+ except Exception:
+ running = 0
+ try:
+ inflight = len(self._futures)
+ except Exception:
+ inflight = 0
+ try:
+ handlers = len(self.handlers)
+ except Exception:
+ handlers = 0
+ return {"running": running, "inflight": inflight, "handlers": handlers}
+
def _default_message_handler(self, messages: list[ScheduleMessageItem]) -> None:
logger.debug(f"Using _default_message_handler to deal with messages: {messages}")
@@ -328,17 +438,17 @@ def run_competitive_tasks(
def run_multiple_tasks(
self,
- tasks: dict[str, tuple[Callable, tuple, dict]],
+ tasks: dict[str, tuple[Callable, tuple]],
use_thread_pool: bool | None = None,
- timeout: float | None = 30.0,
+ timeout: float | None = None,
) -> dict[str, Any]:
"""
Execute multiple tasks concurrently and return all results.
Args:
- tasks: Dictionary mapping task names to (function, args, kwargs) tuples
+ tasks: Dictionary mapping task names to (task_execution_function, task_execution_parameters) tuples
use_thread_pool: Whether to use ThreadPoolExecutor. If None, uses dispatcher's parallel mode setting
- timeout: Maximum time to wait for all tasks to complete (in seconds). None for infinite timeout.
+ timeout: Maximum time to wait for all tasks to complete (in seconds). If None, uses config default.
Returns:
Dictionary mapping task names to their results
@@ -350,7 +460,13 @@ def run_multiple_tasks(
if use_thread_pool is None:
use_thread_pool = self.enable_parallel_dispatch
- logger.info(f"Executing {len(tasks)} tasks concurrently (thread_pool: {use_thread_pool})")
+ # Use config timeout if not explicitly provided
+ if timeout is None:
+ timeout = self.multi_task_running_timeout
+
+ logger.info(
+ f"Executing {len(tasks)} tasks concurrently (thread_pool: {use_thread_pool}, timeout: {timeout})"
+ )
try:
results = self.thread_manager.run_multiple_tasks(
diff --git a/src/memos/mem_scheduler/general_modules/misc.py b/src/memos/mem_scheduler/general_modules/misc.py
index 7dda25a29..b6f48d043 100644
--- a/src/memos/mem_scheduler/general_modules/misc.py
+++ b/src/memos/mem_scheduler/general_modules/misc.py
@@ -127,7 +127,7 @@ class DictConversionMixin:
@field_serializer("timestamp", check_fields=False)
def serialize_datetime(self, dt: datetime | None, _info) -> str | None:
"""
- Custom datetime serialization logic.
+ Custom timestamp serialization logic.
- Supports timezone-aware datetime objects
- Compatible with models without timestamp field (via check_fields=False)
"""
@@ -205,7 +205,9 @@ def put(self, item: T, block: bool = False, timeout: float | None = None) -> Non
"""Put an item into the queue.
If the queue is full, the oldest item will be automatically removed to make space.
- This operation is thread-safe.
+ IMPORTANT: When we drop an item we also call `task_done()` to keep
+ the internal `unfinished_tasks` counter consistent (the dropped task
+ will never be processed).
Args:
item: The item to be put into the queue
@@ -216,19 +218,34 @@ def put(self, item: T, block: bool = False, timeout: float | None = None) -> Non
# First try non-blocking put
super().put(item, block=block, timeout=timeout)
except Full:
+ # Remove oldest item and mark it done to avoid leaking unfinished_tasks
with suppress(Empty):
- self.get_nowait() # Remove oldest item
+ _ = self.get_nowait()
+ # If the removed item had previously incremented unfinished_tasks,
+ # we must decrement here since it will never be processed.
+ with suppress(ValueError):
+ self.task_done()
# Retry putting the new item
super().put(item, block=block, timeout=timeout)
def get_queue_content_without_pop(self) -> list[T]:
"""Return a copy of the queue's contents without modifying it."""
- return list(self.queue)
+ # Ensure a consistent snapshot by holding the mutex
+ with self.mutex:
+ return list(self.queue)
def clear(self) -> None:
"""Remove all items from the queue.
This operation is thread-safe.
+ IMPORTANT: We also decrement `unfinished_tasks` by the number of
+ items cleared, since those tasks will never be processed.
"""
with self.mutex:
+ dropped = len(self.queue)
self.queue.clear()
+ # Call task_done() outside of the mutex to avoid deadlocks because
+ # Queue.task_done() acquires the same condition bound to `self.mutex`.
+ for _ in range(dropped):
+ with suppress(ValueError):
+ self.task_done()
diff --git a/src/memos/mem_scheduler/general_modules/task_threads.py b/src/memos/mem_scheduler/general_modules/task_threads.py
index 913d5fa1d..73b570a8b 100644
--- a/src/memos/mem_scheduler/general_modules/task_threads.py
+++ b/src/memos/mem_scheduler/general_modules/task_threads.py
@@ -5,6 +5,7 @@
from concurrent.futures import as_completed
from typing import Any, TypeVar
+from memos.context.context import ContextThread
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -89,7 +90,7 @@ def worker(
def run_multiple_tasks(
self,
- tasks: dict[str, tuple[Callable, tuple, dict]],
+ tasks: dict[str, tuple[Callable, tuple]],
use_thread_pool: bool = False,
timeout: float | None = None,
) -> dict[str, Any]:
@@ -97,7 +98,7 @@ def run_multiple_tasks(
Run multiple tasks concurrently and return all results.
Args:
- tasks: Dictionary mapping task names to (function, args, kwargs) tuples
+ tasks: Dictionary mapping task names to (task_execution_function, task_execution_parameters) tuples
use_thread_pool: Whether to use ThreadPoolExecutor (True) or regular threads (False)
timeout: Maximum time to wait for all tasks to complete (in seconds). None for infinite timeout.
@@ -115,17 +116,21 @@ def run_multiple_tasks(
start_time = time.time()
if use_thread_pool:
- return self.run_with_thread_pool(tasks, timeout)
+ # Convert tasks format for thread pool compatibility
+ thread_pool_tasks = {}
+ for task_name, (func, args) in tasks.items():
+ thread_pool_tasks[task_name] = (func, args, {})
+ return self.run_with_thread_pool(thread_pool_tasks, timeout)
else:
# Use regular threads
threads = {}
thread_results = {}
exceptions = {}
- def worker(task_name: str, func: Callable, args: tuple, kwargs: dict):
+ def worker(task_name: str, func: Callable, args: tuple):
"""Worker function for regular threads"""
try:
- result = func(*args, **kwargs)
+ result = func(*args)
thread_results[task_name] = result
logger.debug(f"Task '{task_name}' completed successfully")
except Exception as e:
@@ -133,9 +138,9 @@ def worker(task_name: str, func: Callable, args: tuple, kwargs: dict):
logger.error(f"Task '{task_name}' failed with error: {e}")
# Start all threads
- for task_name, (func, args, kwargs) in tasks.items():
- thread = threading.Thread(
- target=worker, args=(task_name, func, args, kwargs), name=f"task-{task_name}"
+ for task_name, (func, args) in tasks.items():
+ thread = ContextThread(
+ target=worker, args=(task_name, func, args), name=f"task-{task_name}"
)
threads[task_name] = thread
thread.start()
@@ -197,44 +202,60 @@ def run_with_thread_pool(
results = {}
start_time = time.time()
- # Use ThreadPoolExecutor for better resource management
- with self.thread_pool_executor as executor:
- # Submit all tasks
- future_to_name = {}
- for task_name, (func, args, kwargs) in tasks.items():
+ # Check if executor is shutdown before using it
+ if self.thread_pool_executor._shutdown:
+ logger.error("ThreadPoolExecutor is already shutdown, cannot submit new tasks")
+ raise RuntimeError("ThreadPoolExecutor is already shutdown")
+
+ # Use ThreadPoolExecutor directly without context manager
+ # The executor lifecycle is managed by the parent SchedulerDispatcher
+ executor = self.thread_pool_executor
+
+ # Submit all tasks
+ future_to_name = {}
+ for task_name, (func, args, kwargs) in tasks.items():
+ try:
future = executor.submit(func, *args, **kwargs)
future_to_name[future] = task_name
logger.debug(f"Submitted task '{task_name}' to thread pool")
+ except RuntimeError as e:
+ if "cannot schedule new futures after shutdown" in str(e):
+ logger.error(
+ f"Cannot submit task '{task_name}': ThreadPoolExecutor is shutdown"
+ )
+ results[task_name] = None
+ else:
+ raise
- # Collect results as they complete
- try:
- # Handle infinite timeout case
- timeout_param = None if timeout is None else timeout
- for future in as_completed(future_to_name, timeout=timeout_param):
- task_name = future_to_name[future]
- try:
- result = future.result()
- results[task_name] = result
- logger.debug(f"Task '{task_name}' completed successfully")
- except Exception as e:
- logger.error(f"Task '{task_name}' failed with error: {e}")
- results[task_name] = None
+ # Collect results as they complete
+ try:
+ # Handle infinite timeout case
+ timeout_param = None if timeout is None else timeout
+ for future in as_completed(future_to_name, timeout=timeout_param):
+ task_name = future_to_name[future]
+ try:
+ result = future.result()
+ results[task_name] = result
+ logger.debug(f"Task '{task_name}' completed successfully")
+ except Exception as e:
+ logger.error(f"Task '{task_name}' failed with error: {e}")
+ results[task_name] = None
- except Exception:
- elapsed_time = time.time() - start_time
- timeout_msg = "infinite" if timeout is None else f"{timeout}s"
- logger.error(
- f"Tasks execution timed out after {elapsed_time:.2f} seconds (timeout: {timeout_msg})"
- )
- # Cancel remaining futures
- for future in future_to_name:
- if not future.done():
- future.cancel()
- task_name = future_to_name[future]
- logger.warning(f"Cancelled task '{task_name}' due to timeout")
- results[task_name] = None
- timeout_seconds = "infinite" if timeout is None else timeout
- logger.error(f"Tasks execution timed out after {timeout_seconds} seconds")
+ except Exception:
+ elapsed_time = time.time() - start_time
+ timeout_msg = "infinite" if timeout is None else f"{timeout}s"
+ logger.error(
+ f"Tasks execution timed out after {elapsed_time:.2f} seconds (timeout: {timeout_msg})"
+ )
+ # Cancel remaining futures
+ for future in future_to_name:
+ if not future.done():
+ future.cancel()
+ task_name = future_to_name[future]
+ logger.warning(f"Cancelled task '{task_name}' due to timeout")
+ results[task_name] = None
+ timeout_seconds = "infinite" if timeout is None else timeout
+ logger.error(f"Tasks execution timed out after {timeout_seconds} seconds")
return results
@@ -263,7 +284,7 @@ def run_race(
# Create and start threads for each task
for task_name, task_func in tasks.items():
- thread = threading.Thread(
+ thread = ContextThread(
target=self.worker, args=(task_func, task_name), name=f"race-{task_name}"
)
self.threads[task_name] = thread
diff --git a/src/memos/mem_scheduler/general_scheduler.py b/src/memos/mem_scheduler/general_scheduler.py
index 25c7b78fd..6840adc2b 100644
--- a/src/memos/mem_scheduler/general_scheduler.py
+++ b/src/memos/mem_scheduler/general_scheduler.py
@@ -1,6 +1,9 @@
+import concurrent.futures
import json
+import traceback
from memos.configs.mem_scheduler import GeneralSchedulerConfig
+from memos.context.context import ContextThreadPoolExecutor
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
from memos.mem_scheduler.base_scheduler import BaseScheduler
@@ -8,6 +11,9 @@
ADD_LABEL,
ANSWER_LABEL,
DEFAULT_MAX_QUERY_KEY_WORDS,
+ MEM_ORGANIZE_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
QUERY_LABEL,
WORKING_MEMORY_TYPE,
MemCubeID,
@@ -16,7 +22,9 @@
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
from memos.mem_scheduler.schemas.monitor_schemas import QueryMonitorItem
from memos.mem_scheduler.utils.filter_utils import is_all_chinese, is_all_english
-from memos.memories.textual.tree import TextualMemoryItem, TreeTextMemory
+from memos.memories.textual.item import TextualMemoryItem
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.memories.textual.tree import TreeTextMemory
logger = get_logger(__name__)
@@ -34,6 +42,9 @@ def __init__(self, config: GeneralSchedulerConfig):
QUERY_LABEL: self._query_message_consumer,
ANSWER_LABEL: self._answer_message_consumer,
ADD_LABEL: self._add_message_consumer,
+ MEM_READ_LABEL: self._mem_read_message_consumer,
+ MEM_ORGANIZE_LABEL: self._mem_reorganize_message_consumer,
+ PREF_ADD_LABEL: self._pref_add_message_consumer,
}
self.dispatcher.register_handlers(handlers)
@@ -142,7 +153,7 @@ def _query_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
logger.info(f"Messages {messages} assigned to {QUERY_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=QUERY_LABEL)
@@ -164,7 +175,7 @@ def _answer_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
"""
logger.info(f"Messages {messages} assigned to {ANSWER_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=ANSWER_LABEL)
@@ -180,7 +191,7 @@ def _answer_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
logger.info(f"Messages {messages} assigned to {ADD_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=ADD_LABEL)
try:
@@ -203,7 +214,15 @@ def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
mem_cube = msg.mem_cube
for memory_id in userinput_memory_ids:
- mem_item: TextualMemoryItem = mem_cube.text_mem.get(memory_id=memory_id)
+ try:
+ mem_item: TextualMemoryItem = mem_cube.text_mem.get(
+ memory_id=memory_id
+ )
+ except Exception:
+ logger.warning(
+ f"This MemoryItem {memory_id} has already been deleted."
+ )
+ continue
mem_type = mem_item.metadata.memory_type
mem_content = mem_item.memory
@@ -222,6 +241,315 @@ def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
except Exception as e:
logger.error(f"Error: {e}", exc_info=True)
+ def _mem_read_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {MEM_READ_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ user_name = message.user_name
+
+ # Parse the memory IDs from content
+ mem_ids = json.loads(content) if isinstance(content, str) else content
+ if not mem_ids:
+ return
+
+ logger.info(
+ f"Processing mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}, mem_ids={mem_ids}"
+ )
+
+ # Get the text memory from the mem_cube
+ text_mem = mem_cube.text_mem
+ if not isinstance(text_mem, TreeTextMemory):
+ logger.error(f"Expected TreeTextMemory but got {type(text_mem).__name__}")
+ return
+
+ # Use mem_reader to process the memories
+ self._process_memories_with_reader(
+ mem_ids=mem_ids,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ text_mem=text_mem,
+ user_name=user_name,
+ )
+
+ logger.info(
+ f"Successfully processed mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing mem_read message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
+ def _process_memories_with_reader(
+ self,
+ mem_ids: list[str],
+ user_id: str,
+ mem_cube_id: str,
+ mem_cube: GeneralMemCube,
+ text_mem: TreeTextMemory,
+ user_name: str,
+ ) -> None:
+ """
+ Process memories using mem_reader for enhanced memory processing.
+
+ Args:
+ mem_ids: List of memory IDs to process
+ user_id: User ID
+ mem_cube_id: Memory cube ID
+ mem_cube: Memory cube instance
+ text_mem: Text memory instance
+ """
+ try:
+ # Get the mem_reader from the parent MOSCore
+ if not hasattr(self, "mem_reader") or self.mem_reader is None:
+ logger.warning(
+ "mem_reader not available in scheduler, skipping enhanced processing"
+ )
+ return
+
+ # Get the original memory items
+ memory_items = []
+ for mem_id in mem_ids:
+ try:
+ memory_item = text_mem.get(mem_id)
+ memory_items.append(memory_item)
+ except Exception as e:
+ logger.warning(f"Failed to get memory {mem_id}: {e}")
+ continue
+
+ if not memory_items:
+ logger.warning("No valid memory items found for processing")
+ return
+
+ # parse working_binding ids from the *original* memory_items (the raw items created in /add)
+ # these still carry metadata.background with "[working_binding:...]" so we can know
+ # which WorkingMemory clones should be cleaned up later.
+ from memos.memories.textual.tree_text_memory.organize.manager import (
+ extract_working_binding_ids,
+ )
+
+ bindings_to_delete = extract_working_binding_ids(memory_items)
+ logger.info(
+ f"Extracted {len(bindings_to_delete)} working_binding ids to cleanup: {list(bindings_to_delete)}"
+ )
+
+ # Use mem_reader to process the memories
+ logger.info(f"Processing {len(memory_items)} memories with mem_reader")
+
+ # Extract memories using mem_reader
+ try:
+ processed_memories = self.mem_reader.fine_transfer_simple_mem(
+ memory_items,
+ type="chat",
+ )
+ except Exception as e:
+ logger.warning(f"{e}: Fail to transfer mem: {memory_items}")
+ processed_memories = []
+
+ if processed_memories and len(processed_memories) > 0:
+ # Flatten the results (mem_reader returns list of lists)
+ flattened_memories = []
+ for memory_list in processed_memories:
+ flattened_memories.extend(memory_list)
+
+ logger.info(f"mem_reader processed {len(flattened_memories)} enhanced memories")
+
+ # Add the enhanced memories back to the memory system
+ if flattened_memories:
+ enhanced_mem_ids = text_mem.add(flattened_memories, user_name=user_name)
+ logger.info(
+ f"Added {len(enhanced_mem_ids)} enhanced memories: {enhanced_mem_ids}"
+ )
+ else:
+ logger.info("No enhanced memories generated by mem_reader")
+ else:
+ logger.info("mem_reader returned no processed memories")
+
+ # build full delete list:
+ # - original raw mem_ids (temporary fast memories)
+ # - any bound working memories referenced by the enhanced memories
+ delete_ids = list(mem_ids)
+ if bindings_to_delete:
+ delete_ids.extend(list(bindings_to_delete))
+ # deduplicate
+ delete_ids = list(dict.fromkeys(delete_ids))
+ if delete_ids:
+ try:
+ text_mem.delete(delete_ids, user_name=user_name)
+ logger.info(
+ f"Delete raw/working mem_ids: {delete_ids} for user_name: {user_name}"
+ )
+ except Exception as e:
+ logger.warning(f"Failed to delete some mem_ids {delete_ids}: {e}")
+ else:
+ logger.info("No mem_ids to delete (nothing to cleanup)")
+
+ text_mem.memory_manager.remove_and_refresh_memory(user_name=user_name)
+ logger.info("Remove and Refresh Memories")
+ logger.debug(f"Finished add {user_id} memory: {mem_ids}")
+
+ except Exception:
+ logger.error(
+ f"Error in _process_memories_with_reader: {traceback.format_exc()}", exc_info=True
+ )
+
+ def _mem_reorganize_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {MEM_READ_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ user_name = message.user_name
+
+ # Parse the memory IDs from content
+ mem_ids = json.loads(content) if isinstance(content, str) else content
+ if not mem_ids:
+ return
+
+ logger.info(
+ f"Processing mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}, mem_ids={mem_ids}"
+ )
+
+ # Get the text memory from the mem_cube
+ text_mem = mem_cube.text_mem
+ if not isinstance(text_mem, TreeTextMemory):
+ logger.error(f"Expected TreeTextMemory but got {type(text_mem).__name__}")
+ return
+
+ # Use mem_reader to process the memories
+ self._process_memories_with_reorganize(
+ mem_ids=mem_ids,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ text_mem=text_mem,
+ user_name=user_name,
+ )
+
+ logger.info(
+ f"Successfully processed mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing mem_read message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
+ def _process_memories_with_reorganize(
+ self,
+ mem_ids: list[str],
+ user_id: str,
+ mem_cube_id: str,
+ mem_cube: GeneralMemCube,
+ text_mem: TreeTextMemory,
+ user_name: str,
+ ) -> None:
+ """
+ Process memories using mem_reorganize for enhanced memory processing.
+
+ Args:
+ mem_ids: List of memory IDs to process
+ user_id: User ID
+ mem_cube_id: Memory cube ID
+ mem_cube: Memory cube instance
+ text_mem: Text memory instance
+ """
+ try:
+ # Get the mem_reader from the parent MOSCore
+ if not hasattr(self, "mem_reader") or self.mem_reader is None:
+ logger.warning(
+ "mem_reader not available in scheduler, skipping enhanced processing"
+ )
+ return
+
+ # Get the original memory items
+ memory_items = []
+ for mem_id in mem_ids:
+ try:
+ memory_item = text_mem.get(mem_id)
+ memory_items.append(memory_item)
+ except Exception as e:
+ logger.warning(f"Failed to get memory {mem_id}: {e}|{traceback.format_exc()}")
+ continue
+
+ if not memory_items:
+ logger.warning("No valid memory items found for processing")
+ return
+
+ # Use mem_reader to process the memories
+ logger.info(f"Processing {len(memory_items)} memories with mem_reader")
+ text_mem.memory_manager.remove_and_refresh_memory(user_name=user_name)
+ logger.info("Remove and Refresh Memories")
+ logger.debug(f"Finished add {user_id} memory: {mem_ids}")
+
+ except Exception:
+ logger.error(
+ f"Error in _process_memories_with_reader: {traceback.format_exc()}", exc_info=True
+ )
+
+ def _pref_add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {PREF_ADD_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ session_id = message.session_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ messages_list = json.loads(content)
+
+ logger.info(f"Processing pref_add for user_id={user_id}, mem_cube_id={mem_cube_id}")
+
+ # Get the preference memory from the mem_cube
+ pref_mem = mem_cube.pref_mem
+ if not isinstance(pref_mem, PreferenceTextMemory):
+ logger.error(f"Expected PreferenceTextMemory but got {type(pref_mem).__name__}")
+ return
+
+ # Use pref_mem.get_memory to process the memories
+ pref_memories = pref_mem.get_memory(
+ messages_list, type="chat", info={"user_id": user_id, "session_id": session_id}
+ )
+ # Add pref_mem to vector db
+ pref_ids = pref_mem.add(pref_memories)
+
+ logger.info(
+ f"Successfully processed and add preferences for user_id={user_id}, mem_cube_id={mem_cube_id}, pref_ids={pref_ids}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing pref_add message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
def process_session_turn(
self,
queries: str | list[str],
diff --git a/src/memos/mem_scheduler/monitors/dispatcher_monitor.py b/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
index 13fe07354..46c4e2d49 100644
--- a/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
+++ b/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
@@ -1,11 +1,10 @@
import threading
import time
-from datetime import datetime
from time import perf_counter
from memos.configs.mem_scheduler import BaseSchedulerConfig
-from memos.context.context import ContextThreadPoolExecutor
+from memos.context.context import ContextThread, ContextThreadPoolExecutor
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
from memos.mem_scheduler.general_modules.dispatcher import SchedulerDispatcher
@@ -14,6 +13,7 @@
DEFAULT_DISPATCHER_MONITOR_MAX_FAILURES,
DEFAULT_STUCK_THREAD_TOLERANCE,
)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
logger = get_logger(__name__)
@@ -84,7 +84,7 @@ def register_pool(
"max_workers": max_workers,
"restart": restart_on_failure,
"failure_count": 0,
- "last_active": datetime.utcnow(),
+ "last_active": get_utc_now(),
"healthy": True,
}
logger.info(f"Registered thread pool '{name}' for monitoring")
@@ -122,54 +122,6 @@ def _monitor_loop(self) -> None:
logger.debug("Monitor loop exiting")
- def start(self) -> bool:
- """
- Start the monitoring thread.
-
- Returns:
- bool: True if monitor started successfully, False if already running
- """
- if self._running:
- logger.warning("Dispatcher Monitor is already running")
- return False
-
- self._running = True
- self._monitor_thread = threading.Thread(
- target=self._monitor_loop, name="threadpool_monitor", daemon=True
- )
- self._monitor_thread.start()
- logger.info("Dispatcher Monitor monitor started")
- return True
-
- def stop(self) -> None:
- """
- Stop the monitoring thread and clean up all managed thread pools.
- Ensures proper shutdown of all monitored executors.
- """
- if not self._running:
- return
-
- # Stop the monitoring loop
- self._running = False
- if self._monitor_thread and self._monitor_thread.is_alive():
- self._monitor_thread.join(timeout=5)
-
- # Shutdown all registered pools
- with self._pool_lock:
- for name, pool_info in self._pools.items():
- executor = pool_info["executor"]
- if not executor._shutdown: # pylint: disable=protected-access
- try:
- logger.info(f"Shutting down thread pool '{name}'")
- executor.shutdown(wait=True, cancel_futures=True)
- logger.info(f"Successfully shut down thread pool '{name}'")
- except Exception as e:
- logger.error(f"Error shutting down pool '{name}': {e!s}", exc_info=True)
-
- # Clear the pool registry
- self._pools.clear()
- logger.info("Thread pool monitor and all pools stopped")
-
def _check_pools_health(self) -> None:
"""Check health of all registered thread pools."""
for name, pool_info in list(self._pools.items()):
@@ -182,7 +134,6 @@ def _check_pools_health(self) -> None:
if is_healthy:
pool_info["failure_count"] = 0
pool_info["healthy"] = True
- return
else:
pool_info["failure_count"] += 1
pool_info["healthy"] = False
@@ -269,27 +220,24 @@ def _check_pool_health(
f"Found {len(stuck_tasks)} stuck tasks (tolerance: {effective_tolerance})",
)
- # Check thread activity
- active_threads = sum(
- 1
- for t in threading.enumerate()
- if t.name.startswith(executor._thread_name_prefix) # pylint: disable=protected-access
- )
-
- # Check if no threads are active but should be
- if active_threads == 0 and pool_info["max_workers"] > 0:
- return False, "No active worker threads"
-
+ # Only check for stuck threads, not inactive threads
# Check if threads are stuck (no activity for specified intervals)
- time_delta = (datetime.utcnow() - pool_info["last_active"]).total_seconds()
+ time_delta = (get_utc_now() - pool_info["last_active"]).total_seconds()
if time_delta >= self.check_interval * stuck_max_interval:
return False, f"No recent activity for {time_delta:.1f} seconds"
# If we got here, pool appears healthy
- pool_info["last_active"] = datetime.utcnow()
+ pool_info["last_active"] = get_utc_now()
# Log health status with comprehensive information
if self.dispatcher:
+ # Check thread activity
+ active_threads = sum(
+ 1
+ for t in threading.enumerate()
+ if t.name.startswith(executor._thread_name_prefix) # pylint: disable=protected-access
+ )
+
task_count = self.dispatcher.get_running_task_count()
max_workers = pool_info.get("max_workers", 0)
stuck_count = len(stuck_tasks)
@@ -338,7 +286,7 @@ def _restart_pool(self, name: str, pool_info: dict) -> None:
pool_info["executor"] = new_executor
pool_info["failure_count"] = 0
pool_info["healthy"] = True
- pool_info["last_active"] = datetime.utcnow()
+ pool_info["last_active"] = get_utc_now()
elapsed_time = perf_counter() - start_time
if elapsed_time > 1:
@@ -379,3 +327,52 @@ def __enter__(self):
def __exit__(self, exc_type, exc_val, exc_tb):
"""Context manager exit point."""
self.stop()
+
+ def start(self) -> bool:
+ """
+ Start the monitoring thread.
+
+ Returns:
+ bool: True if monitor started successfully, False if already running
+ """
+ if self._running:
+ logger.warning("Dispatcher Monitor is already running")
+ return False
+
+ self._running = True
+ self._monitor_thread = ContextThread(
+ target=self._monitor_loop, name="threadpool_monitor", daemon=True
+ )
+ self._monitor_thread.start()
+ logger.info("Dispatcher Monitor monitor started")
+ return True
+
+ def stop(self) -> None:
+ """
+ Stop the monitoring thread and clean up all managed thread pools.
+ Ensures proper shutdown of all monitored executors.
+ """
+ if not self._running:
+ return
+
+ # Stop the monitoring loop
+ self._running = False
+ if self._monitor_thread and self._monitor_thread.is_alive():
+ self._monitor_thread.join(timeout=5)
+
+ # Shutdown all registered pools
+ with self._pool_lock:
+ for name, pool_info in self._pools.items():
+ executor = pool_info["executor"]
+ if not executor._shutdown: # pylint: disable=protected-access
+ try:
+ logger.info(f"Shutting down thread pool '{name}'")
+ executor.shutdown(wait=True, cancel_futures=True)
+ logger.info(f"Successfully shut down thread pool '{name}'")
+ except Exception as e:
+ logger.error(f"Error shutting down pool '{name}': {e!s}", exc_info=True)
+
+ # Clear the pool registry
+ self._pools.clear()
+
+ logger.info("Thread pool monitor and all pools stopped")
diff --git a/src/memos/mem_scheduler/monitors/general_monitor.py b/src/memos/mem_scheduler/monitors/general_monitor.py
index 87d996549..a789d581e 100644
--- a/src/memos/mem_scheduler/monitors/general_monitor.py
+++ b/src/memos/mem_scheduler/monitors/general_monitor.py
@@ -28,6 +28,7 @@
MemoryMonitorManager,
QueryMonitorQueue,
)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.mem_scheduler.utils.misc_utils import extract_json_dict
from memos.memories.textual.tree import TreeTextMemory
@@ -64,7 +65,7 @@ def __init__(
"No database engine provided; falling back to default temporary SQLite engine. "
"This is intended for testing only. Consider providing a configured engine for production use."
)
- self.db_engine = BaseDBManager.create_default_engine()
+ self.db_engine = BaseDBManager.create_default_sqlite_engine()
self.query_monitors: dict[UserID, dict[MemCubeID, DBManagerForQueryMonitorQueue]] = {}
self.working_memory_monitors: dict[
@@ -75,8 +76,8 @@ def __init__(
] = {}
# Lifecycle monitor
- self.last_activation_mem_update_time = datetime.min
- self.last_query_consume_time = datetime.min
+ self.last_activation_mem_update_time = get_utc_now()
+ self.last_query_consume_time = get_utc_now()
self._register_lock = Lock()
self._process_llm = process_llm
@@ -256,7 +257,7 @@ def update_activation_memory_monitors(
activation_db_manager.sync_with_orm(size_limit=self.activation_mem_monitor_capacity)
def timed_trigger(self, last_time: datetime, interval_seconds: float) -> bool:
- now = datetime.utcnow()
+ now = get_utc_now()
elapsed = (now - last_time).total_seconds()
if elapsed >= interval_seconds:
return True
diff --git a/src/memos/mem_scheduler/optimized_scheduler.py b/src/memos/mem_scheduler/optimized_scheduler.py
index dd08954a9..a087ab2df 100644
--- a/src/memos/mem_scheduler/optimized_scheduler.py
+++ b/src/memos/mem_scheduler/optimized_scheduler.py
@@ -1,28 +1,282 @@
+import json
+import os
+
+from collections import OrderedDict
from typing import TYPE_CHECKING
+from memos.api.product_models import APISearchRequest
from memos.configs.mem_scheduler import GeneralSchedulerConfig
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
+from memos.mem_cube.navie import NaiveMemCube
+from memos.mem_scheduler.general_modules.api_misc import SchedulerAPIModule
from memos.mem_scheduler.general_scheduler import GeneralScheduler
from memos.mem_scheduler.schemas.general_schemas import (
+ API_MIX_SEARCH_LABEL,
MemCubeID,
+ SearchMode,
UserID,
)
+from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
+from memos.mem_scheduler.utils.api_utils import format_textual_memory_item
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.memories.textual.tree import TextualMemoryItem, TreeTextMemory
+from memos.types import UserContext
if TYPE_CHECKING:
from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorItem
+ from memos.memories.textual.tree_text_memory.retrieve.searcher import Searcher
+ from memos.reranker.http_bge import HTTPBGEReranker
logger = get_logger(__name__)
class OptimizedScheduler(GeneralScheduler):
- """Optimized scheduler with improved working memory management"""
+ """Optimized scheduler with improved working memory management and support for api"""
def __init__(self, config: GeneralSchedulerConfig):
super().__init__(config)
+ self.window_size = int(os.getenv("API_SEARCH_WINDOW_SIZE", 5))
+ self.history_memory_turns = int(os.getenv("API_SEARCH_HISTORY_TURNS", 5))
+ self.session_counter = OrderedDict()
+ self.max_session_history = 5
+
+ self.api_module = SchedulerAPIModule(
+ window_size=self.window_size,
+ history_memory_turns=self.history_memory_turns,
+ )
+ self.register_handlers(
+ {
+ API_MIX_SEARCH_LABEL: self._api_mix_search_message_consumer,
+ }
+ )
+
+ def submit_memory_history_async_task(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ session_id: str | None = None,
+ ):
+ # Create message for async fine search
+ message_content = {
+ "search_req": {
+ "query": search_req.query,
+ "user_id": search_req.user_id,
+ "session_id": session_id,
+ "top_k": search_req.top_k,
+ "internet_search": search_req.internet_search,
+ "moscube": search_req.moscube,
+ "chat_history": search_req.chat_history,
+ },
+ "user_context": {"mem_cube_id": user_context.mem_cube_id},
+ }
+
+ async_task_id = f"mix_search_{search_req.user_id}_{get_utc_now().timestamp()}"
+
+ # Get mem_cube for the message
+ mem_cube = self.current_mem_cube
+
+ message = ScheduleMessageItem(
+ item_id=async_task_id,
+ user_id=search_req.user_id,
+ mem_cube_id=user_context.mem_cube_id,
+ label=API_MIX_SEARCH_LABEL,
+ mem_cube=mem_cube,
+ content=json.dumps(message_content),
+ timestamp=get_utc_now(),
+ )
+
+ # Submit async task
+ self.submit_messages([message])
+ logger.info(f"Submitted async fine search task for user {search_req.user_id}")
+ return async_task_id
+
+ def search_memories(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ mem_cube: NaiveMemCube,
+ mode: SearchMode,
+ ):
+ """Fine search memories function copied from server_router to avoid circular import"""
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ # Create MemCube and perform search
+ search_results = mem_cube.text_mem.search(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=mode,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ },
+ )
+ return search_results
+
+ def mix_search_memories(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ ):
+ """
+ Mix search memories: fast search + async fine search
+ """
+
+ # Get mem_cube for fast search
+ mem_cube = self.current_mem_cube
+
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ text_mem: TreeTextMemory = mem_cube.text_mem
+ searcher: Searcher = text_mem.get_searcher(
+ manual_close_internet=not search_req.internet_search,
+ moscube=False,
+ )
+ # Rerank Memories - reranker expects TextualMemoryItem objects
+ reranker: HTTPBGEReranker = text_mem.reranker
+ info = {
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ }
+
+ fast_retrieved_memories = searcher.retrieve(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=SearchMode.FAST,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info=info,
+ )
+
+ self.submit_memory_history_async_task(
+ search_req=search_req,
+ user_context=user_context,
+ session_id=search_req.session_id,
+ )
+
+ # Try to get pre-computed fine memories if available
+ history_memories = self.api_module.get_history_memories(
+ user_id=search_req.user_id,
+ mem_cube_id=user_context.mem_cube_id,
+ turns=self.history_memory_turns,
+ )
+
+ if not history_memories:
+ fast_memories = searcher.post_retrieve(
+ retrieved_results=fast_retrieved_memories,
+ top_k=search_req.top_k,
+ user_name=user_context.mem_cube_id,
+ info=info,
+ )
+ # Format fast memories for return
+ formatted_memories = [format_textual_memory_item(data) for data in fast_memories]
+ return formatted_memories
+
+ sorted_history_memories = reranker.rerank(
+ query=search_req.query, # Use search_req.query instead of undefined query
+ graph_results=history_memories, # Pass TextualMemoryItem objects directly
+ top_k=search_req.top_k, # Use search_req.top_k instead of undefined top_k
+ search_filter=search_filter,
+ )
+
+ sorted_results = fast_retrieved_memories + sorted_history_memories
+ final_results = searcher.post_retrieve(
+ retrieved_results=sorted_results,
+ top_k=search_req.top_k,
+ user_name=user_context.mem_cube_id,
+ info=info,
+ )
+
+ formatted_memories = [
+ format_textual_memory_item(item) for item in final_results[: search_req.top_k]
+ ]
+
+ return formatted_memories
+
+ def update_search_memories_to_redis(
+ self,
+ messages: list[ScheduleMessageItem],
+ ):
+ mem_cube: NaiveMemCube = self.current_mem_cube
+
+ for msg in messages:
+ content_dict = json.loads(msg.content)
+ search_req = content_dict["search_req"]
+ user_context = content_dict["user_context"]
+
+ session_id = search_req.get("session_id")
+ if session_id:
+ if session_id not in self.session_counter:
+ self.session_counter[session_id] = 0
+ else:
+ self.session_counter[session_id] += 1
+ session_turn = self.session_counter[session_id]
+
+ # Move the current session to the end to mark it as recently used
+ self.session_counter.move_to_end(session_id)
+
+ # If the counter exceeds the max size, remove the oldest item
+ if len(self.session_counter) > self.max_session_history:
+ self.session_counter.popitem(last=False)
+ else:
+ session_turn = 0
+
+ memories: list[TextualMemoryItem] = self.search_memories(
+ search_req=APISearchRequest(**content_dict["search_req"]),
+ user_context=UserContext(**content_dict["user_context"]),
+ mem_cube=mem_cube,
+ mode=SearchMode.FAST,
+ )
+ formatted_memories = [format_textual_memory_item(data) for data in memories]
+
+ # Sync search data to Redis
+ self.api_module.sync_search_data(
+ item_id=msg.item_id,
+ user_id=search_req["user_id"],
+ mem_cube_id=user_context["mem_cube_id"],
+ query=search_req["query"],
+ memories=memories,
+ formatted_memories=formatted_memories,
+ session_id=session_id,
+ conversation_turn=session_turn,
+ )
+
+ def _api_mix_search_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ """
+ Process and handle query trigger messages from the queue.
+
+ Args:
+ messages: List of query messages to process
+ """
+ logger.info(f"Messages {messages} assigned to {API_MIX_SEARCH_LABEL} handler.")
+
+ # Process the query in a session turn
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
+
+ self.validate_schedule_messages(messages=messages, label=API_MIX_SEARCH_LABEL)
+
+ for user_id in grouped_messages:
+ for mem_cube_id in grouped_messages[user_id]:
+ messages = grouped_messages[user_id][mem_cube_id]
+ if len(messages) == 0:
+ return
+ self.update_search_memories_to_redis(messages=messages)
def replace_working_memory(
self,
diff --git a/src/memos/mem_scheduler/orm_modules/api_redis_model.py b/src/memos/mem_scheduler/orm_modules/api_redis_model.py
new file mode 100644
index 000000000..04cd7e833
--- /dev/null
+++ b/src/memos/mem_scheduler/orm_modules/api_redis_model.py
@@ -0,0 +1,517 @@
+import os
+import time
+
+from typing import Any
+
+from sqlalchemy.orm import declarative_base
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import DatabaseError
+from memos.mem_scheduler.schemas.api_schemas import (
+ APISearchHistoryManager,
+)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
+
+logger = get_logger(__name__)
+
+Base = declarative_base()
+
+
+class APIRedisDBManager:
+ """Redis-based database manager for any serializable object
+
+ This class handles persistence, synchronization, and locking
+ for any object that implements to_json/from_json methods using Redis as the backend storage.
+ """
+
+ # Add orm_class attribute for compatibility
+ orm_class = None
+
+ def __init__(
+ self,
+ user_id: str | None = None,
+ mem_cube_id: str | None = None,
+ obj: APISearchHistoryManager | None = None,
+ lock_timeout: int = 10,
+ redis_client=None,
+ redis_config: dict | None = None,
+ window_size: int = 5,
+ ):
+ """Initialize the Redis database manager
+
+ Args:
+ user_id: Unique identifier for the user
+ mem_cube_id: Unique identifier for the memory cube
+ obj: Optional object instance to manage (must have to_json/from_json methods)
+ lock_timeout: Timeout in seconds for lock acquisition
+ redis_client: Redis client instance (optional)
+ redis_config: Redis configuration dictionary (optional)
+ """
+ # Initialize Redis client
+ self.redis_client = redis_client
+ self.redis_config = redis_config or {}
+
+ if self.redis_client is None:
+ self._init_redis_client()
+
+ # Initialize base attributes without calling parent's init_manager
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.obj = obj
+ self.lock_timeout = lock_timeout
+ self.engine = None # Keep for compatibility but not used
+ self.SessionLocal = None # Not used for Redis
+ self.window_size = window_size
+ self.lock_key = f"{self._get_key_prefix()}:lock"
+
+ logger.info(
+ f"RedisDBManager initialized for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ logger.info(f"Redis client: {type(self.redis_client).__name__}")
+
+ # Test Redis connection
+ try:
+ self.redis_client.ping()
+ logger.info("Redis connection successful")
+ except Exception as e:
+ logger.warning(f"Redis ping failed: {e}")
+ # Don't raise error here as it might be a mock client in tests
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this user and memory cube
+
+ Returns:
+ Redis key prefix string
+ """
+ return f"redis_api:{self.user_id}:{self.mem_cube_id}"
+
+ def _get_data_key(self) -> str:
+ """Generate Redis key for storing serialized data
+
+ Returns:
+ Redis data key string
+ """
+ return f"{self._get_key_prefix()}:data"
+
+ def _init_redis_client(self):
+ """Initialize Redis client from config or environment"""
+ try:
+ import redis
+ except ImportError:
+ logger.error("Redis package not installed. Install with: pip install redis")
+ raise
+
+ # Try to get Redis client from environment first
+ if not self.redis_client:
+ self.redis_client = APIRedisDBManager.load_redis_engine_from_env()
+
+ # If still no client, try from config
+ if not self.redis_client and self.redis_config:
+ redis_kwargs = {
+ "host": self.redis_config.get("host"),
+ "port": self.redis_config.get("port"),
+ "db": self.redis_config.get("db"),
+ "decode_responses": True,
+ }
+
+ if self.redis_config.get("password"):
+ redis_kwargs["password"] = self.redis_config["password"]
+
+ self.redis_client = redis.Redis(**redis_kwargs)
+
+ # Final fallback to localhost
+ if not self.redis_client:
+ logger.warning("No Redis configuration found, using localhost defaults")
+ self.redis_client = redis.Redis(
+ host="localhost", port=6379, db=0, decode_responses=True
+ )
+
+ # Test connection
+ if not self.redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info("Redis client initialized successfully")
+
+ def acquire_lock(self, block: bool = True, **kwargs) -> bool:
+ """Acquire a distributed lock using Redis with atomic operations
+
+ Args:
+ block: Whether to block until lock is acquired
+ **kwargs: Additional filter criteria (ignored for Redis)
+
+ Returns:
+ True if lock was acquired, False otherwise
+ """
+
+ now = get_utc_now()
+
+ # Use Redis SET with NX (only if not exists) and EX (expiry) for atomic lock acquisition
+ lock_value = f"{self._get_key_prefix()}:{now.timestamp()}"
+
+ while True:
+ result = self.redis_client.get(self.lock_key)
+ if result:
+ # Wait a bit before retrying
+ logger.info(
+ f"Waiting for Redis lock to be released for {self.user_id}/{self.mem_cube_id}"
+ )
+ if not block:
+ logger.warning(
+ f"Redis lock is held for {self.user_id}/{self.mem_cube_id}, cannot acquire"
+ )
+ return False
+ else:
+ time.sleep(0.1)
+ continue
+ else:
+ # Try to acquire lock atomically
+ result = self.redis_client.set(
+ self.lock_key,
+ lock_value,
+ ex=self.lock_timeout, # Set expiry in seconds
+ )
+ logger.info(f"Redis lock acquired for {self._get_key_prefix()}")
+ return True
+
+ def release_locks(self, **kwargs):
+ # Delete the lock key to release the lock
+ result = self.redis_client.delete(self.lock_key)
+
+ # Redis DELETE returns the number of keys deleted (0 or 1)
+ if result > 0:
+ logger.info(f"Redis lock released for {self._get_key_prefix()}")
+ else:
+ logger.info(f"No Redis lock found to release for {self._get_key_prefix()}")
+
+ def merge_items(
+ self,
+ redis_data: str,
+ obj_instance: APISearchHistoryManager,
+ size_limit: int,
+ ):
+ """Merge Redis data with current object instance
+
+ Args:
+ redis_data: JSON string from Redis containing serialized APISearchHistoryManager
+ obj_instance: Current APISearchHistoryManager instance
+ size_limit: Maximum number of completed entries to keep
+
+ Returns:
+ APISearchHistoryManager: Merged and synchronized manager instance
+ """
+
+ # Parse Redis data
+ redis_manager = APISearchHistoryManager.from_json(redis_data)
+ logger.debug(
+ f"Loaded Redis manager with {len(redis_manager.completed_entries)} completed and {len(redis_manager.running_item_ids)} running task IDs"
+ )
+
+ # Create a new merged manager with the original window size from obj_instance
+ # Use size_limit only for limiting entries, not as window_size
+ original_window_size = obj_instance.window_size
+ merged_manager = APISearchHistoryManager(window_size=original_window_size)
+
+ # Merge completed entries - combine both sources and deduplicate by task_id
+ # Ensure all entries are APIMemoryHistoryEntryItem instances
+ from memos.mem_scheduler.schemas.api_schemas import APIMemoryHistoryEntryItem
+
+ all_completed = {}
+
+ # Add Redis completed entries
+ for entry in redis_manager.completed_entries:
+ if isinstance(entry, dict):
+ # Convert dict to APIMemoryHistoryEntryItem instance
+ try:
+ entry_obj = APIMemoryHistoryEntryItem(**entry)
+ task_id = entry_obj.item_id
+ all_completed[task_id] = entry_obj
+ except Exception as e:
+ logger.warning(
+ f"Failed to convert dict entry to APIMemoryHistoryEntryItem: {e}"
+ )
+ continue
+ else:
+ task_id = entry.item_id
+ all_completed[task_id] = entry
+
+ # Add current instance completed entries (these take priority if duplicated)
+ for entry in obj_instance.completed_entries:
+ if isinstance(entry, dict):
+ # Convert dict to APIMemoryHistoryEntryItem instance
+ try:
+ entry_obj = APIMemoryHistoryEntryItem(**entry)
+ task_id = entry_obj.item_id
+ all_completed[task_id] = entry_obj
+ except Exception as e:
+ logger.warning(
+ f"Failed to convert dict entry to APIMemoryHistoryEntryItem: {e}"
+ )
+ continue
+ else:
+ task_id = entry.item_id
+ all_completed[task_id] = entry
+
+ # Sort by created_time and apply size limit
+ completed_list = list(all_completed.values())
+
+ def get_created_time(entry):
+ """Helper function to safely extract created_time for sorting"""
+ from datetime import datetime
+
+ # All entries should now be APIMemoryHistoryEntryItem instances
+ return getattr(entry, "created_time", datetime.min)
+
+ completed_list.sort(key=get_created_time, reverse=True)
+ merged_manager.completed_entries = completed_list[:size_limit]
+
+ # Merge running task IDs - combine both sources and deduplicate
+ all_running_item_ids = set()
+
+ # Add Redis running task IDs
+ all_running_item_ids.update(redis_manager.running_item_ids)
+
+ # Add current instance running task IDs
+ all_running_item_ids.update(obj_instance.running_item_ids)
+
+ merged_manager.running_item_ids = list(all_running_item_ids)
+
+ logger.info(
+ f"Merged manager: {len(merged_manager.completed_entries)} completed, {len(merged_manager.running_item_ids)} running task IDs"
+ )
+ return merged_manager
+
+ def sync_with_redis(self, size_limit: int | None = None) -> None:
+ """Synchronize data between Redis and the business object
+
+ Args:
+ size_limit: Optional maximum number of items to keep after synchronization
+ """
+
+ # Use window_size from the object if size_limit is not provided
+ if size_limit is None:
+ size_limit = self.window_size
+
+ # Acquire lock before operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for synchronization")
+ return
+
+ # Load existing data from Redis
+ data_key = self._get_data_key()
+ redis_data = self.redis_client.get(data_key)
+
+ if redis_data:
+ # Merge Redis data with current object
+ merged_obj = self.merge_items(
+ redis_data=redis_data, obj_instance=self.obj, size_limit=size_limit
+ )
+
+ # Update the current object with merged data
+ self.obj = merged_obj
+ logger.info(
+ f"Successfully synchronized with Redis data for {self.user_id}/{self.mem_cube_id}"
+ )
+ else:
+ logger.info(
+ f"No existing Redis data found for {self.user_id}/{self.mem_cube_id}, using current object"
+ )
+
+ # Save the synchronized object back to Redis
+ self.save_to_db(self.obj)
+
+ self.release_locks()
+
+ def save_to_db(self, obj_instance: Any) -> None:
+ """Save the current state of the business object to Redis
+
+ Args:
+ obj_instance: The object instance to save (must have to_json method)
+ """
+
+ data_key = self._get_data_key()
+
+ self.redis_client.set(data_key, obj_instance.to_json())
+
+ logger.info(f"Updated existing Redis record for {data_key}")
+
+ def load_from_db(self) -> Any | None:
+ data_key = self._get_data_key()
+
+ # Load from Redis
+ serialized_data = self.redis_client.get(data_key)
+
+ if not serialized_data:
+ logger.info(f"No Redis record found for {data_key}")
+ return None
+
+ # Deserialize the business object using the actual object type
+ if hasattr(self, "obj_type") and self.obj_type is not None:
+ db_instance = self.obj_type.from_json(serialized_data)
+ else:
+ # Default to APISearchHistoryManager for this class
+ db_instance = APISearchHistoryManager.from_json(serialized_data)
+
+ logger.info(f"Successfully loaded object from Redis for {data_key} ")
+
+ return db_instance
+
+ @classmethod
+ def from_env(
+ cls,
+ user_id: str,
+ mem_cube_id: str,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ env_file_path: str | None = None,
+ ) -> "APIRedisDBManager":
+ """Create RedisDBManager from environment variables
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ obj: Optional MemoryMonitorManager instance
+ lock_timeout: Lock timeout in seconds
+ env_file_path: Optional path to .env file
+
+ Returns:
+ RedisDBManager instance
+ """
+
+ redis_client = APIRedisDBManager.load_redis_engine_from_env(env_file_path)
+ return cls(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=obj,
+ lock_timeout=lock_timeout,
+ redis_client=redis_client,
+ )
+
+ def close(self):
+ """Close the Redis connection and clean up resources"""
+ try:
+ if hasattr(self.redis_client, "close"):
+ self.redis_client.close()
+ logger.info(
+ f"Redis connection closed for user_id: {self.user_id}, mem_cube_id: {self.mem_cube_id}"
+ )
+ except Exception as e:
+ logger.warning(f"Error closing Redis connection: {e}")
+
+ @staticmethod
+ def load_redis_engine_from_env(env_file_path: str | None = None) -> Any:
+ """Load Redis connection from environment variables
+
+ Args:
+ env_file_path: Path to .env file (optional, defaults to loading from current environment)
+
+ Returns:
+ Redis connection instance
+
+ Raises:
+ DatabaseError: If required environment variables are missing or connection fails
+ """
+ try:
+ import redis
+ except ImportError as e:
+ error_msg = "Redis package not installed. Install with: pip install redis"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
+
+ # Load environment variables from file if provided
+ if env_file_path:
+ if os.path.exists(env_file_path):
+ from dotenv import load_dotenv
+
+ load_dotenv(env_file_path)
+ logger.info(f"Loaded environment variables from {env_file_path}")
+ else:
+ logger.warning(
+ f"Environment file not found: {env_file_path}, using current environment variables"
+ )
+ else:
+ logger.info("Using current environment variables (no env_file_path provided)")
+
+ # Get Redis configuration from environment variables
+ redis_host = os.getenv("REDIS_HOST") or os.getenv("MEMSCHEDULER_REDIS_HOST")
+ redis_port_str = os.getenv("REDIS_PORT") or os.getenv("MEMSCHEDULER_REDIS_PORT")
+ redis_db_str = os.getenv("REDIS_DB") or os.getenv("MEMSCHEDULER_REDIS_DB")
+ redis_password = os.getenv("REDIS_PASSWORD") or os.getenv("MEMSCHEDULER_REDIS_PASSWORD")
+
+ # Check required environment variables
+ if not redis_host:
+ error_msg = (
+ "Missing required Redis environment variable: REDIS_HOST or MEMSCHEDULER_REDIS_HOST"
+ )
+ logger.error(error_msg)
+ return None
+
+ # Parse port with validation
+ try:
+ redis_port = int(redis_port_str) if redis_port_str else 6379
+ except ValueError:
+ error_msg = f"Invalid REDIS_PORT value: {redis_port_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Parse database with validation
+ try:
+ redis_db = int(redis_db_str) if redis_db_str else 0
+ except ValueError:
+ error_msg = f"Invalid REDIS_DB value: {redis_db_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Optional timeout settings
+ socket_timeout = os.getenv(
+ "REDIS_SOCKET_TIMEOUT", os.getenv("MEMSCHEDULER_REDIS_TIMEOUT", None)
+ )
+ socket_connect_timeout = os.getenv(
+ "REDIS_SOCKET_CONNECT_TIMEOUT", os.getenv("MEMSCHEDULER_REDIS_CONNECT_TIMEOUT", None)
+ )
+
+ try:
+ # Build Redis connection parameters
+ redis_kwargs = {
+ "host": redis_host,
+ "port": redis_port,
+ "db": redis_db,
+ "decode_responses": True,
+ }
+
+ if redis_password:
+ redis_kwargs["password"] = redis_password
+
+ if socket_timeout:
+ try:
+ redis_kwargs["socket_timeout"] = float(socket_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid REDIS_SOCKET_TIMEOUT value: {socket_timeout}, ignoring"
+ )
+
+ if socket_connect_timeout:
+ try:
+ redis_kwargs["socket_connect_timeout"] = float(socket_connect_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid REDIS_SOCKET_CONNECT_TIMEOUT value: {socket_connect_timeout}, ignoring"
+ )
+
+ # Create Redis connection
+ redis_client = redis.Redis(**redis_kwargs)
+
+ # Test connection
+ if not redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info(
+ f"Successfully created Redis connection: {redis_host}:{redis_port}/{redis_db}"
+ )
+ return redis_client
+
+ except Exception as e:
+ error_msg = f"Failed to create Redis connection from environment variables: {e}"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
diff --git a/src/memos/mem_scheduler/orm_modules/base_model.py b/src/memos/mem_scheduler/orm_modules/base_model.py
index 9d75a12bd..9783cea82 100644
--- a/src/memos/mem_scheduler/orm_modules/base_model.py
+++ b/src/memos/mem_scheduler/orm_modules/base_model.py
@@ -10,13 +10,16 @@
from sqlalchemy import Boolean, Column, DateTime, String, Text, and_, create_engine
from sqlalchemy.engine import Engine
-from sqlalchemy.ext.declarative import declarative_base
-from sqlalchemy.orm import Session, sessionmaker
+from sqlalchemy.orm import Session, declarative_base, sessionmaker
from memos.log import get_logger
from memos.mem_user.user_manager import UserManager
+class DatabaseError(Exception):
+ """Exception raised for database-related errors"""
+
+
T = TypeVar("T") # The model type (MemoryMonitorManager, QueryMonitorManager, etc.)
ORM = TypeVar("ORM") # The ORM model type
@@ -561,7 +564,7 @@ def close(self):
logger.error(f"Error during close operation: {e}")
@staticmethod
- def create_default_engine() -> Engine:
+ def create_default_sqlite_engine() -> Engine:
"""Create SQLAlchemy engine with default database path
Returns:
@@ -633,3 +636,94 @@ def create_mysql_db_path(
else:
db_path = f"mysql+pymysql://{username}@{host}:{port}/{database}?charset={charset}"
return db_path
+
+ @staticmethod
+ def load_mysql_engine_from_env(env_file_path: str | None = None) -> Engine | None:
+ """Load MySQL engine from environment variables
+
+ Args:
+ env_file_path: Path to .env file (optional, defaults to loading from current environment)
+
+ Returns:
+ SQLAlchemy Engine instance configured for MySQL
+
+ Raises:
+ DatabaseError: If required environment variables are missing or connection fails
+ """
+ # Load environment variables from file if provided
+ if env_file_path:
+ if os.path.exists(env_file_path):
+ from dotenv import load_dotenv
+
+ load_dotenv(env_file_path)
+ logger.info(f"Loaded environment variables from {env_file_path}")
+ else:
+ logger.warning(
+ f"Environment file not found: {env_file_path}, using current environment variables"
+ )
+ else:
+ logger.info("Using current environment variables (no env_file_path provided)")
+
+ # Get MySQL configuration from environment variables
+ mysql_host = os.getenv("MYSQL_HOST")
+ mysql_port_str = os.getenv("MYSQL_PORT")
+ mysql_username = os.getenv("MYSQL_USERNAME")
+ mysql_password = os.getenv("MYSQL_PASSWORD")
+ mysql_database = os.getenv("MYSQL_DATABASE")
+ mysql_charset = os.getenv("MYSQL_CHARSET")
+
+ # Check required environment variables
+ required_vars = {
+ "MYSQL_HOST": mysql_host,
+ "MYSQL_USERNAME": mysql_username,
+ "MYSQL_PASSWORD": mysql_password,
+ "MYSQL_DATABASE": mysql_database,
+ }
+
+ missing_vars = [var for var, value in required_vars.items() if not value]
+ if missing_vars:
+ error_msg = f"Missing required MySQL environment variables: {', '.join(missing_vars)}"
+ logger.error(error_msg)
+ return None
+
+ # Parse port with validation
+ try:
+ mysql_port = int(mysql_port_str) if mysql_port_str else 3306
+ except ValueError:
+ error_msg = f"Invalid MYSQL_PORT value: {mysql_port_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Set default charset if not provided
+ if not mysql_charset:
+ mysql_charset = "utf8mb4"
+
+ # Create MySQL connection URL
+ db_url = BaseDBManager.create_mysql_db_path(
+ host=mysql_host,
+ port=mysql_port,
+ username=mysql_username,
+ password=mysql_password,
+ database=mysql_database,
+ charset=mysql_charset,
+ )
+
+ try:
+ # Create and test the engine
+ engine = create_engine(db_url, echo=False)
+
+ # Test connection
+ with engine.connect() as conn:
+ from sqlalchemy import text
+
+ conn.execute(text("SELECT 1"))
+
+ logger.info(
+ f"Successfully created MySQL engine: {mysql_host}:{mysql_port}/{mysql_database}"
+ )
+ return engine
+
+ except Exception as e:
+ error_msg = f"Failed to create MySQL engine from environment variables: {e}"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
diff --git a/src/memos/mem_scheduler/orm_modules/redis_model.py b/src/memos/mem_scheduler/orm_modules/redis_model.py
new file mode 100644
index 000000000..ccfe1b1c8
--- /dev/null
+++ b/src/memos/mem_scheduler/orm_modules/redis_model.py
@@ -0,0 +1,699 @@
+import json
+import time
+
+from typing import Any, TypeVar
+
+from sqlalchemy.engine import Engine
+from sqlalchemy.orm import declarative_base
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
+from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorManager
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
+
+T = TypeVar("T") # The model type (MemoryMonitorManager, QueryMonitorManager, etc.)
+ORM = TypeVar("ORM") # The ORM model type
+
+logger = get_logger(__name__)
+
+Base = declarative_base()
+
+
+class SimpleListManager:
+ """Simple wrapper class for list[str] to work with RedisDBManager"""
+
+ def __init__(self, items: list[str] | None = None):
+ self.items = items or []
+
+ def to_json(self) -> str:
+ """Serialize to JSON string"""
+ return json.dumps({"items": self.items})
+
+ @classmethod
+ def from_json(cls, json_str: str) -> "SimpleListManager":
+ """Deserialize from JSON string"""
+ data = json.loads(json_str)
+ return cls(items=data.get("items", []))
+
+ def add_item(self, item: str):
+ """Add an item to the list"""
+ self.items.append(item)
+
+ def __len__(self):
+ return len(self.items)
+
+ def __str__(self):
+ return f"SimpleListManager(items={self.items})"
+
+
+class RedisLockableORM:
+ """Redis-based implementation of LockableORM interface
+
+ This class provides Redis-based storage for lockable ORM objects,
+ mimicking the SQLAlchemy LockableORM interface but using Redis as the backend.
+ """
+
+ def __init__(self, redis_client, user_id: str, mem_cube_id: str):
+ self.redis_client = redis_client
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.serialized_data = None
+ self.lock_acquired = False
+ self.lock_expiry = None
+ self.version_control = "0"
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this ORM instance"""
+ return f"lockable_orm:{self.user_id}:{self.mem_cube_id}"
+
+ def _get_data_key(self) -> str:
+ """Get Redis key for serialized data"""
+ return f"{self._get_key_prefix()}:data"
+
+ def _get_lock_key(self) -> str:
+ """Get Redis key for lock information"""
+ return f"{self._get_key_prefix()}:lock"
+
+ def _get_version_key(self) -> str:
+ """Get Redis key for version control"""
+ return f"{self._get_key_prefix()}:version"
+
+ def save(self):
+ """Save this ORM instance to Redis"""
+ try:
+ # Save serialized data
+ if self.serialized_data:
+ self.redis_client.set(self._get_data_key(), self.serialized_data)
+
+ # Note: Lock information is now managed by acquire_lock/release_locks methods
+ # We don't save lock info here to avoid conflicts with atomic lock operations
+
+ # Save version control
+ self.redis_client.set(self._get_version_key(), self.version_control)
+
+ logger.debug(f"Saved RedisLockableORM to Redis: {self._get_key_prefix()}")
+
+ except Exception as e:
+ logger.error(f"Failed to save RedisLockableORM to Redis: {e}")
+ raise
+
+ def load(self):
+ """Load this ORM instance from Redis"""
+ try:
+ # Load serialized data
+ data = self.redis_client.get(self._get_data_key())
+ if data:
+ self.serialized_data = data.decode() if isinstance(data, bytes) else data
+ else:
+ self.serialized_data = None
+
+ # Note: Lock information is now managed by acquire_lock/release_locks methods
+ # We don't load lock info here to avoid conflicts with atomic lock operations
+ self.lock_acquired = False
+ self.lock_expiry = None
+
+ # Load version control
+ version = self.redis_client.get(self._get_version_key())
+ if version:
+ self.version_control = version.decode() if isinstance(version, bytes) else version
+ else:
+ self.version_control = "0"
+
+ logger.debug(f"Loaded RedisLockableORM from Redis: {self._get_key_prefix()}")
+ # Return True if we found any data, False otherwise
+ return self.serialized_data is not None
+
+ except Exception as e:
+ logger.error(f"Failed to load RedisLockableORM from Redis: {e}")
+ return False
+
+ def delete(self):
+ """Delete this ORM instance from Redis"""
+ try:
+ keys_to_delete = [self._get_data_key(), self._get_lock_key(), self._get_version_key()]
+ self.redis_client.delete(*keys_to_delete)
+ logger.debug(f"Deleted RedisLockableORM from Redis: {self._get_key_prefix()}")
+ except Exception as e:
+ logger.error(f"Failed to delete RedisLockableORM from Redis: {e}")
+ raise
+
+
+class RedisDBManager(BaseDBManager):
+ """Redis-based database manager for any serializable object
+
+ This class handles persistence, synchronization, and locking
+ for any object that implements to_json/from_json methods using Redis as the backend storage.
+ """
+
+ def __init__(
+ self,
+ engine: Engine | None = None,
+ user_id: str | None = None,
+ mem_cube_id: str | None = None,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ redis_client=None,
+ redis_config: dict | None = None,
+ ):
+ """Initialize the Redis database manager
+
+ Args:
+ engine: SQLAlchemy engine (not used for Redis, kept for compatibility)
+ user_id: Unique identifier for the user
+ mem_cube_id: Unique identifier for the memory cube
+ obj: Optional object instance to manage (must have to_json/from_json methods)
+ lock_timeout: Timeout in seconds for lock acquisition
+ redis_client: Redis client instance (optional)
+ redis_config: Redis configuration dictionary (optional)
+ """
+ # Initialize Redis client
+ self.redis_client = redis_client
+ self.redis_config = redis_config or {}
+
+ if self.redis_client is None:
+ self._init_redis_client()
+
+ # Initialize base attributes without calling parent's init_manager
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.obj = obj
+ self.obj_type = type(obj) if obj is not None else None # Store the actual object type
+ self.lock_timeout = lock_timeout
+ self.engine = engine # Keep for compatibility but not used
+ self.SessionLocal = None # Not used for Redis
+ self.last_version_control = None
+
+ logger.info(
+ f"RedisDBManager initialized for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ logger.info(f"Redis client: {type(self.redis_client).__name__}")
+
+ # Test Redis connection
+ try:
+ self.redis_client.ping()
+ logger.info("Redis connection successful")
+ except Exception as e:
+ logger.warning(f"Redis ping failed: {e}")
+ # Don't raise error here as it might be a mock client in tests
+
+ def _init_redis_client(self):
+ """Initialize Redis client from config or environment"""
+ try:
+ import redis
+
+ # Try to get Redis client from environment first
+ if not self.redis_client:
+ self.redis_client = self.load_redis_engine_from_env()
+
+ # If still no client, try from config
+ if not self.redis_client and self.redis_config:
+ redis_kwargs = {
+ "host": self.redis_config.get("host", "localhost"),
+ "port": self.redis_config.get("port", 6379),
+ "db": self.redis_config.get("db", 0),
+ "decode_responses": True,
+ }
+
+ if self.redis_config.get("password"):
+ redis_kwargs["password"] = self.redis_config["password"]
+
+ self.redis_client = redis.Redis(**redis_kwargs)
+
+ # Final fallback to localhost
+ if not self.redis_client:
+ logger.warning("No Redis configuration found, using localhost defaults")
+ self.redis_client = redis.Redis(
+ host="localhost", port=6379, db=0, decode_responses=True
+ )
+
+ # Test connection
+ if not self.redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info("Redis client initialized successfully")
+
+ except ImportError:
+ logger.error("Redis package not installed. Install with: pip install redis")
+ raise
+ except Exception as e:
+ logger.error(f"Failed to initialize Redis client: {e}")
+ raise
+
+ @property
+ def orm_class(self) -> type[RedisLockableORM]:
+ """Return the Redis-based ORM class"""
+ return RedisLockableORM
+
+ @property
+ def obj_class(self) -> type:
+ """Return the actual object class"""
+ return self.obj_type if self.obj_type is not None else MemoryMonitorManager
+
+ def merge_items(
+ self,
+ orm_instance: RedisLockableORM,
+ obj_instance: Any,
+ size_limit: int,
+ ):
+ """Merge items from Redis with current object instance
+
+ This method provides a generic way to merge data from Redis with the current
+ object instance. It handles different object types and their specific merge logic.
+
+ Args:
+ orm_instance: Redis ORM instance from database
+ obj_instance: Current object instance (any type with to_json/from_json methods)
+ size_limit: Maximum number of items to keep after merge
+ """
+ logger.debug(f"Starting merge_items with size_limit={size_limit}")
+
+ try:
+ if not orm_instance.serialized_data:
+ logger.warning("No serialized data in Redis ORM instance to merge")
+ return obj_instance
+
+ # Deserialize the database object using the actual object type
+ if self.obj_type is not None:
+ db_obj = self.obj_type.from_json(orm_instance.serialized_data)
+ else:
+ db_obj = MemoryMonitorManager.from_json(orm_instance.serialized_data)
+
+ # Handle different object types with specific merge logic based on type
+ obj_type = type(obj_instance)
+ if obj_type.__name__ == "MemoryMonitorManager" or hasattr(obj_instance, "memories"):
+ # MemoryMonitorManager-like objects
+ return self._merge_memory_monitor_items(obj_instance, db_obj, size_limit)
+ elif obj_type.__name__ == "SimpleListManager" or hasattr(obj_instance, "items"):
+ # SimpleListManager-like objects
+ return self._merge_list_items(obj_instance, db_obj, size_limit)
+ else:
+ # Generic objects - just return the current instance
+ logger.info(
+ f"No specific merge logic for object type {obj_type.__name__}, returning current instance"
+ )
+ return obj_instance
+
+ except Exception as e:
+ logger.error(f"Failed to deserialize database instance: {e}", exc_info=True)
+ logger.warning("Skipping merge due to deserialization error, using current object only")
+ return obj_instance
+
+ def _merge_memory_monitor_items(self, obj_instance, db_obj, size_limit: int):
+ """Merge MemoryMonitorManager items"""
+ # Create a mapping of existing memories by their mapping key
+ current_memories_dict = obj_instance.memories_mapping_dict
+
+ # Add memories from database that don't exist in current object
+ for db_memory in db_obj.memories:
+ if db_memory.tree_memory_item_mapping_key not in current_memories_dict:
+ obj_instance.memories.append(db_memory)
+
+ # Apply size limit if specified
+ if size_limit and len(obj_instance.memories) > size_limit:
+ # Sort by recording_count and keep the most recorded ones
+ obj_instance.memories.sort(key=lambda x: x.recording_count, reverse=True)
+ obj_instance.memories = obj_instance.memories[:size_limit]
+ logger.info(
+ f"Applied size limit {size_limit}, kept {len(obj_instance.memories)} memories"
+ )
+
+ logger.info(f"Merged {len(obj_instance.memories)} memory items")
+ return obj_instance
+
+ def _merge_list_items(self, obj_instance, db_obj, size_limit: int):
+ """Merge SimpleListManager-like items"""
+ merged_items = []
+ seen_items = set()
+
+ # First, add all items from current object (higher priority)
+ for item in obj_instance.items:
+ if item not in seen_items:
+ merged_items.append(item)
+ seen_items.add(item)
+
+ # Then, add items from database that aren't in current object
+ for item in db_obj.items:
+ if item not in seen_items:
+ merged_items.append(item)
+ seen_items.add(item)
+
+ # Apply size limit if specified (keep most recent items)
+ if size_limit is not None and size_limit > 0 and len(merged_items) > size_limit:
+ merged_items = merged_items[:size_limit]
+ logger.debug(f"Applied size limit of {size_limit}, kept {len(merged_items)} items")
+
+ # Update the object with merged items
+ obj_instance.items = merged_items
+
+ logger.info(f"Merged {len(merged_items)} list items (size_limit: {size_limit})")
+ return obj_instance
+
+ def _get_redis_orm_instance(self) -> RedisLockableORM:
+ """Get or create a Redis ORM instance"""
+ orm_instance = RedisLockableORM(
+ redis_client=self.redis_client, user_id=self.user_id, mem_cube_id=self.mem_cube_id
+ )
+ return orm_instance
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this ORM instance"""
+ return f"lockable_orm:{self.user_id}:{self.mem_cube_id}"
+
+ def acquire_lock(self, block: bool = True, **kwargs) -> bool:
+ """Acquire a distributed lock using Redis with atomic operations
+
+ Args:
+ block: Whether to block until lock is acquired
+ **kwargs: Additional filter criteria (ignored for Redis)
+
+ Returns:
+ True if lock was acquired, False otherwise
+ """
+ try:
+ lock_key = f"{self._get_key_prefix()}:lock"
+ now = get_utc_now()
+
+ # Use Redis SET with NX (only if not exists) and EX (expiry) for atomic lock acquisition
+ lock_value = f"{self.user_id}:{self.mem_cube_id}:{now.timestamp()}"
+
+ while True:
+ # Try to acquire lock atomically
+ result = self.redis_client.set(
+ lock_key,
+ lock_value,
+ nx=True, # Only set if key doesn't exist
+ ex=self.lock_timeout, # Set expiry in seconds
+ )
+
+ if result:
+ # Successfully acquired lock
+ logger.info(f"Redis lock acquired for {self.user_id}/{self.mem_cube_id}")
+ return True
+
+ if not block:
+ logger.warning(
+ f"Redis lock is held for {self.user_id}/{self.mem_cube_id}, cannot acquire"
+ )
+ return False
+
+ # Wait a bit before retrying
+ logger.info(
+ f"Waiting for Redis lock to be released for {self.user_id}/{self.mem_cube_id}"
+ )
+ time.sleep(0.1)
+
+ except Exception as e:
+ logger.error(f"Failed to acquire Redis lock for {self.user_id}/{self.mem_cube_id}: {e}")
+ return False
+
+ def release_locks(self, user_id: str, mem_cube_id: str, **kwargs):
+ """Release Redis locks for the specified user and memory cube
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ **kwargs: Additional filter criteria (ignored for Redis)
+ """
+ try:
+ lock_key = f"lockable_orm:{user_id}:{mem_cube_id}:lock"
+
+ # Delete the lock key to release the lock
+ result = self.redis_client.delete(lock_key)
+
+ if result:
+ logger.info(f"Redis lock released for {user_id}/{mem_cube_id}")
+ else:
+ logger.warning(f"No Redis lock found to release for {user_id}/{mem_cube_id}")
+
+ except Exception as e:
+ logger.error(f"Failed to release Redis lock for {user_id}/{mem_cube_id}: {e}")
+
+ def sync_with_orm(self, size_limit: int | None = None) -> None:
+ """Synchronize data between Redis and the business object
+
+ Args:
+ size_limit: Optional maximum number of items to keep after synchronization
+ """
+ logger.info(
+ f"Starting Redis sync_with_orm for {self.user_id}/{self.mem_cube_id} with size_limit={size_limit}"
+ )
+
+ try:
+ # Acquire lock before any operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for synchronization")
+ return
+
+ # Get existing data from Redis
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ # If no existing record, create a new one
+ if not exists:
+ if self.obj is None:
+ logger.warning("No object to synchronize and no existing Redis record")
+ return
+
+ orm_instance.serialized_data = self.obj.to_json()
+ orm_instance.version_control = "0"
+ orm_instance.save()
+
+ logger.info("No existing Redis record found. Created a new one.")
+ self.last_version_control = "0"
+ return
+
+ # Check version control and merge data
+ if self.obj is not None:
+ current_redis_tag = orm_instance.version_control
+ new_tag = self._increment_version_control(current_redis_tag)
+
+ # Check if this is the first sync or if we need to merge
+ if self.last_version_control is None:
+ logger.info("First Redis sync, merging data from Redis")
+ # Always merge on first sync to load data from Redis
+ try:
+ self.merge_items(
+ orm_instance=orm_instance, obj_instance=self.obj, size_limit=size_limit
+ )
+ except Exception as merge_error:
+ logger.error(
+ f"Error during Redis merge_items: {merge_error}", exc_info=True
+ )
+ logger.warning("Continuing with current object data without merge")
+ elif current_redis_tag == self.last_version_control:
+ logger.info(
+ f"Redis version control unchanged ({current_redis_tag}), directly update"
+ )
+ else:
+ logger.info(
+ f"Redis version control changed from {self.last_version_control} to {current_redis_tag}, merging data"
+ )
+ try:
+ self.merge_items(
+ orm_instance=orm_instance, obj_instance=self.obj, size_limit=size_limit
+ )
+ except Exception as merge_error:
+ logger.error(
+ f"Error during Redis merge_items: {merge_error}", exc_info=True
+ )
+ logger.warning("Continuing with current object data without merge")
+
+ # Write merged data back to Redis
+ orm_instance.serialized_data = self.obj.to_json()
+ orm_instance.version_control = new_tag
+ orm_instance.save()
+
+ logger.info(f"Updated Redis serialized_data for {self.user_id}/{self.mem_cube_id}")
+ self.last_version_control = orm_instance.version_control
+ else:
+ logger.warning("No current object to merge with Redis data")
+
+ logger.info(f"Redis synchronization completed for {self.user_id}/{self.mem_cube_id}")
+
+ except Exception as e:
+ logger.error(
+ f"Error during Redis synchronization for {self.user_id}/{self.mem_cube_id}: {e}",
+ exc_info=True,
+ )
+ finally:
+ # Always release locks
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def save_to_db(self, obj_instance: Any) -> None:
+ """Save the current state of the business object to Redis
+
+ Args:
+ obj_instance: The object instance to save (must have to_json method)
+ """
+ try:
+ # Acquire lock before operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for saving")
+ return
+
+ # Get or create Redis ORM instance
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ if not exists:
+ # Create new record
+ orm_instance.serialized_data = obj_instance.to_json()
+ orm_instance.version_control = "0"
+ orm_instance.save()
+
+ logger.info(f"Created new Redis record for {self.user_id}/{self.mem_cube_id}")
+ self.last_version_control = "0"
+ else:
+ # Update existing record with version control
+ current_version = orm_instance.version_control
+ new_version = self._increment_version_control(current_version)
+
+ orm_instance.serialized_data = obj_instance.to_json()
+ orm_instance.version_control = new_version
+ orm_instance.save()
+
+ logger.info(
+ f"Updated existing Redis record for {self.user_id}/{self.mem_cube_id} with version {new_version}"
+ )
+ self.last_version_control = new_version
+
+ except Exception as e:
+ logger.error(f"Error saving to Redis for {self.user_id}/{self.mem_cube_id}: {e}")
+ finally:
+ # Always release locks
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def load_from_db(self, acquire_lock: bool = False) -> Any | None:
+ """Load the business object from Redis
+
+ Args:
+ acquire_lock: Whether to acquire a lock during the load operation
+
+ Returns:
+ The deserialized object instance, or None if not found
+ """
+ try:
+ if acquire_lock:
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for loading")
+ return None
+
+ # Load from Redis
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ if not exists or not orm_instance.serialized_data:
+ logger.info(f"No Redis record found for {self.user_id}/{self.mem_cube_id}")
+ return None
+
+ # Deserialize the business object using the actual object type
+ if self.obj_type is not None:
+ db_instance = self.obj_type.from_json(orm_instance.serialized_data)
+ else:
+ db_instance = MemoryMonitorManager.from_json(orm_instance.serialized_data)
+ self.last_version_control = orm_instance.version_control
+
+ logger.info(
+ f"Successfully loaded object from Redis for {self.user_id}/{self.mem_cube_id} with version {orm_instance.version_control}"
+ )
+ return db_instance
+
+ except Exception as e:
+ logger.error(f"Error loading from Redis for {self.user_id}/{self.mem_cube_id}: {e}")
+ return None
+ finally:
+ if acquire_lock:
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def close(self):
+ """Close the Redis manager and clean up resources"""
+ try:
+ # Release any locks held by this manager instance
+ if self.user_id and self.mem_cube_id:
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+ logger.info(f"Released Redis locks for {self.user_id}/{self.mem_cube_id}")
+
+ # Close Redis connection
+ if self.redis_client:
+ self.redis_client.close()
+ logger.info("Redis connection closed")
+
+ # Call parent close method for any additional cleanup
+ super().close()
+
+ except Exception as e:
+ logger.error(f"Error during Redis close operation: {e}")
+
+ @classmethod
+ def from_env(
+ cls,
+ user_id: str,
+ mem_cube_id: str,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ env_file_path: str | None = None,
+ ) -> "RedisDBManager":
+ """Create RedisDBManager from environment variables
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ obj: Optional MemoryMonitorManager instance
+ lock_timeout: Lock timeout in seconds
+ env_file_path: Optional path to .env file
+
+ Returns:
+ RedisDBManager instance
+ """
+ try:
+ redis_client = cls.load_redis_engine_from_env(env_file_path)
+ return cls(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=obj,
+ lock_timeout=lock_timeout,
+ redis_client=redis_client,
+ )
+ except Exception as e:
+ logger.error(f"Failed to create RedisDBManager from environment: {e}")
+ raise
+
+ def list_keys(self, pattern: str | None = None) -> list[str]:
+ """List all Redis keys for this manager's data
+
+ Args:
+ pattern: Optional pattern to filter keys
+
+ Returns:
+ List of Redis keys
+ """
+ try:
+ if pattern is None:
+ pattern = f"lockable_orm:{self.user_id}:{self.mem_cube_id}:*"
+
+ keys = self.redis_client.keys(pattern)
+ return [key.decode() if isinstance(key, bytes) else key for key in keys]
+
+ except Exception as e:
+ logger.error(f"Error listing Redis keys: {e}")
+ return []
+
+ def health_check(self) -> dict[str, bool]:
+ """Check the health of Redis connection
+
+ Returns:
+ Dictionary with health status
+ """
+ try:
+ redis_healthy = self.redis_client.ping()
+ return {
+ "redis": redis_healthy,
+ "mysql": False, # Not applicable for Redis manager
+ }
+ except Exception as e:
+ logger.error(f"Redis health check failed: {e}")
+ return {"redis": False, "mysql": False}
diff --git a/src/memos/mem_scheduler/schemas/api_schemas.py b/src/memos/mem_scheduler/schemas/api_schemas.py
new file mode 100644
index 000000000..6d0de49c4
--- /dev/null
+++ b/src/memos/mem_scheduler/schemas/api_schemas.py
@@ -0,0 +1,233 @@
+from datetime import datetime
+from enum import Enum
+from typing import Any
+from uuid import uuid4
+
+from pydantic import BaseModel, ConfigDict, Field, field_serializer
+
+from memos.log import get_logger
+from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+from memos.memories.textual.item import TextualMemoryItem
+
+
+logger = get_logger(__name__)
+
+
+class TaskRunningStatus(str, Enum):
+ """Enumeration for task running status values."""
+
+ RUNNING = "running"
+ COMPLETED = "completed"
+
+
+class APIMemoryHistoryEntryItem(BaseModel, DictConversionMixin):
+ """Data class for search entry items stored in Redis."""
+
+ item_id: str = Field(
+ description="Unique identifier for the task", default_factory=lambda: str(uuid4())
+ )
+ query: str = Field(..., description="Search query string")
+ formatted_memories: Any = Field(..., description="Formatted search results")
+ memories: list[TextualMemoryItem] = Field(
+ default_factory=list, description="List of TextualMemoryItem objects"
+ )
+ task_status: str = Field(
+ default="running", description="Task status: running, completed, failed"
+ )
+ session_id: str | None = Field(default=None, description="Optional conversation identifier")
+ created_time: datetime = Field(description="Entry creation time", default_factory=get_utc_now)
+ timestamp: datetime | None = Field(default=None, description="Timestamp for the entry")
+ conversation_turn: int = Field(default=0, description="Turn count for the same session_id")
+
+ model_config = ConfigDict(
+ arbitrary_types_allowed=True,
+ validate_assignment=True,
+ )
+
+ @field_serializer("created_time")
+ def serialize_created_time(self, value: datetime) -> str:
+ """Serialize datetime to ISO format string."""
+ return value.isoformat()
+
+ def get(self, key: str, default: Any | None = None) -> Any:
+ """
+ Get attribute value by key name, similar to dict.get().
+
+ Args:
+ key: The attribute name to retrieve
+ default: Default value to return if attribute doesn't exist
+
+ Returns:
+ The attribute value or default if not found
+ """
+ return getattr(self, key, default)
+
+
+class APISearchHistoryManager(BaseModel, DictConversionMixin):
+ """
+ Data structure for managing search history with separate completed and running entries.
+ Supports window_size to limit the number of completed entries.
+ """
+
+ window_size: int = Field(default=5, description="Maximum number of completed entries to keep")
+ completed_entries: list[APIMemoryHistoryEntryItem] = Field(
+ default_factory=list, description="List of completed search entries"
+ )
+ running_item_ids: list[str] = Field(
+ default_factory=list, description="List of running task ids"
+ )
+
+ model_config = ConfigDict(
+ arbitrary_types_allowed=True,
+ validate_assignment=True,
+ )
+
+ def complete_entry(self, task_id: str) -> bool:
+ """
+ Remove task_id from running list when completed.
+ Note: The actual entry data should be managed separately.
+
+ Args:
+ task_id: The task ID to complete
+
+ Returns:
+ True if task_id was found and removed, False otherwise
+ """
+ if task_id in self.running_item_ids:
+ self.running_item_ids.remove(task_id)
+ logger.debug(f"Completed task_id: {task_id}")
+ return True
+
+ logger.warning(f"Task ID {task_id} not found in running task ids")
+ return False
+
+ def get_running_item_ids(self) -> list[str]:
+ """Get all running task IDs"""
+ return self.running_item_ids.copy()
+
+ def get_completed_entries(self) -> list[APIMemoryHistoryEntryItem]:
+ """Get all completed entries"""
+ return self.completed_entries.copy()
+
+ def get_history_memory_entries(
+ self, turns: int | None = None
+ ) -> list[APIMemoryHistoryEntryItem]:
+ """
+ Get the most recent n completed search entries, sorted by created_time.
+
+ Args:
+ turns: Number of entries to return. If None, returns all completed entries.
+
+ Returns:
+ List of completed search entries, sorted by created_time (newest first)
+ """
+ if not self.completed_entries:
+ return []
+
+ # Sort by created_time (newest first)
+ sorted_entries = sorted(self.completed_entries, key=lambda x: x.created_time, reverse=True)
+
+ if turns is None:
+ return sorted_entries
+
+ return sorted_entries[:turns]
+
+ def get_history_memories(self, turns: int | None = None) -> list[TextualMemoryItem]:
+ """
+ Get the most recent n completed search entries, sorted by created_time.
+
+ Args:
+ turns: Number of entries to return. If None, returns all completed entries.
+
+ Returns:
+ List of TextualMemoryItem objects from completed entries, sorted by created_time (newest first)
+ """
+ sorted_entries = self.get_history_memory_entries(turns=turns)
+
+ memories = []
+ for one in sorted_entries:
+ memories.extend(one.memories)
+ return memories
+
+ def find_entry_by_item_id(self, item_id: str) -> tuple[dict[str, Any] | None, str]:
+ """
+ Find an entry by item_id in completed list only.
+ Running entries are now just task IDs, so we can only search completed entries.
+
+ Args:
+ item_id: The item ID to search for
+
+ Returns:
+ Tuple of (entry_dict, location) where location is 'completed' or 'not_found'
+ """
+ # Check completed entries
+ for entry in self.completed_entries:
+ try:
+ if hasattr(entry, "item_id") and entry.item_id == item_id:
+ return entry.to_dict(), "completed"
+ elif isinstance(entry, dict) and entry.get("item_id") == item_id:
+ return entry, "completed"
+ except AttributeError as e:
+ logger.warning(f"Entry missing item_id attribute: {e}, entry type: {type(entry)}")
+ continue
+
+ return None, "not_found"
+
+ def update_entry_by_item_id(
+ self,
+ item_id: str,
+ query: str,
+ formatted_memories: Any,
+ task_status: TaskRunningStatus,
+ session_id: str | None = None,
+ memories: list[TextualMemoryItem] | None = None,
+ ) -> bool:
+ """
+ Update an existing entry by item_id. Since running entries are now just IDs,
+ this method can only update completed entries.
+
+ Args:
+ item_id: The item ID to update
+ query: New query string
+ formatted_memories: New formatted memories
+ task_status: New task status
+ session_id: New conversation ID
+ memories: List of TextualMemoryItem objects
+
+ Returns:
+ True if entry was found and updated, False otherwise
+ """
+ # Find the entry in completed list
+ for entry in self.completed_entries:
+ if entry.item_id == item_id:
+ # Update the entry content
+ entry.query = query
+ entry.formatted_memories = formatted_memories
+ entry.task_status = task_status
+ if session_id is not None:
+ entry.session_id = session_id
+ if memories is not None:
+ entry.memories = memories
+
+ logger.debug(f"Updated entry with item_id: {item_id}, new status: {task_status}")
+ return True
+
+ logger.warning(f"Entry with item_id: {item_id} not found in completed entries")
+ return False
+
+ def get_total_count(self) -> dict[str, int]:
+ """Get count of entries by status"""
+ return {
+ "completed": len(self.completed_entries),
+ "running": len(self.running_item_ids),
+ "total": len(self.completed_entries) + len(self.running_item_ids),
+ }
+
+ def __len__(self) -> int:
+ """Return total number of entries (completed + running)"""
+ return len(self.completed_entries) + len(self.running_item_ids)
+
+
+# Alias for easier usage
+SearchHistoryManager = APISearchHistoryManager
diff --git a/src/memos/mem_scheduler/schemas/general_schemas.py b/src/memos/mem_scheduler/schemas/general_schemas.py
index d0d83091b..f3d2191f8 100644
--- a/src/memos/mem_scheduler/schemas/general_schemas.py
+++ b/src/memos/mem_scheduler/schemas/general_schemas.py
@@ -1,13 +1,26 @@
+from enum import Enum
from pathlib import Path
from typing import NewType
+class SearchMode(str, Enum):
+ """Enumeration for search modes."""
+
+ FAST = "fast"
+ FINE = "fine"
+ MIXTURE = "mixture"
+
+
FILE_PATH = Path(__file__).absolute()
BASE_DIR = FILE_PATH.parent.parent.parent.parent.parent
QUERY_LABEL = "query"
ANSWER_LABEL = "answer"
ADD_LABEL = "add"
+MEM_READ_LABEL = "mem_read"
+MEM_ORGANIZE_LABEL = "mem_organize"
+API_MIX_SEARCH_LABEL = "api_mix_search"
+PREF_ADD_LABEL = "pref_add"
TreeTextMemory_SEARCH_METHOD = "tree_text_memory_search"
TreeTextMemory_FINE_SEARCH_METHOD = "tree_text_memory_fine_search"
@@ -17,11 +30,16 @@
DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT = 30
DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT = 20
DEFAULT_ACT_MEM_DUMP_PATH = f"{BASE_DIR}/outputs/mem_scheduler/mem_cube_scheduler_test.kv_cache"
-DEFAULT_THREAD_POOL_MAX_WORKERS = 30
+DEFAULT_THREAD_POOL_MAX_WORKERS = 50
DEFAULT_CONSUME_INTERVAL_SECONDS = 0.05
DEFAULT_DISPATCHER_MONITOR_CHECK_INTERVAL = 300
DEFAULT_DISPATCHER_MONITOR_MAX_FAILURES = 2
DEFAULT_STUCK_THREAD_TOLERANCE = 10
+DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE = 1000000
+DEFAULT_TOP_K = 10
+DEFAULT_CONTEXT_WINDOW_SIZE = 5
+DEFAULT_USE_REDIS_QUEUE = False
+DEFAULT_MULTI_TASK_RUNNING_TIMEOUT = 30
# startup mode configuration
STARTUP_BY_THREAD = "thread"
diff --git a/src/memos/mem_scheduler/schemas/message_schemas.py b/src/memos/mem_scheduler/schemas/message_schemas.py
index 9b5bd5d81..7f328474f 100644
--- a/src/memos/mem_scheduler/schemas/message_schemas.py
+++ b/src/memos/mem_scheduler/schemas/message_schemas.py
@@ -6,8 +6,9 @@
from typing_extensions import TypedDict
from memos.log import get_logger
-from memos.mem_cube.general import GeneralMemCube
+from memos.mem_cube.base import BaseMemCube
from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from .general_schemas import NOT_INITIALIZED
@@ -36,10 +37,18 @@ class ScheduleMessageItem(BaseModel, DictConversionMixin):
user_id: str = Field(..., description="user id")
mem_cube_id: str = Field(..., description="memcube id")
label: str = Field(..., description="Label of the schedule message")
- mem_cube: GeneralMemCube | str = Field(..., description="memcube for schedule")
+ mem_cube: BaseMemCube | str = Field(..., description="memcube for schedule")
content: str = Field(..., description="Content of the schedule message")
timestamp: datetime = Field(
- default_factory=lambda: datetime.utcnow(), description="submit time for schedule_messages"
+ default_factory=get_utc_now, description="submit time for schedule_messages"
+ )
+ user_name: str | None = Field(
+ default=None,
+ description="user name / display name (optional)",
+ )
+ session_id: str | None = Field(
+ default=None,
+ description="session_id (optional)",
)
# Pydantic V2 model configuration
@@ -59,16 +68,17 @@ class ScheduleMessageItem(BaseModel, DictConversionMixin):
"mem_cube": "obj of GeneralMemCube", # Added mem_cube example
"content": "sample content", # Example message content
"timestamp": "2024-07-22T12:00:00Z", # Added timestamp example
+ "user_name": "Alice", # Added username example
}
},
)
@field_serializer("mem_cube")
- def serialize_mem_cube(self, cube: GeneralMemCube | str, _info) -> str:
- """Custom serializer for GeneralMemCube objects to string representation"""
+ def serialize_mem_cube(self, cube: BaseMemCube | str, _info) -> str:
+ """Custom serializer for BaseMemCube objects to string representation"""
if isinstance(cube, str):
return cube
- return f""
+ return f"<{type(cube).__name__}:{id(cube)}>"
def to_dict(self) -> dict:
"""Convert model to dictionary suitable for Redis Stream"""
@@ -80,6 +90,7 @@ def to_dict(self) -> dict:
"cube": "Not Applicable", # Custom cube serialization
"content": self.content,
"timestamp": self.timestamp.isoformat(),
+ "user_name": self.user_name,
}
@classmethod
@@ -88,11 +99,12 @@ def from_dict(cls, data: dict) -> "ScheduleMessageItem":
return cls(
item_id=data.get("item_id", str(uuid4())),
user_id=data["user_id"],
- cube_id=data["cube_id"],
+ mem_cube_id=data["cube_id"],
label=data["label"],
- cube="Not Applicable", # Custom cube deserialization
+ mem_cube="Not Applicable", # Custom cube deserialization
content=data["content"],
timestamp=datetime.fromisoformat(data["timestamp"]),
+ user_name=data.get("user_name"),
)
@@ -131,7 +143,7 @@ class ScheduleLogForWebItem(BaseModel, DictConversionMixin):
description="Maximum capacities of memory partitions",
)
timestamp: datetime = Field(
- default_factory=lambda: datetime.utcnow(),
+ default_factory=get_utc_now,
description="Timestamp indicating when the log entry was created",
)
diff --git a/src/memos/mem_scheduler/schemas/task_schemas.py b/src/memos/mem_scheduler/schemas/task_schemas.py
index d189797ae..168a25b5d 100644
--- a/src/memos/mem_scheduler/schemas/task_schemas.py
+++ b/src/memos/mem_scheduler/schemas/task_schemas.py
@@ -7,6 +7,7 @@
from memos.log import get_logger
from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
logger = get_logger(__name__)
@@ -26,7 +27,7 @@ class RunningTaskItem(BaseModel, DictConversionMixin):
mem_cube_id: str = Field(..., description="Required memory cube identifier", min_length=1)
task_info: str = Field(..., description="Information about the task being executed")
task_name: str = Field(..., description="Name/type of the task handler")
- start_time: datetime = Field(description="Task start time", default_factory=datetime.utcnow)
+ start_time: datetime = Field(description="Task start time", default_factory=get_utc_now)
end_time: datetime | None = Field(default=None, description="Task completion time")
status: str = Field(default="running", description="Task status: running, completed, failed")
result: Any | None = Field(default=None, description="Task execution result")
@@ -37,13 +38,13 @@ class RunningTaskItem(BaseModel, DictConversionMixin):
def mark_completed(self, result: Any | None = None) -> None:
"""Mark task as completed with optional result."""
- self.end_time = datetime.utcnow()
+ self.end_time = get_utc_now()
self.status = "completed"
self.result = result
def mark_failed(self, error_message: str) -> None:
"""Mark task as failed with error message."""
- self.end_time = datetime.utcnow()
+ self.end_time = get_utc_now()
self.status = "failed"
self.error_message = error_message
diff --git a/src/memos/mem_scheduler/utils/api_utils.py b/src/memos/mem_scheduler/utils/api_utils.py
new file mode 100644
index 000000000..c8d096517
--- /dev/null
+++ b/src/memos/mem_scheduler/utils/api_utils.py
@@ -0,0 +1,76 @@
+import uuid
+
+from typing import Any
+
+from memos.memories.textual.item import TreeNodeTextualMemoryMetadata
+from memos.memories.textual.tree import TextualMemoryItem
+
+
+def format_textual_memory_item(memory_data: Any) -> dict[str, Any]:
+ """Format a single memory item for API response."""
+ memory = memory_data.model_dump()
+ memory_id = memory["id"]
+ ref_id = f"[{memory_id.split('-')[0]}]"
+
+ memory["ref_id"] = ref_id
+ memory["metadata"]["embedding"] = []
+ memory["metadata"]["sources"] = []
+ memory["metadata"]["ref_id"] = ref_id
+ memory["metadata"]["id"] = memory_id
+ memory["metadata"]["memory"] = memory["memory"]
+
+ return memory
+
+
+def make_textual_item(memory_data):
+ return memory_data
+
+
+def text_to_textual_memory_item(
+ text: str,
+ user_id: str | None = None,
+ session_id: str | None = None,
+ memory_type: str = "WorkingMemory",
+ tags: list[str] | None = None,
+ key: str | None = None,
+ sources: list | None = None,
+ background: str = "",
+ confidence: float = 0.99,
+ embedding: list[float] | None = None,
+) -> TextualMemoryItem:
+ """
+ Convert text into a TextualMemoryItem object.
+
+ Args:
+ text: Memory content text
+ user_id: User ID
+ session_id: Session ID
+ memory_type: Memory type, defaults to "WorkingMemory"
+ tags: List of tags
+ key: Memory key or title
+ sources: List of sources
+ background: Background information
+ confidence: Confidence score (0-1)
+ embedding: Vector embedding
+
+ Returns:
+ TextualMemoryItem: Wrapped memory item
+ """
+ return TextualMemoryItem(
+ id=str(uuid.uuid4()),
+ memory=text,
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id=user_id,
+ session_id=session_id,
+ memory_type=memory_type,
+ status="activated",
+ tags=tags or [],
+ key=key,
+ embedding=embedding or [],
+ usage=[],
+ sources=sources or [],
+ background=background,
+ confidence=confidence,
+ type="fact",
+ ),
+ )
diff --git a/src/memos/mem_scheduler/utils/db_utils.py b/src/memos/mem_scheduler/utils/db_utils.py
index 5d7cc52c3..4c7402a9d 100644
--- a/src/memos/mem_scheduler/utils/db_utils.py
+++ b/src/memos/mem_scheduler/utils/db_utils.py
@@ -1,5 +1,22 @@
import os
import sqlite3
+import sys
+
+from datetime import datetime, timezone
+
+
+# Compatibility handling: Python 3.11+ supports UTC, earlier versions use timezone.utc
+if sys.version_info >= (3, 11):
+ from datetime import UTC
+
+ def get_utc_now():
+ """Get current UTC datetime with compatibility for different Python versions"""
+ return datetime.now(UTC)
+else:
+
+ def get_utc_now():
+ """Get current UTC datetime with compatibility for different Python versions"""
+ return datetime.now(timezone.utc)
def print_db_tables(db_path: str):
diff --git a/src/memos/mem_scheduler/utils/metrics.py b/src/memos/mem_scheduler/utils/metrics.py
new file mode 100644
index 000000000..5155c98b3
--- /dev/null
+++ b/src/memos/mem_scheduler/utils/metrics.py
@@ -0,0 +1,250 @@
+# metrics.py
+from __future__ import annotations
+
+import threading
+import time
+
+from dataclasses import dataclass, field
+
+
+# ==== global window config ====
+WINDOW_SEC = 120 # 2 minutes sliding window
+
+
+# ---------- O(1) EWMA ----------
+class Ewma:
+ """
+ Time-decayed EWMA:
+ """
+
+ __slots__ = ("alpha", "last_ts", "tau", "value")
+
+ def __init__(self, alpha: float = 0.3, tau: float = WINDOW_SEC):
+ self.alpha = alpha
+ self.value = 0.0
+ self.last_ts: float = time.time()
+ self.tau = max(1e-6, float(tau))
+
+ def _decay_to(self, now: float | None = None):
+ now = time.time() if now is None else now
+ dt = max(0.0, now - self.last_ts)
+ if dt <= 0:
+ return
+ from math import exp
+
+ self.value *= exp(-dt / self.tau)
+ self.last_ts = now
+
+ def update(self, instant: float, now: float | None = None):
+ self._decay_to(now)
+ self.value = self.alpha * instant + (1 - self.alpha) * self.value
+
+ def value_at(self, now: float | None = None) -> float:
+ now = time.time() if now is None else now
+ dt = max(0.0, now - self.last_ts)
+ if dt <= 0:
+ return self.value
+ from math import exp
+
+ return self.value * exp(-dt / self.tau)
+
+
+# ---------- approximate P95(Reservoir sample) ----------
+class ReservoirP95:
+ __slots__ = ("_i", "buf", "k", "n", "window")
+
+ def __init__(self, k: int = 512, window: float = WINDOW_SEC):
+ self.k = k
+ self.buf: list[tuple[float, float]] = [] # (value, ts)
+ self.n = 0
+ self._i = 0
+ self.window = float(window)
+
+ def _gc(self, now: float):
+ win_start = now - self.window
+ self.buf = [p for p in self.buf if p[1] >= win_start]
+ if self.buf:
+ self._i %= len(self.buf)
+ else:
+ self._i = 0
+
+ def add(self, x: float, now: float | None = None):
+ now = time.time() if now is None else now
+ self._gc(now)
+ self.n += 1
+ if len(self.buf) < self.k:
+ self.buf.append((x, now))
+ return
+ self.buf[self._i] = (x, now)
+ self._i = (self._i + 1) % self.k
+
+ def p95(self, now: float | None = None) -> float:
+ now = time.time() if now is None else now
+ self._gc(now)
+ if not self.buf:
+ return 0.0
+ arr = sorted(v for v, _ in self.buf)
+ idx = int(0.95 * (len(arr) - 1))
+ return arr[idx]
+
+
+# ---------- Space-Saving Top-K ----------
+class SpaceSaving:
+ """only topK:add(key) O(1),query topk O(K log K)"""
+
+ def __init__(self, k: int = 100):
+ self.k = k
+ self.cnt: dict[str, int] = {}
+
+ def add(self, key: str):
+ if key in self.cnt:
+ self.cnt[key] += 1
+ return
+ if len(self.cnt) < self.k:
+ self.cnt[key] = 1
+ return
+ victim = min(self.cnt, key=self.cnt.get)
+ self.cnt[key] = self.cnt.pop(victim) + 1
+
+ def topk(self) -> list[tuple[str, int]]:
+ return sorted(self.cnt.items(), key=lambda kv: kv[1], reverse=True)
+
+
+@dataclass
+class KeyStats:
+ backlog: int = 0
+ lambda_ewma: Ewma = field(default_factory=lambda: Ewma(0.3, WINDOW_SEC))
+ mu_ewma: Ewma = field(default_factory=lambda: Ewma(0.3, WINDOW_SEC))
+ wait_p95: ReservoirP95 = field(default_factory=lambda: ReservoirP95(512, WINDOW_SEC))
+ last_ts: float = field(default_factory=time.time)
+ # last event timestamps for rate estimation
+ last_enqueue_ts: float | None = None
+ last_done_ts: float | None = None
+
+ def snapshot(self, now: float | None = None) -> dict:
+ now = time.time() if now is None else now
+ lam = self.lambda_ewma.value_at(now)
+ mu = self.mu_ewma.value_at(now)
+ delta = mu - lam
+ eta = float("inf") if delta <= 1e-9 else self.backlog / delta
+ return {
+ "backlog": self.backlog,
+ "lambda": round(lam, 3),
+ "mu": round(mu, 3),
+ "delta": round(delta, 3),
+ "eta_sec": None if eta == float("inf") else round(eta, 1),
+ "wait_p95_sec": round(self.wait_p95.p95(now), 3),
+ }
+
+
+class MetricsRegistry:
+ """
+ metrics:
+ - 1st phase:label(must)
+ - 2nd phase:labelXmem_cube_id(only Top-K)
+ - on_enqueue(label, mem_cube_id)
+ - on_start(label, mem_cube_id, wait_sec)
+ - on_done(label, mem_cube_id)
+ """
+
+ def __init__(self, topk_per_label: int = 50):
+ self._lock = threading.RLock()
+ self._label_stats: dict[str, KeyStats] = {}
+ self._label_topk: dict[str, SpaceSaving] = {}
+ self._detail_stats: dict[tuple[str, str], KeyStats] = {}
+ self._topk_per_label = topk_per_label
+
+ # ---------- helpers ----------
+ def _get_label(self, label: str) -> KeyStats:
+ if label not in self._label_stats:
+ self._label_stats[label] = KeyStats()
+ self._label_topk[label] = SpaceSaving(self._topk_per_label)
+ return self._label_stats[label]
+
+ def _get_detail(self, label: str, mem_cube_id: str) -> KeyStats | None:
+ # 只有 Top-K 的 mem_cube_id 才建细粒度 key
+ ss = self._label_topk[label]
+ if mem_cube_id in ss.cnt or len(ss.cnt) < ss.k:
+ key = (label, mem_cube_id)
+ if key not in self._detail_stats:
+ self._detail_stats[key] = KeyStats()
+ return self._detail_stats[key]
+ return None
+
+ # ---------- events ----------
+ def on_enqueue(
+ self, label: str, mem_cube_id: str, inst_rate: float = 1.0, now: float | None = None
+ ):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ # derive instantaneous arrival rate from inter-arrival time (events/sec)
+ prev_ts = ls.last_enqueue_ts
+ dt = (now - prev_ts) if prev_ts is not None else None
+ inst_rate = (1.0 / max(1e-3, dt)) if dt is not None else 0.0 # first sample: no spike
+ ls.last_enqueue_ts = now
+ ls.backlog += 1
+ old_lam = ls.lambda_ewma.value_at(now)
+ ls.lambda_ewma.update(inst_rate, now)
+ new_lam = ls.lambda_ewma.value_at(now)
+ print(
+ f"[DEBUG enqueue] {label} backlog={ls.backlog} dt={dt if dt is not None else '—'}s inst={inst_rate:.3f} λ {old_lam:.3f}→{new_lam:.3f}"
+ )
+ self._label_topk[label].add(mem_cube_id)
+ ds = self._get_detail(label, mem_cube_id)
+ if ds:
+ prev_ts_d = ds.last_enqueue_ts
+ dt_d = (now - prev_ts_d) if prev_ts_d is not None else None
+ inst_rate_d = (1.0 / max(1e-3, dt_d)) if dt_d is not None else 0.0
+ ds.last_enqueue_ts = now
+ ds.backlog += 1
+ ds.lambda_ewma.update(inst_rate_d, now)
+
+ def on_start(self, label: str, mem_cube_id: str, wait_sec: float, now: float | None = None):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ ls.wait_p95.add(wait_sec, now)
+ ds = self._detail_stats.get((label, mem_cube_id))
+ if ds:
+ ds.wait_p95.add(wait_sec, now)
+
+ def on_done(
+ self, label: str, mem_cube_id: str, inst_rate: float = 1.0, now: float | None = None
+ ):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ # derive instantaneous service rate from inter-completion time (events/sec)
+ prev_ts = ls.last_done_ts
+ dt = (now - prev_ts) if prev_ts is not None else None
+ inst_rate = (1.0 / max(1e-3, dt)) if dt is not None else 0.0
+ ls.last_done_ts = now
+ if ls.backlog > 0:
+ ls.backlog -= 1
+ old_mu = ls.mu_ewma.value_at(now)
+ ls.mu_ewma.update(inst_rate, now)
+ new_mu = ls.mu_ewma.value_at(now)
+ print(
+ f"[DEBUG done] {label} backlog={ls.backlog} dt={dt if dt is not None else '—'}s inst={inst_rate:.3f} μ {old_mu:.3f}→{new_mu:.3f}"
+ )
+ ds = self._detail_stats.get((label, mem_cube_id))
+ if ds:
+ prev_ts_d = ds.last_done_ts
+ dt_d = (now - prev_ts_d) if prev_ts_d is not None else None
+ inst_rate_d = (1.0 / max(1e-3, dt_d)) if dt_d is not None else 0.0
+ ds.last_done_ts = now
+ if ds.backlog > 0:
+ ds.backlog -= 1
+ ds.mu_ewma.update(inst_rate_d, now)
+
+ # ---------- snapshots ----------
+ def snapshot(self) -> dict:
+ with self._lock:
+ now = time.time()
+ by_label = {lbl: ks.snapshot(now) for lbl, ks in self._label_stats.items()}
+ heavy = {lbl: self._label_topk[lbl].topk() for lbl in self._label_topk}
+ details = {}
+ for (lbl, cube), ks in self._detail_stats.items():
+ details.setdefault(lbl, {})[cube] = ks.snapshot(now)
+ return {"by_label": by_label, "heavy": heavy, "details": details}
diff --git a/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py b/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
index 8865c2232..3c0dff907 100644
--- a/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
+++ b/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
@@ -6,6 +6,7 @@
from pathlib import Path
from memos.configs.mem_scheduler import AuthConfig, RabbitMQConfig
+from memos.context.context import ContextThread
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -67,39 +68,42 @@ def initialize_rabbitmq(
"""
Establish connection to RabbitMQ using pika.
"""
- from pika.adapters.select_connection import SelectConnection
-
- if config is None:
- if config_path is None and AuthConfig.default_config_exists():
- auth_config = AuthConfig.from_local_config()
- elif Path(config_path).exists():
- auth_config = AuthConfig.from_local_config(config_path=config_path)
+ try:
+ from pika.adapters.select_connection import SelectConnection
+
+ if config is None:
+ if config_path is None and AuthConfig.default_config_exists():
+ auth_config = AuthConfig.from_local_config()
+ elif Path(config_path).exists():
+ auth_config = AuthConfig.from_local_config(config_path=config_path)
+ else:
+ logger.error("Fail to initialize auth_config")
+ return
+ self.rabbitmq_config = auth_config.rabbitmq
+ elif isinstance(config, RabbitMQConfig):
+ self.rabbitmq_config = config
+ elif isinstance(config, dict):
+ self.rabbitmq_config = AuthConfig.from_dict(config).rabbitmq
else:
- logger.error("Fail to initialize auth_config")
- return
- self.rabbitmq_config = auth_config.rabbitmq
- elif isinstance(config, RabbitMQConfig):
- self.rabbitmq_config = config
- elif isinstance(config, dict):
- self.rabbitmq_config = AuthConfig.from_dict(config).rabbitmq
- else:
- logger.error("Not implemented")
-
- # Start connection process
- parameters = self.get_rabbitmq_connection_param()
- self.rabbitmq_connection = SelectConnection(
- parameters,
- on_open_callback=self.on_rabbitmq_connection_open,
- on_open_error_callback=self.on_rabbitmq_connection_error,
- on_close_callback=self.on_rabbitmq_connection_closed,
- )
+ logger.error("Not implemented")
+
+ # Start connection process
+ parameters = self.get_rabbitmq_connection_param()
+ self.rabbitmq_connection = SelectConnection(
+ parameters,
+ on_open_callback=self.on_rabbitmq_connection_open,
+ on_open_error_callback=self.on_rabbitmq_connection_error,
+ on_close_callback=self.on_rabbitmq_connection_closed,
+ )
- # Start IOLoop in dedicated thread
- self._io_loop_thread = threading.Thread(
- target=self.rabbitmq_connection.ioloop.start, daemon=True
- )
- self._io_loop_thread.start()
- logger.info("RabbitMQ connection process started")
+ # Start IOLoop in dedicated thread
+ self._io_loop_thread = ContextThread(
+ target=self.rabbitmq_connection.ioloop.start, daemon=True
+ )
+ self._io_loop_thread.start()
+ logger.info("RabbitMQ connection process started")
+ except Exception:
+ logger.error("Fail to initialize auth_config", exc_info=True)
def get_rabbitmq_queue_size(self) -> int:
"""Get the current number of messages in the queue.
diff --git a/src/memos/mem_scheduler/webservice_modules/redis_service.py b/src/memos/mem_scheduler/webservice_modules/redis_service.py
index 5b04ec280..5439af9c6 100644
--- a/src/memos/mem_scheduler/webservice_modules/redis_service.py
+++ b/src/memos/mem_scheduler/webservice_modules/redis_service.py
@@ -1,9 +1,12 @@
import asyncio
-import threading
+import os
+import subprocess
+import time
from collections.abc import Callable
from typing import Any
+from memos.context.context import ContextThread
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -27,14 +30,18 @@ def __init__(self):
super().__init__()
# settings for redis
- self.redis_host: str = None
- self.redis_port: int = None
- self.redis_db: int = None
+ self.redis_host: str | None = None
+ self.redis_port: int | None = None
+ self.redis_db: int | None = None
+ self.redis_password: str | None = None
+ self.socket_timeout: float | None = None
+ self.socket_connect_timeout: float | None = None
self._redis_conn = None
+ self._local_redis_process = None
self.query_list_capacity = 1000
self._redis_listener_running = False
- self._redis_listener_thread: threading.Thread | None = None
+ self._redis_listener_thread: ContextThread | None = None
self._redis_listener_loop: asyncio.AbstractEventLoop | None = None
@property
@@ -46,19 +53,40 @@ def redis(self, value: Any) -> None:
self._redis_conn = value
def initialize_redis(
- self, redis_host: str = "localhost", redis_port: int = 6379, redis_db: int = 0
+ self,
+ redis_host: str = "localhost",
+ redis_port: int = 6379,
+ redis_db: int = 0,
+ redis_password: str | None = None,
+ socket_timeout: float | None = None,
+ socket_connect_timeout: float | None = None,
):
import redis
self.redis_host = redis_host
self.redis_port = redis_port
self.redis_db = redis_db
+ self.redis_password = redis_password
+ self.socket_timeout = socket_timeout
+ self.socket_connect_timeout = socket_connect_timeout
try:
logger.debug(f"Connecting to Redis at {redis_host}:{redis_port}/{redis_db}")
- self._redis_conn = redis.Redis(
- host=self.redis_host, port=self.redis_port, db=self.redis_db, decode_responses=True
- )
+ redis_kwargs = {
+ "host": self.redis_host,
+ "port": self.redis_port,
+ "db": self.redis_db,
+ "password": redis_password,
+ "decode_responses": True,
+ }
+
+ # Add timeout parameters if provided
+ if socket_timeout is not None:
+ redis_kwargs["socket_timeout"] = socket_timeout
+ if socket_connect_timeout is not None:
+ redis_kwargs["socket_connect_timeout"] = socket_connect_timeout
+
+ self._redis_conn = redis.Redis(**redis_kwargs)
# test conn
if not self._redis_conn.ping():
logger.error("Redis connection failed")
@@ -68,7 +96,184 @@ def initialize_redis(
self._redis_conn.xtrim("user:queries:stream", self.query_list_capacity)
return self._redis_conn
- async def redis_add_message_stream(self, message: dict):
+ @require_python_package(
+ import_name="redis",
+ install_command="pip install redis",
+ install_link="https://redis.readthedocs.io/en/stable/",
+ )
+ def auto_initialize_redis(self) -> bool:
+ """
+ Auto-initialize Redis with fallback strategies:
+ 1. Try to initialize from config
+ 2. Try to initialize from environment variables
+ 3. Try to start local Redis server as fallback
+
+ Returns:
+ bool: True if Redis connection is successfully established, False otherwise
+ """
+ import redis
+
+ # Strategy 1: Try to initialize from config
+ if hasattr(self, "config") and hasattr(self.config, "redis_config"):
+ try:
+ redis_config = self.config.redis_config
+ logger.info("Attempting to initialize Redis from config")
+
+ self._redis_conn = redis.Redis(
+ host=redis_config.get("host", "localhost"),
+ port=redis_config.get("port", 6379),
+ db=redis_config.get("db", 0),
+ password=redis_config.get("password", None),
+ decode_responses=True,
+ )
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.info("Redis initialized successfully from config")
+ self.redis_host = redis_config.get("host", "localhost")
+ self.redis_port = redis_config.get("port", 6379)
+ self.redis_db = redis_config.get("db", 0)
+ self.redis_password = redis_config.get("password", None)
+ self.socket_timeout = redis_config.get("socket_timeout", None)
+ self.socket_connect_timeout = redis_config.get("socket_connect_timeout", None)
+ return True
+ else:
+ logger.warning("Redis config connection test failed")
+ self._redis_conn = None
+ except Exception as e:
+ logger.warning(f"Failed to initialize Redis from config: {e}")
+ self._redis_conn = None
+
+ # Strategy 2: Try to initialize from environment variables
+ try:
+ redis_host = os.getenv("MEMSCHEDULER_REDIS_HOST", "localhost")
+ redis_port = int(os.getenv("MEMSCHEDULER_REDIS_PORT", "6379"))
+ redis_db = int(os.getenv("MEMSCHEDULER_REDIS_DB", "0"))
+ redis_password = os.getenv("MEMSCHEDULER_REDIS_PASSWORD", None)
+ socket_timeout = os.getenv("MEMSCHEDULER_REDIS_TIMEOUT", None)
+ socket_connect_timeout = os.getenv("MEMSCHEDULER_REDIS_CONNECT_TIMEOUT", None)
+
+ logger.info(
+ f"Attempting to initialize Redis from environment variables: {redis_host}:{redis_port}"
+ )
+
+ redis_kwargs = {
+ "host": redis_host,
+ "port": redis_port,
+ "db": redis_db,
+ "password": redis_password,
+ "decode_responses": True,
+ }
+
+ # Add timeout parameters if provided
+ if socket_timeout is not None:
+ try:
+ redis_kwargs["socket_timeout"] = float(socket_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid MEMSCHEDULER_REDIS_TIMEOUT value: {socket_timeout}, ignoring"
+ )
+
+ if socket_connect_timeout is not None:
+ try:
+ redis_kwargs["socket_connect_timeout"] = float(socket_connect_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid MEMSCHEDULER_REDIS_CONNECT_TIMEOUT value: {socket_connect_timeout}, ignoring"
+ )
+
+ self._redis_conn = redis.Redis(**redis_kwargs)
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.info("Redis initialized successfully from environment variables")
+ self.redis_host = redis_host
+ self.redis_port = redis_port
+ self.redis_db = redis_db
+ self.redis_password = redis_password
+ self.socket_timeout = float(socket_timeout) if socket_timeout is not None else None
+ self.socket_connect_timeout = (
+ float(socket_connect_timeout) if socket_connect_timeout is not None else None
+ )
+ return True
+ else:
+ logger.warning("Redis environment connection test failed")
+ self._redis_conn = None
+ except Exception as e:
+ logger.warning(f"Failed to initialize Redis from environment variables: {e}")
+ self._redis_conn = None
+
+ # Strategy 3: Try to start local Redis server as fallback
+ try:
+ logger.warning(
+ "Attempting to start local Redis server as fallback (not recommended for production)"
+ )
+
+ # Try to start Redis server locally
+ self._local_redis_process = subprocess.Popen(
+ ["redis-server", "--port", "6379", "--daemonize", "no"],
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ preexec_fn=os.setsid if hasattr(os, "setsid") else None,
+ )
+
+ # Wait a moment for Redis to start
+ time.sleep(0.5)
+
+ # Try to connect to local Redis
+ self._redis_conn = redis.Redis(host="localhost", port=6379, db=0, decode_responses=True)
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.warning("Local Redis server started and connected successfully")
+ logger.warning("WARNING: Using local Redis server - not suitable for production!")
+ self.redis_host = "localhost"
+ self.redis_port = 6379
+ self.redis_db = 0
+ self.redis_password = None
+ self.socket_timeout = None
+ self.socket_connect_timeout = None
+ return True
+ else:
+ logger.error("Local Redis server connection test failed")
+ self._cleanup_local_redis()
+ return False
+
+ except Exception as e:
+ logger.error(f"Failed to start local Redis server: {e}")
+ self._cleanup_local_redis()
+ return False
+
+ def _cleanup_local_redis(self):
+ """Clean up local Redis process if it exists"""
+ if self._local_redis_process:
+ try:
+ self._local_redis_process.terminate()
+ self._local_redis_process.wait(timeout=5)
+ logger.info("Local Redis process terminated")
+ except subprocess.TimeoutExpired:
+ logger.warning("Local Redis process did not terminate gracefully, killing it")
+ self._local_redis_process.kill()
+ self._local_redis_process.wait()
+ except Exception as e:
+ logger.error(f"Error cleaning up local Redis process: {e}")
+ finally:
+ self._local_redis_process = None
+
+ def _cleanup_redis_resources(self):
+ """Clean up Redis connection and local process"""
+ if self._redis_conn:
+ try:
+ self._redis_conn.close()
+ logger.info("Redis connection closed")
+ except Exception as e:
+ logger.error(f"Error closing Redis connection: {e}")
+ finally:
+ self._redis_conn = None
+
+ self._cleanup_local_redis()
+
+ def redis_add_message_stream(self, message: dict):
logger.debug(f"add_message_stream: {message}")
return self._redis_conn.xadd("user:queries:stream", message)
@@ -131,7 +336,7 @@ def redis_start_listening(self, handler: Callable | None = None):
if handler is None:
handler = self.redis_consume_message_stream
- self._redis_listener_thread = threading.Thread(
+ self._redis_listener_thread = ContextThread(
target=self._redis_run_listener_async,
args=(handler,),
daemon=True,
@@ -150,7 +355,5 @@ def redis_stop_listening(self):
logger.info("Redis stream listener stopped")
def redis_close(self):
- """Close Redis connection"""
- if self._redis_conn is not None:
- self._redis_conn.close()
- self._redis_conn = None
+ """Close Redis connection and clean up resources"""
+ self._cleanup_redis_resources()
diff --git a/src/memos/mem_user/persistent_user_manager.py b/src/memos/mem_user/persistent_user_manager.py
index e3c476262..d6f7b3155 100644
--- a/src/memos/mem_user/persistent_user_manager.py
+++ b/src/memos/mem_user/persistent_user_manager.py
@@ -177,7 +177,7 @@ def delete_user_config(self, user_id: str) -> bool:
finally:
session.close()
- def list_user_configs(self) -> dict[str, MOSConfig]:
+ def list_user_configs(self, limit: int = 1) -> dict[str, MOSConfig]:
"""List all user configurations.
Returns:
@@ -185,7 +185,7 @@ def list_user_configs(self) -> dict[str, MOSConfig]:
"""
session = self._get_session()
try:
- user_configs = session.query(UserConfig).all()
+ user_configs = session.query(UserConfig).limit(limit).all()
result = {}
for user_config in user_configs:
diff --git a/src/memos/memories/activation/item.py b/src/memos/memories/activation/item.py
index ba1619371..9267e6920 100644
--- a/src/memos/memories/activation/item.py
+++ b/src/memos/memories/activation/item.py
@@ -6,6 +6,8 @@
from pydantic import BaseModel, ConfigDict, Field
from transformers import DynamicCache
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
class ActivationMemoryItem(BaseModel):
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
@@ -23,7 +25,7 @@ class KVCacheRecords(BaseModel):
description="Single string combining all text_memories using assembly template",
)
timestamp: datetime = Field(
- default_factory=datetime.utcnow, description="submit time for schedule_messages"
+ default_factory=get_utc_now, description="submit time for schedule_messages"
)
diff --git a/src/memos/memories/activation/kv.py b/src/memos/memories/activation/kv.py
index 2fa08590f..98d611dbf 100644
--- a/src/memos/memories/activation/kv.py
+++ b/src/memos/memories/activation/kv.py
@@ -237,16 +237,36 @@ def _concat_caches(self, caches: list[DynamicCache]) -> DynamicCache:
def move_dynamic_cache_htod(dynamic_cache: DynamicCache, device: str) -> DynamicCache:
"""
+ Move DynamicCache from CPU to GPU device.
+ Compatible with both old and new transformers versions.
+
In SimpleMemChat.run(), if self.config.enable_activation_memory is enabled,
we load serialized kv cache from a [class KVCacheMemory] object, which has a kv_cache_memories on CPU.
So before inferring with DynamicCache, we should move it to GPU in-place first.
"""
- # Currently, we put this function outside [class KVCacheMemory]
- for i in range(len(dynamic_cache.key_cache)):
- if dynamic_cache.key_cache[i] is not None:
- dynamic_cache.key_cache[i] = dynamic_cache.key_cache[i].to(device, non_blocking=True)
- if dynamic_cache.value_cache[i] is not None:
- dynamic_cache.value_cache[i] = dynamic_cache.value_cache[i].to(
- device, non_blocking=True
- )
+ # Handle compatibility between old and new transformers versions
+ if hasattr(dynamic_cache, "layers"):
+ # New version: use layers attribute
+ for layer in dynamic_cache.layers:
+ if hasattr(layer, "key_cache") and layer.key_cache is not None:
+ layer.key_cache = layer.key_cache.to(device, non_blocking=True)
+ if hasattr(layer, "value_cache") and layer.value_cache is not None:
+ layer.value_cache = layer.value_cache.to(device, non_blocking=True)
+ elif hasattr(layer, "keys") and hasattr(layer, "values"):
+ # Alternative attribute names in some versions
+ if layer.keys is not None:
+ layer.keys = layer.keys.to(device, non_blocking=True)
+ if layer.values is not None:
+ layer.values = layer.values.to(device, non_blocking=True)
+ elif hasattr(dynamic_cache, "key_cache") and hasattr(dynamic_cache, "value_cache"):
+ # Old version: use key_cache and value_cache attributes
+ for i in range(len(dynamic_cache.key_cache)):
+ if dynamic_cache.key_cache[i] is not None:
+ dynamic_cache.key_cache[i] = dynamic_cache.key_cache[i].to(
+ device, non_blocking=True
+ )
+ if dynamic_cache.value_cache[i] is not None:
+ dynamic_cache.value_cache[i] = dynamic_cache.value_cache[i].to(
+ device, non_blocking=True
+ )
return dynamic_cache
diff --git a/src/memos/memories/factory.py b/src/memos/memories/factory.py
index bcf7fdd9b..5ba1c6726 100644
--- a/src/memos/memories/factory.py
+++ b/src/memos/memories/factory.py
@@ -10,6 +10,8 @@
from memos.memories.textual.base import BaseTextMemory
from memos.memories.textual.general import GeneralTextMemory
from memos.memories.textual.naive import NaiveTextMemory
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.memories.textual.simple_preference import SimplePreferenceTextMemory
from memos.memories.textual.simple_tree import SimpleTreeTextMemory
from memos.memories.textual.tree import TreeTextMemory
@@ -22,6 +24,8 @@ class MemoryFactory(BaseMemory):
"general_text": GeneralTextMemory,
"tree_text": TreeTextMemory,
"simple_tree_text": SimpleTreeTextMemory,
+ "pref_text": PreferenceTextMemory,
+ "simple_pref_text": SimplePreferenceTextMemory,
"kv_cache": KVCacheMemory,
"vllm_kv_cache": VLLMKVCacheMemory,
"lora": LoRAMemory,
diff --git a/src/memos/memories/textual/base.py b/src/memos/memories/textual/base.py
index 82dad4486..8a6113345 100644
--- a/src/memos/memories/textual/base.py
+++ b/src/memos/memories/textual/base.py
@@ -10,6 +10,9 @@
class BaseTextMemory(BaseMemory):
"""Base class for all textual memory implementations."""
+ # Default mode configuration - can be overridden by subclasses
+ mode: str = "sync" # Default mode: 'async' or 'sync'
+
@abstractmethod
def __init__(self, config: BaseTextMemoryConfig):
"""Initialize memory with the given configuration."""
diff --git a/src/memos/memories/textual/general.py b/src/memos/memories/textual/general.py
index 9793224b5..d71a86d2e 100644
--- a/src/memos/memories/textual/general.py
+++ b/src/memos/memories/textual/general.py
@@ -26,6 +26,8 @@ class GeneralTextMemory(BaseTextMemory):
def __init__(self, config: GeneralTextMemoryConfig):
"""Initialize memory with the given configuration."""
+ # Set mode from class default or override if needed
+ self.mode = getattr(self.__class__, "mode", "sync")
self.config: GeneralTextMemoryConfig = config
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.extractor_llm
diff --git a/src/memos/memories/textual/item.py b/src/memos/memories/textual/item.py
index 2da283d47..2c23ae193 100644
--- a/src/memos/memories/textual/item.py
+++ b/src/memos/memories/textual/item.py
@@ -1,6 +1,7 @@
"""Defines memory item types for textual memory."""
import json
+import logging
import uuid
from datetime import datetime
@@ -123,6 +124,25 @@ class TreeNodeTextualMemoryMetadata(TextualMemoryMetadata):
def coerce_sources(cls, v):
if v is None:
return v
+ # Handle string representation of sources (e.g., from PostgreSQL array or malformed data)
+ if isinstance(v, str):
+ logging.info(f"[coerce_sources] v: {v} type: {type(v)}")
+ # If it's a string that looks like a list representation, try to parse it
+ # This handles cases like: "[uuid1, uuid2, uuid3]" or "[item1, item2]"
+ v_stripped = v.strip()
+ if v_stripped.startswith("[") and v_stripped.endswith("]"):
+ # Remove brackets and split by comma
+ content = v_stripped[1:-1].strip()
+ if content:
+ # Split by comma and clean up each item
+ items = [item.strip() for item in content.split(",")]
+ # Convert to list of strings
+ v = items
+ else:
+ v = []
+ else:
+ # Single string, wrap in list
+ v = [v]
if not isinstance(v, list):
raise TypeError("sources must be a list")
out = []
@@ -167,6 +187,19 @@ class SearchedTreeNodeTextualMemoryMetadata(TreeNodeTextualMemoryMetadata):
)
+class PreferenceTextualMemoryMetadata(TextualMemoryMetadata):
+ """Metadata for preference memory item."""
+
+ preference_type: Literal["explicit_preference", "implicit_preference"] = Field(
+ default="explicit_preference", description="Type of preference."
+ )
+ dialog_id: str | None = Field(default=None, description="ID of the dialog.")
+ original_text: str | None = Field(default=None, description="String of the dialog.")
+ embedding: list[float] | None = Field(default=None, description="Vector of the dialog.")
+ preference: str | None = Field(default=None, description="Preference.")
+ created_at: str | None = Field(default=None, description="Timestamp of the dialog.")
+
+
class TextualMemoryItem(BaseModel):
"""Represents a single memory item in the textual memory.
@@ -180,6 +213,7 @@ class TextualMemoryItem(BaseModel):
SearchedTreeNodeTextualMemoryMetadata
| TreeNodeTextualMemoryMetadata
| TextualMemoryMetadata
+ | PreferenceTextualMemoryMetadata
) = Field(default_factory=TextualMemoryMetadata)
model_config = ConfigDict(extra="forbid")
@@ -204,12 +238,26 @@ def _coerce_metadata(cls, v: Any):
v,
SearchedTreeNodeTextualMemoryMetadata
| TreeNodeTextualMemoryMetadata
- | TextualMemoryMetadata,
+ | TextualMemoryMetadata
+ | PreferenceTextualMemoryMetadata,
):
return v
if isinstance(v, dict):
+ if "metadata" in v and isinstance(v["metadata"], dict):
+ nested_metadata = v["metadata"]
+ nested_metadata = nested_metadata.copy()
+ nested_metadata.pop("id", None)
+ nested_metadata.pop("memory", None)
+ v = nested_metadata
+ else:
+ v = v.copy()
+ v.pop("id", None)
+ v.pop("memory", None)
+
if v.get("relativity") is not None:
return SearchedTreeNodeTextualMemoryMetadata(**v)
+ if v.get("preference_type") is not None:
+ return PreferenceTextualMemoryMetadata(**v)
if any(k in v for k in ("sources", "memory_type", "embedding", "background", "usage")):
return TreeNodeTextualMemoryMetadata(**v)
return TextualMemoryMetadata(**v)
diff --git a/src/memos/memories/textual/naive.py b/src/memos/memories/textual/naive.py
index f8684729a..7bc49e767 100644
--- a/src/memos/memories/textual/naive.py
+++ b/src/memos/memories/textual/naive.py
@@ -61,6 +61,8 @@ class NaiveTextMemory(BaseTextMemory):
def __init__(self, config: NaiveTextMemoryConfig):
"""Initialize memory with the given configuration."""
+ # Set mode from class default or override if needed
+ self.mode = getattr(self.__class__, "mode", "sync")
self.config = config
self.extractor_llm = LLMFactory.from_config(config.extractor_llm)
self.memories = []
diff --git a/src/memos/memories/textual/prefer_text_memory/__init__.py b/src/memos/memories/textual/prefer_text_memory/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/src/memos/memories/textual/prefer_text_memory/adder.py b/src/memos/memories/textual/prefer_text_memory/adder.py
new file mode 100644
index 000000000..a78601e86
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/adder.py
@@ -0,0 +1,423 @@
+import json
+import os
+
+from abc import ABC, abstractmethod
+from concurrent.futures import as_completed
+from datetime import datetime
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.log import get_logger
+from memos.memories.textual.item import TextualMemoryItem
+from memos.templates.prefer_complete_prompt import (
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT,
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE,
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE,
+)
+from memos.vec_dbs.item import MilvusVecDBItem
+
+
+logger = get_logger(__name__)
+
+
+class BaseAdder(ABC):
+ """Abstract base class for adders."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the adder."""
+
+ @abstractmethod
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]], *args, **kwargs) -> list[str]:
+ """Add the instruct preference memories.
+ Args:
+ memories (list[TextualMemoryItem | dict[str, Any]]): The memories to add.
+ **kwargs: Additional keyword arguments.
+ Returns:
+ list[str]: List of added memory IDs.
+ """
+
+
+class NaiveAdder(BaseAdder):
+ """Naive adder."""
+
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the naive adder."""
+ super().__init__(llm_provider, embedder, vector_db)
+ self.llm_provider = llm_provider
+ self.embedder = embedder
+ self.vector_db = vector_db
+
+ def _judge_update_or_add_fast(self, old_msg: str, new_msg: str) -> bool:
+ """Judge if the new message expresses the same core content as the old message."""
+ # Use the template prompt with placeholders
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT.replace("{old_information}", old_msg).replace(
+ "{new_information}", new_msg
+ )
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ response = result.get("is_same", False)
+ return response if isinstance(response, bool) else response.lower() == "true"
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add: {e}")
+ # Fallback to simple string comparison
+ return old_msg == new_msg
+
+ def _judge_update_or_add_fine(self, new_mem: str, retrieved_mems: str) -> dict[str, Any] | None:
+ if not retrieved_mems:
+ return None
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE.replace("{new_memory}", new_mem).replace(
+ "{retrieved_memories}", retrieved_mems
+ )
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ return result
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add_fine: {e}")
+ return None
+
+ def _judge_update_or_add_trace_op(
+ self, new_mems: str, retrieved_mems: str
+ ) -> dict[str, Any] | None:
+ if not retrieved_mems:
+ return None
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE.replace(
+ "{new_memories}", new_mems
+ ).replace("{retrieved_memories}", retrieved_mems)
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ return result
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add_trace_op: {e}")
+ return None
+
+ def _update_memory_op_trace(
+ self,
+ new_memories: list[TextualMemoryItem],
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> list[str] | str:
+ # create new vec db items
+ new_vec_db_items: list[MilvusVecDBItem] = []
+ for new_memory in new_memories:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ new_vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+ new_vec_db_items.append(new_vec_db_item)
+
+ new_mem_inputs = [
+ {
+ "id": new_memory.id,
+ "context_summary": new_memory.memory,
+ "preference": new_memory.payload["preference"],
+ }
+ for new_memory in new_vec_db_items
+ if new_memory.payload.get("preference", None)
+ ]
+ retrieved_mem_inputs = [
+ {
+ "id": mem.id,
+ "context_summary": mem.memory,
+ "preference": mem.payload["preference"],
+ }
+ for mem in retrieved_memories
+ if mem.payload.get("preference", None)
+ ]
+
+ rsp = self._judge_update_or_add_trace_op(
+ new_mems=json.dumps(new_mem_inputs),
+ retrieved_mems=json.dumps(retrieved_mem_inputs) if retrieved_mem_inputs else "",
+ )
+ if not rsp:
+ with ContextThreadPoolExecutor(max_workers=min(len(new_vec_db_items), 5)) as executor:
+ futures = {
+ executor.submit(self.vector_db.add, collection_name, [db_item]): db_item
+ for db_item in new_vec_db_items
+ }
+ for future in as_completed(futures):
+ result = future.result()
+ return [db_item.id for db_item in new_vec_db_items]
+
+ new_mem_db_item_map = {db_item.id: db_item for db_item in new_vec_db_items}
+ retrieved_mem_db_item_map = {db_item.id: db_item for db_item in retrieved_memories}
+
+ def execute_op(
+ op,
+ new_mem_db_item_map: dict[str, MilvusVecDBItem],
+ retrieved_mem_db_item_map: dict[str, MilvusVecDBItem],
+ ) -> str | None:
+ op_type = op["type"].lower()
+ if op_type == "add":
+ if op["target_id"] in new_mem_db_item_map:
+ self.vector_db.add(collection_name, [new_mem_db_item_map[op["target_id"]]])
+ return new_mem_db_item_map[op["target_id"]].id
+ return None
+ elif op_type == "update":
+ if op["target_id"] in retrieved_mem_db_item_map:
+ update_mem_db_item = retrieved_mem_db_item_map[op["target_id"]]
+ update_mem_db_item.payload["preference"] = op["new_preference"]
+ update_mem_db_item.payload["updated_at"] = datetime.now().isoformat()
+ update_mem_db_item.memory = op["new_context_summary"]
+ update_mem_db_item.original_text = op["new_context_summary"]
+ update_mem_db_item.vector = self.embedder.embed([op["new_context_summary"]])[0]
+ self.vector_db.update(collection_name, op["target_id"], update_mem_db_item)
+ return op["target_id"]
+ return None
+ elif op_type == "delete":
+ self.vector_db.delete(collection_name, [op["target_id"]])
+ return None
+
+ with ContextThreadPoolExecutor(max_workers=min(len(rsp["trace"]), 5)) as executor:
+ future_to_op = {
+ executor.submit(execute_op, op, new_mem_db_item_map, retrieved_mem_db_item_map): op
+ for op in rsp["trace"]
+ }
+ added_ids = []
+ for future in as_completed(future_to_op):
+ result = future.result()
+ if result is not None:
+ added_ids.append(result)
+
+ return added_ids
+
+ def _update_memory_fine(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> str:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+
+ new_mem_input = {"memory": new_memory.memory, "preference": new_memory.metadata.preference}
+ retrieved_mem_inputs = [
+ {
+ "id": mem.id,
+ "memory": mem.memory,
+ "preference": mem.payload["preference"],
+ }
+ for mem in retrieved_memories
+ if mem.payload.get("preference", None)
+ ]
+ rsp = self._judge_update_or_add_fine(
+ new_mem=json.dumps(new_mem_input),
+ retrieved_mems=json.dumps(retrieved_mem_inputs) if retrieved_mem_inputs else "",
+ )
+ need_update = rsp.get("need_update", False) if rsp else False
+ need_update = (
+ need_update if isinstance(need_update, bool) else need_update.lower() == "true"
+ )
+ update_item = (
+ [mem for mem in retrieved_memories if mem.id == rsp["id"]]
+ if rsp and "id" in rsp
+ else []
+ )
+ if need_update and update_item and rsp:
+ update_vec_db_item = update_item[0]
+ update_vec_db_item.payload["preference"] = rsp["new_preference"]
+ update_vec_db_item.payload["updated_at"] = vec_db_item.payload["updated_at"]
+ update_vec_db_item.memory = rsp["new_memory"]
+ update_vec_db_item.original_text = vec_db_item.original_text
+ update_vec_db_item.vector = self.embedder.embed([rsp["new_memory"]])[0]
+
+ self.vector_db.update(collection_name, rsp["id"], update_vec_db_item)
+ return rsp["id"]
+ else:
+ self.vector_db.add(collection_name, [vec_db_item])
+ return vec_db_item.id
+
+ def _update_memory_fast(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> str:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+ recall = retrieved_memories[0] if retrieved_memories else None
+ if not recall or (recall.score is not None and recall.score < 0.5):
+ self.vector_db.add(collection_name, [vec_db_item])
+ return new_memory.id
+
+ old_msg_str = recall.memory
+ new_msg_str = new_memory.memory
+ is_same = self._judge_update_or_add_fast(old_msg=old_msg_str, new_msg=new_msg_str)
+ if is_same:
+ vec_db_item.id = recall.id
+ self.vector_db.update(collection_name, recall.id, vec_db_item)
+ self.vector_db.add(collection_name, [vec_db_item])
+ return new_memory.id
+
+ def _update_memory(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ update_mode: str = "fast",
+ ) -> list[str] | str | None:
+ """Update the memory.
+ Args:
+ new_memory: TextualMemoryItem
+ retrieved_memories: list[MilvusVecDBItem]
+ collection_name: str
+ update_mode: str, "fast" or "fine"
+ """
+ if update_mode == "fast":
+ return self._update_memory_fast(new_memory, retrieved_memories, collection_name)
+ elif update_mode == "fine":
+ return self._update_memory_fine(new_memory, retrieved_memories, collection_name)
+ else:
+ raise ValueError(f"Invalid update mode: {update_mode}")
+
+ def _process_single_memory(self, memory: TextualMemoryItem) -> list[str] | str | None:
+ """Process a single memory and return its ID if added successfully."""
+ try:
+ pref_type_collection_map = {
+ "explicit_preference": "explicit_preference",
+ "implicit_preference": "implicit_preference",
+ }
+ preference_type = memory.metadata.preference_type
+ collection_name = pref_type_collection_map[preference_type]
+
+ search_results = self.vector_db.search(
+ query_vector=memory.metadata.embedding,
+ query=memory.memory,
+ collection_name=collection_name,
+ top_k=5,
+ filter={"user_id": memory.metadata.user_id},
+ )
+ search_results.sort(key=lambda x: x.score, reverse=True)
+
+ return self._update_memory(
+ memory,
+ search_results,
+ collection_name,
+ update_mode=os.getenv("PREFERENCE_ADDER_MODE", "fast"),
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing memory {memory.id}: {e}")
+ return None
+
+ def process_memory_batch(self, memories: list[TextualMemoryItem], *args, **kwargs) -> list[str]:
+ pref_type_collection_map = {
+ "explicit_preference": "explicit_preference",
+ "implicit_preference": "implicit_preference",
+ }
+
+ explicit_new_mems = []
+ implicit_new_mems = []
+ explicit_recalls = []
+ implicit_recalls = []
+
+ for memory in memories:
+ preference_type = memory.metadata.preference_type
+ collection_name = pref_type_collection_map[preference_type]
+ search_results = self.vector_db.search(
+ query_vector=memory.metadata.embedding,
+ query=memory.memory,
+ collection_name=collection_name,
+ top_k=5,
+ filter={"user_id": memory.metadata.user_id},
+ )
+ if preference_type == "explicit_preference":
+ explicit_recalls.extend(search_results)
+ explicit_new_mems.append(memory)
+ elif preference_type == "implicit_preference":
+ implicit_recalls.extend(search_results)
+ implicit_new_mems.append(memory)
+
+ explicit_recalls = list({recall.id: recall for recall in explicit_recalls}.values())
+ implicit_recalls = list({recall.id: recall for recall in implicit_recalls}.values())
+
+ # 使用线程池并行处理显式和隐式偏好
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ explicit_future = executor.submit(
+ self._update_memory_op_trace,
+ explicit_new_mems,
+ explicit_recalls,
+ pref_type_collection_map["explicit_preference"],
+ )
+ implicit_future = executor.submit(
+ self._update_memory_op_trace,
+ implicit_new_mems,
+ implicit_recalls,
+ pref_type_collection_map["implicit_preference"],
+ )
+
+ explicit_added_ids = explicit_future.result()
+ implicit_added_ids = implicit_future.result()
+
+ return explicit_added_ids + implicit_added_ids
+
+ def process_memory_single(
+ self, memories: list[TextualMemoryItem], max_workers: int = 8, *args, **kwargs
+ ) -> list[str]:
+ added_ids: list[str] = []
+ with ContextThreadPoolExecutor(max_workers=min(max_workers, len(memories))) as executor:
+ future_to_memory = {
+ executor.submit(self._process_single_memory, memory): memory for memory in memories
+ }
+
+ for future in as_completed(future_to_memory):
+ try:
+ memory_id = future.result()
+ if memory_id:
+ if isinstance(memory_id, list):
+ added_ids.extend(memory_id)
+ else:
+ added_ids.append(memory_id)
+ except Exception as e:
+ memory = future_to_memory[future]
+ logger.error(f"Error processing memory {memory.id}: {e}")
+ continue
+ return added_ids
+
+ def add(
+ self,
+ memories: list[TextualMemoryItem | dict[str, Any]],
+ max_workers: int = 8,
+ *args,
+ **kwargs,
+ ) -> list[str]:
+ """Add the instruct preference memories using thread pool for acceleration."""
+ if not memories:
+ return []
+
+ process_map = {
+ "single": self.process_memory_single,
+ "batch": self.process_memory_batch,
+ }
+
+ process_func = process_map["single"]
+ return process_func(memories, max_workers)
diff --git a/src/memos/memories/textual/prefer_text_memory/config.py b/src/memos/memories/textual/prefer_text_memory/config.py
new file mode 100644
index 000000000..7e8354747
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/config.py
@@ -0,0 +1,106 @@
+from typing import Any, ClassVar
+
+from pydantic import Field, field_validator, model_validator
+
+from memos.configs.base import BaseConfig
+
+
+class BaseAdderConfig(BaseConfig):
+ """Base configuration class for Adder."""
+
+
+class NaiveAdderConfig(BaseAdderConfig):
+ """Configuration for Naive Adder."""
+
+ # No additional config needed since components are passed from parent
+
+
+class AdderConfigFactory(BaseConfig):
+ """Factory class for creating Adder configurations."""
+
+ backend: str = Field(..., description="Backend for Adder")
+ config: dict[str, Any] = Field(..., description="Configuration for the Adder backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveAdderConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "AdderConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
+
+
+class BaseExtractorConfig(BaseConfig):
+ """Base configuration class for Extractor."""
+
+
+class NaiveExtractorConfig(BaseExtractorConfig):
+ """Configuration for Naive Extractor."""
+
+
+class ExtractorConfigFactory(BaseConfig):
+ """Factory class for creating Extractor configurations."""
+
+ backend: str = Field(..., description="Backend for Extractor")
+ config: dict[str, Any] = Field(..., description="Configuration for the Extractor backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveExtractorConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "ExtractorConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
+
+
+class BaseRetrieverConfig(BaseConfig):
+ """Base configuration class for Retrievers."""
+
+
+class NaiveRetrieverConfig(BaseRetrieverConfig):
+ """Configuration for Naive Retriever."""
+
+
+class RetrieverConfigFactory(BaseConfig):
+ """Factory class for creating Retriever configurations."""
+
+ backend: str = Field(..., description="Backend for Retriever")
+ config: dict[str, Any] = Field(..., description="Configuration for the Retriever backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveRetrieverConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "RetrieverConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
diff --git a/src/memos/memories/textual/prefer_text_memory/extractor.py b/src/memos/memories/textual/prefer_text_memory/extractor.py
new file mode 100644
index 000000000..d5eab2aec
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/extractor.py
@@ -0,0 +1,201 @@
+import json
+import uuid
+
+from abc import ABC, abstractmethod
+from concurrent.futures import as_completed
+from datetime import datetime
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.log import get_logger
+from memos.mem_reader.simple_struct import detect_lang
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.prefer_text_memory.spliter import Splitter
+from memos.memories.textual.prefer_text_memory.utils import convert_messages_to_string
+from memos.templates.prefer_complete_prompt import (
+ NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+)
+from memos.types import MessageList
+
+
+logger = get_logger(__name__)
+
+
+class BaseExtractor(ABC):
+ """Abstract base class for extractors."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the extractor."""
+
+
+class NaiveExtractor(BaseExtractor):
+ """Extractor."""
+
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the extractor."""
+ super().__init__(llm_provider, embedder, vector_db)
+ self.llm_provider = llm_provider
+ self.embedder = embedder
+ self.vector_db = vector_db
+ self.splitter = Splitter()
+
+ def extract_basic_info(self, qa_pair: MessageList) -> dict[str, Any]:
+ """Extract basic information from a QA pair (no LLM needed)."""
+ basic_info = {
+ "dialog_id": str(uuid.uuid4()),
+ "original_text": convert_messages_to_string(qa_pair),
+ "created_at": datetime.now().isoformat(),
+ }
+
+ return basic_info
+
+ def extract_explicit_preference(self, qa_pair: MessageList | str) -> dict[str, Any] | None:
+ """Extract explicit preference from a QA pair."""
+ qa_pair_str = convert_messages_to_string(qa_pair) if isinstance(qa_pair, list) else qa_pair
+ lang = detect_lang(qa_pair_str)
+ _map = {
+ "zh": NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ "en": NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ }
+ prompt = _map[lang].replace("{qa_pair}", qa_pair_str)
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ for d in result:
+ d["preference"] = d.pop("explicit_preference")
+ return result
+ except Exception as e:
+ logger.error(f"Error extracting explicit preference: {e}, return None")
+ return None
+
+ def extract_implicit_preference(self, qa_pair: MessageList | str) -> dict[str, Any] | None:
+ """Extract implicit preferences from cluster qa pairs."""
+ if not qa_pair:
+ return None
+ qa_pair_str = convert_messages_to_string(qa_pair) if isinstance(qa_pair, list) else qa_pair
+ lang = detect_lang(qa_pair_str)
+ _map = {
+ "zh": NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ "en": NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ }
+ prompt = _map[lang].replace("{qa_pair}", qa_pair_str)
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ result["preference"] = result.pop("implicit_preference")
+ return result
+ except Exception as e:
+ logger.error(f"Error extracting implicit preferences: {e}, return None")
+ return None
+
+ def _process_single_chunk_explicit(
+ self, chunk: MessageList, msg_type: str, info: dict[str, Any]
+ ) -> TextualMemoryItem | None:
+ """Process a single chunk and return a TextualMemoryItem."""
+ basic_info = self.extract_basic_info(chunk)
+ if not basic_info["original_text"]:
+ return None
+
+ explicit_pref = self.extract_explicit_preference(basic_info["original_text"])
+ if not explicit_pref:
+ return None
+
+ memories = []
+ for pref in explicit_pref:
+ vector_info = {
+ "embedding": self.embedder.embed([pref["context_summary"]])[0],
+ }
+ extract_info = {**basic_info, **pref, **vector_info, **info}
+
+ metadata = PreferenceTextualMemoryMetadata(
+ type=msg_type, preference_type="explicit_preference", **extract_info
+ )
+ memory = TextualMemoryItem(
+ id=str(uuid.uuid4()), memory=pref["context_summary"], metadata=metadata
+ )
+
+ memories.append(memory)
+
+ return memories
+
+ def _process_single_chunk_implicit(
+ self, chunk: MessageList, msg_type: str, info: dict[str, Any]
+ ) -> TextualMemoryItem | None:
+ basic_info = self.extract_basic_info(chunk)
+ if not basic_info["original_text"]:
+ return None
+ implicit_pref = self.extract_implicit_preference(basic_info["original_text"])
+ if not implicit_pref:
+ return None
+
+ vector_info = {
+ "embedding": self.embedder.embed([implicit_pref["context_summary"]])[0],
+ }
+
+ extract_info = {**basic_info, **implicit_pref, **vector_info, **info}
+
+ metadata = PreferenceTextualMemoryMetadata(
+ type=msg_type, preference_type="implicit_preference", **extract_info
+ )
+ memory = TextualMemoryItem(
+ id=extract_info["dialog_id"], memory=implicit_pref["context_summary"], metadata=metadata
+ )
+
+ return memory
+
+ def extract(
+ self,
+ messages: list[MessageList],
+ msg_type: str,
+ info: dict[str, Any],
+ max_workers: int = 10,
+ ) -> list[TextualMemoryItem]:
+ """Extract preference memories based on the messages using thread pool for acceleration."""
