Simple Recurrent Units for Highly Parallelizable Recurrence #60
Description
Lei, Tao, Yu Zhang, Sida I. Wang, Hui Dai, and Yoav Artzi. 2017. “Simple Recurrent Units for Highly Parallelizable Recurrence.” arXiv [cs.CL]. arXiv. http://arxiv.org/abs/1709.02755.
revised 7 Sep 2018
- Lei, ACL Anthology 2021 のベースとなった仕事
- 2017年当時の自然言語処理研究の中心であった Recurrent neural network (RNN) の高速化
- 並列処理のできる軽量なリカレントユニットを提案し、Simple Recurrent Unit (SRU) と命名
Abstract
Common recurrent neural architectures scale poorly due to the intrinsic difficulty in parallelizing their state computations. In this work, we propose the Simple Recurrent Unit (SRU), a light recurrent unit that balances model capacity and scalability. SRU is designed to provide expressive recurrence, enable highly parallelized implementation, and comes with careful initialization to facilitate training of deep models. We demonstrate the effectiveness of SRU on multiple NLP tasks. SRU achieves 5--9x speed-up over cuDNN-optimized LSTM on classification and question answering datasets, and delivers stronger results than LSTM and convolutional models. We also obtain an average of 0.7 BLEU improvement over the Transformer model on translation by incorporating SRU into the architecture.
(DeepL翻訳)
一般的なリカレントニューラルアーキテクチャは、その状態計算の並列化が本質的に困難であるため、スケーラビリティが低い。本研究では、モデル容量とスケーラビリティを両立させた軽量なリカレントユニット、Simple Recurrent Unit (SRU)を提案します。SRUは、表現力豊かなリカレントを提供し、高度な並列化実装を可能にし、ディープモデルの学習を容易にするために慎重な初期化が付属するように設計されている。我々は、複数のNLPタスクでSRUの有効性を実証しています。SRUは、分類と質問応答データセットにおいて、cuDNN最適化LSTMの5〜9倍の速度向上を達成し、LSTMや畳み込みモデルよりも強い結果を出しました。また、SRUをアーキテクチャに組み込むことで、翻訳においてTransformerモデルよりも平均0.7BLEUの改善を得ることができました。
コード
- https://github.com/asappresearch/sru
- https://paperswithcode.com/paper/simple-recurrent-units-for-highly
解決した課題/先行研究との比較
- 2017年だとGPTが出る前、Transformerが出た年。
- 当時の自然言語処理の研究では RNN が中心となっていた。
- 課題であったのがモデルのスケーラビリティ。モデルサイズも学習にかかる時間もどんどん大きくなってきていた。
- 特にリカレント系のアーキテクチャで時間がかかる要因となっていたのが、前のステップの計算が終わるまで次のステップの計算が始められないという点。
- 本論文では並列処理のできる軽量なリカレントユニット (Simple Recurrent Unit: SRU) を提案。
技術・手法のポイント
- Quasi-RNN (Bradbury et al., 2017) やKernel NN (Lei et al., 2017) で、「簡略化されたリカレント性のある層の積み重ねによって強いモデリング能力を保持できる」ことが示唆されていた。
- 本研究では、以下の計算により状態ベクトル
$\mathbf{c_t}$ と出力ベクトル$\mathbf{h_t}$ を更新。
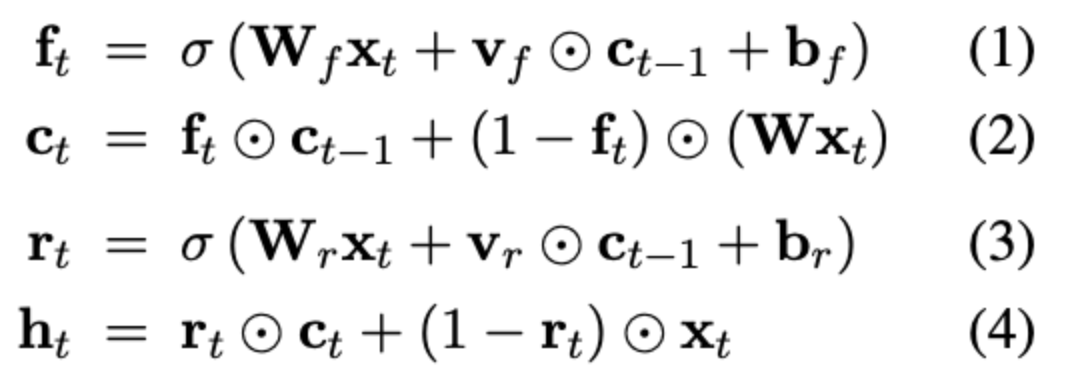
- Light recurrence (式1, 2)
- 数式の概要
- 式1: 入力
