|
8 | 8 | "\n", |
9 | 9 | "---\n", |
10 | 10 | "\n", |
11 | | - "\n", |
12 | 11 | "**Objective:** The file provides a simple *boilerplate* to concentrate on what is necessary, and stop doing same tasks! The boilerplate is also configured with certain [**nbextensions**](https://gitlab.com/ZenithClown/computer-configurations-and-setups) that I personally use. Install them, if required, else ignore them as they do not participate in any type of code-optimizations. For any new project *edit* this file or `File > Make a Copy` to get started with the project. Some settings and configurations are already provided, as mentioned below." |
13 | 12 | ] |
14 | 13 | }, |
15 | 14 | { |
16 | 15 | "cell_type": "code", |
17 | | - "execution_count": 2, |
| 16 | + "execution_count": 1, |
18 | 17 | "metadata": { |
19 | 18 | "ExecuteTime": { |
20 | | - "end_time": "2023-01-11T15:50:13.490916Z", |
21 | | - "start_time": "2023-01-11T15:50:13.479904Z" |
| 19 | + "end_time": "2023-04-12T08:16:36.922254Z", |
| 20 | + "start_time": "2023-04-12T08:16:36.904106Z" |
22 | 21 | } |
23 | 22 | }, |
24 | 23 | "outputs": [ |
25 | 24 | { |
26 | 25 | "name": "stdout", |
27 | 26 | "output_type": "stream", |
28 | 27 | "text": [ |
29 | | - "Current Code Version: v0.1.0-beta\n" |
| 28 | + "Current Code Version: v0.1.1\n", |
| 29 | + "\n" |
30 | 30 | ] |
31 | 31 | } |
32 | 32 | ], |
|
59 | 59 | }, |
60 | 60 | { |
61 | 61 | "cell_type": "code", |
62 | | - "execution_count": 3, |
| 62 | + "execution_count": 2, |
63 | 63 | "metadata": { |
64 | 64 | "ExecuteTime": { |
65 | | - "end_time": "2023-01-11T15:50:34.230463Z", |
66 | | - "start_time": "2023-01-11T15:50:34.217051Z" |
| 65 | + "end_time": "2023-04-12T08:16:55.883978Z", |
| 66 | + "start_time": "2023-04-12T08:16:55.867980Z" |
67 | 67 | } |
68 | 68 | }, |
69 | 69 | "outputs": [], |
|
75 | 75 | }, |
76 | 76 | { |
77 | 77 | "cell_type": "code", |
78 | | - "execution_count": 4, |
| 78 | + "execution_count": 3, |
79 | 79 | "metadata": { |
80 | 80 | "ExecuteTime": { |
81 | | - "end_time": "2023-01-11T15:51:07.931774Z", |
82 | | - "start_time": "2023-01-11T15:51:07.926776Z" |
| 81 | + "end_time": "2023-04-12T08:28:01.539456Z", |
| 82 | + "start_time": "2023-04-12T08:28:01.534825Z" |
83 | 83 | } |
84 | 84 | }, |
85 | 85 | "outputs": [], |
|
100 | 100 | }, |
101 | 101 | "outputs": [], |
102 | 102 | "source": [ |
103 | | - "from copy import deepcopy # dataframe is mutable\n", |
| 103 | + "# from copy import deepcopy # dataframe is mutable\n", |
104 | 104 | "# from tqdm import tqdm as TQ # progress bar for loops\n", |
105 | 105 | "# from uuid import uuid4 as UUID # unique identifier for objs" |
106 | 106 | ] |
|
133 | 133 | }, |
134 | 134 | "outputs": [], |
135 | 135 | "source": [ |
136 | | - "import logging # configure logging on `global arguments` section, as file path is required" |
