Replies: 2 comments 4 replies
-
|
First-round cut of features To winnow the 108 static features to a list of those that should be included in a "full" model, I first inspected the features and eliminated some that we're not interested in. These included:
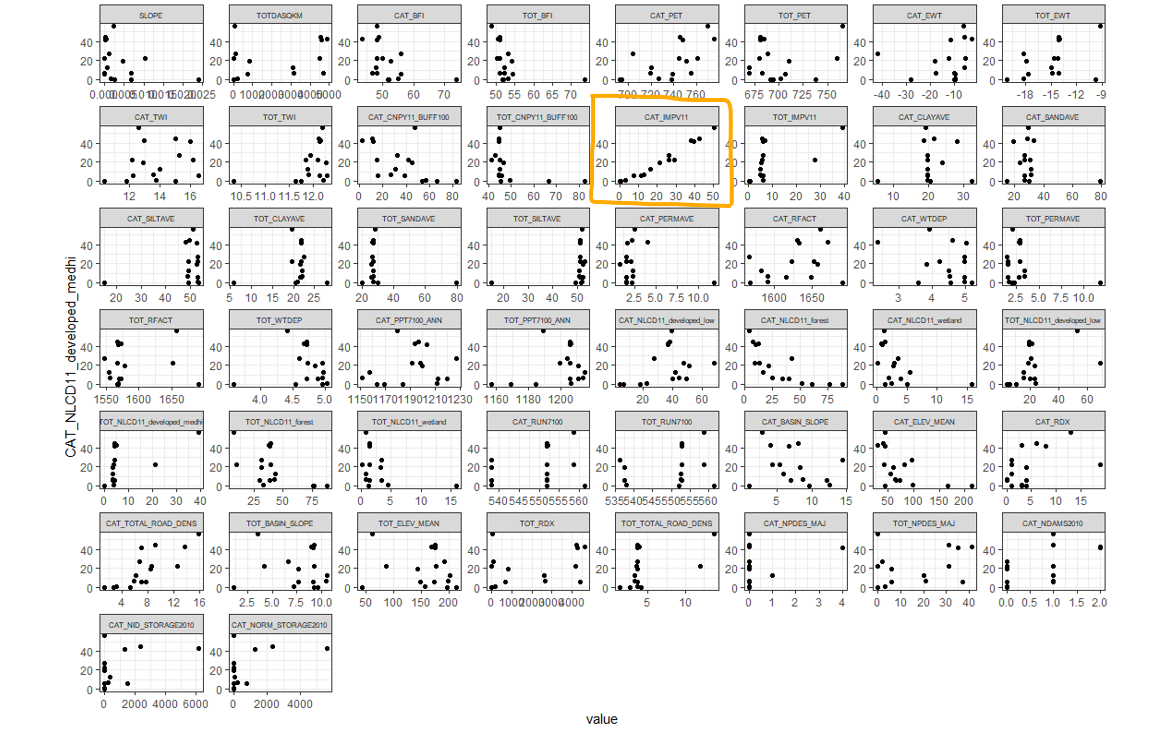
I then used pearson correlation coefficients and correlation plots to look at which of the remaining features are highly-correlated. For example, medium-high development in the catchment is highly correlated with percent imperviousness:
Because of high correlations with other features, I ended up dropping 17 additional static attributes from the list. These are:
These steps leave 26 static attributes to be added to the LSTM. |
Beta Was this translation helpful? Give feedback.
-
|
I think this all makes sense, was there a threshold for the correlation that you used to make the cutoff? Also, thinking about a feature selection figure for the manuscript, we could make a table of all possible attributes, and then label them as "used", "removed due to high correlation", "removed due to domain knowledge" or something like that as a summary. Probably best in the SI |
Beta Was this translation helpful? Give feedback.
-
|
Good question - because our dataset is relatively small (n = 16 reaches), I visually inspected all correlations that had a pearson correlation coefficient >= 0.8. I like that idea for a supplemental table/figure! |
Beta Was this translation helpful? Give feedback.
-
|
I also like that idea for an SI figure/table. |
Beta Was this translation helpful? Give feedback.
