-
Notifications
You must be signed in to change notification settings - Fork 0
Expand file tree
/
Copy pathautodiff.Rmd
More file actions
763 lines (572 loc) · 25.9 KB
/
autodiff.Rmd
File metadata and controls
763 lines (572 loc) · 25.9 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
---
title: "autodiff"
author: "Félix Cheysson, Julien Chiquet, Mahendra Mariadassou, Tristan Mary-Huard"
date: "`r Sys.Date()`"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
# Exploration de `{{torch}}` pour la différentiation automatique
## Installation
Le package [`torch`]() permet de faire de la différentiation automatique à condition de réécrire son code avec les fonctions de `torch`. Il est basé sur la librairie C++ `libtorch` fournie dans PyTorch. Contrairement à d'anciennes versions, torch ne **fait pas** appel à python et ne nécessite pas reticulate. L'installation en est d'autant plus simple:
```{r, eval = FALSE}
install.packages(torch)
```
Lors de la première utilisation, `torch` vous demandera de télécharger des fichiers supplémentaires via:
```{r, eval = FALSE}
torch::install_torch() ## si vous avez un GPU compatible avec CUDA
## torch::install_torch(type = "cpu") ## sinon
```
`torch` est surtout utilisé pour des applications en ML/IA mais on peut aussi l'utiliser pour des calculs de gradients, hessiennes et de l'optimisation dans des modèles plus simples. On va l'illustrer ici pour de la régression logistique.
```{r}
library(tidyverse)
library(torch)
```
## Principe du calcul de gradient
`torch` fonctionne avec ses propres types numériques, qu'il faut créer avec la fonction `torch_tensor()` et ses propres fonctions `torch_*()`. Considérons un exemple très simple: \$ x \mapsto x\^2\$
```{r}
x <- torch_tensor(3)
y <- torch_square(x)
x; y
```
On va pouvoir calculer $\frac{dy}{dx}$ en définissant `x` avec l'argument `require_grad = TRUE`. Cet argument va spécifier que 'x' est entrainable et va démarrer l'enregistrement par autograd des opérations sur ce tenseur.
Autograd est un module de `torch` qui permet de collecter les gradients. Il le fait en enregistrant des données (tenseurs) et toutes les opérations exécutées dans un graphe acyclique dirigé dont les feuilles sont les tenseurs d'entrée et les racines les tenseurs de sorties. Ces opérations sont stockées comme des fonctions et au moment du calcul des gradients, sont appliquées depuis le noeud de sortie en 'backpropagation' le long du réseau.
```{r}
x <- torch_tensor(2, requires_grad = TRUE)
x
```
On remarque que `x` possède désormais un champ `$grad` (même si ce dernier n'est pas encore défini).
```{r}
x$grad
```
Lorsqu'on calcule $y = x^2$, ce dernier va également hériter d'un nouveau champ `$grad_fn`:
```{r}
y <- torch_log(torch_square(x))
y
y$grad_fn
```
qui indique comment calculer le gradient en utilisant la dérivée des fonctions composées:
$$
(g\circ f)'(x) = f'(x) \times g'(f(x))
$$
et les fonctions
$$
\frac{dx^2}{dx} = 2x \quad \frac{d \log(x)}{dx} = \frac{1}{x}
$$
Le calcul effectif du gradient est déclenché lors de l'appel à la méthode `$backward()` de `y` et est stocké dans le champ `$grad` de `x`.
```{r}
x$grad ## gradient non défini
y$backward()
x$grad ## gradient défini = 1
```
On a bien:
$$
\frac{dy}{dx} = \underbrace{\frac{dy}{dz}}_{\log}(z) \times \underbrace{\frac{dz}{dx}}_{\text{power}}(x) = \frac{1}{4} \times 2*2 = 1
$$ Intuitivement au moment du calcul de `y`, `torch` construit un graphe computationnel qui lui permet d'évaluer **numériquement** $y$ et qui va **également** servir pour calculer $\frac{dy}{dz}$ au moment de l'appel à la fonction `$backward()` issue du module autograd.