$\mathbf{x_t}$ と前時刻の状態ベクトル$\mathbf{c_{t-1}}$ により、0~1のベクトル$\mathbf{f_t}$ を計算(忘却ゲート) - 式2: 忘却ゲート
$\mathbf{f_t}$ により、前時刻の状態ベクトル$\mathbf{c_{t-1}}$ と入力$\mathbf{x_t}$ の重み付け和を計算し、状態ベクトル$\mathbf{c_t}$ を更新
- 式1: 入力
- 工夫されている点
- 式1で、前時刻の状態ベクトル
$\mathbf{c_{t-1}}$ を要素ごとの積でしか用いない - LSTM等の過去手法では、ここがベクトル積になっていて、重いし並列化もしにくかった
- 要素ごとの積は、ベクトル積のようにすべての要素が確定するまで計算開始を待つ必要がなく、並列化しやすい
- 式1で、前時刻の状態ベクトル
- 数式の概要
- Highway connections (式 3, 4. Srivastava et al., 2015)
- 数式の概要
- 式3: 入力
$\mathbf{x_t}$ と前時刻の状態ベクトル$\mathbf{c_{t-1}}$ により、0~1のベクトル$\mathbf{r_t}$ を計算(リセットゲート)- ほぼ式1と同様だが、パラメータ行列・パラメータベクトルは式1とは別のものを使用している
- 式4: リセットゲート
$\mathbf{r_t}$ により、状態ベクトル$\mathbf{c_t}$ と、入力$\mathbf{x_t}$ の重み付け和を計算し、出力ベクトル$\mathbf{h_t}$ を更新
- 式3: 入力
- 工夫されている点
- 式4で、スキップ接続
$(1 - \mathbf{r_t})\mathbf{x_t}$ を使用- 入力がそのまま、出力ベクトルの計算に利用されることで、RNN系モデルの共通課題である勾配消失問題に対応
- 原理的には、ResNetのスキップ接続の時系列版と言える
- モデルのスケーラビリティに寄与
- 式4で、スキップ接続
- 数式の概要
- 全体のアーキテクチャがシンプルかつスケーラブルに!
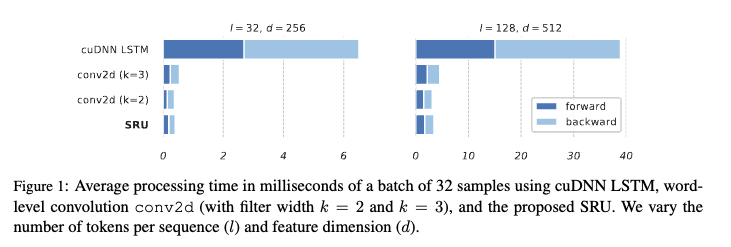
評価指標
- Text classification, Q&A (SQuAD)でLSTMと同程度〜良い性能を出しつつ、トレーニングにかかる時間が3分の1から8分の1程度に短縮。
- 英独翻訳 (BLEU) で、TransformerにSRUを加えることで、速度や性能を上げることが出来た。
- Character-level language modeling (Enwik8) も同様に、短時間でLSTMと同程度の性能や、同程度の時間を使ってより高い性能に達することが出来た。
残された課題・議論
- 本論文では、1層ごとの計算量を減らしてもモデルの深さを増やすことでモデルの能力を維持できると結論づけていたが、それは経験的なものであって根拠が明確にできていない。
重要な引用
- アイデアのもとになった論文
- Bradbury, James, Stephen Merity, Caiming Xiong, and Richard Socher. 2016. “Quasi-Recurrent Neural Networks.” arXiv [cs.NE]. arXiv. http://arxiv.org/abs/1611.01576.
- Lei, Tao, Wengong Jin, Regina Barzilay, and Tommi Jaakkola. 06--11 Aug 2017. “Deriving Neural Architectures from Sequence and Graph Kernels.” In Proceedings of the 34th International Conference on Machine Learning, edited by Doina Precup and Yee Whye Teh, 70:2024–33. Proceedings of Machine Learning Research. PMLR.
- Highway connections
- Srivastava, Rupesh K., Klaus Greff, and Jürgen Schmidhuber. 2015. “Training Very Deep Networks.” Advances in Neural Information Processing Systems 28. https://papers.nips.cc/paper/2015/hash/215a71a12769b056c3c32e7299f1c5ed-Abstract.html.
関連論文
- 本論文をベースにした、さらなる高速化。
- Lei, Tao. 2021. “When Attention Meets Fast Recurrence: Training Language Models with Reduced Compute.” In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 7633–48. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics.