|
| 1 | +{ |
| 2 | + "cells": [ |
| 3 | + { |
| 4 | + "cell_type": "code", |
| 5 | + "execution_count": null, |
| 6 | + "metadata": { |
| 7 | + "vscode": { |
| 8 | + "languageId": "python" |
| 9 | + } |
| 10 | + }, |
| 11 | + "outputs": [], |
| 12 | + "source": [ |
| 13 | + "\"\"\"Understanding t** transform function in pandas.\"\"\"" |
| 14 | + ] |
| 15 | + }, |
| 16 | + { |
| 17 | + "cell_type": "markdown", |
| 18 | + "metadata": { |
| 19 | + "id": "NN1-fNNUrV37" |
| 20 | + }, |
| 21 | + "source": [ |
| 22 | + "# Понимание функции transform в pandas" |
| 23 | + ] |
| 24 | + }, |
| 25 | + { |
| 26 | + "cell_type": "markdown", |
| 27 | + "metadata": { |
| 28 | + "id": "COAZvgV4rV4F" |
| 29 | + }, |
| 30 | + "source": [ |
| 31 | + "## Введение\n", |
| 32 | + "\n", |
| 33 | + "Одной из привлекательных особенностей pandas является наличие богатой библиотеки методов для управления данными. Однако бывают случаи, когда неясно, что делают функции и как их использовать. Если вы подходите к проблеме с точки зрения Excel, может быть сложно перевести решение в незнакомую команду pandas. Одна из таких \"неизвестных\" функций - метод [`transform`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.core.groupby.DataFrameGroupBy.transform.html).\n", |
| 34 | + "\n", |
| 35 | + "> Оригинал статьи Криса [тут](https://pbpython.com/pandas_transform.html)\n", |
| 36 | + "\n", |
| 37 | + "Даже после длительного использования pandas у меня никогда не было возможности использовать эту функцию, поэтому я потратил время на выяснение, как она может пригодиться для анализа реального мира. В этой статье будет рассмотрен пример, в котором `transform` используется для эффективного суммирования данных." |
| 38 | + ] |
| 39 | + }, |
| 40 | + { |
| 41 | + "cell_type": "markdown", |
| 42 | + "metadata": { |
| 43 | + "id": "o_36ePRXrV4H" |
| 44 | + }, |
| 45 | + "source": [ |
| 46 | + "## Что такое трансформация?\n", |
| 47 | + "\n", |
| 48 | + "Лучшее описание этой темы нашел в книге `Python Data Science Handbook` Джейка Вандерпласа (Jake VanderPlas).\n", |
| 49 | + "\n", |
| 50 | + "> книга в оригинале свободно доступна на [сайте](https://jakevdp.github.io/PythonDataScienceHandbook/)\n", |
| 51 | + "\n", |
| 52 | + "Как сказано в книге, `transform` - это операция, используемая вместе с `groupby` (которая является одной из самых полезных в pandas).\n", |
| 53 | + "\n", |
| 54 | + "Я подозреваю, что большинство пользователей pandas использовали `aggregate`, `filter` или `apply` с `groupby` для обобщения данных. Однако `transform` немного сложнее понять, особенно из мира Excel.\n", |
| 55 | + "\n", |
| 56 | + "Поскольку Джейк сделал свою книгу доступной через Jupyter блокноты, это хорошее место, чтобы понять уникальность [transform](https://nbviewer.jupyter.org/github/jakevdp/PythonDataScienceHandbook/blob/master/notebooks/03.08-Aggregation-and-Grouping.ipynb):" |
