Lightgbm: A Highly Efficient Gradient Boosting Decision Tree #56
Description
Ke, Guolin, et al. “Lightgbm: A Highly Efficient Gradient Boosting Decision Tree.” Advances in Neural Information Processing Systems, vol. 30, 2017, https://proceedings.neurips.cc/paper_files/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf.
- みんな大好きLightGBMの原著論文
- Gradient-based One-Size Sampling (GOSS) と Exclusive Feature Bundling (EFB) という2つの工夫により、それぞれデータサイズと特徴量の数を減らし、計算量を削減。
- LightGBMはXGBoost等(2017年時点で公開されていた)従来の決定木モデルと比較して、学習プロセスが最大20倍以上高速化・ほぼ同じ精度を達成
Abstract
Gradient Boosting Decision Tree (GBDT) is a popular machine learning algorithm, and has quite a few effective implementations such as XGBoost and pGBRT. Although many engineering optimizations have been adopted in these implementations, the efficiency and scalability are still unsatisfactory when the feature dimension is high and data size is large. A major reason is that for each feature, they need to scan all the data instances to estimate the information gain of all possible split points, which is very time consuming. To tackle this problem, we propose two novel techniques: Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB). With GOSS, we exclude a significant proportion of data instances with small gradients, and only use the rest to estimate the information gain. We prove that, since the data instances with larger gradients play a more important role in the computation of information gain, GOSS can obtain quite accurate estimation of the information gain with a much smaller data size. With EFB, we bundle mutually exclusive features (i.e., they rarely take nonzero values simultaneously), to reduce the number of features. We prove that finding the optimal bundling of exclusive features is NP-hard, but a greedy algorithm can achieve quite good approximation ratio (and thus can effectively reduce the number of features without hurting the accuracy of split point determination by much). We call our new GBDT implementation with GOSS and EFB LightGBM. Our experiments on multiple public datasets show that, LightGBM speeds up the training process of conventional GBDT by up to over 20 times while achieving almost the same accuracy.
(DeepL翻訳)