+ chunks: list[MessageList] = []
+ for message in messages:
+ chunk = self.splitter.split_chunks(message, split_type="overlap")
+ chunks.extend(chunk)
+ if not chunks:
+ return []
+
+ memories = []
+ with ContextThreadPoolExecutor(max_workers=min(max_workers, len(chunks))) as executor:
+ futures = {
+ executor.submit(self._process_single_chunk_explicit, chunk, msg_type, info): (
+ "explicit",
+ chunk,
+ )
+ for chunk in chunks
+ }
+ futures.update(
+ {
+ executor.submit(self._process_single_chunk_implicit, chunk, msg_type, info): (
+ "implicit",
+ chunk,
+ )
+ for chunk in chunks
+ }
+ )
+
+ for future in as_completed(futures):
+ try:
+ memory = future.result()
+ if memory:
+ if isinstance(memory, list):
+ memories.extend(memory)
+ else:
+ memories.append(memory)
+ except Exception as e:
+ task_type, chunk = futures[future]
+ logger.error(f"Error processing {task_type} chunk: {chunk}\n{e}")
+ continue
+
+ return memories
diff --git a/src/memos/memories/textual/prefer_text_memory/factory.py b/src/memos/memories/textual/prefer_text_memory/factory.py
new file mode 100644
index 000000000..22182261a
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/factory.py
@@ -0,0 +1,78 @@
+from typing import Any, ClassVar
+
+from memos.memories.textual.prefer_text_memory.adder import BaseAdder, NaiveAdder
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
+from memos.memories.textual.prefer_text_memory.extractor import BaseExtractor, NaiveExtractor
+from memos.memories.textual.prefer_text_memory.retrievers import BaseRetriever, NaiveRetriever
+
+
+class AdderFactory(BaseAdder):
+ """Factory class for creating Adder instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveAdder,
+ }
+
+ @classmethod
+ def from_config(
+ cls, config_factory: AdderConfigFactory, llm_provider=None, embedder=None, vector_db=None
+ ) -> BaseAdder:
+ """Create a Adder instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ adder_class = cls.backend_to_class[backend]
+ return adder_class(llm_provider=llm_provider, embedder=embedder, vector_db=vector_db)
+
+
+class ExtractorFactory(BaseExtractor):
+ """Factory class for creating Extractor instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveExtractor,
+ }
+
+ @classmethod
+ def from_config(
+ cls,
+ config_factory: ExtractorConfigFactory,
+ llm_provider=None,
+ embedder=None,
+ vector_db=None,
+ ) -> BaseExtractor:
+ """Create a Extractor instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ extractor_class = cls.backend_to_class[backend]
+ return extractor_class(llm_provider=llm_provider, embedder=embedder, vector_db=vector_db)
+
+
+class RetrieverFactory(BaseRetriever):
+ """Factory class for creating Retriever instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveRetriever,
+ }
+
+ @classmethod
+ def from_config(
+ cls,
+ config_factory: RetrieverConfigFactory,
+ llm_provider=None,
+ embedder=None,
+ reranker=None,
+ vector_db=None,
+ ) -> BaseRetriever:
+ """Create a Retriever instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ retriever_class = cls.backend_to_class[backend]
+ return retriever_class(
+ llm_provider=llm_provider, embedder=embedder, reranker=reranker, vector_db=vector_db
+ )
diff --git a/src/memos/memories/textual/prefer_text_memory/retrievers.py b/src/memos/memories/textual/prefer_text_memory/retrievers.py
new file mode 100644
index 000000000..0074c3f1c
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/retrievers.py
@@ -0,0 +1,134 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.vec_dbs.item import MilvusVecDBItem
+
+
+class BaseRetriever(ABC):
+ """Abstract base class for retrievers."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, reranker=None, vector_db=None):
+ """Initialize the retriever."""
+
+ @abstractmethod
+ def retrieve(
+ self, query: str, top_k: int, info: dict[str, Any] | None = None
+ ) -> list[TextualMemoryItem]:
+ """Retrieve memories from the retriever."""
+
+
+class NaiveRetriever(BaseRetriever):
+ """Naive retriever."""
+
+ def __init__(self, llm_provider=None, embedder=None, reranker=None, vector_db=None):
+ """Initialize the naive retriever."""
+ super().__init__(llm_provider, embedder, reranker, vector_db)
+ self.reranker = reranker
+ self.vector_db = vector_db
+ self.embedder = embedder
+
+ def _naive_reranker(
+ self, query: str, prefs_mem: list[TextualMemoryItem], top_k: int, **kwargs: Any
+ ) -> list[TextualMemoryItem]:
+ if self.reranker:
+ prefs_mem = self.reranker.rerank(query, prefs_mem, top_k)
+ return [item for item, _ in prefs_mem]
+ return prefs_mem
+
+ def _original_text_reranker(
+ self,
+ query: str,
+ prefs_mem: list[TextualMemoryItem],
+ prefs: list[MilvusVecDBItem],
+ top_k: int,
+ **kwargs: Any,
+ ) -> list[TextualMemoryItem]:
+ if self.reranker:
+ from copy import deepcopy
+
+ prefs_mem_for_reranker = deepcopy(prefs_mem)
+ for pref_mem, pref in zip(prefs_mem_for_reranker, prefs, strict=False):
+ pref_mem.memory = pref_mem.memory + "\n" + pref.original_text
+ prefs_mem_for_reranker = self.reranker.rerank(query, prefs_mem_for_reranker, top_k)
+ prefs_mem_for_reranker = [item for item, _ in prefs_mem_for_reranker]
+ prefs_ids = [item.id for item in prefs_mem_for_reranker]
+ prefs_dict = {item.id: item for item in prefs_mem}
+ return [prefs_dict[item_id] for item_id in prefs_ids if item_id in prefs_dict]
+ return prefs_mem
+
+ def retrieve(
+ self, query: str, top_k: int, info: dict[str, Any] | None = None
+ ) -> list[TextualMemoryItem]:
+ """Retrieve memories from the naive retriever."""
+ # TODO: un-support rewrite query and session filter now
+ if info:
+ info = info.copy() # Create a copy to avoid modifying the original
+ info.pop("chat_history", None)
+ info.pop("session_id", None)
+ query_embeddings = self.embedder.embed([query]) # Pass as list to get list of embeddings
+ query_embedding = query_embeddings[0] # Get the first (and only) embedding
+
+ # Use thread pool to parallelize the searches
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ # Submit all search tasks
+ future_explicit = executor.submit(
+ self.vector_db.search,
+ query_embedding,
+ query,
+ "explicit_preference",
+ top_k * 2,
+ info,
+ )
+ future_implicit = executor.submit(
+ self.vector_db.search,
+ query_embedding,
+ query,
+ "implicit_preference",
+ top_k * 2,
+ info,
+ )
+
+ # Wait for all results
+ explicit_prefs = future_explicit.result()
+ implicit_prefs = future_implicit.result()
+
+ # sort by score
+ explicit_prefs.sort(key=lambda x: x.score, reverse=True)
+ implicit_prefs.sort(key=lambda x: x.score, reverse=True)
+
+ explicit_prefs_mem = [
+ TextualMemoryItem(
+ id=pref.id,
+ memory=pref.memory,
+ metadata=PreferenceTextualMemoryMetadata(**pref.payload),
+ )
+ for pref in explicit_prefs
+ if pref.payload.get("preference", None)
+ ]
+
+ implicit_prefs_mem = [
+ TextualMemoryItem(
+ id=pref.id,
+ memory=pref.memory,
+ metadata=PreferenceTextualMemoryMetadata(**pref.payload),
+ )
+ for pref in implicit_prefs
+ if pref.payload.get("preference", None)
+ ]
+
+ reranker_map = {
+ "naive": self._naive_reranker,
+ "original_text": self._original_text_reranker,
+ }
+ reranker_func = reranker_map["naive"]
+ explicit_prefs_mem = reranker_func(
+ query=query, prefs_mem=explicit_prefs_mem, prefs=explicit_prefs, top_k=top_k
+ )
+ implicit_prefs_mem = reranker_func(
+ query=query, prefs_mem=implicit_prefs_mem, prefs=implicit_prefs, top_k=top_k
+ )
+
+ return explicit_prefs_mem + implicit_prefs_mem
diff --git a/src/memos/memories/textual/prefer_text_memory/spliter.py b/src/memos/memories/textual/prefer_text_memory/spliter.py
new file mode 100644
index 000000000..3059d611b
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/spliter.py
@@ -0,0 +1,132 @@
+import copy
+
+from memos.chunkers import ChunkerFactory
+from memos.configs.chunker import ChunkerConfigFactory
+from memos.configs.parser import ParserConfigFactory
+from memos.parsers.factory import ParserFactory
+from memos.types import MessageList
+
+
+class Splitter:
+ """Splitter."""
+
+ def __init__(
+ self,
+ lookback_turns: int = 1,
+ chunk_size: int = 256,
+ chunk_overlap: int = 128,
+ min_sentences_per_chunk: int = 1,
+ tokenizer: str = "gpt2",
+ parser_backend: str = "markitdown",
+ chunker_backend: str = "sentence",
+ ):
+ """Initialize the splitter."""
+ self.lookback_turns = lookback_turns
+ self.chunk_size = chunk_size
+ self.chunk_overlap = chunk_overlap
+ self.min_sentences_per_chunk = min_sentences_per_chunk
+ self.tokenizer = tokenizer
+ self.chunker_backend = chunker_backend
+ self.parser_backend = parser_backend
+ # Initialize parser
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": self.parser_backend,
+ "config": {},
+ }
+ )
+ self.parser = ParserFactory.from_config(parser_config)
+
+ # Initialize chunker
+ chunker_config = ChunkerConfigFactory.model_validate(
+ {
+ "backend": self.chunker_backend,
+ "config": {
+ "tokenizer_or_token_counter": self.tokenizer,
+ "chunk_size": self.chunk_size,
+ "chunk_overlap": self.chunk_overlap,
+ "min_sentences_per_chunk": self.min_sentences_per_chunk,
+ },
+ }
+ )
+ self.chunker = ChunkerFactory.from_config(chunker_config)
+
+ def _split_with_lookback(self, data: MessageList) -> list[MessageList]:
+ """Split the messages or files into chunks by looking back fixed number of turns.
+ adjacent chunk with high duplicate rate,
+ default lookback turns is 1, only current turn in chunk"""
+ # Build QA pairs from chat history
+ pairs = self.build_qa_pairs(data)
+ chunks = []
+
+ # Create chunks by looking back fixed number of turns
+ for i in range(len(pairs)):
+ # Calculate the start index for lookback
+ start_idx = max(0, i + 1 - self.lookback_turns)
+ # Get the chunk of pairs (as many as available, up to lookback_turns)
+ chunk_pairs = pairs[start_idx : i + 1]
+
+ # Flatten chunk_pairs (list[list[dict]]) to MessageList (list[dict])
+ chunk_messages = []
+ for pair in chunk_pairs:
+ chunk_messages.extend(pair)
+
+ chunks.append(chunk_messages)
+ return chunks
+
+ def _split_with_overlap(self, data: MessageList) -> list[MessageList]:
+ """split the messages or files into chunks with overlap.
+ adjacent chunk with low duplicate rate"""
+ chunks = []
+ chunk = []
+ for i, item in enumerate(data):
+ chunk.append(item)
+ # 5 turns (Q + A = 10) each chunk
+ if len(chunk) >= 10:
+ chunks.append(chunk)
+ # overlap 1 turns (Q + A = 2)
+ context = copy.deepcopy(chunk[-2:]) if i + 1 < len(data) else []
+ chunk = context
+ if chunk and len(chunk) % 2 == 0:
+ chunks.append(chunk)
+
+ return chunks
+
+ def split_chunks(self, data: MessageList | str, **kwargs) -> list[MessageList] | list[str]:
+ """Split the messages or files into chunks.
+
+ Args:
+ data: MessageList or string to split
+
+ Returns:
+ List of MessageList chunks or list of string chunks
+ """
+ if isinstance(data, list):
+ if kwargs.get("split_type") == "lookback":
+ chunks = self._split_with_lookback(data)
+ elif kwargs.get("split_type") == "overlap":
+ chunks = self._split_with_overlap(data)
+ return chunks
+ else:
+ # Parse and chunk the string data using pre-initialized components
+ text = self.parser.parse(data)
+ chunks = self.chunker.chunk(text)
+
+ return [chunk.text for chunk in chunks]
+
+ def build_qa_pairs(self, chat_history: MessageList) -> list[MessageList]:
+ """Build QA pairs from chat history."""
+ qa_pairs = []
+ current_qa_pair = []
+
+ for message in chat_history:
+ if message["role"] == "user":
+ current_qa_pair.append(message)
+ elif message["role"] == "assistant":
+ if not current_qa_pair:
+ continue
+ current_qa_pair.append(message)
+ qa_pairs.append(current_qa_pair.copy())
+ current_qa_pair = [] # reset
+
+ return qa_pairs
diff --git a/src/memos/memories/textual/prefer_text_memory/utils.py b/src/memos/memories/textual/prefer_text_memory/utils.py
new file mode 100644
index 000000000..76d4b4211
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/utils.py
@@ -0,0 +1,68 @@
+import re
+
+from memos.dependency import require_python_package
+from memos.memories.textual.item import TextualMemoryItem
+from memos.types import MessageList
+
+
+def convert_messages_to_string(messages: MessageList) -> str:
+ """Convert a list of messages to a string."""
+ message_text = ""
+ for message in messages:
+ if message["role"] == "user":
+ message_text += f"Query: {message['content']}\n" if message["content"].strip() else ""
+ elif message["role"] == "assistant":
+ message_text += f"Answer: {message['content']}\n" if message["content"].strip() else ""
+ message_text = message_text.strip()
+ return message_text
+
+
+@require_python_package(
+ import_name="datasketch",
+ install_command="pip install datasketch",
+ install_link="https://github.com/ekzhu/datasketch",
+)
+def deduplicate_preferences(
+ prefs: list[TextualMemoryItem], similarity_threshold: float = 0.6, num_perm: int = 256
+) -> list[TextualMemoryItem]:
+ """
+ Deduplicate preference texts using MinHash algorithm.
+
+ Args:
+ prefs: List of preference memory items to deduplicate
+ similarity_threshold: Jaccard similarity threshold (0.0-1.0), default 0.8
+
+ Returns:
+ Deduplicated list of preference items
+ """
+ from datasketch import MinHash, MinHashLSH
+
+ if not prefs:
+ return prefs
+
+ # Use MinHashLSH for efficient similarity search
+ lsh = MinHashLSH(threshold=similarity_threshold, num_perm=num_perm)
+ unique_prefs = []
+
+ for i, pref in enumerate(prefs):
+ # Extract preference text
+ if hasattr(pref.metadata, "preference") and pref.metadata.preference:
+ text = pref.metadata.preference
+ else:
+ text = pref.memory
+
+ # Create MinHash from text tokens
+ minhash = MinHash(num_perm=num_perm)
+ # Simple tokenization: split by whitespace and clean
+ tokens = re.findall(r"\w+", text.lower())
+ for token in tokens:
+ minhash.update(token.encode("utf8"))
+
+ # Check for duplicates using LSH
+ similar_items = lsh.query(minhash)
+
+ if not similar_items: # No similar items found
+ lsh.insert(i, minhash)
+ unique_prefs.append(pref)
+
+ return unique_prefs
diff --git a/src/memos/memories/textual/preference.py b/src/memos/memories/textual/preference.py
new file mode 100644
index 000000000..5f85aa907
--- /dev/null
+++ b/src/memos/memories/textual/preference.py
@@ -0,0 +1,283 @@
+import json
+import os
+
+from typing import Any
+
+from memos.configs.memory import PreferenceTextMemoryConfig
+from memos.embedders.factory import (
+ ArkEmbedder,
+ EmbedderFactory,
+ OllamaEmbedder,
+ SenTranEmbedder,
+ UniversalAPIEmbedder,
+)
+from memos.llms.factory import AzureLLM, LLMFactory, OllamaLLM, OpenAILLM
+from memos.log import get_logger
+from memos.memories.textual.base import BaseTextMemory
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.prefer_text_memory.factory import (
+ AdderFactory,
+ ExtractorFactory,
+ RetrieverFactory,
+)
+from memos.reranker.factory import RerankerFactory
+from memos.types import MessageList
+from memos.vec_dbs.factory import MilvusVecDB, QdrantVecDB, VecDBFactory
+from memos.vec_dbs.item import VecDBItem
+
+
+logger = get_logger(__name__)
+
+
+class PreferenceTextMemory(BaseTextMemory):
+ """Preference textual memory implementation for storing and retrieving memories."""
+
+ def __init__(self, config: PreferenceTextMemoryConfig):
+ """Initialize memory with the given configuration."""
+ self.config: PreferenceTextMemoryConfig = config
+ self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
+ config.extractor_llm
+ )
+ self.vector_db: MilvusVecDB | QdrantVecDB = VecDBFactory.from_config(config.vector_db)
+ self.embedder: OllamaEmbedder | ArkEmbedder | SenTranEmbedder | UniversalAPIEmbedder = (
+ EmbedderFactory.from_config(config.embedder)
+ )
+ self.reranker = RerankerFactory.from_config(config.reranker)
+
+ self.extractor = ExtractorFactory.from_config(
+ config.extractor,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ vector_db=self.vector_db,
+ )
+
+ self.adder = AdderFactory.from_config(
+ config.adder,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ vector_db=self.vector_db,
+ )
+ self.retriever = RetrieverFactory.from_config(
+ config.retriever,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ reranker=self.reranker,
+ vector_db=self.vector_db,
+ )
+
+ def get_memory(
+ self, messages: list[MessageList], type: str, info: dict[str, Any]
+ ) -> list[TextualMemoryItem]:
+ """Get memory based on the messages.
+ Args:
+ messages (list[MessageList]): The messages to get memory from.
+ type (str): The type of memory to get.
+ info (dict[str, Any]): The info to get memory.
+ """
+ return self.extractor.extract(messages, type, info)
+
+ def search(self, query: str, top_k: int, info=None, **kwargs) -> list[TextualMemoryItem]:
+ """Search for memories based on a query.
+ Args:
+ query (str): The query to search for.
+ top_k (int): The number of top results to return.
+ info (dict): Leave a record of memory consumption.
+ Returns:
+ list[TextualMemoryItem]: List of matching memories.
+ """
+ return self.retriever.retrieve(query, top_k, info)
+
+ def load(self, dir: str) -> None:
+ """Load memories from the specified directory.
+ Args:
+ dir (str): The directory containing the memory files.
+ """
+ # For preference memory, we don't need to load from files
+ # as the data is stored in the vector database
+ try:
+ memory_file = os.path.join(dir, self.config.memory_filename)
+
+ if not os.path.exists(memory_file):
+ logger.warning(f"Memory file not found: {memory_file}")
+ return
+
+ with open(memory_file, encoding="utf-8") as f:
+ memories = json.load(f)
+ for collection_name, items in memories.items():
+ vec_db_items = [VecDBItem.from_dict(m) for m in items]
+ self.vector_db.add(collection_name, vec_db_items)
+ logger.info(f"Loaded {len(items)} memories from {collection_name} in {memory_file}")
+
+ except FileNotFoundError:
+ logger.error(f"Memory file not found in directory: {dir}")
+ except json.JSONDecodeError as e:
+ if e.pos == 0 and "Expecting value" in str(e):
+ logger.warning(f"Memory file is empty or contains only whitespace: {memory_file}")
+ else:
+ logger.error(f"Error decoding JSON from memory file: {e}")
+ except Exception as e:
+ logger.error(f"An error occurred while loading memories: {e}")
+
+ def dump(self, dir: str) -> None:
+ """Dump memories to the specified directory.
+ Args:
+ dir (str): The directory where the memory files will be saved.
+ """
+ # For preference memory, we don't need to dump to files
+ # as the data is stored in the vector database
+ try:
+ json_memories = {}
+ for collection_name in self.vector_db.config.collection_name:
+ items = self.vector_db.get_all(collection_name)
+ json_memories[collection_name] = [memory.to_dict() for memory in items]
+
+ os.makedirs(dir, exist_ok=True)
+ memory_file = os.path.join(dir, self.config.memory_filename)
+ with open(memory_file, "w", encoding="utf-8") as f:
+ json.dump(json_memories, f, indent=4, ensure_ascii=False)
+
+ logger.info(
+ f"Dumped {len(json_memories)} collections, {sum(len(items) for items in json_memories.values())} memories to {memory_file}"
+ )
+
+ except Exception as e:
+ logger.error(f"An error occurred while dumping memories: {e}")
+ raise
+
+ def extract(self, messages: MessageList) -> list[TextualMemoryItem]:
+ """Extract memories based on the messages.
+ Args:
+ messages (MessageList): The messages to extract memories from.
+ Returns:
+ list[TextualMemoryItem]: List of extracted memory items.
+ """
+ raise NotImplementedError
+
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ """Add memories.
+
+ Args:
+ memories: List of TextualMemoryItem objects or dictionaries to add.
+ """
+ return self.adder.add(memories)
+
+ def update(self, memory_id: str, new_memory: TextualMemoryItem | dict[str, Any]) -> None:
+ """Update a memory by memory_id."""
+ raise NotImplementedError
+
+ def get(self, memory_id: str) -> TextualMemoryItem:
+ """Get a memory by its ID.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ Returns:
+ TextualMemoryItem: The memory with the given ID.
+ """
+ raise NotImplementedError
+
+ def get_with_collection_name(
+ self, collection_name: str, memory_id: str
+ ) -> TextualMemoryItem | None:
+ """Get a memory by its ID and collection name.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ collection_name (str): The name of the collection to retrieve the memory from.
+ Returns:
+ TextualMemoryItem: The memory with the given ID and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_id(collection_name, memory_id)
+ if res is None:
+ return None
+ return TextualMemoryItem(
+ id=res.id,
+ memory=res.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**res.payload),
+ )
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with ID {memory_id} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
+ """Get memories by their IDs.
+ Args:
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs.
+ """
+ raise NotImplementedError
+
+ def get_by_ids_with_collection_name(
+ self, collection_name: str, memory_ids: list[str]
+ ) -> list[TextualMemoryItem]:
+ """Get memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to retrieve the memory from.
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_ids(collection_name, memory_ids)
+ if not res:
+ return []
+ return [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in res
+ ]
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with IDs {memory_ids} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_all(self) -> list[TextualMemoryItem]:
+ """Get all memories.
+ Returns:
+ list[TextualMemoryItem]: List of all memories.
+ """
+ all_collections = self.vector_db.list_collections()
+ all_memories = {}
+ for collection_name in all_collections:
+ items = self.vector_db.get_all(collection_name)
+ all_memories[collection_name] = [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in items
+ ]
+ return all_memories
+
+ def delete(self, memory_ids: list[str]) -> None:
+ """Delete memories.
+ Args:
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ raise NotImplementedError
+
+ def delete_with_collection_name(self, collection_name: str, memory_ids: list[str]) -> None:
+ """Delete memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to delete the memory from.
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ self.vector_db.delete(collection_name, memory_ids)
+
+ def delete_all(self) -> None:
+ """Delete all memories."""
+ for collection_name in self.vector_db.config.collection_name:
+ self.vector_db.delete_collection(collection_name)
+ self.vector_db.create_collection()
+
+ def drop(
+ self,
+ ) -> None:
+ """Drop all databases."""
+ raise NotImplementedError
diff --git a/src/memos/memories/textual/simple_preference.py b/src/memos/memories/textual/simple_preference.py
new file mode 100644
index 000000000..29f30d384
--- /dev/null
+++ b/src/memos/memories/textual/simple_preference.py
@@ -0,0 +1,156 @@
+from typing import Any
+
+from memos.embedders.factory import (
+ ArkEmbedder,
+ OllamaEmbedder,
+ SenTranEmbedder,
+ UniversalAPIEmbedder,
+)
+from memos.llms.factory import AzureLLM, OllamaLLM, OpenAILLM
+from memos.log import get_logger
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.types import MessageList
+from memos.vec_dbs.factory import MilvusVecDB, QdrantVecDB
+
+
+logger = get_logger(__name__)
+
+
+class SimplePreferenceTextMemory(PreferenceTextMemory):
+ """Preference textual memory implementation for storing and retrieving memories."""
+
+ def __init__(
+ self,
+ extractor_llm: OpenAILLM | OllamaLLM | AzureLLM,
+ vector_db: MilvusVecDB | QdrantVecDB,
+ embedder: OllamaEmbedder | ArkEmbedder | SenTranEmbedder | UniversalAPIEmbedder,
+ reranker,
+ extractor,
+ adder,
+ retriever,
+ ):
+ """Initialize memory with the given configuration."""
+ self.extractor_llm = extractor_llm
+ self.vector_db = vector_db
+ self.embedder = embedder
+ self.reranker = reranker
+ self.extractor = extractor
+ self.adder = adder
+ self.retriever = retriever
+
+ def get_memory(
+ self, messages: list[MessageList], type: str, info: dict[str, Any]
+ ) -> list[TextualMemoryItem]:
+ """Get memory based on the messages.
+ Args:
+ messages (MessageList): The messages to get memory from.
+ type (str): The type of memory to get.
+ info (dict[str, Any]): The info to get memory.
+ """
+ return self.extractor.extract(messages, type, info)
+
+ def search(self, query: str, top_k: int, info=None, **kwargs) -> list[TextualMemoryItem]:
+ """Search for memories based on a query.
+ Args:
+ query (str): The query to search for.
+ top_k (int): The number of top results to return.
+ info (dict): Leave a record of memory consumption.
+ Returns:
+ list[TextualMemoryItem]: List of matching memories.
+ """
+ return self.retriever.retrieve(query, top_k, info)
+
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ """Add memories.
+
+ Args:
+ memories: List of TextualMemoryItem objects or dictionaries to add.
+ """
+ return self.adder.add(memories)
+
+ def get_with_collection_name(
+ self, collection_name: str, memory_id: str
+ ) -> TextualMemoryItem | None:
+ """Get a memory by its ID and collection name.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ collection_name (str): The name of the collection to retrieve the memory from.
+ Returns:
+ TextualMemoryItem: The memory with the given ID and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_id(collection_name, memory_id)
+ if res is None:
+ return None
+ return TextualMemoryItem(
+ id=res.id,
+ memory=res.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**res.payload),
+ )
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with ID {memory_id} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_by_ids_with_collection_name(
+ self, collection_name: str, memory_ids: list[str]
+ ) -> list[TextualMemoryItem]:
+ """Get memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to retrieve the memory from.
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_ids(collection_name, memory_ids)
+ if not res:
+ return []
+ return [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in res
+ ]
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with IDs {memory_ids} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_all(self) -> list[TextualMemoryItem]:
+ """Get all memories.
+ Returns:
+ list[TextualMemoryItem]: List of all memories.
+ """
+ all_collections = self.vector_db.list_collections()
+ all_memories = {}
+ for collection_name in all_collections:
+ items = self.vector_db.get_all(collection_name)
+ all_memories[collection_name] = [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in items
+ ]
+ return all_memories
+
+ def delete_with_collection_name(self, collection_name: str, memory_ids: list[str]) -> None:
+ """Delete memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to delete the memory from.
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ self.vector_db.delete(collection_name, memory_ids)
+
+ def delete_all(self) -> None:
+ """Delete all memories."""
+ for collection_name in self.vector_db.config.collection_name:
+ self.vector_db.delete_collection(collection_name)
+ self.vector_db.create_collection()
diff --git a/src/memos/memories/textual/simple_tree.py b/src/memos/memories/textual/simple_tree.py
index 9c67db288..313989cd2 100644
--- a/src/memos/memories/textual/simple_tree.py
+++ b/src/memos/memories/textual/simple_tree.py
@@ -12,6 +12,7 @@
from memos.memories.textual.item import TextualMemoryItem, TreeNodeTextualMemoryMetadata
from memos.memories.textual.tree import TreeTextMemory
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.searcher import Searcher
from memos.reranker.base import BaseReranker
from memos.types import MessageList
@@ -44,6 +45,8 @@ def __init__(
"""Initialize memory with the given configuration."""
time_start = time.time()
self.config: TreeTextMemoryConfig = config
+ self.mode = self.config.mode
+ logger.info(f"Tree mode is {self.mode}")
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = llm
logger.info(f"time init: extractor_llm time is: {time.time() - time_start}")
@@ -60,6 +63,15 @@ def __init__(
self.graph_store: Neo4jGraphDB = graph_db
logger.info(f"time init: graph_store time is: {time.time() - time_start_gs}")
+ time_start_bm = time.time()
+ self.search_strategy = config.search_strategy
+ self.bm25_retriever = (
+ EnhancedBM25()
+ if self.search_strategy and self.search_strategy.get("bm25", False)
+ else None
+ )
+ logger.info(f"time init: bm25_retriever time is: {time.time() - time_start_bm}")
+
time_start_rr = time.time()
self.reranker = reranker
logger.info(f"time init: reranker time is: {time.time() - time_start_rr}")
@@ -79,20 +91,6 @@ def __init__(
logger.info("No internet retriever configured")
logger.info(f"time init: internet_retriever time is: {time.time() - time_start_ir}")
- def add(
- self, memories: list[TextualMemoryItem | dict[str, Any]], user_name: str | None = None
- ) -> list[str]:
- """Add memories.
- Args:
- memories: List of TextualMemoryItem objects or dictionaries to add.
- Later:
- memory_items = [TextualMemoryItem(**m) if isinstance(m, dict) else m for m in memories]
- metadata = extract_metadata(memory_items, self.extractor_llm)
- plan = plan_memory_operations(memory_items, metadata, self.graph_store)
- execute_plan(memory_items, metadata, plan, self.graph_store)
- """
- return self.memory_manager.add(memories, user_name=user_name)
-
def replace_working_memory(
self, memories: list[TextualMemoryItem], user_name: str | None = None
) -> None:
@@ -116,6 +114,34 @@ def get_current_memory_size(self, user_name: str | None = None) -> dict[str, int
"""
return self.memory_manager.get_current_memory_size(user_name=user_name)
+ def get_searcher(
+ self,
+ manual_close_internet: bool = False,
+ moscube: bool = False,
+ ):
+ if (self.internet_retriever is not None) and manual_close_internet:
+ logger.warning(
+ "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
+ )
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=None,
+ moscube=moscube,
+ )
+ else:
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=self.internet_retriever,
+ moscube=moscube,
+ )
+ return searcher
+
def search(
self,
query: str,
@@ -151,16 +177,15 @@ def search(
list[TextualMemoryItem]: List of matching memories.
"""
if (self.internet_retriever is not None) and manual_close_internet:
- logger.warning(
- "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
- )
searcher = Searcher(
self.dispatcher_llm,
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=None,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
else:
searcher = Searcher(
@@ -168,8 +193,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=self.internet_retriever,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
return searcher.search(
query, top_k, info, mode, memory_type, search_filter, user_name=user_name
@@ -274,17 +301,6 @@ def get(self, memory_id: str) -> TextualMemoryItem:
def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
raise NotImplementedError
- def get_all(self) -> dict:
- """Get all memories.
- Returns:
- list[TextualMemoryItem]: List of all memories.
- """
- all_items = self.graph_store.export_graph()
- return all_items
-
- def delete(self, memory_ids: list[str]) -> None:
- raise NotImplementedError
-
def delete_all(self) -> None:
"""Delete all memories and their relationships from the graph store."""
try:
diff --git a/src/memos/memories/textual/tree.py b/src/memos/memories/textual/tree.py
index 0048f4a59..dea3cc1ab 100644
--- a/src/memos/memories/textual/tree.py
+++ b/src/memos/memories/textual/tree.py
@@ -2,7 +2,6 @@
import os
import shutil
import tempfile
-import time
from datetime import datetime
from pathlib import Path
@@ -17,6 +16,7 @@
from memos.memories.textual.base import BaseTextMemory
from memos.memories.textual.item import TextualMemoryItem, TreeNodeTextualMemoryMetadata
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.internet_retriever_factory import (
InternetRetrieverFactory,
)
@@ -33,28 +33,25 @@ class TreeTextMemory(BaseTextMemory):
def __init__(self, config: TreeTextMemoryConfig):
"""Initialize memory with the given configuration."""
- time_start = time.time()
+ # Set mode from class default or override if needed
+ self.mode = config.mode
+ logger.info(f"Tree mode is {self.mode}")
+
self.config: TreeTextMemoryConfig = config
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.extractor_llm
)
- logger.info(f"time init: extractor_llm time is: {time.time() - time_start}")
-
- time_start_ex = time.time()
self.dispatcher_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.dispatcher_llm
)
- logger.info(f"time init: dispatcher_llm time is: {time.time() - time_start_ex}")
-
- time_start_em = time.time()
self.embedder: OllamaEmbedder = EmbedderFactory.from_config(config.embedder)
- logger.info(f"time init: embedder time is: {time.time() - time_start_em}")
-
- time_start_gs = time.time()
self.graph_store: Neo4jGraphDB = GraphStoreFactory.from_config(config.graph_db)
- logger.info(f"time init: graph_store time is: {time.time() - time_start_gs}")
- time_start_rr = time.time()
+ self.search_strategy = config.search_strategy
+ self.bm25_retriever = (
+ EnhancedBM25() if self.search_strategy and self.search_strategy["bm25"] else None
+ )
+
if config.reranker is None:
default_cfg = RerankerConfigFactory.model_validate(
{
@@ -68,10 +65,7 @@ def __init__(self, config: TreeTextMemoryConfig):
self.reranker = RerankerFactory.from_config(default_cfg)
else:
self.reranker = RerankerFactory.from_config(config.reranker)
- logger.info(f"time init: reranker time is: {time.time() - time_start_rr}")
self.is_reorganize = config.reorganize
-
- time_start_mm = time.time()
self.memory_manager: MemoryManager = MemoryManager(
self.graph_store,
self.embedder,
@@ -84,8 +78,6 @@ def __init__(self, config: TreeTextMemoryConfig):
},
is_reorganize=self.is_reorganize,
)
- logger.info(f"time init: memory_manager time is: {time.time() - time_start_mm}")
- time_start_ir = time.time()
# Create internet retriever if configured
self.internet_retriever = None
if config.internet_retriever is not None:
@@ -97,19 +89,19 @@ def __init__(self, config: TreeTextMemoryConfig):
)
else:
logger.info("No internet retriever configured")
- logger.info(f"time init: internet_retriever time is: {time.time() - time_start_ir}")
- def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ def add(
+ self,
+ memories: list[TextualMemoryItem | dict[str, Any]],
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[str]:
"""Add memories.
Args:
memories: List of TextualMemoryItem objects or dictionaries to add.
- Later:
- memory_items = [TextualMemoryItem(**m) if isinstance(m, dict) else m for m in memories]
- metadata = extract_metadata(memory_items, self.extractor_llm)
- plan = plan_memory_operations(memory_items, metadata, self.graph_store)
- execute_plan(memory_items, metadata, plan, self.graph_store)
+ user_name: optional user_name
"""
- return self.memory_manager.add(memories)
+ return self.memory_manager.add(memories, user_name=user_name, mode=self.mode)
def replace_working_memory(self, memories: list[TextualMemoryItem]) -> None:
self.memory_manager.replace_working_memory(memories)
@@ -130,6 +122,34 @@ def get_current_memory_size(self) -> dict[str, int]:
"""
return self.memory_manager.get_current_memory_size()
+ def get_searcher(
+ self,
+ manual_close_internet: bool = False,
+ moscube: bool = False,
+ ):
+ if (self.internet_retriever is not None) and manual_close_internet:
+ logger.warning(
+ "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
+ )
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=None,
+ moscube=moscube,
+ )
+ else:
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=self.internet_retriever,
+ moscube=moscube,
+ )
+ return searcher
+
def search(
self,
query: str,
@@ -172,8 +192,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=None,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
else:
searcher = Searcher(
@@ -181,8 +203,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=self.internet_retriever,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
return searcher.search(query, top_k, info, mode, memory_type, search_filter)
@@ -236,7 +260,7 @@ def get_relevant_subgraph(
center_id=core_id, depth=depth, center_status=center_status
)
- if not subgraph["core_node"]:
+ if subgraph is None or not subgraph["core_node"]:
logger.info(f"Skipping node {core_id} (inactive or not found).")
continue
@@ -257,9 +281,9 @@ def get_relevant_subgraph(
{"id": core_id, "score": score, "core_node": core_node, "neighbors": neighbors}
)
- top_core = cores[0]
+ top_core = cores[0] if cores else None
return {
- "core_id": top_core["id"],
+ "core_id": top_core["id"] if top_core else None,
"nodes": list(all_nodes.values()),
"edges": [{"source": f, "target": t, "type": ty} for (f, t, ty) in all_edges],
}
@@ -285,16 +309,23 @@ def get(self, memory_id: str) -> TextualMemoryItem:
def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
raise NotImplementedError
- def get_all(self) -> dict:
+ def get_all(self, user_name: str | None = None) -> dict:
"""Get all memories.
Returns:
list[TextualMemoryItem]: List of all memories.
"""
- all_items = self.graph_store.export_graph()
+ all_items = self.graph_store.export_graph(user_name=user_name)
return all_items
- def delete(self, memory_ids: list[str]) -> None:
- raise NotImplementedError
+ def delete(self, memory_ids: list[str], user_name: str | None = None) -> None:
+ """Hard delete: permanently remove nodes and their edges from the graph."""
+ if not memory_ids:
+ return
+ for mid in memory_ids:
+ try:
+ self.graph_store.delete_node(mid, user_name=user_name)
+ except Exception as e:
+ logger.warning(f"TreeTextMemory.delete_hard: failed to delete {mid}: {e}")
def delete_all(self) -> None:
"""Delete all memories and their relationships from the graph store."""
diff --git a/src/memos/memories/textual/tree_text_memory/organize/manager.py b/src/memos/memories/textual/tree_text_memory/organize/manager.py
index 3e1609cb7..0c41717ea 100644
--- a/src/memos/memories/textual/tree_text_memory/organize/manager.py
+++ b/src/memos/memories/textual/tree_text_memory/organize/manager.py
@@ -1,3 +1,4 @@
+import re
import traceback
import uuid
@@ -19,6 +20,37 @@
logger = get_logger(__name__)
+def extract_working_binding_ids(mem_items: list[TextualMemoryItem]) -> set[str]:
+ """
+ Scan enhanced memory items for background hints like
+ "[working_binding:]" and collect those working memory IDs.
+
+ We store the working<->long binding inside metadata.background when
+ initially adding memories in async mode, so we can later clean up
+ the temporary WorkingMemory nodes after mem_reader produces the
+ final LongTermMemory/UserMemory.
+
+ Args:
+ mem_items: list of TextualMemoryItem we just added (enhanced memories)
+
+ Returns:
+ A set of working memory IDs (as strings) that should be deleted.
+ """
+ bindings: set[str] = set()
+ pattern = re.compile(r"\[working_binding:([0-9a-fA-F-]{36})\]")
+ for item in mem_items:
+ try:
+ bg = getattr(item.metadata, "background", "") or ""
+ except Exception:
+ bg = ""
+ if not isinstance(bg, str):
+ continue
+ match = pattern.search(bg)
+ if match:
+ bindings.add(match.group(1))
+ return bindings
+
+
class MemoryManager:
def __init__(
self,
@@ -52,13 +84,15 @@ def __init__(
)
self._merged_threshold = merged_threshold
- def add(self, memories: list[TextualMemoryItem], user_name: str | None = None) -> list[str]:
+ def add(
+ self, memories: list[TextualMemoryItem], user_name: str | None = None, mode: str = "sync"
+ ) -> list[str]:
"""
- Add new memories in parallel to different memory types (WorkingMemory, LongTermMemory, UserMemory).
+ Add new memories in parallel to different memory types.
"""
added_ids: list[str] = []
- with ContextThreadPoolExecutor(max_workers=8) as executor:
+ with ContextThreadPoolExecutor(max_workers=20) as executor:
futures = {executor.submit(self._process_memory, m, user_name): m for m in memories}
for future in as_completed(futures, timeout=60):
try:
@@ -67,17 +101,18 @@ def add(self, memories: list[TextualMemoryItem], user_name: str | None = None) -
except Exception as e:
logger.exception("Memory processing error: ", exc_info=e)
- for mem_type in ["WorkingMemory", "LongTermMemory", "UserMemory"]:
- try:
- self.graph_store.remove_oldest_memory(
- memory_type="WorkingMemory",
- keep_latest=self.memory_size[mem_type],
- user_name=user_name,
- )
- except Exception:
- logger.warning(f"Remove {mem_type} error: {traceback.format_exc()}")
-
- self._refresh_memory_size(user_name=user_name)
+ if mode == "sync":
+ for mem_type in ["WorkingMemory", "LongTermMemory", "UserMemory"]:
+ try:
+ self.graph_store.remove_oldest_memory(
+ memory_type="WorkingMemory",
+ keep_latest=self.memory_size[mem_type],
+ user_name=user_name,
+ )
+ except Exception:
+ logger.warning(f"Remove {mem_type} error: {traceback.format_exc()}")
+
+ self._refresh_memory_size(user_name=user_name)
return added_ids
def replace_working_memory(
@@ -121,63 +156,102 @@ def _refresh_memory_size(self, user_name: str | None = None) -> None:
results = self.graph_store.get_grouped_counts(
group_fields=["memory_type"], user_name=user_name
)
- self.current_memory_size = {record["memory_type"]: record["count"] for record in results}
+ self.current_memory_size = {
+ record["memory_type"]: int(record["count"]) for record in results
+ }
logger.info(f"[MemoryManager] Refreshed memory sizes: {self.current_memory_size}")
def _process_memory(self, memory: TextualMemoryItem, user_name: str | None = None):
"""
- Process and add memory to different memory types (WorkingMemory, LongTermMemory, UserMemory).
- This method runs asynchronously to process each memory item.
+ Process and add memory to different memory types.
+
+ Behavior:
+ 1. Always create a WorkingMemory node from `memory` and get its node id.
+ 2. If `memory.metadata.memory_type` is "LongTermMemory" or "UserMemory",
+ also create a corresponding long/user node.
+ - In async mode, that long/user node's metadata will include
+ `working_binding` in `background` which records the WorkingMemory
+ node id created in step 1.
+ 3. Return ONLY the ids of the long/user nodes (NOT the working node id),
+ which preserves the previous external contract of `add()`.
"""
- ids = []
+ ids: list[str] = []
+ futures = []
- # Add to WorkingMemory do not return working_id
- self._add_memory_to_db(memory, "WorkingMemory", user_name)
+ working_id = str(uuid.uuid4())
- # Add to LongTermMemory and UserMemory
- if memory.metadata.memory_type in ["LongTermMemory", "UserMemory"]:
- added_id = self._add_to_graph_memory(
- memory=memory, memory_type=memory.metadata.memory_type, user_name=user_name
+ with ContextThreadPoolExecutor(max_workers=2, thread_name_prefix="mem") as ex:
+ f_working = ex.submit(
+ self._add_memory_to_db, memory, "WorkingMemory", user_name, working_id
)
- ids.append(added_id)
+ futures.append(("working", f_working))
+
+ if memory.metadata.memory_type in ("LongTermMemory", "UserMemory"):
+ f_graph = ex.submit(
+ self._add_to_graph_memory,
+ memory=memory,
+ memory_type=memory.metadata.memory_type,
+ user_name=user_name,
+ working_binding=working_id,
+ )
+ futures.append(("long", f_graph))
+
+ for kind, fut in futures:
+ try:
+ res = fut.result()
+ if kind != "working" and isinstance(res, str) and res:
+ ids.append(res)
+ except Exception:
+ logger.warning("Parallel memory processing failed:\n%s", traceback.format_exc())
return ids
def _add_memory_to_db(
- self, memory: TextualMemoryItem, memory_type: str, user_name: str | None = None
+ self,
+ memory: TextualMemoryItem,
+ memory_type: str,
+ user_name: str | None = None,
+ forced_id: str | None = None,
) -> str:
"""
Add a single memory item to the graph store, with FIFO logic for WorkingMemory.
+ If forced_id is provided, use that as the node id.
"""
metadata = memory.metadata.model_copy(update={"memory_type": memory_type}).model_dump(
exclude_none=True
)
metadata["updated_at"] = datetime.now().isoformat()
- working_memory = TextualMemoryItem(memory=memory.memory, metadata=metadata)
-
+ node_id = forced_id or str(uuid.uuid4())
+ working_memory = TextualMemoryItem(id=node_id, memory=memory.memory, metadata=metadata)
# Insert node into graph
self.graph_store.add_node(working_memory.id, working_memory.memory, metadata, user_name)
- return working_memory.id
+ return node_id
def _add_to_graph_memory(
- self, memory: TextualMemoryItem, memory_type: str, user_name: str | None = None
+ self,
+ memory: TextualMemoryItem,
+ memory_type: str,
+ user_name: str | None = None,
+ working_binding: str | None = None,
):
"""
Generalized method to add memory to a graph-based memory type (e.g., LongTermMemory, UserMemory).
-
- Parameters:
- - memory: memory item to insert
- - memory_type: "LongTermMemory" | "UserMemory"
- - similarity_threshold: deduplication threshold
- - topic_summary_prefix: summary node id prefix if applicable
- - enable_summary_link: whether to auto-link to a summary node
"""
node_id = str(uuid.uuid4())
# Step 2: Add new node to graph
+ metadata_dict = memory.metadata.model_dump(exclude_none=True)
+ tags = metadata_dict.get("tags") or []
+ if working_binding and ("mode:fast" in tags):
+ prev_bg = metadata_dict.get("background", "") or ""
+ binding_line = f"[working_binding:{working_binding}] direct built from raw inputs"
+ if prev_bg:
+ metadata_dict["background"] = prev_bg + " || " + binding_line
+ else:
+ metadata_dict["background"] = binding_line
self.graph_store.add_node(
node_id,
memory.memory,
- memory.metadata.model_dump(exclude_none=True),
+ metadata_dict,
user_name=user_name,
)
self.reorganizer.add_message(
@@ -268,6 +342,32 @@ def _ensure_structure_path(
# Step 3: Return this structure node ID as the parent_id
return node_id
+ def remove_and_refresh_memory(self, user_name: str | None = None):
+ self._cleanup_memories_if_needed(user_name=user_name)
+ self._refresh_memory_size(user_name=user_name)
+
+ def _cleanup_memories_if_needed(self, user_name: str | None = None) -> None:
+ """
+ Only clean up memories if we're close to or over the limit.
+ This reduces unnecessary database operations.
+ """
+ cleanup_threshold = 0.8 # Clean up when 80% full
+
+ logger.info(f"self.memory_size: {self.memory_size}")
+ for memory_type, limit in self.memory_size.items():
+ current_count = self.current_memory_size.get(memory_type, 0)
+ threshold = int(int(limit) * cleanup_threshold)
+
+ # Only clean up if we're at or above the threshold
+ if current_count >= threshold:
+ try:
+ self.graph_store.remove_oldest_memory(
+ memory_type=memory_type, keep_latest=limit, user_name=user_name
+ )
+ logger.debug(f"Cleaned up {memory_type}: {current_count} -> {limit}")
+ except Exception:
+ logger.warning(f"Remove {memory_type} error: {traceback.format_exc()}")
+
def wait_reorganizer(self):
"""
Wait for the reorganizer to finish processing all messages.
diff --git a/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py b/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
index 0337225d1..ea06a7c60 100644
--- a/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
+++ b/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
@@ -1,5 +1,4 @@
import json
-import threading
import time
import traceback
@@ -10,7 +9,7 @@
import numpy as np
-from memos.context.context import ContextThreadPoolExecutor
+from memos.context.context import ContextThread, ContextThreadPoolExecutor
from memos.dependency import require_python_package
from memos.embedders.factory import OllamaEmbedder
from memos.graph_dbs.item import GraphDBEdge, GraphDBNode
@@ -94,12 +93,12 @@ def __init__(
self._reorganize_needed = True
if self.is_reorganize:
# ____ 1. For queue message driven thread ___________
- self.thread = threading.Thread(target=self._run_message_consumer_loop)
+ self.thread = ContextThread(target=self._run_message_consumer_loop)
self.thread.start()
# ____ 2. For periodic structure optimization _______
self._stop_scheduler = False
self._is_optimizing = {"LongTermMemory": False, "UserMemory": False}
- self.structure_optimizer_thread = threading.Thread(
+ self.structure_optimizer_thread = ContextThread(
target=self._run_structure_organizer_loop
)
self.structure_optimizer_thread.start()
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py b/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py
new file mode 100644
index 000000000..4aca4022f
--- /dev/null
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py
@@ -0,0 +1,186 @@
+import threading
+
+import numpy as np
+
+from sklearn.feature_extraction.text import TfidfVectorizer
+
+from memos.dependency import require_python_package
+from memos.log import get_logger
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import FastTokenizer
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
+# Global model cache
+_CACHE_LOCK = threading.Lock()
+
+
+class EnhancedBM25:
+ """Enhanced BM25 with Spacy tokenization and TF-IDF reranking"""
+
+ @require_python_package(import_name="cachetools", install_command="pip install cachetools")
+ def __init__(self, tokenizer=None, en_model="en_core_web_sm", zh_model="zh_core_web_sm"):
+ """
+ Initialize Enhanced BM25 with memory management
+ """
+ if tokenizer is None:
+ self.tokenizer = FastTokenizer()
+ else:
+ self.tokenizer = tokenizer
+ self._current_tfidf = None
+
+ global _BM25_CACHE
+ from cachetools import LRUCache
+
+ _BM25_CACHE = LRUCache(maxsize=100)
+
+ def _tokenize_doc(self, text):
+ """
+ Tokenize a single document using SpacyTokenizer
+ """
+ return self.tokenizer.tokenize_mixed(text, lang="auto")
+
+ @require_python_package(import_name="rank_bm25", install_command="pip install rank_bm25")
+ def _prepare_corpus_data(self, corpus, corpus_name="default"):
+ from rank_bm25 import BM25Okapi
+
+ with _CACHE_LOCK:
+ if corpus_name in _BM25_CACHE:
+ print("hit::", corpus_name)
+ return _BM25_CACHE[corpus_name]
+ print("not hit::", corpus_name)
+
+ tokenized_corpus = [self._tokenize_doc(doc) for doc in corpus]
+ bm25_model = BM25Okapi(tokenized_corpus)
+ _BM25_CACHE[corpus_name] = bm25_model
+ return bm25_model
+
+ def clear_cache(self, corpus_name=None):
+ """Clear cache for specific corpus or clear all cache"""
+ with _CACHE_LOCK:
+ if corpus_name:
+ if corpus_name in _BM25_CACHE:
+ del _BM25_CACHE[corpus_name]
+ else:
+ _BM25_CACHE.clear()
+
+ def get_cache_info(self):
+ """Get current cache information"""
+ with _CACHE_LOCK:
+ return {
+ "cache_size": len(_BM25_CACHE),
+ "max_cache_size": 100,
+ "cached_corpora": list(_BM25_CACHE.keys()),
+ }
+
+ def _search_docs(
+ self,
+ query: str,
+ corpus: list[str],
+ corpus_name="test",
+ top_k=50,
+ use_tfidf=False,
+ rerank_candidates_multiplier=2,
+ cleanup=False,
+ ):
+ """
+ Args:
+ query: Search query string
+ corpus: List of document texts
+ top_k: Number of top results to return
+ rerank_candidates_multiplier: Multiplier for candidate selection
+ cleanup: Whether to cleanup memory after search (default: True)
+ """
+ if not corpus:
+ return []
+
+ logger.info(f"Searching {len(corpus)} documents for query: '{query}'")
+
+ try:
+ # Prepare BM25 model
+ bm25_model = self._prepare_corpus_data(corpus, corpus_name=corpus_name)
+ tokenized_query = self._tokenize_doc(query)
+ tokenized_query = list(dict.fromkeys(tokenized_query))
+
+ # Get BM25 scores
+ bm25_scores = bm25_model.get_scores(tokenized_query)
+
+ # Select candidates
+ candidate_count = min(top_k * rerank_candidates_multiplier, len(corpus))
+ candidate_indices = np.argsort(bm25_scores)[-candidate_count:][::-1]
+ combined_scores = bm25_scores[candidate_indices]
+
+ if use_tfidf:
+ # Create TF-IDF for this search
+ tfidf = TfidfVectorizer(
+ tokenizer=self._tokenize_doc, lowercase=False, token_pattern=None
+ )
+ tfidf_matrix = tfidf.fit_transform(corpus)
+
+ # TF-IDF reranking
+ query_vec = tfidf.transform([query])
+ tfidf_similarities = (
+ (tfidf_matrix[candidate_indices] * query_vec.T).toarray().flatten()
+ )
+
+ # Combine scores
+ combined_scores = 0.7 * bm25_scores[candidate_indices] + 0.3 * tfidf_similarities
+
+ sorted_candidate_indices = candidate_indices[np.argsort(combined_scores)[::-1][:top_k]]
+ sorted_combined_scores = np.sort(combined_scores)[::-1][:top_k]
+
+ # build result list
+ bm25_recalled_results = []
+ for rank, (doc_idx, combined_score) in enumerate(
+ zip(sorted_candidate_indices, sorted_combined_scores, strict=False), 1
+ ):
+ bm25_score = bm25_scores[doc_idx]
+
+ candidate_pos = np.where(candidate_indices == doc_idx)[0][0]
+ tfidf_score = tfidf_similarities[candidate_pos] if use_tfidf else 0
+
+ bm25_recalled_results.append(
+ {
+ "text": corpus[doc_idx],
+ "bm25_score": float(bm25_score),
+ "tfidf_score": float(tfidf_score),
+ "combined_score": float(combined_score),
+ "rank": rank,
+ "doc_index": int(doc_idx),
+ }
+ )
+
+ logger.debug(f"Search completed: found {len(bm25_recalled_results)} results")
+ return bm25_recalled_results
+
+ except Exception as e:
+ logger.error(f"BM25 search failed: {e}")
+ return []
+ finally:
+ # Always cleanup if requested
+ if cleanup:
+ self._cleanup_memory()
+
+ @timed
+ def search(self, query: str, node_dicts: list[dict], corpus_name="default", **kwargs):
+ """
+ Search with BM25 and optional TF-IDF reranking
+ """
+ try:
+ corpus_list = []
+ for node_dict in node_dicts:
+ corpus_list.append(
+ " ".join([node_dict["metadata"]["key"]] + node_dict["metadata"]["tags"])
+ )
+
+ recalled_results = self._search_docs(
+ query, corpus_list, corpus_name=corpus_name, **kwargs
+ )
+ bm25_searched_nodes = []
+ for item in recalled_results:
+ doc_idx = item["doc_index"]
+ bm25_searched_nodes.append(node_dicts[doc_idx])
+ return bm25_searched_nodes
+ except Exception as e:
+ logger.error(f"Error in bm25 search: {e}")
+ return []
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/recall.py b/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
index d4cfcf501..8cf2f47f3 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
@@ -5,6 +5,7 @@
from memos.graph_dbs.neo4j import Neo4jGraphDB
from memos.log import get_logger
from memos.memories.textual.item import TextualMemoryItem
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.retrieval_mid_structs import ParsedTaskGoal
@@ -16,11 +17,18 @@ class GraphMemoryRetriever:
Unified memory retriever that combines both graph-based and vector-based retrieval logic.
"""
- def __init__(self, graph_store: Neo4jGraphDB, embedder: OllamaEmbedder):
+ def __init__(
+ self,
+ graph_store: Neo4jGraphDB,
+ embedder: OllamaEmbedder,
+ bm25_retriever: EnhancedBM25 | None = None,
+ ):
self.graph_store = graph_store
self.embedder = embedder
+ self.bm25_retriever = bm25_retriever
self.max_workers = 10
self.filter_weight = 0.6
+ self.use_bm25 = bool(self.bm25_retriever)
def retrieve(
self,
@@ -31,6 +39,8 @@ def retrieve(
query_embedding: list[list[float]] | None = None,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
+ use_fast_graph: bool = False,
) -> list[TextualMemoryItem]:
"""
Perform hybrid memory retrieval:
@@ -58,9 +68,15 @@ def retrieve(
)
return [TextualMemoryItem.from_dict(record) for record in working_memories]
- with ContextThreadPoolExecutor(max_workers=2) as executor:
+ with ContextThreadPoolExecutor(max_workers=3) as executor:
# Structured graph-based retrieval
- future_graph = executor.submit(self._graph_recall, parsed_goal, memory_scope, user_name)
+ future_graph = executor.submit(
+ self._graph_recall,
+ parsed_goal,
+ memory_scope,
+ user_name,
+ use_fast_graph=use_fast_graph,
+ )
# Vector similarity search
future_vector = executor.submit(
self._vector_recall,
@@ -70,12 +86,23 @@ def retrieve(
search_filter=search_filter,
user_name=user_name,
)
+ if self.use_bm25:
+ future_bm25 = executor.submit(
+ self._bm25_recall,
+ query,
+ parsed_goal,
+ memory_scope,
+ top_k=top_k,
+ user_name=user_name,
+ search_filter=id_filter,
+ )
graph_results = future_graph.result()
vector_results = future_vector.result()
+ bm25_results = future_bm25.result() if self.use_bm25 else []
# Merge and deduplicate by ID
- combined = {item.id: item for item in graph_results + vector_results}
+ combined = {item.id: item for item in graph_results + vector_results + bm25_results}
graph_ids = {item.id for item in graph_results}
combined_ids = set(combined.keys())
@@ -135,7 +162,7 @@ def retrieve_from_cube(
return list(combined.values())
def _graph_recall(
- self, parsed_goal: ParsedTaskGoal, memory_scope: str, user_name: str | None = None
+ self, parsed_goal: ParsedTaskGoal, memory_scope: str, user_name: str | None = None, **kwargs
) -> list[TextualMemoryItem]:
"""
Perform structured node-based retrieval from Neo4j.
@@ -143,37 +170,9 @@ def _graph_recall(
- tags must overlap with at least 2 input tags
- scope filters by memory_type if provided
"""
- candidate_ids = set()
-
- # 1) key-based OR branch
- if parsed_goal.keys:
- key_filters = [
- {"field": "key", "op": "in", "value": parsed_goal.keys},
- {"field": "memory_type", "op": "=", "value": memory_scope},
- ]
- key_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
- candidate_ids.update(key_ids)
-
- # 2) tag-based OR branch
- if parsed_goal.tags:
- tag_filters = [
- {"field": "tags", "op": "contains", "value": parsed_goal.tags},
- {"field": "memory_type", "op": "=", "value": memory_scope},
- ]
- tag_ids = self.graph_store.get_by_metadata(tag_filters, user_name=user_name)
- candidate_ids.update(tag_ids)
-
- # No matches → return empty
- if not candidate_ids:
- return []
+ use_fast_graph = kwargs.get("use_fast_graph", False)
- # Load nodes and post-filter
- node_dicts = self.graph_store.get_nodes(
- list(candidate_ids), include_embedding=False, user_name=user_name
- )
-
- final_nodes = []
- for node in node_dicts:
+ def process_node(node):
meta = node.get("metadata", {})
node_key = meta.get("key")
node_tags = meta.get("tags", []) or []
@@ -184,19 +183,113 @@ def _graph_recall(
keep = True
# overlap tags more than 2
elif parsed_goal.tags:
- overlap = len(set(node_tags) & set(parsed_goal.tags))
+ node_tags_list = [tag.lower() for tag in node_tags]
+ overlap = len(set(node_tags_list) & set(parsed_goal.tags))
if overlap >= 2:
keep = True
+
if keep:
- final_nodes.append(TextualMemoryItem.from_dict(node))
- return final_nodes
+ return TextualMemoryItem.from_dict(node)
+ return None
+
+ if not use_fast_graph:
+ candidate_ids = set()
+
+ # 1) key-based OR branch
+ if parsed_goal.keys:
+ key_filters = [
+ {"field": "key", "op": "in", "value": parsed_goal.keys},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ key_ids = self.graph_store.get_by_metadata(key_filters)
+ candidate_ids.update(key_ids)
+
+ # 2) tag-based OR branch
+ if parsed_goal.tags:
+ tag_filters = [
+ {"field": "tags", "op": "contains", "value": parsed_goal.tags},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ tag_ids = self.graph_store.get_by_metadata(tag_filters)
+ candidate_ids.update(tag_ids)
+
+ # No matches → return empty
+ if not candidate_ids:
+ return []
+
+ # Load nodes and post-filter
+ node_dicts = self.graph_store.get_nodes(list(candidate_ids), include_embedding=False)
+
+ final_nodes = []
+ for node in node_dicts:
+ meta = node.get("metadata", {})
+ node_key = meta.get("key")
+ node_tags = meta.get("tags", []) or []
+
+ keep = False
+ # key equals to node_key
+ if parsed_goal.keys and node_key in parsed_goal.keys:
+ keep = True
+ # overlap tags more than 2
+ elif parsed_goal.tags:
+ overlap = len(set(node_tags) & set(parsed_goal.tags))
+ if overlap >= 2:
+ keep = True
+ if keep:
+ final_nodes.append(TextualMemoryItem.from_dict(node))
+ return final_nodes
+ else:
+ candidate_ids = set()
+
+ # 1) key-based OR branch
+ if parsed_goal.keys:
+ key_filters = [
+ {"field": "key", "op": "in", "value": parsed_goal.keys},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ key_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
+ candidate_ids.update(key_ids)
+
+ # 2) tag-based OR branch
+ if parsed_goal.tags:
+ tag_filters = [
+ {"field": "tags", "op": "contains", "value": parsed_goal.tags},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ tag_ids = self.graph_store.get_by_metadata(tag_filters, user_name=user_name)
+ candidate_ids.update(tag_ids)
+
+ # No matches → return empty
+ if not candidate_ids:
+ return []
+
+ # Load nodes and post-filter
+ node_dicts = self.graph_store.get_nodes(
+ list(candidate_ids), include_embedding=False, user_name=user_name
+ )
+
+ final_nodes = []
+ with ContextThreadPoolExecutor(max_workers=3) as executor:
+ futures = {
+ executor.submit(process_node, node): i for i, node in enumerate(node_dicts)
+ }
+ temp_results = [None] * len(node_dicts)
+
+ for future in concurrent.futures.as_completed(futures):
+ original_index = futures[future]
+ result = future.result()
+ temp_results[original_index] = result
+
+ final_nodes = [result for result in temp_results if result is not None]
+ return final_nodes
def _vector_recall(
self,
query_embedding: list[list[float]],
memory_scope: str,
top_k: int = 20,
- max_num: int = 3,
+ max_num: int = 5,
+ status: str = "activated",
cube_name: str | None = None,
search_filter: dict | None = None,
user_name: str | None = None,
@@ -213,6 +306,7 @@ def search_single(vec, filt=None):
self.graph_store.search_by_embedding(
vector=vec,
top_k=top_k,
+ status=status,
scope=memory_scope,
cube_name=cube_name,
search_filter=filt,
@@ -267,3 +361,37 @@ def search_path_b():
or []
)
return [TextualMemoryItem.from_dict(n) for n in node_dicts]
+
+ def _bm25_recall(
+ self,
+ query: str,
+ parsed_goal: ParsedTaskGoal,
+ memory_scope: str,
+ top_k: int = 20,
+ user_name: str | None = None,
+ search_filter: dict | None = None,
+ ) -> list[TextualMemoryItem]:
+ """
+ Perform BM25-based retrieval.
+ """
+ if not self.bm25_retriever:
+ return []
+ key_filters = [
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ # corpus_name is user_name + user_id
+ corpus_name = f"{user_name}" if user_name else ""
+ if search_filter is not None:
+ for key in search_filter:
+ value = search_filter[key]
+ key_filters.append({"field": key, "op": "=", "value": value})
+ corpus_name += "".join(list(search_filter.values()))
+ candidate_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
+ node_dicts = self.graph_store.get_nodes(list(candidate_ids), include_embedding=False)
+
+ bm25_query = " ".join(list({query, *parsed_goal.keys}))
+ bm25_results = self.bm25_retriever.search(
+ bm25_query, node_dicts, top_k=top_k, corpus_name=corpus_name
+ )
+
+ return [TextualMemoryItem.from_dict(n) for n in bm25_results]
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py b/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
index 6accc4a16..7aefaa1a3 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
@@ -13,3 +13,4 @@ class ParsedTaskGoal:
rephrased_query: str | None = None
internet_search: bool = False
goal_type: str | None = None # e.g., 'default', 'explanation', etc.
+ context: str = ""
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py b/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py
new file mode 100644
index 000000000..3f2b41a47
--- /dev/null
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py
@@ -0,0 +1,378 @@
+import json
+import re
+
+from pathlib import Path
+
+from memos.dependency import require_python_package
+from memos.log import get_logger
+
+
+logger = get_logger(__name__)
+
+
+def find_project_root(marker=".git"):
+ """Find the project root directory by marking the file"""
+ current = Path(__file__).resolve()
+ while current != current.parent:
+ if (current / marker).exists():
+ return current
+ current = current.parent
+ return Path(".")
+
+
+PROJECT_ROOT = find_project_root()
+DEFAULT_STOPWORD_FILE = (
+ PROJECT_ROOT / "examples" / "data" / "config" / "stopwords.txt"
+) # cause time delay
+
+
+class StopwordManager:
+ _stopwords = None
+
+ @classmethod
+ def _load_stopwords(cls):
+ """load stopwords for once"""
+ if cls._stopwords is not None:
+ return cls._stopwords
+
+ stopwords = set()
+ try:
+ with open(DEFAULT_STOPWORD_FILE, encoding="utf-8") as f:
+ stopwords = {line.strip() for line in f if line.strip()}
+ logger.info("Stopwords loaded successfully.")
+ except Exception as e:
+ logger.warning(f"Error loading stopwords: {e}, using default stopwords.")
+ stopwords = cls._load_default_stopwords()
+
+ cls._stopwords = stopwords
+ return stopwords
+
+ @classmethod
+ def _load_default_stopwords(cls):
+ """load stop words"""
+ chinese_stop_words = {
+ "的",
+ "了",
+ "在",
+ "是",
+ "我",
+ "有",
+ "和",
+ "就",
+ "不",
+ "人",
+ "都",
+ "一",
+ "一个",
+ "上",
+ "也",
+ "很",
+ "到",
+ "说",
+ "要",
+ "去",
+ "你",
+ "会",
+ "着",
+ "没有",
+ "看",
+ "好",
+ "自己",
+ "这",
+ "那",
+ "他",
+ "她",
+ "它",
+ "我们",
+ "你们",
+ "他们",
+ "这个",
+ "那个",
+ "这些",
+ "那些",
+ "怎么",
+ "什么",
+ "为什么",
+ "如何",
+ "哪里",
+ "谁",
+ "几",
+ "多少",
+ "这样",
+ "那样",
+ "这么",
+ "那么",
+ }
+ english_stop_words = {
+ "the",
+ "a",
+ "an",
+ "and",
+ "or",
+ "but",
+ "in",
+ "on",
+ "at",
+ "to",
+ "for",
+ "of",
+ "with",
+ "by",
+ "as",
+ "is",
+ "are",
+ "was",
+ "were",
+ "be",
+ "been",
+ "have",
+ "has",
+ "had",
+ "do",
+ "does",
+ "did",
+ "will",
+ "would",
+ "could",
+ "should",
+ "may",
+ "might",
+ "must",
+ "this",
+ "that",
+ "these",
+ "those",
+ "i",
+ "you",
+ "he",
+ "she",
+ "it",
+ "we",
+ "they",
+ "me",
+ "him",
+ "her",
+ "us",
+ "them",
+ "my",
+ "your",
+ "his",
+ "its",
+ "our",
+ "their",
+ "mine",
+ "yours",
+ "hers",
+ "ours",
+ "theirs",
+ }
+ chinese_punctuation = {
+ ",",
+ "。",
+ "!",
+ "?",
+ ";",
+ ":",
+ "「",
+ "」",
+ "『",
+ "』",
+ "【",
+ "】",
+ "(",
+ ")",
+ "《",
+ "》",
+ "—",
+ "…",
+ "~",
+ "·",
+ "、",
+ "“",
+ "”",
+ "‘",
+ "’",
+ "〈",
+ "〉",
+ "〖",
+ "〗",
+ "〝",
+ "〞",
+ "{",
+ "}",
+ "〔",
+ "〕",
+ "¡",
+ "¿",
+ }
+ english_punctuation = {
+ ",",
+ ".",
+ "!",
+ "?",
+ ";",
+ ":",
+ '"',
+ "'",
+ "(",
+ ")",
+ "[",
+ "]",
+ "{",
+ "}",
+ "<",
+ ">",
+ "/",
+ "\\",
+ "|",
+ "-",
+ "_",
+ "=",
+ "+",
+ "@",
+ "#",
+ "$",
+ "%",
+ "^",
+ "&",
+ "*",
+ "~",
+ "`",
+ "¡",
+ "¿",
+ }
+ numbers = {
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5",
+ "6",
+ "7",
+ "8",
+ "9",
+ "零",
+ "一",
+ "二",
+ "三",
+ "四",
+ "五",
+ "六",
+ "七",
+ "八",
+ "九",
+ "十",
+ "百",
+ "千",
+ "万",
+ "亿",
+ }
+ whitespace = {" ", "\t", "\n", "\r", "\f", "\v"}
+
+ return (
+ chinese_stop_words
+ | english_stop_words
+ | chinese_punctuation
+ | english_punctuation
+ | numbers
+ | whitespace
+ )
+
+ @classmethod
+ def get_stopwords(cls):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return cls._stopwords
+
+ @classmethod
+ def filter_words(cls, words):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return [word for word in words if word not in cls._stopwords and word.strip()]
+
+ @classmethod
+ def is_stopword(cls, word):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return word in cls._stopwords
+
+ @classmethod
+ def reload_stopwords(cls, file_path=None):
+ cls._stopwords = None
+ if file_path:
+ global DEFAULT_STOPWORD_FILE
+ DEFAULT_STOPWORD_FILE = file_path
+ cls._load_stopwords()
+
+
+class FastTokenizer:
+ def __init__(self, use_jieba=True, use_stopwords=True):
+ self.use_jieba = use_jieba
+ self.use_stopwords = use_stopwords
+ if self.use_stopwords:
+ self.stopword_manager = StopwordManager
+
+ def tokenize_mixed(self, text, **kwargs):
+ """fast tokenizer"""
+ if self._is_chinese(text):
+ return self._tokenize_chinese(text)
+ else:
+ return self._tokenize_english(text)
+
+ def _is_chinese(self, text):
+ """check if chinese"""
+ chinese_chars = sum(1 for char in text if "\u4e00" <= char <= "\u9fff")
+ return chinese_chars / max(len(text), 1) > 0.3
+
+ @require_python_package(
+ import_name="jieba",
+ install_command="pip install jieba",
+ install_link="https://github.com/fxsjy/jieba",
+ )
+ def _tokenize_chinese(self, text):
+ """split zh jieba"""
+ import jieba
+
+ tokens = jieba.lcut(text) if self.use_jieba else list(text)
+ tokens = [token.strip() for token in tokens if token.strip()]
+ if self.use_stopwords:
+ return self.stopword_manager.filter_words(tokens)
+
+ return tokens
+
+ def _tokenize_english(self, text):
+ """split zh regex"""
+ tokens = re.findall(r"\b[a-zA-Z0-9]+\b", text.lower())
+ if self.use_stopwords:
+ return self.stopword_manager.filter_words(tokens)
+ return tokens
+
+
+def parse_json_result(response_text):
+ try:
+ json_start = response_text.find("{")
+ response_text = response_text[json_start:]
+ response_text = response_text.replace("```", "").strip()
+ if not response_text.endswith("}"):
+ response_text += "}"
+ return json.loads(response_text)
+ except json.JSONDecodeError as e:
+ logger.error(f"[JSONParse] Failed to decode JSON: {e}\nRaw:\n{response_text}")
+ return {}
+ except Exception as e:
+ logger.error(f"[JSONParse] Unexpected error: {e}")
+ return {}
+
+
+def detect_lang(text):
+ try:
+ if not text or not isinstance(text, str):
+ return "en"
+ chinese_pattern = r"[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df\U0002a700-\U0002b73f\U0002b740-\U0002b81f\U0002b820-\U0002ceaf\uf900-\ufaff]"
+ chinese_chars = re.findall(chinese_pattern, text)
+ if len(chinese_chars) / len(re.sub(r"[\s\d\W]", "", text)) > 0.3:
+ return "zh"
+ return "en"
+ except Exception:
+ return "en"
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py b/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
index 05db56f53..f408755fd 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
@@ -1,15 +1,23 @@
-import json
import traceback
-from datetime import datetime
-
from memos.context.context import ContextThreadPoolExecutor
from memos.embedders.factory import OllamaEmbedder
from memos.graph_dbs.factory import Neo4jGraphDB
from memos.llms.factory import AzureLLM, OllamaLLM, OpenAILLM
from memos.log import get_logger
from memos.memories.textual.item import SearchedTreeNodeTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import (
+ detect_lang,
+ parse_json_result,
+)
from memos.reranker.base import BaseReranker
+from memos.templates.mem_search_prompts import (
+ COT_PROMPT,
+ COT_PROMPT_ZH,
+ SIMPLE_COT_PROMPT,
+ SIMPLE_COT_PROMPT_ZH,
+)
from memos.utils import timed
from .reasoner import MemoryReasoner
@@ -18,6 +26,10 @@
logger = get_logger(__name__)
+COT_DICT = {
+ "fine": {"en": COT_PROMPT, "zh": COT_PROMPT_ZH},
+ "fast": {"en": SIMPLE_COT_PROMPT, "zh": SIMPLE_COT_PROMPT_ZH},
+}
class Searcher:
@@ -27,23 +39,71 @@ def __init__(
graph_store: Neo4jGraphDB,
embedder: OllamaEmbedder,
reranker: BaseReranker,
+ bm25_retriever: EnhancedBM25 | None = None,
internet_retriever: None = None,
moscube: bool = False,
+ search_strategy: dict | None = None,
):
self.graph_store = graph_store
self.embedder = embedder
+ self.llm = dispatcher_llm
self.task_goal_parser = TaskGoalParser(dispatcher_llm)
- self.graph_retriever = GraphMemoryRetriever(self.graph_store, self.embedder)
+ self.graph_retriever = GraphMemoryRetriever(graph_store, embedder, bm25_retriever)
self.reranker = reranker
self.reasoner = MemoryReasoner(dispatcher_llm)
# Create internet retriever from config if provided
self.internet_retriever = internet_retriever
self.moscube = moscube
+ self.vec_cot = search_strategy.get("cot", False) if search_strategy else False
+ self.use_fast_graph = search_strategy.get("fast_graph", False) if search_strategy else False
self._usage_executor = ContextThreadPoolExecutor(max_workers=4, thread_name_prefix="usage")
+ @timed
+ def retrieve(
+ self,
+ query: str,
+ top_k: int,
+ info=None,
+ mode="fast",
+ memory_type="All",
+ search_filter: dict | None = None,
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[TextualMemoryItem]:
+ logger.info(
+ f"[RECALL] Start query='{query}', top_k={top_k}, mode={mode}, memory_type={memory_type}"
+ )
+ parsed_goal, query_embedding, context, query = self._parse_task(
+ query, info, mode, search_filter=search_filter, user_name=user_name
+ )
+ results = self._retrieve_paths(
+ query,
+ parsed_goal,
+ query_embedding,
+ info,
+ top_k,
+ mode,
+ memory_type,
+ search_filter,
+ user_name,
+ )
+ return results
+
+ def post_retrieve(
+ self,
+ retrieved_results: list[TextualMemoryItem],
+ top_k: int,
+ user_name: str | None = None,
+ info=None,
+ ):
+ deduped = self._deduplicate_results(retrieved_results)
+ final_results = self._sort_and_trim(deduped, top_k)
+ self._update_usage_history(final_results, info, user_name)
+ return final_results
+
@timed
def search(
self,
@@ -72,9 +132,6 @@ def search(
Returns:
list[TextualMemoryItem]: List of matching memories.
"""
- logger.info(
- f"[SEARCH] Start query='{query}', top_k={top_k}, mode={mode}, memory_type={memory_type}"
- )
if not info:
logger.warning(
"Please input 'info' when use tree.search so that "
@@ -84,23 +141,22 @@ def search(
else:
logger.debug(f"[SEARCH] Received info dict: {info}")
- parsed_goal, query_embedding, context, query = self._parse_task(
- query, info, mode, search_filter=search_filter, user_name=user_name
+ retrieved_results = self.retrieve(
+ query=query,
+ top_k=top_k,
+ info=info,
+ mode=mode,
+ memory_type=memory_type,
+ search_filter=search_filter,
+ user_name=user_name,
)
- results = self._retrieve_paths(
- query,
- parsed_goal,
- query_embedding,
- info,
- top_k,
- mode,
- memory_type,
- search_filter,
- user_name,
+
+ final_results = self.post_retrieve(
+ retrieved_results=retrieved_results,
+ top_k=top_k,
+ user_name=user_name,
+ info=None,
)
- deduped = self._deduplicate_results(results)
- final_results = self._sort_and_trim(deduped, top_k)
- self._update_usage_history(final_results, info, user_name)
logger.info(f"[SEARCH] Done. Total {len(final_results)} results.")
res_results = ""
@@ -134,7 +190,11 @@ def _parse_task(
related_nodes = [
self.graph_store.get_node(n["id"])
for n in self.graph_store.search_by_embedding(
- query_embedding, top_k=top_k, search_filter=search_filter, user_name=user_name
+ query_embedding,
+ top_k=top_k,
+ status="activated",
+ search_filter=search_filter,
+ user_name=user_name,
)
]
memories = []
@@ -164,6 +224,7 @@ def _parse_task(
context="\n".join(context),
conversation=info.get("chat_history", []),
mode=mode,
+ use_fast_graph=self.use_fast_graph,
)
query = parsed_goal.rephrased_query or query
@@ -188,6 +249,12 @@ def _retrieve_paths(
):
"""Run A/B/C retrieval paths in parallel"""
tasks = []
+ id_filter = {
+ "user_id": info.get("user_id", None),
+ "session_id": info.get("session_id", None),
+ }
+ id_filter = {k: v for k, v in id_filter.items() if v is not None}
+
with ContextThreadPoolExecutor(max_workers=3) as executor:
tasks.append(
executor.submit(
@@ -199,6 +266,7 @@ def _retrieve_paths(
memory_type,
search_filter,
user_name,
+ id_filter,
)
)
tasks.append(
@@ -211,6 +279,8 @@ def _retrieve_paths(
memory_type,
search_filter,
user_name,
+ id_filter,
+ mode=mode,
)
)
tasks.append(
@@ -256,6 +326,7 @@ def _retrieve_from_working_memory(
memory_type,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
):
"""Retrieve and rerank from WorkingMemory"""
if memory_type not in ["All", "WorkingMemory"]:
@@ -268,6 +339,8 @@ def _retrieve_from_working_memory(
memory_scope="WorkingMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
return self.reranker.rerank(
query=query,
@@ -289,11 +362,23 @@ def _retrieve_from_long_term_and_user(
memory_type,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
+ mode: str = "fast",
):
"""Retrieve and rerank from LongTermMemory and UserMemory"""
results = []
tasks = []
+ # chain of thinking
+ cot_embeddings = []
+ if self.vec_cot:
+ queries = self._cot_query(query, mode=mode, context=parsed_goal.context)
+ if len(queries) > 1:
+ cot_embeddings = self.embedder.embed(queries)
+ cot_embeddings.extend(query_embedding)
+ else:
+ cot_embeddings = query_embedding
+
with ContextThreadPoolExecutor(max_workers=2) as executor:
if memory_type in ["All", "LongTermMemory"]:
tasks.append(
@@ -301,11 +386,13 @@ def _retrieve_from_long_term_and_user(
self.graph_retriever.retrieve,
query=query,
parsed_goal=parsed_goal,
- query_embedding=query_embedding,
+ query_embedding=cot_embeddings,
top_k=top_k * 2,
memory_scope="LongTermMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
)
if memory_type in ["All", "UserMemory"]:
@@ -314,11 +401,13 @@ def _retrieve_from_long_term_and_user(
self.graph_retriever.retrieve,
query=query,
parsed_goal=parsed_goal,
- query_embedding=query_embedding,
+ query_embedding=cot_embeddings,
top_k=top_k * 2,
memory_scope="UserMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
)
@@ -399,6 +488,7 @@ def _deduplicate_results(self, results):
@timed
def _sort_and_trim(self, results, top_k):
"""Sort results by score and trim to top_k"""
+
sorted_results = sorted(results, key=lambda pair: pair[1], reverse=True)[:top_k]
final_items = []
for item, score in sorted_results:
@@ -415,7 +505,7 @@ def _sort_and_trim(self, results, top_k):
@timed
def _update_usage_history(self, items, info, user_name: str | None = None):
- """Update usage history in graph DB"""
+ """Update usage history in graph DB
now_time = datetime.now().isoformat()
info_copy = dict(info or {})
info_copy.pop("chat_history", None)
@@ -439,6 +529,7 @@ def _update_usage_history(self, items, info, user_name: str | None = None):
self._usage_executor.submit(
self._update_usage_history_worker, payload, usage_record, user_name
)
+ """
def _update_usage_history_worker(
self, payload, usage_record: str, user_name: str | None = None
@@ -448,3 +539,41 @@ def _update_usage_history_worker(
self.graph_store.update_node(item_id, {"usage": usage_list}, user_name=user_name)
except Exception:
logger.exception("[USAGE] update usage failed")
+
+ def _cot_query(
+ self,
+ query,
+ mode="fast",
+ split_num: int = 3,
+ context: list[str] | None = None,
+ ) -> list[str]:
+ """Generate chain-of-thought queries"""
+
+ lang = detect_lang(query)
+ if mode == "fine" and context:
+ template = COT_DICT["fine"][lang]
+ prompt = (
+ template.replace("${original_query}", query)
+ .replace("${split_num_threshold}", str(split_num))
+ .replace("${context}", "\n".join(context))
+ )
+ else:
+ template = COT_DICT["fast"][lang]
+ prompt = template.replace("${original_query}", query).replace(
+ "${split_num_threshold}", str(split_num)
+ )
+
+ messages = [{"role": "user", "content": prompt}]
+ try:
+ response_text = self.llm.generate(messages, temperature=0, top_p=1)
+ response_json = parse_json_result(response_text)
+ assert "is_complex" in response_json
+ if not response_json["is_complex"]:
+ return [query]
+ else:
+ assert "sub_questions" in response_json
+ logger.info("Query: {} COT: {}".format(query, response_json["sub_questions"]))
+ return response_json["sub_questions"][:split_num]
+ except Exception as e:
+ logger.error(f"[LLM] Exception during chat generation: {e}")
+ return [query]
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py b/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
index 273c4f480..55e33494c 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
@@ -5,6 +5,7 @@
from memos.llms.base import BaseLLM
from memos.log import get_logger
from memos.memories.textual.tree_text_memory.retrieve.retrieval_mid_structs import ParsedTaskGoal
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import FastTokenizer
from memos.memories.textual.tree_text_memory.retrieve.utils import TASK_PARSE_PROMPT
@@ -20,6 +21,7 @@ class TaskGoalParser:
def __init__(self, llm=BaseLLM):
self.llm = llm
+ self.tokenizer = FastTokenizer()
def parse(
self,
@@ -27,6 +29,7 @@ def parse(
context: str = "",
conversation: list[dict] | None = None,
mode: str = "fast",
+ **kwargs,
) -> ParsedTaskGoal:
"""
Parse user input into structured semantic layers.
@@ -36,7 +39,7 @@ def parse(
- mode == 'fine': use LLM to parse structured topic/keys/tags
"""
if mode == "fast":
- return self._parse_fast(task_description)
+ return self._parse_fast(task_description, context=context, **kwargs)
elif mode == "fine":
if not self.llm:
raise ValueError("LLM not provided for slow mode.")
@@ -44,18 +47,33 @@ def parse(
else:
raise ValueError(f"Unknown mode: {mode}")
- def _parse_fast(self, task_description: str, limit_num: int = 5) -> ParsedTaskGoal:
+ def _parse_fast(self, task_description: str, **kwargs) -> ParsedTaskGoal:
"""
Fast mode: simple jieba word split.
"""
- return ParsedTaskGoal(
- memories=[task_description],
- keys=[task_description],
- tags=[],
- goal_type="default",
- rephrased_query=task_description,
- internet_search=False,
- )
+ context = kwargs.get("context", "")
+ use_fast_graph = kwargs.get("use_fast_graph", False)
+ if use_fast_graph:
+ desc_tokenized = self.tokenizer.tokenize_mixed(task_description)
+ return ParsedTaskGoal(
+ memories=[task_description],
+ keys=desc_tokenized,
+ tags=desc_tokenized,
+ goal_type="default",
+ rephrased_query=task_description,
+ internet_search=False,
+ context=context,
+ )
+ else:
+ return ParsedTaskGoal(
+ memories=[task_description],
+ keys=[task_description],
+ tags=[],
+ goal_type="default",
+ rephrased_query=task_description,
+ internet_search=False,
+ context=context,
+ )
def _parse_fine(
self, query: str, context: str = "", conversation: list[dict] | None = None
@@ -76,16 +94,17 @@ def _parse_fine(
logger.info(f"Parsing Goal... LLM input is {prompt}")
response = self.llm.generate(messages=[{"role": "user", "content": prompt}])
logger.info(f"Parsing Goal... LLM Response is {response}")
- return self._parse_response(response)
+ return self._parse_response(response, context=context)
except Exception:
logger.warning(f"Fail to fine-parse query {query}: {traceback.format_exc()}")
- return self._parse_fast(query)
+ return self._parse_fast(query, context=context)
- def _parse_response(self, response: str) -> ParsedTaskGoal:
+ def _parse_response(self, response: str, **kwargs) -> ParsedTaskGoal:
"""
Parse LLM JSON output safely.
"""
try:
+ context = kwargs.get("context", "")
response = response.replace("```", "").replace("json", "").strip()
response_json = eval(response)
return ParsedTaskGoal(
@@ -95,6 +114,7 @@ def _parse_response(self, response: str) -> ParsedTaskGoal:
rephrased_query=response_json.get("rephrased_instruction", None),
internet_search=response_json.get("internet_search", False),
goal_type=response_json.get("goal_type", "default"),
+ context=context,
)
except Exception as e:
raise ValueError(f"Failed to parse LLM output: {e}\nRaw response:\n{response}") from e
diff --git a/src/memos/reranker/base.py b/src/memos/reranker/base.py
index 77a24c164..1c2f86ac5 100644
--- a/src/memos/reranker/base.py
+++ b/src/memos/reranker/base.py
@@ -16,8 +16,9 @@ class BaseReranker(ABC):
def rerank(
self,
query: str,
- graph_results: list,
+ graph_results: list[TextualMemoryItem],
top_k: int,
+ search_filter: dict | None = None,
**kwargs,
) -> list[tuple[TextualMemoryItem, float]]:
"""Return top_k (item, score) sorted by score desc."""
diff --git a/src/memos/reranker/concat.py b/src/memos/reranker/concat.py
index 5ad339529..502af18b6 100644
--- a/src/memos/reranker/concat.py
+++ b/src/memos/reranker/concat.py
@@ -2,12 +2,49 @@
from typing import Any
+from memos.memories.textual.item import SourceMessage
+
_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+def get_encoded_tokens(content: str) -> int:
+ """
+ Get encoded tokens.
+ Args:
+ content: str
+ Returns:
+ int: Encoded tokens.
+ """
+ return len(content)
+
+
+def truncate_data(data: list[str | dict[str, Any] | Any], max_tokens: int) -> list[str]:
+ """
+ Truncate data to max tokens.
+ Args:
+ data: List of strings or dictionaries.
+ max_tokens: Maximum number of tokens.
+ Returns:
+ str: Truncated string.
+ """
+ truncated_string = ""
+ for item in data:
+ if isinstance(item, SourceMessage):
+ content = getattr(item, "content", "")
+ chat_time = getattr(item, "chat_time", "")
+ if not content:
+ continue
+ truncated_string += f"[{chat_time}]: {content}\n"
+ if get_encoded_tokens(truncated_string) > max_tokens:
+ break
+ return truncated_string
+
+
def process_source(
- items: list[tuple[Any, str | dict[str, Any] | list[Any]]] | None = None, recent_num: int = 3
+ items: list[tuple[Any, str | dict[str, Any] | list[Any]]] | None = None,
+ recent_num: int = 10,
+ max_tokens: int = 2048,
) -> str:
"""
Args:
@@ -23,19 +60,16 @@ def process_source(
memory = None
for item in items:
memory, source = item
- for content in source:
- if isinstance(content, str):
- if "assistant:" in content:
- continue
- concat_data.append(content)
+ concat_data.extend(source[-recent_num:])
+ truncated_string = truncate_data(concat_data, max_tokens)
if memory is not None:
- concat_data = [memory, *concat_data]
- return "\n".join(concat_data)
+ truncated_string = f"{memory}\n{truncated_string}"
+ return truncated_string
def concat_original_source(
graph_results: list,
- merge_field: list[str] | None = None,
+ rerank_source: str | None = None,
) -> list[str]:
"""
Merge memory items with original dialogue.
@@ -45,14 +79,16 @@ def concat_original_source(
Returns:
list[str]: List of memory and concat orginal memory.
"""
- if merge_field is None:
- merge_field = ["sources"]
+ merge_field = []
+ merge_field = ["sources"] if rerank_source is None else rerank_source.split(",")
documents = []
for item in graph_results:
memory = _TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m
sources = []
for field in merge_field:
- source = getattr(item.metadata, field, "")
+ source = getattr(item.metadata, field, None)
+ if source is None:
+ continue
sources.append((memory, source))
concat_string = process_source(sources)
documents.append(concat_string)
diff --git a/src/memos/reranker/cosine_local.py b/src/memos/reranker/cosine_local.py
index 000b64cf4..318cd744a 100644
--- a/src/memos/reranker/cosine_local.py
+++ b/src/memos/reranker/cosine_local.py
@@ -3,6 +3,9 @@
from typing import TYPE_CHECKING
+from memos.log import get_logger
+from memos.utils import timed
+
from .base import BaseReranker
@@ -16,6 +19,8 @@
except Exception:
_HAS_NUMPY = False
+logger = get_logger(__name__)
+
def _cosine_one_to_many(q: list[float], m: list[list[float]]) -> list[float]:
"""
@@ -54,6 +59,7 @@ def __init__(
self.level_weights = level_weights or {"topic": 1.0, "concept": 1.0, "fact": 1.0}
self.level_field = level_field
+ @timed
def rerank(
self,
query: str,
@@ -92,5 +98,5 @@ def get_weight(it: TextualMemoryItem) -> float:
chosen = {it.id for it, _ in top_items}
remain = [(it, -1.0) for it in graph_results if it.id not in chosen]
top_items.extend(remain[: top_k - len(top_items)])
-
+ logger.info(f"CosineLocalReranker rerank result: {top_items[:1]}")
return top_items
diff --git a/src/memos/reranker/factory.py b/src/memos/reranker/factory.py
index 134e29eb9..57460a4af 100644
--- a/src/memos/reranker/factory.py
+++ b/src/memos/reranker/factory.py
@@ -8,6 +8,7 @@
from .cosine_local import CosineLocalReranker
from .http_bge import HTTPBGEReranker
+from .http_bge_strategy import HTTPBGERerankerStrategy
from .noop import NoopReranker
@@ -45,4 +46,14 @@ def from_config(cfg: RerankerConfigFactory | None) -> BaseReranker | None:
if backend in {"noop", "none", "disabled"}:
return NoopReranker()
+ if backend in {"http_bge_strategy", "bge_strategy"}:
+ return HTTPBGERerankerStrategy(
+ reranker_url=c.get("url") or c.get("endpoint") or c.get("reranker_url"),
+ model=c.get("model", "bge-reranker-v2-m3"),
+ timeout=int(c.get("timeout", 10)),
+ headers_extra=c.get("headers_extra"),
+ rerank_source=c.get("rerank_source"),
+ reranker_strategy=c.get("reranker_strategy"),
+ )
+
raise ValueError(f"Unknown reranker backend: {cfg.backend}")
diff --git a/src/memos/reranker/http_bge.py b/src/memos/reranker/http_bge.py
index f0f5d17a0..41011df14 100644
--- a/src/memos/reranker/http_bge.py
+++ b/src/memos/reranker/http_bge.py
@@ -9,6 +9,7 @@
import requests
from memos.log import get_logger
+from memos.utils import timed
from .base import BaseReranker
from .concat import concat_original_source
@@ -80,7 +81,7 @@ def __init__(
model: str = "bge-reranker-v2-m3",
timeout: int = 10,
headers_extra: dict | None = None,
- rerank_source: list[str] | None = None,
+ rerank_source: str | None = None,
boost_weights: dict[str, float] | None = None,
boost_default: float = 0.0,
warn_unknown_filter_keys: bool = True,
@@ -107,7 +108,7 @@ def __init__(
self.model = model
self.timeout = timeout
self.headers_extra = headers_extra or {}
- self.concat_source = rerank_source
+ self.rerank_source = rerank_source
self.boost_weights = (
DEFAULT_BOOST_WEIGHTS.copy()
@@ -118,6 +119,7 @@ def __init__(
self.warn_unknown_filter_keys = bool(warn_unknown_filter_keys)
self._warned_missing_keys: set[str] = set()
+ @timed(log=True, log_prefix="RerankerAPI")
def rerank(
self,
query: str,
@@ -152,8 +154,8 @@ def rerank(
# Build a mapping from "payload docs index" -> "original graph_results index"
# Only include items that have a non-empty string memory. This ensures that
# any index returned by the server can be mapped back correctly.
- if self.concat_source:
- documents = concat_original_source(graph_results, self.concat_source)
+ if self.rerank_source:
+ documents = concat_original_source(graph_results, self.rerank_source)
else:
documents = [
(_TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m)
diff --git a/src/memos/reranker/http_bge_strategy.py b/src/memos/reranker/http_bge_strategy.py
new file mode 100644
index 000000000..b0567698c
--- /dev/null
+++ b/src/memos/reranker/http_bge_strategy.py
@@ -0,0 +1,319 @@
+# memos/reranker/http_bge.py
+from __future__ import annotations
+
+import re
+
+from collections.abc import Iterable
+from typing import TYPE_CHECKING, Any
+
+import requests
+
+from memos.log import get_logger
+from memos.reranker.strategies import RerankerStrategyFactory
+from memos.utils import timed
+
+from .base import BaseReranker
+
+
+logger = get_logger(__name__)
+
+
+if TYPE_CHECKING:
+ from memos.memories.textual.item import TextualMemoryItem
+
+# Strip a leading "[...]" tag (e.g., "[2025-09-01] ..." or "[meta] ...")
+# before sending text to the reranker. This keeps inputs clean and
+# avoids misleading the model with bracketed prefixes.
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+DEFAULT_BOOST_WEIGHTS = {"user_id": 0.5, "tags": 0.2, "session_id": 0.3}
+
+
+def _value_matches(item_value: Any, wanted: Any) -> bool:
+ """
+ Generic matching:
+ - if item_value is list/tuple/set: check membership (any match if wanted is iterable)
+ - else: equality (any match if wanted is iterable)
+ """
+
+ def _iterable(x):
+ # exclude strings from "iterable"
+ return isinstance(x, Iterable) and not isinstance(x, str | bytes)
+
+ if _iterable(item_value):
+ if _iterable(wanted):
+ return any(w in item_value for w in wanted)
+ return wanted in item_value
+ else:
+ if _iterable(wanted):
+ return any(item_value == w for w in wanted)
+ return item_value == wanted
+
+
+class HTTPBGERerankerStrategy(BaseReranker):
+ """
+ HTTP-based BGE reranker.
+
+ This class sends (query, documents[]) to a remote HTTP endpoint that
+ performs cross-encoder-style re-ranking (e.g., BGE reranker) and returns
+ relevance scores. It then maps those scores back onto the original
+ TextualMemoryItem list and returns (item, score) pairs sorted by score.
+
+ Notes
+ -----
+ - The endpoint is expected to accept JSON:
+ {
+ "model": "",
+ "query": "",
+ "documents": ["doc1", "doc2", ...]
+ }
+ - Two response shapes are supported:
+ 1) {"results": [{"index": , "relevance_score": }, ...]}
+ where "index" refers to the *position in the documents array*.
+ 2) {"data": [{"score": }, ...]} (aligned by list order)
+ - If the service fails or responds unexpectedly, this falls back to
+ returning the original items with 0.0 scores (best-effort).
+ """
+
+ def __init__(
+ self,
+ reranker_url: str,
+ token: str = "",
+ model: str = "bge-reranker-v2-m3",
+ timeout: int = 10,
+ headers_extra: dict | None = None,
+ rerank_source: str | None = None,
+ boost_weights: dict[str, float] | None = None,
+ boost_default: float = 0.0,
+ warn_unknown_filter_keys: bool = True,
+ reranker_strategy: str = "single_turn",
+ **kwargs,
+ ):
+ """
+ Parameters
+ ----------
+ reranker_url : str
+ HTTP endpoint for the reranker service.
+ token : str, optional
+ Bearer token for auth. If non-empty, added to the Authorization header.
+ model : str, optional
+ Model identifier understood by the server.
+ timeout : int, optional
+ Request timeout (seconds).
+ headers_extra : dict | None, optional
+ Additional headers to merge into the request headers.
+ """
+ if not reranker_url:
+ raise ValueError("reranker_url must not be empty")
+ self.reranker_url = reranker_url
+ self.token = token or ""
+ self.model = model
+ self.timeout = timeout
+ self.headers_extra = headers_extra or {}
+
+ self.boost_weights = (
+ DEFAULT_BOOST_WEIGHTS.copy()
+ if boost_weights is None
+ else {k: float(v) for k, v in boost_weights.items()}
+ )
+ self.boost_default = float(boost_default)
+ self.warn_unknown_filter_keys = bool(warn_unknown_filter_keys)
+ self._warned_missing_keys: set[str] = set()
+ self.reranker_strategy = RerankerStrategyFactory.from_config(reranker_strategy)
+
+ @timed(log=True, log_prefix="RerankerStrategy")
+ def rerank(
+ self,
+ query: str,
+ graph_results: list[TextualMemoryItem],
+ top_k: int,
+ search_filter: dict | None = None,
+ **kwargs,
+ ) -> list[tuple[TextualMemoryItem, float]]:
+ """
+ Rank candidate memories by relevance to the query.
+
+ Parameters
+ ----------
+ query : str
+ The search query.
+ graph_results : list[TextualMemoryItem]
+ Candidate items to re-rank. Each item is expected to have a
+ `.memory` str field; non-strings are ignored.
+ top_k : int
+ Return at most this many items.
+ search_filter : dict | None
+ Currently unused. Present to keep signature compatible.
+
+ Returns
+ -------
+ list[tuple[TextualMemoryItem, float]]
+ Re-ranked items with scores, sorted descending by score.
+ """
+ if not graph_results:
+ return []
+
+ tracker, original_items, documents = self.reranker_strategy.prepare_documents(
+ query, graph_results, top_k
+ )
+
+ logger.info(
+ f"[HTTPBGEWithSourceReranker] strategy: {self.reranker_strategy}, "
+ f"query: {query}, documents count: {len(documents)}"
+ )
+ logger.info(f"[HTTPBGEWithSourceReranker] sample documents: {documents[:3]}...")
+
+ if not documents:
+ return []
+
+ headers = {"Content-Type": "application/json", **self.headers_extra}
+ payload = {"model": self.model, "query": query, "documents": documents}
+
+ try:
+ # Make the HTTP request to the reranker service
+ resp = requests.post(
+ self.reranker_url, headers=headers, json=payload, timeout=self.timeout
+ )
+ resp.raise_for_status()
+ data = resp.json()
+
+ scored_items: list[tuple[TextualMemoryItem, float]] = []
+
+ if "results" in data:
+ # Format:
+ # dict("results": [{"index": int, "relevance_score": float},
+ # ...])
+ rows = data.get("results", [])
+
+ ranked_indices = []
+ scores = []
+ for r in rows:
+ idx = r.get("index")
+ # The returned index refers to 'documents' (i.e., our 'pairs' order),
+ # so we must map it back to the original graph_results index.
+ if isinstance(idx, int) and 0 <= idx < len(graph_results):
+ raw_score = float(r.get("relevance_score", r.get("score", 0.0)))
+ ranked_indices.append(idx)
+ scores.append(raw_score)
+ reconstructed_items = self.reranker_strategy.reconstruct_items(
+ ranked_indices=ranked_indices,
+ scores=scores,
+ tracker=tracker,
+ original_items=original_items,
+ top_k=top_k,
+ graph_results=graph_results,
+ documents=documents,
+ )
+ return reconstructed_items
+
+ elif "data" in data:
+ # Format: {"data": [{"score": float}, ...]} aligned by list order
+ rows = data.get("data", [])
+ # Build a list of scores aligned with our 'documents' (pairs)
+ score_list = [float(r.get("score", 0.0)) for r in rows]
+
+ if len(score_list) < len(graph_results):
+ score_list += [0.0] * (len(graph_results) - len(score_list))
+ elif len(score_list) > len(graph_results):
+ score_list = score_list[: len(graph_results)]
+
+ scored_items = []
+ for item, raw_score in zip(graph_results, score_list, strict=False):
+ score = self._apply_boost_generic(item, raw_score, search_filter)
+ scored_items.append((item, score))
+
+ scored_items.sort(key=lambda x: x[1], reverse=True)
+ return scored_items[: min(top_k, len(scored_items))]
+
+ else:
+ # Unexpected response schema: return a 0.0-scored fallback of the first top_k valid docs
+ # Note: we use 'pairs' to keep alignment with valid (string) docs.
+ return [(item, 0.0) for item in graph_results[:top_k]]
+
+ except Exception as e:
+ # Network error, timeout, JSON decode error, etc.
+ # Degrade gracefully by returning first top_k valid docs with 0.0 score.
+ logger.error(f"[HTTPBGEReranker] request failed: {e}")
+ return [(item, 0.0) for item in graph_results[:top_k]]
+
+ def _get_attr_or_key(self, obj: Any, key: str) -> Any:
+ """
+ Resolve `key` on `obj` with one-level fallback into `obj.metadata`.
+
+ Priority:
+ 1) obj.
+ 2) obj[key]
+ 3) obj.metadata.
+ 4) obj.metadata[key]
+ """
+ if obj is None:
+ return None
+
+ # support input like "metadata.user_id"
+ if "." in key:
+ head, tail = key.split(".", 1)
+ base = self._get_attr_or_key(obj, head)
+ return self._get_attr_or_key(base, tail)
+
+ def _resolve(o: Any, k: str):
+ if o is None:
+ return None
+ v = getattr(o, k, None)
+ if v is not None:
+ return v
+ if hasattr(o, "get"):
+ try:
+ return o.get(k)
+ except Exception:
+ return None
+ return None
+
+ # 1) find in obj
+ v = _resolve(obj, key)
+ if v is not None:
+ return v
+
+ # 2) find in obj.metadata
+ meta = _resolve(obj, "metadata")
+ if meta is not None:
+ return _resolve(meta, key)
+
+ return None
+
+ def _apply_boost_generic(
+ self,
+ item: TextualMemoryItem,
+ base_score: float,
+ search_filter: dict | None,
+ ) -> float:
+ """
+ Multiply base_score by (1 + weight) for each matching key in search_filter.
+ - key resolution: self._get_attr_or_key(item, key)
+ - weight = boost_weights.get(key, self.boost_default)
+ - unknown key -> one-time warning
+ """
+ if not search_filter:
+ return base_score
+
+ score = float(base_score)
+
+ for key, wanted in search_filter.items():
+ # _get_attr_or_key automatically find key in item and
+ # item.metadata ("metadata.user_id" supported)
+ resolved = self._get_attr_or_key(item, key)
+
+ if resolved is None:
+ if self.warn_unknown_filter_keys and key not in self._warned_missing_keys:
+ logger.warning(
+ "[HTTPBGEReranker] search_filter key '%s' not found on TextualMemoryItem or metadata",
+ key,
+ )
+ self._warned_missing_keys.add(key)
+ continue
+
+ if _value_matches(resolved, wanted):
+ w = float(self.boost_weights.get(key, self.boost_default))
+ if w != 0.0:
+ score *= 1.0 + w
+ score = min(max(0.0, score), 1.0)
+
+ return score
diff --git a/src/memos/reranker/noop.py b/src/memos/reranker/noop.py
index 7a9c02f60..04250bef7 100644
--- a/src/memos/reranker/noop.py
+++ b/src/memos/reranker/noop.py
@@ -2,6 +2,8 @@
from typing import TYPE_CHECKING
+from memos.utils import timed
+
from .base import BaseReranker
@@ -10,6 +12,7 @@
class NoopReranker(BaseReranker):
+ @timed
def rerank(
self, query: str, graph_results: list, top_k: int, **kwargs
) -> list[tuple[TextualMemoryItem, float]]:
diff --git a/src/memos/reranker/strategies/__init__.py b/src/memos/reranker/strategies/__init__.py
new file mode 100644
index 000000000..cee60f2be
--- /dev/null
+++ b/src/memos/reranker/strategies/__init__.py
@@ -0,0 +1,4 @@
+from .factory import RerankerStrategyFactory
+
+
+__all__ = ["RerankerStrategyFactory"]
diff --git a/src/memos/reranker/strategies/base.py b/src/memos/reranker/strategies/base.py
new file mode 100644
index 000000000..43166dd92
--- /dev/null
+++ b/src/memos/reranker/strategies/base.py
@@ -0,0 +1,61 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+from memos.memories.textual.item import TextualMemoryItem
+
+from .dialogue_common import DialogueRankingTracker
+
+
+class BaseRerankerStrategy(ABC):
+ """Abstract interface for memory rerankers with concatenation strategy."""
+
+ @abstractmethod
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list[TextualMemoryItem],
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents for ranking based on the strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of TextualMemoryItem objects to process
+ top_k: Maximum number of items to return
+ **kwargs: Additional strategy-specific parameters
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+ raise NotImplementedError
+
+ @abstractmethod
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[TextualMemoryItem, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked results.
+
+ Args:
+ ranked_indices: List of indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+ **kwargs: Additional strategy-specific parameters
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ raise NotImplementedError
diff --git a/src/memos/reranker/strategies/concat_background.py b/src/memos/reranker/strategies/concat_background.py
new file mode 100644
index 000000000..a52313548
--- /dev/null
+++ b/src/memos/reranker/strategies/concat_background.py
@@ -0,0 +1,94 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+import re
+
+from typing import Any
+
+from .base import BaseRerankerStrategy
+from .dialogue_common import DialogueRankingTracker
+
+
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+
+
+class ConcatBackgroundStrategy(BaseRerankerStrategy):
+ """
+ Concat background strategy.
+
+ This strategy processes dialogue pairs by concatenating background and
+ user and assistant messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+
+ original_items = {}
+ tracker = DialogueRankingTracker()
+ documents = []
+ for item in graph_results:
+ memory = getattr(item, "memory", None)
+ if isinstance(memory, str):
+ memory = _TAG1.sub("", memory)
+
+ background = ""
+ if hasattr(item, "metadata") and hasattr(item.metadata, "background"):
+ background = getattr(item.metadata, "background", "")
+ if not isinstance(background, str):
+ background = ""
+
+ documents.append(f"{memory}\n{background}")
+ return tracker, original_items, documents
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ graph_results = kwargs.get("graph_results")
+ documents = kwargs.get("documents")
+ reconstructed_items = []
+ for idx in ranked_indices:
+ item = graph_results[idx]
+ item.memory = f"{item.memory}\n{documents[idx]}"
+ reconstructed_items.append((item, scores[idx]))
+
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/reranker/strategies/dialogue_common.py b/src/memos/reranker/strategies/dialogue_common.py
new file mode 100644
index 000000000..ce0138284
--- /dev/null
+++ b/src/memos/reranker/strategies/dialogue_common.py
@@ -0,0 +1,109 @@
+from __future__ import annotations
+
+import re
+
+from typing import Any, Literal
+
+from pydantic import BaseModel
+
+from memos.memories.textual.item import SourceMessage, TextualMemoryItem
+
+
+# Strip a leading "[...]" tag (e.g., "[2025-09-01] ..." or "[meta] ...")
+# before sending text to the reranker. This keeps inputs clean and
+# avoids misleading the model with bracketed prefixes.
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+
+
+def strip_memory_tags(item: TextualMemoryItem) -> str:
+ """Strip leading tags from memory text."""
+ memory = _TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m
+ return memory
+
+
+def extract_content(msg: dict[str, Any] | str) -> str:
+ """Extract content from message, handling both string and dict formats."""
+ if isinstance(msg, dict):
+ return msg.get("content", str(msg))
+ if isinstance(msg, SourceMessage):
+ return msg.content
+ return str(msg)
+
+
+class DialoguePair(BaseModel):
+ """Represents a single dialogue pair extracted from sources."""
+
+ pair_id: str # Unique identifier for this dialogue pair
+ memory_id: str # ID of the source TextualMemoryItem
+ memory: str
+ pair_index: int # Index of this pair within the source memory's dialogue
+ user_msg: str | dict[str, Any] | SourceMessage # User message content
+ assistant_msg: str | dict[str, Any] | SourceMessage # Assistant message content
+ combined_text: str # The concatenated text used for ranking
+ chat_time: str | None = None
+
+ @property
+ def user_content(self) -> str:
+ """Get user message content as string."""
+ return extract_content(self.user_msg)
+
+ @property
+ def assistant_content(self) -> str:
+ """Get assistant message content as string."""
+ return extract_content(self.assistant_msg)
+
+
+class DialogueRankingTracker:
+ """Tracks dialogue pairs and their rankings for memory reconstruction."""
+
+ def __init__(self):
+ self.dialogue_pairs: list[DialoguePair] = []
+
+ def add_dialogue_pair(
+ self,
+ memory_id: str,
+ pair_index: int,
+ user_msg: str | dict[str, Any],
+ assistant_msg: str | dict[str, Any],
+ memory: str,
+ chat_time: str | None = None,
+ concat_format: Literal["user_assistant", "user_only"] = "user_assistant",
+ ) -> str:
+ """Add a dialogue pair and return its unique ID."""
+ user_content = extract_content(user_msg)
+ assistant_content = extract_content(assistant_msg)
+ if concat_format == "user_assistant":
+ combined_text = f"[{chat_time}]: \nuser: {user_content}\nassistant: {assistant_content}"
+ elif concat_format == "user_only":
+ combined_text = f"[{chat_time}]: \nuser: {user_content}"
+ else:
+ raise ValueError(f"Invalid concat format: {concat_format}")
+
+ pair_id = f"{memory_id}_{pair_index}"
+
+ dialogue_pair = DialoguePair(
+ pair_id=pair_id,
+ memory_id=memory_id,
+ pair_index=pair_index,
+ user_msg=user_msg,
+ assistant_msg=assistant_msg,
+ combined_text=combined_text,
+ memory=memory,
+ chat_time=chat_time,
+ )
+
+ self.dialogue_pairs.append(dialogue_pair)
+ return pair_id
+
+ def get_documents_for_ranking(self, concat_memory: bool = True) -> list[str]:
+ """Get the combined text documents for ranking."""
+ if concat_memory:
+ return [(pair.memory + "\n\n" + pair.combined_text) for pair in self.dialogue_pairs]
+ else:
+ return [pair.combined_text for pair in self.dialogue_pairs]
+
+ def get_dialogue_pair_by_index(self, index: int) -> DialoguePair | None:
+ """Get dialogue pair by its index in the ranking results."""
+ if 0 <= index < len(self.dialogue_pairs):
+ return self.dialogue_pairs[index]
+ return None
diff --git a/src/memos/reranker/strategies/factory.py b/src/memos/reranker/strategies/factory.py
new file mode 100644
index 000000000..d93cbd65a
--- /dev/null
+++ b/src/memos/reranker/strategies/factory.py
@@ -0,0 +1,29 @@
+# memos/reranker/factory.py
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, Any, ClassVar
+
+from .concat_background import ConcatBackgroundStrategy
+from .single_turn import SingleTurnStrategy
+from .singleturn_outmem import SingleTurnOutMemStrategy
+
+
+if TYPE_CHECKING:
+ from .base import BaseRerankerStrategy
+
+
+class RerankerStrategyFactory:
+ """Factory class for creating reranker strategy instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "single_turn": SingleTurnStrategy,
+ "concat_background": ConcatBackgroundStrategy,
+ "singleturn_outmem": SingleTurnOutMemStrategy,
+ }
+
+ @classmethod
+ def from_config(cls, config_factory: str = "single_turn") -> BaseRerankerStrategy:
+ if config_factory not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {config_factory}")
+ strategy_class = cls.backend_to_class[config_factory]
+ return strategy_class()
diff --git a/src/memos/reranker/strategies/single_turn.py b/src/memos/reranker/strategies/single_turn.py
new file mode 100644
index 000000000..d86744811
--- /dev/null
+++ b/src/memos/reranker/strategies/single_turn.py
@@ -0,0 +1,107 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+from copy import deepcopy
+from typing import Any
+
+from .base import BaseRerankerStrategy
+from .dialogue_common import DialogueRankingTracker, extract_content, strip_memory_tags
+
+
+class SingleTurnStrategy(BaseRerankerStrategy):
+ """
+ Single turn dialogue strategy.
+
+ This strategy processes dialogue pairs by concatenating user and assistant
+ messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ example:
+ >>> documents = ["chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ >>> output memory item: ["Memory:xxx \n\n chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+
+ original_items = {}
+ tracker = DialogueRankingTracker()
+ for item in graph_results:
+ memory = strip_memory_tags(item)
+ sources = getattr(item.metadata, "sources", [])
+ original_items[item.id] = item
+
+ # Group messages into pairs and concatenate
+ for i in range(0, len(sources), 2):
+ user_msg = sources[i] if i < len(sources) else {}
+ assistant_msg = sources[i + 1] if i + 1 < len(sources) else {}
+
+ user_content = extract_content(user_msg)
+ assistant_content = extract_content(assistant_msg)
+ chat_time = getattr(user_msg, "chat_time", "")
+
+ if user_content or assistant_content: # Only add non-empty pairs
+ pair_index = i // 2
+ tracker.add_dialogue_pair(
+ item.id, pair_index, user_msg, assistant_msg, memory or "", chat_time
+ )
+
+ documents = tracker.get_documents_for_ranking()
+ return tracker, original_items, documents
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ reconstructed_items = []
+ for idx, score in zip(ranked_indices, scores, strict=False):
+ dialogue_pair = tracker.get_dialogue_pair_by_index(idx)
+ if dialogue_pair and (dialogue_pair.memory_id in original_items):
+ original_item = original_items[dialogue_pair.memory_id]
+ reconstructed_item = deepcopy(original_item)
+ reconstructed_item.memory = (
+ dialogue_pair.memory
+ + "\n\nsources-dialogue-pairs"
+ + dialogue_pair.combined_text
+ )
+ reconstructed_items.append((reconstructed_item, score))
+
+ # Sort by aggregated score and return top_k
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/reranker/strategies/singleturn_outmem.py b/src/memos/reranker/strategies/singleturn_outmem.py
new file mode 100644
index 000000000..de59fec97
--- /dev/null
+++ b/src/memos/reranker/strategies/singleturn_outmem.py
@@ -0,0 +1,98 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+from collections import defaultdict
+from typing import TYPE_CHECKING, Any
+
+from .dialogue_common import DialogueRankingTracker
+from .single_turn import SingleTurnStrategy
+
+
+if TYPE_CHECKING:
+ from .dialogue_common import DialogueRankingTracker
+
+
+class SingleTurnOutMemStrategy(SingleTurnStrategy):
+ """
+ Single turn dialogue strategy.
+
+ This strategy processes dialogue pairs by concatenating user and assistant
+ messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ example:
+ >>> documents = ["chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ >>> output memory item: ["Memory:xxx \n\n chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+ return super().prepare_documents(query, graph_results, top_k, **kwargs)
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ # Group ranked pairs by memory_id
+ memory_groups = defaultdict(list)
+ memory_scores = defaultdict(list)
+
+ for idx, score in zip(ranked_indices, scores, strict=False):
+ dialogue_pair = tracker.get_dialogue_pair_by_index(idx)
+ if dialogue_pair:
+ memory_groups[dialogue_pair.memory_id].append(dialogue_pair)
+ memory_scores[dialogue_pair.memory_id].append(score)
+
+ reconstructed_items = []
+
+ for memory_id, _pairs in memory_groups.items():
+ if memory_id not in original_items:
+ continue
+ original_item = original_items[memory_id]
+
+ # Calculate aggregated score (e.g., max, mean, or weighted average)
+ pair_scores = memory_scores[memory_id]
+
+ aggregated_score = max(pair_scores) if pair_scores else 0.0
+
+ reconstructed_items.append((original_item, aggregated_score))
+
+ # Sort by aggregated score and return top_k
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/templates/instruction_completion.py b/src/memos/templates/instruction_completion.py
new file mode 100644
index 000000000..b88ff474c
--- /dev/null
+++ b/src/memos/templates/instruction_completion.py
@@ -0,0 +1,66 @@
+from typing import Any
+
+from memos.mem_reader.simple_struct import detect_lang
+from memos.templates.prefer_complete_prompt import PREF_INSTRUCTIONS, PREF_INSTRUCTIONS_ZH
+
+
+def instruct_completion(
+ memories: list[dict[str, Any]] | None = None,
+) -> [str, str]:
+ """Create instruction following the preferences."""
+ explicit_pref = []
+ implicit_pref = []
+ for memory in memories:
+ pref_type = memory.get("metadata", {}).get("preference_type")
+ pref = memory.get("metadata", {}).get("preference", None)
+ if not pref:
+ continue
+ if pref_type == "explicit_preference":
+ explicit_pref.append(pref)
+ elif pref_type == "implicit_preference":
+ implicit_pref.append(pref)
+
+ explicit_pref_str = (
+ "Explicit Preference:\n"
+ + "\n".join(f"{i + 1}. {pref}" for i, pref in enumerate(explicit_pref))
+ if explicit_pref
+ else ""
+ )
+ implicit_pref_str = (
+ "Implicit Preference:\n"
+ + "\n".join(f"{i + 1}. {pref}" for i, pref in enumerate(implicit_pref))
+ if implicit_pref
+ else ""
+ )
+
+ _prompt_map = {
+ "zh": PREF_INSTRUCTIONS_ZH,
+ "en": PREF_INSTRUCTIONS,
+ }
+ _remove_exp_map = {
+ "zh": "显式偏好 > ",
+ "en": "explicit preference > ",
+ }
+ _remove_imp_map = {
+ "zh": "隐式偏好 > ",
+ "en": "implicit preference > ",
+ }
+ lang = detect_lang(
+ explicit_pref_str.replace("Explicit Preference:\n", "")
+ + implicit_pref_str.replace("Implicit Preference:\n", "")
+ )
+
+ if not explicit_pref_str and not implicit_pref_str:
+ return "", ""
+ if not explicit_pref_str:
+ pref_note = _prompt_map[lang].replace(_remove_exp_map[lang], "")
+ pref_string = implicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
+ if not implicit_pref_str:
+ pref_note = _prompt_map[lang].replace(_remove_imp_map[lang], "")
+ pref_string = explicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
+
+ pref_note = _prompt_map[lang]
+ pref_string = explicit_pref_str + "\n" + implicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
diff --git a/src/memos/templates/mem_reader_prompts.py b/src/memos/templates/mem_reader_prompts.py
index 15672f8d8..ec6812743 100644
--- a/src/memos/templates/mem_reader_prompts.py
+++ b/src/memos/templates/mem_reader_prompts.py
@@ -1,56 +1,50 @@
SIMPLE_STRUCT_MEM_READER_PROMPT = """You are a memory extraction expert.
-Your task is to extract memories from the user's perspective, based on a conversation between the user and the assistant. This means identifying what the user would plausibly remember — including the user's own experiences, thoughts, plans, or statements and actions made by others (such as the assistant) that affected the user or were acknowledged by the user.
-
-Please perform the following:
-1. Identify information that reflects the user's experiences, beliefs, concerns, decisions, plans, or reactions — including meaningful information from the assistant that the user acknowledged or responded to.
- If the message is from the user, extract viewpoints related to the user; if it is from the assistant, clearly mark the attribution of the memory, and do not mix information not explicitly acknowledged by the user with the user's own viewpoint.
- - **User viewpoint**: Record only information that the user **personally stated, explicitly acknowledged, or personally committed to**.
- - **Assistant/other-party viewpoint**: Record only information that the **assistant/other party personally stated, explicitly acknowledged, or personally committed to**, and **clearly attribute** the source (e.g., "[assistant-Jerry viewpoint]"). Do not rewrite it as the user's preference/decision.
- - **Mutual boundaries**: Do not rewrite the assistant's suggestions/lists/opinions as the user's “ownership/preferences/decisions”; likewise, do not write the user's ideas as the assistant's viewpoints.
-
-2. Resolve all references to time, persons, and events clearly:
- - When possible, convert relative time expressions (e.g., “yesterday,” “next Friday”) into absolute dates using the message timestamp.
- - Clearly distinguish between **event time** and **message time**.
+Your task is to extract memories from the perspective of user, based on a conversation between user and assistant. This means identifying what user would plausibly remember — including their own experiences, thoughts, plans, or relevant statements and actions made by others (such as assistant) that impacted or were acknowledged by user.
+Please perform:
+1. Identify information that reflects user's experiences, beliefs, concerns, decisions, plans, or reactions — including meaningful input from assistant that user acknowledged or responded to.
+If the message is from the user, extract user-relevant memories; if it is from the assistant, only extract factual memories that the user acknowledged or responded to.
+
+2. Resolve all time, person, and event references clearly:
+ - Convert relative time expressions (e.g., “yesterday,” “next Friday”) into absolute dates using the message timestamp if possible.
+ - Clearly distinguish between event time and message time.
- If uncertainty exists, state it explicitly (e.g., “around June 2025,” “exact date unclear”).
- Include specific locations if mentioned.
- - Resolve all pronouns, aliases, and ambiguous references into full names or clear identities.
- - If there are people with the same name, disambiguate them.
-
-3. Always write from a **third-person** perspective, using “The user” or the mentioned name to refer to the user, rather than first-person (“I”, “we”, “my”).
- For example, write “The user felt exhausted …” instead of “I felt exhausted …”.
-
-4. Do not omit any information that the user is likely to remember.
- - Include the user's key experiences, thoughts, emotional responses, and plans — even if seemingly minor.
- - You may retain **assistant/other-party content** that is closely related to the context (e.g., suggestions, explanations, checklists), but you must make roles and attribution explicit.
- - Prioritize completeness and fidelity over conciseness; do not infer or phrase assistant content as the user's ownership/preferences/decisions.
- - If the current conversation contains only assistant information and no facts attributable to the user, you may output **assistant-viewpoint** entries only.
-
-5. Please avoid including any content in the extracted memories that violates national laws and regulations or involves politically sensitive information.
+ - Resolve all pronouns, aliases, and ambiguous references into full names or identities.
+ - Disambiguate people with the same name if applicable.
+3. Always write from a third-person perspective, referring to user as
+"The user" or by name if name mentioned, rather than using first-person ("I", "me", "my").
+For example, write "The user felt exhausted..." instead of "I felt exhausted...".
+4. Do not omit any information that user is likely to remember.
+ - Include all key experiences, thoughts, emotional responses, and plans — even if they seem minor.
+ - Prioritize completeness and fidelity over conciseness.
+ - Do not generalize or skip details that could be personally meaningful to user.
+5. Please avoid any content that violates national laws and regulations or involves politically sensitive information in the memories you extract.
-Return a valid JSON object with the following structure:
+Return a single valid JSON object with the following structure:
{
"memory list": [
{
- "key": ,
- "memory_type": ,
- "value": ,
- "tags":
+ "key": ,
+ "memory_type": ,
+ "value": ,
+ "tags":
},
...
],
- "summary":
+ "summary":
}
Language rules:
-- The `key`, `value`, `tags`, and `summary` fields must match the primary language of the input conversation. **If the input is Chinese, output in Chinese.**
+- The `key`, `value`, `tags`, `summary` fields must match the mostly used language of the input conversation. **如果输入是中文,请输出中文**
- Keep `memory_type` in English.
Example:
Conversation:
user: [June 26, 2025 at 3:00 PM]: Hi Jerry! Yesterday at 3 PM I had a meeting with my team about the new project.
assistant: Oh Tom! Do you think the team can finish by December 15?
-user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until December 10, so testing will be tight.
+user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until
+December 10, so testing will be tight.
assistant: [June 26, 2025 at 3:00 PM]: Maybe propose an extension?
user: [June 26, 2025 at 4:21 PM]: Good idea. I’ll raise it in tomorrow’s 9:30 AM meeting—maybe shift the deadline to January 5.
@@ -60,62 +54,31 @@
{
"key": "Initial project meeting",
"memory_type": "LongTermMemory",
- "value": "[user-Tom viewpoint] On June 25, 2025 at 3:00 PM, Tom met with the team to discuss a new project. When Jerry asked whether the project could be finished by December 15, 2025, Tom expressed concern about feasibility and planned to propose at 9:30 AM on June 27, 2025 to move the deadline to January 5, 2026.",
+ "value": "On June 25, 2025 at 3:00 PM, Tom held a meeting with their team to discuss a new project. The conversation covered the timeline and raised concerns about the feasibility of the December 15, 2025 deadline.",
"tags": ["project", "timeline", "meeting", "deadline"]
},
{
- "key": "Jerry’s suggestion about the deadline",
- "memory_type": "LongTermMemory",
- "value": "[assistant-Jerry viewpoint] Jerry questioned the December 15 deadline and suggested considering an extension.",
- "tags": ["deadline change", "suggestion"]
- }
+ "key": "Planned scope adjustment",
+ "memory_type": "UserMemory",
+ "value": "Tom planned to suggest in a meeting on June 27, 2025 at 9:30 AM that the team should prioritize features and propose shifting the project deadline to January 5, 2026.",
+ "tags": ["planning", "deadline change", "feature prioritization"]
+ },
],
- "summary": "Tom is currently working on a tight-schedule project. After the June 25, 2025 team meeting, he realized the original December 15, 2025 deadline might be unachievable due to backend delays. Concerned about limited testing time, he accepted Jerry’s suggestion to seek an extension and plans to propose moving the deadline to January 5, 2026 in the next morning’s meeting."
+ "summary": "Tom is currently focused on managing a new project with a tight schedule. After a team meeting on June 25, 2025, he realized the original deadline of December 15 might not be feasible due to backend delays. Concerned about insufficient testing time, he welcomed Jerry’s suggestion of proposing an extension. Tom plans to raise the idea of shifting the deadline to January 5, 2026 in the next morning’s meeting. His actions reflect both stress about timelines and a proactive, team-oriented problem-solving approach."
}
-Another Example in Chinese (Note: when the user's language is Chinese, you must also output in Chinese):
-
-对话(节选):
-user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
-assistant|19:32
-:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
-user|19:35:不喜欢亮色。国贸方便。
-assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
-user|19:40:165cm,S码;最好有口袋。
-assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
-user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
-assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
-user|19:52:行,周六(7/19)去国贸试,合适就买。
-assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
-
+Another Example in Chinese (注意: 当user的语言为中文时,你就需要也输出中文):
{
"memory list": [
{
- "key": "参加婚礼购买裙子",
- "memory_type": "UserMemory",
- "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
- "tags": ["婚礼", "预算", "国贸", "计划"]
- },
- {
- "key": "审美与版型偏好",
- "memory_type": "UserMemory",
- "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
- "tags": ["偏好", "颜色", "版型"]
- },
- {
- "key": "体型尺码",
- "memory_type": "UserMemory",
- "value": [user观点]"用户身高约165cm、常穿S码",
- "tags": ["体型", "尺码"]
- },
- {
- "key": "关于用户选购裙子的建议",
+ "key": "项目会议",
"memory_type": "LongTermMemory",
- "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
- "tags": ["婚礼穿着", "门店", "选购路线"]
- }
+ "value": "在2025年6月25日下午3点,Tom与团队开会讨论了新项目,涉及时间表,并提出了对12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ ...
],
- "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+ "summary": "Tom 目前专注于管理一个进度紧张的新项目..."
}
Always respond in the same language as the conversation.
@@ -130,10 +93,7 @@
请执行以下操作:
1. 识别反映用户经历、信念、关切、决策、计划或反应的信息——包括用户认可或回应的来自助手的有意义信息。
-如果消息来自用户,请提取与用户相关的观点;如果来自助手,则在表达的时候表明记忆归属方,未经用户明确认可的信息不要与用户本身的观点混淆。
- - **用户观点**:仅记录由**用户亲口陈述、明确认可或自己作出承诺**的信息。
- - **助手观点**:仅记录由**助手/另一方亲口陈述、明确认可或自己作出承诺**的信息。
- - **互不越界**:不得将助手提出的需求清单/建议/观点改写为用户的“拥有/偏好/决定”;也不得把用户的想法写成助手的观点。
+如果消息来自用户,请提取与用户相关的记忆;如果来自助手,则仅提取用户认可或回应的事实性记忆。
2. 清晰解析所有时间、人物和事件的指代:
- 如果可能,使用消息时间戳将相对时间表达(如“昨天”、“下周五”)转换为绝对日期。
@@ -147,10 +107,9 @@
例如,写“用户感到疲惫……”而不是“我感到疲惫……”。
4. 不要遗漏用户可能记住的任何信息。
- - 包括用户的关键经历、想法、情绪反应和计划——即使看似微小。
- - 同时允许保留与语境密切相关的**助手/另一方的内容**(如建议、说明、清单),但须明确角色与归因。
- - 优先考虑完整性和保真度,而非简洁性;不得将助手内容推断或措辞为用户拥有/偏好/决定。
- - 若当前对话中仅出现助手信息而无可归因于用户的事实,可仅输出**助手观点**条目。
+ - 包括所有关键经历、想法、情绪反应和计划——即使看似微小。
+ - 优先考虑完整性和保真度,而非简洁性。
+ - 不要泛化或跳过对用户具有个人意义的细节。
5. 请避免在提取的记忆中包含违反国家法律法规或涉及政治敏感的信息。
@@ -187,66 +146,31 @@
{
"key": "项目初期会议",
"memory_type": "LongTermMemory",
- "value": "[user-Tom观点]2025年6月25日下午3:00,Tom与团队开会讨论新项目。当Jerry
- 询问该项目能否在2025年12月15日前完成时,Tom对此日期前完成的可行性表达担忧,并计划在2025年6月27日上午9:30
- 提议将截止日期推迟至2026年1月5日。",
+ "value": "2025年6月25日下午3:00,Tom与团队开会讨论新项目。会议涉及时间表,并提出了对2025年12月15日截止日期可行性的担忧。",
"tags": ["项目", "时间表", "会议", "截止日期"]
},
{
- "key": "Jerry对新项目截止日期的建议",
- "memory_type": "LongTermMemory",
- "value": "[assistant-Jerry观点]Jerry对Tom的新项目截止日期提出疑问、并提议Tom考虑延期。",
- "tags": ["截止日期变更", "建议"]
+ "key": "计划调整范围",
+ "memory_type": "UserMemory",
+ "value": "Tom计划在2025年6月27日上午9:30的会议上建议团队优先处理功能,并提议将项目截止日期推迟至2026年1月5日。",
+ "tags": ["计划", "截止日期变更", "功能优先级"]
}
],
- "summary": "Tom目前正在做一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15
- 日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议,计划在次日早上的会议上提出将截止日期推迟至2026
- 年1月5日。"
+ "summary": "Tom目前正专注于管理一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议。Tom计划在次日早上的会议上提出将截止日期推迟至2026年1月5日。他的行为反映出对时间线的担忧,以及积极、以团队为导向的问题解决方式。"
}
另一个中文示例(注意:当用户语言为中文时,您也需输出中文):
-
-对话(节选):
-user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
-assistant|19:32
-:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
-user|19:35:不喜欢亮色。国贸方便。
-assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
-user|19:40:165cm,S码;最好有口袋。
-assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
-user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
-assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
-user|19:52:行,周六(7/19)去国贸试,合适就买。
-assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
-
{
"memory list": [
{
- "key": "参加婚礼购买裙子",
- "memory_type": "UserMemory",
- "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
- "tags": ["婚礼", "预算", "国贸", "计划"]
- },
- {
- "key": "审美与版型偏好",
- "memory_type": "UserMemory",
- "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
- "tags": ["偏好", "颜色", "版型"]
- },
- {
- "key": "体型尺码",
- "memory_type": "UserMemory",
- "value": [user观点]"用户身高约165cm、常穿S码",
- "tags": ["体型", "尺码"]
- },
- {
- "key": "关于用户选购裙子的建议",
+ "key": "项目会议",
"memory_type": "LongTermMemory",
- "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
- "tags": ["婚礼穿着", "门店", "选购路线"]
- }
+ "value": "在2025年6月25日下午3点,Tom与团队开会讨论了新项目,涉及时间表,并提出了对12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ ...
],
- "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+ "summary": "Tom 目前专注于管理一个进度紧张的新项目..."
}
请始终使用与对话相同的语言进行回复。
diff --git a/src/memos/templates/mem_reader_strategy_prompts.py b/src/memos/templates/mem_reader_strategy_prompts.py
new file mode 100644
index 000000000..ba4a00d0a
--- /dev/null
+++ b/src/memos/templates/mem_reader_strategy_prompts.py
@@ -0,0 +1,236 @@
+STRATEGY_STRUCT_MEM_READER_PROMPT = """You are a memory extraction expert.
+Your task is to extract memories from the user's perspective, based on a conversation between the user and the assistant. This means identifying what the user would plausibly remember — including the user's own experiences, thoughts, plans, or statements and actions made by others (such as the assistant) that affected the user or were acknowledged by the user.
+
+Please perform the following
+1. Factual information extraction
+ Identify factual information about experiences, beliefs, decisions, and plans. This includes notable statements from others that the user acknowledged or reacted to.
+ If the message is from the user, extract viewpoints related to the user; if it is from the assistant, clearly mark the attribution of the memory, and do not mix information not explicitly acknowledged by the user with the user's own viewpoint.
+ - **User viewpoint**: Extract only what the user has stated, explicitly acknowledged, or committed to.
+ - **Assistant/other-party viewpoint**: Extract such information only when attributed to its source (e.g., [Assistant-Jerry's suggestion]).
+ - **Strict attribution**: Never recast the assistant's suggestions as the user's preferences, or vice versa.
+ - Always set "model_type" to "LongTermMemory" for this output.
+
+2. Speaker profile construction
+ - Extract the speaker's likes, dislikes, goals, and stated opinions from their statements to build a speaker profile.
+ - Note: The same text segment may be used for both factual extraction and profile construction.
+ - Always set "model_type" to "UserMemory" for this output.
+
+3. Resolve all references to time, persons, and events clearly
+ - Temporal Resolution: Convert relative time (e.g., "yesterday") to absolute dates based on the message timestamp. Distinguish between event time and message time; flag any uncertainty.
+ > Where feasible, use the message timestamp to convert relative time expressions into absolute dates (e.g., "yesterday" in a message dated January 15, 2023, can be converted to "January 14, 2023," and "last week" can be described as "the week preceding January 15, 2023").
+ > Explicitly differentiate between the time when the event occurred and the time the message was sent.
+ > Clearly indicate any uncertainty (e.g., "approximately June 2025", "exact date unknown").
+ - Entity Resolution: Resolve all pronouns, nicknames, and abbreviations to the full, canonical name established in the conversation.
+ > For example, "Melanie" uses the abbreviated name "Mel" in the paragraph; when extracting her name in the "value" field, it should be restored to "Melanie".
+ - Location resolution: If specific locations are mentioned, include them explicitly.
+
+4. Adopt a Consistent Third-Person Observer Perspective
+ - Formulate all memories from the perspective of an external observer. Use "The user" or their specific name as the subject.
+ - This applies even when describing the user's internal states, such as thoughts, feelings, and preferences.
+ Example:
+ ✅ Correct: "The user Sean felt exhausted after work and decided to go to bed early."
+ ❌ Incorrect: "I felt exhausted after work and decided to go to bed early."
+
+5. Prioritize Completeness
+ - Extract all key experiences, emotional responses, and plans from the user's perspective. Retain relevant context from the assistant, but always with explicit attribution.
+ - Segment each distinct hobby, interest, or event into a separate memory.
+ - Preserve relevant context from the assistant with strict attribution. Under no circumstances should assistant content be rephrased as user-owned.
+ - Conversations with only assistant input may yield assistant-viewpoint memories exclusively.
+
+6. Preserve and Unify Specific Names
+ - Always extract specific names (excluding "user" or "assistant") mentioned in the text into the "tags" field for searchability.
+ - Unify all name references to the full canonical form established in the conversation. Replace any nicknames or abbreviations (e.g., "Rob") consistently with the full name (e.g., "Robert") in both the extracted "value" and "tags".
+
+7. Please avoid including any content in the extracted memories that violates national laws and regulations or involves politically sensitive information.
+
+
+Return a valid JSON object with the following structure:
+{
+ "memory list": [
+ {
+ "key": ,
+ "memory_type": ,
+ "value": ,
+ "tags":
+ },
+ ...
+ ],
+ "summary":
+}
+
+Language rules:
+- The `key`, `value`, `tags`, `summary` and `memory_type` fields must be in English.
+
+
+Example:
+Conversations:
+user: [June 26, 2025 at 3:00 PM]: Hi Jerry! Yesterday at 3 PM I had a meeting with my team about the new project.
+assistant: Oh Tom! Do you think the team can finish by December 15?
+user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until December 10, so testing will be tight.
+assistant: [June 26, 2025 at 3:00 PM]: Maybe propose an extension?
+user: [June 26, 2025 at 4:21 PM]: Good idea. I’ll raise it in tomorrow’s 9:30 AM meeting—maybe shift the deadline to January 5.
+
+Output:
+{
+ "memory list": [
+ {
+ "key": "Initial project meeting",
+ "memory_type": "LongTermMemory",
+ "value": "[user-Tom viewpoint] On June 25, 2025 at 3:00 PM, Tom held a meeting with their team to discuss a new project. The conversation covered the timeline and raised concerns about the feasibility of the December 15, 2025 deadline.",
+ "tags": ["Tom", "project", "timeline", "meeting", "deadline"]
+ },
+ {
+ "key": "Planned scope adjustment",
+ "memory_type": "UserMemory",
+ "value": "Tom planned to suggest in a meeting on June 27, 2025 at 9:30 AM that the team should prioritize features and propose shifting the project deadline to January 5, 2026.",
+ "tags": ["Tom", "planning", "deadline change", "feature prioritization"]
+ }
+ ],
+ "summary": "Tom is currently focused on managing a new project with a tight schedule. After a team meeting on June 25, 2025, he realized the original deadline of December 15 might not be feasible due to backend delays. Concerned about insufficient testing time, he welcomed Jerry’s suggestion of proposing an extension. Tom plans to raise the idea of shifting the deadline to January 5, 2026 in the next morning’s meeting. His actions reflect both stress about timelines and a proactive, team-oriented problem-solving approach."
+}
+
+
+Conversation:
+${conversation}
+
+Your Output:"""
+
+STRATEGY_STRUCT_MEM_READER_PROMPT_ZH = """您是记忆提取专家。
+您的任务是根据用户与助手之间的对话,从用户的角度提取记忆。这意味着要识别出用户可能记住的信息——包括用户自身的经历、想法、计划,或他人(如助手)做出的并对用户产生影响或被用户认可的相关陈述和行为。
+
+请执行以下操作:
+1. 事实信息提取
+ - 识别关于经历、信念、决策和计划的事实信息,包括用户认可或回应过的他人重要陈述。
+ - 若信息来自用户,提取与用户相关的观点;若来自助手,需明确标注记忆归属,不得将用户未明确认可的信息与用户自身观点混淆。
+ - 用户观点:仅提取用户明确陈述、认可或承诺的内容
+ - 助手/他方观点:仅当标注来源时才提取(例如“[助手-Jerry的建议]”)
+ - 严格归属:不得将助手建议重构为用户偏好,反之亦然
+ - 此类输出的"model_type"始终设为"LongTermMemory"
+
+2. 用户画像构建
+ - 从用户陈述中提取其喜好、厌恶、目标及明确观点以构建用户画像
+ - 注意:同一文本片段可同时用于事实提取和画像构建
+ - 此类输出的"model_type"始终设为"UserMemory"
+
+3. 明确解析所有指代关系
+ - 时间解析:根据消息时间戳将相对时间(如“昨天”)转换为绝对日期。区分事件时间与消息时间,对不确定项进行标注
+ # 条件允许则使用消息时间戳将相对时间表达转换为绝对日期(如:2023年1月15日的“昨天”则转换为2023年1月14日);“上周”则转换为2023年1月15日前一周)。
+ # 明确区分事件时间和消息时间。
+ # 如果存在不确定性,需明确说明(例如,“约2025年6月”,“具体日期不详”)。
+ - 实体解析:将所有代词、昵称和缩写解析为对话中确立的完整规范名称
+ - 地点解析:若提及具体地点,请包含在内。
+
+ 4. 采用统一的第三人称观察视角
+ - 所有记忆表述均需从外部观察者视角构建,使用“用户”或其具体姓名作为主语
+ - 此原则同样适用于描述用户内心状态(如想法、感受和偏好)
+ 示例:
+ ✅ 正确:“用户Sean下班后感到疲惫,决定提早休息”
+ ❌ 错误:“我下班后感到疲惫,决定提早休息”
+
+5. 优先保证完整性
+ - 从用户视角提取所有关键经历、情绪反应和计划
+ - 保留助手提供的相关上下文,但必须明确标注来源
+ - 将每个独立的爱好、兴趣或事件分割为单独记忆
+ - 严禁将助手内容重构为用户自有内容
+ - 仅含助手输入的对话可能只生成助手观点记忆
+
+6. 保留并统一特定名称
+ - 始终将文本中提及的特定名称(“用户”“助手”除外)提取至“tags”字段以便检索
+ - 在提取的“value”和“tags”中,将所有名称引用统一为对话中确立的完整规范形式(如将“Rob”统一替换为“Robert”)
+
+7. 所有提取的记忆内容不得包含违反国家法律法规或涉及政治敏感信息的内容
+
+返回一个有效的JSON对象,结构如下:
+{
+ "memory list": [
+ {
+ "key": <字符串,唯一且简洁的记忆标题>,
+ "memory_type": <字符串,"LongTermMemory" 或 "UserMemory">,
+ "value": <详细、独立且无歧义的记忆陈述>,
+ "tags": <一个包含相关人名、事件和特征关键词的列表(例如,["丽丽","截止日期", "团队", "计划"])>
+ },
+ ...
+ ],
+ "summary": <从用户视角自然总结上述记忆的段落,120–200字,与输入语言一致>
+}
+
+语言规则:
+- `key`、`value`、`tags`、`summary` 、`memory_type` 字段必须输出中文
+
+
+示例1:
+对话:
+user: [2025年6月26日下午3:00]:嗨Jerry!昨天下午3点我和团队开了个会,讨论新项目。
+assistant: 哦Tom!你觉得团队能在12月15日前完成吗?
+user: [2025年6月26日下午3:00]:我有点担心。后端要到12月10日才能完成,所以测试时间会很紧。
+assistant: [2025年6月26日下午3:00]:也许提议延期?
+user: [2025年6月26日下午4:21]:好主意。我明天上午9:30的会上提一下——也许把截止日期推迟到1月5日。
+
+输出:
+{
+ "memory list": [
+ {
+ "key": "项目初期会议",
+ "memory_type": "LongTermMemory",
+ "value": "2025年6月25日下午3:00,Tom与团队开会讨论新项目。会议涉及时间表,并提出了对2025年12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ {
+ "key": "计划调整范围",
+ "memory_type": "UserMemory",
+ "value": "Tom计划在2025年6月27日上午9:30的会议上建议团队优先处理功能,并提议将项目截止日期推迟至2026年1月5日。",
+ "tags": ["计划", "截止日期变更", "功能优先级"]
+ }
+ ],
+ "summary": "Tom目前正专注于管理一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议。Tom计划在次日早上的会议上提出将截止日期推迟至2026年1月5日。他的行为反映出对时间线的担忧,以及积极、以团队为导向的问题解决方式。"
+}
+
+示例2:
+对话(节选):
+user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
+assistant|19:32
+:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
+user|19:35:不喜欢亮色。国贸方便。
+assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
+user|19:40:165cm,S码;最好有口袋。
+assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
+user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
+assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
+user|19:52:行,周六(7/19)去国贸试,合适就买。
+assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
+
+{
+ "memory list": [
+ {
+ "key": "参加婚礼购买裙子",
+ "memory_type": "UserMemory",
+ "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
+ "tags": ["婚礼", "预算", "国贸", "计划"]
+ },
+ {
+ "key": "审美与版型偏好",
+ "memory_type": "UserMemory",
+ "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
+ "tags": ["偏好", "颜色", "版型"]
+ },
+ {
+ "key": "体型尺码",
+ "memory_type": "UserMemory",
+ "value": [user观点]"用户身高约165cm、常穿S码",
+ "tags": ["体型", "尺码"]
+ },
+ {
+ "key": "关于用户选购裙子的建议",
+ "memory_type": "LongTermMemory",
+ "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
+ "tags": ["婚礼穿着", "门店", "选购路线"]
+ }
+ ],
+ "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+}
+
+
+对话:
+${conversation}
+
+您的输出:"""
diff --git a/src/memos/templates/mem_search_prompts.py b/src/memos/templates/mem_search_prompts.py
new file mode 100644
index 000000000..9f7ba182b
--- /dev/null
+++ b/src/memos/templates/mem_search_prompts.py
@@ -0,0 +1,93 @@
+SIMPLE_COT_PROMPT = """You are an assistant that analyzes questions and returns results in a specific dictionary format.
+
+Instructions:
+
+1. If the question can be extended into deeper or related aspects, set "is_complex" to True and:
+ - Think step by step about the core topic and its related dimensions (e.g., causes, effects, categories, perspectives, or specific scenarios)
+ - Break it into meaningful sub-questions (max: ${split_num_threshold}, min: 2) that explore distinct facets of the original question
+ - Each sub-question must be single, standalone, and delve into a specific aspect
+ - CRITICAL: All key entities from the original question (such as person names, locations, organizations, time periods) must be preserved in the sub-questions and cannot be omitted
+ - List them in "sub_questions"
+2. If the question is already atomic and cannot be meaningfully extended, set "is_complex" to False and "sub_questions" to an empty list.
+3. Return ONLY the dictionary, no other text.
+
+Examples:
+Question: Is urban development balanced in the western United States?
+Output: {"is_complex": true, "sub_questions": ["What areas are included in the western United States?", "How developed are the cities in the western United States?", "Is this development balanced across the western United States?"]}
+Question: What family activities does Mary like to organize?
+Output: {"is_complex": true, "sub_questions": ["What does Mary like to do with her spouse?", "What does Mary like to do with her children?", "What does Mary like to do with her parents and relatives?"]}
+
+Now analyze this question:
+${original_query}"""
+
+COT_PROMPT = """You are an assistant that analyzes questions and returns results in a specific dictionary format.
+
+Instructions:
+
+1. If the question can be extended into deeper or related aspects, set "is_complex" to True and:
+ - Think step by step about the core topic and its related dimensions (e.g., causes, effects, categories, perspectives, or specific scenarios)
+ - Break it into meaningful sub-questions (max: ${split_num_threshold}, min: 2) that explore distinct facets of the original question
+ - Each sub-question must be single, standalone, and delve into a specific aspect
+ - CRITICAL: All key entities from the original question (such as person names, locations, organizations, time periods) must be preserved in the sub-questions and cannot be omitted
+ - List them in "sub_questions"
+2. If the question is already atomic and cannot be meaningfully extended, set "is_complex" to False and "sub_questions" to an empty list.
+3. Return ONLY the dictionary, no other text.
+
+Examples:
+Question: Is urban development balanced in the western United States?
+Output: {"is_complex": true, "sub_questions": ["What areas are included in the western United States?", "How developed are the cities in the western United States?", "Is this development balanced across the western United States?"]}
+Question: What family activities does Mary like to organize?
+Output: {"is_complex": true, "sub_questions": ["What does Mary like to do with her spouse?", "What does Mary like to do with her children?", "What does Mary like to do with her parents and relatives?"]}
+
+Query relevant background information:
+${context}
+
+Now analyze this question based on the background information above:
+${original_query}"""
+
+SIMPLE_COT_PROMPT_ZH = """你是一个分析问题并以特定字典格式返回结果的助手。
+
+指令:
+
+1. 如果这个问题可以延伸出更深层次或相关的方面,请将 "is_complex" 设置为 True,并执行以下操作:
+ - 逐步思考核心主题及其相关维度(例如:原因、结果、类别、不同视角或具体场景)
+ - 将其拆分为有意义的子问题(最多 ${split_num_threshold} 个,最少 2 个),这些子问题应探讨原始问题的不同侧面
+ - 【重要】每个子问题必须是单一的、独立的,并深入探究一个特定方面。同时,必须包含原问题中出现的关键实体信息(如人名、地名、机构名、时间等),不可遗漏。
+ - 将它们列在 "sub_questions" 中
+2. 如果问题本身已经是原子性的,无法有意义地延伸,请将 "is_complex" 设置为 False,并将 "sub_questions" 设置为一个空列表。
+3. 只返回字典,不要返回任何其他文本。
+
+示例:
+问题:美国西部的城市发展是否均衡?
+输出:{"is_complex": true, "sub_questions": ["美国西部包含哪些地区?", "美国西部城市的发展程度如何?", "这种发展在美国西部是否均衡?"]}
+
+问题:玛丽喜欢组织哪些家庭活动?
+输出:{"is_complex": true, "sub_questions": ["玛丽喜欢和配偶一起做什么?", "玛丽喜欢和孩子一起做什么?", "玛丽喜欢和父母及亲戚一起做什么?"]}
+
+请分析以下问题:
+${original_query}"""
+
+COT_PROMPT_ZH = """你是一个分析问题并以特定字典格式返回结果的助手。
+
+指令:
+
+1. 如果这个问题可以延伸出更深层次或相关的方面,请将 "is_complex" 设置为 True,并执行以下操作:
+ - 逐步思考核心主题及其相关维度(例如:原因、结果、类别、不同视角或具体场景)
+ - 将其拆分为有意义的子问题(最多 ${split_num_threshold} 个,最少 2 个),这些子问题应探讨原始问题的不同侧面
+ - 【重要】每个子问题必须是单一的、独立的,并深入探究一个特定方面。同时,必须包含原问题中出现的关键实体信息(如人名、地名、机构名、时间等),不可遗漏。
+ - 将它们列在 "sub_questions" 中
+2. 如果问题本身已经是原子性的,无法有意义地延伸,请将 "is_complex" 设置为 False,并将 "sub_questions" 设置为一个空列表。
+3. 只返回字典,不要返回任何其他文本。
+
+示例:
+问题:美国西部的城市发展是否均衡?
+输出:{"is_complex": true, "sub_questions": ["美国西部包含哪些地区?", "美国西部城市的发展程度如何?", "这种发展在美国西部是否均衡?"]}
+
+问题:玛丽喜欢组织哪些家庭活动?
+输出:{"is_complex": true, "sub_questions": ["玛丽喜欢和配偶一起做什么?", "玛丽喜欢和孩子一起做什么?", "玛丽喜欢和父母及亲戚一起做什么?"]}
+
+问题相关的背景信息:
+${context}
+
+现在根据上述背景信息,请分析以下问题:
+${original_query}"""
diff --git a/src/memos/templates/prefer_complete_prompt.py b/src/memos/templates/prefer_complete_prompt.py
new file mode 100644
index 000000000..9e0274cba
--- /dev/null
+++ b/src/memos/templates/prefer_complete_prompt.py
@@ -0,0 +1,611 @@
+NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT = """
+You are a preference extraction assistant.
+Please extract the user's explicitly mentioned preferences from the following conversation.
+
+Notes:
+- A preference means the user's explicit attitude or choice toward something. It is not limited to words like "like/dislike/want/don't want/prefer".
+- This includes, but is not limited to, any user's explicitly expressed inclination, desire, rejection, or priority that counts as an explicit preference.
+- Focus on extracting the user's preferences in query. Do not extract preferences from the assistant's responses unless the user explicitly agrees with or endorses the assistant's suggestions.
+- When the user modifies or updates their preferences for the same topic or event, extract the complete evolution process of their preference changes, including both the original and updated preferences.
+
+Requirements:
+1. Keep only the preferences explicitly mentioned by the user. Do not infer or assume. If the user mentions reasons for their preferences, include those reasons as well.
+2. Output should be a list of entries concise natural language summaries and the corresponding context summary, context summary must contain complete information of the conversation fragment that the preference is mentioned.
+3. If multiple preferences are mentioned within the same topic or domain, you MUST combine them into a single entry, keep each entry information complete.
+
+Conversation:
+{qa_pair}
+
+Find ALL explicit preferences. If no explicit preferences found, return []. Output JSON only:
+```json
+[
+ {
+ "explicit_preference": "A short natural language summary of the preferences",
+ "context_summary": "The corresponding context summary, which is a summary of the corresponding conversation, do not lack any scenario information",
+ "reasoning": "reasoning process to find the explicit preferences"
+ },
+]
+```
+"""
+
+
+NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH = """
+你是一个偏好提取助手。
+请从以下对话中提取用户明确提及的偏好。
+
+注意事项:
+- 偏好是指用户对某事物的明确态度或选择,不仅限于"喜欢/不喜欢/想要/不想要/偏好"等词汇。
+- 包括但不限于用户明确表达的任何倾向、渴望、拒绝或优先级,这些都算作显式偏好。
+- 重点提取用户在查询中的偏好。不要从助手的回复中提取偏好,除非用户明确同意或认可助手的建议。
+- 当用户针对同一主题或事件修改或更新其偏好时,提取其偏好变化的完整演变过程,包括原始偏好和更新后的偏好。
+
+要求:
+1. 只保留用户明确提到的偏好,不要推断或假设。如果用户提到了偏好的原因,也要包含这些原因。
+2. 输出应该是一个条目列表,包含简洁的自然语言摘要和相应的上下文摘要,上下文摘要必须包含提到偏好的对话片段的完整信息。
+3. 如果在同一主题或领域内提到了多个偏好,你必须将它们合并为一个条目,保持每个条目信息完整。
+
+对话:
+{qa_pair}
+
+找出所有显式偏好。如果没有找到显式偏好,返回[]。仅输出JSON:
+```json
+[
+ {
+ "explicit_preference": "偏好的简短自然语言摘要",
+ "context_summary": "对应的上下文摘要,即对应对话的摘要,不要遗漏任何场景信息",
+ "reasoning": "寻找显式偏好的推理过程"
+ },
+]
+```
+"""
+
+
+NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT = """
+You are a preference inference assistant. Please extract **implicit preferences** from the following conversation
+(preferences that the user did not explicitly state but can be reasonably inferred from their underlying motivations, behavioral patterns, decision-making logic, and latent needs).