| 57 | + ] |
| 58 | + }, |
| 59 | + { |
| 60 | + "cell_type": "markdown", |
| 61 | + "metadata": { |
| 62 | + "id": "KtPDsbGDrV4I" |
| 63 | + }, |
| 64 | + "source": [ |
| 65 | + "> *В то время как агрегирующая функция должна возвращать сокращенную версию данных, преобразование может вернуть версию полного набора данных, преобразованную ради дальнейшей их переком позиции. При подобном преобразовании форма выходных данных совпадает с формой входных. Распространённый пример – центрирование данных путем вычитания среднего значения по группам.*" |
| 66 | + ] |
| 67 | + }, |
| 68 | + { |
| 69 | + "cell_type": "markdown", |
| 70 | + "metadata": { |
| 71 | + "id": "_-uIbm1nrV4J" |
| 72 | + }, |
| 73 | + "source": [ |
| 74 | + "Используя это базовое определение, я рассмотрю еще один пример." |
| 75 | + ] |
| 76 | + }, |
| 77 | + { |
| 78 | + "cell_type": "markdown", |
| 79 | + "metadata": { |
| 80 | + "id": "-CWp85CtrV4K" |
| 81 | + }, |
| 82 | + "source": [ |
| 83 | + "## Набор данных\n", |
| 84 | + "\n", |
| 85 | + "В этом примере проанализируем фиктивные данные о сделках купли-продажи:" |
| 86 | + ] |
| 87 | + }, |
| 88 | + { |
| 89 | + "cell_type": "code", |
| 90 | + "execution_count": null, |
| 91 | + "metadata": { |
| 92 | + "id": "5ZYboUXcrV4M", |
| 93 | + "vscode": { |
| 94 | + "languageId": "python" |
| 95 | + } |
| 96 | + }, |
| 97 | + "outputs": [], |
| 98 | + "source": [ |
| 99 | + "import pandas as pd\n", |
| 100 | + "\n", |
| 101 | + "df_var = pd.read_excel(\n", |
| 102 | + " \"https://github.com/chris1610/pbpython/blob/master/data/\"\n", |
| 103 | + " \"sales_transactions.xlsx?raw=true\"\n", |
| 104 | + ")\n", |
| 105 | + "df_var" |
| 106 | + ] |
| 107 | + }, |
| 108 | + { |
| 109 | + "cell_type": "markdown", |
| 110 | + "metadata": { |
| 111 | + "id": "fbTebE8YrV4P" |
| 112 | + }, |
| 113 | + "source": [ |
| 114 | + "Вы можете видеть, что файл содержит три разных заказа (`10001`, `10005` и `10006`) и что каждый заказ состоит из нескольких продуктов (`sku`).\n", |
| 115 | + "\n", |
| 116 | + "Вопрос, на который мы бы хотели ответить: \"Какой процент от общей суммы составляет каждый продукт (`sku`)?\"\n", |
| 117 | + "\n", |
| 118 | + "Например, если мы посмотрим на заказ `10001` на общую сумму `576,12 у.е.`, то разбивка будет следующая:" |
| 119 | + ] |
| 120 | + }, |
| 121 | + { |
| 122 | + "cell_type": "markdown", |
| 123 | + "metadata": { |
| 124 | + "id": "IXcKbWCPrV4Q" |
| 125 | + }, |
| 126 | + "source": [ |
| 127 | + "`B1-20000` = `$235.83` или `40.9%`\n", |
| 128 | + "\n", |
| 129 | + "`S1-27722` = `$232.32` или `40.3%`\n", |
| 130 | + "\n", |
| 131 | + "`B1-86481` = `$107.97` или `18.7%`" |
| 132 | + ] |
| 133 | + }, |
| 134 | + { |
| 135 | + "cell_type": "markdown", |
| 136 | + "metadata": { |