Essayons de reproduire le calcul dans notre exemple. Le calcul **forward** donne
$$
x = 2 \xrightarrow{x \mapsto x^2} z = 4 \mapsto \xrightarrow{x \mapsto \log(x)} y = \log(4)
$$
Pour le calcul **backward**, il faut donc construire le graphe formel suivant. La première étape du graphe est accessible via `$grad_fn`
```{r}
y$grad_fn
```
et les fonctions suivantes via `$next_functions`
```{r}
y$grad_fn$next_functions
```
Dans notre exemple, on a donc:
$$
\frac{dy}{dy} = 1 \xrightarrow{x \mapsto \text{logBackward}(x)} \frac{dy}{dz} = \frac{dy}{dy} \times \text{logBackward}(z) \xrightarrow{x \mapsto \text{powerBackward}(x)} \frac{dy}{dx} = \frac{dy}{dz} \times \text{logBackward}(x)
$$
Dans cet exemple:
- $\text{logBackward}(x) = \frac{1}{x}$
- $\text{powBackward}(x) = 2x$
Et la propagation des dérivées donne donc
$$
\frac{dy}{dy} = 1 \to \frac{dy}{dz} = 1 \times \frac{1}{4} = \frac{1}{4} \to \frac{dy}{dx} = \frac{1}{4} \times 4 = 1
$$
Ce graphe est illustré ci-dessous pour la fonction $(x_1, x_2) \mapsto z = sin(x_2) log(x_1 x_2)$
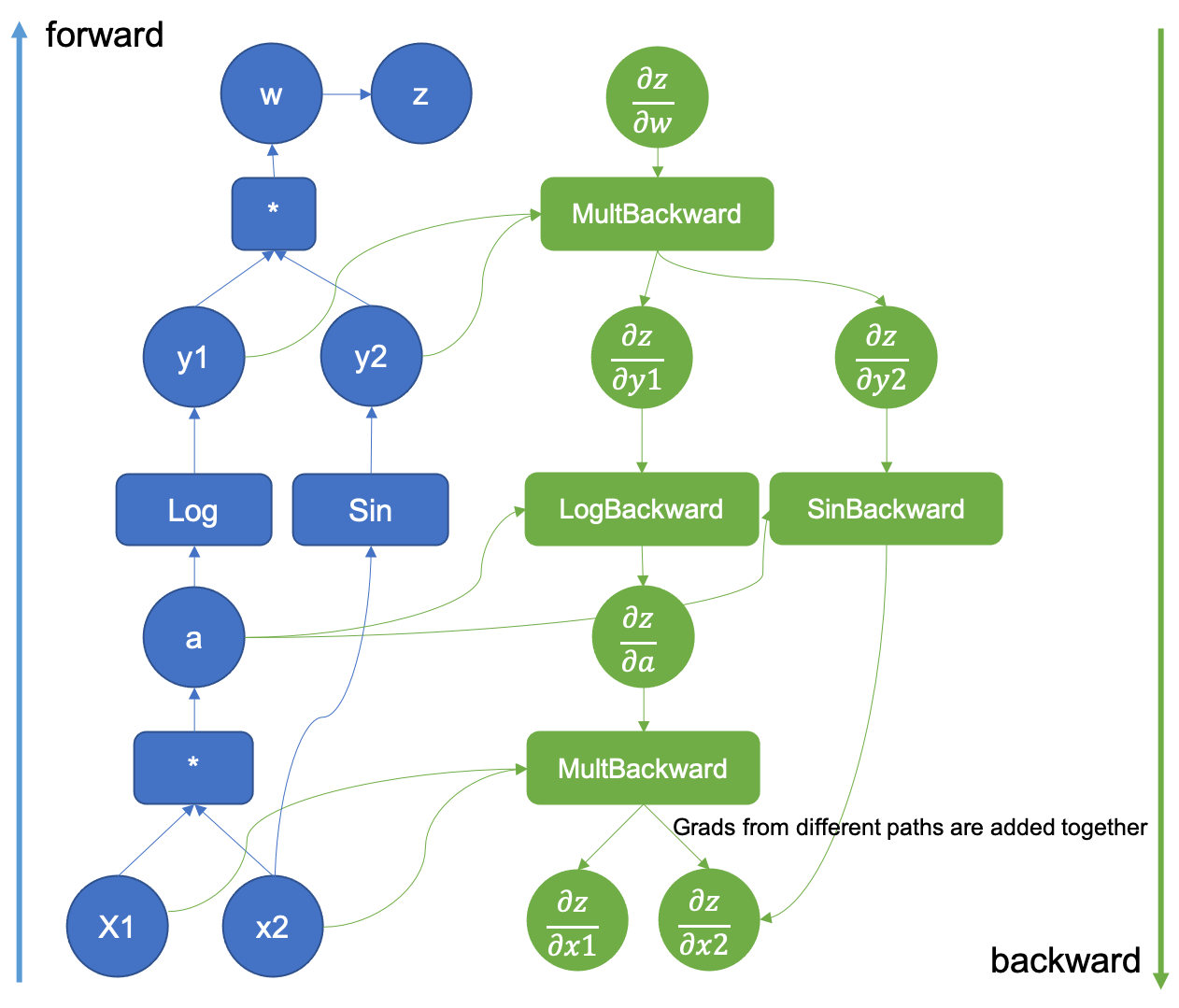
Pour (beaucoup) plus de détails sur le graphe computationnel, on peut consulter la [documentation officielle de PyTorch](https://pytorch.org/blog/how-computational-graphs-are-executed-in-pytorch/).