+
+Notes:
+- Implicit preferences refer to user inclinations or choices that are not directly expressed, but can be deeply inferred by analyzing:
+ * **Hidden motivations**: What underlying needs or goals might drive the user's behavior?
+ * **Behavioral patterns**: What recurring patterns or tendencies can be observed?
+ * **Decision-making logic**: What reasoning or trade-offs might the user be considering?
+ * **Latent preferences**: What preferences might the user have but haven't yet articulated?
+ * **Contextual signals**: What do the user's choices, comparisons, exclusions, or scenario selections reveal about their deeper preferences?
+- Do not treat explicitly stated preferences as implicit preferences; this prompt is only for inferring preferences that are not directly mentioned.
+- Go beyond surface-level facts to understand the user's hidden possibilities and underlying logic.
+
+Requirements:
+1. Only make inferences when there is sufficient evidence in the conversation; avoid unsupported or far-fetched guesses.
+2. Inferred implicit preferences must not conflict with explicit preferences.
+3. For implicit_preference: only output the preference statement itself; do not include any extra explanation, reasoning, or confidence information. Put all reasoning and explanation in the reasoning field.
+4. In the reasoning field, explicitly explain the underlying logic and hidden motivations you identified.
+5. If no implicit preference can be reasonably inferred, leave the implicit_preference field empty (do not output anything else).
+
+Conversation:
+{qa_pair}
+
+Output format:
+```json
+{
+ "implicit_preference": "A concise natural language statement of the implicit preferences reasonably inferred from the conversation, or an empty string",
+ "context_summary": "The corresponding context summary, which is a summary of the corresponding conversation, do not lack any scenario information",
+ "reasoning": "Explain the underlying logic, hidden motivations, and behavioral patterns that led to this inference"
+}
+```
+Don't output anything except the JSON.
+"""
+
+
+NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH = """
+你是一个偏好推理助手。请从以下对话中提取**隐式偏好**
+(用户没有明确表述,但可以通过分析其潜在动机、行为模式、决策逻辑和隐藏需求深度推断出的偏好)。
+
+注意事项:
+- 隐式偏好是指用户未直接表达,但可以通过深入分析以下方面推断出的倾向或选择:
+ * **隐藏动机**:什么样的潜在需求或目标可能驱动用户的行为?
+ * **行为模式**:可以观察到什么样的重复模式或倾向?
+ * **决策逻辑**:用户可能在考虑什么样的推理或权衡?
+ * **潜在偏好**:用户可能有但尚未明确表达的偏好是什么?
+ * **情境信号**:用户的选择、比较、排除或场景选择揭示了什么样的深层偏好?
+- 不要将明确陈述的偏好视为隐式偏好;此提示仅用于推断未直接提及的偏好。
+- 超越表面事实,理解用户的隐藏可能性和背后的逻辑。
+
+要求:
+1. 仅在对话中有充分证据时进行推断;避免无根据或牵强的猜测。
+2. 推断的隐式偏好不得与显式偏好冲突。
+3. 对于 implicit_preference:仅输出偏好陈述本身;不要包含任何额外的解释、推理或置信度信息。将所有推理和解释放在 reasoning 字段中。
+4. 在 reasoning 字段中,明确解释你识别出的底层逻辑和隐藏动机。
+5. 如果无法合理推断出隐式偏好,则将 implicit_preference 字段留空(不要输出其他任何内容)。
+
+对话:
+{qa_pair}
+
+输出格式:
+```json
+{
+ "implicit_preference": "从对话中合理推断出的隐式偏好的简洁自然语言陈述,或空字符串",
+ "context_summary": "对应的上下文摘要,即对应对话的摘要,不要遗漏任何场景信息",
+ "reasoning": "解释推断出该偏好的底层逻辑、隐藏动机和行为模式"
+}
+```
+除JSON外不要输出任何其他内容。
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT = """
+You are a content comparison expert. Now you are given old and new information, each containing a question, answer topic name and topic description.
+Please judge whether these two information express the **same question or core content**, regardless of expression differences, details or example differences. The judgment criteria are as follows:
+
+- Core content is consistent, that is, the essence of the question, goal or core concept to be solved is the same, it counts as "same".
+- Different expressions, different examples, but the core meaning is consistent, also counts as "same".
+- If the question goals, concepts involved or solution ideas are different, it counts as "different".
+
+Please output JSON format:
+{
+ "is_same": true/false,
+ "reasoning": "Briefly explain the judgment basis, highlighting whether the core content is consistent"
+}
+
+**Old Information:**
+{old_information}
+
+**New Information:**
+{new_information}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_ZH = """
+你是一个内容比较专家。现在给你旧信息和新信息,每个信息都包含问题、答案主题名称和主题描述。
+请判断这两个信息是否表达**相同的问题或核心内容**,不考虑表达差异、细节或示例差异。判断标准如下:
+
+- 核心内容一致,即要解决的问题本质、目标或核心概念相同,算作"相同"。
+- 表达方式不同、示例不同,但核心含义一致,也算作"相同"。
+- 如果问题目标、涉及的概念或解决思路不同,则算作"不同"。
+
+请输出JSON格式:
+{
+ "is_same": true/false,
+ "reasoning": "简要解释判断依据,突出核心内容是否一致"
+}
+
+**旧信息:**
+{old_information}
+
+**新信息:**
+{new_information}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE = """
+You are a preference memory comparison expert. Analyze if the new preference memory describes the same topic as any retrieved memories by considering BOTH the memory field and preference field. At most one retrieved memory can match the new memory.
+
+**Task:** Compare the new preference memory with retrieved memories to determine if they discuss the same topic and whether an update is needed.
+
+**Comparison Criteria:**
+- **Memory field**: Compare the core topics, scenarios, and contexts described
+- **Preference field**: Compare the actual preference statements, choices, and attitudes expressed
+- **Same topic**: Both memory AND preference content relate to the same subject matter
+- **Different topics**: Either memory OR preference content differs significantly
+- **Content evolution**: Same topic but preference has changed/evolved or memory has been updated
+- **Identical content**: Both memory and preference fields are essentially the same
+
+**Decision Logic:**
+- Same core topic (both memory and preference) = need to check if update is needed
+- Different topics (either memory or preference differs) = no update needed
+- If same topic but content has changed/evolved = update needed
+- If same topic and content is identical = update needed
+
+**Output JSON:**
+```json
+{
+ "need_update": true/false,
+ "id": "ID of the memory being updated (empty string if no update needed)",
+ "new_memory": "Updated memory field with merged/evolved memory content (empty string if no update needed)",
+ "new_preference": "Updated preference field with merged/evolved preference content (empty string if no update needed)",
+ "reasoning": "Brief explanation of the comparison considering both memory and preference fields"
+}
+```
+
+**New preference memory:**
+{new_memory}
+
+**Retrieved preference memories:**
+{retrieved_memories}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE_ZH = """
+你是一个偏好记忆比较专家。通过同时考虑 memory 字段和 preference 字段,分析新的偏好记忆是否与任何召回记忆描述相同的主题。最多只有一个召回记忆可以与新记忆匹配。
+
+**任务:** 比较新的偏好记忆与召回记忆,以确定它们是否讨论相同的主题以及是否需要更新。
+
+**比较标准:**
+- **Memory 字段**:比较所描述的核心主题、场景和上下文
+- **Preference 字段**:比较表达的实际偏好陈述、选择和态度
+- **相同主题**:memory 和 preference 内容都涉及相同的主题
+- **不同主题**:memory 或 preference 内容有显著差异
+- **内容演变**:相同主题但偏好已改变/演变或记忆已更新
+- **内容相同**:memory 和 preference 字段本质上相同
+
+**决策逻辑:**
+- 核心主题相同(memory 和 preference 都相同)= 需要检查是否需要更新
+- 主题不同(memory 或 preference 有差异)= 不需要更新
+- 如果主题相同但内容已改变/演变 = 需要更新
+- 如果主题相同且内容完全相同 = 需要更新
+
+**输出 JSON:**
+```json
+{
+ "need_update": true/false,
+ "id": "正在更新的记忆的ID(如果不需要更新则为空字符串)",
+ "new_memory": "合并/演变后的更新 memory 字段(如果不需要更新则为空字符串)",
+ "new_preference": "合并/演变后的更新 preference 字段(如果不需要更新则为空字符串)",
+ "reasoning": "简要解释比较结果,同时考虑 memory 和 preference 字段"
+}
+```
+
+**新的偏好记忆:**
+{new_memory}
+
+**召回的偏好记忆:**
+{retrieved_memories}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE = """
+# User Preference Memory Management Agent
+
+You are a **User Preference Memory Management Agent**.
+Your goal is to maintain a user's long-term **preference memory base** by analyzing new preference information and determining how it should update existing memories.
+
+Each memory entry contains three fields:
+- **id**: a unique identifier for the memory.
+- **context_summary**: a factual summary of the dialogue or situation from which the preference was extracted.
+- **preference**: the extracted statement describing the user's preference or tendency.
+
+When updating a preference, you should also integrate and update the corresponding `context_summary` to ensure both fields stay semantically consistent.
+
+You must produce a complete **operation trace**, showing which memory entries (identified by unique IDs) should be **added**, **updated**, or **deleted**.
+
+## Input Format
+
+New preference memories (new_memories):
+{new_memories}
+
+Retrieved preference memories (retrieved_memories):
+{retrieved_memories}
+## Task Instructions
+
+1. For each new memory, analyze its relationship with the retrieved memories:
+ - If a new memory is **unrelated** to all retrieved memories → perform `"ADD"` (insert as a new independent memory);
+ - If a new memory is **related** to one or more retrieved memories → perform `"UPDATE"` on those related retrieved memories (refine, supplement, or merge both the `preference` and the `context_summary`, while preserving change history trajectory information);
+ - If one or more retrieved memories are merged into one updated memory → perform `"DELETE"` on those retrieved memories.
+
+2. **Important**: Only retrieved memories that are related to the new memories should be updated or deleted. Retrieved memories that are unrelated to any new memory must be preserved.
+
+3. If multiple retrieved memories describe the same preference theme, merge them into one updated memory entry, combining both their `preference` information and their `context_summary` in a coherent and concise way.
+
+4. Output a structured list of **operation traces**, each explicitly stating:
+ - which memory (by ID) is affected,
+ - what operation is performed,
+ - the before/after `preference` and `context_summary`,
+ - and the reasoning behind it.
+
+## Output Format (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(the old memory ID; null if ADD)",
+ "old_preference": "(the old preference text; null if ADD)",
+ "old_context_summary": "(the old context summary; null if ADD)",
+ "new_preference": "(the updated or newly created preference, if applicable)",
+ "new_context_summary": "(the updated or newly created context summary, if applicable)",
+ "reason": "(brief natural-language explanation for the decision)"
+ }
+ ]
+}
+
+## Output Requirements
+
+- The output **must** be valid JSON.
+- Each operation must include both `preference` and `context_summary` updates where applicable.
+- Each operation must include a clear `reason`.
+- Multiple retrieved memories may be merged into one unified updated memory.
+- Do **not** include any explanatory text outside the JSON.
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE_ZH = """
+# 用户偏好记忆管理代理
+
+你是一个**用户偏好记忆管理代理**。
+你的目标是通过分析新的偏好信息并确定如何更新现有记忆,来维护用户的长期**偏好记忆库**。
+
+每个记忆条目包含三个字段:
+- **id**:记忆的唯一标识符。
+- **context_summary**:从中提取偏好的对话或情境的事实摘要。
+- **preference**:描述用户偏好或倾向的提取陈述。
+
+更新偏好时,你还应该整合并更新相应的 `context_summary`,以确保两个字段保持语义一致。
+
+你必须生成完整的**操作跟踪**,显示应该**添加**、**更新**或**删除**哪些记忆条目(通过唯一 ID 标识)。
+
+## 输入格式
+
+新的偏好记忆 (new_memories):
+{new_memories}
+
+召回的偏好记忆 (retrieved_memories):
+{retrieved_memories}
+## 任务说明
+
+1. 对于每个新记忆,分析其与召回记忆的关系:
+ - 如果新记忆与所有召回记忆**无关** → 执行 `"ADD"`(作为新的独立记忆插入);
+ - 如果新记忆与一个或多个召回记忆**相关** → 对这些相关的召回记忆执行 `"UPDATE"`(细化、补充或合并 `preference` 和 `context_summary`,同时保留变化历史轨迹信息);
+ - 如果一个或多个召回记忆被合并到一个更新的记忆中 → 对这些召回记忆执行 `"DELETE"`。
+
+2. **重要**:只有与新记忆相关的召回记忆才应该被更新或删除。与任何新记忆都无关的召回记忆必须保留。
+
+3. 如果多个召回记忆描述相同的偏好主题,将它们合并为一个更新的记忆条目,以连贯简洁的方式结合它们的 `preference` 信息和 `context_summary`。
+
+4. 输出结构化的**操作跟踪**列表,每个操作明确说明:
+ - 受影响的记忆(通过 ID);
+ - 执行的操作类型;
+ - 更新前后的 `preference` 和 `context_summary`;
+ - 以及决策的原因。
+
+## 输出格式 (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(旧记忆 ID;如果是 ADD 则为 null)",
+ "old_preference": "(旧的偏好文本;如果是 ADD 则为 null)",
+ "old_context_summary": "(旧的上下文摘要;如果是 ADD 则为 null)",
+ "new_preference": "(更新或新创建的偏好,如果适用)",
+ "new_context_summary": "(更新或新创建的上下文摘要,如果适用)",
+ "reason": "(决策的简要自然语言解释)"
+ }
+ ]
+}
+
+## 输出要求
+
+- 输出**必须**是有效的 JSON。
+- 每个操作必须包含 `preference` 和 `context_summary` 的更新(如果适用)。
+- 每个操作必须包含清晰的 `reason`。
+- 多个召回记忆可以合并为一个统一的更新记忆。
+- **不要**在 JSON 之外包含任何解释性文本。
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE_WITH_ONE_SHOT = """
+# User Preference Memory Management Agent
+
+You are a **User Preference Memory Management Agent**.
+Your goal is to maintain a user's long-term **preference memory base** by analyzing new preference information and determining how it should update existing memories.
+
+Each memory entry contains three fields:
+- **id**: a unique identifier for the memory.
+- **context_summary**: a factual summary of the dialogue or situation from which the preference was extracted.
+- **preference**: the extracted statement describing the user's preference or tendency.
+
+When updating a preference, you should also integrate and update the corresponding `context_summary` to ensure both fields stay semantically consistent.
+
+You must produce a complete **operation trace**, showing which memory entries (identified by unique IDs) should be **added**, **updated**, or **deleted**, and then output the **final memory state** after all operations.
+
+## Input Format
+
+New preference memories (new_memories):
+{new_memories}
+
+Retrieved preference memories (retrieved_memories):
+{retrieved_memories}
+## Task Instructions
+
+1. For each new memory, analyze its relationship with the retrieved memories:
+ - If a new memory is **unrelated** to all retrieved memories → perform `"ADD"` (insert as a new independent memory);
+ - If a new memory is **related** to one or more retrieved memories → perform `"UPDATE"` on those related retrieved memories (refine, supplement, or merge both the `preference` and the `context_summary`, while preserving change history trajectory information);
+ - If one or more retrieved memories are merged into one updated memory → perform `"DELETE"` on those retrieved memories.
+
+2. **Important**: Only retrieved memories that are related to the new memories should be updated or deleted. Retrieved memories that are unrelated to any new memory must be preserved as-is in the final state.
+
+3. If multiple retrieved memories describe the same preference theme, merge them into one updated memory entry, combining both their `preference` information and their `context_summary` in a coherent and concise way.
+
+4. Output a structured list of **operation traces**, each explicitly stating:
+ - which memory (by ID) is affected,
+ - what operation is performed,
+ - the before/after `preference` and `context_summary`,
+ - and the reasoning behind it.
+
+5. Output the **final memory state (after_update_state)**, representing the complete preference memory base after applying all operations. This must include:
+ - All newly added memories (from ADD operations)
+ - All updated memories (from UPDATE operations)
+ - All unrelated retrieved memories that were preserved unchanged
+
+## Output Format (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(the old memory ID; null if ADD)",
+ "old_preference": "(the old preference text; null if ADD)",
+ "old_context_summary": "(the old context summary; null if ADD)",
+ "new_preference": "(the updated or newly created preference, if applicable)",
+ "new_context_summary": "(the updated or newly created context summary, if applicable)",
+ "reason": "(brief natural-language explanation for the decision)"
+ }
+ ],
+ "after_update_state": [
+ {
+ "id": "id1",
+ "context_summary": "updated factual summary of the context",
+ "preference": "updated or final preference text"
+ }
+ ]
+}
+
+## Example
+
+**Input:**
+new_memories:
+[
+ {
+ "id": "new_id1",
+ "context_summary": "During a recent chat about study habits, the user mentioned that he often studies in quiet coffee shops and has started preferring lattes over Americanos, which he only drinks occasionally.",
+ "preference": "User now prefers lattes but occasionally drinks Americanos; he also enjoys studying in quiet coffee shops."
+ },
+ {
+ "id": "new_id2",
+ "context_summary": "The user mentioned in a conversation about beverages that he has recently started enjoying green tea in the morning.",
+ "preference": "User now enjoys drinking green tea in the morning."
+ },
+ {
+ "id": "new_id3",
+ "context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "preference": "User enjoys playing guitar and practices regularly in the evenings."
+ }
+]
+
+retrieved_memories:
+[
+ {
+ "id": "id1",
+ "context_summary": "The user previously said he likes coffee in general.",
+ "preference": "User likes coffee."
+ },
+ {
+ "id": "id2",
+ "context_summary": "The user once mentioned preferring Americanos during work breaks.",
+ "preference": "User prefers Americanos."
+ },
+ {
+ "id": "id3",
+ "context_summary": "The user said he often works from home",
+ "preference": "User likes working from home."
+ },
+ {
+ "id": "id4",
+ "context_summary": "The user noted he doesn't drink tea very often.",
+ "preference": "User has no particular interest in tea."
+ },
+ {
+ "id": "id5",
+ "context_summary": "The user mentioned he enjoys running in the park on weekends.",
+ "preference": "User likes running outdoors on weekends."
+ }
+]
+
+**Output:**
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "UPDATE",
+ "target_id": "id1",
+ "old_preference": "User likes coffee.",
+ "old_context_summary": "The user previously said he likes coffee in general.",
+ "new_preference": "User likes coffee, especially lattes, but occasionally drinks Americanos.",
+ "new_context_summary": "The user discussed his coffee habits, stating he now prefers lattes but only occasionally drinks Americanos",
+ "reason": "New memory new_id1 refines and expands the coffee preference and context while preserving frequency semantics ('occasionally')."
+ },
+ {
+ "op_id": "op_2",
+ "type": "DELETE",
+ "target_id": "id2",
+ "old_preference": "User prefers Americanos.",
+ "old_context_summary": "The user once mentioned preferring Americanos during work breaks.",
+ "new_preference": null,
+ "new_context_summary": null,
+ "reason": "This old memory is now merged into the updated coffee preference (id1)."
+ },
+ {
+ "op_id": "op_3",
+ "type": "UPDATE",
+ "target_id": "id3",
+ "old_preference": "User likes working from home.",
+ "old_context_summary": "The user said he often works from home.",
+ "new_preference": "User now prefers studying in quiet coffee shops instead of working from home.",
+ "new_context_summary": "The user mentioned shifting from working at home to studying in quiet cafes, reflecting a new preferred environment.",
+ "reason": "New memory new_id1 indicates a preference change for the working environment."
+ },
+ {
+ "op_id": "op_4",
+ "type": "UPDATE",
+ "target_id": "id4",
+ "old_preference": "User has no particular interest in tea.",
+ "old_context_summary": "The user noted he doesn't drink tea very often.",
+ "new_preference": "The user does not drink tea very often before, but now enjoys drinking green tea in the morning.",
+ "new_context_summary": "The user mentioned that he has recently started enjoying green tea in the morning.",
+ "reason": "New memory new_id2 indicates a preference change for tea consumption."
+ },
+ {
+ "op_id": "op_5",
+ "type": "ADD",
+ "target_id": "new_id3",
+ "old_preference": null,
+ "old_context_summary": null,
+ "new_preference": "User enjoys playing guitar and practices regularly in the evenings.",
+ "new_context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "reason": "This is a completely new preference unrelated to any existing memories, so it should be added as a new entry."
+ }
+ ],
+ "after_update_state": [
+ {
+ "id": "id1",
+ "context_summary": "The user discussed his coffee habits, saying he now prefers lattes but only occasionally drinks Americanos.",
+ "preference": "User likes coffee, especially lattes, but occasionally drinks Americanos."
+ },
+ {
+ "id": "id3",
+ "context_summary": "The user mentioned shifting from working at home to studying in quiet cafes, reflecting a new preferred environment.",
+ "preference": "User now prefers studying in quiet coffee shops instead of working from home."
+ },
+ {
+ "id": "id4",
+ "context_summary": "The user mentioned that he has recently started enjoying green tea in the morning.",
+ "preference": "The user does not drink tea very often before, but now enjoys drinking green tea in the morning."
+ },
+ {
+ "id": "id5",
+ "context_summary": "The user mentioned he enjoys running in the park on weekends.",
+ "preference": "User likes running outdoors on weekends."
+ },
+ {
+ "id": "new_id3",
+ "context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "preference": "User enjoys playing guitar and practices regularly in the evenings."
+ }
+ ]
+}
+
+## Output Requirements
+
+- The output **must** be valid JSON.
+- Each operation must include both `preference` and `context_summary` updates where applicable.
+- Each operation must include a clear `reason`.
+- Multiple retrieved memories may be merged into one unified updated memory.
+- `after_update_state` must reflect the final, post-update state of the preference memory base.
+- Do **not** include any explanatory text outside the JSON.
+"""
+
+
+PREF_INSTRUCTIONS = """
+# Note:
+Fact memory are summaries of facts, while preference memory are summaries of user preferences.
+Your response must not violate any of the user's preferences, whether explicit or implicit, and briefly explain why you answer this way to avoid conflicts.
+"""
+
+
+PREF_INSTRUCTIONS_ZH = """
+# 注意:
+事实记忆是事实的摘要,而偏好记忆是用户偏好的摘要。
+你的回复不得违反用户的任何偏好,无论是显式偏好还是隐式偏好,并简要解释你为什么这样回答以避免冲突。
+"""
diff --git a/src/memos/utils.py b/src/memos/utils.py
index 6a1d42558..08934ed34 100644
--- a/src/memos/utils.py
+++ b/src/memos/utils.py
@@ -6,14 +6,24 @@
logger = get_logger(__name__)
-def timed(func):
- """Decorator to measure and log time of retrieval steps."""
+def timed(func=None, *, log=False, log_prefix=""):
+ """Decorator to measure and optionally log time of retrieval steps.
- def wrapper(*args, **kwargs):
- start = time.perf_counter()
- result = func(*args, **kwargs)
- elapsed = time.perf_counter() - start
- logger.info(f"[TIMER] {func.__name__} took {elapsed:.2f} s")
- return result
+ Can be used as @timed or @timed(log=True)
+ """
- return wrapper
+ def decorator(fn):
+ def wrapper(*args, **kwargs):
+ start = time.perf_counter()
+ result = fn(*args, **kwargs)
+ elapsed = time.perf_counter() - start
+ if log:
+ logger.info(f"[TIMER] {log_prefix or fn.__name__} took {elapsed:.2f} seconds")
+ return result
+
+ return wrapper
+
+ # Handle both @timed and @timed(log=True) cases
+ if func is None:
+ return decorator
+ return decorator(func)
diff --git a/src/memos/vec_dbs/factory.py b/src/memos/vec_dbs/factory.py
index 8df22d14d..f2950b4ea 100644
--- a/src/memos/vec_dbs/factory.py
+++ b/src/memos/vec_dbs/factory.py
@@ -2,6 +2,7 @@
from memos.configs.vec_db import VectorDBConfigFactory
from memos.vec_dbs.base import BaseVecDB
+from memos.vec_dbs.milvus import MilvusVecDB
from memos.vec_dbs.qdrant import QdrantVecDB
@@ -10,6 +11,7 @@ class VecDBFactory(BaseVecDB):
backend_to_class: ClassVar[dict[str, Any]] = {
"qdrant": QdrantVecDB,
+ "milvus": MilvusVecDB,
}
@classmethod
diff --git a/src/memos/vec_dbs/item.py b/src/memos/vec_dbs/item.py
index 6f74879ac..c6aa1c9c2 100644
--- a/src/memos/vec_dbs/item.py
+++ b/src/memos/vec_dbs/item.py
@@ -41,3 +41,10 @@ def from_dict(cls, data: dict[str, Any]) -> "VecDBItem":
def to_dict(self) -> dict[str, Any]:
"""Convert to dictionary format."""
return self.model_dump(exclude_none=True)
+
+
+class MilvusVecDBItem(VecDBItem):
+ """Represents a single item in the Milvus vector database."""
+
+ memory: str | None = Field(default=None, description="Memory string")
+ original_text: str | None = Field(default=None, description="Original text content")
diff --git a/src/memos/vec_dbs/milvus.py b/src/memos/vec_dbs/milvus.py
index 7bb1ceeba..e50c8ce18 100644
--- a/src/memos/vec_dbs/milvus.py
+++ b/src/memos/vec_dbs/milvus.py
@@ -4,7 +4,7 @@
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.vec_dbs.base import BaseVecDB
-from memos.vec_dbs.item import VecDBItem
+from memos.vec_dbs.item import MilvusVecDBItem
logger = get_logger(__name__)
@@ -34,17 +34,36 @@ def __init__(self, config: MilvusVecDBConfig):
def create_schema(self):
"""Create schema for the milvus collection."""
- from pymilvus import DataType
+ from pymilvus import DataType, Function, FunctionType
schema = self.client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(
field_name="id", datatype=DataType.VARCHAR, max_length=65535, is_primary=True
)
+ analyzer_params = {"tokenizer": "standard", "filter": ["lowercase"]}
+ schema.add_field(
+ field_name="memory",
+ datatype=DataType.VARCHAR,
+ max_length=65535,
+ analyzer_params=analyzer_params,
+ enable_match=True,
+ enable_analyzer=True,
+ )
+ schema.add_field(field_name="original_text", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(
field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=self.config.vector_dimension
)
schema.add_field(field_name="payload", datatype=DataType.JSON)
+ schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
+ bm25_function = Function(
+ name="bm25",
+ function_type=FunctionType.BM25,
+ input_field_names=["memory"],
+ output_field_names="sparse_vector",
+ )
+ schema.add_function(bm25_function)
+
return schema
def create_index(self):
@@ -53,6 +72,11 @@ def create_index(self):
index_params.add_index(
field_name="vector", index_type="FLAT", metric_type=self._get_metric_type()
)
+ index_params.add_index(
+ field_name="sparse_vector",
+ index_type="SPARSE_INVERTED_INDEX",
+ metric_type="BM25",
+ )
return index_params
@@ -101,13 +125,97 @@ def collection_exists(self, name: str) -> bool:
"""Check if a collection exists."""
return self.client.has_collection(collection_name=name)
+ def _dense_search(
+ self,
+ collection_name: str,
+ query_vector: list[float],
+ top_k: int,
+ filter: str = "",
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Dense search for similar items in the database."""
+ results = self.client.search(
+ collection_name=collection_name,
+ data=[query_vector],
+ limit=top_k,
+ filter=filter,
+ output_fields=["*"],
+ anns_field="vector",
+ )
+ return results
+
+ def _sparse_search(
+ self,
+ collection_name: str,
+ query: str,
+ top_k: int,
+ filter: str = "",
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Sparse search for similar items in the database."""
+ results = self.client.search(
+ collection_name=collection_name,
+ data=[query],
+ limit=top_k,
+ filter=filter,
+ output_fields=["*"],
+ anns_field="sparse_vector",
+ )
+ return results
+
+ def _hybrid_search(
+ self,
+ collection_name: str,
+ query_vector: list[float],
+ query: str,
+ top_k: int,
+ filter: str | None = None,
+ ranker_type: str = "rrf", # rrf, weighted
+ sparse_weight=1.0,
+ dense_weight=1.0,
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Hybrid search for similar items in the database."""
+ from pymilvus import AnnSearchRequest, RRFRanker, WeightedRanker
+
+ # Set up BM25 search request
+ expr = filter if filter else None
+ sparse_request = AnnSearchRequest(
+ data=[query],
+ anns_field="sparse_vector",
+ param={"metric_type": "BM25"},
+ limit=top_k,
+ expr=expr,
+ )
+ # Set up dense vector search request
+ dense_request = AnnSearchRequest(
+ data=[query_vector],
+ anns_field="vector",
+ param={"metric_type": self._get_metric_type()},
+ limit=top_k,
+ expr=expr,
+ )
+ ranker = (
+ RRFRanker() if ranker_type == "rrf" else WeightedRanker(sparse_weight, dense_weight)
+ )
+ results = self.client.hybrid_search(
+ collection_name=collection_name,
+ reqs=[sparse_request, dense_request],
+ ranker=ranker,
+ limit=top_k,
+ output_fields=["*"],
+ )
+ return results
+
def search(
self,
query_vector: list[float],
+ query: str,
collection_name: str,
top_k: int,
filter: dict[str, Any] | None = None,
- ) -> list[VecDBItem]:
+ search_type: str = "dense", # dense, sparse, hybrid
+ ) -> list[MilvusVecDBItem]:
"""
Search for similar items in the database.
@@ -123,12 +231,18 @@ def search(
# Convert filter to Milvus expression
expr = self._dict_to_expr(filter) if filter else ""
- results = self.client.search(
+ search_func_map = {
+ "dense": self._dense_search,
+ "sparse": self._sparse_search,
+ "hybrid": self._hybrid_search,
+ }
+
+ results = search_func_map[search_type](
collection_name=collection_name,
- data=[query_vector],
- limit=top_k,
+ query_vector=query_vector,
+ query=query,
+ top_k=top_k,
filter=expr,
- output_fields=["*"], # Return all fields
)
items = []
@@ -136,8 +250,10 @@ def search(
entity = hit.get("entity", {})
items.append(
- VecDBItem(
- id=str(hit["id"]),
+ MilvusVecDBItem(
+ id=str(entity.get("id")),
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=entity.get("payload", {}),
score=1 - float(hit["distance"]),
@@ -178,7 +294,7 @@ def _get_metric_type(self) -> str:
}
return metric_map.get(self.config.distance_metric, "L2")
- def get_by_id(self, collection_name: str, id: str) -> VecDBItem | None:
+ def get_by_id(self, collection_name: str, id: str) -> MilvusVecDBItem | None:
"""Get a single item by ID."""
results = self.client.get(
collection_name=collection_name,
@@ -191,13 +307,15 @@ def get_by_id(self, collection_name: str, id: str) -> VecDBItem | None:
entity = results[0]
payload = {k: v for k, v in entity.items() if k not in ["id", "vector", "score"]}
- return VecDBItem(
+ return MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
- def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
+ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[MilvusVecDBItem]:
"""Get multiple items by their IDs."""
results = self.client.get(
collection_name=collection_name,
@@ -211,8 +329,10 @@ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
for entity in results:
payload = {k: v for k, v in entity.items() if k not in ["id", "vector", "score"]}
items.append(
- VecDBItem(
+ MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
@@ -222,7 +342,7 @@ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
def get_by_filter(
self, collection_name: str, filter: dict[str, Any], scroll_limit: int = 100
- ) -> list[VecDBItem]:
+ ) -> list[MilvusVecDBItem]:
"""
Retrieve all items that match the given filter criteria using query_iterator.
@@ -252,13 +372,15 @@ def get_by_filter(
if not batch_results:
break
- # Convert batch results to VecDBItem objects
+ # Convert batch results to MilvusVecDBItem objects
for entity in batch_results:
# Extract the actual payload from Milvus entity
payload = entity.get("payload", {})
all_items.append(
- VecDBItem(
+ MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
@@ -274,7 +396,7 @@ def get_by_filter(
logger.info(f"Milvus retrieve by filter completed with {len(all_items)} results.")
return all_items
- def get_all(self, collection_name: str, scroll_limit=100) -> list[VecDBItem]:
+ def get_all(self, collection_name: str, scroll_limit=100) -> list[MilvusVecDBItem]:
"""Retrieve all items in the vector database."""
return self.get_by_filter(collection_name, {}, scroll_limit=scroll_limit)
@@ -295,13 +417,14 @@ def count(self, collection_name: str, filter: dict[str, Any] | None = None) -> i
# Extract row count from stats - stats is a dict, not a list
return int(stats.get("row_count", 0))
- def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> None:
+ def add(self, collection_name: str, data: list[MilvusVecDBItem | dict[str, Any]]) -> None:
"""
Add data to the vector database.
Args:
- data: List of VecDBItem objects or dictionaries containing:
+ data: List of MilvusVecDBItem objects or dictionaries containing:
- 'id': unique identifier
+ - 'memory': memory string
- 'vector': embedding vector
- 'payload': additional fields for filtering/retrieval
"""
@@ -309,11 +432,13 @@ def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> N
for item in data:
if isinstance(item, dict):
item = item.copy()
- item = VecDBItem.from_dict(item)
+ item = MilvusVecDBItem.from_dict(item)
# Prepare entity data
entity = {
"id": item.id,
+ "memory": item.memory,
+ "original_text": item.original_text,
"vector": item.vector,
"payload": item.payload if item.payload else {},
}
@@ -326,11 +451,15 @@ def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> N
data=entities,
)
- def update(self, collection_name: str, id: str, data: VecDBItem | dict[str, Any]) -> None:
+ def update(self, collection_name: str, id: str, data: MilvusVecDBItem | dict[str, Any]) -> None:
"""Update an item in the vector database."""
+ if id != data.id:
+ raise ValueError(
+ f"The id of the data to update must be the same as the id of the item to update, ID mismatch: expected {id}, got {data.id}"
+ )
if isinstance(data, dict):
data = data.copy()
- data = VecDBItem.from_dict(data)
+ data = MilvusVecDBItem.from_dict(data)
# Use upsert for updates
self.upsert(collection_name, [data])
@@ -347,7 +476,7 @@ def ensure_payload_indexes(self, fields: list[str]) -> None:
# Field indexes are created automatically for scalar fields
logger.info(f"Milvus automatically indexes scalar fields: {fields}")
- def upsert(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> None:
+ def upsert(self, collection_name: str, data: list[MilvusVecDBItem | dict[str, Any]]) -> None:
"""
Add or update data in the vector database.
diff --git a/tests/configs/test_mem_cube.py b/tests/configs/test_mem_cube.py
index 6c962dd01..c50195558 100644
--- a/tests/configs/test_mem_cube.py
+++ b/tests/configs/test_mem_cube.py
@@ -28,7 +28,7 @@ def test_base_mem_cube_config():
def test_general_mem_cube_config():
check_config_base_class(
GeneralMemCubeConfig,
- factory_fields=["text_mem", "act_mem", "para_mem"],
+ factory_fields=["text_mem", "act_mem", "para_mem", "pref_mem"],
required_fields=[],
optional_fields=["config_filename", "user_id", "cube_id"],
reserved_fields=["model_schema"],
diff --git a/tests/llms/test_hf.py b/tests/llms/test_hf.py
index 8a266e58d..595995ad1 100644
--- a/tests/llms/test_hf.py
+++ b/tests/llms/test_hf.py
@@ -93,15 +93,50 @@ def test_build_kv_cache_and_generation(self):
add_generation_prompt=True,
)
llm = self._create_llm(config)
+
+ # Ensure the mock model returns an object with past_key_values attribute
+ forward_output = MagicMock()
+ forward_output.logits = torch.ones(1, 1, 100)
+
+ # Create a DynamicCache that's compatible with both old and new transformers versions
+ kv_cache = DynamicCache()
+
+ # Mock the DynamicCache to have both old and new version attributes for compatibility
+ # New version uses 'layers' attribute
+ mock_layer = MagicMock()
+ mock_layer.key_cache = torch.tensor([[[[1.0, 2.0]]]])
+ mock_layer.value_cache = torch.tensor([[[[3.0, 4.0]]]])
+ kv_cache.layers = [mock_layer]
+
+ # Old version uses 'key_cache' and 'value_cache' lists
+ kv_cache.key_cache = [torch.tensor([[[[1.0, 2.0]]]])]
+ kv_cache.value_cache = [torch.tensor([[[[3.0, 4.0]]]])]
+
+ forward_output.past_key_values = kv_cache
+ # Make sure the mock model call returns the forward_output when called with **kwargs
+ self.mock_model.return_value = forward_output
+
kv_cache = llm.build_kv_cache("The capital of France is Paris.")
self.assertIsInstance(kv_cache, DynamicCache)
resp = llm.generate(
[{"role": "user", "content": "What's its population?"}], past_key_values=kv_cache
)
self.assertEqual(resp, self.standard_response)
- first_kwargs = self.mock_model.call_args_list[0][1]
- self.assertIs(first_kwargs["past_key_values"], kv_cache)
- self.assertTrue(first_kwargs["use_cache"])
+ # Check that the model was called with past_key_values during _prefill
+ # The model should be called multiple times during generation with cache
+ found_past_key_values = False
+ for call_args in self.mock_model.call_args_list:
+ if len(call_args) > 1 and "past_key_values" in call_args[1]:
+ found_past_key_values = True
+ break
+ self.assertTrue(found_past_key_values, "Model should be called with past_key_values")
+ # Check that use_cache was used
+ found_use_cache = False
+ for call_args in self.mock_model.call_args_list:
+ if len(call_args) > 1 and call_args[1].get("use_cache"):
+ found_use_cache = True
+ break
+ self.assertTrue(found_use_cache, "Model should be called with use_cache=True")
def test_think_prefix_removal(self):
config = HFLLMConfig(
diff --git a/tests/mem_scheduler/test_dispatcher.py b/tests/mem_scheduler/test_dispatcher.py
index ed2093dea..e3064660b 100644
--- a/tests/mem_scheduler/test_dispatcher.py
+++ b/tests/mem_scheduler/test_dispatcher.py
@@ -233,7 +233,7 @@ def test_dispatch_parallel(self):
self.assertEqual(len(label2_messages), 1)
self.assertEqual(label2_messages[0].item_id, "msg2")
- def test_group_messages_by_user_and_cube(self):
+ def test_group_messages_by_user_and_mem_cube(self):
"""Test grouping messages by user and cube."""
# Check actual grouping logic
with patch("memos.mem_scheduler.general_modules.dispatcher.logger.debug"):
@@ -261,47 +261,6 @@ def test_group_messages_by_user_and_cube(self):
for msg in expected[user_id][cube_id]:
self.assertIn(msg.item_id, [m.item_id for m in result[user_id][cube_id]])
- def test_thread_race(self):
- """Test the ThreadRace integration."""
-
- # Define test tasks
- def task1(stop_flag):
- time.sleep(0.1)
- return "result1"
-
- def task2(stop_flag):
- time.sleep(0.2)
- return "result2"
-
- # Run competitive tasks
- tasks = {
- "task1": task1,
- "task2": task2,
- }
-
- result = self.dispatcher.run_competitive_tasks(tasks, timeout=1.0)
-
- # Verify the result
- self.assertIsNotNone(result)
- self.assertEqual(result[0], "task1") # task1 should win
- self.assertEqual(result[1], "result1")
-
- def test_thread_race_timeout(self):
- """Test ThreadRace with timeout."""
-
- # Define a task that takes longer than the timeout
- def slow_task(stop_flag):
- time.sleep(0.5)
- return "slow_result"
-
- tasks = {"slow": slow_task}
-
- # Run with a short timeout
- result = self.dispatcher.run_competitive_tasks(tasks, timeout=0.1)
-
- # Verify no result was returned due to timeout
- self.assertIsNone(result)
-
def test_thread_race_cooperative_termination(self):
"""Test that ThreadRace properly terminates slower threads when one completes."""
@@ -459,3 +418,190 @@ def test_dispatcher_monitor_logs_stuck_task_messages(self):
self.assertIn("Messages: 2 items", expected_log)
self.assertIn("Stuck message 1", expected_log)
self.assertIn("Stuck message 2", expected_log)
+
+ def test_get_running_tasks_no_filter(self):
+ """Test get_running_tasks without filter returns all running tasks."""
+ # Create test tasks manually
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+
+ # Get all running tasks
+ running_tasks = self.dispatcher.get_running_tasks()
+
+ # Verify all tasks are returned
+ self.assertEqual(len(running_tasks), 2)
+ self.assertIn(task1.item_id, running_tasks)
+ self.assertIn(task2.item_id, running_tasks)
+ self.assertEqual(running_tasks[task1.item_id], task1)
+ self.assertEqual(running_tasks[task2.item_id], task2)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_user_id(self):
+ """Test get_running_tasks with user_id filter."""
+ # Create test tasks with different user_ids
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+ task3 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube3",
+ task_info="Test task 3",
+ task_name="handler3",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+ self.dispatcher._running_tasks[task3.item_id] = task3
+
+ # Filter by user_id
+ user1_tasks = self.dispatcher.get_running_tasks(lambda task: task.user_id == "user1")
+
+ # Verify only user1 tasks are returned
+ self.assertEqual(len(user1_tasks), 2)
+ self.assertIn(task1.item_id, user1_tasks)
+ self.assertIn(task3.item_id, user1_tasks)
+ self.assertNotIn(task2.item_id, user1_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_multiple_conditions(self):
+ """Test get_running_tasks with multiple filter conditions."""
+ # Create test tasks with different attributes
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="test_handler",
+ )
+ task2 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="other_handler",
+ )
+ task3 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube1",
+ task_info="Test task 3",
+ task_name="test_handler",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+ self.dispatcher._running_tasks[task3.item_id] = task3
+
+ # Filter by multiple conditions: user_id == "user1" AND task_name == "test_handler"
+ filtered_tasks = self.dispatcher.get_running_tasks(
+ lambda task: task.user_id == "user1" and task.task_name == "test_handler"
+ )
+
+ # Verify only task1 matches both conditions
+ self.assertEqual(len(filtered_tasks), 1)
+ self.assertIn(task1.item_id, filtered_tasks)
+ self.assertNotIn(task2.item_id, filtered_tasks)
+ self.assertNotIn(task3.item_id, filtered_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_status(self):
+ """Test get_running_tasks with status filter."""
+ # Create test tasks with different statuses
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+
+ # Manually set different statuses
+ task1.status = "running"
+ task2.status = "completed"
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+
+ # Filter by status
+ running_status_tasks = self.dispatcher.get_running_tasks(
+ lambda task: task.status == "running"
+ )
+
+ # Verify only running tasks are returned
+ self.assertEqual(len(running_status_tasks), 1)
+ self.assertIn(task1.item_id, running_status_tasks)
+ self.assertNotIn(task2.item_id, running_status_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_thread_safety(self):
+ """Test get_running_tasks is thread-safe."""
+ # Create test task
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+
+ # Add task to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+
+ # Get running tasks (should work without deadlock)
+ running_tasks = self.dispatcher.get_running_tasks()
+
+ # Verify task is returned
+ self.assertEqual(len(running_tasks), 1)
+ self.assertIn(task1.item_id, running_tasks)
+
+ # Test with filter (should also work without deadlock)
+ filtered_tasks = self.dispatcher.get_running_tasks(lambda task: task.user_id == "user1")
+ self.assertEqual(len(filtered_tasks), 1)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
diff --git a/tests/mem_scheduler/test_orm.py b/tests/mem_scheduler/test_orm.py
deleted file mode 100644
index ddf4fea8b..000000000
--- a/tests/mem_scheduler/test_orm.py
+++ /dev/null
@@ -1,299 +0,0 @@
-import os
-import tempfile
-import time
-
-from datetime import datetime, timedelta
-
-import pytest
-
-from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
-
-# Import the classes to test
-from memos.mem_scheduler.orm_modules.monitor_models import (
- DBManagerForMemoryMonitorManager,
- DBManagerForQueryMonitorQueue,
-)
-from memos.mem_scheduler.schemas.monitor_schemas import (
- MemoryMonitorItem,
- MemoryMonitorManager,
- QueryMonitorItem,
- QueryMonitorQueue,
-)
-
-
-# Test data
-TEST_USER_ID = "test_user"
-TEST_MEM_CUBE_ID = "test_mem_cube"
-TEST_QUEUE_ID = "test_queue"
-
-
-class TestBaseDBManager:
- """Base class for DBManager tests with common fixtures"""
-
- @pytest.fixture
- def temp_db(self):
- """Create a temporary database for testing."""
- temp_dir = tempfile.mkdtemp()
- db_path = os.path.join(temp_dir, "test_scheduler_orm.db")
- yield db_path
- # Cleanup
- try:
- if os.path.exists(db_path):
- os.remove(db_path)
- os.rmdir(temp_dir)
- except (OSError, PermissionError):
- pass # Ignore cleanup errors (e.g., file locked on Windows)
-
- @pytest.fixture
- def memory_manager_obj(self):
- """Create a MemoryMonitorManager object for testing"""
- return MemoryMonitorManager(
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- items=[
- MemoryMonitorItem(
- item_id="custom-id-123",
- memory_text="Full test memory",
- tree_memory_item=None,
- tree_memory_item_mapping_key="full_test_key",
- keywords_score=0.8,
- sorting_score=0.9,
- importance_score=0.7,
- recording_count=3,
- )
- ],
- )
-
- @pytest.fixture
- def query_queue_obj(self):
- """Create a QueryMonitorQueue object for testing"""
- queue = QueryMonitorQueue()
- queue.put(
- QueryMonitorItem(
- item_id="query1",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text="How are you?",
- timestamp=datetime.now(),
- keywords=["how", "you"],
- )
- )
- return queue
-
- @pytest.fixture
- def query_monitor_manager(self, temp_db, query_queue_obj):
- """Create DBManagerForQueryMonitorQueue instance with temp DB."""
- engine = BaseDBManager.create_engine_from_db_path(temp_db)
- manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
-
- assert manager.engine is not None
- assert manager.SessionLocal is not None
- assert os.path.exists(temp_db)
-
- yield manager
- manager.close()
-
- @pytest.fixture
- def memory_monitor_manager(self, temp_db, memory_manager_obj):
- """Create DBManagerForMemoryMonitorManager instance with temp DB."""
- engine = BaseDBManager.create_engine_from_db_path(temp_db)
- manager = DBManagerForMemoryMonitorManager(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=memory_manager_obj,
- lock_timeout=10,
- )
-
- assert manager.engine is not None
- assert manager.SessionLocal is not None
- assert os.path.exists(temp_db)
-
- yield manager
- manager.close()
-
- def test_save_and_load_query_queue(self, query_monitor_manager, query_queue_obj):
- """Test saving and loading QueryMonitorQueue."""
- # Save to database
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Load in a new manager
- engine = BaseDBManager.create_engine_from_db_path(query_monitor_manager.engine.url.database)
- new_manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=None,
- lock_timeout=10,
- )
- loaded_queue = new_manager.load_from_db(acquire_lock=True)
-
- assert loaded_queue is not None
- items = loaded_queue.get_queue_content_without_pop()
- assert len(items) == 1
- assert items[0].item_id == "query1"
- assert items[0].query_text == "How are you?"
- new_manager.close()
-
- def test_lock_mechanism(self, query_monitor_manager, query_queue_obj):
- """Test lock acquisition and release."""
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Acquire lock
- acquired = query_monitor_manager.acquire_lock(block=True)
- assert acquired
-
- # Try to acquire again (should fail without blocking)
- assert not query_monitor_manager.acquire_lock(block=False)
-
- # Release lock
- query_monitor_manager.release_locks(
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- )
-
- # Should be able to acquire again
- assert query_monitor_manager.acquire_lock(block=False)
-
- def test_lock_timeout(self, query_monitor_manager, query_queue_obj):
- """Test lock timeout mechanism."""
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- query_monitor_manager.lock_timeout = 1
-
- # Acquire lock
- assert query_monitor_manager.acquire_lock(block=True)
-
- # Wait for lock to expire
- time.sleep(1.1)
-
- # Should be able to acquire again
- assert query_monitor_manager.acquire_lock(block=False)
-
- def test_sync_with_orm(self, query_monitor_manager, query_queue_obj):
- """Test synchronization between ORM and object."""
- query_queue_obj.put(
- QueryMonitorItem(
- item_id="query2",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text="What's your name?",
- timestamp=datetime.now(),
- keywords=["name"],
- )
- )
-
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Create sync manager with empty queue
- empty_queue = QueryMonitorQueue(maxsize=10)
- engine = BaseDBManager.create_engine_from_db_path(query_monitor_manager.engine.url.database)
- sync_manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=empty_queue,
- lock_timeout=10,
- )
-
- # First sync - should create a new record with empty queue
- sync_manager.sync_with_orm(size_limit=None)
- items = sync_manager.obj.get_queue_content_without_pop()
- assert len(items) == 0 # Empty queue since no existing data to merge
-
- # Now save the empty queue to create a record
- sync_manager.save_to_db(empty_queue)
-
- # Test that sync_with_orm correctly handles version control
- # The sync should increment version but not merge data when versions are the same
- sync_manager.sync_with_orm(size_limit=None)
- items = sync_manager.obj.get_queue_content_without_pop()
- assert len(items) == 0 # Should remain empty since no merge occurred
-
- # Verify that the version was incremented
- assert sync_manager.last_version_control == "3" # Should increment from 2 to 3
-
- sync_manager.close()
-
- def test_sync_with_size_limit(self, query_monitor_manager, query_queue_obj):
- """Test synchronization with size limit."""
- now = datetime.now()
- item_size = 1
- for i in range(2, 6):
- item_size += 1
- query_queue_obj.put(
- QueryMonitorItem(
- item_id=f"query{i}",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text=f"Question {i}",
- timestamp=now + timedelta(minutes=i),
- keywords=[f"kw{i}"],
- )
- )
-
- # First sync - should create a new record (size_limit not applied for new records)
- size_limit = 3
- query_monitor_manager.sync_with_orm(size_limit=size_limit)
- items = query_monitor_manager.obj.get_queue_content_without_pop()
- assert len(items) == item_size # All items since size_limit not applied for new records
-
- # Save to create the record
- query_monitor_manager.save_to_db(query_monitor_manager.obj)
-
- # Test that sync_with_orm correctly handles version control
- # The sync should increment version but not merge data when versions are the same
- query_monitor_manager.sync_with_orm(size_limit=size_limit)
- items = query_monitor_manager.obj.get_queue_content_without_pop()
- assert len(items) == item_size # Should remain the same since no merge occurred
-
- # Verify that the version was incremented
- assert query_monitor_manager.last_version_control == "2"
-
- def test_concurrent_access(self, temp_db, query_queue_obj):
- """Test concurrent access to the same database."""
-
- # Manager 1
- engine1 = BaseDBManager.create_engine_from_db_path(temp_db)
- manager1 = DBManagerForQueryMonitorQueue(
- engine=engine1,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
- manager1.save_to_db(query_queue_obj)
-
- # Manager 2
- engine2 = BaseDBManager.create_engine_from_db_path(temp_db)
- manager2 = DBManagerForQueryMonitorQueue(
- engine=engine2,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
-
- # Manager1 acquires lock
- assert manager1.acquire_lock(block=True)
-
- # Manager2 fails to acquire
- assert not manager2.acquire_lock(block=False)
-
- # Manager1 releases
- manager1.release_locks(user_id=TEST_USER_ID, mem_cube_id=TEST_MEM_CUBE_ID)
-
- # Manager2 can now acquire
- assert manager2.acquire_lock(block=False)
-
- manager1.close()
- manager2.close()
diff --git a/tests/mem_scheduler/test_scheduler.py b/tests/mem_scheduler/test_scheduler.py
index 15338006d..03a8e4318 100644
--- a/tests/mem_scheduler/test_scheduler.py
+++ b/tests/mem_scheduler/test_scheduler.py
@@ -26,6 +26,7 @@
)
from memos.mem_scheduler.schemas.message_schemas import (
ScheduleLogForWebItem,
+ ScheduleMessageItem,
)
from memos.memories.textual.tree import TreeTextMemory
@@ -36,6 +37,9 @@
class TestGeneralScheduler(unittest.TestCase):
+ # Control whether to run activation memory tests that require GPU, default is False
+ RUN_ACTIVATION_MEMORY_TESTS = True
+
def _create_mock_auth_config(self):
"""Create a mock AuthConfig for testing purposes."""
# Create mock configs with valid test values
@@ -68,6 +72,19 @@ def setUp(self):
self.llm = MagicMock(spec=BaseLLM)
self.mem_cube = MagicMock(spec=GeneralMemCube)
self.tree_text_memory = MagicMock(spec=TreeTextMemory)
+ # Add memory_manager mock to prevent AttributeError in scheduler_logger
+ self.tree_text_memory.memory_manager = MagicMock()
+ self.tree_text_memory.memory_manager.memory_size = {
+ "LongTermMemory": 10000,
+ "UserMemory": 10000,
+ "WorkingMemory": 20,
+ }
+ # Mock get_current_memory_size method
+ self.tree_text_memory.get_current_memory_size.return_value = {
+ "LongTermMemory": 100,
+ "UserMemory": 50,
+ "WorkingMemory": 10,
+ }
self.mem_cube.text_mem = self.tree_text_memory
self.mem_cube.act_mem = MagicMock()
@@ -185,8 +202,71 @@ def test_scheduler_startup_mode_thread(self):
# Stop the scheduler
self.scheduler.stop()
- # Verify cleanup
- self.assertFalse(self.scheduler._running)
+ def test_redis_message_queue(self):
+ """Test Redis message queue functionality for sending and receiving messages."""
+ import time
+
+ from unittest.mock import MagicMock, patch
+
+ # Mock Redis connection and operations
+ mock_redis = MagicMock()
+ mock_redis.xadd = MagicMock(return_value=b"1234567890-0")
+
+ # Track received messages
+ received_messages = []
+
+ def redis_handler(messages: list[ScheduleMessageItem]) -> None:
+ """Handler for Redis messages."""
+ received_messages.extend(messages)
+
+ # Register Redis handler
+ redis_label = "test_redis"
+ handlers = {redis_label: redis_handler}
+ self.scheduler.register_handlers(handlers)
+
+ # Enable Redis queue for this test
+ with (
+ patch.object(self.scheduler, "use_redis_queue", True),
+ patch.object(self.scheduler, "_redis_conn", mock_redis),
+ ):
+ # Start scheduler
+ self.scheduler.start()
+
+ # Create test message for Redis
+ redis_message = ScheduleMessageItem(
+ label=redis_label,
+ content="Redis test message",
+ user_id="redis_user",
+ mem_cube_id="redis_cube",
+ mem_cube="redis_mem_cube_obj",
+ timestamp=datetime.now(),
+ )
+
+ # Submit message to Redis queue
+ self.scheduler.submit_messages(redis_message)
+
+ # Verify Redis xadd was called
+ mock_redis.xadd.assert_called_once()
+ call_args = mock_redis.xadd.call_args
+ self.assertEqual(call_args[0][0], "user:queries:stream")
+
+ # Verify message data was serialized correctly
+ message_data = call_args[0][1]
+ self.assertEqual(message_data["label"], redis_label)
+ self.assertEqual(message_data["content"], "Redis test message")
+ self.assertEqual(message_data["user_id"], "redis_user")
+ self.assertEqual(message_data["cube_id"], "redis_cube") # Note: to_dict uses cube_id
+
+ # Simulate Redis message consumption
+ # This would normally be handled by the Redis consumer in the scheduler
+ time.sleep(0.1) # Brief wait for async operations
+
+ # Stop scheduler
+ self.scheduler.stop()
+
+ print("Redis message queue test completed successfully!")
+
+ # Removed test_robustness method - was too time-consuming for CI/CD pipeline
def test_scheduler_startup_mode_process(self):
"""Test scheduler with process startup mode."""
@@ -219,3 +299,232 @@ def test_scheduler_startup_mode_constants(self):
"""Test that startup mode constants are properly defined."""
self.assertEqual(STARTUP_BY_THREAD, "thread")
self.assertEqual(STARTUP_BY_PROCESS, "process")
+
+ def test_activation_memory_update(self):
+ """Test activation memory update functionality with DynamicCache handling."""
+ if not self.RUN_ACTIVATION_MEMORY_TESTS:
+ self.skipTest(
+ "Skipping activation memory test. Set RUN_ACTIVATION_MEMORY_TESTS=True to enable."
+ )
+
+ from unittest.mock import Mock
+
+ from transformers import DynamicCache
+
+ from memos.memories.activation.kv import KVCacheMemory
+
+ # Mock the mem_cube with activation memory
+ mock_kv_cache_memory = Mock(spec=KVCacheMemory)
+ self.mem_cube.act_mem = mock_kv_cache_memory
+
+ # Mock get_all to return empty list (no existing cache items)
+ mock_kv_cache_memory.get_all.return_value = []
+
+ # Create a mock DynamicCache with layers attribute
+ mock_cache = Mock(spec=DynamicCache)
+ mock_cache.layers = []
+
+ # Create mock layers with key_cache and value_cache
+ for _ in range(2): # Simulate 2 layers
+ mock_layer = Mock()
+ mock_layer.key_cache = Mock()
+ mock_layer.value_cache = Mock()
+ mock_cache.layers.append(mock_layer)
+
+ # Mock the extract method to return a KVCacheItem
+ mock_cache_item = Mock()
+ mock_cache_item.records = Mock()
+ mock_cache_item.records.text_memories = []
+ mock_cache_item.records.timestamp = None
+ mock_kv_cache_memory.extract.return_value = mock_cache_item
+
+ # Test data
+ test_memories = ["Test memory 1", "Test memory 2"]
+ user_id = "test_user"
+ mem_cube_id = "test_cube"
+
+ # Call the method under test
+ try:
+ self.scheduler.update_activation_memory(
+ new_memories=test_memories,
+ label=QUERY_LABEL,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=self.mem_cube,
+ )
+
+ # Verify that extract was called
+ mock_kv_cache_memory.extract.assert_called_once()
+
+ # Verify that add was called with the extracted cache item
+ mock_kv_cache_memory.add.assert_called_once()
+
+ # Verify that dump was called
+ mock_kv_cache_memory.dump.assert_called_once()
+
+ print("✅ Activation memory update test passed - DynamicCache layers handled correctly")
+
+ except Exception as e:
+ self.fail(f"Activation memory update failed: {e}")
+
+ def test_dynamic_cache_layers_access(self):
+ """Test DynamicCache layers attribute access for compatibility."""
+ if not self.RUN_ACTIVATION_MEMORY_TESTS:
+ self.skipTest(
+ "Skipping activation memory test. Set RUN_ACTIVATION_MEMORY_TESTS=True to enable."
+ )
+
+ from unittest.mock import Mock
+
+ from transformers import DynamicCache
+
+ # Create a real DynamicCache instance
+ cache = DynamicCache()
+
+ # Check if it has layers attribute (may vary by transformers version)
+ if hasattr(cache, "layers"):
+ self.assertIsInstance(cache.layers, list, "DynamicCache.layers should be a list")
+
+ # Test with mock layers
+ mock_layer = Mock()
+ mock_layer.key_cache = Mock()
+ mock_layer.value_cache = Mock()
+ cache.layers.append(mock_layer)
+
+ # Verify we can access layer attributes
+ self.assertEqual(len(cache.layers), 1)
+ self.assertTrue(hasattr(cache.layers[0], "key_cache"))
+ self.assertTrue(hasattr(cache.layers[0], "value_cache"))
+
+ print("✅ DynamicCache layers access test passed")
+ else:
+ # If layers attribute doesn't exist, verify our fix handles this case
+ print("⚠️ DynamicCache doesn't have 'layers' attribute in this transformers version")
+ print("✅ Test passed - our code should handle this gracefully")
+
+ def test_get_running_tasks_with_filter(self):
+ """Test get_running_tasks method with filter function."""
+ # Mock dispatcher and its get_running_tasks method
+ mock_task_item1 = MagicMock()
+ mock_task_item1.item_id = "task_1"
+ mock_task_item1.user_id = "user_1"
+ mock_task_item1.mem_cube_id = "cube_1"
+ mock_task_item1.task_info = {"type": "query"}
+ mock_task_item1.task_name = "test_task_1"
+ mock_task_item1.start_time = datetime.now()
+ mock_task_item1.end_time = None
+ mock_task_item1.status = "running"
+ mock_task_item1.result = None
+ mock_task_item1.error_message = None
+ mock_task_item1.messages = []
+
+ # Define a filter function
+ def user_filter(task):
+ return task.user_id == "user_1"
+
+ # Mock the filtered result (only task_1 matches the filter)
+ with patch.object(
+ self.scheduler.dispatcher, "get_running_tasks", return_value={"task_1": mock_task_item1}
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks with filter
+ result = self.scheduler.get_running_tasks(filter_func=user_filter)
+
+ # Verify result
+ self.assertIsInstance(result, dict)
+ self.assertIn("task_1", result)
+ self.assertEqual(len(result), 1)
+
+ # Verify dispatcher method was called with filter
+ mock_get_running_tasks.assert_called_once_with(filter_func=user_filter)
+
+ def test_get_running_tasks_empty_result(self):
+ """Test get_running_tasks method when no tasks are running."""
+ # Mock dispatcher to return empty dict
+ with patch.object(
+ self.scheduler.dispatcher, "get_running_tasks", return_value={}
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify empty result
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 0)
+
+ # Verify dispatcher method was called
+ mock_get_running_tasks.assert_called_once_with(filter_func=None)
+
+ def test_get_running_tasks_no_dispatcher(self):
+ """Test get_running_tasks method when dispatcher is None."""
+ # Temporarily set dispatcher to None
+ original_dispatcher = self.scheduler.dispatcher
+ self.scheduler.dispatcher = None
+
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify empty result and warning behavior
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 0)
+
+ # Restore dispatcher
+ self.scheduler.dispatcher = original_dispatcher
+
+ def test_get_running_tasks_multiple_tasks(self):
+ """Test get_running_tasks method with multiple tasks."""
+ # Mock multiple task items
+ mock_task_item1 = MagicMock()
+ mock_task_item1.item_id = "task_1"
+ mock_task_item1.user_id = "user_1"
+ mock_task_item1.mem_cube_id = "cube_1"
+ mock_task_item1.task_info = {"type": "query"}
+ mock_task_item1.task_name = "test_task_1"
+ mock_task_item1.start_time = datetime.now()
+ mock_task_item1.end_time = None
+ mock_task_item1.status = "running"
+ mock_task_item1.result = None
+ mock_task_item1.error_message = None
+ mock_task_item1.messages = []
+
+ mock_task_item2 = MagicMock()
+ mock_task_item2.item_id = "task_2"
+ mock_task_item2.user_id = "user_2"
+ mock_task_item2.mem_cube_id = "cube_2"
+ mock_task_item2.task_info = {"type": "answer"}
+ mock_task_item2.task_name = "test_task_2"
+ mock_task_item2.start_time = datetime.now()
+ mock_task_item2.end_time = None
+ mock_task_item2.status = "completed"
+ mock_task_item2.result = "success"
+ mock_task_item2.error_message = None
+ mock_task_item2.messages = ["message1", "message2"]
+
+ with patch.object(
+ self.scheduler.dispatcher,
+ "get_running_tasks",
+ return_value={"task_1": mock_task_item1, "task_2": mock_task_item2},
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify result structure
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 2)
+ self.assertIn("task_1", result)
+ self.assertIn("task_2", result)
+
+ # Verify task_1 details
+ task1_dict = result["task_1"]
+ self.assertEqual(task1_dict["item_id"], "task_1")
+ self.assertEqual(task1_dict["user_id"], "user_1")
+ self.assertEqual(task1_dict["status"], "running")
+
+ # Verify task_2 details
+ task2_dict = result["task_2"]
+ self.assertEqual(task2_dict["item_id"], "task_2")
+ self.assertEqual(task2_dict["user_id"], "user_2")
+ self.assertEqual(task2_dict["status"], "completed")
+ self.assertEqual(task2_dict["result"], "success")
+ self.assertEqual(task2_dict["messages"], ["message1", "message2"])
+
+ # Verify dispatcher method was called
+ mock_get_running_tasks.assert_called_once_with(filter_func=None)
diff --git a/tests/memories/textual/test_tree.py b/tests/memories/textual/test_tree.py
index f3e662992..a72709ec5 100644
--- a/tests/memories/textual/test_tree.py
+++ b/tests/memories/textual/test_tree.py
@@ -66,7 +66,9 @@ def test_add_calls_manager(mock_tree_text_memory):
metadata=TreeNodeTextualMemoryMetadata(updated_at=None),
)
mock_tree_text_memory.add([mock_item])
- mock_tree_text_memory.memory_manager.add.assert_called_once()
+ mock_tree_text_memory.memory_manager.add.assert_called_once_with(
+ [mock_item], user_name=None, mode="sync"
+ )
def test_get_working_memory_sorted(mock_tree_text_memory):
@@ -161,4 +163,6 @@ def test_add_returns_ids(mock_tree_text_memory):
result = mock_tree_text_memory.add(mock_items)
assert result == dummy_ids
- mock_tree_text_memory.memory_manager.add.assert_called_once_with(mock_items)
+ mock_tree_text_memory.memory_manager.add.assert_called_once_with(
+ mock_items, user_name=None, mode="sync"
+ )
diff --git a/tests/memories/textual/test_tree_searcher.py b/tests/memories/textual/test_tree_searcher.py
index d99664817..2a5536cf8 100644
--- a/tests/memories/textual/test_tree_searcher.py
+++ b/tests/memories/textual/test_tree_searcher.py
@@ -69,13 +69,6 @@ def test_searcher_fast_path(mock_searcher):
assert len(result) <= 2
assert all(isinstance(item, TextualMemoryItem) for item in result)
- # Should update usage and call update_node
- for item in result:
- assert len(item.metadata.usage) > 0
- mock_searcher.graph_store.update_node.assert_any_call(
- item.id, {"usage": item.metadata.usage}, user_name=None
- )
-
def test_searcher_fine_mode_triggers_reasoner(mock_searcher):
parsed_goal = MagicMock()
diff --git a/tests/memories/textual/test_tree_task_goal_parser.py b/tests/memories/textual/test_tree_task_goal_parser.py
index c71af4b06..899e2454b 100644
--- a/tests/memories/textual/test_tree_task_goal_parser.py
+++ b/tests/memories/textual/test_tree_task_goal_parser.py
@@ -20,12 +20,7 @@ def generate(self, messages):
def test_parse_fast_returns_expected():
parser = TaskGoalParser()
result = parser.parse("Tell me about cats", mode="fast")
-
assert isinstance(result, ParsedTaskGoal)
- assert result.memories == ["Tell me about cats"]
- assert result.keys == ["Tell me about cats"]
- assert result.tags == []
- assert result.goal_type == "default"
def test_parse_fine_calls_llm_and_parses():
diff --git a/tests/test_hello_world.py b/tests/test_hello_world.py
index 986839bc9..e9c81c7f0 100644
--- a/tests/test_hello_world.py
+++ b/tests/test_hello_world.py
@@ -118,6 +118,8 @@ def test_memos_yuqingchen_hello_world_logger_called():
def test_memos_chen_tang_hello_world():
+ import warnings
+
from memos.memories.textual.general import GeneralTextMemory
# Define return values for os.getenv
@@ -130,7 +132,10 @@ def mock_getenv(key, default=None):
}
return mock_values.get(key, default)
- # Use patch to mock os.getenv
- with patch("os.getenv", side_effect=mock_getenv):
- memory = memos_chentang_hello_world()
- assert isinstance(memory, GeneralTextMemory)
+ # Filter Pydantic serialization warnings
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=UserWarning, module="pydantic")
+ # Use patch to mock os.getenv
+ with patch("os.getenv", side_effect=mock_getenv):
+ memory = memos_chentang_hello_world()
+ assert isinstance(memory, GeneralTextMemory)
+### Detailed Evaluation Results
+- We use gpt-4o-mini as the processing and judging LLM and bge-m3 as embedding model in MemOS evaluation.
+- The evaluation was conducted under conditions that align various settings as closely as possible. Reproduce the results with our scripts at [`evaluation`](./evaluation).
+- Check the full search and response details at huggingface https://huggingface.co/datasets/MemTensor/MemOS_eval_result.
+> 💡 **MemOS outperforms all other methods (Mem0, Zep, Memobase, SuperMemory et al.) across all benchmarks!**
## ✨ Key Features
@@ -83,6 +81,27 @@ MemOS demonstrates significant improvements over baseline memory solutions in mu
## 🚀 Getting Started
+### ⭐️ MemOS online API
+The easiest way to use MemOS. Equip your agent with memory **in minutes**!
+
+Sign up and get started on[`MemOS dashboard`](https://memos-dashboard.openmem.net/cn/quickstart/?source=landing).
+
+
+### Self-Hosted Server
+1. Get the repository.
+```bash
+git clone https://github.com/MemTensor/MemOS.git
+cd MemOS
+pip install -r ./docker/requirements.txt
+```
+
+2. Configure `docker/.env.example` and copy to `MemOS/.env`
+3. Start the service.
+```bash
+uvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 8
+```
+
+### Local SDK
Here's a quick example of how to create a **`MemCube`**, load it from a directory, access its memories, and save it.
```python
@@ -104,7 +123,7 @@ for item in mem_cube.act_mem.get_all():
mem_cube.dump("tmp/mem_cube")
```
-What about **`MOS`** (Memory Operating System)? It's a higher-level orchestration layer that manages multiple MemCubes and provides a unified API for memory operations. Here's a quick example of how to use MOS:
+**`MOS`** (Memory Operating System) is a higher-level orchestration layer that manages multiple MemCubes and provides a unified API for memory operations. Here's a quick example of how to use MOS:
```python
from memos.configs.mem_os import MOSConfig
diff --git a/docker/.env.example b/docker/.env.example
index 33f7ae853..0f4fcb65d 100644
--- a/docker/.env.example
+++ b/docker/.env.example
@@ -1,29 +1,60 @@
# MemOS Environment Variables Configuration
+TZ=Asia/Shanghai
-# Path to memory storage (e.g. /tmp/data_test)
-MOS_CUBE_PATH=
+MOS_CUBE_PATH="/tmp/data_test" # Path to memory storage (e.g. /tmp/data_test)
+MOS_ENABLE_DEFAULT_CUBE_CONFIG="true" # Enable default cube config (true/false)
# OpenAI Configuration
-OPENAI_API_KEY= # Your OpenAI API key
-OPENAI_API_BASE= # OpenAI API base URL (default: https://api.openai.com/v1)
+OPENAI_API_KEY="sk-xxx" # Your OpenAI API key
+OPENAI_API_BASE="http://xxx" # OpenAI API base URL (default: https://api.openai.com/v1)
-# MemOS Feature Toggles
-MOS_ENABLE_DEFAULT_CUBE_CONFIG= # Enable default cube config (true/false)
-MOS_ENABLE_SCHEDULER= # Enable background scheduler (true/false)
+# MemOS Chat Model Configuration
+MOS_CHAT_MODEL=gpt-4o-mini
+MOS_CHAT_TEMPERATURE=0.8
+MOS_MAX_TOKENS=8000
+MOS_TOP_P=0.9
+MOS_TOP_K=50
+MOS_CHAT_MODEL_PROVIDER=openai
-# Neo4j Configuration
-NEO4J_URI= # Neo4j connection URI (e.g. bolt://localhost:7687)
-NEO4J_USER= # Neo4j username
-NEO4J_PASSWORD= # Neo4j password
-MOS_NEO4J_SHARED_DB= # Shared Neo4j database name (if using multi-db)
+# graph db
+# neo4j
+NEO4J_BACKEND=xxx
+NEO4J_URI=bolt://xxx
+NEO4J_USER=xxx
+NEO4J_PASSWORD=xxx
+MOS_NEO4J_SHARED_DB=xxx
+NEO4J_DB_NAME=xxx
+
+# tetxmem reog
+MOS_ENABLE_REORGANIZE=false
# MemOS User Configuration
-MOS_USER_ID= # Unique user ID
-MOS_SESSION_ID= # Session ID for current chat
-MOS_MAX_TURNS_WINDOW= # Max number of turns to keep in memory
+MOS_USER_ID=root
+MOS_SESSION_ID=default_session
+MOS_MAX_TURNS_WINDOW=20
+
+# MemRader Configuration
+MEMRADER_MODEL=gpt-4o-mini
+MEMRADER_API_KEY=sk-xxx
+MEMRADER_API_BASE=http://xxx:3000/v1
+MEMRADER_MAX_TOKENS=5000
+
+#embedding & rerank
+EMBEDDING_DIMENSION=1024
+MOS_EMBEDDER_BACKEND=universal_api
+MOS_EMBEDDER_MODEL=bge-m3
+MOS_EMBEDDER_API_BASE=http://xxx
+MOS_EMBEDDER_API_KEY=EMPTY
+MOS_RERANKER_BACKEND=http_bge
+MOS_RERANKER_URL=http://xxx
+# Ollama Configuration (for embeddings)
+#OLLAMA_API_BASE=http://xxx
-# Ollama Configuration (for local embedding models)
-OLLAMA_API_BASE= # Ollama API base URL (e.g. http://localhost:11434)
+# milvus for pref mem
+MILVUS_URI=http://xxx
+MILVUS_USER_NAME=xxx
+MILVUS_PASSWORD=xxx
-# Embedding Configuration
-MOS_EMBEDDER_BACKEND= # Embedding backend: openai, ollama, etc.
+# pref mem
+ENABLE_PREFERENCE_MEMORY=true
+RETURN_ORIGINAL_PREF_MEM=true
diff --git a/docker/requirements.txt b/docker/requirements.txt
index d20c0b36e..4846f1832 100644
--- a/docker/requirements.txt
+++ b/docker/requirements.txt
@@ -157,4 +157,4 @@ volcengine-python-sdk==4.0.6
watchfiles==1.1.0
websockets==15.0.1
xlrd==2.0.2
-xlsxwriter==3.2.5
\ No newline at end of file
+xlsxwriter==3.2.5
diff --git a/docs/openapi.json b/docs/openapi.json
index 5a3471ac0..ee2ff1368 100644
--- a/docs/openapi.json
+++ b/docs/openapi.json
@@ -884,7 +884,7 @@
"type": "string",
"title": "Session Id",
"description": "Session ID for the MOS. This is used to distinguish between different dialogue",
- "default": "0ce84b9c-0615-4b9d-83dd-fba50537d5d3"
+ "default": "41bb5e18-252d-4948-918c-07d82aa47086"
},
"chat_model": {
"$ref": "#/components/schemas/LLMConfigFactory",
@@ -939,6 +939,12 @@
"description": "Enable parametric memory for the MemChat",
"default": false
},
+ "enable_preference_memory": {
+ "type": "boolean",
+ "title": "Enable Preference Memory",
+ "description": "Enable preference memory for the MemChat",
+ "default": false
+ },
"enable_mem_scheduler": {
"type": "boolean",
"title": "Enable Mem Scheduler",
diff --git a/evaluation/.env-example b/evaluation/.env-example
index fc57344da..5381532c2 100644
--- a/evaluation/.env-example
+++ b/evaluation/.env-example
@@ -3,39 +3,22 @@ MODEL="gpt-4o-mini"
OPENAI_API_KEY="sk-***REDACTED***"
OPENAI_BASE_URL="http://***.***.***.***:3000/v1"
-MEM0_API_KEY="m0-***REDACTED***"
-
-ZEP_API_KEY="z_***REDACTED***"
# response model
CHAT_MODEL="gpt-4o-mini"
CHAT_MODEL_BASE_URL="http://***.***.***.***:3000/v1"
CHAT_MODEL_API_KEY="sk-***REDACTED***"
+# memos
MEMOS_KEY="Token mpg-xxxxx"
-MEMOS_URL="https://apigw-pre.memtensor.cn/api/openmem/v1"
-PRE_SPLIT_CHUNK=false # pre split chunk in client end
-
-MEMOBASE_API_KEY="xxxxx"
-MEMOBASE_PROJECT_URL="http://xxx.xxx.xxx.xxx:8019"
-
-# Configuration Only For Scheduler
-# RabbitMQ Configuration
-MEMSCHEDULER_RABBITMQ_HOST_NAME=rabbitmq-cn-***.cn-***.amqp-32.net.mq.amqp.aliyuncs.com
-MEMSCHEDULER_RABBITMQ_USER_NAME=***
-MEMSCHEDULER_RABBITMQ_PASSWORD=***
-MEMSCHEDULER_RABBITMQ_VIRTUAL_HOST=memos
-MEMSCHEDULER_RABBITMQ_ERASE_ON_CONNECT=true
-MEMSCHEDULER_RABBITMQ_PORT=5672
+MEMOS_URL="http://127.0.0.1:8001"
+MEMOS_ONLINE_URL="https://memos.memtensor.cn/api/openmem/v1"
-# OpenAI Configuration
-MEMSCHEDULER_OPENAI_API_KEY=sk-***
-MEMSCHEDULER_OPENAI_BASE_URL=http://***.***.***.***:3000/v1
-MEMSCHEDULER_OPENAI_DEFAULT_MODEL=gpt-4o-mini
+# other memory agents
+MEM0_API_KEY="m0-xxx"
+ZEP_API_KEY="z_xxx"
+MEMU_API_KEY="mu_xxx"
+SUPERMEMORY_API_KEY="sm_xxx"
+MEMOBASE_API_KEY="xxx"
+MEMOBASE_PROJECT_URL="http://***.***.***.***:8019"
-# Graph DB Configuration
-MEMSCHEDULER_GRAPHDBAUTH_URI=bolt://localhost:7687
-MEMSCHEDULER_GRAPHDBAUTH_USER=neo4j
-MEMSCHEDULER_GRAPHDBAUTH_PASSWORD=***
-MEMSCHEDULER_GRAPHDBAUTH_DB_NAME=neo4j
-MEMSCHEDULER_GRAPHDBAUTH_AUTO_CREATE=true
\ No newline at end of file
diff --git a/evaluation/README.md b/evaluation/README.md
index 16752c075..a5a4f32ca 100644
--- a/evaluation/README.md
+++ b/evaluation/README.md
@@ -1,6 +1,6 @@
# Evaluation Memory Framework
-This repository provides tools and scripts for evaluating the LoCoMo dataset using various models and APIs.
+This repository provides tools and scripts for evaluating the `LoCoMo`, `LongMemEval`, `PrefEval`, `personaMem` dataset using various models and APIs.
## Installation
@@ -16,16 +16,35 @@ This repository provides tools and scripts for evaluating the LoCoMo dataset usi
```
## Configuration
+Copy the `.env-example` file to `.env`, and fill in the required environment variables according to your environment and API keys.
-1. Copy the `.env-example` file to `.env`, and fill in the required environment variables according to your environment and API keys.
+## Setup MemOS
+### local server
+```bash
+# modify {project_dir}/.env file and start server
+uvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 8
+
+# configure {project_dir}/evaluation/.env file
+MEMOS_URL="http://127.0.0.1:8001"
+```
+### online service
+```bash
+# get your api key at https://memos-dashboard.openmem.net/cn/quickstart/
+# configure {project_dir}/evaluation/.env file
+MEMOS_KEY="Token mpg-xxxxx"
+MEMOS_ONLINE_URL="https://memos.memtensor.cn/api/openmem/v1"
+
+```
-2. Copy the `configs-example/` directory to a new directory named `configs/`, and modify the configuration files inside it as needed. This directory contains model and API-specific settings.
+## Supported frameworks
+We support `memos-api` and `memos-api-online` in our scripts.
+And give unofficial implementations for the following memory frameworks:`zep`, `mem0`, `memobase`, `supermemory`, `memu`.
## Evaluation Scripts
### LoCoMo Evaluation
-⚙️ To evaluate the **LoCoMo** dataset using one of the supported memory frameworks — `memos`, `mem0`, or `zep` — run the following [script](./scripts/run_locomo_eval.sh):
+⚙️ To evaluate the **LoCoMo** dataset using one of the supported memory frameworks — run the following [script](./scripts/run_locomo_eval.sh):
```bash
# Edit the configuration in ./scripts/run_locomo_eval.sh
@@ -45,10 +64,21 @@ First prepare the dataset `longmemeval_s` from https://huggingface.co/datasets/x
./scripts/run_lme_eval.sh
```
-### prefEval Evaluation
+### PrefEval Evaluation
+Downloading benchmark_dataset/filtered_inter_turns.json from https://github.com/amazon-science/PrefEval/blob/main/benchmark_dataset/filtered_inter_turns.json and save it as `./data/prefeval/filtered_inter_turns.json`.
+To evaluate the **Prefeval** dataset — run the following [script](./scripts/run_prefeval_eval.sh):
-### personaMem Evaluation
+```bash
+# Edit the configuration in ./scripts/run_prefeval_eval.sh
+# Specify the model and memory backend you want to use (e.g., mem0, zep, etc.)
+./scripts/run_prefeval_eval.sh
+```
+
+### PersonaMem Evaluation
get `questions_32k.csv` and `shared_contexts_32k.jsonl` from https://huggingface.co/datasets/bowen-upenn/PersonaMem and save them at `data/personamem/`
```bash
+# Edit the configuration in ./scripts/run_pm_eval.sh
+# Specify the model and memory backend you want to use (e.g., mem0, zep, etc.)
+# If you want to use MIRIX, edit the the configuration in ./scripts/personamem/config.yaml
./scripts/run_pm_eval.sh
```
diff --git a/evaluation/configs-example/mem_cube_config.json b/evaluation/configs-example/mem_cube_config.json
deleted file mode 100644
index d609d27b0..000000000
--- a/evaluation/configs-example/mem_cube_config.json
+++ /dev/null
@@ -1,51 +0,0 @@
-{
- "user_id": "__USER_ID__",
- "cube_id": "__USER_ID__",
- "text_mem": {
- "backend": "tree_text",
- "config": {
- "extractor_llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "dispatcher_llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "graph_db": {
- "backend": "neo4j",
- "config": {
- "uri": "bolt://***.***.***.***:7687",
- "user": "***REDACTED***",
- "password": "***REDACTED***",
- "db_name": "__DB_NAME__",
- "auto_create": true
- }
- },
- "embedder": {
- "backend": "ollama",
- "config": {
- "model_name_or_path": "nomic-embed-text:latest"
- }
- }
- }
- },
- "act_mem": {},
- "para_mem": {}
-}
diff --git a/evaluation/configs-example/mos_memos_config.json b/evaluation/configs-example/mos_memos_config.json
deleted file mode 100644
index b7f2767b7..000000000
--- a/evaluation/configs-example/mos_memos_config.json
+++ /dev/null
@@ -1,51 +0,0 @@
-{
- "user_id": "root",
- "chat_model": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1",
- "temperature": 0.1,
- "remove_think_prefix": true,
- "max_tokens": 4096
- }
- },
- "mem_reader": {
- "backend": "simple_struct",
- "config": {
- "llm": {
- "backend": "openai",
- "config": {
- "model_name_or_path": "gpt-4o-mini",
- "temperature": 0.8,
- "max_tokens": 1024,
- "top_p": 0.9,
- "top_k": 50,
- "api_key": "sk-***REDACTED***",
- "api_base": "http://***.***.***.***:3000/v1"
- }
- },
- "embedder": {
- "backend": "ollama",
- "config": {
- "model_name_or_path": "nomic-embed-text:latest"
- }
- },
- "chunker": {
- "backend": "sentence",
- "config": {
- "tokenizer_or_token_counter": "gpt2",
- "chunk_size": 512,
- "chunk_overlap": 128,
- "min_sentences_per_chunk": 1
- }
- }
- }
- },
- "max_turns_window": 30,
- "top_k": "__TOP_K__",
- "enable_textual_memory": true,
- "enable_activation_memory": false,
- "enable_parametric_memory": false
-}
diff --git a/evaluation/scripts/PrefEval/pref_eval.py b/evaluation/scripts/PrefEval/pref_eval.py
index cd9c5dde2..ec079614d 100644
--- a/evaluation/scripts/PrefEval/pref_eval.py
+++ b/evaluation/scripts/PrefEval/pref_eval.py
@@ -1,24 +1,24 @@
+import argparse
import asyncio
import json
+import os
import re
-import argparse
-from typing import Dict, Any
+
from collections import Counter
-from tqdm.asyncio import tqdm
-import os
+from typing import Any
+
import pandas as pd
+
from dotenv import load_dotenv
from openai import OpenAI
+from tqdm.asyncio import tqdm
+
load_dotenv()
API_KEY = os.getenv("OPENAI_API_KEY")
API_URL = os.getenv("OPENAI_BASE_URL")
-INPUT_FILE = "./results/prefeval/pref_memos_process.jsonl"
-OUTPUT_FILE = "./results/prefeval/eval_pref_memos.jsonl"
-OUTPUT_EXCEL_FILE = "./results/prefeval/eval_pref_memos_summary.xlsx"
-
async def call_gpt4o_mini_async(client: OpenAI, prompt: str) -> str:
messages = [{"role": "user", "content": prompt}]
@@ -34,7 +34,7 @@ async def call_gpt4o_mini_async(client: OpenAI, prompt: str) -> str:
)
return response.choices[0].message.content
except Exception as e:
- print(f"API call failed: {str(e)}")
+ print(f"API call failed: {e!s}")
return ""
@@ -45,7 +45,7 @@ def parse_xml_response(response: str, tag: str) -> str:
async def evaluate_violate_preference_async(
client: OpenAI, preference: str, question: str, response: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant's response violates the user's stated preference.
Evaluate the response based on these criteria:
@@ -77,8 +77,8 @@ async def evaluate_violate_preference_async(
async def evaluate_acknowledge_preference_async(
client: OpenAI, question: str, response: str
-) -> Dict[str, str]:
- prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant acknowledges any user preference in answering the user's query.
+) -> dict[str, str]:
+ prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant acknowledges any user preference in answering the user's query.
Evaluate the response based on these stringent criteria:
@@ -86,7 +86,7 @@ async def evaluate_acknowledge_preference_async(
Answer "Yes" if:
-1. The response explicitly mentions or refers to a user preference in answering the user's question. Examples include: "Based on your previous preference for xxxx"; "Based on your previous preference, I would suggest you xxxx"; "Since you mentioned you prefer/dislike xxxx"; "Since you are a xxxx"; "I will recommend the following given your preference for xxx", etc. You should extract the "xxxx" in your answer. If it only says "Based on our previous conversation, I recommend..." and does not explicitly mention any preference, you should answer 'No'.
+1. The response explicitly mentions or refers to a user preference in answering the user's question. Examples include: "Based on your previous preference for xxxx"; "Based on your previous preference, I would suggest you xxxx"; "Since you mentioned you prefer/dislike xxxx"; "Since you are a xxxx"; "I will recommend the following given your preference for xxx", etc. You should extract the "xxxx" in your answer. If it only says "Based on our previous conversation, I recommend..." and does not explicitly mention any preference, you should answer 'No'.
2. The response assumes the user preference in answering the user's question implicitly. For example, when the user asks 'Can you recommend me cars to drive?', if the response is 'Based on your preference, I will recommend non-EV cars, ...', then this indicates the assistant assumes that the user's preference is a dislike of EV cars, and you should answer 'Yes'.
Answer "No" if the response does not mention or refer to any user preference explicitly or implicitly. If you cannot extract the sentence stating what the preference is, answer 'No'.
@@ -107,7 +107,7 @@ async def evaluate_acknowledge_preference_async(
async def evaluate_hallucinate_preference_async(
client: OpenAI, preference: str, restatement: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
if not restatement.strip():
return {"explanation": "No restatement provided by assistant", "answer": "No"}
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant's restatement of the user's stated preference is the same preference. Evaluate the response based on these stringent criteria to answer if the assistant has hallucinated the preference or not:
@@ -124,10 +124,10 @@ async def evaluate_hallucinate_preference_async(
2. The assistant's restatement is a minor paraphrase that fully preserves the meaning and intent of the original preference.
3. The restatement is just empty, no hallucination.
-Here is the information:
-Original user preference: "{preference}"
-Assistant's restatement: "{restatement}"
-Examine the original preference and the assistant's restatement meticulously and answer. Please answer in this exact XML format without any other additional text:
+Here is the information:
+Original user preference: "{preference}"
+Assistant's restatement: "{restatement}"
+Examine the original preference and the assistant's restatement meticulously and answer. Please answer in this exact XML format without any other additional text:
[1 short sentence explanation]
[Yes/No]"""
@@ -140,7 +140,7 @@ async def evaluate_hallucinate_preference_async(
async def evaluate_helpful_response_async(
client: OpenAI, question: str, response: str
-) -> Dict[str, str]:
+) -> dict[str, str]:
prompt = f"""You will analyze a conversation between a user and an assistant, focusing on whether the assistant provides any substantive response to the user's query.
Evaluate the response based on these stringent criteria:
@@ -178,7 +178,7 @@ async def evaluate_helpful_response_async(
}
-def classify_error_type(evaluation_results: Dict[str, Any]) -> str:
+def classify_error_type(evaluation_results: dict[str, Any]) -> str:
violate = evaluation_results["violate_preference"]["answer"]
acknowledge = evaluation_results["acknowledge_preference"]["answer"]
hallucinate = evaluation_results["hallucinate_preference"]["answer"]
@@ -196,7 +196,7 @@ def classify_error_type(evaluation_results: Dict[str, Any]) -> str:
return "Personalized Response"
-async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore) -> Dict[str, Any]:
+async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore) -> dict[str, Any]:
async with semaphore:
data = json.loads(line.strip())
preference = data["preference"]
@@ -227,7 +227,7 @@ async def process_line(line: str, client: OpenAI, semaphore: asyncio.Semaphore)
return result
-def log_summary(error_counter: Counter, total_samples: int) -> Dict[str, Dict[str, float]]:
+def log_summary(error_counter: Counter, total_samples: int) -> dict[str, dict[str, float]]:
summary_data = {}
print("\n--- Error Type Summary ---")
@@ -251,13 +251,14 @@ def log_summary(error_counter: Counter, total_samples: int) -> Dict[str, Dict[st
def generate_excel_summary(
- summary_results: Dict[str, Dict[str, float]],
+ summary_results: dict[str, dict[str, float]],
avg_search_time: float,
avg_context_tokens: float,
avg_add_time: float,
+ output_excel_file: str,
model_name: str = "gpt-4o-mini",
):
- print(f"Generating Excel summary at {OUTPUT_EXCEL_FILE}...")
+ print(f"Generating Excel summary at {output_excel_file}...")
def get_pct(key):
return summary_results.get(key, {}).get("percentage", 0)
@@ -282,7 +283,7 @@ def get_pct(key):
df = pd.DataFrame(data)
- with pd.ExcelWriter(OUTPUT_EXCEL_FILE, engine="xlsxwriter") as writer:
+ with pd.ExcelWriter(output_excel_file, engine="xlsxwriter") as writer:
df.to_excel(writer, index=False, sheet_name="Summary")
workbook = writer.book
@@ -300,10 +301,10 @@ def get_pct(key):
bold_pct_format = workbook.add_format({"num_format": "0.0%", "bold": True})
worksheet.set_column("F:F", 18, bold_pct_format)
- print(f"Successfully saved summary to {OUTPUT_EXCEL_FILE}")
+ print(f"Successfully saved summary to {output_excel_file}")
-async def main(concurrency_limit: int):
+async def main(concurrency_limit: int, input_file: str, output_file: str, output_excel_file: str):
semaphore = asyncio.Semaphore(concurrency_limit)
error_counter = Counter()
@@ -313,17 +314,17 @@ async def main(concurrency_limit: int):
total_add_time = 0
print(f"Starting evaluation with a concurrency limit of {concurrency_limit}...")
- print(f"Input file: {INPUT_FILE}")
- print(f"Output JSONL: {OUTPUT_FILE}")
- print(f"Output Excel: {OUTPUT_EXCEL_FILE}")
+ print(f"Input file: {input_file}")
+ print(f"Output JSONL: {output_file}")
+ print(f"Output Excel: {output_excel_file}")
client = OpenAI(api_key=API_KEY, base_url=API_URL)
try:
- with open(INPUT_FILE, "r", encoding="utf-8") as f:
+ with open(input_file, encoding="utf-8") as f:
lines = f.readlines()
except FileNotFoundError:
- print(f"Error: Input file not found at '{INPUT_FILE}'")
+ print(f"Error: Input file not found at '{input_file}'")
return
if not lines:
@@ -332,7 +333,7 @@ async def main(concurrency_limit: int):
tasks = [process_line(line, client, semaphore) for line in lines]
- with open(OUTPUT_FILE, "w", encoding="utf-8") as outfile:
+ with open(output_file, "w", encoding="utf-8") as outfile:
pbar = tqdm(
asyncio.as_completed(tasks),
total=len(tasks),
@@ -382,6 +383,7 @@ async def main(concurrency_limit: int):
avg_search_time,
avg_context_tokens,
avg_add_time,
+ output_excel_file,
)
except Exception as e:
print(f"\nFailed to generate Excel file: {e}")
@@ -389,12 +391,46 @@ async def main(concurrency_limit: int):
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Evaluate assistant responses from a JSONL file.")
+
+ parser.add_argument("--input", type=str, required=True, help="Path to the input JSONL file.")
+
parser.add_argument(
"--concurrency-limit",
type=int,
default=10,
help="The maximum number of concurrent API calls.",
)
+
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ "zep",
+ ],
+ default="memos-api",
+ help="Which library to use (used in 'add' mode).",
+ )
+
args = parser.parse_args()
- asyncio.run(main(concurrency_limit=args.concurrency_limit))
+ input_path = args.input
+ output_dir = os.path.dirname(input_path)
+
+ output_jsonl_path = os.path.join(output_dir, f"eval_pref_{args.lib}.jsonl")
+ output_excel_path = os.path.join(output_dir, f"eval_pref_{args.lib}_summary.xlsx")
+
+ asyncio.run(
+ main(
+ concurrency_limit=args.concurrency_limit,
+ input_file=input_path,
+ output_file=output_jsonl_path,
+ output_excel_file=output_excel_path,
+ )
+ )
diff --git a/evaluation/scripts/PrefEval/pref_mem0.py b/evaluation/scripts/PrefEval/pref_mem0.py
new file mode 100644
index 000000000..300e0ede3
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_mem0.py
@@ -0,0 +1,324 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+os.environ["MEM0_API_KEY"] = os.getenv("MEM0_API_KEY")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+ timestamp_add = int(time.time() * 100)
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ timestamp=timestamp_add,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memory_list = relevant_memories.get("results", [])
+ memories_str = "\n".join(f"- {entry['memory']}" for entry in memory_list)
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["mem0", "mem0_graph"],
+ default="mem0",
+ help="Which Mem0 library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import Mem0Client
+
+ mem_client = Mem0Client(enable_graph="graph" in args.lib)
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_memobase.py b/evaluation/scripts/PrefEval/pref_memobase.py
new file mode 100644
index 000000000..776642657
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_memobase.py
@@ -0,0 +1,332 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+ mem_client.delete_user(user_id)
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+ if conversation:
+ messages = []
+
+ for chunk_start in range(len(conversation)):
+ chunk = conversation[chunk_start : chunk_start + 1]
+ timestamp_add = str(int(time.time() * 100))
+ time.sleep(0.001) # Ensure unique timestamp
+
+ messages.append(
+ {
+ "role": chunk[0]["role"],
+ "content": chunk[0]["content"][:8000],
+ "created_at": timestamp_add,
+ }
+ )
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(messages=conversation[msg_idx : msg_idx + 2], user_id=user_id)
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = relevant_memories
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["memobase"],
+ default="memobase",
+ help="Which Memobase library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import MemobaseClient
+
+ mem_client = MemobaseClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_memos.py b/evaluation/scripts/PrefEval/pref_memos.py
index d1a901dd2..bbe1788b5 100644
--- a/evaluation/scripts/PrefEval/pref_memos.py
+++ b/evaluation/scripts/PrefEval/pref_memos.py
@@ -4,12 +4,14 @@
import os
import sys
import time
+
import tiktoken
+
from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
from openai import OpenAI
from tqdm import tqdm
-from irrelevant_conv import irre_10, irre_300
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
@@ -18,6 +20,7 @@
sys.path.insert(0, ROOT_DIR)
sys.path.insert(0, EVAL_SCRIPTS_DIR)
+
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
BASE_URL = os.getenv("OPENAI_BASE_URL")
@@ -26,8 +29,8 @@
def add_memory_for_line(
- line_data: tuple, mem_client, num_irrelevant_turns: int, lib: str, version: str
-) -> dict:
+ line_data, mem_client, num_irrelevant_turns, lib, version, success_records, f
+):
"""
Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
"""
@@ -43,15 +46,22 @@ def add_memory_for_line(
elif num_irrelevant_turns == 300:
conversation = conversation + irre_300
- turns_add = 5
start_time_add = time.monotonic()
- if conversation:
- if os.getenv("PRE_SPLIT_CHUNK", "false").lower() == "true":
- for chunk_start in range(0, len(conversation), turns_add * 2):
- chunk = conversation[chunk_start : chunk_start + turns_add * 2]
- mem_client.add(messages=chunk, user_id=user_id, conv_id=None)
- else:
- mem_client.add(messages=conversation, user_id=user_id, conv_id=None)
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ conv_id=None,
+ batch_size=2,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
end_time_add = time.monotonic()
add_duration = end_time_add - start_time_add
@@ -64,12 +74,11 @@ def add_memory_for_line(
return None
-def process_line_with_id(
- line_data: tuple, mem_client, openai_client: OpenAI, top_k_value: int, lib: str, version: str
-) -> dict:
+def search_memory_for_line(line_data, mem_client, top_k_value):
"""
- Processes a single line of data using a pre-existing user_id, searching memory and generating a response.
+ Processes a single line of data, searching memory based on the question.
"""
+
i, line = line_data
try:
original_data = json.loads(line)
@@ -79,33 +88,27 @@ def process_line_with_id(
metrics_dict = original_data.get("metrics", {})
if not user_id:
- original_data["response"] = (
+ original_data["error"] = (
"Error: user_id not found in this line. Please run 'add' mode first."
)
return original_data
if not question:
- original_data["response"] = "Question not found in this line."
+ original_data["error"] = "Question not found in this line."
return original_data
start_time_search = time.monotonic()
relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
search_memories_duration = time.monotonic() - start_time_search
- memories_str = "\n".join(
- f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ memories_str = (
+ "\n".join(
+ f"- {entry.get('memory', '')}"
+ for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+ + f"\n{relevant_memories.get('pref_string', '')}"
)
memory_tokens_used = len(tokenizer.encode(memories_str))
- system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
- messages = [
- {"role": "system", "content": system_prompt},
- {"role": "user", "content": question},
- ]
-
- response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
- assistant_response = response.choices[0].message.content
- original_data["response"] = assistant_response
-
metrics_dict.update(
{
"search_memories_duration_seconds": search_memories_duration,
@@ -119,38 +122,94 @@ def process_line_with_id(
except Exception as e:
user_id_from_data = json.loads(line).get("user_id", "N/A")
- print(f"Error processing line {i + 1} (user_id: {user_id_from_data}): {e}")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data, openai_client, lib):
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ from utils.prompts import PREFEVAL_ANSWER_PROMPT
+
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = PREFEVAL_ANSWER_PROMPT.format(context=memories_str)
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
return None
def main():
parser = argparse.ArgumentParser(
- description="Process conversations with MemOS. Run 'add' mode first, then 'process' mode."
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
)
parser.add_argument(
"mode",
- choices=["add", "process"],
- help="The mode to run the script in ('add' or 'process').",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
)
parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
- parser.add_argument("--top-k", type=int, default=10, help="Number of memories to retrieve.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
parser.add_argument(
"--add-turn",
type=int,
choices=[0, 10, 300],
default=0,
- help="Number of irrelevant turns to add (0, 10, or 300).",
+ help="Number of irrelevant turns to add (used in 'add' mode).",
)
parser.add_argument(
"--lib",
type=str,
- choices=["memos-api", "memos-local"],
+ choices=["memos-api", "memos-api-online"],
default="memos-api",
- help="Which MemOS library to use.",
+ help="Which MemOS library to use (used in 'add' mode).",
)
parser.add_argument(
- "--version", type=str, default="0929-1", help="Version identifier for user_id generation."
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
)
parser.add_argument(
"--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
@@ -159,15 +218,28 @@ def main():
args = parser.parse_args()
try:
- with open(args.input, "r", encoding="utf-8") as infile:
+ with open(args.input, encoding="utf-8") as infile:
lines = infile.readlines()
except FileNotFoundError:
print(f"Error: Input file '{args.input}' not found")
return
- from utils.client import memosApiClient
+ from utils.client import MemosApiClient, MemosApiOnlineClient
- mem_client = memosApiClient()
+ if args.lib == "memos-api":
+ mem_client = MemosApiClient()
+ elif args.lib == "memos-api-online":
+ mem_client = MemosApiOnlineClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
if args.mode == "add":
print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
@@ -176,6 +248,7 @@ def main():
with (
open(args.output, "w", encoding="utf-8") as outfile,
concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as record_f,
):
futures = [
executor.submit(
@@ -185,6 +258,8 @@ def main():
args.add_turn,
args.lib,
args.version,
+ success_records,
+ record_f,
)
for i, line in enumerate(lines)
]
@@ -200,38 +275,55 @@ def main():
outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
- elif args.mode == "process":
- print(f"Running in 'process' mode. Processing questions from '{args.input}'...")
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
print(f"Retrieving top {args.top_k} memories for each query.")
print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
with (
open(args.output, "w", encoding="utf-8") as outfile,
concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
):
futures = [
- executor.submit(
- process_line_with_id,
- (i, line),
- mem_client,
- openai_client,
- args.top_k,
- args.lib,
- args.version,
- )
+ executor.submit(generate_response_for_line, (i, line), openai_client, args.lib)
for i, line in enumerate(lines)
]
pbar = tqdm(
concurrent.futures.as_completed(futures),
total=len(lines),
- desc="Processing questions...",
+ desc="Generating responses...",
)
for future in pbar:
result = future.result()
if result:
outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
- print(f"\n'process' mode complete! Final results written to '{args.output}'.")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
if __name__ == "__main__":
diff --git a/evaluation/scripts/PrefEval/pref_memu.py b/evaluation/scripts/PrefEval/pref_memu.py
new file mode 100644
index 000000000..00c411eb7
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_memu.py
@@ -0,0 +1,326 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+from datetime import datetime
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ iso_date=datetime.now().isoformat(),
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = "\n".join(
+ f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["memu"],
+ default="memu",
+ help="Which Memu library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import MemuClient
+
+ mem_client = MemuClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_supermemory.py b/evaluation/scripts/PrefEval/pref_supermemory.py
new file mode 100644
index 000000000..7386bc462
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_supermemory.py
@@ -0,0 +1,358 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = relevant_memories
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["supermemory"],
+ default="supermemory",
+ help="Which Supermemory library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ class SupermemoryClient:
+ def __init__(self):
+ from supermemory import Supermemory
+
+ self.client = Supermemory(api_key=os.getenv("SUPERMEMORY_API_KEY"))
+
+ def add(self, messages, user_id):
+ content = "\n".join([f"{msg['role']}: {msg['content']}" for msg in messages])
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ self.client.memories.add(content=content, container_tag=user_id)
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ def search(self, query, user_id, top_k):
+ max_retries = 10
+ for attempt in range(max_retries):
+ try:
+ results = self.client.search.memories(
+ q=query,
+ container_tag=user_id,
+ threshold=0,
+ rerank=True,
+ rewrite_query=True,
+ limit=top_k,
+ )
+ context = "\n\n".join([r.memory for r in results.results])
+ return context
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ mem_client = SupermemoryClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/pref_zep.py b/evaluation/scripts/PrefEval/pref_zep.py
new file mode 100644
index 000000000..8a4d50558
--- /dev/null
+++ b/evaluation/scripts/PrefEval/pref_zep.py
@@ -0,0 +1,327 @@
+import argparse
+import concurrent.futures
+import json
+import os
+import sys
+import time
+
+from datetime import datetime
+
+import tiktoken
+
+from dotenv import load_dotenv
+from irrelevant_conv import irre_10, irre_300
+from openai import OpenAI
+from tqdm import tqdm
+
+
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+load_dotenv()
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
+BASE_URL = os.getenv("OPENAI_BASE_URL")
+MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
+tokenizer = tiktoken.get_encoding("cl100k_base")
+
+
+def add_memory_for_line(
+ line_data: tuple,
+ mem_client,
+ num_irrelevant_turns: int,
+ lib: str,
+ version: str,
+ success_records,
+ f,
+) -> dict:
+ """
+ Adds conversation memory for a single line of data to MemOS and returns the data with a persistent user_id.
+ """
+ i, line = line_data
+ user_id = f"{lib}_user_pref_eval_{i}_{version}"
+
+ try:
+ original_data = json.loads(line)
+ conversation = original_data.get("conversation", [])
+
+ if num_irrelevant_turns == 10:
+ conversation = conversation + irre_10
+ elif num_irrelevant_turns == 300:
+ conversation = conversation + irre_300
+
+ start_time_add = time.monotonic()
+
+ for idx, _ in enumerate(conversation[::2]):
+ msg_idx = idx * 2
+ record_id = f"{lib}_user_pref_eval_{i}_{version}_{msg_idx!s}"
+
+ if record_id not in success_records:
+ mem_client.add(
+ messages=conversation[msg_idx : msg_idx + 2],
+ user_id=user_id,
+ conv_id=None,
+ timestamp=datetime.now().isoformat(),
+ )
+ f.write(f"{record_id}\n")
+ f.flush()
+
+ end_time_add = time.monotonic()
+ add_duration = end_time_add - start_time_add
+
+ original_data["user_id"] = user_id
+ original_data["metrics"] = {"add_memories_duration_seconds": add_duration}
+ return original_data
+
+ except Exception as e:
+ print(f"Error adding memory for line {i + 1} (user_id: {user_id}): {e}")
+ return None
+
+
+def search_memory_for_line(line_data: tuple, mem_client, top_k_value: int) -> dict:
+ """
+ Processes a single line of data, searching memory based on the question.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ user_id = original_data.get("user_id")
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+
+ if not user_id:
+ original_data["error"] = (
+ "Error: user_id not found in this line. Please run 'add' mode first."
+ )
+ return original_data
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ start_time_search = time.monotonic()
+ relevant_memories = mem_client.search(query=question, user_id=user_id, top_k=top_k_value)
+ search_memories_duration = time.monotonic() - start_time_search
+ memories_str = "\n".join(
+ f"- {entry.get('memory', '')}" for entry in relevant_memories["text_mem"][0]["memories"]
+ )
+
+ memory_tokens_used = len(tokenizer.encode(memories_str))
+
+ metrics_dict.update(
+ {
+ "search_memories_duration_seconds": search_memories_duration,
+ "memory_tokens_used": memory_tokens_used,
+ "retrieved_memories_text": memories_str,
+ }
+ )
+ original_data["metrics"] = metrics_dict
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error searching memory for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def generate_response_for_line(line_data: tuple, openai_client: OpenAI) -> dict:
+ """
+ Generates a response for a single line of data using pre-fetched memories.
+ """
+ i, line = line_data
+ try:
+ original_data = json.loads(line)
+
+ question = original_data.get("question")
+ metrics_dict = original_data.get("metrics", {})
+ memories_str = metrics_dict.get("retrieved_memories_text")
+
+ # If an error occurred in 'add' or 'search' mode, just pass the line through
+ if original_data.get("error"):
+ return original_data
+
+ if not question:
+ original_data["error"] = "Question not found in this line."
+ return original_data
+
+ # Check for None, as an empty string (no memories found) is a valid result
+ if memories_str is None:
+ original_data["error"] = (
+ "Error: retrieved_memories_text not found in metrics. "
+ "Please run 'search' mode first."
+ )
+ return original_data
+
+ system_prompt = f"You are a helpful AI. Answer the question based on the query and the following memories:\nUser Memories:\n{memories_str}"
+ messages = [
+ {"role": "system", "content": system_prompt},
+ {"role": "user", "content": question},
+ ]
+
+ response = openai_client.chat.completions.create(model=MODEL_NAME, messages=messages)
+ assistant_response = response.choices[0].message.content
+ original_data["response"] = assistant_response
+
+ return original_data
+
+ except Exception as e:
+ user_id_from_data = json.loads(line).get("user_id", "N/A")
+ print(f"Error generating response for line {i + 1} (user_id: {user_id_from_data}): {e}")
+ return None
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="Process conversations with MemOS. Run 'add', then 'search', then 'response'."
+ )
+ parser.add_argument(
+ "mode",
+ choices=["add", "search", "response"],
+ help="The mode to run the script in ('add', 'search', or 'response').",
+ )
+ parser.add_argument("--input", required=True, help="Path to the input JSONL file.")
+ parser.add_argument("--output", required=True, help="Path to the output JSONL file.")
+ parser.add_argument(
+ "--top-k",
+ type=int,
+ default=10,
+ help="Number of memories to retrieve (used in 'search' mode).",
+ )
+ parser.add_argument(
+ "--add-turn",
+ type=int,
+ choices=[0, 10, 300],
+ default=0,
+ help="Number of irrelevant turns to add (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=["zep"],
+ default="zep",
+ help="Which Zep library to use (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--version",
+ type=str,
+ default="0929-1",
+ help="Version identifier for user_id generation (used in 'add' mode).",
+ )
+ parser.add_argument(
+ "--max-workers", type=int, default=20, help="Maximum number of concurrent workers."
+ )
+
+ args = parser.parse_args()
+
+ try:
+ with open(args.input, encoding="utf-8") as infile:
+ lines = infile.readlines()
+ except FileNotFoundError:
+ print(f"Error: Input file '{args.input}' not found")
+ return
+
+ from utils.client import ZepClient
+
+ mem_client = ZepClient()
+
+ os.makedirs(f"results/prefeval/{args.lib}_{args.version}", exist_ok=True)
+ success_records = set()
+ record_file = f"results/prefeval/{args.lib}_{args.version}/success_records.txt"
+ if os.path.exists(record_file):
+ print(f"Loading existing success records from {record_file}...")
+ with open(record_file, encoding="utf-8") as f:
+ for i in f.readlines():
+ success_records.add(i.strip())
+ print(f"Loaded {len(success_records)} records.")
+
+ if args.mode == "add":
+ print(f"Running in 'add' mode. Ingesting memories from '{args.input}'...")
+ print(f"Adding {args.add_turn} irrelevant turns.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ open(record_file, "a+", encoding="utf-8") as f,
+ ):
+ futures = [
+ executor.submit(
+ add_memory_for_line,
+ (i, line),
+ mem_client,
+ args.add_turn,
+ args.lib,
+ args.version,
+ success_records,
+ f,
+ )
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Adding memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'add' mode complete! Data with user_id written to '{args.output}'.")
+
+ elif args.mode == "search":
+ print(f"Running in 'search' mode. Searching memories based on '{args.input}'...")
+ print(f"Retrieving top {args.top_k} memories for each query.")
+ print(f"Using {args.max_workers} workers.")
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(search_memory_for_line, (i, line), mem_client, args.top_k)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Searching memories...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(
+ f"\n'search' mode complete! Results with retrieved memories written to '{args.output}'."
+ )
+
+ elif args.mode == "response":
+ print(f"Running in 'response' mode. Generating responses based on '{args.input}'...")
+ print(f"Using {args.max_workers} workers.")
+ openai_client = OpenAI(api_key=OPENAI_API_KEY, base_url=BASE_URL)
+ with (
+ open(args.output, "w", encoding="utf-8") as outfile,
+ concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor,
+ ):
+ futures = [
+ executor.submit(generate_response_for_line, (i, line), openai_client)
+ for i, line in enumerate(lines)
+ ]
+
+ pbar = tqdm(
+ concurrent.futures.as_completed(futures),
+ total=len(lines),
+ desc="Generating responses...",
+ )
+ for future in pbar:
+ result = future.result()
+ if result:
+ outfile.write(json.dumps(result, ensure_ascii=False) + "\n")
+ print(f"\n'response' mode complete! Final results written to '{args.output}'.")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/evaluation/scripts/PrefEval/prefeval_preprocess.py b/evaluation/scripts/PrefEval/prefeval_preprocess.py
index 004d5e505..b8ccf3f34 100644
--- a/evaluation/scripts/PrefEval/prefeval_preprocess.py
+++ b/evaluation/scripts/PrefEval/prefeval_preprocess.py
@@ -1,7 +1,8 @@
-from datasets import load_dataset
import json
import os
+from datasets import load_dataset
+
def convert_dataset_to_jsonl(dataset_name, output_dir="./scripts/PrefEval"):
if not os.path.exists(output_dir):
@@ -64,7 +65,7 @@ def process_jsonl_file(input_filepath, output_filepath):
line_count = 0
print(f"Start processing file: {input_filepath}")
with (
- open(input_filepath, "r", encoding="utf-8") as infile,
+ open(input_filepath, encoding="utf-8") as infile,
open(output_filepath, "w", encoding="utf-8") as outfile,
):
for line in infile:
@@ -93,6 +94,7 @@ def process_jsonl_file(input_filepath, output_filepath):
def main():
huggingface_dataset_name = "siyanzhao/prefeval_implicit_persona"
output_directory = "./data/prefeval"
+ os.makedirs(output_directory, exist_ok=True)
input_file_path = os.path.join(output_directory, "train.jsonl")
processed_file_path = os.path.join(output_directory, "pref_processed.jsonl")
diff --git a/evaluation/scripts/locomo/locomo_eval.py b/evaluation/scripts/locomo/locomo_eval.py
index f142fe130..b431e7768 100644
--- a/evaluation/scripts/locomo/locomo_eval.py
+++ b/evaluation/scripts/locomo/locomo_eval.py
@@ -363,7 +363,15 @@ async def limited_task(task):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_ingestion.py b/evaluation/scripts/locomo/locomo_ingestion.py
index 2a177a52a..a9e4d5f02 100644
--- a/evaluation/scripts/locomo/locomo_ingestion.py
+++ b/evaluation/scripts/locomo/locomo_ingestion.py
@@ -1,12 +1,16 @@
-import os
-import sys
import argparse
import concurrent.futures
+import os
+import sys
import time
+
from datetime import datetime, timezone
+
import pandas as pd
+
from dotenv import load_dotenv
+
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
@@ -40,26 +44,33 @@ def ingest_session(client, session, frame, version, metadata):
speaker_a_messages.append({"role": "assistant", "content": data})
speaker_b_messages.append({"role": "user", "content": data})
- if frame == "memos-api":
+ if "memos-api" in frame:
for m in speaker_a_messages:
m["chat_time"] = iso_date
for m in speaker_b_messages:
m["chat_time"] = iso_date
- client.add(speaker_a_messages, speaker_a_user_id, f"{conv_id}_{metadata['session_key']}")
- client.add(speaker_b_messages, speaker_b_user_id, f"{conv_id}_{metadata['session_key']}")
+ client.add(
+ speaker_a_messages,
+ speaker_a_user_id,
+ f"{conv_id}_{metadata['session_key']}",
+ batch_size=2,
+ )
+ client.add(
+ speaker_b_messages,
+ speaker_b_user_id,
+ f"{conv_id}_{metadata['session_key']}",
+ batch_size=2,
+ )
elif "mem0" in frame:
- for i in range(0, len(speaker_a_messages), 2):
- batch_messages_a = speaker_a_messages[i : i + 2]
- batch_messages_b = speaker_b_messages[i : i + 2]
- client.add(batch_messages_a, speaker_a_user_id, timestamp)
- client.add(batch_messages_b, speaker_b_user_id, timestamp)
+ client.add(speaker_a_messages, speaker_a_user_id, timestamp, batch_size=2)
+ client.add(speaker_b_messages, speaker_b_user_id, timestamp, batch_size=2)
elif frame == "memobase":
for m in speaker_a_messages:
m["created_at"] = iso_date
for m in speaker_b_messages:
m["created_at"] = iso_date
- client.add(speaker_a_messages, speaker_a_user_id)
- client.add(speaker_b_messages, speaker_b_user_id)
+ client.add(speaker_a_messages, speaker_a_user_id, batch_size=2)
+ client.add(speaker_b_messages, speaker_b_user_id, batch_size=2)
elif frame == "memu":
client.add(speaker_a_messages, speaker_a_user_id, iso_date)
client.add(speaker_b_messages, speaker_b_user_id, iso_date)
@@ -77,7 +88,7 @@ def ingest_session(client, session, frame, version, metadata):
return elapsed_time
-def process_user(conv_idx, frame, locomo_df, version):
+def process_user(conv_idx, frame, locomo_df, version, success_records, f):
conversation = locomo_df["conversation"].iloc[conv_idx]
max_session_count = 35
start_time = time.time()
@@ -88,8 +99,8 @@ def process_user(conv_idx, frame, locomo_df, version):
client = None
if frame == "mem0" or frame == "mem0_graph":
- from utils.client import Mem0Client
from prompts import custom_instructions
+ from utils.client import Mem0Client
client = Mem0Client(enable_graph="graph" in frame)
client.client.update_project(custom_instructions=custom_instructions)
@@ -99,16 +110,16 @@ def process_user(conv_idx, frame, locomo_df, version):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- all_users = client.client.get_all_users(limit=5000)
- for user in all_users:
- if user["additional_fields"]["user_id"] in [speaker_a_user_id, speaker_b_user_id]:
- client.client.delete_user(user["id"])
- speaker_a_user_id = client.client.add_user({"user_id": speaker_a_user_id})
- speaker_b_user_id = client.client.add_user({"user_id": speaker_b_user_id})
+ client.delete_user(speaker_a_user_id)
+ client.delete_user(speaker_b_user_id)
elif frame == "memu":
from utils.client import MemuClient
@@ -138,11 +149,15 @@ def process_user(conv_idx, frame, locomo_df, version):
print(f"Processing {valid_sessions} sessions for user {conv_idx}")
- for session, metadata in sessions_to_process:
- session_time = ingest_session(client, session, frame, version, metadata)
- total_session_time += session_time
- print(f"User {conv_idx}, {metadata['session_key']} processed in {session_time} seconds")
-
+ for session_idx, (session, metadata) in enumerate(sessions_to_process):
+ if f"{conv_idx}_{session_idx}" not in success_records:
+ session_time = ingest_session(client, session, frame, version, metadata)
+ total_session_time += session_time
+ print(f"User {conv_idx}, {metadata['session_key']} processed in {session_time} seconds")
+ f.write(f"{conv_idx}_{session_idx}\n")
+ f.flush()
+ else:
+ print(f"Session {conv_idx}_{session_idx} already ingested")
end_time = time.time()
elapsed_time = round(end_time - start_time, 2)
print(f"User {conv_idx} processed successfully in {elapsed_time} seconds")
@@ -159,9 +174,20 @@ def main(frame, version="default", num_workers=4):
print(
f"Starting processing for {num_users} users in serial mode, each user using {num_workers} workers for sessions..."
)
- with concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor:
+ os.makedirs(f"results/locomo/{frame}-{version}/", exist_ok=True)
+ success_records = []
+ record_file = f"results/locomo/{frame}-{version}/success_records.txt"
+ if os.path.exists(record_file):
+ with open(record_file) as f:
+ for i in f.readlines():
+ success_records.append(i.strip())
+
+ with (
+ concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor,
+ open(record_file, "a+") as f,
+ ):
futures = [
- executor.submit(process_user, user_id, frame, locomo_df, version)
+ executor.submit(process_user, user_id, frame, locomo_df, version, success_records, f)
for user_id in range(num_users)
]
for future in concurrent.futures.as_completed(futures):
@@ -187,17 +213,25 @@ def main(frame, version="default", num_workers=4):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
"--version",
type=str,
- default="default1",
+ default="default",
help="Version identifier for saving results (e.g., 1010)",
)
parser.add_argument(
- "--workers", type=int, default=3, help="Number of parallel workers to process users"
+ "--workers", type=int, default=10, help="Number of parallel workers to process users"
)
args = parser.parse_args()
lib = args.lib
diff --git a/evaluation/scripts/locomo/locomo_metric.py b/evaluation/scripts/locomo/locomo_metric.py
index 6ddcdf127..e63888d45 100644
--- a/evaluation/scripts/locomo/locomo_metric.py
+++ b/evaluation/scripts/locomo/locomo_metric.py
@@ -9,7 +9,15 @@
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_responses.py b/evaluation/scripts/locomo/locomo_responses.py
index 4e3b966a3..6c082b31d 100644
--- a/evaluation/scripts/locomo/locomo_responses.py
+++ b/evaluation/scripts/locomo/locomo_responses.py
@@ -2,6 +2,7 @@
import asyncio
import json
import os
+import sys
from time import time
@@ -13,6 +14,15 @@
from tqdm import tqdm
+ROOT_DIR = os.path.dirname(
+ os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+)
+EVAL_SCRIPTS_DIR = os.path.join(ROOT_DIR, "evaluation", "scripts")
+
+sys.path.insert(0, ROOT_DIR)
+sys.path.insert(0, EVAL_SCRIPTS_DIR)
+
+
async def locomo_response(frame, llm_client, context: str, question: str) -> str:
if frame == "zep":
prompt = ANSWER_PROMPT_ZEP.format(
@@ -47,7 +57,9 @@ async def process_qa(frame, qa, search_result, oai_client):
gold_answer = qa.get("answer")
qa_category = qa.get("category")
- answer = await locomo_response(frame, oai_client, search_result.get("context"), query)
+ context = search_result.get("context")
+
+ answer = await locomo_response(frame, oai_client, context, query)
response_duration_ms = (time() - start) * 1000
@@ -122,7 +134,15 @@ async def main(frame, version="default"):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "openai", "memos-api", "memobase"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/locomo/locomo_search.py b/evaluation/scripts/locomo/locomo_search.py
index d976b8f67..24f6149ec 100644
--- a/evaluation/scripts/locomo/locomo_search.py
+++ b/evaluation/scripts/locomo/locomo_search.py
@@ -1,14 +1,18 @@
-import os
-import sys
import argparse
import json
+import os
+import sys
+
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from time import time
+
import pandas as pd
+
from dotenv import load_dotenv
from tqdm import tqdm
+
ROOT_DIR = os.path.dirname(
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
)
@@ -100,11 +104,14 @@ def memos_api_search(
start = time()
search_a_results = client.search(query=query, user_id=speaker_a_user_id, top_k=top_k)
search_b_results = client.search(query=query, user_id=speaker_b_user_id, top_k=top_k)
- speaker_a_context = "\n".join(
- [i["memory"] for i in search_a_results["text_mem"][0]["memories"]]
+
+ speaker_a_context = (
+ "\n".join([i["memory"] for i in search_a_results["text_mem"][0]["memories"]])
+ + f"\n{search_a_results.get('pref_string', '')}"
)
- speaker_b_context = "\n".join(
- [i["memory"] for i in search_b_results["text_mem"][0]["memories"]]
+ speaker_b_context = (
+ "\n".join([i["memory"] for i in search_b_results["text_mem"][0]["memories"]])
+ + f"\n{search_b_results.get('pref_string', '')}"
)
context = TEMPLATE_MEMOS.format(
@@ -191,7 +198,7 @@ def search_query(client, query, metadata, frame, version, top_k=20):
context, duration_ms = mem0_graph_search(
client, query, speaker_a_user_id, speaker_b_user_id, top_k, speaker_a, speaker_b
)
- elif frame == "memos-api":
+ elif "memos-api" in frame:
context, duration_ms = memos_api_search(
client, query, speaker_a_user_id, speaker_b_user_id, top_k, speaker_a, speaker_b
)
@@ -250,16 +257,14 @@ def process_user(conv_idx, locomo_df, frame, version, top_k=20, num_workers=1):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- users = client.client.get_all_users(limit=5000)
- for u in users:
- if u["additional_fields"]["user_id"] == speaker_a_user_id:
- speaker_a_user_id = u["id"]
- if u["additional_fields"]["user_id"] == speaker_b_user_id:
- speaker_b_user_id = u["id"]
elif frame == "memu":
from utils.client import MemuClient
@@ -335,7 +340,15 @@ def main(frame, version="default", num_workers=1, top_k=20):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
@@ -348,7 +361,7 @@ def main(frame, version="default", num_workers=1, top_k=20):
"--workers", type=int, default=5, help="Number of parallel workers to process users"
)
parser.add_argument(
- "--top_k", type=int, default=20, help="Number of results to retrieve in search queries"
+ "--top_k", type=int, default=15, help="Number of results to retrieve in search queries"
)
args = parser.parse_args()
lib = args.lib
diff --git a/evaluation/scripts/locomo/prompts.py b/evaluation/scripts/locomo/prompts.py
index 2827716a0..152e5b87f 100644
--- a/evaluation/scripts/locomo/prompts.py
+++ b/evaluation/scripts/locomo/prompts.py
@@ -49,12 +49,12 @@
5. Always convert relative time references to specific dates, months, or years.
6. Be as specific as possible when talking about people, places, and events
7. Timestamps in memories represent the actual time the event occurred, not the time the event was mentioned in a message.
-
+
Clarification:
When interpreting memories, use the timestamp to determine when the described event happened, not when someone talked about the event.
-
+
Example:
-
+
Memory: (2023-03-15T16:33:00Z) I went to the vet yesterday.
Question: What day did I go to the vet?
Correct Answer: March 15, 2023
@@ -111,6 +111,7 @@
Answer:
"""
+
custom_instructions = """
Generate personal memories that follow these guidelines:
diff --git a/evaluation/scripts/longmemeval/lme_eval.py b/evaluation/scripts/longmemeval/lme_eval.py
index 45c038a2b..20681ac2c 100644
--- a/evaluation/scripts/longmemeval/lme_eval.py
+++ b/evaluation/scripts/longmemeval/lme_eval.py
@@ -26,6 +26,7 @@
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.prompts import LME_JUDGE_MODEL_TEMPLATE
+
encoding = tiktoken.get_encoding("cl100k_base")
logging.basicConfig(level=logging.CRITICAL)
transformers.logging.set_verbosity_error()
@@ -343,7 +344,15 @@ async def main(frame, version, nlp_options, num_runs=3, num_workers=5):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
@@ -354,7 +363,7 @@ async def main(frame, version, nlp_options, num_runs=3, num_workers=5):
type=str,
nargs="+",
default=["lexical"],
- choices=["lexical", "semantic"],
+ choices=["lexical"],
help="NLP options to use for evaluation.",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_ingestion.py b/evaluation/scripts/longmemeval/lme_ingestion.py
index 6e9bd5ab4..e846a254c 100644
--- a/evaluation/scripts/longmemeval/lme_ingestion.py
+++ b/evaluation/scripts/longmemeval/lme_ingestion.py
@@ -1,11 +1,15 @@
import argparse
import os
import sys
+
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime, timezone
+
import pandas as pd
+
from tqdm import tqdm
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
@@ -14,7 +18,7 @@ def ingest_session(session, date, user_id, session_id, frame, client):
if "mem0" in frame:
for _idx, msg in enumerate(session):
messages.append({"role": msg["role"], "content": msg["content"][:8000]})
- client.add(messages, user_id, int(date.timestamp()))
+ client.add(messages, user_id, int(date.timestamp()), batch_size=2)
elif frame == "memobase":
for _idx, msg in enumerate(session):
messages.append(
@@ -24,8 +28,8 @@ def ingest_session(session, date, user_id, session_id, frame, client):
"created_at": date.isoformat(),
}
)
- client.add(messages, user_id)
- elif frame == "memos-api":
+ client.add(messages, user_id, batch_size=2)
+ elif "memos-api" in frame:
for msg in session:
messages.append(
{
@@ -35,7 +39,7 @@ def ingest_session(session, date, user_id, session_id, frame, client):
}
)
if messages:
- client.add(messages=messages, user_id=user_id, conv_id=session_id)
+ client.add(messages=messages, user_id=user_id, conv_id=session_id, batch_size=2)
elif frame == "memu":
for _idx, msg in enumerate(session):
messages.append({"role": msg["role"], "content": msg["content"][:8000]})
@@ -76,15 +80,15 @@ def ingest_conv(lme_df, version, conv_idx, frame, success_records, f):
from utils.client import MemosApiClient
client = MemosApiClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
elif frame == "memobase":
from utils.client import MemobaseClient
client = MemobaseClient()
- all_users = client.client.get_all_users(limit=5000)
- for user in all_users:
- if user["additional_fields"]["user_id"] == user_id:
- client.client.delete_user(user["id"])
- user_id = client.client.add_user({"user_id": user_id})
+ client.delete_user(user_id)
elif frame == "memu":
from utils.client import MemuClient
@@ -130,7 +134,7 @@ def main(frame, version, num_workers=2):
success_records = []
record_file = f"results/lme/{frame}-{version}/success_records.txt"
if os.path.exists(record_file):
- with open(record_file, "r") as f:
+ with open(record_file) as f:
for i in f.readlines():
success_records.append(i.strip())
@@ -167,7 +171,15 @@ def main(frame, version, num_workers=2):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_metric.py b/evaluation/scripts/longmemeval/lme_metric.py
index 93fa1de21..3664b47ba 100644
--- a/evaluation/scripts/longmemeval/lme_metric.py
+++ b/evaluation/scripts/longmemeval/lme_metric.py
@@ -258,7 +258,15 @@ def calculate_scores(data, grade_path, output_path):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_responses.py b/evaluation/scripts/longmemeval/lme_responses.py
index 3df3e2da4..7d82358d6 100644
--- a/evaluation/scripts/longmemeval/lme_responses.py
+++ b/evaluation/scripts/longmemeval/lme_responses.py
@@ -21,7 +21,6 @@ def lme_response(llm_client, context, question, question_date):
question_date=question_date,
context=context,
)
-
response = llm_client.chat.completions.create(
model=os.getenv("CHAT_MODEL"),
messages=[
@@ -133,7 +132,15 @@ def main(frame, version, num_workers=4):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/longmemeval/lme_search.py b/evaluation/scripts/longmemeval/lme_search.py
index a24c0eaf5..8e0e3c5c2 100644
--- a/evaluation/scripts/longmemeval/lme_search.py
+++ b/evaluation/scripts/longmemeval/lme_search.py
@@ -3,6 +3,7 @@
import os
import sys
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
@@ -10,13 +11,12 @@
from time import time
import pandas as pd
+
from tqdm import tqdm
from utils.prompts import (
MEM0_CONTEXT_TEMPLATE,
MEM0_GRAPH_CONTEXT_TEMPLATE,
- MEMOBASE_CONTEXT_TEMPLATE,
MEMOS_CONTEXT_TEMPLATE,
- ZEP_CONTEXT_TEMPLATE,
)
@@ -44,7 +44,10 @@ def mem0_search(client, query, user_id, top_k):
def memos_search(client, query, user_id, top_k):
start = time()
results = client.search(query=query, user_id=user_id, top_k=top_k)
- context = "\n".join([i["memory"] for i in results["text_mem"][0]["memories"]])
+ context = (
+ "\n".join([i["memory"] for i in results["text_mem"][0]["memories"]])
+ + f"\n{results.get('pref_string', '')}"
+ )
context = MEMOS_CONTEXT_TEMPLATE.format(user_id=user_id, memories=context)
duration_ms = (time() - start) * 1000
return context, duration_ms
@@ -114,16 +117,17 @@ def process_user(lme_df, conv_idx, frame, version, top_k=20):
from utils.client import MemobaseClient
client = MemobaseClient()
- users = client.client.get_all_users(limit=5000)
- for u in users:
- if u["additional_fields"]["user_id"] == user_id:
- user_id = u["id"]
context, duration_ms = memobase_search(client, question, user_id, top_k)
elif frame == "memos-api":
from utils.client import MemosApiClient
client = MemosApiClient()
context, duration_ms = memos_search(client, question, user_id, top_k)
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+ context, duration_ms = memos_search(client, question, user_id, top_k)
elif frame == "memu":
from utils.client import MemuClient
@@ -219,7 +223,15 @@ def main(frame, version, top_k=20, num_workers=2):
parser.add_argument(
"--lib",
type=str,
- choices=["mem0", "mem0_graph", "memos-api", "memobase", "memu", "supermemory"],
+ choices=[
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
default="memos-api",
)
parser.add_argument(
diff --git a/evaluation/scripts/personamem/pm_ingestion.py b/evaluation/scripts/personamem/pm_ingestion.py
index 5cd9d38a6..b960aa157 100644
--- a/evaluation/scripts/personamem/pm_ingestion.py
+++ b/evaluation/scripts/personamem/pm_ingestion.py
@@ -1,48 +1,63 @@
import argparse
-import os
-import sys
import csv
import json
+import os
+import sys
+import time
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
from tqdm import tqdm
-from utils.client import mem0_client,zep_client,memos_api_client
-from zep_cloud.types import Message
+
+
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
def ingest_session(session, user_id, session_id, frame, client):
messages = []
if frame == "zep":
pass
+ elif "mem0" in frame:
for idx, msg in enumerate(session):
+ messages.append({"role": msg["role"], "content": msg["content"][:8000]})
print(
- f"[{frame}] 💬 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}...")
- client.memory.add(messages=[Message(role=msg["role"], role_type=msg["role"], content=msg["content"], )], )
- elif frame == "mem0-local" or frame == "mem0-api":
- for idx, msg in enumerate(session):
- messages.append({"role": msg["role"], "content": msg["content"]})
- print(
- f"[{frame}] 📝 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}...")
- if frame == "mem0-local":
- client.add(messages=messages, user_id=user_id)
- elif frame == "mem0-api":
- client.add(messages=messages,
- user_id=user_id,
- session_id=session_id,
- version="v2", )
+ f"[{frame}] 📝 Session [{session_id}: [{idx + 1}/{len(session)}] Ingesting message: {msg['role']} - {msg['content'][:50]}..."
+ )
+ timestamp_add = int(time.time() * 100)
+ client.add(messages=messages, user_id=user_id, timestamp=timestamp_add, batch_size=10)
+ print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
+ elif frame == "memos-api":
+ client.add(messages=session, user_id=user_id, conv_id=session_id, batch_size=10)
+ print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(session)} messages")
+ elif frame == "memobase":
+ for _idx, msg in enumerate(session):
+ if msg["role"] != "system":
+ messages.append(
+ {
+ "role": msg["role"],
+ "content": msg["content"],
+ "created_at": datetime.now().isoformat(),
+ }
+ )
+ client.add(messages, user_id, batch_size=10)
print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
- elif frame == "memos-local" or frame == "memos-api":
- if os.getenv("PRE_SPLIT_CHUNK")=="true":
- for i in range(0, len(session), 10):
- messages = session[i: i + 10]
- client.add(messages=messages, user_id=user_id, conv_id=session_id)
- print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(messages)} messages")
- else:
- client.add(messages=session, user_id=user_id, conv_id=session_id)
- print(f"[{frame}] ✅ Session [{session_id}]: Ingested {len(session)} messages")
+ elif frame == "supermemory":
+ for _idx, msg in enumerate(session):
+ messages.append(
+ {
+ "role": msg["role"],
+ "content": msg["content"][:8000],
+ "chat_time": datetime.now().astimezone().isoformat(),
+ }
+ )
+ client.add(messages, user_id)
+ elif frame == "memu":
+ for _idx, msg in enumerate(session):
+ messages.append({"role": msg["role"], "content": msg["content"]})
+ client.add(messages, user_id, datetime.now().astimezone().isoformat())
+ elif frame == "memos-api-online":
+ client.add(messages, user_id, session_id, batch_size=10)
def build_jsonl_index(jsonl_path):
@@ -51,7 +66,7 @@ def build_jsonl_index(jsonl_path):
Assumes each line is a JSON object with a single key-value pair.
"""
index = {}
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
while True:
offset = f.tell()
line = f.readline()
@@ -63,14 +78,14 @@ def build_jsonl_index(jsonl_path):
def load_context_by_id(jsonl_path, offset):
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
f.seek(offset)
item = json.loads(f.readline())
return next(iter(item.values()))
def load_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for _, row in enumerate(reader, start=1):
row_data = {}
@@ -82,7 +97,7 @@ def load_rows(csv_path):
def load_rows_with_context(csv_path, jsonl_path):
jsonl_index = build_jsonl_index(jsonl_path)
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
prev_sid = None
prev_context = None
@@ -102,13 +117,17 @@ def load_rows_with_context(csv_path, jsonl_path):
def count_csv_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as f:
+ with open(csv_path, newline="", encoding="utf-8") as f:
return sum(1 for _ in f) - 1
-def ingest_conv(row_data, context, version, conv_idx, frame):
+def ingest_conv(row_data, context, version, conv_idx, frame, success_records, f):
+ if str(conv_idx) in success_records:
+ print(f"✅ Conversation {conv_idx} already ingested, skipping...")
+ return conv_idx
+
end_index_in_shared_context = row_data["end_index_in_shared_context"]
- context = context[:int(end_index_in_shared_context)]
+ context = context[: int(end_index_in_shared_context)]
user_id = f"pm_exper_user_{conv_idx}_{version}"
print(f"👤 User ID: {user_id}")
print("\n" + "=" * 80)
@@ -116,43 +135,65 @@ def ingest_conv(row_data, context, version, conv_idx, frame):
print("=" * 80)
if frame == "zep":
- client = zep_client()
+ from utils.client import ZepClient
+
+ client = ZepClient()
print("🔌 Using Zep client for ingestion...")
client.user.delete(user_id)
print(f"🗑️ Deleted existing user {user_id} from Zep memory...")
client.user.add(user_id=user_id)
print(f"➕ Added user {user_id} to Zep memory...")
- elif frame == "mem0-local":
- client = mem0_client(mode="local")
- print("🔌 Using Mem0 Local client for ingestion...")
- client.delete_all(user_id=user_id)
- print(f"🗑️ Deleted existing memories for user {user_id}...")
- elif frame == "mem0-api":
- client = mem0_client(mode="api")
- print("🔌 Using Mem0 API client for ingestion...")
- client.delete_all(user_id=user_id)
+ elif frame == "mem0" or frame == "mem0_graph":
+ from utils.client import Mem0Client
+
+ client = Mem0Client(enable_graph="graph" in frame)
+ print("🔌 Using Mem0 client for ingestion...")
+ client.client.delete_all(user_id=user_id)
print(f"🗑️ Deleted existing memories for user {user_id}...")
- elif frame == "memos-local":
- client = memos_client(
- mode="local",
- db_name=f"pm_{frame}-{version}",
- user_id=user_id,
- top_k=20,
- mem_cube_path=f"results/pm/{frame}-{version}/storages/{user_id}",
- mem_cube_config_path="configs/mu_mem_cube_config.json",
- mem_os_config_path="configs/mos_memos_config.json",
- addorsearch="add",
- )
- print("🔌 Using Memos Local client for ingestion...")
elif frame == "memos-api":
- client = memos_api_client()
+ from utils.client import MemosApiClient
- ingest_session(session=context, user_id=user_id, session_id=conv_idx, frame=frame, client=client)
- print(f"✅ Ingestion of conversation {conv_idx} completed")
- print("=" * 80)
+ client = MemosApiClient()
+ elif frame == "memobase":
+ from utils.client import MemobaseClient
+
+ client = MemobaseClient()
+ elif frame == "supermemory":
+ from utils.client import SupermemoryClient
+
+ client = SupermemoryClient()
+ elif frame == "memu":
+ from utils.client import MemuClient
+
+ client = MemuClient()
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+
+ try:
+ ingest_session(
+ session=context, user_id=user_id, session_id=conv_idx, frame=frame, client=client
+ )
+ print(f"✅ Ingestion of conversation {conv_idx} completed")
+ print("=" * 80)
+
+ f.write(f"{conv_idx}\n")
+ f.flush()
+ return conv_idx
+ except Exception as e:
+ print(f"❌ Error ingesting conversation {conv_idx}: {e}")
+ raise
+
+
+def main(frame, version, num_workers=2, clear=False):
+ os.makedirs(f"results/pm/{frame}-{version}/", exist_ok=True)
+ record_file = f"results/pm/{frame}-{version}/success_records.txt"
+ if clear and os.path.exists(record_file):
+ os.remove(record_file)
+ print("🧹 Cleared progress records")
-def main(frame, version, num_workers=2):
print("\n" + "=" * 80)
print(f"🚀 PERSONAMEM INGESTION - {frame.upper()} v{version}".center(80))
print("=" * 80)
@@ -164,22 +205,53 @@ def main(frame, version, num_workers=2):
print(f"📚 Loaded PersonaMem dataset from {question_csv_path} and {context_jsonl_path}")
print("-" * 80)
- start_time = datetime.now()
+ success_records = set()
+ if os.path.exists(record_file):
+ with open(record_file) as f:
+ success_records = {line.strip() for line in f}
+ print(
+ f"📊 Found {len(success_records)} completed conversations, {total_rows - len(success_records)} remaining"
+ )
+ start_time = datetime.now()
all_data = list(load_rows_with_context(question_csv_path, context_jsonl_path))
- with ThreadPoolExecutor(max_workers=num_workers) as executor:
- future_to_idx = {
- executor.submit(ingest_conv, row_data=row_data, context=context, version=version, conv_idx=idx,
- frame=frame, ): idx
- for idx, (row_data, context) in enumerate(all_data)}
-
- for future in tqdm(as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"):
- idx = future_to_idx[future]
+ pending_data = [
+ (idx, row_data, context)
+ for idx, (row_data, context) in enumerate(all_data)
+ if str(idx) not in success_records
+ ]
+
+ if not pending_data:
+ print("✅ All conversations have been processed!")
+ return
+
+ print(f"🔄 Processing {len(pending_data)} conversations...")
+
+ with ThreadPoolExecutor(max_workers=num_workers) as executor, open(record_file, "a") as f:
+ futures = []
+ for idx, row_data, context in pending_data:
+ future = executor.submit(
+ ingest_conv,
+ row_data=row_data,
+ context=context,
+ version=version,
+ conv_idx=idx,
+ frame=frame,
+ success_records=success_records,
+ f=f,
+ )
+ futures.append(future)
+
+ completed_count = 0
+ for future in tqdm(
+ as_completed(futures), total=len(futures), desc="Processing conversations"
+ ):
try:
future.result()
+ completed_count += 1
except Exception as exc:
- print(f'\n❌ Conversation {idx} generated an exception: {exc}')
+ print(f"\n❌ Conversation generated an exception: {exc}")
end_time = datetime.now()
elapsed_time = end_time - start_time
@@ -190,15 +262,34 @@ def main(frame, version, num_workers=2):
print("=" * 80)
print(f"⏱️ Total time taken to ingest {total_rows} rows: {elapsed_time_str}")
print(f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}")
+ print(f"📈 Processed: {len(success_records) + completed_count}/{total_rows} conversations")
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Ingestion Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
- default='memos-api')
- parser.add_argument("--version", type=str, default="0925-1", help="Version of the evaluation framework.")
- parser.add_argument("--workers", type=int, default=3, help="Number of parallel workers for processing users.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ "zep",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=3, help="Number of parallel workers for processing users."
+ )
+ parser.add_argument("--clear", action="store_true", help="Clear progress and start fresh")
args = parser.parse_args()
- main(frame=args.lib, version=args.version, num_workers=args.workers)
+ main(frame=args.lib, version=args.version, num_workers=args.workers, clear=args.clear)
diff --git a/evaluation/scripts/personamem/pm_metric.py b/evaluation/scripts/personamem/pm_metric.py
index 0f6a1e138..4c93ec0c6 100644
--- a/evaluation/scripts/personamem/pm_metric.py
+++ b/evaluation/scripts/personamem/pm_metric.py
@@ -8,40 +8,48 @@
def save_to_excel(results, output_path):
"""Save results to Excel file"""
combined_data = []
-
+
# Add overall statistics row
- overall_row = {"category": "overall", "accuracy": results["metrics"]["accuracy"],
- "accuracy_std": results["metrics"]["accuracy_std"],
- "total_questions": results["metrics"]["total_questions"],
- "total_runs": results["metrics"]["total_runs"]}
+ overall_row = {
+ "category": "overall",
+ "accuracy": results["metrics"]["accuracy"],
+ "accuracy_std": results["metrics"]["accuracy_std"],
+ "total_questions": results["metrics"]["total_questions"],
+ "total_runs": results["metrics"]["total_runs"],
+ }
# Add response duration metrics
for metric, value in results["metrics"]["response_duration"].items():
overall_row[f"response_{metric}"] = value
-
+
# Add search duration metrics (if exists)
if "search_duration" in results["metrics"] and results["metrics"]["search_duration"]:
for metric, value in results["metrics"]["search_duration"].items():
overall_row[f"search_{metric}"] = value
-
+
combined_data.append(overall_row)
-
+
# Add category statistics rows
for category, scores in results["category_scores"].items():
- category_row = {"category": category, "accuracy": scores["accuracy"], "accuracy_std": scores["accuracy_std"],
- "total_questions": scores["total_questions"], "total_runs": scores["total_runs"]}
+ category_row = {
+ "category": category,
+ "accuracy": scores["accuracy"],
+ "accuracy_std": scores["accuracy_std"],
+ "total_questions": scores["total_questions"],
+ "total_runs": scores["total_runs"],
+ }
# Add response duration metrics
for metric, value in scores["response_duration"].items():
category_row[f"response_{metric}"] = value
-
+
# Add search duration metrics (if exists)
- if "search_duration" in scores and scores["search_duration"]:
+ if scores.get("search_duration"):
for metric, value in scores["search_duration"].items():
category_row[f"search_{metric}"] = value
-
+
combined_data.append(category_row)
-
+
# Save to Excel
df = pd.DataFrame(combined_data)
df.to_excel(output_path, sheet_name="PersonaMem_Metrics", index=False)
@@ -50,62 +58,62 @@ def save_to_excel(results, output_path):
def calculate_scores(data, grade_path, output_path):
"""Calculate PersonaMem evaluation metrics"""
-
+
# Initialize statistics variables
category_scores = {}
user_metrics = {}
-
+
# Overall metrics - collect accuracy for each run
all_response_durations = []
all_search_durations = []
total_questions = 0
-
+
# For calculating accuracy across multiple runs
num_runs = None # Will be determined from first user's data
run_accuracies = [] # List to store accuracy for each run across all users
-
+
# Category-wise statistics
category_response_durations = {}
category_search_durations = {}
category_run_accuracies = {} # Store accuracy for each run by category
-
+
print(f"📋 Processing response data for {len(data)} users...")