| 136 | + "# import logging # configure logging on `global arguments` section, as file path is required" |
137 | 137 | ] |
138 | 138 | }, |
139 | 139 | { |
|
167 | 167 | "plt.style.use('default-style');\n", |
168 | 168 | "\n", |
169 | 169 | "pd.set_option('display.max_rows', 50) # max. rows to show\n", |
170 | | - "pd.set_option('display.max_columns', 15) # max. cols to show\n", |
| 170 | + "pd.set_option('display.max_columns', 17) # max. cols to show\n", |
171 | 171 | "np.set_printoptions(precision = 3, threshold = 15) # set np options\n", |
172 | | - "pd.options.display.float_format = '{:,.2f}'.format # float precisions" |
| 172 | + "pd.options.display.float_format = '{:,.3f}'.format # float precisions" |
| 173 | + ] |
| 174 | + }, |
| 175 | + { |
| 176 | + "cell_type": "code", |
| 177 | + "execution_count": null, |
| 178 | + "metadata": {}, |
| 179 | + "outputs": [], |
| 180 | + "source": [ |
| 181 | + "# sklearn metrices for analysis can be imported as below\n", |
| 182 | + "# considering `regression` problem, rmse is imported metrics\n", |
| 183 | + "# for rmse, use `squared = False` : https://stackoverflow.com/a/18623635/\n", |
| 184 | + "# from sklearn.metrics import mean_squared_error as MSE" |
| 185 | + ] |
| 186 | + }, |
| 187 | + { |
| 188 | + "cell_type": "code", |
| 189 | + "execution_count": null, |
| 190 | + "metadata": {}, |
| 191 | + "outputs": [], |
| 192 | + "source": [ |
| 193 | + "import tensorflow as tf\n", |
| 194 | + "print(f\"Tensorflow Version: {tf.__version__}\", end = \"\\n\") # required >= 2.8\n", |
| 195 | + "\n", |
| 196 | + "# check physical devices, and gpu compute capability (if available)\n", |
| 197 | + "if len(tf.config.list_physical_devices(device_type = \"GPU\")):\n", |
| 198 | + " # https://stackoverflow.com/q/38009682/6623589\n", |
| 199 | + " # https://stackoverflow.com/a/59179238/6623589\n", |
| 200 | + " print(\"GPU Computing Available.\", end = \" \")\n", |
| 201 | + " \n", |
| 202 | + " # experimentally, get the gpu details and computation power\n", |
| 203 | + " # https://www.tensorflow.org/api_docs/python/tf/config/experimental/get_device_details\n", |
| 204 | + " devices = tf.config.list_physical_devices(device_type = \"GPU\")[0] # first\n", |
| 205 | + " details = tf.config.experimental.get_device_details(devices) # only first\n", |
| 206 | + " details.get('device_name', 'compute_capability')\n", |
| 207 | + " print(f\"EXPERIMENTAL : {details}\")\n", |
| 208 | + "else:\n", |
| 209 | + " print(\"GPU Computing Not Available. If `GPU` is present, check configuration. Detected Devices:\")\n", |
| 210 | + " print(\" > \", tf.config.list_physical_devices())" |
173 | 211 | ] |
174 | 212 | }, |
175 | 213 | { |
|
192 | 230 | "echo %VARNAME%\n", |
193 | 231 | "```\n", |
194 | 232 | "\n", |
