{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note: All images in this directory, unless specified otherwise, are licensed under CC BY-NC 4.0.
| Figure number | Description | Notes |
|---|---|---|
| 4-1 | RGB histogram-based "Similar Image Detector" program | |
| 4-2 | Product scanner in Amazon app with visual features highlighted | |
| 4-3 | Progress bar shown with tqdm_notebook | |
| 4-4 | The query image from the Caltech-101 dataset | |
| 4-5 | The nearest neighbor to our query image | |
| 4-6 | The second nearest neighbour of the queried image | |
| 4-7 | Nearest neighbor for different images returns similar-looking images | |
| 4-8 | t-SNE visualizing clusters of image features, where each cluster represents one object class in the same color | |
| 4-9 | t-SNE visualization showing image clusters; similar images in the same cluster | |
| 4-10 | t-SNE visualization with tiled images; similar images are close together | |
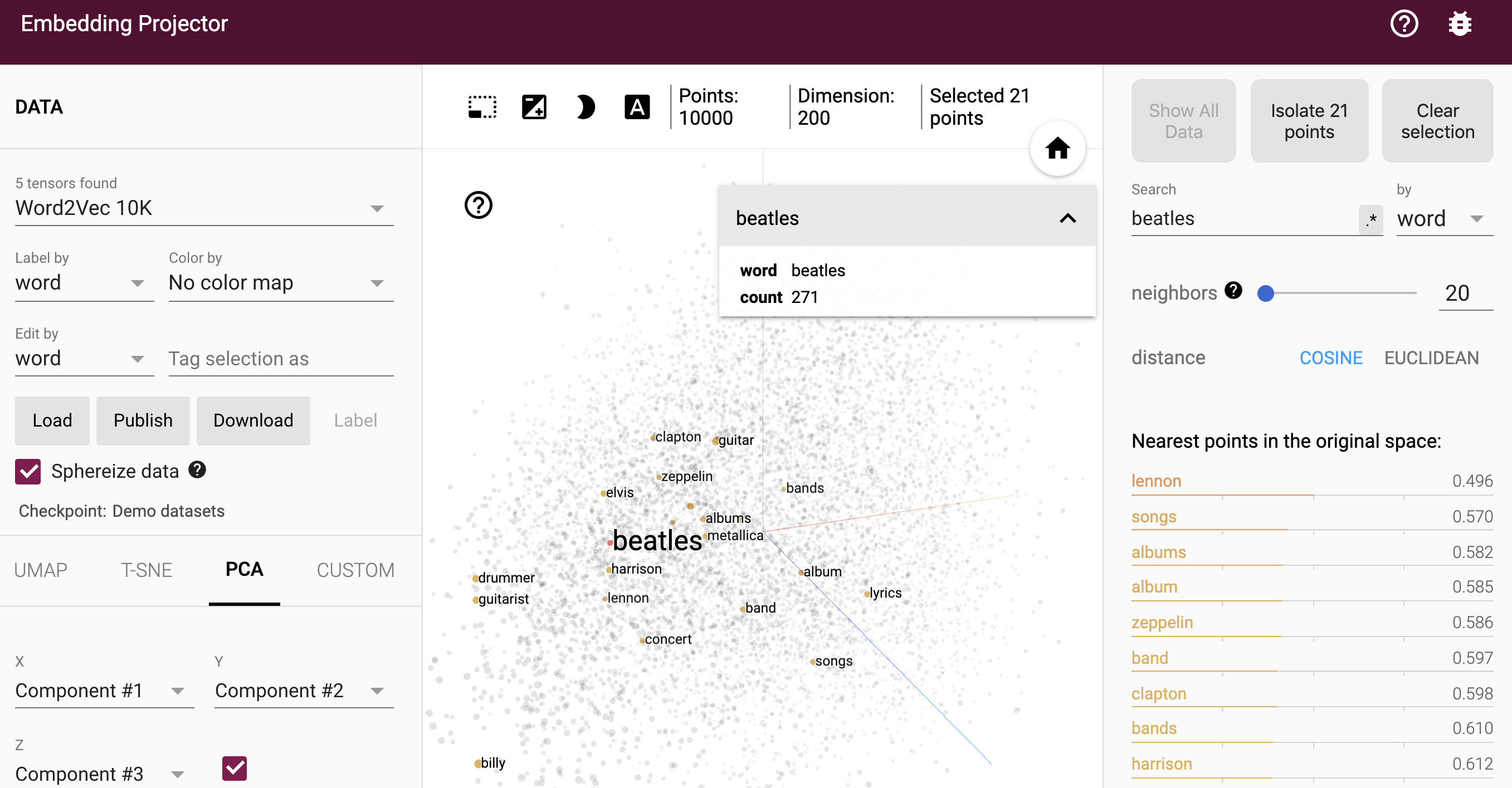
| 4-11 | TensorFlow Embedding projector showing a 3D representation of 10,000 common English words and highlighting words related to "Beatles" | |
| 4-12 | Variance for each PCA dimension | |
