El cubo rubik es un puzzle combinatorio tridimensional consistente en un cubo donde cada una de las seis caras tiene un color distinto y a su vez dicha cara está dividida en 9 cuadrados distribuidos en una cuadrícula de 3x3. En este puzzle se puede rotar cada cara sobre su propio eje y el desafío es, únicamente mediante la rotación de las distintas caras, mezclar los colores del cubo y luego lograr volver al estado original en donde cada cara tiene cuadrados de un único color.
Figura 1: cubo rubik en acción
Este puzzle tiene más de 43 trillones de posibles estados o permutaciones distintas de sus piezas y sólo se considera a uno de todos esos estados como la solución. Como ya se adelantó, ese único estado es aquel en el que cada cara tiene piezas de un solo color. Teniendo en cuenta esta gran cantidad de estados y considerando a su vez que el estado objetivo es únicamente uno, se revela a simple vista que una aproximación para resolver este problema mediante fuerza bruta es inviable.
Para resolver este puzzle se hizo una implementación de Inteligencia Artificial que intenta resolver un cubo rubik de 3x3 mediante un algoritmo genético sin ningún conocimiento a priori más que el estado objetivo del cubo (tener cada cara completa de un solo color) y las 12 rotaciones posibles que se pueden hacer sobre las caras del cubo.
En el presente informe, se explica en detalle la implementación de este algoritmo y su funcionamiento. Adicionalmente, se evalúan los resultados obtenidos y se comparan con resultados obtenidos para el mismo problema mediante movimientos aleatorios.
Ya se introdujo que el cubo rubik es un puzzle combinatorio tridimensional consistente en un cubo donde cada una de las seis caras tiene un color distinto y a su vez dicha cara está dividida en 9 cuadrados distribuidos en una cuadrícula de 3x3. Las únicas acciones permitidas en este puzzle son rotaciones de las caras sobre su propio eje, lo cual suma un total de 12 acciones o rotaciones posibles, tomadas desde el punto de vista de la persona que sostiene el cubo:
- Cara Frente sentido reloj
- Cara Frente sentido contrarreloj
- Cara Detrás sentido Reloj
- Cara Detrás sentido contrarreloj
- Cara Izquierda sentido Reloj
- Cara Izquierda sentido contrarreloj
- Cara Derecha sentido Reloj
- Cara Derecha sentido contrarreloj
- Cara Arriba sentido Reloj
- Cara Arriba sentido contrarreloj
- Cara Abajo sentido Reloj
- Cara Abajo sentido contrarreloj
Vale destacar que quien sostiene el cubo puede rotarlo completo, por lo que la cara del frente no siempre tendrá el mismo color central y lo mismo con las otras 5 caras. Pero para la implementación del modelo se restringió el cubo completo a una sola orientación, dado que esta rotación agrega complejidad innecesaria a la implementación y no agrega funcionalidad alguna. Por lo que en el modelo la cara de frente siempre es color azul, la cara de debajo siempre es color blanco y lo mismo con las otras 4 caras, siempre tienen el mismo color central.
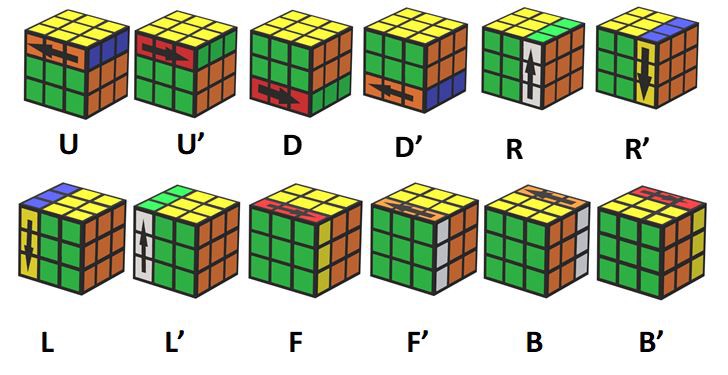
Figura 2: notación estándar de rotaciones
A nivel estructural, el cubo original está compuesto por 26 piezas tridimensionales con las siguientes características:
-
6 piezas fijas con 1 solo lado de color. Estas son las piezas del centro de cada cara. Al ser fijas, el color de esta pieza determina cuál debe ser el color de la cara completa.
-
12 piezas móviles con 2 lados de color. Estas piezas son las aristas del cubo y cambian de posición al realizar rotaciones.
-
8 piezas móviles con 3 lados de color. Estas piezas son las esquinas o vértices del cubo y cambian de posición al realizar rotaciones.

Figura 3: cubo rubik desensamblado
Es importante conocer la estructura interna del cubo ya que esta impone restricciones sobre el dominio de posibilidades del cubo que se deben implementar en el modelo computacional del mismo y sirve para definir correctamente la condición de "pieza colocada correctamente".
De forma intuitiva, se puede decir que mientras más piezas estén colocadas en el lugar correcto, más cerca se encuentra el cubo del estado objetivo. De modo que es importante definir cuándo una pieza está correctamente colocada. Las piezas centrales (aquellas con 1 solo color) siempre están colocadas correctamente, por lo cual no son tenidas en cuenta. Tanto para las aristas como para los vértices (piezas con 2 y 3 colores respectivamente) se puede decir que están colocadas correctamente cuando todos sus colores se encuentran en una cara del mismo color. Esto implica que la pieza debe estar tridimensionalmente colocada en su lugar original y con la rotación indicada.
En numerosos trabajos se ha implementado este problema [1][2][3][4][5][6] para los cuales se han utilizado distintos modelos computacionales para representar el cubo rubik. En este trabajo se decidió no utilizar ningún modelo previo y para representar un cubo rubik se creó desde cero una estructura de datos apropiada para el problema. Este modelo se visualiza como una versión bidimensional del cubo original tridimensional.