勾配ブースティング決定木(GBDT)は一般的な機械学習アルゴリズムであり、XGBoostやpGBRTなど多くの効果的な実装がある。これらの実装では多くの工学的最適化が採用されているが、特徴次元が高くデータサイズが大きい場合、効率とスケーラビリティはまだ満足できるものではない。その主な理由は、各特徴について、可能性のあるすべての分割点の情報利得を推定するために、すべてのデータインスタンスをスキャンする必要があり、非常に時間がかかるからである。この問題に対処するために、我々は2つの新しい手法を提案する: 勾配に基づく片側サンプリング(GOSS)と排他的特徴バンドル(EFB)である。GOSSでは、勾配が小さいデータインスタンスのかなりの割合を除外し、残りの部分のみを情報利得の推定に用いる。より大きな勾配を持つデータインスタンスは情報利得の計算においてより重要な役割を果たすため、GOSSはより少ないデータサイズでかなり正確な情報利得の推定が可能であることを証明する。EFBでは、特徴数を減らすために、互いに排他的な特徴(すなわち、同時に非ゼロ値をとることが少ない)を束ねる。我々は、排他的特徴量の最適な束ね方を見つけることはNP困難であるが、貪欲なアルゴリズムがかなり良い近似比を達成できることを証明する(したがって、分割点決定の精度をそれほど損なうことなく、特徴量の数を効果的に減らすことができる)。我々はGOSSとEFBを用いた新しいGBDT実装をLightGBMと呼ぶ。複数の公開データセットを用いた実験により、LightGBMは従来のGBDTの学習プロセスを最大20倍以上高速化し、ほぼ同じ精度を達成することが示された。
コード
https://github.com/Microsoft/LightGBM
解決した課題/先行研究との比較
- 勾配ブースティング決定木 (Gradient Boosting Decision Tree, GBDT) はその効率、精度、解釈性から広く使われてきた。
- しかし、GBDTはデータの次元が高くなると/データサイズが大きくなると計算に非常に時間がかかるようになるという課題があった。
- 本論文での提案手法は Gradient-based One-Size Sampling (GOSS) と Exclusive Feature Bundling (EFB) という2つの技術を導入し、件数の多い高次元データでも高速な処理を可能にした。
技術・手法のポイント
-
Gradient-based One-Size Sampling (GOSS)
- 決定木モデルにおいて、データセットの分割は目的関数の勾配を計算することで行われるため、勾配により大きく寄与するデータは重要な役割を果たす。
- GOSSでは勾配への寄与が大きいデータ(例えばある閾値より大きいとか上位X%とか)を残し、そうでないデータをランダムに落とす。
- しかし、ただランダムに落とすだけだとデータの分布が変わり、学習したモデルの精度が落ちてしまう。
- そのため、勾配の計算において、"勾配への寄与が小さいデータでランダムに落とされなかったもの" の勾配計算への寄与度を、データを減らした分だけ増幅。
- → データの分布を大きくは変えずに、しかし少ないデータで勾配が計算できるように。
- 全データで学習したときと同じような精度を達成できた (Table 4)。
-
Exclusive Feature Bundling (EFB)
- データの次元が大きくなる、すなわち特徴量の数が増えてくると、特徴量のほとんどの値がゼロになるものもしばしば出てくる。
- ほとんどがゼロの特徴量を束ねる (bundle) できれば、特徴量の数を減らせる。これがEFBの発想。
- 互いに排他的な特徴、すなわち同時にゼロ以外の値をとることが少ない(not とることがない)を束ねる。
- NP-hard 問題なので近似探索。
- この処理があるためLightGBMはカテゴリカルの値や欠損値も扱える。
- 束ねるときにはデータの範囲(最小値・最大値)を揃える。
- 特徴量の数が減ることで、計算時間を削減。
評価指標
- 複数の公開データセットを用いて評価。
- LightGBMはXGBoost等(2017年時点で公開されていた)従来の決定木モデルと比較して、学習プロセスが最大20倍以上高速化・ほぼ同じ精度を達成 (Figs.1,2, Tables 2,3)
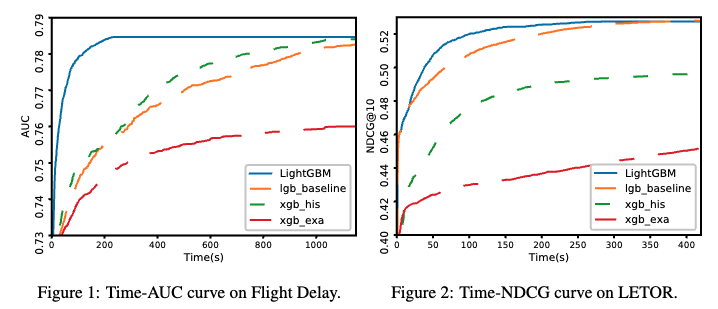
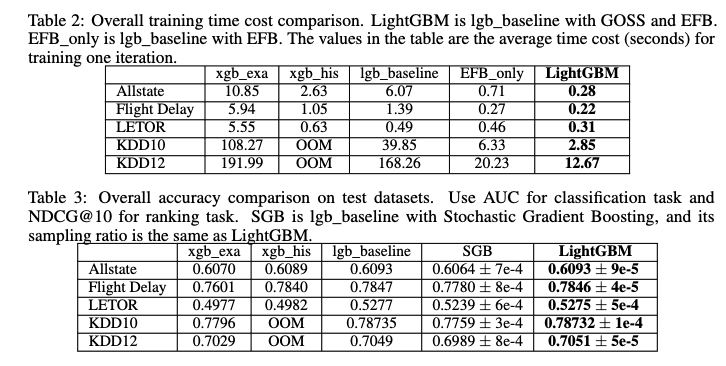
残された課題・議論・感想
- GOSSの閾値の決め方が最適化できていない。
- EFBもパフォーマンスの改善ができそうと議論されている。
- 欠損値の扱いが楽な反面、思いもしない挙動をしうるので要注意。
重要な引用
- XGBoost(比較対象&サマリー執筆時点でもよく使われる)
- Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. ACM, 2016.
参考情報
- LightGBM公式ドキュメンテーション
- 盆暗の学習記録 - LightGBMにおける欠損値の扱い
- 簡単なレポート - なぜCatboostの推論は速いの?
- 計算量を減らすアプローチがLightGBM, 推論自体の速度を上げるアプローチがCatboost
- v.4.0.0でGPU対応してさらに高速化
https://twitter.com/momijiame/status/1679705732579741701
