SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training #59
Description
Somepalli, Gowthami, Micah Goldblum, Avi Schwarzschild, C. Bayan Bruss, and Tom Goldstein. 2021. “SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2106.01342.
- テーブルデータへの適用に特化したニューラルネットワークアーキテクチャ
- Intersample attentionという方法により列の間のAttentionを実現
- 分類タスクのベンチマークデータにおいてはXGBoostやCatBoost, LightGBMよりも良い性能が得られた
Abstract
Tabular data underpins numerous high-impact applications of machine learning from fraud detection to genomics and healthcare. Classical approaches to solving tabular problems, such as gradient boosting and random forests, are widely used by practitioners. However, recent deep learning methods have achieved a degree of performance competitive with popular techniques. We devise a hybrid deep learning approach to solving tabular data problems. Our method, SAINT, performs attention over both rows and columns, and it includes an enhanced embedding method. We also study a new contrastive self-supervised pre-training method for use when labels are scarce. SAINT consistently improves performance over previous deep learning methods, and it even outperforms gradient boosting methods, including XGBoost, CatBoost, and LightGBM, on average over a variety of benchmark tasks.
(DeepL翻訳)
表形式データは、不正行為の検出からゲノミクスやヘルスケアまで、機械学習の多くのインパクトのあるアプリケーションを支えている。表形式問題を解く古典的なアプローチ、例えば勾配ブースティングやランダムフォレストは、実務家に広く利用されている。しかし、最近の深層学習手法は、一般的な手法に負けない性能を達成している。我々は、表形式データ問題を解くためのハイブリッド深層学習アプローチを考案する。我々の手法であるSAINTは、行と列の両方に対する注意を実行し、強化された埋め込み方法を含む。また、ラベルが乏しい場合に使用する、新しい対照的な自己教師付き事前学習法も研究する。SAINTはこれまでの深層学習手法よりも一貫して性能を向上させ、様々なベンチマークタスクにおいてXGBoost、CatBoost、LightGBMなどの勾配ブースティング手法を平均的に上回る性能さえ持つ。
コード
- https://paperswithcode.com/paper/saint-improved-neural-networks-for-tabular
- 公式: https://github.com/somepago/saint
解決した課題/先行研究との比較
- ニューラルネットワークは自然言語や画像処理の分野で大きな成果を挙げてきた。しかし、テーブルデータへの適用はあまり進んでいなかった。
- なぜ?
- テーブルデータには連続値、カテゴリ値、順序値など、異なる形式のデータが混ざっている。
- データ間の相関があったりなかったり。
- 列の順序が任意 = (画像や言語のような) 固有の位置情報がない。
- 本論文はテーブルデータに適用して良い性能を出すニューラルネットワークアーキテクチャ Self-Attention and Intersample Attention Transformer (SAINT) を提案している。
技術・手法のポイント
-
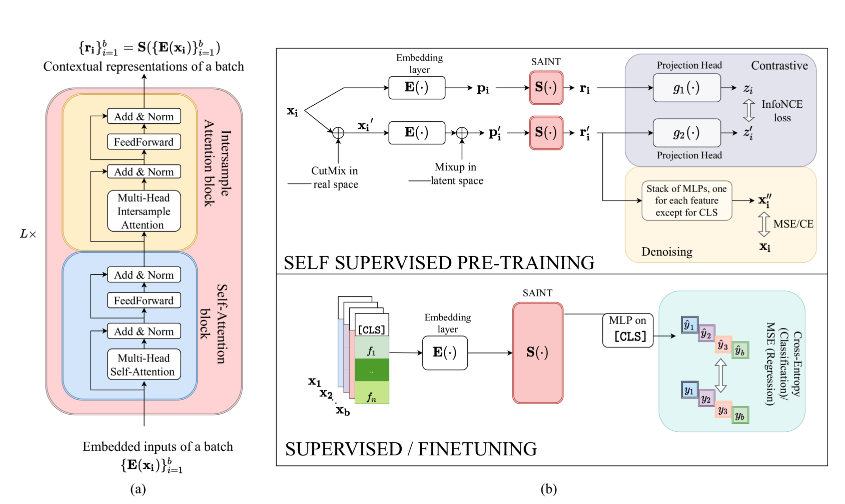
連続・カテゴリカル型の両方の特徴量をトークン化し、Self-AttentionとIntersample attentionを持ったTransformerに渡す (Fig.1)。