195 | | - "Once you've setup your system with [`PYTHONPATH`](https://bic-berkeley.github.io/psych-214-fall-2016/using_pythonpath.html) as per [*python documentation*](https://docs.python.org/3/using/cmdline.html#envvar-PYTHONPATH) is an important directory where any `import` statements looks for based on their order of importance. If a source code/module is not available check necessary environment variables and/or ask the administrator for the source files. For testing purpose, the module boasts the use of `src`, `utils` and `config` directories. However, these directories are available at `ROOT` level, and thus using `sys.path.append()` to add directories while importing." |
| 233 | + "Once you've setup your system with [`PYTHONPATH`](https://bic-berkeley.github.io/psych-214-fall-2016/using_pythonpath.html) as per [*python documentation*](https://docs.python.org/3/using/cmdline.html#envvar-PYTHONPATH) is an important directory where any `import` statements looks for based on their order of importance. If a source code/module is not available check necessary environment variables and/or ask the administrator for the source files. For testing purpose, the module boasts the use of `src`, `utils` and `config` directories. However, these directories are available at `ROOT` level, and thus using `sys.path.append()` to add directories while importing.\n", |
| 234 | + "\n", |
| 235 | + "**Getting Started** with **`submodules`**\n", |
| 236 | + "\n", |
| 237 | + "A [`submodule`](https://git-scm.com/book/en/v2/Git-Tools-Submodules) provides functionality to integrate a seperate project in the current repository - this is typically useful to remove code-duplicacy and central repository to control dependent modules. More information on initializing and using submodule is available [here](https://www.youtube.com/watch?v=gSlXo2iLBro). Check [Github-GISTS/ZenithClown](https://gist.github.com/ZenithClown) for more information." |
196 | 238 | ] |
197 | 239 | }, |
198 | 240 | { |
|
203 | 245 | "source": [ |
204 | 246 | "# append `src` and sub-modules to call additional files these directory are\n", |
205 | 247 | "# project specific and not to be added under environment or $PATH variable\n", |
206 | | - "sys.path.append(os.path.join(\"..\", \"src\")) # parent/source files directory\n", |
207 | 248 | "sys.path.append(os.path.join(\"..\", \"src\", \"agents\")) # agents for reinforcement modelling\n", |
208 | 249 | "sys.path.append(os.path.join(\"..\", \"src\", \"engine\")) # derivative engines for model control\n", |
209 | 250 | "sys.path.append(os.path.join(\"..\", \"src\", \"models\")) # actual models for decision making tools" |
210 | 251 | ] |
211 | 252 | }, |
| 253 | + { |
| 254 | + "cell_type": "code", |
| 255 | + "execution_count": null, |
| 256 | + "metadata": {}, |
| 257 | + "outputs": [], |
| 258 | + "source": [ |
| 259 | + "# also append the `utilities` directory for additional helpful codes\n", |
