|
| 1 | +# Core concepts |
| 2 | + |
| 3 | +The following sections describe the core concepts and terminology used in the acquire-zarr library. |
| 4 | +See the [Concepts and terminology](https://zarr-specs.readthedocs.io/en/latest/v3/core/index.html#concepts-and-terminology) section of the Zarr V3 specification for more details. |
| 5 | + |
| 6 | +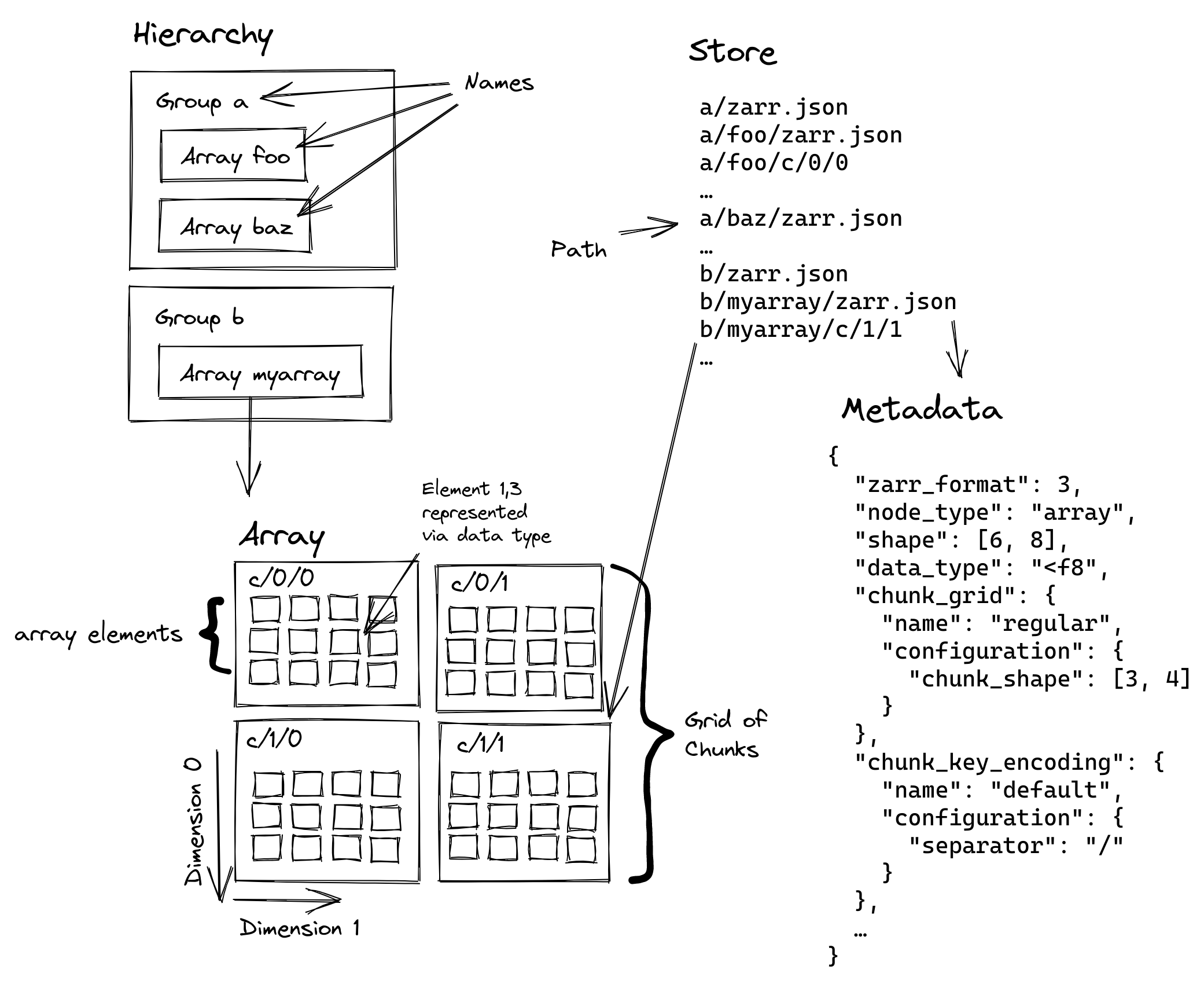 |
| 7 | + |
| 8 | +## Zarr |
| 9 | + |
| 10 | +Zarr is a specification for storing large, multi-dimensional arrays in a "cloud-ready" format, i.e., one which is designed to be efficient for both local and remote storage. |
| 11 | +Arrays are stored as a grid of chunks, which are (optionally) compressed blocks of data that can be accessed independently. |
| 12 | +Zarr supports multiple storage backends, including local filesystems and cloud storage services like S3. |
| 13 | +There are two major versions of the Zarr specification: [V2](https://zarr-specs.readthedocs.io/en/latest/v2/v2.0.html) and [V3](https://zarr-specs.readthedocs.io/en/latest/v3/core/index.html). |
| 14 | +The acquire-zarr library implements both specifications. |
| 15 | + |
| 16 | +> [!WARNING] |
| 17 | +> The V2 specification is currently deprecated and will be removed in a future release. |
| 18 | +> We recommend using V3 for new projects. |
| 19 | +
|
| 20 | +## OME-Zarr |
| 21 | + |
| 22 | +The [OME-Zarr](https://ngff.openmicroscopy.org/latest/) specification is an extension of the Zarr specification that adds support for additional metadata and multiscale arrays. |
| 23 | + |
| 24 | +## Stream |
| 25 | + |
| 26 | +A *stream* is the primary interface for writing data to Zarr arrays in acquire-zarr. |
| 27 | +The stream manages the process of organizing incoming data into chunks and shards, applying compression, and writing to the underlying storage backend. |
| 28 | + |
| 29 | +> [!NOTE] |
| 30 | +> acquire-zarr is designed to be used in a streaming fashion, meaning you can append data to the stream incrementally. |
| 31 | +> This is particularly useful for large datasets that cannot be loaded into memory all at once. |
| 32 | +> This means that random-access writing, i.e., writing to arbitrary locations in the array, is not supported; neither is reading from the stream. |
| 33 | +> While this is limiting in some use cases, it provides several advantages: |
| 34 | +> - **High throughput**: acquire-zarr is optimized for high-speed data acquisition, allowing you to write large amounts of data quickly. |
| 35 | +> - **Low memory usage**: acquire-zarr does not require loading the entire dataset into memory, making it suitable for large datasets. |
| 36 | +> - **Real-time data acquisition**: acquire-zarr is designed for real-time data acquisition, allowing you to write data as it is generated. |
| 37 | +
|
| 38 | +You configure a stream by specifying one or more arrays, their dimensions, and storage settings. |
| 39 | +Once created, you can append data to the stream, and acquire-zarr handles all the details of chunking, compression, and storage. |
