diff --git a/sites/en/docs/Robotics/Robot_Kits/Lerobot/Lerobot_SO100Arm_New.md b/sites/en/docs/Robotics/Robot_Kits/Lerobot/Lerobot_SO100Arm_New.md
index 42c459bc25c6c..bc630c4f3a7a7 100644
--- a/sites/en/docs/Robotics/Robot_Kits/Lerobot/Lerobot_SO100Arm_New.md
+++ b/sites/en/docs/Robotics/Robot_Kits/Lerobot/Lerobot_SO100Arm_New.md
@@ -10,7 +10,7 @@ image: https://files.seeedstudio.com/wiki/robotics/projects/lerobot/Arm_kit.webp
slug: /lerobot_so100m_new
sku: 114993666,114993667,114993668,101090144
last_update:
- date: 3/2/2026
+ date: 3/11/2026
author: ZhangJiaQuan
translation:
skip:
@@ -814,7 +814,6 @@ If you have more cameras, you can change `--robot.cameras` to add cameras. You s
Images in the `fourcc: "MJPG"` format are compressed. You can try higher resolutions, and you may also attempt the `YUYV` format. However, the latter will reduce the image resolution and FPS, leading to lag in the robotic arm's operation. Currently, under the `MJPG` format, it can support 3 cameras at a resolution of `1920*1080` while maintaining `30FPS`. That said, connecting 2 cameras to a computer via the same USB HUB is still not recommended.
:::
-
For example, you want to add a side camera:
```bash
@@ -833,7 +832,6 @@ lerobot-teleoperate \
Images in the `fourcc: "MJPG"` format are compressed. You can try higher resolutions, and you may also attempt the `YUYV` format. However, the latter will reduce the image resolution and FPS, leading to lag in the robotic arm's operation. Currently, under the `MJPG` format, it can support 3 cameras at a resolution of `1920*1080` while maintaining `30FPS`. That said, connecting 2 cameras to a computer via the same USB HUB is still not recommended.
:::
-
:::tip
If you find bug like this.
@@ -1049,18 +1047,16 @@ Your robot should replicate movements similar to those you recorded.
## Train And Evaluate
-
[ACT](https://huggingface.co/docs/lerobot/act)
Refer to[ACT](https://huggingface.co/docs/lerobot/act)
-To train a policy to control your robot, use the [lerobot-train](https://github.com/huggingface/lerobot/blob/main/src/lerobot/scripts/train.py) script.
+To train a policy to control your robot, use the [lerobot-train](https://github.com/huggingface/lerobot/blob/main/src/lerobot/scripts/train.py) script.
**Train**
-
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/so101_test \
@@ -1094,7 +1090,6 @@ Let's explain it:
- **Device selection**: We provide `policy.device=cuda` because we are training on an Nvidia GPU, but you can use `policy.device=mps` for training on Apple Silicon.
- **Visualization tool**: We provide `wandb.enable=true` to visualize training charts using [Weights and Biases](https://docs.wandb.ai/quickstart). This is optional, but if you use it, ensure you have logged in by running `wandb login`.
