-
|
Hello authors, I have been trying to understand the localization loss formula better. Say the true emitter location is [y,x]=[2,0] and the detected emitter location is [y,x] = [0,1]. DECODE states that it predicts "the coordinates of the detected emitter Δxk, Δyk, Δzk relative to the center of the pixel xk, yk, zk". What did you mean by "center of the pixel"? What would be the coordinates of the detect emitter based on the example I suggest? I got confused because the paper states those delta would be the coordinates of detected emitters but "delta sign" means some sort of difference between two quantities? Thank you. |
Beta Was this translation helpful? Give feedback.
Replies: 3 comments 1 reply
-
|
Hey, |
Beta Was this translation helpful? Give feedback.
-
|
Hello, Thank you very much for the precise explanation. In a broader sense, I want to ask about the location loss:
|
Beta Was this translation helpful? Give feedback.
-
|
In other words, I've seen the common usage of pairwise comparison, which is what I mentioned of comparing predicted location of a barcode to the groundtruth location of that barcode. But in the case of DECODE's location loss, it reminds me of the Kullback Leibler Divergence. |
Beta Was this translation helpful? Give feedback.
-
|
Hey
That is true, but it is not a straightforward thing to do in this case. Let's think about a different setting where we only had one emitter in each image. In that case, we could easily train the network to predict x,y,z with some standard loss (like RMSE). One solution is to only calculate the loss for predictions and ground truth positions that are in the same pixel (and we tried that).
|
Beta Was this translation helpful? Give feedback.
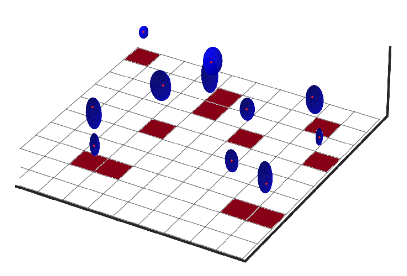
Hey,
the DECODE network represents every localization as the sum of the pixel coordinate and the offset coordinate.
So If the true position is at [2,0] the network basically has two possibilities. It can activate the pixel p(k=[1,0]) = 1 (with pixel centers at 1.5, and 0.5) and then in order to point to y=2 it has to add Δy(k=[1,0]) = 0.5, Δx(k=[1,0])=-0.5. Or it can activate the pixel above and then point down: p(k=[2,0]) = 1, Δy(k=[2,0]) = -0.5, Δx(k=[2,0])=-0.5