-
|
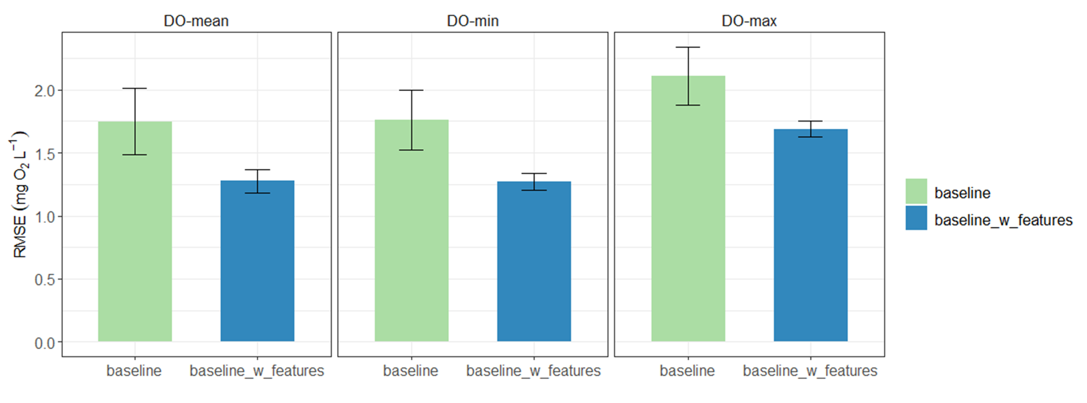
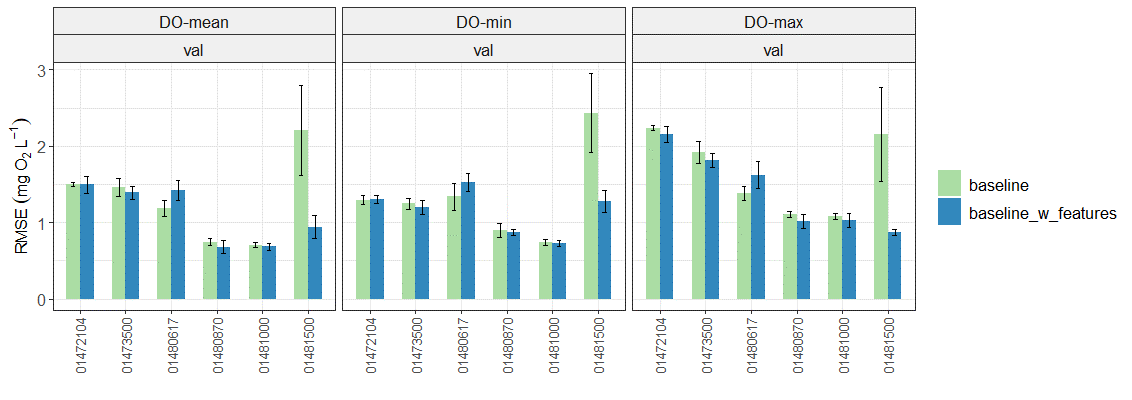
Global permutation feature importance I ran 5 model replicates of the baseline LSTM with 4 dynamic features (daily precip, min/max temperature, and incoming solar radiation) and 26 static attributes. Overall, it seems like adding more static attributes to the model improves predictive performance across sites and observations. In the plots below, "baseline" (green) is the original model with 11 total features and "baseline_w_features" (blue) is the model with the expanded feature set (30 total features):
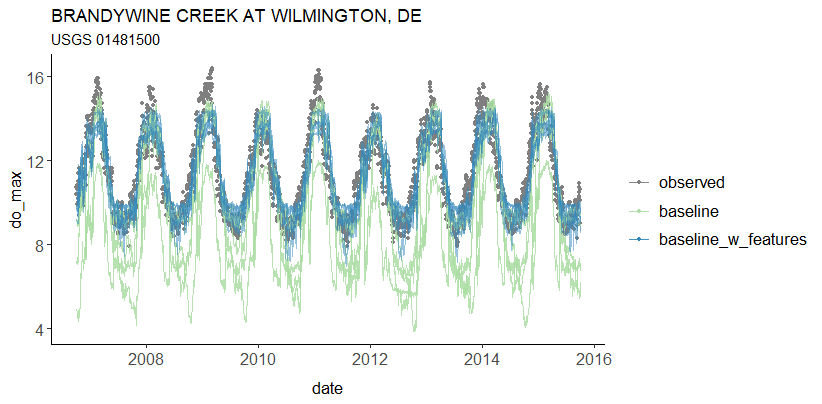
What perhaps feels familiar at this point is that the gains largely come from one site,
The model version w/ the expanded set of attributes seems to do much better at predicting the summer trough of DO-mean. The original model contains a lot of variability among reps and some reps also really struggled with the seasonal transition from summer lows to winter highs. Interestingly, this also seems much better in the model with more attributes:
I calculated global permutation feature importance (Δ RMSE) across the model reps for each feature. Not surprisingly, daily min/max air temperature (
6 of the 30 features had a mean ΔRMSE that was negative, suggesting that the information contained in these variables is no better than noise. I take this to mean that these variables could be omitted from the model
|
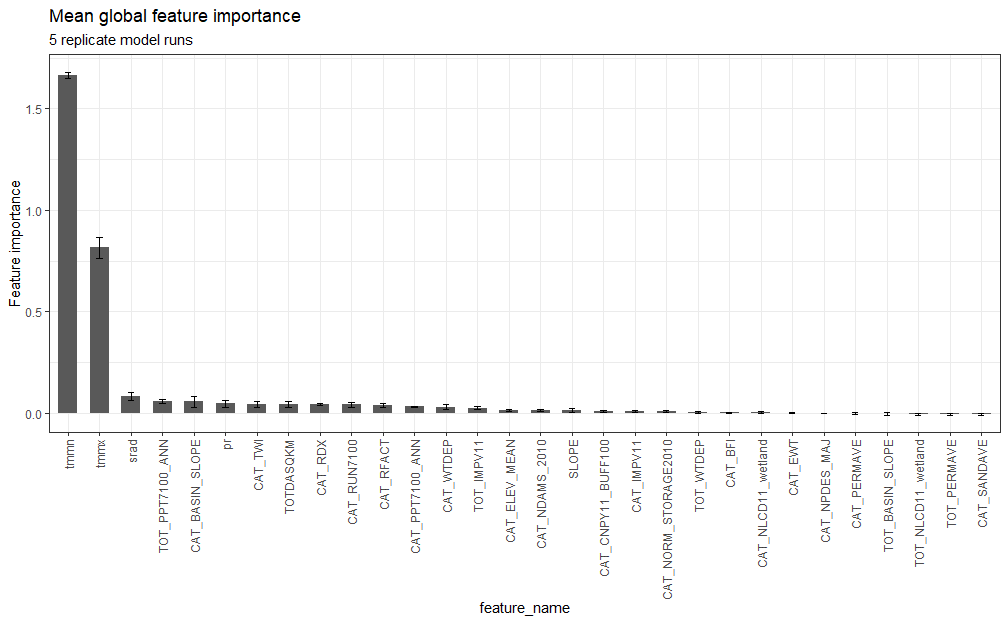
Beta Was this translation helpful? Give feedback.
-
|
