|
| 1 | +# Hybrid RAG with NetApp |
| 2 | + |
| 3 | +**BM25 + Vector Retrieval with Governance Built In** |
| 4 | + |
| 5 | +## 1. Introduction |
| 6 | + |
| 7 | +This project highlights a **Hybrid Retrieval-Augmented Generation (Hybrid RAG)** architecture developed and validated by **NetApp**. |
| 8 | + |
| 9 | +The design combines **BM25 lexical search** for deterministic, explainable grounding with **vector embeddings** for semantic coverage. The result is a retrieval system that balances **precision and recall** while remaining **observable, auditable, and enterprise-ready**. |
| 10 | + |
| 11 | +This page provides a NetApp-focused overview of the architecture and its enterprise implications. |
| 12 | +The full open source reference implementation lives here: |
| 13 | +👉 **[https://github.com/davidvonthenen-com/hybrid-rag-bm25-with-ai-governance](https://github.com/davidvonthenen-com/hybrid-rag-bm25-with-ai-governance)** |
| 14 | + |
| 15 | +## 2. Why Hybrid RAG |
| 16 | + |
| 17 | +Pure vector RAG is good at "semantic vibes" but weak at answering hard questions like: |
| 18 | + |
| 19 | +* Why did this document match? |
| 20 | +* Which terms actually mattered? |
| 21 | +* Can we reproduce this result next week? |
| 22 | +* Can we defend it to auditors? |
| 23 | + |
| 24 | +Hybrid RAG addresses those gaps by **anchoring retrieval in BM25 first**, then using vectors as **supporting context**, not the source of truth. |
| 25 | + |
| 26 | +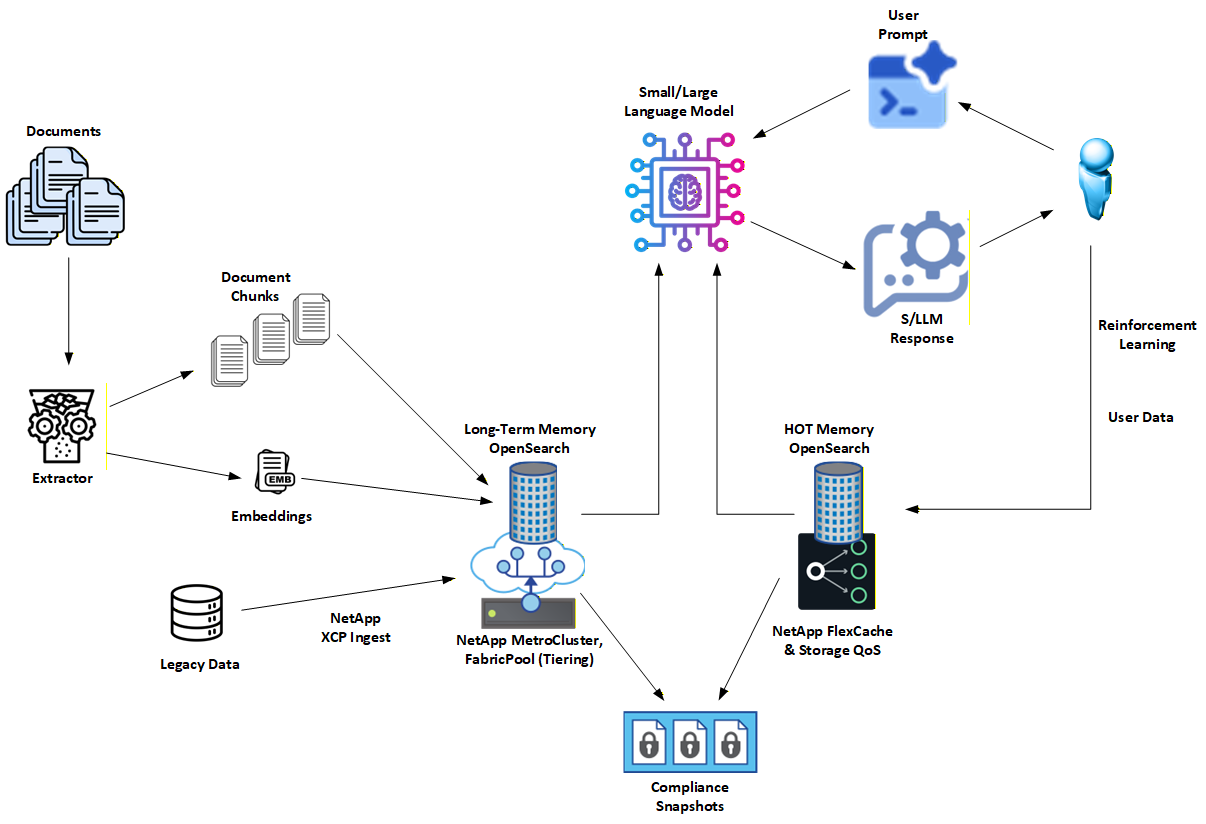 |
| 27 | + |
| 28 | +Key reasons Hybrid RAG works: |
| 29 | + |
| 30 | +* **Deterministic grounding**: BM25 provides explicit, traceable matches against known terms and entities. |
| 31 | + |
| 32 | +* **Semantic coverage without drift**: Vector embeddings expand recall for paraphrases and long-tail phrasing without replacing lexical evidence. |
| 33 | + |
| 34 | +* **Explainability by design**: Every result can be tied back to fields, terms, and highlights rather than opaque similarity scores. |
| 35 | + |
| 36 | +* **Lower hallucination risk**: LLM responses are grounded in retrieved documents with clear provenance before any stylistic refinement. |
| 37 | + |
| 38 | +* **Practical governance**: Retrieval behavior is inspectable and reproducible, which matters in regulated environments. |
| 39 | + |
| 40 | +This approach delivers many of the governance benefits people look to Graph RAG for, **without the operational overhead of graph databases or ontology management**. |
