Replies: 6 comments 9 replies
-
|
using gradient steps at 2 and batch size of 4 we get a speed of 5.44s/it which gives us .56 per image thats the same speed we get running steps at 1 and a batch of 3. try a batch of 2 next but definitely a speed up from standard 1.04s/it |
Beta Was this translation helpful? Give feedback.
-
|
interesting |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
not sure what a gradient steps have effect i can setup 15 gs and speed well be fust - what a sense? example: batch 8 gs 5 speed 5.81s/it, but how i undestud u mean it must be like: 8x5? |
Beta Was this translation helpful? Give feedback.
-
|
Gs=gradient steps Gs is a way to increase your bs by moving it to ram then recording another a bs of 2 and a gs of 2 Every step up in bs or gs will decrease speed per step but give more scans Ideally in dreambooth we train a few subjects, one of the things that can If your not training on 1.5 at 512 this could break dreambooth and crash, Note that it has been stated too high of a gradient step very well will Sd was made using 4 steps at a batch of 4 on many a100 gpus resulting in a stick with even numbers |
Beta Was this translation helpful? Give feedback.
-
|
I'm trying batch 4, gradient step 2. I have pro, not sure what gpu I have atm but I'm getting 6.7s/it. I'll compare how this fares at 500 steps. rudalle training had amazing results with higher batch sizes (although I could never go above 2), so I'm curious how SD looks. |
Beta Was this translation helpful? Give feedback.
-
Main advantage ive found is that you write less often per image scanned, SD was trained with a batch size of 2050 at a rate of 1e-4 quick example i can now produce a goku and a gohan that do not look similar despite their names being similar (granted we are only talking about a difference in hair here but that's more impressive to me since there's less defining what's not the same. this could be due to me changing the regularization images to DBZ faces (and aliens) i got so close using the doing 1 epoch with faces and text encoder then 4x4 at 4 epochs (so 32 scans of each image + 2 from encoding + 1 ) i used an lr of 2e-6 for the text and regularization then a single epoch at a low rate of 5e-7 (this was to emulate the 10,000 warm up steps SD and Waifu diffusion and other "fine tunning models" use i set warm up steps to be 10% of the total steps taken after the initial slow epoch. was hoping to have a guide ready but imma have to redo some of these settings and see what happened. Sample of images taken showing training info and added code to make user input easy (and auto adjust warm up steps) https://imgur.com/a/Z1cX7hY <-- silly link not working so here |
Beta Was this translation helpful? Give feedback.
-
to use premium you would need to change to a premiumn GPU runtime under change runtime options.. but dont. it takes your rate from 1.9 credits an hour to 13 an hour. |
Beta Was this translation helpful? Give feedback.
-
Thats pretty high are you using 2.0 or a resolution other then 512 or recording speed while text encoder is active? my settings where lr_rate:Changes and shouldnt influence this i am using Hiram, not sure if the hiram has a quicker write speed cause that could effect Gradient steps.. maybe... in all honesty im probably trying to blend this repo with everydream trainer. and just waisting credits, but the speed up was a nice finding |
Beta Was this translation helpful? Give feedback.
-
|
Oh, I forgot to mention resolution was 640x. I'm comparing to another ckpt with everything the same expect for the gradient/batch size change. Original model: 29 640x images, 1500 steps, text encode unchecked, everything else default Here's a test at 500 steps on "painting of bride of Frankenstein" |