Il faut juste noter que dans `torch`, le graphe computationnel est construit de **façon dynamique**, au moment du calcul de `y`.
## Régression logistique avec `torch`
On va adopter un simple modèle de régression logistique:
$$
Y_i \sim \mathcal{B}(\sigma(\theta^T x_i)) \quad \text{avec} \quad \sigma(x) = \frac{1}{1 + e^{-x}}
$$
Le but est d'estimer $\theta$ et éventuellement les erreurs associées. On commence par générer des données.
```{r}
set.seed(45)
n <- 100
p <- 3
X <- matrix(rnorm(n = n*p), ncol = p, nrow = n)
theta <- rnorm(3) %>% round(digits = 2)
probs <- (X %*% theta) %>% as.vector()
Y <- rbernoulli(n = n, p = probs) + 0.
```
`torch` fonctionne avec ses propres types numériques, qu'il faut créer avec la fonction `torch_tensor()`.
```{r}
x <- torch_tensor(X)
y <- torch_tensor(Y)
```
On écrit ensuite la fonction de vraisemblance
$$
\mathcal{L}(\mathbf{X}, \mathbf{y}; \theta) = \sum_{i=1}^n y_i (\theta^Tx_i) - \sum_{i=1}^n log(1 + e^{\theta^T x_i})
$$
```{r}
logistic_loss <- function(theta, x, y) {
if (!is(theta, "torch_tensor")) {
stop("theta must be a torch tensor")
}
odds <- torch_matmul(x, theta)
log_lik <- torch_dot(y, odds) - torch_sum(torch_log(1 + torch_exp(odds)))
return(-log_lik)
}
```
avant de vérifier qu'elle fonctionne:
```{r}
logistic_loss(theta = torch_tensor(theta), x = x, y = y)
```
On veut ensuite définir une fonction objective à maximiser (qui ne dépend que de `theta`):
```{r}
eval_loss <- function(theta, verbose = TRUE) {
loss <- logistic_loss(theta, x, y)
if (verbose) {
cat(paste(theta |> as.numeric(), collapse=", "), ": ", as.numeric(loss), "\n")
}
return(loss)
}
```
et vérifier qu'elle fonctionne
```{r}
eval_loss(torch_tensor(theta), verbose = FALSE)
```
avant de procéder à l'optimisation à proprement parler. Pour cette dernière, on commence par définir notre paramètre sous forme d'un tenseur qui va être mis à jour
```{r}
theta_current <- torch_tensor(rep(0, length(theta)), requires_grad = TRUE)
```
et d'un optimiseur:
```{r}
theta_optimizer <- optim_rprop(theta_current)
```
On considère ici l'optimiseur Rprop (resilient backpropagation) qui ne prend pas en compte l'amplitude du gradient mais uniquement le signe de ses coordonnées (voir [ici pour une introduction pédagogique à Rprop](https://florian.github.io/rprop/)).
Intuitivement, l'optimiseur a juste besoin de la valeur de $\theta$ et de son gradient pour le mettre à jour. Mais à ce stade on ne connaît pas encore le gradient $\nabla_\theta \mathcal{L}(\mathbf{X}, \mathbf{y}; \theta)$
```{r}
theta_current$grad
```
et il faut donc le calculer:
```{r}
loss <- eval_loss(theta_current, verbose = FALSE)
loss$backward()
```
On peut vérifier que le gradient est stocké dans `theta`
```{r}
theta_current$grad
```
et effectuer la mise à jour avec une étape d'optimisation
```{r}
theta_optimizer$step()
```
On peut vérifier que le paramètre courant a été mis à jour.
