RSYNC 改造方案 - 少一
#1697
Replies: 2 comments 1 reply
-
|
1、优先简单配置文件传输的速度 |
Beta Was this translation helpful? Give feedback.
0 replies
-
|
@luky116 @wangshao1 当前3.5.1已经合入主从复制新机制。请问这个方案是否与实际方案完全一致? |
Beta Was this translation helpful? Give feedback.
1 reply
-
|
@chenbt-hz 上面这些资料显然已经过时了哈 |
Beta Was this translation helpful? Give feedback.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Uh oh!
There was an error while loading. Please reload this page.
-
背景
pika主从节点进行全量数据同步通过rsync命令实现。rsync命令需要单独启动一个进程来实现数据传输,在pika进程重启/退出或者机器故障等情况下与pika进程不同步。因此计划将dump文件传输的功能进行集成到pika进程中,使用单独线程进行处理。
团队调研了openrsync工具以及braft中下载snapshot的代码以及基于pika的网络pink自己实现文件传输的功能。综合对比后,考虑基于pink网络库实现文件传输。新的文件传输方式需同时实现:1.支持限速策略。2.容忍网络丢包,重传。3.支持文件级数据校验。
主从复制流程
Pika支持了redis中的slaveof命令用于在不同的pika实例间进行数据同步。数据同步包括全量同步和增量同步两部分。pika中使用了两个状态机和Auxilary_thread后台线程维护整个同步状态。
主从同步整体执行流程为:
整体同步流程涉及到两个状态机,一个状态机表示pika_server状态,主要用于slave节点收到slaveof请求之后到开始同步数据之前的状态流转。包括:
PIKA_REPL_NO_CONNECT,PIKA_REPL_SHOULD_META_SYNC,PIKA_REPL_META_SYNC_DONE,PIKA_REPL_ERROR。第二个状态机表示每个slot的状态,状态包括kNoConnect,kTryConnect,kTryDBSync,kWaitDBSync,kWaitReply,kConnected,kError,kDBNoConnect。状态流转图如下所示:
注:图中集中在增量同步之前阶段的状态转移,未包含请求错误导致状态流转到kError的情况,也没有包括连接keepalive超时或连接断开时状态被重置为kNoConnect的过程。
状态流转主要是通过auxiliary_thread线程的大while循环与网络库的回调函数完成状态的流转。大致流程为:
PIKA_REPL_NO_CONNECT -> PIKA_REPL_SHOULD_META_SYNC: 当slave节点收到slaveof节点请求之后,会调用removeMaster删除已有的master,接着调用SetMaster设置pika_server的状态为meta_sync。
PIKA_REPL_SHOULD_META_SYNC -> PIKA_REPL_SHOULD_METASYNC_DONE: PikaAuxiliaryThread在大循环中检测到该状态之后,执行SendMetaSyncRequest向master节点发起metasync请求。当slave节点收到metasync的回包之后,会执行HandleMetaSyncResponse函数,如果请求成功且解析成功,比对主从节点的db拓扑结构,如果一致,将状态变为PIKA_REPL_META_SYNC_DONE,同时激活SyncSlaveSlot状态机,将slot状态流转到kTryConnect。
**kNoConnect -> kTryConnect:**metasync阶段执行完成后,会启动SyncSlaveSlot的状态机,并将状态流转到kTryConnect。
**kTryConnect -> kWaitReply:**PikaAuxiliaryThread检测到某个slot处于该状态之后,发送trysync命令给master,状态流转到kWaitReply。
kWaitReply -> kConnected: 收到trysync命令的回包之后,如果master节点有对应binlog的offset,状态流转到kConnected。
kWaitReply -> kTryDBSync: 收到trySync命令的回包之后,如果master节点没有对应binlog的offset,状态流转到kTryDBSync。
kTryDBSync -> kWaitDBSync: 对处于kWaitDBSync状态的slot,auxiliaryThread会发送dbsync命令给master,slot状态重新流转到kWaitReply。
