随机采样一致性与特征图匹配 #29
Description
Rocco[1] 等人在其弱监督语义级别图像匹配的工作中,将特征匹配与随机采样一致性算法(RANdom SAmple Consensus, RANSAC)联系在一起,提出了一个可微分的基于语义的评分损失函数,文中对于语义特征匹配和 RANSAC 算法的阐述令人耳目一新,遂作此文对相关概念追本溯源。
随机采样一致性(RANSAC)
真实世界的数据往往充满各种各样的噪声,如果想得到足够鲁棒的适用于所有场景的模型,就要尽量降低噪声的影响。由 Fischler[3] 等人提出的随机采样一致性算法,可以很好从含有大量离群点和噪音地数据中恢复出足够准确地模型参数。相对于在统计学领域中大量使用的 M 估计(M-estimators)和最小均方回归(Least Median Square Regression)等稳健估计方法(Robust Estimation),RANSAC 则主要应用于计算机视觉领域,而且从 Fichler[3] 的论文就可以看出,RANSAC 算法从诞生之初便和图像匹配存在不解之缘。
简略来看,RANSAC 从所有数据中采样尽量少的观测点来估计模型参数,而不是像其他依赖于从尽可能多的数据中过滤掉离群点,RANSCAC 使用一组足够少的点来初始化算法,然后不断地使用迭代式方法来增大具有数据一致性的可信点规模。
算法的流程可以简要地描述如下:
- 从数据样本
$S$ 中随机选取$K$ 个点,得到假设子集$S_K$ ,然后使用$S_K$ 优化模型参数$M(\theta)$ ,得到初始模型; - 对所有数据样本
$S$ 应用模型$M(\theta)$ ,然后根据每个数据样本的误差$||M(\theta, x_i) - y_i||$ 来所有数据样本划分为内群点(inliner points)和离群点(outliner points),其中误差大于超参数$\epsilon$ 的称为离群点$S_{outliner}$ ,反正则为内群点$S_{inliner}$ ; - 如果内群点的占比
$R = \frac{S_{inliner}}{S}$ 大于超参数阈值$\tau$ ,则使用所有的内群点$S_{inliner}$ 来重新优化模型参数,并将得到的模型作为最终模型,终止迭代; - 否则使用内群点
$S_{inliner}$ 优化模型,并重复执行步骤 2,直到条件 3 满足,或者达到迭代次数上限$N$ 。