| 40 | + |
| 41 | +## Storage |
| 42 | + |
| 43 | +### Store |
| 44 | + |
| 45 | +When we refer to a *store*, we mean a Zarr store, which is a hierarchical key-value store that can be used to store Zarr datasets. |
| 46 | +The store can be local (on disk) or remote (e.g., in cloud storage). |
| 47 | +We sometimes use this term interchangeably with "Zarr dataset" when the context is clear. |
| 48 | +The store contains child *nodes*, which can be either *arrays* or *groups*. |
| 49 | + |
| 50 | +### Array |
| 51 | + |
| 52 | +By *array* we mean a multi-dimensional array that can be stored as a child node in a Zarr store. |
| 53 | +Arrays can have any number of dimensions and can consist of one of several data types supported by acquire-zarr. |
| 54 | +Those data types are: |
| 55 | + |
| 56 | +- Unsigned integral types: |
| 57 | + - `uint8` |
| 58 | + - `uint16` |
| 59 | + - `uint32` |
| 60 | + - `uint64` |
| 61 | +- Signed integral types: |
| 62 | + - `int8` |
| 63 | + - `int16` |
| 64 | + - `int32` |
| 65 | + - `int64` |
| 66 | +- Floating-point types: |
| 67 | + - `float32` |
| 68 | + - `float64` |
| 69 | + |
| 70 | +#### Multiscale arrays |
| 71 | + |
| 72 | +In acquire-zarr, arrays may be *multiscale* (see below), meaning they can store data at multiple resolutions or scales. |
| 73 | +Multiscale arrays are represented in the hierarchy as a group containing multiple arrays, each representing a different scale, e.g., |
| 74 | + |
| 75 | +```plaintext |
| 76 | +my_array.zarr/ |
| 77 | + ├── 0/ |
| 78 | + │ └── ... (data) |
| 79 | + ├── 1/ |
| 80 | + │ └── ... (data) |
| 81 | + └── 2/ |
| 82 | + └── ... (data) |
| 83 | +``` |
| 84 | + |
| 85 | +An image in the array at scale 0 is the full resolution image, while at scale `n`, the image is downsampled by a factor of `2^n` in x, y, and, if applicable, z. |
| 86 | +See [Dimensions](#dimensions) below for more information. |
| 87 | + |
| 88 | +#### Output key |
| 89 | + |
| 90 | +The *output key* is the path within a Zarr store where an array is located. |
| 91 | +This allows you to organize multiple arrays within a single store using a hierarchical structure. |
| 92 | +For example, you might use output keys like `"sample1/brightfield"` and `"sample1/fluorescence"` to organize different imaging modalities for the same sample, or you might additionally have a `"labels"` array for segmentation data. |
| 93 | + |
| 94 | +### Group |
| 95 | + |
| 96 | +A *group* is a node in a Zarr store that may contain other nodes, such as arrays or other groups. |
| 97 | + |
| 98 | +### S3 storage |
| 99 | + |
| 100 | +The acquire-zarr library can work with S3-compatible storage backends. |
| 101 | +When using S3, the Zarr store is represented as a hierarchy of objects in an S3 bucket. |
| 102 | +Each object corresponds to a node in the Zarr store, and the hierarchy is maintained using prefixes in the object keys. |
| 103 | + |
| 104 | +```plaintext |
| 105 | +s3://my-bucket/my_array.zarr/ |
| 106 | + ├── 0/ |
| 107 | + │ └── ... (data) |