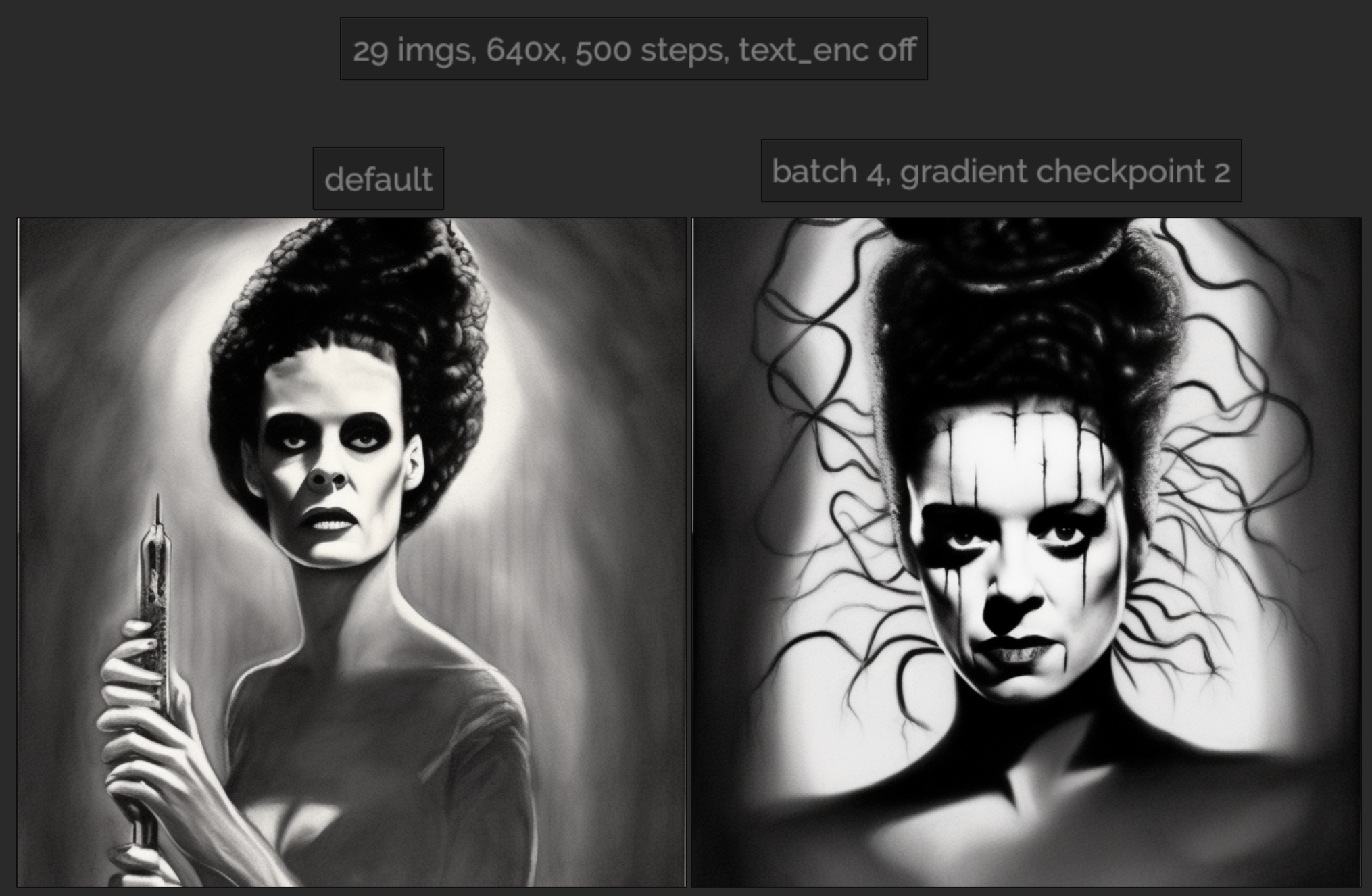
Beta Was this translation helpful? Give feedback.
-
|
think i like the second one better as the first just looks like frankenstine on a girl, but if both are at 500 steps then one is 500 and the other is 4000 scans may want to up one or the other for a better comparison. the face artifacts or makeup i have mixed feelings of could be a mess up in training or part of stylizing honestly. |
Beta Was this translation helpful? Give feedback.
-
|
Gs=gradient steps
Bs=batch size
Gs is a way to increase your bs by moving it to ram then recording another
batch before writing it to a model
a bs of 2 and a gs of 2
Would be the same as a bs of 4
Every step up in bs or gs will decrease speed per step but give more scans
per step.
Ideally in dreambooth we train a few subjects, one of the things that can
cause blending is shifting of the model between each writing. This could
possibly help with that, however I posted this because using gradient
checkpointing results in a slowdown - this is done so that v2 can run
freeing up vram- instead of complaining its now the default setting I've
messed with batch size to see if we can gain some speed back while training
on v1.5 at 512px
If your not training on 1.5 at 512 this could break dreambooth and crash,
im sure you could do 560 with but much higher and you will run out of
resources.
Note that it has been stated too high of a gradient step very well will
mess up your model. Don't remember why.
Sd was made using 4 steps at a batch of 4 on many a100 gpus resulting in a
batch size of like 2040. So batch size shouldn't matter but gradient steps
may according to reddit user I don't remember.
…On Thu, Dec 1, 2022, 7:35 PM newacc88800000 ***@***.***> wrote:
not sure what a gradient steps have effect i can setup 15 gs and speed
well be fust - what a sense? example: batch 8 gs 5 speed 5.81s/it, but how
i undestud u mean it must be like: 8x5?
"--gradient_accumulation_steps", type=int,="Number of updates steps to
accumulate before performing a backward/update pass.",
—
Reply to this email directly, view it on GitHub
<#753 (reply in thread)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AZPYLSB4USQEL7ACFW6IBC3WLFG4VANCNFSM6AAAAAASPGOMUQ>
.
You are receiving this because you authored the thread.Message ID:
<TheLastBen/fast-stable-diffusion/repo-discussions/753/comments/4288379@
github.com>
|
Beta Was this translation helpful? Give feedback.
-
|
so 5g 5b well be 5gradient steps+5batch size? 5gradient steps x 5batch size? |
Beta Was this translation helpful? Give feedback.
-
|
5 images per batch with 5 batches. 5 is higher however then what was used
on the a100. Making sd each hard was running a 4x4. I wouldn't put steps
above that but maybe ya can idk
…On Fri, Dec 2, 2022, 8:37 AM newacc88800000 ***@***.***> wrote:
[image: unnamed]
<https://user-images.githubusercontent.com/119526973/205316951-7e753cbe-3679-4f43-be3c-2f20cf654f53.jpg>
—
Reply to this email directly, view it on GitHub
<#753 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AZPYLSDGRDXS2HOOEMMSCUTWLICSPANCNFSM6AAAAAASPGOMUQ>
.
You are receiving this because you authored the thread.Message ID:
<TheLastBen/fast-stable-diffusion/repo-discussions/753/comments/4293021@
github.com>
|
{kind=link}
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Now that Gradient Checkpointing is on by default no reason not to bump up the resolution or even the batch, doing a batch of 3 now @ 1.77s/it using free GPU not too shabby :D
Beta Was this translation helpful? Give feedback.
All reactions