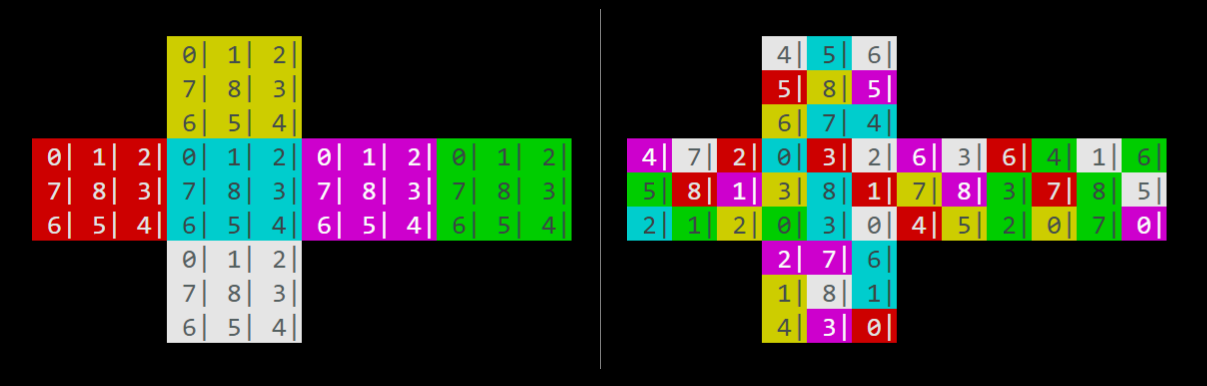
Figura 4: representación visual del cubo resuelto y desarmado.
Cuando se inicializa un objeto Cubo, este se encuentra en el estado objetivo y luego puede ser alterado mediante la ejecución de rotaciones. Este modelo cuenta con seis atributos, cada uno representando una cara del cubo, independientes entre sí: cara de frente, arriba, abajo, izquierda, derecha y detrás.
Como ya se adelantó, si se compara con un cubo tridimensional, este modelo lo representa de tal forma que el cubo completo no se mueve en ningún momento. Es decir, tomado desde la perspectiva de quien lo arma, la cara azul siempre estará al frente y la cara blanca siempre estará abajo, lo mismo para los demás colores, siempre están al mismo lado.
Las piezas no se representan tridimensionalmente, sino que los colores de cada cara son independientes entre sí, pero los métodos o acciones para modificar el cubo están diseñadas de tal forma que simulen las restricciones impuestas por la tridimensionalidad de las piezas en el puzzle real. Al ejecutar una rotación sobre una cara del cubo, no sólo se ven afectadas las piezas de esa cara, sino que también son afectadas las piezas de las caras circundantes, como en el cubo original. Cada una de las 6 caras cuenta con dos atributos importantes: color, que es el color de la pieza central de esa cara, que no se mueve; y una lista de 8 piezas de color, representando cada una de las piezas movibles de esa cara, ordenadas y numeradas empezando por la esquina superior izquierda y continuando en sentido reloj. Al inicializar el cubo, todas las piezas de una cara tienen el mismo color y están ordenadas, pero al ejecutar rotaciones sobre el cubo, el color y el número de cada pieza de la lista van variando.
El cubo guarda también una lista conteniendo el historial de las acciones o rotaciones que se han ejecutado desde su inicialización en el estado objetivo. Es interesante que, conociendo este historial, el cubo siempre podría ser devuelto al estado objetivo ejecutando la acción opuesta a cada rotación de la lista (es decir, para la misma cara, una rotación en el sentido opuesto, ya sea reloj o contrarreloj) desde el final hacia el principio de la lista. Si los algoritmos tuvieran conocimiento de esto, entonces la solución sería trivial. De modo que se implementó este historial, pero los algoritmos no tienen conocimiento de su funcionamiento.
El cubo tiene métodos para: calcular su fitness (qué tan cerca está del estado objetivo o armado), aplicar una acción (rotar cualquiera de sus seis caras en sentido horario o contra horario, dando un total de 12 acciones que alteran el estado del cubo), aplicar una serie de acciones (de entre las 12 permitidas, pudiendo estar la lista predefinida o ser aleatoria) e imprimir el estado del cubo, incluyendo una representación visual de este, su fitness y su historial de acciones aplicadas.
La función de fitness implementada para este problema devuelve un número en el rango [0, 1]. Teniendo en consideración que el cubo rubik tridimensional en el cual se basa esta representación cuenta con piezas tridimensionales móviles, cada una con dos o tres colores que se posicionan alrededor de los ejes de cubo, la función pondera en base a cuántas piezas tridimensionales del cubo están colocadas correctamente. Esto significa que no sólo uno de los colores de esa pieza debe estar en la cara correcta, sino que todos los colores de esa pieza se deben encontrar en una cara de su mismo color. Bajo la representación del cubo que se hizo, esto se puede validar asignando un número a cada posición de una cara, de modo que luego se verifica si un color está en la cara del color correcto y también en la posición correcta. Por cada pieza colocada en la posición correcta se acumulan puntos. Si todas las piezas están en la posición correcta, la función fitness devuelve 1 e indica que el cubo está en el estado objetivo. Caso contrario, se devuelve un número en el rango [0, 1) que será más cercano a 1 mientras más piezas se encuentren colocadas correctamente.
La búsqueda por fuerza bruta es el algoritmo de búsqueda más común y más simple de implementar, ya que no requiere ningún conocimiento de dominio. Todo lo que se requiere para implementar este algoritmo es una descripción de estado, operadores legales, el estado inicial y la descripción de un estado objetivo [7]. A su vez su complejidad computacional suele ser alta y depende completamente de la potencia informática para probar posibles combinaciones. Habitualmente, para un mismo problema, este algoritmo de búsqueda es el que peor rendimiento presenta.
Para problemas discretos en los que no se conoce una solución eficiente, se hace necesario realizar una búsqueda exhaustiva. Esto implica probar todas y cada una de las soluciones posibles de manera sistemática y secuencial.