| 108 | + ├── 1/ |
| 109 | + │ └── ... (data) |
| 110 | + └── 2/ |
| 111 | + └── ... (data) |
| 112 | +``` |
| 113 | + |
| 114 | +## Dimensions, chunking, and sharding |
| 115 | + |
| 116 | +### Dimension |
| 117 | + |
| 118 | +A *dimension* is a named axis of an array that can be used to organize and access the data within the array. |
| 119 | +Each dimension has a name, a type, and a size. |
| 120 | +The dimension type can be one of the following: |
| 121 | + |
| 122 | +- Time |
| 123 | +- Channel |
| 124 | +- Space (e.g., x, y, z) |
| 125 | +- Other (custom types can be defined) |
| 126 | + |
| 127 | +When creating a stream with acquire-zarr, you must specify *at least 3* dimensions: a spatial dimension X, a spatial dimension Y, and a third dimension of any type. |
| 128 | +Apart from this constraint, you can define as many dimensions of any type as you like, though you should keep in mind that if you are targeting the OME-Zarr specification, there are [some constraints on the types and order](https://ngff.openmicroscopy.org/latest/#multiscale-md) of your dimensions. |
| 129 | + |
| 130 | +When you configure a dimension in acquire-zarr, you must specify the following properties: |
| 131 | +- `name`: The name of the dimension (e.g., "t", "c", "z", "y", "x") |
| 132 | +- `type`: The type of the dimension (as above) |
| 133 | +- `array_size_px`: The size of the array in pixels for this dimension |
| 134 | +- `chunk_size_px`: The size of the chunk (see below) in pixels for this dimension |
| 135 | +- `shard_size_chunks`: The size of the shard (see below) in chunks for this dimension (Zarr V3 only) |
| 136 | + |
| 137 | +Dimensions are configured in order of *slowest changing* to *fastest changing*. |
| 138 | +For example, if you have a 4D array with dimensions time, channel, y, and x, you would configure the dimensions in that order. |
| 139 | + |
| 140 | +#### Append dimension |
| 141 | + |
| 142 | +The *append dimension* is the slowest-varying dimension in the array, meaning it is the dimension that changes the least frequently as you append data to the stream. |
| 143 | +It is called the append dimension because it is the dimension that grows dynamically as you append new data to the stream, with no predetermined limit. |
| 144 | +In the example above, the append dimension is the time dimension. |
| 145 | +You can set `array_size_px` to any value for this dimension, but it will be ignored in favor of the actual size of the data you append to the stream, so it's typical to set it to 0. |
| 146 | +Append dimensions are usually time or spatial dimensions, but can be any type. |
| 147 | + |
| 148 | +### Chunk |
| 149 | + |
| 150 | +A *chunk* is a contiguous block of data within an array that is stored together. |
| 151 | +Chunks are used to optimize data access and storage efficiency, and are considered *compressible units*. |
| 152 | +When you stream data to an array, acquire-zarr will automatically divide the data into chunks based on the chunk size specified in the stream settings. |