-
**Evaluate**
:::tip
@@ -1141,10 +1136,8 @@ lerobot-record \
-
-
SmolVLA
@@ -1288,17 +1281,17 @@ LeRobot uses MuJoCo for simulation. You need to set the rendering backend before
-
[Pi0](https://huggingface.co/docs/lerobot/pi0)
-Refer to [Pi0](https://huggingface.co/docs/lerobot/pi0)
+Refer to [Pi0](https://huggingface.co/docs/lerobot/pi0)
```bash
pip install -e ".[pi]"
```
**Train**
+
```bash
lerobot-train \
--policy.type=pi0 \
@@ -1329,20 +1322,19 @@ lerobot-record \
--policy.path=outputs/pi0_training/checkpoints/last/pretrained_model
```
-
-
[Pi0.5](https://huggingface.co/docs/lerobot/pi05)
-Refer to [Pi0.5](https://huggingface.co/docs/lerobot/pi05)
+Refer to [Pi0.5](https://huggingface.co/docs/lerobot/pi05)
```bash
pip install -e ".[pi]"
```
**Train**
+
```bash
lerobot-train \
--dataset.repo_id=seeed/eval_test123 \
@@ -1373,11 +1365,8 @@ lerobot-record \
--policy.path=outputs/pi05_training/checkpoints/last/pretrained_model
```
-
-
-
[GR00T N1.5](https://huggingface.co/docs/lerobot/groot)
@@ -1683,7 +1672,335 @@ For advanced configuration and troubleshooting, see the Accelerate documentation
+
+
+(Optional) Asynchronous Inference
+
+When asynchronous inference is not enabled, LeRobot’s control flow can be understood as **conventional sequential / synchronous inference**: the policy first predicts a segment of actions, then executes that segment, and only after that waits for the next prediction.
+
+For larger models, this can cause the robot to noticeably pause while waiting for the next action chunk.
+
+The goal of asynchronous inference is to let the robot execute the current action chunk while computing the next one in advance, thereby reducing idle time and improving responsiveness.
+
+Asynchronous inference is applicable to policies supported by LeRobot, including **chunk-based action policies** such as **ACT, OpenVLA, Pi0, and SmolVLA**.
+
+Since inference is decoupled from actual control, asynchronous inference also helps leverage machines with stronger compute resources to perform inference for the robot.
+
+You can read more about asynchronous inference in the [blog by Hugging Face](https://huggingface.co/blog/async-robot-inference)
+
+Let us first introduce some basic concepts:
+
+- **Client**: connects to the robotic arm and cameras, collects observation data (such as images and robot poses), sends these observations to the server, and receives the action chunks returned by the server and executes them in order.
+
+- **Server**: the device that provides compute resources. It receives camera data and robotic arm data, performs inference (that is, computation) to produce action chunks, and sends them back to the client. It can be the same device connected to the robotic arm and cameras, another computer on the same local network, or a rented cloud server on the Internet.
+
+- **Action chunk**: a sequence of robotic arm action commands obtained by policy inference on the server side.
+
+Three deployment scenarios for asynchronous inference
+
+1. Single-machine deployment
+
+The robot, cameras, client, and server are all on the same device.
+
+This is the simplest case: the server can listen on 127.0.0.1, and the client can also connect to 127.0.0.1:port. The command example in the official documentation is for this scenario.
+
+2. LAN deployment
+
+The robot and cameras are connected to a lightweight device, while the policy server runs on another high-compute machine in the same local network.
+
+In this case, the server must listen on an address that is accessible by other machines, and the client must also connect to the server’s LAN IP, rather than 127.0.0.1.
+
+3. Cross-network / cloud deployment
+
+The policy server runs on a publicly accessible cloud host, and the client connects to it over the public Internet.
+
+This approach can use the stronger GPU of the cloud host. When network conditions are good, the round-trip network time (network latency) can sometimes be relatively small compared with inference time, but this depends on your actual network environment.
+
+Security note: the LeRobot async inference pipeline has a risk related to unauthenticated gRPC + pickle deserialization. If there is important information or important services on the server, it is not recommended to expose the service directly to the Internet in a public deployment. A safer approach is to use VPN or SSH tunneling, or at least restrict the allowed source IPs in the security group to your own client public IP.
+
+### Getting started with asynchronous inference deployment
+
+#### Step 1: Environment setup
+
+First, use pip to install the additional dependencies required for asynchronous inference. Both the client and the server need to have lerobot installed along with the extra dependencies:
+
+```bash
+pip install -e ".[async]"
+```
+
+#### Step 2: Network configuration and checks
+
+1. **Proxy issues**
+
+If your current terminal is configured to use a proxy and the connection behaves abnormally, you can temporarily unset the proxy environment variables:
+
+```bash
+unset http_proxy https_proxy ftp_proxy all_proxy HTTP_PROXY HTTPS_PROXY FTP_PROXY ALL_PROXY
+```
+
+Note: the command above only affects the current terminal session. If you open another terminal window, you need to run it again.