Para el problema del cubo rubik, existen 12 acciones posibles para realizar sobre el cubo y se ha comprobado que se requieren como máximo 20 acciones para resolver el cubo partiendo desde cualquiera de sus 43 trillones de estados posibles [8][9]. Para resolver este problema mediante fuerza bruta, se requeriría probar todas las secuencias de 20 o menos acciones posibles. Si n es el número de acciones posibles y m es el número máximo de acciones de la secuencia, la expresión más simplificada de la cota superior para este problema es O(n^m), donde n=12 y m=20, es decir, se probarían en el peor caso 3840 trillones de combinaciones [10].
Debido a la alta complejidad de este algoritmo para resolver el cubo rubik, es un enfoque que no suele utilizarse en la práctica dado que el poder de cómputo disponible habitualmente es insuficiente.
Existe el planteo de si el problema del cubo rubik es probabilísticamente soluble aplicando rotaciones aleatorias [11]. Teniendo presente la complejidad del algoritmo de fuerza bruta, es posible estimar vagamente esta probabilidad como la inversa de dicha complejidad. Es decir, la probabilidad de resolver el cubo rubik tras aplicar 20 rotaciones aleatorias es de 1 entre 3840 trillones, que es el total de secuencias distintas posibles de 20 rotaciones en el cubo.
A pesar de la casi nula probabilidad de que este algoritmo encuentre la solución del problema, vale la pena rescatar este método para usar sus resultados como referencia a la hora medir la eficiencia real del algoritmo genético que se implementó para resolver este mismo problema.
En la implementación, el algoritmo aleatorio es muy simple de lograr y consiste simplemente en tomar un cubo en un estado dado y aplicarle cierta cantidad predefinida de rotaciones seleccionadas aleatoriamente para luego calcular el fitness del cubo resultante. Ya que es completamente aleatorio, este procedimiento se debe repetir numerosas veces para tener una métrica confiable de este algoritmo.
Un algoritmo genético es una metaheurística inspirada en el proceso de selección natural perteneciente a la clase de los algoritmos evolutivos. Los algoritmos genéticos se utilizan comúnmente para generar soluciones de alta calidad para problemas de optimización y búsqueda basándose en operadores inspirados en la biología, como la mutación, el entrecruzamiento y la selección del más apto. Estos algoritmos parten de una población aleatoria y la hacen evolucionar sometiéndola a acciones aleatorias semejantes a las que actúan en la evolución biológica (mutaciones y recombinaciones genéticas), así como también a una selección de acuerdo con algún criterio. En función de este criterio se decide cuáles son los individuos más adaptados, que sobreviven, y cuáles son los menos aptos, que son descartados. [12][13][14]
Los algoritmos genéticos comienzan su ejecución con un conjunto de tamaño predefinido de estados o individuos generados aleatoriamente, llamados población. Iterativamente, el algoritmo produce una nueva generación de individuos a partir de la población disponible. El algoritmo finaliza al obtener un individuo con el estado objetivo o tras un número preestablecido de iteraciones o generaciones, retornando el individuo más apto logrado.
Cada individuo de la población es evaluado mediante una función de idoneidad o fitness. Una función de idoneidad debería devolver valores más altos para estados más deseables, teniendo un valor máximo para el estado ideal, si es que lo hay. En base a los resultados de esta evaluación, se eligen individuos aleatorios con probabilidad para reproducirse y generar la siguiente población. La probabilidad de ser elegido para la reproducción es proporcional al resultado de la función de idoneidad, aunque pueden también tenerse en cuenta otros parámetros para esta selección. Es destacable que un individuo puede no ser seleccionado para reproducirse, mientras que otro individuo puede reproducirse múltiples veces en una misma generación.
Existen numerosas técnicas de entrecruzamiento entre un par de individuos. La más utilizada consiste en elegir un punto de cruce y combinar porciones del estado de ambos individuos separadas por dicho punto de cruce, resultando en uno o más individuos nuevos. Cuando dos estados padres son bastante diferentes, la operación de cruce puede producir un estado que está lejos de cualquiera de los estados padre. Esto es a menudo lo que ocurre en las primeras generaciones, en las que la población es bastante diversa. De modo que el cruce con frecuencia realiza pasos grandes al principio en el espacio de estados en el proceso de búsqueda y pasos más pequeños más tarde, cuando la mayor parte de individuos son bastante similares.
El último paso en la generación de una nueva población es la mutación. Cada nuevo individuo está sujeto a una mutación aleatoria en su estado con una pequeña probabilidad independiente. Tras esta mutación se elige para conformar la nueva generación un número predefinido de los individuos más aptos o idóneos de la nueva población o entre la nueva población y la anterior, dependiendo de la implementación.
Los algoritmos genéticos combinan una tendencia ascendente con exploración aleatoria e intercambian información entre los hilos paralelos de búsqueda. La principal ventaja del algoritmo genético viene de la operación de entrecruzamiento. Puede demostrarse matemáticamente que, si las posiciones del código genético o estado se permutan al principio en un orden aleatorio, el entrecruzamiento no comunica ninguna ventaja. Intuitivamente, la ventaja viene de la capacidad del entrecruzamiento para combinar bloques grandes de genoma que han evolucionado independientemente para así realizar funciones útiles, de modo que se aumente el nivel de granularidad en el que funciona la búsqueda [12].
Para la resolución del problema del cubo rubik mediante un algoritmo genético, se hizo una implementación que sigue la secuencia de pasos especificada a continuación:
-
Al inicializarse, el algoritmo recibe por parámetro un cubo previamente mezclado, cuyo estado no es el estado objetivo. El algoritmo buscará encontrar la solución a este estado del cubo en específico, sin saber cómo se llegó a dicho estado. Por practicidad, se denominará a este cubo como el "estado inicial". Este cubo ya está mezclado, pero su historial se vacía para que el algoritmo no pueda aprovecharse de este conocimiento y revertir los movimientos realizados. De modo que, en este algoritmo, el historial de los cubos comienza a considerarse durante la ejecución del algoritmo genético, pero no antes.
-
Como primer paso, se crean n individuos copias del estado inicial. A cada copia le aplica una secuencia distinta de m acciones aleatorias. De este modo, se ha generado la población inicial o primera generación. Los números m y n son parámetros constantes durante toda la ejecución del algoritmo que son definidos antes de comenzar su ejecución.