-
Self-Attentionは個々の特徴量に着目
-
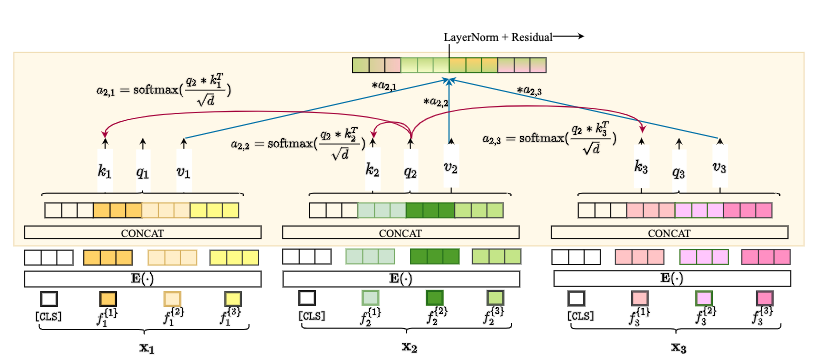
Intersample Attentionにより列ごとの関連付けを行う (Fig.2)。
-
データのエンコーディングにも工夫あり。
- 言語モデルであれば全てのトークンを同じ方法で埋め込めるが、テーブルでは列ごとに性質が異なるため同様の方法が使えない。
- 連続値もカテゴリカル値も単一全結合層を用い、1次元入力をd次元空間に射影してから、変数エンコーダで埋め込むことで一律の処理を行う。
-
事前学習にも一工夫。
- テーブルの列の順番が同じとは限らない→順序の入れ替えや切り抜きなど、ラベルを保持したデータの見方に対して不変なモデルを事前に学習する必要がある。
- そのために Constructive Learning を導入。「重要な引用」項参照。
評価指標
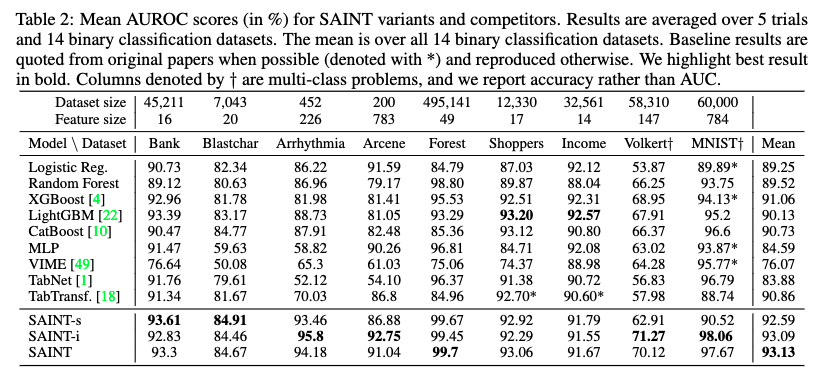
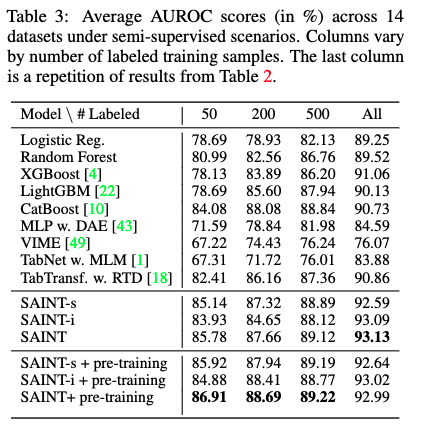
- 14種の二値分類と2種の多分類タスクデータセットで評価。
- 多くのデータセットでXGBoostやCatBoost, LightGBMよりも良いスコアが得られている。
残された課題・議論
- 画像やテキストとテーブルが融合したデータセットへのアプリケーション
- ベンチマークのデータは綺麗→ノイズが多いまたは不均衡なデータセットで論文のように良いスコアが出るかは不明
重要な引用
- Axial Attention. 行ごと・列ごとにAttentionを適用する
- Ho, Jonathan, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. 2019. “Axial Attention in Multidimensional Transformers.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/1912.12180.
- Constructive Learning
- Chen, Ting, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 13--18 Jul 2020. “A Simple Framework for Contrastive Learning of Visual Representations.” In Proceedings of the 37th International Conference on Machine Learning, edited by Hal Daumé Iii and Aarti Singh, 119:1597–1607. Proceedings of Machine Learning Research. PMLR.
- Grill, Jean-Bastien, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, et al. 2020. “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning.” arXiv [cs.LG]. arXiv. http://arxiv.org/abs/2006.07733.
- He, Kaiming, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2019. “Momentum Contrast for Unsupervised Visual Representation Learning.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/1911.05722.
- Pathak, Deepak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros. 2016. “Context Encoders: Feature Learning by Inpainting.” arXiv [cs.CV]. arXiv. http://arxiv.org/abs/1604.07379.
- Vincent, Pascal, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. 2008. “Extracting and Composing Robust Features with Denoising Autoencoders.” In Proceedings of the 25th International Conference on Machine Learning, 1096–1103. ICML ’08. New York, NY, USA: Association for Computing Machinery.