diff --git a/docs/source/user-guide/triton-rerope/results.png b/docs/source/_static/images/rerope_performace.png
similarity index 100%
rename from docs/source/user-guide/triton-rerope/results.png
rename to docs/source/_static/images/rerope_performace.png
diff --git a/docs/source/index.md b/docs/source/index.md
index b494115bb..6469ec6e5 100644
--- a/docs/source/index.md
+++ b/docs/source/index.md
@@ -57,6 +57,7 @@ user-guide/prefix-cache/index
user-guide/sparse-attention/index
user-guide/pd-disaggregation/index
user-guide/metrics/metrics
+user-guide/rerope/rerope
:::
:::{toctree}
diff --git a/docs/source/user-guide/triton-rerope/rerope.md b/docs/source/user-guide/rerope/rerope.md
similarity index 74%
rename from docs/source/user-guide/triton-rerope/rerope.md
rename to docs/source/user-guide/rerope/rerope.md
index 3cf7f2c3c..91f0142cc 100644
--- a/docs/source/user-guide/triton-rerope/rerope.md
+++ b/docs/source/user-guide/rerope/rerope.md
@@ -1,26 +1,34 @@
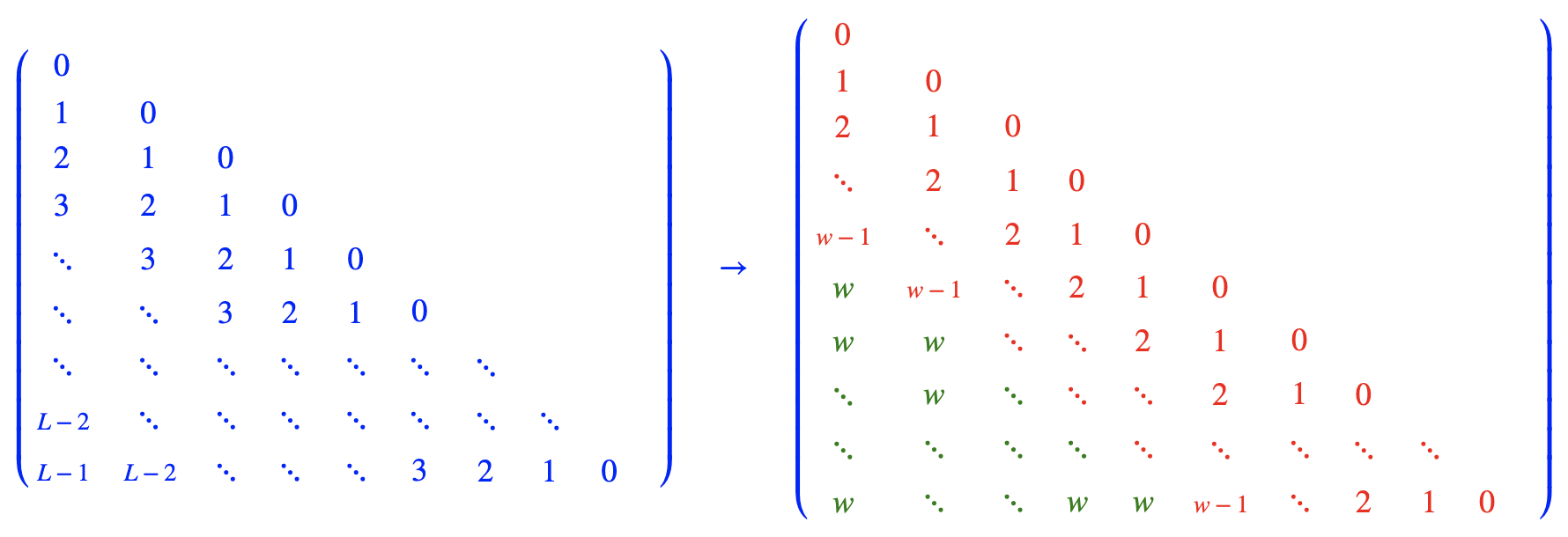
-# Rectified Rotary Position Embeddings (ReRoPE)
+# Rectified Rotary Position Embeddings
-Using ReRoPE, we can more effectively extend the context length of LLM without the need for fine-tuning. This is about the Triton implementation of ReRoPE and its integration into the vLLM inference framework.
+Using Rectified Rotary Position Embeddings (ReRoPE), we can more effectively extend the context length of LLM without the need for fine-tuning. This is about the Triton implementation of ReRoPE and its integration into the vLLM inference framework.
+
+
**🚀 ReRoPE | 📄 blog [https://kexue.fm/archives/9708] [https://normxu.github.io/Rethinking-Rotary-Position-Embedding-3]**
+
[](https://github.com/ModelEngine-Group/unified-cache-management/blob/main/LICENSE)
[](https://python.org)
+
## 🌟 What is ReRoPE?
+
+
+