```{r}
theta_current
```
Il ne reste plus qu'à recommencer pour un nombre d'itérations donné. **Attention,** il faut réinitialiser le gradient avant de le mettre à jour, le comportement par défaut de mise à jour étant l'*accumulation* plutôt que le *remplacement*.
```{r}
num_iterations <- 100
loss_vector <- vector("numeric", length = num_iterations)
for (i in 1:num_iterations) {
theta_optimizer$zero_grad()
loss <- eval_loss(theta_current, verbose = FALSE)
loss$backward()
theta_optimizer$step()
loss_vector[i] <- loss %>% as.numeric()
}
```
On vérifie que la perte diminue au cours du temps.
```{r}
plot(1:num_iterations, loss_vector)
```
On constate que notre optimiseur aboutit au même résultat que `glm()`
```{r}
tibble(
torch = theta_current |> as.numeric(),
glm = glm(Y ~ 0 + X, family = "binomial") |> coefficients()
)
```
**Attention** la mécanique présentée ci-dessus avec `$step()` ne fonctionne pas pour certaines routines d'optimisation (BFGS, gradient conjugué) qui nécessite de calculer plusieurs fois la fonction objective. Dans ce cas, il faut définir une *closure*, qui renvoie la fonction objective, et la passer en argument à `$step()`.
```{r}
## remise à 0 du paramètre courant
theta_current <- torch_tensor(rep(0, length(theta)), requires_grad = TRUE)
theta_optimizer <- optim_rprop(theta_current)
## définition de la closure
calc_loss <- function() {
theta_optimizer$zero_grad()
loss <- eval_loss(theta_current, verbose = FALSE)
loss$backward()
loss
}
## Optimisation avec la closure
num_iterations <- 100
loss_vector <- vector("numeric", length = num_iterations)
for (i in 1:num_iterations) {
loss_vector[i] <- theta_optimizer$step(calc_loss) %>% as.numeric()
}
```
On peut vérifier qu'on obtient des résultats identiques dans les deux cas d'utilisation:
```{r}
theta_current
```
```{r}
plot(1:num_iterations, loss_vector)
```
## Exemple de régression multivariée
On considère un exemple de régression multiple, réalisé à partir du blog [torch for optimization](https://blogs.rstudio.com/ai/posts/2021-04-22-torch-for-optimization/), où l'on cherche à estimer les paramètres de moyenne ainsi que la variance par maximisation de la vraisemblance.
On génère les données
```{r}
## Generate the data
X <- cbind(rep(1,100),matrix(rnorm(1000),100,10))
Beta.true <- rnorm(11)
Y <- X%*%Beta.true + rnorm(100)
n <- nrow(X)
```
La fonction de perte à optimiser (ici la log-vraisemblance) va dépendre d'inputs définis comme des "tenseurs torch":
```{r}
## Declare the loss function
Theta <- torch_tensor(rep(1,12) %>% as.matrix, requires_grad = TRUE)
X.tensor <- torch_tensor(X)
```
Quelques remarques :
\- le paramètre $\theta$ à optimiser est ici défini comme un tenseur, i.e. un objet qui va notamment stocker la valeur courante de $\theta$. Avec l'option "requires_grad=TRUE" la valeur courante du gradient de la dernière fonction appelée dépendant de $\theta$ va aussi être stockée.
