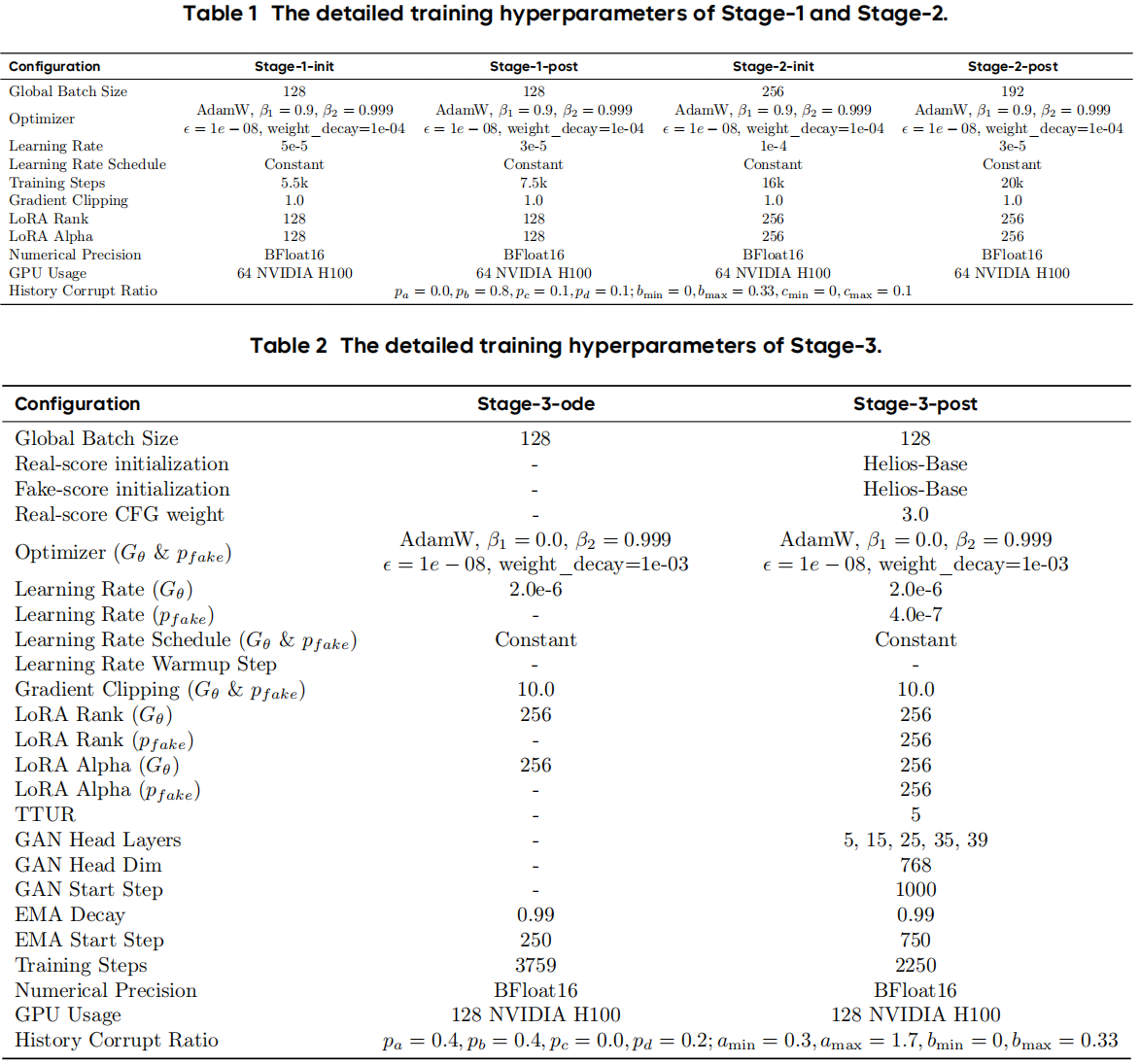
We use a three-stage progressive pipeline, all the setting can be found here. Stage-1 (Base) performs architectural adaptation: we apply Unified History Injection, Easy Anti-Drifting, and Multi-Term Memory Patchification to convert the bidirectional pretrained model into an autoregressive generator. Stage-2 (Mid) targets token compression by introducing Pyramid Unified Predictor Corrector, which aggressively reduces the number of noisy tokens and thus the overall computation. Stage-3 (Distilled) applies Adversarial Hierarchical Distillation, reducing the sampling steps from 50 to 3 and eliminating the need for classifier-free guidance (CFG). Throughout training, we apply dynamic shifting to all timestep-dependent operations to match the noise schedule to the latent size. For Stages 1 and 2, training is further divided into two phases: a high learning-rate phase for rapid convergence, followed by a low learning-rate phase for refinement.