| 41 | + |
| 42 | +## 3. How NetApp Enhances This Architecture |
| 43 | + |
| 44 | +NetApp extends Hybrid RAG with **enterprise-grade data management and storage primitives** that make the architecture operational at scale. |
| 45 | + |
| 46 | +Key NetApp contributions include: |
| 47 | + |
| 48 | +* **Dual-tier memory model** |
| 49 | + |
| 50 | + * **Long-Term (LT)**: authoritative, durable knowledge store |
| 51 | + * **HOT (unstable)**: short-lived, user- or session-specific working set |
| 52 | + |
| 53 | +* **Governance-first tiering** |
| 54 | + |
| 55 | + * HOT exists for retention control, policy asymmetry, and isolation |
| 56 | + * LT remains conservative, stable, and audit-ready |
| 57 | + |
| 58 | +* **High-performance locality** |
| 59 | + |
| 60 | + * NetApp FlexCache keeps frequently accessed shards close to compute |
| 61 | + * Eviction is explicit and policy-driven, not accidental |
| 62 | + |
| 63 | +* **Enterprise resilience** |
| 64 | + |
| 65 | + * SnapMirror and MetroCluster support replication and disaster recovery |
| 66 | + * Snapshots enable point-in-time audits of "what the AI knew" |
| 67 | + |
| 68 | +* **Safe experimentation** |
| 69 | + |
| 70 | + * FlexClone allows instant, space-efficient copies of indices for testing new analyzers or embedding models without touching production |
| 71 | + |
| 72 | +NetApp's role is not to change how Hybrid RAG works logically, but to **make it reliable, governable, and operable in real enterprise environments**. |
| 73 | + |
| 74 | +## 4. Visit the GitHub Project for More Details |
| 75 | + |
| 76 | +This page is intentionally concise. |
| 77 | + |
| 78 | +For full technical details, code, and deployment guidance, visit the open source project: |
| 79 | + |
| 80 | +👉 **[https://github.com/NetApp/hybrid-rag-bm25-with-ai-governance](https://github.com/NetApp/hybrid-rag-bm25-with-ai-governance)** |
| 81 | + |
| 82 | +There you'll find: |
| 83 | + |
| 84 | +* A complete Hybrid RAG reference implementation |
| 85 | +* Community and enterprise deployment paths |
| 86 | +* Detailed explanations of BM25 grounding, vector augmentation, and HOT/LT promotion workflows |
| 87 | + |
| 88 | +If you're building RAG systems that need to be **accurate, explainable, and defensible**, that repository is the place to start. |
0 commit comments