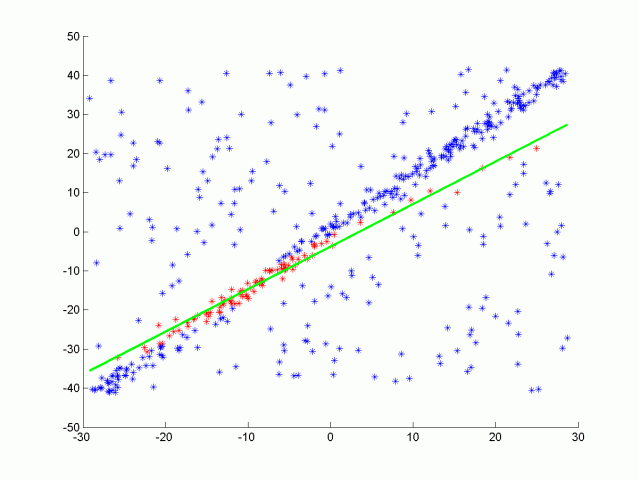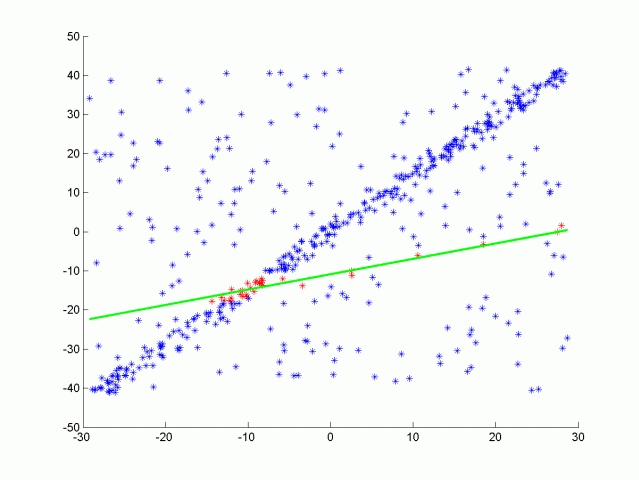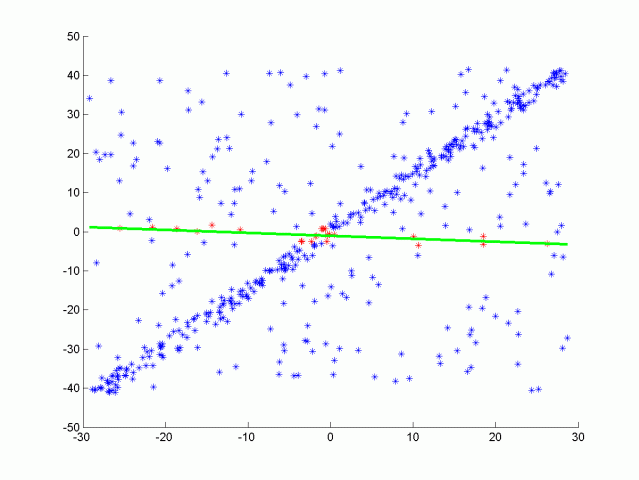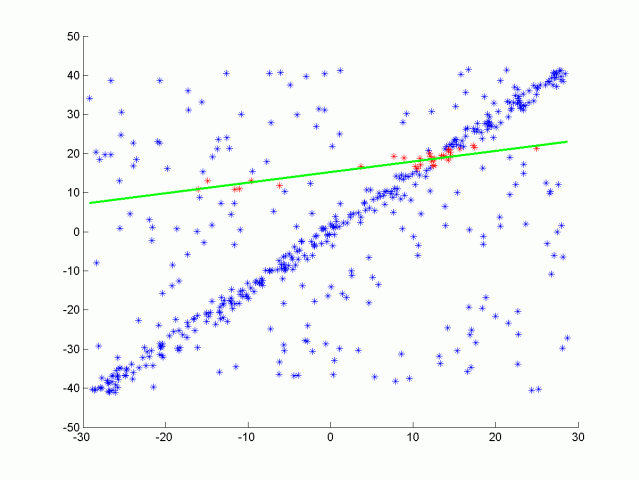
图 1 RANSAC 迭代过程演示
可以看到 RANSAC 算法的性能由超参数
假设每次随机选择一个点,该点为内群点的概率为
从而估计出
举个粒子,假设数据总量
此外,RANSAC 算法还有很多变种,比如在估计离群点时应用极大似然估计的 MLESAC[4],每次迭代采样时使用权重采样的 IMPSAC[5]。
图像特征匹配(Image Feature Matching)
图像特征匹配是计算机视觉中的经典任务,无论是做图像检索、三维重建,还是做相机重定位或者 SLAM,都需要先从图像中提取出匹配好的特征点对。以两幅图像为例,图像特征匹配一般包含两个阶段[6]:
- 从图像对
$(I_s, I_t)$ 中分别提取特征点$(F_s, F_t)$ ; - 对两个特征点集进行匹配,得到匹配完毕的特征对
$M_{s \rightarrow t}$ 。
其中第一步提取的特征点,可以是经典的手动构造的特征描述子 SIFT、SURF 或者 ORB 等,也可以是由神经网络端到端地生成特征描述子,比如 LIFT[7]、DELF[8] 以及 D2-Net[9] 等。然后对得到的特征点进行特征匹配,常见的策略有 opencv 自带的 Brute-Force 暴力匹配和快速近似 k 近邻匹配[10]、朴素最近邻匹配、双向最近邻(或称 cycle consistent)等匹配方法。
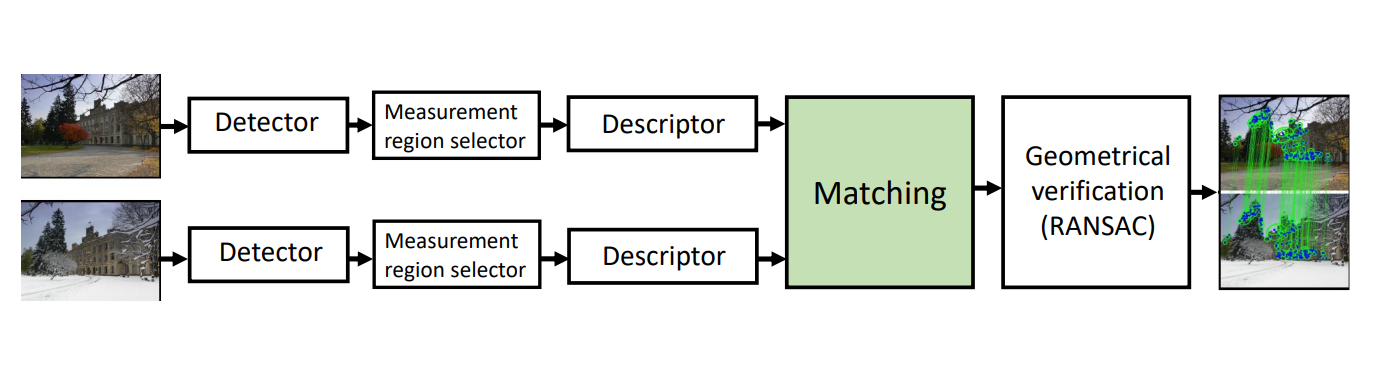
图 2 图像匹配的一般流程[11]
在进行特征点匹配时,为了保证匹配的鲁棒性,需要尽可能多得降低离群点以及错误匹配的影响,此时就要结合前文中提到的 RANSAC 算法过滤掉离群点。

图 3 使用 RANSAC 过滤离群点。A 和 B 中的红色点表示在另一幅图中不存在对应的特征点,蓝色点表示存在对应的特征点,但是没有得到完美匹配,黄色的点表示匹配成功。
考虑同一个场景下的图像匹配,如图 3 所示,两张图片在同一场景的不同视角进行拍摄,因此我们如果想要将两张图片对齐,就要求解出两个视角的单应矩阵
- 从
