|
| 1 | +## History |
| 2 | + |
| 3 | +**1. Airbyte** |
| 4 | + |
| 5 | +Tested using Airbyte and their API - was pretty expensive |
| 6 | + |
| 7 | +**2. DLT** |
| 8 | + |
| 9 | +Used DLT (data load tool) - worked well for the most part, we had a good line of comms with the DLT guys (went to breakfast with them in London too). They had a handful of example sources for us to replicate, made for an easy set up process |
| 10 | + |
| 11 | +They added features for us too, such as incremental syncing (merging of data). They were storing everything in deltalake tables which is where that tech came from for us. |
| 12 | + |
| 13 | +Problems were that the pipeline was very rigid, very little flexibility to build out our own stuff within the pipeline section, a bunch of "magic" was happening that was hard to debug, we were getting a bunch of OOM errors (more to come on that!), and data was downloaded onto local disk first, then flushed to S3 as a sequential step, causing lots of local disk bloat. |
| 14 | + |
| 15 | +**3. Chunked pipeline** |
| 16 | + |
| 17 | +Rebuilt the whole pipeline in plain python without magic third parties. Used pyarrow and deltalake internally to move data around. The pipeline would chunk data so that we were incrementally writing data to S3 (chunk size is dynamic dependent on source). |
| 18 | + |
| 19 | +We have full control over the pipeline, we do our own data normalization, we can do our own triggering of external processes off the back of syncs, etc etc. |
| 20 | + |
| 21 | +Writing to deltalake still, chatting to the delta-rs guys semi-regularly. OOMs are still an issue, but we're "managing" to an extent. The pipeline scales well outside of the OOMs (solving that will unlock us a bunch more though). |
| 22 | + |
| 23 | +**3.1 Source orchestration/registry pattern** |
| 24 | + |
| 25 | +Implemented a source registry pattern so all sources followed the same pattern, meant the pipeline doesn't care about what source its dealing with, we just have a common interface. |
| 26 | + |
| 27 | +Makes building new sources a breeze, we now have other teams building sources (such as the web analytics team, they've built out a lot of our ad sources). Even using AI to build sources is 95% there with our examples + documentation! |
| 28 | + |
| 29 | +**Further reading**: |
| 30 | + |
| 31 | +- Limited internal workings of the pipeline and handling OOMs: https://github.com/PostHog/posthog/blob/master/posthog/temporal/data_imports/README.md |
| 32 | +- How to build a new source: https://github.com/PostHog/posthog/blob/master/posthog/temporal/data_imports/sources/README.md |
| 33 | + |
| 34 | +### Problems |
| 35 | + |
| 36 | +##### 1 - OOMs |
| 37 | + |
| 38 | +We have a problem with pods OOMing. This mostly happens on incremental jobs when we're merging data into a deltalake table on S3. Merging of the data occurs on the pod and it'll load the whole table (or a specific partition), rewrite the necessary files and then rewrite them out to S3. Some of these tables/partitions can be very big, and the merging operation isn't cheap - its generally recommended to have 10-20x of the compressed file size available in memory for merging (e.g. a 1GB compressed table will require 10-20 GB of memory). Our deltalake library, delta-rs, do some optimizations, but it's often not enough. Because of this, the pod will load too much data and the pod will OOM, causing all the jobs running on the pod to retry. |
| 39 | + |
| 40 | +##### 2 - Wide tables |
| 41 | + |
| 42 | +Similar to the above, we limit how much data we're pulling in from sources at once to keep a low memory footprint - we want to have as much available memory as possible to allow for deltalake merging. If a source (mostly SQL databases) have a very wide table (e.g. have massive JSON blobs within the table), then we severely limit how many rows we pull at once, causing syncs to take much longer to run. On occasion, we will still pull too much data from the source DB and OOM the pod, for example, if we pull 1000 rows of 30 MB each, then we're effectively pulling 30 GB of data, this will OOM the pod. |