| 137 | + "id": "10rJeiQCrV4Q" |
| 138 | + }, |
| 139 | + "source": [ |
| 140 | + "Сложность заключается в том, что нам нужно получить общую сумму для каждого заказа и объединить её обратно на уровне транзакции, чтобы получить проценты.\n", |
| 141 | + "\n", |
| 142 | + "В Excel вы можете использовать какую-либо версию промежуточного итога, чтобы вычислить значения." |
| 143 | + ] |
| 144 | + }, |
| 145 | + { |
| 146 | + "cell_type": "markdown", |
| 147 | + "metadata": { |
| 148 | + "id": "1vFDVKtqrV4R" |
| 149 | + }, |
| 150 | + "source": [ |
| 151 | + "## Первый подход - merge\n", |
| 152 | + "\n", |
| 153 | + "Если вы знакомы с pandas, то первым желанием будет сгруппировать данные в новый `DataFrame` и затем объединить их.\n", |
| 154 | + "\n", |
| 155 | + "Вот как будет выглядеть этот подход. Определим итоговую сумму (`ext price`) для заказов (`order`) с помощью стандартной `groupby` агрегации:" |
| 156 | + ] |
| 157 | + }, |
| 158 | + { |
| 159 | + "cell_type": "code", |
| 160 | + "execution_count": null, |
| 161 | + "metadata": { |
| 162 | + "id": "kZi2FQb6rV4S" |
| 163 | + }, |
| 164 | + "outputs": [], |
| 165 | + "source": [ |
| 166 | + "df_var.groupby(\"order\")[\"ext price\"].sum()" |
| 167 | + ] |
| 168 | + }, |
| 169 | + { |
| 170 | + "cell_type": "markdown", |
| 171 | + "metadata": { |
| 172 | + "id": "8JFY1e5qrV4S" |
| 173 | + }, |
| 174 | + "source": [ |
| 175 | + "Вот схема, показывающая, что происходит в стандартной функции `groupby`:" |
| 176 | + ] |
| 177 | + }, |
| 178 | + { |
| 179 | + "cell_type": "markdown", |
| 180 | + "metadata": { |
| 181 | + "id": "GkHSyC_VrV4T" |
| 182 | + }, |
| 183 | + "source": [ |
| 184 | + "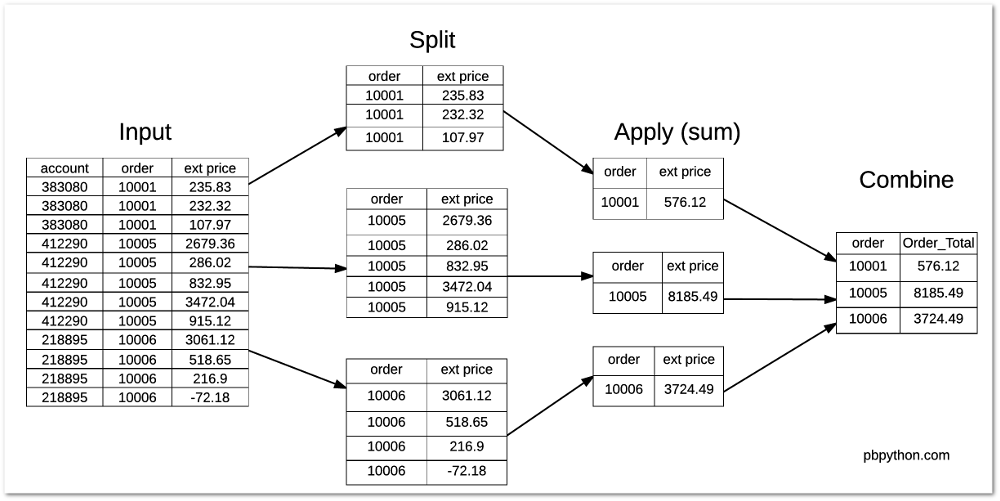" |
| 185 | + ] |
| 186 | + }, |
| 187 | + { |
| 188 | + "cell_type": "markdown", |
| 189 | + "metadata": { |
| 190 | + "id": "ChDWBytwrV4T" |
| 191 | + }, |
| 192 | + "source": [ |
| 193 | + "Сложная часть - придумать, как объединить полученные данные обратно с исходным `DataFrame`.\n", |
| 194 | + "\n", |
| 195 | + "Первое желание - создать новый `DataFrame` с итогами по заказам (`order`) и затем объединить его с оригиналом с помощью [`merge`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html). \n", |
| 196 | + "\n", |
| 197 | + "Мы могли бы сделать что-то вроде такого:" |
| 198 | + ] |
| 199 | + }, |
| 200 | + { |
| 201 | + "cell_type": "code", |
| 202 | + "execution_count": null, |
| 203 | + "metadata": { |
| 204 | + "id": "N-zjIh3prV4U", |
| 205 | + "vscode": { |
| 206 | + "languageId": "python" |
| 207 | + } |
| 208 | + }, |
| 209 | + "outputs": [], |
| 210 | + "source": [ |
| 211 | + "order_total_var = (\n", |
| 212 | + " df_var.groupby(\"order\")[\"ext price\"].sum().rename(\"Order_Total\").reset_index()\n", |
| 213 | + ")\n", |
| 214 | + "order_total_var" |
| 215 | + ] |
| 216 | + }, |
| 217 | + { |
