diff --git a/README.md b/README.md
index 6631937d6c..a85601d60b 100644
--- a/README.md
+++ b/README.md
@@ -1,130 +1,157 @@
-
-
-
-
+
+
+Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
+
[](https://arxiv.org/abs/2505.17826)
[](https://modelscope.github.io/Trinity-RFT/)
-[](https://pypi.org/project/trinity-rft/0.1.1/)
+[](https://pypi.org/project/trinity-rft/)

-**Trinity-RFT is a general-purpose, flexible, scalable and user-friendly framework designed for reinforcement fine-tuning (RFT) of large language models (LLM).**
+## 🚀 News
-Built with a decoupled design, seamless integration for agent-environment interaction, and systematic data processing pipelines, Trinity-RFT can be easily adapted for diverse application scenarios, and serve as a unified platform for exploring advanced reinforcement learning (RL) paradigms.
+* [2025-07] Trinity-RFT v0.2.0 is released.
+* [2025-07] We update the [technical report](https://arxiv.org/abs/2505.17826) (arXiv v2) with new features, examples, and experiments.
+* [2025-06] Trinity-RFT v0.1.1 is released.
+* [2025-05] We release Trinity-RFT v0.1.0 and a technical report.
+* [2025-04] The initial codebase of Trinity-RFT is open.
+## 💡 What is Trinity-RFT?
-## Vision of this project
+Trinity-RFT is a general-purpose, flexible and easy-to-use framework for reinforcement fine-tuning (RFT) of large language models (LLM).
+It is designed to support diverse application scenarios and serve as a unified platform for exploring advanced RL paradigms in the [era of experience](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf).
-Current RFT approaches, such as RLHF (Reinforcement Learning from Human Feedback) with proxy reward models or training long-CoT reasoning models with rule-based rewards, are limited in their ability to handle dynamic, real-world, and continuous learning.
-Trinity-RFT envisions a future where AI agents learn by interacting directly with environments, collecting delayed or complex reward signals, and continuously refining their behavior through RL.
+## ✨ Key Features
+* **Unified RFT Core:**
-For example, imagine an AI scientist that designs an experiment, executes it, waits for feedback (while working on other tasks concurrently), and iteratively updates itself based on true environmental rewards when the experiment is finally finished.
+ Supports *synchronous/asynchronous*, *on-policy/off-policy*, and *online/offline* training. Rollout and training can run separately and scale independently on different devices.
+* **First-Class Agent-Environment Interaction:**
-Trinity-RFT offers a path into this future by providing various useful features.
+ Handles lagged feedback, long-tailed latencies, and agent/env failures gracefully. Supports multi-turn agent-env interaction.
+* **Optimized Data Pipelines:**
+ Treats rollout tasks and experiences as dynamic assets, enabling active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
+* **User-Friendly Design:**
+ Modular and decoupled architecture for easy adoption and development, plus rich graphical user interfaces for low-code usage.
-## Key features
+
+  + Figure: The high-level design of Trinity-RFT
+
+ Figure: The high-level design of Trinity-RFT
+
-+ **Unified RFT modes & algorithm support.**
-Trinity-RFT unifies and generalizes existing RFT methodologies into a flexible and configurable framework, supporting synchronous/asynchronous, on-policy/off-policy, and online/offline training, as well as hybrid modes that combine them seamlessly into a single learning process.
+
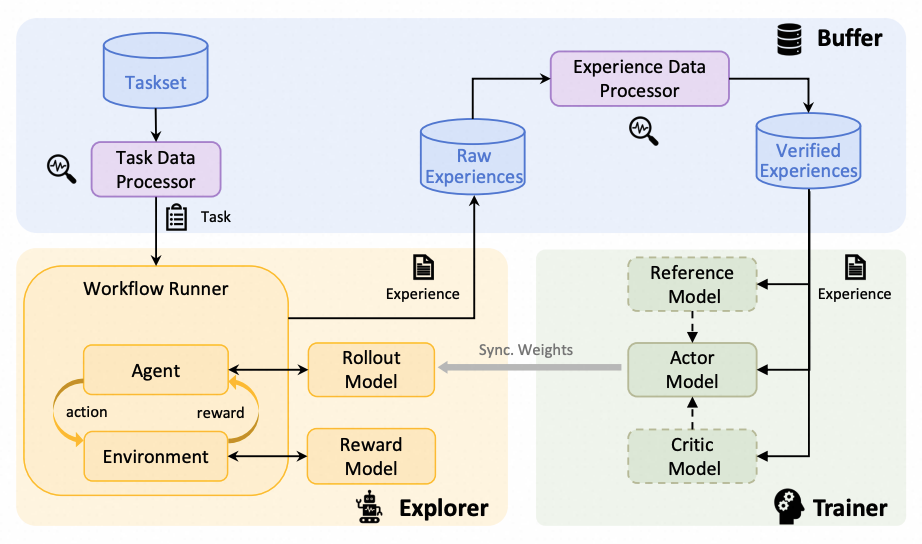
+Figure: The architecture of RFT-core
-+ **Agent-environment interaction as a first-class citizen.**
-Trinity-RFT allows delayed rewards in multi-step/time-lagged feedback loops, handles long-tailed latencies and environment/agent failures gracefully, and supports distributed deployment where explorers and trainers can operate across separate devices and scale up independently.