-
De forma iterativa, el algoritmo repetirá una serie de pasos. Implementado mediante un bucle while, a cada iteración del bucle se generará una nueva generación de individuos y se guardará registro de cuál es individuo más apto de entre esa generación y las anteriores. Las condiciones de parada del bucle son dos:
- Que se haya hallado la solución del problema. Es decir, que se haya generado un individuo con valor de fitness igual a 1.
- Que se haya alcanzado el número máximo de iteraciones permitidas.
En cualquiera de los dos casos, tras salir del bucle, justo antes de terminar su ejecución, el algoritmo registra y retorna el mejor resultado obtenido entre todas las iteraciones (sin importar si alcanzó el estado objetivo o sólo se acercó).
Los pasos que se efectúan secuencialmente dentro del bucle para cada generación se explican a continuación:
-
Selección de padres: se selecciona cierta cantidad predefinida de pares de individuos de la población. Cada par de individuos actuará como padres para generar 2 individuos hijos a partir de ellos. Posteriormente los individuos hijos conformarán la siguiente generación. Cada padre es elegido de entre los individuos de la población con una probabilidad proporcional a su aptitud.
-
Entrecruzamiento: a partir de cada par de padres, se generan 2 individuos hijos. Cada individuo guarda registro del historial de acciones que le fueron aplicadas para llegar desde el estado inicial a su estado actual y para la operación de entrecruzamiento, se hace uso del historial de ambos padres. Aleatoriamente se elige un punto de cruce para cada padre. Esto es porque se busca que no todos los individuos tengan un historial de la misma longitud. El historial de cada padre se corta en dos partes en el punto correspondiente y se generan dos nuevos historiales: uno con la primera mitad del historial del primer padre y la segunda mitad del segundo padre; y otro con la primera mitad del historial del segundo padre y la segunda mitad del primer padre, como se puede visualizar en la Figura 5. Luego se generan dos individuos copias del estado inicial y se le aplica a cada uno una de estas listas de acciones. De este modo se obtienen los dos hijos. Si se quisieran obtener más de dos hijos por pareja de padres, bastaría repetir el procedimiento de entrecruzamiento n/2 veces, donde n es el número de hijos que se quiere obtener. Vale mencionar que el entrecruzamiento se implementó mezclando los historiales de los padres y no el estado actual porque, de haber sido así, no respetaría el funcionamiento del cubo rubik real y simplemente entrecruzar la combinación de piezas de ambos padres podría conducir a estados irresolubles del cubo aplicando solo secuencias de las 12 acciones ya descriptas.
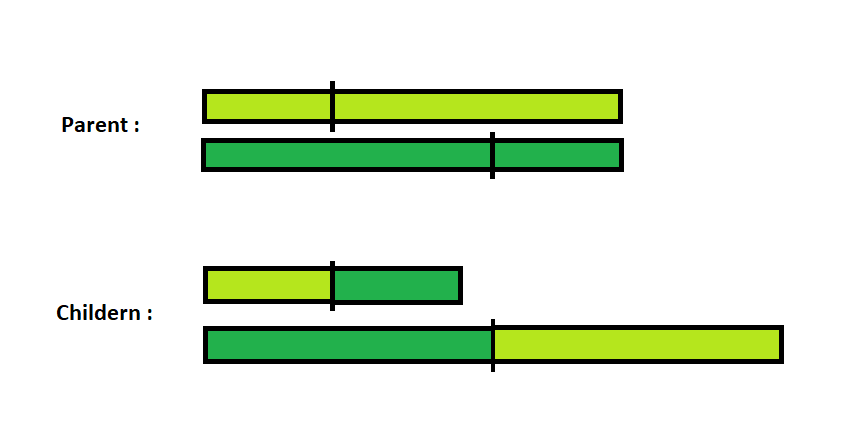
Figura 5: operación de entrecruzamiento
-
Mutación: cada individuo hijo tiene una mínima probabilidad predefinida de sufrir una mutación en su historial y, en consecuencia, en su estado actual. Si el individuo efectivamente es elegido para la operación de mutación, se selecciona aleatoriamente 3 acciones de su historial y se las remplaza con 3 nuevas acciones también aleatorias. Tras alterar el historial del individuo, se actualiza su estado actual para reflejar el cambio.
-
Luego se calcula la aptitud de cada nuevo individuo hijo que se ha generado. Y se procede a seleccionar a los individuos para la nueva generación entre los individuos de la población actual y los nuevos individuos hijos generados. Se elige un conjunto con los individuos más aptos de cada grupo, siendo mayor la proporción de hijos elegidos que de individuos de la población actual. Este nuevo conjunto conforma la nueva generación, la cual será la población o generación actual en la próxima iteración del bucle.
-
Por último, de esta nueva generación se registra si el individuo más apto es aún más apto que el de las generaciones previas. Si esto es así, este pasa a ser el nuevo individuo más apto; caso contrario, el individuo más apto registrado continúa siendo el de la generación previa. Y de este modo, el algoritmo ya está listo para la siguiente iteración del bucle.
Como ya se adelantó, al finalizar la ejecución del algoritmo, este retorna el individuo más apto logrado. Es decir, devuelve el individuo con más piezas colocadas correctamente que se logró a lo largo de su ejecución. Este individuo puede o no estar en el estado objetivo.
Reinforcement learning es una forma de machine learning donde los agentes aprenden a realizar acciones en un entorno para maximizar una recompensa. En estos algoritmos no hay información disponible a partir de la cual aprender. Sus dos componentes principales son: el entorno, que representa el problema a resolver, y el agente, que representa el algoritmo de aprendizaje. El agente puede interactuar con el entorno y después de cada interacción recibe una recompensa. A partir de un proceso de prueba y error, el agente aprende cómo funciona realmente el entorno. Este problema a menudo se modela matemáticamente como un proceso de decisión de Markov [15], donde el agente en cada paso de tiempo está en un estado s, realiza una acción a, recibe una recompensa escalar y pasa al siguiente estado s' según la dinámica del entorno. El agente intenta aprender una política, o mapear de observaciones a acciones, para maximizar la suma de recompensas.