Interesting that those 6 features were adding no information. In the manuscript when we talk about this, we'll have to point out that that doesn't mean wetlands and NPDES sites, for example, are not important to DO, but that for these sites and for these time periods, that information did not help the model make any better predictions. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Our "base" configuration of the LSTM model relied on 11 input features to make predictions of daily min/max/mean DO. Dynamic features included daily precipitation, air temperature (min/max), and solar radiation, and static features included catchment slope, catchment area, catchment impervious cover, stream slope, riparian canopy cover, and topographic wetness index in the catchment.
In #165, we expanded the list of static features that we download and process so that they're available for modeling. The new static input variables were selected based on hypothesized relationships between these variables and DO. The expanded feature set includes 108 static attributes. This number seems high because 1) some features are "pseudo-dynamic," i.e. the number of dams built on or before 1960, 1970, 1980, etc..., and 2) we compile the values aggregated for both the local catchment and the full upstream watershed area. The features fall under a few general categories, including river/basin characteristics, climate, hydrologic modification, soils, and land cover:
Not all of the 108 static features should necessarily be added to the model. For example, some features are highly correlated across our sites and so include redundant information. My general approach to feature selection includes the following steps, and I'll include results in the discussion thread below.
Beta Was this translation helpful? Give feedback.
All reactions