-
+
# First pass: determine number of runs and initialize run accuracy arrays
- for user_id, user_data in data.items():
+ for _user_id, user_data in data.items():
# Skip incomplete data (users with only topic field)
if len(user_data) <= 2 and "topic" in user_data:
continue
-
+
results = user_data.get("results", [])
if not results:
continue
-
+
if num_runs is None:
num_runs = len(results)
run_accuracies = [[] for _ in range(num_runs)] # Initialize for each run
print(f"📊 Detected {num_runs} runs per user")
break
-
+
if num_runs is None:
print("❌ Error: Could not determine number of runs from data")
return
-
+
# Iterate through all user data
for user_id, user_data in data.items():
# Skip incomplete data (users with only topic field)
if len(user_data) <= 2 and "topic" in user_data:
print(f"⚠️ Skipping incomplete data for user {user_id}")
continue
-
+
# Get category and results
category = user_data.get("category", "unknown")
results = user_data.get("results", [])
-
+
if not results:
print(f"⚠️ No results found for user {user_id}")
continue
-
+
# Initialize category if not exists
if category not in category_scores:
category_scores[category] = {
@@ -115,39 +123,39 @@ def calculate_scores(data, grade_path, output_path):
"accuracy": 0.0,
"accuracy_std": 0.0,
"response_duration": {},
- "search_duration": {}
+ "search_duration": {},
}
category_response_durations[category] = []
category_search_durations[category] = []
category_run_accuracies[category] = [[] for _ in range(num_runs)]
-
+
# Process each run for this user
user_response_durations = []
for run_idx, result in enumerate(results):
is_correct = result.get("is_correct", False)
-
+
# Collect accuracy for each run (1 if correct, 0 if not)
if run_idx < num_runs:
run_accuracies[run_idx].append(1.0 if is_correct else 0.0)
category_run_accuracies[category][run_idx].append(1.0 if is_correct else 0.0)
-
+
# Collect response duration
response_duration = result.get("response_duration_ms", 0)
if response_duration > 0:
user_response_durations.append(response_duration)
all_response_durations.append(response_duration)
category_response_durations[category].append(response_duration)
-
+
# Get search duration (usually same for all runs)
search_duration = user_data.get("search_duration_ms", 0)
if search_duration > 0:
all_search_durations.append(search_duration)
category_search_durations[category].append(search_duration)
-
+
# Calculate user-level accuracy (average across runs)
user_correct_count = sum(1 for result in results if result.get("is_correct", False))
user_accuracy = user_correct_count / len(results) if results else 0.0
-
+
# Store user-level metrics
user_metrics[user_id] = {
"user_id": user_id,
@@ -156,22 +164,26 @@ def calculate_scores(data, grade_path, output_path):
"accuracy": user_accuracy,
"total_runs": len(results),
"correct_runs": user_correct_count,
- "avg_response_duration_ms": np.mean(user_response_durations) if user_response_durations else 0.0,
+ "avg_response_duration_ms": np.mean(user_response_durations)
+ if user_response_durations
+ else 0.0,
"search_duration_ms": search_duration,
"golden_answer": user_data.get("golden_answer", ""),
- "topic": user_data.get("topic", "")
+ "topic": user_data.get("topic", ""),
}
-
+
# Count statistics
total_questions += 1
category_scores[category]["total_questions"] += 1
category_scores[category]["total_runs"] += len(results)
-
+
# Calculate overall accuracy and std across runs
overall_run_accuracies = [np.mean(run_acc) for run_acc in run_accuracies if run_acc]
overall_accuracy = np.mean(overall_run_accuracies) if overall_run_accuracies else 0.0
- overall_accuracy_std = np.std(overall_run_accuracies) if len(overall_run_accuracies) > 1 else 0.0
-
+ overall_accuracy_std = (
+ np.std(overall_run_accuracies) if len(overall_run_accuracies) > 1 else 0.0
+ )
+
# Calculate response duration statistics
response_duration_stats = {}
if all_response_durations:
@@ -182,9 +194,9 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(all_response_durations, 95),
"std": np.std(all_response_durations),
"min": np.min(all_response_durations),
- "max": np.max(all_response_durations)
+ "max": np.max(all_response_durations),
}
-
+
# Calculate search duration statistics
search_duration_stats = {}
if all_search_durations:
@@ -195,16 +207,22 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(all_search_durations, 95),
"std": np.std(all_search_durations),
"min": np.min(all_search_durations),
- "max": np.max(all_search_durations)
+ "max": np.max(all_search_durations),
}
-
+
# Calculate category-wise metrics
for category in category_scores:
# Calculate accuracy mean and std across runs for this category
- cat_run_accuracies = [np.mean(run_acc) for run_acc in category_run_accuracies[category] if run_acc]
- category_scores[category]["accuracy"] = np.mean(cat_run_accuracies) if cat_run_accuracies else 0.0
- category_scores[category]["accuracy_std"] = np.std(cat_run_accuracies) if len(cat_run_accuracies) > 1 else 0.0
-
+ cat_run_accuracies = [
+ np.mean(run_acc) for run_acc in category_run_accuracies[category] if run_acc
+ ]
+ category_scores[category]["accuracy"] = (
+ np.mean(cat_run_accuracies) if cat_run_accuracies else 0.0
+ )
+ category_scores[category]["accuracy_std"] = (
+ np.std(cat_run_accuracies) if len(cat_run_accuracies) > 1 else 0.0
+ )
+
# Response duration statistics for this category
if category_response_durations[category]:
durations = category_response_durations[category]
@@ -215,14 +233,19 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(durations, 95),
"std": np.std(durations),
"min": np.min(durations),
- "max": np.max(durations)
+ "max": np.max(durations),
}
else:
category_scores[category]["response_duration"] = {
- "mean": 0.0, "median": 0.0, "p50": 0.0, "p95": 0.0,
- "std": 0.0, "min": 0.0, "max": 0.0
+ "mean": 0.0,
+ "median": 0.0,
+ "p50": 0.0,
+ "p95": 0.0,
+ "std": 0.0,
+ "min": 0.0,
+ "max": 0.0,
}
-
+
# Search duration statistics for this category
if category_search_durations[category]:
durations = category_search_durations[category]
@@ -233,14 +256,19 @@ def calculate_scores(data, grade_path, output_path):
"p95": np.percentile(durations, 95),
"std": np.std(durations),
"min": np.min(durations),
- "max": np.max(durations)
+ "max": np.max(durations),
}
else:
category_scores[category]["search_duration"] = {
- "mean": 0.0, "median": 0.0, "p50": 0.0, "p95": 0.0,
- "std": 0.0, "min": 0.0, "max": 0.0
+ "mean": 0.0,
+ "median": 0.0,
+ "p50": 0.0,
+ "p95": 0.0,
+ "std": 0.0,
+ "min": 0.0,
+ "max": 0.0,
}
-
+
# Build final results
results = {
"metrics": {
@@ -249,22 +277,22 @@ def calculate_scores(data, grade_path, output_path):
"total_questions": total_questions,
"total_runs": total_questions * num_runs if num_runs else 0,
"response_duration": response_duration_stats,
- "search_duration": search_duration_stats
+ "search_duration": search_duration_stats,
},
"category_scores": category_scores,
- "user_scores": user_metrics
+ "user_scores": user_metrics,
}
-
+
# Save results to JSON file
with open(grade_path, "w") as outfile:
json.dump(results, outfile, indent=4, ensure_ascii=False)
-
+
# Save to Excel
save_to_excel(results, output_path)
-
+
# Print summary
print_summary(results)
-
+
return results
@@ -273,19 +301,19 @@ def print_summary(results):
print("\n" + "=" * 80)
print("📊 PERSONAMEM EVALUATION SUMMARY".center(80))
print("=" * 80)
-
+
# Overall accuracy
accuracy = results["metrics"]["accuracy"]
accuracy_std = results["metrics"]["accuracy_std"]
total_questions = results["metrics"]["total_questions"]
total_runs = results["metrics"]["total_runs"]
-
+
print(f"🎯 Overall Accuracy: {accuracy:.4f} ± {accuracy_std:.4f}")
print(f"📋 Total Questions: {total_questions}")
print(f"🔄 Total Runs: {total_runs}")
-
+
print("-" * 80)
-
+
# Response duration statistics
if results["metrics"]["response_duration"]:
rd = results["metrics"]["response_duration"]
@@ -294,7 +322,7 @@ def print_summary(results):
print(f" P50: \033[96m{rd['p50']:.2f}")
print(f" P95: \033[91m{rd['p95']:.2f}")
print(f" Std Dev: {rd['std']:.2f}")
-
+
# Search duration statistics
if results["metrics"]["search_duration"]:
sd = results["metrics"]["search_duration"]
@@ -303,9 +331,9 @@ def print_summary(results):
print(f" P50: \033[96m{sd['p50']:.2f}")
print(f" P95: \033[91m{sd['p95']:.2f}")
print(f" Std Dev: {sd['std']:.2f}")
-
+
print("-" * 80)
-
+
# Category-wise accuracy
print("📂 Category-wise Accuracy:")
for category, scores in results["category_scores"].items():
@@ -313,50 +341,58 @@ def print_summary(results):
acc_std = scores["accuracy_std"]
total_cat = scores["total_questions"]
total_runs_cat = scores["total_runs"]
- print(f" {category:<35}: {acc:.4f} ± {acc_std:.4f} ({total_cat} questions, {total_runs_cat} runs)")
-
+ print(
+ f" {category:<35}: {acc:.4f} ± {acc_std:.4f} ({total_cat} questions, {total_runs_cat} runs)"
+ )
+
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem evaluation metrics calculation script")
parser.add_argument(
- "--lib",
- type=str,
- choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
+ "--lib",
+ type=str,
+ choices=[
+ "zep",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memos-api-online",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
required=True,
help="Memory library to evaluate",
- default='memos-api'
+ default="memos-api",
)
parser.add_argument(
- "--version",
- type=str,
- default="0925",
- help="Evaluation framework version"
+ "--version", type=str, default="default", help="Evaluation framework version"
)
-
+
args = parser.parse_args()
lib, version = args.lib, args.version
-
+
# Define file paths
responses_path = f"results/pm/{lib}-{version}/{lib}_pm_responses.json"
grade_path = f"results/pm/{lib}-{version}/{lib}_pm_grades.json"
output_path = f"results/pm/{lib}-{version}/{lib}_pm_results.xlsx"
-
+
print(f"📂 Loading response data from: {responses_path}")
-
+
try:
- with open(responses_path, 'r', encoding='utf-8') as file:
+ with open(responses_path, encoding="utf-8") as file:
data = json.load(file)
-
+
# Calculate metrics
results = calculate_scores(data, grade_path, output_path)
-
+
print(f"📁 Results saved to: {grade_path}")
print(f"📊 Excel report saved to: {output_path}")
-
+
except FileNotFoundError:
print(f"❌ Error: File not found {responses_path}")
print("Please make sure to run pm_responses.py first to generate response data")
except Exception as e:
- print(f"❌ Error occurred during processing: {e}")
\ No newline at end of file
+ print(f"❌ Error occurred during processing: {e}")
diff --git a/evaluation/scripts/personamem/pm_responses.py b/evaluation/scripts/personamem/pm_responses.py
index c48933c11..171b5af1a 100644
--- a/evaluation/scripts/personamem/pm_responses.py
+++ b/evaluation/scripts/personamem/pm_responses.py
@@ -10,20 +10,21 @@
from openai import OpenAI
from tqdm import tqdm
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-from utils.prompts import PM_ANSWER_PROMPT
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import re
+from utils.prompts import PM_ANSWER_PROMPT
+
def extract_choice_answer(predicted_answer, correct_answer):
def _extract_only_options(text):
text = text.lower()
- in_parens = re.findall(r'\(([a-d])\)', text)
+ in_parens = re.findall(r"\(([a-d])\)", text)
if in_parens:
return set(in_parens)
else:
- return set(re.findall(r'\b([a-d])\b', text))
+ return set(re.findall(r"\b([a-d])\b", text))
correct = correct_answer.lower().strip("() ")
@@ -33,7 +34,7 @@ def _extract_only_options(text):
if "" in predicted_answer:
predicted_answer = predicted_answer.split("")[-1].strip()
if predicted_answer.endswith(""):
- predicted_answer = predicted_answer[:-len("")].strip()
+ predicted_answer = predicted_answer[: -len("")].strip()
pred_options = _extract_only_options(predicted_answer)
@@ -79,12 +80,14 @@ def process_qa(user_id, search_result, num_runs, llm_client):
is_correct, answer = extract_choice_answer(answer, search_result.get("golden_answer", ""))
response_duration_ms = (time() - start) * 1000
- run_results.append({
- "run_id": idx + 1,
- "answer": answer,
- "is_correct": is_correct,
- "response_duration_ms": response_duration_ms,
- })
+ run_results.append(
+ {
+ "run_id": idx + 1,
+ "answer": answer,
+ "is_correct": is_correct,
+ "response_duration_ms": response_duration_ms,
+ }
+ )
response_duration_ms = sum(result["response_duration_ms"] for result in run_results) / num_runs
@@ -95,8 +98,11 @@ def process_qa(user_id, search_result, num_runs, llm_client):
print(f"💡 Golden Answer: {search_result.get('golden_answer', 'N/A')}")
for idx, result in enumerate(run_results, start=1):
print(f"\n🔄 Run {idx}/{num_runs}:")
- print(f"💬 Run Answer: {result['answer'][:150]}..." if len(
- result['answer']) > 150 else f"💬 Run Answer: {result['answer']}")
+ print(
+ f"💬 Run Answer: {result['answer'][:150]}..."
+ if len(result["answer"]) > 150
+ else f"💬 Run Answer: {result['answer']}"
+ )
print(f"✅ Run Is Correct: {result['is_correct']}")
print(f"⏱️ Run Duration: {result['response_duration_ms']:.2f} ms")
print("-" * 80)
@@ -122,7 +128,9 @@ def main(frame, version, num_runs=3, num_workers=4):
load_dotenv()
- oai_client = OpenAI(api_key=os.getenv("CHAT_MODEL_API_KEY"), base_url=os.getenv("CHAT_MODEL_BASE_URL"))
+ oai_client = OpenAI(
+ api_key=os.getenv("CHAT_MODEL_API_KEY"), base_url=os.getenv("CHAT_MODEL_BASE_URL")
+ )
print(f"🔌 Using OpenAI client with model: {os.getenv('CHAT_MODEL')}")
search_path = f"results/pm/{frame}-{version}/{frame}_pm_search_results.json"
@@ -146,9 +154,9 @@ def main(frame, version, num_runs=3, num_workers=4):
future_to_user_id[future] = user_id
for future in tqdm(
- as_completed(future_to_user_id),
- total=len(future_to_user_id),
- desc="📝 Generating responses",
+ as_completed(future_to_user_id),
+ total=len(future_to_user_id),
+ desc="📝 Generating responses",
):
user_id = future_to_user_id[future]
try:
@@ -177,10 +185,30 @@ def main(frame, version, num_runs=3, num_workers=4):
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Response Generation Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"], default='memos-api')
- parser.add_argument("--version", type=str, default="0925", help="Version of the evaluation framework.")
- parser.add_argument("--num_runs", type=int, default=3, help="Number of runs for LLM-as-a-Judge evaluation.")
- parser.add_argument("--workers", type=int, default=3, help="Number of worker threads to use for processing.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "zep",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--num_runs", type=int, default=3, help="Number of runs for LLM-as-a-Judge evaluation."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=10, help="Number of worker threads to use for processing."
+ )
args = parser.parse_args()
main(frame=args.lib, version=args.version, num_runs=args.num_runs, num_workers=args.workers)
diff --git a/evaluation/scripts/personamem/pm_search.py b/evaluation/scripts/personamem/pm_search.py
index 50f46f692..80a65e09b 100644
--- a/evaluation/scripts/personamem/pm_search.py
+++ b/evaluation/scripts/personamem/pm_search.py
@@ -1,18 +1,19 @@
import argparse
+import csv
import json
import os
import sys
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from collections import defaultdict
from concurrent.futures import ThreadPoolExecutor, as_completed
from datetime import datetime
from time import time
-import csv
-
from tqdm import tqdm
-from utils.client import mem0_client,zep_client,memos_api_client
+
+
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+
from utils.prompts import (
MEM0_CONTEXT_TEMPLATE,
MEM0_GRAPH_CONTEXT_TEMPLATE,
@@ -50,93 +51,69 @@ def zep_search(client, user_id, query, top_k=20):
return context, duration_ms
-def mem0_search(client, user_id, query, top_k=20, enable_graph=False, frame="mem0-api"):
+def mem0_search(client, query, user_id, top_k):
start = time()
-
- if frame == "mem0-local":
- results = client.search(
- query=query,
- user_id=user_id,
- top_k=top_k,
- )
- search_memories = "\n".join(
+ results = client.search(query, user_id, top_k)
+ memory = [f"{memory['created_at']}: {memory['memory']}" for memory in results["results"]]
+ if client.enable_graph:
+ graph = "\n".join(
[
- f" - {item['memory']} (date: {item['metadata']['timestamp']})"
- for item in results["results"]
+ f" - 'source': {item.get('source', '?')} -> 'target': {item.get('target', '?')} "
+ f"(relationship: {item.get('relationship', '?')})"
+ for item in results.get("relations", [])
]
)
- search_graph = (
- "\n".join(
- [
- f" - 'source': {item.get('source', '?')} -> 'target': {item.get('destination', '?')} (relationship: {item.get('relationship', '?')})"
- for item in results.get("relations", [])
- ]
- )
- if enable_graph
- else ""
- )
-
- elif frame == "mem0-api":
- results = client.search(
- query=query,
- user_id=user_id,
- top_k=top_k,
- version="v2",
- output_format="v1.1",
- enable_graph=enable_graph,
- filters={"AND": [{"user_id": user_id}, {"run_id": "*"}]},
- )
- search_memories = "\n".join(
- [f" - {item['memory']} (date: {item['created_at']})" for item in results["results"]]
- )
- search_graph = (
- "\n".join(
- [
- f" - 'source': {item.get('source', '?')} -> 'target': {item.get('target', '?')} (relationship: {item.get('relationship', '?')})"
- for item in results.get("relations", [])
- ]
- )
- if enable_graph
- else ""
- )
- if enable_graph:
context = MEM0_GRAPH_CONTEXT_TEMPLATE.format(
- user_id=user_id, memories=search_memories, relations=search_graph
+ user_id=user_id, memories=memory, relations=graph
)
else:
- context = MEM0_CONTEXT_TEMPLATE.format(user_id=user_id, memories=search_memories)
+ context = MEM0_CONTEXT_TEMPLATE.format(user_id=user_id, memories=memory)
duration_ms = (time() - start) * 1000
return context, duration_ms
-def memos_search(client, user_id, query, top_k, frame="memos-local"):
+def memobase_search(client, query, user_id, top_k):
start = time()
- if frame == "memos-local":
- results = client.search(
- query=query,
- user_id=user_id,
- )
+ context = client.search(query=query, user_id=user_id, top_k=top_k)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
- results = filter_memory_data(results)["text_mem"][0]["memories"]
- search_memories = "\n".join([f" - {item['memory']}" for item in results])
- elif frame == "memos-api":
- results = client.search(query=query, user_id=user_id, top_k=top_k)
- search_memories = "\n".join(f"- {entry.get('memory_value', '')}"
- for entry in results.get("memory_detail_list", []))
+def memos_search(client, user_id, query, top_k):
+ start = time()
+ results = client.search(query=query, user_id=user_id, top_k=top_k)
+ search_memories = (
+ "\n".join(item["memory"] for cube in results["text_mem"] for item in cube["memories"])
+ + f"\n{results.get('pref_string', '')}"
+ )
context = MEMOS_CONTEXT_TEMPLATE.format(user_id=user_id, memories=search_memories)
duration_ms = (time() - start) * 1000
return context, duration_ms
+def supermemory_search(client, query, user_id, top_k):
+ start = time()
+ context = client.search(query, user_id, top_k)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
+
+
+def memu_search(client, query, user_id, top_k):
+ start = time()
+ results = client.search(query, user_id, top_k)
+ context = "\n".join(results)
+ duration_ms = (time() - start) * 1000
+ return context, duration_ms
+
+
def build_jsonl_index(jsonl_path):
"""
Scan the JSONL file once to build a mapping: {key: file_offset}.
Assumes each line is a JSON object with a single key-value pair.
"""
index = {}
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
while True:
offset = f.tell()
line = f.readline()
@@ -148,14 +125,14 @@ def build_jsonl_index(jsonl_path):
def load_context_by_id(jsonl_path, offset):
- with open(jsonl_path, 'r', encoding='utf-8') as f:
+ with open(jsonl_path, encoding="utf-8") as f:
f.seek(offset)
item = json.loads(f.readline())
return next(iter(item.values()))
def load_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
for _, row in enumerate(reader, start=1):
row_data = {}
@@ -167,7 +144,7 @@ def load_rows(csv_path):
def load_rows_with_context(csv_path, jsonl_path):
jsonl_index = build_jsonl_index(jsonl_path)
- with open(csv_path, mode='r', newline='', encoding='utf-8') as csvfile:
+ with open(csv_path, newline="", encoding="utf-8") as csvfile:
reader = csv.DictReader(csvfile)
prev_sid = None
prev_context = None
@@ -190,7 +167,7 @@ def load_rows_with_context(csv_path, jsonl_path):
def count_csv_rows(csv_path):
- with open(csv_path, mode='r', newline='', encoding='utf-8') as f:
+ with open(csv_path, newline="", encoding="utf-8") as f:
return sum(1 for _ in f) - 1
@@ -219,35 +196,48 @@ def process_user(row_data, conv_idx, frame, version, top_k=20):
return existing_results
if frame == "zep":
- client = zep_client()
+ from utils.client import ZepClient
+
+ client = ZepClient()
print("🔌 Using Zep client for search...")
context, duration_ms = zep_search(client, user_id, question)
- elif frame == "mem0-local":
- client = mem0_client(mode="local")
- print("🔌 Using Mem0 Local client for search...")
- context, duration_ms = mem0_search(client, user_id, question, top_k=top_k, frame=frame)
- elif frame == "mem0-api":
- client = mem0_client(mode="api")
+ elif frame == "mem0" or frame == "mem0-graph":
+ from utils.client import Mem0Client
+
+ client = Mem0Client(enable_graph="graph" in frame)
print("🔌 Using Mem0 API client for search...")
- context, duration_ms = mem0_search(client, user_id, question, top_k=top_k, frame=frame)
- elif frame == "memos-local":
- client = memos_client(
- mode="local",
- db_name=f"pm_{frame}-{version}",
- user_id=user_id,
- top_k=top_k,
- mem_cube_path=f"results/pm/{frame}-{version}/storages/{user_id}",
- mem_cube_config_path="configs/mu_mem_cube_config.json",
- mem_os_config_path="configs/mos_memos_config.json",
- addorsearch="search",
- )
- print("🔌 Using Memos Local client for search...")
- context, duration_ms = memos_search(client, user_id, question, frame=frame)
+ context, duration_ms = mem0_search(client, question, user_id, top_k)
elif frame == "memos-api":
- client = memos_api_client()
+ from utils.client import MemosApiClient
+
+ client = MemosApiClient()
print("🔌 Using Memos API client for search...")
- context, duration_ms = memos_search(client, user_id, question, top_k=top_k, frame=frame)
+ context, duration_ms = memos_search(client, user_id, question, top_k=top_k)
+ elif frame == "supermemory":
+ from utils.client import SupermemoryClient
+
+ client = SupermemoryClient()
+ print("🔌 Using supermemory client for search...")
+ context, duration_ms = supermemory_search(client, question, user_id, top_k)
+ elif frame == "memu":
+ from utils.client import MemuClient
+
+ client = MemuClient()
+ print("🔌 Using memu client for search...")
+ context, duration_ms = memu_search(client, question, user_id, top_k)
+ elif frame == "memobase":
+ from utils.client import MemobaseClient
+
+ client = MemobaseClient()
+ print("🔌 Using Memobase client for search...")
+ context, duration_ms = memobase_search(client, question, user_id, top_k)
+ elif frame == "memos-api-online":
+ from utils.client import MemosApiOnlineClient
+
+ client = MemosApiOnlineClient()
+ print("🔌 Using memos-api-online client for search...")
+ context, duration_ms = memos_search(client, question, user_id, top_k)
search_results[user_id].append(
{
@@ -266,25 +256,23 @@ def process_user(row_data, conv_idx, frame, version, top_k=20):
os.makedirs(f"results/pm/{frame}-{version}/tmp", exist_ok=True)
with open(
- f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{conv_idx}.json", "w"
+ f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{conv_idx}.json", "w"
) as f:
json.dump(search_results, f, indent=4)
- print(f"💾 \033[92mSearch results for conversation {conv_idx} saved...")
+ print(f"💾 Search results for conversation {conv_idx} saved...")
print("-" * 80)
return search_results
def load_existing_results(frame, version, group_idx):
- result_path = (
- f"results/locomo/{frame}-{version}/tmp/{frame}_locomo_search_results_{group_idx}.json"
- )
+ result_path = f"results/pm/{frame}-{version}/tmp/{frame}_pm_search_results_{group_idx}.json"
if os.path.exists(result_path):
try:
with open(result_path) as f:
return json.load(f), True
except Exception as e:
- print(f"\033[91m❌ Error loading existing results for group {group_idx}: {e}")
+ print(f"❌ Error loading existing results for group {group_idx}: {e}")
return {}, False
@@ -299,9 +287,7 @@ def main(frame, version, top_k=20, num_workers=2):
print(f"📚 Loaded PersonaMem dataset from {question_csv_path} and {context_jsonl_path}")
print(f"📊 Total conversations: {total_rows}")
- print(
- f"⚙️ Search parameters: top_k={top_k}, workers={num_workers}"
- )
+ print(f"⚙️ Search parameters: top_k={top_k}, workers={num_workers}")
print("-" * 80)
all_search_results = defaultdict(list)
@@ -320,7 +306,9 @@ def main(frame, version, top_k=20, num_workers=2):
for idx, (row_data, _) in enumerate(all_data)
}
- for future in tqdm(as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"):
+ for future in tqdm(
+ as_completed(future_to_idx), total=len(future_to_idx), desc="Processing conversations"
+ ):
idx = future_to_idx[future]
try:
search_results = future.result()
@@ -328,37 +316,49 @@ def main(frame, version, top_k=20, num_workers=2):
all_search_results[user_id].extend(results)
print(f"✅ Conversation {idx} processed successfully.")
except Exception as exc:
- print(f'\n❌ Conversation {idx} generated an exception: {exc}')
+ print(f"\n❌ Conversation {idx} generated an exception: {exc}")
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_time_str = str(elapsed_time).split(".")[0]
print("\n" + "=" * 80)
- print("✅ \033[1;32mSEARCH COMPLETE".center(80))
+ print("✅ SEARCH COMPLETE".center(80))
print("=" * 80)
- print(
- f"⏱️ Total time taken to search {total_rows} users: \033[92m{elapsed_time_str}"
- )
- print(
- f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}"
- )
+ print(f"⏱️ Total time taken to search {total_rows} users: {elapsed_time_str}")
+ print(f"🔄 Framework: {frame} | Version: {version} | Workers: {num_workers}")
with open(f"results/pm/{frame}-{version}/{frame}_pm_search_results.json", "w") as f:
json.dump(dict(all_search_results), f, indent=4)
- print(
- f"📁 Results saved to: \033[1;94mresults/pm/{frame}-{version}/{frame}_pm_search_results.json"
- )
+ print(f"📁 Results saved to: mresults/pm/{frame}-{version}/{frame}_pm_search_results.json")
print("=" * 80 + "\n")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="PersonaMem Search Script")
- parser.add_argument("--lib", type=str, choices=["mem0-local", "mem0-api", "memos-local", "memos-api", "zep"],
- default='memos-api')
- parser.add_argument("--version", type=str, default="0925", help="Version of the evaluation framework.")
- parser.add_argument("--top_k", type=int, default=20, help="Number of top results to retrieve from the search.")
- parser.add_argument("--workers", type=int, default=3, help="Number of parallel workers for processing users.")
+ parser.add_argument(
+ "--lib",
+ type=str,
+ choices=[
+ "memos-api-online",
+ "mem0",
+ "mem0_graph",
+ "memos-api",
+ "memobase",
+ "memu",
+ "supermemory",
+ ],
+ default="memos-api",
+ )
+ parser.add_argument(
+ "--version", type=str, default="default", help="Version of the evaluation framework."
+ )
+ parser.add_argument(
+ "--top_k", type=int, default=20, help="Number of top results to retrieve from the search."
+ )
+ parser.add_argument(
+ "--workers", type=int, default=3, help="Number of parallel workers for processing users."
+ )
args = parser.parse_args()
diff --git a/evaluation/scripts/run_lme_eval.sh b/evaluation/scripts/run_lme_eval.sh
index 08e431312..8fa8d6c7e 100755
--- a/evaluation/scripts/run_lme_eval.sh
+++ b/evaluation/scripts/run_lme_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="1020"
+VERSION="default"
WORKERS=10
TOPK=20
diff --git a/evaluation/scripts/run_locomo_eval.sh b/evaluation/scripts/run_locomo_eval.sh
index d9c13a1ac..37569956f 100755
--- a/evaluation/scripts/run_locomo_eval.sh
+++ b/evaluation/scripts/run_locomo_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="072001"
+VERSION="default"
WORKERS=10
TOPK=20
diff --git a/evaluation/scripts/run_openai_eval.sh b/evaluation/scripts/run_openai_eval.sh
index 27bb712af..e07f113e5 100755
--- a/evaluation/scripts/run_openai_eval.sh
+++ b/evaluation/scripts/run_openai_eval.sh
@@ -2,7 +2,7 @@
# Common parameters for all scripts
LIB="openai"
-VERSION="063001"
+VERSION="default"
WORKERS=10
NUM_RUNS=3
diff --git a/evaluation/scripts/run_pm_eval.sh b/evaluation/scripts/run_pm_eval.sh
index 89484616b..39d9e72ca 100755
--- a/evaluation/scripts/run_pm_eval.sh
+++ b/evaluation/scripts/run_pm_eval.sh
@@ -2,40 +2,54 @@
# Common parameters for all scripts
LIB="memos-api"
-VERSION="072201"
+VERSION="default"
WORKERS=10
TOPK=20
-# echo "downloading data..."
-# export HF_ENDPOINT=https://hf-mirror.com
-# huggingface-cli download --repo-type dataset bowen-upenn/PersonaMem --local-dir /mnt/afs/codes/ljl/MemOS/evaluation/data/personamem
+if ["$LIB" = "zep"]; then
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion_zep.py --version $VERSION --workers $WORKERS
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search_zep.py --version $VERSION --top_k $TOPK --workers $WORKERS
+ echo "Running pm_responses.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_responses.py"
+ exit 1
+ fi
-echo "Running pm_ingestion.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion.py --lib $LIB --version $VERSION --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_ingestion.py"
- exit 1
-fi
+ echo "Running pm_metric.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_metric.py"
+ exit 1
+ fi
+else
+ echo "Running pm_ingestion.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_ingestion.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_ingestion.py"
+ exit 1
+ fi
-echo "Running pm_search.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search.py --lib $LIB --version $VERSION --top_k $TOPK --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_search.py"
- exit 1
-fi
+ echo "Running pm_search.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_search.py --lib $LIB --version $VERSION --top_k $TOPK --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_search.py"
+ exit 1
+ fi
-echo "Running pm_responses.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
-if [ $? -ne 0 ]; then
- echo "Error running pm_responses.py"
- exit 1
-fi
+ echo "Running pm_responses.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_responses.py --lib $LIB --version $VERSION --workers $WORKERS
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_responses.py"
+ exit 1
+ fi
-echo "Running pm_metric.py..."
-CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
-if [ $? -ne 0 ]; then
- echo "Error running pm_metric.py"
- exit 1
+ echo "Running pm_metric.py..."
+ CUDA_VISIBLE_DEVICES=0 python scripts/personamem/pm_metric.py --lib $LIB --version $VERSION
+ if [ $? -ne 0 ]; then
+ echo "Error running pm_metric.py"
+ exit 1
+ fi
fi
echo "All scripts completed successfully!"
diff --git a/evaluation/scripts/run_prefeval_eval.sh b/evaluation/scripts/run_prefeval_eval.sh
old mode 100644
new mode 100755
index 8e718192a..6f5f3b7b0
--- a/evaluation/scripts/run_prefeval_eval.sh
+++ b/evaluation/scripts/run_prefeval_eval.sh
@@ -6,24 +6,46 @@
# Number of workers for parallel processing.
# This variable controls both pref_memos.py (--max-workers)
# and pref_eval.py (--concurrency-limit).
-WORKERS=10
+WORKERS=20
# Parameters for pref_memos.py
TOP_K=10
-ADD_TURN=0 # Options: 0, 10, or 300
-LIB="memos-api"
-VERSION="1021-5"
+ADD_TURN=10 # Options: 0, 10, or 300
+LIB="memos-api" # Options: memos-api, memos-api-online, mem0, mem0-graph, memobase, supermemory, memu, zep
+VERSION="default"
# --- File Paths ---
# You may need to adjust these paths based on your project structure.
-# Assumes Step 1 (preprocess) outputs this file:
-PREPROCESSED_FILE="data/prefeval/pref_processed.jsonl"
+# Step 1 (preprocess) outputs this file:
+PREPROCESSED_FILE="data/prefeval/pref_processed.jsonl"
+
+# Create a directory name based on the *specific* LIB (e.g., "memos")
+OUTPUT_DIR="results/prefeval/${LIB}_${VERSION}"
+
+
+if [[ "$LIB" == *"mem0"* ]]; then
+ SCRIPT_NAME_BASE="mem0"
+elif [[ "$LIB" == *"memos"* ]]; then
+ SCRIPT_NAME_BASE="memos"
+elif [[ "$LIB" == *"memobase"* ]]; then
+ SCRIPT_NAME_BASE="memobase"
+elif [[ "$LIB" == *"supermemory"* ]]; then
+ SCRIPT_NAME_BASE="supermemory"
+elif [[ "$LIB" == *"memu"* ]]; then
+ SCRIPT_NAME_BASE="memu"
+elif [[ "$LIB" == *"zep"* ]]; then
+ SCRIPT_NAME_BASE="zep"
+else
+ SCRIPT_NAME_BASE=$LIB
+fi
-# Intermediate file (output of 'add' mode, input for 'process' mode)
-IDS_FILE="results/prefeval/pref_memos_add.jsonl"
+# The script to be executed (e.g., pref_mem0.py)
+LIB_SCRIPT="scripts/PrefEval/pref_${SCRIPT_NAME_BASE}.py"
-# Final response file (output of 'process' mode, input for Step 3)
-RESPONSE_FILE="results/prefeval/pref_memos_process.jsonl"
+# Output files will be unique to the $LIB (e.g., pref_memos-api_add.jsonl)
+IDS_FILE="${OUTPUT_DIR}/pref_${LIB}_add.jsonl"
+SEARCH_FILE="${OUTPUT_DIR}/pref_${LIB}_search.jsonl"
+RESPONSE_FILE="${OUTPUT_DIR}/pref_${LIB}_response.jsonl"
# Set the Hugging Face mirror endpoint
@@ -31,6 +53,8 @@ export HF_ENDPOINT="https://hf-mirror.com"
echo "--- Starting PrefEval Pipeline ---"
echo "Configuration: WORKERS=$WORKERS, TOP_K=$TOP_K, ADD_TURN=$ADD_TURN, LIB=$LIB, VERSION=$VERSION, HF_ENDPOINT=$HF_ENDPOINT"
+echo "Results will be saved to: $OUTPUT_DIR"
+echo "Using script: $LIB_SCRIPT (mapped from LIB=$LIB)"
echo ""
# --- Step 1: Preprocess the data ---
@@ -42,11 +66,29 @@ if [ $? -ne 0 ]; then
exit 1
fi
-# --- Step 2: Generate responses using MemOS (split into 'add' and 'process') ---
+# --- Create output directory ---
+echo ""
+echo "Creating output directory: $OUTPUT_DIR"
+mkdir -p $OUTPUT_DIR
+if [ $? -ne 0 ]; then
+ echo "Error: Could not create output directory '$OUTPUT_DIR'."
+ exit 1
+fi
+
+# Check if the *mapped* script exists
+if [ ! -f "$LIB_SCRIPT" ]; then
+ echo "Error: Script not found for library '$LIB' (mapped to $LIB_SCRIPT)"
+ exit 1
+fi
+
+# --- Step 2: Generate responses based on LIB ---
echo ""
-echo "Running pref_memos.py in 'add' mode..."
+echo "--- Step 2: Generate responses using $LIB (3-Step Process) ---"
+
+echo ""
+echo "Running $LIB_SCRIPT in 'add' mode..."
# Step 2a: Ingest conversations into memory and generate user_ids
-python scripts/PrefEval/pref_memos.py add \
+python $LIB_SCRIPT add \
--input $PREPROCESSED_FILE \
--output $IDS_FILE \
--add-turn $ADD_TURN \
@@ -55,35 +97,50 @@ python scripts/PrefEval/pref_memos.py add \
--version $VERSION
if [ $? -ne 0 ]; then
- echo "Error: pref_memos.py 'add' mode failed."
+ echo "Error: $LIB_SCRIPT 'add' mode failed."
exit 1
fi
echo ""
-echo "Running pref_memos.py in 'process' mode..."
-# Step 2b: Search memories using user_ids and generate responses
-python scripts/PrefEval/pref_memos.py process \
+echo "Running $LIB_SCRIPT in 'search' mode..."
+# Step 2b: Search memories using user_ids
+python $LIB_SCRIPT search \
--input $IDS_FILE \
- --output $RESPONSE_FILE \
+ --output $SEARCH_FILE \
--top-k $TOP_K \
- --max-workers $WORKERS \
- --lib $LIB \
- --version $VERSION
+ --max-workers $WORKERS
if [ $? -ne 0 ]; then
- echo "Error: pref_memos.py 'process' mode failed."
+ echo "Error: $LIB_SCRIPT 'search' mode failed."
+ exit 1
+fi
+
+echo ""
+echo "Running $LIB_SCRIPT in 'response' mode..."
+# Step 2c: Generate responses based on searched memories
+python $LIB_SCRIPT response \
+ --input $SEARCH_FILE \
+ --output $RESPONSE_FILE \
+ --max-workers $WORKERS
+
+if [ $? -ne 0 ]; then
+ echo "Error: $LIB_SCRIPT 'response' mode failed."
exit 1
fi
# --- Step 3: Evaluate the generated responses ---
echo ""
echo "Running pref_eval.py..."
-# Pass the WORKERS variable to the script's --concurrency-limit argument
-python scripts/PrefEval/pref_eval.py --concurrency-limit $WORKERS
+python scripts/PrefEval/pref_eval.py \
+ --input $RESPONSE_FILE \
+ --concurrency-limit $WORKERS \
+ --lib $LIB
+
if [ $? -ne 0 ]; then
echo "Error: Evaluation script failed."
exit 1
fi
echo ""
-echo "--- PrefEval Pipeline completed successfully! ---"
\ No newline at end of file
+echo "--- PrefEval Pipeline completed successfully! ---"
+echo "Final results are in $RESPONSE_FILE"
diff --git a/evaluation/scripts/utils/client.py b/evaluation/scripts/utils/client.py
index 87b863e86..157c3f8ea 100644
--- a/evaluation/scripts/utils/client.py
+++ b/evaluation/scripts/utils/client.py
@@ -2,10 +2,16 @@
import os
import sys
import time
+import uuid
+
+from contextlib import suppress
from datetime import datetime
-from dotenv import load_dotenv
+
import requests
+from dotenv import load_dotenv
+
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
load_dotenv()
@@ -17,7 +23,7 @@ def __init__(self):
api_key = os.getenv("ZEP_API_KEY")
self.client = Zep(api_key=api_key)
- def add(self, messages, user_id, conv_id, timestamp):
+ def add(self, messages, user_id, timestamp):
iso_date = datetime.fromtimestamp(timestamp).isoformat()
for msg in messages:
self.client.graph.add(
@@ -49,39 +55,40 @@ def __init__(self, enable_graph=False):
self.client = MemoryClient(api_key=os.getenv("MEM0_API_KEY"))
self.enable_graph = enable_graph
- def add(self, messages, user_id, timestamp):
- if self.enable_graph:
- self.client.add(
- messages=messages,
- timestamp=timestamp,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- enable_graph=True,
- )
- else:
- self.client.add(messages=messages, timestamp=timestamp, user_id=user_id, version="v2")
+ def add(self, messages, user_id, timestamp, batch_size=2):
+ max_retries = 5
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ for attempt in range(max_retries):
+ try:
+ if self.enable_graph:
+ self.client.add(
+ messages=batch_messages,
+ timestamp=timestamp,
+ user_id=user_id,
+ enable_graph=True,
+ )
+ else:
+ self.client.add(
+ messages=batch_messages,
+ timestamp=timestamp,
+ user_id=user_id,
+ )
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
def search(self, query, user_id, top_k):
- if self.enable_graph:
- res = self.client.search(
- query=query,
- top_k=top_k,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- enable_graph=True,
- filters={"AND": [{"user_id": f"{user_id}"}, {"run_id": "*"}]},
- )
- else:
- res = self.client.search(
- query=query,
- top_k=top_k,
- user_id=user_id,
- output_format="v1.1",
- version="v2",
- filters={"AND": [{"user_id": f"{user_id}"}, {"run_id": "*"}]},
- )
+ res = self.client.search(
+ query=query,
+ top_k=top_k,
+ user_id=user_id,
+ enable_graph=self.enable_graph,
+ filters={"AND": [{"user_id": f"{user_id}"}]},
+ )
return res
@@ -93,18 +100,29 @@ def __init__(self):
project_url=os.getenv("MEMOBASE_PROJECT_URL"), api_key=os.getenv("MEMOBASE_API_KEY")
)
- def add(self, messages, user_id):
- from memobase import ChatBlob
-
+ def add(self, messages, user_id, batch_size=2):
"""
- user_id: memobase user_id
messages = [{"role": "assistant", "content": data, "created_at": iso_date}]
"""
- user = self.client.get_user(user_id, no_get=True)
- user.insert(ChatBlob(messages=messages), sync=True)
+ from memobase import ChatBlob
+
+ real_uid = self.string_to_uuid(user_id)
+ user = self.client.get_or_create_user(real_uid)
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ _ = user.insert(ChatBlob(messages=batch_messages), sync=True)
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
def search(self, query, user_id, top_k):
- user = self.client.get_user(user_id, no_get=True)
+ real_uid = self.string_to_uuid(user_id)
+ user = self.client.get_user(real_uid, no_get=True)
memories = user.context(
max_token_size=top_k * 100,
chats=[{"role": "user", "content": query}],
@@ -113,26 +131,45 @@ def search(self, query, user_id, top_k):
)
return memories
+ def delete_user(self, user_id):
+ from memobase.error import ServerError
+
+ real_uid = self.string_to_uuid(user_id)
+ with suppress(ServerError):
+ self.client.delete_user(real_uid)
+
+ def string_to_uuid(self, s: str, salt="memobase_client"):
+ return str(uuid.uuid5(uuid.NAMESPACE_DNS, s + salt))
+
class MemosApiClient:
def __init__(self):
self.memos_url = os.getenv("MEMOS_URL")
self.headers = {"Content-Type": "application/json", "Authorization": os.getenv("MEMOS_KEY")}
- def add(self, messages, user_id, conv_id):
+ def add(self, messages, user_id, conv_id, batch_size: int = 9999):
+ """
+ messages = [{"role": "assistant", "content": data, "chat_time": date_str}]
+ """
url = f"{self.memos_url}/product/add"
- payload = json.dumps(
- {
- "messages": messages,
- "user_id": user_id,
- "mem_cube_id": user_id,
- "conversation_id": conv_id,
- }
- )
- response = requests.request("POST", url, data=payload, headers=self.headers)
- assert response.status_code == 200, response.text
- assert json.loads(response.text)["message"] == "Memory added successfully", response.text
- return response.text
+ added_memories = []
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ payload = json.dumps(
+ {
+ "messages": batch_messages,
+ "user_id": user_id,
+ "mem_cube_id": user_id,
+ "conversation_id": conv_id,
+ }
+ )
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "Memory added successfully", (
+ response.text
+ )
+ added_memories += json.loads(response.text)["data"]
+ return added_memories
def search(self, query, user_id, top_k):
"""Search memories."""
@@ -144,6 +181,9 @@ def search(self, query, user_id, top_k):
"mem_cube_id": user_id,
"conversation_id": "",
"top_k": top_k,
+ "mode": os.getenv("SEARCH_MODE", "fast"),
+ "include_preference": True,
+ "pref_top_k": 6,
},
ensure_ascii=False,
)
@@ -155,6 +195,85 @@ def search(self, query, user_id, top_k):
return json.loads(response.text)["data"]
+class MemosApiOnlineClient:
+ def __init__(self):
+ self.memos_url = os.getenv("MEMOS_ONLINE_URL")
+ self.headers = {"Content-Type": "application/json", "Authorization": os.getenv("MEMOS_KEY")}
+
+ def add(self, messages, user_id, conv_id=None, batch_size: int = 9999):
+ url = f"{self.memos_url}/add/message"
+ for i in range(0, len(messages), batch_size):
+ batch_messages = messages[i : i + batch_size]
+ payload = json.dumps(
+ {
+ "messages": batch_messages,
+ "user_id": user_id,
+ "conversation_id": conv_id,
+ }
+ )
+
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "ok", response.text
+ break
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+ def search(self, query, user_id, top_k):
+ """Search memories."""
+ url = f"{self.memos_url}/search/memory"
+ payload = json.dumps(
+ {
+ "query": query,
+ "user_id": user_id,
+ "memory_limit_number": top_k,
+ "mode": os.getenv("SEARCH_MODE", "fast"),
+ "include_preference": True,
+ "pref_top_k": 6,
+ }
+ )
+
+ max_retries = 5
+ for attempt in range(max_retries):
+ try:
+ response = requests.request("POST", url, data=payload, headers=self.headers)
+ assert response.status_code == 200, response.text
+ assert json.loads(response.text)["message"] == "ok", response.text
+ text_mem_res = json.loads(response.text)["data"]["memory_detail_list"]
+ pref_mem_res = json.loads(response.text)["data"]["preference_detail_list"]
+ preference_note = json.loads(response.text)["data"]["preference_note"]
+ for i in text_mem_res:
+ i.update({"memory": i.pop("memory_value")})
+ explicit_pref_string = "Explicit Preference:"
+ implicit_pref_string = "\n\nImplicit Preference:"
+ explicit_idx = 0
+ implicit_idx = 0
+ for pref in pref_mem_res:
+ if pref["preference_type"] == "explicit_preference":
+ explicit_pref_string += f"\n{explicit_idx + 1}. {pref['preference']}"
+ explicit_idx += 1
+ if pref["preference_type"] == "implicit_preference":
+ implicit_pref_string += f"\n{implicit_idx + 1}. {pref['preference']}"
+ implicit_idx += 1
+
+ return {
+ "text_mem": [{"memories": text_mem_res}],
+ "pref_string": explicit_pref_string + implicit_pref_string + preference_note,
+ }
+
+ except Exception as e:
+ if attempt < max_retries - 1:
+ time.sleep(2**attempt)
+ else:
+ raise e
+
+
class SupermemoryClient:
def __init__(self):
from supermemory import Supermemory
@@ -172,7 +291,7 @@ def add(self, messages, user_id):
break
except Exception as e:
if attempt < max_retries - 1:
- time.sleep(2**attempt) # 指数退避
+ time.sleep(2**attempt)
else:
raise e
@@ -192,7 +311,7 @@ def search(self, query, user_id, top_k):
return context
except Exception as e:
if attempt < max_retries - 1:
- time.sleep(2**attempt) # 指数退避
+ time.sleep(2**attempt)
else:
raise e
@@ -216,7 +335,7 @@ def add(self, messages, user_id, iso_date):
agent_name=self.agent_id,
session_date=iso_date,
)
- self.wait_for_completion(response.task_id)
+ self.wait_for_completion(response.item_id)
except Exception as error:
print("❌ Error saving conversation:", error)
@@ -245,3 +364,11 @@ def wait_for_completion(self, task_id):
timestamp = 1682899200
query = "杭州西湖有什么"
top_k = 5
+
+ # MEMOS-API
+ client = MemosApiClient()
+ for m in messages:
+ m["created_at"] = iso_date
+ client.add(messages, user_id, user_id)
+ memories = client.search(query, user_id, top_k)
+ print(memories)
diff --git a/evaluation/scripts/utils/mirix_utils.py b/evaluation/scripts/utils/mirix_utils.py
new file mode 100644
index 000000000..63cd490df
--- /dev/null
+++ b/evaluation/scripts/utils/mirix_utils.py
@@ -0,0 +1,84 @@
+import os
+
+import yaml
+
+from tqdm import tqdm
+
+
+def get_mirix_client(config_path, load_from=None):
+ if os.path.exists(os.path.expanduser("~/.mirix")):
+ os.system("rm -rf ~/.mirix/*")
+
+ with open(config_path) as f:
+ agent_config = yaml.safe_load(f)
+
+ os.environ["OPENAI_API_KEY"] = agent_config["api_key"]
+ import mirix
+
+ from mirix import EmbeddingConfig, LLMConfig, Mirix
+
+ embedding_default_config = EmbeddingConfig(
+ embedding_model=agent_config["embedding_model_name"],
+ embedding_endpoint_type="openai",
+ embedding_endpoint=agent_config["model_endpoint"],
+ embedding_dim=1536,
+ embedding_chunk_size=8191,
+ )
+
+ llm_default_config = LLMConfig(
+ model=agent_config["model_name"],
+ model_endpoint_type="openai",
+ model_endpoint=agent_config["model_endpoint"],
+ api_key=agent_config["api_key"],
+ model_wrapper=None,
+ context_window=128000,
+ )
+
+ def embedding_default_config_func(cls, model_name=None, provider=None):
+ return embedding_default_config
+
+ def llm_default_config_func(cls, model_name=None, provider=None):
+ return llm_default_config
+
+ mirix.EmbeddingConfig.default_config = embedding_default_config_func
+ mirix.LLMConfig.default_config = llm_default_config_func
+
+ assistant = Mirix(
+ api_key=agent_config["api_key"],
+ config_path=config_path,
+ model=agent_config["model_name"],
+ load_from=load_from,
+ )
+ return assistant
+
+
+if __name__ == "__main__":
+ config_path = "configs-example/mirix_config.yaml"
+ out_dir = "results/mirix-test"
+
+ assistant = get_mirix_client(config_path)
+
+ chunks = [
+ "I prefer coffee over tea",
+ "My work hours are 9 AM to 5 PM",
+ "Important meeting with client on Friday at 2 PM",
+ ]
+
+ for _idx, chunk in tqdm(enumerate(chunks), total=len(chunks)):
+ response = assistant.add(chunk)
+
+ assistant.save(out_dir)
+
+ assistant = get_mirix_client(config_path, load_from=out_dir)
+ response = assistant.chat("What's my schedule like this week?")
+
+ print(response)
+ assistant.create_user(user_name="user1")
+ assistant.create_user(user_name="user2")
+ user1 = assistant.get_user_by_name(user_name="user1")
+ user2 = assistant.get_user_by_name(user_name="user2")
+ assistant.add("i prefer tea over coffee", user_id=user1.id)
+ assistant.add("my favourite drink is coke", user_id=user2.id)
+ response1 = assistant.chat("What drink do I prefer?", user_id=user1.id)
+ response2 = assistant.chat("What drink do I prefer?", user_id=user2.id)
+ print(response1, response2)
diff --git a/evaluation/scripts/utils/prompts.py b/evaluation/scripts/utils/prompts.py
index bd418af54..32e6d6729 100644
--- a/evaluation/scripts/utils/prompts.py
+++ b/evaluation/scripts/utils/prompts.py
@@ -27,6 +27,7 @@
Answer:
"""
+
PM_ANSWER_PROMPT = """
You are a helpful assistant tasked with selecting the best answer to a user question, based solely on summarized conversation memories.
@@ -58,6 +59,13 @@
"""
+PREFEVAL_ANSWER_PROMPT = """
+ You are a helpful AI. Answer the question based on the query and the following memories:
+ User Memories:
+ {context}
+"""
+
+
ZEP_CONTEXT_TEMPLATE = """
FACTS and ENTITIES represent relevant context to the current conversation.
diff --git a/examples/mem_os/simple_prefs_memos_product.py b/examples/mem_os/simple_prefs_memos_product.py
new file mode 100644
index 000000000..40ec920f5
--- /dev/null
+++ b/examples/mem_os/simple_prefs_memos_product.py
@@ -0,0 +1,399 @@
+from memos.configs.mem_cube import GeneralMemCubeConfig
+from memos.configs.mem_os import MOSConfig
+from memos.mem_cube.general import GeneralMemCube
+from memos.mem_os.product import MOSProduct
+
+
+def get_config(user_id: str):
+ llm_config = {
+ "backend": "openai",
+ "config": {
+ "model_name_or_path": "gpt-4o-mini",
+ "api_key": "sk-xxxxx",
+ "api_base": "http://xxxx/v1",
+ "temperature": 0.1,
+ "remove_think_prefix": True,
+ "max_tokens": 4096,
+ },
+ }
+
+ embedder_config = {
+ "backend": "ollama",
+ "config": {"model_name_or_path": "nomic-embed-text:latest"},
+ }
+
+ # init MOS
+ mos_config = {
+ "user_id": user_id,
+ "chat_model": llm_config,
+ "mem_reader": {
+ "backend": "simple_struct",
+ "config": {
+ "llm": llm_config,
+ "embedder": embedder_config,
+ "chunker": {
+ "backend": "sentence",
+ "config": {
+ "tokenizer_or_token_counter": "gpt2",
+ "chunk_size": 512,
+ "chunk_overlap": 128,
+ "min_sentences_per_chunk": 1,
+ },
+ },
+ },
+ },
+ "max_turns_window": 20,
+ "top_k": 5,
+ "enable_textual_memory": True,
+ "enable_activation_memory": False,
+ "enable_parametric_memory": False,
+ "enable_preference_memory": True,
+ }
+
+ cube_config = {
+ "model_schema": "memos.configs.mem_cube.GeneralMemCubeConfig",
+ "user_id": user_id,
+ "cube_id": f"{user_id}/mem_cube",
+ "text_mem": {
+ "backend": "tree_text",
+ "config": {
+ "cube_id": f"{user_id}/mem_cube",
+ "extractor_llm": llm_config,
+ "dispatcher_llm": llm_config,
+ "graph_db": {
+ "backend": "neo4j",
+ "config": {
+ "uri": "bolt://localhost:7687",
+ "user": "neo4j",
+ "password": "12345678",
+ "db_name": "neo4j",
+ "user_name": "memosneo4j",
+ "embedding_dimension": 768,
+ "use_multi_db": False,
+ "auto_create": False,
+ },
+ },
+ "embedder": embedder_config,
+ },
+ },
+ "act_mem": {"backend": "uninitialized", "config": {}},
+ "para_mem": {"backend": "uninitialized", "config": {}},
+ "pref_mem": {
+ "backend": "pref_text",
+ "config": {
+ "cube_id": f"{user_id}/mem_cube",
+ "extractor_llm": llm_config,
+ "vector_db": {
+ "backend": "milvus",
+ "config": {
+ "collection_name": [
+ "explicit_preference",
+ "implicit_preference",
+ ],
+ "vector_dimension": 768,
+ "distance_metric": "cosine",
+ "uri": "./milvus_demo.db",
+ },
+ },
+ "embedder": embedder_config,
+ "extractor": {"backend": "naive", "config": {}},
+ "adder": {"backend": "naive", "config": {}},
+ "retriever": {"backend": "naive", "config": {}},
+ },
+ },
+ }
+ mos_config = MOSConfig(**mos_config)
+ cube_config = GeneralMemCubeConfig.model_validate(cube_config)
+
+ return mos_config, cube_config
+
+
+user_id = "superman"
+mos_config, mem_cube_config = get_config(user_id)
+
+memory = MOSProduct(default_config=mos_config)
+
+# register user and mem cube
+mem_cube = GeneralMemCube(mem_cube_config)
+
+register_result = memory.user_register(
+ user_id=user_id, user_name=user_id, default_mem_cube=mem_cube
+)
+print(f"register_result: {register_result}")
+
+# add memory for user
+memory.add(
+ messages=[
+ # Sports and hobbies
+ {"role": "user", "content": "I like playing football."},
+ {
+ "role": "assistant",
+ "content": "I like playing football too. It's a great way to stay active and work as a team.",
+ },
+ {"role": "user", "content": "Do you enjoy watching basketball games?"},
+ {
+ "role": "assistant",
+ "content": "Yes, I find basketball exciting to watch, especially the fast-paced action and strategic plays.",
+ },
+ {"role": "user", "content": "I'm learning to play tennis this summer."},
+ {
+ "role": "assistant",
+ "content": "That's wonderful! Tennis is a fantastic sport that improves both physical fitness and mental focus.",
+ },
+ # Food and cooking
+ {"role": "user", "content": "What's your favorite type of cuisine?"},
+ {
+ "role": "assistant",
+ "content": "I really enjoy Italian cuisine, especially pasta dishes and authentic pizza.",
+ },
+ {"role": "user", "content": "I love cooking Asian food at home."},
+ {
+ "role": "assistant",
+ "content": "Asian cooking is amazing! The balance of flavors and techniques is so interesting to learn.",
+ },
+ {"role": "user", "content": "Have you ever tried making homemade bread?"},
+ {
+ "role": "assistant",
+ "content": "Yes, there's something magical about the process of making bread from scratch. The smell is incredible!",
+ },
+ # Travel and places
+ {"role": "user", "content": "I'm planning a trip to Japan next year."},
+ {
+ "role": "assistant",
+ "content": "Japan is an incredible destination! The culture, food, and technology blend is fascinating.",
+ },
+ {"role": "user", "content": "What's the most beautiful place you've ever seen?"},
+ {
+ "role": "assistant",
+ "content": "I find mountain landscapes particularly breathtaking, especially during sunrise or sunset.",
+ },
+ {"role": "user", "content": "I prefer beach vacations over city trips."},
+ {
+ "role": "assistant",
+ "content": "Beach vacations are so relaxing! The sound of waves and warm sand is perfect for unwinding.",
+ },
+ # Technology and innovation
+ {"role": "user", "content": "What do you think about artificial intelligence?"},
+ {
+ "role": "assistant",
+ "content": "AI is transforming many aspects of our lives. It's exciting to see how it can help solve complex problems.",
+ },
+ {"role": "user", "content": "I'm learning to code in Python."},
+ {
+ "role": "assistant",
+ "content": "Python is a great language to start with! It's versatile and has a wonderful community.",
+ },
+ {"role": "user", "content": "Do you use any productivity apps?"},
+ {
+ "role": "assistant",
+ "content": "I find task management apps really helpful for organizing daily activities and staying focused.",
+ },
+ # Music and entertainment
+ {"role": "user", "content": "What kind of music do you enjoy?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate many genres, but I particularly enjoy jazz and classical music for their complexity.",
+ },
+ {"role": "user", "content": "I play the guitar in my free time."},
+ {
+ "role": "assistant",
+ "content": "That's fantastic! Playing an instrument is such a rewarding creative outlet.",
+ },
+ {"role": "user", "content": "Have you seen any good movies lately?"},
+ {
+ "role": "assistant",
+ "content": "I enjoy films that make you think deeply about human nature and society.",
+ },
+ # Books and learning
+ {"role": "user", "content": "Do you read books regularly?"},
+ {
+ "role": "assistant",
+ "content": "Yes, reading is one of my favorite ways to learn and explore new ideas.",
+ },
+ {"role": "user", "content": "I'm currently reading a science fiction novel."},
+ {
+ "role": "assistant",
+ "content": "Science fiction is great for exploring possibilities and imagining different futures.",
+ },
+ {"role": "user", "content": "What's your favorite subject to learn about?"},
+ {
+ "role": "assistant",
+ "content": "I'm fascinated by psychology and how the human mind works.",
+ },
+ # Nature and environment
+ {"role": "user", "content": "I love hiking in the mountains."},
+ {
+ "role": "assistant",
+ "content": "Hiking is wonderful! It's a great way to connect with nature and get exercise.",
+ },
+ {"role": "user", "content": "Are you concerned about climate change?"},
+ {
+ "role": "assistant",
+ "content": "Yes, it's one of the most important challenges of our time that requires collective action.",
+ },
+ {"role": "user", "content": "I try to recycle and reduce waste at home."},
+ {
+ "role": "assistant",
+ "content": "That's commendable! Every small action contributes to environmental protection.",
+ },
+ # Work and career
+ {"role": "user", "content": "What do you do for work?"},
+ {
+ "role": "assistant",
+ "content": "I work in technology, helping people solve problems and improve their daily lives.",
+ },
+ {"role": "user", "content": "I'm considering a career change."},
+ {
+ "role": "assistant",
+ "content": "Career changes can be challenging but also very rewarding when you find the right fit.",
+ },
+ {"role": "user", "content": "Do you work from home or in an office?"},
+ {
+ "role": "assistant",
+ "content": "I work remotely, which gives me flexibility in how I organize my day.",
+ },
+ # Health and wellness
+ {"role": "user", "content": "I've started doing yoga in the morning."},
+ {
+ "role": "assistant",
+ "content": "Yoga is excellent for both physical and mental well-being. Great way to start the day!",
+ },
+ {"role": "user", "content": "How do you manage stress?"},
+ {
+ "role": "assistant",
+ "content": "I find meditation and regular exercise help me stay balanced and focused.",
+ },
+ {"role": "user", "content": "I'm trying to eat more vegetables."},
+ {
+ "role": "assistant",
+ "content": "That's a great health goal! Vegetables provide so many essential nutrients.",
+ },
+ # Art and creativity
+ {"role": "user", "content": "Do you enjoy painting or drawing?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate visual arts, though I'm more of an observer than a creator.",
+ },
+ {"role": "user", "content": "I'm learning photography."},
+ {
+ "role": "assistant",
+ "content": "Photography is a beautiful way to capture moments and express your perspective.",
+ },
+ {"role": "user", "content": "What's your favorite type of art?"},
+ {
+ "role": "assistant",
+ "content": "I'm drawn to abstract art because it allows for personal interpretation.",
+ },
+ # Family and relationships
+ {"role": "user", "content": "I have two siblings."},
+ {
+ "role": "assistant",
+ "content": "Having siblings can be wonderful - they're often our first friends and lifelong companions.",
+ },
+ {"role": "user", "content": "Do you have any pets?"},
+ {
+ "role": "assistant",
+ "content": "I don't have pets, but I think they bring so much joy and companionship to people's lives.",
+ },
+ {"role": "user", "content": "I'm planning to visit my grandparents this weekend."},
+ {
+ "role": "assistant",
+ "content": "That's lovely! Grandparents often have such interesting stories and wisdom to share.",
+ },
+ # Education and growth
+ {"role": "user", "content": "I'm taking an online course in data science."},
+ {
+ "role": "assistant",
+ "content": "Data science is a fascinating field with many applications across different industries.",
+ },
+ {"role": "user", "content": "What's the best way to learn a new language?"},
+ {
+ "role": "assistant",
+ "content": "Immersion and consistent practice are key, along with finding methods that work for your learning style.",
+ },
+ {"role": "user", "content": "I enjoy attending workshops and conferences."},
+ {
+ "role": "assistant",
+ "content": "Workshops are great for hands-on learning and networking with like-minded people.",
+ },
+ # Hobbies and interests
+ {"role": "user", "content": "I collect vintage postcards."},
+ {
+ "role": "assistant",
+ "content": "What a unique hobby! Postcards offer glimpses into different times and places.",
+ },
+ {"role": "user", "content": "Do you garden?"},
+ {
+ "role": "assistant",
+ "content": "I appreciate gardening, though I'm more of a plant observer than a gardener myself.",
+ },
+ {"role": "user", "content": "I love solving puzzles and brain teasers."},
+ {
+ "role": "assistant",
+ "content": "Puzzles are excellent for keeping the mind sharp and developing problem-solving skills.",
+ },
+ # Future and goals
+ {"role": "user", "content": "What are your goals for next year?"},
+ {
+ "role": "assistant",
+ "content": "I aim to continue learning and growing, helping more people with their challenges.",
+ },
+ {"role": "user", "content": "I want to start my own business someday."},
+ {
+ "role": "assistant",
+ "content": "Entrepreneurship is exciting! It requires courage, planning, and persistence.",
+ },
+ {"role": "user", "content": "Do you believe in setting New Year's resolutions?"},
+ {
+ "role": "assistant",
+ "content": "I think any time is good for setting positive goals and making positive changes.",
+ },
+ # Philosophy and life
+ {"role": "user", "content": "What's the meaning of life to you?"},
+ {
+ "role": "assistant",
+ "content": "I believe it's about learning, growing, and making positive connections with others.",
+ },
+ {"role": "user", "content": "I try to practice gratitude daily."},
+ {
+ "role": "assistant",
+ "content": "Gratitude is such a powerful practice that can transform your perspective on life.",
+ },
+ {"role": "user", "content": "What's your biggest fear?"},
+ {
+ "role": "assistant",
+ "content": "I think fear of not being able to help when someone really needs it would be challenging.",
+ },
+ # Technology and daily life
+ {"role": "user", "content": "How has technology changed your daily routine?"},
+ {
+ "role": "assistant",
+ "content": "Technology has made many tasks more efficient and connected me with people worldwide.",
+ },
+ {"role": "user", "content": "I'm trying to reduce my screen time."},
+ {
+ "role": "assistant",
+ "content": "That's a healthy goal! Finding balance with technology is important for well-being.",
+ },
+ {"role": "user", "content": "Do you use social media?"},
+ {
+ "role": "assistant",
+ "content": "I think social media can be a great tool for connection when used mindfully.",
+ },
+ # Final thoughts
+ {"role": "user", "content": "This has been a great conversation!"},
+ {
+ "role": "assistant",
+ "content": "I've really enjoyed our chat too! It's wonderful to explore so many different topics together.",
+ },
+ ],
+ user_id=user_id,
+ mem_cube_id=register_result["default_cube_id"],
+)
+
+retrieved_memories = memory.search(query="What do you like?", user_id=user_id)
+print(
+ f"len_pref_memories: {len(retrieved_memories['pref_mem'][0]['memories'])}"
+ if retrieved_memories["pref_mem"]
+ else 0
+)
diff --git a/examples/mem_reader/reader.py b/examples/mem_reader/reader.py
index e26d00a67..3da5d5e76 100644
--- a/examples/mem_reader/reader.py
+++ b/examples/mem_reader/reader.py
@@ -2,6 +2,11 @@
from memos.configs.mem_reader import SimpleStructMemReaderConfig
from memos.mem_reader.simple_struct import SimpleStructMemReader
+from memos.memories.textual.item import (
+ SourceMessage,
+ TextualMemoryItem,
+ TreeNodeTextualMemoryMetadata,
+)
def main():
@@ -11,7 +16,7 @@ def main():
)
reader = SimpleStructMemReader(reader_config)
- # 3. Define scene data
+ # 2. Define scene data
scene_data = [
[
{"role": "user", "chat_time": "3 May 2025", "content": "I'm feeling a bit down today."},
@@ -187,32 +192,389 @@ def main():
],
]
- # 4. Acquiring memories
+ print("=== Mem-Reader Fast vs Fine Mode Comparison ===\n")
+
+ # 3. Test Fine Mode (default)
+ print("🔄 Testing FINE mode (default, with LLM processing)...")
+ start_time = time.time()
+ fine_memory = reader.get_memory(
+ scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}, mode="fine"
+ )
+ fine_time = time.time() - start_time
+ print(f"✅ Fine mode completed in {fine_time:.2f} seconds")
+ print(f"📊 Fine mode generated {sum(len(mem_list) for mem_list in fine_memory)} memory items")
+
+ # 4. Test Fast Mode
+ print("\n⚡ Testing FAST mode (quick processing, no LLM calls)...")
start_time = time.time()
- chat_memory = reader.get_memory(
- scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}
+ fast_memory = reader.get_memory(
+ scene_data, type="chat", info={"user_id": "user1", "session_id": "session1"}, mode="fast"
)
- print("\nChat Memory:\n", chat_memory)
+ fast_time = time.time() - start_time
+ print(f"✅ Fast mode completed in {fast_time:.2f} seconds")
+ print(f"📊 Fast mode generated {sum(len(mem_list) for mem_list in fast_memory)} memory items")
+
+ # 5. Performance Comparison
+ print("\n📈 Performance Comparison:")
+ print(f" Fine mode: {fine_time:.2f}s")
+ print(f" Fast mode: {fast_time:.2f}s")
+ print(f" Speed improvement: {fine_time / fast_time:.1f}x faster")
+
+ # 6. Show sample results from both modes
+ print("\n🔍 Sample Results Comparison:")
+ print("\n--- FINE Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fine_memory[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
- # 5. Example of processing documents
- print("\n=== Processing Documents ===")
+ print("\n--- FAST Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fast_memory[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
+
+ # 7. Example of transfer fast mode result into fine result
+ fast_mode_memories = [
+ TextualMemoryItem(
+ id="4553141b-3a33-4548-b779-e677ec797a9f",
+ memory="user: Nate:Oh cool! I might check that one out some time soon! I do love watching classics.\nassistant: Joanna:Yep, that movie is awesome. I first watched it around 3 years ago. I even went out and got a physical copy!\nuser: Nate:Sounds cool! Have you seen it a lot? sounds like you know the movie well!\nassistant: Joanna:A few times. It's one of my favorites! I really like the idea and the acting.\nuser: Nate:Cool! I'll definitely check it out. Thanks for the recommendation!\nassistant: Joanna:No problem, Nate! Let me know if you like it!\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:Oh cool",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.094877+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.094919+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ TextualMemoryItem(
+ id="752e42fa-92b6-491a-a430-6864a7730fba",
+ memory="user: Nate:It was! How about you? Do you have any hobbies you love?\nassistant: Joanna:Yeah! Besides writing, I also enjoy reading, watching movies, and exploring nature. Anything else you enjoy doing, Nate?\nuser: Nate:Playing video games and watching movies are my main hobbies.\nassistant: Joanna:Cool, Nate! So we both have similar interests. What type of movies do you like best?\nuser: Nate:I love action and sci-fi movies, the effects are so cool! What about you, what's your favorite genre?\nassistant: Joanna:I'm all about dramas and romcoms. I love getting immersed in the feelings and plots.\nuser: Nate:Wow, movies can be so powerful! Do you have any recommendations for me?\nassistant: Joanna:Yeah, totally! Have you seen this romantic drama that's all about memory and relationships? It's such a good one.\nuser: Nate:Oh cool! I might check that one out some time soon! I do love watching classics.\nassistant: Joanna:Yep, that movie is awesome. I first watched it around 3 years ago. I even went out and got a physical copy!\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:It was",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.095726+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=6,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=7,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=8,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=9,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.095767+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ TextualMemoryItem(
+ id="c9cf448c-deee-43a8-bafd-eb15fde535b2",
+ memory="user: Nate:Hey Joanna! Long time no see! What's up? Anything fun going on?\nassistant: Joanna:Hey Nate! Long time no see! I've been working on a project lately - it's been pretty cool. What about you - any fun projects or hobbies?\nuser: Nate:Hey Joanna! That's cool! I won my first video game tournament last week - so exciting!\nassistant: Joanna:Wow Nate! Congrats on winning! Tell me more - what game was it?\nuser: Nate:Thanks! it's a team shooter game.\nassistant: Joanna:Wow, great job! What was is called?\nuser: Nate:The game was called Counter-Strike: Global Offensive, and me and my team had a blast to the very end!\nassistant: Joanna:Cool, Nate! Sounds like a fun experience, even if I'm not into games.\nuser: Nate:It was! How about you? Do you have any hobbies you love?\nassistant: Joanna:Yeah! Besides writing, I also enjoy reading, watching movies, and exploring nature. Anything else you enjoy doing, Nate?\n",
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id="nate_test",
+ session_id="root_session",
+ status="activated",
+ type="fact",
+ key="user: Nate:Hey Joanna",
+ confidence=0.9900000095367432,
+ source=None,
+ tags=["mode:fast", "lang:en", "role:assistant", "role:user"],
+ visibility=None,
+ updated_at="2025-10-16T17:16:30.098208+08:00",
+ memory_type="LongTermMemory",
+ sources=[
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=0,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=1,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=2,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=3,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=4,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=5,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=6,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=7,
+ ),
+ SourceMessage(
+ type="chat",
+ role="user",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=8,
+ ),
+ SourceMessage(
+ type="chat",
+ role="assistant",
+ chat_time="7:31 pm on 21 January, 2022",
+ message_id=None,
+ content=None,
+ doc_path=None,
+ index=9,
+ ),
+ ],
+ embedding=None,
+ created_at="2025-10-16T17:16:30.098246+08:00",
+ usage=[],
+ background="",
+ ),
+ ),
+ ]
+ fine_memories = reader.fine_transfer_simple_mem(fast_mode_memories, type="chat")
+ print("\n--- Transfer Mode Results (first 3 items) ---")
+ for i, mem_list in enumerate(fine_memories[:3]):
+ for j, mem_item in enumerate(mem_list[:2]): # Show first 2 items from each list
+ print(f" [{i}][{j}] {mem_item.memory[:100]}...")
+
+ # 7. Example of processing documents (only in fine mode)
+ print("\n=== Processing Documents (Fine Mode Only) ===")
# Example document paths (you should replace these with actual document paths)
doc_paths = [
"examples/mem_reader/text1.txt",
"examples/mem_reader/text2.txt",
]
- # 6. Acquiring memories from documents
- doc_memory = reader.get_memory(
- doc_paths,
- "doc",
- info={
- "user_id": "1111",
- "session_id": "2222",
- },
- )
- print("\nDocument Memory:\n", doc_memory)
- end_time = time.time()
- print(f"The runtime is {end_time - start_time} seconds.")
+
+ try:
+ # 6. Acquiring memories from documents
+ doc_memory = reader.get_memory(
+ doc_paths,
+ "doc",
+ info={
+ "user_id": "1111",
+ "session_id": "2222",
+ },
+ mode="fine",
+ )
+ print(
+ f"\n📄 Document Memory generated {sum(len(mem_list) for mem_list in doc_memory)} items"
+ )
+ except Exception as e:
+ print(f"⚠️ Document processing failed: {e}")
+ print(" (This is expected if document files don't exist)")
+
+ print("\n🎯 Summary:")
+ print(f" • Fast mode: {fast_time:.2f}s - Quick processing, no LLM calls")
+ print(f" • Fine mode: {fine_time:.2f}s - Full LLM processing for better understanding")
+ print(" • Use fast mode for: Real-time applications, high-throughput scenarios")
+ print(" • Use fine mode for: Quality analysis, detailed memory extraction")
if __name__ == "__main__":
diff --git a/examples/mem_scheduler/orm_examples.py b/examples/mem_scheduler/orm_examples.py
new file mode 100644
index 000000000..bbb57b4ab
--- /dev/null
+++ b/examples/mem_scheduler/orm_examples.py
@@ -0,0 +1,374 @@
+#!/usr/bin/env python3
+"""
+ORM Examples for MemScheduler
+
+This script demonstrates how to use the BaseDBManager's new environment variable loading methods
+for MySQL and Redis connections.
+"""
+
+import multiprocessing
+import os
+import sys
+
+from pathlib import Path
+
+
+# Add the src directory to the Python path
+sys.path.insert(0, str(Path(__file__).parent.parent.parent / "src"))
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager, DatabaseError
+from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager, SimpleListManager
+
+
+logger = get_logger(__name__)
+
+
+def test_mysql_engine_from_env():
+ """Test loading MySQL engine from environment variables"""
+ print("\n" + "=" * 60)
+ print("Testing MySQL Engine from Environment Variables")
+ print("=" * 60)
+
+ try:
+ # Test loading MySQL engine from current environment variables
+ mysql_engine = BaseDBManager.load_mysql_engine_from_env()
+ if mysql_engine is None:
+ print("❌ Failed to create MySQL engine - check environment variables")
+ return
+
+ print(f"✅ Successfully created MySQL engine: {mysql_engine}")
+ print(f" Engine URL: {mysql_engine.url}")
+
+ # Test connection
+ with mysql_engine.connect() as conn:
+ from sqlalchemy import text
+
+ result = conn.execute(text("SELECT 'MySQL connection test successful' as message"))
+ message = result.fetchone()[0]
+ print(f" Connection test: {message}")
+
+ mysql_engine.dispose()
+ print(" MySQL engine disposed successfully")
+
+ except DatabaseError as e:
+ print(f"❌ DatabaseError: {e}")
+ except Exception as e:
+ print(f"❌ Unexpected error: {e}")
+
+
+def test_redis_connection_from_env():
+ """Test loading Redis connection from environment variables"""
+ print("\n" + "=" * 60)
+ print("Testing Redis Connection from Environment Variables")
+ print("=" * 60)
+
+ try:
+ # Test loading Redis connection from current environment variables
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection - check environment variables")
+ return
+
+ print(f"✅ Successfully created Redis connection: {redis_client}")
+
+ # Test basic Redis operations
+ redis_client.set("test_key", "Hello from ORM Examples!")
+ value = redis_client.get("test_key")
+ print(f" Redis test - Set/Get: {value}")
+
+ # Test Redis info
+ info = redis_client.info("server")
+ redis_version = info.get("redis_version", "unknown")
+ print(f" Redis server version: {redis_version}")
+
+ # Clean up test key
+ redis_client.delete("test_key")
+ print(" Test key cleaned up")
+
+ redis_client.close()
+ print(" Redis connection closed successfully")
+
+ except DatabaseError as e:
+ print(f"❌ DatabaseError: {e}")
+ except Exception as e:
+ print(f"❌ Unexpected error: {e}")
+
+
+def test_environment_variables():
+ """Test and display current environment variables"""
+ print("\n" + "=" * 60)
+ print("Current Environment Variables")
+ print("=" * 60)
+
+ # MySQL environment variables
+ mysql_vars = [
+ "MYSQL_HOST",
+ "MYSQL_PORT",
+ "MYSQL_USERNAME",
+ "MYSQL_PASSWORD",
+ "MYSQL_DATABASE",
+ "MYSQL_CHARSET",
+ ]
+
+ print("\nMySQL Environment Variables:")
+ for var in mysql_vars:
+ value = os.getenv(var, "Not set")
+ # Mask password for security
+ if "PASSWORD" in var and value != "Not set":
+ value = "*" * len(value)
+ print(f" {var}: {value}")
+
+ # Redis environment variables
+ redis_vars = [
+ "REDIS_HOST",
+ "REDIS_PORT",
+ "REDIS_DB",
+ "REDIS_PASSWORD",
+ "MEMSCHEDULER_REDIS_HOST",
+ "MEMSCHEDULER_REDIS_PORT",
+ "MEMSCHEDULER_REDIS_DB",
+ "MEMSCHEDULER_REDIS_PASSWORD",
+ ]
+
+ print("\nRedis Environment Variables:")
+ for var in redis_vars:
+ value = os.getenv(var, "Not set")
+ # Mask password for security
+ if "PASSWORD" in var and value != "Not set":
+ value = "*" * len(value)
+ print(f" {var}: {value}")
+
+
+def test_manual_env_loading():
+ """Test loading environment variables manually from .env file"""
+ print("\n" + "=" * 60)
+ print("Testing Manual Environment Loading")
+ print("=" * 60)
+
+ env_file_path = "/Users/travistang/Documents/codes/memos/.env"
+
+ if not os.path.exists(env_file_path):
+ print(f"❌ Environment file not found: {env_file_path}")
+ return
+
+ try:
+ from dotenv import load_dotenv
+
+ # Load environment variables
+ load_dotenv(env_file_path)
+ print(f"✅ Successfully loaded environment variables from {env_file_path}")
+
+ # Test some key variables
+ test_vars = ["OPENAI_API_KEY", "MOS_CHAT_MODEL", "TZ"]
+ for var in test_vars:
+ value = os.getenv(var, "Not set")
+ if "KEY" in var and value != "Not set":
+ value = f"{value[:10]}..." if len(value) > 10 else value
+ print(f" {var}: {value}")
+
+ except ImportError:
+ print("❌ python-dotenv not installed. Install with: pip install python-dotenv")
+ except Exception as e:
+ print(f"❌ Error loading environment file: {e}")
+
+
+def test_redis_lockable_orm_with_list():
+ """Test RedisDBManager with list[str] type synchronization"""
+ print("\n" + "=" * 60)
+ print("Testing RedisDBManager with list[str]")
+ print("=" * 60)
+
+ try:
+ from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager
+
+ # Create a simple list manager instance
+ list_manager = SimpleListManager(["apple", "banana", "cherry"])
+ print(f"Original list manager: {list_manager}")
+
+ # Create RedisDBManager instance
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection - check environment variables")
+ return
+
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="test_list_cube",
+ obj=list_manager,
+ )
+
+ # Save to Redis
+ db_manager.save_to_db(list_manager)
+ print("✅ List manager saved to Redis")
+
+ # Load from Redis
+ loaded_manager = db_manager.load_from_db()
+ if loaded_manager:
+ print(f"Loaded list manager: {loaded_manager}")
+ print(f"Items match: {list_manager.items == loaded_manager.items}")
+ else:
+ print("❌ Failed to load list manager from Redis")
+
+ # Clean up
+ redis_client.delete("lockable_orm:test_user:test_list_cube:data")
+ redis_client.delete("lockable_orm:test_user:test_list_cube:lock")
+ redis_client.delete("lockable_orm:test_user:test_list_cube:version")
+ redis_client.close()
+
+ except Exception as e:
+ print(f"❌ Error in RedisDBManager test: {e}")
+
+
+def modify_list_process(process_id: int, items_to_add: list[str]):
+ """Function to be run in separate processes to modify the list using merge_items"""
+ try:
+ from memos.mem_scheduler.orm_modules.redis_model import RedisDBManager
+
+ # Create Redis connection
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print(f"Process {process_id}: Failed to create Redis connection")
+ return
+
+ # Create a temporary list manager for this process with items to add
+ temp_manager = SimpleListManager()
+
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=temp_manager,
+ )
+
+ print(f"Process {process_id}: Starting modification with items: {items_to_add}")
+ for item in items_to_add:
+ db_manager.obj.add_item(item)
+ # Use sync_with_orm which internally uses merge_items
+ db_manager.sync_with_orm(size_limit=None)
+
+ print(f"Process {process_id}: Successfully synchronized with Redis")
+
+ redis_client.close()
+
+ except Exception as e:
+ print(f"Process {process_id}: Error - {e}")
+ import traceback
+
+ traceback.print_exc()
+
+
+def test_multiprocess_synchronization():
+ """Test multiprocess synchronization with RedisDBManager"""
+ print("\n" + "=" * 60)
+ print("Testing Multiprocess Synchronization")
+ print("=" * 60)
+
+ try:
+ # Initialize Redis with empty list
+ redis_client = BaseDBManager.load_redis_engine_from_env()
+ if redis_client is None:
+ print("❌ Failed to create Redis connection")
+ return
+
+ # Initialize with empty list
+ initial_manager = SimpleListManager([])
+ db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=initial_manager,
+ )
+ db_manager.save_to_db(initial_manager)
+ print("✅ Initialized empty list manager in Redis")
+
+ # Define items for each process to add
+ process_items = [
+ ["item1", "item2"],
+ ["item3", "item4"],
+ ["item5", "item6"],
+ ["item1", "item7"], # item1 is duplicate, should not be added twice
+ ]
+
+ # Create and start processes
+ processes = []
+ for i, items in enumerate(process_items):
+ p = multiprocessing.Process(target=modify_list_process, args=(i + 1, items))
+ processes.append(p)
+ p.start()
+
+ # Wait for all processes to complete
+ for p in processes:
+ p.join()
+
+ print("\n" + "-" * 40)
+ print("All processes completed. Checking final result...")
+
+ # Load final result
+ final_db_manager = RedisDBManager(
+ redis_client=redis_client,
+ user_id="test_user",
+ mem_cube_id="multiprocess_list",
+ obj=SimpleListManager([]),
+ )
+ final_manager = final_db_manager.load_from_db()
+
+ if final_manager:
+ print(f"Final synchronized list manager: {final_manager}")
+ print(f"Final list length: {len(final_manager)}")
+ print("Expected items: {'item1', 'item2', 'item3', 'item4', 'item5', 'item6', 'item7'}")
+ print(f"Actual items: {set(final_manager.items)}")
+
+ # Check if all unique items are present
+ expected_items = {"item1", "item2", "item3", "item4", "item5", "item6", "item7"}
+ actual_items = set(final_manager.items)
+
+ if expected_items == actual_items:
+ print("✅ All processes contributed correctly - synchronization successful!")
+ else:
+ print(f"❌ Expected items: {expected_items}")
+ print(f" Actual items: {actual_items}")
+ else:
+ print("❌ Failed to load final result")
+
+ # Clean up
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:data")
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:lock")
+ redis_client.delete("lockable_orm:test_user:multiprocess_list:version")
+ redis_client.close()
+
+ except Exception as e:
+ print(f"❌ Error in multiprocess synchronization test: {e}")
+
+
+def main():
+ """Main function to run all tests"""
+ print("ORM Examples - Environment Variable Loading Tests")
+ print("=" * 80)
+
+ # Test environment variables display
+ test_environment_variables()
+
+ # Test manual environment loading
+ test_manual_env_loading()
+
+ # Test MySQL engine loading
+ test_mysql_engine_from_env()
+
+ # Test Redis connection loading
+ test_redis_connection_from_env()
+
+ # Test RedisLockableORM with list[str]
+ test_redis_lockable_orm_with_list()
+
+ # Test multiprocess synchronization
+ test_multiprocess_synchronization()
+
+ print("\n" + "=" * 80)
+ print("All tests completed!")
+ print("=" * 80)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/poetry.lock b/poetry.lock
index d34f964b6..926d580fb 100644
--- a/poetry.lock
+++ b/poetry.lock
@@ -1,4 +1,4 @@
-# This file is automatically @generated by Poetry 2.1.4 and should not be changed by hand.
+# This file is automatically @generated by Poetry 2.1.3 and should not be changed by hand.
[[package]]
name = "absl-py"
@@ -192,6 +192,19 @@ torch = ">=1.0.0"
tqdm = ">=4.31.1"
transformers = ">=3.0.0"
+[[package]]
+name = "cachetools"
+version = "6.2.1"
+description = "Extensible memoizing collections and decorators"
+optional = true
+python-versions = ">=3.9"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "cachetools-6.2.1-py3-none-any.whl", hash = "sha256:09868944b6dde876dfd44e1d47e18484541eaf12f26f29b7af91b26cc892d701"},
+ {file = "cachetools-6.2.1.tar.gz", hash = "sha256:3f391e4bd8f8bf0931169baf7456cc822705f4e2a31f840d218f445b9a854201"},
+]
+
[[package]]
name = "certifi"
version = "2025.7.14"
@@ -690,6 +703,30 @@ toml = ["tomli (>=2.0.0) ; python_version < \"3.11\""]
trio = ["trio (>=0.10.0)"]
yaml = ["pyyaml (>=6.0.1)"]
+[[package]]
+name = "datasketch"
+version = "1.6.5"
+description = "Probabilistic data structures for processing and searching very large datasets"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"pref-mem\" or extra == \"all\""
+files = [
+ {file = "datasketch-1.6.5-py3-none-any.whl", hash = "sha256:59311b2925b2f37536e9f7c2f46bbc25e8e54379c8635a3fa7ca55d2abb66d1b"},
+ {file = "datasketch-1.6.5.tar.gz", hash = "sha256:ba2848cb74f23d6d3dd444cf24edcbc47b1c34a171b1803231793ed4d74d4fcf"},
+]
+
+[package.dependencies]
+numpy = ">=1.11"
+scipy = ">=1.0.0"
+
+[package.extras]
+benchmark = ["SetSimilaritySearch (>=0.1.7)", "matplotlib (>=3.1.2)", "nltk (>=3.4.5)", "pandas (>=0.25.3)", "pyfarmhash (>=0.2.2)", "pyhash (>=0.9.3)", "scikit-learn (>=0.21.3)", "scipy (>=1.3.3)"]
+cassandra = ["cassandra-driver (>=3.20)"]
+experimental-aio = ["aiounittest ; python_version >= \"3.6\"", "motor ; python_version >= \"3.6\""]
+redis = ["redis (>=2.10.0)"]
+test = ["cassandra-driver (>=3.20)", "coverage", "mock (>=2.0.0)", "mockredispy", "nose (>=1.3.7)", "nose-exclude (>=0.5.0)", "pymongo (>=3.9.0)", "pytest", "redis (>=2.10.0)"]
+
[[package]]
name = "defusedxml"
version = "0.7.1"
@@ -1222,7 +1259,7 @@ files = [
{file = "grpcio-1.73.1-cp39-cp39-win_amd64.whl", hash = "sha256:42f0660bce31b745eb9d23f094a332d31f210dcadd0fc8e5be7e4c62a87ce86b"},
{file = "grpcio-1.73.1.tar.gz", hash = "sha256:7fce2cd1c0c1116cf3850564ebfc3264fba75d3c74a7414373f1238ea365ef87"},
]
-markers = {main = "extra == \"all\""}
+markers = {main = "extra == \"pref-mem\" or extra == \"all\""}
[package.extras]
protobuf = ["grpcio-tools (>=1.73.1)"]
@@ -1529,6 +1566,18 @@ files = [
{file = "itsdangerous-2.2.0.tar.gz", hash = "sha256:e0050c0b7da1eea53ffaf149c0cfbb5c6e2e2b69c4bef22c81fa6eb73e5f6173"},
]
+[[package]]
+name = "jieba"
+version = "0.42"
+description = "Chinese Words Segmentation Utilities"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "jieba-0.42.tar.gz", hash = "sha256:34a3c960cc2943d9da16d6d2565110cf5f305921a67413dddf04f84de69c939b"},
+]
+
[[package]]
name = "jinja2"
version = "3.1.6"
@@ -3241,7 +3290,7 @@ files = [
{file = "pandas-2.3.1-cp39-cp39-win_amd64.whl", hash = "sha256:b4b0de34dc8499c2db34000ef8baad684cfa4cbd836ecee05f323ebfba348c7d"},
{file = "pandas-2.3.1.tar.gz", hash = "sha256:0a95b9ac964fe83ce317827f80304d37388ea77616b1425f0ae41c9d2d0d7bb2"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[package.dependencies]
numpy = [
@@ -3560,7 +3609,7 @@ files = [
{file = "protobuf-6.31.1-py3-none-any.whl", hash = "sha256:720a6c7e6b77288b85063569baae8536671b39f15cc22037ec7045658d80489e"},
{file = "protobuf-6.31.1.tar.gz", hash = "sha256:d8cac4c982f0b957a4dc73a80e2ea24fab08e679c0de9deb835f4a12d69aca9a"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[[package]]
name = "pycparser"
@@ -3773,6 +3822,33 @@ files = [
[package.extras]
windows-terminal = ["colorama (>=0.4.6)"]
+[[package]]
+name = "pymilvus"
+version = "2.6.2"
+description = "Python Sdk for Milvus"
+optional = true
+python-versions = ">=3.8"
+groups = ["main"]
+markers = "extra == \"pref-mem\" or extra == \"all\""
+files = [
+ {file = "pymilvus-2.6.2-py3-none-any.whl", hash = "sha256:933e447e09424d490dcf595053b01a7277dadea7ae3235cd704363bd6792509d"},
+ {file = "pymilvus-2.6.2.tar.gz", hash = "sha256:b4802cc954de8f2d47bf8d6230e92196514dcb8a3726ba6098dc27909d4bc8e3"},
+]
+
+[package.dependencies]
+grpcio = ">=1.66.2,<1.68.0 || >1.68.0,<1.68.1 || >1.68.1,<1.69.0 || >1.69.0,<1.70.0 || >1.70.0,<1.70.1 || >1.70.1,<1.71.0 || >1.71.0,<1.72.1 || >1.72.1,<1.73.0 || >1.73.0"
+pandas = ">=1.2.4"
+protobuf = ">=5.27.2"
+python-dotenv = ">=1.0.1,<2.0.0"
+setuptools = ">69"
+ujson = ">=2.0.0"
+
+[package.extras]
+bulk-writer = ["azure-storage-blob", "minio (>=7.0.0)", "pyarrow (>=12.0.0)", "requests", "urllib3"]
+dev = ["azure-storage-blob", "black", "grpcio (==1.66.2)", "grpcio-testing (==1.66.2)", "grpcio-tools (==1.66.2)", "minio (>=7.0.0)", "pyarrow (>=12.0.0)", "pytest (>=5.3.4)", "pytest-asyncio", "pytest-cov (>=5.0.0)", "pytest-timeout (>=1.3.4)", "requests", "ruff (>=0.12.9,<1)", "scipy", "urllib3"]
+milvus-lite = ["milvus-lite (>=2.4.0) ; sys_platform != \"win32\""]
+model = ["pymilvus.model (>=0.3.0)"]
+
[[package]]
name = "pymysql"
version = "1.1.2"
@@ -3946,7 +4022,7 @@ files = [
{file = "pytz-2025.2-py2.py3-none-any.whl", hash = "sha256:5ddf76296dd8c44c26eb8f4b6f35488f3ccbf6fbbd7adee0b7262d43f0ec2f00"},
{file = "pytz-2025.2.tar.gz", hash = "sha256:360b9e3dbb49a209c21ad61809c7fb453643e048b38924c765813546746e81c3"},
]
-markers = {main = "extra == \"tree-mem\" or extra == \"all\" or extra == \"mem-reader\""}
+markers = {main = "extra == \"tree-mem\" or extra == \"all\" or extra == \"mem-reader\" or extra == \"pref-mem\""}
[[package]]
name = "pywin32"
@@ -4072,6 +4148,25 @@ urllib3 = ">=1.26.14,<3"
fastembed = ["fastembed (>=0.7,<0.8)"]
fastembed-gpu = ["fastembed-gpu (>=0.7,<0.8)"]
+[[package]]
+name = "rank-bm25"
+version = "0.2.2"
+description = "Various BM25 algorithms for document ranking"
+optional = true
+python-versions = "*"
+groups = ["main"]
+markers = "extra == \"all\""
+files = [
+ {file = "rank_bm25-0.2.2-py3-none-any.whl", hash = "sha256:7bd4a95571adadfc271746fa146a4bcfd89c0cf731e49c3d1ad863290adbe8ae"},
+ {file = "rank_bm25-0.2.2.tar.gz", hash = "sha256:096ccef76f8188563419aaf384a02f0ea459503fdf77901378d4fd9d87e5e51d"},
+]
+
+[package.dependencies]
+numpy = "*"
+
+[package.extras]
+dev = ["pytest"]
+
[[package]]
name = "redis"
version = "6.2.0"
@@ -4955,7 +5050,7 @@ files = [
{file = "setuptools-80.9.0-py3-none-any.whl", hash = "sha256:062d34222ad13e0cc312a4c02d73f059e86a4acbfbdea8f8f76b28c99f306922"},
{file = "setuptools-80.9.0.tar.gz", hash = "sha256:f36b47402ecde768dbfafc46e8e4207b4360c654f1f3bb84475f0a28628fb19c"},
]
-markers = {main = "extra == \"all\" and platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\" and extra == \"all\"", eval = "platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\""}
+markers = {main = "platform_system == \"Linux\" and platform_machine == \"x86_64\" and (extra == \"all\" or extra == \"pref-mem\") or extra == \"pref-mem\" or extra == \"all\"", eval = "platform_system == \"Linux\" and platform_machine == \"x86_64\" or python_version >= \"3.12\""}
[package.extras]
check = ["pytest-checkdocs (>=2.4)", "pytest-ruff (>=0.2.1) ; sys_platform != \"cygwin\"", "ruff (>=0.8.0) ; sys_platform != \"cygwin\""]
@@ -5578,7 +5673,7 @@ files = [
{file = "tzdata-2025.2-py2.py3-none-any.whl", hash = "sha256:1a403fada01ff9221ca8044d701868fa132215d84beb92242d9acd2147f667a8"},
{file = "tzdata-2025.2.tar.gz", hash = "sha256:b60a638fcc0daffadf82fe0f57e53d06bdec2f36c4df66280ae79bce6bd6f2b9"},
]
-markers = {main = "extra == \"mem-reader\" or extra == \"all\""}
+markers = {main = "extra == \"mem-reader\" or extra == \"all\" or extra == \"pref-mem\""}
[[package]]
name = "ujson"
@@ -6301,13 +6396,14 @@ cffi = {version = ">=1.11", markers = "platform_python_implementation == \"PyPy\
cffi = ["cffi (>=1.11)"]
[extras]
-all = ["chonkie", "markitdown", "neo4j", "pika", "pymysql", "qdrant-client", "redis", "schedule", "sentence-transformers", "torch", "volcengine-python-sdk"]
+all = ["cachetools", "chonkie", "datasketch", "jieba", "markitdown", "neo4j", "pika", "pymilvus", "pymysql", "qdrant-client", "rank-bm25", "redis", "schedule", "sentence-transformers", "torch", "volcengine-python-sdk"]
mem-reader = ["chonkie", "markitdown"]
mem-scheduler = ["pika", "redis"]
mem-user = ["pymysql"]
+pref-mem = ["datasketch", "pymilvus"]
tree-mem = ["neo4j", "schedule"]
[metadata]
lock-version = "2.1"
python-versions = ">=3.10,<4.0"
-content-hash = "d85cb8a08870d67df6e462610231f1e735ba5293bd3fe5b0c4a212b3ccff7b72"
\ No newline at end of file
+content-hash = "ec17679a44205ada4494fbc485ac592883281fde273d5e73d6b8cbc6f7f9ed10"
diff --git a/pyproject.toml b/pyproject.toml
index a03b9174b..2f88797a8 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -88,6 +88,12 @@ mem-reader = [
"markitdown[docx,pdf,pptx,xls,xlsx] (>=0.1.1,<0.2.0)", # Markdown parser for various file formats
]
+# PreferenceTextMemory
+pref-mem = [
+ "pymilvus (>=2.6.1,<3.0.0)", # Milvus Vector DB
+ "datasketch (>=1.6.5,<2.0.0)", # MinHash library
+]
+
# All optional dependencies
# Allow users to install with `pip install MemoryOS[all]`
all = [
@@ -99,7 +105,11 @@ all = [
"pymysql (>=1.1.0,<2.0.0)",
"chonkie (>=1.0.7,<2.0.0)",
"markitdown[docx,pdf,pptx,xls,xlsx] (>=0.1.1,<0.2.0)",
-
+ "pymilvus (>=2.6.1,<3.0.0)",
+ "datasketch (>=1.6.5,<2.0.0)",
+ "jieba (>=0.38.1,<0.42.1)",
+ "rank-bm25 (>=0.2.2)",
+ "cachetools (>=6.0.0)",
# NOT exist in the above optional groups
# Because they are either huge-size dependencies or infrequently used dependencies.
# We kindof don't want users to install them.
diff --git a/src/memos/api/config.py b/src/memos/api/config.py
index d552369c5..f02edaad6 100644
--- a/src/memos/api/config.py
+++ b/src/memos/api/config.py
@@ -1,18 +1,258 @@
+import base64
+import hashlib
+import hmac
import json
+import logging
import os
+import re
+import time
from typing import Any
+import requests
+
from dotenv import load_dotenv
from memos.configs.mem_cube import GeneralMemCubeConfig
from memos.configs.mem_os import MOSConfig
+from memos.context.context import ContextThread
from memos.mem_cube.general import GeneralMemCube
# Load environment variables
load_dotenv()
+logger = logging.getLogger(__name__)
+
+
+def _update_env_from_dict(data: dict[str, Any]) -> None:
+ """Apply a dict to environment variables, with change logging."""
+
+ def _is_sensitive(name: str) -> bool:
+ n = name.upper()
+ return any(s in n for s in ["PASSWORD", "SECRET", "AK", "SK", "TOKEN", "KEY"])
+
+ for k, v in data.items():
+ if isinstance(v, dict):
+ new_val = json.dumps(v, ensure_ascii=False)
+ elif isinstance(v, bool):
+ new_val = "true" if v else "false"
+ elif v is None:
+ new_val = ""
+ else:
+ new_val = str(v)
+
+ old_val = os.environ.get(k)
+ os.environ[k] = new_val
+
+ try:
+ log_old = "***" if _is_sensitive(k) else (old_val if old_val is not None else "")
+ log_new = "***" if _is_sensitive(k) else new_val
+ if old_val != new_val:
+ logger.info(f"Nacos config update: {k}={log_new} (was {log_old})")
+ except Exception as e:
+ # Avoid logging failures blocking config updates
+ logger.debug(f"Skip logging change for {k}: {e}")
+
+
+def get_config_json(name: str, default: Any | None = None) -> Any:
+ """Read JSON object/array from env and parse. Returns default on missing/invalid."""
+ raw = os.getenv(name)
+ if not raw:
+ return default
+ try:
+ return json.loads(raw)
+ except Exception:
+ logger.warning(f"Invalid JSON in env '{name}', returning default.")
+ return default
+
+
+def get_config_value(path: str, default: Any | None = None) -> Any:
+ """Read value from env with optional dot-path for structured configs.
+
+ Examples:
+ - get_config_value("MONGODB_CONFIG.base_uri")
+ - get_config_value("MONGODB_BASE_URI")
+ """
+ if "." not in path:
+ val = os.getenv(path)
+ return val if val is not None else default
+ root, *subkeys = path.split(".")
+ data = get_config_json(root, default=None)
+ if not isinstance(data, dict):
+ return default
+ cur: Any = data
+ for key in subkeys:
+ if isinstance(cur, dict) and key in cur:
+ cur = cur[key]
+ else:
+ return default
+ return cur
+
+
+class NacosConfigManager:
+ _client = None
+ _data_id = None
+ _group = None
+ _enabled = False
+
+ # Pre-compile regex patterns for better performance
+ _KEY_VALUE_PATTERN = re.compile(r"^([^=]+)=(.*)$")
+ _INTEGER_PATTERN = re.compile(r"^[+-]?\d+$")
+ _FLOAT_PATTERN = re.compile(r"^[+-]?(\d+\.?\d*|\.\d+)([eE][+-]?\d+)?$")
+
+ @classmethod
+ def _sign(cls, secret_key: str, data: str) -> str:
+ """HMAC-SHA1 sgin"""
+ signature = hmac.new(secret_key.encode("utf-8"), data.encode("utf-8"), hashlib.sha1)
+ return base64.b64encode(signature.digest()).decode()
+
+ @staticmethod
+ def _parse_value(value: str) -> Any:
+ """Parse string value to appropriate Python type.
+
+ Supports: bool, int, float, and string.
+ """
+ if not value:
+ return value
+
+ val_lower = value.lower()
+
+ # Boolean
+ if val_lower in ("true", "false"):
+ return val_lower == "true"
+
+ # Integer
+ if NacosConfigManager._INTEGER_PATTERN.match(value):
+ try:
+ return int(value)
+ except (ValueError, OverflowError):
+ return value
+
+ # Float
+ if NacosConfigManager._FLOAT_PATTERN.match(value):
+ try:
+ return float(value)
+ except (ValueError, OverflowError):
+ return value
+
+ # Default to string
+ return value
+
+ @staticmethod
+ def parse_properties(content: str) -> dict[str, Any]:
+ """Parse properties file content to dictionary with type inference.
+
+ Supports:
+ - Comments (lines starting with #)
+ - Key-value pairs (KEY=VALUE)
+ - Type inference (bool, int, float, string)
+ """
+ data: dict[str, Any] = {}
+
+ for line in content.splitlines():
+ line = line.strip()
+
+ # Skip empty lines and comments
+ if not line or line.startswith("#"):
+ continue
+
+ # Parse key-value pair
+ match = NacosConfigManager._KEY_VALUE_PATTERN.match(line)
+ if match:
+ key = match.group(1).strip()
+ value = match.group(2).strip()
+ data[key] = NacosConfigManager._parse_value(value)
+
+ return data
+
+ @classmethod
+ def start_config_watch(cls):
+ while True:
+ cls.init()
+ time.sleep(60)
+
+ @classmethod
+ def start_watch_if_enabled(cls) -> None:
+ enable = os.getenv("NACOS_ENABLE_WATCH", "false").lower() == "true"
+ print("enable:", enable)
+ if not enable:
+ return
+ interval = int(os.getenv("NACOS_WATCH_INTERVAL", "60"))
+
+ def _loop() -> None:
+ while True:
+ try:
+ cls.init()
+ except Exception as e:
+ logger.error(f"❌ Nacos watch loop error: {e}")
+ time.sleep(interval)
+
+ ContextThread(target=_loop, daemon=True).start()
+ logger.info(f"Nacos watch thread started (interval={interval}s).")
+
+ @classmethod
+ def init(cls) -> None:
+ server_addr = os.getenv("NACOS_SERVER_ADDR")
+ data_id = os.getenv("NACOS_DATA_ID")
+ group = os.getenv("NACOS_GROUP", "DEFAULT_GROUP")
+ namespace = os.getenv("NACOS_NAMESPACE", "")
+ ak = os.getenv("AK")
+ sk = os.getenv("SK")
+
+ if not (server_addr and data_id and ak and sk):
+ logger.warning("❌ missing NACOS_SERVER_ADDR / AK / SK / DATA_ID")
+ return
+
+ base_url = f"http://{server_addr}/nacos/v1/cs/configs"
+
+ def _auth_headers():
+ ts = str(int(time.time() * 1000))
+
+ sign_data = namespace + "+" + group + "+" + ts if namespace else group + "+" + ts
+ signature = cls._sign(sk, sign_data)
+ return {
+ "Spas-AccessKey": ak,
+ "Spas-Signature": signature,
+ "timeStamp": ts,
+ }
+
+ try:
+ params = {
+ "dataId": data_id,
+ "group": group,
+ "tenant": namespace,
+ }
+
+ headers = _auth_headers()
+ resp = requests.get(base_url, headers=headers, params=params, timeout=10)
+
+ if resp.status_code != 200:
+ logger.error(f"Nacos AK/SK fail: {resp.status_code} {resp.text}")
+ return
+
+ content = resp.text.strip()
+ if not content:
+ logger.warning("⚠️ Nacos is empty")
+ return
+ try:
+ data_props = cls.parse_properties(content)
+ logger.info("nacos config:", data_props)
+ _update_env_from_dict(data_props)
+ logger.info("✅ parse Nacos setting is Properties ")
+ except Exception as e:
+ logger.error(f"⚠️ Nacos parse fail(not JSON/YAML/Properties): {e}")
+ raise Exception(f"Nacos configuration parsing failed: {e}") from e
+
+ except Exception as e:
+ logger.error(f"❌ Nacos AK/SK init fail: {e}")
+ raise Exception(f"❌ Nacos AK/SK init fail: {e}") from e
+
+
+# init Nacos
+NacosConfigManager.init()
+NacosConfigManager.start_watch_if_enabled()
+
class APIConfig:
"""Centralized configuration management for MemOS APIs."""
@@ -23,7 +263,7 @@ def get_openai_config() -> dict[str, Any]:
return {
"model_name_or_path": os.getenv("MOS_CHAT_MODEL", "gpt-4o-mini"),
"temperature": float(os.getenv("MOS_CHAT_TEMPERATURE", "0.8")),
- "max_tokens": int(os.getenv("MOS_MAX_TOKENS", "1024")),
+ "max_tokens": int(os.getenv("MOS_MAX_TOKENS", "8000")),
"top_p": float(os.getenv("MOS_TOP_P", "0.9")),
"top_k": int(os.getenv("MOS_TOP_K", "50")),
"remove_think_prefix": True,
@@ -84,7 +324,7 @@ def get_memreader_config() -> dict[str, Any]:
"config": {
"model_name_or_path": os.getenv("MEMRADER_MODEL", "gpt-4o-mini"),
"temperature": 0.6,
- "max_tokens": int(os.getenv("MEMRADER_MAX_TOKENS", "5000")),
+ "max_tokens": int(os.getenv("MEMRADER_MAX_TOKENS", "8000")),
"top_p": 0.95,
"top_k": 20,
"api_key": os.getenv("MEMRADER_API_KEY", "EMPTY"),
@@ -108,20 +348,40 @@ def get_activation_vllm_config() -> dict[str, Any]:
},
}
+ @staticmethod
+ def get_preference_memory_config() -> dict[str, Any]:
+ """Get preference memory configuration."""
+ return {
+ "backend": "pref_text",
+ "config": {
+ "extractor_llm": APIConfig.get_memreader_config(),
+ "vector_db": {
+ "backend": "milvus",
+ "config": APIConfig.get_milvus_config(),
+ },
+ "embedder": APIConfig.get_embedder_config(),
+ "reranker": APIConfig.get_reranker_config(),
+ "extractor": {"backend": "naive", "config": {}},
+ "adder": {"backend": "naive", "config": {}},
+ "retriever": {"backend": "naive", "config": {}},
+ },
+ }
+
@staticmethod
def get_reranker_config() -> dict[str, Any]:
"""Get embedder configuration."""
embedder_backend = os.getenv("MOS_RERANKER_BACKEND", "http_bge")
- if embedder_backend == "http_bge":
+ if embedder_backend in ["http_bge", "http_bge_strategy"]:
return {
- "backend": "http_bge",
+ "backend": embedder_backend,
"config": {
"url": os.getenv("MOS_RERANKER_URL"),
"model": os.getenv("MOS_RERANKER_MODEL", "bge-reranker-v2-m3"),
"timeout": 10,
"headers_extra": os.getenv("MOS_RERANKER_HEADERS_EXTRA"),
"rerank_source": os.getenv("MOS_RERANK_SOURCE"),
+ "reranker_strategy": os.getenv("MOS_RERANKER_STRATEGY", "single_turn"),
},
}
else:
@@ -159,9 +419,23 @@ def get_embedder_config() -> dict[str, Any]:
},
}
+ @staticmethod
+ def get_reader_config() -> dict[str, Any]:
+ """Get reader configuration."""
+ return {
+ "backend": os.getenv("MEM_READER_BACKEND", "simple_struct"),
+ "config": {
+ "chunk_type": os.getenv("MEM_READER_CHAT_CHUNK_TYPE", "default"),
+ "chunk_length": int(os.getenv("MEM_READER_CHAT_CHUNK_TOKEN_SIZE", 1600)),
+ "chunk_session": int(os.getenv("MEM_READER_CHAT_CHUNK_SESS_SIZE", 10)),
+ "chunk_overlap": int(os.getenv("MEM_READER_CHAT_CHUNK_OVERLAP", 2)),
+ },
+ }
+
@staticmethod
def get_internet_config() -> dict[str, Any]:
"""Get embedder configuration."""
+ reader_config = APIConfig.get_reader_config()
return {
"backend": "bocha",
"config": {
@@ -169,7 +443,7 @@ def get_internet_config() -> dict[str, Any]:
"max_results": 15,
"num_per_request": 10,
"reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": {
"backend": "openai",
@@ -195,6 +469,7 @@ def get_internet_config() -> dict[str, Any]:
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
},
@@ -275,6 +550,46 @@ def get_nebular_config(user_id: str | None = None) -> dict[str, Any]:
"embedding_dimension": int(os.getenv("EMBEDDING_DIMENSION", 3072)),
}
+ @staticmethod
+ def get_milvus_config():
+ return {
+ "collection_name": [
+ "explicit_preference",
+ "implicit_preference",
+ ],
+ "vector_dimension": int(os.getenv("EMBEDDING_DIMENSION", 1024)),
+ "distance_metric": "cosine",
+ "uri": os.getenv("MILVUS_URI", "http://localhost:19530"),
+ "user_name": os.getenv("MILVUS_USER_NAME", "root"),
+ "password": os.getenv("MILVUS_PASSWORD", "12345678"),
+ }
+
+ @staticmethod
+ def get_polardb_config(user_id: str | None = None) -> dict[str, Any]:
+ """Get PolarDB configuration."""
+ use_multi_db = os.getenv("POLAR_DB_USE_MULTI_DB", "false").lower() == "true"
+
+ if use_multi_db:
+ # Multi-DB mode: each user gets their own database (physical isolation)
+ db_name = f"memos{user_id.replace('-', '')}" if user_id else "memos_default"
+ user_name = None
+ else:
+ # Shared-DB mode: all users share one database with user_name tag (logical isolation)
+ db_name = os.getenv("POLAR_DB_DB_NAME", "shared_memos_db")
+ user_name = f"memos{user_id.replace('-', '')}" if user_id else "memos_default"
+
+ return {
+ "host": os.getenv("POLAR_DB_HOST", "localhost"),
+ "port": int(os.getenv("POLAR_DB_PORT", "5432")),
+ "user": os.getenv("POLAR_DB_USER", "root"),
+ "password": os.getenv("POLAR_DB_PASSWORD", "123456"),
+ "db_name": db_name,
+ "user_name": user_name,
+ "use_multi_db": use_multi_db,
+ "auto_create": True,
+ "embedding_dimension": int(os.getenv("EMBEDDING_DIMENSION", 1024)),
+ }
+
@staticmethod
def get_mysql_config() -> dict[str, Any]:
"""Get MySQL configuration."""
@@ -299,10 +614,10 @@ def get_scheduler_config() -> dict[str, Any]:
),
"context_window_size": int(os.getenv("MOS_SCHEDULER_CONTEXT_WINDOW_SIZE", "5")),
"thread_pool_max_workers": int(
- os.getenv("MOS_SCHEDULER_THREAD_POOL_MAX_WORKERS", "10")
+ os.getenv("MOS_SCHEDULER_THREAD_POOL_MAX_WORKERS", "10000")
),
- "consume_interval_seconds": int(
- os.getenv("MOS_SCHEDULER_CONSUME_INTERVAL_SECONDS", "3")
+ "consume_interval_seconds": float(
+ os.getenv("MOS_SCHEDULER_CONSUME_INTERVAL_SECONDS", "0.01")
),
"enable_parallel_dispatch": os.getenv(
"MOS_SCHEDULER_ENABLE_PARALLEL_DISPATCH", "true"
@@ -356,6 +671,8 @@ def get_product_default_config() -> dict[str, Any]:
openai_config = APIConfig.get_openai_config()
qwen_config = APIConfig.qwen_config()
vllm_config = APIConfig.vllm_config()
+ reader_config = APIConfig.get_reader_config()
+
backend_model = {
"openai": openai_config,
"huggingface": qwen_config,
@@ -367,7 +684,7 @@ def get_product_default_config() -> dict[str, Any]:
"user_id": os.getenv("MOS_USER_ID", "root"),
"chat_model": {"backend": backend, "config": backend_model[backend]},
"mem_reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": APIConfig.get_memreader_config(),
"embedder": APIConfig.get_embedder_config(),
@@ -380,11 +697,14 @@ def get_product_default_config() -> dict[str, Any]:
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": int(os.getenv("MOS_TOP_K", "50")),
"max_turns_window": int(os.getenv("MOS_MAX_TURNS_WINDOW", "20")),
}
@@ -414,6 +734,8 @@ def get_start_default_config() -> dict[str, Any]:
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": int(os.getenv("MOS_TOP_K", "5")),
"chat_model": {
"backend": os.getenv("MOS_CHAT_MODEL_PROVIDER", "openai"),
@@ -446,6 +768,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
qwen_config = APIConfig.qwen_config()
vllm_config = APIConfig.vllm_config()
mysql_config = APIConfig.get_mysql_config()
+ reader_config = APIConfig.get_reader_config()
backend = os.getenv("MOS_CHAT_MODEL_PROVIDER", "openai")
backend_model = {
"openai": openai_config,
@@ -460,7 +783,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"config": backend_model[backend],
},
"mem_reader": {
- "backend": "simple_struct",
+ "backend": reader_config["backend"],
"config": {
"llm": APIConfig.get_memreader_config(),
"embedder": APIConfig.get_embedder_config(),
@@ -473,11 +796,14 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"min_sentences_per_chunk": 1,
},
},
+ "chat_chunker": reader_config,
},
},
"enable_textual_memory": True,
"enable_activation_memory": os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower()
== "true",
+ "enable_preference_memory": os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower()
+ == "true",
"top_k": 30,
"max_turns_window": 20,
}
@@ -500,6 +826,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
neo4j_community_config = APIConfig.get_neo4j_community_config(user_id)
neo4j_config = APIConfig.get_neo4j_config(user_id)
nebular_config = APIConfig.get_nebular_config(user_id)
+ polardb_config = APIConfig.get_polardb_config(user_id)
internet_config = (
APIConfig.get_internet_config()
if os.getenv("ENABLE_INTERNET", "false").lower() == "true"
@@ -509,6 +836,7 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"neo4j-community": neo4j_community_config,
"neo4j": neo4j_config,
"nebular": nebular_config,
+ "polardb": polardb_config,
}
graph_db_backend = os.getenv("NEO4J_BACKEND", "neo4j-community").lower()
if graph_db_backend in graph_db_backend_map:
@@ -533,9 +861,14 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
"reorganize": os.getenv("MOS_ENABLE_REORGANIZE", "false").lower()
== "true",
"memory_size": {
- "WorkingMemory": os.getenv("NEBULAR_WORKING_MEMORY", 20),
- "LongTermMemory": os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6),
- "UserMemory": os.getenv("NEBULAR_USER_MEMORY", 1e6),
+ "WorkingMemory": int(os.getenv("NEBULAR_WORKING_MEMORY", 20)),
+ "LongTermMemory": int(os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6)),
+ "UserMemory": int(os.getenv("NEBULAR_USER_MEMORY", 1e6)),
+ },
+ "search_strategy": {
+ "fast_graph": bool(os.getenv("FAST_GRAPH", "false") == "true"),
+ "bm25": bool(os.getenv("BM25_CALL", "false") == "true"),
+ "cot": bool(os.getenv("VEC_COT_CALL", "false") == "true"),
},
},
},
@@ -543,6 +876,9 @@ def create_user_config(user_name: str, user_id: str) -> tuple[MOSConfig, General
if os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower() == "false"
else APIConfig.get_activation_vllm_config(),
"para_mem": {},
+ "pref_mem": {}
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() == "false"
+ else APIConfig.get_preference_memory_config(),
}
)
else:
@@ -564,10 +900,12 @@ def get_default_cube_config() -> GeneralMemCubeConfig | None:
neo4j_community_config = APIConfig.get_neo4j_community_config(user_id="default")
neo4j_config = APIConfig.get_neo4j_config(user_id="default")
nebular_config = APIConfig.get_nebular_config(user_id="default")
+ polardb_config = APIConfig.get_polardb_config(user_id="default")
graph_db_backend_map = {
"neo4j-community": neo4j_community_config,
"neo4j": neo4j_config,
"nebular": nebular_config,
+ "polardb": polardb_config,
}
internet_config = (
APIConfig.get_internet_config()
@@ -595,16 +933,25 @@ def get_default_cube_config() -> GeneralMemCubeConfig | None:
== "true",
"internet_retriever": internet_config,
"memory_size": {
- "WorkingMemory": os.getenv("NEBULAR_WORKING_MEMORY", 20),
- "LongTermMemory": os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6),
- "UserMemory": os.getenv("NEBULAR_USER_MEMORY", 1e6),
+ "WorkingMemory": int(os.getenv("NEBULAR_WORKING_MEMORY", 20)),
+ "LongTermMemory": int(os.getenv("NEBULAR_LONGTERM_MEMORY", 1e6)),
+ "UserMemory": int(os.getenv("NEBULAR_USER_MEMORY", 1e6)),
+ },
+ "search_strategy": {
+ "fast_graph": bool(os.getenv("FAST_GRAPH", "false") == "true"),
+ "bm25": bool(os.getenv("BM25_CALL", "false") == "true"),
+ "cot": bool(os.getenv("VEC_COT_CALL", "false") == "true"),
},
+ "mode": os.getenv("ASYNC_MODE", "sync"),
},
},
"act_mem": {}
if os.getenv("ENABLE_ACTIVATION_MEMORY", "false").lower() == "false"
else APIConfig.get_activation_vllm_config(),
"para_mem": {},
+ "pref_mem": {}
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() == "false"
+ else APIConfig.get_preference_memory_config(),
}
)
else:
diff --git a/src/memos/api/exceptions.py b/src/memos/api/exceptions.py
index 2fd22ad52..10a14b4d1 100644
--- a/src/memos/api/exceptions.py
+++ b/src/memos/api/exceptions.py
@@ -1,5 +1,6 @@
import logging
+from fastapi.exceptions import HTTPException, RequestValidationError
from fastapi.requests import Request
from fastapi.responses import JSONResponse
@@ -10,9 +11,24 @@
class APIExceptionHandler:
"""Centralized exception handling for MemOS APIs."""
+ @staticmethod
+ async def validation_error_handler(request: Request, exc: RequestValidationError):
+ """Handle request validation errors."""
+ logger.error(f"Validation error: {exc.errors()}")
+ return JSONResponse(
+ status_code=422,
+ content={
+ "code": 422,
+ "message": "Parameter validation error",
+ "detail": exc.errors(),
+ "data": None,
+ },
+ )
+
@staticmethod
async def value_error_handler(request: Request, exc: ValueError):
"""Handle ValueError exceptions globally."""
+ logger.error(f"ValueError: {exc}")
return JSONResponse(
status_code=400,
content={"code": 400, "message": str(exc), "data": None},
@@ -21,8 +37,17 @@ async def value_error_handler(request: Request, exc: ValueError):
@staticmethod
async def global_exception_handler(request: Request, exc: Exception):
"""Handle all unhandled exceptions globally."""
- logger.exception("Unhandled error:")
+ logger.error(f"Exception: {exc}")
return JSONResponse(
status_code=500,
content={"code": 500, "message": str(exc), "data": None},
)
+
+ @staticmethod
+ async def http_error_handler(request: Request, exc: HTTPException):
+ """Handle HTTP exceptions globally."""
+ logger.error(f"HTTP error {exc.status_code}: {exc.detail}")
+ return JSONResponse(
+ status_code=exc.status_code,
+ content={"code": exc.status_code, "message": str(exc.detail), "data": None},
+ )
diff --git a/src/memos/api/middleware/request_context.py b/src/memos/api/middleware/request_context.py
index cb41428d4..025a0f9eb 100644
--- a/src/memos/api/middleware/request_context.py
+++ b/src/memos/api/middleware/request_context.py
@@ -2,6 +2,8 @@
Request context middleware for automatic trace_id injection.
"""
+import time
+
from collections.abc import Callable
from starlette.middleware.base import BaseHTTPMiddleware
@@ -34,30 +36,66 @@ class RequestContextMiddleware(BaseHTTPMiddleware):
3. Ensures the context is available throughout the request lifecycle
"""
+ def __init__(self, app, source: str | None = None):
+ """
+ Initialize the middleware.
+
+ Args:
+ app: The ASGI application
+ source: Source identifier (e.g., 'product' or 'server') to distinguish request origin
+ """
+ super().__init__(app)
+ self.source = source or "api"
+
async def dispatch(self, request: Request, call_next: Callable) -> Response:
# Extract or generate trace_id
trace_id = extract_trace_id_from_headers(request) or generate_trace_id()
+ env = request.headers.get("x-env")
+ user_type = request.headers.get("x-user-type")
+ user_name = request.headers.get("x-user-name")
+ start_time = time.time()
+
# Create and set request context
- context = RequestContext(trace_id=trace_id, api_path=request.url.path)
+ context = RequestContext(
+ trace_id=trace_id,
+ api_path=request.url.path,
+ env=env,
+ user_type=user_type,
+ user_name=user_name,
+ source=self.source,
+ )
set_request_context(context)
- # Log request start with parameters
- params_log = {}
-
- # Get query parameters
- if request.query_params:
- params_log["query_params"] = dict(request.query_params)
+ logger.info(
+ f"Request started, source: {self.source}, method: {request.method}, path: {request.url.path}, "
+ f"headers: {request.headers}"
+ )
- logger.info(f"Request started: {request.method} {request.url.path}, {params_log}")
-
- # Process the request
response = await call_next(request)
+ end_time = time.time()
- # Log request completion with output
- logger.info(f"Request completed: {request.url.path}, status: {response.status_code}")
-
- # Add trace_id to response headers for debugging
- response.headers["x-trace-id"] = trace_id
+ # Process the request
+ try:
+ if not response:
+ logger.error(
+ f"Request Failed No Response, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+
+ return response
+
+ if response.status_code == 200:
+ logger.info(
+ f"Request completed: source: {self.source}, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+ else:
+ logger.error(
+ f"Request Failed: source: {self.source}, path: {request.url.path}, status: {response.status_code}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
+ except Exception as e:
+ end_time = time.time()
+ logger.error(
+ f"Request Exception Error: source: {self.source}, path: {request.url.path}, error: {e}, cost: {(end_time - start_time) * 1000:.2f}ms"
+ )
return response
diff --git a/src/memos/api/product_api.py b/src/memos/api/product_api.py
index 709ad74fb..ec5cccae1 100644
--- a/src/memos/api/product_api.py
+++ b/src/memos/api/product_api.py
@@ -17,7 +17,7 @@
version="1.0.1",
)
-app.add_middleware(RequestContextMiddleware)
+app.add_middleware(RequestContextMiddleware, source="product_api")
# Include routers
app.include_router(product_router)
diff --git a/src/memos/api/product_models.py b/src/memos/api/product_models.py
index 86751b008..0412754c3 100644
--- a/src/memos/api/product_models.py
+++ b/src/memos/api/product_models.py
@@ -5,6 +5,7 @@
from pydantic import BaseModel, Field
# Import message types from core types module
+from memos.mem_scheduler.schemas.general_schemas import SearchMode
from memos.types import MessageDict, PermissionDict
@@ -170,7 +171,7 @@ class APISearchRequest(BaseRequest):
query: str = Field(..., description="Search query")
user_id: str = Field(None, description="User ID")
mem_cube_id: str | None = Field(None, description="Cube ID to search in")
- mode: str = Field("fast", description="search mode fast or fine")
+ mode: SearchMode = Field(SearchMode.FAST, description="search mode: fast, fine, or mixture")
internet_search: bool = Field(False, description="Whether to use internet search")
moscube: bool = Field(False, description="Whether to use MemOSCube")
top_k: int = Field(10, description="Number of results to return")
@@ -179,6 +180,8 @@ class APISearchRequest(BaseRequest):
operation: list[PermissionDict] | None = Field(
None, description="operation ids for multi cubes"
)
+ include_preference: bool = Field(True, description="Whether to handle preference memory")
+ pref_top_k: int = Field(6, description="Number of preference results to return")
class APIADDRequest(BaseRequest):
diff --git a/src/memos/api/routers/server_router.py b/src/memos/api/routers/server_router.py
index a332de583..8df383bfb 100644
--- a/src/memos/api/routers/server_router.py
+++ b/src/memos/api/routers/server_router.py
@@ -1,9 +1,16 @@
+import json
import os
+import random as _random
+import socket
+import time
import traceback
-from typing import Any
+from collections.abc import Iterable
+from datetime import datetime
+from typing import TYPE_CHECKING, Any
from fastapi import APIRouter, HTTPException
+from fastapi.responses import StreamingResponse
from memos.api.config import APIConfig
from memos.api.product_models import (
@@ -18,7 +25,10 @@
from memos.configs.internet_retriever import InternetRetrieverConfigFactory
from memos.configs.llm import LLMConfigFactory
from memos.configs.mem_reader import MemReaderConfigFactory
+from memos.configs.mem_scheduler import SchedulerConfigFactory
from memos.configs.reranker import RerankerConfigFactory
+from memos.configs.vec_db import VectorDBConfigFactory
+from memos.context.context import ContextThreadPoolExecutor
from memos.embedders.factory import EmbedderFactory
from memos.graph_dbs.factory import GraphStoreFactory
from memos.llms.factory import LLMFactory
@@ -26,17 +36,52 @@
from memos.mem_cube.navie import NaiveMemCube
from memos.mem_os.product_server import MOSServer
from memos.mem_reader.factory import MemReaderFactory
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
+from memos.mem_scheduler.scheduler_factory import SchedulerFactory
+from memos.mem_scheduler.schemas.general_schemas import (
+ ADD_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
+ SearchMode,
+)
+from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
+from memos.memories.textual.prefer_text_memory.factory import (
+ AdderFactory,
+ ExtractorFactory,
+ RetrieverFactory,
+)
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
from memos.memories.textual.tree_text_memory.retrieve.internet_retriever_factory import (
InternetRetrieverFactory,
)
from memos.reranker.factory import RerankerFactory
+from memos.templates.instruction_completion import instruct_completion
+
+
+if TYPE_CHECKING:
+ from memos.mem_scheduler.optimized_scheduler import OptimizedScheduler
from memos.types import MOSSearchResult, UserContext
+from memos.vec_dbs.factory import VecDBFactory
logger = get_logger(__name__)
router = APIRouter(prefix="/product", tags=["Server API"])
+INSTANCE_ID = f"{socket.gethostname()}:{os.getpid()}:{_random.randint(1000, 9999)}"
+
+
+def _to_iter(running: Any) -> Iterable:
+ """Normalize running tasks to an iterable of task objects."""
+ if running is None:
+ return []
+ if isinstance(running, dict):
+ return running.values()
+ return running # assume it's already an iterable (e.g., list)
def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
@@ -45,6 +90,7 @@ def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
"neo4j-community": APIConfig.get_neo4j_community_config(user_id=user_id),
"neo4j": APIConfig.get_neo4j_config(user_id=user_id),
"nebular": APIConfig.get_nebular_config(user_id=user_id),
+ "polardb": APIConfig.get_polardb_config(user_id=user_id),
}
graph_db_backend = os.getenv("NEO4J_BACKEND", "nebular").lower()
@@ -56,6 +102,16 @@ def _build_graph_db_config(user_id: str = "default") -> dict[str, Any]:
)
+def _build_vec_db_config() -> dict[str, Any]:
+ """Build vector database configuration."""
+ return VectorDBConfigFactory.model_validate(
+ {
+ "backend": "milvus",
+ "config": APIConfig.get_milvus_config(),
+ }
+ )
+
+
def _build_llm_config() -> dict[str, Any]:
"""Build LLM configuration."""
return LLMConfigFactory.model_validate(
@@ -88,6 +144,21 @@ def _build_internet_retriever_config() -> dict[str, Any]:
return InternetRetrieverConfigFactory.model_validate(APIConfig.get_internet_config())
+def _build_pref_extractor_config() -> dict[str, Any]:
+ """Build extractor configuration."""
+ return ExtractorConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
+def _build_pref_adder_config() -> dict[str, Any]:
+ """Build adder configuration."""
+ return AdderConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
+def _build_pref_retriever_config() -> dict[str, Any]:
+ """Build retriever configuration."""
+ return RetrieverConfigFactory.model_validate({"backend": "naive", "config": {}})
+
+
def _get_default_memory_size(cube_config) -> dict[str, int]:
"""Get default memory size configuration."""
return getattr(cube_config.text_mem.config, "memory_size", None) or {
@@ -104,15 +175,19 @@ def init_server():
# Build component configurations
graph_db_config = _build_graph_db_config()
- print(graph_db_config)
llm_config = _build_llm_config()
embedder_config = _build_embedder_config()
mem_reader_config = _build_mem_reader_config()
reranker_config = _build_reranker_config()
internet_retriever_config = _build_internet_retriever_config()
+ vector_db_config = _build_vec_db_config()
+ pref_extractor_config = _build_pref_extractor_config()
+ pref_adder_config = _build_pref_adder_config()
+ pref_retriever_config = _build_pref_retriever_config()
# Create component instances
graph_db = GraphStoreFactory.from_config(graph_db_config)
+ vector_db = VecDBFactory.from_config(vector_db_config)
llm = LLMFactory.from_config(llm_config)
embedder = EmbedderFactory.from_config(embedder_config)
mem_reader = MemReaderFactory.from_config(mem_reader_config)
@@ -120,6 +195,25 @@ def init_server():
internet_retriever = InternetRetrieverFactory.from_config(
internet_retriever_config, embedder=embedder
)
+ pref_extractor = ExtractorFactory.from_config(
+ config_factory=pref_extractor_config,
+ llm_provider=llm,
+ embedder=embedder,
+ vector_db=vector_db,
+ )
+ pref_adder = AdderFactory.from_config(
+ config_factory=pref_adder_config,
+ llm_provider=llm,
+ embedder=embedder,
+ vector_db=vector_db,
+ )
+ pref_retriever = RetrieverFactory.from_config(
+ config_factory=pref_retriever_config,
+ llm_provider=llm,
+ embedder=embedder,
+ reranker=reranker,
+ vector_db=vector_db,
+ )
# Initialize memory manager
memory_manager = MemoryManager(
@@ -134,6 +228,40 @@ def init_server():
llm=llm,
online_bot=False,
)
+
+ naive_mem_cube = NaiveMemCube(
+ llm=llm,
+ embedder=embedder,
+ mem_reader=mem_reader,
+ graph_db=graph_db,
+ reranker=reranker,
+ internet_retriever=internet_retriever,
+ memory_manager=memory_manager,
+ default_cube_config=default_cube_config,
+ vector_db=vector_db,
+ pref_extractor=pref_extractor,
+ pref_adder=pref_adder,
+ pref_retriever=pref_retriever,
+ )
+
+ # Initialize Scheduler
+ scheduler_config_dict = APIConfig.get_scheduler_config()
+ scheduler_config = SchedulerConfigFactory(
+ backend="optimized_scheduler", config=scheduler_config_dict
+ )
+ mem_scheduler: OptimizedScheduler = SchedulerFactory.from_config(scheduler_config)
+ mem_scheduler.initialize_modules(
+ chat_llm=llm,
+ process_llm=mem_reader.llm,
+ db_engine=BaseDBManager.create_default_sqlite_engine(),
+ mem_reader=mem_reader,
+ )
+ mem_scheduler.current_mem_cube = naive_mem_cube
+ mem_scheduler.start()
+
+ # Initialize SchedulerAPIModule
+ api_module = mem_scheduler.api_module
+
return (
graph_db,
mem_reader,
@@ -144,6 +272,13 @@ def init_server():
memory_manager,
default_cube_config,
mos_server,
+ mem_scheduler,
+ naive_mem_cube,
+ api_module,
+ vector_db,
+ pref_extractor,
+ pref_adder,
+ pref_retriever,
)
@@ -158,24 +293,16 @@ def init_server():
memory_manager,
default_cube_config,
mos_server,
+ mem_scheduler,
+ naive_mem_cube,
+ api_module,
+ vector_db,
+ pref_extractor,
+ pref_adder,
+ pref_retriever,
) = init_server()
-def _create_naive_mem_cube() -> NaiveMemCube:
- """Create a NaiveMemCube instance with initialized components."""
- naive_mem_cube = NaiveMemCube(
- llm=llm,
- embedder=embedder,
- mem_reader=mem_reader,
- graph_db=graph_db,
- reranker=reranker,
- internet_retriever=internet_retriever,
- memory_manager=memory_manager,
- default_cube_config=default_cube_config,
- )
- return naive_mem_cube
-
-
def _format_memory_item(memory_data: Any) -> dict[str, Any]:
"""Format a single memory item for API response."""
memory = memory_data.model_dump()
@@ -185,6 +312,7 @@ def _format_memory_item(memory_data: Any) -> dict[str, Any]:
memory["ref_id"] = ref_id
memory["metadata"]["embedding"] = []
memory["metadata"]["sources"] = []
+ memory["metadata"]["usage"] = []
memory["metadata"]["ref_id"] = ref_id
memory["metadata"]["id"] = memory_id
memory["metadata"]["memory"] = memory["memory"]
@@ -192,6 +320,26 @@ def _format_memory_item(memory_data: Any) -> dict[str, Any]:
return memory
+def _post_process_pref_mem(
+ memories_result: list[dict[str, Any]],
+ pref_formatted_mem: list[dict[str, Any]],
+ mem_cube_id: str,
+ include_preference: bool,
+):
+ if include_preference:
+ memories_result["pref_mem"].append(
+ {
+ "cube_id": mem_cube_id,
+ "memories": pref_formatted_mem,
+ }
+ )
+ pref_instruction, pref_note = instruct_completion(pref_formatted_mem)
+ memories_result["pref_string"] = pref_instruction
+ memories_result["pref_note"] = pref_note
+
+ return memories_result
+
+
@router.post("/search", summary="Search memories", response_model=SearchResponse)
def search_memories(search_req: APISearchRequest):
"""Search memories for a specific user."""
@@ -201,24 +349,107 @@ def search_memories(search_req: APISearchRequest):
mem_cube_id=search_req.mem_cube_id,
session_id=search_req.session_id or "default_session",
)
- logger.info(f"Search user_id is: {user_context.mem_cube_id}")
+ logger.info(f"Search Req is: {search_req}")
memories_result: MOSSearchResult = {
"text_mem": [],
"act_mem": [],
"para_mem": [],
+ "pref_mem": [],
+ "pref_note": "",
}
+
+ search_mode = search_req.mode
+
+ def _search_text():
+ if search_mode == SearchMode.FAST:
+ formatted_memories = fast_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ elif search_mode == SearchMode.FINE:
+ formatted_memories = fine_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ elif search_mode == SearchMode.MIXTURE:
+ formatted_memories = mix_search_memories(
+ search_req=search_req, user_context=user_context
+ )
+ else:
+ logger.error(f"Unsupported search mode: {search_mode}")
+ raise HTTPException(status_code=400, detail=f"Unsupported search mode: {search_mode}")
+ return formatted_memories
+
+ def _search_pref():
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() != "true":
+ return []
+ results = naive_mem_cube.pref_mem.search(
+ query=search_req.query,
+ top_k=search_req.pref_top_k,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": search_req.session_id,
+ "chat_history": search_req.chat_history,
+ },
+ )
+ return [_format_memory_item(data) for data in results]
+
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(_search_text)
+ pref_future = executor.submit(_search_pref)
+ text_formatted_memories = text_future.result()
+ pref_formatted_memories = pref_future.result()
+
+ memories_result["text_mem"].append(
+ {
+ "cube_id": search_req.mem_cube_id,
+ "memories": text_formatted_memories,
+ }
+ )
+
+ memories_result = _post_process_pref_mem(
+ memories_result,
+ pref_formatted_memories,
+ search_req.mem_cube_id,
+ search_req.include_preference,
+ )
+
+ logger.info(f"Search memories result: {memories_result}")
+
+ return SearchResponse(
+ message="Search completed successfully",
+ data=memories_result,
+ )
+
+
+def mix_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
+ """
+ Mix search memories: fast search + async fine search
+ """
+
+ formatted_memories = mem_scheduler.mix_search_memories(
+ search_req=search_req,
+ user_context=user_context,
+ )
+ return formatted_memories
+
+
+def fine_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
target_session_id = search_req.session_id
if not target_session_id:
target_session_id = "default_session"
search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
# Create MemCube and perform search
- naive_mem_cube = _create_naive_mem_cube()
search_results = naive_mem_cube.text_mem.search(
query=search_req.query,
user_name=user_context.mem_cube_id,
top_k=search_req.top_k,
- mode=search_req.mode,
+ mode=SearchMode.FINE,
manual_close_internet=not search_req.internet_search,
moscube=search_req.moscube,
search_filter=search_filter,
@@ -230,17 +461,36 @@ def search_memories(search_req: APISearchRequest):
)
formatted_memories = [_format_memory_item(data) for data in search_results]
- memories_result["text_mem"].append(
- {
- "cube_id": search_req.mem_cube_id,
- "memories": formatted_memories,
- }
- )
+ return formatted_memories
- return SearchResponse(
- message="Search completed successfully",
- data=memories_result,
+
+def fast_search_memories(
+ search_req: APISearchRequest,
+ user_context: UserContext,
+):
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ # Create MemCube and perform search
+ search_results = naive_mem_cube.text_mem.search(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=SearchMode.FAST,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ },
)
+ formatted_memories = [_format_memory_item(data) for data in search_results]
+
+ return formatted_memories
@router.post("/add", summary="Add memories", response_model=MemoryResponse)
@@ -252,51 +502,299 @@ def add_memories(add_req: APIADDRequest):
mem_cube_id=add_req.mem_cube_id,
session_id=add_req.session_id or "default_session",
)
- naive_mem_cube = _create_naive_mem_cube()
+
+ logger.info(f"Add Req is: {add_req}")
+
target_session_id = add_req.session_id
if not target_session_id:
target_session_id = "default_session"
- memories = mem_reader.get_memory(
- [add_req.messages],
- type="chat",
- info={
- "user_id": add_req.user_id,
- "session_id": target_session_id,
- },
- )
- # Flatten memory list
- flattened_memories = [mm for m in memories for mm in m]
- logger.info(f"Memory extraction completed for user {add_req.user_id}")
- mem_id_list: list[str] = naive_mem_cube.text_mem.add(
- flattened_memories,
- user_name=user_context.mem_cube_id,
- )
+ # If text memory backend works in async mode, submit tasks to scheduler
+ try:
+ sync_mode = getattr(naive_mem_cube.text_mem, "mode", "sync")
+ except Exception:
+ sync_mode = "sync"
+ logger.info(f"Add sync_mode mode is: {sync_mode}")
+
+ def _process_text_mem() -> list[dict[str, str]]:
+ memories_local = mem_reader.get_memory(
+ [add_req.messages],
+ type="chat",
+ info={
+ "user_id": add_req.user_id,
+ "session_id": target_session_id,
+ },
+ mode="fast" if sync_mode == "async" else "fine",
+ )
+ flattened_local = [mm for m in memories_local for mm in m]
+ logger.info(f"Memory extraction completed for user {add_req.user_id}")
+ mem_ids_local: list[str] = naive_mem_cube.text_mem.add(
+ flattened_local,
+ user_name=user_context.mem_cube_id,
+ )
+ logger.info(
+ f"Added {len(mem_ids_local)} memories for user {add_req.user_id} "
+ f"in session {add_req.session_id}: {mem_ids_local}"
+ )
+ if sync_mode == "async":
+ try:
+ message_item_read = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids_local),
+ timestamp=datetime.utcnow(),
+ user_name=add_req.mem_cube_id,
+ )
+ mem_scheduler.submit_messages(messages=[message_item_read])
+ logger.info(f"2105Submit messages!!!!!: {json.dumps(mem_ids_local)}")
+ except Exception as e:
+ logger.error(f"Failed to submit async memory tasks: {e}", exc_info=True)
+ else:
+ message_item_add = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids_local),
+ timestamp=datetime.utcnow(),
+ user_name=add_req.mem_cube_id,
+ )
+ mem_scheduler.submit_messages(messages=[message_item_add])
+ return [
+ {
+ "memory": memory.memory,
+ "memory_id": memory_id,
+ "memory_type": memory.metadata.memory_type,
+ }
+ for memory_id, memory in zip(mem_ids_local, flattened_local, strict=False)
+ ]
+
+ def _process_pref_mem() -> list[dict[str, str]]:
+ if os.getenv("ENABLE_PREFERENCE_MEMORY", "false").lower() != "true":
+ return []
+ # Follow async behavior similar to core.py: enqueue when async
+ if sync_mode == "async":
+ try:
+ messages_list = [add_req.messages]
+ message_item_pref = ScheduleMessageItem(
+ user_id=add_req.user_id,
+ session_id=target_session_id,
+ mem_cube_id=add_req.mem_cube_id,
+ mem_cube=naive_mem_cube,
+ label=PREF_ADD_LABEL,
+ content=json.dumps(messages_list),
+ timestamp=datetime.utcnow(),
+ )
+ mem_scheduler.submit_messages(messages=[message_item_pref])
+ logger.info("Submitted preference add to scheduler (async mode)")
+ except Exception as e:
+ logger.error(f"Failed to submit PREF_ADD task: {e}", exc_info=True)
+ return []
+ else:
+ pref_memories_local = naive_mem_cube.pref_mem.get_memory(
+ [add_req.messages],
+ type="chat",
+ info={
+ "user_id": add_req.user_id,
+ "session_id": target_session_id,
+ },
+ )
+ pref_ids_local: list[str] = naive_mem_cube.pref_mem.add(pref_memories_local)
+ logger.info(
+ f"Added {len(pref_ids_local)} preferences for user {add_req.user_id} "
+ f"in session {add_req.session_id}: {pref_ids_local}"
+ )
+ return [
+ {
+ "memory": memory.memory,
+ "memory_id": memory_id,
+ "memory_type": memory.metadata.preference_type,
+ }
+ for memory_id, memory in zip(pref_ids_local, pref_memories_local, strict=False)
+ ]
+
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(_process_text_mem)
+ pref_future = executor.submit(_process_pref_mem)
+ text_response_data = text_future.result()
+ pref_response_data = pref_future.result()
+
+ logger.info(f"add_memories Text response data: {text_response_data}")
+ logger.info(f"add_memories Pref response data: {pref_response_data}")
- logger.info(
- f"Added {len(mem_id_list)} memories for user {add_req.user_id} "
- f"in session {add_req.session_id}: {mem_id_list}"
- )
- response_data = [
- {
- "memory": memory.memory,
- "memory_id": memory_id,
- "memory_type": memory.metadata.memory_type,
- }
- for memory_id, memory in zip(mem_id_list, flattened_memories, strict=False)
- ]
return MemoryResponse(
message="Memory added successfully",
- data=response_data,
+ data=text_response_data + pref_response_data,
)
+@router.get("/scheduler/status", summary="Get scheduler running status")
+def scheduler_status(user_name: str | None = None):
+ try:
+ if user_name:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: getattr(task, "mem_cube_id", None) == user_name
+ )
+ tasks_iter = list(_to_iter(running))
+ running_count = len(tasks_iter)
+ return {
+ "message": "ok",
+ "data": {
+ "scope": "user",
+ "user_name": user_name,
+ "running_tasks": running_count,
+ "timestamp": time.time(),
+ "instance_id": INSTANCE_ID,
+ },
+ }
+ else:
+ running_all = mem_scheduler.dispatcher.get_running_tasks(lambda _t: True)
+ tasks_iter = list(_to_iter(running_all))
+ running_count = len(tasks_iter)
+
+ task_count_per_user: dict[str, int] = {}
+ for task in tasks_iter:
+ cube = getattr(task, "mem_cube_id", "unknown")
+ task_count_per_user[cube] = task_count_per_user.get(cube, 0) + 1
+
+ try:
+ metrics_snapshot = mem_scheduler.dispatcher.metrics.snapshot()
+ except Exception:
+ metrics_snapshot = {}
+
+ return {
+ "message": "ok",
+ "data": {
+ "scope": "global",
+ "running_tasks": running_count,
+ "task_count_per_user": task_count_per_user,
+ "timestamp": time.time(),
+ "instance_id": INSTANCE_ID,
+ "metrics": metrics_snapshot,
+ },
+ }
+ except Exception as err:
+ logger.error("Failed to get scheduler status: %s", traceback.format_exc())
+ raise HTTPException(status_code=500, detail="Failed to get scheduler status") from err
+
+
+@router.post("/scheduler/wait", summary="Wait until scheduler is idle for a specific user")
+def scheduler_wait(
+ user_name: str,
+ timeout_seconds: float = 120.0,
+ poll_interval: float = 0.2,
+):
+ """
+ Block until scheduler has no running tasks for the given user_name, or timeout.
+ """
+ start = time.time()
+ try:
+ while True:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: task.mem_cube_id == user_name
+ )
+ running_count = len(running)
+ elapsed = time.time() - start
+
+ # success -> scheduler is idle
+ if running_count == 0:
+ return {
+ "message": "idle",
+ "data": {
+ "running_tasks": 0,
+ "waited_seconds": round(elapsed, 3),
+ "timed_out": False,
+ "user_name": user_name,
+ },
+ }
+
+ # timeout check
+ if elapsed > timeout_seconds:
+ return {
+ "message": "timeout",
+ "data": {
+ "running_tasks": running_count,
+ "waited_seconds": round(elapsed, 3),
+ "timed_out": True,
+ "user_name": user_name,
+ },
+ }
+
+ time.sleep(poll_interval)
+
+ except Exception as err:
+ logger.error("Failed while waiting for scheduler: %s", traceback.format_exc())
+ raise HTTPException(status_code=500, detail="Failed while waiting for scheduler") from err
+
+
+@router.get("/scheduler/wait/stream", summary="Stream scheduler progress for a user")
+def scheduler_wait_stream(
+ user_name: str,
+ timeout_seconds: float = 120.0,
+ poll_interval: float = 0.2,
+):
+ """
+ Stream scheduler progress via Server-Sent Events (SSE).
+
+ Contract:
+ - We emit periodic heartbeat frames while tasks are still running.
+ - Each heartbeat frame is JSON, prefixed with "data: ".
+ - On final frame, we include status = "idle" or "timeout" and timed_out flag,
+ with the same semantics as /scheduler/wait.
+
+ Example curl:
+ curl -N "${API_HOST}/product/scheduler/wait/stream?timeout_seconds=10&poll_interval=0.5"
+ """
+
+ def event_generator():
+ start = time.time()
+ try:
+ while True:
+ running = mem_scheduler.dispatcher.get_running_tasks(
+ lambda task: task.mem_cube_id == user_name
+ )
+ running_count = len(running)
+ elapsed = time.time() - start
+
+ payload = {
+ "user_name": user_name,
+ "running_tasks": running_count,
+ "elapsed_seconds": round(elapsed, 3),
+ "status": "running" if running_count > 0 else "idle",
+ "instance_id": INSTANCE_ID,
+ }
+ yield "data: " + json.dumps(payload, ensure_ascii=False) + "\n\n"
+
+ if running_count == 0 or elapsed > timeout_seconds:
+ payload["status"] = "idle" if running_count == 0 else "timeout"
+ payload["timed_out"] = running_count > 0
+ yield "data: " + json.dumps(payload, ensure_ascii=False) + "\n\n"
+ break
+
+ time.sleep(poll_interval)
+
+ except Exception as e:
+ err_payload = {
+ "status": "error",
+ "detail": "stream_failed",
+ "exception": str(e),
+ "user_name": user_name,
+ }
+ logger.error(f"Scheduler stream error for {user_name}: {traceback.format_exc()}")
+ yield "data: " + json.dumps(err_payload, ensure_ascii=False) + "\n\n"
+
+ return StreamingResponse(event_generator(), media_type="text/event-stream")
+
+
@router.post("/chat/complete", summary="Chat with MemOS (Complete Response)")
def chat_complete(chat_req: APIChatCompleteRequest):
"""Chat with MemOS for a specific user. Returns complete response (non-streaming)."""
try:
# Collect all responses from the generator
- naive_mem_cube = _create_naive_mem_cube()
content, references = mos_server.chat(
query=chat_req.query,
user_id=chat_req.user_id,
diff --git a/src/memos/api/server_api.py b/src/memos/api/server_api.py
index 78e05ef85..0dfef99d9 100644
--- a/src/memos/api/server_api.py
+++ b/src/memos/api/server_api.py
@@ -1,6 +1,7 @@
import logging
-from fastapi import FastAPI
+from fastapi import FastAPI, HTTPException
+from fastapi.exceptions import RequestValidationError
from memos.api.exceptions import APIExceptionHandler
from memos.api.middleware.request_context import RequestContextMiddleware
@@ -17,12 +18,17 @@
version="1.0.1",
)
-app.add_middleware(RequestContextMiddleware)
+app.add_middleware(RequestContextMiddleware, source="server_api")
# Include routers
app.include_router(server_router)
-# Exception handlers
+# Request validation failed
+app.exception_handler(RequestValidationError)(APIExceptionHandler.validation_error_handler)
+# Invalid business code parameters
app.exception_handler(ValueError)(APIExceptionHandler.value_error_handler)
+# Business layer manual exception
+app.exception_handler(HTTPException)(APIExceptionHandler.http_error_handler)
+# Fallback for unknown errors
app.exception_handler(Exception)(APIExceptionHandler.global_exception_handler)
diff --git a/src/memos/chunkers/sentence_chunker.py b/src/memos/chunkers/sentence_chunker.py
index 4de0cf32b..080962482 100644
--- a/src/memos/chunkers/sentence_chunker.py
+++ b/src/memos/chunkers/sentence_chunker.py
@@ -28,7 +28,7 @@ def __init__(self, config: SentenceChunkerConfig):
)
logger.info(f"Initialized SentenceChunker with config: {config}")
- def chunk(self, text: str) -> list[Chunk]:
+ def chunk(self, text: str) -> list[str] | list[Chunk]:
"""Chunk the given text into smaller chunks based on sentences."""
chonkie_chunks = self.chunker.chunk(text)
diff --git a/src/memos/configs/graph_db.py b/src/memos/configs/graph_db.py
index 2df917166..ce180606b 100644
--- a/src/memos/configs/graph_db.py
+++ b/src/memos/configs/graph_db.py
@@ -154,6 +154,59 @@ def validate_config(self):
return self
+class PolarDBGraphDBConfig(BaseConfig):
+ """
+ PolarDB-specific configuration.
+
+ Key concepts:
+ - `db_name`: The name of the target PolarDB database
+ - `user_name`: Used for logical tenant isolation if needed
+ - `auto_create`: Whether to automatically create the target database if it does not exist
+ - `use_multi_db`: Whether to use multi-database mode for physical isolation
+
+ Example:
+ ---
+ host = "localhost"
+ port = 5432
+ user = "postgres"
+ password = "password"
+ db_name = "memos_db"
+ user_name = "alice"
+ use_multi_db = True
+ auto_create = True
+ """
+
+ host: str = Field(..., description="Database host")
+ port: int = Field(default=5432, description="Database port")
+ user: str = Field(..., description="Database user")
+ password: str = Field(..., description="Database password")
+ db_name: str = Field(..., description="The name of the target PolarDB database")
+ user_name: str | None = Field(
+ default=None,
+ description="Logical user or tenant ID for data isolation (optional, used in metadata tagging)",
+ )
+ auto_create: bool = Field(
+ default=False,
+ description="Whether to auto-create the database if it does not exist",
+ )
+ use_multi_db: bool = Field(
+ default=True,
+ description=(
+ "If True: use multi-database mode for physical isolation; "
+ "each tenant typically gets a separate database. "
+ "If False: use a single shared database with logical isolation by user_name."
+ ),
+ )
+ embedding_dimension: int = Field(default=1024, description="Dimension of vector embedding")
+
+ @model_validator(mode="after")
+ def validate_config(self):
+ """Validate config."""
+ if not self.db_name:
+ raise ValueError("`db_name` must be provided")
+ return self
+
+
class GraphDBConfigFactory(BaseModel):
backend: str = Field(..., description="Backend for graph database")
config: dict[str, Any] = Field(..., description="Configuration for the graph database backend")
@@ -162,6 +215,7 @@ class GraphDBConfigFactory(BaseModel):
"neo4j": Neo4jGraphDBConfig,
"neo4j-community": Neo4jCommunityGraphDBConfig,
"nebular": NebulaGraphDBConfig,
+ "polardb": PolarDBGraphDBConfig,
}
@field_validator("backend")
diff --git a/src/memos/configs/mem_cube.py b/src/memos/configs/mem_cube.py
index b9868fa99..4bd709fab 100644
--- a/src/memos/configs/mem_cube.py
+++ b/src/memos/configs/mem_cube.py
@@ -54,6 +54,11 @@ class GeneralMemCubeConfig(BaseMemCubeConfig):
default_factory=MemoryConfigFactory,
description="Configuration for the parametric memory",
)
+ pref_mem: MemoryConfigFactory = Field(
+ ...,
+ default_factory=MemoryConfigFactory,
+ description="Configuration for the preference memory",
+ )
@field_validator("text_mem")
@classmethod
@@ -87,3 +92,14 @@ def validate_para_mem(cls, para_mem: MemoryConfigFactory) -> MemoryConfigFactory
f"GeneralMemCubeConfig requires para_mem backend to be one of {allowed_backends}, got '{para_mem.backend}'"
)
return para_mem
+
+ @field_validator("pref_mem")
+ @classmethod
+ def validate_pref_mem(cls, pref_mem: MemoryConfigFactory) -> MemoryConfigFactory:
+ """Validate the pref_mem field."""
+ allowed_backends = ["pref_text", "uninitialized"]
+ if pref_mem.backend not in allowed_backends:
+ raise ConfigurationError(
+ f"GeneralMemCubeConfig requires pref_mem backend to be one of {allowed_backends}, got '{pref_mem.backend}'"
+ )
+ return pref_mem
diff --git a/src/memos/configs/mem_os.py b/src/memos/configs/mem_os.py
index 0645fce44..549e55792 100644
--- a/src/memos/configs/mem_os.py
+++ b/src/memos/configs/mem_os.py
@@ -58,6 +58,10 @@ class MOSConfig(BaseConfig):
default=False,
description="Enable parametric memory for the MemChat",
)
+ enable_preference_memory: bool = Field(
+ default=False,
+ description="Enable preference memory for the MemChat",
+ )
enable_mem_scheduler: bool = Field(
default=False,
description="Enable memory scheduler for automated memory management",
diff --git a/src/memos/configs/mem_reader.py b/src/memos/configs/mem_reader.py
index 1c62087a3..dc8d37a35 100644
--- a/src/memos/configs/mem_reader.py
+++ b/src/memos/configs/mem_reader.py
@@ -36,11 +36,19 @@ def parse_datetime(cls, value):
description="whether remove example in memory extraction prompt to save token",
)
+ chat_chunker: dict[str, Any] = Field(
+ default=None, description="Configuration for the MemReader chat chunk strategy"
+ )
+
class SimpleStructMemReaderConfig(BaseMemReaderConfig):
"""SimpleStruct MemReader configuration class."""
+class StrategyStructMemReaderConfig(BaseMemReaderConfig):
+ """StrategyStruct MemReader configuration class."""
+
+
class MemReaderConfigFactory(BaseConfig):
"""Factory class for creating MemReader configurations."""