| 260 | + "sys.path.append(os.path.join(\"..\", \"utilities\"))" |
| 261 | + ] |
| 262 | + }, |
212 | 263 | { |
213 | 264 | "cell_type": "markdown", |
214 | 265 | "metadata": {}, |
|
230 | 281 | "outputs": [], |
231 | 282 | "source": [ |
232 | 283 | "ROOT = \"..\" # the document root is one level up, that contains all code structure\n", |
233 | | - "DATA = join(ROOT, \"data\") # the directory contains all data files, subdirectory (if any) can also be used/defined\n", |
| 284 | + "DATA = os.path.join(ROOT, \"data\") # the directory contains all data files, subdirectory (if any) can also be used/defined\n", |
234 | 285 | "\n", |
235 | 286 | "# processed data directory can be used, such that preprocessing steps is not\n", |
236 | 287 | "# required to run again-and-again each time on kernel restart\n", |
237 | | - "PROCESSED_DATA = join(DATA, \"processed\")" |
| 288 | + "PROCESSED_DATA = os.path.join(DATA, \"processed\")" |
238 | 289 | ] |
239 | 290 | }, |
240 | 291 | { |
241 | 292 | "cell_type": "code", |
242 | | - "execution_count": null, |
| 293 | + "execution_count": 5, |
243 | 294 | "metadata": { |
244 | 295 | "ExecuteTime": { |
245 | | - "end_time": "2022-05-07T12:02:38.898998Z", |
246 | | - "start_time": "2022-05-07T12:02:38.888970Z" |
| 296 | + "end_time": "2023-04-12T08:28:13.816861Z", |
| 297 | + "start_time": "2023-04-12T08:28:13.803865Z" |
247 | 298 | } |
248 | 299 | }, |
249 | | - "outputs": [], |
| 300 | + "outputs": [ |
| 301 | + { |
| 302 | + "name": "stdout", |
| 303 | + "output_type": "stream", |
| 304 | + "text": [ |
| 305 | + "Code Execution Started on: Wed, Apr 12 2023\n" |
| 306 | + ] |
| 307 | + } |
| 308 | + ], |
250 | 309 | "source": [ |
251 | 310 | "# long projects can be overwhelming, and keeping track of files, outputs and\n", |
252 | 311 | "# saved models can be intriguing! to help this out, `today` can be used. for\n", |
253 | 312 | "# instance output can be stored at `output/<today>/` etc.\n", |
254 | 313 | "# `today` is so configured that it permits windows/*.nix file/directory names\n", |
255 | | - "today = dt.strftime(dt.strptime(ctime(), \"%a %b %d %H:%M:%S %Y\"), \"%a, %b %d %Y\")\n", |
| 314 | + "today = dt.datetime.strftime(dt.datetime.strptime(time.ctime(), \"%a %b %d %H:%M:%S %Y\"), \"%a, %b %d %Y\")\n", |
256 | 315 | "print(f\"Code Execution Started on: {today}\") # only date, name of the sub-directory" |
257 | 316 | ] |
258 | 317 | }, |
|
267 | 326 | }, |
268 | 327 | "outputs": [], |
269 | 328 | "source": [ |
270 | | - "OUTPUT_DIR = join(ROOT, \"output\", today)\n", |
271 | | - "makedirs(OUTPUT_DIR, exist_ok = True) # create dir if not exist\n", |
| 329 | + "OUTPUT_DIR = os.path.join(ROOT, \"output\", today)\n", |
| 330 | + "os.makedirs(OUTPUT_DIR, exist_ok = True) # create dir if not exist\n", |
272 | 331 | "\n", |
273 | 332 | "# also create directory for `logs`\n", |