| 153 | + |
| 154 | +When you configure a dimension in acquire-zarr, you must specify the chunk size, in pixels, for that dimension. |
| 155 | +The chunk size for a given dimension need not evenly divide the array size for that dimension. |
| 156 | +Such a dimension is said to be *ragged* in its chunking. |
| 157 | + |
| 158 | +For example, if you have an array with a size of 1080 pixels in the Y dimension and a chunk size of 256 pixels, the array will be divided into 5 chunks, 4 of which will be of size 256 pixels and the last one will be of size 1080 - 4 * 256 = 56 pixels. |
| 159 | + |
| 160 | +### Shard |
| 161 | + |
| 162 | +A *shard* is a contiguous group of chunks (a superchunk, if you will) that are stored together in a single object in the Zarr store. |
| 163 | +Sharding is used to optimize data access and storage efficiency, especially for large arrays. |
| 164 | +When you stream data to an array, acquire-zarr will automatically divide the data into chunks as above, and then aggregate those chunks into shards based on the shard size specified in the stream settings. |
| 165 | + |
| 166 | +When you configure a dimension in acquire-zarr, you must specify the shard size, in units of chunks, for that dimension. |
| 167 | +The shard size for a given dimension need not evenly divide the number of chunks for that dimension. |
| 168 | +For example, if you have an array with 10 chunks in the Y dimension and a shard size of 3 chunks, the array will be divided into 4 shards, 3 of which will contain 3 chunks and the last one will contain 1 chunk. |
| 169 | + |
| 170 | +## Compression |
| 171 | + |
| 172 | +Zarr supports compression of chunks to reduce storage space and improve data transfer speeds. |
| 173 | +When you stream data to an array, acquire-zarr can compress the chunks based on the compression settings specified in the stream settings. |
| 174 | +Because acquire-zarr uses [Blosc](https://www.blosc.org/pages/blosc-in-depth/) for compression, it supports multiple compression codecs, including LZ4 and Zstandard. |
| 175 | +You can also specify the compression level, 0-9, where 0 means no compression and 9 means maximum compression, and the shuffle filter, which can be used to improve compression ratios for certain data types. |
| 176 | +(See this article for a discussion of the shuffle filter: [New 'bitshuffle' filter](https://www.blosc.org/posts/new-bitshuffle-filter/).) |
| 177 | + |
| 178 | +## Write behavior |
| 179 | + |
| 180 | +The timing of when data is written to storage depends on the storage backend: |
| 181 | + |
| 182 | +- **Filesystem**: Data is written when chunks are complete, allowing for efficient streaming of large datasets. |
| 183 | +- **S3**: Because S3 objects cannot be appended to, data is written when entire shards are complete. This means you may need to configure larger shards when using S3 to avoid frequent uploads. However, you should take care not to make shards too large, as this can lead to inefficient storage and retrieval. |
0 commit comments