@@ -49,6 +57,7 @@ class MemReaderConfigFactory(BaseConfig):
backend_to_class: ClassVar[dict[str, Any]] = {
"simple_struct": SimpleStructMemReaderConfig,
+ "strategy_struct": StrategyStructMemReaderConfig,
}
@field_validator("backend")
diff --git a/src/memos/configs/mem_scheduler.py b/src/memos/configs/mem_scheduler.py
index 39586081c..e757f243b 100644
--- a/src/memos/configs/mem_scheduler.py
+++ b/src/memos/configs/mem_scheduler.py
@@ -11,8 +11,15 @@
from memos.mem_scheduler.schemas.general_schemas import (
BASE_DIR,
DEFAULT_ACT_MEM_DUMP_PATH,
+ DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT,
DEFAULT_CONSUME_INTERVAL_SECONDS,
+ DEFAULT_CONTEXT_WINDOW_SIZE,
+ DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
+ DEFAULT_MULTI_TASK_RUNNING_TIMEOUT,
DEFAULT_THREAD_POOL_MAX_WORKERS,
+ DEFAULT_TOP_K,
+ DEFAULT_USE_REDIS_QUEUE,
+ DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT,
)
@@ -20,7 +27,8 @@ class BaseSchedulerConfig(BaseConfig):
"""Base configuration class for mem_scheduler."""
top_k: int = Field(
- default=10, description="Number of top candidates to consider in initial retrieval"
+ default=DEFAULT_TOP_K,
+ description="Number of top candidates to consider in initial retrieval",
)
enable_parallel_dispatch: bool = Field(
default=True, description="Whether to enable parallel message processing using thread pool"
@@ -28,19 +36,34 @@ class BaseSchedulerConfig(BaseConfig):
thread_pool_max_workers: int = Field(
default=DEFAULT_THREAD_POOL_MAX_WORKERS,
gt=1,
- lt=20,
description=f"Maximum worker threads in pool (default: {DEFAULT_THREAD_POOL_MAX_WORKERS})",
)
consume_interval_seconds: float = Field(
default=DEFAULT_CONSUME_INTERVAL_SECONDS,
gt=0,
- le=60,
description=f"Interval for consuming messages from queue in seconds (default: {DEFAULT_CONSUME_INTERVAL_SECONDS})",
)
auth_config_path: str | None = Field(
default=None,
description="Path to the authentication configuration file containing private credentials",
)
+ # Redis queue configuration
+ use_redis_queue: bool = Field(
+ default=DEFAULT_USE_REDIS_QUEUE,
+ description="Whether to use Redis queue instead of local memory queue",
+ )
+ redis_config: dict[str, Any] = Field(
+ default_factory=lambda: {"host": "localhost", "port": 6379, "db": 0},
+ description="Redis connection configuration",
+ )
+ max_internal_message_queue_size: int = Field(
+ default=DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
+ description="Maximum size of internal message queue when not using Redis",
+ )
+ multi_task_running_timeout: int = Field(
+ default=DEFAULT_MULTI_TASK_RUNNING_TIMEOUT,
+ description="Default timeout for multi-task running operations in seconds",
+ )
class GeneralSchedulerConfig(BaseSchedulerConfig):
@@ -49,7 +72,8 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
default=300, description="Interval in seconds for updating activation memory"
)
context_window_size: int | None = Field(
- default=10, description="Size of the context window for conversation history"
+ default=DEFAULT_CONTEXT_WINDOW_SIZE,
+ description="Size of the context window for conversation history",
)
act_mem_dump_path: str | None = Field(
default=DEFAULT_ACT_MEM_DUMP_PATH, # Replace with DEFAULT_ACT_MEM_DUMP_PATH
@@ -59,10 +83,12 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
default=False, description="Whether to enable automatic activation memory updates"
)
working_mem_monitor_capacity: int = Field(
- default=30, description="Capacity of the working memory monitor"
+ default=DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT,
+ description="Capacity of the working memory monitor",
)
activation_mem_monitor_capacity: int = Field(
- default=20, description="Capacity of the activation memory monitor"
+ default=DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT,
+ description="Capacity of the activation memory monitor",
)
# Database configuration for ORM persistence
@@ -79,6 +105,14 @@ class GeneralSchedulerConfig(BaseSchedulerConfig):
)
+class OptimizedSchedulerConfig(GeneralSchedulerConfig):
+ """Configuration for the optimized scheduler.
+
+ This class inherits all fields from `GeneralSchedulerConfig`
+ and is used to distinguish optimized scheduling logic via type.
+ """
+
+
class SchedulerConfigFactory(BaseConfig):
"""Factory class for creating scheduler configurations."""
@@ -88,7 +122,7 @@ class SchedulerConfigFactory(BaseConfig):
model_config = ConfigDict(extra="forbid", strict=True)
backend_to_class: ClassVar[dict[str, Any]] = {
"general_scheduler": GeneralSchedulerConfig,
- "optimized_scheduler": GeneralSchedulerConfig, # optimized_scheduler uses same config as general_scheduler
+ "optimized_scheduler": OptimizedSchedulerConfig, # optimized_scheduler uses same config as general_scheduler
}
@field_validator("backend")
diff --git a/src/memos/configs/memory.py b/src/memos/configs/memory.py
index 237450e15..34967849a 100644
--- a/src/memos/configs/memory.py
+++ b/src/memos/configs/memory.py
@@ -10,6 +10,11 @@
from memos.configs.reranker import RerankerConfigFactory
from memos.configs.vec_db import VectorDBConfigFactory
from memos.exceptions import ConfigurationError
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
# ─── 1. Global Base Memory Config ─────────────────────────────────────────────
@@ -179,11 +184,62 @@ class TreeTextMemoryConfig(BaseTextMemoryConfig):
),
)
+ search_strategy: dict[str, Any] | None = Field(
+ default=None,
+ description=(
+ 'Set search strategy for this memory configuration.{"bm25": true, "cot": false}'
+ ),
+ )
+
+ mode: str | None = Field(
+ default="sync",
+ description=("whether use asynchronous mode in memory add"),
+ )
+
class SimpleTreeTextMemoryConfig(TreeTextMemoryConfig):
"""Simple tree text memory configuration class."""
+class PreferenceTextMemoryConfig(BaseTextMemoryConfig):
+ """Preference memory configuration class."""
+
+ extractor_llm: LLMConfigFactory = Field(
+ ...,
+ default_factory=LLMConfigFactory,
+ description="LLM configuration for the memory extractor",
+ )
+ vector_db: VectorDBConfigFactory = Field(
+ ...,
+ default_factory=VectorDBConfigFactory,
+ description="Vector database configuration for the memory storage",
+ )
+ embedder: EmbedderConfigFactory = Field(
+ ...,
+ default_factory=EmbedderConfigFactory,
+ description="Embedder configuration for the memory embedding",
+ )
+ reranker: RerankerConfigFactory | None = Field(
+ None,
+ description="Reranker configuration (optional).",
+ )
+ extractor: ExtractorConfigFactory = Field(
+ ...,
+ default_factory=ExtractorConfigFactory,
+ description="Extractor configuration for the memory extracting",
+ )
+ adder: AdderConfigFactory = Field(
+ ...,
+ default_factory=AdderConfigFactory,
+ description="Adder configuration for the memory adding",
+ )
+ retriever: RetrieverConfigFactory = Field(
+ ...,
+ default_factory=RetrieverConfigFactory,
+ description="Retriever configuration for the memory retrieving",
+ )
+
+
# ─── 3. Global Memory Config Factory ──────────────────────────────────────────
@@ -198,6 +254,7 @@ class MemoryConfigFactory(BaseConfig):
"general_text": GeneralTextMemoryConfig,
"simple_tree_text": SimpleTreeTextMemoryConfig,
"tree_text": TreeTextMemoryConfig,
+ "pref_text": PreferenceTextMemoryConfig,
"kv_cache": KVCacheMemoryConfig,
"vllm_kv_cache": KVCacheMemoryConfig, # Use same config as kv_cache
"lora": LoRAMemoryConfig,
diff --git a/src/memos/context/context.py b/src/memos/context/context.py
index 4f54348fb..b5d4c24fe 100644
--- a/src/memos/context/context.py
+++ b/src/memos/context/context.py
@@ -29,9 +29,21 @@ class RequestContext:
This provides a Flask g-like object for FastAPI applications.
"""
- def __init__(self, trace_id: str | None = None, api_path: str | None = None):
+ def __init__(
+ self,
+ trace_id: str | None = None,
+ api_path: str | None = None,
+ env: str | None = None,
+ user_type: str | None = None,
+ user_name: str | None = None,
+ source: str | None = None,
+ ):
self.trace_id = trace_id or "trace-id"
self.api_path = api_path
+ self.env = env
+ self.user_type = user_type
+ self.user_name = user_name
+ self.source = source
self._data: dict[str, Any] = {}
def set(self, key: str, value: Any) -> None:
@@ -43,7 +55,14 @@ def get(self, key: str, default: Any | None = None) -> Any:
return self._data.get(key, default)
def __setattr__(self, name: str, value: Any) -> None:
- if name.startswith("_") or name in ("trace_id", "api_path"):
+ if name.startswith("_") or name in (
+ "trace_id",
+ "api_path",
+ "env",
+ "user_type",
+ "user_name",
+ "source",
+ ):
super().__setattr__(name, value)
else:
if not hasattr(self, "_data"):
@@ -58,7 +77,15 @@ def __getattr__(self, name: str) -> Any:
def to_dict(self) -> dict[str, Any]:
"""Convert context to dictionary."""
- return {"trace_id": self.trace_id, "api_path": self.api_path, "data": self._data.copy()}
+ return {
+ "trace_id": self.trace_id,
+ "api_path": self.api_path,
+ "env": self.env,
+ "user_type": self.user_type,
+ "user_name": self.user_name,
+ "source": self.source,
+ "data": self._data.copy(),
+ }
def set_request_context(context: RequestContext) -> None:
@@ -93,6 +120,46 @@ def get_current_api_path() -> str | None:
return None
+def get_current_env() -> str | None:
+ """
+ Get the current request's env.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("env")
+ return "prod"
+
+
+def get_current_user_type() -> str | None:
+ """
+ Get the current request's user type.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("user_type")
+ return "opensource"
+
+
+def get_current_user_name() -> str | None:
+ """
+ Get the current request's user name.
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("user_name")
+ return "memos"
+
+
+def get_current_source() -> str | None:
+ """
+ Get the current request's source (e.g., 'product_api' or 'server_api').
+ """
+ context = _request_context.get()
+ if context:
+ return context.get("source")
+ return None
+
+
def get_current_context() -> RequestContext | None:
"""
Get the current request context.
@@ -103,7 +170,12 @@ def get_current_context() -> RequestContext | None:
context_dict = _request_context.get()
if context_dict:
ctx = RequestContext(
- trace_id=context_dict.get("trace_id"), api_path=context_dict.get("api_path")
+ trace_id=context_dict.get("trace_id"),
+ api_path=context_dict.get("api_path"),
+ env=context_dict.get("env"),
+ user_type=context_dict.get("user_type"),
+ user_name=context_dict.get("user_name"),
+ source=context_dict.get("source"),
)
ctx._data = context_dict.get("data", {}).copy()
return ctx
@@ -141,6 +213,9 @@ def __init__(self, target, args=(), kwargs=None, **thread_kwargs):
self.main_trace_id = get_current_trace_id()
self.main_api_path = get_current_api_path()
+ self.main_env = get_current_env()
+ self.main_user_type = get_current_user_type()
+ self.main_user_name = get_current_user_name()
self.main_context = get_current_context()
def run(self):
@@ -148,7 +223,11 @@ def run(self):
if self.main_context:
# Copy the context data
child_context = RequestContext(
- trace_id=self.main_trace_id, api_path=self.main_context.api_path
+ trace_id=self.main_trace_id,
+ api_path=self.main_api_path,
+ env=self.main_env,
+ user_type=self.main_user_type,
+ user_name=self.main_user_name,
)
child_context._data = self.main_context._data.copy()
@@ -171,13 +250,22 @@ def submit(self, fn: Callable[..., T], *args: Any, **kwargs: Any) -> Any:
"""
main_trace_id = get_current_trace_id()
main_api_path = get_current_api_path()
+ main_env = get_current_env()
+ main_user_type = get_current_user_type()
+ main_user_name = get_current_user_name()
main_context = get_current_context()
@functools.wraps(fn)
def wrapper(*args: Any, **kwargs: Any) -> Any:
if main_context:
# Create and set new context in worker thread
- child_context = RequestContext(trace_id=main_trace_id, api_path=main_api_path)
+ child_context = RequestContext(
+ trace_id=main_trace_id,
+ api_path=main_api_path,
+ env=main_env,
+ user_type=main_user_type,
+ user_name=main_user_name,
+ )
child_context._data = main_context._data.copy()
set_request_context(child_context)
@@ -198,13 +286,22 @@ def map(
"""
main_trace_id = get_current_trace_id()
main_api_path = get_current_api_path()
+ main_env = get_current_env()
+ main_user_type = get_current_user_type()
+ main_user_name = get_current_user_name()
main_context = get_current_context()
@functools.wraps(fn)
def wrapper(*args: Any, **kwargs: Any) -> Any:
if main_context:
# Create and set new context in worker thread
- child_context = RequestContext(trace_id=main_trace_id, api_path=main_api_path)
+ child_context = RequestContext(
+ trace_id=main_trace_id,
+ api_path=main_api_path,
+ env=main_env,
+ user_type=main_user_type,
+ user_name=main_user_name,
+ )
child_context._data = main_context._data.copy()
set_request_context(child_context)
diff --git a/src/memos/embedders/universal_api.py b/src/memos/embedders/universal_api.py
index 72116cf05..fc51cf073 100644
--- a/src/memos/embedders/universal_api.py
+++ b/src/memos/embedders/universal_api.py
@@ -3,6 +3,11 @@
from memos.configs.embedder import UniversalAPIEmbedderConfig
from memos.embedders.base import BaseEmbedder
+from memos.log import get_logger
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
class UniversalAPIEmbedder(BaseEmbedder):
@@ -19,14 +24,18 @@ def __init__(self, config: UniversalAPIEmbedderConfig):
api_key=config.api_key,
)
else:
- raise ValueError(f"Unsupported provider: {self.provider}")
+ raise ValueError(f"Embeddings unsupported provider: {self.provider}")
+ @timed(log=True, log_prefix="EmbedderAPI")
def embed(self, texts: list[str]) -> list[list[float]]:
if self.provider == "openai" or self.provider == "azure":
- response = self.client.embeddings.create(
- model=getattr(self.config, "model_name_or_path", "text-embedding-3-large"),
- input=texts,
- )
- return [r.embedding for r in response.data]
+ try:
+ response = self.client.embeddings.create(
+ model=getattr(self.config, "model_name_or_path", "text-embedding-3-large"),
+ input=texts,
+ )
+ return [r.embedding for r in response.data]
+ except Exception as e:
+ raise Exception(f"Embeddings request ended with error: {e}") from e
else:
- raise ValueError(f"Unsupported provider: {self.provider}")
+ raise ValueError(f"Embeddings unsupported provider: {self.provider}")
diff --git a/src/memos/graph_dbs/factory.py b/src/memos/graph_dbs/factory.py
index 0b38287eb..ec9cbcda0 100644
--- a/src/memos/graph_dbs/factory.py
+++ b/src/memos/graph_dbs/factory.py
@@ -5,6 +5,7 @@
from memos.graph_dbs.nebular import NebulaGraphDB
from memos.graph_dbs.neo4j import Neo4jGraphDB
from memos.graph_dbs.neo4j_community import Neo4jCommunityGraphDB
+from memos.graph_dbs.polardb import PolarDBGraphDB
class GraphStoreFactory(BaseGraphDB):
@@ -14,6 +15,7 @@ class GraphStoreFactory(BaseGraphDB):
"neo4j": Neo4jGraphDB,
"neo4j-community": Neo4jCommunityGraphDB,
"nebular": NebulaGraphDB,
+ "polardb": PolarDBGraphDB,
}
@classmethod
diff --git a/src/memos/graph_dbs/nebular.py b/src/memos/graph_dbs/nebular.py
index 9a74373d7..89b58f417 100644
--- a/src/memos/graph_dbs/nebular.py
+++ b/src/memos/graph_dbs/nebular.py
@@ -439,21 +439,24 @@ def remove_oldest_memory(
Args:
memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name(str): optional user_name.
"""
- optional_condition = ""
-
- user_name = user_name if user_name else self.config.user_name
-
- optional_condition = f"AND n.user_name = '{user_name}'"
- query = f"""
- MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
- WHERE n.memory_type = '{memory_type}'
- {optional_condition}
- ORDER BY n.updated_at DESC
- OFFSET {int(keep_latest)}
- DETACH DELETE n
- """
- self.execute_query(query)
+ try:
+ user_name = user_name if user_name else self.config.user_name
+ optional_condition = f"AND n.user_name = '{user_name}'"
+ count = self.count_nodes(memory_type, user_name)
+ if count > keep_latest:
+ delete_query = f"""
+ MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
+ WHERE n.memory_type = '{memory_type}'
+ {optional_condition}
+ ORDER BY n.updated_at DESC
+ OFFSET {int(keep_latest)}
+ DETACH DELETE n
+ """
+ self.execute_query(delete_query)
+ except Exception as e:
+ logger.warning(f"Delete old mem error: {e}")
@timed
def add_node(
@@ -683,8 +686,7 @@ def get_node(
Returns:
dict: Node properties as key-value pairs, or None if not found.
"""
- user_name = user_name if user_name else self.config.user_name
- filter_clause = f'n.user_name = "{user_name}" AND n.id = "{id}"'
+ filter_clause = f'n.id = "{id}"'
return_fields = self._build_return_fields(include_embedding)
gql = f"""
MATCH (n@Memory)
@@ -728,16 +730,13 @@ def get_nodes(
"""
if not ids:
return []
-
- user_name = user_name if user_name else self.config.user_name
- where_user = f" AND n.user_name = '{user_name}'"
# Safe formatting of the ID list
id_list = ",".join(f'"{_id}"' for _id in ids)
return_fields = self._build_return_fields(include_embedding)
query = f"""
MATCH (n@Memory /*+ INDEX(idx_memory_user_name) */)
- WHERE n.id IN [{id_list}] {where_user}
+ WHERE n.id IN [{id_list}]
RETURN {return_fields}
"""
nodes = []
@@ -1175,7 +1174,6 @@ def get_grouped_counts(
MATCH (n /*+ INDEX(idx_memory_user_name) */)
{where_clause}
RETURN {", ".join(return_fields)}, COUNT(n) AS count
- GROUP BY {", ".join(group_by_fields)}
"""
result = self.execute_query(gql) # Pure GQL string execution
@@ -1496,10 +1494,10 @@ def _ensure_space_exists(cls, tmp_client, cfg):
return
try:
- res = tmp_client.execute("SHOW GRAPHS;")
+ res = tmp_client.execute("SHOW GRAPHS")
existing = {row.values()[0].as_string() for row in res}
if db_name not in existing:
- tmp_client.execute(f"CREATE GRAPH IF NOT EXISTS `{db_name}` TYPED MemOSBgeM3Type;")
+ tmp_client.execute(f"CREATE GRAPH IF NOT EXISTS `{db_name}` TYPED MemOSBgeM3Type")
logger.info(f"✅ Graph `{db_name}` created before session binding.")
else:
logger.debug(f"Graph `{db_name}` already exists.")
@@ -1550,7 +1548,7 @@ def _ensure_database_exists(self):
"""
self.execute_query(create_tag, auto_set_db=False)
else:
- describe_query = f"DESCRIBE NODE TYPE Memory OF {graph_type_name};"
+ describe_query = f"DESCRIBE NODE TYPE Memory OF {graph_type_name}"
desc_result = self.execute_query(describe_query, auto_set_db=False)
memory_fields = []
@@ -1620,7 +1618,13 @@ def _create_basic_property_indexes(self) -> None:
Create standard B-tree indexes on user_name when use Shared Database
Multi-Tenant Mode.
"""
- fields = ["status", "memory_type", "created_at", "updated_at", "user_name"]
+ fields = [
+ "status",
+ "memory_type",
+ "created_at",
+ "updated_at",
+ "user_name",
+ ]
for field in fields:
index_name = f"idx_memory_{field}"
diff --git a/src/memos/graph_dbs/neo4j.py b/src/memos/graph_dbs/neo4j.py
index 55db60ed2..367b486cd 100644
--- a/src/memos/graph_dbs/neo4j.py
+++ b/src/memos/graph_dbs/neo4j.py
@@ -149,6 +149,7 @@ def remove_oldest_memory(
Args:
memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name(str): optional user_name.
"""
user_name = user_name if user_name else self.config.user_name
query = f"""
@@ -157,7 +158,7 @@ def remove_oldest_memory(
"""
if not self.config.use_multi_db and (self.config.user_name or user_name):
query += f"\nAND n.user_name = '{user_name}'"
-
+ keep_latest = int(keep_latest)
query += f"""
WITH n ORDER BY n.updated_at DESC
SKIP {keep_latest}
@@ -669,7 +670,7 @@ def search_by_embedding(
vector (list[float]): The embedding vector representing query semantics.
top_k (int): Number of top similar nodes to retrieve.
scope (str, optional): Memory type filter (e.g., 'WorkingMemory', 'LongTermMemory').
- status (str, optional): Node status filter (e.g., 'active', 'archived').
+ status (str, optional): Node status filter (e.g., 'activated', 'archived').
If provided, restricts results to nodes with matching status.
threshold (float, optional): Minimum similarity score threshold (0 ~ 1).
search_filter (dict, optional): Additional metadata filters for search results.
@@ -1071,7 +1072,7 @@ def drop_database(self) -> None:
with self.driver.session(database=self.system_db_name) as session:
session.run(f"DROP DATABASE {self.db_name} IF EXISTS")
- print(f"Database '{self.db_name}' has been dropped.")
+ logger.info(f"Database '{self.db_name}' has been dropped.")
else:
raise ValueError(
f"Refusing to drop protected database: {self.db_name} in "
diff --git a/src/memos/graph_dbs/polardb.py b/src/memos/graph_dbs/polardb.py
new file mode 100644
index 000000000..60902420f
--- /dev/null
+++ b/src/memos/graph_dbs/polardb.py
@@ -0,0 +1,3039 @@
+import json
+import random
+
+from datetime import datetime
+from typing import Any, Literal
+
+import numpy as np
+
+from memos.configs.graph_db import PolarDBGraphDBConfig
+from memos.dependency import require_python_package
+from memos.graph_dbs.base import BaseGraphDB
+from memos.log import get_logger
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
+
+
+def _compose_node(item: dict[str, Any]) -> tuple[str, str, dict[str, Any]]:
+ node_id = item["id"]
+ memory = item["memory"]
+ metadata = item.get("metadata", {})
+ return node_id, memory, metadata
+
+
+def _prepare_node_metadata(metadata: dict[str, Any]) -> dict[str, Any]:
+ """
+ Ensure metadata has proper datetime fields and normalized types.
+
+ - Fill `created_at` and `updated_at` if missing (in ISO 8601 format).
+ - Convert embedding to list of float if present.
+ """
+ now = datetime.utcnow().isoformat()
+
+ # Fill timestamps if missing
+ metadata.setdefault("created_at", now)
+ metadata.setdefault("updated_at", now)
+
+ # Normalize embedding type
+ embedding = metadata.get("embedding")
+ if embedding and isinstance(embedding, list):
+ metadata["embedding"] = [float(x) for x in embedding]
+
+ return metadata
+
+
+def generate_vector(dim=1024, low=-0.2, high=0.2):
+ """Generate a random vector for testing purposes."""
+ return [round(random.uniform(low, high), 6) for _ in range(dim)]
+
+
+def find_embedding(metadata):
+ def find_embedding(item):
+ """Find an embedding vector within nested structures"""
+ for key in ["embedding", "embedding_1024", "embedding_3072", "embedding_768"]:
+ if key in item and isinstance(item[key], list):
+ return item[key]
+ if "metadata" in item and key in item["metadata"]:
+ return item["metadata"][key]
+ if "properties" in item and key in item["properties"]:
+ return item["properties"][key]
+ return None
+
+
+def detect_embedding_field(embedding_list):
+ if not embedding_list:
+ return None
+ dim = len(embedding_list)
+ if dim == 1024:
+ return "embedding"
+ else:
+ logger.warning(f"Unknown embedding dimension {dim}, skipping this vector")
+ return None
+
+
+def convert_to_vector(embedding_list):
+ if not embedding_list:
+ return None
+ if isinstance(embedding_list, np.ndarray):
+ embedding_list = embedding_list.tolist()
+ return "[" + ",".join(str(float(x)) for x in embedding_list) + "]"
+
+
+def clean_properties(props):
+ """Remove vector fields"""
+ vector_keys = {"embedding", "embedding_1024", "embedding_3072", "embedding_768"}
+ if not isinstance(props, dict):
+ return {}
+ return {k: v for k, v in props.items() if k not in vector_keys}
+
+
+class PolarDBGraphDB(BaseGraphDB):
+ """PolarDB-based implementation using Apache AGE graph database extension."""
+
+ @require_python_package(
+ import_name="psycopg2",
+ install_command="pip install psycopg2-binary",
+ install_link="https://pypi.org/project/psycopg2-binary/",
+ )
+ def __init__(self, config: PolarDBGraphDBConfig):
+ """PolarDB-based implementation using Apache AGE.
+
+ Tenant Modes:
+ - use_multi_db = True:
+ Dedicated Database Mode (Multi-Database Multi-Tenant).
+ Each tenant or logical scope uses a separate PolarDB database.
+ `db_name` is the specific tenant database.
+ `user_name` can be None (optional).
+
+ - use_multi_db = False:
+ Shared Database Multi-Tenant Mode.
+ All tenants share a single PolarDB database.
+ `db_name` is the shared database.
+ `user_name` is required to isolate each tenant's data at the node level.
+ All node queries will enforce `user_name` in WHERE conditions and store it in metadata,
+ but it will be removed automatically before returning to external consumers.
+ """
+ import psycopg2
+ import psycopg2.pool
+
+ self.config = config
+
+ # Handle both dict and object config
+ if isinstance(config, dict):
+ self.db_name = config.get("db_name")
+ self.user_name = config.get("user_name")
+ host = config.get("host")
+ port = config.get("port")
+ user = config.get("user")
+ password = config.get("password")
+ else:
+ self.db_name = config.db_name
+ self.user_name = config.user_name
+ host = config.host
+ port = config.port
+ user = config.user
+ password = config.password
+ """
+ # Create connection
+ self.connection = psycopg2.connect(
+ host=host, port=port, user=user, password=password, dbname=self.db_name,minconn=10, maxconn=2000
+ )
+ """
+
+ # Create connection pool
+ self.connection_pool = psycopg2.pool.ThreadedConnectionPool(
+ minconn=5,
+ maxconn=2000,
+ host=host,
+ port=port,
+ user=user,
+ password=password,
+ dbname=self.db_name,
+ connect_timeout=60, # Connection timeout in seconds
+ keepalives_idle=40, # Seconds of inactivity before sending keepalive (should be < server idle timeout)
+ keepalives_interval=15, # Seconds between keepalive retries
+ keepalives_count=5, # Number of keepalive retries before considering connection dead
+ )
+
+ # Keep a reference to the pool for cleanup
+ self._pool_closed = False
+
+ """
+ # Handle auto_create
+ # auto_create = config.get("auto_create", False) if isinstance(config, dict) else config.auto_create
+ # if auto_create:
+ # self._ensure_database_exists()
+
+ # Create graph and tables
+ # self.create_graph()
+ # self.create_edge()
+ # self._create_graph()
+
+ # Handle embedding_dimension
+ # embedding_dim = config.get("embedding_dimension", 1024) if isinstance(config,dict) else config.embedding_dimension
+ # self.create_index(dimensions=embedding_dim)
+ """
+
+ def _get_config_value(self, key: str, default=None):
+ """Safely get config value from either dict or object."""
+ if isinstance(self.config, dict):
+ return self.config.get(key, default)
+ else:
+ return getattr(self.config, key, default)
+
+ def _get_connection_old(self):
+ """Get a connection from the pool."""
+ if self._pool_closed:
+ raise RuntimeError("Connection pool has been closed")
+ conn = self.connection_pool.getconn()
+ # Set autocommit for PolarDB compatibility
+ conn.autocommit = True
+ return conn
+
+ def _get_connection(self):
+ """Get a connection from the pool."""
+ if self._pool_closed:
+ raise RuntimeError("Connection pool has been closed")
+
+ max_retries = 3
+ for attempt in range(max_retries):
+ try:
+ conn = self.connection_pool.getconn()
+
+ # Check if connection is closed
+ if conn.closed != 0:
+ # Connection is closed, close it explicitly and try again
+ try:
+ conn.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+ if attempt < max_retries - 1:
+ continue
+ else:
+ raise RuntimeError("Pool returned a closed connection")
+
+ # Set autocommit for PolarDB compatibility
+ conn.autocommit = True
+ return conn
+ except Exception as e:
+ if attempt >= max_retries - 1:
+ raise RuntimeError(f"Failed to get a valid connection from pool: {e}") from e
+ continue
+
+ def _return_connection(self, connection):
+ """Return a connection to the pool."""
+ if not self._pool_closed and connection:
+ try:
+ # Check if connection is closed
+ if hasattr(connection, "closed") and connection.closed != 0:
+ # Connection is closed, just close it and don't return to pool
+ try:
+ connection.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+ return
+
+ # Connection is valid, return to pool
+ self.connection_pool.putconn(connection)
+ except Exception as e:
+ # If putconn fails, close the connection
+ logger.warning(f"Failed to return connection to pool: {e}")
+ try:
+ connection.close()
+ except Exception as e:
+ logger.warning(f"Failed to close connection: {e}")
+
+ def _return_connection_old(self, connection):
+ """Return a connection to the pool."""
+ if not self._pool_closed and connection:
+ self.connection_pool.putconn(connection)
+
+ def _ensure_database_exists(self):
+ """Create database if it doesn't exist."""
+ try:
+ # For PostgreSQL/PolarDB, we need to connect to a default database first
+ # This is a simplified implementation - in production you might want to handle this differently
+ logger.info(f"Using database '{self.db_name}'")
+ except Exception as e:
+ logger.error(f"Failed to access database '{self.db_name}': {e}")
+ raise
+
+ @timed
+ def _create_graph(self):
+ """Create PostgreSQL schema and table for graph storage."""
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Create schema if it doesn't exist
+ cursor.execute(f'CREATE SCHEMA IF NOT EXISTS "{self.db_name}_graph";')
+ logger.info(f"Schema '{self.db_name}_graph' ensured.")
+
+ # Create Memory table if it doesn't exist
+ cursor.execute(f"""
+ CREATE TABLE IF NOT EXISTS "{self.db_name}_graph"."Memory" (
+ id TEXT PRIMARY KEY,
+ properties JSONB NOT NULL,
+ created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
+ updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
+ );
+ """)
+ logger.info(f"Memory table created in schema '{self.db_name}_graph'.")
+
+ # Add embedding column if it doesn't exist (using JSONB for compatibility)
+ try:
+ cursor.execute(f"""
+ ALTER TABLE "{self.db_name}_graph"."Memory"
+ ADD COLUMN IF NOT EXISTS embedding JSONB;
+ """)
+ logger.info("Embedding column added to Memory table.")
+ except Exception as e:
+ logger.warning(f"Failed to add embedding column: {e}")
+
+ # Create indexes
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_properties
+ ON "{self.db_name}_graph"."Memory" USING GIN (properties);
+ """)
+
+ # Create vector index for embedding field
+ try:
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_embedding
+ ON "{self.db_name}_graph"."Memory" USING ivfflat (embedding vector_cosine_ops)
+ WITH (lists = 100);
+ """)
+ logger.info("Vector index created for Memory table.")
+ except Exception as e:
+ logger.warning(f"Vector index creation failed (might not be supported): {e}")
+
+ logger.info("Indexes created for Memory table.")
+
+ except Exception as e:
+ logger.error(f"Failed to create graph schema: {e}")
+ raise e
+ finally:
+ self._return_connection(conn)
+
+ def create_index(
+ self,
+ label: str = "Memory",
+ vector_property: str = "embedding",
+ dimensions: int = 1024,
+ index_name: str = "memory_vector_index",
+ ) -> None:
+ """
+ Create indexes for embedding and other fields.
+ Note: This creates PostgreSQL indexes on the underlying tables.
+ """
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Create indexes on the underlying PostgreSQL tables
+ # Apache AGE stores data in regular PostgreSQL tables
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_properties
+ ON "{self.db_name}_graph"."Memory" USING GIN (properties);
+ """)
+
+ # Try to create vector index, but don't fail if it doesn't work
+ try:
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_memory_embedding
+ ON "{self.db_name}_graph"."Memory" USING ivfflat (embedding vector_cosine_ops);
+ """)
+ except Exception as ve:
+ logger.warning(f"Vector index creation failed (might not be supported): {ve}")
+
+ logger.debug("Indexes created successfully.")
+ except Exception as e:
+ logger.warning(f"Failed to create indexes: {e}")
+ finally:
+ self._return_connection(conn)
+
+ def get_memory_count(self, memory_type: str, user_name: str | None = None) -> int:
+ """Get count of memory nodes by type."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ query = f"""
+ SELECT COUNT(*)
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ """
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params = [self.format_param_value(memory_type), self.format_param_value(user_name)]
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return result[0] if result else 0
+ except Exception as e:
+ logger.error(f"[get_memory_count] Failed: {e}")
+ return -1
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def node_not_exist(self, scope: str, user_name: str | None = None) -> int:
+ """Check if a node with given scope exists."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ query = f"""
+ SELECT id
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ """
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ query += "\nLIMIT 1"
+ params = [self.format_param_value(scope), self.format_param_value(user_name)]
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return 1 if result else 0
+ except Exception as e:
+ logger.error(f"[node_not_exist] Query failed: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def remove_oldest_memory(
+ self, memory_type: str, keep_latest: int, user_name: str | None = None
+ ) -> None:
+ """
+ Remove all WorkingMemory nodes except the latest `keep_latest` entries.
+
+ Args:
+ memory_type (str): Memory type (e.g., 'WorkingMemory', 'LongTermMemory').
+ keep_latest (int): Number of latest WorkingMemory entries to keep.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Use actual OFFSET logic, consistent with nebular.py
+ # First find IDs to delete, then delete them
+ select_query = f"""
+ SELECT id FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"memory_type"'::agtype) = %s::agtype
+ AND ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = %s::agtype
+ ORDER BY ag_catalog.agtype_access_operator(properties, '"updated_at"'::agtype) DESC
+ OFFSET %s
+ """
+ select_params = [
+ self.format_param_value(memory_type),
+ self.format_param_value(user_name),
+ keep_latest,
+ ]
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Execute query to get IDs to delete
+ cursor.execute(select_query, select_params)
+ ids_to_delete = [row[0] for row in cursor.fetchall()]
+
+ if not ids_to_delete:
+ logger.info(f"No {memory_type} memories to remove for user {user_name}")
+ return
+
+ # Build delete query
+ placeholders = ",".join(["%s"] * len(ids_to_delete))
+ delete_query = f"""
+ DELETE FROM "{self.db_name}_graph"."Memory"
+ WHERE id IN ({placeholders})
+ """
+ delete_params = ids_to_delete
+
+ # Execute deletion
+ cursor.execute(delete_query, delete_params)
+ deleted_count = cursor.rowcount
+ logger.info(
+ f"Removed {deleted_count} oldest {memory_type} memories, keeping {keep_latest} latest for user {user_name}"
+ )
+ except Exception as e:
+ logger.error(f"[remove_oldest_memory] Failed: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def update_node(self, id: str, fields: dict[str, Any], user_name: str | None = None) -> None:
+ """
+ Update node fields in PolarDB, auto-converting `created_at` and `updated_at` to datetime type if present.
+ """
+ if not fields:
+ return
+
+ user_name = user_name if user_name else self.config.user_name
+
+ # Get the current node
+ current_node = self.get_node(id, user_name=user_name)
+ if not current_node:
+ return
+
+ # Update properties but keep original id and memory fields
+ properties = current_node["metadata"].copy()
+ original_id = properties.get("id", id) # Preserve original ID
+ original_memory = current_node.get("memory", "") # Preserve original memory
+
+ # If fields include memory, use it; otherwise keep original memory
+ if "memory" in fields:
+ original_memory = fields.pop("memory")
+
+ properties.update(fields)
+ properties["id"] = original_id # Ensure ID is not overwritten
+ properties["memory"] = original_memory # Ensure memory is not overwritten
+
+ # Handle embedding field
+ embedding_vector = None
+ if "embedding" in fields:
+ embedding_vector = fields.pop("embedding")
+ if not isinstance(embedding_vector, list):
+ embedding_vector = None
+
+ # Build update query
+ if embedding_vector is not None:
+ query = f"""
+ UPDATE "{self.db_name}_graph"."Memory"
+ SET properties = %s, embedding = %s
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [
+ json.dumps(properties),
+ json.dumps(embedding_vector),
+ self.format_param_value(id),
+ ]
+ else:
+ query = f"""
+ UPDATE "{self.db_name}_graph"."Memory"
+ SET properties = %s
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [json.dumps(properties), self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ except Exception as e:
+ logger.error(f"[update_node] Failed to update node '{id}': {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def delete_node(self, id: str, user_name: str | None = None) -> None:
+ """
+ Delete a node from the graph.
+ Args:
+ id: Node identifier to delete.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ query = f"""
+ DELETE FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ except Exception as e:
+ logger.error(f"[delete_node] Failed to delete node '{id}': {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_extension(self):
+ extensions = [("polar_age", "Graph engine"), ("vector", "Vector engine")]
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Ensure in the correct database context
+ cursor.execute("SELECT current_database();")
+ current_db = cursor.fetchone()[0]
+ logger.info(f"Current database context: {current_db}")
+
+ for ext_name, ext_desc in extensions:
+ try:
+ cursor.execute(f"create extension if not exists {ext_name};")
+ logger.info(f"Extension '{ext_name}' ({ext_desc}) ensured.")
+ except Exception as e:
+ if "already exists" in str(e):
+ logger.info(f"Extension '{ext_name}' ({ext_desc}) already exists.")
+ else:
+ logger.warning(
+ f"Failed to create extension '{ext_name}' ({ext_desc}): {e}"
+ )
+ logger.error(
+ f"Failed to create extension '{ext_name}': {e}", exc_info=True
+ )
+ except Exception as e:
+ logger.warning(f"Failed to access database context: {e}")
+ logger.error(f"Failed to access database context: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_graph(self):
+ # Get a connection from the pool
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(f"""
+ SELECT COUNT(*) FROM ag_catalog.ag_graph
+ WHERE name = '{self.db_name}_graph';
+ """)
+ graph_exists = cursor.fetchone()[0] > 0
+
+ if graph_exists:
+ logger.info(f"Graph '{self.db_name}_graph' already exists.")
+ else:
+ cursor.execute(f"select create_graph('{self.db_name}_graph');")
+ logger.info(f"Graph database '{self.db_name}_graph' created.")
+ except Exception as e:
+ logger.warning(f"Failed to create graph '{self.db_name}_graph': {e}")
+ logger.error(f"Failed to create graph '{self.db_name}_graph': {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def create_edge(self):
+ """Create all valid edge types if they do not exist"""
+
+ valid_rel_types = {"AGGREGATE_TO", "FOLLOWS", "INFERS", "MERGED_TO", "RELATE_TO", "PARENT"}
+
+ for label_name in valid_rel_types:
+ print(f"🪶 Creating elabel: {label_name}")
+ conn = self._get_connection()
+ logger.info(f"Creating elabel: {label_name}")
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(f"select create_elabel('{self.db_name}_graph', '{label_name}');")
+ logger.info(f"Successfully created elabel: {label_name}")
+ except Exception as e:
+ if "already exists" in str(e):
+ logger.info(f"Label '{label_name}' already exists, skipping.")
+ else:
+ logger.warning(f"Failed to create label {label_name}: {e}")
+ logger.error(f"Failed to create elabel '{label_name}': {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def add_edge(
+ self, source_id: str, target_id: str, type: str, user_name: str | None = None
+ ) -> None:
+ if not source_id or not target_id:
+ raise ValueError("[add_edge] source_id and target_id must be provided")
+
+ source_exists = self.get_node(source_id) is not None
+ target_exists = self.get_node(target_id) is not None
+
+ if not source_exists or not target_exists:
+ raise ValueError("[add_edge] source_id and target_id must be provided")
+
+ properties = {}
+ if user_name is not None:
+ properties["user_name"] = user_name
+ query = f"""
+ INSERT INTO {self.db_name}_graph."{type}"(id, start_id, end_id, properties)
+ SELECT
+ ag_catalog._next_graph_id('{self.db_name}_graph'::name, '{type}'),
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{source_id}'::text::cstring),
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{target_id}'::text::cstring),
+ jsonb_build_object('user_name', '{user_name}')::text::agtype
+ WHERE NOT EXISTS (
+ SELECT 1 FROM {self.db_name}_graph."{type}"
+ WHERE start_id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{source_id}'::text::cstring)
+ AND end_id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, '{target_id}'::text::cstring)
+ );
+ """
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, (source_id, target_id, type, json.dumps(properties)))
+ logger.info(f"Edge created: {source_id} -[{type}]-> {target_id}")
+ except Exception as e:
+ logger.error(f"Failed to insert edge: {e}", exc_info=True)
+ raise
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def delete_edge(self, source_id: str, target_id: str, type: str) -> None:
+ """
+ Delete a specific edge between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type to remove.
+ """
+ query = f"""
+ DELETE FROM "{self.db_name}_graph"."Edges"
+ WHERE source_id = %s AND target_id = %s AND edge_type = %s
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, (source_id, target_id, type))
+ logger.info(f"Edge deleted: {source_id} -[{type}]-> {target_id}")
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def edge_exists_old(
+ self, source_id: str, target_id: str, type: str = "ANY", direction: str = "OUTGOING"
+ ) -> bool:
+ """
+ Check if an edge exists between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type. Use "ANY" to match any relationship type.
+ direction: Direction of the edge.
+ Use "OUTGOING" (default), "INCOMING", or "ANY".
+ Returns:
+ True if the edge exists, otherwise False.
+ """
+ where_clauses = []
+ params = []
+ # SELECT * FROM
+ # cypher('memtensor_memos_graph', $$
+ # MATCH(a: Memory
+ # {id: "13bb9df6-0609-4442-8bed-bba77dadac92"})-[r] - (b:Memory {id: "2dd03a5b-5d5f-49c9-9e0a-9a2a2899b98d"})
+ # RETURN
+ # r
+ # $$) AS(r
+ # agtype);
+
+ if direction == "OUTGOING":
+ where_clauses.append("source_id = %s AND target_id = %s")
+ params.extend([source_id, target_id])
+ elif direction == "INCOMING":
+ where_clauses.append("source_id = %s AND target_id = %s")
+ params.extend([target_id, source_id])
+ elif direction == "ANY":
+ where_clauses.append(
+ "((source_id = %s AND target_id = %s) OR (source_id = %s AND target_id = %s))"
+ )
+ params.extend([source_id, target_id, target_id, source_id])
+ else:
+ raise ValueError(
+ f"Invalid direction: {direction}. Must be 'OUTGOING', 'INCOMING', or 'ANY'."
+ )
+
+ if type != "ANY":
+ where_clauses.append("edge_type = %s")
+ params.append(type)
+
+ where_clause = " AND ".join(where_clauses)
+
+ query = f"""
+ SELECT 1 FROM "{self.db_name}_graph"."Edges"
+ WHERE {where_clause}
+ LIMIT 1
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+ return result is not None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def edge_exists(
+ self,
+ source_id: str,
+ target_id: str,
+ type: str = "ANY",
+ direction: str = "OUTGOING",
+ user_name: str | None = None,
+ ) -> bool:
+ """
+ Check if an edge exists between two nodes.
+ Args:
+ source_id: ID of the source node.
+ target_id: ID of the target node.
+ type: Relationship type. Use "ANY" to match any relationship type.
+ direction: Direction of the edge.
+ Use "OUTGOING" (default), "INCOMING", or "ANY".
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ Returns:
+ True if the edge exists, otherwise False.
+ """
+
+ # Prepare the relationship pattern
+ user_name = user_name if user_name else self.config.user_name
+
+ # Prepare the match pattern with direction
+ if direction == "OUTGOING":
+ pattern = "(a:Memory)-[r]->(b:Memory)"
+ elif direction == "INCOMING":
+ pattern = "(a:Memory)<-[r]-(b:Memory)"
+ elif direction == "ANY":
+ pattern = "(a:Memory)-[r]-(b:Memory)"
+ else:
+ raise ValueError(
+ f"Invalid direction: {direction}. Must be 'OUTGOING', 'INCOMING', or 'ANY'."
+ )
+ query = f"SELECT * FROM cypher('{self.db_name}_graph', $$"
+ query += f"\nMATCH {pattern}"
+ query += f"\nWHERE a.user_name = '{user_name}' AND b.user_name = '{user_name}'"
+ query += f"\nAND a.id = '{source_id}' AND b.id = '{target_id}'"
+ if type != "ANY":
+ query += f"\n AND type(r) = '{type}'"
+
+ query += "\nRETURN r"
+ query += "\n$$) AS (r agtype)"
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ result = cursor.fetchone()
+ return result is not None and result[0] is not None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_node(
+ self, id: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> dict[str, Any] | None:
+ """
+ Retrieve a Memory node by its unique ID.
+
+ Args:
+ id (str): Node ID (Memory.id)
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ dict: Node properties as key-value pairs, or None if not found.
+ """
+
+ select_fields = "id, properties, embedding" if include_embedding else "id, properties"
+
+ query = f"""
+ SELECT {select_fields}
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"id"'::agtype) = %s::agtype
+ """
+ params = [self.format_param_value(id)]
+
+ # Only add user filter when user_name is provided
+ if user_name is not None:
+ query += "\nAND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ result = cursor.fetchone()
+
+ if result:
+ if include_embedding:
+ _, properties_json, embedding_json = result
+ else:
+ _, properties_json = result
+ embedding_json = None
+
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse properties for node {id}")
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding from JSONB if it exists and include_embedding is True
+ if include_embedding and embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {id}")
+
+ return self._parse_node(
+ {
+ "id": id,
+ "memory": properties.get("memory", ""),
+ **properties,
+ }
+ )
+ return None
+
+ except Exception as e:
+ logger.error(f"[get_node] Failed to retrieve node '{id}': {e}", exc_info=True)
+ return None
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_nodes(
+ self, ids: list[str], user_name: str | None = None, **kwargs
+ ) -> list[dict[str, Any]]:
+ """
+ Retrieve the metadata and memory of a list of nodes.
+ Args:
+ ids: List of Node identifier.
+ Returns:
+ list[dict]: Parsed node records containing 'id', 'memory', and 'metadata'.
+
+ Notes:
+ - Assumes all provided IDs are valid and exist.
+ - Returns empty list if input is empty.
+ """
+ if not ids:
+ return []
+
+ # Build WHERE clause using agtype_access_operator like get_node method
+ where_conditions = []
+ params = []
+
+ for id_val in ids:
+ where_conditions.append(
+ "ag_catalog.agtype_access_operator(properties, '\"id\"'::agtype) = %s::agtype"
+ )
+ params.append(self.format_param_value(id_val))
+
+ where_clause = " OR ".join(where_conditions)
+
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ({where_clause})
+ """
+
+ user_name = user_name if user_name else self.config.user_name
+ query += " AND ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ params.append(self.format_param_value(user_name))
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse properties for node {node_id}")
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding from JSONB if it exists
+ if embedding_json is not None:
+ try:
+ # remove embedding
+ """
+ embedding = json.loads(embedding_json) if isinstance(embedding_json, str) else embedding_json
+ # properties["embedding"] = embedding
+ """
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+ nodes.append(
+ self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ )
+ return nodes
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_edges_old(
+ self, id: str, type: str = "ANY", direction: str = "ANY"
+ ) -> list[dict[str, str]]:
+ """
+ Get edges connected to a node, with optional type and direction filter.
+
+ Args:
+ id: Node ID to retrieve edges for.
+ type: Relationship type to match, or 'ANY' to match all.
+ direction: 'OUTGOING', 'INCOMING', or 'ANY'.
+
+ Returns:
+ List of edges:
+ [
+ {"from": "source_id", "to": "target_id", "type": "RELATE"},
+ ...
+ ]
+ """
+
+ # Create a simple edge table to store relationships (if not exists)
+ try:
+ with self.connection.cursor() as cursor:
+ # Create edge table
+ cursor.execute(f"""
+ CREATE TABLE IF NOT EXISTS "{self.db_name}_graph"."Edges" (
+ id SERIAL PRIMARY KEY,
+ source_id TEXT NOT NULL,
+ target_id TEXT NOT NULL,
+ edge_type TEXT NOT NULL,
+ properties JSONB,
+ created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
+ FOREIGN KEY (source_id) REFERENCES "{self.db_name}_graph"."Memory"(id),
+ FOREIGN KEY (target_id) REFERENCES "{self.db_name}_graph"."Memory"(id)
+ );
+ """)
+
+ # Create indexes
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_source
+ ON "{self.db_name}_graph"."Edges" (source_id);
+ """)
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_target
+ ON "{self.db_name}_graph"."Edges" (target_id);
+ """)
+ cursor.execute(f"""
+ CREATE INDEX IF NOT EXISTS idx_edges_type
+ ON "{self.db_name}_graph"."Edges" (edge_type);
+ """)
+ except Exception as e:
+ logger.warning(f"Failed to create edges table: {e}")
+
+ # Query edges
+ where_clauses = []
+ params = [id]
+
+ if type != "ANY":
+ where_clauses.append("edge_type = %s")
+ params.append(type)
+
+ if direction == "OUTGOING":
+ where_clauses.append("source_id = %s")
+ elif direction == "INCOMING":
+ where_clauses.append("target_id = %s")
+ else: # ANY
+ where_clauses.append("(source_id = %s OR target_id = %s)")
+ params.append(id) # Add second parameter for ANY direction
+
+ where_clause = " AND ".join(where_clauses)
+
+ query = f"""
+ SELECT source_id, target_id, edge_type
+ FROM "{self.db_name}_graph"."Edges"
+ WHERE {where_clause}
+ """
+
+ with self.connection.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ edges = []
+ for row in results:
+ source_id, target_id, edge_type = row
+ edges.append({"from": source_id, "to": target_id, "type": edge_type})
+ return edges
+
+ def get_neighbors(
+ self, id: str, type: str, direction: Literal["in", "out", "both"] = "out"
+ ) -> list[str]:
+ """Get connected node IDs in a specific direction and relationship type."""
+ raise NotImplementedError
+
+ @timed
+ def get_neighbors_by_tag_old(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ # Build query conditions
+ where_clauses = []
+ params = []
+
+ # Exclude specified IDs
+ if exclude_ids:
+ placeholders = ",".join(["%s"] * len(exclude_ids))
+ where_clauses.append(f"id NOT IN ({placeholders})")
+ params.extend(exclude_ids)
+
+ # Status filter
+ where_clauses.append("properties->>'status' = %s")
+ params.append("activated")
+
+ # Type filter
+ where_clauses.append("properties->>'type' != %s")
+ params.append("reasoning")
+
+ where_clauses.append("properties->>'memory_type' != %s")
+ params.append("WorkingMemory")
+
+ # User filter
+ if not self._get_config_value("use_multi_db", True) and self._get_config_value("user_name"):
+ where_clauses.append("properties->>'user_name' = %s")
+ params.append(self._get_config_value("user_name"))
+
+ where_clause = " AND ".join(where_clauses)
+
+ # Get all candidate nodes
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE {where_clause}
+ """
+
+ with self.connection.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes_with_overlap = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding
+ if embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+
+ # Compute tag overlap
+ node_tags = properties.get("tags", [])
+ if isinstance(node_tags, str):
+ try:
+ node_tags = json.loads(node_tags)
+ except (json.JSONDecodeError, TypeError):
+ node_tags = []
+
+ overlap_tags = [tag for tag in tags if tag in node_tags]
+ overlap_count = len(overlap_tags)
+
+ if overlap_count >= min_overlap:
+ node_data = self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ nodes_with_overlap.append((node_data, overlap_count))
+
+ # Sort by overlap count and return top_k
+ nodes_with_overlap.sort(key=lambda x: x[1], reverse=True)
+ return [node for node, _ in nodes_with_overlap[:top_k]]
+
+ @timed
+ def get_children_with_embeddings(
+ self, id: str, user_name: str | None = None
+ ) -> list[dict[str, Any]]:
+ """Get children nodes with their embeddings."""
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ where_user = f"AND p.user_name = '{user_name}' AND c.user_name = '{user_name}'"
+
+ query = f"""
+ WITH t as (
+ SELECT *
+ FROM cypher('{self.db_name}_graph', $$
+ MATCH (p:Memory)-[r:PARENT]->(c:Memory)
+ WHERE p.id = '{id}' {where_user}
+ RETURN id(c) as cid, c.id AS id, c.memory AS memory
+ $$) as (cid agtype, id agtype, memory agtype)
+ )
+ SELECT t.id, m.embedding, t.memory FROM t,
+ "{self.db_name}_graph"."Memory" m
+ WHERE t.cid::graphid = m.id;
+ """
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ children = []
+ for row in results:
+ # Handle child_id - remove possible quotes
+ child_id_raw = row[0].value if hasattr(row[0], "value") else str(row[0])
+ if isinstance(child_id_raw, str):
+ # If string starts and ends with quotes, remove quotes
+ if child_id_raw.startswith('"') and child_id_raw.endswith('"'):
+ child_id = child_id_raw[1:-1]
+ else:
+ child_id = child_id_raw
+ else:
+ child_id = str(child_id_raw)
+
+ # Handle embedding - get from database embedding column
+ embedding_raw = row[1]
+ embedding = []
+ if embedding_raw is not None:
+ try:
+ if isinstance(embedding_raw, str):
+ # If it is a JSON string, parse it
+ embedding = json.loads(embedding_raw)
+ elif isinstance(embedding_raw, list):
+ # If already a list, use directly
+ embedding = embedding_raw
+ else:
+ # Try converting to list
+ embedding = list(embedding_raw)
+ except (json.JSONDecodeError, TypeError, ValueError) as e:
+ logger.warning(
+ f"Failed to parse embedding for child node {child_id}: {e}"
+ )
+ embedding = []
+
+ # Handle memory - remove possible quotes
+ memory_raw = row[2].value if hasattr(row[2], "value") else str(row[2])
+ if isinstance(memory_raw, str):
+ # If string starts and ends with quotes, remove quotes
+ if memory_raw.startswith('"') and memory_raw.endswith('"'):
+ memory = memory_raw[1:-1]
+ else:
+ memory = memory_raw
+ else:
+ memory = str(memory_raw)
+
+ children.append({"id": child_id, "embedding": embedding, "memory": memory})
+
+ return children
+
+ except Exception as e:
+ logger.error(f"[get_children_with_embeddings] Failed: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def get_path(self, source_id: str, target_id: str, max_depth: int = 3) -> list[str]:
+ """Get the path of nodes from source to target within a limited depth."""
+ raise NotImplementedError
+
+ @timed
+ def get_subgraph(
+ self,
+ center_id: str,
+ depth: int = 2,
+ center_status: str = "activated",
+ user_name: str | None = None,
+ ) -> dict[str, Any]:
+ """
+ Retrieve a local subgraph centered at a given node.
+ Args:
+ center_id: The ID of the center node.
+ depth: The hop distance for neighbors.
+ center_status: Required status for center node.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ Returns:
+ {
+ "core_node": {...},
+ "neighbors": [...],
+ "edges": [...]
+ }
+ """
+ if not 1 <= depth <= 5:
+ raise ValueError("depth must be 1-5")
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ if center_id.startswith('"') and center_id.endswith('"'):
+ center_id = center_id[1:-1]
+ # Use a simplified query to get the subgraph (temporarily only direct neighbors)
+ """
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH(center: Memory)-[r * 1..{depth}]->(neighbor:Memory)
+ WHERE
+ center.id = '{center_id}'
+ AND center.status = '{center_status}'
+ AND center.user_name = '{user_name}'
+ RETURN
+ collect(DISTINCT
+ center), collect(DISTINCT
+ neighbor), collect(DISTINCT
+ r)
+ $$ ) as (centers agtype, neighbors agtype, rels agtype);
+ """
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH(center: Memory)-[r * 1..{depth}]->(neighbor:Memory)
+ WHERE
+ center.id = '{center_id}'
+ AND center.status = '{center_status}'
+ AND center.user_name = '{user_name}'
+ RETURN
+ collect(DISTINCT
+ center), collect(DISTINCT
+ neighbor), collect(DISTINCT
+ r)
+ $$ ) as (centers agtype, neighbors agtype, rels agtype);
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ result = cursor.fetchone()
+
+ if not result or not result[0]:
+ return {"core_node": None, "neighbors": [], "edges": []}
+
+ # Parse center node
+ centers_data = result[0] if result[0] else "[]"
+ neighbors_data = result[1] if result[1] else "[]"
+ edges_data = result[2] if result[2] else "[]"
+
+ # Parse JSON data
+ try:
+ # Clean ::vertex and ::edge suffixes in data
+ if isinstance(centers_data, str):
+ centers_data = centers_data.replace("::vertex", "")
+ if isinstance(neighbors_data, str):
+ neighbors_data = neighbors_data.replace("::vertex", "")
+ if isinstance(edges_data, str):
+ edges_data = edges_data.replace("::edge", "")
+
+ centers_list = (
+ json.loads(centers_data) if isinstance(centers_data, str) else centers_data
+ )
+ neighbors_list = (
+ json.loads(neighbors_data)
+ if isinstance(neighbors_data, str)
+ else neighbors_data
+ )
+ edges_list = (
+ json.loads(edges_data) if isinstance(edges_data, str) else edges_data
+ )
+ except json.JSONDecodeError as e:
+ logger.error(f"Failed to parse JSON data: {e}")
+ return {"core_node": None, "neighbors": [], "edges": []}
+
+ # Parse center node
+ core_node = None
+ if centers_list and len(centers_list) > 0:
+ center_data = centers_list[0]
+ if isinstance(center_data, dict) and "properties" in center_data:
+ core_node = self._parse_node(center_data["properties"])
+
+ # Parse neighbor nodes
+ neighbors = []
+ if isinstance(neighbors_list, list):
+ for neighbor_data in neighbors_list:
+ if isinstance(neighbor_data, dict) and "properties" in neighbor_data:
+ neighbor_parsed = self._parse_node(neighbor_data["properties"])
+ neighbors.append(neighbor_parsed)
+
+ # Parse edges
+ edges = []
+ if isinstance(edges_list, list):
+ for edge_group in edges_list:
+ if isinstance(edge_group, list):
+ for edge_data in edge_group:
+ if isinstance(edge_data, dict):
+ edges.append(
+ {
+ "type": edge_data.get("label", ""),
+ "source": edge_data.get("start_id", ""),
+ "target": edge_data.get("end_id", ""),
+ }
+ )
+
+ return self._convert_graph_edges(
+ {"core_node": core_node, "neighbors": neighbors, "edges": edges}
+ )
+
+ except Exception as e:
+ logger.error(f"Failed to get subgraph: {e}", exc_info=True)
+ return {"core_node": None, "neighbors": [], "edges": []}
+ finally:
+ self._return_connection(conn)
+
+ def get_context_chain(self, id: str, type: str = "FOLLOWS") -> list[str]:
+ """Get the ordered context chain starting from a node."""
+ raise NotImplementedError
+
+ @timed
+ def search_by_embedding(
+ self,
+ vector: list[float],
+ top_k: int = 5,
+ scope: str | None = None,
+ status: str | None = None,
+ threshold: float | None = None,
+ search_filter: dict | None = None,
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[dict]:
+ """
+ Retrieve node IDs based on vector similarity using PostgreSQL vector operations.
+ """
+ # Build WHERE clause dynamically like nebular.py
+ where_clauses = []
+ if scope:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"memory_type\"'::agtype) = '\"{scope}\"'::agtype"
+ )
+ if status:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"{status}\"'::agtype"
+ )
+ else:
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"activated\"'::agtype"
+ )
+ where_clauses.append("embedding is not null")
+ # Add user_name filter like nebular.py
+
+ """
+ # user_name = self._get_config_value("user_name")
+ # if not self.config.use_multi_db and user_name:
+ # if kwargs.get("cube_name"):
+ # where_clauses.append(f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{kwargs['cube_name']}\"'::agtype")
+ # else:
+ # where_clauses.append(f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype")
+ """
+ user_name = user_name if user_name else self.config.user_name
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype"
+ )
+
+ # Add search_filter conditions like nebular.py
+ if search_filter:
+ for key, value in search_filter.items():
+ if isinstance(value, str):
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{key}\"'::agtype) = '\"{value}\"'::agtype"
+ )
+ else:
+ where_clauses.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{key}\"'::agtype) = {value}::agtype"
+ )
+
+ where_clause = f"WHERE {' AND '.join(where_clauses)}" if where_clauses else ""
+
+ # Keep original simple query structure but add dynamic WHERE clause
+ query = f"""
+ WITH t AS (
+ SELECT id,
+ properties,
+ timeline,
+ ag_catalog.agtype_access_operator(properties, '"id"'::agtype) AS old_id,
+ (1 - (embedding <=> %s::vector(1024))) AS scope
+ FROM "{self.db_name}_graph"."Memory"
+ {where_clause}
+ ORDER BY scope DESC
+ LIMIT {top_k}
+ )
+ SELECT *
+ FROM t
+ WHERE scope > 0.1;
+ """
+ params = [vector]
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+ output = []
+ for row in results:
+ """
+ polarId = row[0] # id
+ properties = row[1] # properties
+ # embedding = row[3] # embedding
+ """
+ oldid = row[3] # old_id
+ score = row[4] # scope
+ id_val = str(oldid)
+ score_val = float(score)
+ score_val = (score_val + 1) / 2 # align to neo4j, Normalized Cosine Score
+ if threshold is None or score_val >= threshold:
+ output.append({"id": id_val, "score": score_val})
+ return output[:top_k]
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_by_metadata(
+ self, filters: list[dict[str, Any]], user_name: str | None = None
+ ) -> list[str]:
+ """
+ Retrieve node IDs that match given metadata filters.
+ Supports exact match.
+
+ Args:
+ filters: List of filter dicts like:
+ [
+ {"field": "key", "op": "in", "value": ["A", "B"]},
+ {"field": "confidence", "op": ">=", "value": 80},
+ {"field": "tags", "op": "contains", "value": "AI"},
+ ...
+ ]
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[str]: Node IDs whose metadata match the filter conditions. (AND logic).
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build WHERE conditions for cypher query
+ where_conditions = []
+
+ for f in filters:
+ field = f["field"]
+ op = f.get("op", "=")
+ value = f["value"]
+
+ # Format value
+ if isinstance(value, str):
+ # Escape single quotes in string values
+ escaped_str = value.replace("'", "''")
+ escaped_value = f"'{escaped_str}'"
+ elif isinstance(value, list):
+ # Handle list values - use double quotes for Cypher arrays
+ list_items = []
+ for v in value:
+ if isinstance(v, str):
+ # Escape double quotes in string values for Cypher
+ escaped_str = v.replace('"', '\\"')
+ list_items.append(f'"{escaped_str}"')
+ else:
+ list_items.append(str(v))
+ escaped_value = f"[{', '.join(list_items)}]"
+ else:
+ escaped_value = f"'{value}'" if isinstance(value, str) else str(value)
+ # Build WHERE conditions
+ if op == "=":
+ where_conditions.append(f"n.{field} = {escaped_value}")
+ elif op == "in":
+ where_conditions.append(f"n.{field} IN {escaped_value}")
+ """
+ # where_conditions.append(f"{escaped_value} IN n.{field}")
+ """
+ elif op == "contains":
+ where_conditions.append(f"{escaped_value} IN n.{field}")
+ """
+ # where_conditions.append(f"size(filter(n.{field}, t -> t IN {escaped_value})) > 0")
+ """
+ elif op == "starts_with":
+ where_conditions.append(f"n.{field} STARTS WITH {escaped_value}")
+ elif op == "ends_with":
+ where_conditions.append(f"n.{field} ENDS WITH {escaped_value}")
+ elif op in [">", ">=", "<", "<="]:
+ where_conditions.append(f"n.{field} {op} {escaped_value}")
+ else:
+ raise ValueError(f"Unsupported operator: {op}")
+
+ # Add user_name filter
+ escaped_user_name = user_name.replace("'", "''")
+ where_conditions.append(f"n.user_name = '{escaped_user_name}'")
+
+ where_str = " AND ".join(where_conditions)
+
+ # Use cypher query
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE {where_str}
+ RETURN n.id AS id
+ $$) AS (id agtype)
+ """
+
+ ids = []
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+ ids = [str(item[0]).strip('"') for item in results]
+ except Exception as e:
+ logger.error(f"Failed to get metadata: {e}, query is {cypher_query}")
+ finally:
+ self._return_connection(conn)
+
+ return ids
+
+ @timed
+ def get_grouped_counts1(
+ self,
+ group_fields: list[str],
+ where_clause: str = "",
+ params: dict[str, Any] | None = None,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Count nodes grouped by any fields.
+
+ Args:
+ group_fields (list[str]): Fields to group by, e.g., ["memory_type", "status"]
+ where_clause (str, optional): Extra WHERE condition. E.g.,
+ "WHERE n.status = 'activated'"
+ params (dict, optional): Parameters for WHERE clause.
+
+ Returns:
+ list[dict]: e.g., [{ 'memory_type': 'WorkingMemory', 'status': 'active', 'count': 10 }, ...]
+ """
+ user_name = user_name if user_name else self.config.user_name
+ if not group_fields:
+ raise ValueError("group_fields cannot be empty")
+
+ final_params = params.copy() if params else {}
+ if not self.config.use_multi_db and (self.config.user_name or user_name):
+ user_clause = "n.user_name = $user_name"
+ final_params["user_name"] = user_name
+ if where_clause:
+ where_clause = where_clause.strip()
+ if where_clause.upper().startswith("WHERE"):
+ where_clause += f" AND {user_clause}"
+ else:
+ where_clause = f"WHERE {where_clause} AND {user_clause}"
+ else:
+ where_clause = f"WHERE {user_clause}"
+ # Force RETURN field AS field to guarantee key match
+ group_fields_cypher = ", ".join([f"n.{field} AS {field}" for field in group_fields])
+ """
+ # group_fields_cypher_polardb = "agtype, ".join([f"{field}" for field in group_fields])
+ """
+ group_fields_cypher_polardb = ", ".join([f"{field} agtype" for field in group_fields])
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ {where_clause}
+ RETURN {group_fields_cypher}, COUNT(n) AS count1
+ $$ ) as ({group_fields_cypher_polardb}, count1 agtype);
+ """
+ try:
+ with self.connection.cursor() as cursor:
+ # Handle parameterized query
+ if params and isinstance(params, list):
+ cursor.execute(query, final_params)
+ else:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ output = []
+ for row in results:
+ group_values = {}
+ for i, field in enumerate(group_fields):
+ value = row[i]
+ if hasattr(value, "value"):
+ group_values[field] = value.value
+ else:
+ group_values[field] = str(value)
+ count_value = row[-1] # Last column is count
+ output.append({**group_values, "count": count_value})
+
+ return output
+
+ except Exception as e:
+ logger.error(f"Failed to get grouped counts: {e}", exc_info=True)
+ return []
+
+ @timed
+ def get_grouped_counts(
+ self,
+ group_fields: list[str],
+ where_clause: str = "",
+ params: dict[str, Any] | None = None,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Count nodes grouped by any fields.
+
+ Args:
+ group_fields (list[str]): Fields to group by, e.g., ["memory_type", "status"]
+ where_clause (str, optional): Extra WHERE condition. E.g.,
+ "WHERE n.status = 'activated'"
+ params (dict, optional): Parameters for WHERE clause.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: e.g., [{ 'memory_type': 'WorkingMemory', 'status': 'active', 'count': 10 }, ...]
+ """
+ if not group_fields:
+ raise ValueError("group_fields cannot be empty")
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build user clause
+ user_clause = f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype"
+ if where_clause:
+ where_clause = where_clause.strip()
+ if where_clause.upper().startswith("WHERE"):
+ where_clause += f" AND {user_clause}"
+ else:
+ where_clause = f"WHERE {where_clause} AND {user_clause}"
+ else:
+ where_clause = f"WHERE {user_clause}"
+
+ # Inline parameters if provided
+ if params and isinstance(params, dict):
+ for key, value in params.items():
+ # Handle different value types appropriately
+ if isinstance(value, str):
+ value = f"'{value}'"
+ where_clause = where_clause.replace(f"${key}", str(value))
+
+ # Handle user_name parameter in where_clause
+ if "user_name = %s" in where_clause:
+ where_clause = where_clause.replace(
+ "user_name = %s",
+ f"ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = '\"{user_name}\"'::agtype",
+ )
+
+ # Build return fields and group by fields
+ return_fields = []
+ group_by_fields = []
+
+ for field in group_fields:
+ alias = field.replace(".", "_")
+ return_fields.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{field}\"'::agtype)::text AS {alias}"
+ )
+ group_by_fields.append(
+ f"ag_catalog.agtype_access_operator(properties, '\"{field}\"'::agtype)::text"
+ )
+
+ # Full SQL query construction
+ query = f"""
+ SELECT {", ".join(return_fields)}, COUNT(*) AS count
+ FROM "{self.db_name}_graph"."Memory"
+ {where_clause}
+ GROUP BY {", ".join(group_by_fields)}
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Handle parameterized query
+ if params and isinstance(params, list):
+ cursor.execute(query, params)
+ else:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ output = []
+ for row in results:
+ group_values = {}
+ for i, field in enumerate(group_fields):
+ value = row[i]
+ if hasattr(value, "value"):
+ group_values[field] = value.value
+ else:
+ group_values[field] = str(value)
+ count_value = row[-1] # Last column is count
+ output.append({**group_values, "count": int(count_value)})
+
+ return output
+
+ except Exception as e:
+ logger.error(f"Failed to get grouped counts: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def deduplicate_nodes(self) -> None:
+ """Deduplicate redundant or semantically similar nodes."""
+ raise NotImplementedError
+
+ def detect_conflicts(self) -> list[tuple[str, str]]:
+ """Detect conflicting nodes based on logical or semantic inconsistency."""
+ raise NotImplementedError
+
+ def merge_nodes(self, id1: str, id2: str) -> str:
+ """Merge two similar or duplicate nodes into one."""
+ raise NotImplementedError
+
+ @timed
+ def clear(self, user_name: str | None = None) -> None:
+ """
+ Clear the entire graph if the target database exists.
+
+ Args:
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ try:
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.user_name = '{user_name}'
+ DETACH DELETE n
+ $$) AS (result agtype)
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ logger.info("Cleared all nodes from database.")
+ finally:
+ self._return_connection(conn)
+
+ except Exception as e:
+ logger.error(f"[ERROR] Failed to clear database: {e}")
+
+ @timed
+ def export_graph(
+ self, include_embedding: bool = False, user_name: str | None = None
+ ) -> dict[str, Any]:
+ """
+ Export all graph nodes and edges in a structured form.
+ Args:
+ include_embedding (bool): Whether to include the large embedding field.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ {
+ "nodes": [ { "id": ..., "memory": ..., "metadata": {...} }, ... ],
+ "edges": [ { "source": ..., "target": ..., "type": ... }, ... ]
+ }
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ conn = self._get_connection()
+ try:
+ # Export nodes
+ if include_embedding:
+ node_query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = '\"{user_name}\"'::agtype
+ """
+ else:
+ node_query = f"""
+ SELECT id, properties
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE ag_catalog.agtype_access_operator(properties, '"user_name"'::agtype) = '\"{user_name}\"'::agtype
+ """
+
+ with conn.cursor() as cursor:
+ cursor.execute(node_query)
+ node_results = cursor.fetchall()
+ nodes = []
+
+ for row in node_results:
+ if include_embedding:
+ properties_json, embedding_json = row
+ else:
+ properties_json = row
+ embedding_json = None
+
+ # Parse properties from JSONB if it's a string
+ if isinstance(properties_json, str):
+ try:
+ properties = json.loads(properties_json)
+ except json.JSONDecodeError:
+ properties = {}
+ else:
+ properties = properties_json if properties_json else {}
+
+ # # Build node data
+
+ """
+ # node_data = {
+ # "id": properties.get("id", node_id),
+ # "memory": properties.get("memory", ""),
+ # "metadata": properties
+ # }
+ """
+
+ if include_embedding and embedding_json is not None:
+ properties["embedding"] = embedding_json
+
+ nodes.append(self._parse_node(json.loads(properties[1])))
+
+ except Exception as e:
+ logger.error(f"[EXPORT GRAPH - NODES] Exception: {e}", exc_info=True)
+ raise RuntimeError(f"[EXPORT GRAPH - NODES] Exception: {e}") from e
+ finally:
+ self._return_connection(conn)
+
+ conn = self._get_connection()
+ try:
+ # Export edges using cypher query
+ edge_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (a:Memory)-[r]->(b:Memory)
+ WHERE a.user_name = '{user_name}' AND b.user_name = '{user_name}'
+ RETURN a.id AS source, b.id AS target, type(r) as edge
+ $$) AS (source agtype, target agtype, edge agtype)
+ """
+
+ with conn.cursor() as cursor:
+ cursor.execute(edge_query)
+ edge_results = cursor.fetchall()
+ edges = []
+
+ for row in edge_results:
+ source_agtype, target_agtype, edge_agtype = row
+
+ # Extract and clean source
+ source_raw = (
+ source_agtype.value
+ if hasattr(source_agtype, "value")
+ else str(source_agtype)
+ )
+ if (
+ isinstance(source_raw, str)
+ and source_raw.startswith('"')
+ and source_raw.endswith('"')
+ ):
+ source = source_raw[1:-1]
+ else:
+ source = str(source_raw)
+
+ # Extract and clean target
+ target_raw = (
+ target_agtype.value
+ if hasattr(target_agtype, "value")
+ else str(target_agtype)
+ )
+ if (
+ isinstance(target_raw, str)
+ and target_raw.startswith('"')
+ and target_raw.endswith('"')
+ ):
+ target = target_raw[1:-1]
+ else:
+ target = str(target_raw)
+
+ # Extract and clean edge type
+ type_raw = (
+ edge_agtype.value if hasattr(edge_agtype, "value") else str(edge_agtype)
+ )
+ if (
+ isinstance(type_raw, str)
+ and type_raw.startswith('"')
+ and type_raw.endswith('"')
+ ):
+ edge_type = type_raw[1:-1]
+ else:
+ edge_type = str(type_raw)
+
+ edges.append(
+ {
+ "source": source,
+ "target": target,
+ "type": edge_type,
+ }
+ )
+
+ except Exception as e:
+ logger.error(f"[EXPORT GRAPH - EDGES] Exception: {e}", exc_info=True)
+ raise RuntimeError(f"[EXPORT GRAPH - EDGES] Exception: {e}") from e
+ finally:
+ self._return_connection(conn)
+
+ return {"nodes": nodes, "edges": edges}
+
+ @timed
+ def count_nodes(self, scope: str, user_name: str | None = None) -> int:
+ user_name = user_name if user_name else self.config.user_name
+
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}'
+ AND n.user_name = '{user_name}'
+ RETURN count(n)
+ $$) AS (count agtype)
+ """
+ conn = self._get_connection()
+ try:
+ result = self.execute_query(query, conn)
+ return int(result.one_or_none()["count"].value)
+ finally:
+ self._return_connection(conn)
+
+ @timed
+ def get_all_memory_items(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Retrieve all memory items of a specific memory_type.
+
+ Args:
+ scope (str): Must be one of 'WorkingMemory', 'LongTermMemory', or 'UserMemory'.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: Full list of memory items under this scope.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ if scope not in {"WorkingMemory", "LongTermMemory", "UserMemory", "OuterMemory"}:
+ raise ValueError(f"Unsupported memory type scope: {scope}")
+
+ # Use cypher query to retrieve memory items
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN id(n) as id1,n
+ LIMIT 100
+ $$) AS (id1 agtype,n agtype)
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id;
+ """
+ nodes = []
+ node_ids = set()
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ """
+ if isinstance(row, (list, tuple)) and len(row) >= 2:
+ """
+ if isinstance(row, list | tuple) and len(row) >= 2:
+ embedding_val, node_val = row[0], row[1]
+ else:
+ embedding_val, node_val = None, row[0]
+
+ node = self._build_node_from_agtype(node_val, embedding_val)
+ if node:
+ node_id = node["id"]
+ if node_id not in node_ids:
+ nodes.append(node)
+ node_ids.add(node_id)
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return nodes
+ else:
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN properties(n) as props
+ LIMIT 100
+ $$) AS (nprops agtype)
+ """
+
+ nodes = []
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ """
+ if isinstance(row[0], str):
+ memory_data = json.loads(row[0])
+ else:
+ memory_data = row[0] # 如果已经是字典,直接使用
+ nodes.append(self._parse_node(memory_data))
+ """
+ memory_data = json.loads(row[0]) if isinstance(row[0], str) else row[0]
+ nodes.append(self._parse_node(memory_data))
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return nodes
+
+ def get_all_memory_items_old(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Retrieve all memory items of a specific memory_type.
+
+ Args:
+ scope (str): Must be one of 'WorkingMemory', 'LongTermMemory', or 'UserMemory'.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ list[dict]: Full list of memory items under this scope.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+ if scope not in {"WorkingMemory", "LongTermMemory", "UserMemory", "OuterMemory"}:
+ raise ValueError(f"Unsupported memory type scope: {scope}")
+
+ # Use cypher query to retrieve memory items
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN id(n) as id1,n
+ LIMIT 100
+ $$) AS (id1 agtype,n agtype)
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id;
+ """
+ else:
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}' AND n.user_name = '{user_name}'
+ RETURN properties(n) as props
+ LIMIT 100
+ $$) AS (nprops agtype)
+ """
+
+ nodes = []
+ try:
+ with self.connection.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+
+ for row in results:
+ node_agtype = row[0]
+
+ # Handle string-formatted data
+ if isinstance(node_agtype, str):
+ try:
+ # Remove ::vertex suffix
+ json_str = node_agtype.replace("::vertex", "")
+ node_data = json.loads(json_str)
+
+ if isinstance(node_data, dict) and "properties" in node_data:
+ properties = node_data["properties"]
+ # Build node data
+ parsed_node_data = {
+ "id": properties.get("id", ""),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+
+ if include_embedding and "embedding" in properties:
+ parsed_node_data["embedding"] = properties["embedding"]
+
+ nodes.append(self._parse_node(parsed_node_data))
+ logger.debug(
+ f"[get_all_memory_items] Parsed node successfully: {properties.get('id', '')}"
+ )
+ else:
+ logger.warning(f"Invalid node data format: {node_data}")
+
+ except (json.JSONDecodeError, TypeError) as e:
+ logger.error(f"JSON parsing failed: {e}")
+ elif node_agtype and hasattr(node_agtype, "value"):
+ # Handle agtype object
+ node_props = node_agtype.value
+ if isinstance(node_props, dict):
+ # Parse node properties
+ node_data = {
+ "id": node_props.get("id", ""),
+ "memory": node_props.get("memory", ""),
+ "metadata": node_props,
+ }
+
+ if include_embedding and "embedding" in node_props:
+ node_data["embedding"] = node_props["embedding"]
+
+ nodes.append(self._parse_node(node_data))
+ else:
+ logger.warning(f"Unknown data format: {type(node_agtype)}")
+
+ except Exception as e:
+ logger.error(f"Failed to get memories: {e}", exc_info=True)
+
+ return nodes
+
+ @timed
+ def get_structure_optimization_candidates(
+ self, scope: str, include_embedding: bool = False, user_name: str | None = None
+ ) -> list[dict]:
+ """
+ Find nodes that are likely candidates for structure optimization:
+ - Isolated nodes, nodes with empty background, or nodes with exactly one child.
+ - Plus: the child of any parent node that has exactly one child.
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build return fields based on include_embedding flag
+ if include_embedding:
+ return_fields = "id(n) as id1,n"
+ return_fields_agtype = " id1 agtype,n agtype"
+ else:
+ # Build field list without embedding
+ return_fields = ",".join(
+ [
+ "n.id AS id",
+ "n.memory AS memory",
+ "n.user_name AS user_name",
+ "n.user_id AS user_id",
+ "n.session_id AS session_id",
+ "n.status AS status",
+ "n.key AS key",
+ "n.confidence AS confidence",
+ "n.tags AS tags",
+ "n.created_at AS created_at",
+ "n.updated_at AS updated_at",
+ "n.memory_type AS memory_type",
+ "n.sources AS sources",
+ "n.source AS source",
+ "n.node_type AS node_type",
+ "n.visibility AS visibility",
+ "n.usage AS usage",
+ "n.background AS background",
+ "n.graph_id as graph_id",
+ ]
+ )
+ fields = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "usage",
+ "background",
+ "graph_id",
+ ]
+ return_fields_agtype = ", ".join([f"{field} agtype" for field in fields])
+
+ # Use OPTIONAL MATCH to find isolated nodes (no parents or children)
+ cypher_query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH (n:Memory)
+ WHERE n.memory_type = '{scope}'
+ AND n.status = 'activated'
+ AND n.user_name = '{user_name}'
+ OPTIONAL MATCH (n)-[:PARENT]->(c:Memory)
+ OPTIONAL MATCH (p:Memory)-[:PARENT]->(n)
+ WITH n, c, p
+ WHERE c IS NULL AND p IS NULL
+ RETURN {return_fields}
+ $$) AS ({return_fields_agtype})
+ """
+ if include_embedding:
+ cypher_query = f"""
+ WITH t as (
+ {cypher_query}
+ )
+ SELECT
+ m.embedding,
+ t.n
+ FROM t,
+ {self.db_name}_graph."Memory" m
+ WHERE t.id1 = m.id
+ """
+ logger.info(f"[get_structure_optimization_candidates] query: {cypher_query}")
+
+ candidates = []
+ node_ids = set()
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(cypher_query)
+ results = cursor.fetchall()
+ logger.info(f"Found {len(results)} structure optimization candidates")
+ for row in results:
+ if include_embedding:
+ # When include_embedding=True, return full node object
+ """
+ if isinstance(row, (list, tuple)) and len(row) >= 2:
+ """
+ if isinstance(row, list | tuple) and len(row) >= 2:
+ embedding_val, node_val = row[0], row[1]
+ else:
+ embedding_val, node_val = None, row[0]
+
+ node = self._build_node_from_agtype(node_val, embedding_val)
+ if node:
+ node_id = node["id"]
+ if node_id not in node_ids:
+ candidates.append(node)
+ node_ids.add(node_id)
+ else:
+ # When include_embedding=False, return field dictionary
+ # Define field names matching the RETURN clause
+ field_names = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "usage",
+ "background",
+ "graph_id",
+ ]
+
+ # Convert row to dictionary
+ node_data = {}
+ for i, field_name in enumerate(field_names):
+ if i < len(row):
+ value = row[i]
+ # Handle special fields
+ if field_name in ["tags", "sources", "usage"] and isinstance(
+ value, str
+ ):
+ try:
+ # Try parsing JSON string
+ node_data[field_name] = json.loads(value)
+ except (json.JSONDecodeError, TypeError):
+ node_data[field_name] = value
+ else:
+ node_data[field_name] = value
+
+ # Parse node using _parse_node_new
+ try:
+ node = self._parse_node_new(node_data)
+ node_id = node["id"]
+
+ if node_id not in node_ids:
+ candidates.append(node)
+ node_ids.add(node_id)
+ logger.debug(f"Parsed node successfully: {node_id}")
+ except Exception as e:
+ logger.error(f"Failed to parse node: {e}")
+
+ except Exception as e:
+ logger.error(f"Failed to get structure optimization candidates: {e}", exc_info=True)
+ finally:
+ self._return_connection(conn)
+
+ return candidates
+
+ def drop_database(self) -> None:
+ """Permanently delete the entire graph this instance is using."""
+ return
+ if self._get_config_value("use_multi_db", True):
+ with self.connection.cursor() as cursor:
+ cursor.execute(f"SELECT drop_graph('{self.db_name}_graph', true)")
+ logger.info(f"Graph '{self.db_name}_graph' has been dropped.")
+ else:
+ raise ValueError(
+ f"Refusing to drop graph '{self.db_name}_graph' in "
+ f"Shared Database Multi-Tenant mode"
+ )
+
+ def _parse_node(self, node_data: dict[str, Any]) -> dict[str, Any]:
+ """Parse node data from database format to standard format."""
+ node = node_data.copy()
+
+ # Convert datetime to string
+ for time_field in ("created_at", "updated_at"):
+ if time_field in node and hasattr(node[time_field], "isoformat"):
+ node[time_field] = node[time_field].isoformat()
+
+ return {"id": node.get("id"), "memory": node.get("memory", ""), "metadata": node}
+
+ def _parse_node_new(self, node_data: dict[str, Any]) -> dict[str, Any]:
+ """Parse node data from database format to standard format."""
+ node = node_data.copy()
+
+ # Normalize string values that may arrive as quoted literals (e.g., '"abc"')
+ def _strip_wrapping_quotes(value: Any) -> Any:
+ """
+ if isinstance(value, str) and len(value) >= 2:
+ if value[0] == value[-1] and value[0] in ("'", '"'):
+ return value[1:-1]
+ return value
+ """
+ if (
+ isinstance(value, str)
+ and len(value) >= 2
+ and value[0] == value[-1]
+ and value[0] in ("'", '"')
+ ):
+ return value[1:-1]
+ return value
+
+ for k, v in list(node.items()):
+ if isinstance(v, str):
+ node[k] = _strip_wrapping_quotes(v)
+
+ # Convert datetime to string
+ for time_field in ("created_at", "updated_at"):
+ if time_field in node and hasattr(node[time_field], "isoformat"):
+ node[time_field] = node[time_field].isoformat()
+
+ # Do not remove user_name; keep all fields
+
+ return {"id": node.pop("id"), "memory": node.pop("memory", ""), "metadata": node}
+
+ def __del__(self):
+ """Close database connection when object is destroyed."""
+ if hasattr(self, "connection") and self.connection:
+ self.connection.close()
+
+ @timed
+ def add_node(
+ self, id: str, memory: str, metadata: dict[str, Any], user_name: str | None = None
+ ) -> None:
+ """Add a memory node to the graph."""
+ logger.info(f"In add node polardb: id-{id} memory-{memory}")
+
+ # user_name comes from metadata; fallback to config if missing
+ metadata["user_name"] = user_name if user_name else self.config.user_name
+
+ # Safely process metadata
+ metadata = _prepare_node_metadata(metadata)
+
+ # Merge node and set metadata
+ created_at = metadata.pop("created_at", datetime.utcnow().isoformat())
+ updated_at = metadata.pop("updated_at", datetime.utcnow().isoformat())
+
+ # Prepare properties
+ properties = {
+ "id": id,
+ "memory": memory,
+ "created_at": created_at,
+ "updated_at": updated_at,
+ **metadata,
+ }
+
+ # Generate embedding if not provided
+ if "embedding" not in properties or not properties["embedding"]:
+ properties["embedding"] = generate_vector(
+ self._get_config_value("embedding_dimension", 1024)
+ )
+
+ # serialization - JSON-serialize sources and usage fields
+ for field_name in ["sources", "usage"]:
+ if properties.get(field_name):
+ if isinstance(properties[field_name], list):
+ for idx in range(len(properties[field_name])):
+ # Serialize only when element is not a string
+ if not isinstance(properties[field_name][idx], str):
+ properties[field_name][idx] = json.dumps(properties[field_name][idx])
+ elif isinstance(properties[field_name], str):
+ # If already a string, leave as-is
+ pass
+
+ # Extract embedding for separate column
+ embedding_vector = properties.pop("embedding", [])
+ if not isinstance(embedding_vector, list):
+ embedding_vector = []
+
+ # Select column name based on embedding dimension
+ embedding_column = "embedding" # default column
+ if len(embedding_vector) == 3072:
+ embedding_column = "embedding_3072"
+ elif len(embedding_vector) == 1024:
+ embedding_column = "embedding"
+ elif len(embedding_vector) == 768:
+ embedding_column = "embedding_768"
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ # Delete existing record first (if any)
+ delete_query = f"""
+ DELETE FROM {self.db_name}_graph."Memory"
+ WHERE id = ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring)
+ """
+ cursor.execute(delete_query, (id,))
+ #
+ get_graph_id_query = f"""
+ SELECT ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring)
+ """
+ cursor.execute(get_graph_id_query, (id,))
+ graph_id = cursor.fetchone()[0]
+ properties["graph_id"] = str(graph_id)
+
+ # Then insert new record
+ if embedding_vector:
+ insert_query = f"""
+ INSERT INTO {self.db_name}_graph."Memory"(id, properties, {embedding_column})
+ VALUES (
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring),
+ %s,
+ %s
+ )
+ """
+ cursor.execute(
+ insert_query, (id, json.dumps(properties), json.dumps(embedding_vector))
+ )
+ else:
+ insert_query = f"""
+ INSERT INTO {self.db_name}_graph."Memory"(id, properties)
+ VALUES (
+ ag_catalog._make_graph_id('{self.db_name}_graph'::name, 'Memory'::name, %s::text::cstring),
+ %s
+ )
+ """
+ cursor.execute(insert_query, (id, json.dumps(properties)))
+ logger.info(f"Added node {id} to graph '{self.db_name}_graph'.")
+ finally:
+ logger.info(f"In add node polardb: id-{id} memory-{memory} query-{insert_query}")
+ self._return_connection(conn)
+
+ def _build_node_from_agtype(self, node_agtype, embedding=None):
+ """
+ Parse the cypher-returned column `n` (agtype or JSON string)
+ into a standard node and merge embedding into properties.
+ """
+ try:
+ # String case: '{"id":...,"label":[...],"properties":{...}}::vertex'
+ if isinstance(node_agtype, str):
+ json_str = node_agtype.replace("::vertex", "")
+ obj = json.loads(json_str)
+ if not (isinstance(obj, dict) and "properties" in obj):
+ return None
+ props = obj["properties"]
+ # agtype case: has `value` attribute
+ elif node_agtype and hasattr(node_agtype, "value"):
+ val = node_agtype.value
+ if not (isinstance(val, dict) and "properties" in val):
+ return None
+ props = val["properties"]
+ else:
+ return None
+
+ if embedding is not None:
+ props["embedding"] = embedding
+
+ # Return standard format directly
+ return {"id": props.get("id", ""), "memory": props.get("memory", ""), "metadata": props}
+ except Exception:
+ return None
+
+ @timed
+ def get_neighbors_by_tag(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ include_embedding: bool = False,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ if not tags:
+ return []
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build query conditions - more relaxed filters
+ where_clauses = []
+ params = []
+
+ # Exclude specified IDs - use id in properties
+ if exclude_ids:
+ exclude_conditions = []
+ for exclude_id in exclude_ids:
+ exclude_conditions.append(
+ "ag_catalog.agtype_access_operator(properties, '\"id\"'::agtype) != %s::agtype"
+ )
+ params.append(self.format_param_value(exclude_id))
+ where_clauses.append(f"({' AND '.join(exclude_conditions)})")
+
+ # Status filter - keep only 'activated'
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"status\"'::agtype) = '\"activated\"'::agtype"
+ )
+
+ # Type filter - exclude 'reasoning' type
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"node_type\"'::agtype) != '\"reasoning\"'::agtype"
+ )
+
+ # User filter
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"user_name\"'::agtype) = %s::agtype"
+ )
+ params.append(self.format_param_value(user_name))
+
+ # Testing showed no data; annotate.
+ where_clauses.append(
+ "ag_catalog.agtype_access_operator(properties, '\"memory_type\"'::agtype) != '\"WorkingMemory\"'::agtype"
+ )
+
+ where_clause = " AND ".join(where_clauses)
+
+ # Fetch all candidate nodes
+ query = f"""
+ SELECT id, properties, embedding
+ FROM "{self.db_name}_graph"."Memory"
+ WHERE {where_clause}
+ """
+
+ logger.debug(f"[get_neighbors_by_tag] query: {query}, params: {params}")
+
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query, params)
+ results = cursor.fetchall()
+
+ nodes_with_overlap = []
+ for row in results:
+ node_id, properties_json, embedding_json = row
+ properties = properties_json if properties_json else {}
+
+ # Parse embedding
+ if include_embedding and embedding_json is not None:
+ try:
+ embedding = (
+ json.loads(embedding_json)
+ if isinstance(embedding_json, str)
+ else embedding_json
+ )
+ properties["embedding"] = embedding
+ except (json.JSONDecodeError, TypeError):
+ logger.warning(f"Failed to parse embedding for node {node_id}")
+
+ # Compute tag overlap
+ node_tags = properties.get("tags", [])
+ if isinstance(node_tags, str):
+ try:
+ node_tags = json.loads(node_tags)
+ except (json.JSONDecodeError, TypeError):
+ node_tags = []
+
+ overlap_tags = [tag for tag in tags if tag in node_tags]
+ overlap_count = len(overlap_tags)
+
+ if overlap_count >= min_overlap:
+ node_data = self._parse_node(
+ {
+ "id": properties.get("id", node_id),
+ "memory": properties.get("memory", ""),
+ "metadata": properties,
+ }
+ )
+ nodes_with_overlap.append((node_data, overlap_count))
+
+ # Sort by overlap count and return top_k items
+ nodes_with_overlap.sort(key=lambda x: x[1], reverse=True)
+ return [node for node, _ in nodes_with_overlap[:top_k]]
+
+ except Exception as e:
+ logger.error(f"Failed to get neighbors by tag: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def get_neighbors_by_tag_ccl(
+ self,
+ tags: list[str],
+ exclude_ids: list[str],
+ top_k: int = 5,
+ min_overlap: int = 1,
+ include_embedding: bool = False,
+ user_name: str | None = None,
+ ) -> list[dict[str, Any]]:
+ """
+ Find top-K neighbor nodes with maximum tag overlap.
+
+ Args:
+ tags: The list of tags to match.
+ exclude_ids: Node IDs to exclude (e.g., local cluster).
+ top_k: Max number of neighbors to return.
+ min_overlap: Minimum number of overlapping tags required.
+ include_embedding: with/without embedding
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of dicts with node details and overlap count.
+ """
+ if not tags:
+ return []
+
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Build query conditions; keep consistent with nebular.py
+ where_clauses = [
+ 'n.status = "activated"',
+ 'NOT (n.node_type = "reasoning")',
+ 'NOT (n.memory_type = "WorkingMemory")',
+ ]
+ where_clauses = [
+ 'n.status = "activated"',
+ 'NOT (n.memory_type = "WorkingMemory")',
+ ]
+
+ if exclude_ids:
+ exclude_ids_str = "[" + ", ".join(f'"{id}"' for id in exclude_ids) + "]"
+ where_clauses.append(f"NOT (n.id IN {exclude_ids_str})")
+
+ where_clauses.append(f'n.user_name = "{user_name}"')
+
+ where_clause = " AND ".join(where_clauses)
+ tag_list_literal = "[" + ", ".join(f'"{t}"' for t in tags) + "]"
+
+ return_fields = [
+ "n.id AS id",
+ "n.memory AS memory",
+ "n.user_name AS user_name",
+ "n.user_id AS user_id",
+ "n.session_id AS session_id",
+ "n.status AS status",
+ "n.key AS key",
+ "n.confidence AS confidence",
+ "n.tags AS tags",
+ "n.created_at AS created_at",
+ "n.updated_at AS updated_at",
+ "n.memory_type AS memory_type",
+ "n.sources AS sources",
+ "n.source AS source",
+ "n.node_type AS node_type",
+ "n.visibility AS visibility",
+ "n.background AS background",
+ ]
+
+ if include_embedding:
+ return_fields.append("n.embedding AS embedding")
+
+ return_fields_str = ", ".join(return_fields)
+ result_fields = []
+ for field in return_fields:
+ # Extract field name 'id' from 'n.id AS id'
+ field_name = field.split(" AS ")[-1]
+ result_fields.append(f"{field_name} agtype")
+
+ # Add overlap_count
+ result_fields.append("overlap_count agtype")
+ result_fields_str = ", ".join(result_fields)
+ # Use Cypher query; keep consistent with nebular.py
+ query = f"""
+ SELECT * FROM (
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ WITH {tag_list_literal} AS tag_list
+ MATCH (n:Memory)
+ WHERE {where_clause}
+ RETURN {return_fields_str},
+ size([tag IN n.tags WHERE tag IN tag_list]) AS overlap_count
+ $$) AS ({result_fields_str})
+ ) AS subquery
+ ORDER BY (overlap_count::integer) DESC
+ LIMIT {top_k}
+ """
+ logger.debug(f"get_neighbors_by_tag: {query}")
+ try:
+ with self.connection.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ neighbors = []
+ for row in results:
+ # Parse results
+ props = {}
+ overlap_count = None
+
+ # Manually parse each field
+ field_names = [
+ "id",
+ "memory",
+ "user_name",
+ "user_id",
+ "session_id",
+ "status",
+ "key",
+ "confidence",
+ "tags",
+ "created_at",
+ "updated_at",
+ "memory_type",
+ "sources",
+ "source",
+ "node_type",
+ "visibility",
+ "background",
+ ]
+
+ if include_embedding:
+ field_names.append("embedding")
+ field_names.append("overlap_count")
+
+ for i, field in enumerate(field_names):
+ if field == "overlap_count":
+ overlap_count = row[i].value if hasattr(row[i], "value") else row[i]
+ else:
+ props[field] = row[i].value if hasattr(row[i], "value") else row[i]
+ overlap_int = int(overlap_count)
+ if overlap_count is not None and overlap_int >= min_overlap:
+ parsed = self._parse_node(props)
+ parsed["overlap_count"] = overlap_int
+ neighbors.append(parsed)
+
+ # Sort by overlap count
+ neighbors.sort(key=lambda x: x["overlap_count"], reverse=True)
+ neighbors = neighbors[:top_k]
+
+ # Remove overlap_count field
+ result = []
+ for neighbor in neighbors:
+ neighbor.pop("overlap_count", None)
+ result.append(neighbor)
+
+ return result
+
+ except Exception as e:
+ logger.error(f"Failed to get neighbors by tag: {e}", exc_info=True)
+ return []
+
+ @timed
+ def import_graph(self, data: dict[str, Any], user_name: str | None = None) -> None:
+ """
+ Import the entire graph from a serialized dictionary.
+
+ Args:
+ data: A dictionary containing all nodes and edges to be loaded.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ # Import nodes
+ for node in data.get("nodes", []):
+ try:
+ id, memory, metadata = _compose_node(node)
+ metadata["user_name"] = user_name
+ metadata = _prepare_node_metadata(metadata)
+ metadata.update({"id": id, "memory": memory})
+
+ # Use add_node to insert node
+ self.add_node(id, memory, metadata)
+
+ except Exception as e:
+ logger.error(f"Fail to load node: {node}, error: {e}")
+
+ # Import edges
+ for edge in data.get("edges", []):
+ try:
+ source_id, target_id = edge["source"], edge["target"]
+ edge_type = edge["type"]
+
+ # Use add_edge to insert edge
+ self.add_edge(source_id, target_id, edge_type, user_name)
+
+ except Exception as e:
+ logger.error(f"Fail to load edge: {edge}, error: {e}")
+
+ @timed
+ def get_edges(
+ self, id: str, type: str = "ANY", direction: str = "ANY", user_name: str | None = None
+ ) -> list[dict[str, str]]:
+ """
+ Get edges connected to a node, with optional type and direction filter.
+
+ Args:
+ id: Node ID to retrieve edges for.
+ type: Relationship type to match, or 'ANY' to match all.
+ direction: 'OUTGOING', 'INCOMING', or 'ANY'.
+ user_name (str, optional): User name for filtering in non-multi-db mode
+
+ Returns:
+ List of edges:
+ [
+ {"from": "source_id", "to": "target_id", "type": "RELATE"},
+ ...
+ ]
+ """
+ user_name = user_name if user_name else self._get_config_value("user_name")
+
+ if direction == "OUTGOING":
+ pattern = "(a:Memory)-[r]->(b:Memory)"
+ where_clause = f"a.id = '{id}'"
+ elif direction == "INCOMING":
+ pattern = "(a:Memory)<-[r]-(b:Memory)"
+ where_clause = f"a.id = '{id}'"
+ elif direction == "ANY":
+ pattern = "(a:Memory)-[r]-(b:Memory)"
+ where_clause = f"a.id = '{id}' OR b.id = '{id}'"
+ else:
+ raise ValueError("Invalid direction. Must be 'OUTGOING', 'INCOMING', or 'ANY'.")
+
+ # Add type filter
+ if type != "ANY":
+ where_clause += f" AND type(r) = '{type}'"
+
+ # Add user filter
+ where_clause += f" AND a.user_name = '{user_name}' AND b.user_name = '{user_name}'"
+
+ query = f"""
+ SELECT * FROM cypher('{self.db_name}_graph', $$
+ MATCH {pattern}
+ WHERE {where_clause}
+ RETURN a.id AS from_id, b.id AS to_id, type(r) AS edge_type
+ $$) AS (from_id agtype, to_id agtype, edge_type agtype)
+ """
+ conn = self._get_connection()
+ try:
+ with conn.cursor() as cursor:
+ cursor.execute(query)
+ results = cursor.fetchall()
+
+ edges = []
+ for row in results:
+ # Extract and clean from_id
+ from_id_raw = row[0].value if hasattr(row[0], "value") else row[0]
+ if (
+ isinstance(from_id_raw, str)
+ and from_id_raw.startswith('"')
+ and from_id_raw.endswith('"')
+ ):
+ from_id = from_id_raw[1:-1]
+ else:
+ from_id = str(from_id_raw)
+
+ # Extract and clean to_id
+ to_id_raw = row[1].value if hasattr(row[1], "value") else row[1]
+ if (
+ isinstance(to_id_raw, str)
+ and to_id_raw.startswith('"')
+ and to_id_raw.endswith('"')
+ ):
+ to_id = to_id_raw[1:-1]
+ else:
+ to_id = str(to_id_raw)
+
+ # Extract and clean edge_type
+ edge_type_raw = row[2].value if hasattr(row[2], "value") else row[2]
+ if (
+ isinstance(edge_type_raw, str)
+ and edge_type_raw.startswith('"')
+ and edge_type_raw.endswith('"')
+ ):
+ edge_type = edge_type_raw[1:-1]
+ else:
+ edge_type = str(edge_type_raw)
+
+ edges.append({"from": from_id, "to": to_id, "type": edge_type})
+ return edges
+
+ except Exception as e:
+ logger.error(f"Failed to get edges: {e}", exc_info=True)
+ return []
+ finally:
+ self._return_connection(conn)
+
+ def _convert_graph_edges(self, core_node: dict) -> dict:
+ import copy
+
+ data = copy.deepcopy(core_node)
+ id_map = {}
+ core_node = data.get("core_node", {})
+ if not core_node:
+ return core_node
+ core_meta = core_node.get("metadata", {})
+ if "graph_id" in core_meta and "id" in core_node:
+ id_map[core_meta["graph_id"]] = core_node["id"]
+ for neighbor in data.get("neighbors", []):
+ n_meta = neighbor.get("metadata", {})
+ if "graph_id" in n_meta and "id" in neighbor:
+ id_map[n_meta["graph_id"]] = neighbor["id"]
+ for edge in data.get("edges", []):
+ src = edge.get("source")
+ tgt = edge.get("target")
+ if src in id_map:
+ edge["source"] = id_map[src]
+ if tgt in id_map:
+ edge["target"] = id_map[tgt]
+ return data
+
+ def format_param_value(self, value: str | None) -> str:
+ """Format parameter value to handle both quoted and unquoted formats"""
+ # Handle None value
+ if value is None:
+ logger.warning("format_param_value: value is None")
+ return "null"
+
+ # Remove outer quotes if they exist
+ if value.startswith('"') and value.endswith('"'):
+ # Already has double quotes, return as is
+ return value
+ else:
+ # Add double quotes
+ return f'"{value}"'
diff --git a/src/memos/llms/hf.py b/src/memos/llms/hf.py
index 00081b581..be0d1d95f 100644
--- a/src/memos/llms/hf.py
+++ b/src/memos/llms/hf.py
@@ -379,10 +379,52 @@ def build_kv_cache(self, messages) -> DynamicCache:
raise ValueError(
"Prompt after chat template is empty, cannot build KV cache. Check your messages input."
)
- kv = DynamicCache()
+ # Create cache and perform forward pass without pre-existing cache
with torch.no_grad():
- self.model(**inputs, use_cache=True, past_key_values=kv)
- for i, (k, v) in enumerate(zip(kv.key_cache, kv.value_cache, strict=False)):
- kv.key_cache[i] = k[:, :, :seq_len, :]
- kv.value_cache[i] = v[:, :, :seq_len, :]
- return kv
+ outputs = self.model(**inputs, use_cache=True)
+
+ # Get the cache from model outputs
+ if hasattr(outputs, "past_key_values") and outputs.past_key_values is not None:
+ kv = outputs.past_key_values
+
+ # Convert from legacy tuple format to DynamicCache if needed
+ if isinstance(kv, tuple):
+ kv = DynamicCache.from_legacy_cache(kv)
+
+ # Handle compatibility between old and new transformers versions
+ # In newer versions, DynamicCache uses 'layers' attribute
+ # In older versions, it uses 'key_cache' and 'value_cache' attributes
+ if hasattr(kv, "layers"):
+ # New version: trim cache using layers attribute
+ for layer in kv.layers:
+ if hasattr(layer, "key_cache") and hasattr(layer, "value_cache"):
+ # Trim each layer's cache to the sequence length
+ if layer.key_cache is not None:
+ layer.key_cache = layer.key_cache[:, :, :seq_len, :]
+ if layer.value_cache is not None:
+ layer.value_cache = layer.value_cache[:, :, :seq_len, :]
+ elif hasattr(layer, "keys") and hasattr(layer, "values"):
+ # Alternative attribute names in some versions
+ if layer.keys is not None:
+ layer.keys = layer.keys[:, :, :seq_len, :]
+ if layer.values is not None:
+ layer.values = layer.values[:, :, :seq_len, :]
+ elif hasattr(kv, "key_cache") and hasattr(kv, "value_cache"):
+ # Old version: trim cache using key_cache and value_cache attributes
+ for i in range(len(kv.key_cache)):
+ if kv.key_cache[i] is not None:
+ kv.key_cache[i] = kv.key_cache[i][:, :, :seq_len, :]
+ if kv.value_cache[i] is not None:
+ kv.value_cache[i] = kv.value_cache[i][:, :, :seq_len, :]
+ else:
+ # Fallback: log warning but continue without trimming
+ logger.warning(
+ f"DynamicCache object of type {type(kv)} has unexpected structure. "
+ f"Cache trimming skipped. Available attributes: {dir(kv)}"
+ )
+
+ return kv
+ else:
+ raise RuntimeError(
+ "Failed to build KV cache: no cache data available from model outputs"
+ )
diff --git a/src/memos/llms/openai.py b/src/memos/llms/openai.py
index 698bc3265..1a1703340 100644
--- a/src/memos/llms/openai.py
+++ b/src/memos/llms/openai.py
@@ -11,6 +11,7 @@
from memos.llms.utils import remove_thinking_tags
from memos.log import get_logger
from memos.types import MessageList
+from memos.utils import timed
logger = get_logger(__name__)
@@ -56,15 +57,19 @@ def clear_cache(cls):
cls._instances.clear()
logger.info("OpenAI LLM instance cache cleared")
- def generate(self, messages: MessageList) -> str:
- """Generate a response from OpenAI LLM."""
+ @timed(log=True, log_prefix="OpenAI LLM")
+ def generate(self, messages: MessageList, **kwargs) -> str:
+ """Generate a response from OpenAI LLM, optionally overriding generation params."""
+ temperature = kwargs.get("temperature", self.config.temperature)
+ max_tokens = kwargs.get("max_tokens", self.config.max_tokens)
+ top_p = kwargs.get("top_p", self.config.top_p)
response = self.client.chat.completions.create(
model=self.config.model_name_or_path,
messages=messages,
extra_body=self.config.extra_body,
- temperature=self.config.temperature,
- max_tokens=self.config.max_tokens,
- top_p=self.config.top_p,
+ temperature=temperature,
+ max_tokens=max_tokens,
+ top_p=top_p,
)
logger.info(f"Response from OpenAI: {response.model_dump_json()}")
response_content = response.choices[0].message.content
@@ -73,6 +78,7 @@ def generate(self, messages: MessageList) -> str:
else:
return response_content
+ @timed(log=True, log_prefix="OpenAI LLM")
def generate_stream(self, messages: MessageList, **kwargs) -> Generator[str, None, None]:
"""Stream response from OpenAI LLM with optional reasoning support."""
response = self.client.chat.completions.create(
diff --git a/src/memos/log.py b/src/memos/log.py
index 339d13f26..faa808414 100644
--- a/src/memos/log.py
+++ b/src/memos/log.py
@@ -14,7 +14,13 @@
from dotenv import load_dotenv
from memos import settings
-from memos.context.context import get_current_api_path, get_current_trace_id
+from memos.context.context import (
+ get_current_api_path,
+ get_current_env,
+ get_current_trace_id,
+ get_current_user_name,
+ get_current_user_type,
+)
# Load environment variables
@@ -34,15 +40,22 @@ def _setup_logfile() -> Path:
return logfile
-class TraceIDFilter(logging.Filter):
- """add trace_id to the log record"""
+class ContextFilter(logging.Filter):
+ """add context to the log record"""
def filter(self, record):
try:
trace_id = get_current_trace_id()
record.trace_id = trace_id if trace_id else "trace-id"
+ record.env = get_current_env()
+ record.user_type = get_current_user_type()
+ record.user_name = get_current_user_name()
+ record.api_path = get_current_api_path()
except Exception:
record.trace_id = "trace-id"
+ record.env = "prod"
+ record.user_type = "normal"
+ record.user_name = "unknown"
return True
@@ -86,13 +99,24 @@ def emit(self, record):
try:
trace_id = get_current_trace_id() or "trace-id"
api_path = get_current_api_path()
+ env = get_current_env()
+ user_type = get_current_user_type()
+ user_name = get_current_user_name()
if api_path is not None:
- self._executor.submit(self._send_log_sync, record.getMessage(), trace_id, api_path)
+ self._executor.submit(
+ self._send_log_sync,
+ record.getMessage(),
+ trace_id,
+ api_path,
+ env,
+ user_type,
+ user_name,
+ )
except Exception as e:
if not self._is_shutting_down.is_set():
print(f"Error sending log: {e}")
- def _send_log_sync(self, message, trace_id, api_path):
+ def _send_log_sync(self, message, trace_id, api_path, env, user_type, user_name):
"""Send log message synchronously in a separate thread"""
try:
logger_url = os.getenv("CUSTOM_LOGGER_URL")
@@ -104,6 +128,9 @@ def _send_log_sync(self, message, trace_id, api_path):
"trace_id": trace_id,
"action": api_path,
"current_time": round(time.time(), 3),
+ "env": env,
+ "user_type": user_type,
+ "user_name": user_name,
}
# Add auth token if exists
@@ -145,18 +172,18 @@ def close(self):
"disable_existing_loggers": False,
"formatters": {
"standard": {
- "format": "%(asctime)s [%(trace_id)s] - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
+ "format": "%(asctime)s | %(trace_id)s | path=%(api_path)s | env=%(env)s | user_type=%(user_type)s | user_name=%(user_name)s | %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
},
"no_datetime": {
- "format": "[%(trace_id)s] - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
+ "format": "%(trace_id)s | path=%(api_path)s | %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(funcName)s - %(message)s"
},
"simplified": {
- "format": "%(asctime)s | %(trace_id)s | %(levelname)s | %(filename)s:%(lineno)d: %(funcName)s | %(message)s"
+ "format": "%(asctime)s | %(trace_id)s | path=%(api_path)s | % %(levelname)s | %(filename)s:%(lineno)d: %(funcName)s | %(message)s"
},
},
"filters": {
"package_tree_filter": {"()": "logging.Filter", "name": settings.LOG_FILTER_TREE_PREFIX},
- "trace_id_filter": {"()": "memos.log.TraceIDFilter"},
+ "context_filter": {"()": "memos.log.ContextFilter"},
},
"handlers": {
"console": {
@@ -164,7 +191,7 @@ def close(self):
"class": "logging.StreamHandler",
"stream": stdout,
"formatter": "no_datetime",
- "filters": ["package_tree_filter", "trace_id_filter"],
+ "filters": ["package_tree_filter", "context_filter"],
},
"file": {
"level": "DEBUG",
@@ -173,7 +200,7 @@ def close(self):
"maxBytes": 1024**2 * 10,
"backupCount": 10,
"formatter": "standard",
- "filters": ["trace_id_filter"],
+ "filters": ["context_filter"],
},
"custom_logger": {
"level": "INFO",
diff --git a/src/memos/mem_cube/base.py b/src/memos/mem_cube/base.py
index 7d7c5e779..349d511fb 100644
--- a/src/memos/mem_cube/base.py
+++ b/src/memos/mem_cube/base.py
@@ -19,6 +19,7 @@ def __init__(self, config: BaseMemCubeConfig):
self.text_mem: BaseTextMemory
self.act_mem: BaseActMemory
self.para_mem: BaseParaMemory
+ self.pref_mem: BaseTextMemory
@abstractmethod
def load(self, dir: str) -> None:
diff --git a/src/memos/mem_cube/general.py b/src/memos/mem_cube/general.py
index 17e45809c..1238ae050 100644
--- a/src/memos/mem_cube/general.py
+++ b/src/memos/mem_cube/general.py
@@ -41,16 +41,23 @@ def __init__(self, config: GeneralMemCubeConfig):
if config.para_mem.backend != "uninitialized"
else None
)
+ self._pref_mem: BaseTextMemory | None = (
+ MemoryFactory.from_config(config.pref_mem)
+ if config.pref_mem.backend != "uninitialized"
+ else None
+ )
def load(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Load memories.
Args:
dir (str): The directory containing the memory files.
memory_types (list[str], optional): List of memory types to load.
If None, loads all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
loaded_schema = get_json_file_model_schema(os.path.join(dir, self.config.config_filename))
if loaded_schema != self.config.model_schema:
@@ -61,7 +68,7 @@ def load(
# If no specific memory types specified, load all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Load specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -76,17 +83,23 @@ def load(
self.para_mem.load(dir)
logger.info(f"Loaded para_mem from {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.load(dir)
+ logger.info(f"Loaded pref_mem from {dir}")
+
logger.info(f"MemCube loaded successfully from {dir} (types: {memory_types})")
def dump(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump memories.
Args:
dir (str): The directory where the memory files will be saved.
memory_types (list[str], optional): List of memory types to dump.
If None, dumps all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
if os.path.exists(dir) and os.listdir(dir):
raise MemCubeError(
@@ -98,7 +111,7 @@ def dump(
# If no specific memory types specified, dump all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Dump specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -113,12 +126,16 @@ def dump(
self.para_mem.dump(dir)
logger.info(f"Dumped para_mem to {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.dump(dir)
+ logger.info(f"Dumped pref_mem to {dir}")
+
logger.info(f"MemCube dumped successfully to {dir} (types: {memory_types})")
@staticmethod
def init_from_dir(
dir: str,
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""Create a MemCube instance from a MemCube directory.
@@ -148,7 +165,7 @@ def init_from_dir(
def init_from_remote_repo(
cube_id: str,
base_url: str = "https://huggingface.co/datasets",
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
default_config: GeneralMemCubeConfig | None = None,
) -> "GeneralMemCube":
"""Create a MemCube instance from a remote repository.
@@ -207,3 +224,17 @@ def para_mem(self, value: BaseParaMemory) -> None:
if not isinstance(value, BaseParaMemory):
raise TypeError(f"Expected BaseParaMemory, got {type(value).__name__}")
self._para_mem = value
+
+ @property
+ def pref_mem(self) -> "BaseTextMemory | None":
+ """Get the preference memory."""
+ if self._pref_mem is None:
+ logger.warning("Preference memory is not initialized. Returning None.")
+ return self._pref_mem
+
+ @pref_mem.setter
+ def pref_mem(self, value: BaseTextMemory) -> None:
+ """Set the preference memory."""
+ if not isinstance(value, BaseTextMemory):
+ raise TypeError(f"Expected BaseTextMemory, got {type(value).__name__}")
+ self._pref_mem = value
diff --git a/src/memos/mem_cube/navie.py b/src/memos/mem_cube/navie.py
index 7ce3ca642..ba9f136b7 100644
--- a/src/memos/mem_cube/navie.py
+++ b/src/memos/mem_cube/navie.py
@@ -14,9 +14,14 @@
from memos.memories.activation.base import BaseActMemory
from memos.memories.parametric.base import BaseParaMemory
from memos.memories.textual.base import BaseTextMemory
+from memos.memories.textual.prefer_text_memory.adder import BaseAdder
+from memos.memories.textual.prefer_text_memory.extractor import BaseExtractor
+from memos.memories.textual.prefer_text_memory.retrievers import BaseRetriever
+from memos.memories.textual.simple_preference import SimplePreferenceTextMemory
from memos.memories.textual.simple_tree import SimpleTreeTextMemory
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
from memos.reranker.base import BaseReranker
+from memos.vec_dbs.base import BaseVecDB
logger = get_logger(__name__)
@@ -34,7 +39,11 @@ def __init__(
reranker: BaseReranker,
memory_manager: MemoryManager,
default_cube_config: GeneralMemCubeConfig,
+ vector_db: BaseVecDB,
internet_retriever: None = None,
+ pref_extractor: BaseExtractor | None = None,
+ pref_adder: BaseAdder | None = None,
+ pref_retriever: BaseRetriever | None = None,
):
"""Initialize the MemCube with a configuration."""
self._text_mem: BaseTextMemory | None = SimpleTreeTextMemory(
@@ -49,6 +58,15 @@ def __init__(
)
self._act_mem: BaseActMemory | None = None
self._para_mem: BaseParaMemory | None = None
+ self._pref_mem: BaseTextMemory | None = SimplePreferenceTextMemory(
+ extractor_llm=llm,
+ vector_db=vector_db,
+ embedder=embedder,
+ reranker=reranker,
+ extractor=pref_extractor,
+ adder=pref_adder,
+ retriever=pref_retriever,
+ )
def load(
self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
@@ -69,7 +87,7 @@ def load(
# If no specific memory types specified, load all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Load specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -84,17 +102,23 @@ def load(
self.para_mem.load(dir)
logger.info(f"Loaded para_mem from {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.load(dir)
+ logger.info(f"Loaded pref_mem from {dir}")
+
logger.info(f"MemCube loaded successfully from {dir} (types: {memory_types})")
def dump(
- self, dir: str, memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None
+ self,
+ dir: str,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump memories.
Args:
dir (str): The directory where the memory files will be saved.
memory_types (list[str], optional): List of memory types to dump.
If None, dumps all available memory types.
- Options: ["text_mem", "act_mem", "para_mem"]
+ Options: ["text_mem", "act_mem", "para_mem", "pref_mem"]
"""
if os.path.exists(dir) and os.listdir(dir):
raise MemCubeError(
@@ -106,7 +130,7 @@ def dump(
# If no specific memory types specified, dump all
if memory_types is None:
- memory_types = ["text_mem", "act_mem", "para_mem"]
+ memory_types = ["text_mem", "act_mem", "para_mem", "pref_mem"]
# Dump specified memory types
if "text_mem" in memory_types and self.text_mem:
@@ -121,6 +145,10 @@ def dump(
self.para_mem.dump(dir)
logger.info(f"Dumped para_mem to {dir}")
+ if "pref_mem" in memory_types and self.pref_mem:
+ self.pref_mem.dump(dir)
+ logger.info(f"Dumped pref_mem to {dir}")
+
logger.info(f"MemCube dumped successfully to {dir} (types: {memory_types})")
@property
@@ -164,3 +192,17 @@ def para_mem(self, value: BaseParaMemory) -> None:
if not isinstance(value, BaseParaMemory):
raise TypeError(f"Expected BaseParaMemory, got {type(value).__name__}")
self._para_mem = value
+
+ @property
+ def pref_mem(self) -> "BaseTextMemory | None":
+ """Get the preference memory."""
+ if self._pref_mem is None:
+ logger.warning("Preference memory is not initialized. Returning None.")
+ return self._pref_mem
+
+ @pref_mem.setter
+ def pref_mem(self, value: BaseTextMemory) -> None:
+ """Set the preference memory."""
+ if not isinstance(value, BaseTextMemory):
+ raise TypeError(f"Expected BaseTextMemory, got {type(value).__name__}")
+ self._pref_mem = value
diff --git a/src/memos/mem_cube/utils.py b/src/memos/mem_cube/utils.py
index a413ccce5..24836c509 100644
--- a/src/memos/mem_cube/utils.py
+++ b/src/memos/mem_cube/utils.py
@@ -68,44 +68,80 @@ def merge_config_with_default(
if "graph_db" in existing_text_config and "graph_db" in default_text_config:
existing_graph_config = existing_text_config["graph_db"]["config"]
default_graph_config = default_text_config["graph_db"]["config"]
-
- # Define graph_db fields to preserve (user-specific)
- preserve_graph_fields = {
- "auto_create",
- "user_name",
- "use_multi_db",
- }
-
- # Create merged graph_db config
- merged_graph_config = copy.deepcopy(existing_graph_config)
- for key, value in default_graph_config.items():
- if key not in preserve_graph_fields:
- merged_graph_config[key] = value
- logger.debug(
- f"Updated graph_db field '{key}': {existing_graph_config.get(key)} -> {value}"
+ existing_backend = existing_text_config["graph_db"]["backend"]
+ default_backend = default_text_config["graph_db"]["backend"]
+
+ # Detect backend change
+ backend_changed = existing_backend != default_backend
+
+ if backend_changed:
+ logger.info(
+ f"Detected graph_db backend change: {existing_backend} -> {default_backend}. "
+ f"Migrating configuration..."
+ )
+ # Start with default config as base when backend changes
+ merged_graph_config = copy.deepcopy(default_graph_config)
+
+ # Preserve user-specific fields if they exist in both configs
+ preserve_graph_fields = {
+ "auto_create",
+ "user_name",
+ "use_multi_db",
+ }
+ for field in preserve_graph_fields:
+ if field in existing_graph_config:
+ merged_graph_config[field] = existing_graph_config[field]
+ logger.debug(
+ f"Preserved graph_db field '{field}': {existing_graph_config[field]}"
+ )
+
+ # Clean up backend-specific fields that don't exist in the new backend
+ # This approach is generic: remove any field from merged config that's not in default config
+ # and not in the preserve list
+ fields_to_remove = []
+ for field in list(merged_graph_config.keys()):
+ if field not in default_graph_config and field not in preserve_graph_fields:
+ fields_to_remove.append(field)
+
+ for field in fields_to_remove:
+ removed_value = merged_graph_config.pop(field)
+ logger.info(
+ f"Removed {existing_backend}-specific field '{field}' (value: {removed_value}) "
+ f"during migration to {default_backend}"
)
- if not default_graph_config.get("use_multi_db", True):
- # set original use_multi_db to False if default_graph_config.use_multi_db is False
- if merged_graph_config.get("use_multi_db", True):
- merged_graph_config["use_multi_db"] = False
- merged_graph_config["user_name"] = merged_graph_config.get("db_name")
- merged_graph_config["db_name"] = default_graph_config.get("db_name")
- else:
- logger.info("use_multi_db is already False, no need to change")
- if "neo4j" not in default_text_config["graph_db"]["backend"]:
- if "db_name" in merged_graph_config:
- merged_graph_config.pop("db_name")
- logger.info("neo4j is not supported, remove db_name")
- else:
- logger.info("db_name is not in merged_graph_config, no need to remove")
else:
- if "space" in merged_graph_config:
- merged_graph_config.pop("space")
- logger.info("neo4j is not supported, remove db_name")
- else:
- logger.info("space is not in merged_graph_config, no need to remove")
+ # Same backend: merge configs while preserving user-specific fields
+ logger.debug(f"Same graph_db backend ({default_backend}), merging configurations")
+ preserve_graph_fields = {
+ "auto_create",
+ "user_name",
+ "use_multi_db",
+ }
+
+ # Start with existing config as base
+ merged_graph_config = copy.deepcopy(existing_graph_config)
+
+ # Update with default config except preserved fields
+ for key, value in default_graph_config.items():
+ if key not in preserve_graph_fields:
+ merged_graph_config[key] = value
+ logger.debug(
+ f"Updated graph_db field '{key}': {existing_graph_config.get(key)} -> {value}"
+ )
+
+ # Handle use_multi_db transition
+ if not default_graph_config.get("use_multi_db", True) and merged_graph_config.get(
+ "use_multi_db", True
+ ):
+ merged_graph_config["use_multi_db"] = False
+ # For Neo4j: db_name becomes user_name in single-db mode
+ if "neo4j" in default_backend and "db_name" in merged_graph_config:
+ merged_graph_config["user_name"] = merged_graph_config.get("db_name")
+ merged_graph_config["db_name"] = default_graph_config.get("db_name")
+ logger.info("Transitioned to single-db mode (use_multi_db=False)")
+
preserved_graph_db = {
- "backend": default_text_config["graph_db"]["backend"],
+ "backend": default_backend,
"config": merged_graph_config,
}
diff --git a/src/memos/mem_os/core.py b/src/memos/mem_os/core.py
index 958cc140c..97ff9879f 100644
--- a/src/memos/mem_os/core.py
+++ b/src/memos/mem_os/core.py
@@ -8,6 +8,7 @@
from typing import Any, Literal
from memos.configs.mem_os import MOSConfig
+from memos.context.context import ContextThreadPoolExecutor
from memos.llms.factory import LLMFactory
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
@@ -17,6 +18,8 @@
from memos.mem_scheduler.schemas.general_schemas import (
ADD_LABEL,
ANSWER_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
QUERY_LABEL,
)
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
@@ -70,6 +73,7 @@ def __init__(self, config: MOSConfig, user_manager: UserManager | None = None):
if self.enable_mem_scheduler:
self._mem_scheduler = self._initialize_mem_scheduler()
self._mem_scheduler.mem_cubes = self.mem_cubes
+ self._mem_scheduler.mem_reader = self.mem_reader
else:
self._mem_scheduler: GeneralScheduler = None
@@ -308,18 +312,20 @@ def chat(self, query: str, user_id: str | None = None, base_prompt: str | None =
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # TODO this only one cubes
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # TODO this only one cubes
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
break
# Generate response
response = self.chat_llm.generate(current_messages, past_key_values=past_key_values)
@@ -586,6 +592,7 @@ def search(
"text_mem": [],
"act_mem": [],
"para_mem": [],
+ "pref_mem": [],
}
if install_cube_ids is None:
install_cube_ids = user_cube_ids
@@ -600,33 +607,78 @@ def search(
)
for mem_cube_id, mem_cube in tmp_mem_cubes.items():
- if (
- (mem_cube_id in install_cube_ids)
- and (mem_cube.text_mem is not None)
- and self.config.enable_textual_memory
- ):
- time_start = time.time()
- memories = mem_cube.text_mem.search(
- query,
- top_k=top_k if top_k else self.config.top_k,
- mode=mode,
- manual_close_internet=not internet_search,
- info={
- "user_id": target_user_id,
- "session_id": target_session_id,
- "chat_history": chat_history.chat_history,
- },
- moscube=moscube,
- search_filter=search_filter,
- )
- result["text_mem"].append({"cube_id": mem_cube_id, "memories": memories})
- logger.info(
- f"🧠 [Memory] Searched memories from {mem_cube_id}:\n{self._str_memories(memories)}\n"
- )
- search_time_end = time.time()
- logger.info(
- f"time search graph: search graph time user_id: {target_user_id} time is: {search_time_end - time_start}"
- )
+ # Define internal functions for parallel search execution
+ def search_textual_memory(cube_id, cube):
+ if (
+ (cube_id in install_cube_ids)
+ and (cube.text_mem is not None)
+ and self.config.enable_textual_memory
+ ):
+ time_start = time.time()
+ memories = cube.text_mem.search(
+ query,
+ top_k=top_k if top_k else self.config.top_k,
+ mode=mode,
+ manual_close_internet=not internet_search,
+ info={
+ "user_id": target_user_id,
+ "session_id": target_session_id,
+ "chat_history": chat_history.chat_history,
+ },
+ moscube=moscube,
+ search_filter=search_filter,
+ )
+ search_time_end = time.time()
+ logger.info(
+ f"🧠 [Memory] Searched memories from {cube_id}:\n{self._str_memories(memories)}\n"
+ )
+ logger.info(
+ f"time search graph: search graph time user_id: {target_user_id} time is: {search_time_end - time_start}"
+ )
+ return {"cube_id": cube_id, "memories": memories}
+ return None
+
+ def search_preference_memory(cube_id, cube):
+ if (
+ (cube_id in install_cube_ids)
+ and (cube.pref_mem is not None)
+ and self.config.enable_preference_memory
+ ):
+ time_start = time.time()
+ memories = cube.pref_mem.search(
+ query,
+ top_k=top_k if top_k else self.config.top_k,
+ info={
+ "user_id": target_user_id,
+ "session_id": self.session_id,
+ "chat_history": chat_history.chat_history,
+ },
+ )
+ search_time_end = time.time()
+ logger.info(
+ f"🧠 [Memory] Searched preferences from {cube_id}:\n{self._str_memories(memories)}\n"
+ )
+ logger.info(
+ f"time search pref: search pref time user_id: {target_user_id} time is: {search_time_end - time_start}"
+ )
+ return {"cube_id": cube_id, "memories": memories}
+ return None
+
+ # Execute both search functions in parallel
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(search_textual_memory, mem_cube_id, mem_cube)
+ pref_future = executor.submit(search_preference_memory, mem_cube_id, mem_cube)
+
+ # Wait for both tasks to complete and collect results
+ text_result = text_future.result()
+ pref_result = pref_future.result()
+
+ # Add results to the main result dictionary
+ if text_result is not None:
+ result["text_mem"].append(text_result)
+ if pref_result is not None:
+ result["pref_mem"].append(pref_result)
+
return result
def add(
@@ -675,63 +727,111 @@ def add(
f"time add: get mem_cube_id time user_id: {target_user_id} time is: {time.time() - time_start}"
)
- time_start_0 = time.time()
if mem_cube_id not in self.mem_cubes:
raise ValueError(f"MemCube '{mem_cube_id}' is not loaded. Please register.")
- logger.info(
- f"time add: get mem_cube_id check in mem_cubes time user_id: {target_user_id} time is: {time.time() - time_start_0}"
- )
- time_start_1 = time.time()
- if (
- (messages is not None)
- and self.config.enable_textual_memory
- and self.mem_cubes[mem_cube_id].text_mem
- ):
- logger.info(
- f"time add: messages is not None and enable_textual_memory and text_mem is not None time user_id: {target_user_id} time is: {time.time() - time_start_1}"
+
+ sync_mode = self.mem_cubes[mem_cube_id].text_mem.mode
+ if sync_mode == "async":
+ assert self.mem_scheduler is not None, (
+ "Mem-Scheduler must be working when use asynchronous memory adding."
)
- if self.mem_cubes[mem_cube_id].config.text_mem.backend != "tree_text":
- add_memory = []
- metadata = TextualMemoryMetadata(
- user_id=target_user_id, session_id=target_session_id, source="conversation"
- )
- for message in messages:
- add_memory.append(
- TextualMemoryItem(memory=message["content"], metadata=metadata)
+ logger.debug(f"Mem-reader mode is: {sync_mode}")
+
+ def process_textual_memory():
+ if (
+ (messages is not None)
+ and self.config.enable_textual_memory
+ and self.mem_cubes[mem_cube_id].text_mem
+ ):
+ if self.mem_cubes[mem_cube_id].config.text_mem.backend != "tree_text":
+ add_memory = []
+ metadata = TextualMemoryMetadata(
+ user_id=target_user_id, session_id=target_session_id, source="conversation"
)
- self.mem_cubes[mem_cube_id].text_mem.add(add_memory)
- else:
+ for message in messages:
+ add_memory.append(
+ TextualMemoryItem(memory=message["content"], metadata=metadata)
+ )
+ self.mem_cubes[mem_cube_id].text_mem.add(add_memory)
+ else:
+ messages_list = [messages]
+ memories = self.mem_reader.get_memory(
+ messages_list,
+ type="chat",
+ info={"user_id": target_user_id, "session_id": target_session_id},
+ mode="fast" if sync_mode == "async" else "fine",
+ )
+ memories_flatten = [m for m_list in memories for m in m_list]
+ mem_ids: list[str] = self.mem_cubes[mem_cube_id].text_mem.add(memories_flatten)
+ logger.info(
+ f"Added memory user {target_user_id} to memcube {mem_cube_id}: {mem_ids}"
+ )
+ # submit messages for scheduler
+ if self.enable_mem_scheduler and self.mem_scheduler is not None:
+ mem_cube = self.mem_cubes[mem_cube_id]
+ if sync_mode == "async":
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+ else:
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+
+ def process_preference_memory():
+ if (
+ (messages is not None)
+ and self.config.enable_preference_memory
+ and self.mem_cubes[mem_cube_id].pref_mem
+ ):
messages_list = [messages]
- time_start_2 = time.time()
- memories = self.mem_reader.get_memory(
- messages_list,
- type="chat",
- info={"user_id": target_user_id, "session_id": target_session_id},
- )
- logger.info(
- f"time add: get mem_reader time user_id: {target_user_id} time is: {time.time() - time_start_2}"
- )
- mem_ids = []
- for mem in memories:
- mem_id_list: list[str] = self.mem_cubes[mem_cube_id].text_mem.add(mem)
- mem_ids.extend(mem_id_list)
+ mem_cube = self.mem_cubes[mem_cube_id]
+ if sync_mode == "sync":
+ pref_memories = self.mem_cubes[mem_cube_id].pref_mem.get_memory(
+ messages_list,
+ type="chat",
+ info={"user_id": target_user_id, "session_id": self.session_id},
+ )
+ pref_ids = self.mem_cubes[mem_cube_id].pref_mem.add(pref_memories)
logger.info(
- f"Added memory user {target_user_id} to memcube {mem_cube_id}: {mem_id_list}"
+ f"Added preferences user {target_user_id} to memcube {mem_cube_id}: {pref_ids}"
+ )
+ elif sync_mode == "async":
+ assert self.mem_scheduler is not None, (
+ "Mem-Scheduler must be working when use asynchronous memory adding."
)
-
- # submit messages for scheduler
- if self.enable_mem_scheduler and self.mem_scheduler is not None:
- mem_cube = self.mem_cubes[mem_cube_id]
message_item = ScheduleMessageItem(
user_id=target_user_id,
+ session_id=target_session_id,
mem_cube_id=mem_cube_id,
mem_cube=mem_cube,
- label=ADD_LABEL,
- content=json.dumps(mem_ids),
+ label=PREF_ADD_LABEL,
+ content=json.dumps(messages_list),
timestamp=datetime.utcnow(),
)
self.mem_scheduler.submit_messages(messages=[message_item])
+ # Execute both memory processing functions in parallel
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ text_future = executor.submit(process_textual_memory)
+ pref_future = executor.submit(process_preference_memory)
+
+ # Wait for both tasks to complete
+ text_future.result()
+ pref_future.result()
+
# user profile
if (
(memory_content is not None)
@@ -749,10 +849,12 @@ def add(
messages_list = [
[{"role": "user", "content": memory_content}]
] # for only user-str input and convert message
+
memories = self.mem_reader.get_memory(
messages_list,
type="chat",
info={"user_id": target_user_id, "session_id": target_session_id},
+ mode="fast" if sync_mode == "async" else "fine",
)
mem_ids = []
@@ -766,15 +868,26 @@ def add(
# submit messages for scheduler
if self.enable_mem_scheduler and self.mem_scheduler is not None:
mem_cube = self.mem_cubes[mem_cube_id]
- message_item = ScheduleMessageItem(
- user_id=target_user_id,
- mem_cube_id=mem_cube_id,
- mem_cube=mem_cube,
- label=ADD_LABEL,
- content=json.dumps(mem_ids),
- timestamp=datetime.utcnow(),
- )
- self.mem_scheduler.submit_messages(messages=[message_item])
+ if sync_mode == "async":
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=MEM_READ_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
+ else:
+ message_item = ScheduleMessageItem(
+ user_id=target_user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ label=ADD_LABEL,
+ content=json.dumps(mem_ids),
+ timestamp=datetime.utcnow(),
+ )
+ self.mem_scheduler.submit_messages(messages=[message_item])
# user doc input
if (
@@ -998,7 +1111,7 @@ def load(
load_dir: str,
user_id: str | None = None,
mem_cube_id: str | None = None,
- memory_types: list[Literal["text_mem", "act_mem", "para_mem"]] | None = None,
+ memory_types: list[Literal["text_mem", "act_mem", "para_mem", "pref_mem"]] | None = None,
) -> None:
"""Dump the MemCube to a dictionary.
Args:
diff --git a/src/memos/mem_os/main.py b/src/memos/mem_os/main.py
index 2e5b32548..6fc64c5e3 100644
--- a/src/memos/mem_os/main.py
+++ b/src/memos/mem_os/main.py
@@ -312,23 +312,25 @@ def _generate_enhanced_response_with_context(
# Handle activation memory if enabled (same as core method)
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # Get accessible cubes for the user
- target_user_id = user_id if user_id is not None else self.user_id
- accessible_cubes = self.user_manager.get_user_cubes(target_user_id)
- user_cube_ids = [cube.cube_id for cube in accessible_cubes]
-
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
- break
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # Get accessible cubes for the user
+ target_user_id = user_id if user_id is not None else self.user_id
+ accessible_cubes = self.user_manager.get_user_cubes(target_user_id)
+ user_cube_ids = [cube.cube_id for cube in accessible_cubes]
+
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
+ break
try:
# Generate the enhanced response using the chat LLM with same parameters as core
diff --git a/src/memos/mem_os/product.py b/src/memos/mem_os/product.py
index 7e0ed9aef..89e468bd7 100644
--- a/src/memos/mem_os/product.py
+++ b/src/memos/mem_os/product.py
@@ -1044,22 +1044,15 @@ def chat(
m.metadata.embedding = []
new_memories_list.append(m)
memories_list = new_memories_list
- # Build base system prompt without memory
- system_prompt = self._build_base_system_prompt(base_prompt, mode="base")
-
- # Build memory context to be included in user message
- memory_context = self._build_memory_context(memories_list, mode="base")
-
- # Combine memory context with user query
- user_content = memory_context + query if memory_context else query
+ system_prompt = super()._build_system_prompt(memories_list, base_prompt)
history_info = []
if history:
history_info = history[-20:]
current_messages = [
{"role": "system", "content": system_prompt},
*history_info,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
response = self.chat_llm.generate(current_messages)
time_end = time.time()
@@ -1129,16 +1122,8 @@ def chat_with_references(
reference = prepare_reference_data(memories_list)
yield f"data: {json.dumps({'type': 'reference', 'data': reference})}\n\n"
-
- # Build base system prompt without memory
- system_prompt = self._build_base_system_prompt(mode="enhance")
-
- # Build memory context to be included in user message
- memory_context = self._build_memory_context(memories_list, mode="enhance")
-
- # Combine memory context with user query
- user_content = memory_context + query if memory_context else query
-
+ # Build custom system prompt with relevant memories)
+ system_prompt = self._build_enhance_system_prompt(user_id, memories_list)
# Get chat history
if user_id not in self.chat_history_manager:
self._register_chat_history(user_id, session_id)
@@ -1149,7 +1134,7 @@ def chat_with_references(
current_messages = [
{"role": "system", "content": system_prompt},
*chat_history.chat_history,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
logger.info(
f"user_id: {user_id}, cube_id: {cube_id}, current_system_prompt: {system_prompt}"
@@ -1443,6 +1428,24 @@ def search(
reformat_memory_list.append({"cube_id": memory["cube_id"], "memories": memories_list})
logger.info(f"search memory list is : {reformat_memory_list}")
search_result["text_mem"] = reformat_memory_list
+
+ pref_memory_list = search_result["pref_mem"]
+ reformat_pref_memory_list = []
+ for memory in pref_memory_list:
+ memories_list = []
+ for data in memory["memories"]:
+ memories = data.model_dump()
+ memories["ref_id"] = f"[{memories['id'].split('-')[0]}]"
+ memories["metadata"]["embedding"] = []
+ memories["metadata"]["sources"] = []
+ memories["metadata"]["ref_id"] = f"[{memories['id'].split('-')[0]}]"
+ memories["metadata"]["id"] = memories["id"]
+ memories["metadata"]["memory"] = memories["memory"]
+ memories_list.append(memories)
+ reformat_pref_memory_list.append(
+ {"cube_id": memory["cube_id"], "memories": memories_list}
+ )
+ search_result["pref_mem"] = reformat_pref_memory_list
time_end = time.time()
logger.info(
f"time search: total time for user_id: {user_id} time is: {time_end - time_start}"
diff --git a/src/memos/mem_os/product_server.py b/src/memos/mem_os/product_server.py
index b94b26f65..758f2794d 100644
--- a/src/memos/mem_os/product_server.py
+++ b/src/memos/mem_os/product_server.py
@@ -71,11 +71,7 @@ def chat(
m.metadata.embedding = []
new_memories_list.append(m)
memories_list = new_memories_list
- system_prompt = self._build_base_system_prompt(base_prompt, mode="base")
-
- memory_context = self._build_memory_context(memories_list, mode="base")
-
- user_content = memory_context + query if memory_context else query
+ system_prompt = self._build_system_prompt(memories_list, base_prompt)
history_info = []
if history:
@@ -83,7 +79,7 @@ def chat(
current_messages = [
{"role": "system", "content": system_prompt},
*history_info,
- {"role": "user", "content": user_content},
+ {"role": "user", "content": query},
]
response = self.chat_llm.generate(current_messages)
time_end = time.time()
@@ -187,6 +183,42 @@ def _build_base_system_prompt(
prefix = (base_prompt.strip() + "\n\n") if base_prompt else ""
return prefix + sys_body
+ def _build_system_prompt(
+ self,
+ memories: list[TextualMemoryItem] | list[str] | None = None,
+ base_prompt: str | None = None,
+ **kwargs,
+ ) -> str:
+ """Build system prompt with optional memories context."""
+ if base_prompt is None:
+ base_prompt = (
+ "You are a knowledgeable and helpful AI assistant. "
+ "You have access to conversation memories that help you provide more personalized responses. "
+ "Use the memories to understand the user's context, preferences, and past interactions. "
+ "If memories are provided, reference them naturally when relevant, but don't explicitly mention having memories."
+ )
+
+ memory_context = ""
+ if memories:
+ memory_list = []
+ for i, memory in enumerate(memories, 1):
+ if isinstance(memory, TextualMemoryItem):
+ text_memory = memory.memory
+ else:
+ if not isinstance(memory, str):
+ logger.error("Unexpected memory type.")
+ text_memory = memory
+ memory_list.append(f"{i}. {text_memory}")
+ memory_context = "\n".join(memory_list)
+
+ if "{memories}" in base_prompt:
+ return base_prompt.format(memories=memory_context)
+ elif base_prompt and memories:
+ # For backward compatibility, append memories if no placeholder is found
+ memory_context_with_header = "\n\n## Memories:\n" + memory_context
+ return base_prompt + memory_context_with_header
+ return base_prompt
+
def _build_memory_context(
self,
memories_all: list[TextualMemoryItem],
diff --git a/src/memos/mem_reader/base.py b/src/memos/mem_reader/base.py
index f092c3870..3095a0bc6 100644
--- a/src/memos/mem_reader/base.py
+++ b/src/memos/mem_reader/base.py
@@ -18,10 +18,17 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
@abstractmethod
def get_memory(
- self, scene_data: list, type: str, info: dict[str, Any]
+ self, scene_data: list, type: str, info: dict[str, Any], mode: str = "fast"
) -> list[list[TextualMemoryItem]]:
"""Various types of memories extracted from scene_data"""
@abstractmethod
def transform_memreader(self, data: dict) -> list[TextualMemoryItem]:
"""Transform the memory data into a list of TextualMemoryItem objects."""
+
+ @abstractmethod
+ def fine_transfer_simple_mem(
+ self, input_memories: list[list[TextualMemoryItem]], type: str
+ ) -> list[list[TextualMemoryItem]]:
+ """Fine Transform TextualMemoryItem List into another list of
+ TextualMemoryItem objects via calling llm to better understand users."""
diff --git a/src/memos/mem_reader/factory.py b/src/memos/mem_reader/factory.py
index 52eed8d9d..2205a0215 100644
--- a/src/memos/mem_reader/factory.py
+++ b/src/memos/mem_reader/factory.py
@@ -3,6 +3,7 @@
from memos.configs.mem_reader import MemReaderConfigFactory
from memos.mem_reader.base import BaseMemReader
from memos.mem_reader.simple_struct import SimpleStructMemReader
+from memos.mem_reader.strategy_struct import StrategyStructMemReader
from memos.memos_tools.singleton import singleton_factory
@@ -11,6 +12,7 @@ class MemReaderFactory(BaseMemReader):
backend_to_class: ClassVar[dict[str, Any]] = {
"simple_struct": SimpleStructMemReader,
+ "strategy_struct": StrategyStructMemReader,
}
@classmethod
diff --git a/src/memos/mem_reader/simple_struct.py b/src/memos/mem_reader/simple_struct.py
index b439cb2b2..13515c038 100644
--- a/src/memos/mem_reader/simple_struct.py
+++ b/src/memos/mem_reader/simple_struct.py
@@ -3,6 +3,7 @@
import json
import os
import re
+import traceback
from abc import ABC
from typing import Any
@@ -41,14 +42,43 @@
"doc": {"en": SIMPLE_STRUCT_DOC_READER_PROMPT, "zh": SIMPLE_STRUCT_DOC_READER_PROMPT_ZH},
}
+try:
+ import tiktoken
+
+ try:
+ _ENC = tiktoken.encoding_for_model("gpt-4o-mini")
+ except Exception:
+ _ENC = tiktoken.get_encoding("cl100k_base")
+
+ def _count_tokens_text(s: str) -> int:
+ return len(_ENC.encode(s or ""))
+except Exception:
+ # Heuristic fallback: zh chars ~1 token, others ~1 token per ~4 chars
+ def _count_tokens_text(s: str) -> int:
+ if not s:
+ return 0
+ zh_chars = re.findall(r"[\u4e00-\u9fff]", s)
+ zh = len(zh_chars)
+ rest = len(s) - zh
+ return zh + max(1, rest // 4)
+
def detect_lang(text):
try:
if not text or not isinstance(text, str):
return "en"
+ cleaned_text = text
+ # remove role and timestamp
+ cleaned_text = re.sub(
+ r"\b(user|assistant|query|answer)\s*:", "", cleaned_text, flags=re.IGNORECASE
+ )
+ cleaned_text = re.sub(r"\[[\d\-:\s]+\]", "", cleaned_text)
+
+ # extract chinese characters
chinese_pattern = r"[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df\U0002a700-\U0002b73f\U0002b740-\U0002b81f\U0002b820-\U0002ceaf\uf900-\ufaff]"
- chinese_chars = re.findall(chinese_pattern, text)
- if len(chinese_chars) / len(re.sub(r"[\s\d\W]", "", text)) > 0.3:
+ chinese_chars = re.findall(chinese_pattern, cleaned_text)
+ text_without_special = re.sub(r"[\s\d\W]", "", cleaned_text)
+ if text_without_special and len(chinese_chars) / len(text_without_special) > 0.3:
return "zh"
return "en"
except Exception:
@@ -112,6 +142,14 @@ def _build_node(idx, message, info, scene_file, llm, parse_json_result, embedder
return None
+def _derive_key(text: str, max_len: int = 80) -> str:
+ """default key when without LLM: first max_len words"""
+ if not text:
+ return ""
+ sent = re.split(r"[。!?!?]\s*|\n", text.strip())[0]
+ return (sent[:max_len]).strip()
+
+
class SimpleStructMemReader(BaseMemReader, ABC):
"""Naive implementation of MemReader."""
@@ -126,27 +164,50 @@ def __init__(self, config: SimpleStructMemReaderConfig):
self.llm = LLMFactory.from_config(config.llm)
self.embedder = EmbedderFactory.from_config(config.embedder)
self.chunker = ChunkerFactory.from_config(config.chunker)
+ self.memory_max_length = 8000
+ # Use token-based windowing; default to ~5000 tokens if not configured
+ self.chat_window_max_tokens = getattr(self.config, "chat_window_max_tokens", 1024)
+ self._count_tokens = _count_tokens_text
+
+ def _make_memory_item(
+ self,
+ value: str,
+ info: dict,
+ memory_type: str,
+ tags: list[str] | None = None,
+ key: str | None = None,
+ sources: list | None = None,
+ background: str = "",
+ type_: str = "fact",
+ confidence: float = 0.99,
+ ) -> TextualMemoryItem:
+ """construct memory item"""
+ return TextualMemoryItem(
+ memory=value,
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id=info.get("user_id", ""),
+ session_id=info.get("session_id", ""),
+ memory_type=memory_type,
+ status="activated",
+ tags=tags or [],
+ key=key if key is not None else _derive_key(value),
+ embedding=self.embedder.embed([value])[0],
+ usage=[],
+ sources=sources or [],
+ background=background,
+ confidence=confidence,
+ type=type_,
+ ),
+ )
- @timed
- def _process_chat_data(self, scene_data_info, info):
- mem_list = []
- for item in scene_data_info:
- if "chat_time" in item:
- mem = item["role"] + ": " + f"[{item['chat_time']}]: " + item["content"]
- mem_list.append(mem)
- else:
- mem = item["role"] + ":" + item["content"]
- mem_list.append(mem)
- lang = detect_lang("\n".join(mem_list))
+ def _get_llm_response(self, mem_str: str) -> dict:
+ lang = detect_lang(mem_str)
template = PROMPT_DICT["chat"][lang]
examples = PROMPT_DICT["chat"][f"{lang}_example"]
-
- prompt = template.replace("${conversation}", "\n".join(mem_list))
+ prompt = template.replace("${conversation}", mem_str)
if self.config.remove_prompt_example:
prompt = prompt.replace(examples, "")
-
messages = [{"role": "user", "content": prompt}]
-
try:
response_text = self.llm.generate(messages)
response_json = self.parse_json_result(response_text)
@@ -155,15 +216,118 @@ def _process_chat_data(self, scene_data_info, info):
response_json = {
"memory list": [
{
- "key": "\n".join(mem_list)[:10],
+ "key": mem_str[:10],
"memory_type": "UserMemory",
- "value": "\n".join(mem_list),
+ "value": mem_str,
"tags": [],
}
],
- "summary": "\n".join(mem_list),
+ "summary": mem_str,
}
+ return response_json
+
+ def _iter_chat_windows(self, scene_data_info, max_tokens=None, overlap=200):
+ """
+ use token counter to get a slide window generator
+ """
+ max_tokens = max_tokens or self.chat_window_max_tokens
+ buf, sources, start_idx = [], [], 0
+ cur_text = ""
+ for idx, item in enumerate(scene_data_info):
+ role = item.get("role", "")
+ content = item.get("content", "")
+ chat_time = item.get("chat_time", None)
+ parts = []
+ if role and str(role).lower() != "mix":
+ parts.append(f"{role}: ")
+ if chat_time:
+ parts.append(f"[{chat_time}]: ")
+ prefix = "".join(parts)
+ line = f"{prefix}{content}\n"
+
+ if self._count_tokens(cur_text + line) > max_tokens and cur_text:
+ text = "".join(buf)
+ yield {"text": text, "sources": sources.copy(), "start_idx": start_idx}
+ while buf and self._count_tokens("".join(buf)) > overlap:
+ buf.pop(0)
+ sources.pop(0)
+ start_idx = idx
+ cur_text = "".join(buf)
+
+ buf.append(line)
+ sources.append(
+ {
+ "type": "chat",
+ "index": idx,
+ "role": role,
+ "chat_time": chat_time,
+ "content": content,
+ }
+ )
+ cur_text = "".join(buf)
+
+ if buf:
+ yield {"text": "".join(buf), "sources": sources.copy(), "start_idx": start_idx}
+
+ @timed
+ def _process_chat_data(self, scene_data_info, info, **kwargs):
+ mode = kwargs.get("mode", "fine")
+ windows = list(self._iter_chat_windows(scene_data_info))
+
+ if mode == "fast":
+ logger.debug("Using unified Fast Mode")
+
+ def _build_fast_node(w):
+ text = w["text"]
+ roles = {s.get("role", "") for s in w["sources"] if s.get("role")}
+ mem_type = "UserMemory" if roles == {"user"} else "LongTermMemory"
+ tags = ["mode:fast"]
+ return self._make_memory_item(
+ value=text, info=info, memory_type=mem_type, tags=tags, sources=w["sources"]
+ )
+ with ContextThreadPoolExecutor(max_workers=8) as ex:
+ futures = {ex.submit(_build_fast_node, w): i for i, w in enumerate(windows)}
+ results = [None] * len(futures)
+ for fut in concurrent.futures.as_completed(futures):
+ i = futures[fut]
+ try:
+ node = fut.result()
+ if node:
+ results[i] = node
+ except Exception as e:
+ logger.error(f"[ChatFast] error: {e}")
+ chat_nodes = [r for r in results if r]
+ return chat_nodes
+ else:
+ logger.debug("Using unified Fine Mode")
+ chat_read_nodes = []
+ for w in windows:
+ resp = self._get_llm_response(w["text"])
+ for m in resp.get("memory list", []):
+ try:
+ memory_type = (
+ m.get("memory_type", "LongTermMemory")
+ .replace("长期记忆", "LongTermMemory")
+ .replace("用户记忆", "UserMemory")
+ )
+ node = self._make_memory_item(
+ value=m.get("value", ""),
+ info=info,
+ memory_type=memory_type,
+ tags=m.get("tags", []),
+ key=m.get("key", ""),
+ sources=w["sources"],
+ background=resp.get("summary", ""),
+ )
+ chat_read_nodes.append(node)
+ except Exception as e:
+ logger.error(f"[ChatFine] parse error: {e}")
+ return chat_read_nodes
+
+ def _process_transfer_chat_data(self, raw_node: TextualMemoryItem):
+ raw_memory = raw_node.memory
+ response_json = self._get_llm_response(raw_memory)
chat_read_nodes = []
for memory_i_raw in response_json.get("memory list", []):
try:
@@ -172,28 +336,23 @@ def _process_chat_data(self, scene_data_info, info):
.replace("长期记忆", "LongTermMemory")
.replace("用户记忆", "UserMemory")
)
-
if memory_type not in ["LongTermMemory", "UserMemory"]:
memory_type = "LongTermMemory"
-
- node_i = TextualMemoryItem(
- memory=memory_i_raw.get("value", ""),
- metadata=TreeNodeTextualMemoryMetadata(
- user_id=info.get("user_id"),
- session_id=info.get("session_id"),
- memory_type=memory_type,
- status="activated",
- tags=memory_i_raw.get("tags", [])
- if type(memory_i_raw.get("tags", [])) is list
- else [],
- key=memory_i_raw.get("key", ""),
- embedding=self.embedder.embed([memory_i_raw.get("value", "")])[0],
- usage=[],
- sources=scene_data_info,
- background=response_json.get("summary", ""),
- confidence=0.99,
- type="fact",
- ),
+ node_i = self._make_memory_item(
+ value=memory_i_raw.get("value", ""),
+ info={
+ "user_id": raw_node.metadata.user_id,
+ "session_id": raw_node.metadata.session_id,
+ },
+ memory_type=memory_type,
+ tags=memory_i_raw.get("tags", [])
+ if isinstance(memory_i_raw.get("tags", []), list)
+ else [],
+ key=memory_i_raw.get("key", ""),
+ sources=raw_node.metadata.sources,
+ background=response_json.get("summary", ""),
+ type_="fact",
+ confidence=0.99,
)
chat_read_nodes.append(node_i)
except Exception as e:
@@ -202,7 +361,7 @@ def _process_chat_data(self, scene_data_info, info):
return chat_read_nodes
def get_memory(
- self, scene_data: list, type: str, info: dict[str, Any]
+ self, scene_data: list, type: str, info: dict[str, Any], mode: str = "fine"
) -> list[list[TextualMemoryItem]]:
"""
Extract and classify memory content from scene_data.
