Typical learning metrics behavior? new training parameters #73
-
|
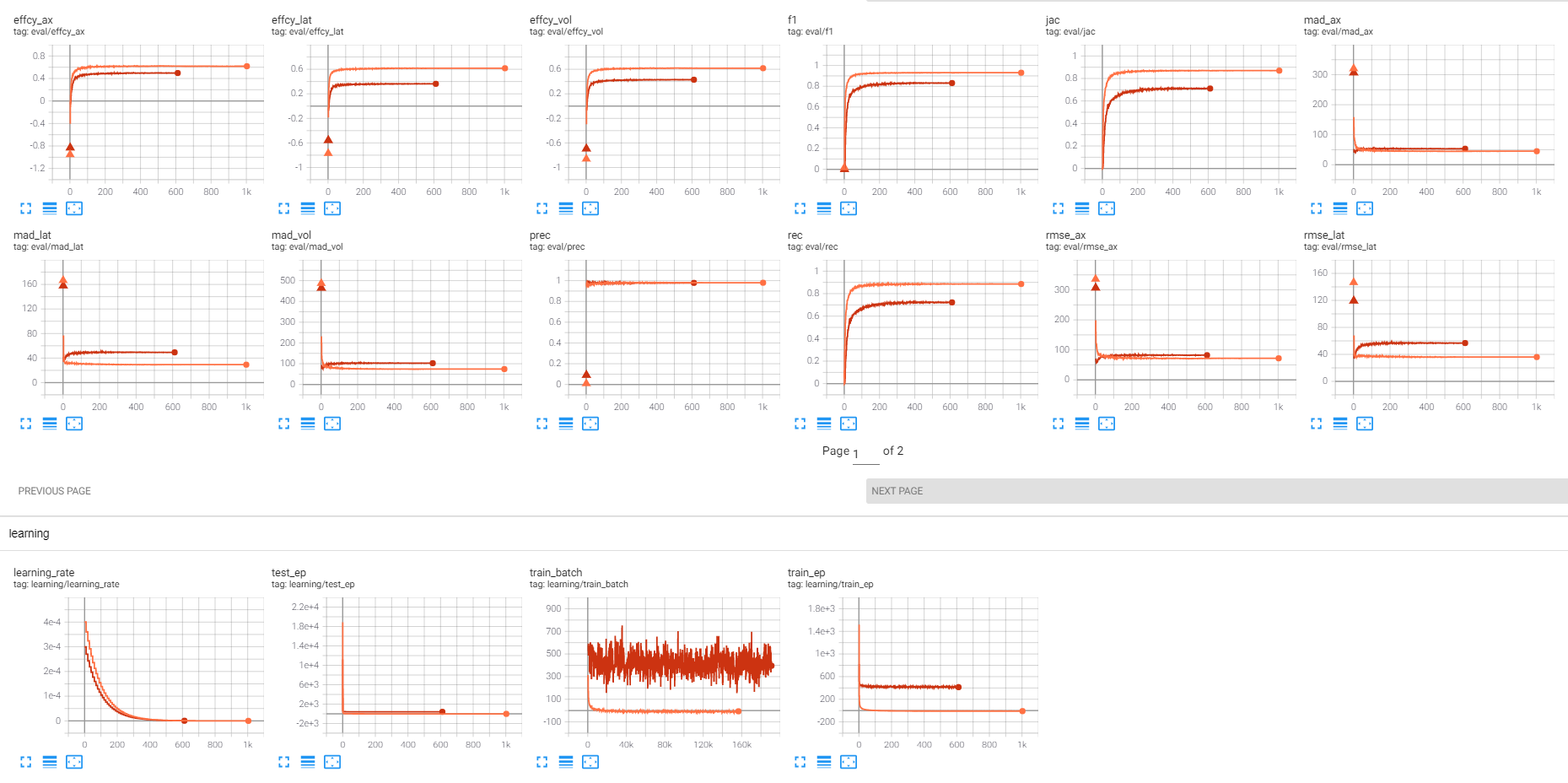
Hi, For my latest training I changed a couple of parameters:
This is what the currently running training looks like for the sCMOS (red) compared to an older training with the default parameters on the EMCCD (orange): I understand the efficiency/fi/jac/mad/rec/rmse metrics for the red training are not as good as the orange one due to lower S/N. However I'm not sure about two things:
Sorry for the pestering, it's just that the current training is running for 36 hours now and it would be quite time-consuming to find out what is a good training or not by trial and error! Thanks |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment
-
|
Hey,
And no worries, keep the questions coming! |
Beta Was this translation helpful? Give feedback.
Hey,