\- la matrice $X$ est aussi définie comme un tenseur, mais l'option "requires_grad=TRUE" n'a pas été spécifiée, le gradient ne sera donc pas stocké pour cet objet. Cette distinction est explicitée lorsque l'on affiche les deux objets:
```{r}
Theta[1:3]
X.tensor[1:3,1:3]
```
La fonction de perte est ici la log-vraisemblance, elle-même définie à partir d'opérateurs torch élémentaires :
```{r}
LogLik <- function(){
torch_mul(n,torch_log(Theta[12])) + torch_square(torch_norm(Y-torch_matmul(X.tensor,Theta[1:11])))/(2*torch_square(Theta[12]))
}
```
La fonction LogLik peut être appliquée comme une fonction R qui prendra directement en argument les valeurs courantes de X.tensor et $\theta$, et produira en sortie un tenseur
```{r}
LogLik()
```
Outre la valeur courante de la fonction, ce tenseur contient la "recette" du graphe computationnel utilisé dans calcul backward du gradient de la fonction LogLik par rapport à $\theta$. On peut ainsi afficher la dernière opération de ce graphe
```{r}
toto <- LogLik()
toto$grad_fn
```
correspondant à l'addition (AddBackward) des deux termes $$ n\times \log(\theta[12]) \quad \text{et} \quad ||Y-X\theta[1:11]||^2/(2*\theta[12]^2)$$ dans le calcul de la perte. On peut afficher les opérations suivantes dans le graphe comme suit:
```{r}
toto$grad_fn$next_functions
```
L'étape suivante consiste à choisir la méthode d'optimisation à appliquer. L'intérêt d'utiliser le package \`{{torch}}\` est d'avoir accès à une large gamme de méthodes d'optimisation, on considère ici la méthode rprop qui réalise une descente de gradient à pas adaptatif et spécifique à chaque coordonnée:
```{r}
## Specify the optimization parameters
lr <- 0.01
optimizer <- optim_rprop(Theta,lr)
```
On décrit maintenant un pas de calcul du gradient, contenant les étapes suivantes : - réinitialisation du gradient de $\theta$,\
- évaluation de la fonction de perte (avec la valeur courante de $\theta$),\
- calcul backward du gradient. On inclut tout cela dans une fonction:
```{r}
## Optimization step description
calc_loss <- function() {
optimizer$zero_grad()
value <- LogLik()
value$backward()
value
}
```
Commençons par regarder ce que fait concrètement cette fonction. L'état courant du paramètre est le suivant:
```{r}
Theta
Theta$grad
```
On applique une première fois la fonction, et on obtient la mise à jour suivante :
```{r}
calc_loss()
Theta
Theta$grad
```
Comme on le voit la valeur courante du paramètre n'a pas changée, en revanche Theta\$grad contient maintenant le gradient de la fonction de perte calculé en $\theta$. Dans le cas où la méthode d'optimisation considérée n'a besoin que de la valeur courante du gradient et du paramètre, on peut directement faire la mise à jour de $\theta$ :
```{r}
optimizer$step()
Theta
Theta$grad
```
Il n'y a plus qu'à itérer !
```{r}
## Run the optimization
num_iterations <- 100
LogLik.hist <- rep(NA,num_iterations)
for (i in 1:num_iterations) {
LogLik.hist[i] <- calc_loss() %>% as.numeric
optimizer$step()
}
```
On vérifie que l'optimisation s'est bien passée (ie que l'on a minimisé la fonction de perte)
```{r}
## How does the loss function behave ?
plot(LogLik.hist,cex=0.4)
## Are the gradients at 0 ?
Theta$grad
```
et que le résultat est comparable à la solution classique obtenue par OLS :
```{r}
## Compare the coef estimates with the ones of lm
Res <- lm(Y ~ X[,-1] )
plot(Res$coefficients,as.numeric(Theta)[-12])
abline(a=0,b=1,col=2)
## Compare the variances
summary(Res)$sigma**2
Theta[12]
```
# Fonctions de torch compatibles avec autograd
## Fonctions usuelles définies dans torch
- `torch_ones(NB_OF_ROWS, NB_OF_COLS, requires_grad = TRUE)` ou `torch_ones(VECTOR_OF_DIMS, requires_grad = TRUE)` : crée un tenseur rempli de 1.
- `torch_tensor(OBJECT, requires_grad = TRUE)` : convertit un objet R (vecteur, matrice ou array) en un tenseur torch.
- `$mean()`, `$sum()`, `$pow(ORDER)`, `$mm(MATRIX)` (matrix multiplication), cf les fonctions torch\_\* de la documentation R de torch.
- Les fonctions de torch peuvent s'utiliser de manière analogue aux pipes. Par exemple, `x$mm(w1)$add(b1)$clamp(min = 0)$mm(w2)$add(b2)`.
- `output$backward()` : effectue la propagation backward pour calculer les gradients successifs.
- `input$grad` : récupère le gradient de `output` par rapport à `input`.
- `midput$retain_grad()` : à lancer avant \`$backward()$ et permet de stocker les gradients intermédiaires.
## Comment implémenter une fonction compatible avec autograd ?
Une fonction compatible avec autograd doit être définie comme une classe via l'opérateur `autograd_function`, et posséder deux méthodes, `forward` et `backward`, qui déterminent respectivement quelle opération est exécutée par le code et comment calculer le gradient.
- `ctx` correspond aux objets partagés entre la méthode `forward` et la méthode `backward`, et est toujours le premier argument de ces deux méthodes.