@@ -219,6 +378,8 @@ def get_memory(
- topic_chunk_overlap: Overlap for large topic chunks (default: 100)
- chunk_size: Size for small chunks (default: 256)
- chunk_overlap: Overlap for small chunks (default: 50)
+ mode: mem-reader mode, fast for quick process while fine for
+ better understanding via calling llm
Returns:
list[list[TextualMemoryItem]] containing memory content with summaries as keys and original text as values
Raises:
@@ -253,13 +414,48 @@ def get_memory(
# Process Q&A pairs concurrently with context propagation
with ContextThreadPoolExecutor() as executor:
futures = [
- executor.submit(processing_func, scene_data_info, info)
+ executor.submit(processing_func, scene_data_info, info, mode=mode)
for scene_data_info in list_scene_data_info
]
for future in concurrent.futures.as_completed(futures):
- res_memory = future.result()
- memory_list.append(res_memory)
+ try:
+ res_memory = future.result()
+ if res_memory is not None:
+ memory_list.append(res_memory)
+ except Exception as e:
+ logger.error(f"Task failed with exception: {e}")
+ logger.error(traceback.format_exc())
+ return memory_list
+
+ def fine_transfer_simple_mem(
+ self, input_memories: list[TextualMemoryItem], type: str
+ ) -> list[list[TextualMemoryItem]]:
+ if not input_memories:
+ return []
+
+ memory_list = []
+
+ if type == "chat":
+ processing_func = self._process_transfer_chat_data
+ elif type == "doc":
+ processing_func = self._process_transfer_doc_data
+ else:
+ processing_func = self._process_transfer_doc_data
+ # Process Q&A pairs concurrently with context propagation
+ with ContextThreadPoolExecutor() as executor:
+ futures = [
+ executor.submit(processing_func, scene_data_info)
+ for scene_data_info in input_memories
+ ]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ res_memory = future.result()
+ if res_memory is not None:
+ memory_list.append(res_memory)
+ except Exception as e:
+ logger.error(f"Task failed with exception: {e}")
+ logger.error(traceback.format_exc())
return memory_list
def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
@@ -275,30 +471,26 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
List of strings containing the processed scene data
"""
results = []
- parser_config = ParserConfigFactory.model_validate(
- {
- "backend": "markitdown",
- "config": {},
- }
- )
- parser = ParserFactory.from_config(parser_config)
if type == "chat":
for items in scene_data:
result = []
- for item in items:
- # Convert dictionary to string
- if "chat_time" in item:
- result.append(item)
- else:
- result.append(item)
+ for i, item in enumerate(items):
+ result.append(item)
if len(result) >= 10:
results.append(result)
- context = copy.deepcopy(result[-2:])
+ context = copy.deepcopy(result[-2:]) if i + 1 < len(items) else []
result = context
if result:
results.append(result)
elif type == "doc":
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": "markitdown",
+ "config": {},
+ }
+ )
+ parser = ParserFactory.from_config(parser_config)
for item in scene_data:
try:
if os.path.exists(item):
@@ -317,6 +509,9 @@ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
return results
def _process_doc_data(self, scene_data_info, info, **kwargs):
+ mode = kwargs.get("mode", "fine")
+ if mode == "fast":
+ raise NotImplementedError
chunks = self.chunker.chunk(scene_data_info["text"])
messages = []
for chunk in chunks:
@@ -357,19 +552,48 @@ def _process_doc_data(self, scene_data_info, info, **kwargs):
logger.error(f"[DocReader] Future task failed: {e}")
return doc_nodes
- def parse_json_result(self, response_text):
+ def _process_transfer_doc_data(self, raw_node: TextualMemoryItem):
+ raise NotImplementedError
+
+ def parse_json_result(self, response_text: str) -> dict:
+ s = (response_text or "").strip()
+
+ m = re.search(r"```(?:json)?\s*([\s\S]*?)```", s, flags=re.I)
+ s = (m.group(1) if m else s.replace("```", "")).strip()
+
+ i = s.find("{")
+ if i == -1:
+ return {}
+ s = s[i:].strip()
+
+ try:
+ return json.loads(s)
+ except json.JSONDecodeError:
+ pass
+
+ j = max(s.rfind("}"), s.rfind("]"))
+ if j != -1:
+ try:
+ return json.loads(s[: j + 1])
+ except json.JSONDecodeError:
+ pass
+
+ def _cheap_close(t: str) -> str:
+ t += "}" * max(0, t.count("{") - t.count("}"))
+ t += "]" * max(0, t.count("[") - t.count("]"))
+ return t
+
+ t = _cheap_close(s)
try:
- json_start = response_text.find("{")
- response_text = response_text[json_start:]
- response_text = response_text.replace("```", "").strip()
- if not response_text.endswith("}"):
- response_text += "}"
- return json.loads(response_text)
+ return json.loads(t)
except json.JSONDecodeError as e:
- logger.error(f"[JSONParse] Failed to decode JSON: {e}\nRaw:\n{response_text}")
- return {}
- except Exception as e:
- logger.error(f"[JSONParse] Unexpected error: {e}")
+ if "Invalid \\escape" in str(e):
+ s = s.replace("\\", "\\\\")
+ return json.loads(s)
+ logger.error(
+ f"[JSONParse] Failed to decode JSON: {e}\nTail: Raw {response_text} \
+ json: {s}"
+ )
return {}
def transform_memreader(self, data: dict) -> list[TextualMemoryItem]:
diff --git a/src/memos/mem_reader/strategy_struct.py b/src/memos/mem_reader/strategy_struct.py
new file mode 100644
index 000000000..1fc21461e
--- /dev/null
+++ b/src/memos/mem_reader/strategy_struct.py
@@ -0,0 +1,151 @@
+import os
+
+from abc import ABC
+
+from memos import log
+from memos.configs.mem_reader import StrategyStructMemReaderConfig
+from memos.configs.parser import ParserConfigFactory
+from memos.mem_reader.simple_struct import SimpleStructMemReader, detect_lang
+from memos.parsers.factory import ParserFactory
+from memos.templates.mem_reader_prompts import (
+ SIMPLE_STRUCT_DOC_READER_PROMPT,
+ SIMPLE_STRUCT_DOC_READER_PROMPT_ZH,
+ SIMPLE_STRUCT_MEM_READER_EXAMPLE,
+ SIMPLE_STRUCT_MEM_READER_EXAMPLE_ZH,
+)
+from memos.templates.mem_reader_strategy_prompts import (
+ STRATEGY_STRUCT_MEM_READER_PROMPT,
+ STRATEGY_STRUCT_MEM_READER_PROMPT_ZH,
+)
+
+
+logger = log.get_logger(__name__)
+STRATEGY_PROMPT_DICT = {
+ "chat": {
+ "en": STRATEGY_STRUCT_MEM_READER_PROMPT,
+ "zh": STRATEGY_STRUCT_MEM_READER_PROMPT_ZH,
+ "en_example": SIMPLE_STRUCT_MEM_READER_EXAMPLE,
+ "zh_example": SIMPLE_STRUCT_MEM_READER_EXAMPLE_ZH,
+ },
+ "doc": {"en": SIMPLE_STRUCT_DOC_READER_PROMPT, "zh": SIMPLE_STRUCT_DOC_READER_PROMPT_ZH},
+}
+
+
+class StrategyStructMemReader(SimpleStructMemReader, ABC):
+ """Naive implementation of MemReader."""
+
+ def __init__(self, config: StrategyStructMemReaderConfig):
+ super().__init__(config)
+ self.chat_chunker = config.chat_chunker["config"]
+
+ def _get_llm_response(self, mem_str: str) -> dict:
+ lang = detect_lang(mem_str)
+ template = STRATEGY_PROMPT_DICT["chat"][lang]
+ examples = STRATEGY_PROMPT_DICT["chat"][f"{lang}_example"]
+ prompt = template.replace("${conversation}", mem_str)
+ if self.config.remove_prompt_example: # TODO unused
+ prompt = prompt.replace(examples, "")
+ messages = [{"role": "user", "content": prompt}]
+ try:
+ response_text = self.llm.generate(messages)
+ response_json = self.parse_json_result(response_text)
+ except Exception as e:
+ logger.error(f"[LLM] Exception during chat generation: {e}")
+ response_json = {
+ "memory list": [
+ {
+ "key": mem_str[:10],
+ "memory_type": "UserMemory",
+ "value": mem_str,
+ "tags": [],
+ }
+ ],
+ "summary": mem_str,
+ }
+ return response_json
+
+ def get_scene_data_info(self, scene_data: list, type: str) -> list[str]:
+ """
+ Get raw information from scene_data.
+ If scene_data contains dictionaries, convert them to strings.
+ If scene_data contains file paths, parse them using the parser.
+
+ Args:
+ scene_data: List of dialogue information or document paths
+ type: Type of scene data: ['doc', 'chat']
+ Returns:
+ List of strings containing the processed scene data
+ """
+ results = []
+
+ if type == "chat":
+ if self.chat_chunker["chunk_type"] == "content_length":
+ content_len_thredshold = self.chat_chunker["chunk_length"]
+ for items in scene_data:
+ if not items:
+ continue
+
+ results.append([])
+ current_length = 0
+
+ for _i, item in enumerate(items):
+ content_length = (
+ len(item.get("content", ""))
+ if isinstance(item, dict)
+ else len(str(item))
+ )
+ if not results[-1]:
+ results[-1].append(item)
+ current_length = content_length
+ continue
+
+ if current_length + content_length <= content_len_thredshold:
+ results[-1].append(item)
+ current_length += content_length
+ else:
+ overlap_item = results[-1][-1]
+ overlap_length = (
+ len(overlap_item.get("content", ""))
+ if isinstance(overlap_item, dict)
+ else len(str(overlap_item))
+ )
+
+ results.append([overlap_item, item])
+ current_length = overlap_length + content_length
+ else:
+ cut_size, cut_overlap = (
+ self.chat_chunker["chunk_session"],
+ self.chat_chunker["chunk_overlap"],
+ )
+ for items in scene_data:
+ step = cut_size - cut_overlap
+ end = len(items) - cut_overlap
+ if end <= 0:
+ results.extend([items[:]])
+ else:
+ results.extend([items[i : i + cut_size] for i in range(0, end, step)])
+
+ elif type == "doc":
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": "markitdown",
+ "config": {},
+ }
+ )
+ parser = ParserFactory.from_config(parser_config)
+ for item in scene_data:
+ try:
+ if os.path.exists(item):
+ try:
+ parsed_text = parser.parse(item)
+ results.append({"file": item, "text": parsed_text})
+ except Exception as e:
+ logger.error(f"[SceneParser] Error parsing {item}: {e}")
+ continue
+ else:
+ parsed_text = item
+ results.append({"file": "pure_text", "text": parsed_text})
+ except Exception as e:
+ print(f"Error parsing file {item}: {e!s}")
+
+ return results
diff --git a/src/memos/mem_scheduler/analyzer/api_analyzer.py b/src/memos/mem_scheduler/analyzer/api_analyzer.py
index e69de29bb..28ca182e5 100644
--- a/src/memos/mem_scheduler/analyzer/api_analyzer.py
+++ b/src/memos/mem_scheduler/analyzer/api_analyzer.py
@@ -0,0 +1,717 @@
+"""
+API Analyzer for Scheduler
+
+This module provides the APIAnalyzerForScheduler class that handles API requests
+for search and add operations with reusable instance variables.
+"""
+
+import http.client
+import json
+import time
+
+from typing import Any
+from urllib.parse import urlparse
+
+import requests
+
+from memos.log import get_logger
+
+
+logger = get_logger(__name__)
+
+
+class APIAnalyzerForScheduler:
+ """
+ API Analyzer class for scheduler operations.
+
+ This class provides methods to interact with APIs for search and add operations,
+ with reusable instance variables for better performance and configuration management.
+ """
+
+ def __init__(
+ self,
+ base_url: str = "http://127.0.0.1:8002",
+ default_headers: dict[str, str] | None = None,
+ timeout: int = 30,
+ ):
+ """
+ Initialize the APIAnalyzerForScheduler.
+
+ Args:
+ base_url: Base URL for API requests
+ default_headers: Default headers to use for all requests
+ timeout: Request timeout in seconds
+ """
+ self.base_url = base_url.rstrip("/")
+ self.timeout = timeout
+
+ # Default headers
+ self.default_headers = default_headers or {"Content-Type": "application/json"}
+
+ # Parse URL for http.client usage
+ parsed_url = urlparse(self.base_url)
+ self.host = parsed_url.hostname
+ self.port = parsed_url.port or 8002
+ self.is_https = parsed_url.scheme == "https"
+
+ # Reusable connection for http.client
+ self._connection = None
+
+ # Attributes
+ self.user_id = "test_user_id"
+ self.mem_cube_id = "test_mem_cube_id"
+
+ logger.info(f"APIAnalyzerForScheduler initialized with base_url: {self.base_url}")
+
+ def _get_connection(self) -> http.client.HTTPConnection | http.client.HTTPSConnection:
+ """
+ Get or create a reusable HTTP connection.
+
+ Returns:
+ HTTP connection object
+ """
+ if self._connection is None:
+ if self.is_https:
+ self._connection = http.client.HTTPSConnection(self.host, self.port)
+ else:
+ self._connection = http.client.HTTPConnection(self.host, self.port)
+ return self._connection
+
+ def _close_connection(self):
+ """Close the HTTP connection if it exists."""
+ if self._connection:
+ self._connection.close()
+ self._connection = None
+
+ def search(
+ self, user_id: str, mem_cube_id: str, query: str, top: int = 50, use_requests: bool = True
+ ) -> dict[str, Any]:
+ """
+ Search for memories using the product/search API endpoint.
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ query: Search query string
+ top: Number of top results to return
+ use_requests: Whether to use requests library (True) or http.client (False)
+
+ Returns:
+ Dictionary containing the API response
+ """
+ payload = {"user_id": user_id, "mem_cube_id": mem_cube_id, "query": query, "top": top}
+
+ try:
+ if use_requests:
+ return self._search_with_requests(payload)
+ else:
+ return self._search_with_http_client(payload)
+ except Exception as e:
+ logger.error(f"Error in search operation: {e}")
+ return {"error": str(e), "success": False}
+
+ def _search_with_requests(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform search using requests library.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ url = f"{self.base_url}/product/search"
+
+ response = requests.post(
+ url, headers=self.default_headers, data=json.dumps(payload), timeout=self.timeout
+ )
+
+ logger.info(f"Search request to {url} completed with status: {response.status_code}")
+
+ try:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": response.json() if response.content else {},
+ "text": response.text,
+ }
+ except json.JSONDecodeError:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": {},
+ "text": response.text,
+ }
+
+ def _search_with_http_client(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform search using http.client.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ conn = self._get_connection()
+
+ try:
+ conn.request("POST", "/product/search", json.dumps(payload), self.default_headers)
+
+ response = conn.getresponse()
+ data = response.read()
+ response_text = data.decode("utf-8")
+
+ logger.info(f"Search request completed with status: {response.status}")
+
+ try:
+ response_data = json.loads(response_text) if response_text else {}
+ except json.JSONDecodeError:
+ response_data = {}
+
+ return {
+ "success": True,
+ "status_code": response.status,
+ "data": response_data,
+ "text": response_text,
+ }
+ except Exception as e:
+ logger.error(f"Error in http.client search: {e}")
+ return {"error": str(e), "success": False}
+
+ def add(
+ self, messages: list, user_id: str, mem_cube_id: str, use_requests: bool = True
+ ) -> dict[str, Any]:
+ """
+ Add memories using the product/add API endpoint.
+
+ Args:
+ messages: List of message objects with role and content
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ use_requests: Whether to use requests library (True) or http.client (False)
+
+ Returns:
+ Dictionary containing the API response
+ """
+ payload = {"messages": messages, "user_id": user_id, "mem_cube_id": mem_cube_id}
+
+ try:
+ if use_requests:
+ return self._add_with_requests(payload)
+ else:
+ return self._add_with_http_client(payload)
+ except Exception as e:
+ logger.error(f"Error in add operation: {e}")
+ return {"error": str(e), "success": False}
+
+ def _add_with_requests(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform add using requests library.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ url = f"{self.base_url}/product/add"
+
+ response = requests.post(
+ url, headers=self.default_headers, data=json.dumps(payload), timeout=self.timeout
+ )
+
+ logger.info(f"Add request to {url} completed with status: {response.status_code}")
+
+ try:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": response.json() if response.content else {},
+ "text": response.text,
+ }
+ except json.JSONDecodeError:
+ return {
+ "success": True,
+ "status_code": response.status_code,
+ "data": {},
+ "text": response.text,
+ }
+
+ def _add_with_http_client(self, payload: dict[str, Any]) -> dict[str, Any]:
+ """
+ Perform add using http.client.
+
+ Args:
+ payload: Request payload
+
+ Returns:
+ Dictionary containing the API response
+ """
+ conn = self._get_connection()
+
+ try:
+ conn.request("POST", "/product/add", json.dumps(payload), self.default_headers)
+
+ response = conn.getresponse()
+ data = response.read()
+ response_text = data.decode("utf-8")
+
+ logger.info(f"Add request completed with status: {response.status}")
+
+ try:
+ response_data = json.loads(response_text) if response_text else {}
+ except json.JSONDecodeError:
+ response_data = {}
+
+ return {
+ "success": True,
+ "status_code": response.status,
+ "data": response_data,
+ "text": response_text,
+ }
+ except Exception as e:
+ logger.error(f"Error in http.client add: {e}")
+ return {"error": str(e), "success": False}
+
+ def update_base_url(self, new_base_url: str):
+ """
+ Update the base URL and reinitialize connection parameters.
+
+ Args:
+ new_base_url: New base URL for API requests
+ """
+ self._close_connection()
+ self.base_url = new_base_url.rstrip("/")
+
+ # Re-parse URL
+ parsed_url = urlparse(self.base_url)
+ self.host = parsed_url.hostname
+ self.port = parsed_url.port or (443 if parsed_url.scheme == "https" else 80)
+ self.is_https = parsed_url.scheme == "https"
+
+ logger.info(f"Base URL updated to: {self.base_url}")
+
+ def update_headers(self, headers: dict[str, str]):
+ """
+ Update default headers.
+
+ Args:
+ headers: New headers to merge with existing ones
+ """
+ self.default_headers.update(headers)
+ logger.info("Headers updated")
+
+ def __del__(self):
+ """Cleanup method to close connection when object is destroyed."""
+ self._close_connection()
+
+ def analyze_service(self):
+ # Example add operation
+ messages = [
+ {"role": "user", "content": "Where should I go for New Year's Eve in Shanghai?"},
+ {
+ "role": "assistant",
+ "content": "You could head to the Bund for the countdown, attend a rooftop party, or enjoy the fireworks at Disneyland Shanghai.",
+ },
+ ]
+
+ add_result = self.add(
+ messages=messages, user_id="test_user_id", mem_cube_id="test_mem_cube_id"
+ )
+ print("Add result:", add_result)
+
+ # Example search operation
+ search_result = self.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
+
+ def analyze_features(self):
+ try:
+ # Test basic search functionality
+ search_result = self.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
+ except Exception as e:
+ logger.error(f"Feature analysis failed: {e}")
+
+
+class DirectSearchMemoriesAnalyzer:
+ """
+ Direct analyzer for testing search_memories function
+ Used for debugging and analyzing search_memories function behavior without starting a full API server
+ """
+
+ def __init__(self):
+ """Initialize the analyzer"""
+ # Import necessary modules
+ try:
+ from memos.api.product_models import APIADDRequest, APISearchRequest
+ from memos.api.routers.server_router import add_memories, search_memories
+ from memos.types import MessageDict, UserContext
+
+ self.APISearchRequest = APISearchRequest
+ self.APIADDRequest = APIADDRequest
+ self.search_memories = search_memories
+ self.add_memories = add_memories
+ self.UserContext = UserContext
+ self.MessageDict = MessageDict
+
+ # Initialize conversation history for continuous conversation support
+ self.conversation_history = []
+ self.current_session_id = None
+ self.current_user_id = None
+ self.current_mem_cube_id = None
+
+ logger.info("DirectSearchMemoriesAnalyzer initialized successfully")
+ except ImportError as e:
+ logger.error(f"Failed to import modules: {e}")
+ raise
+
+ def start_conversation(self, user_id="test_user", mem_cube_id="test_cube", session_id=None):
+ """
+ Start a new conversation session for continuous dialogue.
+
+ Args:
+ user_id: User ID for the conversation
+ mem_cube_id: Memory cube ID for the conversation
+ session_id: Session ID for the conversation (auto-generated if None)
+ """
+ self.current_user_id = user_id
+ self.current_mem_cube_id = mem_cube_id
+ self.current_session_id = (
+ session_id or f"session_{hash(user_id + mem_cube_id)}_{len(self.conversation_history)}"
+ )
+ self.conversation_history = []
+
+ logger.info(f"Started conversation session: {self.current_session_id}")
+ print(f"🚀 Started new conversation session: {self.current_session_id}")
+ print(f" User ID: {self.current_user_id}")
+ print(f" Mem Cube ID: {self.current_mem_cube_id}")
+
+ def add_to_conversation(self, user_message, assistant_message=None):
+ """
+ Add messages to the current conversation and store them in memory.
+
+ Args:
+ user_message: User's message content
+ assistant_message: Assistant's response (optional)
+
+ Returns:
+ Result from add_memories function
+ """
+ if not self.current_session_id:
+ raise ValueError("No active conversation session. Call start_conversation() first.")
+
+ # Prepare messages for adding to memory
+ messages = [{"role": "user", "content": user_message}]
+ if assistant_message:
+ messages.append({"role": "assistant", "content": assistant_message})
+
+ # Add to conversation history
+ self.conversation_history.extend(messages)
+
+ # Create add request
+ add_req = self.create_test_add_request(
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ messages=messages,
+ session_id=self.current_session_id,
+ )
+
+ print(f"💬 Adding to conversation (Session: {self.current_session_id}):")
+ print(f" User: {user_message}")
+ if assistant_message:
+ print(f" Assistant: {assistant_message}")
+
+ # Add to memory
+ result = self.add_memories(add_req)
+ print(" ✅ Added to memory successfully")
+
+ return result
+
+ def search_in_conversation(self, query, mode="fast", top_k=10, include_history=True):
+ """
+ Search memories within the current conversation context.
+
+ Args:
+ query: Search query
+ mode: Search mode ("fast", "fine", or "mixture")
+ top_k: Number of results to return
+ include_history: Whether to include conversation history in the search
+
+ Returns:
+ Search results
+ """
+ if not self.current_session_id:
+ raise ValueError("No active conversation session. Call start_conversation() first.")
+
+ # Prepare chat history if requested
+ chat_history = self.conversation_history if include_history else None
+
+ # Create search request
+ search_req = self.create_test_search_request(
+ query=query,
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ mode=mode,
+ top_k=top_k,
+ chat_history=chat_history,
+ session_id=self.current_session_id,
+ )
+
+ print(f"🔍 Searching in conversation (Session: {self.current_session_id}):")
+ print(f" Query: {query}")
+ print(f" Mode: {mode}")
+ print(f" Top K: {top_k}")
+ print(f" Include History: {include_history}")
+ print(f" History Length: {len(self.conversation_history) if chat_history else 0}")
+
+ # Perform search
+ result = self.search_memories(search_req)
+
+ print(" ✅ Search completed")
+ if hasattr(result, "data") and result.data:
+ total_memories = sum(
+ len(mem_list) for mem_list in result.data.values() if isinstance(mem_list, list)
+ )
+ print(f" 📊 Found {total_memories} total memories")
+
+ return result
+
+ def test_continuous_conversation(self):
+ """Test continuous conversation functionality"""
+ print("=" * 80)
+ print("Testing Continuous Conversation Functionality")
+ print("=" * 80)
+
+ try:
+ # Start a conversation
+ self.start_conversation(user_id="conv_test_user", mem_cube_id="conv_test_cube")
+
+ # Prepare all conversation messages for batch addition
+ all_messages = [
+ {
+ "role": "user",
+ "content": "I'm planning a trip to Shanghai for New Year's Eve. What are some good places to visit?",
+ },
+ {
+ "role": "assistant",
+ "content": "Shanghai has many great places for New Year's Eve! You could visit the Bund for the countdown, go to a rooftop party, or enjoy fireworks at Disneyland Shanghai. The French Concession also has nice bars and restaurants.",
+ },
+ {"role": "user", "content": "What about food? Any restaurant recommendations?"},
+ {
+ "role": "assistant",
+ "content": "For New Year's Eve dining in Shanghai, I'd recommend trying some local specialties like xiaolongbao at Din Tai Fung, or for a fancy dinner, you could book at restaurants in the Bund area with great views.",
+ },
+ {"role": "user", "content": "I'm on a budget though. Any cheaper alternatives?"},
+ {
+ "role": "assistant",
+ "content": "For budget-friendly options, try street food in Yuyuan Garden area, local noodle shops, or food courts in shopping malls. You can also watch the fireworks from free public areas along the Huangpu River.",
+ },
+ ]
+
+ # Add all conversation messages at once
+ print("\n📝 Adding all conversation messages at once:")
+ add_req = self.create_test_add_request(
+ user_id=self.current_user_id,
+ mem_cube_id=self.current_mem_cube_id,
+ messages=all_messages,
+ session_id=self.current_session_id,
+ )
+
+ print(
+ f"💬 Adding {len(all_messages)} messages to conversation (Session: {self.current_session_id})"
+ )
+ self.add_memories(add_req)
+
+ # Update conversation history
+ self.conversation_history.extend(all_messages)
+ print(" ✅ Added all messages to memory successfully")
+
+ # Test searching within the conversation
+ print("\n🔍 Testing search within conversation:")
+
+ # Search for trip-related information
+ self.search_in_conversation(
+ query="New Year's Eve Shanghai recommendations", mode="mixture", top_k=5
+ )
+
+ # Search for food-related information
+ self.search_in_conversation(query="budget food Shanghai", mode="mixture", top_k=3)
+
+ # Search without conversation history
+ self.search_in_conversation(
+ query="Shanghai travel", mode="mixture", top_k=3, include_history=False
+ )
+
+ print("\n✅ Continuous conversation test completed successfully!")
+ return True
+
+ except Exception as e:
+ print(f"❌ Continuous conversation test failed: {e}")
+ import traceback
+
+ traceback.print_exc()
+ return False
+
+ def create_test_search_request(
+ self,
+ query="test query",
+ user_id="test_user",
+ mem_cube_id="test_cube",
+ mode="fast",
+ top_k=10,
+ chat_history=None,
+ session_id=None,
+ ):
+ """
+ Create a test APISearchRequest object with the given parameters.
+
+ Args:
+ query: Search query string
+ user_id: User ID for the request
+ mem_cube_id: Memory cube ID for the request
+ mode: Search mode ("fast" or "fine")
+ top_k: Number of results to return
+ chat_history: Chat history for context (optional)
+ session_id: Session ID for the request (optional)
+
+ Returns:
+ APISearchRequest: A configured request object
+ """
+ return self.APISearchRequest(
+ query=query,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mode=mode,
+ top_k=top_k,
+ chat_history=chat_history,
+ session_id=session_id,
+ )
+
+ def create_test_add_request(
+ self,
+ user_id="test_user",
+ mem_cube_id="test_cube",
+ messages=None,
+ memory_content=None,
+ session_id=None,
+ ):
+ """
+ Create a test APIADDRequest object with the given parameters.
+
+ Args:
+ user_id: User ID for the request
+ mem_cube_id: Memory cube ID for the request
+ messages: List of messages to add (optional)
+ memory_content: Direct memory content to add (optional)
+ session_id: Session ID for the request (optional)
+
+ Returns:
+ APIADDRequest: A configured request object
+ """
+ if messages is None and memory_content is None:
+ # Default test messages
+ messages = [
+ {"role": "user", "content": "What's the weather like today?"},
+ {
+ "role": "assistant",
+ "content": "I don't have access to real-time weather data, but you can check a weather app or website for current conditions.",
+ },
+ ]
+
+ # Ensure we have a valid session_id
+ if session_id is None:
+ session_id = "test_session_" + str(hash(user_id + mem_cube_id))[:8]
+
+ return self.APIADDRequest(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ messages=messages,
+ memory_content=memory_content,
+ session_id=session_id,
+ doc_path=None,
+ source="api_analyzer_test",
+ chat_history=None,
+ operation=None,
+ )
+
+ def run_all_tests(self):
+ """Run all available tests"""
+ print("🚀 Starting comprehensive test suite")
+ print("=" * 80)
+
+ # Test continuous conversation functionality
+ print("\n💬 Testing CONTINUOUS CONVERSATION functions:")
+ try:
+ self.test_continuous_conversation()
+ time.sleep(5)
+ print("✅ Continuous conversation test completed successfully")
+ except Exception as e:
+ print(f"❌ Continuous conversation test failed: {e}")
+
+ print("\n" + "=" * 80)
+ print("✅ All tests completed!")
+
+
+# Example usage
+if __name__ == "__main__":
+ import argparse
+
+ parser = argparse.ArgumentParser(description="API Analyzer for Memory Scheduler")
+ parser.add_argument(
+ "--mode",
+ choices=["direct", "api"],
+ default="direct",
+ help="Test mode: 'direct' for direct function testing, 'api' for API testing (default: direct)",
+ )
+
+ args = parser.parse_args()
+
+ if args.mode == "direct":
+ # Direct test mode for search_memories and add_memories functions
+ print("Using direct test mode")
+ try:
+ direct_analyzer = DirectSearchMemoriesAnalyzer()
+ direct_analyzer.run_all_tests()
+ except Exception as e:
+ print(f"Direct test mode failed: {e}")
+ import traceback
+
+ traceback.print_exc()
+ else:
+ # Original API test mode
+ print("Using API test mode")
+ analyzer = APIAnalyzerForScheduler()
+
+ # Test add operation
+ messages = [
+ {"role": "user", "content": "Where should I go for New Year's Eve in Shanghai?"},
+ {
+ "role": "assistant",
+ "content": "You could head to the Bund for the countdown, attend a rooftop party, or enjoy the fireworks at Disneyland Shanghai.",
+ },
+ ]
+
+ add_result = analyzer.add(
+ messages=messages, user_id="test_user_id", mem_cube_id="test_mem_cube_id"
+ )
+ print("Add result:", add_result)
+
+ # Test search operation
+ search_result = analyzer.search(
+ user_id="test_user_id",
+ mem_cube_id="test_mem_cube_id",
+ query="What are some good places to celebrate New Year's Eve in Shanghai?",
+ top=50,
+ )
+ print("Search result:", search_result)
diff --git a/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py b/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
index 7cd085ada..ace67eff6 100644
--- a/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
+++ b/src/memos/mem_scheduler/analyzer/mos_for_test_scheduler.py
@@ -485,18 +485,20 @@ def chat(self, query: str, user_id: str | None = None) -> str:
past_key_values = None
if self.config.enable_activation_memory:
- assert self.config.chat_model.backend == "huggingface", (
- "Activation memory only used for huggingface backend."
- )
- # TODO this only one cubes
- for mem_cube_id, mem_cube in self.mem_cubes.items():
- if mem_cube_id not in user_cube_ids:
- continue
- if mem_cube.act_mem:
- kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
- past_key_values = (
- kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
- )
+ if self.config.chat_model.backend != "huggingface":
+ logger.error(
+ "Activation memory only used for huggingface backend. Skipping activation memory."
+ )
+ else:
+ # TODO this only one cubes
+ for mem_cube_id, mem_cube in self.mem_cubes.items():
+ if mem_cube_id not in user_cube_ids:
+ continue
+ if mem_cube.act_mem:
+ kv_cache = next(iter(mem_cube.act_mem.get_all()), None)
+ past_key_values = (
+ kv_cache.memory if (kv_cache and hasattr(kv_cache, "memory")) else None
+ )
break
# Generate response
response = self.chat_llm.generate(current_messages, past_key_values=past_key_values)
diff --git a/src/memos/mem_scheduler/base_scheduler.py b/src/memos/mem_scheduler/base_scheduler.py
index 4f8b0719b..028fe8e3f 100644
--- a/src/memos/mem_scheduler/base_scheduler.py
+++ b/src/memos/mem_scheduler/base_scheduler.py
@@ -1,3 +1,4 @@
+import contextlib
import multiprocessing
import queue
import threading
@@ -6,10 +7,12 @@
from collections.abc import Callable
from datetime import datetime
from pathlib import Path
+from typing import TYPE_CHECKING
from sqlalchemy.engine import Engine
from memos.configs.mem_scheduler import AuthConfig, BaseSchedulerConfig
+from memos.context.context import ContextThread
from memos.llms.base import BaseLLM
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
@@ -22,8 +25,12 @@
from memos.mem_scheduler.schemas.general_schemas import (
DEFAULT_ACT_MEM_DUMP_PATH,
DEFAULT_CONSUME_INTERVAL_SECONDS,
+ DEFAULT_CONTEXT_WINDOW_SIZE,
+ DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE,
DEFAULT_STARTUP_MODE,
DEFAULT_THREAD_POOL_MAX_WORKERS,
+ DEFAULT_TOP_K,
+ DEFAULT_USE_REDIS_QUEUE,
STARTUP_BY_PROCESS,
MemCubeID,
TreeTextMemory_SEARCH_METHOD,
@@ -34,6 +41,7 @@
ScheduleMessageItem,
)
from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorItem
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.mem_scheduler.utils.filter_utils import (
transform_name_to_key,
)
@@ -45,6 +53,10 @@
from memos.templates.mem_scheduler_prompts import MEMORY_ASSEMBLY_TEMPLATE
+if TYPE_CHECKING:
+ from memos.mem_cube.base import BaseMemCube
+
+
logger = get_logger(__name__)
@@ -57,11 +69,13 @@ def __init__(self, config: BaseSchedulerConfig):
self.config = config
# hyper-parameters
- self.top_k = self.config.get("top_k", 10)
- self.context_window_size = self.config.get("context_window_size", 5)
+ self.top_k = self.config.get("top_k", DEFAULT_TOP_K)
+ self.context_window_size = self.config.get(
+ "context_window_size", DEFAULT_CONTEXT_WINDOW_SIZE
+ )
self.enable_activation_memory = self.config.get("enable_activation_memory", False)
self.act_mem_dump_path = self.config.get("act_mem_dump_path", DEFAULT_ACT_MEM_DUMP_PATH)
- self.search_method = TreeTextMemory_SEARCH_METHOD
+ self.search_method = self.config.get("search_method", TreeTextMemory_SEARCH_METHOD)
self.enable_parallel_dispatch = self.config.get("enable_parallel_dispatch", True)
self.thread_pool_max_workers = self.config.get(
"thread_pool_max_workers", DEFAULT_THREAD_POOL_MAX_WORKERS
@@ -76,6 +90,7 @@ def __init__(self, config: BaseSchedulerConfig):
self.db_engine: Engine | None = None
self.monitor: SchedulerGeneralMonitor | None = None
self.dispatcher_monitor: SchedulerDispatcherMonitor | None = None
+ self.mem_reader = None # Will be set by MOSCore
self.dispatcher = SchedulerDispatcher(
config=self.config,
max_workers=self.thread_pool_max_workers,
@@ -85,13 +100,22 @@ def __init__(self, config: BaseSchedulerConfig):
# optional configs
self.disable_handlers: list | None = self.config.get("disable_handlers", None)
- # internal message queue
+ # message queue configuration
+ self.use_redis_queue = self.config.get("use_redis_queue", DEFAULT_USE_REDIS_QUEUE)
self.max_internal_message_queue_size = self.config.get(
- "max_internal_message_queue_size", 100
- )
- self.memos_message_queue: Queue[ScheduleMessageItem] = Queue(
- maxsize=self.max_internal_message_queue_size
+ "max_internal_message_queue_size", DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE
)
+
+ # Initialize message queue based on configuration
+ if self.use_redis_queue:
+ self.memos_message_queue = None # Will use Redis instead
+ # Initialize Redis if using Redis queue with auto-initialization
+ self.auto_initialize_redis()
+ else:
+ self.memos_message_queue: Queue[ScheduleMessageItem] = Queue(
+ maxsize=self.max_internal_message_queue_size
+ )
+
self.max_web_log_queue_size = self.config.get("max_web_log_queue_size", 50)
self._web_log_message_queue: Queue[ScheduleLogForWebItem] = Queue(
maxsize=self.max_web_log_queue_size
@@ -107,7 +131,7 @@ def __init__(self, config: BaseSchedulerConfig):
self._context_lock = threading.Lock()
self.current_user_id: UserID | str | None = None
self.current_mem_cube_id: MemCubeID | str | None = None
- self.current_mem_cube: GeneralMemCube | None = None
+ self.current_mem_cube: BaseMemCube | None = None
self.auth_config_path: str | Path | None = self.config.get("auth_config_path", None)
self.auth_config = None
self.rabbitmq_config = None
@@ -117,6 +141,7 @@ def initialize_modules(
chat_llm: BaseLLM,
process_llm: BaseLLM | None = None,
db_engine: Engine | None = None,
+ mem_reader=None,
):
if process_llm is None:
process_llm = chat_llm
@@ -133,17 +158,25 @@ def initialize_modules(
self.dispatcher_monitor = SchedulerDispatcherMonitor(config=self.config)
self.retriever = SchedulerRetriever(process_llm=self.process_llm, config=self.config)
+ if mem_reader:
+ self.mem_reader = mem_reader
+
if self.enable_parallel_dispatch:
self.dispatcher_monitor.initialize(dispatcher=self.dispatcher)
self.dispatcher_monitor.start()
# initialize with auth_config
- if self.auth_config_path is not None and Path(self.auth_config_path).exists():
- self.auth_config = AuthConfig.from_local_config(config_path=self.auth_config_path)
- elif AuthConfig.default_config_exists():
- self.auth_config = AuthConfig.from_local_config()
- else:
- self.auth_config = AuthConfig.from_local_env()
+ try:
+ if self.auth_config_path is not None and Path(self.auth_config_path).exists():
+ self.auth_config = AuthConfig.from_local_config(
+ config_path=self.auth_config_path
+ )
+ elif AuthConfig.default_config_exists():
+ self.auth_config = AuthConfig.from_local_config()
+ else:
+ self.auth_config = AuthConfig.from_local_env()
+ except Exception:
+ pass
if self.auth_config is not None:
self.rabbitmq_config = self.auth_config.rabbitmq
@@ -157,6 +190,8 @@ def initialize_modules(
self._cleanup_on_init_failure()
raise
+ # start queue monitor if enabled and a bot is set later
+
def _cleanup_on_init_failure(self):
"""Clean up resources if initialization fails."""
try:
@@ -384,7 +419,7 @@ def update_activation_memory(
cache_item = act_mem.extract(new_text_memory)
cache_item.records.text_memories = new_text_memories
- cache_item.records.timestamp = datetime.utcnow()
+ cache_item.records.timestamp = get_utc_now()
act_mem.add([cache_item])
act_mem.dump(self.act_mem_dump_path)
@@ -465,7 +500,7 @@ def update_activation_memory_periodically(
mem_cube=mem_cube,
)
- self.monitor.last_activation_mem_update_time = datetime.utcnow()
+ self.monitor.last_activation_mem_update_time = get_utc_now()
logger.debug(
f"Activation memory update completed at {self.monitor.last_activation_mem_update_time}"
@@ -474,14 +509,14 @@ def update_activation_memory_periodically(
else:
logger.info(
f"Skipping update - {interval_seconds} second interval not yet reached. "
- f"Last update time is {self.monitor.last_activation_mem_update_time} and now is"
- f"{datetime.utcnow()}"
+ f"Last update time is {self.monitor.last_activation_mem_update_time} and now is "
+ f"{get_utc_now()}"
)
except Exception as e:
logger.error(f"Error in update_activation_memory_periodically: {e}", exc_info=True)
def submit_messages(self, messages: ScheduleMessageItem | list[ScheduleMessageItem]):
- """Submit multiple messages to the message queue."""
+ """Submit messages to the message queue (either local queue or Redis)."""
if isinstance(messages, ScheduleMessageItem):
messages = [messages] # transform single message to list
@@ -491,13 +526,27 @@ def submit_messages(self, messages: ScheduleMessageItem | list[ScheduleMessageIt
logger.error(error_msg)
raise TypeError(error_msg)
- # Check if this handler is disabled
+ if getattr(message, "timestamp", None) is None:
+ with contextlib.suppress(Exception):
+ message.timestamp = datetime.utcnow()
+
if self.disable_handlers and message.label in self.disable_handlers:
logger.info(f"Skipping disabled handler: {message.label} - {message.content}")
continue
- self.memos_message_queue.put(message)
- logger.info(f"Submitted message: {message.label} - {message.content}")
+ if self.use_redis_queue:
+ # Use Redis stream for message queue
+ self.redis_add_message_stream(message.to_dict())
+ logger.info(f"Submitted message to Redis: {message.label} - {message.content}")
+ else:
+ # Use local queue
+ self.memos_message_queue.put(message)
+ logger.info(
+ f"Submitted message to local queue: {message.label} - {message.content}"
+ )
+ with contextlib.suppress(Exception):
+ if messages:
+ self.dispatcher.on_messages_enqueued(messages)
def _submit_web_logs(
self, messages: ScheduleLogForWebItem | list[ScheduleLogForWebItem]
@@ -550,36 +599,64 @@ def _message_consumer(self) -> None:
Continuously checks the queue for messages and dispatches them.
Runs in a dedicated thread to process messages at regular intervals.
+ For Redis queue, this method starts the Redis listener.
"""
- while self._running: # Use a running flag for graceful shutdown
- try:
- # Get all available messages at once (thread-safe approach)
- messages = []
- while True:
- try:
- # Use get_nowait() directly without empty() check to avoid race conditions
- message = self.memos_message_queue.get_nowait()
- messages.append(message)
- except queue.Empty:
- # No more messages available
- break
-
- if messages:
- try:
- self.dispatcher.dispatch(messages)
- except Exception as e:
- logger.error(f"Error dispatching messages: {e!s}")
- finally:
- # Mark all messages as processed
- for _ in messages:
- self.memos_message_queue.task_done()
-
- # Sleep briefly to prevent busy waiting
- time.sleep(self._consume_interval) # Adjust interval as needed
-
- except Exception as e:
- logger.error(f"Unexpected error in message consumer: {e!s}")
- time.sleep(self._consume_interval) # Prevent tight error loops
+ if self.use_redis_queue:
+ # For Redis queue, start the Redis listener
+ def redis_message_handler(message_data):
+ """Handler for Redis messages"""
+ try:
+ # Redis message data needs to be decoded from bytes to string
+ decoded_data = {}
+ for key, value in message_data.items():
+ if isinstance(key, bytes):
+ key = key.decode("utf-8")
+ if isinstance(value, bytes):
+ value = value.decode("utf-8")
+ decoded_data[key] = value
+
+ message = ScheduleMessageItem.from_dict(decoded_data)
+ self.dispatcher.dispatch([message])
+ except Exception as e:
+ logger.error(f"Error processing Redis message: {e}")
+ logger.error(f"Message data: {message_data}")
+
+ self.redis_start_listening(handler=redis_message_handler)
+
+ # Keep the thread alive while Redis listener is running
+ while self._running:
+ time.sleep(self._consume_interval)
+ else:
+ # Original local queue logic
+ while self._running: # Use a running flag for graceful shutdown
+ try:
+ # Get all available messages at once (thread-safe approach)
+ messages = []
+ while True:
+ try:
+ # Use get_nowait() directly without empty() check to avoid race conditions
+ message = self.memos_message_queue.get_nowait()
+ messages.append(message)
+ except queue.Empty:
+ # No more messages available
+ break
+
+ if messages:
+ try:
+ self.dispatcher.dispatch(messages)
+ except Exception as e:
+ logger.error(f"Error dispatching messages: {e!s}")
+ finally:
+ # Mark all messages as processed
+ for _ in messages:
+ self.memos_message_queue.task_done()
+
+ # Sleep briefly to prevent busy waiting
+ time.sleep(self._consume_interval) # Adjust interval as needed
+
+ except Exception as e:
+ logger.error(f"Unexpected error in message consumer: {e!s}")
+ time.sleep(self._consume_interval) # Prevent tight error loops
def start(self) -> None:
"""
@@ -613,7 +690,7 @@ def start(self) -> None:
logger.info("Message consumer process started")
else:
# Default to thread mode
- self._consumer_thread = threading.Thread(
+ self._consumer_thread = ContextThread(
target=self._message_consumer,
daemon=True,
name="MessageConsumerThread",
@@ -716,17 +793,226 @@ def unregister_handlers(self, labels: list[str]) -> dict[str, bool]:
return self.dispatcher.unregister_handlers(labels)
+ def get_running_tasks(self, filter_func: Callable | None = None) -> dict[str, dict]:
+ if not self.dispatcher:
+ logger.warning("Dispatcher is not initialized, returning empty tasks dict")
+ return {}
+
+ running_tasks = self.dispatcher.get_running_tasks(filter_func=filter_func)
+
+ # Convert RunningTaskItem objects to dictionaries for easier consumption
+ result = {}
+ for task_id, task_item in running_tasks.items():
+ result[task_id] = {
+ "item_id": task_item.item_id,
+ "user_id": task_item.user_id,
+ "mem_cube_id": task_item.mem_cube_id,
+ "task_info": task_item.task_info,
+ "task_name": task_item.task_name,
+ "start_time": task_item.start_time,
+ "end_time": task_item.end_time,
+ "status": task_item.status,
+ "result": task_item.result,
+ "error_message": task_item.error_message,
+ "messages": task_item.messages,
+ }
+
+ return result
+
def _cleanup_queues(self) -> None:
"""Ensure all queues are emptied and marked as closed."""
- try:
- while not self.memos_message_queue.empty():
- self.memos_message_queue.get_nowait()
- self.memos_message_queue.task_done()
- except queue.Empty:
- pass
+ if self.use_redis_queue:
+ # For Redis queue, stop the listener and close connection
+ try:
+ self.redis_stop_listening()
+ self.redis_close()
+ except Exception as e:
+ logger.error(f"Error cleaning up Redis connection: {e}")
+ else:
+ # Original local queue cleanup
+ try:
+ while not self.memos_message_queue.empty():
+ self.memos_message_queue.get_nowait()
+ self.memos_message_queue.task_done()
+ except queue.Empty:
+ pass
try:
while not self._web_log_message_queue.empty():
self._web_log_message_queue.get_nowait()
except queue.Empty:
pass
+
+ def mem_scheduler_wait(
+ self, timeout: float = 180.0, poll: float = 0.1, log_every: float = 0.01
+ ) -> bool:
+ """
+ Uses EWMA throughput, detects leaked `unfinished_tasks`, and waits for dispatcher.
+ """
+ deadline = time.monotonic() + timeout
+
+ # --- helpers (local, no external deps) ---
+ def _unfinished() -> int:
+ """Prefer `unfinished_tasks`; fallback to `qsize()`."""
+ try:
+ u = getattr(self.memos_message_queue, "unfinished_tasks", None)
+ if u is not None:
+ return int(u)
+ except Exception:
+ pass
+ try:
+ return int(self.memos_message_queue.qsize())
+ except Exception:
+ return 0
+
+ def _fmt_eta(seconds: float | None) -> str:
+ """Format seconds to human-readable string."""
+ if seconds is None or seconds != seconds or seconds == float("inf"):
+ return "unknown"
+ s = max(0, int(seconds))
+ h, s = divmod(s, 3600)
+ m, s = divmod(s, 60)
+ if h > 0:
+ return f"{h:d}h{m:02d}m{s:02d}s"
+ if m > 0:
+ return f"{m:d}m{s:02d}s"
+ return f"{s:d}s"
+
+ # --- EWMA throughput state (tasks/s) ---
+ alpha = 0.3
+ rate = 0.0
+ last_t = None # type: float | None
+ last_done = 0
+
+ # --- dynamic totals & stuck detection ---
+ init_unfinished = _unfinished()
+ done_total = 0
+ last_unfinished = None
+ stuck_ticks = 0
+ next_log = 0.0
+
+ while True:
+ # 1) read counters
+ curr_unfinished = _unfinished()
+ try:
+ qsz = int(self.memos_message_queue.qsize())
+ except Exception:
+ qsz = -1
+
+ pend = run = 0
+ stats_fn = getattr(self.dispatcher, "stats", None)
+ if self.enable_parallel_dispatch and self.dispatcher is not None and callable(stats_fn):
+ try:
+ st = (
+ stats_fn()
+ ) # expected: {'pending':int,'running':int,'done':int?,'rate':float?}
+ pend = int(st.get("pending", 0))
+ run = int(st.get("running", 0))
+ except Exception:
+ pass
+
+ # 2) dynamic total (allows new tasks queued while waiting)
+ total_now = max(init_unfinished, done_total + curr_unfinished)
+ done_total = max(0, total_now - curr_unfinished)
+
+ # 3) update EWMA throughput
+ now = time.monotonic()
+ if last_t is None:
+ last_t = now
+ else:
+ dt = max(1e-6, now - last_t)
+ dc = max(0, done_total - last_done)
+ inst = dc / dt
+ rate = inst if rate == 0.0 else alpha * inst + (1 - alpha) * rate
+ last_t = now
+ last_done = done_total
+
+ eta = None if rate <= 1e-9 else (curr_unfinished / rate)
+
+ # 4) progress log (throttled)
+ if now >= next_log:
+ print(
+ f"[mem_scheduler_wait] remaining≈{curr_unfinished} | throughput≈{rate:.2f} msg/s | ETA≈{_fmt_eta(eta)} "
+ f"| qsize={qsz} pending={pend} running={run}"
+ )
+ next_log = now + max(0.2, log_every)
+
+ # 5) exit / stuck detection
+ idle_dispatcher = (
+ (pend == 0 and run == 0)
+ if (self.enable_parallel_dispatch and self.dispatcher is not None)
+ else True
+ )
+ if curr_unfinished == 0:
+ break
+ if curr_unfinished > 0 and qsz == 0 and idle_dispatcher:
+ if last_unfinished == curr_unfinished:
+ stuck_ticks += 1
+ else:
+ stuck_ticks = 0
+ else:
+ stuck_ticks = 0
+ last_unfinished = curr_unfinished
+
+ if stuck_ticks >= 3:
+ logger.warning(
+ "mem_scheduler_wait: detected leaked 'unfinished_tasks' -> treating queue as drained"
+ )
+ break
+
+ if now >= deadline:
+ logger.warning("mem_scheduler_wait: queue did not drain before timeout")
+ return False
+
+ time.sleep(poll)
+
+ # 6) wait dispatcher (second stage)
+ remaining = max(0.0, deadline - time.monotonic())
+ if self.enable_parallel_dispatch and self.dispatcher is not None:
+ try:
+ ok = self.dispatcher.join(timeout=remaining if remaining > 0 else 0)
+ except TypeError:
+ ok = self.dispatcher.join()
+ if not ok:
+ logger.warning("mem_scheduler_wait: dispatcher did not complete before timeout")
+ return False
+
+ return True
+
+ def _gather_queue_stats(self) -> dict:
+ """Collect queue/dispatcher stats for reporting."""
+ stats: dict[str, int | float | str] = {}
+ stats["use_redis_queue"] = bool(self.use_redis_queue)
+ # local queue metrics
+ if not self.use_redis_queue:
+ try:
+ stats["qsize"] = int(self.memos_message_queue.qsize())
+ except Exception:
+ stats["qsize"] = -1
+ # unfinished_tasks if available
+ try:
+ stats["unfinished_tasks"] = int(
+ getattr(self.memos_message_queue, "unfinished_tasks", 0) or 0
+ )
+ except Exception:
+ stats["unfinished_tasks"] = -1
+ stats["maxsize"] = int(self.max_internal_message_queue_size)
+ try:
+ maxsize = int(self.max_internal_message_queue_size) or 1
+ qsize = int(stats.get("qsize", 0))
+ stats["utilization"] = min(1.0, max(0.0, qsize / maxsize))
+ except Exception:
+ stats["utilization"] = 0.0
+ # dispatcher stats
+ try:
+ d_stats = self.dispatcher.stats()
+ stats.update(
+ {
+ "running": int(d_stats.get("running", 0)),
+ "inflight": int(d_stats.get("inflight", 0)),
+ "handlers": int(d_stats.get("handlers", 0)),
+ }
+ )
+ except Exception:
+ stats.update({"running": 0, "inflight": 0, "handlers": 0})
+ return stats
diff --git a/src/memos/mem_scheduler/general_modules/api_misc.py b/src/memos/mem_scheduler/general_modules/api_misc.py
new file mode 100644
index 000000000..1b10804fc
--- /dev/null
+++ b/src/memos/mem_scheduler/general_modules/api_misc.py
@@ -0,0 +1,137 @@
+from typing import Any
+
+from memos.log import get_logger
+from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
+from memos.mem_scheduler.orm_modules.api_redis_model import APIRedisDBManager
+from memos.mem_scheduler.schemas.api_schemas import (
+ APIMemoryHistoryEntryItem,
+ APISearchHistoryManager,
+ TaskRunningStatus,
+)
+from memos.memories.textual.item import TextualMemoryItem
+
+
+logger = get_logger(__name__)
+
+
+class SchedulerAPIModule(BaseSchedulerModule):
+ def __init__(self, window_size: int | None = None, history_memory_turns: int | None = None):
+ super().__init__()
+ self.window_size = window_size
+ self.history_memory_turns = history_memory_turns
+ self.search_history_managers: dict[str, APIRedisDBManager] = {}
+
+ def get_search_history_manager(self, user_id: str, mem_cube_id: str) -> APIRedisDBManager:
+ """Get or create a Redis manager for search history."""
+ logger.info(
+ f"Getting search history manager for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ key = f"search_history:{user_id}:{mem_cube_id}"
+ if key not in self.search_history_managers:
+ logger.info(f"Creating new search history manager for key: {key}")
+ self.search_history_managers[key] = APIRedisDBManager(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=APISearchHistoryManager(window_size=self.window_size),
+ )
+ return self.search_history_managers[key]
+
+ def sync_search_data(
+ self,
+ item_id: str,
+ user_id: str,
+ mem_cube_id: str,
+ query: str,
+ memories: list[TextualMemoryItem],
+ formatted_memories: Any,
+ session_id: str | None = None,
+ conversation_turn: int = 0,
+ ) -> Any:
+ logger.info(
+ f"Syncing search data for item_id: {item_id}, user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ # Get the search history manager
+ manager = self.get_search_history_manager(user_id, mem_cube_id)
+ manager.sync_with_redis(size_limit=self.window_size)
+
+ search_history = manager.obj
+
+ # Check if entry with item_id already exists
+ existing_entry, location = search_history.find_entry_by_item_id(item_id)
+
+ if existing_entry is not None:
+ # Update existing entry
+ success = search_history.update_entry_by_item_id(
+ item_id=item_id,
+ query=query,
+ formatted_memories=formatted_memories,
+ task_status=TaskRunningStatus.COMPLETED, # Use the provided running_status
+ session_id=session_id,
+ memories=memories,
+ )
+
+ if success:
+ logger.info(f"Updated existing entry with item_id: {item_id} in {location} list")
+ else:
+ logger.warning(f"Failed to update entry with item_id: {item_id}")
+ else:
+ # Add new entry based on running_status
+ entry_item = APIMemoryHistoryEntryItem(
+ item_id=item_id,
+ query=query,
+ formatted_memories=formatted_memories,
+ memories=memories,
+ task_status=TaskRunningStatus.COMPLETED,
+ session_id=session_id,
+ conversation_turn=conversation_turn,
+ )
+
+ # Add directly to completed list as APIMemoryHistoryEntryItem instance
+ search_history.completed_entries.append(entry_item)
+
+ # Maintain window size
+ if len(search_history.completed_entries) > search_history.window_size:
+ search_history.completed_entries = search_history.completed_entries[
+ -search_history.window_size :
+ ]
+
+ # Remove from running task IDs
+ if item_id in search_history.running_item_ids:
+ search_history.running_item_ids.remove(item_id)
+
+ logger.info(f"Created new entry with item_id: {item_id}")
+
+ # Update manager's object with the modified search history
+ manager.obj = search_history
+
+ # Use sync_with_redis to handle Redis synchronization with merging
+ manager.sync_with_redis(size_limit=self.window_size)
+ return manager
+
+ def get_history_memories(
+ self, user_id: str, mem_cube_id: str, turns: int | None = None
+ ) -> list:
+ """Get history memories for backward compatibility with tests."""
+ logger.info(
+ f"Getting history memories for user_id: {user_id}, mem_cube_id: {mem_cube_id}, turns: {turns}"
+ )
+ manager = self.get_search_history_manager(user_id, mem_cube_id)
+ existing_data = manager.load_from_db()
+
+ if existing_data is None:
+ return []
+
+ if turns is None:
+ turns = self.history_memory_turns
+
+ # Handle different data formats
+ if isinstance(existing_data, APISearchHistoryManager):
+ search_history = existing_data
+ else:
+ # Try to convert to APISearchHistoryManager
+ try:
+ search_history = APISearchHistoryManager(**existing_data)
+ except Exception:
+ return []
+
+ return search_history.get_history_memories(turns=turns)
diff --git a/src/memos/mem_scheduler/general_modules/dispatcher.py b/src/memos/mem_scheduler/general_modules/dispatcher.py
index 4584beb96..c2407b9e6 100644
--- a/src/memos/mem_scheduler/general_modules/dispatcher.py
+++ b/src/memos/mem_scheduler/general_modules/dispatcher.py
@@ -1,8 +1,10 @@
import concurrent
import threading
+import time
from collections import defaultdict
from collections.abc import Callable
+from datetime import timezone
from typing import Any
from memos.context.context import ContextThreadPoolExecutor
@@ -11,6 +13,7 @@
from memos.mem_scheduler.general_modules.task_threads import ThreadManager
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
from memos.mem_scheduler.schemas.task_schemas import RunningTaskItem
+from memos.mem_scheduler.utils.metrics import MetricsRegistry
logger = get_logger(__name__)
@@ -36,6 +39,11 @@ def __init__(self, max_workers=30, enable_parallel_dispatch=True, config=None):
# Main dispatcher thread pool
self.max_workers = max_workers
+ # Get multi-task timeout from config
+ self.multi_task_running_timeout = (
+ self.config.get("multi_task_running_timeout") if self.config else None
+ )
+
# Only initialize thread pool if in parallel mode
self.enable_parallel_dispatch = enable_parallel_dispatch
self.thread_name_prefix = "dispatcher"
@@ -62,6 +70,21 @@ def __init__(self, max_workers=30, enable_parallel_dispatch=True, config=None):
# Task tracking for monitoring
self._running_tasks: dict[str, RunningTaskItem] = {}
self._task_lock = threading.Lock()
+ self._completed_tasks = []
+ self.completed_tasks_max_show_size = 10
+
+ self.metrics = MetricsRegistry(
+ topk_per_label=(self.config or {}).get("metrics_topk_per_label", 50)
+ )
+
+ def on_messages_enqueued(self, msgs: list[ScheduleMessageItem]) -> None:
+ if not msgs:
+ return
+ now = time.time()
+ for m in msgs:
+ self.metrics.on_enqueue(
+ label=m.label, mem_cube_id=m.mem_cube_id, inst_rate=1.0, now=now
+ )
def _create_task_wrapper(self, handler: Callable, task_item: RunningTaskItem):
"""
@@ -77,39 +100,101 @@ def _create_task_wrapper(self, handler: Callable, task_item: RunningTaskItem):
def wrapped_handler(messages: list[ScheduleMessageItem]):
try:
+ # --- mark start: record queuing time(now - enqueue_ts)---
+ now = time.time()
+ for m in messages:
+ enq_ts = getattr(m, "timestamp", None)
+
+ # Path 1: epoch seconds (preferred)
+ if isinstance(enq_ts, int | float):
+ enq_epoch = float(enq_ts)
+
+ # Path 2: datetime -> normalize to UTC epoch
+ elif hasattr(enq_ts, "timestamp"):
+ dt = enq_ts
+ if dt.tzinfo is None:
+ # treat naive as UTC to neutralize +8h skew
+ dt = dt.replace(tzinfo=timezone.utc)
+ enq_epoch = dt.timestamp()
+ else:
+ # fallback: treat as "just now"
+ enq_epoch = now
+
+ wait_sec = max(0.0, now - enq_epoch)
+ self.metrics.on_start(
+ label=m.label, mem_cube_id=m.mem_cube_id, wait_sec=wait_sec, now=now
+ )
+
# Execute the original handler
result = handler(messages)
+ # --- mark done ---
+ for m in messages:
+ self.metrics.on_done(label=m.label, mem_cube_id=m.mem_cube_id, now=time.time())
# Mark task as completed and remove from tracking
with self._task_lock:
if task_item.item_id in self._running_tasks:
task_item.mark_completed(result)
del self._running_tasks[task_item.item_id]
-
+ self._completed_tasks.append(task_item)
+ if len(self._completed_tasks) > self.completed_tasks_max_show_size:
+ self._completed_tasks[-self.completed_tasks_max_show_size :]
logger.info(f"Task completed: {task_item.get_execution_info()}")
return result
except Exception as e:
# Mark task as failed and remove from tracking
+ for m in messages:
+ self.metrics.on_done(label=m.label, mem_cube_id=m.mem_cube_id, now=time.time())
+ # Mark task as failed and remove from tracking
with self._task_lock:
if task_item.item_id in self._running_tasks:
task_item.mark_failed(str(e))
del self._running_tasks[task_item.item_id]
-
+ if len(self._completed_tasks) > self.completed_tasks_max_show_size:
+ self._completed_tasks[-self.completed_tasks_max_show_size :]
logger.error(f"Task failed: {task_item.get_execution_info()}, Error: {e}")
raise
return wrapped_handler
- def get_running_tasks(self) -> dict[str, RunningTaskItem]:
+ def get_running_tasks(
+ self, filter_func: Callable[[RunningTaskItem], bool] | None = None
+ ) -> dict[str, RunningTaskItem]:
"""
- Get a copy of currently running tasks.
+ Get a copy of currently running tasks, optionally filtered by a custom function.
+
+ Args:
+ filter_func: Optional function that takes a RunningTaskItem and returns True if it should be included.
+ Common filters can be created using helper methods like filter_by_user_id, filter_by_task_name, etc.
Returns:
Dictionary of running tasks keyed by task ID
+
+ Examples:
+ # Get all running tasks
+ all_tasks = dispatcher.get_running_tasks()
+
+ # Get tasks for specific user
+ user_tasks = dispatcher.get_running_tasks(lambda task: task.user_id == "user123")
+
+ # Get tasks for specific task name
+ handler_tasks = dispatcher.get_running_tasks(lambda task: task.task_name == "test_handler")
+
+ # Get tasks with multiple conditions
+ filtered_tasks = dispatcher.get_running_tasks(
+ lambda task: task.user_id == "user123" and task.status == "running"
+ )
"""
with self._task_lock:
- return self._running_tasks.copy()
+ if filter_func is None:
+ return self._running_tasks.copy()
+
+ return {
+ task_id: task_item
+ for task_id, task_item in self._running_tasks.items()
+ if filter_func(task_item)
+ }
def get_running_task_count(self) -> int:
"""
@@ -186,6 +271,31 @@ def unregister_handlers(self, labels: list[str]) -> dict[str, bool]:
logger.info(f"Unregistered handlers for {len(labels)} labels")
return results
+ def stats(self) -> dict[str, int]:
+ """
+ Lightweight runtime stats for monitoring.
+
+ Returns:
+ {
+ 'running': ,
+ 'inflight': ,
+ 'handlers': ,
+ }
+ """
+ try:
+ running = self.get_running_task_count()
+ except Exception:
+ running = 0
+ try:
+ inflight = len(self._futures)
+ except Exception:
+ inflight = 0
+ try:
+ handlers = len(self.handlers)
+ except Exception:
+ handlers = 0
+ return {"running": running, "inflight": inflight, "handlers": handlers}
+
def _default_message_handler(self, messages: list[ScheduleMessageItem]) -> None:
logger.debug(f"Using _default_message_handler to deal with messages: {messages}")
@@ -328,17 +438,17 @@ def run_competitive_tasks(
def run_multiple_tasks(
self,
- tasks: dict[str, tuple[Callable, tuple, dict]],
+ tasks: dict[str, tuple[Callable, tuple]],
use_thread_pool: bool | None = None,
- timeout: float | None = 30.0,
+ timeout: float | None = None,
) -> dict[str, Any]:
"""
Execute multiple tasks concurrently and return all results.
Args:
- tasks: Dictionary mapping task names to (function, args, kwargs) tuples
+ tasks: Dictionary mapping task names to (task_execution_function, task_execution_parameters) tuples
use_thread_pool: Whether to use ThreadPoolExecutor. If None, uses dispatcher's parallel mode setting
- timeout: Maximum time to wait for all tasks to complete (in seconds). None for infinite timeout.
+ timeout: Maximum time to wait for all tasks to complete (in seconds). If None, uses config default.
Returns:
Dictionary mapping task names to their results
@@ -350,7 +460,13 @@ def run_multiple_tasks(
if use_thread_pool is None:
use_thread_pool = self.enable_parallel_dispatch
- logger.info(f"Executing {len(tasks)} tasks concurrently (thread_pool: {use_thread_pool})")
+ # Use config timeout if not explicitly provided
+ if timeout is None:
+ timeout = self.multi_task_running_timeout
+
+ logger.info(
+ f"Executing {len(tasks)} tasks concurrently (thread_pool: {use_thread_pool}, timeout: {timeout})"
+ )
try:
results = self.thread_manager.run_multiple_tasks(
diff --git a/src/memos/mem_scheduler/general_modules/misc.py b/src/memos/mem_scheduler/general_modules/misc.py
index 7dda25a29..b6f48d043 100644
--- a/src/memos/mem_scheduler/general_modules/misc.py
+++ b/src/memos/mem_scheduler/general_modules/misc.py
@@ -127,7 +127,7 @@ class DictConversionMixin:
@field_serializer("timestamp", check_fields=False)
def serialize_datetime(self, dt: datetime | None, _info) -> str | None:
"""
- Custom datetime serialization logic.
+ Custom timestamp serialization logic.
- Supports timezone-aware datetime objects
- Compatible with models without timestamp field (via check_fields=False)
"""
@@ -205,7 +205,9 @@ def put(self, item: T, block: bool = False, timeout: float | None = None) -> Non
"""Put an item into the queue.
If the queue is full, the oldest item will be automatically removed to make space.
- This operation is thread-safe.
+ IMPORTANT: When we drop an item we also call `task_done()` to keep
+ the internal `unfinished_tasks` counter consistent (the dropped task
+ will never be processed).
Args:
item: The item to be put into the queue
@@ -216,19 +218,34 @@ def put(self, item: T, block: bool = False, timeout: float | None = None) -> Non
# First try non-blocking put
super().put(item, block=block, timeout=timeout)
except Full:
+ # Remove oldest item and mark it done to avoid leaking unfinished_tasks
with suppress(Empty):
- self.get_nowait() # Remove oldest item
+ _ = self.get_nowait()
+ # If the removed item had previously incremented unfinished_tasks,
+ # we must decrement here since it will never be processed.
+ with suppress(ValueError):
+ self.task_done()
# Retry putting the new item
super().put(item, block=block, timeout=timeout)
def get_queue_content_without_pop(self) -> list[T]:
"""Return a copy of the queue's contents without modifying it."""
- return list(self.queue)
+ # Ensure a consistent snapshot by holding the mutex
+ with self.mutex:
+ return list(self.queue)
def clear(self) -> None:
"""Remove all items from the queue.
This operation is thread-safe.
+ IMPORTANT: We also decrement `unfinished_tasks` by the number of
+ items cleared, since those tasks will never be processed.
"""
with self.mutex:
+ dropped = len(self.queue)
self.queue.clear()
+ # Call task_done() outside of the mutex to avoid deadlocks because
+ # Queue.task_done() acquires the same condition bound to `self.mutex`.
+ for _ in range(dropped):
+ with suppress(ValueError):
+ self.task_done()
diff --git a/src/memos/mem_scheduler/general_modules/task_threads.py b/src/memos/mem_scheduler/general_modules/task_threads.py
index 913d5fa1d..73b570a8b 100644
--- a/src/memos/mem_scheduler/general_modules/task_threads.py
+++ b/src/memos/mem_scheduler/general_modules/task_threads.py
@@ -5,6 +5,7 @@
from concurrent.futures import as_completed
from typing import Any, TypeVar
+from memos.context.context import ContextThread
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -89,7 +90,7 @@ def worker(
def run_multiple_tasks(
self,
- tasks: dict[str, tuple[Callable, tuple, dict]],
+ tasks: dict[str, tuple[Callable, tuple]],
use_thread_pool: bool = False,
timeout: float | None = None,
) -> dict[str, Any]:
@@ -97,7 +98,7 @@ def run_multiple_tasks(
Run multiple tasks concurrently and return all results.
Args:
- tasks: Dictionary mapping task names to (function, args, kwargs) tuples
+ tasks: Dictionary mapping task names to (task_execution_function, task_execution_parameters) tuples
use_thread_pool: Whether to use ThreadPoolExecutor (True) or regular threads (False)
timeout: Maximum time to wait for all tasks to complete (in seconds). None for infinite timeout.
@@ -115,17 +116,21 @@ def run_multiple_tasks(
start_time = time.time()
if use_thread_pool:
- return self.run_with_thread_pool(tasks, timeout)
+ # Convert tasks format for thread pool compatibility
+ thread_pool_tasks = {}
+ for task_name, (func, args) in tasks.items():
+ thread_pool_tasks[task_name] = (func, args, {})
+ return self.run_with_thread_pool(thread_pool_tasks, timeout)
else:
# Use regular threads
threads = {}
thread_results = {}
exceptions = {}
- def worker(task_name: str, func: Callable, args: tuple, kwargs: dict):
+ def worker(task_name: str, func: Callable, args: tuple):
"""Worker function for regular threads"""
try:
- result = func(*args, **kwargs)
+ result = func(*args)
thread_results[task_name] = result
logger.debug(f"Task '{task_name}' completed successfully")
except Exception as e:
@@ -133,9 +138,9 @@ def worker(task_name: str, func: Callable, args: tuple, kwargs: dict):
logger.error(f"Task '{task_name}' failed with error: {e}")
# Start all threads
- for task_name, (func, args, kwargs) in tasks.items():
- thread = threading.Thread(
- target=worker, args=(task_name, func, args, kwargs), name=f"task-{task_name}"
+ for task_name, (func, args) in tasks.items():
+ thread = ContextThread(
+ target=worker, args=(task_name, func, args), name=f"task-{task_name}"
)
threads[task_name] = thread
thread.start()
@@ -197,44 +202,60 @@ def run_with_thread_pool(
results = {}
start_time = time.time()
- # Use ThreadPoolExecutor for better resource management
- with self.thread_pool_executor as executor:
- # Submit all tasks
- future_to_name = {}
- for task_name, (func, args, kwargs) in tasks.items():
+ # Check if executor is shutdown before using it
+ if self.thread_pool_executor._shutdown:
+ logger.error("ThreadPoolExecutor is already shutdown, cannot submit new tasks")
+ raise RuntimeError("ThreadPoolExecutor is already shutdown")
+
+ # Use ThreadPoolExecutor directly without context manager
+ # The executor lifecycle is managed by the parent SchedulerDispatcher
+ executor = self.thread_pool_executor
+
+ # Submit all tasks
+ future_to_name = {}
+ for task_name, (func, args, kwargs) in tasks.items():
+ try:
future = executor.submit(func, *args, **kwargs)
future_to_name[future] = task_name
logger.debug(f"Submitted task '{task_name}' to thread pool")
+ except RuntimeError as e:
+ if "cannot schedule new futures after shutdown" in str(e):
+ logger.error(
+ f"Cannot submit task '{task_name}': ThreadPoolExecutor is shutdown"
+ )
+ results[task_name] = None
+ else:
+ raise
- # Collect results as they complete
- try:
- # Handle infinite timeout case
- timeout_param = None if timeout is None else timeout
- for future in as_completed(future_to_name, timeout=timeout_param):
- task_name = future_to_name[future]
- try:
- result = future.result()
- results[task_name] = result
- logger.debug(f"Task '{task_name}' completed successfully")
- except Exception as e:
- logger.error(f"Task '{task_name}' failed with error: {e}")
- results[task_name] = None
+ # Collect results as they complete
+ try:
+ # Handle infinite timeout case
+ timeout_param = None if timeout is None else timeout
+ for future in as_completed(future_to_name, timeout=timeout_param):
+ task_name = future_to_name[future]
+ try:
+ result = future.result()
+ results[task_name] = result
+ logger.debug(f"Task '{task_name}' completed successfully")
+ except Exception as e:
+ logger.error(f"Task '{task_name}' failed with error: {e}")
+ results[task_name] = None
- except Exception:
- elapsed_time = time.time() - start_time
- timeout_msg = "infinite" if timeout is None else f"{timeout}s"
- logger.error(
- f"Tasks execution timed out after {elapsed_time:.2f} seconds (timeout: {timeout_msg})"
- )
- # Cancel remaining futures
- for future in future_to_name:
- if not future.done():
- future.cancel()
- task_name = future_to_name[future]
- logger.warning(f"Cancelled task '{task_name}' due to timeout")
- results[task_name] = None
- timeout_seconds = "infinite" if timeout is None else timeout
- logger.error(f"Tasks execution timed out after {timeout_seconds} seconds")
+ except Exception:
+ elapsed_time = time.time() - start_time
+ timeout_msg = "infinite" if timeout is None else f"{timeout}s"
+ logger.error(
+ f"Tasks execution timed out after {elapsed_time:.2f} seconds (timeout: {timeout_msg})"
+ )
+ # Cancel remaining futures
+ for future in future_to_name:
+ if not future.done():
+ future.cancel()
+ task_name = future_to_name[future]
+ logger.warning(f"Cancelled task '{task_name}' due to timeout")
+ results[task_name] = None
+ timeout_seconds = "infinite" if timeout is None else timeout
+ logger.error(f"Tasks execution timed out after {timeout_seconds} seconds")
return results
@@ -263,7 +284,7 @@ def run_race(
# Create and start threads for each task
for task_name, task_func in tasks.items():
- thread = threading.Thread(
+ thread = ContextThread(
target=self.worker, args=(task_func, task_name), name=f"race-{task_name}"
)
self.threads[task_name] = thread
diff --git a/src/memos/mem_scheduler/general_scheduler.py b/src/memos/mem_scheduler/general_scheduler.py
index 25c7b78fd..6840adc2b 100644
--- a/src/memos/mem_scheduler/general_scheduler.py
+++ b/src/memos/mem_scheduler/general_scheduler.py
@@ -1,6 +1,9 @@
+import concurrent.futures
import json
+import traceback
from memos.configs.mem_scheduler import GeneralSchedulerConfig
+from memos.context.context import ContextThreadPoolExecutor
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
from memos.mem_scheduler.base_scheduler import BaseScheduler
@@ -8,6 +11,9 @@
ADD_LABEL,
ANSWER_LABEL,
DEFAULT_MAX_QUERY_KEY_WORDS,
+ MEM_ORGANIZE_LABEL,
+ MEM_READ_LABEL,
+ PREF_ADD_LABEL,
QUERY_LABEL,
WORKING_MEMORY_TYPE,
MemCubeID,
@@ -16,7 +22,9 @@
from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
from memos.mem_scheduler.schemas.monitor_schemas import QueryMonitorItem
from memos.mem_scheduler.utils.filter_utils import is_all_chinese, is_all_english
-from memos.memories.textual.tree import TextualMemoryItem, TreeTextMemory
+from memos.memories.textual.item import TextualMemoryItem
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.memories.textual.tree import TreeTextMemory
logger = get_logger(__name__)
@@ -34,6 +42,9 @@ def __init__(self, config: GeneralSchedulerConfig):
QUERY_LABEL: self._query_message_consumer,
ANSWER_LABEL: self._answer_message_consumer,
ADD_LABEL: self._add_message_consumer,
+ MEM_READ_LABEL: self._mem_read_message_consumer,
+ MEM_ORGANIZE_LABEL: self._mem_reorganize_message_consumer,
+ PREF_ADD_LABEL: self._pref_add_message_consumer,
}
self.dispatcher.register_handlers(handlers)
@@ -142,7 +153,7 @@ def _query_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
logger.info(f"Messages {messages} assigned to {QUERY_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=QUERY_LABEL)
@@ -164,7 +175,7 @@ def _answer_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
"""
logger.info(f"Messages {messages} assigned to {ANSWER_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=ANSWER_LABEL)
@@ -180,7 +191,7 @@ def _answer_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
logger.info(f"Messages {messages} assigned to {ADD_LABEL} handler.")
# Process the query in a session turn
- grouped_messages = self.dispatcher.group_messages_by_user_and_cube(messages=messages)
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
self.validate_schedule_messages(messages=messages, label=ADD_LABEL)
try:
@@ -203,7 +214,15 @@ def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
mem_cube = msg.mem_cube
for memory_id in userinput_memory_ids:
- mem_item: TextualMemoryItem = mem_cube.text_mem.get(memory_id=memory_id)
+ try:
+ mem_item: TextualMemoryItem = mem_cube.text_mem.get(
+ memory_id=memory_id
+ )
+ except Exception:
+ logger.warning(
+ f"This MemoryItem {memory_id} has already been deleted."
+ )
+ continue
mem_type = mem_item.metadata.memory_type
mem_content = mem_item.memory
@@ -222,6 +241,315 @@ def _add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
except Exception as e:
logger.error(f"Error: {e}", exc_info=True)
+ def _mem_read_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {MEM_READ_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ user_name = message.user_name
+
+ # Parse the memory IDs from content
+ mem_ids = json.loads(content) if isinstance(content, str) else content
+ if not mem_ids:
+ return
+
+ logger.info(
+ f"Processing mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}, mem_ids={mem_ids}"
+ )
+
+ # Get the text memory from the mem_cube
+ text_mem = mem_cube.text_mem
+ if not isinstance(text_mem, TreeTextMemory):
+ logger.error(f"Expected TreeTextMemory but got {type(text_mem).__name__}")
+ return
+
+ # Use mem_reader to process the memories
+ self._process_memories_with_reader(
+ mem_ids=mem_ids,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ text_mem=text_mem,
+ user_name=user_name,
+ )
+
+ logger.info(
+ f"Successfully processed mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing mem_read message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
+ def _process_memories_with_reader(
+ self,
+ mem_ids: list[str],
+ user_id: str,
+ mem_cube_id: str,
+ mem_cube: GeneralMemCube,
+ text_mem: TreeTextMemory,
+ user_name: str,
+ ) -> None:
+ """
+ Process memories using mem_reader for enhanced memory processing.
+
+ Args:
+ mem_ids: List of memory IDs to process
+ user_id: User ID
+ mem_cube_id: Memory cube ID
+ mem_cube: Memory cube instance
+ text_mem: Text memory instance
+ """
+ try:
+ # Get the mem_reader from the parent MOSCore
+ if not hasattr(self, "mem_reader") or self.mem_reader is None:
+ logger.warning(
+ "mem_reader not available in scheduler, skipping enhanced processing"
+ )
+ return
+
+ # Get the original memory items
+ memory_items = []
+ for mem_id in mem_ids:
+ try:
+ memory_item = text_mem.get(mem_id)
+ memory_items.append(memory_item)
+ except Exception as e:
+ logger.warning(f"Failed to get memory {mem_id}: {e}")
+ continue
+
+ if not memory_items:
+ logger.warning("No valid memory items found for processing")
+ return
+
+ # parse working_binding ids from the *original* memory_items (the raw items created in /add)
+ # these still carry metadata.background with "[working_binding:...]" so we can know
+ # which WorkingMemory clones should be cleaned up later.
+ from memos.memories.textual.tree_text_memory.organize.manager import (
+ extract_working_binding_ids,
+ )
+
+ bindings_to_delete = extract_working_binding_ids(memory_items)
+ logger.info(
+ f"Extracted {len(bindings_to_delete)} working_binding ids to cleanup: {list(bindings_to_delete)}"
+ )
+
+ # Use mem_reader to process the memories
+ logger.info(f"Processing {len(memory_items)} memories with mem_reader")
+
+ # Extract memories using mem_reader
+ try:
+ processed_memories = self.mem_reader.fine_transfer_simple_mem(
+ memory_items,
+ type="chat",
+ )
+ except Exception as e:
+ logger.warning(f"{e}: Fail to transfer mem: {memory_items}")
+ processed_memories = []
+
+ if processed_memories and len(processed_memories) > 0:
+ # Flatten the results (mem_reader returns list of lists)
+ flattened_memories = []
+ for memory_list in processed_memories:
+ flattened_memories.extend(memory_list)
+
+ logger.info(f"mem_reader processed {len(flattened_memories)} enhanced memories")
+
+ # Add the enhanced memories back to the memory system
+ if flattened_memories:
+ enhanced_mem_ids = text_mem.add(flattened_memories, user_name=user_name)
+ logger.info(
+ f"Added {len(enhanced_mem_ids)} enhanced memories: {enhanced_mem_ids}"
+ )
+ else:
+ logger.info("No enhanced memories generated by mem_reader")
+ else:
+ logger.info("mem_reader returned no processed memories")
+
+ # build full delete list:
+ # - original raw mem_ids (temporary fast memories)
+ # - any bound working memories referenced by the enhanced memories
+ delete_ids = list(mem_ids)
+ if bindings_to_delete:
+ delete_ids.extend(list(bindings_to_delete))
+ # deduplicate
+ delete_ids = list(dict.fromkeys(delete_ids))
+ if delete_ids:
+ try:
+ text_mem.delete(delete_ids, user_name=user_name)
+ logger.info(
+ f"Delete raw/working mem_ids: {delete_ids} for user_name: {user_name}"
+ )
+ except Exception as e:
+ logger.warning(f"Failed to delete some mem_ids {delete_ids}: {e}")
+ else:
+ logger.info("No mem_ids to delete (nothing to cleanup)")
+
+ text_mem.memory_manager.remove_and_refresh_memory(user_name=user_name)
+ logger.info("Remove and Refresh Memories")
+ logger.debug(f"Finished add {user_id} memory: {mem_ids}")
+
+ except Exception:
+ logger.error(
+ f"Error in _process_memories_with_reader: {traceback.format_exc()}", exc_info=True
+ )
+
+ def _mem_reorganize_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {MEM_READ_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ user_name = message.user_name
+
+ # Parse the memory IDs from content
+ mem_ids = json.loads(content) if isinstance(content, str) else content
+ if not mem_ids:
+ return
+
+ logger.info(
+ f"Processing mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}, mem_ids={mem_ids}"
+ )
+
+ # Get the text memory from the mem_cube
+ text_mem = mem_cube.text_mem
+ if not isinstance(text_mem, TreeTextMemory):
+ logger.error(f"Expected TreeTextMemory but got {type(text_mem).__name__}")
+ return
+
+ # Use mem_reader to process the memories
+ self._process_memories_with_reorganize(
+ mem_ids=mem_ids,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=mem_cube,
+ text_mem=text_mem,
+ user_name=user_name,
+ )
+
+ logger.info(
+ f"Successfully processed mem_read for user_id={user_id}, mem_cube_id={mem_cube_id}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing mem_read message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
+ def _process_memories_with_reorganize(
+ self,
+ mem_ids: list[str],
+ user_id: str,
+ mem_cube_id: str,
+ mem_cube: GeneralMemCube,
+ text_mem: TreeTextMemory,
+ user_name: str,
+ ) -> None:
+ """
+ Process memories using mem_reorganize for enhanced memory processing.
+
+ Args:
+ mem_ids: List of memory IDs to process
+ user_id: User ID
+ mem_cube_id: Memory cube ID
+ mem_cube: Memory cube instance
+ text_mem: Text memory instance
+ """
+ try:
+ # Get the mem_reader from the parent MOSCore
+ if not hasattr(self, "mem_reader") or self.mem_reader is None:
+ logger.warning(
+ "mem_reader not available in scheduler, skipping enhanced processing"
+ )
+ return
+
+ # Get the original memory items
+ memory_items = []
+ for mem_id in mem_ids:
+ try:
+ memory_item = text_mem.get(mem_id)
+ memory_items.append(memory_item)
+ except Exception as e:
+ logger.warning(f"Failed to get memory {mem_id}: {e}|{traceback.format_exc()}")
+ continue
+
+ if not memory_items:
+ logger.warning("No valid memory items found for processing")
+ return
+
+ # Use mem_reader to process the memories
+ logger.info(f"Processing {len(memory_items)} memories with mem_reader")
+ text_mem.memory_manager.remove_and_refresh_memory(user_name=user_name)
+ logger.info("Remove and Refresh Memories")
+ logger.debug(f"Finished add {user_id} memory: {mem_ids}")
+
+ except Exception:
+ logger.error(
+ f"Error in _process_memories_with_reader: {traceback.format_exc()}", exc_info=True
+ )
+
+ def _pref_add_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ logger.info(f"Messages {messages} assigned to {PREF_ADD_LABEL} handler.")
+
+ def process_message(message: ScheduleMessageItem):
+ try:
+ user_id = message.user_id
+ session_id = message.session_id
+ mem_cube_id = message.mem_cube_id
+ mem_cube = message.mem_cube
+ content = message.content
+ messages_list = json.loads(content)
+
+ logger.info(f"Processing pref_add for user_id={user_id}, mem_cube_id={mem_cube_id}")
+
+ # Get the preference memory from the mem_cube
+ pref_mem = mem_cube.pref_mem
+ if not isinstance(pref_mem, PreferenceTextMemory):
+ logger.error(f"Expected PreferenceTextMemory but got {type(pref_mem).__name__}")
+ return
+
+ # Use pref_mem.get_memory to process the memories
+ pref_memories = pref_mem.get_memory(
+ messages_list, type="chat", info={"user_id": user_id, "session_id": session_id}
+ )
+ # Add pref_mem to vector db
+ pref_ids = pref_mem.add(pref_memories)
+
+ logger.info(
+ f"Successfully processed and add preferences for user_id={user_id}, mem_cube_id={mem_cube_id}, pref_ids={pref_ids}"
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing pref_add message: {e}", exc_info=True)
+
+ with ContextThreadPoolExecutor(max_workers=min(8, len(messages))) as executor:
+ futures = [executor.submit(process_message, msg) for msg in messages]
+ for future in concurrent.futures.as_completed(futures):
+ try:
+ future.result()
+ except Exception as e:
+ logger.error(f"Thread task failed: {e}", exc_info=True)
+
def process_session_turn(
self,
queries: str | list[str],
diff --git a/src/memos/mem_scheduler/monitors/dispatcher_monitor.py b/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
index 13fe07354..46c4e2d49 100644
--- a/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
+++ b/src/memos/mem_scheduler/monitors/dispatcher_monitor.py
@@ -1,11 +1,10 @@
import threading
import time
-from datetime import datetime
from time import perf_counter
from memos.configs.mem_scheduler import BaseSchedulerConfig
-from memos.context.context import ContextThreadPoolExecutor
+from memos.context.context import ContextThread, ContextThreadPoolExecutor
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
from memos.mem_scheduler.general_modules.dispatcher import SchedulerDispatcher
@@ -14,6 +13,7 @@
DEFAULT_DISPATCHER_MONITOR_MAX_FAILURES,
DEFAULT_STUCK_THREAD_TOLERANCE,
)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
logger = get_logger(__name__)
@@ -84,7 +84,7 @@ def register_pool(
"max_workers": max_workers,
"restart": restart_on_failure,
"failure_count": 0,
- "last_active": datetime.utcnow(),
+ "last_active": get_utc_now(),
"healthy": True,
}
logger.info(f"Registered thread pool '{name}' for monitoring")
@@ -122,54 +122,6 @@ def _monitor_loop(self) -> None:
logger.debug("Monitor loop exiting")
- def start(self) -> bool:
- """
- Start the monitoring thread.
-
- Returns:
- bool: True if monitor started successfully, False if already running
- """
- if self._running:
- logger.warning("Dispatcher Monitor is already running")
- return False
-
- self._running = True
- self._monitor_thread = threading.Thread(
- target=self._monitor_loop, name="threadpool_monitor", daemon=True
- )
- self._monitor_thread.start()
- logger.info("Dispatcher Monitor monitor started")
- return True
-
- def stop(self) -> None:
- """
- Stop the monitoring thread and clean up all managed thread pools.
- Ensures proper shutdown of all monitored executors.
- """
- if not self._running:
- return
-
- # Stop the monitoring loop
- self._running = False
- if self._monitor_thread and self._monitor_thread.is_alive():
- self._monitor_thread.join(timeout=5)
-
- # Shutdown all registered pools
- with self._pool_lock:
- for name, pool_info in self._pools.items():
- executor = pool_info["executor"]
- if not executor._shutdown: # pylint: disable=protected-access
- try:
- logger.info(f"Shutting down thread pool '{name}'")
- executor.shutdown(wait=True, cancel_futures=True)
- logger.info(f"Successfully shut down thread pool '{name}'")
- except Exception as e:
- logger.error(f"Error shutting down pool '{name}': {e!s}", exc_info=True)
-
- # Clear the pool registry
- self._pools.clear()
- logger.info("Thread pool monitor and all pools stopped")
-
def _check_pools_health(self) -> None:
"""Check health of all registered thread pools."""
for name, pool_info in list(self._pools.items()):
@@ -182,7 +134,6 @@ def _check_pools_health(self) -> None:
if is_healthy:
pool_info["failure_count"] = 0
pool_info["healthy"] = True
- return
else:
pool_info["failure_count"] += 1
pool_info["healthy"] = False
@@ -269,27 +220,24 @@ def _check_pool_health(
f"Found {len(stuck_tasks)} stuck tasks (tolerance: {effective_tolerance})",
)
- # Check thread activity
- active_threads = sum(
- 1
- for t in threading.enumerate()
- if t.name.startswith(executor._thread_name_prefix) # pylint: disable=protected-access
- )
-
- # Check if no threads are active but should be
- if active_threads == 0 and pool_info["max_workers"] > 0:
- return False, "No active worker threads"
-
+ # Only check for stuck threads, not inactive threads
# Check if threads are stuck (no activity for specified intervals)
- time_delta = (datetime.utcnow() - pool_info["last_active"]).total_seconds()
+ time_delta = (get_utc_now() - pool_info["last_active"]).total_seconds()
if time_delta >= self.check_interval * stuck_max_interval:
return False, f"No recent activity for {time_delta:.1f} seconds"
# If we got here, pool appears healthy
- pool_info["last_active"] = datetime.utcnow()
+ pool_info["last_active"] = get_utc_now()
# Log health status with comprehensive information
if self.dispatcher:
+ # Check thread activity
+ active_threads = sum(
+ 1
+ for t in threading.enumerate()
+ if t.name.startswith(executor._thread_name_prefix) # pylint: disable=protected-access
+ )
+
task_count = self.dispatcher.get_running_task_count()
max_workers = pool_info.get("max_workers", 0)
stuck_count = len(stuck_tasks)
@@ -338,7 +286,7 @@ def _restart_pool(self, name: str, pool_info: dict) -> None:
pool_info["executor"] = new_executor
pool_info["failure_count"] = 0
pool_info["healthy"] = True
- pool_info["last_active"] = datetime.utcnow()
+ pool_info["last_active"] = get_utc_now()
elapsed_time = perf_counter() - start_time
if elapsed_time > 1:
@@ -379,3 +327,52 @@ def __enter__(self):
def __exit__(self, exc_type, exc_val, exc_tb):
"""Context manager exit point."""
self.stop()
+
+ def start(self) -> bool:
+ """
+ Start the monitoring thread.
+
+ Returns:
+ bool: True if monitor started successfully, False if already running
+ """
+ if self._running:
+ logger.warning("Dispatcher Monitor is already running")
+ return False
+
+ self._running = True
+ self._monitor_thread = ContextThread(
+ target=self._monitor_loop, name="threadpool_monitor", daemon=True
+ )
+ self._monitor_thread.start()
+ logger.info("Dispatcher Monitor monitor started")
+ return True
+
+ def stop(self) -> None:
+ """
+ Stop the monitoring thread and clean up all managed thread pools.
+ Ensures proper shutdown of all monitored executors.
+ """
+ if not self._running:
+ return
+
+ # Stop the monitoring loop
+ self._running = False
+ if self._monitor_thread and self._monitor_thread.is_alive():
+ self._monitor_thread.join(timeout=5)
+
+ # Shutdown all registered pools
+ with self._pool_lock:
+ for name, pool_info in self._pools.items():
+ executor = pool_info["executor"]
+ if not executor._shutdown: # pylint: disable=protected-access
+ try:
+ logger.info(f"Shutting down thread pool '{name}'")
+ executor.shutdown(wait=True, cancel_futures=True)
+ logger.info(f"Successfully shut down thread pool '{name}'")
+ except Exception as e:
+ logger.error(f"Error shutting down pool '{name}': {e!s}", exc_info=True)
+
+ # Clear the pool registry
+ self._pools.clear()
+
+ logger.info("Thread pool monitor and all pools stopped")
diff --git a/src/memos/mem_scheduler/monitors/general_monitor.py b/src/memos/mem_scheduler/monitors/general_monitor.py
index 87d996549..a789d581e 100644
--- a/src/memos/mem_scheduler/monitors/general_monitor.py
+++ b/src/memos/mem_scheduler/monitors/general_monitor.py
@@ -28,6 +28,7 @@
MemoryMonitorManager,
QueryMonitorQueue,
)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.mem_scheduler.utils.misc_utils import extract_json_dict
from memos.memories.textual.tree import TreeTextMemory
@@ -64,7 +65,7 @@ def __init__(
"No database engine provided; falling back to default temporary SQLite engine. "
"This is intended for testing only. Consider providing a configured engine for production use."
)
- self.db_engine = BaseDBManager.create_default_engine()
+ self.db_engine = BaseDBManager.create_default_sqlite_engine()
self.query_monitors: dict[UserID, dict[MemCubeID, DBManagerForQueryMonitorQueue]] = {}
self.working_memory_monitors: dict[
@@ -75,8 +76,8 @@ def __init__(
] = {}
# Lifecycle monitor
- self.last_activation_mem_update_time = datetime.min
- self.last_query_consume_time = datetime.min
+ self.last_activation_mem_update_time = get_utc_now()
+ self.last_query_consume_time = get_utc_now()
self._register_lock = Lock()
self._process_llm = process_llm
@@ -256,7 +257,7 @@ def update_activation_memory_monitors(
activation_db_manager.sync_with_orm(size_limit=self.activation_mem_monitor_capacity)
def timed_trigger(self, last_time: datetime, interval_seconds: float) -> bool:
- now = datetime.utcnow()
+ now = get_utc_now()
elapsed = (now - last_time).total_seconds()
if elapsed >= interval_seconds:
return True
diff --git a/src/memos/mem_scheduler/optimized_scheduler.py b/src/memos/mem_scheduler/optimized_scheduler.py
index dd08954a9..a087ab2df 100644
--- a/src/memos/mem_scheduler/optimized_scheduler.py
+++ b/src/memos/mem_scheduler/optimized_scheduler.py
@@ -1,28 +1,282 @@
+import json
+import os
+
+from collections import OrderedDict
from typing import TYPE_CHECKING
+from memos.api.product_models import APISearchRequest
from memos.configs.mem_scheduler import GeneralSchedulerConfig
from memos.log import get_logger
from memos.mem_cube.general import GeneralMemCube
+from memos.mem_cube.navie import NaiveMemCube
+from memos.mem_scheduler.general_modules.api_misc import SchedulerAPIModule
from memos.mem_scheduler.general_scheduler import GeneralScheduler
from memos.mem_scheduler.schemas.general_schemas import (
+ API_MIX_SEARCH_LABEL,
MemCubeID,
+ SearchMode,
UserID,
)
+from memos.mem_scheduler.schemas.message_schemas import ScheduleMessageItem
+from memos.mem_scheduler.utils.api_utils import format_textual_memory_item
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from memos.memories.textual.tree import TextualMemoryItem, TreeTextMemory
+from memos.types import UserContext
if TYPE_CHECKING:
from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorItem
+ from memos.memories.textual.tree_text_memory.retrieve.searcher import Searcher
+ from memos.reranker.http_bge import HTTPBGEReranker
logger = get_logger(__name__)
class OptimizedScheduler(GeneralScheduler):
- """Optimized scheduler with improved working memory management"""
+ """Optimized scheduler with improved working memory management and support for api"""
def __init__(self, config: GeneralSchedulerConfig):
super().__init__(config)
+ self.window_size = int(os.getenv("API_SEARCH_WINDOW_SIZE", 5))
+ self.history_memory_turns = int(os.getenv("API_SEARCH_HISTORY_TURNS", 5))
+ self.session_counter = OrderedDict()
+ self.max_session_history = 5
+
+ self.api_module = SchedulerAPIModule(
+ window_size=self.window_size,
+ history_memory_turns=self.history_memory_turns,
+ )
+ self.register_handlers(
+ {
+ API_MIX_SEARCH_LABEL: self._api_mix_search_message_consumer,
+ }
+ )
+
+ def submit_memory_history_async_task(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ session_id: str | None = None,
+ ):
+ # Create message for async fine search
+ message_content = {
+ "search_req": {
+ "query": search_req.query,
+ "user_id": search_req.user_id,
+ "session_id": session_id,
+ "top_k": search_req.top_k,
+ "internet_search": search_req.internet_search,
+ "moscube": search_req.moscube,
+ "chat_history": search_req.chat_history,
+ },
+ "user_context": {"mem_cube_id": user_context.mem_cube_id},
+ }
+
+ async_task_id = f"mix_search_{search_req.user_id}_{get_utc_now().timestamp()}"
+
+ # Get mem_cube for the message
+ mem_cube = self.current_mem_cube
+
+ message = ScheduleMessageItem(
+ item_id=async_task_id,
+ user_id=search_req.user_id,
+ mem_cube_id=user_context.mem_cube_id,
+ label=API_MIX_SEARCH_LABEL,
+ mem_cube=mem_cube,
+ content=json.dumps(message_content),
+ timestamp=get_utc_now(),
+ )
+
+ # Submit async task
+ self.submit_messages([message])
+ logger.info(f"Submitted async fine search task for user {search_req.user_id}")
+ return async_task_id
+
+ def search_memories(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ mem_cube: NaiveMemCube,
+ mode: SearchMode,
+ ):
+ """Fine search memories function copied from server_router to avoid circular import"""
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ # Create MemCube and perform search
+ search_results = mem_cube.text_mem.search(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=mode,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info={
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ },
+ )
+ return search_results
+
+ def mix_search_memories(
+ self,
+ search_req: APISearchRequest,
+ user_context: UserContext,
+ ):
+ """
+ Mix search memories: fast search + async fine search
+ """
+
+ # Get mem_cube for fast search
+ mem_cube = self.current_mem_cube
+
+ target_session_id = search_req.session_id
+ if not target_session_id:
+ target_session_id = "default_session"
+ search_filter = {"session_id": search_req.session_id} if search_req.session_id else None
+
+ text_mem: TreeTextMemory = mem_cube.text_mem
+ searcher: Searcher = text_mem.get_searcher(
+ manual_close_internet=not search_req.internet_search,
+ moscube=False,
+ )
+ # Rerank Memories - reranker expects TextualMemoryItem objects
+ reranker: HTTPBGEReranker = text_mem.reranker
+ info = {
+ "user_id": search_req.user_id,
+ "session_id": target_session_id,
+ "chat_history": search_req.chat_history,
+ }
+
+ fast_retrieved_memories = searcher.retrieve(
+ query=search_req.query,
+ user_name=user_context.mem_cube_id,
+ top_k=search_req.top_k,
+ mode=SearchMode.FAST,
+ manual_close_internet=not search_req.internet_search,
+ moscube=search_req.moscube,
+ search_filter=search_filter,
+ info=info,
+ )
+
+ self.submit_memory_history_async_task(
+ search_req=search_req,
+ user_context=user_context,
+ session_id=search_req.session_id,
+ )
+
+ # Try to get pre-computed fine memories if available
+ history_memories = self.api_module.get_history_memories(
+ user_id=search_req.user_id,
+ mem_cube_id=user_context.mem_cube_id,
+ turns=self.history_memory_turns,
+ )
+
+ if not history_memories:
+ fast_memories = searcher.post_retrieve(
+ retrieved_results=fast_retrieved_memories,
+ top_k=search_req.top_k,
+ user_name=user_context.mem_cube_id,
+ info=info,
+ )
+ # Format fast memories for return
+ formatted_memories = [format_textual_memory_item(data) for data in fast_memories]
+ return formatted_memories
+
+ sorted_history_memories = reranker.rerank(
+ query=search_req.query, # Use search_req.query instead of undefined query
+ graph_results=history_memories, # Pass TextualMemoryItem objects directly
+ top_k=search_req.top_k, # Use search_req.top_k instead of undefined top_k
+ search_filter=search_filter,
+ )
+
+ sorted_results = fast_retrieved_memories + sorted_history_memories
+ final_results = searcher.post_retrieve(
+ retrieved_results=sorted_results,
+ top_k=search_req.top_k,
+ user_name=user_context.mem_cube_id,
+ info=info,
+ )
+
+ formatted_memories = [
+ format_textual_memory_item(item) for item in final_results[: search_req.top_k]
+ ]
+
+ return formatted_memories
+
+ def update_search_memories_to_redis(
+ self,
+ messages: list[ScheduleMessageItem],
+ ):
+ mem_cube: NaiveMemCube = self.current_mem_cube
+
+ for msg in messages:
+ content_dict = json.loads(msg.content)
+ search_req = content_dict["search_req"]
+ user_context = content_dict["user_context"]
+
+ session_id = search_req.get("session_id")
+ if session_id:
+ if session_id not in self.session_counter:
+ self.session_counter[session_id] = 0
+ else:
+ self.session_counter[session_id] += 1
+ session_turn = self.session_counter[session_id]
+
+ # Move the current session to the end to mark it as recently used
+ self.session_counter.move_to_end(session_id)
+
+ # If the counter exceeds the max size, remove the oldest item
+ if len(self.session_counter) > self.max_session_history:
+ self.session_counter.popitem(last=False)
+ else:
+ session_turn = 0
+
+ memories: list[TextualMemoryItem] = self.search_memories(
+ search_req=APISearchRequest(**content_dict["search_req"]),
+ user_context=UserContext(**content_dict["user_context"]),
+ mem_cube=mem_cube,
+ mode=SearchMode.FAST,
+ )
+ formatted_memories = [format_textual_memory_item(data) for data in memories]
+
+ # Sync search data to Redis
+ self.api_module.sync_search_data(
+ item_id=msg.item_id,
+ user_id=search_req["user_id"],
+ mem_cube_id=user_context["mem_cube_id"],
+ query=search_req["query"],
+ memories=memories,
+ formatted_memories=formatted_memories,
+ session_id=session_id,
+ conversation_turn=session_turn,
+ )
+
+ def _api_mix_search_message_consumer(self, messages: list[ScheduleMessageItem]) -> None:
+ """
+ Process and handle query trigger messages from the queue.
+
+ Args:
+ messages: List of query messages to process
+ """
+ logger.info(f"Messages {messages} assigned to {API_MIX_SEARCH_LABEL} handler.")
+
+ # Process the query in a session turn
+ grouped_messages = self.dispatcher._group_messages_by_user_and_mem_cube(messages=messages)
+
+ self.validate_schedule_messages(messages=messages, label=API_MIX_SEARCH_LABEL)
+
+ for user_id in grouped_messages:
+ for mem_cube_id in grouped_messages[user_id]:
+ messages = grouped_messages[user_id][mem_cube_id]
+ if len(messages) == 0:
+ return
+ self.update_search_memories_to_redis(messages=messages)
def replace_working_memory(
self,
diff --git a/src/memos/mem_scheduler/orm_modules/api_redis_model.py b/src/memos/mem_scheduler/orm_modules/api_redis_model.py
new file mode 100644
index 000000000..04cd7e833
--- /dev/null
+++ b/src/memos/mem_scheduler/orm_modules/api_redis_model.py
@@ -0,0 +1,517 @@
+import os
+import time
+
+from typing import Any
+
+from sqlalchemy.orm import declarative_base
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import DatabaseError
+from memos.mem_scheduler.schemas.api_schemas import (
+ APISearchHistoryManager,
+)
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
+
+logger = get_logger(__name__)
+
+Base = declarative_base()
+
+
+class APIRedisDBManager:
+ """Redis-based database manager for any serializable object
+
+ This class handles persistence, synchronization, and locking
+ for any object that implements to_json/from_json methods using Redis as the backend storage.
+ """
+
+ # Add orm_class attribute for compatibility
+ orm_class = None
+
+ def __init__(
+ self,
+ user_id: str | None = None,
+ mem_cube_id: str | None = None,
+ obj: APISearchHistoryManager | None = None,
+ lock_timeout: int = 10,
+ redis_client=None,
+ redis_config: dict | None = None,
+ window_size: int = 5,
+ ):
+ """Initialize the Redis database manager
+
+ Args:
+ user_id: Unique identifier for the user
+ mem_cube_id: Unique identifier for the memory cube
+ obj: Optional object instance to manage (must have to_json/from_json methods)
+ lock_timeout: Timeout in seconds for lock acquisition
+ redis_client: Redis client instance (optional)
+ redis_config: Redis configuration dictionary (optional)
+ """
+ # Initialize Redis client
+ self.redis_client = redis_client
+ self.redis_config = redis_config or {}
+
+ if self.redis_client is None:
+ self._init_redis_client()
+
+ # Initialize base attributes without calling parent's init_manager
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.obj = obj
+ self.lock_timeout = lock_timeout
+ self.engine = None # Keep for compatibility but not used
+ self.SessionLocal = None # Not used for Redis
+ self.window_size = window_size
+ self.lock_key = f"{self._get_key_prefix()}:lock"
+
+ logger.info(
+ f"RedisDBManager initialized for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ logger.info(f"Redis client: {type(self.redis_client).__name__}")
+
+ # Test Redis connection
+ try:
+ self.redis_client.ping()
+ logger.info("Redis connection successful")
+ except Exception as e:
+ logger.warning(f"Redis ping failed: {e}")
+ # Don't raise error here as it might be a mock client in tests
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this user and memory cube
+
+ Returns:
+ Redis key prefix string
+ """
+ return f"redis_api:{self.user_id}:{self.mem_cube_id}"
+
+ def _get_data_key(self) -> str:
+ """Generate Redis key for storing serialized data
+
+ Returns:
+ Redis data key string
+ """
+ return f"{self._get_key_prefix()}:data"
+
+ def _init_redis_client(self):
+ """Initialize Redis client from config or environment"""
+ try:
+ import redis
+ except ImportError:
+ logger.error("Redis package not installed. Install with: pip install redis")
+ raise
+
+ # Try to get Redis client from environment first
+ if not self.redis_client:
+ self.redis_client = APIRedisDBManager.load_redis_engine_from_env()
+
+ # If still no client, try from config
+ if not self.redis_client and self.redis_config:
+ redis_kwargs = {
+ "host": self.redis_config.get("host"),
+ "port": self.redis_config.get("port"),
+ "db": self.redis_config.get("db"),
+ "decode_responses": True,
+ }
+
+ if self.redis_config.get("password"):
+ redis_kwargs["password"] = self.redis_config["password"]
+
+ self.redis_client = redis.Redis(**redis_kwargs)
+
+ # Final fallback to localhost
+ if not self.redis_client:
+ logger.warning("No Redis configuration found, using localhost defaults")
+ self.redis_client = redis.Redis(
+ host="localhost", port=6379, db=0, decode_responses=True
+ )
+
+ # Test connection
+ if not self.redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info("Redis client initialized successfully")
+
+ def acquire_lock(self, block: bool = True, **kwargs) -> bool:
+ """Acquire a distributed lock using Redis with atomic operations
+
+ Args:
+ block: Whether to block until lock is acquired
+ **kwargs: Additional filter criteria (ignored for Redis)
+
+ Returns:
+ True if lock was acquired, False otherwise
+ """
+
+ now = get_utc_now()
+
+ # Use Redis SET with NX (only if not exists) and EX (expiry) for atomic lock acquisition
+ lock_value = f"{self._get_key_prefix()}:{now.timestamp()}"
+
+ while True:
+ result = self.redis_client.get(self.lock_key)
+ if result:
+ # Wait a bit before retrying
+ logger.info(
+ f"Waiting for Redis lock to be released for {self.user_id}/{self.mem_cube_id}"
+ )
+ if not block:
+ logger.warning(
+ f"Redis lock is held for {self.user_id}/{self.mem_cube_id}, cannot acquire"
+ )
+ return False
+ else:
+ time.sleep(0.1)
+ continue
+ else:
+ # Try to acquire lock atomically
+ result = self.redis_client.set(
+ self.lock_key,
+ lock_value,
+ ex=self.lock_timeout, # Set expiry in seconds
+ )
+ logger.info(f"Redis lock acquired for {self._get_key_prefix()}")
+ return True
+
+ def release_locks(self, **kwargs):
+ # Delete the lock key to release the lock
+ result = self.redis_client.delete(self.lock_key)
+
+ # Redis DELETE returns the number of keys deleted (0 or 1)
+ if result > 0:
+ logger.info(f"Redis lock released for {self._get_key_prefix()}")
+ else:
+ logger.info(f"No Redis lock found to release for {self._get_key_prefix()}")
+
+ def merge_items(
+ self,
+ redis_data: str,
+ obj_instance: APISearchHistoryManager,
+ size_limit: int,
+ ):
+ """Merge Redis data with current object instance
+
+ Args:
+ redis_data: JSON string from Redis containing serialized APISearchHistoryManager
+ obj_instance: Current APISearchHistoryManager instance
+ size_limit: Maximum number of completed entries to keep
+
+ Returns:
+ APISearchHistoryManager: Merged and synchronized manager instance
+ """
+
+ # Parse Redis data
+ redis_manager = APISearchHistoryManager.from_json(redis_data)
+ logger.debug(
+ f"Loaded Redis manager with {len(redis_manager.completed_entries)} completed and {len(redis_manager.running_item_ids)} running task IDs"
+ )
+
+ # Create a new merged manager with the original window size from obj_instance
+ # Use size_limit only for limiting entries, not as window_size
+ original_window_size = obj_instance.window_size
+ merged_manager = APISearchHistoryManager(window_size=original_window_size)
+
+ # Merge completed entries - combine both sources and deduplicate by task_id
+ # Ensure all entries are APIMemoryHistoryEntryItem instances
+ from memos.mem_scheduler.schemas.api_schemas import APIMemoryHistoryEntryItem
+
+ all_completed = {}
+
+ # Add Redis completed entries
+ for entry in redis_manager.completed_entries:
+ if isinstance(entry, dict):
+ # Convert dict to APIMemoryHistoryEntryItem instance
+ try:
+ entry_obj = APIMemoryHistoryEntryItem(**entry)
+ task_id = entry_obj.item_id
+ all_completed[task_id] = entry_obj
+ except Exception as e:
+ logger.warning(
+ f"Failed to convert dict entry to APIMemoryHistoryEntryItem: {e}"
+ )
+ continue
+ else:
+ task_id = entry.item_id
+ all_completed[task_id] = entry
+
+ # Add current instance completed entries (these take priority if duplicated)
+ for entry in obj_instance.completed_entries:
+ if isinstance(entry, dict):
+ # Convert dict to APIMemoryHistoryEntryItem instance
+ try:
+ entry_obj = APIMemoryHistoryEntryItem(**entry)
+ task_id = entry_obj.item_id
+ all_completed[task_id] = entry_obj
+ except Exception as e:
+ logger.warning(
+ f"Failed to convert dict entry to APIMemoryHistoryEntryItem: {e}"
+ )
+ continue
+ else:
+ task_id = entry.item_id
+ all_completed[task_id] = entry
+
+ # Sort by created_time and apply size limit
+ completed_list = list(all_completed.values())
+
+ def get_created_time(entry):
+ """Helper function to safely extract created_time for sorting"""
+ from datetime import datetime
+
+ # All entries should now be APIMemoryHistoryEntryItem instances
+ return getattr(entry, "created_time", datetime.min)
+
+ completed_list.sort(key=get_created_time, reverse=True)
+ merged_manager.completed_entries = completed_list[:size_limit]
+
+ # Merge running task IDs - combine both sources and deduplicate
+ all_running_item_ids = set()
+
+ # Add Redis running task IDs
+ all_running_item_ids.update(redis_manager.running_item_ids)
+
+ # Add current instance running task IDs
+ all_running_item_ids.update(obj_instance.running_item_ids)
+
+ merged_manager.running_item_ids = list(all_running_item_ids)
+
+ logger.info(
+ f"Merged manager: {len(merged_manager.completed_entries)} completed, {len(merged_manager.running_item_ids)} running task IDs"
+ )
+ return merged_manager
+
+ def sync_with_redis(self, size_limit: int | None = None) -> None:
+ """Synchronize data between Redis and the business object
+
+ Args:
+ size_limit: Optional maximum number of items to keep after synchronization
+ """
+
+ # Use window_size from the object if size_limit is not provided
+ if size_limit is None:
+ size_limit = self.window_size
+
+ # Acquire lock before operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for synchronization")
+ return
+
+ # Load existing data from Redis
+ data_key = self._get_data_key()
+ redis_data = self.redis_client.get(data_key)
+
+ if redis_data:
+ # Merge Redis data with current object
+ merged_obj = self.merge_items(
+ redis_data=redis_data, obj_instance=self.obj, size_limit=size_limit
+ )
+
+ # Update the current object with merged data
+ self.obj = merged_obj
+ logger.info(
+ f"Successfully synchronized with Redis data for {self.user_id}/{self.mem_cube_id}"
+ )
+ else:
+ logger.info(
+ f"No existing Redis data found for {self.user_id}/{self.mem_cube_id}, using current object"
+ )
+
+ # Save the synchronized object back to Redis
+ self.save_to_db(self.obj)
+
+ self.release_locks()
+
+ def save_to_db(self, obj_instance: Any) -> None:
+ """Save the current state of the business object to Redis
+
+ Args:
+ obj_instance: The object instance to save (must have to_json method)
+ """
+
+ data_key = self._get_data_key()
+
+ self.redis_client.set(data_key, obj_instance.to_json())
+
+ logger.info(f"Updated existing Redis record for {data_key}")
+
+ def load_from_db(self) -> Any | None:
+ data_key = self._get_data_key()
+
+ # Load from Redis
+ serialized_data = self.redis_client.get(data_key)
+
+ if not serialized_data:
+ logger.info(f"No Redis record found for {data_key}")
+ return None
+
+ # Deserialize the business object using the actual object type
+ if hasattr(self, "obj_type") and self.obj_type is not None:
+ db_instance = self.obj_type.from_json(serialized_data)
+ else:
+ # Default to APISearchHistoryManager for this class
+ db_instance = APISearchHistoryManager.from_json(serialized_data)
+
+ logger.info(f"Successfully loaded object from Redis for {data_key} ")
+
+ return db_instance
+
+ @classmethod
+ def from_env(
+ cls,
+ user_id: str,
+ mem_cube_id: str,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ env_file_path: str | None = None,
+ ) -> "APIRedisDBManager":
+ """Create RedisDBManager from environment variables
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ obj: Optional MemoryMonitorManager instance
+ lock_timeout: Lock timeout in seconds
+ env_file_path: Optional path to .env file
+
+ Returns:
+ RedisDBManager instance
+ """
+
+ redis_client = APIRedisDBManager.load_redis_engine_from_env(env_file_path)
+ return cls(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=obj,
+ lock_timeout=lock_timeout,
+ redis_client=redis_client,
+ )
+
+ def close(self):
+ """Close the Redis connection and clean up resources"""
+ try:
+ if hasattr(self.redis_client, "close"):
+ self.redis_client.close()
+ logger.info(
+ f"Redis connection closed for user_id: {self.user_id}, mem_cube_id: {self.mem_cube_id}"
+ )
+ except Exception as e:
+ logger.warning(f"Error closing Redis connection: {e}")
+
+ @staticmethod
+ def load_redis_engine_from_env(env_file_path: str | None = None) -> Any:
+ """Load Redis connection from environment variables
+
+ Args:
+ env_file_path: Path to .env file (optional, defaults to loading from current environment)
+
+ Returns:
+ Redis connection instance
+
+ Raises:
+ DatabaseError: If required environment variables are missing or connection fails
+ """
+ try:
+ import redis
+ except ImportError as e:
+ error_msg = "Redis package not installed. Install with: pip install redis"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
+
+ # Load environment variables from file if provided
+ if env_file_path:
+ if os.path.exists(env_file_path):
+ from dotenv import load_dotenv
+
+ load_dotenv(env_file_path)
+ logger.info(f"Loaded environment variables from {env_file_path}")
+ else:
+ logger.warning(
+ f"Environment file not found: {env_file_path}, using current environment variables"
+ )
+ else:
+ logger.info("Using current environment variables (no env_file_path provided)")
+
+ # Get Redis configuration from environment variables
+ redis_host = os.getenv("REDIS_HOST") or os.getenv("MEMSCHEDULER_REDIS_HOST")
+ redis_port_str = os.getenv("REDIS_PORT") or os.getenv("MEMSCHEDULER_REDIS_PORT")
+ redis_db_str = os.getenv("REDIS_DB") or os.getenv("MEMSCHEDULER_REDIS_DB")
+ redis_password = os.getenv("REDIS_PASSWORD") or os.getenv("MEMSCHEDULER_REDIS_PASSWORD")
+
+ # Check required environment variables
+ if not redis_host:
+ error_msg = (
+ "Missing required Redis environment variable: REDIS_HOST or MEMSCHEDULER_REDIS_HOST"
+ )
+ logger.error(error_msg)
+ return None
+
+ # Parse port with validation
+ try:
+ redis_port = int(redis_port_str) if redis_port_str else 6379
+ except ValueError:
+ error_msg = f"Invalid REDIS_PORT value: {redis_port_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Parse database with validation
+ try:
+ redis_db = int(redis_db_str) if redis_db_str else 0
+ except ValueError:
+ error_msg = f"Invalid REDIS_DB value: {redis_db_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Optional timeout settings
+ socket_timeout = os.getenv(
+ "REDIS_SOCKET_TIMEOUT", os.getenv("MEMSCHEDULER_REDIS_TIMEOUT", None)
+ )
+ socket_connect_timeout = os.getenv(
+ "REDIS_SOCKET_CONNECT_TIMEOUT", os.getenv("MEMSCHEDULER_REDIS_CONNECT_TIMEOUT", None)
+ )
+
+ try:
+ # Build Redis connection parameters
+ redis_kwargs = {
+ "host": redis_host,
+ "port": redis_port,
+ "db": redis_db,
+ "decode_responses": True,
+ }
+
+ if redis_password:
+ redis_kwargs["password"] = redis_password
+
+ if socket_timeout:
+ try:
+ redis_kwargs["socket_timeout"] = float(socket_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid REDIS_SOCKET_TIMEOUT value: {socket_timeout}, ignoring"
+ )
+
+ if socket_connect_timeout:
+ try:
+ redis_kwargs["socket_connect_timeout"] = float(socket_connect_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid REDIS_SOCKET_CONNECT_TIMEOUT value: {socket_connect_timeout}, ignoring"
+ )
+
+ # Create Redis connection
+ redis_client = redis.Redis(**redis_kwargs)
+
+ # Test connection
+ if not redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info(
+ f"Successfully created Redis connection: {redis_host}:{redis_port}/{redis_db}"
+ )
+ return redis_client
+
+ except Exception as e:
+ error_msg = f"Failed to create Redis connection from environment variables: {e}"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
diff --git a/src/memos/mem_scheduler/orm_modules/base_model.py b/src/memos/mem_scheduler/orm_modules/base_model.py
index 9d75a12bd..9783cea82 100644
--- a/src/memos/mem_scheduler/orm_modules/base_model.py
+++ b/src/memos/mem_scheduler/orm_modules/base_model.py
@@ -10,13 +10,16 @@
from sqlalchemy import Boolean, Column, DateTime, String, Text, and_, create_engine
from sqlalchemy.engine import Engine
-from sqlalchemy.ext.declarative import declarative_base
-from sqlalchemy.orm import Session, sessionmaker
+from sqlalchemy.orm import Session, declarative_base, sessionmaker
from memos.log import get_logger
from memos.mem_user.user_manager import UserManager
+class DatabaseError(Exception):
+ """Exception raised for database-related errors"""
+
+
T = TypeVar("T") # The model type (MemoryMonitorManager, QueryMonitorManager, etc.)
ORM = TypeVar("ORM") # The ORM model type
@@ -561,7 +564,7 @@ def close(self):
logger.error(f"Error during close operation: {e}")
@staticmethod
- def create_default_engine() -> Engine:
+ def create_default_sqlite_engine() -> Engine:
"""Create SQLAlchemy engine with default database path
Returns:
@@ -633,3 +636,94 @@ def create_mysql_db_path(
else:
db_path = f"mysql+pymysql://{username}@{host}:{port}/{database}?charset={charset}"
return db_path
+
+ @staticmethod
+ def load_mysql_engine_from_env(env_file_path: str | None = None) -> Engine | None:
+ """Load MySQL engine from environment variables
+
+ Args:
+ env_file_path: Path to .env file (optional, defaults to loading from current environment)
+
+ Returns:
+ SQLAlchemy Engine instance configured for MySQL
+
+ Raises:
+ DatabaseError: If required environment variables are missing or connection fails
+ """
+ # Load environment variables from file if provided
+ if env_file_path:
+ if os.path.exists(env_file_path):
+ from dotenv import load_dotenv
+
+ load_dotenv(env_file_path)
+ logger.info(f"Loaded environment variables from {env_file_path}")
+ else:
+ logger.warning(
+ f"Environment file not found: {env_file_path}, using current environment variables"
+ )
+ else:
+ logger.info("Using current environment variables (no env_file_path provided)")
+
+ # Get MySQL configuration from environment variables
+ mysql_host = os.getenv("MYSQL_HOST")
+ mysql_port_str = os.getenv("MYSQL_PORT")
+ mysql_username = os.getenv("MYSQL_USERNAME")
+ mysql_password = os.getenv("MYSQL_PASSWORD")
+ mysql_database = os.getenv("MYSQL_DATABASE")
+ mysql_charset = os.getenv("MYSQL_CHARSET")
+
+ # Check required environment variables
+ required_vars = {
+ "MYSQL_HOST": mysql_host,
+ "MYSQL_USERNAME": mysql_username,
+ "MYSQL_PASSWORD": mysql_password,
+ "MYSQL_DATABASE": mysql_database,
+ }
+
+ missing_vars = [var for var, value in required_vars.items() if not value]
+ if missing_vars:
+ error_msg = f"Missing required MySQL environment variables: {', '.join(missing_vars)}"
+ logger.error(error_msg)
+ return None
+
+ # Parse port with validation
+ try:
+ mysql_port = int(mysql_port_str) if mysql_port_str else 3306
+ except ValueError:
+ error_msg = f"Invalid MYSQL_PORT value: {mysql_port_str}. Must be a valid integer."
+ logger.error(error_msg)
+ return None
+
+ # Set default charset if not provided
+ if not mysql_charset:
+ mysql_charset = "utf8mb4"
+
+ # Create MySQL connection URL
+ db_url = BaseDBManager.create_mysql_db_path(
+ host=mysql_host,
+ port=mysql_port,
+ username=mysql_username,
+ password=mysql_password,
+ database=mysql_database,
+ charset=mysql_charset,
+ )
+
+ try:
+ # Create and test the engine
+ engine = create_engine(db_url, echo=False)
+
+ # Test connection
+ with engine.connect() as conn:
+ from sqlalchemy import text
+
+ conn.execute(text("SELECT 1"))
+
+ logger.info(
+ f"Successfully created MySQL engine: {mysql_host}:{mysql_port}/{mysql_database}"
+ )
+ return engine
+
+ except Exception as e:
+ error_msg = f"Failed to create MySQL engine from environment variables: {e}"
+ logger.error(error_msg)
+ raise DatabaseError(error_msg) from e
diff --git a/src/memos/mem_scheduler/orm_modules/redis_model.py b/src/memos/mem_scheduler/orm_modules/redis_model.py
new file mode 100644
index 000000000..ccfe1b1c8
--- /dev/null
+++ b/src/memos/mem_scheduler/orm_modules/redis_model.py
@@ -0,0 +1,699 @@
+import json
+import time
+
+from typing import Any, TypeVar
+
+from sqlalchemy.engine import Engine
+from sqlalchemy.orm import declarative_base
+
+from memos.log import get_logger
+from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
+from memos.mem_scheduler.schemas.monitor_schemas import MemoryMonitorManager
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
+
+T = TypeVar("T") # The model type (MemoryMonitorManager, QueryMonitorManager, etc.)
+ORM = TypeVar("ORM") # The ORM model type
+
+logger = get_logger(__name__)
+
+Base = declarative_base()
+
+
+class SimpleListManager:
+ """Simple wrapper class for list[str] to work with RedisDBManager"""
+
+ def __init__(self, items: list[str] | None = None):
+ self.items = items or []
+
+ def to_json(self) -> str:
+ """Serialize to JSON string"""
+ return json.dumps({"items": self.items})
+
+ @classmethod
+ def from_json(cls, json_str: str) -> "SimpleListManager":
+ """Deserialize from JSON string"""
+ data = json.loads(json_str)
+ return cls(items=data.get("items", []))
+
+ def add_item(self, item: str):
+ """Add an item to the list"""
+ self.items.append(item)
+
+ def __len__(self):
+ return len(self.items)
+
+ def __str__(self):
+ return f"SimpleListManager(items={self.items})"
+
+
+class RedisLockableORM:
+ """Redis-based implementation of LockableORM interface
+
+ This class provides Redis-based storage for lockable ORM objects,
+ mimicking the SQLAlchemy LockableORM interface but using Redis as the backend.
+ """
+
+ def __init__(self, redis_client, user_id: str, mem_cube_id: str):
+ self.redis_client = redis_client
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.serialized_data = None
+ self.lock_acquired = False
+ self.lock_expiry = None
+ self.version_control = "0"
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this ORM instance"""
+ return f"lockable_orm:{self.user_id}:{self.mem_cube_id}"
+
+ def _get_data_key(self) -> str:
+ """Get Redis key for serialized data"""
+ return f"{self._get_key_prefix()}:data"
+
+ def _get_lock_key(self) -> str:
+ """Get Redis key for lock information"""
+ return f"{self._get_key_prefix()}:lock"
+
+ def _get_version_key(self) -> str:
+ """Get Redis key for version control"""
+ return f"{self._get_key_prefix()}:version"
+
+ def save(self):
+ """Save this ORM instance to Redis"""
+ try:
+ # Save serialized data
+ if self.serialized_data:
+ self.redis_client.set(self._get_data_key(), self.serialized_data)
+
+ # Note: Lock information is now managed by acquire_lock/release_locks methods
+ # We don't save lock info here to avoid conflicts with atomic lock operations
+
+ # Save version control
+ self.redis_client.set(self._get_version_key(), self.version_control)
+
+ logger.debug(f"Saved RedisLockableORM to Redis: {self._get_key_prefix()}")
+
+ except Exception as e:
+ logger.error(f"Failed to save RedisLockableORM to Redis: {e}")
+ raise
+
+ def load(self):
+ """Load this ORM instance from Redis"""
+ try:
+ # Load serialized data
+ data = self.redis_client.get(self._get_data_key())
+ if data:
+ self.serialized_data = data.decode() if isinstance(data, bytes) else data
+ else:
+ self.serialized_data = None
+
+ # Note: Lock information is now managed by acquire_lock/release_locks methods
+ # We don't load lock info here to avoid conflicts with atomic lock operations
+ self.lock_acquired = False
+ self.lock_expiry = None
+
+ # Load version control
+ version = self.redis_client.get(self._get_version_key())
+ if version:
+ self.version_control = version.decode() if isinstance(version, bytes) else version
+ else:
+ self.version_control = "0"
+
+ logger.debug(f"Loaded RedisLockableORM from Redis: {self._get_key_prefix()}")
+ # Return True if we found any data, False otherwise
+ return self.serialized_data is not None
+
+ except Exception as e:
+ logger.error(f"Failed to load RedisLockableORM from Redis: {e}")
+ return False
+
+ def delete(self):
+ """Delete this ORM instance from Redis"""
+ try:
+ keys_to_delete = [self._get_data_key(), self._get_lock_key(), self._get_version_key()]
+ self.redis_client.delete(*keys_to_delete)
+ logger.debug(f"Deleted RedisLockableORM from Redis: {self._get_key_prefix()}")
+ except Exception as e:
+ logger.error(f"Failed to delete RedisLockableORM from Redis: {e}")
+ raise
+
+
+class RedisDBManager(BaseDBManager):
+ """Redis-based database manager for any serializable object
+
+ This class handles persistence, synchronization, and locking
+ for any object that implements to_json/from_json methods using Redis as the backend storage.
+ """
+
+ def __init__(
+ self,
+ engine: Engine | None = None,
+ user_id: str | None = None,
+ mem_cube_id: str | None = None,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ redis_client=None,
+ redis_config: dict | None = None,
+ ):
+ """Initialize the Redis database manager
+
+ Args:
+ engine: SQLAlchemy engine (not used for Redis, kept for compatibility)
+ user_id: Unique identifier for the user
+ mem_cube_id: Unique identifier for the memory cube
+ obj: Optional object instance to manage (must have to_json/from_json methods)
+ lock_timeout: Timeout in seconds for lock acquisition
+ redis_client: Redis client instance (optional)
+ redis_config: Redis configuration dictionary (optional)
+ """
+ # Initialize Redis client
+ self.redis_client = redis_client
+ self.redis_config = redis_config or {}
+
+ if self.redis_client is None:
+ self._init_redis_client()
+
+ # Initialize base attributes without calling parent's init_manager
+ self.user_id = user_id
+ self.mem_cube_id = mem_cube_id
+ self.obj = obj
+ self.obj_type = type(obj) if obj is not None else None # Store the actual object type
+ self.lock_timeout = lock_timeout
+ self.engine = engine # Keep for compatibility but not used
+ self.SessionLocal = None # Not used for Redis
+ self.last_version_control = None
+
+ logger.info(
+ f"RedisDBManager initialized for user_id: {user_id}, mem_cube_id: {mem_cube_id}"
+ )
+ logger.info(f"Redis client: {type(self.redis_client).__name__}")
+
+ # Test Redis connection
+ try:
+ self.redis_client.ping()
+ logger.info("Redis connection successful")
+ except Exception as e:
+ logger.warning(f"Redis ping failed: {e}")
+ # Don't raise error here as it might be a mock client in tests
+
+ def _init_redis_client(self):
+ """Initialize Redis client from config or environment"""
+ try:
+ import redis
+
+ # Try to get Redis client from environment first
+ if not self.redis_client:
+ self.redis_client = self.load_redis_engine_from_env()
+
+ # If still no client, try from config
+ if not self.redis_client and self.redis_config:
+ redis_kwargs = {
+ "host": self.redis_config.get("host", "localhost"),
+ "port": self.redis_config.get("port", 6379),
+ "db": self.redis_config.get("db", 0),
+ "decode_responses": True,
+ }
+
+ if self.redis_config.get("password"):
+ redis_kwargs["password"] = self.redis_config["password"]
+
+ self.redis_client = redis.Redis(**redis_kwargs)
+
+ # Final fallback to localhost
+ if not self.redis_client:
+ logger.warning("No Redis configuration found, using localhost defaults")
+ self.redis_client = redis.Redis(
+ host="localhost", port=6379, db=0, decode_responses=True
+ )
+
+ # Test connection
+ if not self.redis_client.ping():
+ raise ConnectionError("Redis ping failed")
+
+ logger.info("Redis client initialized successfully")
+
+ except ImportError:
+ logger.error("Redis package not installed. Install with: pip install redis")
+ raise
+ except Exception as e:
+ logger.error(f"Failed to initialize Redis client: {e}")
+ raise
+
+ @property
+ def orm_class(self) -> type[RedisLockableORM]:
+ """Return the Redis-based ORM class"""
+ return RedisLockableORM
+
+ @property
+ def obj_class(self) -> type:
+ """Return the actual object class"""
+ return self.obj_type if self.obj_type is not None else MemoryMonitorManager
+
+ def merge_items(
+ self,
+ orm_instance: RedisLockableORM,
+ obj_instance: Any,
+ size_limit: int,
+ ):
+ """Merge items from Redis with current object instance
+
+ This method provides a generic way to merge data from Redis with the current
+ object instance. It handles different object types and their specific merge logic.
+
+ Args:
+ orm_instance: Redis ORM instance from database
+ obj_instance: Current object instance (any type with to_json/from_json methods)
+ size_limit: Maximum number of items to keep after merge
+ """
+ logger.debug(f"Starting merge_items with size_limit={size_limit}")
+
+ try:
+ if not orm_instance.serialized_data:
+ logger.warning("No serialized data in Redis ORM instance to merge")
+ return obj_instance
+
+ # Deserialize the database object using the actual object type
+ if self.obj_type is not None:
+ db_obj = self.obj_type.from_json(orm_instance.serialized_data)
+ else:
+ db_obj = MemoryMonitorManager.from_json(orm_instance.serialized_data)
+
+ # Handle different object types with specific merge logic based on type
+ obj_type = type(obj_instance)
+ if obj_type.__name__ == "MemoryMonitorManager" or hasattr(obj_instance, "memories"):
+ # MemoryMonitorManager-like objects
+ return self._merge_memory_monitor_items(obj_instance, db_obj, size_limit)
+ elif obj_type.__name__ == "SimpleListManager" or hasattr(obj_instance, "items"):
+ # SimpleListManager-like objects
+ return self._merge_list_items(obj_instance, db_obj, size_limit)
+ else:
+ # Generic objects - just return the current instance
+ logger.info(
+ f"No specific merge logic for object type {obj_type.__name__}, returning current instance"
+ )
+ return obj_instance
+
+ except Exception as e:
+ logger.error(f"Failed to deserialize database instance: {e}", exc_info=True)
+ logger.warning("Skipping merge due to deserialization error, using current object only")
+ return obj_instance
+
+ def _merge_memory_monitor_items(self, obj_instance, db_obj, size_limit: int):
+ """Merge MemoryMonitorManager items"""
+ # Create a mapping of existing memories by their mapping key
+ current_memories_dict = obj_instance.memories_mapping_dict
+
+ # Add memories from database that don't exist in current object
+ for db_memory in db_obj.memories:
+ if db_memory.tree_memory_item_mapping_key not in current_memories_dict:
+ obj_instance.memories.append(db_memory)
+
+ # Apply size limit if specified
+ if size_limit and len(obj_instance.memories) > size_limit:
+ # Sort by recording_count and keep the most recorded ones
+ obj_instance.memories.sort(key=lambda x: x.recording_count, reverse=True)
+ obj_instance.memories = obj_instance.memories[:size_limit]
+ logger.info(
+ f"Applied size limit {size_limit}, kept {len(obj_instance.memories)} memories"
+ )
+
+ logger.info(f"Merged {len(obj_instance.memories)} memory items")
+ return obj_instance
+
+ def _merge_list_items(self, obj_instance, db_obj, size_limit: int):
+ """Merge SimpleListManager-like items"""
+ merged_items = []
+ seen_items = set()
+
+ # First, add all items from current object (higher priority)
+ for item in obj_instance.items:
+ if item not in seen_items:
+ merged_items.append(item)
+ seen_items.add(item)
+
+ # Then, add items from database that aren't in current object
+ for item in db_obj.items:
+ if item not in seen_items:
+ merged_items.append(item)
+ seen_items.add(item)
+
+ # Apply size limit if specified (keep most recent items)
+ if size_limit is not None and size_limit > 0 and len(merged_items) > size_limit:
+ merged_items = merged_items[:size_limit]
+ logger.debug(f"Applied size limit of {size_limit}, kept {len(merged_items)} items")
+
+ # Update the object with merged items
+ obj_instance.items = merged_items
+
+ logger.info(f"Merged {len(merged_items)} list items (size_limit: {size_limit})")
+ return obj_instance
+
+ def _get_redis_orm_instance(self) -> RedisLockableORM:
+ """Get or create a Redis ORM instance"""
+ orm_instance = RedisLockableORM(
+ redis_client=self.redis_client, user_id=self.user_id, mem_cube_id=self.mem_cube_id
+ )
+ return orm_instance
+
+ def _get_key_prefix(self) -> str:
+ """Generate Redis key prefix for this ORM instance"""
+ return f"lockable_orm:{self.user_id}:{self.mem_cube_id}"
+
+ def acquire_lock(self, block: bool = True, **kwargs) -> bool:
+ """Acquire a distributed lock using Redis with atomic operations
+
+ Args:
+ block: Whether to block until lock is acquired
+ **kwargs: Additional filter criteria (ignored for Redis)
+
+ Returns:
+ True if lock was acquired, False otherwise
+ """
+ try:
+ lock_key = f"{self._get_key_prefix()}:lock"
+ now = get_utc_now()
+
+ # Use Redis SET with NX (only if not exists) and EX (expiry) for atomic lock acquisition
+ lock_value = f"{self.user_id}:{self.mem_cube_id}:{now.timestamp()}"
+
+ while True:
+ # Try to acquire lock atomically
+ result = self.redis_client.set(
+ lock_key,
+ lock_value,
+ nx=True, # Only set if key doesn't exist
+ ex=self.lock_timeout, # Set expiry in seconds
+ )
+
+ if result:
+ # Successfully acquired lock
+ logger.info(f"Redis lock acquired for {self.user_id}/{self.mem_cube_id}")
+ return True
+
+ if not block:
+ logger.warning(
+ f"Redis lock is held for {self.user_id}/{self.mem_cube_id}, cannot acquire"
+ )
+ return False
+
+ # Wait a bit before retrying
+ logger.info(
+ f"Waiting for Redis lock to be released for {self.user_id}/{self.mem_cube_id}"
+ )
+ time.sleep(0.1)
+
+ except Exception as e:
+ logger.error(f"Failed to acquire Redis lock for {self.user_id}/{self.mem_cube_id}: {e}")
+ return False
+
+ def release_locks(self, user_id: str, mem_cube_id: str, **kwargs):
+ """Release Redis locks for the specified user and memory cube
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ **kwargs: Additional filter criteria (ignored for Redis)
+ """
+ try:
+ lock_key = f"lockable_orm:{user_id}:{mem_cube_id}:lock"
+
+ # Delete the lock key to release the lock
+ result = self.redis_client.delete(lock_key)
+
+ if result:
+ logger.info(f"Redis lock released for {user_id}/{mem_cube_id}")
+ else:
+ logger.warning(f"No Redis lock found to release for {user_id}/{mem_cube_id}")
+
+ except Exception as e:
+ logger.error(f"Failed to release Redis lock for {user_id}/{mem_cube_id}: {e}")
+
+ def sync_with_orm(self, size_limit: int | None = None) -> None:
+ """Synchronize data between Redis and the business object
+
+ Args:
+ size_limit: Optional maximum number of items to keep after synchronization
+ """
+ logger.info(
+ f"Starting Redis sync_with_orm for {self.user_id}/{self.mem_cube_id} with size_limit={size_limit}"
+ )
+
+ try:
+ # Acquire lock before any operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for synchronization")
+ return
+
+ # Get existing data from Redis
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ # If no existing record, create a new one
+ if not exists:
+ if self.obj is None:
+ logger.warning("No object to synchronize and no existing Redis record")
+ return
+
+ orm_instance.serialized_data = self.obj.to_json()
+ orm_instance.version_control = "0"
+ orm_instance.save()
+
+ logger.info("No existing Redis record found. Created a new one.")
+ self.last_version_control = "0"
+ return
+
+ # Check version control and merge data
+ if self.obj is not None:
+ current_redis_tag = orm_instance.version_control
+ new_tag = self._increment_version_control(current_redis_tag)
+
+ # Check if this is the first sync or if we need to merge
+ if self.last_version_control is None:
+ logger.info("First Redis sync, merging data from Redis")
+ # Always merge on first sync to load data from Redis
+ try:
+ self.merge_items(
+ orm_instance=orm_instance, obj_instance=self.obj, size_limit=size_limit
+ )
+ except Exception as merge_error:
+ logger.error(
+ f"Error during Redis merge_items: {merge_error}", exc_info=True
+ )
+ logger.warning("Continuing with current object data without merge")
+ elif current_redis_tag == self.last_version_control:
+ logger.info(
+ f"Redis version control unchanged ({current_redis_tag}), directly update"
+ )
+ else:
+ logger.info(
+ f"Redis version control changed from {self.last_version_control} to {current_redis_tag}, merging data"
+ )
+ try:
+ self.merge_items(
+ orm_instance=orm_instance, obj_instance=self.obj, size_limit=size_limit
+ )
+ except Exception as merge_error:
+ logger.error(
+ f"Error during Redis merge_items: {merge_error}", exc_info=True
+ )
+ logger.warning("Continuing with current object data without merge")
+
+ # Write merged data back to Redis
+ orm_instance.serialized_data = self.obj.to_json()
+ orm_instance.version_control = new_tag
+ orm_instance.save()
+
+ logger.info(f"Updated Redis serialized_data for {self.user_id}/{self.mem_cube_id}")
+ self.last_version_control = orm_instance.version_control
+ else:
+ logger.warning("No current object to merge with Redis data")
+
+ logger.info(f"Redis synchronization completed for {self.user_id}/{self.mem_cube_id}")
+
+ except Exception as e:
+ logger.error(
+ f"Error during Redis synchronization for {self.user_id}/{self.mem_cube_id}: {e}",
+ exc_info=True,
+ )
+ finally:
+ # Always release locks
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def save_to_db(self, obj_instance: Any) -> None:
+ """Save the current state of the business object to Redis
+
+ Args:
+ obj_instance: The object instance to save (must have to_json method)
+ """
+ try:
+ # Acquire lock before operations
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for saving")
+ return
+
+ # Get or create Redis ORM instance
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ if not exists:
+ # Create new record
+ orm_instance.serialized_data = obj_instance.to_json()
+ orm_instance.version_control = "0"
+ orm_instance.save()
+
+ logger.info(f"Created new Redis record for {self.user_id}/{self.mem_cube_id}")
+ self.last_version_control = "0"
+ else:
+ # Update existing record with version control
+ current_version = orm_instance.version_control
+ new_version = self._increment_version_control(current_version)
+
+ orm_instance.serialized_data = obj_instance.to_json()
+ orm_instance.version_control = new_version
+ orm_instance.save()
+
+ logger.info(
+ f"Updated existing Redis record for {self.user_id}/{self.mem_cube_id} with version {new_version}"
+ )
+ self.last_version_control = new_version
+
+ except Exception as e:
+ logger.error(f"Error saving to Redis for {self.user_id}/{self.mem_cube_id}: {e}")
+ finally:
+ # Always release locks
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def load_from_db(self, acquire_lock: bool = False) -> Any | None:
+ """Load the business object from Redis
+
+ Args:
+ acquire_lock: Whether to acquire a lock during the load operation
+
+ Returns:
+ The deserialized object instance, or None if not found
+ """
+ try:
+ if acquire_lock:
+ lock_status = self.acquire_lock(block=True)
+ if not lock_status:
+ logger.error("Failed to acquire Redis lock for loading")
+ return None
+
+ # Load from Redis
+ orm_instance = self._get_redis_orm_instance()
+ exists = orm_instance.load()
+
+ if not exists or not orm_instance.serialized_data:
+ logger.info(f"No Redis record found for {self.user_id}/{self.mem_cube_id}")
+ return None
+
+ # Deserialize the business object using the actual object type
+ if self.obj_type is not None:
+ db_instance = self.obj_type.from_json(orm_instance.serialized_data)
+ else:
+ db_instance = MemoryMonitorManager.from_json(orm_instance.serialized_data)
+ self.last_version_control = orm_instance.version_control
+
+ logger.info(
+ f"Successfully loaded object from Redis for {self.user_id}/{self.mem_cube_id} with version {orm_instance.version_control}"
+ )
+ return db_instance
+
+ except Exception as e:
+ logger.error(f"Error loading from Redis for {self.user_id}/{self.mem_cube_id}: {e}")
+ return None
+ finally:
+ if acquire_lock:
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+
+ def close(self):
+ """Close the Redis manager and clean up resources"""
+ try:
+ # Release any locks held by this manager instance
+ if self.user_id and self.mem_cube_id:
+ self.release_locks(user_id=self.user_id, mem_cube_id=self.mem_cube_id)
+ logger.info(f"Released Redis locks for {self.user_id}/{self.mem_cube_id}")
+
+ # Close Redis connection
+ if self.redis_client:
+ self.redis_client.close()
+ logger.info("Redis connection closed")
+
+ # Call parent close method for any additional cleanup
+ super().close()
+
+ except Exception as e:
+ logger.error(f"Error during Redis close operation: {e}")
+
+ @classmethod
+ def from_env(
+ cls,
+ user_id: str,
+ mem_cube_id: str,
+ obj: Any | None = None,
+ lock_timeout: int = 10,
+ env_file_path: str | None = None,
+ ) -> "RedisDBManager":
+ """Create RedisDBManager from environment variables
+
+ Args:
+ user_id: User identifier
+ mem_cube_id: Memory cube identifier
+ obj: Optional MemoryMonitorManager instance
+ lock_timeout: Lock timeout in seconds
+ env_file_path: Optional path to .env file
+
+ Returns:
+ RedisDBManager instance
+ """
+ try:
+ redis_client = cls.load_redis_engine_from_env(env_file_path)
+ return cls(
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ obj=obj,
+ lock_timeout=lock_timeout,
+ redis_client=redis_client,
+ )
+ except Exception as e:
+ logger.error(f"Failed to create RedisDBManager from environment: {e}")
+ raise
+
+ def list_keys(self, pattern: str | None = None) -> list[str]:
+ """List all Redis keys for this manager's data
+
+ Args:
+ pattern: Optional pattern to filter keys
+
+ Returns:
+ List of Redis keys
+ """
+ try:
+ if pattern is None:
+ pattern = f"lockable_orm:{self.user_id}:{self.mem_cube_id}:*"
+
+ keys = self.redis_client.keys(pattern)
+ return [key.decode() if isinstance(key, bytes) else key for key in keys]
+
+ except Exception as e:
+ logger.error(f"Error listing Redis keys: {e}")
+ return []
+
+ def health_check(self) -> dict[str, bool]:
+ """Check the health of Redis connection
+
+ Returns:
+ Dictionary with health status
+ """
+ try:
+ redis_healthy = self.redis_client.ping()
+ return {
+ "redis": redis_healthy,
+ "mysql": False, # Not applicable for Redis manager
+ }
+ except Exception as e:
+ logger.error(f"Redis health check failed: {e}")
+ return {"redis": False, "mysql": False}
diff --git a/src/memos/mem_scheduler/schemas/api_schemas.py b/src/memos/mem_scheduler/schemas/api_schemas.py
new file mode 100644
index 000000000..6d0de49c4
--- /dev/null
+++ b/src/memos/mem_scheduler/schemas/api_schemas.py
@@ -0,0 +1,233 @@
+from datetime import datetime
+from enum import Enum
+from typing import Any
+from uuid import uuid4
+
+from pydantic import BaseModel, ConfigDict, Field, field_serializer
+
+from memos.log import get_logger
+from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+from memos.memories.textual.item import TextualMemoryItem
+
+
+logger = get_logger(__name__)
+
+
+class TaskRunningStatus(str, Enum):
+ """Enumeration for task running status values."""
+
+ RUNNING = "running"
+ COMPLETED = "completed"
+
+
+class APIMemoryHistoryEntryItem(BaseModel, DictConversionMixin):
+ """Data class for search entry items stored in Redis."""
+
+ item_id: str = Field(
+ description="Unique identifier for the task", default_factory=lambda: str(uuid4())
+ )
+ query: str = Field(..., description="Search query string")
+ formatted_memories: Any = Field(..., description="Formatted search results")
+ memories: list[TextualMemoryItem] = Field(
+ default_factory=list, description="List of TextualMemoryItem objects"
+ )
+ task_status: str = Field(
+ default="running", description="Task status: running, completed, failed"
+ )
+ session_id: str | None = Field(default=None, description="Optional conversation identifier")
+ created_time: datetime = Field(description="Entry creation time", default_factory=get_utc_now)
+ timestamp: datetime | None = Field(default=None, description="Timestamp for the entry")
+ conversation_turn: int = Field(default=0, description="Turn count for the same session_id")
+
+ model_config = ConfigDict(
+ arbitrary_types_allowed=True,
+ validate_assignment=True,
+ )
+
+ @field_serializer("created_time")
+ def serialize_created_time(self, value: datetime) -> str:
+ """Serialize datetime to ISO format string."""
+ return value.isoformat()
+
+ def get(self, key: str, default: Any | None = None) -> Any:
+ """
+ Get attribute value by key name, similar to dict.get().