+
+  +
+
+
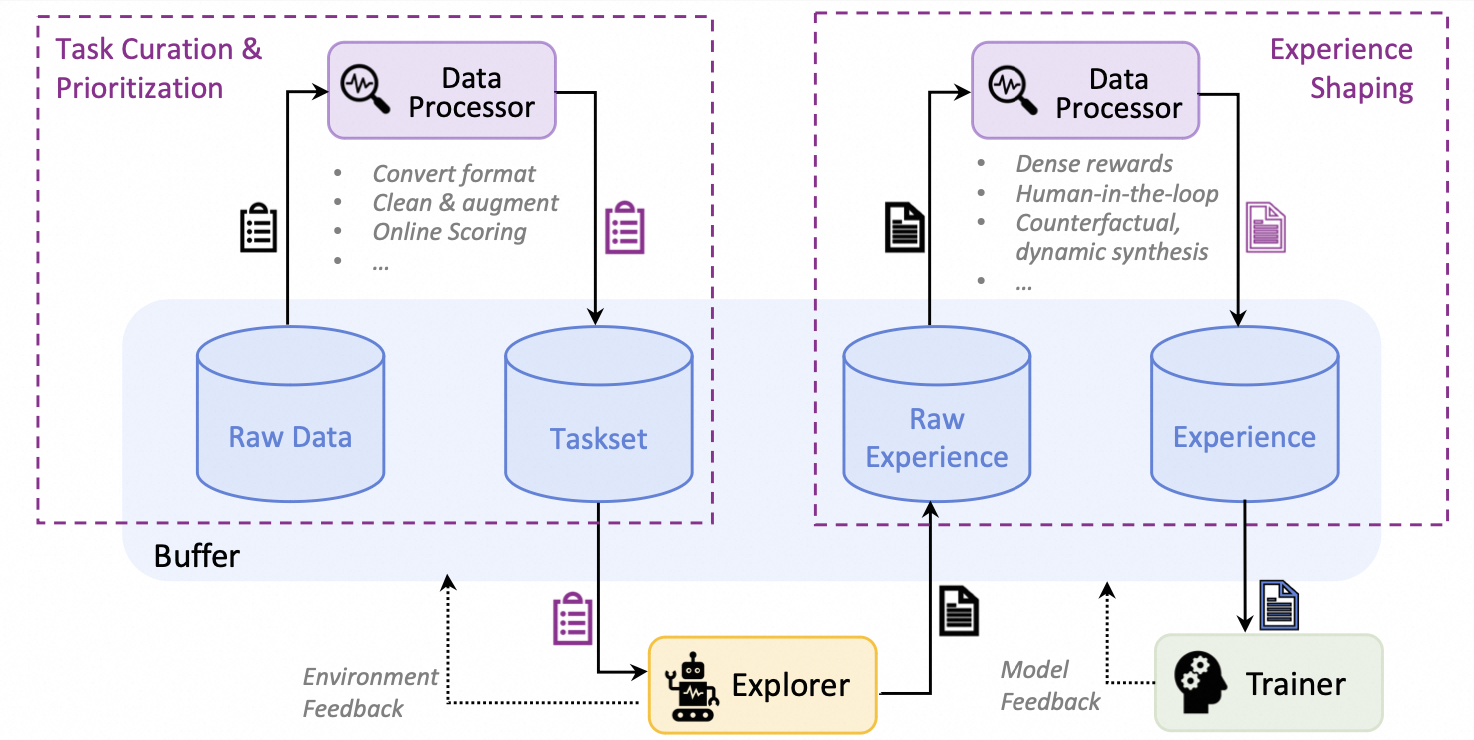
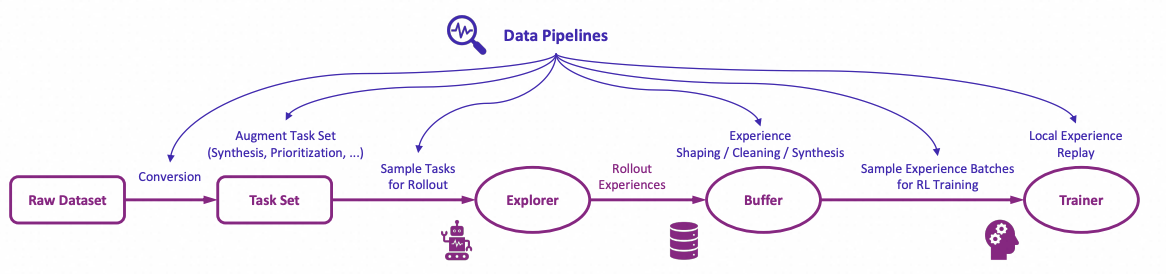
-+ **Data processing pipelines optimized for RFT with diverse/messy data.**
-These include converting raw datasets to task sets for RL, cleaning/filtering/prioritizing experiences stored in the replay buffer, synthesizing data for tasks and experiences, offering user interfaces for human in the loop, etc.
+
+Figure: Some RFT modes supported by Trinity-RFT
+
+  +
+
-## The design of Trinity-RFT
+
-
+
+Figure: The architecture of data processors
-
-
-
+  +
+
+
+
+Figure: The high-level design of data pipelines in Trinity-RFT
+
+  +
+
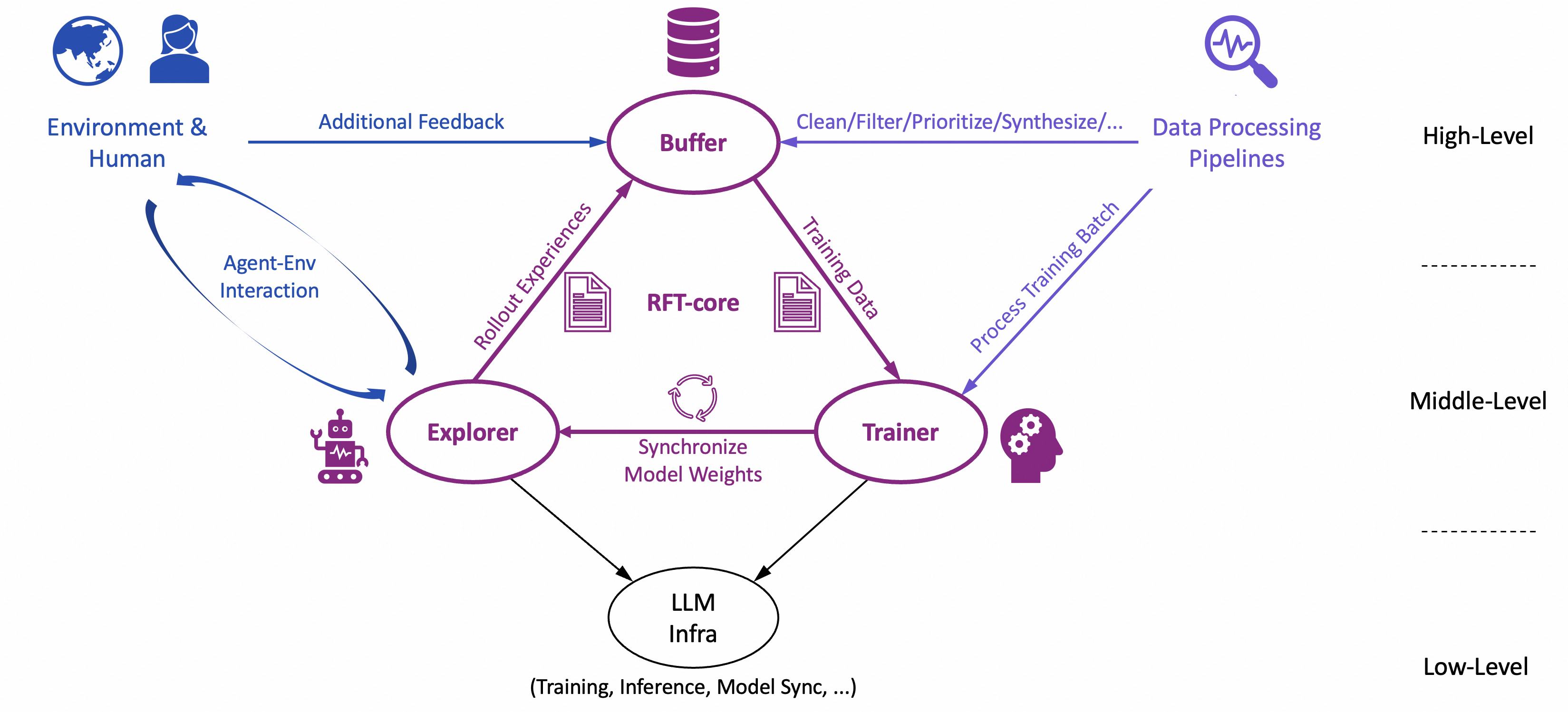
-The overall design of Trinity-RFT exhibits a trinity:
-+ RFT-core;
-+ agent-environment interaction;
-+ data processing pipelines;
+
-and the design of RFT-core also exhibits a trinity:
-+ explorer;
-+ trainer;
-+ buffer.
+## 🛠️ What can I use Trinity-RFT for?
-The *explorer*, powered by the rollout model, interacts with the environment and generates rollout trajectories to be stored in the experience buffer.
-The *trainer*, powered by the policy model, samples batches of experiences from the buffer and updates the policy model via RL algorithms.
+* **Adaptation to New Scenarios:**