Deep learning es una forma de machine learning que utiliza una red neuronal para transformar un conjunto de entradas en un conjunto de salidas a través de una red neuronal artificial. Se ha probado que los métodos de deep learning, que a menudo usan aprendizaje supervisado con conjuntos de datos etiquetados, resuelven tareas que implican un manejo complejo de datos de entrada de gran dimensión con menos ingeniería manual que otros métodos.
Deep Reinforcement Learning, abreviado DRL, es una forma de machine learning que combina reinforcement learning y deep learning. Mientras que reinforcement learning considera el problema del agente que aprende a tomar decisiones mediante prueba y error, DRL incorpora deep learning en la solución, lo que permite a los agentes tomar decisiones a partir de grandes conjuntos de datos de entrada no estructurados.
Deep Q-Learning es un algoritmo de deep reinforcement learning que combina el algoritmo de Q-learning junto con deep learning y le suma una técnica llamada "experience replay". Por su parte, Q-learning es una técnica de reinforcement learning cuyo objetivo es aprender una serie de normas que le diga al agente qué acción tomar bajo qué circunstancias. Este algoritmo esencialmente construye una tabla de mapeos de estados de entrada a acciones de salida.
Numerosos autores han utilizado DRL para afrontar el problema del cubo rubik [2][3][4][5][6]. Para este trabajo también se hizo una implementación tentativa del problema mediante un algoritmo de DRL. La solución implementada para este trabajo estuvo basada en una implementación de DRL para un problema similar [16][17]. El desarrollo de este algoritmo fue incompleto ya que, si bien ejecuta sin errores, no arroja los resultados esperados, dado que no logra ningún progreso en el armado del cubo. Sus resultados son similares a los del algoritmo de combinación aleatoria. Por este motivo, no es tenido en cuenta a la hora de medir los resultados obtenidos.
El algoritmo implementado utiliza un modelo de DQN tomado y adaptado de [17] utilizado originalmente para una implementación del juego Snake haciendo uso de la librería Tensorflow para la implementación de la red neuronal [16]. El modelo es entrenado a lo largo de una secuencia de episodios y al finalizar guarda los resultados de cada episodio en un archivo de salida para su evaluación posterior.
El entrenamiento consiste en la ejecución de una serie de episodios, donde en cada episodio el agente tiene la oportunidad de aplicar un número predefinido m de acciones a un cubo previamente mezclado, con m=400, y aprender de cada acción. Cuando arranca cada episodio, el cubo está en el mismo estado inicial, es decir, mezclado de la misma forma. Por lo tanto, al igual que en el algoritmo genético, este agente aprende a resolver específicamente el cubo que se ha establecido como estado inicial.
El conjunto de acciones que el agente puede elegir son 12, todas las posibles rotaciones de cada cara del cubo, nombradas con anterioridad.
El conjunto de estados posibles para este problema es tan amplio como estados posibles tiene el cubo rubik, es decir, aproximadamente 43 trillones de estados. Este estado se representa como un arreglo de 48 números distintos, donde cada número representa una de las 48 piezas de color del cubo y su índice en el arreglo indica su posición en las caras el cubo. Por tanto, hay solo un orden de los números que es el estado objetivo y, por cómo se implementó, este orden objetivo es que los números estén en orden ascendente. En la Figura 6 se puede apreciar la transformación entre la representación visual del estado objetivo y su forma de arreglo.
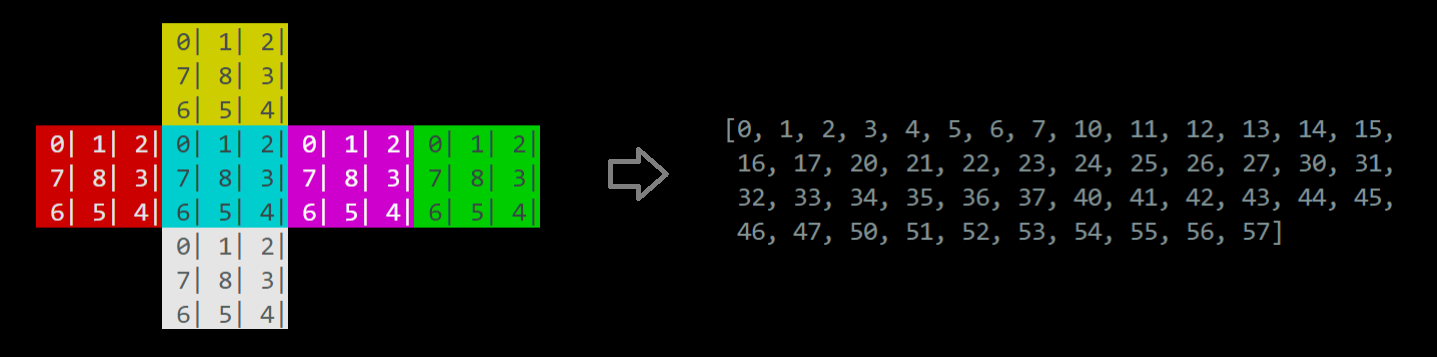
Figura 6: distintas representaciones del cubo rubik
La recompensa por cada acción es una diferencia entre la función de fitness del entorno antes de realizar la acción y después de realizarla. La función de fitness es la misma utilizada en el algoritmo genético, que indica qué tan cerca está el cubo del estado objetivo.
A partir del estado actual del entorno, el agente elige una acción. Esta acción se ejecuta en el entorno, es decir, se efectúa una rotación en el cubo, y se obtiene un nuevo estado y una recompensa (ya sea positiva o negativa). El agente utiliza la recompensa obtenida en su función de optimización para corregir o mantener su política, en búsqueda de obtener las mayores recompensas en la próxima oportunidad.