$M_{s \rightarrow t}$ 中随机选取$k$ 个特征点对$M_k$ ; - 使用
$M_k$ 求解单应矩阵$H$ ; - 对图像
$I_s$ 中的所有特征点$F_s$ 应用单应矩阵$H$ ,将其投影到图像$I_s$ 的成像坐标系中,得到投影后的特征点$\hat F_s = Project(H, F_s)$ ; - 根据预设定阈值
$\epsilon$ 计算内群点,即满足$D(\hat{F_s}, M_{s \rightarrow t}F_s) \leq \epsilon$ 的匹配; - 如果内群点占比不满足条件,则重复上述步骤 2 - 4;否则使用当前的所有内群点对重新计算
$H$ 作为最终结果。
结合了 RANSAC 的改进算法和各种改良后的特征描述子的特征匹配算法的性能已经足够良好[6],并且能够稳定地胜任 SLAM、三维重建和位姿估计等视觉任务。然而上述算法却无法直接应用到神经网络中,这是因为每次采样选点的过程都是不可微分的,这与梯度下降法的使用场景相悖。此外,经典的视觉特征描述子也很难描述出图像中物体的语义特征,因此,可微分的 RANSAC 算法应运而生,而随着深度学习的兴起,语义层面的特征匹配方法也层出不穷。
语义特征匹配
前文提到,在大多数计算机视觉任务中,我们只需要找到同一个场景中在不同视角拍摄的图片之间的响应或者匹配,就可以完成三维重建或者相机重定位等任务,然而有时候我们需要对不同场景的图像进行语义级别的匹配,比如当场景中存在动态物体时,传统匹配方法无法灵活处理动态部分的场景,这时候就需要我们使用语义级别的特征匹配方法。

图 4 语义级别的图像匹配[13]
为了解决传统特征描述子的描述能力受限的问题,人们首先考虑从深度学习学到的特征开始入手,使用各种各样的 CNN 学习到的特征描述子进行特征匹配[14],比如使用物体级别的框体匹配(learned at the object-proposal level)的 SC-NET [15][16],以及直接使用手工标注的特征响应的有监督的方法 [17]。
首个弱监督的端到端的语义特征匹配方法是 Rocco 的这篇文章[1],作者声称从经典的 RANSAC 算法中得到启发,直接从特征相关矩阵中学习特征相似度较大的区域,从而学习到密集的特征响应信号,同时为了使得整个流程可以微分,使用了 Spatial Transformer Networks 中的图像变换模型来执行图像采样。
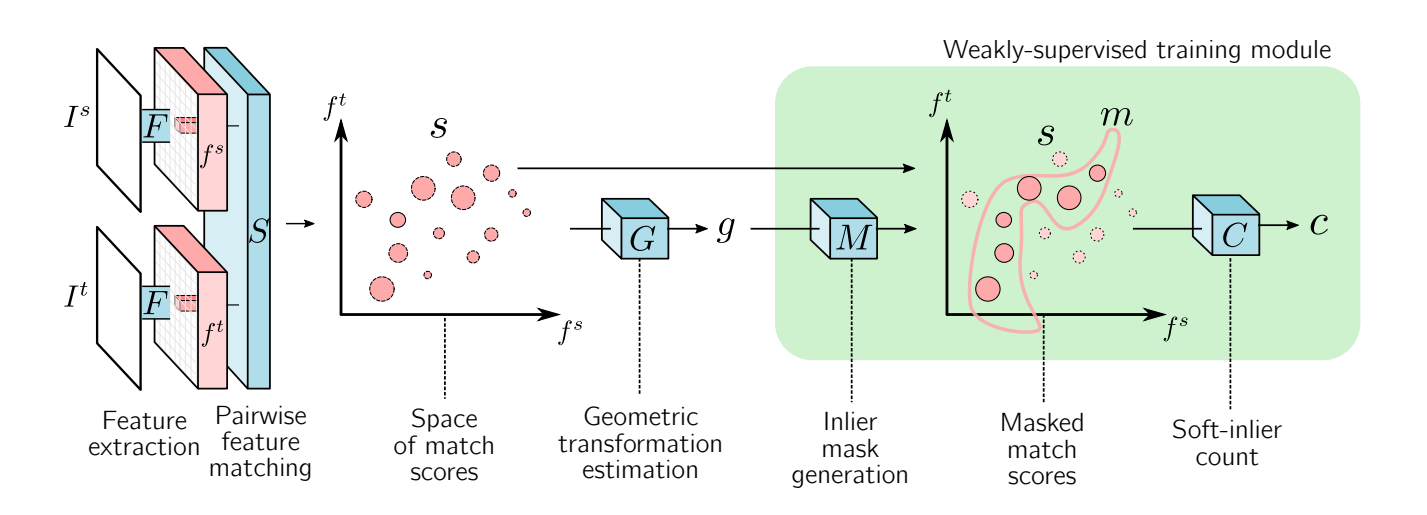