- `$save_for_backward()` permet de sauvegarder des valeurs des inputs et/ou outputs à utiliser lors du calcul du gradient dans la méthode `backward`.
Exemple de code :
```{r}
log_base = autograd_function(
forward = function(ctx, input, base) {
ctx$save_for_backward(input = input, base = base)
input$log() / log(base)
},
backward = function(ctx, grad_output) {
vars = ctx$saved_variables
list(input = grad_output / (vars$input * log(vars$base)))
}
)
x <- torch_tensor(2, requires_grad = TRUE)
y <- log_base(x, 10)
y$backward()
x$grad
1 / (2 * log(10))
```
`backward` doit être capable de propager le calcul du gradient aux inputs de la fonction implémentée. Par exemple, en considérant que la fonction implémentée correspond à la fonction $f$ dans le chaînage $$x \xrightarrow[]{f} y \rightarrow z,$$ La méthode `backward` de la fonction $f$ doit être capable de sortir $\partial z / \partial x = (\partial y / \partial x)(\partial z / \partial y)$, où dans l'exemple précédent $\partial z / \partial y$ est représenté par l'argument `grad_output`.
# Un exemple pratique: le modèle Poisson Lognormal
### Le modèle
Le modèle Poisson lognormal multivarié lie des vecteurs de comptages $p$-dimensionnel $\mathbf{Y}_i$ observés à des vecteurs gaussiens $p$-dimensionnel latents $\mathbf{Z}_i$ comme suit
```{=tex}
\begin{equation}
\begin{array}{rcl}
\text{espace latent} & \mathbf{Z}_i \sim \mathcal{N}({\boldsymbol 0},\boldsymbol\Sigma) , \\
\text{espace des observations} & Y_{ij} | Z_{ij} \quad \text{indep.} & \mathbf{Y}_i | \mathbf{Z}_i\sim\mathcal{P}\left(\exp\{{\mathbf{o}_i + \mathbf{x}_i^\top\boldsymbol B} + \mathbf{Z}_i\}\right).
\end{array}
\end{equation}
```
L'effet principal est dû à une combinaison linéaire de $d$ covariables $\mathbf{x}_i$ (includant un vecteur de constantes). Le vecteur fixé $\mathbf{o}_i$ correspond à un vecteur d'offsets, c'est-à-dire un effet connu est fixé sur les $p$ variables dans chaque échantillon. Les paramètres à estimer sont la matrice des coefficients de régression $\boldsymbol B$ et la matrice de covariance $\boldsymbol\Sigma = \mathbf{\Omega}^{-1}$ décrivant la structure de dépendance résiduelle entre les $p$ variables dans l'espace latent. On note $\theta = ({\boldsymbol B}, \mathbf{\Omega})$ le vecteur des paramètres du modèles.
### Approximation variationnelle
Une manière classique d'estimer l'ajustement de ce modèle consiste en l'utilisation d'une approximation variationnelle de la vraisemblance, appelée vraisemblance variationnelle ou ELBO (Evidence Lower Bound) qui prend la forme suivante:
\begin{multline}
\label{eq:elbo}
\mathcal{J}_n(\theta, \mathbf{\psi})
= \mathrm{trace} ( \mathbf{Y}^\top [\mathbf{O} + \mathbf{M} + \mathbf{X}\boldsymbol{B}]) -
\mathrm{trace}(\tilde{\mathbf{A}}^\top \mathbf{1}_{n,p}) + K(\mathbf{Y}) + \frac{n}2\log|\mathbf{\Omega}|\\
- \frac12 \mathrm{trace}(\mathbf{M} \mathbf{\Omega} \mathbf{M}^\top) - \frac12 \mathrm{trace}(\bar{\mathbf{S}}^2 \mathbf{\Omega}) +
\mathrm{trace}(\log(\mathbf{S})^\top \mathbf{1}_{n,p}) + \frac12 np,
\end{multline} où $\mathbf{M} = [\mathbf{m}_1, \dots, \mathbf{m}_n]^\top$, $\mathbf{S} = [\mathbf{s}_1, \dots, \mathbf{s}_n]^\top$, $\bar{\mathbf{S}}^2 = \sum_{i=1}^n \mathrm{diag}(\mathbf{s}_i\circ \mathbf{s}_{i})$ sont des paramètres additionnels dits "variationnels" gérant l'approximation de la vraie loi conditionnelle de $\mathbf{Z} | \mathbf{Y}$ et consécutivement de la log-vraisemblance. On note $\psi = (\mathbf{M}, \mathbf{S})$ l'ensemble de ces paramètres.