-These two can be completely decoupled and act asynchronously on separate machines, except that they share the same experience buffer, and their model weights are synchronized once in a while.
-Such a decoupled design is crucial for making the aforementioned features of Trinity-RFT possible.
+ Implement agent-environment interaction logic in a single `Workflow` or `MultiTurnWorkflow` class. ([Example](./docs/sphinx_doc/source/tutorial/example_multi_turn.md))
-
+* **RL Algorithm Development:**
+ Develop custom RL algorithms (loss design, sampling, data processing) in compact, plug-and-play classes. ([Example](./docs/sphinx_doc/source/tutorial/example_mix_algo.md))
-Meanwhile, Trinity-RFT has done a lot of work to ensure high efficiency and robustness in every component of the framework,
-e.g., utilizing NCCL (when feasible) for model weight synchronization, sequence concatenation with proper masking for multi-turn conversations and ReAct-style workflows, pipeline parallelism for the synchronous RFT mode,
-asynchronous and concurrent LLM inference for rollout,
-fault tolerance for agent/environment failures,
-among many others.
+* **Low-Code Usage:**
+ Use graphical interfaces for easy monitoring and tracking of the learning process.
-## Getting started
+---
-> [!NOTE]
-> This project is currently under active development. Comments and suggestions are welcome!
