You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+52-4Lines changed: 52 additions & 4 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -15,7 +15,7 @@ Made in Vancouver, Canada by [Picovoice](https://picovoice.ai)
15
15
picoLLM Inference Engine is a highly accurate and cross-platform SDK optimized for running compressed large language
16
16
models. picoLLM Inference Engine is:
17
17
18
-
- Accurate; picoLLM Compression improves GPTQ by up to 98%.
18
+
- Accurate; picoLLM Compression improves GPTQ by [significant margins](https://picovoice.ai/blog/picollm-towards-optimal-llm-quantization/)
19
19
- Private; LLM inference runs 100% locally.
20
20
- Cross-Platform
21
21
- Linux (x86_64), macOS (arm64, x86_64), and Windows (x86_64)
@@ -29,6 +29,15 @@ models. picoLLM Inference Engine is:
29
29
30
30
-[picoLLM](#picollm-inference-engine)
31
31
-[Table of Contents](#table-of-contents)
32
+
-[Showcases](#showcases)
33
+
-[Raspberry Pi](#raspberry-pi)
34
+
-[Android](#android)
35
+
-[iOS](#ios)
36
+
-[Cross-Browser Local LLM](#cross-browser-local-llm)
37
+
-[Llama-3-70B-Instruct on GeForce RTX 4090](#llama-3-70b-instruct-on-geforce-rtx-4090)
38
+
-[Local LLM-Powered Voice Assistant on Raspberry Pi](#local-llm-powered-voice-assistant-on-raspberry-pi)
39
+
-[Local Llama-3-8B-Instruct Voice Assistant on CPU](#local-llama-3-8b-instruct-voice-assistant-on-cpu)
40
+
-[Accuracy](#accuracy)
32
41
-[Models](#models)
33
42
-[AccessKey](#accesskey)
34
43
-[Demos](#demos)
@@ -48,6 +57,45 @@ models. picoLLM Inference Engine is:
48
57
-[Releases](#releases)
49
58
-[FAQ](#faq)
50
59
60
+
## Showcases
61
+
62
+
### Raspberry Pi
63
+
64
+
[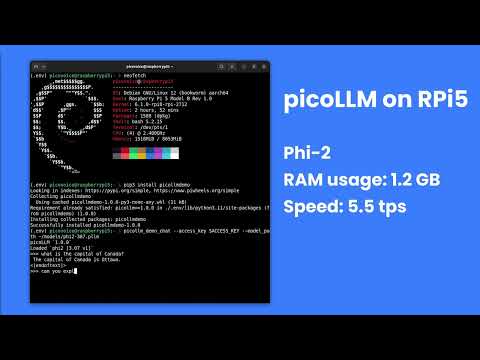](https://www.youtube.com/watch?v=CeKPXZ_8hkI)
65
+
66
+
### Android
67
+
68
+
[](https://www.youtube.com/watch?v=XeUMkue-5lI)
69
+
70
+
### iOS
71
+
72
+
[](https://www.youtube.com/watch?v=dNK5esdkI0Y)
73
+
74
+
### Cross-Browser Local LLM
75
+
76
+
[Live Demo — Works offline!](https://picovoice.ai/picollm/)
77
+
78
+
### Llama-3-70B-Instruct on GeForce RTX 4090
79
+
80
+
[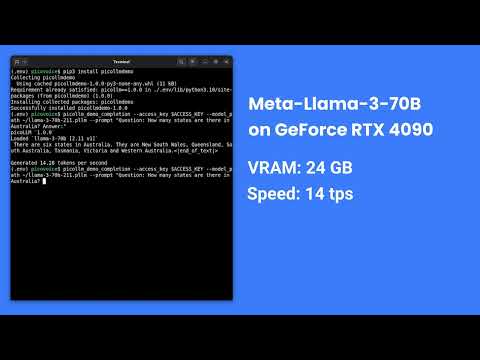](https://www.youtube.com/watch?v=4mcVwbOOIqk)
81
+
82
+
### Local LLM-Powered Voice Assistant on Raspberry Pi
83
+
84
+
[](https://www.youtube.com/watch?v=GEndT3RGRvw)
85
+
86
+
### Local Llama-3-8B-Instruct Voice Assistant on CPU
87
+
88
+
[](https://www.youtube.com/watch?v=uV0GlXDFSPw)
89
+
90
+
## Accuracy
91
+
92
+
picoLLM Compression is a novel large language model (LLM) quantization algorithm developed within Picovoice. Given a task-specific cost function, picoLLM Compression automatically learns the optimal bit allocation strategy across and within LLM's weights. Existing techniques require a fixed bit allocation scheme, which is subpar.
93
+
94
+
For example, picoLLM Compression recovers MMLU score degradation of widely adopted GPTQ by 91%, 99%, and 100% at 2, 3,
95
+
and 4-bit settings. The figure below depicts the MMLU comparison between picoLLM and GPTQ for Llama-3-8b [[1]](https://picovoice.ai/blog/picollm-towards-optimal-llm-quantization/).
96
+
97
+

98
+
51
99
## Models
52
100
53
101
picoLLM Inference Engine supports the following open-weight models. The models are on
Replace `${ACCESS_KEY}` with yours obtained from Picovoice Console, `${MODEL_PATH}` with the path to a model file
127
175
downloaded from Picovoice Console, and `${PROMPT}` with a prompt string.
128
176
129
-
For more information about Node.js demos go to [demo/nodejs](./demo/nodejs).
177
+
For more information about Node.js demos go to [Node.js demo](./demo/nodejs).
130
178
131
179
### Android Demos
132
180
133
-
Using Android Studio, open the [Completion demo](demo/android/Completion/) as an Android project, copy your AccessKey into MainActivity.java, and run the application.
181
+
Using Android Studio, open the [Completion demo](demo/android/Completion) as an Android project, copy your AccessKey into MainActivity.java, and run the application.
134
182
135
-
To learn about how to use picoLLM in a chat application, try out the [Chat demo](demo/android/Chat/).
183
+
To learn about how to use picoLLM in a chat application, try out the [Chat demo](demo/android/Chat).
136
184
137
185
For more information about Android demos go to [demo/android](demo/android/README.md).
0 commit comments