Notre approche consiste à utiliser une forme dite variationnelle de l'algorithme EM alternant l'estimation des paramètres $\theta$ et $\psi$:
```{=tex}
\begin{align}
\label{eq:vem}
\mathrm{VE-step} & \left( \hat{\psi}^{\text{ve}} \right) = \arg\max_{\psi} \mathcal{J}_n (\psi, \theta)\\
\mathrm{M-step} & \left(\hat{\theta} \right) = \arg\max_{\theta} \mathcal{J}_n(\psi, \theta)\\
\end{align}
```
### Optimiseur classique
L'optimiseur implémenté dans **PLNmodels** s'appuie sur les gradients des paramètres $\theta$ et $\psi$
```{=tex}
\begin{align}
\label{eq:derivatives-elbo-model}
\begin{split}
\nabla_{\mathbf{B}} J_n(\theta) & = \mathbf{X}^\top (\mathbf{Y} - \mathbf{A}), \\
%
\nabla_{\mathbf{\Omega}} J_n(\theta) & = \frac{n}{2} \left[ \mathbf{\Omega}^{-1} - \frac{\mathbf{M}^\top\mathbf{M} + \bar{\mathbf{S}}^2}{n} \right] \Leftrightarrow \mathbf{\Omega}^{-1} = \frac{1}{n}\left(\mathbf{M}^\top\mathbf{M} + \bar{\mathbf{S}}^2\right) \\
\nabla_{\mathbf{M}} J_n(\mathbf{\psi}) & = \mathbf{Y} - \tilde{\!\mathbf{A}} - \mathbf{M}\mathbf{\Omega} \\[1.5ex]
%
\nabla_{\mathbf{S}} J_n(\mathbf{\psi}) & = -\mathbf{S} \circ \tilde{\!\mathbf{A}} + 1/\mathbf{S} - \mathbf{S}\mathbf{D}_{\mathbf{\Omega}}\\[1.5ex]
%
\end{split}
\end{align}
```
où
```{=tex}
\begin{equation*}
\mathbf{A} = \exp\{\mathbf{O} + \mathbf{X}\mathbf{B} + \mathbf{M} + \mathbf{S}^2/2\}.
\end{equation*}
```
On utilise le fait qu'il existe une forme explicite pour $\Sigma$ dans l'étape M et on fait une descente de gradient sur les autres paramtères $(\mathbf{M}, \mathbf{S}, \mathbf{B})$.
```{r}
library(PLNmodels)
data(oaks)
myPLN_classical <- PLN(Abundance ~ 1 + offset(log(Offset)), data = oaks)
```
### Utilisation de torch et l'autodifférentiation
Avec torch, et pourvu qu'on détermine un bon optimiseur, il suffit de spécifier l'ELBO avec les objets adéquats et faire le calcul de $\Sigma$ de manière explicite.
On propose ci-dessous une implémentation dans une classe R6 (faite avec Bastien et Mahendra).