Los autores del trabajo [17] explican cómo está conformado el modelo que se tomó como base para esta implementación:
El modelo utiliza un conjunto de capas de tipo Dense, cada una con un total de 128 variables ocultas o "weights" que utilizan la función de activación de Keras "Relu". También hace uso de una técnica llamada "Replay" que ayuda considerablemente con el aprendizaje. La técnica Replay se basa en almacenar experiencias pasadas, para posteriormente "rejugarlas" todas a cada paso que da, un paralelismo un poco más claro es ver la repetición de un partido que ya jugaste antes de jugar el próximo, para así entender tus errores y obtener más información de cada una de tus decisiones, algo así como un repaso de experiencias pasadas.
Para probar el algoritmo genético, este se configuró con distintos conjuntos de parámetros y se realizaron 30 ejecuciones con cada conjunto de parámetros. En la Figura 7 se puede visualizar un gráfico de cajas con los resultados para cada prueba.
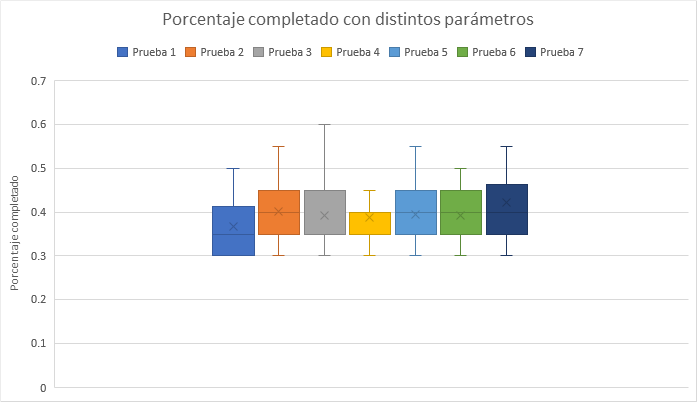
Figura 7: gráfico de cajas de resultados probando distintos parámetros.
Los parámetros variables fueron: individuos por generación, probabilidad de mutación, split percent, acciones iniciales e hijos por pareja de padres. A continuación se listan los valores usados para cada parámetro en cada una de las distintas pruebas:
- Prueba 1:
- Número máximo de generaciones: 100
- Individuos por generación: 150
- Probabilidad de mutación: 0.05
- Split percent: 0
- Acciones iniciales: 20
- Hijos por pareja de padres: 2
- Prueba 2:
- Número máximo de generaciones: 100
- Individuos por generación: 250
- Probabilidad de mutación: 0.5
- Split percent: 0.2
- Acciones iniciales: 20
- Hijos por pareja de padres: 2
- Prueba 3:
- Número máximo de generaciones: 100
- Individuos por generación: 250
- Probabilidad de mutación: 0.5
- Split percent: 0.2
- Acciones iniciales: 30
- Hijos por pareja de padres: 4
- Prueba 4:
- Número máximo de generaciones: 100
- Individuos por generación: 150
- Probabilidad de mutación: 0.05
- Split percent: 0.2
- Acciones iniciales: 30
- Hijos por pareja de padres: 2
- Prueba 5:
- Número máximo de generaciones: 100
- Individuos por generación: 150
- Probabilidad de mutación: 0.2
- Split percent: 0.2
- Acciones iniciales: 30
- Hijos por pareja de padres: 4
- Prueba 6:
- Número máximo de generaciones: 100
- Individuos por generación: 300
- Probabilidad de mutación: 0.5
- Split percent: 0.4
- Acciones iniciales: 20
- Hijos por pareja de padres: 4
- Prueba 7:
- Número máximo de generaciones: 100
- Individuos por generación: 250
- Probabilidad de mutación: 0.5
- Split percent: 0.2
- Acciones iniciales: 30
- Hijos por pareja de padres: 2
En la Figura 7 se puede apreciar que la Prueba 7 obtuvo los mejores resultados, con la media más alta de todas y los dos cuartiles superiores iguales o mayores a los de las demás pruebas. Por este motivo, con la combinación de parámetros de la Prueba 7 se corrieron 135 ejecuciones del mismo algoritmo y se registró su tiempo de ejecución y resultados. De modo que para esta instancia el algoritmo genético fue configurado con los siguientes parámetros:
- Número máximo de generaciones: 100
- Individuos por generación: 250
- Probabilidad de mutación: 0.5
- Split percent: 0.2
- Acciones iniciales: 30
- Hijos por pareja de padres: 2
El parámetro split percent indica qué porcentaje de la población previa se conservará en cada nueva generación. El parámetro acciones iniciales indica qué cantidad de acciones aleatorias se aplicará a cada individuo de la primera generación.
Para medir la eficiencia de los resultados se utilizó el algoritmo completamente aleatorio. El procedimiento en cada ejecución fue el siguiente:
- Se inicializa un objeto CuboRubik y se le aplican 30 movimientos aleatorios. Este mismo cubo posteriormente se utiliza como estado inicial para el algoritmo aleatorio y para el genético.
2.Se ejecuta 50000 veces el algoritmo aleatorio para este cubo en particular. El algoritmo se configuró para efectuar 20 movimientos y registrar el puntaje de fitness obtenido. Se eligió el número 50000 dado que el algoritmo genético a lo largo de su ejecución crea exactamente ese número de individuos (se obtiene este número al multiplicar la cantidad máxima de generaciones por la cantidad de individuos por generación). Se guarda registro del mejor individuo obtenido entre todas las ejecuciones y el tiempo total de ejecución entre todas las iteraciones.
- Se ejecuta el algoritmo genético utilizando el mismo cubo como estado inicial con los parámetros previamente expuestos. Se registra el resultado obtenido y el tiempo de ejecución.
En la Figura 8 se puede observar un gráfico de cajas de los tiempos de ejecución de ambos algoritmos en cada iteración. El promedio de tiempo de ejecución para el algoritmo aleatorio fue de 33 segundos, mientras que para el algoritmo genético fue de 57.7 segundos. El algoritmo aleatorio ejecutó en promedio 57% más rápido que su contraparte, lo cual es esperable debido a la mayor complejidad del algoritmo genético.