+
+2. **Open the port in the firewall / security group**
+
+Single-machine deployment: this can usually be skipped.
+
+LAN deployment: you need to open the listening port on the server side.
+
+Example for opening the listening port on a LAN setup (run on the server side):
+
+```bash
+sudo ufw allow 8080/tcp
+```
+
+Cloud deployment: you need to open this port in the cloud server security group, and it is recommended to restrict the source IPs as much as possible.
+
+If you are running on a cloud server:
+
+Open port 8080 in the server management console’s security group, or use another port that is already open. Different cloud service platforms handle this differently; refer to your cloud provider’s documentation.
+
+3. **Confirm the IP address**
+
+This step can be skipped for single-machine deployment (the IP address for a single machine is always 127.0.0.1).
+
+If this is a LAN deployment:
+
+You need to confirm and remember the LAN IP address of the server side. When the client connects, what should be filled in is the LAN IP of the machine running policy_server, not the client’s own IP.
+
+Linux / Jetson / Raspberry Pi:
+
+```bash
+hostname -I
+```
+
+If multiple addresses are shown, generally choose the one corresponding to the current LAN network interface, for example 192.168.x.x.
+
+You can also use:
+
+```bash
+ip addr
+```
+
+to view the inet field under the currently connected network interface.
+
+Windows:
+
+```shell
+ipconfig
+```
+
+Find a field like IPv4 Address . . . . . . . . . . . : 192.168.14.140; that is the LAN IP address of that machine.
+
+macOS:
+
+```bash
+ifconfig
+```
+
+Find the inet field corresponding to the currently connected network interface; that is the LAN IP address.
+
+We need to remember the server-side LAN IP address. We will use `` to refer to it.
+
+If this is a cloud server deployment:
+
+Look for the public IP in the server control panel. It is usually called one of the following:
+
+Public IPv4
+
+External IP
+
+Public IP address
+
+EIP
+
+Public IP
+We need to remember the public IP address. We will use` `to refer to it.
+
+4. **Connection test**
+
+Single-machine deployment: this step can be skipped
+
+LAN / cloud deployment: it is recommended to test from the client side whether the server port is reachable. Example tests are as follows:
+
+LAN example: run on the client side
+
+```bash
+nc -vz 8080
+```
+
+Cloud example: run on the client side
+
+```bash
+nc -vz 8080
+```
+
+#### Step 3: Start the service
+
+**Scenario A: Single-machine deployment**
+
+Start the local service in one terminal:
+
+```bash
+python -m lerobot.async_inference.policy_server \
+--host=127.0.0.1 \
+--port=8080
+```
+
+After it starts successfully, you need to keep this terminal open. You will need to open a new terminal to run other commands.
+
+**Scenario B: LAN deployment**
+
+Run on the server side:
+
+```bash
+python -m lerobot.async_inference.policy_server \
+--host=0.0.0.0 \
+--port=8080
+```
+
+In this case, when the client connects, the --server_address should be the server-side LAN IP address, that is,`:8080`.
+
+**Scenario C: Cloud server deployment**
+
+Run on the server side:
+
+```bash
+python -m lerobot.async_inference.policy_server \
+--host=0.0.0.0 \
+--port=8080
+```
+
+In this case, when the client connects, the --server_address should be the server’s public IP address, that is, `:8080`.
+
+#### Step 4: Choose inference parameters
+
+Run on the client side:
+
+```bash
+python -m lerobot.async_inference.robot_client \
+--server_address=:8080 \
+--robot.type=so100_follower \
+--robot.port=/dev/tty.usbmodem585A0076841 \
+--robot.id=follower_so100 \
+--robot.cameras="{ laptop: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}, phone: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
+--task="dummy" \
+--policy_type=your_policy_type \
+--pretrained_name_or_path=user/model \
+--policy_device=cuda \
+--actions_per_chunk=50 \
+--chunk_size_threshold=0.5 \
+--aggregate_fn_name=weighted_average \
+--debug_visualize_queue_size=True
+```
+
+Parameter explanations:
+
+- `--server_address`
+
+Specifies the address and port of the policy server. `` should be replaced with 127.0.0.1 (local machine), ``(LAN), or`` (cloud server).