图 5 Rocco[1] 提出的端到端的特征特征匹配流程
前文提到,图像匹配的流程一般包含两个步骤,首先是特征提取,其次是特征匹配。Rocco[1] 的 pipeline 使用一个参数共享的孪生 CNN 来提取原始图像的特征图,从而得到图像对的特征图
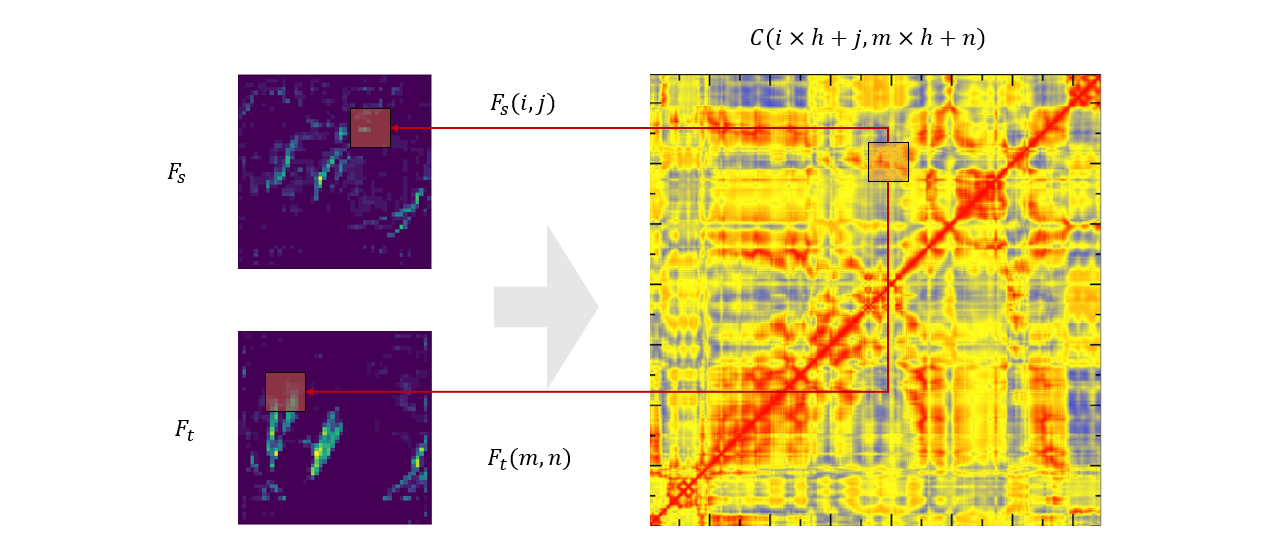
图 6 相关性矩阵的计算
直观上理解相关性矩阵的计算,就是用特征图中位于
可以发现,特征图
为了增加鲁棒性,不仅考虑
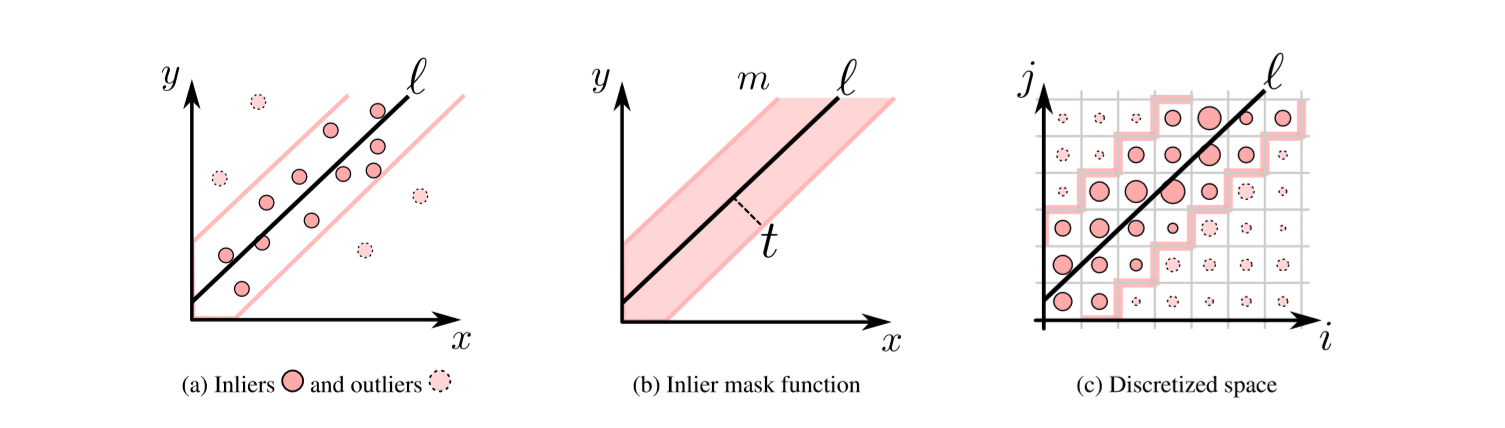
图 7 学习图像变换模型的过程就是 RANSAC 采样的过程
如果我们把相关矩阵
到此为止,图像变换矩阵
扩展应用
相较于直接使用
参考资料
- Rocco, Ignacio, Relja Arandjelović, and Josef Sivic. "End-to-end weakly-supervised semantic alignment." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
- Derpanis, Konstantinos G. "Overview of the RANSAC Algorithm." Image Rochester NY 4.1 (2010): 2-3.
- Fischler, Martin A., and Robert C. Bolles. "Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography." Communications of the ACM 24.6 (1981): 381-395.Communications of the ACM, 24(6):381–395, 1981.
- Torr, Philip HS, and Andrew Zisserman. "MLESAC: A new robust estimator with application to estimating image geometry." Computer vision and image understanding 78.1 (2000): 138-156.
- Torr, Philip H. S., and Colin Davidson. "IMPSAC: Synthesis of importance sampling and random sample consensus." IEEE Transactions on Pattern Analysis and Machine Intelligence 25.3 (2003): 354-364.
- Jin, Yuhe, et al. "Image Matching across Wide Baselines: From Paper to Practice." arXiv preprint arXiv:2003.01587 (2020).
- Yi, Kwang Moo, et al. "Lift: Learned invariant feature transform." European Conference on Computer Vision. Springer, Cham, 2016.
- Noh, Hyeonwoo, et al. "Large-scale image retrieval with attentive deep local features." Proceedings of the IEEE international conference on computer vision. 2017.
- Dusmanu, Mihai, et al. "D2-Net: A Trainable CNN for Joint Description and Detection of Local Features." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- “Feature Matching.” OpenCV, opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_matcher/py_matcher.html.
- http://cmp.felk.cvut.cz/~mishkdmy/slides/EECVC2019_Mishkin_image_matching.pdf
- https://people.cs.umass.edu/~elm/Teaching/ppt/370/370_10_RANSAC.pptx.pdf
- Chen, Yun-Chun, et al. "Deep semantic matching with foreground detection and cycle-consistency." Asian Conference on Computer Vision. Springer, Cham, 2018.
- Ufer, Nikolai, and Bjorn Ommer. "Deep semantic feature matching." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
- Han, Kai, et al. "Scnet: Learning semantic correspondence." Proceedings of the IEEE International Conference on Computer Vision. 2017.
- Ufer, Nikolai, and Bjorn Ommer. "Deep semantic feature matching." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
- Rocco, Ignacio, Relja Arandjelovic, and Josef Sivic. "Convolutional neural network architecture for geometric matching." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
- Jaderberg, Max, Karen Simonyan, and Andrew Zisserman. "Spatial transformer networks." Advances in neural information processing systems. 2015.
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
- Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Wang, Xiaolong, Allan Jabri, and Alexei A. Efros. "Learning correspondence from the cycle-consistency of time." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.