| 4-13 | Cumulative variance with each PCA dimension | |
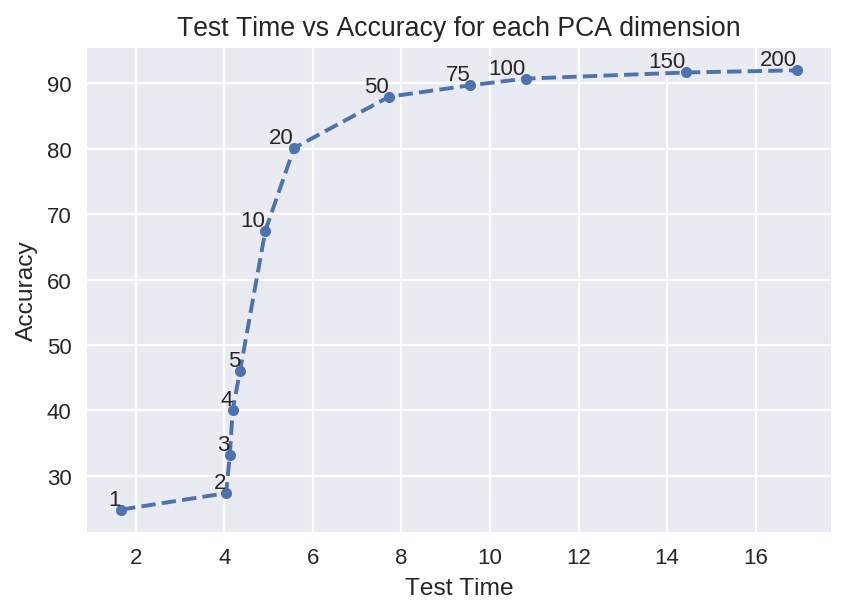
| 4-14 | Test time versus accuracy for each PCA dimension | |
| 4-15 | Comparison of ANN libraries (data source) | |
| 4-16 | t-SNE visualization of feature vectors of least-accurate classes before fine tuning | |
| 4-17 | t-SNE visualization of feature vectors of least-accurate classes after fine tuning | |
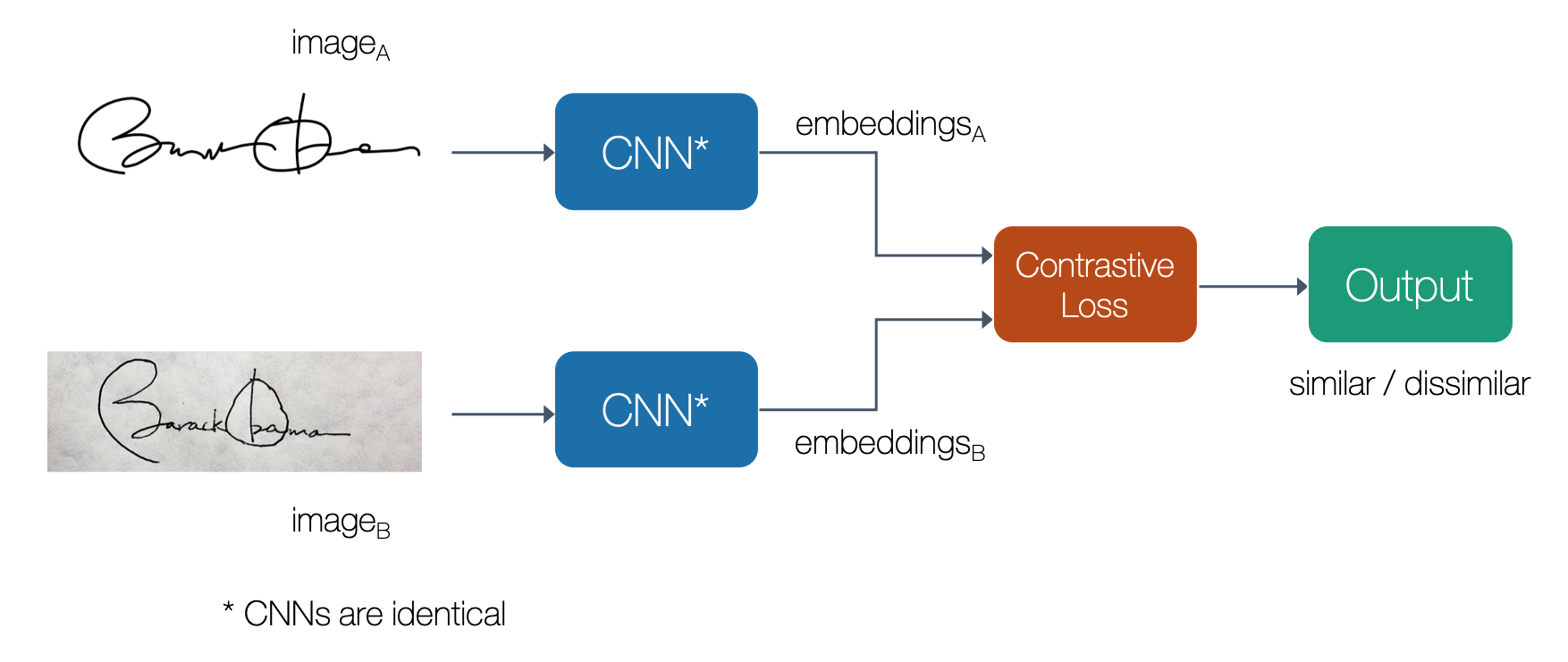
| 4-18 | A Siamese network for signature verification; note that the same CNN was used for both input images | |
| 4-19 | Similar patterns of a desert photo | |
| 4-20 | The Similar Looks feature of the Pinterest application | |
| 4-21 | Testing our friend Pete Warden’s photo on the celebslike.me website | |
| 4-22 | t-SNE visualization of the distribution of predicted usage patterns, using latent factors predicted from audio | Page 7 |
| 4-23a, 4-23b, 4-23c | Image captioning feature in Seeing AI: the Talking Camera App for the blind community | |
| 4-24 | Defining a CNN and visualizing the output of each layer during training in ConvNetJS | Page 2 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}