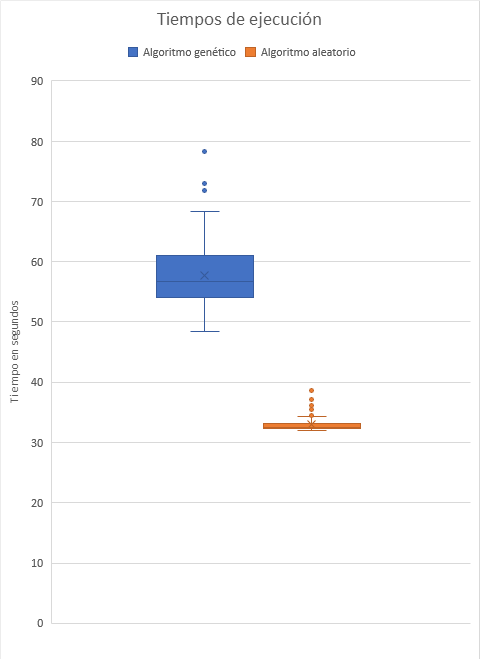
Figura 8: gráfico de cajas de tiempos de ejecución
Tanto el algoritmo genético como el aleatorio no fueron capaces de llegar al estado objetivo en ninguna ejecución. Es por esto que se tomó el mejor cubo que cada algoritmo logró generar y se midió su porcentaje de piezas colocadas correctamente. En las Figuras 9 y 10 se pueden visualizar los resultados alcanzados por ambos algoritmos en cada iteración. El promedio de progreso alcanzado por el algoritmo aleatorio fue de 34%, mientras que para el algoritmo genético fue de 42%. Esto revela una diferencia del 8% entre ambos algoritmos. Si bien es de esperarse que el algoritmo genético obtenga mejores resultados que el algoritmo aleatorio gracias a su técnica más compleja, resulta sorprendente que esta diferencia no sea significativa.
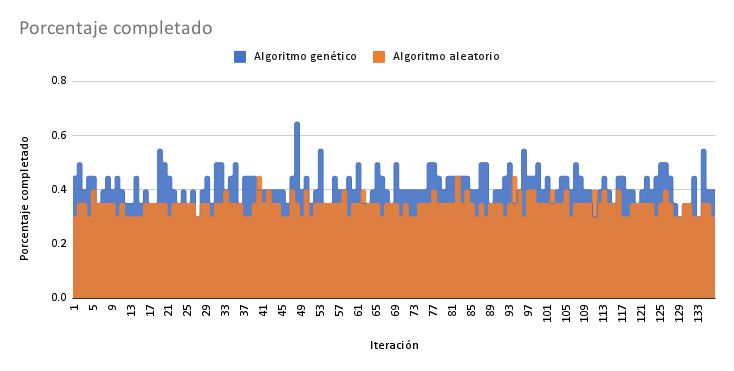
Figura 9: resultados por ejecución
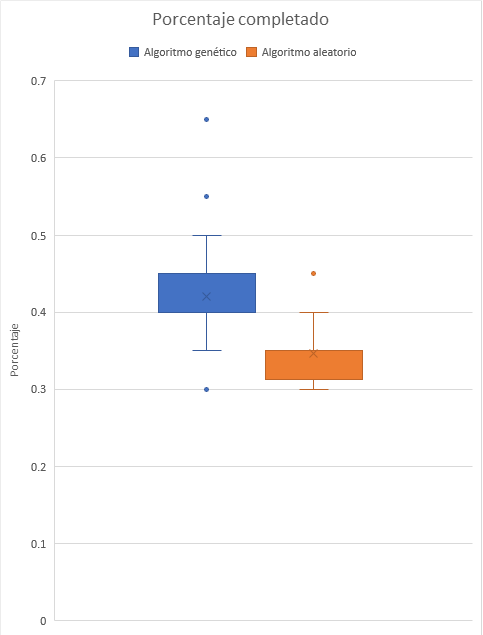
Figura 10: gráfico de cajas de resultados de cada algoritmo
Para el algoritmo aleatorio, todos los resultados tuvieron una totalidad de 20 acciones en su historial, dado que el algoritmo fue configurado para que así fuera. Mientras que el algoritmo genético fue implementado de forma que este número varía para cada individuo. En las Figuras 11 y 12 se puede visualizar el número de acciones ejecutadas para el cubo resultado de cada iteración. El promedio de este número entre todas las ejecuciones es de 21 acciones, que resulta casi ideal, dado que el número ideal de movimientos es 20 o menos [8]. Igualmente cabe mencionar que en el gráfico de cajas en la Figura 12 se puede apreciar que hay una gran varianza entre los resultados, por lo cual este promedio puede no ser tan ideal como aparenta a primera vista.
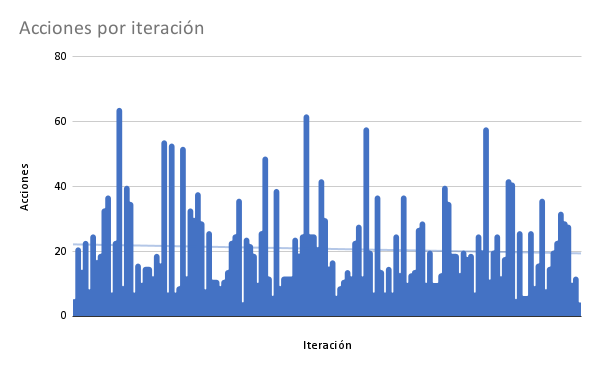
Figura 11: acciones por cubo
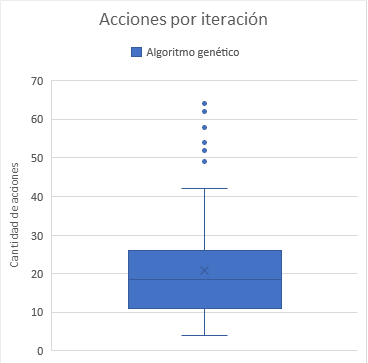
Figura 12: gráfico de cajas de acciones por cubo
Durante las pruebas realizadas, saltó a la vista que el algoritmo completamente aleatorio tiene algunas cualidades muy relevantes: tiene una implementación trivial, su tiempo de ejecución es mucho menor que el del algoritmo genético y la calidad de sus resultados es cercana a la del algoritmo genético. Mientras que las primeras dos son ventajas respecto al algoritmo genético, la tercera es una desventaja, pero es posible que sea una cualidad mejorable. Si se pudiera lograr que la calidad de los resultados de este algoritmo igualara o superara la calidad del algoritmo genético, el algoritmo aleatorio superaría al genético en todos los aspectos.