+
+ Args:
+ key: The attribute name to retrieve
+ default: Default value to return if attribute doesn't exist
+
+ Returns:
+ The attribute value or default if not found
+ """
+ return getattr(self, key, default)
+
+
+class APISearchHistoryManager(BaseModel, DictConversionMixin):
+ """
+ Data structure for managing search history with separate completed and running entries.
+ Supports window_size to limit the number of completed entries.
+ """
+
+ window_size: int = Field(default=5, description="Maximum number of completed entries to keep")
+ completed_entries: list[APIMemoryHistoryEntryItem] = Field(
+ default_factory=list, description="List of completed search entries"
+ )
+ running_item_ids: list[str] = Field(
+ default_factory=list, description="List of running task ids"
+ )
+
+ model_config = ConfigDict(
+ arbitrary_types_allowed=True,
+ validate_assignment=True,
+ )
+
+ def complete_entry(self, task_id: str) -> bool:
+ """
+ Remove task_id from running list when completed.
+ Note: The actual entry data should be managed separately.
+
+ Args:
+ task_id: The task ID to complete
+
+ Returns:
+ True if task_id was found and removed, False otherwise
+ """
+ if task_id in self.running_item_ids:
+ self.running_item_ids.remove(task_id)
+ logger.debug(f"Completed task_id: {task_id}")
+ return True
+
+ logger.warning(f"Task ID {task_id} not found in running task ids")
+ return False
+
+ def get_running_item_ids(self) -> list[str]:
+ """Get all running task IDs"""
+ return self.running_item_ids.copy()
+
+ def get_completed_entries(self) -> list[APIMemoryHistoryEntryItem]:
+ """Get all completed entries"""
+ return self.completed_entries.copy()
+
+ def get_history_memory_entries(
+ self, turns: int | None = None
+ ) -> list[APIMemoryHistoryEntryItem]:
+ """
+ Get the most recent n completed search entries, sorted by created_time.
+
+ Args:
+ turns: Number of entries to return. If None, returns all completed entries.
+
+ Returns:
+ List of completed search entries, sorted by created_time (newest first)
+ """
+ if not self.completed_entries:
+ return []
+
+ # Sort by created_time (newest first)
+ sorted_entries = sorted(self.completed_entries, key=lambda x: x.created_time, reverse=True)
+
+ if turns is None:
+ return sorted_entries
+
+ return sorted_entries[:turns]
+
+ def get_history_memories(self, turns: int | None = None) -> list[TextualMemoryItem]:
+ """
+ Get the most recent n completed search entries, sorted by created_time.
+
+ Args:
+ turns: Number of entries to return. If None, returns all completed entries.
+
+ Returns:
+ List of TextualMemoryItem objects from completed entries, sorted by created_time (newest first)
+ """
+ sorted_entries = self.get_history_memory_entries(turns=turns)
+
+ memories = []
+ for one in sorted_entries:
+ memories.extend(one.memories)
+ return memories
+
+ def find_entry_by_item_id(self, item_id: str) -> tuple[dict[str, Any] | None, str]:
+ """
+ Find an entry by item_id in completed list only.
+ Running entries are now just task IDs, so we can only search completed entries.
+
+ Args:
+ item_id: The item ID to search for
+
+ Returns:
+ Tuple of (entry_dict, location) where location is 'completed' or 'not_found'
+ """
+ # Check completed entries
+ for entry in self.completed_entries:
+ try:
+ if hasattr(entry, "item_id") and entry.item_id == item_id:
+ return entry.to_dict(), "completed"
+ elif isinstance(entry, dict) and entry.get("item_id") == item_id:
+ return entry, "completed"
+ except AttributeError as e:
+ logger.warning(f"Entry missing item_id attribute: {e}, entry type: {type(entry)}")
+ continue
+
+ return None, "not_found"
+
+ def update_entry_by_item_id(
+ self,
+ item_id: str,
+ query: str,
+ formatted_memories: Any,
+ task_status: TaskRunningStatus,
+ session_id: str | None = None,
+ memories: list[TextualMemoryItem] | None = None,
+ ) -> bool:
+ """
+ Update an existing entry by item_id. Since running entries are now just IDs,
+ this method can only update completed entries.
+
+ Args:
+ item_id: The item ID to update
+ query: New query string
+ formatted_memories: New formatted memories
+ task_status: New task status
+ session_id: New conversation ID
+ memories: List of TextualMemoryItem objects
+
+ Returns:
+ True if entry was found and updated, False otherwise
+ """
+ # Find the entry in completed list
+ for entry in self.completed_entries:
+ if entry.item_id == item_id:
+ # Update the entry content
+ entry.query = query
+ entry.formatted_memories = formatted_memories
+ entry.task_status = task_status
+ if session_id is not None:
+ entry.session_id = session_id
+ if memories is not None:
+ entry.memories = memories
+
+ logger.debug(f"Updated entry with item_id: {item_id}, new status: {task_status}")
+ return True
+
+ logger.warning(f"Entry with item_id: {item_id} not found in completed entries")
+ return False
+
+ def get_total_count(self) -> dict[str, int]:
+ """Get count of entries by status"""
+ return {
+ "completed": len(self.completed_entries),
+ "running": len(self.running_item_ids),
+ "total": len(self.completed_entries) + len(self.running_item_ids),
+ }
+
+ def __len__(self) -> int:
+ """Return total number of entries (completed + running)"""
+ return len(self.completed_entries) + len(self.running_item_ids)
+
+
+# Alias for easier usage
+SearchHistoryManager = APISearchHistoryManager
diff --git a/src/memos/mem_scheduler/schemas/general_schemas.py b/src/memos/mem_scheduler/schemas/general_schemas.py
index d0d83091b..f3d2191f8 100644
--- a/src/memos/mem_scheduler/schemas/general_schemas.py
+++ b/src/memos/mem_scheduler/schemas/general_schemas.py
@@ -1,13 +1,26 @@
+from enum import Enum
from pathlib import Path
from typing import NewType
+class SearchMode(str, Enum):
+ """Enumeration for search modes."""
+
+ FAST = "fast"
+ FINE = "fine"
+ MIXTURE = "mixture"
+
+
FILE_PATH = Path(__file__).absolute()
BASE_DIR = FILE_PATH.parent.parent.parent.parent.parent
QUERY_LABEL = "query"
ANSWER_LABEL = "answer"
ADD_LABEL = "add"
+MEM_READ_LABEL = "mem_read"
+MEM_ORGANIZE_LABEL = "mem_organize"
+API_MIX_SEARCH_LABEL = "api_mix_search"
+PREF_ADD_LABEL = "pref_add"
TreeTextMemory_SEARCH_METHOD = "tree_text_memory_search"
TreeTextMemory_FINE_SEARCH_METHOD = "tree_text_memory_fine_search"
@@ -17,11 +30,16 @@
DEFAULT_WORKING_MEM_MONITOR_SIZE_LIMIT = 30
DEFAULT_ACTIVATION_MEM_MONITOR_SIZE_LIMIT = 20
DEFAULT_ACT_MEM_DUMP_PATH = f"{BASE_DIR}/outputs/mem_scheduler/mem_cube_scheduler_test.kv_cache"
-DEFAULT_THREAD_POOL_MAX_WORKERS = 30
+DEFAULT_THREAD_POOL_MAX_WORKERS = 50
DEFAULT_CONSUME_INTERVAL_SECONDS = 0.05
DEFAULT_DISPATCHER_MONITOR_CHECK_INTERVAL = 300
DEFAULT_DISPATCHER_MONITOR_MAX_FAILURES = 2
DEFAULT_STUCK_THREAD_TOLERANCE = 10
+DEFAULT_MAX_INTERNAL_MESSAGE_QUEUE_SIZE = 1000000
+DEFAULT_TOP_K = 10
+DEFAULT_CONTEXT_WINDOW_SIZE = 5
+DEFAULT_USE_REDIS_QUEUE = False
+DEFAULT_MULTI_TASK_RUNNING_TIMEOUT = 30
# startup mode configuration
STARTUP_BY_THREAD = "thread"
diff --git a/src/memos/mem_scheduler/schemas/message_schemas.py b/src/memos/mem_scheduler/schemas/message_schemas.py
index 9b5bd5d81..7f328474f 100644
--- a/src/memos/mem_scheduler/schemas/message_schemas.py
+++ b/src/memos/mem_scheduler/schemas/message_schemas.py
@@ -6,8 +6,9 @@
from typing_extensions import TypedDict
from memos.log import get_logger
-from memos.mem_cube.general import GeneralMemCube
+from memos.mem_cube.base import BaseMemCube
from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
from .general_schemas import NOT_INITIALIZED
@@ -36,10 +37,18 @@ class ScheduleMessageItem(BaseModel, DictConversionMixin):
user_id: str = Field(..., description="user id")
mem_cube_id: str = Field(..., description="memcube id")
label: str = Field(..., description="Label of the schedule message")
- mem_cube: GeneralMemCube | str = Field(..., description="memcube for schedule")
+ mem_cube: BaseMemCube | str = Field(..., description="memcube for schedule")
content: str = Field(..., description="Content of the schedule message")
timestamp: datetime = Field(
- default_factory=lambda: datetime.utcnow(), description="submit time for schedule_messages"
+ default_factory=get_utc_now, description="submit time for schedule_messages"
+ )
+ user_name: str | None = Field(
+ default=None,
+ description="user name / display name (optional)",
+ )
+ session_id: str | None = Field(
+ default=None,
+ description="session_id (optional)",
)
# Pydantic V2 model configuration
@@ -59,16 +68,17 @@ class ScheduleMessageItem(BaseModel, DictConversionMixin):
"mem_cube": "obj of GeneralMemCube", # Added mem_cube example
"content": "sample content", # Example message content
"timestamp": "2024-07-22T12:00:00Z", # Added timestamp example
+ "user_name": "Alice", # Added username example
}
},
)
@field_serializer("mem_cube")
- def serialize_mem_cube(self, cube: GeneralMemCube | str, _info) -> str:
- """Custom serializer for GeneralMemCube objects to string representation"""
+ def serialize_mem_cube(self, cube: BaseMemCube | str, _info) -> str:
+ """Custom serializer for BaseMemCube objects to string representation"""
if isinstance(cube, str):
return cube
- return f""
+ return f"<{type(cube).__name__}:{id(cube)}>"
def to_dict(self) -> dict:
"""Convert model to dictionary suitable for Redis Stream"""
@@ -80,6 +90,7 @@ def to_dict(self) -> dict:
"cube": "Not Applicable", # Custom cube serialization
"content": self.content,
"timestamp": self.timestamp.isoformat(),
+ "user_name": self.user_name,
}
@classmethod
@@ -88,11 +99,12 @@ def from_dict(cls, data: dict) -> "ScheduleMessageItem":
return cls(
item_id=data.get("item_id", str(uuid4())),
user_id=data["user_id"],
- cube_id=data["cube_id"],
+ mem_cube_id=data["cube_id"],
label=data["label"],
- cube="Not Applicable", # Custom cube deserialization
+ mem_cube="Not Applicable", # Custom cube deserialization
content=data["content"],
timestamp=datetime.fromisoformat(data["timestamp"]),
+ user_name=data.get("user_name"),
)
@@ -131,7 +143,7 @@ class ScheduleLogForWebItem(BaseModel, DictConversionMixin):
description="Maximum capacities of memory partitions",
)
timestamp: datetime = Field(
- default_factory=lambda: datetime.utcnow(),
+ default_factory=get_utc_now,
description="Timestamp indicating when the log entry was created",
)
diff --git a/src/memos/mem_scheduler/schemas/task_schemas.py b/src/memos/mem_scheduler/schemas/task_schemas.py
index d189797ae..168a25b5d 100644
--- a/src/memos/mem_scheduler/schemas/task_schemas.py
+++ b/src/memos/mem_scheduler/schemas/task_schemas.py
@@ -7,6 +7,7 @@
from memos.log import get_logger
from memos.mem_scheduler.general_modules.misc import DictConversionMixin
+from memos.mem_scheduler.utils.db_utils import get_utc_now
logger = get_logger(__name__)
@@ -26,7 +27,7 @@ class RunningTaskItem(BaseModel, DictConversionMixin):
mem_cube_id: str = Field(..., description="Required memory cube identifier", min_length=1)
task_info: str = Field(..., description="Information about the task being executed")
task_name: str = Field(..., description="Name/type of the task handler")
- start_time: datetime = Field(description="Task start time", default_factory=datetime.utcnow)
+ start_time: datetime = Field(description="Task start time", default_factory=get_utc_now)
end_time: datetime | None = Field(default=None, description="Task completion time")
status: str = Field(default="running", description="Task status: running, completed, failed")
result: Any | None = Field(default=None, description="Task execution result")
@@ -37,13 +38,13 @@ class RunningTaskItem(BaseModel, DictConversionMixin):
def mark_completed(self, result: Any | None = None) -> None:
"""Mark task as completed with optional result."""
- self.end_time = datetime.utcnow()
+ self.end_time = get_utc_now()
self.status = "completed"
self.result = result
def mark_failed(self, error_message: str) -> None:
"""Mark task as failed with error message."""
- self.end_time = datetime.utcnow()
+ self.end_time = get_utc_now()
self.status = "failed"
self.error_message = error_message
diff --git a/src/memos/mem_scheduler/utils/api_utils.py b/src/memos/mem_scheduler/utils/api_utils.py
new file mode 100644
index 000000000..c8d096517
--- /dev/null
+++ b/src/memos/mem_scheduler/utils/api_utils.py
@@ -0,0 +1,76 @@
+import uuid
+
+from typing import Any
+
+from memos.memories.textual.item import TreeNodeTextualMemoryMetadata
+from memos.memories.textual.tree import TextualMemoryItem
+
+
+def format_textual_memory_item(memory_data: Any) -> dict[str, Any]:
+ """Format a single memory item for API response."""
+ memory = memory_data.model_dump()
+ memory_id = memory["id"]
+ ref_id = f"[{memory_id.split('-')[0]}]"
+
+ memory["ref_id"] = ref_id
+ memory["metadata"]["embedding"] = []
+ memory["metadata"]["sources"] = []
+ memory["metadata"]["ref_id"] = ref_id
+ memory["metadata"]["id"] = memory_id
+ memory["metadata"]["memory"] = memory["memory"]
+
+ return memory
+
+
+def make_textual_item(memory_data):
+ return memory_data
+
+
+def text_to_textual_memory_item(
+ text: str,
+ user_id: str | None = None,
+ session_id: str | None = None,
+ memory_type: str = "WorkingMemory",
+ tags: list[str] | None = None,
+ key: str | None = None,
+ sources: list | None = None,
+ background: str = "",
+ confidence: float = 0.99,
+ embedding: list[float] | None = None,
+) -> TextualMemoryItem:
+ """
+ Convert text into a TextualMemoryItem object.
+
+ Args:
+ text: Memory content text
+ user_id: User ID
+ session_id: Session ID
+ memory_type: Memory type, defaults to "WorkingMemory"
+ tags: List of tags
+ key: Memory key or title
+ sources: List of sources
+ background: Background information
+ confidence: Confidence score (0-1)
+ embedding: Vector embedding
+
+ Returns:
+ TextualMemoryItem: Wrapped memory item
+ """
+ return TextualMemoryItem(
+ id=str(uuid.uuid4()),
+ memory=text,
+ metadata=TreeNodeTextualMemoryMetadata(
+ user_id=user_id,
+ session_id=session_id,
+ memory_type=memory_type,
+ status="activated",
+ tags=tags or [],
+ key=key,
+ embedding=embedding or [],
+ usage=[],
+ sources=sources or [],
+ background=background,
+ confidence=confidence,
+ type="fact",
+ ),
+ )
diff --git a/src/memos/mem_scheduler/utils/db_utils.py b/src/memos/mem_scheduler/utils/db_utils.py
index 5d7cc52c3..4c7402a9d 100644
--- a/src/memos/mem_scheduler/utils/db_utils.py
+++ b/src/memos/mem_scheduler/utils/db_utils.py
@@ -1,5 +1,22 @@
import os
import sqlite3
+import sys
+
+from datetime import datetime, timezone
+
+
+# Compatibility handling: Python 3.11+ supports UTC, earlier versions use timezone.utc
+if sys.version_info >= (3, 11):
+ from datetime import UTC
+
+ def get_utc_now():
+ """Get current UTC datetime with compatibility for different Python versions"""
+ return datetime.now(UTC)
+else:
+
+ def get_utc_now():
+ """Get current UTC datetime with compatibility for different Python versions"""
+ return datetime.now(timezone.utc)
def print_db_tables(db_path: str):
diff --git a/src/memos/mem_scheduler/utils/metrics.py b/src/memos/mem_scheduler/utils/metrics.py
new file mode 100644
index 000000000..5155c98b3
--- /dev/null
+++ b/src/memos/mem_scheduler/utils/metrics.py
@@ -0,0 +1,250 @@
+# metrics.py
+from __future__ import annotations
+
+import threading
+import time
+
+from dataclasses import dataclass, field
+
+
+# ==== global window config ====
+WINDOW_SEC = 120 # 2 minutes sliding window
+
+
+# ---------- O(1) EWMA ----------
+class Ewma:
+ """
+ Time-decayed EWMA:
+ """
+
+ __slots__ = ("alpha", "last_ts", "tau", "value")
+
+ def __init__(self, alpha: float = 0.3, tau: float = WINDOW_SEC):
+ self.alpha = alpha
+ self.value = 0.0
+ self.last_ts: float = time.time()
+ self.tau = max(1e-6, float(tau))
+
+ def _decay_to(self, now: float | None = None):
+ now = time.time() if now is None else now
+ dt = max(0.0, now - self.last_ts)
+ if dt <= 0:
+ return
+ from math import exp
+
+ self.value *= exp(-dt / self.tau)
+ self.last_ts = now
+
+ def update(self, instant: float, now: float | None = None):
+ self._decay_to(now)
+ self.value = self.alpha * instant + (1 - self.alpha) * self.value
+
+ def value_at(self, now: float | None = None) -> float:
+ now = time.time() if now is None else now
+ dt = max(0.0, now - self.last_ts)
+ if dt <= 0:
+ return self.value
+ from math import exp
+
+ return self.value * exp(-dt / self.tau)
+
+
+# ---------- approximate P95(Reservoir sample) ----------
+class ReservoirP95:
+ __slots__ = ("_i", "buf", "k", "n", "window")
+
+ def __init__(self, k: int = 512, window: float = WINDOW_SEC):
+ self.k = k
+ self.buf: list[tuple[float, float]] = [] # (value, ts)
+ self.n = 0
+ self._i = 0
+ self.window = float(window)
+
+ def _gc(self, now: float):
+ win_start = now - self.window
+ self.buf = [p for p in self.buf if p[1] >= win_start]
+ if self.buf:
+ self._i %= len(self.buf)
+ else:
+ self._i = 0
+
+ def add(self, x: float, now: float | None = None):
+ now = time.time() if now is None else now
+ self._gc(now)
+ self.n += 1
+ if len(self.buf) < self.k:
+ self.buf.append((x, now))
+ return
+ self.buf[self._i] = (x, now)
+ self._i = (self._i + 1) % self.k
+
+ def p95(self, now: float | None = None) -> float:
+ now = time.time() if now is None else now
+ self._gc(now)
+ if not self.buf:
+ return 0.0
+ arr = sorted(v for v, _ in self.buf)
+ idx = int(0.95 * (len(arr) - 1))
+ return arr[idx]
+
+
+# ---------- Space-Saving Top-K ----------
+class SpaceSaving:
+ """only topK:add(key) O(1),query topk O(K log K)"""
+
+ def __init__(self, k: int = 100):
+ self.k = k
+ self.cnt: dict[str, int] = {}
+
+ def add(self, key: str):
+ if key in self.cnt:
+ self.cnt[key] += 1
+ return
+ if len(self.cnt) < self.k:
+ self.cnt[key] = 1
+ return
+ victim = min(self.cnt, key=self.cnt.get)
+ self.cnt[key] = self.cnt.pop(victim) + 1
+
+ def topk(self) -> list[tuple[str, int]]:
+ return sorted(self.cnt.items(), key=lambda kv: kv[1], reverse=True)
+
+
+@dataclass
+class KeyStats:
+ backlog: int = 0
+ lambda_ewma: Ewma = field(default_factory=lambda: Ewma(0.3, WINDOW_SEC))
+ mu_ewma: Ewma = field(default_factory=lambda: Ewma(0.3, WINDOW_SEC))
+ wait_p95: ReservoirP95 = field(default_factory=lambda: ReservoirP95(512, WINDOW_SEC))
+ last_ts: float = field(default_factory=time.time)
+ # last event timestamps for rate estimation
+ last_enqueue_ts: float | None = None
+ last_done_ts: float | None = None
+
+ def snapshot(self, now: float | None = None) -> dict:
+ now = time.time() if now is None else now
+ lam = self.lambda_ewma.value_at(now)
+ mu = self.mu_ewma.value_at(now)
+ delta = mu - lam
+ eta = float("inf") if delta <= 1e-9 else self.backlog / delta
+ return {
+ "backlog": self.backlog,
+ "lambda": round(lam, 3),
+ "mu": round(mu, 3),
+ "delta": round(delta, 3),
+ "eta_sec": None if eta == float("inf") else round(eta, 1),
+ "wait_p95_sec": round(self.wait_p95.p95(now), 3),
+ }
+
+
+class MetricsRegistry:
+ """
+ metrics:
+ - 1st phase:label(must)
+ - 2nd phase:labelXmem_cube_id(only Top-K)
+ - on_enqueue(label, mem_cube_id)
+ - on_start(label, mem_cube_id, wait_sec)
+ - on_done(label, mem_cube_id)
+ """
+
+ def __init__(self, topk_per_label: int = 50):
+ self._lock = threading.RLock()
+ self._label_stats: dict[str, KeyStats] = {}
+ self._label_topk: dict[str, SpaceSaving] = {}
+ self._detail_stats: dict[tuple[str, str], KeyStats] = {}
+ self._topk_per_label = topk_per_label
+
+ # ---------- helpers ----------
+ def _get_label(self, label: str) -> KeyStats:
+ if label not in self._label_stats:
+ self._label_stats[label] = KeyStats()
+ self._label_topk[label] = SpaceSaving(self._topk_per_label)
+ return self._label_stats[label]
+
+ def _get_detail(self, label: str, mem_cube_id: str) -> KeyStats | None:
+ # 只有 Top-K 的 mem_cube_id 才建细粒度 key
+ ss = self._label_topk[label]
+ if mem_cube_id in ss.cnt or len(ss.cnt) < ss.k:
+ key = (label, mem_cube_id)
+ if key not in self._detail_stats:
+ self._detail_stats[key] = KeyStats()
+ return self._detail_stats[key]
+ return None
+
+ # ---------- events ----------
+ def on_enqueue(
+ self, label: str, mem_cube_id: str, inst_rate: float = 1.0, now: float | None = None
+ ):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ # derive instantaneous arrival rate from inter-arrival time (events/sec)
+ prev_ts = ls.last_enqueue_ts
+ dt = (now - prev_ts) if prev_ts is not None else None
+ inst_rate = (1.0 / max(1e-3, dt)) if dt is not None else 0.0 # first sample: no spike
+ ls.last_enqueue_ts = now
+ ls.backlog += 1
+ old_lam = ls.lambda_ewma.value_at(now)
+ ls.lambda_ewma.update(inst_rate, now)
+ new_lam = ls.lambda_ewma.value_at(now)
+ print(
+ f"[DEBUG enqueue] {label} backlog={ls.backlog} dt={dt if dt is not None else '—'}s inst={inst_rate:.3f} λ {old_lam:.3f}→{new_lam:.3f}"
+ )
+ self._label_topk[label].add(mem_cube_id)
+ ds = self._get_detail(label, mem_cube_id)
+ if ds:
+ prev_ts_d = ds.last_enqueue_ts
+ dt_d = (now - prev_ts_d) if prev_ts_d is not None else None
+ inst_rate_d = (1.0 / max(1e-3, dt_d)) if dt_d is not None else 0.0
+ ds.last_enqueue_ts = now
+ ds.backlog += 1
+ ds.lambda_ewma.update(inst_rate_d, now)
+
+ def on_start(self, label: str, mem_cube_id: str, wait_sec: float, now: float | None = None):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ ls.wait_p95.add(wait_sec, now)
+ ds = self._detail_stats.get((label, mem_cube_id))
+ if ds:
+ ds.wait_p95.add(wait_sec, now)
+
+ def on_done(
+ self, label: str, mem_cube_id: str, inst_rate: float = 1.0, now: float | None = None
+ ):
+ with self._lock:
+ now = time.time() if now is None else now
+ ls = self._get_label(label)
+ # derive instantaneous service rate from inter-completion time (events/sec)
+ prev_ts = ls.last_done_ts
+ dt = (now - prev_ts) if prev_ts is not None else None
+ inst_rate = (1.0 / max(1e-3, dt)) if dt is not None else 0.0
+ ls.last_done_ts = now
+ if ls.backlog > 0:
+ ls.backlog -= 1
+ old_mu = ls.mu_ewma.value_at(now)
+ ls.mu_ewma.update(inst_rate, now)
+ new_mu = ls.mu_ewma.value_at(now)
+ print(
+ f"[DEBUG done] {label} backlog={ls.backlog} dt={dt if dt is not None else '—'}s inst={inst_rate:.3f} μ {old_mu:.3f}→{new_mu:.3f}"
+ )
+ ds = self._detail_stats.get((label, mem_cube_id))
+ if ds:
+ prev_ts_d = ds.last_done_ts
+ dt_d = (now - prev_ts_d) if prev_ts_d is not None else None
+ inst_rate_d = (1.0 / max(1e-3, dt_d)) if dt_d is not None else 0.0
+ ds.last_done_ts = now
+ if ds.backlog > 0:
+ ds.backlog -= 1
+ ds.mu_ewma.update(inst_rate_d, now)
+
+ # ---------- snapshots ----------
+ def snapshot(self) -> dict:
+ with self._lock:
+ now = time.time()
+ by_label = {lbl: ks.snapshot(now) for lbl, ks in self._label_stats.items()}
+ heavy = {lbl: self._label_topk[lbl].topk() for lbl in self._label_topk}
+ details = {}
+ for (lbl, cube), ks in self._detail_stats.items():
+ details.setdefault(lbl, {})[cube] = ks.snapshot(now)
+ return {"by_label": by_label, "heavy": heavy, "details": details}
diff --git a/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py b/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
index 8865c2232..3c0dff907 100644
--- a/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
+++ b/src/memos/mem_scheduler/webservice_modules/rabbitmq_service.py
@@ -6,6 +6,7 @@
from pathlib import Path
from memos.configs.mem_scheduler import AuthConfig, RabbitMQConfig
+from memos.context.context import ContextThread
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -67,39 +68,42 @@ def initialize_rabbitmq(
"""
Establish connection to RabbitMQ using pika.
"""
- from pika.adapters.select_connection import SelectConnection
-
- if config is None:
- if config_path is None and AuthConfig.default_config_exists():
- auth_config = AuthConfig.from_local_config()
- elif Path(config_path).exists():
- auth_config = AuthConfig.from_local_config(config_path=config_path)
+ try:
+ from pika.adapters.select_connection import SelectConnection
+
+ if config is None:
+ if config_path is None and AuthConfig.default_config_exists():
+ auth_config = AuthConfig.from_local_config()
+ elif Path(config_path).exists():
+ auth_config = AuthConfig.from_local_config(config_path=config_path)
+ else:
+ logger.error("Fail to initialize auth_config")
+ return
+ self.rabbitmq_config = auth_config.rabbitmq
+ elif isinstance(config, RabbitMQConfig):
+ self.rabbitmq_config = config
+ elif isinstance(config, dict):
+ self.rabbitmq_config = AuthConfig.from_dict(config).rabbitmq
else:
- logger.error("Fail to initialize auth_config")
- return
- self.rabbitmq_config = auth_config.rabbitmq
- elif isinstance(config, RabbitMQConfig):
- self.rabbitmq_config = config
- elif isinstance(config, dict):
- self.rabbitmq_config = AuthConfig.from_dict(config).rabbitmq
- else:
- logger.error("Not implemented")
-
- # Start connection process
- parameters = self.get_rabbitmq_connection_param()
- self.rabbitmq_connection = SelectConnection(
- parameters,
- on_open_callback=self.on_rabbitmq_connection_open,
- on_open_error_callback=self.on_rabbitmq_connection_error,
- on_close_callback=self.on_rabbitmq_connection_closed,
- )
+ logger.error("Not implemented")
+
+ # Start connection process
+ parameters = self.get_rabbitmq_connection_param()
+ self.rabbitmq_connection = SelectConnection(
+ parameters,
+ on_open_callback=self.on_rabbitmq_connection_open,
+ on_open_error_callback=self.on_rabbitmq_connection_error,
+ on_close_callback=self.on_rabbitmq_connection_closed,
+ )
- # Start IOLoop in dedicated thread
- self._io_loop_thread = threading.Thread(
- target=self.rabbitmq_connection.ioloop.start, daemon=True
- )
- self._io_loop_thread.start()
- logger.info("RabbitMQ connection process started")
+ # Start IOLoop in dedicated thread
+ self._io_loop_thread = ContextThread(
+ target=self.rabbitmq_connection.ioloop.start, daemon=True
+ )
+ self._io_loop_thread.start()
+ logger.info("RabbitMQ connection process started")
+ except Exception:
+ logger.error("Fail to initialize auth_config", exc_info=True)
def get_rabbitmq_queue_size(self) -> int:
"""Get the current number of messages in the queue.
diff --git a/src/memos/mem_scheduler/webservice_modules/redis_service.py b/src/memos/mem_scheduler/webservice_modules/redis_service.py
index 5b04ec280..5439af9c6 100644
--- a/src/memos/mem_scheduler/webservice_modules/redis_service.py
+++ b/src/memos/mem_scheduler/webservice_modules/redis_service.py
@@ -1,9 +1,12 @@
import asyncio
-import threading
+import os
+import subprocess
+import time
from collections.abc import Callable
from typing import Any
+from memos.context.context import ContextThread
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.mem_scheduler.general_modules.base import BaseSchedulerModule
@@ -27,14 +30,18 @@ def __init__(self):
super().__init__()
# settings for redis
- self.redis_host: str = None
- self.redis_port: int = None
- self.redis_db: int = None
+ self.redis_host: str | None = None
+ self.redis_port: int | None = None
+ self.redis_db: int | None = None
+ self.redis_password: str | None = None
+ self.socket_timeout: float | None = None
+ self.socket_connect_timeout: float | None = None
self._redis_conn = None
+ self._local_redis_process = None
self.query_list_capacity = 1000
self._redis_listener_running = False
- self._redis_listener_thread: threading.Thread | None = None
+ self._redis_listener_thread: ContextThread | None = None
self._redis_listener_loop: asyncio.AbstractEventLoop | None = None
@property
@@ -46,19 +53,40 @@ def redis(self, value: Any) -> None:
self._redis_conn = value
def initialize_redis(
- self, redis_host: str = "localhost", redis_port: int = 6379, redis_db: int = 0
+ self,
+ redis_host: str = "localhost",
+ redis_port: int = 6379,
+ redis_db: int = 0,
+ redis_password: str | None = None,
+ socket_timeout: float | None = None,
+ socket_connect_timeout: float | None = None,
):
import redis
self.redis_host = redis_host
self.redis_port = redis_port
self.redis_db = redis_db
+ self.redis_password = redis_password
+ self.socket_timeout = socket_timeout
+ self.socket_connect_timeout = socket_connect_timeout
try:
logger.debug(f"Connecting to Redis at {redis_host}:{redis_port}/{redis_db}")
- self._redis_conn = redis.Redis(
- host=self.redis_host, port=self.redis_port, db=self.redis_db, decode_responses=True
- )
+ redis_kwargs = {
+ "host": self.redis_host,
+ "port": self.redis_port,
+ "db": self.redis_db,
+ "password": redis_password,
+ "decode_responses": True,
+ }
+
+ # Add timeout parameters if provided
+ if socket_timeout is not None:
+ redis_kwargs["socket_timeout"] = socket_timeout
+ if socket_connect_timeout is not None:
+ redis_kwargs["socket_connect_timeout"] = socket_connect_timeout
+
+ self._redis_conn = redis.Redis(**redis_kwargs)
# test conn
if not self._redis_conn.ping():
logger.error("Redis connection failed")
@@ -68,7 +96,184 @@ def initialize_redis(
self._redis_conn.xtrim("user:queries:stream", self.query_list_capacity)
return self._redis_conn
- async def redis_add_message_stream(self, message: dict):
+ @require_python_package(
+ import_name="redis",
+ install_command="pip install redis",
+ install_link="https://redis.readthedocs.io/en/stable/",
+ )
+ def auto_initialize_redis(self) -> bool:
+ """
+ Auto-initialize Redis with fallback strategies:
+ 1. Try to initialize from config
+ 2. Try to initialize from environment variables
+ 3. Try to start local Redis server as fallback
+
+ Returns:
+ bool: True if Redis connection is successfully established, False otherwise
+ """
+ import redis
+
+ # Strategy 1: Try to initialize from config
+ if hasattr(self, "config") and hasattr(self.config, "redis_config"):
+ try:
+ redis_config = self.config.redis_config
+ logger.info("Attempting to initialize Redis from config")
+
+ self._redis_conn = redis.Redis(
+ host=redis_config.get("host", "localhost"),
+ port=redis_config.get("port", 6379),
+ db=redis_config.get("db", 0),
+ password=redis_config.get("password", None),
+ decode_responses=True,
+ )
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.info("Redis initialized successfully from config")
+ self.redis_host = redis_config.get("host", "localhost")
+ self.redis_port = redis_config.get("port", 6379)
+ self.redis_db = redis_config.get("db", 0)
+ self.redis_password = redis_config.get("password", None)
+ self.socket_timeout = redis_config.get("socket_timeout", None)
+ self.socket_connect_timeout = redis_config.get("socket_connect_timeout", None)
+ return True
+ else:
+ logger.warning("Redis config connection test failed")
+ self._redis_conn = None
+ except Exception as e:
+ logger.warning(f"Failed to initialize Redis from config: {e}")
+ self._redis_conn = None
+
+ # Strategy 2: Try to initialize from environment variables
+ try:
+ redis_host = os.getenv("MEMSCHEDULER_REDIS_HOST", "localhost")
+ redis_port = int(os.getenv("MEMSCHEDULER_REDIS_PORT", "6379"))
+ redis_db = int(os.getenv("MEMSCHEDULER_REDIS_DB", "0"))
+ redis_password = os.getenv("MEMSCHEDULER_REDIS_PASSWORD", None)
+ socket_timeout = os.getenv("MEMSCHEDULER_REDIS_TIMEOUT", None)
+ socket_connect_timeout = os.getenv("MEMSCHEDULER_REDIS_CONNECT_TIMEOUT", None)
+
+ logger.info(
+ f"Attempting to initialize Redis from environment variables: {redis_host}:{redis_port}"
+ )
+
+ redis_kwargs = {
+ "host": redis_host,
+ "port": redis_port,
+ "db": redis_db,
+ "password": redis_password,
+ "decode_responses": True,
+ }
+
+ # Add timeout parameters if provided
+ if socket_timeout is not None:
+ try:
+ redis_kwargs["socket_timeout"] = float(socket_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid MEMSCHEDULER_REDIS_TIMEOUT value: {socket_timeout}, ignoring"
+ )
+
+ if socket_connect_timeout is not None:
+ try:
+ redis_kwargs["socket_connect_timeout"] = float(socket_connect_timeout)
+ except ValueError:
+ logger.warning(
+ f"Invalid MEMSCHEDULER_REDIS_CONNECT_TIMEOUT value: {socket_connect_timeout}, ignoring"
+ )
+
+ self._redis_conn = redis.Redis(**redis_kwargs)
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.info("Redis initialized successfully from environment variables")
+ self.redis_host = redis_host
+ self.redis_port = redis_port
+ self.redis_db = redis_db
+ self.redis_password = redis_password
+ self.socket_timeout = float(socket_timeout) if socket_timeout is not None else None
+ self.socket_connect_timeout = (
+ float(socket_connect_timeout) if socket_connect_timeout is not None else None
+ )
+ return True
+ else:
+ logger.warning("Redis environment connection test failed")
+ self._redis_conn = None
+ except Exception as e:
+ logger.warning(f"Failed to initialize Redis from environment variables: {e}")
+ self._redis_conn = None
+
+ # Strategy 3: Try to start local Redis server as fallback
+ try:
+ logger.warning(
+ "Attempting to start local Redis server as fallback (not recommended for production)"
+ )
+
+ # Try to start Redis server locally
+ self._local_redis_process = subprocess.Popen(
+ ["redis-server", "--port", "6379", "--daemonize", "no"],
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ preexec_fn=os.setsid if hasattr(os, "setsid") else None,
+ )
+
+ # Wait a moment for Redis to start
+ time.sleep(0.5)
+
+ # Try to connect to local Redis
+ self._redis_conn = redis.Redis(host="localhost", port=6379, db=0, decode_responses=True)
+
+ # Test connection
+ if self._redis_conn.ping():
+ logger.warning("Local Redis server started and connected successfully")
+ logger.warning("WARNING: Using local Redis server - not suitable for production!")
+ self.redis_host = "localhost"
+ self.redis_port = 6379
+ self.redis_db = 0
+ self.redis_password = None
+ self.socket_timeout = None
+ self.socket_connect_timeout = None
+ return True
+ else:
+ logger.error("Local Redis server connection test failed")
+ self._cleanup_local_redis()
+ return False
+
+ except Exception as e:
+ logger.error(f"Failed to start local Redis server: {e}")
+ self._cleanup_local_redis()
+ return False
+
+ def _cleanup_local_redis(self):
+ """Clean up local Redis process if it exists"""
+ if self._local_redis_process:
+ try:
+ self._local_redis_process.terminate()
+ self._local_redis_process.wait(timeout=5)
+ logger.info("Local Redis process terminated")
+ except subprocess.TimeoutExpired:
+ logger.warning("Local Redis process did not terminate gracefully, killing it")
+ self._local_redis_process.kill()
+ self._local_redis_process.wait()
+ except Exception as e:
+ logger.error(f"Error cleaning up local Redis process: {e}")
+ finally:
+ self._local_redis_process = None
+
+ def _cleanup_redis_resources(self):
+ """Clean up Redis connection and local process"""
+ if self._redis_conn:
+ try:
+ self._redis_conn.close()
+ logger.info("Redis connection closed")
+ except Exception as e:
+ logger.error(f"Error closing Redis connection: {e}")
+ finally:
+ self._redis_conn = None
+
+ self._cleanup_local_redis()
+
+ def redis_add_message_stream(self, message: dict):
logger.debug(f"add_message_stream: {message}")
return self._redis_conn.xadd("user:queries:stream", message)
@@ -131,7 +336,7 @@ def redis_start_listening(self, handler: Callable | None = None):
if handler is None:
handler = self.redis_consume_message_stream
- self._redis_listener_thread = threading.Thread(
+ self._redis_listener_thread = ContextThread(
target=self._redis_run_listener_async,
args=(handler,),
daemon=True,
@@ -150,7 +355,5 @@ def redis_stop_listening(self):
logger.info("Redis stream listener stopped")
def redis_close(self):
- """Close Redis connection"""
- if self._redis_conn is not None:
- self._redis_conn.close()
- self._redis_conn = None
+ """Close Redis connection and clean up resources"""
+ self._cleanup_redis_resources()
diff --git a/src/memos/mem_user/persistent_user_manager.py b/src/memos/mem_user/persistent_user_manager.py
index e3c476262..d6f7b3155 100644
--- a/src/memos/mem_user/persistent_user_manager.py
+++ b/src/memos/mem_user/persistent_user_manager.py
@@ -177,7 +177,7 @@ def delete_user_config(self, user_id: str) -> bool:
finally:
session.close()
- def list_user_configs(self) -> dict[str, MOSConfig]:
+ def list_user_configs(self, limit: int = 1) -> dict[str, MOSConfig]:
"""List all user configurations.
Returns:
@@ -185,7 +185,7 @@ def list_user_configs(self) -> dict[str, MOSConfig]:
"""
session = self._get_session()
try:
- user_configs = session.query(UserConfig).all()
+ user_configs = session.query(UserConfig).limit(limit).all()
result = {}
for user_config in user_configs:
diff --git a/src/memos/memories/activation/item.py b/src/memos/memories/activation/item.py
index ba1619371..9267e6920 100644
--- a/src/memos/memories/activation/item.py
+++ b/src/memos/memories/activation/item.py
@@ -6,6 +6,8 @@
from pydantic import BaseModel, ConfigDict, Field
from transformers import DynamicCache
+from memos.mem_scheduler.utils.db_utils import get_utc_now
+
class ActivationMemoryItem(BaseModel):
id: str = Field(default_factory=lambda: str(uuid.uuid4()))
@@ -23,7 +25,7 @@ class KVCacheRecords(BaseModel):
description="Single string combining all text_memories using assembly template",
)
timestamp: datetime = Field(
- default_factory=datetime.utcnow, description="submit time for schedule_messages"
+ default_factory=get_utc_now, description="submit time for schedule_messages"
)
diff --git a/src/memos/memories/activation/kv.py b/src/memos/memories/activation/kv.py
index 2fa08590f..98d611dbf 100644
--- a/src/memos/memories/activation/kv.py
+++ b/src/memos/memories/activation/kv.py
@@ -237,16 +237,36 @@ def _concat_caches(self, caches: list[DynamicCache]) -> DynamicCache:
def move_dynamic_cache_htod(dynamic_cache: DynamicCache, device: str) -> DynamicCache:
"""
+ Move DynamicCache from CPU to GPU device.
+ Compatible with both old and new transformers versions.
+
In SimpleMemChat.run(), if self.config.enable_activation_memory is enabled,
we load serialized kv cache from a [class KVCacheMemory] object, which has a kv_cache_memories on CPU.
So before inferring with DynamicCache, we should move it to GPU in-place first.
"""
- # Currently, we put this function outside [class KVCacheMemory]
- for i in range(len(dynamic_cache.key_cache)):
- if dynamic_cache.key_cache[i] is not None:
- dynamic_cache.key_cache[i] = dynamic_cache.key_cache[i].to(device, non_blocking=True)
- if dynamic_cache.value_cache[i] is not None:
- dynamic_cache.value_cache[i] = dynamic_cache.value_cache[i].to(
- device, non_blocking=True
- )
+ # Handle compatibility between old and new transformers versions
+ if hasattr(dynamic_cache, "layers"):
+ # New version: use layers attribute
+ for layer in dynamic_cache.layers:
+ if hasattr(layer, "key_cache") and layer.key_cache is not None:
+ layer.key_cache = layer.key_cache.to(device, non_blocking=True)
+ if hasattr(layer, "value_cache") and layer.value_cache is not None:
+ layer.value_cache = layer.value_cache.to(device, non_blocking=True)
+ elif hasattr(layer, "keys") and hasattr(layer, "values"):
+ # Alternative attribute names in some versions
+ if layer.keys is not None:
+ layer.keys = layer.keys.to(device, non_blocking=True)
+ if layer.values is not None:
+ layer.values = layer.values.to(device, non_blocking=True)
+ elif hasattr(dynamic_cache, "key_cache") and hasattr(dynamic_cache, "value_cache"):
+ # Old version: use key_cache and value_cache attributes
+ for i in range(len(dynamic_cache.key_cache)):
+ if dynamic_cache.key_cache[i] is not None:
+ dynamic_cache.key_cache[i] = dynamic_cache.key_cache[i].to(
+ device, non_blocking=True
+ )
+ if dynamic_cache.value_cache[i] is not None:
+ dynamic_cache.value_cache[i] = dynamic_cache.value_cache[i].to(
+ device, non_blocking=True
+ )
return dynamic_cache
diff --git a/src/memos/memories/factory.py b/src/memos/memories/factory.py
index bcf7fdd9b..5ba1c6726 100644
--- a/src/memos/memories/factory.py
+++ b/src/memos/memories/factory.py
@@ -10,6 +10,8 @@
from memos.memories.textual.base import BaseTextMemory
from memos.memories.textual.general import GeneralTextMemory
from memos.memories.textual.naive import NaiveTextMemory
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.memories.textual.simple_preference import SimplePreferenceTextMemory
from memos.memories.textual.simple_tree import SimpleTreeTextMemory
from memos.memories.textual.tree import TreeTextMemory
@@ -22,6 +24,8 @@ class MemoryFactory(BaseMemory):
"general_text": GeneralTextMemory,
"tree_text": TreeTextMemory,
"simple_tree_text": SimpleTreeTextMemory,
+ "pref_text": PreferenceTextMemory,
+ "simple_pref_text": SimplePreferenceTextMemory,
"kv_cache": KVCacheMemory,
"vllm_kv_cache": VLLMKVCacheMemory,
"lora": LoRAMemory,
diff --git a/src/memos/memories/textual/base.py b/src/memos/memories/textual/base.py
index 82dad4486..8a6113345 100644
--- a/src/memos/memories/textual/base.py
+++ b/src/memos/memories/textual/base.py
@@ -10,6 +10,9 @@
class BaseTextMemory(BaseMemory):
"""Base class for all textual memory implementations."""
+ # Default mode configuration - can be overridden by subclasses
+ mode: str = "sync" # Default mode: 'async' or 'sync'
+
@abstractmethod
def __init__(self, config: BaseTextMemoryConfig):
"""Initialize memory with the given configuration."""
diff --git a/src/memos/memories/textual/general.py b/src/memos/memories/textual/general.py
index 9793224b5..d71a86d2e 100644
--- a/src/memos/memories/textual/general.py
+++ b/src/memos/memories/textual/general.py
@@ -26,6 +26,8 @@ class GeneralTextMemory(BaseTextMemory):
def __init__(self, config: GeneralTextMemoryConfig):
"""Initialize memory with the given configuration."""
+ # Set mode from class default or override if needed
+ self.mode = getattr(self.__class__, "mode", "sync")
self.config: GeneralTextMemoryConfig = config
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.extractor_llm
diff --git a/src/memos/memories/textual/item.py b/src/memos/memories/textual/item.py
index 2da283d47..2c23ae193 100644
--- a/src/memos/memories/textual/item.py
+++ b/src/memos/memories/textual/item.py
@@ -1,6 +1,7 @@
"""Defines memory item types for textual memory."""
import json
+import logging
import uuid
from datetime import datetime
@@ -123,6 +124,25 @@ class TreeNodeTextualMemoryMetadata(TextualMemoryMetadata):
def coerce_sources(cls, v):
if v is None:
return v
+ # Handle string representation of sources (e.g., from PostgreSQL array or malformed data)
+ if isinstance(v, str):
+ logging.info(f"[coerce_sources] v: {v} type: {type(v)}")
+ # If it's a string that looks like a list representation, try to parse it
+ # This handles cases like: "[uuid1, uuid2, uuid3]" or "[item1, item2]"
+ v_stripped = v.strip()
+ if v_stripped.startswith("[") and v_stripped.endswith("]"):
+ # Remove brackets and split by comma
+ content = v_stripped[1:-1].strip()
+ if content:
+ # Split by comma and clean up each item
+ items = [item.strip() for item in content.split(",")]
+ # Convert to list of strings
+ v = items
+ else:
+ v = []
+ else:
+ # Single string, wrap in list
+ v = [v]
if not isinstance(v, list):
raise TypeError("sources must be a list")
out = []
@@ -167,6 +187,19 @@ class SearchedTreeNodeTextualMemoryMetadata(TreeNodeTextualMemoryMetadata):
)
+class PreferenceTextualMemoryMetadata(TextualMemoryMetadata):
+ """Metadata for preference memory item."""
+
+ preference_type: Literal["explicit_preference", "implicit_preference"] = Field(
+ default="explicit_preference", description="Type of preference."
+ )
+ dialog_id: str | None = Field(default=None, description="ID of the dialog.")
+ original_text: str | None = Field(default=None, description="String of the dialog.")
+ embedding: list[float] | None = Field(default=None, description="Vector of the dialog.")
+ preference: str | None = Field(default=None, description="Preference.")
+ created_at: str | None = Field(default=None, description="Timestamp of the dialog.")
+
+
class TextualMemoryItem(BaseModel):
"""Represents a single memory item in the textual memory.
@@ -180,6 +213,7 @@ class TextualMemoryItem(BaseModel):
SearchedTreeNodeTextualMemoryMetadata
| TreeNodeTextualMemoryMetadata
| TextualMemoryMetadata
+ | PreferenceTextualMemoryMetadata
) = Field(default_factory=TextualMemoryMetadata)
model_config = ConfigDict(extra="forbid")
@@ -204,12 +238,26 @@ def _coerce_metadata(cls, v: Any):
v,
SearchedTreeNodeTextualMemoryMetadata
| TreeNodeTextualMemoryMetadata
- | TextualMemoryMetadata,
+ | TextualMemoryMetadata
+ | PreferenceTextualMemoryMetadata,
):
return v
if isinstance(v, dict):
+ if "metadata" in v and isinstance(v["metadata"], dict):
+ nested_metadata = v["metadata"]
+ nested_metadata = nested_metadata.copy()
+ nested_metadata.pop("id", None)
+ nested_metadata.pop("memory", None)
+ v = nested_metadata
+ else:
+ v = v.copy()
+ v.pop("id", None)
+ v.pop("memory", None)
+
if v.get("relativity") is not None:
return SearchedTreeNodeTextualMemoryMetadata(**v)
+ if v.get("preference_type") is not None:
+ return PreferenceTextualMemoryMetadata(**v)
if any(k in v for k in ("sources", "memory_type", "embedding", "background", "usage")):
return TreeNodeTextualMemoryMetadata(**v)
return TextualMemoryMetadata(**v)
diff --git a/src/memos/memories/textual/naive.py b/src/memos/memories/textual/naive.py
index f8684729a..7bc49e767 100644
--- a/src/memos/memories/textual/naive.py
+++ b/src/memos/memories/textual/naive.py
@@ -61,6 +61,8 @@ class NaiveTextMemory(BaseTextMemory):
def __init__(self, config: NaiveTextMemoryConfig):
"""Initialize memory with the given configuration."""
+ # Set mode from class default or override if needed
+ self.mode = getattr(self.__class__, "mode", "sync")
self.config = config
self.extractor_llm = LLMFactory.from_config(config.extractor_llm)
self.memories = []
diff --git a/src/memos/memories/textual/prefer_text_memory/__init__.py b/src/memos/memories/textual/prefer_text_memory/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/src/memos/memories/textual/prefer_text_memory/adder.py b/src/memos/memories/textual/prefer_text_memory/adder.py
new file mode 100644
index 000000000..a78601e86
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/adder.py
@@ -0,0 +1,423 @@
+import json
+import os
+
+from abc import ABC, abstractmethod
+from concurrent.futures import as_completed
+from datetime import datetime
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.log import get_logger
+from memos.memories.textual.item import TextualMemoryItem
+from memos.templates.prefer_complete_prompt import (
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT,
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE,
+ NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE,
+)
+from memos.vec_dbs.item import MilvusVecDBItem
+
+
+logger = get_logger(__name__)
+
+
+class BaseAdder(ABC):
+ """Abstract base class for adders."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the adder."""
+
+ @abstractmethod
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]], *args, **kwargs) -> list[str]:
+ """Add the instruct preference memories.
+ Args:
+ memories (list[TextualMemoryItem | dict[str, Any]]): The memories to add.
+ **kwargs: Additional keyword arguments.
+ Returns:
+ list[str]: List of added memory IDs.
+ """
+
+
+class NaiveAdder(BaseAdder):
+ """Naive adder."""
+
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the naive adder."""
+ super().__init__(llm_provider, embedder, vector_db)
+ self.llm_provider = llm_provider
+ self.embedder = embedder
+ self.vector_db = vector_db
+
+ def _judge_update_or_add_fast(self, old_msg: str, new_msg: str) -> bool:
+ """Judge if the new message expresses the same core content as the old message."""
+ # Use the template prompt with placeholders
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT.replace("{old_information}", old_msg).replace(
+ "{new_information}", new_msg
+ )
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ response = result.get("is_same", False)
+ return response if isinstance(response, bool) else response.lower() == "true"
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add: {e}")
+ # Fallback to simple string comparison
+ return old_msg == new_msg
+
+ def _judge_update_or_add_fine(self, new_mem: str, retrieved_mems: str) -> dict[str, Any] | None:
+ if not retrieved_mems:
+ return None
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE.replace("{new_memory}", new_mem).replace(
+ "{retrieved_memories}", retrieved_mems
+ )
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ return result
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add_fine: {e}")
+ return None
+
+ def _judge_update_or_add_trace_op(
+ self, new_mems: str, retrieved_mems: str
+ ) -> dict[str, Any] | None:
+ if not retrieved_mems:
+ return None
+ prompt = NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE.replace(
+ "{new_memories}", new_mems
+ ).replace("{retrieved_memories}", retrieved_mems)
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ return result
+ except Exception as e:
+ logger.error(f"Error in judge_update_or_add_trace_op: {e}")
+ return None
+
+ def _update_memory_op_trace(
+ self,
+ new_memories: list[TextualMemoryItem],
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> list[str] | str:
+ # create new vec db items
+ new_vec_db_items: list[MilvusVecDBItem] = []
+ for new_memory in new_memories:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ new_vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+ new_vec_db_items.append(new_vec_db_item)
+
+ new_mem_inputs = [
+ {
+ "id": new_memory.id,
+ "context_summary": new_memory.memory,
+ "preference": new_memory.payload["preference"],
+ }
+ for new_memory in new_vec_db_items
+ if new_memory.payload.get("preference", None)
+ ]
+ retrieved_mem_inputs = [
+ {
+ "id": mem.id,
+ "context_summary": mem.memory,
+ "preference": mem.payload["preference"],
+ }
+ for mem in retrieved_memories
+ if mem.payload.get("preference", None)
+ ]
+
+ rsp = self._judge_update_or_add_trace_op(
+ new_mems=json.dumps(new_mem_inputs),
+ retrieved_mems=json.dumps(retrieved_mem_inputs) if retrieved_mem_inputs else "",
+ )
+ if not rsp:
+ with ContextThreadPoolExecutor(max_workers=min(len(new_vec_db_items), 5)) as executor:
+ futures = {
+ executor.submit(self.vector_db.add, collection_name, [db_item]): db_item
+ for db_item in new_vec_db_items
+ }
+ for future in as_completed(futures):
+ result = future.result()
+ return [db_item.id for db_item in new_vec_db_items]
+
+ new_mem_db_item_map = {db_item.id: db_item for db_item in new_vec_db_items}
+ retrieved_mem_db_item_map = {db_item.id: db_item for db_item in retrieved_memories}
+
+ def execute_op(
+ op,
+ new_mem_db_item_map: dict[str, MilvusVecDBItem],
+ retrieved_mem_db_item_map: dict[str, MilvusVecDBItem],
+ ) -> str | None:
+ op_type = op["type"].lower()
+ if op_type == "add":
+ if op["target_id"] in new_mem_db_item_map:
+ self.vector_db.add(collection_name, [new_mem_db_item_map[op["target_id"]]])
+ return new_mem_db_item_map[op["target_id"]].id
+ return None
+ elif op_type == "update":
+ if op["target_id"] in retrieved_mem_db_item_map:
+ update_mem_db_item = retrieved_mem_db_item_map[op["target_id"]]
+ update_mem_db_item.payload["preference"] = op["new_preference"]
+ update_mem_db_item.payload["updated_at"] = datetime.now().isoformat()
+ update_mem_db_item.memory = op["new_context_summary"]
+ update_mem_db_item.original_text = op["new_context_summary"]
+ update_mem_db_item.vector = self.embedder.embed([op["new_context_summary"]])[0]
+ self.vector_db.update(collection_name, op["target_id"], update_mem_db_item)
+ return op["target_id"]
+ return None
+ elif op_type == "delete":
+ self.vector_db.delete(collection_name, [op["target_id"]])
+ return None
+
+ with ContextThreadPoolExecutor(max_workers=min(len(rsp["trace"]), 5)) as executor:
+ future_to_op = {
+ executor.submit(execute_op, op, new_mem_db_item_map, retrieved_mem_db_item_map): op
+ for op in rsp["trace"]
+ }
+ added_ids = []
+ for future in as_completed(future_to_op):
+ result = future.result()
+ if result is not None:
+ added_ids.append(result)
+
+ return added_ids
+
+ def _update_memory_fine(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> str:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+
+ new_mem_input = {"memory": new_memory.memory, "preference": new_memory.metadata.preference}
+ retrieved_mem_inputs = [
+ {
+ "id": mem.id,
+ "memory": mem.memory,
+ "preference": mem.payload["preference"],
+ }
+ for mem in retrieved_memories
+ if mem.payload.get("preference", None)
+ ]
+ rsp = self._judge_update_or_add_fine(
+ new_mem=json.dumps(new_mem_input),
+ retrieved_mems=json.dumps(retrieved_mem_inputs) if retrieved_mem_inputs else "",
+ )
+ need_update = rsp.get("need_update", False) if rsp else False
+ need_update = (
+ need_update if isinstance(need_update, bool) else need_update.lower() == "true"
+ )
+ update_item = (
+ [mem for mem in retrieved_memories if mem.id == rsp["id"]]
+ if rsp and "id" in rsp
+ else []
+ )
+ if need_update and update_item and rsp:
+ update_vec_db_item = update_item[0]
+ update_vec_db_item.payload["preference"] = rsp["new_preference"]
+ update_vec_db_item.payload["updated_at"] = vec_db_item.payload["updated_at"]
+ update_vec_db_item.memory = rsp["new_memory"]
+ update_vec_db_item.original_text = vec_db_item.original_text
+ update_vec_db_item.vector = self.embedder.embed([rsp["new_memory"]])[0]
+
+ self.vector_db.update(collection_name, rsp["id"], update_vec_db_item)
+ return rsp["id"]
+ else:
+ self.vector_db.add(collection_name, [vec_db_item])
+ return vec_db_item.id
+
+ def _update_memory_fast(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ ) -> str:
+ payload = new_memory.to_dict()["metadata"]
+ fields_to_remove = {"dialog_id", "original_text", "embedding"}
+ payload = {k: v for k, v in payload.items() if k not in fields_to_remove}
+ vec_db_item = MilvusVecDBItem(
+ id=new_memory.id,
+ memory=new_memory.memory,
+ original_text=new_memory.metadata.original_text,
+ vector=new_memory.metadata.embedding,
+ payload=payload,
+ )
+ recall = retrieved_memories[0] if retrieved_memories else None
+ if not recall or (recall.score is not None and recall.score < 0.5):
+ self.vector_db.add(collection_name, [vec_db_item])
+ return new_memory.id
+
+ old_msg_str = recall.memory
+ new_msg_str = new_memory.memory
+ is_same = self._judge_update_or_add_fast(old_msg=old_msg_str, new_msg=new_msg_str)
+ if is_same:
+ vec_db_item.id = recall.id
+ self.vector_db.update(collection_name, recall.id, vec_db_item)
+ self.vector_db.add(collection_name, [vec_db_item])
+ return new_memory.id
+
+ def _update_memory(
+ self,
+ new_memory: TextualMemoryItem,
+ retrieved_memories: list[MilvusVecDBItem],
+ collection_name: str,
+ update_mode: str = "fast",
+ ) -> list[str] | str | None:
+ """Update the memory.
+ Args:
+ new_memory: TextualMemoryItem
+ retrieved_memories: list[MilvusVecDBItem]
+ collection_name: str
+ update_mode: str, "fast" or "fine"
+ """
+ if update_mode == "fast":
+ return self._update_memory_fast(new_memory, retrieved_memories, collection_name)
+ elif update_mode == "fine":
+ return self._update_memory_fine(new_memory, retrieved_memories, collection_name)
+ else:
+ raise ValueError(f"Invalid update mode: {update_mode}")
+
+ def _process_single_memory(self, memory: TextualMemoryItem) -> list[str] | str | None:
+ """Process a single memory and return its ID if added successfully."""
+ try:
+ pref_type_collection_map = {
+ "explicit_preference": "explicit_preference",
+ "implicit_preference": "implicit_preference",
+ }
+ preference_type = memory.metadata.preference_type
+ collection_name = pref_type_collection_map[preference_type]
+
+ search_results = self.vector_db.search(
+ query_vector=memory.metadata.embedding,
+ query=memory.memory,
+ collection_name=collection_name,
+ top_k=5,
+ filter={"user_id": memory.metadata.user_id},
+ )
+ search_results.sort(key=lambda x: x.score, reverse=True)
+
+ return self._update_memory(
+ memory,
+ search_results,
+ collection_name,
+ update_mode=os.getenv("PREFERENCE_ADDER_MODE", "fast"),
+ )
+
+ except Exception as e:
+ logger.error(f"Error processing memory {memory.id}: {e}")
+ return None
+
+ def process_memory_batch(self, memories: list[TextualMemoryItem], *args, **kwargs) -> list[str]:
+ pref_type_collection_map = {
+ "explicit_preference": "explicit_preference",
+ "implicit_preference": "implicit_preference",
+ }
+
+ explicit_new_mems = []
+ implicit_new_mems = []
+ explicit_recalls = []
+ implicit_recalls = []
+
+ for memory in memories:
+ preference_type = memory.metadata.preference_type
+ collection_name = pref_type_collection_map[preference_type]
+ search_results = self.vector_db.search(
+ query_vector=memory.metadata.embedding,
+ query=memory.memory,
+ collection_name=collection_name,
+ top_k=5,
+ filter={"user_id": memory.metadata.user_id},
+ )
+ if preference_type == "explicit_preference":
+ explicit_recalls.extend(search_results)
+ explicit_new_mems.append(memory)
+ elif preference_type == "implicit_preference":
+ implicit_recalls.extend(search_results)
+ implicit_new_mems.append(memory)
+
+ explicit_recalls = list({recall.id: recall for recall in explicit_recalls}.values())
+ implicit_recalls = list({recall.id: recall for recall in implicit_recalls}.values())
+
+ # 使用线程池并行处理显式和隐式偏好
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ explicit_future = executor.submit(
+ self._update_memory_op_trace,
+ explicit_new_mems,
+ explicit_recalls,
+ pref_type_collection_map["explicit_preference"],
+ )
+ implicit_future = executor.submit(
+ self._update_memory_op_trace,
+ implicit_new_mems,
+ implicit_recalls,
+ pref_type_collection_map["implicit_preference"],
+ )
+
+ explicit_added_ids = explicit_future.result()
+ implicit_added_ids = implicit_future.result()
+
+ return explicit_added_ids + implicit_added_ids
+
+ def process_memory_single(
+ self, memories: list[TextualMemoryItem], max_workers: int = 8, *args, **kwargs
+ ) -> list[str]:
+ added_ids: list[str] = []
+ with ContextThreadPoolExecutor(max_workers=min(max_workers, len(memories))) as executor:
+ future_to_memory = {
+ executor.submit(self._process_single_memory, memory): memory for memory in memories
+ }
+
+ for future in as_completed(future_to_memory):
+ try:
+ memory_id = future.result()
+ if memory_id:
+ if isinstance(memory_id, list):
+ added_ids.extend(memory_id)
+ else:
+ added_ids.append(memory_id)
+ except Exception as e:
+ memory = future_to_memory[future]
+ logger.error(f"Error processing memory {memory.id}: {e}")
+ continue
+ return added_ids
+
+ def add(
+ self,
+ memories: list[TextualMemoryItem | dict[str, Any]],
+ max_workers: int = 8,
+ *args,
+ **kwargs,
+ ) -> list[str]:
+ """Add the instruct preference memories using thread pool for acceleration."""
+ if not memories:
+ return []
+
+ process_map = {
+ "single": self.process_memory_single,
+ "batch": self.process_memory_batch,
+ }
+
+ process_func = process_map["single"]
+ return process_func(memories, max_workers)
diff --git a/src/memos/memories/textual/prefer_text_memory/config.py b/src/memos/memories/textual/prefer_text_memory/config.py
new file mode 100644
index 000000000..7e8354747
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/config.py
@@ -0,0 +1,106 @@
+from typing import Any, ClassVar
+
+from pydantic import Field, field_validator, model_validator
+
+from memos.configs.base import BaseConfig
+
+
+class BaseAdderConfig(BaseConfig):
+ """Base configuration class for Adder."""
+
+
+class NaiveAdderConfig(BaseAdderConfig):
+ """Configuration for Naive Adder."""
+
+ # No additional config needed since components are passed from parent
+
+
+class AdderConfigFactory(BaseConfig):
+ """Factory class for creating Adder configurations."""
+
+ backend: str = Field(..., description="Backend for Adder")
+ config: dict[str, Any] = Field(..., description="Configuration for the Adder backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveAdderConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "AdderConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
+
+
+class BaseExtractorConfig(BaseConfig):
+ """Base configuration class for Extractor."""
+
+
+class NaiveExtractorConfig(BaseExtractorConfig):
+ """Configuration for Naive Extractor."""
+
+
+class ExtractorConfigFactory(BaseConfig):
+ """Factory class for creating Extractor configurations."""
+
+ backend: str = Field(..., description="Backend for Extractor")
+ config: dict[str, Any] = Field(..., description="Configuration for the Extractor backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveExtractorConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "ExtractorConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
+
+
+class BaseRetrieverConfig(BaseConfig):
+ """Base configuration class for Retrievers."""
+
+
+class NaiveRetrieverConfig(BaseRetrieverConfig):
+ """Configuration for Naive Retriever."""
+
+
+class RetrieverConfigFactory(BaseConfig):
+ """Factory class for creating Retriever configurations."""
+
+ backend: str = Field(..., description="Backend for Retriever")
+ config: dict[str, Any] = Field(..., description="Configuration for the Retriever backend")
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveRetrieverConfig,
+ }
+
+ @field_validator("backend")
+ @classmethod
+ def validate_backend(cls, backend: str) -> str:
+ """Validate the backend field."""
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ return backend
+
+ @model_validator(mode="after")
+ def create_config(self) -> "RetrieverConfigFactory":
+ config_class = self.backend_to_class[self.backend]
+ self.config = config_class(**self.config)
+ return self
diff --git a/src/memos/memories/textual/prefer_text_memory/extractor.py b/src/memos/memories/textual/prefer_text_memory/extractor.py
new file mode 100644
index 000000000..d5eab2aec
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/extractor.py
@@ -0,0 +1,201 @@
+import json
+import uuid
+
+from abc import ABC, abstractmethod
+from concurrent.futures import as_completed
+from datetime import datetime
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.log import get_logger
+from memos.mem_reader.simple_struct import detect_lang
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.prefer_text_memory.spliter import Splitter
+from memos.memories.textual.prefer_text_memory.utils import convert_messages_to_string
+from memos.templates.prefer_complete_prompt import (
+ NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+)
+from memos.types import MessageList
+
+
+logger = get_logger(__name__)
+
+
+class BaseExtractor(ABC):
+ """Abstract base class for extractors."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the extractor."""
+
+
+class NaiveExtractor(BaseExtractor):
+ """Extractor."""
+
+ def __init__(self, llm_provider=None, embedder=None, vector_db=None):
+ """Initialize the extractor."""
+ super().__init__(llm_provider, embedder, vector_db)
+ self.llm_provider = llm_provider
+ self.embedder = embedder
+ self.vector_db = vector_db
+ self.splitter = Splitter()
+
+ def extract_basic_info(self, qa_pair: MessageList) -> dict[str, Any]:
+ """Extract basic information from a QA pair (no LLM needed)."""
+ basic_info = {
+ "dialog_id": str(uuid.uuid4()),
+ "original_text": convert_messages_to_string(qa_pair),
+ "created_at": datetime.now().isoformat(),
+ }
+
+ return basic_info
+
+ def extract_explicit_preference(self, qa_pair: MessageList | str) -> dict[str, Any] | None:
+ """Extract explicit preference from a QA pair."""
+ qa_pair_str = convert_messages_to_string(qa_pair) if isinstance(qa_pair, list) else qa_pair
+ lang = detect_lang(qa_pair_str)
+ _map = {
+ "zh": NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ "en": NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ }
+ prompt = _map[lang].replace("{qa_pair}", qa_pair_str)
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ for d in result:
+ d["preference"] = d.pop("explicit_preference")
+ return result
+ except Exception as e:
+ logger.error(f"Error extracting explicit preference: {e}, return None")
+ return None
+
+ def extract_implicit_preference(self, qa_pair: MessageList | str) -> dict[str, Any] | None:
+ """Extract implicit preferences from cluster qa pairs."""
+ if not qa_pair:
+ return None
+ qa_pair_str = convert_messages_to_string(qa_pair) if isinstance(qa_pair, list) else qa_pair
+ lang = detect_lang(qa_pair_str)
+ _map = {
+ "zh": NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH,
+ "en": NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT,
+ }
+ prompt = _map[lang].replace("{qa_pair}", qa_pair_str)
+
+ try:
+ response = self.llm_provider.generate([{"role": "user", "content": prompt}])
+ response = response.strip().replace("```json", "").replace("```", "").strip()
+ result = json.loads(response)
+ result["preference"] = result.pop("implicit_preference")
+ return result
+ except Exception as e:
+ logger.error(f"Error extracting implicit preferences: {e}, return None")
+ return None
+
+ def _process_single_chunk_explicit(
+ self, chunk: MessageList, msg_type: str, info: dict[str, Any]
+ ) -> TextualMemoryItem | None:
+ """Process a single chunk and return a TextualMemoryItem."""
+ basic_info = self.extract_basic_info(chunk)
+ if not basic_info["original_text"]:
+ return None
+
+ explicit_pref = self.extract_explicit_preference(basic_info["original_text"])
+ if not explicit_pref:
+ return None
+
+ memories = []
+ for pref in explicit_pref:
+ vector_info = {
+ "embedding": self.embedder.embed([pref["context_summary"]])[0],
+ }
+ extract_info = {**basic_info, **pref, **vector_info, **info}
+
+ metadata = PreferenceTextualMemoryMetadata(
+ type=msg_type, preference_type="explicit_preference", **extract_info
+ )
+ memory = TextualMemoryItem(
+ id=str(uuid.uuid4()), memory=pref["context_summary"], metadata=metadata
+ )
+
+ memories.append(memory)
+
+ return memories
+
+ def _process_single_chunk_implicit(
+ self, chunk: MessageList, msg_type: str, info: dict[str, Any]
+ ) -> TextualMemoryItem | None:
+ basic_info = self.extract_basic_info(chunk)
+ if not basic_info["original_text"]:
+ return None
+ implicit_pref = self.extract_implicit_preference(basic_info["original_text"])
+ if not implicit_pref:
+ return None
+
+ vector_info = {
+ "embedding": self.embedder.embed([implicit_pref["context_summary"]])[0],
+ }
+
+ extract_info = {**basic_info, **implicit_pref, **vector_info, **info}
+
+ metadata = PreferenceTextualMemoryMetadata(
+ type=msg_type, preference_type="implicit_preference", **extract_info
+ )
+ memory = TextualMemoryItem(
+ id=extract_info["dialog_id"], memory=implicit_pref["context_summary"], metadata=metadata
+ )
+
+ return memory
+
+ def extract(
+ self,
+ messages: list[MessageList],
+ msg_type: str,
+ info: dict[str, Any],
+ max_workers: int = 10,
+ ) -> list[TextualMemoryItem]:
+ """Extract preference memories based on the messages using thread pool for acceleration."""
+ chunks: list[MessageList] = []
+ for message in messages:
+ chunk = self.splitter.split_chunks(message, split_type="overlap")
+ chunks.extend(chunk)
+ if not chunks:
+ return []
+
+ memories = []
+ with ContextThreadPoolExecutor(max_workers=min(max_workers, len(chunks))) as executor:
+ futures = {
+ executor.submit(self._process_single_chunk_explicit, chunk, msg_type, info): (
+ "explicit",
+ chunk,
+ )
+ for chunk in chunks
+ }
+ futures.update(
+ {
+ executor.submit(self._process_single_chunk_implicit, chunk, msg_type, info): (
+ "implicit",
+ chunk,
+ )
+ for chunk in chunks
+ }
+ )
+
+ for future in as_completed(futures):
+ try:
+ memory = future.result()
+ if memory:
+ if isinstance(memory, list):
+ memories.extend(memory)
+ else:
+ memories.append(memory)
+ except Exception as e:
+ task_type, chunk = futures[future]
+ logger.error(f"Error processing {task_type} chunk: {chunk}\n{e}")
+ continue
+
+ return memories
diff --git a/src/memos/memories/textual/prefer_text_memory/factory.py b/src/memos/memories/textual/prefer_text_memory/factory.py
new file mode 100644
index 000000000..22182261a
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/factory.py
@@ -0,0 +1,78 @@
+from typing import Any, ClassVar
+
+from memos.memories.textual.prefer_text_memory.adder import BaseAdder, NaiveAdder
+from memos.memories.textual.prefer_text_memory.config import (
+ AdderConfigFactory,
+ ExtractorConfigFactory,
+ RetrieverConfigFactory,
+)
+from memos.memories.textual.prefer_text_memory.extractor import BaseExtractor, NaiveExtractor
+from memos.memories.textual.prefer_text_memory.retrievers import BaseRetriever, NaiveRetriever
+
+
+class AdderFactory(BaseAdder):
+ """Factory class for creating Adder instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveAdder,
+ }
+
+ @classmethod
+ def from_config(
+ cls, config_factory: AdderConfigFactory, llm_provider=None, embedder=None, vector_db=None
+ ) -> BaseAdder:
+ """Create a Adder instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ adder_class = cls.backend_to_class[backend]
+ return adder_class(llm_provider=llm_provider, embedder=embedder, vector_db=vector_db)
+
+
+class ExtractorFactory(BaseExtractor):
+ """Factory class for creating Extractor instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveExtractor,
+ }
+
+ @classmethod
+ def from_config(
+ cls,
+ config_factory: ExtractorConfigFactory,
+ llm_provider=None,
+ embedder=None,
+ vector_db=None,
+ ) -> BaseExtractor:
+ """Create a Extractor instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ extractor_class = cls.backend_to_class[backend]
+ return extractor_class(llm_provider=llm_provider, embedder=embedder, vector_db=vector_db)
+
+
+class RetrieverFactory(BaseRetriever):
+ """Factory class for creating Retriever instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "naive": NaiveRetriever,
+ }
+
+ @classmethod
+ def from_config(
+ cls,
+ config_factory: RetrieverConfigFactory,
+ llm_provider=None,
+ embedder=None,
+ reranker=None,
+ vector_db=None,
+ ) -> BaseRetriever:
+ """Create a Retriever instance from a configuration factory."""
+ backend = config_factory.backend
+ if backend not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {backend}")
+ retriever_class = cls.backend_to_class[backend]
+ return retriever_class(
+ llm_provider=llm_provider, embedder=embedder, reranker=reranker, vector_db=vector_db
+ )
diff --git a/src/memos/memories/textual/prefer_text_memory/retrievers.py b/src/memos/memories/textual/prefer_text_memory/retrievers.py
new file mode 100644
index 000000000..0074c3f1c
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/retrievers.py
@@ -0,0 +1,134 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+from memos.context.context import ContextThreadPoolExecutor
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.vec_dbs.item import MilvusVecDBItem
+
+
+class BaseRetriever(ABC):
+ """Abstract base class for retrievers."""
+
+ @abstractmethod
+ def __init__(self, llm_provider=None, embedder=None, reranker=None, vector_db=None):
+ """Initialize the retriever."""
+
+ @abstractmethod
+ def retrieve(
+ self, query: str, top_k: int, info: dict[str, Any] | None = None
+ ) -> list[TextualMemoryItem]:
+ """Retrieve memories from the retriever."""
+
+
+class NaiveRetriever(BaseRetriever):
+ """Naive retriever."""
+
+ def __init__(self, llm_provider=None, embedder=None, reranker=None, vector_db=None):
+ """Initialize the naive retriever."""
+ super().__init__(llm_provider, embedder, reranker, vector_db)
+ self.reranker = reranker
+ self.vector_db = vector_db
+ self.embedder = embedder
+
+ def _naive_reranker(
+ self, query: str, prefs_mem: list[TextualMemoryItem], top_k: int, **kwargs: Any
+ ) -> list[TextualMemoryItem]:
+ if self.reranker:
+ prefs_mem = self.reranker.rerank(query, prefs_mem, top_k)
+ return [item for item, _ in prefs_mem]
+ return prefs_mem
+
+ def _original_text_reranker(
+ self,
+ query: str,
+ prefs_mem: list[TextualMemoryItem],
+ prefs: list[MilvusVecDBItem],
+ top_k: int,
+ **kwargs: Any,
+ ) -> list[TextualMemoryItem]:
+ if self.reranker:
+ from copy import deepcopy
+
+ prefs_mem_for_reranker = deepcopy(prefs_mem)
+ for pref_mem, pref in zip(prefs_mem_for_reranker, prefs, strict=False):
+ pref_mem.memory = pref_mem.memory + "\n" + pref.original_text
+ prefs_mem_for_reranker = self.reranker.rerank(query, prefs_mem_for_reranker, top_k)
+ prefs_mem_for_reranker = [item for item, _ in prefs_mem_for_reranker]
+ prefs_ids = [item.id for item in prefs_mem_for_reranker]
+ prefs_dict = {item.id: item for item in prefs_mem}
+ return [prefs_dict[item_id] for item_id in prefs_ids if item_id in prefs_dict]
+ return prefs_mem
+
+ def retrieve(
+ self, query: str, top_k: int, info: dict[str, Any] | None = None
+ ) -> list[TextualMemoryItem]:
+ """Retrieve memories from the naive retriever."""
+ # TODO: un-support rewrite query and session filter now
+ if info:
+ info = info.copy() # Create a copy to avoid modifying the original
+ info.pop("chat_history", None)
+ info.pop("session_id", None)
+ query_embeddings = self.embedder.embed([query]) # Pass as list to get list of embeddings
+ query_embedding = query_embeddings[0] # Get the first (and only) embedding
+
+ # Use thread pool to parallelize the searches
+ with ContextThreadPoolExecutor(max_workers=2) as executor:
+ # Submit all search tasks
+ future_explicit = executor.submit(
+ self.vector_db.search,
+ query_embedding,
+ query,
+ "explicit_preference",
+ top_k * 2,
+ info,
+ )
+ future_implicit = executor.submit(
+ self.vector_db.search,
+ query_embedding,
+ query,
+ "implicit_preference",
+ top_k * 2,
+ info,
+ )
+
+ # Wait for all results
+ explicit_prefs = future_explicit.result()
+ implicit_prefs = future_implicit.result()
+
+ # sort by score
+ explicit_prefs.sort(key=lambda x: x.score, reverse=True)
+ implicit_prefs.sort(key=lambda x: x.score, reverse=True)
+
+ explicit_prefs_mem = [
+ TextualMemoryItem(
+ id=pref.id,
+ memory=pref.memory,
+ metadata=PreferenceTextualMemoryMetadata(**pref.payload),
+ )
+ for pref in explicit_prefs
+ if pref.payload.get("preference", None)
+ ]
+
+ implicit_prefs_mem = [
+ TextualMemoryItem(
+ id=pref.id,
+ memory=pref.memory,
+ metadata=PreferenceTextualMemoryMetadata(**pref.payload),
+ )
+ for pref in implicit_prefs
+ if pref.payload.get("preference", None)
+ ]
+
+ reranker_map = {
+ "naive": self._naive_reranker,
+ "original_text": self._original_text_reranker,
+ }
+ reranker_func = reranker_map["naive"]
+ explicit_prefs_mem = reranker_func(
+ query=query, prefs_mem=explicit_prefs_mem, prefs=explicit_prefs, top_k=top_k
+ )
+ implicit_prefs_mem = reranker_func(
+ query=query, prefs_mem=implicit_prefs_mem, prefs=implicit_prefs, top_k=top_k
+ )
+
+ return explicit_prefs_mem + implicit_prefs_mem
diff --git a/src/memos/memories/textual/prefer_text_memory/spliter.py b/src/memos/memories/textual/prefer_text_memory/spliter.py
new file mode 100644
index 000000000..3059d611b
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/spliter.py
@@ -0,0 +1,132 @@
+import copy
+
+from memos.chunkers import ChunkerFactory
+from memos.configs.chunker import ChunkerConfigFactory
+from memos.configs.parser import ParserConfigFactory
+from memos.parsers.factory import ParserFactory
+from memos.types import MessageList
+
+
+class Splitter:
+ """Splitter."""
+
+ def __init__(
+ self,
+ lookback_turns: int = 1,
+ chunk_size: int = 256,
+ chunk_overlap: int = 128,
+ min_sentences_per_chunk: int = 1,
+ tokenizer: str = "gpt2",
+ parser_backend: str = "markitdown",
+ chunker_backend: str = "sentence",
+ ):
+ """Initialize the splitter."""
+ self.lookback_turns = lookback_turns
+ self.chunk_size = chunk_size
+ self.chunk_overlap = chunk_overlap
+ self.min_sentences_per_chunk = min_sentences_per_chunk
+ self.tokenizer = tokenizer
+ self.chunker_backend = chunker_backend
+ self.parser_backend = parser_backend
+ # Initialize parser
+ parser_config = ParserConfigFactory.model_validate(
+ {
+ "backend": self.parser_backend,
+ "config": {},
+ }
+ )
+ self.parser = ParserFactory.from_config(parser_config)
+
+ # Initialize chunker
+ chunker_config = ChunkerConfigFactory.model_validate(
+ {
+ "backend": self.chunker_backend,
+ "config": {
+ "tokenizer_or_token_counter": self.tokenizer,
+ "chunk_size": self.chunk_size,
+ "chunk_overlap": self.chunk_overlap,
+ "min_sentences_per_chunk": self.min_sentences_per_chunk,
+ },
+ }
+ )
+ self.chunker = ChunkerFactory.from_config(chunker_config)
+
+ def _split_with_lookback(self, data: MessageList) -> list[MessageList]:
+ """Split the messages or files into chunks by looking back fixed number of turns.
+ adjacent chunk with high duplicate rate,
+ default lookback turns is 1, only current turn in chunk"""
+ # Build QA pairs from chat history
+ pairs = self.build_qa_pairs(data)
+ chunks = []
+
+ # Create chunks by looking back fixed number of turns
+ for i in range(len(pairs)):
+ # Calculate the start index for lookback
+ start_idx = max(0, i + 1 - self.lookback_turns)
+ # Get the chunk of pairs (as many as available, up to lookback_turns)
+ chunk_pairs = pairs[start_idx : i + 1]
+
+ # Flatten chunk_pairs (list[list[dict]]) to MessageList (list[dict])
+ chunk_messages = []
+ for pair in chunk_pairs:
+ chunk_messages.extend(pair)
+
+ chunks.append(chunk_messages)
+ return chunks
+
+ def _split_with_overlap(self, data: MessageList) -> list[MessageList]:
+ """split the messages or files into chunks with overlap.
+ adjacent chunk with low duplicate rate"""
+ chunks = []
+ chunk = []
+ for i, item in enumerate(data):
+ chunk.append(item)
+ # 5 turns (Q + A = 10) each chunk
+ if len(chunk) >= 10:
+ chunks.append(chunk)
+ # overlap 1 turns (Q + A = 2)
+ context = copy.deepcopy(chunk[-2:]) if i + 1 < len(data) else []
+ chunk = context
+ if chunk and len(chunk) % 2 == 0:
+ chunks.append(chunk)
+
+ return chunks
+
+ def split_chunks(self, data: MessageList | str, **kwargs) -> list[MessageList] | list[str]:
+ """Split the messages or files into chunks.
+
+ Args:
+ data: MessageList or string to split
+
+ Returns:
+ List of MessageList chunks or list of string chunks
+ """
+ if isinstance(data, list):
+ if kwargs.get("split_type") == "lookback":
+ chunks = self._split_with_lookback(data)
+ elif kwargs.get("split_type") == "overlap":
+ chunks = self._split_with_overlap(data)
+ return chunks
+ else:
+ # Parse and chunk the string data using pre-initialized components
+ text = self.parser.parse(data)
+ chunks = self.chunker.chunk(text)
+
+ return [chunk.text for chunk in chunks]
+
+ def build_qa_pairs(self, chat_history: MessageList) -> list[MessageList]:
+ """Build QA pairs from chat history."""
+ qa_pairs = []
+ current_qa_pair = []
+
+ for message in chat_history:
+ if message["role"] == "user":
+ current_qa_pair.append(message)
+ elif message["role"] == "assistant":
+ if not current_qa_pair:
+ continue
+ current_qa_pair.append(message)
+ qa_pairs.append(current_qa_pair.copy())
+ current_qa_pair = [] # reset
+
+ return qa_pairs
diff --git a/src/memos/memories/textual/prefer_text_memory/utils.py b/src/memos/memories/textual/prefer_text_memory/utils.py
new file mode 100644
index 000000000..76d4b4211
--- /dev/null
+++ b/src/memos/memories/textual/prefer_text_memory/utils.py
@@ -0,0 +1,68 @@
+import re
+
+from memos.dependency import require_python_package
+from memos.memories.textual.item import TextualMemoryItem
+from memos.types import MessageList
+
+
+def convert_messages_to_string(messages: MessageList) -> str:
+ """Convert a list of messages to a string."""
+ message_text = ""
+ for message in messages:
+ if message["role"] == "user":
+ message_text += f"Query: {message['content']}\n" if message["content"].strip() else ""
+ elif message["role"] == "assistant":
+ message_text += f"Answer: {message['content']}\n" if message["content"].strip() else ""
+ message_text = message_text.strip()
+ return message_text
+
+
+@require_python_package(
+ import_name="datasketch",
+ install_command="pip install datasketch",
+ install_link="https://github.com/ekzhu/datasketch",
+)
+def deduplicate_preferences(
+ prefs: list[TextualMemoryItem], similarity_threshold: float = 0.6, num_perm: int = 256
+) -> list[TextualMemoryItem]:
+ """
+ Deduplicate preference texts using MinHash algorithm.
+
+ Args:
+ prefs: List of preference memory items to deduplicate
+ similarity_threshold: Jaccard similarity threshold (0.0-1.0), default 0.8
+
+ Returns:
+ Deduplicated list of preference items
+ """
+ from datasketch import MinHash, MinHashLSH
+
+ if not prefs:
+ return prefs
+
+ # Use MinHashLSH for efficient similarity search
+ lsh = MinHashLSH(threshold=similarity_threshold, num_perm=num_perm)
+ unique_prefs = []
+
+ for i, pref in enumerate(prefs):
+ # Extract preference text
+ if hasattr(pref.metadata, "preference") and pref.metadata.preference:
+ text = pref.metadata.preference
+ else:
+ text = pref.memory
+
+ # Create MinHash from text tokens
+ minhash = MinHash(num_perm=num_perm)
+ # Simple tokenization: split by whitespace and clean
+ tokens = re.findall(r"\w+", text.lower())
+ for token in tokens:
+ minhash.update(token.encode("utf8"))
+
+ # Check for duplicates using LSH
+ similar_items = lsh.query(minhash)
+
+ if not similar_items: # No similar items found
+ lsh.insert(i, minhash)
+ unique_prefs.append(pref)
+
+ return unique_prefs
diff --git a/src/memos/memories/textual/preference.py b/src/memos/memories/textual/preference.py
new file mode 100644
index 000000000..5f85aa907
--- /dev/null
+++ b/src/memos/memories/textual/preference.py
@@ -0,0 +1,283 @@
+import json
+import os
+
+from typing import Any
+
+from memos.configs.memory import PreferenceTextMemoryConfig
+from memos.embedders.factory import (
+ ArkEmbedder,
+ EmbedderFactory,
+ OllamaEmbedder,
+ SenTranEmbedder,
+ UniversalAPIEmbedder,
+)
+from memos.llms.factory import AzureLLM, LLMFactory, OllamaLLM, OpenAILLM
+from memos.log import get_logger
+from memos.memories.textual.base import BaseTextMemory
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.prefer_text_memory.factory import (
+ AdderFactory,
+ ExtractorFactory,
+ RetrieverFactory,
+)
+from memos.reranker.factory import RerankerFactory
+from memos.types import MessageList
+from memos.vec_dbs.factory import MilvusVecDB, QdrantVecDB, VecDBFactory
+from memos.vec_dbs.item import VecDBItem
+
+
+logger = get_logger(__name__)
+
+
+class PreferenceTextMemory(BaseTextMemory):
+ """Preference textual memory implementation for storing and retrieving memories."""
+
+ def __init__(self, config: PreferenceTextMemoryConfig):
+ """Initialize memory with the given configuration."""
+ self.config: PreferenceTextMemoryConfig = config
+ self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
+ config.extractor_llm
+ )
+ self.vector_db: MilvusVecDB | QdrantVecDB = VecDBFactory.from_config(config.vector_db)
+ self.embedder: OllamaEmbedder | ArkEmbedder | SenTranEmbedder | UniversalAPIEmbedder = (
+ EmbedderFactory.from_config(config.embedder)
+ )
+ self.reranker = RerankerFactory.from_config(config.reranker)
+
+ self.extractor = ExtractorFactory.from_config(
+ config.extractor,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ vector_db=self.vector_db,
+ )
+
+ self.adder = AdderFactory.from_config(
+ config.adder,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ vector_db=self.vector_db,
+ )
+ self.retriever = RetrieverFactory.from_config(
+ config.retriever,
+ llm_provider=self.extractor_llm,
+ embedder=self.embedder,
+ reranker=self.reranker,
+ vector_db=self.vector_db,
+ )
+
+ def get_memory(
+ self, messages: list[MessageList], type: str, info: dict[str, Any]
+ ) -> list[TextualMemoryItem]:
+ """Get memory based on the messages.
+ Args:
+ messages (list[MessageList]): The messages to get memory from.
+ type (str): The type of memory to get.
+ info (dict[str, Any]): The info to get memory.
+ """
+ return self.extractor.extract(messages, type, info)
+
+ def search(self, query: str, top_k: int, info=None, **kwargs) -> list[TextualMemoryItem]:
+ """Search for memories based on a query.
+ Args:
+ query (str): The query to search for.
+ top_k (int): The number of top results to return.
+ info (dict): Leave a record of memory consumption.
+ Returns:
+ list[TextualMemoryItem]: List of matching memories.
+ """
+ return self.retriever.retrieve(query, top_k, info)
+
+ def load(self, dir: str) -> None:
+ """Load memories from the specified directory.
+ Args:
+ dir (str): The directory containing the memory files.
+ """
+ # For preference memory, we don't need to load from files
+ # as the data is stored in the vector database
+ try:
+ memory_file = os.path.join(dir, self.config.memory_filename)
+
+ if not os.path.exists(memory_file):
+ logger.warning(f"Memory file not found: {memory_file}")
+ return
+
+ with open(memory_file, encoding="utf-8") as f:
+ memories = json.load(f)
+ for collection_name, items in memories.items():
+ vec_db_items = [VecDBItem.from_dict(m) for m in items]
+ self.vector_db.add(collection_name, vec_db_items)
+ logger.info(f"Loaded {len(items)} memories from {collection_name} in {memory_file}")
+
+ except FileNotFoundError:
+ logger.error(f"Memory file not found in directory: {dir}")
+ except json.JSONDecodeError as e:
+ if e.pos == 0 and "Expecting value" in str(e):
+ logger.warning(f"Memory file is empty or contains only whitespace: {memory_file}")
+ else:
+ logger.error(f"Error decoding JSON from memory file: {e}")
+ except Exception as e:
+ logger.error(f"An error occurred while loading memories: {e}")
+
+ def dump(self, dir: str) -> None:
+ """Dump memories to the specified directory.
+ Args:
+ dir (str): The directory where the memory files will be saved.
+ """
+ # For preference memory, we don't need to dump to files
+ # as the data is stored in the vector database
+ try:
+ json_memories = {}
+ for collection_name in self.vector_db.config.collection_name:
+ items = self.vector_db.get_all(collection_name)
+ json_memories[collection_name] = [memory.to_dict() for memory in items]
+
+ os.makedirs(dir, exist_ok=True)
+ memory_file = os.path.join(dir, self.config.memory_filename)
+ with open(memory_file, "w", encoding="utf-8") as f:
+ json.dump(json_memories, f, indent=4, ensure_ascii=False)
+
+ logger.info(
+ f"Dumped {len(json_memories)} collections, {sum(len(items) for items in json_memories.values())} memories to {memory_file}"
+ )
+
+ except Exception as e:
+ logger.error(f"An error occurred while dumping memories: {e}")
+ raise
+
+ def extract(self, messages: MessageList) -> list[TextualMemoryItem]:
+ """Extract memories based on the messages.
+ Args:
+ messages (MessageList): The messages to extract memories from.
+ Returns:
+ list[TextualMemoryItem]: List of extracted memory items.
+ """
+ raise NotImplementedError
+
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ """Add memories.
+
+ Args:
+ memories: List of TextualMemoryItem objects or dictionaries to add.
+ """
+ return self.adder.add(memories)
+
+ def update(self, memory_id: str, new_memory: TextualMemoryItem | dict[str, Any]) -> None:
+ """Update a memory by memory_id."""
+ raise NotImplementedError
+
+ def get(self, memory_id: str) -> TextualMemoryItem:
+ """Get a memory by its ID.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ Returns:
+ TextualMemoryItem: The memory with the given ID.
+ """
+ raise NotImplementedError
+
+ def get_with_collection_name(
+ self, collection_name: str, memory_id: str
+ ) -> TextualMemoryItem | None:
+ """Get a memory by its ID and collection name.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ collection_name (str): The name of the collection to retrieve the memory from.
+ Returns:
+ TextualMemoryItem: The memory with the given ID and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_id(collection_name, memory_id)
+ if res is None:
+ return None
+ return TextualMemoryItem(
+ id=res.id,
+ memory=res.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**res.payload),
+ )
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with ID {memory_id} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
+ """Get memories by their IDs.
+ Args:
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs.
+ """
+ raise NotImplementedError
+
+ def get_by_ids_with_collection_name(
+ self, collection_name: str, memory_ids: list[str]
+ ) -> list[TextualMemoryItem]:
+ """Get memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to retrieve the memory from.
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_ids(collection_name, memory_ids)
+ if not res:
+ return []
+ return [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in res
+ ]
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with IDs {memory_ids} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_all(self) -> list[TextualMemoryItem]:
+ """Get all memories.
+ Returns:
+ list[TextualMemoryItem]: List of all memories.
+ """
+ all_collections = self.vector_db.list_collections()
+ all_memories = {}
+ for collection_name in all_collections:
+ items = self.vector_db.get_all(collection_name)
+ all_memories[collection_name] = [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in items
+ ]
+ return all_memories
+
+ def delete(self, memory_ids: list[str]) -> None:
+ """Delete memories.
+ Args:
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ raise NotImplementedError
+
+ def delete_with_collection_name(self, collection_name: str, memory_ids: list[str]) -> None:
+ """Delete memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to delete the memory from.
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ self.vector_db.delete(collection_name, memory_ids)
+
+ def delete_all(self) -> None:
+ """Delete all memories."""
+ for collection_name in self.vector_db.config.collection_name:
+ self.vector_db.delete_collection(collection_name)
+ self.vector_db.create_collection()
+
+ def drop(
+ self,
+ ) -> None:
+ """Drop all databases."""
+ raise NotImplementedError
diff --git a/src/memos/memories/textual/simple_preference.py b/src/memos/memories/textual/simple_preference.py
new file mode 100644
index 000000000..29f30d384
--- /dev/null
+++ b/src/memos/memories/textual/simple_preference.py
@@ -0,0 +1,156 @@
+from typing import Any
+
+from memos.embedders.factory import (
+ ArkEmbedder,
+ OllamaEmbedder,
+ SenTranEmbedder,
+ UniversalAPIEmbedder,
+)
+from memos.llms.factory import AzureLLM, OllamaLLM, OpenAILLM
+from memos.log import get_logger
+from memos.memories.textual.item import PreferenceTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.preference import PreferenceTextMemory
+from memos.types import MessageList
+from memos.vec_dbs.factory import MilvusVecDB, QdrantVecDB
+
+
+logger = get_logger(__name__)
+
+
+class SimplePreferenceTextMemory(PreferenceTextMemory):
+ """Preference textual memory implementation for storing and retrieving memories."""
+
+ def __init__(
+ self,
+ extractor_llm: OpenAILLM | OllamaLLM | AzureLLM,
+ vector_db: MilvusVecDB | QdrantVecDB,
+ embedder: OllamaEmbedder | ArkEmbedder | SenTranEmbedder | UniversalAPIEmbedder,
+ reranker,
+ extractor,
+ adder,
+ retriever,
+ ):
+ """Initialize memory with the given configuration."""
+ self.extractor_llm = extractor_llm
+ self.vector_db = vector_db
+ self.embedder = embedder
+ self.reranker = reranker
+ self.extractor = extractor
+ self.adder = adder
+ self.retriever = retriever
+
+ def get_memory(
+ self, messages: list[MessageList], type: str, info: dict[str, Any]
+ ) -> list[TextualMemoryItem]:
+ """Get memory based on the messages.
+ Args:
+ messages (MessageList): The messages to get memory from.
+ type (str): The type of memory to get.
+ info (dict[str, Any]): The info to get memory.
+ """
+ return self.extractor.extract(messages, type, info)
+
+ def search(self, query: str, top_k: int, info=None, **kwargs) -> list[TextualMemoryItem]:
+ """Search for memories based on a query.
+ Args:
+ query (str): The query to search for.
+ top_k (int): The number of top results to return.
+ info (dict): Leave a record of memory consumption.
+ Returns:
+ list[TextualMemoryItem]: List of matching memories.
+ """
+ return self.retriever.retrieve(query, top_k, info)
+
+ def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ """Add memories.
+
+ Args:
+ memories: List of TextualMemoryItem objects or dictionaries to add.
+ """
+ return self.adder.add(memories)
+
+ def get_with_collection_name(
+ self, collection_name: str, memory_id: str
+ ) -> TextualMemoryItem | None:
+ """Get a memory by its ID and collection name.
+ Args:
+ memory_id (str): The ID of the memory to retrieve.
+ collection_name (str): The name of the collection to retrieve the memory from.
+ Returns:
+ TextualMemoryItem: The memory with the given ID and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_id(collection_name, memory_id)
+ if res is None:
+ return None
+ return TextualMemoryItem(
+ id=res.id,
+ memory=res.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**res.payload),
+ )
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with ID {memory_id} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_by_ids_with_collection_name(
+ self, collection_name: str, memory_ids: list[str]
+ ) -> list[TextualMemoryItem]:
+ """Get memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to retrieve the memory from.
+ memory_ids (list[str]): List of memory IDs to retrieve.
+ Returns:
+ list[TextualMemoryItem]: List of memories with the specified IDs and collection name.
+ """
+ try:
+ res = self.vector_db.get_by_ids(collection_name, memory_ids)
+ if not res:
+ return []
+ return [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in res
+ ]
+ except Exception as e:
+ # Convert any other exception to ValueError for consistent error handling
+ raise ValueError(
+ f"Memory with IDs {memory_ids} not found in collection {collection_name}: {e}"
+ ) from e
+
+ def get_all(self) -> list[TextualMemoryItem]:
+ """Get all memories.
+ Returns:
+ list[TextualMemoryItem]: List of all memories.
+ """
+ all_collections = self.vector_db.list_collections()
+ all_memories = {}
+ for collection_name in all_collections:
+ items = self.vector_db.get_all(collection_name)
+ all_memories[collection_name] = [
+ TextualMemoryItem(
+ id=memo.id,
+ memory=memo.payload.get("dialog_str", ""),
+ metadata=PreferenceTextualMemoryMetadata(**memo.payload),
+ )
+ for memo in items
+ ]
+ return all_memories
+
+ def delete_with_collection_name(self, collection_name: str, memory_ids: list[str]) -> None:
+ """Delete memories by their IDs and collection name.
+ Args:
+ collection_name (str): The name of the collection to delete the memory from.
+ memory_ids (list[str]): List of memory IDs to delete.
+ """
+ self.vector_db.delete(collection_name, memory_ids)
+
+ def delete_all(self) -> None:
+ """Delete all memories."""
+ for collection_name in self.vector_db.config.collection_name:
+ self.vector_db.delete_collection(collection_name)
+ self.vector_db.create_collection()
diff --git a/src/memos/memories/textual/simple_tree.py b/src/memos/memories/textual/simple_tree.py
index 9c67db288..313989cd2 100644
--- a/src/memos/memories/textual/simple_tree.py
+++ b/src/memos/memories/textual/simple_tree.py
@@ -12,6 +12,7 @@
from memos.memories.textual.item import TextualMemoryItem, TreeNodeTextualMemoryMetadata
from memos.memories.textual.tree import TreeTextMemory
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.searcher import Searcher
from memos.reranker.base import BaseReranker
from memos.types import MessageList
@@ -44,6 +45,8 @@ def __init__(
"""Initialize memory with the given configuration."""
time_start = time.time()
self.config: TreeTextMemoryConfig = config
+ self.mode = self.config.mode
+ logger.info(f"Tree mode is {self.mode}")
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = llm
logger.info(f"time init: extractor_llm time is: {time.time() - time_start}")
@@ -60,6 +63,15 @@ def __init__(
self.graph_store: Neo4jGraphDB = graph_db
logger.info(f"time init: graph_store time is: {time.time() - time_start_gs}")
+ time_start_bm = time.time()
+ self.search_strategy = config.search_strategy
+ self.bm25_retriever = (
+ EnhancedBM25()
+ if self.search_strategy and self.search_strategy.get("bm25", False)
+ else None
+ )
+ logger.info(f"time init: bm25_retriever time is: {time.time() - time_start_bm}")
+
time_start_rr = time.time()
self.reranker = reranker
logger.info(f"time init: reranker time is: {time.time() - time_start_rr}")
@@ -79,20 +91,6 @@ def __init__(
logger.info("No internet retriever configured")
logger.info(f"time init: internet_retriever time is: {time.time() - time_start_ir}")
- def add(
- self, memories: list[TextualMemoryItem | dict[str, Any]], user_name: str | None = None
- ) -> list[str]:
- """Add memories.
- Args:
- memories: List of TextualMemoryItem objects or dictionaries to add.
- Later:
- memory_items = [TextualMemoryItem(**m) if isinstance(m, dict) else m for m in memories]
- metadata = extract_metadata(memory_items, self.extractor_llm)
- plan = plan_memory_operations(memory_items, metadata, self.graph_store)
- execute_plan(memory_items, metadata, plan, self.graph_store)
- """
- return self.memory_manager.add(memories, user_name=user_name)
-
def replace_working_memory(
self, memories: list[TextualMemoryItem], user_name: str | None = None
) -> None:
@@ -116,6 +114,34 @@ def get_current_memory_size(self, user_name: str | None = None) -> dict[str, int
"""
return self.memory_manager.get_current_memory_size(user_name=user_name)
+ def get_searcher(
+ self,
+ manual_close_internet: bool = False,
+ moscube: bool = False,
+ ):
+ if (self.internet_retriever is not None) and manual_close_internet:
+ logger.warning(
+ "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
+ )
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=None,
+ moscube=moscube,
+ )
+ else:
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=self.internet_retriever,
+ moscube=moscube,
+ )
+ return searcher
+
def search(
self,
query: str,
@@ -151,16 +177,15 @@ def search(
list[TextualMemoryItem]: List of matching memories.
"""
if (self.internet_retriever is not None) and manual_close_internet:
- logger.warning(
- "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
- )
searcher = Searcher(
self.dispatcher_llm,
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=None,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
else:
searcher = Searcher(
@@ -168,8 +193,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=self.internet_retriever,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
return searcher.search(
query, top_k, info, mode, memory_type, search_filter, user_name=user_name
@@ -274,17 +301,6 @@ def get(self, memory_id: str) -> TextualMemoryItem:
def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
raise NotImplementedError
- def get_all(self) -> dict:
- """Get all memories.
- Returns:
- list[TextualMemoryItem]: List of all memories.
- """
- all_items = self.graph_store.export_graph()
- return all_items
-
- def delete(self, memory_ids: list[str]) -> None:
- raise NotImplementedError
-
def delete_all(self) -> None:
"""Delete all memories and their relationships from the graph store."""
try:
diff --git a/src/memos/memories/textual/tree.py b/src/memos/memories/textual/tree.py
index 0048f4a59..dea3cc1ab 100644
--- a/src/memos/memories/textual/tree.py
+++ b/src/memos/memories/textual/tree.py
@@ -2,7 +2,6 @@
import os
import shutil
import tempfile
-import time
from datetime import datetime
from pathlib import Path
@@ -17,6 +16,7 @@
from memos.memories.textual.base import BaseTextMemory
from memos.memories.textual.item import TextualMemoryItem, TreeNodeTextualMemoryMetadata
from memos.memories.textual.tree_text_memory.organize.manager import MemoryManager
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.internet_retriever_factory import (
InternetRetrieverFactory,
)
@@ -33,28 +33,25 @@ class TreeTextMemory(BaseTextMemory):
def __init__(self, config: TreeTextMemoryConfig):
"""Initialize memory with the given configuration."""
- time_start = time.time()
+ # Set mode from class default or override if needed
+ self.mode = config.mode
+ logger.info(f"Tree mode is {self.mode}")
+
self.config: TreeTextMemoryConfig = config
self.extractor_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.extractor_llm
)
- logger.info(f"time init: extractor_llm time is: {time.time() - time_start}")
-
- time_start_ex = time.time()
self.dispatcher_llm: OpenAILLM | OllamaLLM | AzureLLM = LLMFactory.from_config(
config.dispatcher_llm
)
- logger.info(f"time init: dispatcher_llm time is: {time.time() - time_start_ex}")
-
- time_start_em = time.time()
self.embedder: OllamaEmbedder = EmbedderFactory.from_config(config.embedder)
- logger.info(f"time init: embedder time is: {time.time() - time_start_em}")
-
- time_start_gs = time.time()
self.graph_store: Neo4jGraphDB = GraphStoreFactory.from_config(config.graph_db)
- logger.info(f"time init: graph_store time is: {time.time() - time_start_gs}")
- time_start_rr = time.time()
+ self.search_strategy = config.search_strategy
+ self.bm25_retriever = (
+ EnhancedBM25() if self.search_strategy and self.search_strategy["bm25"] else None
+ )
+
if config.reranker is None:
default_cfg = RerankerConfigFactory.model_validate(
{
@@ -68,10 +65,7 @@ def __init__(self, config: TreeTextMemoryConfig):
self.reranker = RerankerFactory.from_config(default_cfg)
else:
self.reranker = RerankerFactory.from_config(config.reranker)
- logger.info(f"time init: reranker time is: {time.time() - time_start_rr}")
self.is_reorganize = config.reorganize
-
- time_start_mm = time.time()
self.memory_manager: MemoryManager = MemoryManager(
self.graph_store,
self.embedder,
@@ -84,8 +78,6 @@ def __init__(self, config: TreeTextMemoryConfig):
},
is_reorganize=self.is_reorganize,
)
- logger.info(f"time init: memory_manager time is: {time.time() - time_start_mm}")
- time_start_ir = time.time()
# Create internet retriever if configured
self.internet_retriever = None
if config.internet_retriever is not None:
@@ -97,19 +89,19 @@ def __init__(self, config: TreeTextMemoryConfig):
)
else:
logger.info("No internet retriever configured")
- logger.info(f"time init: internet_retriever time is: {time.time() - time_start_ir}")
- def add(self, memories: list[TextualMemoryItem | dict[str, Any]]) -> list[str]:
+ def add(
+ self,
+ memories: list[TextualMemoryItem | dict[str, Any]],
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[str]:
"""Add memories.
Args:
memories: List of TextualMemoryItem objects or dictionaries to add.
- Later:
- memory_items = [TextualMemoryItem(**m) if isinstance(m, dict) else m for m in memories]
- metadata = extract_metadata(memory_items, self.extractor_llm)
- plan = plan_memory_operations(memory_items, metadata, self.graph_store)
- execute_plan(memory_items, metadata, plan, self.graph_store)
+ user_name: optional user_name
"""
- return self.memory_manager.add(memories)
+ return self.memory_manager.add(memories, user_name=user_name, mode=self.mode)
def replace_working_memory(self, memories: list[TextualMemoryItem]) -> None:
self.memory_manager.replace_working_memory(memories)
@@ -130,6 +122,34 @@ def get_current_memory_size(self) -> dict[str, int]:
"""
return self.memory_manager.get_current_memory_size()
+ def get_searcher(
+ self,
+ manual_close_internet: bool = False,
+ moscube: bool = False,
+ ):
+ if (self.internet_retriever is not None) and manual_close_internet:
+ logger.warning(
+ "Internet retriever is init by config , but this search set manual_close_internet is True and will close it"
+ )
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=None,
+ moscube=moscube,
+ )
+ else:
+ searcher = Searcher(
+ self.dispatcher_llm,
+ self.graph_store,
+ self.embedder,
+ self.reranker,
+ internet_retriever=self.internet_retriever,
+ moscube=moscube,
+ )
+ return searcher
+
def search(
self,
query: str,
@@ -172,8 +192,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=None,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
else:
searcher = Searcher(
@@ -181,8 +203,10 @@ def search(
self.graph_store,
self.embedder,
self.reranker,
+ bm25_retriever=self.bm25_retriever,
internet_retriever=self.internet_retriever,
moscube=moscube,
+ search_strategy=self.search_strategy,
)
return searcher.search(query, top_k, info, mode, memory_type, search_filter)
@@ -236,7 +260,7 @@ def get_relevant_subgraph(
center_id=core_id, depth=depth, center_status=center_status
)
- if not subgraph["core_node"]:
+ if subgraph is None or not subgraph["core_node"]:
logger.info(f"Skipping node {core_id} (inactive or not found).")
continue
@@ -257,9 +281,9 @@ def get_relevant_subgraph(
{"id": core_id, "score": score, "core_node": core_node, "neighbors": neighbors}
)
- top_core = cores[0]
+ top_core = cores[0] if cores else None
return {
- "core_id": top_core["id"],
+ "core_id": top_core["id"] if top_core else None,
"nodes": list(all_nodes.values()),
"edges": [{"source": f, "target": t, "type": ty} for (f, t, ty) in all_edges],
}
@@ -285,16 +309,23 @@ def get(self, memory_id: str) -> TextualMemoryItem:
def get_by_ids(self, memory_ids: list[str]) -> list[TextualMemoryItem]:
raise NotImplementedError
- def get_all(self) -> dict:
+ def get_all(self, user_name: str | None = None) -> dict:
"""Get all memories.
Returns:
list[TextualMemoryItem]: List of all memories.
"""
- all_items = self.graph_store.export_graph()
+ all_items = self.graph_store.export_graph(user_name=user_name)
return all_items
- def delete(self, memory_ids: list[str]) -> None:
- raise NotImplementedError
+ def delete(self, memory_ids: list[str], user_name: str | None = None) -> None:
+ """Hard delete: permanently remove nodes and their edges from the graph."""
+ if not memory_ids:
+ return
+ for mid in memory_ids:
+ try:
+ self.graph_store.delete_node(mid, user_name=user_name)
+ except Exception as e:
+ logger.warning(f"TreeTextMemory.delete_hard: failed to delete {mid}: {e}")
def delete_all(self) -> None:
"""Delete all memories and their relationships from the graph store."""
diff --git a/src/memos/memories/textual/tree_text_memory/organize/manager.py b/src/memos/memories/textual/tree_text_memory/organize/manager.py
index 3e1609cb7..0c41717ea 100644
--- a/src/memos/memories/textual/tree_text_memory/organize/manager.py
+++ b/src/memos/memories/textual/tree_text_memory/organize/manager.py
@@ -1,3 +1,4 @@
+import re
import traceback
import uuid
@@ -19,6 +20,37 @@
logger = get_logger(__name__)
+def extract_working_binding_ids(mem_items: list[TextualMemoryItem]) -> set[str]:
+ """
+ Scan enhanced memory items for background hints like
+ "[working_binding:]" and collect those working memory IDs.
+
+ We store the working<->long binding inside metadata.background when
+ initially adding memories in async mode, so we can later clean up
+ the temporary WorkingMemory nodes after mem_reader produces the
+ final LongTermMemory/UserMemory.
+
+ Args:
+ mem_items: list of TextualMemoryItem we just added (enhanced memories)
+
+ Returns:
+ A set of working memory IDs (as strings) that should be deleted.
+ """
+ bindings: set[str] = set()
+ pattern = re.compile(r"\[working_binding:([0-9a-fA-F-]{36})\]")
+ for item in mem_items:
+ try:
+ bg = getattr(item.metadata, "background", "") or ""
+ except Exception:
+ bg = ""
+ if not isinstance(bg, str):
+ continue
+ match = pattern.search(bg)
+ if match:
+ bindings.add(match.group(1))
+ return bindings
+
+
class MemoryManager:
def __init__(
self,
@@ -52,13 +84,15 @@ def __init__(
)
self._merged_threshold = merged_threshold
- def add(self, memories: list[TextualMemoryItem], user_name: str | None = None) -> list[str]:
+ def add(
+ self, memories: list[TextualMemoryItem], user_name: str | None = None, mode: str = "sync"
+ ) -> list[str]:
"""
- Add new memories in parallel to different memory types (WorkingMemory, LongTermMemory, UserMemory).
+ Add new memories in parallel to different memory types.
"""
added_ids: list[str] = []
- with ContextThreadPoolExecutor(max_workers=8) as executor:
+ with ContextThreadPoolExecutor(max_workers=20) as executor:
futures = {executor.submit(self._process_memory, m, user_name): m for m in memories}
for future in as_completed(futures, timeout=60):
try:
@@ -67,17 +101,18 @@ def add(self, memories: list[TextualMemoryItem], user_name: str | None = None) -
except Exception as e:
logger.exception("Memory processing error: ", exc_info=e)
- for mem_type in ["WorkingMemory", "LongTermMemory", "UserMemory"]:
- try:
- self.graph_store.remove_oldest_memory(
- memory_type="WorkingMemory",
- keep_latest=self.memory_size[mem_type],
- user_name=user_name,
- )
- except Exception:
- logger.warning(f"Remove {mem_type} error: {traceback.format_exc()}")
-
- self._refresh_memory_size(user_name=user_name)
+ if mode == "sync":
+ for mem_type in ["WorkingMemory", "LongTermMemory", "UserMemory"]:
+ try:
+ self.graph_store.remove_oldest_memory(
+ memory_type="WorkingMemory",
+ keep_latest=self.memory_size[mem_type],
+ user_name=user_name,
+ )
+ except Exception:
+ logger.warning(f"Remove {mem_type} error: {traceback.format_exc()}")
+
+ self._refresh_memory_size(user_name=user_name)
return added_ids
def replace_working_memory(
@@ -121,63 +156,102 @@ def _refresh_memory_size(self, user_name: str | None = None) -> None:
results = self.graph_store.get_grouped_counts(
group_fields=["memory_type"], user_name=user_name
)
- self.current_memory_size = {record["memory_type"]: record["count"] for record in results}
+ self.current_memory_size = {
+ record["memory_type"]: int(record["count"]) for record in results
+ }
logger.info(f"[MemoryManager] Refreshed memory sizes: {self.current_memory_size}")
def _process_memory(self, memory: TextualMemoryItem, user_name: str | None = None):
"""
- Process and add memory to different memory types (WorkingMemory, LongTermMemory, UserMemory).
- This method runs asynchronously to process each memory item.
+ Process and add memory to different memory types.
+
+ Behavior:
+ 1. Always create a WorkingMemory node from `memory` and get its node id.
+ 2. If `memory.metadata.memory_type` is "LongTermMemory" or "UserMemory",
+ also create a corresponding long/user node.
+ - In async mode, that long/user node's metadata will include
+ `working_binding` in `background` which records the WorkingMemory
+ node id created in step 1.
+ 3. Return ONLY the ids of the long/user nodes (NOT the working node id),
+ which preserves the previous external contract of `add()`.
"""
- ids = []
+ ids: list[str] = []
+ futures = []
- # Add to WorkingMemory do not return working_id
- self._add_memory_to_db(memory, "WorkingMemory", user_name)
+ working_id = str(uuid.uuid4())
- # Add to LongTermMemory and UserMemory
- if memory.metadata.memory_type in ["LongTermMemory", "UserMemory"]:
- added_id = self._add_to_graph_memory(
- memory=memory, memory_type=memory.metadata.memory_type, user_name=user_name
+ with ContextThreadPoolExecutor(max_workers=2, thread_name_prefix="mem") as ex:
+ f_working = ex.submit(
+ self._add_memory_to_db, memory, "WorkingMemory", user_name, working_id
)
- ids.append(added_id)
+ futures.append(("working", f_working))
+
+ if memory.metadata.memory_type in ("LongTermMemory", "UserMemory"):
+ f_graph = ex.submit(
+ self._add_to_graph_memory,
+ memory=memory,
+ memory_type=memory.metadata.memory_type,
+ user_name=user_name,
+ working_binding=working_id,
+ )
+ futures.append(("long", f_graph))
+
+ for kind, fut in futures:
+ try:
+ res = fut.result()
+ if kind != "working" and isinstance(res, str) and res:
+ ids.append(res)
+ except Exception:
+ logger.warning("Parallel memory processing failed:\n%s", traceback.format_exc())
return ids
def _add_memory_to_db(
- self, memory: TextualMemoryItem, memory_type: str, user_name: str | None = None
+ self,
+ memory: TextualMemoryItem,
+ memory_type: str,
+ user_name: str | None = None,
+ forced_id: str | None = None,
) -> str:
"""
Add a single memory item to the graph store, with FIFO logic for WorkingMemory.
+ If forced_id is provided, use that as the node id.
"""
metadata = memory.metadata.model_copy(update={"memory_type": memory_type}).model_dump(
exclude_none=True
)
metadata["updated_at"] = datetime.now().isoformat()
- working_memory = TextualMemoryItem(memory=memory.memory, metadata=metadata)
-
+ node_id = forced_id or str(uuid.uuid4())
+ working_memory = TextualMemoryItem(id=node_id, memory=memory.memory, metadata=metadata)
# Insert node into graph
self.graph_store.add_node(working_memory.id, working_memory.memory, metadata, user_name)
- return working_memory.id
+ return node_id
def _add_to_graph_memory(
- self, memory: TextualMemoryItem, memory_type: str, user_name: str | None = None
+ self,
+ memory: TextualMemoryItem,
+ memory_type: str,
+ user_name: str | None = None,
+ working_binding: str | None = None,
):
"""
Generalized method to add memory to a graph-based memory type (e.g., LongTermMemory, UserMemory).
-
- Parameters:
- - memory: memory item to insert
- - memory_type: "LongTermMemory" | "UserMemory"
- - similarity_threshold: deduplication threshold
- - topic_summary_prefix: summary node id prefix if applicable
- - enable_summary_link: whether to auto-link to a summary node
"""
node_id = str(uuid.uuid4())
# Step 2: Add new node to graph
+ metadata_dict = memory.metadata.model_dump(exclude_none=True)
+ tags = metadata_dict.get("tags") or []
+ if working_binding and ("mode:fast" in tags):
+ prev_bg = metadata_dict.get("background", "") or ""
+ binding_line = f"[working_binding:{working_binding}] direct built from raw inputs"
+ if prev_bg:
+ metadata_dict["background"] = prev_bg + " || " + binding_line
+ else:
+ metadata_dict["background"] = binding_line
self.graph_store.add_node(
node_id,
memory.memory,
- memory.metadata.model_dump(exclude_none=True),
+ metadata_dict,
user_name=user_name,
)
self.reorganizer.add_message(
@@ -268,6 +342,32 @@ def _ensure_structure_path(
# Step 3: Return this structure node ID as the parent_id
return node_id
+ def remove_and_refresh_memory(self, user_name: str | None = None):
+ self._cleanup_memories_if_needed(user_name=user_name)
+ self._refresh_memory_size(user_name=user_name)
+
+ def _cleanup_memories_if_needed(self, user_name: str | None = None) -> None:
+ """
+ Only clean up memories if we're close to or over the limit.
+ This reduces unnecessary database operations.
+ """
+ cleanup_threshold = 0.8 # Clean up when 80% full
+
+ logger.info(f"self.memory_size: {self.memory_size}")
+ for memory_type, limit in self.memory_size.items():
+ current_count = self.current_memory_size.get(memory_type, 0)
+ threshold = int(int(limit) * cleanup_threshold)
+
+ # Only clean up if we're at or above the threshold
+ if current_count >= threshold:
+ try:
+ self.graph_store.remove_oldest_memory(
+ memory_type=memory_type, keep_latest=limit, user_name=user_name
+ )
+ logger.debug(f"Cleaned up {memory_type}: {current_count} -> {limit}")
+ except Exception:
+ logger.warning(f"Remove {memory_type} error: {traceback.format_exc()}")
+
def wait_reorganizer(self):
"""
Wait for the reorganizer to finish processing all messages.
diff --git a/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py b/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
index 0337225d1..ea06a7c60 100644
--- a/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
+++ b/src/memos/memories/textual/tree_text_memory/organize/reorganizer.py
@@ -1,5 +1,4 @@
import json
-import threading
import time
import traceback
@@ -10,7 +9,7 @@
import numpy as np
-from memos.context.context import ContextThreadPoolExecutor
+from memos.context.context import ContextThread, ContextThreadPoolExecutor
from memos.dependency import require_python_package
from memos.embedders.factory import OllamaEmbedder
from memos.graph_dbs.item import GraphDBEdge, GraphDBNode
@@ -94,12 +93,12 @@ def __init__(
self._reorganize_needed = True
if self.is_reorganize:
# ____ 1. For queue message driven thread ___________
- self.thread = threading.Thread(target=self._run_message_consumer_loop)
+ self.thread = ContextThread(target=self._run_message_consumer_loop)
self.thread.start()
# ____ 2. For periodic structure optimization _______
self._stop_scheduler = False
self._is_optimizing = {"LongTermMemory": False, "UserMemory": False}
- self.structure_optimizer_thread = threading.Thread(
+ self.structure_optimizer_thread = ContextThread(
target=self._run_structure_organizer_loop
)
self.structure_optimizer_thread.start()
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py b/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py
new file mode 100644
index 000000000..4aca4022f
--- /dev/null
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/bm25_util.py
@@ -0,0 +1,186 @@
+import threading
+
+import numpy as np
+
+from sklearn.feature_extraction.text import TfidfVectorizer
+
+from memos.dependency import require_python_package
+from memos.log import get_logger
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import FastTokenizer
+from memos.utils import timed
+
+
+logger = get_logger(__name__)
+# Global model cache
+_CACHE_LOCK = threading.Lock()
+
+
+class EnhancedBM25:
+ """Enhanced BM25 with Spacy tokenization and TF-IDF reranking"""
+
+ @require_python_package(import_name="cachetools", install_command="pip install cachetools")
+ def __init__(self, tokenizer=None, en_model="en_core_web_sm", zh_model="zh_core_web_sm"):
+ """
+ Initialize Enhanced BM25 with memory management
+ """
+ if tokenizer is None:
+ self.tokenizer = FastTokenizer()
+ else:
+ self.tokenizer = tokenizer
+ self._current_tfidf = None
+
+ global _BM25_CACHE
+ from cachetools import LRUCache
+
+ _BM25_CACHE = LRUCache(maxsize=100)
+
+ def _tokenize_doc(self, text):
+ """
+ Tokenize a single document using SpacyTokenizer
+ """
+ return self.tokenizer.tokenize_mixed(text, lang="auto")
+
+ @require_python_package(import_name="rank_bm25", install_command="pip install rank_bm25")
+ def _prepare_corpus_data(self, corpus, corpus_name="default"):
+ from rank_bm25 import BM25Okapi
+
+ with _CACHE_LOCK:
+ if corpus_name in _BM25_CACHE:
+ print("hit::", corpus_name)
+ return _BM25_CACHE[corpus_name]
+ print("not hit::", corpus_name)
+
+ tokenized_corpus = [self._tokenize_doc(doc) for doc in corpus]
+ bm25_model = BM25Okapi(tokenized_corpus)
+ _BM25_CACHE[corpus_name] = bm25_model
+ return bm25_model
+
+ def clear_cache(self, corpus_name=None):
+ """Clear cache for specific corpus or clear all cache"""
+ with _CACHE_LOCK:
+ if corpus_name:
+ if corpus_name in _BM25_CACHE:
+ del _BM25_CACHE[corpus_name]
+ else:
+ _BM25_CACHE.clear()
+
+ def get_cache_info(self):
+ """Get current cache information"""
+ with _CACHE_LOCK:
+ return {
+ "cache_size": len(_BM25_CACHE),
+ "max_cache_size": 100,
+ "cached_corpora": list(_BM25_CACHE.keys()),
+ }
+
+ def _search_docs(
+ self,
+ query: str,
+ corpus: list[str],
+ corpus_name="test",
+ top_k=50,
+ use_tfidf=False,
+ rerank_candidates_multiplier=2,
+ cleanup=False,
+ ):
+ """
+ Args:
+ query: Search query string
+ corpus: List of document texts
+ top_k: Number of top results to return
+ rerank_candidates_multiplier: Multiplier for candidate selection
+ cleanup: Whether to cleanup memory after search (default: True)
+ """
+ if not corpus:
+ return []
+
+ logger.info(f"Searching {len(corpus)} documents for query: '{query}'")
+
+ try:
+ # Prepare BM25 model
+ bm25_model = self._prepare_corpus_data(corpus, corpus_name=corpus_name)
+ tokenized_query = self._tokenize_doc(query)
+ tokenized_query = list(dict.fromkeys(tokenized_query))
+
+ # Get BM25 scores
+ bm25_scores = bm25_model.get_scores(tokenized_query)
+
+ # Select candidates
+ candidate_count = min(top_k * rerank_candidates_multiplier, len(corpus))
+ candidate_indices = np.argsort(bm25_scores)[-candidate_count:][::-1]
+ combined_scores = bm25_scores[candidate_indices]
+
+ if use_tfidf:
+ # Create TF-IDF for this search
+ tfidf = TfidfVectorizer(
+ tokenizer=self._tokenize_doc, lowercase=False, token_pattern=None
+ )
+ tfidf_matrix = tfidf.fit_transform(corpus)
+
+ # TF-IDF reranking
+ query_vec = tfidf.transform([query])
+ tfidf_similarities = (
+ (tfidf_matrix[candidate_indices] * query_vec.T).toarray().flatten()
+ )
+
+ # Combine scores
+ combined_scores = 0.7 * bm25_scores[candidate_indices] + 0.3 * tfidf_similarities
+
+ sorted_candidate_indices = candidate_indices[np.argsort(combined_scores)[::-1][:top_k]]
+ sorted_combined_scores = np.sort(combined_scores)[::-1][:top_k]
+
+ # build result list
+ bm25_recalled_results = []
+ for rank, (doc_idx, combined_score) in enumerate(
+ zip(sorted_candidate_indices, sorted_combined_scores, strict=False), 1
+ ):
+ bm25_score = bm25_scores[doc_idx]
+
+ candidate_pos = np.where(candidate_indices == doc_idx)[0][0]
+ tfidf_score = tfidf_similarities[candidate_pos] if use_tfidf else 0
+
+ bm25_recalled_results.append(
+ {
+ "text": corpus[doc_idx],
+ "bm25_score": float(bm25_score),
+ "tfidf_score": float(tfidf_score),
+ "combined_score": float(combined_score),
+ "rank": rank,
+ "doc_index": int(doc_idx),
+ }
+ )
+
+ logger.debug(f"Search completed: found {len(bm25_recalled_results)} results")
+ return bm25_recalled_results
+
+ except Exception as e:
+ logger.error(f"BM25 search failed: {e}")
+ return []
+ finally:
+ # Always cleanup if requested
+ if cleanup:
+ self._cleanup_memory()
+
+ @timed
+ def search(self, query: str, node_dicts: list[dict], corpus_name="default", **kwargs):
+ """
+ Search with BM25 and optional TF-IDF reranking
+ """
+ try:
+ corpus_list = []
+ for node_dict in node_dicts:
+ corpus_list.append(
+ " ".join([node_dict["metadata"]["key"]] + node_dict["metadata"]["tags"])
+ )
+
+ recalled_results = self._search_docs(
+ query, corpus_list, corpus_name=corpus_name, **kwargs
+ )
+ bm25_searched_nodes = []
+ for item in recalled_results:
+ doc_idx = item["doc_index"]
+ bm25_searched_nodes.append(node_dicts[doc_idx])
+ return bm25_searched_nodes
+ except Exception as e:
+ logger.error(f"Error in bm25 search: {e}")
+ return []
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/recall.py b/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
index d4cfcf501..8cf2f47f3 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/recall.py
@@ -5,6 +5,7 @@
from memos.graph_dbs.neo4j import Neo4jGraphDB
from memos.log import get_logger
from memos.memories.textual.item import TextualMemoryItem
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
from memos.memories.textual.tree_text_memory.retrieve.retrieval_mid_structs import ParsedTaskGoal
@@ -16,11 +17,18 @@ class GraphMemoryRetriever:
Unified memory retriever that combines both graph-based and vector-based retrieval logic.
"""
- def __init__(self, graph_store: Neo4jGraphDB, embedder: OllamaEmbedder):
+ def __init__(
+ self,
+ graph_store: Neo4jGraphDB,
+ embedder: OllamaEmbedder,
+ bm25_retriever: EnhancedBM25 | None = None,
+ ):
self.graph_store = graph_store
self.embedder = embedder
+ self.bm25_retriever = bm25_retriever
self.max_workers = 10
self.filter_weight = 0.6
+ self.use_bm25 = bool(self.bm25_retriever)
def retrieve(
self,
@@ -31,6 +39,8 @@ def retrieve(
query_embedding: list[list[float]] | None = None,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
+ use_fast_graph: bool = False,
) -> list[TextualMemoryItem]:
"""
Perform hybrid memory retrieval:
@@ -58,9 +68,15 @@ def retrieve(
)
return [TextualMemoryItem.from_dict(record) for record in working_memories]
- with ContextThreadPoolExecutor(max_workers=2) as executor:
+ with ContextThreadPoolExecutor(max_workers=3) as executor:
# Structured graph-based retrieval
- future_graph = executor.submit(self._graph_recall, parsed_goal, memory_scope, user_name)
+ future_graph = executor.submit(
+ self._graph_recall,
+ parsed_goal,
+ memory_scope,
+ user_name,
+ use_fast_graph=use_fast_graph,
+ )
# Vector similarity search
future_vector = executor.submit(
self._vector_recall,
@@ -70,12 +86,23 @@ def retrieve(
search_filter=search_filter,
user_name=user_name,
)
+ if self.use_bm25:
+ future_bm25 = executor.submit(
+ self._bm25_recall,
+ query,
+ parsed_goal,
+ memory_scope,
+ top_k=top_k,
+ user_name=user_name,
+ search_filter=id_filter,
+ )
graph_results = future_graph.result()
vector_results = future_vector.result()
+ bm25_results = future_bm25.result() if self.use_bm25 else []
# Merge and deduplicate by ID
- combined = {item.id: item for item in graph_results + vector_results}
+ combined = {item.id: item for item in graph_results + vector_results + bm25_results}
graph_ids = {item.id for item in graph_results}
combined_ids = set(combined.keys())
@@ -135,7 +162,7 @@ def retrieve_from_cube(
return list(combined.values())
def _graph_recall(
- self, parsed_goal: ParsedTaskGoal, memory_scope: str, user_name: str | None = None
+ self, parsed_goal: ParsedTaskGoal, memory_scope: str, user_name: str | None = None, **kwargs
) -> list[TextualMemoryItem]:
"""
Perform structured node-based retrieval from Neo4j.
@@ -143,37 +170,9 @@ def _graph_recall(
- tags must overlap with at least 2 input tags
- scope filters by memory_type if provided
"""
- candidate_ids = set()
-
- # 1) key-based OR branch
- if parsed_goal.keys:
- key_filters = [
- {"field": "key", "op": "in", "value": parsed_goal.keys},
- {"field": "memory_type", "op": "=", "value": memory_scope},
- ]
- key_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
- candidate_ids.update(key_ids)
-
- # 2) tag-based OR branch
- if parsed_goal.tags:
- tag_filters = [
- {"field": "tags", "op": "contains", "value": parsed_goal.tags},
- {"field": "memory_type", "op": "=", "value": memory_scope},
- ]
- tag_ids = self.graph_store.get_by_metadata(tag_filters, user_name=user_name)
- candidate_ids.update(tag_ids)
-
- # No matches → return empty
- if not candidate_ids:
- return []
+ use_fast_graph = kwargs.get("use_fast_graph", False)
- # Load nodes and post-filter
- node_dicts = self.graph_store.get_nodes(
- list(candidate_ids), include_embedding=False, user_name=user_name
- )
-
- final_nodes = []
- for node in node_dicts:
+ def process_node(node):
meta = node.get("metadata", {})
node_key = meta.get("key")
node_tags = meta.get("tags", []) or []
@@ -184,19 +183,113 @@ def _graph_recall(
keep = True
# overlap tags more than 2
elif parsed_goal.tags:
- overlap = len(set(node_tags) & set(parsed_goal.tags))
+ node_tags_list = [tag.lower() for tag in node_tags]
+ overlap = len(set(node_tags_list) & set(parsed_goal.tags))
if overlap >= 2:
keep = True
+
if keep:
- final_nodes.append(TextualMemoryItem.from_dict(node))
- return final_nodes
+ return TextualMemoryItem.from_dict(node)
+ return None
+
+ if not use_fast_graph:
+ candidate_ids = set()
+
+ # 1) key-based OR branch
+ if parsed_goal.keys:
+ key_filters = [
+ {"field": "key", "op": "in", "value": parsed_goal.keys},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ key_ids = self.graph_store.get_by_metadata(key_filters)
+ candidate_ids.update(key_ids)
+
+ # 2) tag-based OR branch
+ if parsed_goal.tags:
+ tag_filters = [
+ {"field": "tags", "op": "contains", "value": parsed_goal.tags},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ tag_ids = self.graph_store.get_by_metadata(tag_filters)
+ candidate_ids.update(tag_ids)
+
+ # No matches → return empty
+ if not candidate_ids:
+ return []
+
+ # Load nodes and post-filter
+ node_dicts = self.graph_store.get_nodes(list(candidate_ids), include_embedding=False)
+
+ final_nodes = []
+ for node in node_dicts:
+ meta = node.get("metadata", {})
+ node_key = meta.get("key")
+ node_tags = meta.get("tags", []) or []
+
+ keep = False
+ # key equals to node_key
+ if parsed_goal.keys and node_key in parsed_goal.keys:
+ keep = True
+ # overlap tags more than 2
+ elif parsed_goal.tags:
+ overlap = len(set(node_tags) & set(parsed_goal.tags))
+ if overlap >= 2:
+ keep = True
+ if keep:
+ final_nodes.append(TextualMemoryItem.from_dict(node))
+ return final_nodes
+ else:
+ candidate_ids = set()
+
+ # 1) key-based OR branch
+ if parsed_goal.keys:
+ key_filters = [
+ {"field": "key", "op": "in", "value": parsed_goal.keys},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ key_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
+ candidate_ids.update(key_ids)
+
+ # 2) tag-based OR branch
+ if parsed_goal.tags:
+ tag_filters = [
+ {"field": "tags", "op": "contains", "value": parsed_goal.tags},
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ tag_ids = self.graph_store.get_by_metadata(tag_filters, user_name=user_name)
+ candidate_ids.update(tag_ids)
+
+ # No matches → return empty
+ if not candidate_ids:
+ return []
+
+ # Load nodes and post-filter
+ node_dicts = self.graph_store.get_nodes(
+ list(candidate_ids), include_embedding=False, user_name=user_name
+ )
+
+ final_nodes = []
+ with ContextThreadPoolExecutor(max_workers=3) as executor:
+ futures = {
+ executor.submit(process_node, node): i for i, node in enumerate(node_dicts)
+ }
+ temp_results = [None] * len(node_dicts)
+
+ for future in concurrent.futures.as_completed(futures):
+ original_index = futures[future]
+ result = future.result()
+ temp_results[original_index] = result
+
+ final_nodes = [result for result in temp_results if result is not None]
+ return final_nodes
def _vector_recall(
self,
query_embedding: list[list[float]],
memory_scope: str,
top_k: int = 20,
- max_num: int = 3,
+ max_num: int = 5,
+ status: str = "activated",
cube_name: str | None = None,
search_filter: dict | None = None,
user_name: str | None = None,
@@ -213,6 +306,7 @@ def search_single(vec, filt=None):
self.graph_store.search_by_embedding(
vector=vec,
top_k=top_k,
+ status=status,
scope=memory_scope,
cube_name=cube_name,
search_filter=filt,
@@ -267,3 +361,37 @@ def search_path_b():
or []
)
return [TextualMemoryItem.from_dict(n) for n in node_dicts]
+
+ def _bm25_recall(
+ self,
+ query: str,
+ parsed_goal: ParsedTaskGoal,
+ memory_scope: str,
+ top_k: int = 20,
+ user_name: str | None = None,
+ search_filter: dict | None = None,
+ ) -> list[TextualMemoryItem]:
+ """
+ Perform BM25-based retrieval.
+ """
+ if not self.bm25_retriever:
+ return []
+ key_filters = [
+ {"field": "memory_type", "op": "=", "value": memory_scope},
+ ]
+ # corpus_name is user_name + user_id
+ corpus_name = f"{user_name}" if user_name else ""
+ if search_filter is not None:
+ for key in search_filter:
+ value = search_filter[key]
+ key_filters.append({"field": key, "op": "=", "value": value})
+ corpus_name += "".join(list(search_filter.values()))
+ candidate_ids = self.graph_store.get_by_metadata(key_filters, user_name=user_name)
+ node_dicts = self.graph_store.get_nodes(list(candidate_ids), include_embedding=False)
+
+ bm25_query = " ".join(list({query, *parsed_goal.keys}))
+ bm25_results = self.bm25_retriever.search(
+ bm25_query, node_dicts, top_k=top_k, corpus_name=corpus_name
+ )
+
+ return [TextualMemoryItem.from_dict(n) for n in bm25_results]
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py b/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
index 6accc4a16..7aefaa1a3 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/retrieval_mid_structs.py
@@ -13,3 +13,4 @@ class ParsedTaskGoal:
rephrased_query: str | None = None
internet_search: bool = False
goal_type: str | None = None # e.g., 'default', 'explanation', etc.
+ context: str = ""
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py b/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py
new file mode 100644
index 000000000..3f2b41a47
--- /dev/null
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/retrieve_utils.py
@@ -0,0 +1,378 @@
+import json
+import re
+
+from pathlib import Path
+
+from memos.dependency import require_python_package
+from memos.log import get_logger
+
+
+logger = get_logger(__name__)
+
+
+def find_project_root(marker=".git"):
+ """Find the project root directory by marking the file"""
+ current = Path(__file__).resolve()
+ while current != current.parent:
+ if (current / marker).exists():
+ return current
+ current = current.parent
+ return Path(".")
+
+
+PROJECT_ROOT = find_project_root()
+DEFAULT_STOPWORD_FILE = (
+ PROJECT_ROOT / "examples" / "data" / "config" / "stopwords.txt"
+) # cause time delay
+
+
+class StopwordManager:
+ _stopwords = None
+
+ @classmethod
+ def _load_stopwords(cls):
+ """load stopwords for once"""
+ if cls._stopwords is not None:
+ return cls._stopwords
+
+ stopwords = set()
+ try:
+ with open(DEFAULT_STOPWORD_FILE, encoding="utf-8") as f:
+ stopwords = {line.strip() for line in f if line.strip()}
+ logger.info("Stopwords loaded successfully.")
+ except Exception as e:
+ logger.warning(f"Error loading stopwords: {e}, using default stopwords.")
+ stopwords = cls._load_default_stopwords()
+
+ cls._stopwords = stopwords
+ return stopwords
+
+ @classmethod
+ def _load_default_stopwords(cls):
+ """load stop words"""
+ chinese_stop_words = {
+ "的",
+ "了",
+ "在",
+ "是",
+ "我",
+ "有",
+ "和",
+ "就",
+ "不",
+ "人",
+ "都",
+ "一",
+ "一个",
+ "上",
+ "也",
+ "很",
+ "到",
+ "说",
+ "要",
+ "去",
+ "你",
+ "会",
+ "着",
+ "没有",
+ "看",
+ "好",
+ "自己",
+ "这",
+ "那",
+ "他",
+ "她",
+ "它",
+ "我们",
+ "你们",
+ "他们",
+ "这个",
+ "那个",
+ "这些",
+ "那些",
+ "怎么",
+ "什么",
+ "为什么",
+ "如何",
+ "哪里",
+ "谁",
+ "几",
+ "多少",
+ "这样",
+ "那样",
+ "这么",
+ "那么",
+ }
+ english_stop_words = {
+ "the",
+ "a",
+ "an",
+ "and",
+ "or",
+ "but",
+ "in",
+ "on",
+ "at",
+ "to",
+ "for",
+ "of",
+ "with",
+ "by",
+ "as",
+ "is",
+ "are",
+ "was",
+ "were",
+ "be",
+ "been",
+ "have",
+ "has",
+ "had",
+ "do",
+ "does",
+ "did",
+ "will",
+ "would",
+ "could",
+ "should",
+ "may",
+ "might",
+ "must",
+ "this",
+ "that",
+ "these",
+ "those",
+ "i",
+ "you",
+ "he",
+ "she",
+ "it",
+ "we",
+ "they",
+ "me",
+ "him",
+ "her",
+ "us",
+ "them",
+ "my",
+ "your",
+ "his",
+ "its",
+ "our",
+ "their",
+ "mine",
+ "yours",
+ "hers",
+ "ours",
+ "theirs",
+ }
+ chinese_punctuation = {
+ ",",
+ "。",
+ "!",
+ "?",
+ ";",
+ ":",
+ "「",
+ "」",
+ "『",
+ "』",
+ "【",
+ "】",
+ "(",
+ ")",
+ "《",
+ "》",
+ "—",
+ "…",
+ "~",
+ "·",
+ "、",
+ "“",
+ "”",
+ "‘",
+ "’",
+ "〈",
+ "〉",
+ "〖",
+ "〗",
+ "〝",
+ "〞",
+ "{",
+ "}",
+ "〔",
+ "〕",
+ "¡",
+ "¿",
+ }
+ english_punctuation = {
+ ",",
+ ".",
+ "!",
+ "?",
+ ";",
+ ":",
+ '"',
+ "'",
+ "(",
+ ")",
+ "[",
+ "]",
+ "{",
+ "}",
+ "<",
+ ">",
+ "/",
+ "\\",
+ "|",
+ "-",
+ "_",
+ "=",
+ "+",
+ "@",
+ "#",
+ "$",
+ "%",
+ "^",
+ "&",
+ "*",
+ "~",
+ "`",
+ "¡",
+ "¿",
+ }
+ numbers = {
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5",
+ "6",
+ "7",
+ "8",
+ "9",
+ "零",
+ "一",
+ "二",
+ "三",
+ "四",
+ "五",
+ "六",
+ "七",
+ "八",
+ "九",
+ "十",
+ "百",
+ "千",
+ "万",
+ "亿",
+ }
+ whitespace = {" ", "\t", "\n", "\r", "\f", "\v"}
+
+ return (
+ chinese_stop_words
+ | english_stop_words
+ | chinese_punctuation
+ | english_punctuation
+ | numbers
+ | whitespace
+ )
+
+ @classmethod
+ def get_stopwords(cls):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return cls._stopwords
+
+ @classmethod
+ def filter_words(cls, words):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return [word for word in words if word not in cls._stopwords and word.strip()]
+
+ @classmethod
+ def is_stopword(cls, word):
+ if cls._stopwords is None:
+ cls._load_stopwords()
+ return word in cls._stopwords
+
+ @classmethod
+ def reload_stopwords(cls, file_path=None):
+ cls._stopwords = None
+ if file_path:
+ global DEFAULT_STOPWORD_FILE
+ DEFAULT_STOPWORD_FILE = file_path
+ cls._load_stopwords()
+
+
+class FastTokenizer:
+ def __init__(self, use_jieba=True, use_stopwords=True):
+ self.use_jieba = use_jieba
+ self.use_stopwords = use_stopwords
+ if self.use_stopwords:
+ self.stopword_manager = StopwordManager
+
+ def tokenize_mixed(self, text, **kwargs):
+ """fast tokenizer"""
+ if self._is_chinese(text):
+ return self._tokenize_chinese(text)
+ else:
+ return self._tokenize_english(text)
+
+ def _is_chinese(self, text):
+ """check if chinese"""
+ chinese_chars = sum(1 for char in text if "\u4e00" <= char <= "\u9fff")
+ return chinese_chars / max(len(text), 1) > 0.3
+
+ @require_python_package(
+ import_name="jieba",
+ install_command="pip install jieba",
+ install_link="https://github.com/fxsjy/jieba",
+ )
+ def _tokenize_chinese(self, text):
+ """split zh jieba"""
+ import jieba
+
+ tokens = jieba.lcut(text) if self.use_jieba else list(text)
+ tokens = [token.strip() for token in tokens if token.strip()]
+ if self.use_stopwords:
+ return self.stopword_manager.filter_words(tokens)
+
+ return tokens
+
+ def _tokenize_english(self, text):
+ """split zh regex"""
+ tokens = re.findall(r"\b[a-zA-Z0-9]+\b", text.lower())
+ if self.use_stopwords:
+ return self.stopword_manager.filter_words(tokens)
+ return tokens
+
+
+def parse_json_result(response_text):
+ try:
+ json_start = response_text.find("{")
+ response_text = response_text[json_start:]
+ response_text = response_text.replace("```", "").strip()
+ if not response_text.endswith("}"):
+ response_text += "}"
+ return json.loads(response_text)
+ except json.JSONDecodeError as e:
+ logger.error(f"[JSONParse] Failed to decode JSON: {e}\nRaw:\n{response_text}")
+ return {}
+ except Exception as e:
+ logger.error(f"[JSONParse] Unexpected error: {e}")
+ return {}
+
+
+def detect_lang(text):
+ try:
+ if not text or not isinstance(text, str):
+ return "en"
+ chinese_pattern = r"[\u4e00-\u9fff\u3400-\u4dbf\U00020000-\U0002a6df\U0002a700-\U0002b73f\U0002b740-\U0002b81f\U0002b820-\U0002ceaf\uf900-\ufaff]"
+ chinese_chars = re.findall(chinese_pattern, text)
+ if len(chinese_chars) / len(re.sub(r"[\s\d\W]", "", text)) > 0.3:
+ return "zh"
+ return "en"
+ except Exception:
+ return "en"
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py b/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
index 05db56f53..f408755fd 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/searcher.py
@@ -1,15 +1,23 @@
-import json
import traceback
-from datetime import datetime
-
from memos.context.context import ContextThreadPoolExecutor
from memos.embedders.factory import OllamaEmbedder
from memos.graph_dbs.factory import Neo4jGraphDB
from memos.llms.factory import AzureLLM, OllamaLLM, OpenAILLM
from memos.log import get_logger
from memos.memories.textual.item import SearchedTreeNodeTextualMemoryMetadata, TextualMemoryItem
+from memos.memories.textual.tree_text_memory.retrieve.bm25_util import EnhancedBM25
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import (
+ detect_lang,
+ parse_json_result,
+)
from memos.reranker.base import BaseReranker
+from memos.templates.mem_search_prompts import (
+ COT_PROMPT,
+ COT_PROMPT_ZH,
+ SIMPLE_COT_PROMPT,
+ SIMPLE_COT_PROMPT_ZH,
+)
from memos.utils import timed
from .reasoner import MemoryReasoner
@@ -18,6 +26,10 @@
logger = get_logger(__name__)
+COT_DICT = {
+ "fine": {"en": COT_PROMPT, "zh": COT_PROMPT_ZH},
+ "fast": {"en": SIMPLE_COT_PROMPT, "zh": SIMPLE_COT_PROMPT_ZH},
+}
class Searcher:
@@ -27,23 +39,71 @@ def __init__(
graph_store: Neo4jGraphDB,
embedder: OllamaEmbedder,
reranker: BaseReranker,
+ bm25_retriever: EnhancedBM25 | None = None,
internet_retriever: None = None,
moscube: bool = False,
+ search_strategy: dict | None = None,
):
self.graph_store = graph_store
self.embedder = embedder
+ self.llm = dispatcher_llm
self.task_goal_parser = TaskGoalParser(dispatcher_llm)
- self.graph_retriever = GraphMemoryRetriever(self.graph_store, self.embedder)
+ self.graph_retriever = GraphMemoryRetriever(graph_store, embedder, bm25_retriever)
self.reranker = reranker
self.reasoner = MemoryReasoner(dispatcher_llm)
# Create internet retriever from config if provided
self.internet_retriever = internet_retriever
self.moscube = moscube
+ self.vec_cot = search_strategy.get("cot", False) if search_strategy else False
+ self.use_fast_graph = search_strategy.get("fast_graph", False) if search_strategy else False
self._usage_executor = ContextThreadPoolExecutor(max_workers=4, thread_name_prefix="usage")
+ @timed
+ def retrieve(
+ self,
+ query: str,
+ top_k: int,
+ info=None,
+ mode="fast",
+ memory_type="All",
+ search_filter: dict | None = None,
+ user_name: str | None = None,
+ **kwargs,
+ ) -> list[TextualMemoryItem]:
+ logger.info(
+ f"[RECALL] Start query='{query}', top_k={top_k}, mode={mode}, memory_type={memory_type}"
+ )
+ parsed_goal, query_embedding, context, query = self._parse_task(
+ query, info, mode, search_filter=search_filter, user_name=user_name
+ )
+ results = self._retrieve_paths(
+ query,
+ parsed_goal,
+ query_embedding,
+ info,
+ top_k,
+ mode,
+ memory_type,
+ search_filter,
+ user_name,
+ )
+ return results
+
+ def post_retrieve(
+ self,
+ retrieved_results: list[TextualMemoryItem],
+ top_k: int,
+ user_name: str | None = None,
+ info=None,
+ ):
+ deduped = self._deduplicate_results(retrieved_results)
+ final_results = self._sort_and_trim(deduped, top_k)
+ self._update_usage_history(final_results, info, user_name)
+ return final_results
+
@timed
def search(
self,
@@ -72,9 +132,6 @@ def search(
Returns:
list[TextualMemoryItem]: List of matching memories.