| 43 | + |
| 44 | +##### 3 - Long running syncs |
| 45 | + |
| 46 | +Some API sources, such as stripe, take a notoriously long time to page - for example, stripe only allows us to pull 100 rows at a time, having 1,000,000 invoices on stripe takes nearly a day to pull. Up until very recently, if a pod died due to an OOM, then we'd have to restart the sync from the beginning as we'd have no way to track where we were in the sync (only on full refresh syncs). So, these tables took a very long time to complete, if ever. |
| 47 | + |
| 48 | +##### 4 - Deployments |
| 49 | + |
| 50 | +On deployments, we give the pods a 6-hour grace period to finish all their jobs before we forcefully kill the pod. Long running full refresh syncs may not complete in this time - we could increase this time limit if we wanted, but it often results in a 30 GB pod running one single job, often wasting resources. |
| 51 | + |
| 52 | +##### 5 - Highly partitioned tables |
| 53 | + |
| 54 | +We merge data into deltalake one partition at a time, deltalake doesn't support true concurrent writing to their tables. Meaning a chunk that touches 100 partitions would have to write to each partition sequentially - this can take a very long time when the partitions are at a reasonable size and thus cause syncs to take a very long time. A recent example of this is FlashAI. |
| 55 | + |
| 56 | +##### 6 - Nested dependent tables |
| 57 | + |
| 58 | +We have a handful of tables that require a parent object to cursor, for example, Stripe invoice line items requires a Stripe invoice object, and so we have to list the invoices, and then iterate each line item for each invoice. It'd be good if we were able to utilize existing tables for these nested dependent tables |
| 59 | + |
| 60 | +### Proposed pipeline |
| 61 | + |
| 62 | +- Generally a more producer/consumer approach |
| 63 | +- One process for reading from sources, and the other for writing to S3 |
| 64 | +- Possibly moving to ducklake instead of deltalake |
| 65 | + - using duckdb to do the data merging - more efficient, less memory intensive |
| 66 | + - Utilising the work Jams/Bill is doing on the duck kubernetes controller |
| 67 | + - FirecrackerVMs |
| 68 | + - Data will be in the same format as the query engine |
| 69 | + - Scalable catalog via postgres |
| 70 | + |
| 71 | +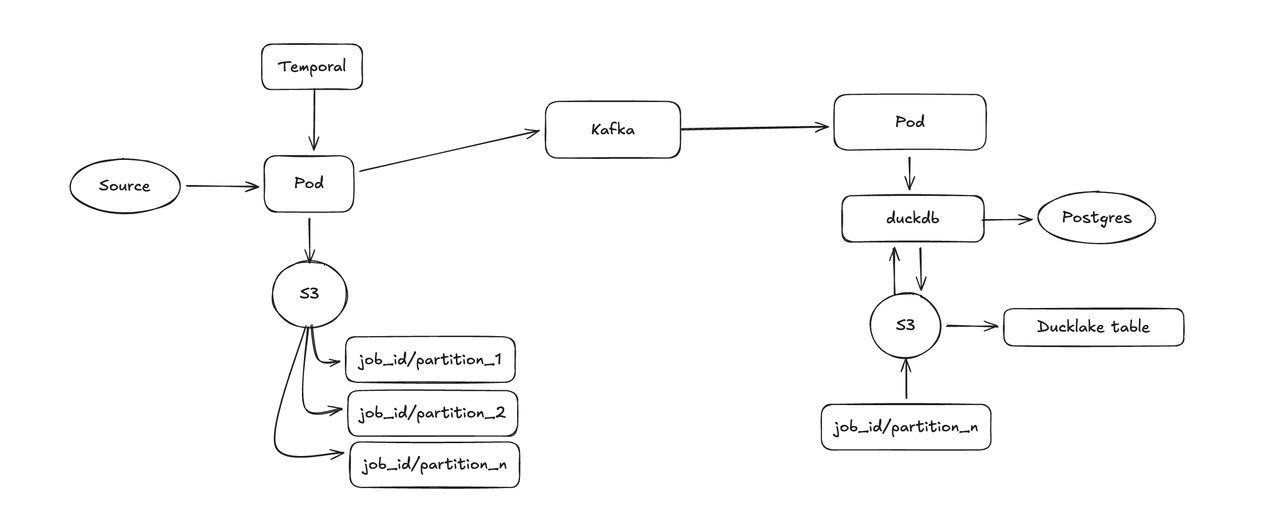 |
| 72 | + |
| 73 | +**Unknowns:** |
| 74 | + |
| 75 | +- How well duckdb will manage memory |
| 76 | +- How efficient ducklake would be for concurrent writes |
| 77 | +- Can we achieve the same level of concurrency and memory safety with deltalake? |
| 78 | + |
| 79 | +### Future of sources |
| 80 | + |
| 81 | +We want lots of sources, of well running sources - that is, sources that run efficiently and don't break. Source maintenance is slowly becoming a bit of a time sink for us and we often don't have enough time to add new sources regularly. To combat this, we wanna utilize the power of AI to help aid us to build self-healing sources and self-building sources. |
| 82 | + |
| 83 | +We've got a decent prompt to one-shot source creation via Claude, examples: |
| 84 | + |
| 85 | +- https://github.com/PostHog/posthog/compare/master...claude/add-klaviyo-warehouse-source-0168rKr1z9DsehvfpUi56vXt |
| 86 | +- https://github.com/PostHog/posthog/compare/master...claude/mailgun-data-warehouse-source-01WUz5GQwBaUarJnrqU2hSeV |
| 87 | + |
| 88 | +The next step is to automate the above process for when a user requests a new source, and then add self-healing sources. |
| 89 | + |
| 90 | +Self-healing sources will utilize our error tracking product to feed an isolated Claude Code sandbox a prompt with all the error tracking context to create PRs for us to review with fixes - with the caveat of ensuring it knows when an error is a system error vs a user error. |
0 commit comments