| 218 | + "cell_type": "code", |
| 219 | + "execution_count": null, |
| 220 | + "metadata": { |
| 221 | + "id": "YwwTxCTZrV4U", |
| 222 | + "vscode": { |
| 223 | + "languageId": "python" |
| 224 | + } |
| 225 | + }, |
| 226 | + "outputs": [], |
| 227 | + "source": [ |
| 228 | + "df_1_var = df_var.merge(order_total_var)\n", |
| 229 | + "df_1_var" |
| 230 | + ] |
| 231 | + }, |
| 232 | + { |
| 233 | + "cell_type": "code", |
| 234 | + "execution_count": null, |
| 235 | + "metadata": { |
| 236 | + "id": "DcOSZIugrV4V", |
| 237 | + "vscode": { |
| 238 | + "languageId": "python" |
| 239 | + } |
| 240 | + }, |
| 241 | + "outputs": [], |
| 242 | + "source": [ |
| 243 | + "df_1_var[\"Percent_of_Order\"] = df_1_var[\"ext price\"] / df_1_var[\"Order_Total\"]\n", |
| 244 | + "df_1_var" |
| 245 | + ] |
| 246 | + }, |
| 247 | + { |
| 248 | + "cell_type": "markdown", |
| 249 | + "metadata": { |
| 250 | + "id": "9wmQp-PfrV4W" |
| 251 | + }, |
| 252 | + "source": [ |
| 253 | + "Безусловно, этот способ работает, но необходимо выполнить несколько шагов, чтобы объединить данные нужным нам образом!" |
| 254 | + ] |
| 255 | + }, |
| 256 | + { |
| 257 | + "cell_type": "markdown", |
| 258 | + "metadata": { |
| 259 | + "id": "SZa5vE9FrV4W" |
| 260 | + }, |
| 261 | + "source": [ |
| 262 | + "## Второй подход - использование transform\n", |
| 263 | + "\n", |
| 264 | + "Используя исходные данные, давайте попробуем вызвать `transform` для результата `groupby`:" |
| 265 | + ] |
| 266 | + }, |
| 267 | + { |
| 268 | + "cell_type": "code", |
| 269 | + "execution_count": null, |
| 270 | + "metadata": { |
| 271 | + "id": "iU_24zs6rV4X", |
| 272 | + "vscode": { |
| 273 | + "languageId": "python" |
| 274 | + } |
| 275 | + }, |
| 276 | + "outputs": [], |
| 277 | + "source": [ |
| 278 | + "df_var.groupby(\"order\")[\"ext price\"].transform(\"sum\")" |
| 279 | + ] |
| 280 | + }, |
| 281 | + { |
| 282 | + "cell_type": "markdown", |
| 283 | + "metadata": { |
| 284 | + "id": "DTrJTC4OrV4Y" |
| 285 | + }, |
| 286 | + "source": [ |
| 287 | + "Вместо того, чтобы показывать только итоги по трем заказам (`orders`), `transform` сохраняет формат исходного набора данных. Это уникальная особенность `transform`!\n", |
| 288 | + "\n", |
| 289 | + "Последний шаг довольно прост:" |
| 290 | + ] |
| 291 | + }, |
| 292 | + { |
| 293 | + "cell_type": "code", |
| 294 | + "execution_count": null, |
| 295 | + "metadata": { |
| 296 | + "id": "aX7bmm-krV4Y", |
| 297 | + "vscode": { |
| 298 | + "languageId": "python" |
| 299 | + } |
| 300 | + }, |
| 301 | + "outputs": [], |
| 302 | + "source": [ |
| 303 | + "df_var[\"Order_Total\"] = df_var.groupby(\"order\")[\"ext price\"].transform(\"sum\")\n", |
| 304 | + "df_var[\"Percent_of_Order\"] = df_var[\"ext price\"] / df_var[\"Order_Total\"]\n", |
| 305 | + "df_var" |
| 306 | + ] |