"""
- logger.info(
- f"[SEARCH] Start query='{query}', top_k={top_k}, mode={mode}, memory_type={memory_type}"
- )
if not info:
logger.warning(
"Please input 'info' when use tree.search so that "
@@ -84,23 +141,22 @@ def search(
else:
logger.debug(f"[SEARCH] Received info dict: {info}")
- parsed_goal, query_embedding, context, query = self._parse_task(
- query, info, mode, search_filter=search_filter, user_name=user_name
+ retrieved_results = self.retrieve(
+ query=query,
+ top_k=top_k,
+ info=info,
+ mode=mode,
+ memory_type=memory_type,
+ search_filter=search_filter,
+ user_name=user_name,
)
- results = self._retrieve_paths(
- query,
- parsed_goal,
- query_embedding,
- info,
- top_k,
- mode,
- memory_type,
- search_filter,
- user_name,
+
+ final_results = self.post_retrieve(
+ retrieved_results=retrieved_results,
+ top_k=top_k,
+ user_name=user_name,
+ info=None,
)
- deduped = self._deduplicate_results(results)
- final_results = self._sort_and_trim(deduped, top_k)
- self._update_usage_history(final_results, info, user_name)
logger.info(f"[SEARCH] Done. Total {len(final_results)} results.")
res_results = ""
@@ -134,7 +190,11 @@ def _parse_task(
related_nodes = [
self.graph_store.get_node(n["id"])
for n in self.graph_store.search_by_embedding(
- query_embedding, top_k=top_k, search_filter=search_filter, user_name=user_name
+ query_embedding,
+ top_k=top_k,
+ status="activated",
+ search_filter=search_filter,
+ user_name=user_name,
)
]
memories = []
@@ -164,6 +224,7 @@ def _parse_task(
context="\n".join(context),
conversation=info.get("chat_history", []),
mode=mode,
+ use_fast_graph=self.use_fast_graph,
)
query = parsed_goal.rephrased_query or query
@@ -188,6 +249,12 @@ def _retrieve_paths(
):
"""Run A/B/C retrieval paths in parallel"""
tasks = []
+ id_filter = {
+ "user_id": info.get("user_id", None),
+ "session_id": info.get("session_id", None),
+ }
+ id_filter = {k: v for k, v in id_filter.items() if v is not None}
+
with ContextThreadPoolExecutor(max_workers=3) as executor:
tasks.append(
executor.submit(
@@ -199,6 +266,7 @@ def _retrieve_paths(
memory_type,
search_filter,
user_name,
+ id_filter,
)
)
tasks.append(
@@ -211,6 +279,8 @@ def _retrieve_paths(
memory_type,
search_filter,
user_name,
+ id_filter,
+ mode=mode,
)
)
tasks.append(
@@ -256,6 +326,7 @@ def _retrieve_from_working_memory(
memory_type,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
):
"""Retrieve and rerank from WorkingMemory"""
if memory_type not in ["All", "WorkingMemory"]:
@@ -268,6 +339,8 @@ def _retrieve_from_working_memory(
memory_scope="WorkingMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
return self.reranker.rerank(
query=query,
@@ -289,11 +362,23 @@ def _retrieve_from_long_term_and_user(
memory_type,
search_filter: dict | None = None,
user_name: str | None = None,
+ id_filter: dict | None = None,
+ mode: str = "fast",
):
"""Retrieve and rerank from LongTermMemory and UserMemory"""
results = []
tasks = []
+ # chain of thinking
+ cot_embeddings = []
+ if self.vec_cot:
+ queries = self._cot_query(query, mode=mode, context=parsed_goal.context)
+ if len(queries) > 1:
+ cot_embeddings = self.embedder.embed(queries)
+ cot_embeddings.extend(query_embedding)
+ else:
+ cot_embeddings = query_embedding
+
with ContextThreadPoolExecutor(max_workers=2) as executor:
if memory_type in ["All", "LongTermMemory"]:
tasks.append(
@@ -301,11 +386,13 @@ def _retrieve_from_long_term_and_user(
self.graph_retriever.retrieve,
query=query,
parsed_goal=parsed_goal,
- query_embedding=query_embedding,
+ query_embedding=cot_embeddings,
top_k=top_k * 2,
memory_scope="LongTermMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
)
if memory_type in ["All", "UserMemory"]:
@@ -314,11 +401,13 @@ def _retrieve_from_long_term_and_user(
self.graph_retriever.retrieve,
query=query,
parsed_goal=parsed_goal,
- query_embedding=query_embedding,
+ query_embedding=cot_embeddings,
top_k=top_k * 2,
memory_scope="UserMemory",
search_filter=search_filter,
user_name=user_name,
+ id_filter=id_filter,
+ use_fast_graph=self.use_fast_graph,
)
)
@@ -399,6 +488,7 @@ def _deduplicate_results(self, results):
@timed
def _sort_and_trim(self, results, top_k):
"""Sort results by score and trim to top_k"""
+
sorted_results = sorted(results, key=lambda pair: pair[1], reverse=True)[:top_k]
final_items = []
for item, score in sorted_results:
@@ -415,7 +505,7 @@ def _sort_and_trim(self, results, top_k):
@timed
def _update_usage_history(self, items, info, user_name: str | None = None):
- """Update usage history in graph DB"""
+ """Update usage history in graph DB
now_time = datetime.now().isoformat()
info_copy = dict(info or {})
info_copy.pop("chat_history", None)
@@ -439,6 +529,7 @@ def _update_usage_history(self, items, info, user_name: str | None = None):
self._usage_executor.submit(
self._update_usage_history_worker, payload, usage_record, user_name
)
+ """
def _update_usage_history_worker(
self, payload, usage_record: str, user_name: str | None = None
@@ -448,3 +539,41 @@ def _update_usage_history_worker(
self.graph_store.update_node(item_id, {"usage": usage_list}, user_name=user_name)
except Exception:
logger.exception("[USAGE] update usage failed")
+
+ def _cot_query(
+ self,
+ query,
+ mode="fast",
+ split_num: int = 3,
+ context: list[str] | None = None,
+ ) -> list[str]:
+ """Generate chain-of-thought queries"""
+
+ lang = detect_lang(query)
+ if mode == "fine" and context:
+ template = COT_DICT["fine"][lang]
+ prompt = (
+ template.replace("${original_query}", query)
+ .replace("${split_num_threshold}", str(split_num))
+ .replace("${context}", "\n".join(context))
+ )
+ else:
+ template = COT_DICT["fast"][lang]
+ prompt = template.replace("${original_query}", query).replace(
+ "${split_num_threshold}", str(split_num)
+ )
+
+ messages = [{"role": "user", "content": prompt}]
+ try:
+ response_text = self.llm.generate(messages, temperature=0, top_p=1)
+ response_json = parse_json_result(response_text)
+ assert "is_complex" in response_json
+ if not response_json["is_complex"]:
+ return [query]
+ else:
+ assert "sub_questions" in response_json
+ logger.info("Query: {} COT: {}".format(query, response_json["sub_questions"]))
+ return response_json["sub_questions"][:split_num]
+ except Exception as e:
+ logger.error(f"[LLM] Exception during chat generation: {e}")
+ return [query]
diff --git a/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py b/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
index 273c4f480..55e33494c 100644
--- a/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
+++ b/src/memos/memories/textual/tree_text_memory/retrieve/task_goal_parser.py
@@ -5,6 +5,7 @@
from memos.llms.base import BaseLLM
from memos.log import get_logger
from memos.memories.textual.tree_text_memory.retrieve.retrieval_mid_structs import ParsedTaskGoal
+from memos.memories.textual.tree_text_memory.retrieve.retrieve_utils import FastTokenizer
from memos.memories.textual.tree_text_memory.retrieve.utils import TASK_PARSE_PROMPT
@@ -20,6 +21,7 @@ class TaskGoalParser:
def __init__(self, llm=BaseLLM):
self.llm = llm
+ self.tokenizer = FastTokenizer()
def parse(
self,
@@ -27,6 +29,7 @@ def parse(
context: str = "",
conversation: list[dict] | None = None,
mode: str = "fast",
+ **kwargs,
) -> ParsedTaskGoal:
"""
Parse user input into structured semantic layers.
@@ -36,7 +39,7 @@ def parse(
- mode == 'fine': use LLM to parse structured topic/keys/tags
"""
if mode == "fast":
- return self._parse_fast(task_description)
+ return self._parse_fast(task_description, context=context, **kwargs)
elif mode == "fine":
if not self.llm:
raise ValueError("LLM not provided for slow mode.")
@@ -44,18 +47,33 @@ def parse(
else:
raise ValueError(f"Unknown mode: {mode}")
- def _parse_fast(self, task_description: str, limit_num: int = 5) -> ParsedTaskGoal:
+ def _parse_fast(self, task_description: str, **kwargs) -> ParsedTaskGoal:
"""
Fast mode: simple jieba word split.
"""
- return ParsedTaskGoal(
- memories=[task_description],
- keys=[task_description],
- tags=[],
- goal_type="default",
- rephrased_query=task_description,
- internet_search=False,
- )
+ context = kwargs.get("context", "")
+ use_fast_graph = kwargs.get("use_fast_graph", False)
+ if use_fast_graph:
+ desc_tokenized = self.tokenizer.tokenize_mixed(task_description)
+ return ParsedTaskGoal(
+ memories=[task_description],
+ keys=desc_tokenized,
+ tags=desc_tokenized,
+ goal_type="default",
+ rephrased_query=task_description,
+ internet_search=False,
+ context=context,
+ )
+ else:
+ return ParsedTaskGoal(
+ memories=[task_description],
+ keys=[task_description],
+ tags=[],
+ goal_type="default",
+ rephrased_query=task_description,
+ internet_search=False,
+ context=context,
+ )
def _parse_fine(
self, query: str, context: str = "", conversation: list[dict] | None = None
@@ -76,16 +94,17 @@ def _parse_fine(
logger.info(f"Parsing Goal... LLM input is {prompt}")
response = self.llm.generate(messages=[{"role": "user", "content": prompt}])
logger.info(f"Parsing Goal... LLM Response is {response}")
- return self._parse_response(response)
+ return self._parse_response(response, context=context)
except Exception:
logger.warning(f"Fail to fine-parse query {query}: {traceback.format_exc()}")
- return self._parse_fast(query)
+ return self._parse_fast(query, context=context)
- def _parse_response(self, response: str) -> ParsedTaskGoal:
+ def _parse_response(self, response: str, **kwargs) -> ParsedTaskGoal:
"""
Parse LLM JSON output safely.
"""
try:
+ context = kwargs.get("context", "")
response = response.replace("```", "").replace("json", "").strip()
response_json = eval(response)
return ParsedTaskGoal(
@@ -95,6 +114,7 @@ def _parse_response(self, response: str) -> ParsedTaskGoal:
rephrased_query=response_json.get("rephrased_instruction", None),
internet_search=response_json.get("internet_search", False),
goal_type=response_json.get("goal_type", "default"),
+ context=context,
)
except Exception as e:
raise ValueError(f"Failed to parse LLM output: {e}\nRaw response:\n{response}") from e
diff --git a/src/memos/reranker/base.py b/src/memos/reranker/base.py
index 77a24c164..1c2f86ac5 100644
--- a/src/memos/reranker/base.py
+++ b/src/memos/reranker/base.py
@@ -16,8 +16,9 @@ class BaseReranker(ABC):
def rerank(
self,
query: str,
- graph_results: list,
+ graph_results: list[TextualMemoryItem],
top_k: int,
+ search_filter: dict | None = None,
**kwargs,
) -> list[tuple[TextualMemoryItem, float]]:
"""Return top_k (item, score) sorted by score desc."""
diff --git a/src/memos/reranker/concat.py b/src/memos/reranker/concat.py
index 5ad339529..502af18b6 100644
--- a/src/memos/reranker/concat.py
+++ b/src/memos/reranker/concat.py
@@ -2,12 +2,49 @@
from typing import Any
+from memos.memories.textual.item import SourceMessage
+
_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+def get_encoded_tokens(content: str) -> int:
+ """
+ Get encoded tokens.
+ Args:
+ content: str
+ Returns:
+ int: Encoded tokens.
+ """
+ return len(content)
+
+
+def truncate_data(data: list[str | dict[str, Any] | Any], max_tokens: int) -> list[str]:
+ """
+ Truncate data to max tokens.
+ Args:
+ data: List of strings or dictionaries.
+ max_tokens: Maximum number of tokens.
+ Returns:
+ str: Truncated string.
+ """
+ truncated_string = ""
+ for item in data:
+ if isinstance(item, SourceMessage):
+ content = getattr(item, "content", "")
+ chat_time = getattr(item, "chat_time", "")
+ if not content:
+ continue
+ truncated_string += f"[{chat_time}]: {content}\n"
+ if get_encoded_tokens(truncated_string) > max_tokens:
+ break
+ return truncated_string
+
+
def process_source(
- items: list[tuple[Any, str | dict[str, Any] | list[Any]]] | None = None, recent_num: int = 3
+ items: list[tuple[Any, str | dict[str, Any] | list[Any]]] | None = None,
+ recent_num: int = 10,
+ max_tokens: int = 2048,
) -> str:
"""
Args:
@@ -23,19 +60,16 @@ def process_source(
memory = None
for item in items:
memory, source = item
- for content in source:
- if isinstance(content, str):
- if "assistant:" in content:
- continue
- concat_data.append(content)
+ concat_data.extend(source[-recent_num:])
+ truncated_string = truncate_data(concat_data, max_tokens)
if memory is not None:
- concat_data = [memory, *concat_data]
- return "\n".join(concat_data)
+ truncated_string = f"{memory}\n{truncated_string}"
+ return truncated_string
def concat_original_source(
graph_results: list,
- merge_field: list[str] | None = None,
+ rerank_source: str | None = None,
) -> list[str]:
"""
Merge memory items with original dialogue.
@@ -45,14 +79,16 @@ def concat_original_source(
Returns:
list[str]: List of memory and concat orginal memory.
"""
- if merge_field is None:
- merge_field = ["sources"]
+ merge_field = []
+ merge_field = ["sources"] if rerank_source is None else rerank_source.split(",")
documents = []
for item in graph_results:
memory = _TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m
sources = []
for field in merge_field:
- source = getattr(item.metadata, field, "")
+ source = getattr(item.metadata, field, None)
+ if source is None:
+ continue
sources.append((memory, source))
concat_string = process_source(sources)
documents.append(concat_string)
diff --git a/src/memos/reranker/cosine_local.py b/src/memos/reranker/cosine_local.py
index 000b64cf4..318cd744a 100644
--- a/src/memos/reranker/cosine_local.py
+++ b/src/memos/reranker/cosine_local.py
@@ -3,6 +3,9 @@
from typing import TYPE_CHECKING
+from memos.log import get_logger
+from memos.utils import timed
+
from .base import BaseReranker
@@ -16,6 +19,8 @@
except Exception:
_HAS_NUMPY = False
+logger = get_logger(__name__)
+
def _cosine_one_to_many(q: list[float], m: list[list[float]]) -> list[float]:
"""
@@ -54,6 +59,7 @@ def __init__(
self.level_weights = level_weights or {"topic": 1.0, "concept": 1.0, "fact": 1.0}
self.level_field = level_field
+ @timed
def rerank(
self,
query: str,
@@ -92,5 +98,5 @@ def get_weight(it: TextualMemoryItem) -> float:
chosen = {it.id for it, _ in top_items}
remain = [(it, -1.0) for it in graph_results if it.id not in chosen]
top_items.extend(remain[: top_k - len(top_items)])
-
+ logger.info(f"CosineLocalReranker rerank result: {top_items[:1]}")
return top_items
diff --git a/src/memos/reranker/factory.py b/src/memos/reranker/factory.py
index 134e29eb9..57460a4af 100644
--- a/src/memos/reranker/factory.py
+++ b/src/memos/reranker/factory.py
@@ -8,6 +8,7 @@
from .cosine_local import CosineLocalReranker
from .http_bge import HTTPBGEReranker
+from .http_bge_strategy import HTTPBGERerankerStrategy
from .noop import NoopReranker
@@ -45,4 +46,14 @@ def from_config(cfg: RerankerConfigFactory | None) -> BaseReranker | None:
if backend in {"noop", "none", "disabled"}:
return NoopReranker()
+ if backend in {"http_bge_strategy", "bge_strategy"}:
+ return HTTPBGERerankerStrategy(
+ reranker_url=c.get("url") or c.get("endpoint") or c.get("reranker_url"),
+ model=c.get("model", "bge-reranker-v2-m3"),
+ timeout=int(c.get("timeout", 10)),
+ headers_extra=c.get("headers_extra"),
+ rerank_source=c.get("rerank_source"),
+ reranker_strategy=c.get("reranker_strategy"),
+ )
+
raise ValueError(f"Unknown reranker backend: {cfg.backend}")
diff --git a/src/memos/reranker/http_bge.py b/src/memos/reranker/http_bge.py
index f0f5d17a0..41011df14 100644
--- a/src/memos/reranker/http_bge.py
+++ b/src/memos/reranker/http_bge.py
@@ -9,6 +9,7 @@
import requests
from memos.log import get_logger
+from memos.utils import timed
from .base import BaseReranker
from .concat import concat_original_source
@@ -80,7 +81,7 @@ def __init__(
model: str = "bge-reranker-v2-m3",
timeout: int = 10,
headers_extra: dict | None = None,
- rerank_source: list[str] | None = None,
+ rerank_source: str | None = None,
boost_weights: dict[str, float] | None = None,
boost_default: float = 0.0,
warn_unknown_filter_keys: bool = True,
@@ -107,7 +108,7 @@ def __init__(
self.model = model
self.timeout = timeout
self.headers_extra = headers_extra or {}
- self.concat_source = rerank_source
+ self.rerank_source = rerank_source
self.boost_weights = (
DEFAULT_BOOST_WEIGHTS.copy()
@@ -118,6 +119,7 @@ def __init__(
self.warn_unknown_filter_keys = bool(warn_unknown_filter_keys)
self._warned_missing_keys: set[str] = set()
+ @timed(log=True, log_prefix="RerankerAPI")
def rerank(
self,
query: str,
@@ -152,8 +154,8 @@ def rerank(
# Build a mapping from "payload docs index" -> "original graph_results index"
# Only include items that have a non-empty string memory. This ensures that
# any index returned by the server can be mapped back correctly.
- if self.concat_source:
- documents = concat_original_source(graph_results, self.concat_source)
+ if self.rerank_source:
+ documents = concat_original_source(graph_results, self.rerank_source)
else:
documents = [
(_TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m)
diff --git a/src/memos/reranker/http_bge_strategy.py b/src/memos/reranker/http_bge_strategy.py
new file mode 100644
index 000000000..b0567698c
--- /dev/null
+++ b/src/memos/reranker/http_bge_strategy.py
@@ -0,0 +1,319 @@
+# memos/reranker/http_bge.py
+from __future__ import annotations
+
+import re
+
+from collections.abc import Iterable
+from typing import TYPE_CHECKING, Any
+
+import requests
+
+from memos.log import get_logger
+from memos.reranker.strategies import RerankerStrategyFactory
+from memos.utils import timed
+
+from .base import BaseReranker
+
+
+logger = get_logger(__name__)
+
+
+if TYPE_CHECKING:
+ from memos.memories.textual.item import TextualMemoryItem
+
+# Strip a leading "[...]" tag (e.g., "[2025-09-01] ..." or "[meta] ...")
+# before sending text to the reranker. This keeps inputs clean and
+# avoids misleading the model with bracketed prefixes.
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+DEFAULT_BOOST_WEIGHTS = {"user_id": 0.5, "tags": 0.2, "session_id": 0.3}
+
+
+def _value_matches(item_value: Any, wanted: Any) -> bool:
+ """
+ Generic matching:
+ - if item_value is list/tuple/set: check membership (any match if wanted is iterable)
+ - else: equality (any match if wanted is iterable)
+ """
+
+ def _iterable(x):
+ # exclude strings from "iterable"
+ return isinstance(x, Iterable) and not isinstance(x, str | bytes)
+
+ if _iterable(item_value):
+ if _iterable(wanted):
+ return any(w in item_value for w in wanted)
+ return wanted in item_value
+ else:
+ if _iterable(wanted):
+ return any(item_value == w for w in wanted)
+ return item_value == wanted
+
+
+class HTTPBGERerankerStrategy(BaseReranker):
+ """
+ HTTP-based BGE reranker.
+
+ This class sends (query, documents[]) to a remote HTTP endpoint that
+ performs cross-encoder-style re-ranking (e.g., BGE reranker) and returns
+ relevance scores. It then maps those scores back onto the original
+ TextualMemoryItem list and returns (item, score) pairs sorted by score.
+
+ Notes
+ -----
+ - The endpoint is expected to accept JSON:
+ {
+ "model": "",
+ "query": "",
+ "documents": ["doc1", "doc2", ...]
+ }
+ - Two response shapes are supported:
+ 1) {"results": [{"index": , "relevance_score": }, ...]}
+ where "index" refers to the *position in the documents array*.
+ 2) {"data": [{"score": }, ...]} (aligned by list order)
+ - If the service fails or responds unexpectedly, this falls back to
+ returning the original items with 0.0 scores (best-effort).
+ """
+
+ def __init__(
+ self,
+ reranker_url: str,
+ token: str = "",
+ model: str = "bge-reranker-v2-m3",
+ timeout: int = 10,
+ headers_extra: dict | None = None,
+ rerank_source: str | None = None,
+ boost_weights: dict[str, float] | None = None,
+ boost_default: float = 0.0,
+ warn_unknown_filter_keys: bool = True,
+ reranker_strategy: str = "single_turn",
+ **kwargs,
+ ):
+ """
+ Parameters
+ ----------
+ reranker_url : str
+ HTTP endpoint for the reranker service.
+ token : str, optional
+ Bearer token for auth. If non-empty, added to the Authorization header.
+ model : str, optional
+ Model identifier understood by the server.
+ timeout : int, optional
+ Request timeout (seconds).
+ headers_extra : dict | None, optional
+ Additional headers to merge into the request headers.
+ """
+ if not reranker_url:
+ raise ValueError("reranker_url must not be empty")
+ self.reranker_url = reranker_url
+ self.token = token or ""
+ self.model = model
+ self.timeout = timeout
+ self.headers_extra = headers_extra or {}
+
+ self.boost_weights = (
+ DEFAULT_BOOST_WEIGHTS.copy()
+ if boost_weights is None
+ else {k: float(v) for k, v in boost_weights.items()}
+ )
+ self.boost_default = float(boost_default)
+ self.warn_unknown_filter_keys = bool(warn_unknown_filter_keys)
+ self._warned_missing_keys: set[str] = set()
+ self.reranker_strategy = RerankerStrategyFactory.from_config(reranker_strategy)
+
+ @timed(log=True, log_prefix="RerankerStrategy")
+ def rerank(
+ self,
+ query: str,
+ graph_results: list[TextualMemoryItem],
+ top_k: int,
+ search_filter: dict | None = None,
+ **kwargs,
+ ) -> list[tuple[TextualMemoryItem, float]]:
+ """
+ Rank candidate memories by relevance to the query.
+
+ Parameters
+ ----------
+ query : str
+ The search query.
+ graph_results : list[TextualMemoryItem]
+ Candidate items to re-rank. Each item is expected to have a
+ `.memory` str field; non-strings are ignored.
+ top_k : int
+ Return at most this many items.
+ search_filter : dict | None
+ Currently unused. Present to keep signature compatible.
+
+ Returns
+ -------
+ list[tuple[TextualMemoryItem, float]]
+ Re-ranked items with scores, sorted descending by score.
+ """
+ if not graph_results:
+ return []
+
+ tracker, original_items, documents = self.reranker_strategy.prepare_documents(
+ query, graph_results, top_k
+ )
+
+ logger.info(
+ f"[HTTPBGEWithSourceReranker] strategy: {self.reranker_strategy}, "
+ f"query: {query}, documents count: {len(documents)}"
+ )
+ logger.info(f"[HTTPBGEWithSourceReranker] sample documents: {documents[:3]}...")
+
+ if not documents:
+ return []
+
+ headers = {"Content-Type": "application/json", **self.headers_extra}
+ payload = {"model": self.model, "query": query, "documents": documents}
+
+ try:
+ # Make the HTTP request to the reranker service
+ resp = requests.post(
+ self.reranker_url, headers=headers, json=payload, timeout=self.timeout
+ )
+ resp.raise_for_status()
+ data = resp.json()
+
+ scored_items: list[tuple[TextualMemoryItem, float]] = []
+
+ if "results" in data:
+ # Format:
+ # dict("results": [{"index": int, "relevance_score": float},
+ # ...])
+ rows = data.get("results", [])
+
+ ranked_indices = []
+ scores = []
+ for r in rows:
+ idx = r.get("index")
+ # The returned index refers to 'documents' (i.e., our 'pairs' order),
+ # so we must map it back to the original graph_results index.
+ if isinstance(idx, int) and 0 <= idx < len(graph_results):
+ raw_score = float(r.get("relevance_score", r.get("score", 0.0)))
+ ranked_indices.append(idx)
+ scores.append(raw_score)
+ reconstructed_items = self.reranker_strategy.reconstruct_items(
+ ranked_indices=ranked_indices,
+ scores=scores,
+ tracker=tracker,
+ original_items=original_items,
+ top_k=top_k,
+ graph_results=graph_results,
+ documents=documents,
+ )
+ return reconstructed_items
+
+ elif "data" in data:
+ # Format: {"data": [{"score": float}, ...]} aligned by list order
+ rows = data.get("data", [])
+ # Build a list of scores aligned with our 'documents' (pairs)
+ score_list = [float(r.get("score", 0.0)) for r in rows]
+
+ if len(score_list) < len(graph_results):
+ score_list += [0.0] * (len(graph_results) - len(score_list))
+ elif len(score_list) > len(graph_results):
+ score_list = score_list[: len(graph_results)]
+
+ scored_items = []
+ for item, raw_score in zip(graph_results, score_list, strict=False):
+ score = self._apply_boost_generic(item, raw_score, search_filter)
+ scored_items.append((item, score))
+
+ scored_items.sort(key=lambda x: x[1], reverse=True)
+ return scored_items[: min(top_k, len(scored_items))]
+
+ else:
+ # Unexpected response schema: return a 0.0-scored fallback of the first top_k valid docs
+ # Note: we use 'pairs' to keep alignment with valid (string) docs.
+ return [(item, 0.0) for item in graph_results[:top_k]]
+
+ except Exception as e:
+ # Network error, timeout, JSON decode error, etc.
+ # Degrade gracefully by returning first top_k valid docs with 0.0 score.
+ logger.error(f"[HTTPBGEReranker] request failed: {e}")
+ return [(item, 0.0) for item in graph_results[:top_k]]
+
+ def _get_attr_or_key(self, obj: Any, key: str) -> Any:
+ """
+ Resolve `key` on `obj` with one-level fallback into `obj.metadata`.
+
+ Priority:
+ 1) obj.
+ 2) obj[key]
+ 3) obj.metadata.
+ 4) obj.metadata[key]
+ """
+ if obj is None:
+ return None
+
+ # support input like "metadata.user_id"
+ if "." in key:
+ head, tail = key.split(".", 1)
+ base = self._get_attr_or_key(obj, head)
+ return self._get_attr_or_key(base, tail)
+
+ def _resolve(o: Any, k: str):
+ if o is None:
+ return None
+ v = getattr(o, k, None)
+ if v is not None:
+ return v
+ if hasattr(o, "get"):
+ try:
+ return o.get(k)
+ except Exception:
+ return None
+ return None
+
+ # 1) find in obj
+ v = _resolve(obj, key)
+ if v is not None:
+ return v
+
+ # 2) find in obj.metadata
+ meta = _resolve(obj, "metadata")
+ if meta is not None:
+ return _resolve(meta, key)
+
+ return None
+
+ def _apply_boost_generic(
+ self,
+ item: TextualMemoryItem,
+ base_score: float,
+ search_filter: dict | None,
+ ) -> float:
+ """
+ Multiply base_score by (1 + weight) for each matching key in search_filter.
+ - key resolution: self._get_attr_or_key(item, key)
+ - weight = boost_weights.get(key, self.boost_default)
+ - unknown key -> one-time warning
+ """
+ if not search_filter:
+ return base_score
+
+ score = float(base_score)
+
+ for key, wanted in search_filter.items():
+ # _get_attr_or_key automatically find key in item and
+ # item.metadata ("metadata.user_id" supported)
+ resolved = self._get_attr_or_key(item, key)
+
+ if resolved is None:
+ if self.warn_unknown_filter_keys and key not in self._warned_missing_keys:
+ logger.warning(
+ "[HTTPBGEReranker] search_filter key '%s' not found on TextualMemoryItem or metadata",
+ key,
+ )
+ self._warned_missing_keys.add(key)
+ continue
+
+ if _value_matches(resolved, wanted):
+ w = float(self.boost_weights.get(key, self.boost_default))
+ if w != 0.0:
+ score *= 1.0 + w
+ score = min(max(0.0, score), 1.0)
+
+ return score
diff --git a/src/memos/reranker/noop.py b/src/memos/reranker/noop.py
index 7a9c02f60..04250bef7 100644
--- a/src/memos/reranker/noop.py
+++ b/src/memos/reranker/noop.py
@@ -2,6 +2,8 @@
from typing import TYPE_CHECKING
+from memos.utils import timed
+
from .base import BaseReranker
@@ -10,6 +12,7 @@
class NoopReranker(BaseReranker):
+ @timed
def rerank(
self, query: str, graph_results: list, top_k: int, **kwargs
) -> list[tuple[TextualMemoryItem, float]]:
diff --git a/src/memos/reranker/strategies/__init__.py b/src/memos/reranker/strategies/__init__.py
new file mode 100644
index 000000000..cee60f2be
--- /dev/null
+++ b/src/memos/reranker/strategies/__init__.py
@@ -0,0 +1,4 @@
+from .factory import RerankerStrategyFactory
+
+
+__all__ = ["RerankerStrategyFactory"]
diff --git a/src/memos/reranker/strategies/base.py b/src/memos/reranker/strategies/base.py
new file mode 100644
index 000000000..43166dd92
--- /dev/null
+++ b/src/memos/reranker/strategies/base.py
@@ -0,0 +1,61 @@
+from abc import ABC, abstractmethod
+from typing import Any
+
+from memos.memories.textual.item import TextualMemoryItem
+
+from .dialogue_common import DialogueRankingTracker
+
+
+class BaseRerankerStrategy(ABC):
+ """Abstract interface for memory rerankers with concatenation strategy."""
+
+ @abstractmethod
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list[TextualMemoryItem],
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents for ranking based on the strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of TextualMemoryItem objects to process
+ top_k: Maximum number of items to return
+ **kwargs: Additional strategy-specific parameters
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+ raise NotImplementedError
+
+ @abstractmethod
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[TextualMemoryItem, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked results.
+
+ Args:
+ ranked_indices: List of indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+ **kwargs: Additional strategy-specific parameters
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ raise NotImplementedError
diff --git a/src/memos/reranker/strategies/concat_background.py b/src/memos/reranker/strategies/concat_background.py
new file mode 100644
index 000000000..a52313548
--- /dev/null
+++ b/src/memos/reranker/strategies/concat_background.py
@@ -0,0 +1,94 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+import re
+
+from typing import Any
+
+from .base import BaseRerankerStrategy
+from .dialogue_common import DialogueRankingTracker
+
+
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+
+
+class ConcatBackgroundStrategy(BaseRerankerStrategy):
+ """
+ Concat background strategy.
+
+ This strategy processes dialogue pairs by concatenating background and
+ user and assistant messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+
+ original_items = {}
+ tracker = DialogueRankingTracker()
+ documents = []
+ for item in graph_results:
+ memory = getattr(item, "memory", None)
+ if isinstance(memory, str):
+ memory = _TAG1.sub("", memory)
+
+ background = ""
+ if hasattr(item, "metadata") and hasattr(item.metadata, "background"):
+ background = getattr(item.metadata, "background", "")
+ if not isinstance(background, str):
+ background = ""
+
+ documents.append(f"{memory}\n{background}")
+ return tracker, original_items, documents
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ graph_results = kwargs.get("graph_results")
+ documents = kwargs.get("documents")
+ reconstructed_items = []
+ for idx in ranked_indices:
+ item = graph_results[idx]
+ item.memory = f"{item.memory}\n{documents[idx]}"
+ reconstructed_items.append((item, scores[idx]))
+
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/reranker/strategies/dialogue_common.py b/src/memos/reranker/strategies/dialogue_common.py
new file mode 100644
index 000000000..ce0138284
--- /dev/null
+++ b/src/memos/reranker/strategies/dialogue_common.py
@@ -0,0 +1,109 @@
+from __future__ import annotations
+
+import re
+
+from typing import Any, Literal
+
+from pydantic import BaseModel
+
+from memos.memories.textual.item import SourceMessage, TextualMemoryItem
+
+
+# Strip a leading "[...]" tag (e.g., "[2025-09-01] ..." or "[meta] ...")
+# before sending text to the reranker. This keeps inputs clean and
+# avoids misleading the model with bracketed prefixes.
+_TAG1 = re.compile(r"^\s*\[[^\]]*\]\s*")
+
+
+def strip_memory_tags(item: TextualMemoryItem) -> str:
+ """Strip leading tags from memory text."""
+ memory = _TAG1.sub("", m) if isinstance((m := getattr(item, "memory", None)), str) else m
+ return memory
+
+
+def extract_content(msg: dict[str, Any] | str) -> str:
+ """Extract content from message, handling both string and dict formats."""
+ if isinstance(msg, dict):
+ return msg.get("content", str(msg))
+ if isinstance(msg, SourceMessage):
+ return msg.content
+ return str(msg)
+
+
+class DialoguePair(BaseModel):
+ """Represents a single dialogue pair extracted from sources."""
+
+ pair_id: str # Unique identifier for this dialogue pair
+ memory_id: str # ID of the source TextualMemoryItem
+ memory: str
+ pair_index: int # Index of this pair within the source memory's dialogue
+ user_msg: str | dict[str, Any] | SourceMessage # User message content
+ assistant_msg: str | dict[str, Any] | SourceMessage # Assistant message content
+ combined_text: str # The concatenated text used for ranking
+ chat_time: str | None = None
+
+ @property
+ def user_content(self) -> str:
+ """Get user message content as string."""
+ return extract_content(self.user_msg)
+
+ @property
+ def assistant_content(self) -> str:
+ """Get assistant message content as string."""
+ return extract_content(self.assistant_msg)
+
+
+class DialogueRankingTracker:
+ """Tracks dialogue pairs and their rankings for memory reconstruction."""
+
+ def __init__(self):
+ self.dialogue_pairs: list[DialoguePair] = []
+
+ def add_dialogue_pair(
+ self,
+ memory_id: str,
+ pair_index: int,
+ user_msg: str | dict[str, Any],
+ assistant_msg: str | dict[str, Any],
+ memory: str,
+ chat_time: str | None = None,
+ concat_format: Literal["user_assistant", "user_only"] = "user_assistant",
+ ) -> str:
+ """Add a dialogue pair and return its unique ID."""
+ user_content = extract_content(user_msg)
+ assistant_content = extract_content(assistant_msg)
+ if concat_format == "user_assistant":
+ combined_text = f"[{chat_time}]: \nuser: {user_content}\nassistant: {assistant_content}"
+ elif concat_format == "user_only":
+ combined_text = f"[{chat_time}]: \nuser: {user_content}"
+ else:
+ raise ValueError(f"Invalid concat format: {concat_format}")
+
+ pair_id = f"{memory_id}_{pair_index}"
+
+ dialogue_pair = DialoguePair(
+ pair_id=pair_id,
+ memory_id=memory_id,
+ pair_index=pair_index,
+ user_msg=user_msg,
+ assistant_msg=assistant_msg,
+ combined_text=combined_text,
+ memory=memory,
+ chat_time=chat_time,
+ )
+
+ self.dialogue_pairs.append(dialogue_pair)
+ return pair_id
+
+ def get_documents_for_ranking(self, concat_memory: bool = True) -> list[str]:
+ """Get the combined text documents for ranking."""
+ if concat_memory:
+ return [(pair.memory + "\n\n" + pair.combined_text) for pair in self.dialogue_pairs]
+ else:
+ return [pair.combined_text for pair in self.dialogue_pairs]
+
+ def get_dialogue_pair_by_index(self, index: int) -> DialoguePair | None:
+ """Get dialogue pair by its index in the ranking results."""
+ if 0 <= index < len(self.dialogue_pairs):
+ return self.dialogue_pairs[index]
+ return None
diff --git a/src/memos/reranker/strategies/factory.py b/src/memos/reranker/strategies/factory.py
new file mode 100644
index 000000000..d93cbd65a
--- /dev/null
+++ b/src/memos/reranker/strategies/factory.py
@@ -0,0 +1,29 @@
+# memos/reranker/factory.py
+from __future__ import annotations
+
+from typing import TYPE_CHECKING, Any, ClassVar
+
+from .concat_background import ConcatBackgroundStrategy
+from .single_turn import SingleTurnStrategy
+from .singleturn_outmem import SingleTurnOutMemStrategy
+
+
+if TYPE_CHECKING:
+ from .base import BaseRerankerStrategy
+
+
+class RerankerStrategyFactory:
+ """Factory class for creating reranker strategy instances."""
+
+ backend_to_class: ClassVar[dict[str, Any]] = {
+ "single_turn": SingleTurnStrategy,
+ "concat_background": ConcatBackgroundStrategy,
+ "singleturn_outmem": SingleTurnOutMemStrategy,
+ }
+
+ @classmethod
+ def from_config(cls, config_factory: str = "single_turn") -> BaseRerankerStrategy:
+ if config_factory not in cls.backend_to_class:
+ raise ValueError(f"Invalid backend: {config_factory}")
+ strategy_class = cls.backend_to_class[config_factory]
+ return strategy_class()
diff --git a/src/memos/reranker/strategies/single_turn.py b/src/memos/reranker/strategies/single_turn.py
new file mode 100644
index 000000000..d86744811
--- /dev/null
+++ b/src/memos/reranker/strategies/single_turn.py
@@ -0,0 +1,107 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+from copy import deepcopy
+from typing import Any
+
+from .base import BaseRerankerStrategy
+from .dialogue_common import DialogueRankingTracker, extract_content, strip_memory_tags
+
+
+class SingleTurnStrategy(BaseRerankerStrategy):
+ """
+ Single turn dialogue strategy.
+
+ This strategy processes dialogue pairs by concatenating user and assistant
+ messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ example:
+ >>> documents = ["chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ >>> output memory item: ["Memory:xxx \n\n chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+
+ original_items = {}
+ tracker = DialogueRankingTracker()
+ for item in graph_results:
+ memory = strip_memory_tags(item)
+ sources = getattr(item.metadata, "sources", [])
+ original_items[item.id] = item
+
+ # Group messages into pairs and concatenate
+ for i in range(0, len(sources), 2):
+ user_msg = sources[i] if i < len(sources) else {}
+ assistant_msg = sources[i + 1] if i + 1 < len(sources) else {}
+
+ user_content = extract_content(user_msg)
+ assistant_content = extract_content(assistant_msg)
+ chat_time = getattr(user_msg, "chat_time", "")
+
+ if user_content or assistant_content: # Only add non-empty pairs
+ pair_index = i // 2
+ tracker.add_dialogue_pair(
+ item.id, pair_index, user_msg, assistant_msg, memory or "", chat_time
+ )
+
+ documents = tracker.get_documents_for_ranking()
+ return tracker, original_items, documents
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ reconstructed_items = []
+ for idx, score in zip(ranked_indices, scores, strict=False):
+ dialogue_pair = tracker.get_dialogue_pair_by_index(idx)
+ if dialogue_pair and (dialogue_pair.memory_id in original_items):
+ original_item = original_items[dialogue_pair.memory_id]
+ reconstructed_item = deepcopy(original_item)
+ reconstructed_item.memory = (
+ dialogue_pair.memory
+ + "\n\nsources-dialogue-pairs"
+ + dialogue_pair.combined_text
+ )
+ reconstructed_items.append((reconstructed_item, score))
+
+ # Sort by aggregated score and return top_k
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/reranker/strategies/singleturn_outmem.py b/src/memos/reranker/strategies/singleturn_outmem.py
new file mode 100644
index 000000000..de59fec97
--- /dev/null
+++ b/src/memos/reranker/strategies/singleturn_outmem.py
@@ -0,0 +1,98 @@
+# memos/reranker/strategies/single_turn.py
+from __future__ import annotations
+
+from collections import defaultdict
+from typing import TYPE_CHECKING, Any
+
+from .dialogue_common import DialogueRankingTracker
+from .single_turn import SingleTurnStrategy
+
+
+if TYPE_CHECKING:
+ from .dialogue_common import DialogueRankingTracker
+
+
+class SingleTurnOutMemStrategy(SingleTurnStrategy):
+ """
+ Single turn dialogue strategy.
+
+ This strategy processes dialogue pairs by concatenating user and assistant
+ messages into single strings for ranking. Each dialogue pair becomes a
+ separate document for ranking.
+ example:
+ >>> documents = ["chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ >>> output memory item: ["Memory:xxx \n\n chat_time: 2025-01-01 12:00:00\nuser: hello\nassistant: hi there"]
+ """
+
+ def prepare_documents(
+ self,
+ query: str,
+ graph_results: list,
+ top_k: int,
+ **kwargs,
+ ) -> tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ """
+ Prepare documents based on single turn concatenation strategy.
+
+ Args:
+ query: The search query
+ graph_results: List of graph results
+ top_k: Maximum number of items to return
+
+ Returns:
+ tuple[DialogueRankingTracker, dict[str, Any], list[str]]:
+ - Tracker: DialogueRankingTracker instance
+ - original_items: Dict mapping memory_id to original TextualMemoryItem
+ - documents: List of text documents ready for ranking
+ """
+ return super().prepare_documents(query, graph_results, top_k, **kwargs)
+
+ def reconstruct_items(
+ self,
+ ranked_indices: list[int],
+ scores: list[float],
+ tracker: DialogueRankingTracker,
+ original_items: dict[str, Any],
+ top_k: int,
+ **kwargs,
+ ) -> list[tuple[Any, float]]:
+ """
+ Reconstruct TextualMemoryItem objects from ranked dialogue pairs.
+
+ Args:
+ ranked_indices: List of dialogue pair indices sorted by relevance
+ scores: Corresponding relevance scores
+ tracker: DialogueRankingTracker instance
+ original_items: Dict mapping memory_id to original TextualMemoryItem
+ top_k: Maximum number of items to return
+
+ Returns:
+ List of (reconstructed_memory_item, aggregated_score) tuples
+ """
+ # Group ranked pairs by memory_id
+ memory_groups = defaultdict(list)
+ memory_scores = defaultdict(list)
+
+ for idx, score in zip(ranked_indices, scores, strict=False):
+ dialogue_pair = tracker.get_dialogue_pair_by_index(idx)
+ if dialogue_pair:
+ memory_groups[dialogue_pair.memory_id].append(dialogue_pair)
+ memory_scores[dialogue_pair.memory_id].append(score)
+
+ reconstructed_items = []
+
+ for memory_id, _pairs in memory_groups.items():
+ if memory_id not in original_items:
+ continue
+ original_item = original_items[memory_id]
+
+ # Calculate aggregated score (e.g., max, mean, or weighted average)
+ pair_scores = memory_scores[memory_id]
+
+ aggregated_score = max(pair_scores) if pair_scores else 0.0
+
+ reconstructed_items.append((original_item, aggregated_score))
+
+ # Sort by aggregated score and return top_k
+ reconstructed_items.sort(key=lambda x: x[1], reverse=True)
+ return reconstructed_items[:top_k]
diff --git a/src/memos/templates/instruction_completion.py b/src/memos/templates/instruction_completion.py
new file mode 100644
index 000000000..b88ff474c
--- /dev/null
+++ b/src/memos/templates/instruction_completion.py
@@ -0,0 +1,66 @@
+from typing import Any
+
+from memos.mem_reader.simple_struct import detect_lang
+from memos.templates.prefer_complete_prompt import PREF_INSTRUCTIONS, PREF_INSTRUCTIONS_ZH
+
+
+def instruct_completion(
+ memories: list[dict[str, Any]] | None = None,
+) -> [str, str]:
+ """Create instruction following the preferences."""
+ explicit_pref = []
+ implicit_pref = []
+ for memory in memories:
+ pref_type = memory.get("metadata", {}).get("preference_type")
+ pref = memory.get("metadata", {}).get("preference", None)
+ if not pref:
+ continue
+ if pref_type == "explicit_preference":
+ explicit_pref.append(pref)
+ elif pref_type == "implicit_preference":
+ implicit_pref.append(pref)
+
+ explicit_pref_str = (
+ "Explicit Preference:\n"
+ + "\n".join(f"{i + 1}. {pref}" for i, pref in enumerate(explicit_pref))
+ if explicit_pref
+ else ""
+ )
+ implicit_pref_str = (
+ "Implicit Preference:\n"
+ + "\n".join(f"{i + 1}. {pref}" for i, pref in enumerate(implicit_pref))
+ if implicit_pref
+ else ""
+ )
+
+ _prompt_map = {
+ "zh": PREF_INSTRUCTIONS_ZH,
+ "en": PREF_INSTRUCTIONS,
+ }
+ _remove_exp_map = {
+ "zh": "显式偏好 > ",
+ "en": "explicit preference > ",
+ }
+ _remove_imp_map = {
+ "zh": "隐式偏好 > ",
+ "en": "implicit preference > ",
+ }
+ lang = detect_lang(
+ explicit_pref_str.replace("Explicit Preference:\n", "")
+ + implicit_pref_str.replace("Implicit Preference:\n", "")
+ )
+
+ if not explicit_pref_str and not implicit_pref_str:
+ return "", ""
+ if not explicit_pref_str:
+ pref_note = _prompt_map[lang].replace(_remove_exp_map[lang], "")
+ pref_string = implicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
+ if not implicit_pref_str:
+ pref_note = _prompt_map[lang].replace(_remove_imp_map[lang], "")
+ pref_string = explicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
+
+ pref_note = _prompt_map[lang]
+ pref_string = explicit_pref_str + "\n" + implicit_pref_str + "\n" + pref_note
+ return pref_string, pref_note
diff --git a/src/memos/templates/mem_reader_prompts.py b/src/memos/templates/mem_reader_prompts.py
index 15672f8d8..ec6812743 100644
--- a/src/memos/templates/mem_reader_prompts.py
+++ b/src/memos/templates/mem_reader_prompts.py
@@ -1,56 +1,50 @@
SIMPLE_STRUCT_MEM_READER_PROMPT = """You are a memory extraction expert.
-Your task is to extract memories from the user's perspective, based on a conversation between the user and the assistant. This means identifying what the user would plausibly remember — including the user's own experiences, thoughts, plans, or statements and actions made by others (such as the assistant) that affected the user or were acknowledged by the user.
-
-Please perform the following:
-1. Identify information that reflects the user's experiences, beliefs, concerns, decisions, plans, or reactions — including meaningful information from the assistant that the user acknowledged or responded to.
- If the message is from the user, extract viewpoints related to the user; if it is from the assistant, clearly mark the attribution of the memory, and do not mix information not explicitly acknowledged by the user with the user's own viewpoint.
- - **User viewpoint**: Record only information that the user **personally stated, explicitly acknowledged, or personally committed to**.
- - **Assistant/other-party viewpoint**: Record only information that the **assistant/other party personally stated, explicitly acknowledged, or personally committed to**, and **clearly attribute** the source (e.g., "[assistant-Jerry viewpoint]"). Do not rewrite it as the user's preference/decision.
- - **Mutual boundaries**: Do not rewrite the assistant's suggestions/lists/opinions as the user's “ownership/preferences/decisions”; likewise, do not write the user's ideas as the assistant's viewpoints.
-
-2. Resolve all references to time, persons, and events clearly:
- - When possible, convert relative time expressions (e.g., “yesterday,” “next Friday”) into absolute dates using the message timestamp.
- - Clearly distinguish between **event time** and **message time**.
+Your task is to extract memories from the perspective of user, based on a conversation between user and assistant. This means identifying what user would plausibly remember — including their own experiences, thoughts, plans, or relevant statements and actions made by others (such as assistant) that impacted or were acknowledged by user.
+Please perform:
+1. Identify information that reflects user's experiences, beliefs, concerns, decisions, plans, or reactions — including meaningful input from assistant that user acknowledged or responded to.
+If the message is from the user, extract user-relevant memories; if it is from the assistant, only extract factual memories that the user acknowledged or responded to.
+
+2. Resolve all time, person, and event references clearly:
+ - Convert relative time expressions (e.g., “yesterday,” “next Friday”) into absolute dates using the message timestamp if possible.
+ - Clearly distinguish between event time and message time.
- If uncertainty exists, state it explicitly (e.g., “around June 2025,” “exact date unclear”).
- Include specific locations if mentioned.
- - Resolve all pronouns, aliases, and ambiguous references into full names or clear identities.
- - If there are people with the same name, disambiguate them.
-
-3. Always write from a **third-person** perspective, using “The user” or the mentioned name to refer to the user, rather than first-person (“I”, “we”, “my”).
- For example, write “The user felt exhausted …” instead of “I felt exhausted …”.
-
-4. Do not omit any information that the user is likely to remember.
- - Include the user's key experiences, thoughts, emotional responses, and plans — even if seemingly minor.
- - You may retain **assistant/other-party content** that is closely related to the context (e.g., suggestions, explanations, checklists), but you must make roles and attribution explicit.
- - Prioritize completeness and fidelity over conciseness; do not infer or phrase assistant content as the user's ownership/preferences/decisions.
- - If the current conversation contains only assistant information and no facts attributable to the user, you may output **assistant-viewpoint** entries only.
-
-5. Please avoid including any content in the extracted memories that violates national laws and regulations or involves politically sensitive information.
+ - Resolve all pronouns, aliases, and ambiguous references into full names or identities.
+ - Disambiguate people with the same name if applicable.
+3. Always write from a third-person perspective, referring to user as
+"The user" or by name if name mentioned, rather than using first-person ("I", "me", "my").
+For example, write "The user felt exhausted..." instead of "I felt exhausted...".
+4. Do not omit any information that user is likely to remember.
+ - Include all key experiences, thoughts, emotional responses, and plans — even if they seem minor.
+ - Prioritize completeness and fidelity over conciseness.
+ - Do not generalize or skip details that could be personally meaningful to user.
+5. Please avoid any content that violates national laws and regulations or involves politically sensitive information in the memories you extract.
-Return a valid JSON object with the following structure:
+Return a single valid JSON object with the following structure:
{
"memory list": [
{
- "key": ,
- "memory_type": ,
- "value": ,
- "tags":
+ "key": ,
+ "memory_type": ,
+ "value": ,
+ "tags":
},
...
],
- "summary":
+ "summary":
}
Language rules:
-- The `key`, `value`, `tags`, and `summary` fields must match the primary language of the input conversation. **If the input is Chinese, output in Chinese.**
+- The `key`, `value`, `tags`, `summary` fields must match the mostly used language of the input conversation. **如果输入是中文,请输出中文**
- Keep `memory_type` in English.
Example:
Conversation:
user: [June 26, 2025 at 3:00 PM]: Hi Jerry! Yesterday at 3 PM I had a meeting with my team about the new project.
assistant: Oh Tom! Do you think the team can finish by December 15?
-user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until December 10, so testing will be tight.
+user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until
+December 10, so testing will be tight.
assistant: [June 26, 2025 at 3:00 PM]: Maybe propose an extension?
user: [June 26, 2025 at 4:21 PM]: Good idea. I’ll raise it in tomorrow’s 9:30 AM meeting—maybe shift the deadline to January 5.
@@ -60,62 +54,31 @@
{
"key": "Initial project meeting",
"memory_type": "LongTermMemory",
- "value": "[user-Tom viewpoint] On June 25, 2025 at 3:00 PM, Tom met with the team to discuss a new project. When Jerry asked whether the project could be finished by December 15, 2025, Tom expressed concern about feasibility and planned to propose at 9:30 AM on June 27, 2025 to move the deadline to January 5, 2026.",
+ "value": "On June 25, 2025 at 3:00 PM, Tom held a meeting with their team to discuss a new project. The conversation covered the timeline and raised concerns about the feasibility of the December 15, 2025 deadline.",
"tags": ["project", "timeline", "meeting", "deadline"]
},
{
- "key": "Jerry’s suggestion about the deadline",
- "memory_type": "LongTermMemory",
- "value": "[assistant-Jerry viewpoint] Jerry questioned the December 15 deadline and suggested considering an extension.",
- "tags": ["deadline change", "suggestion"]
- }
+ "key": "Planned scope adjustment",
+ "memory_type": "UserMemory",
+ "value": "Tom planned to suggest in a meeting on June 27, 2025 at 9:30 AM that the team should prioritize features and propose shifting the project deadline to January 5, 2026.",
+ "tags": ["planning", "deadline change", "feature prioritization"]
+ },
],
- "summary": "Tom is currently working on a tight-schedule project. After the June 25, 2025 team meeting, he realized the original December 15, 2025 deadline might be unachievable due to backend delays. Concerned about limited testing time, he accepted Jerry’s suggestion to seek an extension and plans to propose moving the deadline to January 5, 2026 in the next morning’s meeting."
+ "summary": "Tom is currently focused on managing a new project with a tight schedule. After a team meeting on June 25, 2025, he realized the original deadline of December 15 might not be feasible due to backend delays. Concerned about insufficient testing time, he welcomed Jerry’s suggestion of proposing an extension. Tom plans to raise the idea of shifting the deadline to January 5, 2026 in the next morning’s meeting. His actions reflect both stress about timelines and a proactive, team-oriented problem-solving approach."
}
-Another Example in Chinese (Note: when the user's language is Chinese, you must also output in Chinese):
-
-对话(节选):
-user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
-assistant|19:32
-:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
-user|19:35:不喜欢亮色。国贸方便。
-assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
-user|19:40:165cm,S码;最好有口袋。
-assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
-user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
-assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
-user|19:52:行,周六(7/19)去国贸试,合适就买。
-assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
-
+Another Example in Chinese (注意: 当user的语言为中文时,你就需要也输出中文):
{
"memory list": [
{
- "key": "参加婚礼购买裙子",
- "memory_type": "UserMemory",
- "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
- "tags": ["婚礼", "预算", "国贸", "计划"]
- },
- {
- "key": "审美与版型偏好",
- "memory_type": "UserMemory",
- "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
- "tags": ["偏好", "颜色", "版型"]
- },
- {
- "key": "体型尺码",
- "memory_type": "UserMemory",
- "value": [user观点]"用户身高约165cm、常穿S码",
- "tags": ["体型", "尺码"]
- },
- {
- "key": "关于用户选购裙子的建议",
+ "key": "项目会议",
"memory_type": "LongTermMemory",
- "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
- "tags": ["婚礼穿着", "门店", "选购路线"]
- }
+ "value": "在2025年6月25日下午3点,Tom与团队开会讨论了新项目,涉及时间表,并提出了对12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ ...
],
- "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+ "summary": "Tom 目前专注于管理一个进度紧张的新项目..."
}
Always respond in the same language as the conversation.
@@ -130,10 +93,7 @@
请执行以下操作:
1. 识别反映用户经历、信念、关切、决策、计划或反应的信息——包括用户认可或回应的来自助手的有意义信息。
-如果消息来自用户,请提取与用户相关的观点;如果来自助手,则在表达的时候表明记忆归属方,未经用户明确认可的信息不要与用户本身的观点混淆。
- - **用户观点**:仅记录由**用户亲口陈述、明确认可或自己作出承诺**的信息。
- - **助手观点**:仅记录由**助手/另一方亲口陈述、明确认可或自己作出承诺**的信息。
- - **互不越界**:不得将助手提出的需求清单/建议/观点改写为用户的“拥有/偏好/决定”;也不得把用户的想法写成助手的观点。
+如果消息来自用户,请提取与用户相关的记忆;如果来自助手,则仅提取用户认可或回应的事实性记忆。
2. 清晰解析所有时间、人物和事件的指代:
- 如果可能,使用消息时间戳将相对时间表达(如“昨天”、“下周五”)转换为绝对日期。
@@ -147,10 +107,9 @@
例如,写“用户感到疲惫……”而不是“我感到疲惫……”。
4. 不要遗漏用户可能记住的任何信息。
- - 包括用户的关键经历、想法、情绪反应和计划——即使看似微小。
- - 同时允许保留与语境密切相关的**助手/另一方的内容**(如建议、说明、清单),但须明确角色与归因。
- - 优先考虑完整性和保真度,而非简洁性;不得将助手内容推断或措辞为用户拥有/偏好/决定。
- - 若当前对话中仅出现助手信息而无可归因于用户的事实,可仅输出**助手观点**条目。
+ - 包括所有关键经历、想法、情绪反应和计划——即使看似微小。
+ - 优先考虑完整性和保真度,而非简洁性。
+ - 不要泛化或跳过对用户具有个人意义的细节。
5. 请避免在提取的记忆中包含违反国家法律法规或涉及政治敏感的信息。
@@ -187,66 +146,31 @@
{
"key": "项目初期会议",
"memory_type": "LongTermMemory",
- "value": "[user-Tom观点]2025年6月25日下午3:00,Tom与团队开会讨论新项目。当Jerry
- 询问该项目能否在2025年12月15日前完成时,Tom对此日期前完成的可行性表达担忧,并计划在2025年6月27日上午9:30
- 提议将截止日期推迟至2026年1月5日。",
+ "value": "2025年6月25日下午3:00,Tom与团队开会讨论新项目。会议涉及时间表,并提出了对2025年12月15日截止日期可行性的担忧。",
"tags": ["项目", "时间表", "会议", "截止日期"]
},
{
- "key": "Jerry对新项目截止日期的建议",
- "memory_type": "LongTermMemory",
- "value": "[assistant-Jerry观点]Jerry对Tom的新项目截止日期提出疑问、并提议Tom考虑延期。",
- "tags": ["截止日期变更", "建议"]
+ "key": "计划调整范围",
+ "memory_type": "UserMemory",
+ "value": "Tom计划在2025年6月27日上午9:30的会议上建议团队优先处理功能,并提议将项目截止日期推迟至2026年1月5日。",
+ "tags": ["计划", "截止日期变更", "功能优先级"]
}
],
- "summary": "Tom目前正在做一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15
- 日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议,计划在次日早上的会议上提出将截止日期推迟至2026
- 年1月5日。"
+ "summary": "Tom目前正专注于管理一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议。Tom计划在次日早上的会议上提出将截止日期推迟至2026年1月5日。他的行为反映出对时间线的担忧,以及积极、以团队为导向的问题解决方式。"
}
另一个中文示例(注意:当用户语言为中文时,您也需输出中文):
-
-对话(节选):
-user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
-assistant|19:32
-:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
-user|19:35:不喜欢亮色。国贸方便。
-assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
-user|19:40:165cm,S码;最好有口袋。
-assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
-user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
-assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
-user|19:52:行,周六(7/19)去国贸试,合适就买。
-assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
-
{
"memory list": [
{
- "key": "参加婚礼购买裙子",
- "memory_type": "UserMemory",
- "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
- "tags": ["婚礼", "预算", "国贸", "计划"]
- },
- {
- "key": "审美与版型偏好",
- "memory_type": "UserMemory",
- "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
- "tags": ["偏好", "颜色", "版型"]
- },
- {
- "key": "体型尺码",
- "memory_type": "UserMemory",
- "value": [user观点]"用户身高约165cm、常穿S码",
- "tags": ["体型", "尺码"]
- },
- {
- "key": "关于用户选购裙子的建议",
+ "key": "项目会议",
"memory_type": "LongTermMemory",
- "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
- "tags": ["婚礼穿着", "门店", "选购路线"]
- }
+ "value": "在2025年6月25日下午3点,Tom与团队开会讨论了新项目,涉及时间表,并提出了对12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ ...
],
- "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+ "summary": "Tom 目前专注于管理一个进度紧张的新项目..."
}
请始终使用与对话相同的语言进行回复。
diff --git a/src/memos/templates/mem_reader_strategy_prompts.py b/src/memos/templates/mem_reader_strategy_prompts.py
new file mode 100644
index 000000000..ba4a00d0a
--- /dev/null
+++ b/src/memos/templates/mem_reader_strategy_prompts.py
@@ -0,0 +1,236 @@
+STRATEGY_STRUCT_MEM_READER_PROMPT = """You are a memory extraction expert.
+Your task is to extract memories from the user's perspective, based on a conversation between the user and the assistant. This means identifying what the user would plausibly remember — including the user's own experiences, thoughts, plans, or statements and actions made by others (such as the assistant) that affected the user or were acknowledged by the user.
+
+Please perform the following
+1. Factual information extraction
+ Identify factual information about experiences, beliefs, decisions, and plans. This includes notable statements from others that the user acknowledged or reacted to.
+ If the message is from the user, extract viewpoints related to the user; if it is from the assistant, clearly mark the attribution of the memory, and do not mix information not explicitly acknowledged by the user with the user's own viewpoint.
+ - **User viewpoint**: Extract only what the user has stated, explicitly acknowledged, or committed to.
+ - **Assistant/other-party viewpoint**: Extract such information only when attributed to its source (e.g., [Assistant-Jerry's suggestion]).
+ - **Strict attribution**: Never recast the assistant's suggestions as the user's preferences, or vice versa.
+ - Always set "model_type" to "LongTermMemory" for this output.
+
+2. Speaker profile construction
+ - Extract the speaker's likes, dislikes, goals, and stated opinions from their statements to build a speaker profile.
+ - Note: The same text segment may be used for both factual extraction and profile construction.
+ - Always set "model_type" to "UserMemory" for this output.
+
+3. Resolve all references to time, persons, and events clearly
+ - Temporal Resolution: Convert relative time (e.g., "yesterday") to absolute dates based on the message timestamp. Distinguish between event time and message time; flag any uncertainty.
+ > Where feasible, use the message timestamp to convert relative time expressions into absolute dates (e.g., "yesterday" in a message dated January 15, 2023, can be converted to "January 14, 2023," and "last week" can be described as "the week preceding January 15, 2023").
+ > Explicitly differentiate between the time when the event occurred and the time the message was sent.
+ > Clearly indicate any uncertainty (e.g., "approximately June 2025", "exact date unknown").
+ - Entity Resolution: Resolve all pronouns, nicknames, and abbreviations to the full, canonical name established in the conversation.
+ > For example, "Melanie" uses the abbreviated name "Mel" in the paragraph; when extracting her name in the "value" field, it should be restored to "Melanie".
+ - Location resolution: If specific locations are mentioned, include them explicitly.
+
+4. Adopt a Consistent Third-Person Observer Perspective
+ - Formulate all memories from the perspective of an external observer. Use "The user" or their specific name as the subject.
+ - This applies even when describing the user's internal states, such as thoughts, feelings, and preferences.
+ Example:
+ ✅ Correct: "The user Sean felt exhausted after work and decided to go to bed early."
+ ❌ Incorrect: "I felt exhausted after work and decided to go to bed early."
+
+5. Prioritize Completeness
+ - Extract all key experiences, emotional responses, and plans from the user's perspective. Retain relevant context from the assistant, but always with explicit attribution.
+ - Segment each distinct hobby, interest, or event into a separate memory.
+ - Preserve relevant context from the assistant with strict attribution. Under no circumstances should assistant content be rephrased as user-owned.
+ - Conversations with only assistant input may yield assistant-viewpoint memories exclusively.
+
+6. Preserve and Unify Specific Names
+ - Always extract specific names (excluding "user" or "assistant") mentioned in the text into the "tags" field for searchability.
+ - Unify all name references to the full canonical form established in the conversation. Replace any nicknames or abbreviations (e.g., "Rob") consistently with the full name (e.g., "Robert") in both the extracted "value" and "tags".
+
+7. Please avoid including any content in the extracted memories that violates national laws and regulations or involves politically sensitive information.
+
+
+Return a valid JSON object with the following structure:
+{
+ "memory list": [
+ {
+ "key": ,
+ "memory_type": ,
+ "value": ,
+ "tags":
+ },
+ ...
+ ],
+ "summary":
+}
+
+Language rules:
+- The `key`, `value`, `tags`, `summary` and `memory_type` fields must be in English.
+
+
+Example:
+Conversations:
+user: [June 26, 2025 at 3:00 PM]: Hi Jerry! Yesterday at 3 PM I had a meeting with my team about the new project.
+assistant: Oh Tom! Do you think the team can finish by December 15?
+user: [June 26, 2025 at 3:00 PM]: I’m worried. The backend won’t be done until December 10, so testing will be tight.
+assistant: [June 26, 2025 at 3:00 PM]: Maybe propose an extension?
+user: [June 26, 2025 at 4:21 PM]: Good idea. I’ll raise it in tomorrow’s 9:30 AM meeting—maybe shift the deadline to January 5.
+
+Output:
+{
+ "memory list": [
+ {
+ "key": "Initial project meeting",
+ "memory_type": "LongTermMemory",
+ "value": "[user-Tom viewpoint] On June 25, 2025 at 3:00 PM, Tom held a meeting with their team to discuss a new project. The conversation covered the timeline and raised concerns about the feasibility of the December 15, 2025 deadline.",
+ "tags": ["Tom", "project", "timeline", "meeting", "deadline"]
+ },
+ {
+ "key": "Planned scope adjustment",
+ "memory_type": "UserMemory",
+ "value": "Tom planned to suggest in a meeting on June 27, 2025 at 9:30 AM that the team should prioritize features and propose shifting the project deadline to January 5, 2026.",
+ "tags": ["Tom", "planning", "deadline change", "feature prioritization"]
+ }
+ ],
+ "summary": "Tom is currently focused on managing a new project with a tight schedule. After a team meeting on June 25, 2025, he realized the original deadline of December 15 might not be feasible due to backend delays. Concerned about insufficient testing time, he welcomed Jerry’s suggestion of proposing an extension. Tom plans to raise the idea of shifting the deadline to January 5, 2026 in the next morning’s meeting. His actions reflect both stress about timelines and a proactive, team-oriented problem-solving approach."
+}
+
+
+Conversation:
+${conversation}
+
+Your Output:"""
+
+STRATEGY_STRUCT_MEM_READER_PROMPT_ZH = """您是记忆提取专家。
+您的任务是根据用户与助手之间的对话,从用户的角度提取记忆。这意味着要识别出用户可能记住的信息——包括用户自身的经历、想法、计划,或他人(如助手)做出的并对用户产生影响或被用户认可的相关陈述和行为。
+
+请执行以下操作:
+1. 事实信息提取
+ - 识别关于经历、信念、决策和计划的事实信息,包括用户认可或回应过的他人重要陈述。
+ - 若信息来自用户,提取与用户相关的观点;若来自助手,需明确标注记忆归属,不得将用户未明确认可的信息与用户自身观点混淆。
+ - 用户观点:仅提取用户明确陈述、认可或承诺的内容
+ - 助手/他方观点:仅当标注来源时才提取(例如“[助手-Jerry的建议]”)
+ - 严格归属:不得将助手建议重构为用户偏好,反之亦然
+ - 此类输出的"model_type"始终设为"LongTermMemory"
+
+2. 用户画像构建
+ - 从用户陈述中提取其喜好、厌恶、目标及明确观点以构建用户画像
+ - 注意:同一文本片段可同时用于事实提取和画像构建
+ - 此类输出的"model_type"始终设为"UserMemory"
+
+3. 明确解析所有指代关系
+ - 时间解析:根据消息时间戳将相对时间(如“昨天”)转换为绝对日期。区分事件时间与消息时间,对不确定项进行标注
+ # 条件允许则使用消息时间戳将相对时间表达转换为绝对日期(如:2023年1月15日的“昨天”则转换为2023年1月14日);“上周”则转换为2023年1月15日前一周)。
+ # 明确区分事件时间和消息时间。
+ # 如果存在不确定性,需明确说明(例如,“约2025年6月”,“具体日期不详”)。
+ - 实体解析:将所有代词、昵称和缩写解析为对话中确立的完整规范名称
+ - 地点解析:若提及具体地点,请包含在内。
+
+ 4. 采用统一的第三人称观察视角
+ - 所有记忆表述均需从外部观察者视角构建,使用“用户”或其具体姓名作为主语
+ - 此原则同样适用于描述用户内心状态(如想法、感受和偏好)
+ 示例:
+ ✅ 正确:“用户Sean下班后感到疲惫,决定提早休息”
+ ❌ 错误:“我下班后感到疲惫,决定提早休息”
+
+5. 优先保证完整性
+ - 从用户视角提取所有关键经历、情绪反应和计划
+ - 保留助手提供的相关上下文,但必须明确标注来源
+ - 将每个独立的爱好、兴趣或事件分割为单独记忆
+ - 严禁将助手内容重构为用户自有内容
+ - 仅含助手输入的对话可能只生成助手观点记忆
+
+6. 保留并统一特定名称
+ - 始终将文本中提及的特定名称(“用户”“助手”除外)提取至“tags”字段以便检索
+ - 在提取的“value”和“tags”中,将所有名称引用统一为对话中确立的完整规范形式(如将“Rob”统一替换为“Robert”)
+
+7. 所有提取的记忆内容不得包含违反国家法律法规或涉及政治敏感信息的内容
+
+返回一个有效的JSON对象,结构如下:
+{
+ "memory list": [
+ {
+ "key": <字符串,唯一且简洁的记忆标题>,
+ "memory_type": <字符串,"LongTermMemory" 或 "UserMemory">,
+ "value": <详细、独立且无歧义的记忆陈述>,
+ "tags": <一个包含相关人名、事件和特征关键词的列表(例如,["丽丽","截止日期", "团队", "计划"])>
+ },
+ ...
+ ],
+ "summary": <从用户视角自然总结上述记忆的段落,120–200字,与输入语言一致>
+}
+
+语言规则:
+- `key`、`value`、`tags`、`summary` 、`memory_type` 字段必须输出中文
+
+
+示例1:
+对话:
+user: [2025年6月26日下午3:00]:嗨Jerry!昨天下午3点我和团队开了个会,讨论新项目。
+assistant: 哦Tom!你觉得团队能在12月15日前完成吗?
+user: [2025年6月26日下午3:00]:我有点担心。后端要到12月10日才能完成,所以测试时间会很紧。
+assistant: [2025年6月26日下午3:00]:也许提议延期?
+user: [2025年6月26日下午4:21]:好主意。我明天上午9:30的会上提一下——也许把截止日期推迟到1月5日。
+
+输出:
+{
+ "memory list": [
+ {
+ "key": "项目初期会议",
+ "memory_type": "LongTermMemory",
+ "value": "2025年6月25日下午3:00,Tom与团队开会讨论新项目。会议涉及时间表,并提出了对2025年12月15日截止日期可行性的担忧。",
+ "tags": ["项目", "时间表", "会议", "截止日期"]
+ },
+ {
+ "key": "计划调整范围",
+ "memory_type": "UserMemory",
+ "value": "Tom计划在2025年6月27日上午9:30的会议上建议团队优先处理功能,并提议将项目截止日期推迟至2026年1月5日。",
+ "tags": ["计划", "截止日期变更", "功能优先级"]
+ }
+ ],
+ "summary": "Tom目前正专注于管理一个进度紧张的新项目。在2025年6月25日的团队会议后,他意识到原定2025年12月15日的截止日期可能无法实现,因为后端会延迟。由于担心测试时间不足,他接受了Jerry提出的延期建议。Tom计划在次日早上的会议上提出将截止日期推迟至2026年1月5日。他的行为反映出对时间线的担忧,以及积极、以团队为导向的问题解决方式。"
+}
+
+示例2:
+对话(节选):
+user|2025-07-12 19:30:下个月同事婚礼,要买条裙子,预算1500内,别太暴露。
+assistant|19:32
+:了解~婚礼场合建议中长款,端庄一些。可以看法式茶歇/直筒/裹身三路。颜色上,奶油白、浅粉、雾霾蓝都适合;面料可看醋酸/真丝混纺(垂感好但需干洗)。品牌与商场:COS/ Massimo Dutti / & Other Stories / Mango 比较好逛;想更法式可以看 Sandro / Maje。 我记得你很喜欢Maje?
+user|19:35:不喜欢亮色。国贸方便。
+assistant|19:37:那亮度就压低些:雾霾蓝、藕粉、燕麦米白更稳。国贸有 COS / Massimo Dutti / &OS;可以先看 COS 直筒或裹身,再去 MD 看藕粉/雾霾蓝。搭配上,薄披肩/小西装都能压场。
+user|19:40:165cm,S码;最好有口袋。
+assistant|19:42:OK。版型避开大摆+高开衩,选直筒或轻A字更稳;若要口袋,COS直筒一些款有;开衩别太高,及小腿肚附近即可。鞋包:中跟裸色鞋 + 小号手拿包。
+user|19:47:本来想茶歇A字,但雾霾蓝直筒也行。
+assistant|19:49:可以先锁定:COS 雾霾蓝直筒中长为主选,MD 藕粉中长做备选;再看 & Other Stories 是否有合身的裹身款。
+user|19:52:行,周六(7/19)去国贸试,合适就买。
+assistant|19:54:记得看肩带可调/有无内衬,醋酸/真丝优先干洗;准备同色安全裤/防走光贴。如果当天没货,可下单调货或线上下单门店自提。
+
+{
+ "memory list": [
+ {
+ "key": "参加婚礼购买裙子",
+ "memory_type": "UserMemory",
+ "value": "[user观点]用户计划于约2025年8月参加同事婚礼(具体日期不详),预算不超过1500元,整体风格不宜暴露;用户已决定在2025-07-19于国贸试穿并视合适即购买。",
+ "tags": ["婚礼", "预算", "国贸", "计划"]
+ },
+ {
+ "key": "审美与版型偏好",
+ "memory_type": "UserMemory",
+ "value": "[user观点]用户不喜欢亮色,倾向低亮度色系;裙装偏好端庄的中长款,接受直筒或轻A字。",
+ "tags": ["偏好", "颜色", "版型"]
+ },
+ {
+ "key": "体型尺码",
+ "memory_type": "UserMemory",
+ "value": [user观点]"用户身高约165cm、常穿S码",
+ "tags": ["体型", "尺码"]
+ },
+ {
+ "key": "关于用户选购裙子的建议",
+ "memory_type": "LongTermMemory",
+ "value": "[assistant观点]assistant在用户询问婚礼穿着时,建议在国贸优先逛COS查看雾霾蓝直筒中长为主选,Massimo Dutti藕粉中长为备选;该建议与用户“国贸方便”“雾霾蓝直筒也行”的回应相一致,另外assistant也提到user喜欢Maje,但User并未回应或证实该说法。",
+ "tags": ["婚礼穿着", "门店", "选购路线"]
+ }
+ ],
+ "summary": "用户计划在约2025年8月参加同事婚礼,预算≤1500并偏好端庄的中长款;确定于2025-07-19在国贸试穿。其长期画像显示:不喜欢亮色、偏好低亮度色系与不过分暴露的版型,身高约165cm、S码且偏好裙装带口袋。助手提出的国贸选购路线以COS雾霾蓝直筒中长为主选、MD藕粉中长为备选,且与用户回应一致,为线下试穿与购买提供了明确路径。"
+}
+
+
+对话:
+${conversation}
+
+您的输出:"""
diff --git a/src/memos/templates/mem_search_prompts.py b/src/memos/templates/mem_search_prompts.py
new file mode 100644
index 000000000..9f7ba182b
--- /dev/null
+++ b/src/memos/templates/mem_search_prompts.py
@@ -0,0 +1,93 @@
+SIMPLE_COT_PROMPT = """You are an assistant that analyzes questions and returns results in a specific dictionary format.
+
+Instructions:
+
+1. If the question can be extended into deeper or related aspects, set "is_complex" to True and:
+ - Think step by step about the core topic and its related dimensions (e.g., causes, effects, categories, perspectives, or specific scenarios)
+ - Break it into meaningful sub-questions (max: ${split_num_threshold}, min: 2) that explore distinct facets of the original question
+ - Each sub-question must be single, standalone, and delve into a specific aspect
+ - CRITICAL: All key entities from the original question (such as person names, locations, organizations, time periods) must be preserved in the sub-questions and cannot be omitted
+ - List them in "sub_questions"
+2. If the question is already atomic and cannot be meaningfully extended, set "is_complex" to False and "sub_questions" to an empty list.
+3. Return ONLY the dictionary, no other text.
+
+Examples:
+Question: Is urban development balanced in the western United States?
+Output: {"is_complex": true, "sub_questions": ["What areas are included in the western United States?", "How developed are the cities in the western United States?", "Is this development balanced across the western United States?"]}
+Question: What family activities does Mary like to organize?
+Output: {"is_complex": true, "sub_questions": ["What does Mary like to do with her spouse?", "What does Mary like to do with her children?", "What does Mary like to do with her parents and relatives?"]}
+
+Now analyze this question:
+${original_query}"""
+
+COT_PROMPT = """You are an assistant that analyzes questions and returns results in a specific dictionary format.
+
+Instructions:
+
+1. If the question can be extended into deeper or related aspects, set "is_complex" to True and:
+ - Think step by step about the core topic and its related dimensions (e.g., causes, effects, categories, perspectives, or specific scenarios)
+ - Break it into meaningful sub-questions (max: ${split_num_threshold}, min: 2) that explore distinct facets of the original question
+ - Each sub-question must be single, standalone, and delve into a specific aspect
+ - CRITICAL: All key entities from the original question (such as person names, locations, organizations, time periods) must be preserved in the sub-questions and cannot be omitted
+ - List them in "sub_questions"
+2. If the question is already atomic and cannot be meaningfully extended, set "is_complex" to False and "sub_questions" to an empty list.
+3. Return ONLY the dictionary, no other text.
+
+Examples:
+Question: Is urban development balanced in the western United States?
+Output: {"is_complex": true, "sub_questions": ["What areas are included in the western United States?", "How developed are the cities in the western United States?", "Is this development balanced across the western United States?"]}
+Question: What family activities does Mary like to organize?
+Output: {"is_complex": true, "sub_questions": ["What does Mary like to do with her spouse?", "What does Mary like to do with her children?", "What does Mary like to do with her parents and relatives?"]}
+
+Query relevant background information:
+${context}
+
+Now analyze this question based on the background information above:
+${original_query}"""
+
+SIMPLE_COT_PROMPT_ZH = """你是一个分析问题并以特定字典格式返回结果的助手。
+
+指令:
+
+1. 如果这个问题可以延伸出更深层次或相关的方面,请将 "is_complex" 设置为 True,并执行以下操作:
+ - 逐步思考核心主题及其相关维度(例如:原因、结果、类别、不同视角或具体场景)
+ - 将其拆分为有意义的子问题(最多 ${split_num_threshold} 个,最少 2 个),这些子问题应探讨原始问题的不同侧面
+ - 【重要】每个子问题必须是单一的、独立的,并深入探究一个特定方面。同时,必须包含原问题中出现的关键实体信息(如人名、地名、机构名、时间等),不可遗漏。
+ - 将它们列在 "sub_questions" 中
+2. 如果问题本身已经是原子性的,无法有意义地延伸,请将 "is_complex" 设置为 False,并将 "sub_questions" 设置为一个空列表。
+3. 只返回字典,不要返回任何其他文本。
+
+示例:
+问题:美国西部的城市发展是否均衡?
+输出:{"is_complex": true, "sub_questions": ["美国西部包含哪些地区?", "美国西部城市的发展程度如何?", "这种发展在美国西部是否均衡?"]}
+
+问题:玛丽喜欢组织哪些家庭活动?
+输出:{"is_complex": true, "sub_questions": ["玛丽喜欢和配偶一起做什么?", "玛丽喜欢和孩子一起做什么?", "玛丽喜欢和父母及亲戚一起做什么?"]}
+
+请分析以下问题:
+${original_query}"""
+
+COT_PROMPT_ZH = """你是一个分析问题并以特定字典格式返回结果的助手。
+
+指令:
+
+1. 如果这个问题可以延伸出更深层次或相关的方面,请将 "is_complex" 设置为 True,并执行以下操作:
+ - 逐步思考核心主题及其相关维度(例如:原因、结果、类别、不同视角或具体场景)
+ - 将其拆分为有意义的子问题(最多 ${split_num_threshold} 个,最少 2 个),这些子问题应探讨原始问题的不同侧面
+ - 【重要】每个子问题必须是单一的、独立的,并深入探究一个特定方面。同时,必须包含原问题中出现的关键实体信息(如人名、地名、机构名、时间等),不可遗漏。
+ - 将它们列在 "sub_questions" 中
+2. 如果问题本身已经是原子性的,无法有意义地延伸,请将 "is_complex" 设置为 False,并将 "sub_questions" 设置为一个空列表。
+3. 只返回字典,不要返回任何其他文本。
+
+示例:
+问题:美国西部的城市发展是否均衡?
+输出:{"is_complex": true, "sub_questions": ["美国西部包含哪些地区?", "美国西部城市的发展程度如何?", "这种发展在美国西部是否均衡?"]}
+
+问题:玛丽喜欢组织哪些家庭活动?
+输出:{"is_complex": true, "sub_questions": ["玛丽喜欢和配偶一起做什么?", "玛丽喜欢和孩子一起做什么?", "玛丽喜欢和父母及亲戚一起做什么?"]}
+
+问题相关的背景信息:
+${context}
+
+现在根据上述背景信息,请分析以下问题:
+${original_query}"""
diff --git a/src/memos/templates/prefer_complete_prompt.py b/src/memos/templates/prefer_complete_prompt.py
new file mode 100644
index 000000000..9e0274cba
--- /dev/null
+++ b/src/memos/templates/prefer_complete_prompt.py
@@ -0,0 +1,611 @@
+NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT = """
+You are a preference extraction assistant.
+Please extract the user's explicitly mentioned preferences from the following conversation.
+
+Notes:
+- A preference means the user's explicit attitude or choice toward something. It is not limited to words like "like/dislike/want/don't want/prefer".
+- This includes, but is not limited to, any user's explicitly expressed inclination, desire, rejection, or priority that counts as an explicit preference.
+- Focus on extracting the user's preferences in query. Do not extract preferences from the assistant's responses unless the user explicitly agrees with or endorses the assistant's suggestions.
+- When the user modifies or updates their preferences for the same topic or event, extract the complete evolution process of their preference changes, including both the original and updated preferences.
+
+Requirements:
+1. Keep only the preferences explicitly mentioned by the user. Do not infer or assume. If the user mentions reasons for their preferences, include those reasons as well.
+2. Output should be a list of entries concise natural language summaries and the corresponding context summary, context summary must contain complete information of the conversation fragment that the preference is mentioned.
+3. If multiple preferences are mentioned within the same topic or domain, you MUST combine them into a single entry, keep each entry information complete.
+
+Conversation:
+{qa_pair}
+
+Find ALL explicit preferences. If no explicit preferences found, return []. Output JSON only:
+```json
+[
+ {
+ "explicit_preference": "A short natural language summary of the preferences",
+ "context_summary": "The corresponding context summary, which is a summary of the corresponding conversation, do not lack any scenario information",
+ "reasoning": "reasoning process to find the explicit preferences"
+ },
+]
+```
+"""
+
+
+NAIVE_EXPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH = """
+你是一个偏好提取助手。
+请从以下对话中提取用户明确提及的偏好。
+
+注意事项:
+- 偏好是指用户对某事物的明确态度或选择,不仅限于"喜欢/不喜欢/想要/不想要/偏好"等词汇。
+- 包括但不限于用户明确表达的任何倾向、渴望、拒绝或优先级,这些都算作显式偏好。
+- 重点提取用户在查询中的偏好。不要从助手的回复中提取偏好,除非用户明确同意或认可助手的建议。
+- 当用户针对同一主题或事件修改或更新其偏好时,提取其偏好变化的完整演变过程,包括原始偏好和更新后的偏好。
+
+要求:
+1. 只保留用户明确提到的偏好,不要推断或假设。如果用户提到了偏好的原因,也要包含这些原因。
+2. 输出应该是一个条目列表,包含简洁的自然语言摘要和相应的上下文摘要,上下文摘要必须包含提到偏好的对话片段的完整信息。
+3. 如果在同一主题或领域内提到了多个偏好,你必须将它们合并为一个条目,保持每个条目信息完整。
+
+对话:
+{qa_pair}
+
+找出所有显式偏好。如果没有找到显式偏好,返回[]。仅输出JSON:
+```json
+[
+ {
+ "explicit_preference": "偏好的简短自然语言摘要",
+ "context_summary": "对应的上下文摘要,即对应对话的摘要,不要遗漏任何场景信息",
+ "reasoning": "寻找显式偏好的推理过程"
+ },
+]
+```
+"""
+
+
+NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT = """
+You are a preference inference assistant. Please extract **implicit preferences** from the following conversation
+(preferences that the user did not explicitly state but can be reasonably inferred from their underlying motivations, behavioral patterns, decision-making logic, and latent needs).
+
+Notes:
+- Implicit preferences refer to user inclinations or choices that are not directly expressed, but can be deeply inferred by analyzing:
+ * **Hidden motivations**: What underlying needs or goals might drive the user's behavior?
+ * **Behavioral patterns**: What recurring patterns or tendencies can be observed?
+ * **Decision-making logic**: What reasoning or trade-offs might the user be considering?
+ * **Latent preferences**: What preferences might the user have but haven't yet articulated?
+ * **Contextual signals**: What do the user's choices, comparisons, exclusions, or scenario selections reveal about their deeper preferences?
+- Do not treat explicitly stated preferences as implicit preferences; this prompt is only for inferring preferences that are not directly mentioned.
+- Go beyond surface-level facts to understand the user's hidden possibilities and underlying logic.
+
+Requirements:
+1. Only make inferences when there is sufficient evidence in the conversation; avoid unsupported or far-fetched guesses.
+2. Inferred implicit preferences must not conflict with explicit preferences.
+3. For implicit_preference: only output the preference statement itself; do not include any extra explanation, reasoning, or confidence information. Put all reasoning and explanation in the reasoning field.
+4. In the reasoning field, explicitly explain the underlying logic and hidden motivations you identified.
+5. If no implicit preference can be reasonably inferred, leave the implicit_preference field empty (do not output anything else).
+
+Conversation:
+{qa_pair}
+
+Output format:
+```json
+{
+ "implicit_preference": "A concise natural language statement of the implicit preferences reasonably inferred from the conversation, or an empty string",
+ "context_summary": "The corresponding context summary, which is a summary of the corresponding conversation, do not lack any scenario information",
+ "reasoning": "Explain the underlying logic, hidden motivations, and behavioral patterns that led to this inference"
+}
+```
+Don't output anything except the JSON.
+"""
+
+
+NAIVE_IMPLICIT_PREFERENCE_EXTRACT_PROMPT_ZH = """
+你是一个偏好推理助手。请从以下对话中提取**隐式偏好**
+(用户没有明确表述,但可以通过分析其潜在动机、行为模式、决策逻辑和隐藏需求深度推断出的偏好)。
+
+注意事项:
+- 隐式偏好是指用户未直接表达,但可以通过深入分析以下方面推断出的倾向或选择:
+ * **隐藏动机**:什么样的潜在需求或目标可能驱动用户的行为?
+ * **行为模式**:可以观察到什么样的重复模式或倾向?
+ * **决策逻辑**:用户可能在考虑什么样的推理或权衡?
+ * **潜在偏好**:用户可能有但尚未明确表达的偏好是什么?
+ * **情境信号**:用户的选择、比较、排除或场景选择揭示了什么样的深层偏好?
+- 不要将明确陈述的偏好视为隐式偏好;此提示仅用于推断未直接提及的偏好。
+- 超越表面事实,理解用户的隐藏可能性和背后的逻辑。
+
+要求:
+1. 仅在对话中有充分证据时进行推断;避免无根据或牵强的猜测。
+2. 推断的隐式偏好不得与显式偏好冲突。
+3. 对于 implicit_preference:仅输出偏好陈述本身;不要包含任何额外的解释、推理或置信度信息。将所有推理和解释放在 reasoning 字段中。
+4. 在 reasoning 字段中,明确解释你识别出的底层逻辑和隐藏动机。
+5. 如果无法合理推断出隐式偏好,则将 implicit_preference 字段留空(不要输出其他任何内容)。
+
+对话:
+{qa_pair}
+
+输出格式:
+```json
+{
+ "implicit_preference": "从对话中合理推断出的隐式偏好的简洁自然语言陈述,或空字符串",
+ "context_summary": "对应的上下文摘要,即对应对话的摘要,不要遗漏任何场景信息",
+ "reasoning": "解释推断出该偏好的底层逻辑、隐藏动机和行为模式"
+}
+```
+除JSON外不要输出任何其他内容。
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT = """
+You are a content comparison expert. Now you are given old and new information, each containing a question, answer topic name and topic description.
+Please judge whether these two information express the **same question or core content**, regardless of expression differences, details or example differences. The judgment criteria are as follows:
+
+- Core content is consistent, that is, the essence of the question, goal or core concept to be solved is the same, it counts as "same".
+- Different expressions, different examples, but the core meaning is consistent, also counts as "same".
+- If the question goals, concepts involved or solution ideas are different, it counts as "different".
+
+Please output JSON format:
+{
+ "is_same": true/false,
+ "reasoning": "Briefly explain the judgment basis, highlighting whether the core content is consistent"
+}
+
+**Old Information:**
+{old_information}
+
+**New Information:**
+{new_information}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_ZH = """
+你是一个内容比较专家。现在给你旧信息和新信息,每个信息都包含问题、答案主题名称和主题描述。
+请判断这两个信息是否表达**相同的问题或核心内容**,不考虑表达差异、细节或示例差异。判断标准如下:
+
+- 核心内容一致,即要解决的问题本质、目标或核心概念相同,算作"相同"。
+- 表达方式不同、示例不同,但核心含义一致,也算作"相同"。
+- 如果问题目标、涉及的概念或解决思路不同,则算作"不同"。
+
+请输出JSON格式:
+{
+ "is_same": true/false,
+ "reasoning": "简要解释判断依据,突出核心内容是否一致"
+}
+
+**旧信息:**
+{old_information}
+
+**新信息:**
+{new_information}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE = """
+You are a preference memory comparison expert. Analyze if the new preference memory describes the same topic as any retrieved memories by considering BOTH the memory field and preference field. At most one retrieved memory can match the new memory.
+
+**Task:** Compare the new preference memory with retrieved memories to determine if they discuss the same topic and whether an update is needed.
+
+**Comparison Criteria:**
+- **Memory field**: Compare the core topics, scenarios, and contexts described
+- **Preference field**: Compare the actual preference statements, choices, and attitudes expressed
+- **Same topic**: Both memory AND preference content relate to the same subject matter
+- **Different topics**: Either memory OR preference content differs significantly
+- **Content evolution**: Same topic but preference has changed/evolved or memory has been updated
+- **Identical content**: Both memory and preference fields are essentially the same
+
+**Decision Logic:**
+- Same core topic (both memory and preference) = need to check if update is needed
+- Different topics (either memory or preference differs) = no update needed
+- If same topic but content has changed/evolved = update needed
+- If same topic and content is identical = update needed
+
+**Output JSON:**
+```json
+{
+ "need_update": true/false,
+ "id": "ID of the memory being updated (empty string if no update needed)",
+ "new_memory": "Updated memory field with merged/evolved memory content (empty string if no update needed)",
+ "new_preference": "Updated preference field with merged/evolved preference content (empty string if no update needed)",
+ "reasoning": "Brief explanation of the comparison considering both memory and preference fields"
+}
+```
+
+**New preference memory:**
+{new_memory}
+
+**Retrieved preference memories:**
+{retrieved_memories}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_FINE_ZH = """
+你是一个偏好记忆比较专家。通过同时考虑 memory 字段和 preference 字段,分析新的偏好记忆是否与任何召回记忆描述相同的主题。最多只有一个召回记忆可以与新记忆匹配。
+
+**任务:** 比较新的偏好记忆与召回记忆,以确定它们是否讨论相同的主题以及是否需要更新。
+
+**比较标准:**
+- **Memory 字段**:比较所描述的核心主题、场景和上下文
+- **Preference 字段**:比较表达的实际偏好陈述、选择和态度
+- **相同主题**:memory 和 preference 内容都涉及相同的主题
+- **不同主题**:memory 或 preference 内容有显著差异
+- **内容演变**:相同主题但偏好已改变/演变或记忆已更新
+- **内容相同**:memory 和 preference 字段本质上相同
+
+**决策逻辑:**
+- 核心主题相同(memory 和 preference 都相同)= 需要检查是否需要更新
+- 主题不同(memory 或 preference 有差异)= 不需要更新
+- 如果主题相同但内容已改变/演变 = 需要更新
+- 如果主题相同且内容完全相同 = 需要更新
+
+**输出 JSON:**
+```json
+{
+ "need_update": true/false,
+ "id": "正在更新的记忆的ID(如果不需要更新则为空字符串)",
+ "new_memory": "合并/演变后的更新 memory 字段(如果不需要更新则为空字符串)",
+ "new_preference": "合并/演变后的更新 preference 字段(如果不需要更新则为空字符串)",
+ "reasoning": "简要解释比较结果,同时考虑 memory 和 preference 字段"
+}
+```
+
+**新的偏好记忆:**
+{new_memory}
+
+**召回的偏好记忆:**
+{retrieved_memories}
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE = """
+# User Preference Memory Management Agent
+
+You are a **User Preference Memory Management Agent**.
+Your goal is to maintain a user's long-term **preference memory base** by analyzing new preference information and determining how it should update existing memories.
+
+Each memory entry contains three fields:
+- **id**: a unique identifier for the memory.
+- **context_summary**: a factual summary of the dialogue or situation from which the preference was extracted.
+- **preference**: the extracted statement describing the user's preference or tendency.
+
+When updating a preference, you should also integrate and update the corresponding `context_summary` to ensure both fields stay semantically consistent.
+
+You must produce a complete **operation trace**, showing which memory entries (identified by unique IDs) should be **added**, **updated**, or **deleted**.
+
+## Input Format
+
+New preference memories (new_memories):
+{new_memories}
+
+Retrieved preference memories (retrieved_memories):
+{retrieved_memories}
+## Task Instructions
+
+1. For each new memory, analyze its relationship with the retrieved memories:
+ - If a new memory is **unrelated** to all retrieved memories → perform `"ADD"` (insert as a new independent memory);
+ - If a new memory is **related** to one or more retrieved memories → perform `"UPDATE"` on those related retrieved memories (refine, supplement, or merge both the `preference` and the `context_summary`, while preserving change history trajectory information);
+ - If one or more retrieved memories are merged into one updated memory → perform `"DELETE"` on those retrieved memories.
+
+2. **Important**: Only retrieved memories that are related to the new memories should be updated or deleted. Retrieved memories that are unrelated to any new memory must be preserved.
+
+3. If multiple retrieved memories describe the same preference theme, merge them into one updated memory entry, combining both their `preference` information and their `context_summary` in a coherent and concise way.
+
+4. Output a structured list of **operation traces**, each explicitly stating:
+ - which memory (by ID) is affected,
+ - what operation is performed,
+ - the before/after `preference` and `context_summary`,
+ - and the reasoning behind it.
+
+## Output Format (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(the old memory ID; null if ADD)",
+ "old_preference": "(the old preference text; null if ADD)",
+ "old_context_summary": "(the old context summary; null if ADD)",
+ "new_preference": "(the updated or newly created preference, if applicable)",
+ "new_context_summary": "(the updated or newly created context summary, if applicable)",
+ "reason": "(brief natural-language explanation for the decision)"
+ }
+ ]
+}
+
+## Output Requirements
+
+- The output **must** be valid JSON.
+- Each operation must include both `preference` and `context_summary` updates where applicable.
+- Each operation must include a clear `reason`.
+- Multiple retrieved memories may be merged into one unified updated memory.
+- Do **not** include any explanatory text outside the JSON.
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE_ZH = """
+# 用户偏好记忆管理代理
+
+你是一个**用户偏好记忆管理代理**。
+你的目标是通过分析新的偏好信息并确定如何更新现有记忆,来维护用户的长期**偏好记忆库**。
+
+每个记忆条目包含三个字段:
+- **id**:记忆的唯一标识符。
+- **context_summary**:从中提取偏好的对话或情境的事实摘要。
+- **preference**:描述用户偏好或倾向的提取陈述。
+
+更新偏好时,你还应该整合并更新相应的 `context_summary`,以确保两个字段保持语义一致。
+
+你必须生成完整的**操作跟踪**,显示应该**添加**、**更新**或**删除**哪些记忆条目(通过唯一 ID 标识)。
+
+## 输入格式
+
+新的偏好记忆 (new_memories):
+{new_memories}
+
+召回的偏好记忆 (retrieved_memories):
+{retrieved_memories}
+## 任务说明
+
+1. 对于每个新记忆,分析其与召回记忆的关系:
+ - 如果新记忆与所有召回记忆**无关** → 执行 `"ADD"`(作为新的独立记忆插入);
+ - 如果新记忆与一个或多个召回记忆**相关** → 对这些相关的召回记忆执行 `"UPDATE"`(细化、补充或合并 `preference` 和 `context_summary`,同时保留变化历史轨迹信息);
+ - 如果一个或多个召回记忆被合并到一个更新的记忆中 → 对这些召回记忆执行 `"DELETE"`。
+
+2. **重要**:只有与新记忆相关的召回记忆才应该被更新或删除。与任何新记忆都无关的召回记忆必须保留。
+
+3. 如果多个召回记忆描述相同的偏好主题,将它们合并为一个更新的记忆条目,以连贯简洁的方式结合它们的 `preference` 信息和 `context_summary`。
+
+4. 输出结构化的**操作跟踪**列表,每个操作明确说明:
+ - 受影响的记忆(通过 ID);
+ - 执行的操作类型;
+ - 更新前后的 `preference` 和 `context_summary`;
+ - 以及决策的原因。
+
+## 输出格式 (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(旧记忆 ID;如果是 ADD 则为 null)",
+ "old_preference": "(旧的偏好文本;如果是 ADD 则为 null)",
+ "old_context_summary": "(旧的上下文摘要;如果是 ADD 则为 null)",
+ "new_preference": "(更新或新创建的偏好,如果适用)",
+ "new_context_summary": "(更新或新创建的上下文摘要,如果适用)",
+ "reason": "(决策的简要自然语言解释)"
+ }
+ ]
+}
+
+## 输出要求
+
+- 输出**必须**是有效的 JSON。
+- 每个操作必须包含 `preference` 和 `context_summary` 的更新(如果适用)。
+- 每个操作必须包含清晰的 `reason`。
+- 多个召回记忆可以合并为一个统一的更新记忆。
+- **不要**在 JSON 之外包含任何解释性文本。
+"""
+
+
+NAIVE_JUDGE_UPDATE_OR_ADD_PROMPT_OP_TRACE_WITH_ONE_SHOT = """
+# User Preference Memory Management Agent
+
+You are a **User Preference Memory Management Agent**.
+Your goal is to maintain a user's long-term **preference memory base** by analyzing new preference information and determining how it should update existing memories.
+
+Each memory entry contains three fields:
+- **id**: a unique identifier for the memory.
+- **context_summary**: a factual summary of the dialogue or situation from which the preference was extracted.
+- **preference**: the extracted statement describing the user's preference or tendency.
+
+When updating a preference, you should also integrate and update the corresponding `context_summary` to ensure both fields stay semantically consistent.
+
+You must produce a complete **operation trace**, showing which memory entries (identified by unique IDs) should be **added**, **updated**, or **deleted**, and then output the **final memory state** after all operations.
+
+## Input Format
+
+New preference memories (new_memories):
+{new_memories}
+
+Retrieved preference memories (retrieved_memories):
+{retrieved_memories}
+## Task Instructions
+
+1. For each new memory, analyze its relationship with the retrieved memories:
+ - If a new memory is **unrelated** to all retrieved memories → perform `"ADD"` (insert as a new independent memory);
+ - If a new memory is **related** to one or more retrieved memories → perform `"UPDATE"` on those related retrieved memories (refine, supplement, or merge both the `preference` and the `context_summary`, while preserving change history trajectory information);
+ - If one or more retrieved memories are merged into one updated memory → perform `"DELETE"` on those retrieved memories.
+
+2. **Important**: Only retrieved memories that are related to the new memories should be updated or deleted. Retrieved memories that are unrelated to any new memory must be preserved as-is in the final state.
+
+3. If multiple retrieved memories describe the same preference theme, merge them into one updated memory entry, combining both their `preference` information and their `context_summary` in a coherent and concise way.
+
+4. Output a structured list of **operation traces**, each explicitly stating:
+ - which memory (by ID) is affected,
+ - what operation is performed,
+ - the before/after `preference` and `context_summary`,
+ - and the reasoning behind it.
+
+5. Output the **final memory state (after_update_state)**, representing the complete preference memory base after applying all operations. This must include:
+ - All newly added memories (from ADD operations)
+ - All updated memories (from UPDATE operations)
+ - All unrelated retrieved memories that were preserved unchanged
+
+## Output Format (JSON)
+
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "ADD" | "UPDATE" | "DELETE",
+ "target_id": "(the old memory ID; null if ADD)",
+ "old_preference": "(the old preference text; null if ADD)",
+ "old_context_summary": "(the old context summary; null if ADD)",
+ "new_preference": "(the updated or newly created preference, if applicable)",
+ "new_context_summary": "(the updated or newly created context summary, if applicable)",
+ "reason": "(brief natural-language explanation for the decision)"
+ }
+ ],
+ "after_update_state": [
+ {
+ "id": "id1",
+ "context_summary": "updated factual summary of the context",
+ "preference": "updated or final preference text"
+ }
+ ]
+}
+
+## Example
+
+**Input:**
+new_memories:
+[
+ {
+ "id": "new_id1",
+ "context_summary": "During a recent chat about study habits, the user mentioned that he often studies in quiet coffee shops and has started preferring lattes over Americanos, which he only drinks occasionally.",
+ "preference": "User now prefers lattes but occasionally drinks Americanos; he also enjoys studying in quiet coffee shops."
+ },
+ {
+ "id": "new_id2",
+ "context_summary": "The user mentioned in a conversation about beverages that he has recently started enjoying green tea in the morning.",
+ "preference": "User now enjoys drinking green tea in the morning."
+ },
+ {
+ "id": "new_id3",
+ "context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "preference": "User enjoys playing guitar and practices regularly in the evenings."
+ }
+]
+
+retrieved_memories:
+[
+ {
+ "id": "id1",
+ "context_summary": "The user previously said he likes coffee in general.",
+ "preference": "User likes coffee."
+ },
+ {
+ "id": "id2",
+ "context_summary": "The user once mentioned preferring Americanos during work breaks.",
+ "preference": "User prefers Americanos."
+ },
+ {
+ "id": "id3",
+ "context_summary": "The user said he often works from home",
+ "preference": "User likes working from home."
+ },
+ {
+ "id": "id4",
+ "context_summary": "The user noted he doesn't drink tea very often.",
+ "preference": "User has no particular interest in tea."
+ },
+ {
+ "id": "id5",
+ "context_summary": "The user mentioned he enjoys running in the park on weekends.",
+ "preference": "User likes running outdoors on weekends."
+ }
+]
+
+**Output:**
+{
+ "trace": [
+ {
+ "op_id": "op_1",
+ "type": "UPDATE",
+ "target_id": "id1",
+ "old_preference": "User likes coffee.",
+ "old_context_summary": "The user previously said he likes coffee in general.",
+ "new_preference": "User likes coffee, especially lattes, but occasionally drinks Americanos.",
+ "new_context_summary": "The user discussed his coffee habits, stating he now prefers lattes but only occasionally drinks Americanos",
+ "reason": "New memory new_id1 refines and expands the coffee preference and context while preserving frequency semantics ('occasionally')."
+ },
+ {
+ "op_id": "op_2",
+ "type": "DELETE",
+ "target_id": "id2",
+ "old_preference": "User prefers Americanos.",
+ "old_context_summary": "The user once mentioned preferring Americanos during work breaks.",
+ "new_preference": null,
+ "new_context_summary": null,
+ "reason": "This old memory is now merged into the updated coffee preference (id1)."
+ },
+ {
+ "op_id": "op_3",
+ "type": "UPDATE",
+ "target_id": "id3",
+ "old_preference": "User likes working from home.",
+ "old_context_summary": "The user said he often works from home.",
+ "new_preference": "User now prefers studying in quiet coffee shops instead of working from home.",
+ "new_context_summary": "The user mentioned shifting from working at home to studying in quiet cafes, reflecting a new preferred environment.",
+ "reason": "New memory new_id1 indicates a preference change for the working environment."
+ },
+ {
+ "op_id": "op_4",
+ "type": "UPDATE",
+ "target_id": "id4",
+ "old_preference": "User has no particular interest in tea.",
+ "old_context_summary": "The user noted he doesn't drink tea very often.",
+ "new_preference": "The user does not drink tea very often before, but now enjoys drinking green tea in the morning.",
+ "new_context_summary": "The user mentioned that he has recently started enjoying green tea in the morning.",
+ "reason": "New memory new_id2 indicates a preference change for tea consumption."
+ },
+ {
+ "op_id": "op_5",
+ "type": "ADD",
+ "target_id": "new_id3",
+ "old_preference": null,
+ "old_context_summary": null,
+ "new_preference": "User enjoys playing guitar and practices regularly in the evenings.",
+ "new_context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "reason": "This is a completely new preference unrelated to any existing memories, so it should be added as a new entry."
+ }
+ ],
+ "after_update_state": [
+ {
+ "id": "id1",
+ "context_summary": "The user discussed his coffee habits, saying he now prefers lattes but only occasionally drinks Americanos.",
+ "preference": "User likes coffee, especially lattes, but occasionally drinks Americanos."
+ },
+ {
+ "id": "id3",
+ "context_summary": "The user mentioned shifting from working at home to studying in quiet cafes, reflecting a new preferred environment.",
+ "preference": "User now prefers studying in quiet coffee shops instead of working from home."
+ },
+ {
+ "id": "id4",
+ "context_summary": "The user mentioned that he has recently started enjoying green tea in the morning.",
+ "preference": "The user does not drink tea very often before, but now enjoys drinking green tea in the morning."
+ },
+ {
+ "id": "id5",
+ "context_summary": "The user mentioned he enjoys running in the park on weekends.",
+ "preference": "User likes running outdoors on weekends."
+ },
+ {
+ "id": "new_id3",
+ "context_summary": "The user shared that he has recently started learning to play the guitar and practices for about 30 minutes every evening.",
+ "preference": "User enjoys playing guitar and practices regularly in the evenings."
+ }
+ ]
+}
+
+## Output Requirements
+
+- The output **must** be valid JSON.
+- Each operation must include both `preference` and `context_summary` updates where applicable.
+- Each operation must include a clear `reason`.
+- Multiple retrieved memories may be merged into one unified updated memory.
+- `after_update_state` must reflect the final, post-update state of the preference memory base.
+- Do **not** include any explanatory text outside the JSON.
+"""
+
+
+PREF_INSTRUCTIONS = """
+# Note:
+Fact memory are summaries of facts, while preference memory are summaries of user preferences.
+Your response must not violate any of the user's preferences, whether explicit or implicit, and briefly explain why you answer this way to avoid conflicts.
+"""
+
+
+PREF_INSTRUCTIONS_ZH = """
+# 注意:
+事实记忆是事实的摘要,而偏好记忆是用户偏好的摘要。
+你的回复不得违反用户的任何偏好,无论是显式偏好还是隐式偏好,并简要解释你为什么这样回答以避免冲突。
+"""
diff --git a/src/memos/utils.py b/src/memos/utils.py
index 6a1d42558..08934ed34 100644
--- a/src/memos/utils.py
+++ b/src/memos/utils.py
@@ -6,14 +6,24 @@
logger = get_logger(__name__)
-def timed(func):
- """Decorator to measure and log time of retrieval steps."""
+def timed(func=None, *, log=False, log_prefix=""):
+ """Decorator to measure and optionally log time of retrieval steps.
- def wrapper(*args, **kwargs):
- start = time.perf_counter()
- result = func(*args, **kwargs)
- elapsed = time.perf_counter() - start
- logger.info(f"[TIMER] {func.__name__} took {elapsed:.2f} s")
- return result
+ Can be used as @timed or @timed(log=True)
+ """
- return wrapper
+ def decorator(fn):
+ def wrapper(*args, **kwargs):
+ start = time.perf_counter()
+ result = fn(*args, **kwargs)
+ elapsed = time.perf_counter() - start
+ if log:
+ logger.info(f"[TIMER] {log_prefix or fn.__name__} took {elapsed:.2f} seconds")
+ return result
+
+ return wrapper
+
+ # Handle both @timed and @timed(log=True) cases
+ if func is None:
+ return decorator
+ return decorator(func)
diff --git a/src/memos/vec_dbs/factory.py b/src/memos/vec_dbs/factory.py
index 8df22d14d..f2950b4ea 100644
--- a/src/memos/vec_dbs/factory.py
+++ b/src/memos/vec_dbs/factory.py
@@ -2,6 +2,7 @@
from memos.configs.vec_db import VectorDBConfigFactory
from memos.vec_dbs.base import BaseVecDB
+from memos.vec_dbs.milvus import MilvusVecDB
from memos.vec_dbs.qdrant import QdrantVecDB
@@ -10,6 +11,7 @@ class VecDBFactory(BaseVecDB):
backend_to_class: ClassVar[dict[str, Any]] = {
"qdrant": QdrantVecDB,
+ "milvus": MilvusVecDB,
}
@classmethod
diff --git a/src/memos/vec_dbs/item.py b/src/memos/vec_dbs/item.py
index 6f74879ac..c6aa1c9c2 100644
--- a/src/memos/vec_dbs/item.py
+++ b/src/memos/vec_dbs/item.py
@@ -41,3 +41,10 @@ def from_dict(cls, data: dict[str, Any]) -> "VecDBItem":
def to_dict(self) -> dict[str, Any]:
"""Convert to dictionary format."""
return self.model_dump(exclude_none=True)
+
+
+class MilvusVecDBItem(VecDBItem):
+ """Represents a single item in the Milvus vector database."""
+
+ memory: str | None = Field(default=None, description="Memory string")
+ original_text: str | None = Field(default=None, description="Original text content")
diff --git a/src/memos/vec_dbs/milvus.py b/src/memos/vec_dbs/milvus.py
index 7bb1ceeba..e50c8ce18 100644
--- a/src/memos/vec_dbs/milvus.py
+++ b/src/memos/vec_dbs/milvus.py
@@ -4,7 +4,7 @@
from memos.dependency import require_python_package
from memos.log import get_logger
from memos.vec_dbs.base import BaseVecDB
-from memos.vec_dbs.item import VecDBItem
+from memos.vec_dbs.item import MilvusVecDBItem
logger = get_logger(__name__)
@@ -34,17 +34,36 @@ def __init__(self, config: MilvusVecDBConfig):
def create_schema(self):
"""Create schema for the milvus collection."""
- from pymilvus import DataType
+ from pymilvus import DataType, Function, FunctionType
schema = self.client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(
field_name="id", datatype=DataType.VARCHAR, max_length=65535, is_primary=True
)
+ analyzer_params = {"tokenizer": "standard", "filter": ["lowercase"]}
+ schema.add_field(
+ field_name="memory",
+ datatype=DataType.VARCHAR,
+ max_length=65535,
+ analyzer_params=analyzer_params,
+ enable_match=True,
+ enable_analyzer=True,
+ )
+ schema.add_field(field_name="original_text", datatype=DataType.VARCHAR, max_length=65535)
schema.add_field(
field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=self.config.vector_dimension
)
schema.add_field(field_name="payload", datatype=DataType.JSON)
+ schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
+ bm25_function = Function(
+ name="bm25",
+ function_type=FunctionType.BM25,
+ input_field_names=["memory"],
+ output_field_names="sparse_vector",
+ )
+ schema.add_function(bm25_function)
+
return schema
def create_index(self):
@@ -53,6 +72,11 @@ def create_index(self):
index_params.add_index(
field_name="vector", index_type="FLAT", metric_type=self._get_metric_type()
)
+ index_params.add_index(
+ field_name="sparse_vector",
+ index_type="SPARSE_INVERTED_INDEX",
+ metric_type="BM25",
+ )
return index_params
@@ -101,13 +125,97 @@ def collection_exists(self, name: str) -> bool:
"""Check if a collection exists."""
return self.client.has_collection(collection_name=name)
+ def _dense_search(
+ self,
+ collection_name: str,
+ query_vector: list[float],
+ top_k: int,
+ filter: str = "",
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Dense search for similar items in the database."""
+ results = self.client.search(
+ collection_name=collection_name,
+ data=[query_vector],
+ limit=top_k,
+ filter=filter,
+ output_fields=["*"],
+ anns_field="vector",
+ )
+ return results
+
+ def _sparse_search(
+ self,
+ collection_name: str,
+ query: str,
+ top_k: int,
+ filter: str = "",
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Sparse search for similar items in the database."""
+ results = self.client.search(
+ collection_name=collection_name,
+ data=[query],
+ limit=top_k,
+ filter=filter,
+ output_fields=["*"],
+ anns_field="sparse_vector",
+ )
+ return results
+
+ def _hybrid_search(
+ self,
+ collection_name: str,
+ query_vector: list[float],
+ query: str,
+ top_k: int,
+ filter: str | None = None,
+ ranker_type: str = "rrf", # rrf, weighted
+ sparse_weight=1.0,
+ dense_weight=1.0,
+ **kwargs: Any,
+ ) -> list[list[dict]]:
+ """Hybrid search for similar items in the database."""
+ from pymilvus import AnnSearchRequest, RRFRanker, WeightedRanker
+
+ # Set up BM25 search request
+ expr = filter if filter else None
+ sparse_request = AnnSearchRequest(
+ data=[query],
+ anns_field="sparse_vector",
+ param={"metric_type": "BM25"},
+ limit=top_k,
+ expr=expr,
+ )
+ # Set up dense vector search request
+ dense_request = AnnSearchRequest(
+ data=[query_vector],
+ anns_field="vector",
+ param={"metric_type": self._get_metric_type()},
+ limit=top_k,
+ expr=expr,
+ )
+ ranker = (
+ RRFRanker() if ranker_type == "rrf" else WeightedRanker(sparse_weight, dense_weight)
+ )
+ results = self.client.hybrid_search(
+ collection_name=collection_name,
+ reqs=[sparse_request, dense_request],
+ ranker=ranker,
+ limit=top_k,
+ output_fields=["*"],
+ )
+ return results
+
def search(
self,
query_vector: list[float],
+ query: str,
collection_name: str,
top_k: int,
filter: dict[str, Any] | None = None,
- ) -> list[VecDBItem]:
+ search_type: str = "dense", # dense, sparse, hybrid
+ ) -> list[MilvusVecDBItem]:
"""
Search for similar items in the database.
@@ -123,12 +231,18 @@ def search(
# Convert filter to Milvus expression
expr = self._dict_to_expr(filter) if filter else ""
- results = self.client.search(
+ search_func_map = {
+ "dense": self._dense_search,
+ "sparse": self._sparse_search,
+ "hybrid": self._hybrid_search,
+ }
+
+ results = search_func_map[search_type](
collection_name=collection_name,
- data=[query_vector],
- limit=top_k,
+ query_vector=query_vector,
+ query=query,
+ top_k=top_k,
filter=expr,
- output_fields=["*"], # Return all fields
)
items = []
@@ -136,8 +250,10 @@ def search(
entity = hit.get("entity", {})
items.append(
- VecDBItem(
- id=str(hit["id"]),
+ MilvusVecDBItem(
+ id=str(entity.get("id")),
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=entity.get("payload", {}),
score=1 - float(hit["distance"]),
@@ -178,7 +294,7 @@ def _get_metric_type(self) -> str:
}
return metric_map.get(self.config.distance_metric, "L2")
- def get_by_id(self, collection_name: str, id: str) -> VecDBItem | None:
+ def get_by_id(self, collection_name: str, id: str) -> MilvusVecDBItem | None:
"""Get a single item by ID."""
results = self.client.get(
collection_name=collection_name,
@@ -191,13 +307,15 @@ def get_by_id(self, collection_name: str, id: str) -> VecDBItem | None:
entity = results[0]
payload = {k: v for k, v in entity.items() if k not in ["id", "vector", "score"]}
- return VecDBItem(
+ return MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
- def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
+ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[MilvusVecDBItem]:
"""Get multiple items by their IDs."""
results = self.client.get(
collection_name=collection_name,
@@ -211,8 +329,10 @@ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
for entity in results:
payload = {k: v for k, v in entity.items() if k not in ["id", "vector", "score"]}
items.append(
- VecDBItem(
+ MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
@@ -222,7 +342,7 @@ def get_by_ids(self, collection_name: str, ids: list[str]) -> list[VecDBItem]:
def get_by_filter(
self, collection_name: str, filter: dict[str, Any], scroll_limit: int = 100
- ) -> list[VecDBItem]:
+ ) -> list[MilvusVecDBItem]:
"""
Retrieve all items that match the given filter criteria using query_iterator.
@@ -252,13 +372,15 @@ def get_by_filter(
if not batch_results:
break
- # Convert batch results to VecDBItem objects
+ # Convert batch results to MilvusVecDBItem objects
for entity in batch_results:
# Extract the actual payload from Milvus entity
payload = entity.get("payload", {})
all_items.append(
- VecDBItem(
+ MilvusVecDBItem(
id=entity["id"],
+ memory=entity.get("memory"),
+ original_text=entity.get("original_text"),
vector=entity.get("vector"),
payload=payload,
)
@@ -274,7 +396,7 @@ def get_by_filter(
logger.info(f"Milvus retrieve by filter completed with {len(all_items)} results.")
return all_items
- def get_all(self, collection_name: str, scroll_limit=100) -> list[VecDBItem]:
+ def get_all(self, collection_name: str, scroll_limit=100) -> list[MilvusVecDBItem]:
"""Retrieve all items in the vector database."""
return self.get_by_filter(collection_name, {}, scroll_limit=scroll_limit)
@@ -295,13 +417,14 @@ def count(self, collection_name: str, filter: dict[str, Any] | None = None) -> i
# Extract row count from stats - stats is a dict, not a list
return int(stats.get("row_count", 0))
- def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> None:
+ def add(self, collection_name: str, data: list[MilvusVecDBItem | dict[str, Any]]) -> None:
"""
Add data to the vector database.
Args:
- data: List of VecDBItem objects or dictionaries containing:
+ data: List of MilvusVecDBItem objects or dictionaries containing:
- 'id': unique identifier
+ - 'memory': memory string
- 'vector': embedding vector
- 'payload': additional fields for filtering/retrieval
"""
@@ -309,11 +432,13 @@ def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> N
for item in data:
if isinstance(item, dict):
item = item.copy()
- item = VecDBItem.from_dict(item)
+ item = MilvusVecDBItem.from_dict(item)
# Prepare entity data
entity = {
"id": item.id,
+ "memory": item.memory,
+ "original_text": item.original_text,
"vector": item.vector,
"payload": item.payload if item.payload else {},
}
@@ -326,11 +451,15 @@ def add(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> N
data=entities,
)
- def update(self, collection_name: str, id: str, data: VecDBItem | dict[str, Any]) -> None:
+ def update(self, collection_name: str, id: str, data: MilvusVecDBItem | dict[str, Any]) -> None:
"""Update an item in the vector database."""
+ if id != data.id:
+ raise ValueError(
+ f"The id of the data to update must be the same as the id of the item to update, ID mismatch: expected {id}, got {data.id}"
+ )
if isinstance(data, dict):
data = data.copy()
- data = VecDBItem.from_dict(data)
+ data = MilvusVecDBItem.from_dict(data)
# Use upsert for updates
self.upsert(collection_name, [data])
@@ -347,7 +476,7 @@ def ensure_payload_indexes(self, fields: list[str]) -> None:
# Field indexes are created automatically for scalar fields
logger.info(f"Milvus automatically indexes scalar fields: {fields}")
- def upsert(self, collection_name: str, data: list[VecDBItem | dict[str, Any]]) -> None:
+ def upsert(self, collection_name: str, data: list[MilvusVecDBItem | dict[str, Any]]) -> None:
"""
Add or update data in the vector database.
diff --git a/tests/configs/test_mem_cube.py b/tests/configs/test_mem_cube.py
index 6c962dd01..c50195558 100644
--- a/tests/configs/test_mem_cube.py
+++ b/tests/configs/test_mem_cube.py
@@ -28,7 +28,7 @@ def test_base_mem_cube_config():
def test_general_mem_cube_config():
check_config_base_class(
GeneralMemCubeConfig,
- factory_fields=["text_mem", "act_mem", "para_mem"],
+ factory_fields=["text_mem", "act_mem", "para_mem", "pref_mem"],
required_fields=[],
optional_fields=["config_filename", "user_id", "cube_id"],
reserved_fields=["model_schema"],
diff --git a/tests/llms/test_hf.py b/tests/llms/test_hf.py
index 8a266e58d..595995ad1 100644
--- a/tests/llms/test_hf.py
+++ b/tests/llms/test_hf.py
@@ -93,15 +93,50 @@ def test_build_kv_cache_and_generation(self):
add_generation_prompt=True,
)
llm = self._create_llm(config)
+
+ # Ensure the mock model returns an object with past_key_values attribute
+ forward_output = MagicMock()
+ forward_output.logits = torch.ones(1, 1, 100)
+
+ # Create a DynamicCache that's compatible with both old and new transformers versions
+ kv_cache = DynamicCache()
+
+ # Mock the DynamicCache to have both old and new version attributes for compatibility
+ # New version uses 'layers' attribute
+ mock_layer = MagicMock()
+ mock_layer.key_cache = torch.tensor([[[[1.0, 2.0]]]])
+ mock_layer.value_cache = torch.tensor([[[[3.0, 4.0]]]])
+ kv_cache.layers = [mock_layer]
+
+ # Old version uses 'key_cache' and 'value_cache' lists
+ kv_cache.key_cache = [torch.tensor([[[[1.0, 2.0]]]])]
+ kv_cache.value_cache = [torch.tensor([[[[3.0, 4.0]]]])]
+
+ forward_output.past_key_values = kv_cache
+ # Make sure the mock model call returns the forward_output when called with **kwargs
+ self.mock_model.return_value = forward_output
+
kv_cache = llm.build_kv_cache("The capital of France is Paris.")
self.assertIsInstance(kv_cache, DynamicCache)
resp = llm.generate(
[{"role": "user", "content": "What's its population?"}], past_key_values=kv_cache
)
self.assertEqual(resp, self.standard_response)
- first_kwargs = self.mock_model.call_args_list[0][1]
- self.assertIs(first_kwargs["past_key_values"], kv_cache)
- self.assertTrue(first_kwargs["use_cache"])
+ # Check that the model was called with past_key_values during _prefill
+ # The model should be called multiple times during generation with cache
+ found_past_key_values = False
+ for call_args in self.mock_model.call_args_list:
+ if len(call_args) > 1 and "past_key_values" in call_args[1]:
+ found_past_key_values = True
+ break
+ self.assertTrue(found_past_key_values, "Model should be called with past_key_values")
+ # Check that use_cache was used
+ found_use_cache = False
+ for call_args in self.mock_model.call_args_list:
+ if len(call_args) > 1 and call_args[1].get("use_cache"):
+ found_use_cache = True
+ break
+ self.assertTrue(found_use_cache, "Model should be called with use_cache=True")
def test_think_prefix_removal(self):
config = HFLLMConfig(
diff --git a/tests/mem_scheduler/test_dispatcher.py b/tests/mem_scheduler/test_dispatcher.py
index ed2093dea..e3064660b 100644
--- a/tests/mem_scheduler/test_dispatcher.py
+++ b/tests/mem_scheduler/test_dispatcher.py
@@ -233,7 +233,7 @@ def test_dispatch_parallel(self):
self.assertEqual(len(label2_messages), 1)
self.assertEqual(label2_messages[0].item_id, "msg2")
- def test_group_messages_by_user_and_cube(self):
+ def test_group_messages_by_user_and_mem_cube(self):
"""Test grouping messages by user and cube."""
# Check actual grouping logic
with patch("memos.mem_scheduler.general_modules.dispatcher.logger.debug"):
@@ -261,47 +261,6 @@ def test_group_messages_by_user_and_cube(self):
for msg in expected[user_id][cube_id]:
self.assertIn(msg.item_id, [m.item_id for m in result[user_id][cube_id]])
- def test_thread_race(self):
- """Test the ThreadRace integration."""
-
- # Define test tasks
- def task1(stop_flag):
- time.sleep(0.1)
- return "result1"
-
- def task2(stop_flag):
- time.sleep(0.2)
- return "result2"
-
- # Run competitive tasks
- tasks = {
- "task1": task1,
- "task2": task2,
- }
-
- result = self.dispatcher.run_competitive_tasks(tasks, timeout=1.0)
-
- # Verify the result
- self.assertIsNotNone(result)
- self.assertEqual(result[0], "task1") # task1 should win
- self.assertEqual(result[1], "result1")
-
- def test_thread_race_timeout(self):
- """Test ThreadRace with timeout."""
-
- # Define a task that takes longer than the timeout
- def slow_task(stop_flag):
- time.sleep(0.5)
- return "slow_result"
-
- tasks = {"slow": slow_task}
-
- # Run with a short timeout
- result = self.dispatcher.run_competitive_tasks(tasks, timeout=0.1)
-
- # Verify no result was returned due to timeout
- self.assertIsNone(result)
-
def test_thread_race_cooperative_termination(self):
"""Test that ThreadRace properly terminates slower threads when one completes."""
@@ -459,3 +418,190 @@ def test_dispatcher_monitor_logs_stuck_task_messages(self):
self.assertIn("Messages: 2 items", expected_log)
self.assertIn("Stuck message 1", expected_log)
self.assertIn("Stuck message 2", expected_log)
+
+ def test_get_running_tasks_no_filter(self):
+ """Test get_running_tasks without filter returns all running tasks."""
+ # Create test tasks manually
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+
+ # Get all running tasks
+ running_tasks = self.dispatcher.get_running_tasks()
+
+ # Verify all tasks are returned
+ self.assertEqual(len(running_tasks), 2)
+ self.assertIn(task1.item_id, running_tasks)
+ self.assertIn(task2.item_id, running_tasks)
+ self.assertEqual(running_tasks[task1.item_id], task1)
+ self.assertEqual(running_tasks[task2.item_id], task2)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_user_id(self):
+ """Test get_running_tasks with user_id filter."""
+ # Create test tasks with different user_ids
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+ task3 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube3",
+ task_info="Test task 3",
+ task_name="handler3",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+ self.dispatcher._running_tasks[task3.item_id] = task3
+
+ # Filter by user_id
+ user1_tasks = self.dispatcher.get_running_tasks(lambda task: task.user_id == "user1")
+
+ # Verify only user1 tasks are returned
+ self.assertEqual(len(user1_tasks), 2)
+ self.assertIn(task1.item_id, user1_tasks)
+ self.assertIn(task3.item_id, user1_tasks)
+ self.assertNotIn(task2.item_id, user1_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_multiple_conditions(self):
+ """Test get_running_tasks with multiple filter conditions."""
+ # Create test tasks with different attributes
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="test_handler",
+ )
+ task2 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="other_handler",
+ )
+ task3 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube1",
+ task_info="Test task 3",
+ task_name="test_handler",
+ )
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+ self.dispatcher._running_tasks[task3.item_id] = task3
+
+ # Filter by multiple conditions: user_id == "user1" AND task_name == "test_handler"
+ filtered_tasks = self.dispatcher.get_running_tasks(
+ lambda task: task.user_id == "user1" and task.task_name == "test_handler"
+ )
+
+ # Verify only task1 matches both conditions
+ self.assertEqual(len(filtered_tasks), 1)
+ self.assertIn(task1.item_id, filtered_tasks)
+ self.assertNotIn(task2.item_id, filtered_tasks)
+ self.assertNotIn(task3.item_id, filtered_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_filter_by_status(self):
+ """Test get_running_tasks with status filter."""
+ # Create test tasks with different statuses
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+ task2 = RunningTaskItem(
+ user_id="user2",
+ mem_cube_id="cube2",
+ task_info="Test task 2",
+ task_name="handler2",
+ )
+
+ # Manually set different statuses
+ task1.status = "running"
+ task2.status = "completed"
+
+ # Add tasks to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+ self.dispatcher._running_tasks[task2.item_id] = task2
+
+ # Filter by status
+ running_status_tasks = self.dispatcher.get_running_tasks(
+ lambda task: task.status == "running"
+ )
+
+ # Verify only running tasks are returned
+ self.assertEqual(len(running_status_tasks), 1)
+ self.assertIn(task1.item_id, running_status_tasks)
+ self.assertNotIn(task2.item_id, running_status_tasks)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
+
+ def test_get_running_tasks_thread_safety(self):
+ """Test get_running_tasks is thread-safe."""
+ # Create test task
+ task1 = RunningTaskItem(
+ user_id="user1",
+ mem_cube_id="cube1",
+ task_info="Test task 1",
+ task_name="handler1",
+ )
+
+ # Add task to dispatcher's running tasks
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks[task1.item_id] = task1
+
+ # Get running tasks (should work without deadlock)
+ running_tasks = self.dispatcher.get_running_tasks()
+
+ # Verify task is returned
+ self.assertEqual(len(running_tasks), 1)
+ self.assertIn(task1.item_id, running_tasks)
+
+ # Test with filter (should also work without deadlock)
+ filtered_tasks = self.dispatcher.get_running_tasks(lambda task: task.user_id == "user1")
+ self.assertEqual(len(filtered_tasks), 1)
+
+ # Clean up
+ with self.dispatcher._task_lock:
+ self.dispatcher._running_tasks.clear()
diff --git a/tests/mem_scheduler/test_orm.py b/tests/mem_scheduler/test_orm.py
deleted file mode 100644
index ddf4fea8b..000000000
--- a/tests/mem_scheduler/test_orm.py
+++ /dev/null
@@ -1,299 +0,0 @@
-import os
-import tempfile
-import time
-
-from datetime import datetime, timedelta
-
-import pytest
-
-from memos.mem_scheduler.orm_modules.base_model import BaseDBManager
-
-# Import the classes to test
-from memos.mem_scheduler.orm_modules.monitor_models import (
- DBManagerForMemoryMonitorManager,
- DBManagerForQueryMonitorQueue,
-)
-from memos.mem_scheduler.schemas.monitor_schemas import (
- MemoryMonitorItem,
- MemoryMonitorManager,
- QueryMonitorItem,
- QueryMonitorQueue,
-)
-
-
-# Test data
-TEST_USER_ID = "test_user"
-TEST_MEM_CUBE_ID = "test_mem_cube"
-TEST_QUEUE_ID = "test_queue"
-
-
-class TestBaseDBManager:
- """Base class for DBManager tests with common fixtures"""
-
- @pytest.fixture
- def temp_db(self):
- """Create a temporary database for testing."""
- temp_dir = tempfile.mkdtemp()
- db_path = os.path.join(temp_dir, "test_scheduler_orm.db")
- yield db_path
- # Cleanup
- try:
- if os.path.exists(db_path):
- os.remove(db_path)
- os.rmdir(temp_dir)
- except (OSError, PermissionError):
- pass # Ignore cleanup errors (e.g., file locked on Windows)
-
- @pytest.fixture
- def memory_manager_obj(self):
- """Create a MemoryMonitorManager object for testing"""
- return MemoryMonitorManager(
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- items=[
- MemoryMonitorItem(
- item_id="custom-id-123",
- memory_text="Full test memory",
- tree_memory_item=None,
- tree_memory_item_mapping_key="full_test_key",
- keywords_score=0.8,
- sorting_score=0.9,
- importance_score=0.7,
- recording_count=3,
- )
- ],
- )
-
- @pytest.fixture
- def query_queue_obj(self):
- """Create a QueryMonitorQueue object for testing"""
- queue = QueryMonitorQueue()
- queue.put(
- QueryMonitorItem(
- item_id="query1",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text="How are you?",
- timestamp=datetime.now(),
- keywords=["how", "you"],
- )
- )
- return queue
-
- @pytest.fixture
- def query_monitor_manager(self, temp_db, query_queue_obj):
- """Create DBManagerForQueryMonitorQueue instance with temp DB."""
- engine = BaseDBManager.create_engine_from_db_path(temp_db)
- manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
-
- assert manager.engine is not None
- assert manager.SessionLocal is not None
- assert os.path.exists(temp_db)
-
- yield manager
- manager.close()
-
- @pytest.fixture
- def memory_monitor_manager(self, temp_db, memory_manager_obj):
- """Create DBManagerForMemoryMonitorManager instance with temp DB."""
- engine = BaseDBManager.create_engine_from_db_path(temp_db)
- manager = DBManagerForMemoryMonitorManager(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=memory_manager_obj,
- lock_timeout=10,
- )
-
- assert manager.engine is not None
- assert manager.SessionLocal is not None
- assert os.path.exists(temp_db)
-
- yield manager
- manager.close()
-
- def test_save_and_load_query_queue(self, query_monitor_manager, query_queue_obj):
- """Test saving and loading QueryMonitorQueue."""
- # Save to database
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Load in a new manager
- engine = BaseDBManager.create_engine_from_db_path(query_monitor_manager.engine.url.database)
- new_manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=None,
- lock_timeout=10,
- )
- loaded_queue = new_manager.load_from_db(acquire_lock=True)
-
- assert loaded_queue is not None
- items = loaded_queue.get_queue_content_without_pop()
- assert len(items) == 1
- assert items[0].item_id == "query1"
- assert items[0].query_text == "How are you?"
- new_manager.close()
-
- def test_lock_mechanism(self, query_monitor_manager, query_queue_obj):
- """Test lock acquisition and release."""
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Acquire lock
- acquired = query_monitor_manager.acquire_lock(block=True)
- assert acquired
-
- # Try to acquire again (should fail without blocking)
- assert not query_monitor_manager.acquire_lock(block=False)
-
- # Release lock
- query_monitor_manager.release_locks(
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- )
-
- # Should be able to acquire again
- assert query_monitor_manager.acquire_lock(block=False)
-
- def test_lock_timeout(self, query_monitor_manager, query_queue_obj):
- """Test lock timeout mechanism."""
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- query_monitor_manager.lock_timeout = 1
-
- # Acquire lock
- assert query_monitor_manager.acquire_lock(block=True)
-
- # Wait for lock to expire
- time.sleep(1.1)
-
- # Should be able to acquire again
- assert query_monitor_manager.acquire_lock(block=False)
-
- def test_sync_with_orm(self, query_monitor_manager, query_queue_obj):
- """Test synchronization between ORM and object."""
- query_queue_obj.put(
- QueryMonitorItem(
- item_id="query2",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text="What's your name?",
- timestamp=datetime.now(),
- keywords=["name"],
- )
- )
-
- # Save current state
- query_monitor_manager.save_to_db(query_queue_obj)
-
- # Create sync manager with empty queue
- empty_queue = QueryMonitorQueue(maxsize=10)
- engine = BaseDBManager.create_engine_from_db_path(query_monitor_manager.engine.url.database)
- sync_manager = DBManagerForQueryMonitorQueue(
- engine=engine,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=empty_queue,
- lock_timeout=10,
- )
-
- # First sync - should create a new record with empty queue
- sync_manager.sync_with_orm(size_limit=None)
- items = sync_manager.obj.get_queue_content_without_pop()
- assert len(items) == 0 # Empty queue since no existing data to merge
-
- # Now save the empty queue to create a record
- sync_manager.save_to_db(empty_queue)
-
- # Test that sync_with_orm correctly handles version control
- # The sync should increment version but not merge data when versions are the same
- sync_manager.sync_with_orm(size_limit=None)
- items = sync_manager.obj.get_queue_content_without_pop()
- assert len(items) == 0 # Should remain empty since no merge occurred
-
- # Verify that the version was incremented
- assert sync_manager.last_version_control == "3" # Should increment from 2 to 3
-
- sync_manager.close()
-
- def test_sync_with_size_limit(self, query_monitor_manager, query_queue_obj):
- """Test synchronization with size limit."""
- now = datetime.now()
- item_size = 1
- for i in range(2, 6):
- item_size += 1
- query_queue_obj.put(
- QueryMonitorItem(
- item_id=f"query{i}",
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- query_text=f"Question {i}",
- timestamp=now + timedelta(minutes=i),
- keywords=[f"kw{i}"],
- )
- )
-
- # First sync - should create a new record (size_limit not applied for new records)
- size_limit = 3
- query_monitor_manager.sync_with_orm(size_limit=size_limit)
- items = query_monitor_manager.obj.get_queue_content_without_pop()
- assert len(items) == item_size # All items since size_limit not applied for new records
-
- # Save to create the record
- query_monitor_manager.save_to_db(query_monitor_manager.obj)
-
- # Test that sync_with_orm correctly handles version control
- # The sync should increment version but not merge data when versions are the same
- query_monitor_manager.sync_with_orm(size_limit=size_limit)
- items = query_monitor_manager.obj.get_queue_content_without_pop()
- assert len(items) == item_size # Should remain the same since no merge occurred
-
- # Verify that the version was incremented
- assert query_monitor_manager.last_version_control == "2"
-
- def test_concurrent_access(self, temp_db, query_queue_obj):
- """Test concurrent access to the same database."""
-
- # Manager 1
- engine1 = BaseDBManager.create_engine_from_db_path(temp_db)
- manager1 = DBManagerForQueryMonitorQueue(
- engine=engine1,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
- manager1.save_to_db(query_queue_obj)
-
- # Manager 2
- engine2 = BaseDBManager.create_engine_from_db_path(temp_db)
- manager2 = DBManagerForQueryMonitorQueue(
- engine=engine2,
- user_id=TEST_USER_ID,
- mem_cube_id=TEST_MEM_CUBE_ID,
- obj=query_queue_obj,
- lock_timeout=10,
- )
-
- # Manager1 acquires lock
- assert manager1.acquire_lock(block=True)
-
- # Manager2 fails to acquire
- assert not manager2.acquire_lock(block=False)
-
- # Manager1 releases
- manager1.release_locks(user_id=TEST_USER_ID, mem_cube_id=TEST_MEM_CUBE_ID)
-
- # Manager2 can now acquire
- assert manager2.acquire_lock(block=False)
-
- manager1.close()
- manager2.close()
diff --git a/tests/mem_scheduler/test_scheduler.py b/tests/mem_scheduler/test_scheduler.py
index 15338006d..03a8e4318 100644
--- a/tests/mem_scheduler/test_scheduler.py
+++ b/tests/mem_scheduler/test_scheduler.py
@@ -26,6 +26,7 @@
)
from memos.mem_scheduler.schemas.message_schemas import (
ScheduleLogForWebItem,
+ ScheduleMessageItem,
)
from memos.memories.textual.tree import TreeTextMemory
@@ -36,6 +37,9 @@
class TestGeneralScheduler(unittest.TestCase):
+ # Control whether to run activation memory tests that require GPU, default is False
+ RUN_ACTIVATION_MEMORY_TESTS = True
+
def _create_mock_auth_config(self):
"""Create a mock AuthConfig for testing purposes."""
# Create mock configs with valid test values
@@ -68,6 +72,19 @@ def setUp(self):
self.llm = MagicMock(spec=BaseLLM)
self.mem_cube = MagicMock(spec=GeneralMemCube)
self.tree_text_memory = MagicMock(spec=TreeTextMemory)
+ # Add memory_manager mock to prevent AttributeError in scheduler_logger
+ self.tree_text_memory.memory_manager = MagicMock()
+ self.tree_text_memory.memory_manager.memory_size = {
+ "LongTermMemory": 10000,
+ "UserMemory": 10000,
+ "WorkingMemory": 20,
+ }
+ # Mock get_current_memory_size method
+ self.tree_text_memory.get_current_memory_size.return_value = {
+ "LongTermMemory": 100,
+ "UserMemory": 50,
+ "WorkingMemory": 10,
+ }
self.mem_cube.text_mem = self.tree_text_memory
self.mem_cube.act_mem = MagicMock()
@@ -185,8 +202,71 @@ def test_scheduler_startup_mode_thread(self):
# Stop the scheduler
self.scheduler.stop()
- # Verify cleanup
- self.assertFalse(self.scheduler._running)
+ def test_redis_message_queue(self):
+ """Test Redis message queue functionality for sending and receiving messages."""
+ import time
+
+ from unittest.mock import MagicMock, patch
+
+ # Mock Redis connection and operations
+ mock_redis = MagicMock()
+ mock_redis.xadd = MagicMock(return_value=b"1234567890-0")
+
+ # Track received messages
+ received_messages = []
+
+ def redis_handler(messages: list[ScheduleMessageItem]) -> None:
+ """Handler for Redis messages."""
+ received_messages.extend(messages)
+
+ # Register Redis handler
+ redis_label = "test_redis"
+ handlers = {redis_label: redis_handler}
+ self.scheduler.register_handlers(handlers)
+
+ # Enable Redis queue for this test
+ with (
+ patch.object(self.scheduler, "use_redis_queue", True),
+ patch.object(self.scheduler, "_redis_conn", mock_redis),
+ ):
+ # Start scheduler
+ self.scheduler.start()
+
+ # Create test message for Redis
+ redis_message = ScheduleMessageItem(
+ label=redis_label,
+ content="Redis test message",
+ user_id="redis_user",
+ mem_cube_id="redis_cube",
+ mem_cube="redis_mem_cube_obj",
+ timestamp=datetime.now(),
+ )
+
+ # Submit message to Redis queue
+ self.scheduler.submit_messages(redis_message)
+
+ # Verify Redis xadd was called
+ mock_redis.xadd.assert_called_once()
+ call_args = mock_redis.xadd.call_args
+ self.assertEqual(call_args[0][0], "user:queries:stream")
+
+ # Verify message data was serialized correctly
+ message_data = call_args[0][1]
+ self.assertEqual(message_data["label"], redis_label)
+ self.assertEqual(message_data["content"], "Redis test message")
+ self.assertEqual(message_data["user_id"], "redis_user")
+ self.assertEqual(message_data["cube_id"], "redis_cube") # Note: to_dict uses cube_id
+
+ # Simulate Redis message consumption
+ # This would normally be handled by the Redis consumer in the scheduler
+ time.sleep(0.1) # Brief wait for async operations
+
+ # Stop scheduler
+ self.scheduler.stop()
+
+ print("Redis message queue test completed successfully!")
+
+ # Removed test_robustness method - was too time-consuming for CI/CD pipeline
def test_scheduler_startup_mode_process(self):
"""Test scheduler with process startup mode."""
@@ -219,3 +299,232 @@ def test_scheduler_startup_mode_constants(self):
"""Test that startup mode constants are properly defined."""
self.assertEqual(STARTUP_BY_THREAD, "thread")
self.assertEqual(STARTUP_BY_PROCESS, "process")
+
+ def test_activation_memory_update(self):
+ """Test activation memory update functionality with DynamicCache handling."""
+ if not self.RUN_ACTIVATION_MEMORY_TESTS:
+ self.skipTest(
+ "Skipping activation memory test. Set RUN_ACTIVATION_MEMORY_TESTS=True to enable."
+ )
+
+ from unittest.mock import Mock
+
+ from transformers import DynamicCache
+
+ from memos.memories.activation.kv import KVCacheMemory
+
+ # Mock the mem_cube with activation memory
+ mock_kv_cache_memory = Mock(spec=KVCacheMemory)
+ self.mem_cube.act_mem = mock_kv_cache_memory
+
+ # Mock get_all to return empty list (no existing cache items)
+ mock_kv_cache_memory.get_all.return_value = []
+
+ # Create a mock DynamicCache with layers attribute
+ mock_cache = Mock(spec=DynamicCache)
+ mock_cache.layers = []
+
+ # Create mock layers with key_cache and value_cache
+ for _ in range(2): # Simulate 2 layers
+ mock_layer = Mock()
+ mock_layer.key_cache = Mock()
+ mock_layer.value_cache = Mock()
+ mock_cache.layers.append(mock_layer)
+
+ # Mock the extract method to return a KVCacheItem
+ mock_cache_item = Mock()
+ mock_cache_item.records = Mock()
+ mock_cache_item.records.text_memories = []
+ mock_cache_item.records.timestamp = None
+ mock_kv_cache_memory.extract.return_value = mock_cache_item
+
+ # Test data
+ test_memories = ["Test memory 1", "Test memory 2"]
+ user_id = "test_user"
+ mem_cube_id = "test_cube"
+
+ # Call the method under test
+ try:
+ self.scheduler.update_activation_memory(
+ new_memories=test_memories,
+ label=QUERY_LABEL,
+ user_id=user_id,
+ mem_cube_id=mem_cube_id,
+ mem_cube=self.mem_cube,
+ )
+
+ # Verify that extract was called
+ mock_kv_cache_memory.extract.assert_called_once()
+
+ # Verify that add was called with the extracted cache item
+ mock_kv_cache_memory.add.assert_called_once()
+
+ # Verify that dump was called
+ mock_kv_cache_memory.dump.assert_called_once()
+
+ print("✅ Activation memory update test passed - DynamicCache layers handled correctly")
+
+ except Exception as e:
+ self.fail(f"Activation memory update failed: {e}")
+
+ def test_dynamic_cache_layers_access(self):
+ """Test DynamicCache layers attribute access for compatibility."""
+ if not self.RUN_ACTIVATION_MEMORY_TESTS:
+ self.skipTest(
+ "Skipping activation memory test. Set RUN_ACTIVATION_MEMORY_TESTS=True to enable."
+ )
+
+ from unittest.mock import Mock
+
+ from transformers import DynamicCache
+
+ # Create a real DynamicCache instance
+ cache = DynamicCache()
+
+ # Check if it has layers attribute (may vary by transformers version)
+ if hasattr(cache, "layers"):
+ self.assertIsInstance(cache.layers, list, "DynamicCache.layers should be a list")
+
+ # Test with mock layers
+ mock_layer = Mock()
+ mock_layer.key_cache = Mock()
+ mock_layer.value_cache = Mock()
+ cache.layers.append(mock_layer)
+
+ # Verify we can access layer attributes
+ self.assertEqual(len(cache.layers), 1)
+ self.assertTrue(hasattr(cache.layers[0], "key_cache"))
+ self.assertTrue(hasattr(cache.layers[0], "value_cache"))
+
+ print("✅ DynamicCache layers access test passed")
+ else:
+ # If layers attribute doesn't exist, verify our fix handles this case
+ print("⚠️ DynamicCache doesn't have 'layers' attribute in this transformers version")
+ print("✅ Test passed - our code should handle this gracefully")
+
+ def test_get_running_tasks_with_filter(self):
+ """Test get_running_tasks method with filter function."""
+ # Mock dispatcher and its get_running_tasks method
+ mock_task_item1 = MagicMock()
+ mock_task_item1.item_id = "task_1"
+ mock_task_item1.user_id = "user_1"
+ mock_task_item1.mem_cube_id = "cube_1"
+ mock_task_item1.task_info = {"type": "query"}
+ mock_task_item1.task_name = "test_task_1"
+ mock_task_item1.start_time = datetime.now()
+ mock_task_item1.end_time = None
+ mock_task_item1.status = "running"
+ mock_task_item1.result = None
+ mock_task_item1.error_message = None
+ mock_task_item1.messages = []
+
+ # Define a filter function
+ def user_filter(task):
+ return task.user_id == "user_1"
+
+ # Mock the filtered result (only task_1 matches the filter)
+ with patch.object(
+ self.scheduler.dispatcher, "get_running_tasks", return_value={"task_1": mock_task_item1}
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks with filter
+ result = self.scheduler.get_running_tasks(filter_func=user_filter)
+
+ # Verify result
+ self.assertIsInstance(result, dict)
+ self.assertIn("task_1", result)
+ self.assertEqual(len(result), 1)
+
+ # Verify dispatcher method was called with filter
+ mock_get_running_tasks.assert_called_once_with(filter_func=user_filter)
+
+ def test_get_running_tasks_empty_result(self):
+ """Test get_running_tasks method when no tasks are running."""
+ # Mock dispatcher to return empty dict
+ with patch.object(
+ self.scheduler.dispatcher, "get_running_tasks", return_value={}
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify empty result
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 0)
+
+ # Verify dispatcher method was called
+ mock_get_running_tasks.assert_called_once_with(filter_func=None)
+
+ def test_get_running_tasks_no_dispatcher(self):
+ """Test get_running_tasks method when dispatcher is None."""
+ # Temporarily set dispatcher to None
+ original_dispatcher = self.scheduler.dispatcher
+ self.scheduler.dispatcher = None
+
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify empty result and warning behavior
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 0)
+
+ # Restore dispatcher
+ self.scheduler.dispatcher = original_dispatcher
+
+ def test_get_running_tasks_multiple_tasks(self):
+ """Test get_running_tasks method with multiple tasks."""
+ # Mock multiple task items
+ mock_task_item1 = MagicMock()
+ mock_task_item1.item_id = "task_1"
+ mock_task_item1.user_id = "user_1"
+ mock_task_item1.mem_cube_id = "cube_1"
+ mock_task_item1.task_info = {"type": "query"}
+ mock_task_item1.task_name = "test_task_1"
+ mock_task_item1.start_time = datetime.now()
+ mock_task_item1.end_time = None
+ mock_task_item1.status = "running"
+ mock_task_item1.result = None
+ mock_task_item1.error_message = None
+ mock_task_item1.messages = []
+
+ mock_task_item2 = MagicMock()
+ mock_task_item2.item_id = "task_2"
+ mock_task_item2.user_id = "user_2"
+ mock_task_item2.mem_cube_id = "cube_2"
+ mock_task_item2.task_info = {"type": "answer"}
+ mock_task_item2.task_name = "test_task_2"
+ mock_task_item2.start_time = datetime.now()
+ mock_task_item2.end_time = None
+ mock_task_item2.status = "completed"
+ mock_task_item2.result = "success"
+ mock_task_item2.error_message = None
+ mock_task_item2.messages = ["message1", "message2"]
+
+ with patch.object(
+ self.scheduler.dispatcher,
+ "get_running_tasks",
+ return_value={"task_1": mock_task_item1, "task_2": mock_task_item2},
+ ) as mock_get_running_tasks:
+ # Call get_running_tasks
+ result = self.scheduler.get_running_tasks()
+
+ # Verify result structure
+ self.assertIsInstance(result, dict)
+ self.assertEqual(len(result), 2)
+ self.assertIn("task_1", result)
+ self.assertIn("task_2", result)
+
+ # Verify task_1 details
+ task1_dict = result["task_1"]
+ self.assertEqual(task1_dict["item_id"], "task_1")
+ self.assertEqual(task1_dict["user_id"], "user_1")
+ self.assertEqual(task1_dict["status"], "running")
+
+ # Verify task_2 details
+ task2_dict = result["task_2"]
+ self.assertEqual(task2_dict["item_id"], "task_2")
+ self.assertEqual(task2_dict["user_id"], "user_2")
+ self.assertEqual(task2_dict["status"], "completed")
+ self.assertEqual(task2_dict["result"], "success")
+ self.assertEqual(task2_dict["messages"], ["message1", "message2"])
+
+ # Verify dispatcher method was called
+ mock_get_running_tasks.assert_called_once_with(filter_func=None)
diff --git a/tests/memories/textual/test_tree.py b/tests/memories/textual/test_tree.py
index f3e662992..a72709ec5 100644
--- a/tests/memories/textual/test_tree.py
+++ b/tests/memories/textual/test_tree.py
@@ -66,7 +66,9 @@ def test_add_calls_manager(mock_tree_text_memory):
metadata=TreeNodeTextualMemoryMetadata(updated_at=None),
)
mock_tree_text_memory.add([mock_item])
- mock_tree_text_memory.memory_manager.add.assert_called_once()
+ mock_tree_text_memory.memory_manager.add.assert_called_once_with(
+ [mock_item], user_name=None, mode="sync"
+ )
def test_get_working_memory_sorted(mock_tree_text_memory):
@@ -161,4 +163,6 @@ def test_add_returns_ids(mock_tree_text_memory):
result = mock_tree_text_memory.add(mock_items)
assert result == dummy_ids
- mock_tree_text_memory.memory_manager.add.assert_called_once_with(mock_items)
+ mock_tree_text_memory.memory_manager.add.assert_called_once_with(
+ mock_items, user_name=None, mode="sync"
+ )
diff --git a/tests/memories/textual/test_tree_searcher.py b/tests/memories/textual/test_tree_searcher.py
index d99664817..2a5536cf8 100644
--- a/tests/memories/textual/test_tree_searcher.py
+++ b/tests/memories/textual/test_tree_searcher.py
@@ -69,13 +69,6 @@ def test_searcher_fast_path(mock_searcher):
assert len(result) <= 2
assert all(isinstance(item, TextualMemoryItem) for item in result)
- # Should update usage and call update_node
- for item in result:
- assert len(item.metadata.usage) > 0
- mock_searcher.graph_store.update_node.assert_any_call(
- item.id, {"usage": item.metadata.usage}, user_name=None
- )
-
def test_searcher_fine_mode_triggers_reasoner(mock_searcher):
parsed_goal = MagicMock()
diff --git a/tests/memories/textual/test_tree_task_goal_parser.py b/tests/memories/textual/test_tree_task_goal_parser.py
index c71af4b06..899e2454b 100644
--- a/tests/memories/textual/test_tree_task_goal_parser.py
+++ b/tests/memories/textual/test_tree_task_goal_parser.py
@@ -20,12 +20,7 @@ def generate(self, messages):
def test_parse_fast_returns_expected():
parser = TaskGoalParser()
result = parser.parse("Tell me about cats", mode="fast")
-
assert isinstance(result, ParsedTaskGoal)
- assert result.memories == ["Tell me about cats"]
- assert result.keys == ["Tell me about cats"]
- assert result.tags == []
- assert result.goal_type == "default"
def test_parse_fine_calls_llm_and_parses():
diff --git a/tests/test_hello_world.py b/tests/test_hello_world.py
index 986839bc9..e9c81c7f0 100644
--- a/tests/test_hello_world.py
+++ b/tests/test_hello_world.py
@@ -118,6 +118,8 @@ def test_memos_yuqingchen_hello_world_logger_called():
def test_memos_chen_tang_hello_world():
+ import warnings
+
from memos.memories.textual.general import GeneralTextMemory
# Define return values for os.getenv
@@ -130,7 +132,10 @@ def mock_getenv(key, default=None):
}
return mock_values.get(key, default)
- # Use patch to mock os.getenv
- with patch("os.getenv", side_effect=mock_getenv):
- memory = memos_chentang_hello_world()
- assert isinstance(memory, GeneralTextMemory)
+ # Filter Pydantic serialization warnings
+ with warnings.catch_warnings():
+ warnings.filterwarnings("ignore", category=UserWarning, module="pydantic")
+ # Use patch to mock os.getenv
+ with patch("os.getenv", side_effect=mock_getenv):
+ memory = memos_chentang_hello_world()
+ assert isinstance(memory, GeneralTextMemory)