+
+- `--robot.type, --robot.port, --robot.id, --robot.cameras`
+
+Hardware device parameters. These should be kept consistent with the parameters used during dataset collection.
+
+- `--task`
+
+The task description. Vision-language policies such as SmolVLA can determine the action target based on the task text.
+
+- `--policy_type`
+
+Replace this with the specific policy name, for example:
+
+- smolvla
+
+- act
+
+- `--pretrained_name_or_path`
+
+This value should be replaced with the model path on the server side, or a model path on Hugging Face.
+
+- `--policy_device`
+
+Specifies the inference device used on the server side.
+
+It can be cuda, mps, or cpu.
+
+- `--actions_per_chunk=50`
+
+Specifies how many actions are output in each inference.
+
+The larger this value is:
+
+Advantage: the action buffer is more sufficient, making it less likely to run out
+Disadvantage: the prediction horizon is longer, so control error may accumulate more noticeably
+
+- `--chunk_size_threshold=0.5`
+
+Specifies when to request the next action chunk from the server.
+
+This is a threshold, usually in the range 0 to 1.
+
+It can be understood as: when the remaining proportion of the current action queue falls below this threshold, the client will send a new observation in advance and request the next action chunk.
+
+Setting it to 0.5 here means:
+
+when the current action chunk is about half consumed
+
+the client starts requesting the next action chunk
+
+The larger this value is, the more frequently requests are sent, and the more responsive the system becomes, but the load on the server also increases.
+
+The smaller this value is, the closer the behavior gets to synchronous inference.
+
+- `--aggregate_fn_name=weighted_average`
+
+Specifies the aggregation method for overlapping action intervals.
+
+In asynchronous inference, when the old action chunk has not yet been fully executed, the new action chunk may already have arrived.
+
+In that case, the two chunks overlap over part of the time interval, and an aggregation function is needed to combine them into the final executed action.
+
+The meaning of weighted_average is:
+
+use a weighted average to fuse the overlapping part.
+
+This usually makes action switching smoother and reduces abrupt changes.
+
+- `--debug_visualize_queue_size=True`
+
+Whether to visualize the action queue size at runtime.
+
+When enabled, it allows you to see more directly whether the queue frequently hits the bottom, which helps you tune actions_per_chunk and chunk_size_threshold.
+
+#### Step 5: Adjust parameters based on robot behavior
+
+In asynchronous inference, there are two additional parameters that need adjustment which do not exist in synchronous inference:
+
+Parameter Suggested initial value Description
+
+actions_per_chunk 50 How many actions the policy outputs at one time. Typical values: 10–50.
+
+chunk_size_threshold 0.5 When the remaining proportion of the action queue is ≤ chunk_size_threshold, the client sends a new action chunk request. The value range is [0, 1].
+
+When --debug_visualize_queue_size=True, the change in action queue size will be plotted at runtime.
+
+What asynchronous inference needs to balance is: the speed at which the server generates action chunks must be greater than or equal to the speed at which the client consumes action chunks. Otherwise, the action queue will empty, and the robot will begin to stutter again (this can be seen as the curve hitting the bottom in the queue visualization).
+
+The speed at which the server generates action chunks is affected by factors such as model size, device type, VRAM / memory, and GPU compute power.
+
+The speed at which the client consumes action chunks is affected by the configured execution fps.
+
+If the queue frequently runs empty, you need to increase actions_per_chunk, increase chunk_size_threshold, or reduce fps.