**kWaitReply -> kWaitDBSync: **收到dbsync回包之后,状态流转到kWaitDBSync。等待master通过rsync推送引擎文件。auxiliaryThread会周期性地对处于kWaitDBSync状态的slot执行TryUpdateMasterOffset,其主要工作就是检查数据同步是否已经完成,如果已经完成,切db,更新状态为kConnected。进行后续增量数据同步。
方案
本次主从复制修改的内容对应上一节中的步骤9。类似于rsync,数据同步也是基于client-server模式,主从节点在启动时都需要启动一个server,不同的是rsync需要启动一个子进程。同步文件时,slave节点作为client端,master节点作为server端,slave从server端拉取引擎文件并进行加载。整体交互流程如下图所示:
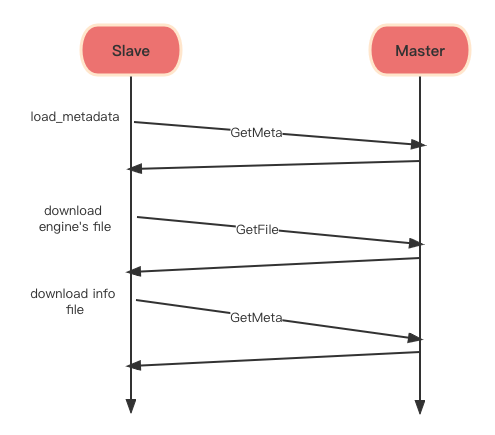
数据传输
新方案的数据传输方式是使用protobuf通信协议,slave节点主动向master拉取文件内容。每个文件可能被拆分为多次网络请求。具体每次请求中传输多少数据量根据限速策略进行调整。proto文件定义如下所示。
slave在GetFileRequest中会设置期望拉取的文件名,本次请求要拉取的字节数,文件的偏移量。master根据请求信息读取文件,将数据添加到GetFileResponse中。其中eof表示请求的文件是否已经读完,如果读取完成,将文件的checksum一同追加到回包中,slave节点在整个文件传输完成之后会比对MD5。
新的主从复制方式考虑使用slave从master拉取文件(pull)的方式。考虑不使用master推送(push)方式的原因包括:
下载限速
文件下载限速的逻辑,计划参考braft中install_snapshot的限速策略。即限制单位时间内下载的数据量。总体思路是:
限制单位时间内下载的数据量,有两个配置参数:_throttle_throughput_bytes,指每秒最多可以接收的字节数。_check_cycle:指每秒被分成多少个周期。在拉取snapshot之前,follower首先调用throttled_by_throughput,传入期望拉取的字节数,throttled_by_throughput内部会判断_cur_throughput_bytes + bytes是否大于_throttle_throughput_bytes/check_cycle,如果小于,表示当前统计周期内余额还没有用完,更新_cur_throughput_bytes即可。否则,表明当前周期内余额不足,检查下当前时间距离当前统计周期是否已经大于一个cycle,如果不是,表明还是在一个统计周期里,那么剩多少余额就返回多少余额。如果不是,表明可以使用新的周期里的余额,更新_last_throughput_check_time_us和_cur_throughput_bytes。
在请求收到回复之后,调用return_unused_throughput返回未使用的余额。分别传入当初成功申请的余额,实际传输的字节数和持续时间。函数内部会首先根据当前时间,_last_throughput_check_time_us和持续时间计算申请的时候是不是在上一个周期,如果是,什么都不做。如果不是,将未使用的token还给_cur_throughput_bytes中。
异常处理
对于slave节点来说,slave节点会记录此时期望拉取的filename和offset,同时会校验收到的GetFileResponse中的filename和offset是否与本地相等。如果不是期望的数据,将请求直接丢弃即可。所以请求是幂等的。
对于master节点来说,本地并不持有状态。对于重传的请求,损耗相当于多读了一次文件。不会对数据一致性造成影响。
2.同步历史数据过程中,如何应对master节点宕机?
master节点本身并不持有状态,只要master宕机重启之后,dump的文件存在且完整,即可正常对外提供服务。
3.同步历史数据过程中,如何应对slave节点宕机?
在之前版本的主从同步实现中,openrsync工具会进行增量同步,已经同步的文件不会再同步,减少不必要的IO。新的主从同步方案中,可以在slave端持久化一些meta信息用来在进程被重新拉起时恢复状态。具体实现是,slave节点在下载完一个文件之后,将文件名和md5 checksum记录在内存中,并周期性持久化到一个指定的文件中。当slave宕机重启恢复之后,进程在启动时会去加载该文件,读出记录的文件名和checksum,遍历记录的文件,计算checksum,如果文件存在且checksum校验通过,就不需要重新拉取,否则重新从master拉取文件。如此实现,可以保证slave节点宕机恢复之后,只需要重新拉取少部分重复文件。
风险点
兼容性。新的主从同步模式需要master和slave同时升级到新版本还可以,存在兼容性。因此初步考虑在第一版实现中,保留rsync和新方案两种方式,默认使用rsync方式,并支持通过client发命令修改主从的历史数据同步方式。
传输性能待验证。基于pink使用protobuf方式同步历史数据,传输性能是否会有降低待验证。目前想到的是如果传输性能不够,slave增加线程数量并行拉取文件。
测试场景
1.多slave建立同步关系。
2.测试主从同步时存量数据量要达到1TB。
Beta Was this translation helpful? Give feedback.
All reactions