La implementación que se hizo del algoritmo completamente aleatorio para este trabajo fue extremadamente simple: se crea un cubo, se le aplica una secuencia aleatoria de 20 rotaciones y se calcula su fitness. Esta acción se repite numerosas veces y se mantiene registro de cuál fue el cubo con mayor fitness entre todas las repeticiones.
A partir de un análisis básico de la naturaleza del cubo rubik, se podría implementar una validación sobre la secuencia de rotaciones aleatorias antes de aplicarla, de modo que la secuencia se considere válida únicamente si no es redundante. Eliminando las secuencias redundantes, es posible que se generen resultados más valiosos y más variados en menor cantidad de iteraciones.
Para esto, primero debería definirse qué es una secuencia redundante. Una secuencia redundante de n rotaciones es una secuencia de rotaciones que, al aplicarse sobre el cubo en un estado dado, deja al cubo en un nuevo estado al cual se podría llegar (desde el estado anterior) en menos de n rotaciones. Por ejemplo, hacer 4 rotaciones iguales de la misma cara seguidas deja al cubo en el mismo estado que si se realizaran 0 rotaciones. O realizar 3 rotaciones seguidas de una misma cara en un sólo sentido deja al cubo en el mismo estado que realizar 1 sola rotación de la misma cara en el sentido contrario.
De este análisis, y de forma muy general, se pueden desprender dos reglas de validación:
- No realizar 3 rotaciones idénticas seguidas (ya que es reducible a 1 rotación inversa).
- No realizar 4 o más rotaciones idénticas seguidas (ya que es igual a n % 4 rotaciones, siendo n la cantidad de rotaciones).
Una implementación posible sería aplicar estas reglas de reducción sobre las redundancias y agregar más rotaciones aleatorias a la secuencia luego de la reducción para completar la secuencia de 30 movimientos (validando que no se vuelva a generar una secuencia redundante). Otra posibilidad sería simplemente descartar las secuencias redundantes y generar una secuencia completamente nueva para remplazarla (y verificar su validez).
Además de las dos reglas básicas previamente definidas, en el paper [9] se explica que el conjunto de secuencias de movimientos del cubo rubik forma un grupo (en la acepción matemática de la palabra). De modo que a través de teoría de grupos podrían elaborarse reglas más complejas de validación, pero que exceden el alcance de este trabajo.
En este trabajo se hizo foco en la resolución del problema mediante el algoritmo genético, a pesar de que numerosos trabajos previos indiquen que el método más efectivo y más utilizado para resolver este problema es Deep Reinforcement Learning.
Visto que una implementación por fuerza bruta sería prácticamente imposible, se hizo una implementación completamente aleatoria únicamente con fines ilustrativos. Sorprendentemente, este algoritmo dio mejores resultados que lo esperado, mientras que los resultados obtenidos mediante el algoritmo genético fueron levemente superiores en calidad, pero peores en tiempo de ejecución. Para este problema en específico resulta más relevante la calidad del resultado antes que el tiempo ocupado, por lo que el algoritmo genético resulta ser más óptimo en esa comparación. Si bien este algoritmo no logró en ninguna ocasión armar el cubo por completo, un promedio del cubo 43% completado es un resultado aceptable para los objetivos de este trabajo. Es destacable que la obtención de resultados parciales es una posibilidad completamente esperable del algoritmo genético dado que es un algoritmo de optimización y esto fue tenido en cuenta al elegir este algoritmo.
A su vez, debido a su simplicidad de implementación del algoritmo completamente aleatorio y su efectividad cercana a la del algoritmo genético, se considera un camino explorable en el futuro realizar mejoras sobre el algoritmo aleatorio, como agregar validación de secuencias redundantes, para lograr resultados de calidad similar a los obtenidos por el algoritmo genético, pero con menor costo computacional.
Si bien la implementación de DRL realizada para este trabajo no dio resultados aceptables, se ha probado que la técnica sí resulta ser efectiva para este problema en numerosos trabajos previos ya citados. De todos modos, se deja fuera del alcance de este trabajo la adaptación de este algoritmo para que entregue resultados valiosos como los obtenidos en otros trabajos mediante la misma técnica.
[1] Novel Rubik’s Cube Problem Solver by Combining Group Theory and Genetic Algorithm
[2] Solving the Rubik’s cube with deep reinforcement learning and search
[3] Solving Rubik's cube using Deep Reinforcement Learning
[4] Understanding Reinforcement Learning by solving Rubik’s Cube
[5] Machine Learning Based Rubik's Cube Solvers
[6] qub3rt: TensorFlow model to solve Rubik's cube
[9] The Mathematics of the Rubik’s Cube
[10] Brute force method of solving the cube: How many moves would it take?
[11] ¿Se puede resolver el cubo mágico (Rubik) al azar?
[12] Russell, S., Norvig, P. (2008). AIMA: Inteligencia Artificial. Un enfoque moderno. Segunda edición. 4.3 Algoritmos genéticos, 131-135.
[13] Algoritmos genéticos: Funcionamiento, Pasos y Aplicaciones
[14] Genetic algorithm
[15] Understanding Markov Decision Process (MDP)
[16] Snake Played by a Deep Reinforcement Learning Agent
[17] Training Snake Agent by Deep Reinforcement Learning
[18] Implementing Deep Reinforcement Learning Models with Tensorflow + OpenAI Gym