+
+If the queue curve fluctuates frequently but the remaining actions in the queue are always sufficient, you can appropriately decrease chunk_size_threshold.
+
+In general:
+
+the empirical range for actions_per_chunk is 10–50
+
+the empirical range for chunk_size_threshold is 0.5–0.7; when tuning, it is recommended to start from 0.5 and gradually increase it
+
+
If you encounter the following error:
@@ -1725,8 +2042,6 @@ huggingface-cli upload ${HF_USER}/act_so101_test${CKPT} \
outputs/train/act_so101_test/checkpoints/${CKPT}/pretrained_model
```
-
-
## FAQ
- If you are following this documentation/tutorial, please git clone the recommended GitHub repository `https://github.com/Seeed-Projects/lerobot.git`. The repository recommended in this documentation is a verified stable version; the official Lerobot repository is continuously updated to the latest version, which may cause unforeseen issues such as different dataset versions, different commands, etc.
diff --git a/sites/zh-CN/docs/Robotics/Robot_Kits/Lerobot/cn_Lerobot_SO100Arm_New.md b/sites/zh-CN/docs/Robotics/Robot_Kits/Lerobot/cn_Lerobot_SO100Arm_New.md
index ea04cd49b5189..c5af6cea62a84 100644
--- a/sites/zh-CN/docs/Robotics/Robot_Kits/Lerobot/cn_Lerobot_SO100Arm_New.md
+++ b/sites/zh-CN/docs/Robotics/Robot_Kits/Lerobot/cn_Lerobot_SO100Arm_New.md
@@ -10,7 +10,7 @@ image: https://files.seeedstudio.com/wiki/robotics/projects/lerobot/Arm_kit.webp
slug: /lerobot_so100m_new
sku: 114993666,114993667,114993668,101090144
last_update:
- date: 3/2/2026
+ date: 3/11/2026
author: ZhangJiaQuan
createdAt: '2025-01-08'
updatedAt: '2026-03-03'
@@ -29,8 +29,8 @@ url: https://wiki.seeedstudio.com/cn/lerobot_so100m_new/
-
### 项目介绍
+
SO-ARM10x 和 reComputer Jetson AI 智能机器人套件无缝结合了高精度的机器人手臂控制与强大的 AI 计算平台,提供了全面的机器人开发解决方案。该套件基于 Jetson Orin 或 AGX Orin 平台,结合 SO-ARM10x 机器人手臂和 LeRobot AI 框架,为用户提供适用于教育、科研和工业自动化等多种场景的智能机器人系统。
本维基提供了 SO ARM10x 的组装和调试教程,并在 Lerobot 框架内实现数据收集和训练。
@@ -68,8 +68,8 @@ Seeed Studio **仅对硬件质量负责**。教程严格按官方文档更新,
- **主臂齿轮比优化**:主臂现在采用了经过优化的齿轮比电机,无需外部减速机构,同时提升了性能。
- **新增功能支持**:主臂现在可以实时跟随从臂动作,这对即将引入的策略尤为关键,可实现人类实时干预并修正机器动作。
-
# 规格参数
+
本教程硬件由[矽递科技Seeed Studio](https://www.seeedstudio.com/)提供
@@ -131,7 +131,7 @@ Seeed Studio **仅对硬件质量负责**。教程严格按官方文档更新,
-
-
## FAQ
- 如果使用本文档教程,请git clone本文档推荐的github仓库`https://github.com/Seeed-Projects/lerobot.git`,本文档推荐的仓库是验证过后的稳定版本,Lerobot官方仓库是实时更新的最新版本,会出现一些无法预知的问题,例如数据集版本不同,指令不同等。
-
- 如果校准舵机ID时候遇到
+
```bash
`Motor ‘gripper’ was not found, Make sure it is connected`
```
+
请仔细检查通讯线是否与舵机连接正常,电源是否正确电压供电。”
- 如果遇到
+
```bash
Could not connect on port "/dev/ttyACM0"
```
+
并且通过`ls /dev/ttyACM*`看到是有ACM0存在的,则是忘记给串口权限了,终端输入`sudo chmod 666 /dev/ttyACM*` 即可`
- 如果遇到
+
```bash
No valid stream found in input file. Is -1 of the desired media type?
```
+
请安装ffmpeg7.1.1,`conda install ffmpeg=7.1.1 -c conda-forge`。
@@ -1860,27 +2072,35 @@ lerobot-train \
- 如果遇到
+
```bash
ConnectionError: Failed to sync read 'Present_Position' on ids=[1,2,3,4,5,6] after 1 tries. [TxRxResult] There is no status packet!
```
+
需要检查对应端口号的机械臂是否接通电源,总线舵机是否出现数据线松动或者脱落,哪个舵机灯不亮就是前面那个舵机的线松了。
- 如果校准机械臂的时候遇到
+
```bash
Magnitude 30841 exceeds 2047 (max for sign_bit_index=11)
```
+
对机械臂进行重新断电和上电,再次尝试校准机械臂。如果在校准过程中遇到 MAX 角度达到上万的值也可以使用这个方法;如果仍然无效,则需要对相应舵机重新进行舵机校准(中位校准和 ID 写入)。
- 如果评估阶段遇到
+
```bash
File exists: 'home/xxxx/.cache/huggingface/lerobot/xxxxx/seeed/eval_xxxx'
```
+
请先删除`eval_`开头的这个文件夹再次运行程序。
- 如果评估阶段遇到
+
```bash
`mean` is infinity. You should either initialize with `stats` as an argument or use a pretrained model
```
+
请注意--robot.cameras这个参数中的front和side等关键词必须和采集数据集的时候保持严格一致。
- 如果你维修或者更换过机械臂零件,请完全删除`~/.cache/huggingface/lerobot/calibration/robots`或者`~/.cache/huggingface/lerobot/calibration/teleoperators`下的文件并重新校准机械臂,否则会出现报错提示,校准的机械臂信息会存储该目录下的json文件中。
@@ -1893,7 +2113,6 @@ lerobot-train \
- 如果程序提示无法读取USB摄像头图像数据,请确保USB摄像头不是接在Hub上的,USB摄像头必须直接接入设备,确保图像传输速率快。
-
:::tip
如果你遇到无法解决的软件问题或环境依赖问题,除了查看本教程末尾的常见问题(FAQ)部分外,请及时在 [LeRobot 平台](https://github.com/huggingface/lerobot) 或 [LeRobot Discord 频道](https://discord.gg/8TnwDdjFGU) 反馈问题。
:::
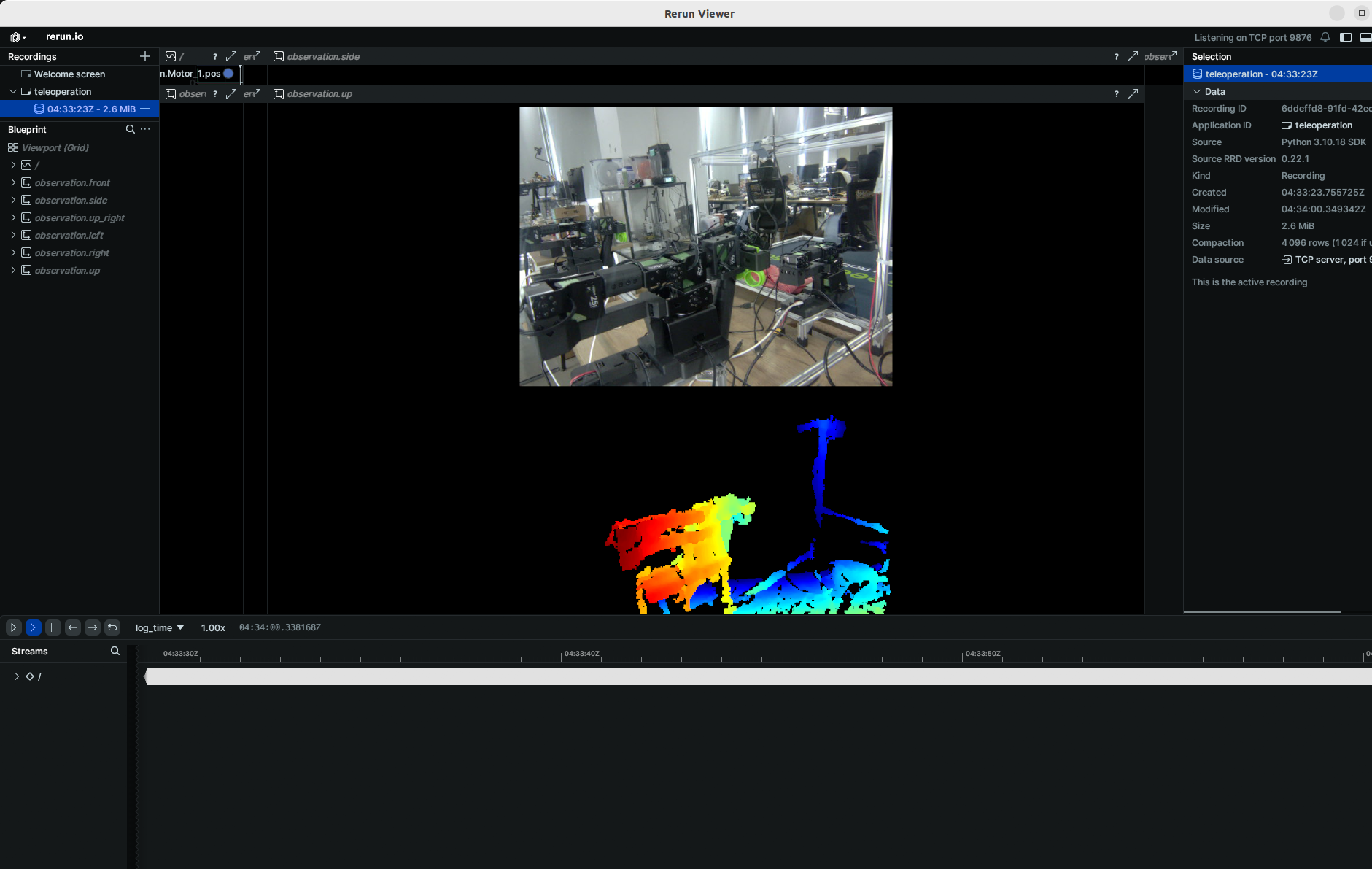
 -
-
-
-- 🚀 步骤 2:函数调用与示例
+- 🚀 步骤 2:函数调用与示例
以下示例均需将 `so101_follower` 替换为你所使用实际机械臂型号(如 `so100` / `so101`)。
-
我们加入了focus_area超参数,因为过远的深度数据对于机械臂没有意义(抓取不到),因此小于或者大于focus_area的深度数据将会变为黑色,默认的focus_area是(20,600)
目前支持的分辨率只限于 width: 640, height: 880
@@ -764,12 +750,10 @@ lerobot-teleoperate \
```
-
-
-
-
-- 🚀 步骤 2:函数调用与示例
+- 🚀 步骤 2:函数调用与示例
以下示例均需将 `so101_follower` 替换为你所使用实际机械臂型号(如 `so100` / `so101`)。
-
我们加入了focus_area超参数,因为过远的深度数据对于机械臂没有意义(抓取不到),因此小于或者大于focus_area的深度数据将会变为黑色,默认的focus_area是(20,600)
目前支持的分辨率只限于 width: 640, height: 880
@@ -764,12 +750,10 @@ lerobot-teleoperate \
```
-
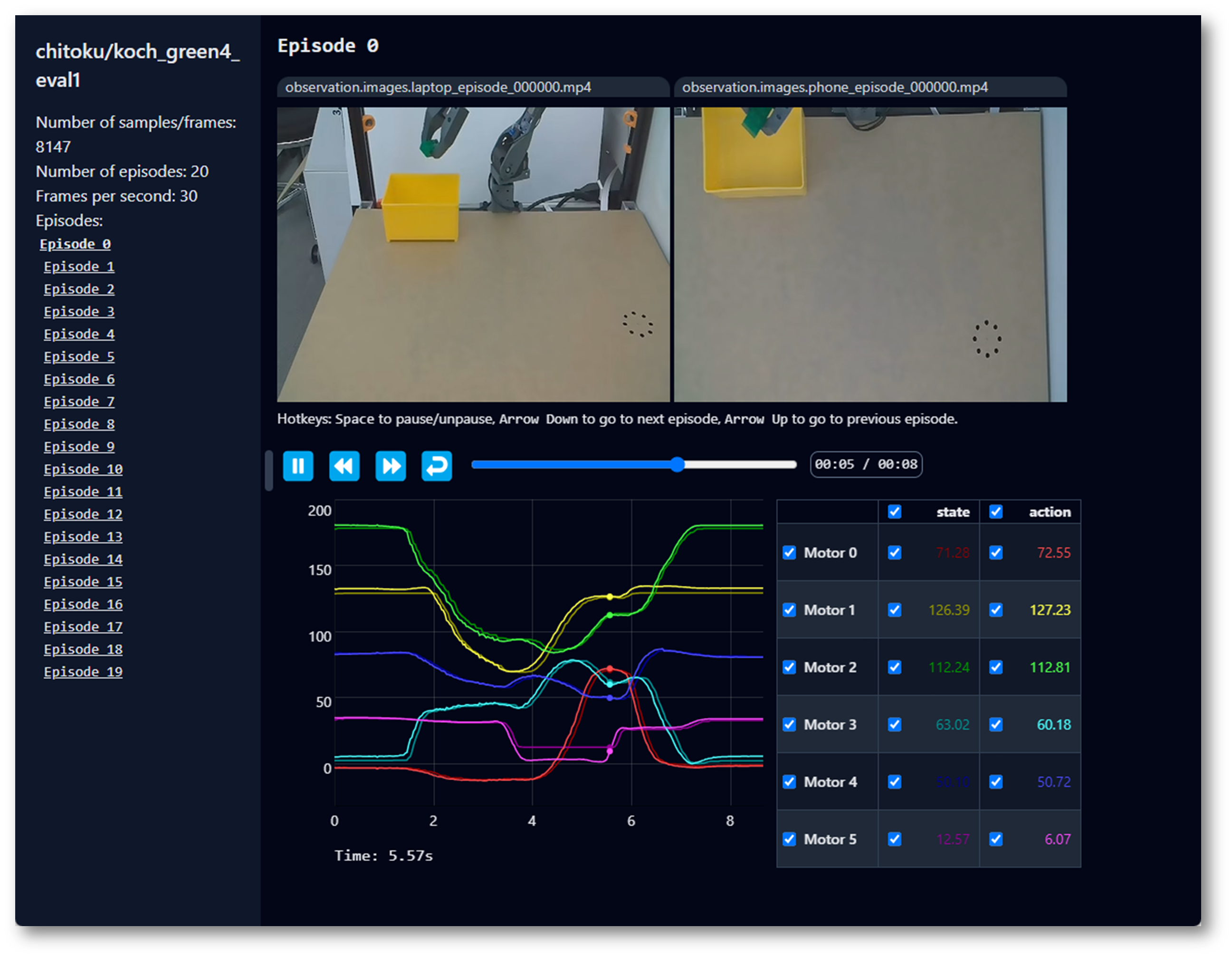 -
## 回放一个数据集
:::tip
@@ -1061,12 +1042,10 @@ lerobot-replay \
## 训练及评估
-
-
## 回放一个数据集
:::tip
@@ -1061,12 +1042,10 @@ lerobot-replay \
## 训练及评估
-