| 307 | + }, |
| 308 | + { |
| 309 | + "cell_type": "markdown", |
| 310 | + "metadata": { |
| 311 | + "id": "T0EmId80rV4Z" |
| 312 | + }, |
| 313 | + "source": [ |
| 314 | + "В качестве дополнительного бонуса можно объединить все в один отчет, если не хотите отображать итоги отдельных заказов:" |
| 315 | + ] |
| 316 | + }, |
| 317 | + { |
| 318 | + "cell_type": "code", |
| 319 | + "execution_count": null, |
| 320 | + "metadata": { |
| 321 | + "id": "cyV-RWzfrV4Z", |
| 322 | + "vscode": { |
| 323 | + "languageId": "python" |
| 324 | + } |
| 325 | + }, |
| 326 | + "outputs": [], |
| 327 | + "source": [ |
| 328 | + "df_var[\"Percent_of_Order\"] = df_var[\"ext price\"] / df_var.groupby(\"order\")[\n", |
| 329 | + " \"ext price\"\n", |
| 330 | + "].transform(\"sum\")\n", |
| 331 | + "df_var" |
| 332 | + ] |
| 333 | + }, |
| 334 | + { |
| 335 | + "cell_type": "markdown", |
| 336 | + "metadata": { |
| 337 | + "id": "qBSIL8O2rV4a" |
| 338 | + }, |
| 339 | + "source": [ |
| 340 | + "Вот схема, показывающая, что происходит:\n", |
| 341 | + "\n", |
| 342 | + "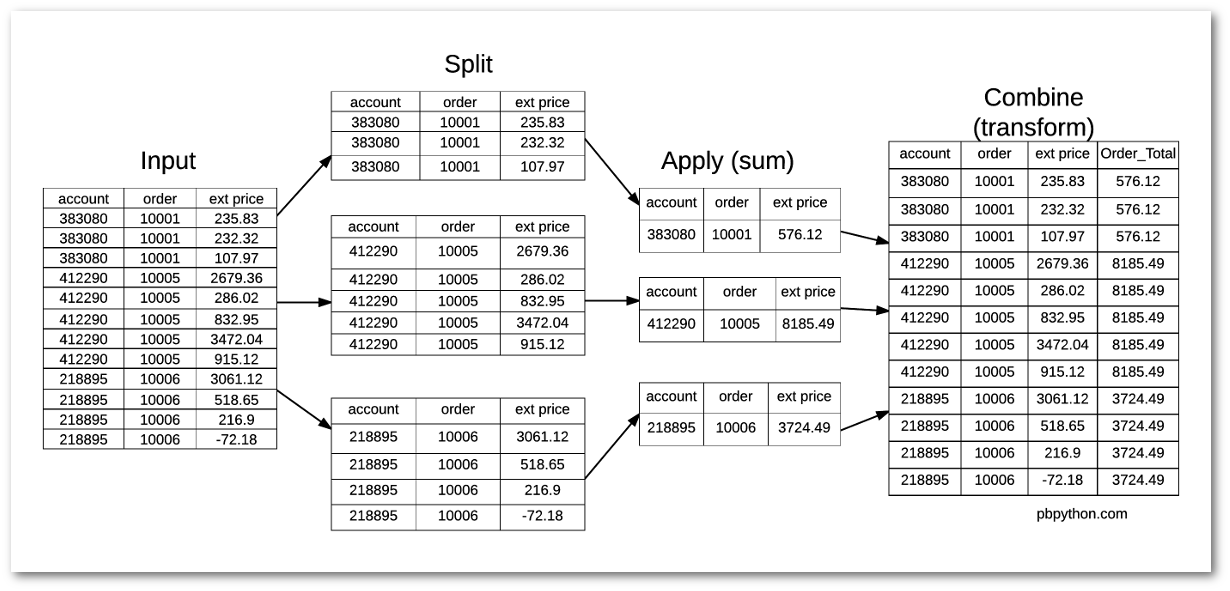" |
| 343 | + ] |
| 344 | + }, |
| 345 | + { |
| 346 | + "cell_type": "markdown", |
| 347 | + "metadata": { |
| 348 | + "id": "kiQkfmabrV4a" |
| 349 | + }, |
| 350 | + "source": [ |
| 351 | + "Потратив время на понимание `transform`, я думаю, вы согласитесь, что этот инструмент может быть очень мощным, даже, если это отличный от стандартного мышления Excel подход." |
| 352 | + ] |
| 353 | + }, |
| 354 | + { |
| 355 | + "cell_type": "markdown", |
| 356 | + "metadata": { |
| 357 | + "id": "fxVfw4etrV4b" |
| 358 | + }, |
| 359 | + "source": [ |
| 360 | + "## Заключение\n", |
| 361 | + "\n", |
| 362 | + "Я постоянно поражаюсь способности pandas делать сложные числовые манипуляции очень эффективными. Несмотря на то, что с длительное время работал с pandas, я никогда не тратил время на понимание работы `transform`. Теперь, когда я знаю, как это работает, уверен, что смогу использовать его в будущем анализе, и надеюсь, что вы сочтете этот пример полезным." |
| 363 | + ] |
| 364 | + } |
| 365 | + ], |
| 366 | + "metadata": { |
| 367 | + "colab": { |
| 368 | + "provenance": [] |
| 369 | + }, |
| 370 | + "kernelspec": { |
| 371 | + "display_name": "Python 3", |
| 372 | + "language": "python", |
| 373 | + "name": "python3" |
| 374 | + }, |
| 375 | + "language_info": { |
| 376 | + "codemirror_mode": { |
| 377 | + "name": "ipython", |
| 378 | + "version": 3 |
| 379 | + }, |
| 380 | + "file_extension": ".py", |
| 381 | + "mimetype": "text/x-python", |
| 382 | + "name": "python3", |
| 383 | + "nbconvert_exporter": "python", |
| 384 | + "pygments_lexer": "ipython3", |
| 385 | + "version": "3.8.3" |
| 386 | + } |
| 387 | + }, |
| 388 | + "nbformat": 4, |
| 389 | + "nbformat_minor": 0 |
| 390 | +} |
0 commit comments