```{r}
library(torch)
library(R6)
log_stirling <- function(n_){
n_ <- n_+ (n_==0)
torch_log(torch_sqrt(2*pi*n_)) + n_*log(n_/exp(1))
}
PLN <-
R6Class("PLN",
public = list(
Y = NULL,
O = NULL,
X = NULL,
n = NULL,
p = NULL,
d = NULL,
M = NULL,
S = NULL,
A = NULL,
B = NULL,
Sigma = NULL,
Omega = NULL,
ELBO_list = NULL,
## Constructor
initialize = function(Y, O, X){
self$Y <- torch_tensor(Y)
self$O <- torch_tensor(O)
self$X <- torch_tensor(X)
self$n <- nrow(Y)
self$p <- ncol(Y)
self$d <- ncol(X)
## Variational parameters
self$M <- torch_zeros(self$n, self$p, requires_grad = TRUE)
self$S <- torch_ones(self$n , self$p, requires_grad = TRUE)
## Model parameters
self$B <- torch_zeros(self$d, self$p, requires_grad = TRUE)
self$Sigma <- torch_eye(self$p)
self$Omega <- torch_eye(self$p)
## Monitoring
self$ELBO_list <- c()
},
get_Sigma = function(M, S){
1/self$n * (torch_matmul(torch_transpose(M,2,1),M) + torch_diag(torch_sum(torch_multiply(S,S), dim = 1)))
},
get_ELBO = function(B, M, S, Omega){
S2 <- torch_multiply(S, S)
XB <- torch_matmul(self$X, B)
A <- torch_exp(self$O + M + XB + S2/2)
elbo <- n/2 * torch_logdet(Omega)
elbo <- torch_add(elbo, torch_sum(- A + torch_multiply(self$Y, self$O + M + XB) + .5 * torch_log(S2)))
elbo <- torch_sub(elbo, .5 * torch_trace(torch_matmul(torch_matmul(torch_transpose(M, 2, 1), M) + torch_diag(torch_sum(S2, dim = 1)), Omega)))
elbo <- torch_add(elbo, .5 * self$n * self$p - torch_sum(log_stirling(self$Y)))
elbo
},
fit = function(N_iter, lr, tol = 1e-8, verbose = FALSE){
self$ELBO_list <- double(length = N_iter)
optimizer <- optim_rprop(c(self$B, self$M, self$S), lr = lr)
objective0 <- Inf
for (i in 1:N_iter){
## reinitialize gradients
optimizer$zero_grad()
## compute current ELBO
loss <- - self$get_ELBO(self$B, self$M, self$S, self$Omega)
## backward propagation and optimization
loss$backward()
optimizer$step()
## update parameters with close form
self$Sigma <- self$get_Sigma(self$M, self$S)
self$Omega <- torch_inverse(self$Sigma)
objective <- -loss$item()
if(verbose && (i %% 50 == 0)){
pr('i : ', i )
pr('ELBO', objective)
}
self$ELBO_list[i] <- objective
if (abs(objective0 - objective)/abs(objective) < tol) {
self$ELBO_list <- self$ELBO_list[1:i]
break
} else {
objective0 <- objective
}
}
},
plotLogNegElbo = function(from = 10){
plot(log(-self$ELBO_list[from:length(self$ELBO_list) ]), type = "l")
}
)
)
```
Ça torche....
```{r}
Y <- oaks$Abundance
X <- cbind(rep(1, nrow(Y)))
O <- log(oaks$Offset)
myPLN <- PLN$new(Y = Y, O = log(O), X = X)
myPLN$fit(30, lr = 0.1, tol = 1e-5)
myPLN$plotLogNegElbo()
```
Des temps de calcul similaires sur ce jeu de données ($n=116, p=114$)
```{r}
system.time(
myPLN_classical <- PLN(Abundance ~ 1 + offset(log(Offset)), data = oaks,
control = list(trace = 0)))
system.time({
myPLN <- PLN$new(Y = Y, O = log(O), X = X)
myPLN$fit(30, 0.1, tol = 1e-5)}
)
```
On est proche en terme d'objectif
```{r}
myPLN_classical$loglik
last(myPLN$ELBO_list)
```
# Les modules `torch`
En `keras` on différencie entre modèle et couche, en `torch` tout est dans `nn_Module()`, classe de base pour tous les modules de réseaux de neurones. Les modules peuvent aussi contenir des sous-modules. Il existe un certain nombre de modules pré-définis.
## Un module de base ('layer')
Exemple d'un module linéaire :
```{r}
mylinearmod <- nn_linear(3, 1)
mylinearmod
```
Ce module a des paramètres de poids et biais. Le fait d'appeler un module lance un `backward`. Plus besoin de mettre un `requires_grad = TRUE`, c'est compris directement dans les modules.
```{r}
data <- torch_randn(10, 3)
out <- mylinearmod(data)
out
out$grad_fn
mylinearmod$weight$grad
mylinearmod$bias$grad
```
On n'a pas encore fait de parcours backward, les valeurs sont donc non définies. Si on lance `out$backward(),` on obtient une erreur, due au fait qu'autograd attend en sortie un scalaire et qu'ici nous avons un tenseur de (10, 1). Une façon de le corriger :
```{r}
d_avg_d_out <- torch_tensor(10)$`repeat`(10)$unsqueeze(1)$t()
out$backward(gradient = d_avg_d_out)
mylinearmod$weight$grad
mylinearmod$bias$grad
```
## Modèle
C'est un module qui contient des modules. Par exemple
```{r}
model <- nn_sequential(
nn_linear(3, 16),
nn_relu(),
nn_linear(16, 1)
)
model
# application
data <- torch_randn(10, 3)
output <- model(data)
output
```