MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering #62
Description
Chan, Jun Shern, et al. “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering.” arXiv [Cs.CL], 9 Oct. 2024, http://arxiv.org/abs/2410.07095. arXiv.
- 機械学習エージェントの性能を評価するための新たなベンチマーク MLE-bench を提案。75個のKaggleコンペティションをベースにした、多様な機械学習エンジニアリングタスクで構成される。
- GPT-4 などの論文公開時の最先端モデルを用いて、オフライン環境でのタスク解決能力を測定。最もうまく動いたエージェントは 16.9% のコンペでメダルを獲得。
Abstract
We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
(DeepL翻訳)
MLE-benchは、AIエージェントが機械学習エンジニアリングにおいてどの程度優れているかを測定するためのベンチマークである。この目的のために、我々はKaggleから75のMLエンジニアリング関連のコンペティションをキュレートし、モデルのトレーニング、データセットの準備、実験の実行など、実世界のMLエンジニアリングスキルをテストする挑戦的なタスクの多様なセットを作成する。Kaggleの公開リーダーボードを使用して、各コンペティションの人間のベースラインを確立します。オープンソースのエージェントスキャフォールドを使用して、いくつかのフロンティア言語モデルをベンチマークで評価し、最もパフォーマンスの良いセットアップ(AIDEスキャフォールドを使用したOpenAIのo1-preview)が、少なくとも16.9%のコンペティションでKaggleの銅メダルのレベルを達成することを発見した。主な結果に加えて、AIエージェントのリソースのスケーリングの様々な形態と、事前学習による汚染の影響についても調査しています。我々は、AIエージェントのMLエンジニアリング能力を理解するための将来の研究を促進するために、我々のベンチマークコード(github.com/openai/mle-bench/)をオープンソース化している。
コード
- ベンチマーク:https://github.com/openai/mle-bench
- AIエージェント:https://github.com/wecoai/aideml
解決した課題/先行研究との比較
- 言語モデルによるコード生成の取り組みでは多くの進歩があり、開発ワークフローの自動化にむけた "AIエージェント" の研究開発が進んでいる。
- しかし、過去の研究の多くは個別のコーディング能力を評価にとどまっており、機械学習エンジニアリング全般にわたる能力を包括的に評価したものは殆どなかった。
- 本論文では機械学習エンジニアリングにおけるAIエージェントのend-to-endでの性能を評価するベンチマーク MLE-bench を提案する。
- MLE: Machine Learning Engineeringの略
技術・手法のポイント
-
Kaggleから、自然言語処理、コンピュータビジョン、信号処理など様々なドメインに渡って人が選定した75のコンペをベンチマークに採用。
-
Kaggleのデータを以下の3プロセスで加工し、ベンチマーク用データセットとした。
- マニュアルでの課題タイプ、複雑さレベルのアノテーション付与を行った。
- テストデータが公開されていないコンペでは学習用データを再分割した。
-
We take care to ensure that the distributions of the original and reconstructed test sets are similar by checking that the example submission scores similarly on both sets.
-
- ローカルで採点を再現できるようにした。
-
3つのオープンソースエージェントフレームワーク(AIDE, MLAB, OpenHands)を用いてモデルにタスク解決のプロセスを実行させた。
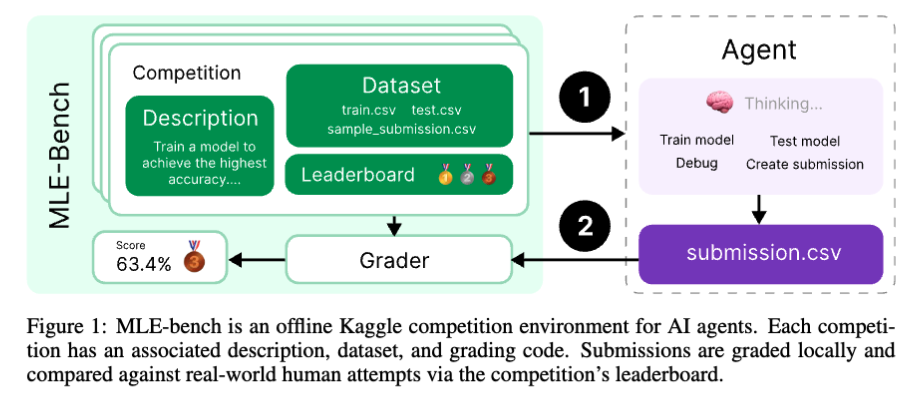
評価指標
- メダル獲得率: エージェントがKaggleの基準に従ってブロンズ、シルバー、ゴールドメダルを獲得できた割合を主要な評価指標とした。
- 1つのタスクに最大24時間、36vCPUと1つのGPUなど、使える計算資源に制限を設けた。
- 結果、o1-previewとAIDEの組み合わせが最も性能が良く、16.9% のコンペでメダルを獲得した。
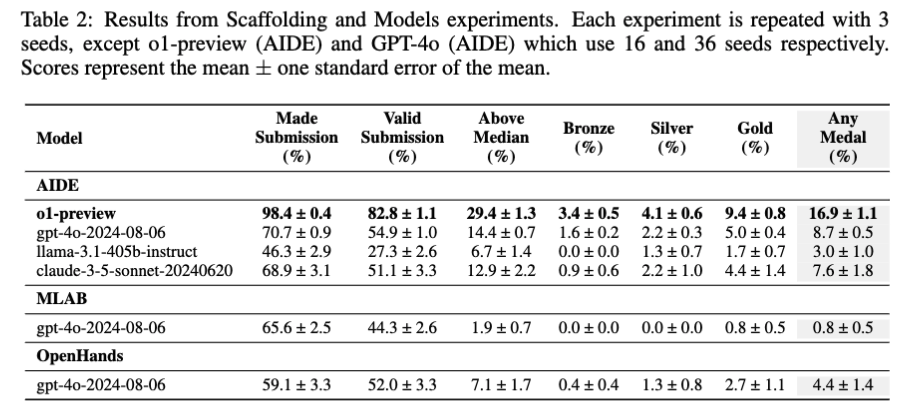
残された課題・議論・感想
- MLABとOpenHandsではエージェントが想定したように動いていないケースが多々見られた。例えば、24時間の猶予を設けて可能な限り最適化するように指示していたにも関わらず、数分で終了してしまっていたり、エージェントにファイルを検索できる柔軟性を持たせた結果、コンテキストウィンドウが検索で埋め尽くされてしまったり (Appendix A.6)。
- 3つ全てのエージェントは使える計算機と計算量、時間の制限を効果的に考慮できていなかった。
- Kaggleの過去コンペに基づくタスクであるため、モデルが学習中にこれらのデータに触れている可能性があり、そもそも公正な評価ではないかもしれない。
- Kaggleコンペはよく整備された問題設定が多い一方で、実際のMLエンジニアリングは不完全なデータや定義の曖昧さなどを伴う場合が多いため、ベンチマークとのギャップがある。
重要な引用
- AIDE
- Dominik Schmidt, Zhengyao Jiang, and Yuxiang Wu. Introducing Weco AIDE, April 2024. URL https://www.weco.ai/blog/technical-report
- MLAB
- Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. MLAgentBench: Evaluating Lan- guage Agents on Machine Learning Experimentation. In Forty-first International Confer- ence on Machine Learning, June 2024b. URL https://openreview.net/forum?id=1Fs1LvjYQW
- OpenHands
- Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenDevin: An Open Platform for AI Software Developers as Generalist Agents, 2024. URL https://arxiv.org/abs/2407.16741