274 | | - "LOGS_DIR = join(ROOT, \"logs\", open(\"../VERSION\", 'rt').read())\n", |
275 | | - "makedirs(LOGS_DIR, exist_ok = True)" |
| 333 | + "# LOGS_DIR = os.path.join(ROOT, \"logs\", open(\"../VERSION\", 'rt').read())\n", |
| 334 | + "# os.makedirs(LOGS_DIR, exist_ok = True)" |
276 | 335 | ] |
277 | 336 | }, |
278 | 337 | { |
|
286 | 345 | }, |
287 | 346 | "outputs": [], |
288 | 347 | "source": [ |
289 | | - "logging.basicConfig(\n", |
290 | | - " filename = join(LOGS_DIR, f\"{today}.log\"), # change `reports` file name\n", |
291 | | - " filemode = \"a\", # append logs to existing file, if file exists\n", |
292 | | - " format = \"%(asctime)s - %(name)s - CLASS:%(levelname)s:%(levelno)s:L#%(lineno)d - %(message)s\",\n", |
293 | | - " level = logging.DEBUG\n", |
294 | | - ")" |
| 348 | + "# logging.basicConfig(\n", |
| 349 | + "# filename = os.path.join(LOGS_DIR, f\"{today}.log\"), # change `reports` file name\n", |
| 350 | + "# filemode = \"a\", # append logs to existing file, if file exists\n", |
| 351 | + "# format = \"%(asctime)s - %(name)s - CLASS:%(levelname)s:%(levelno)s:L#%(lineno)d - %(message)s\",\n", |
| 352 | + "# level = logging.DEBUG\n", |
| 353 | + "# )" |
295 | 354 | ] |
296 | 355 | }, |
297 | 356 | { |
298 | 357 | "cell_type": "markdown", |
299 | 358 | "metadata": {}, |
300 | 359 | "source": [ |
301 | | - "## Read Input File(s)\n", |
302 | | - "\n", |
303 | | - "A typical machine learning project revolves around six important stages (as available in [Amazon ML Life Cycle Documentation](https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/well-architected-machine-learning-lifecycle.html)). The notebook boilerplate is provided to address two pillars:\n", |
304 | | - "\n", |
305 | | - " 1. **Data Processing:** An integral part of any machine learning project, which is the most time consuming step! A brief introduction and best practices is available [here](https://towardsdatascience.com/introduction-to-data-preprocessing-in-machine-learning-a9fa83a5dc9d).\n", |
306 | | - " 2. **Model Development:** From understanding to deployment, this section address development (training, validating and testing) of an machine learning model.\n", |
| 360 | + "## Model Development & PoC Section\n", |
307 | 361 | "\n", |
308 | | - "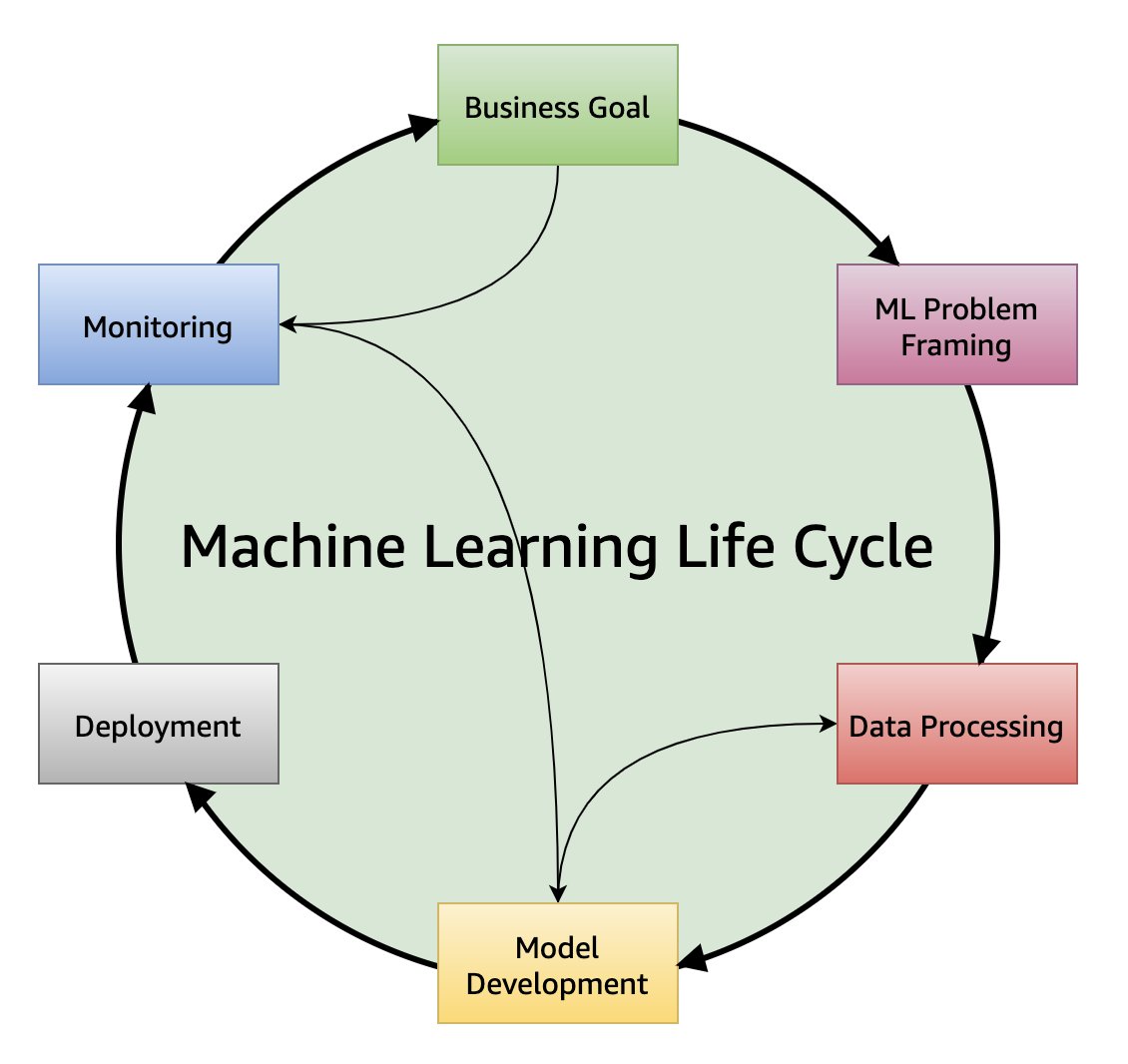" |
| 362 | + "A typical machine learning project revolves around six important stages (as available in [Amazon ML Life Cycle Documentation](https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/well-architected-machine-learning-lifecycle.html)). This notebook boilerplate can be used to understand the data file, perform statitical tests and other EDA as required for any AI/ML application. Later, using the below study a *full-fledged* application can be generated using other sections of the boilerplate." |
309 | 363 | ] |
310 | 364 | } |
311 | 365 | ], |
|
0 commit comments