+## Table of contents
+- [Getting started](#getting-started)
+ - [Step 1: installation](#step-1-installation)
+ - [Step 2: prepare dataset and model](#step-2-prepare-dataset-and-model)
+ - [Step 3: configurations](#step-3-configurations)
+ - [Step 4: run the RFT process](#step-4-run-the-rft-process)
+- [Further tutorials](#further-tutorials)
+- [Upcoming features](#upcoming-features)
+- [Contribution guide](#contribution-guide)
+- [Acknowledgements](#acknowledgements)
+- [Citation](#citation)
-### Step 1: preparations
+## Getting started
+> [!NOTE]
+> This project is currently under active development. Comments and suggestions are welcome!
+
+
+### Step 1: installation
-Installation from source (recommended):
+
+Installation from source **(recommended)**:
```shell
# Pull the source code from GitHub
@@ -159,7 +186,7 @@ pip install -e .\[flash_attn\]
Installation using pip:
```shell
-pip install trinity-rft==0.1.1
+pip install trinity-rft==0.2.0
```
Installation from docker:
@@ -179,7 +206,7 @@ docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v = 3.10,
CUDA version >= 12.4,
and at least 2 GPUs.
@@ -201,7 +228,7 @@ huggingface-cli download {model_name} --local-dir $MODEL_PATH/{model_name}
modelscope download {model_name} --local_dir $MODEL_PATH/{model_name}
```
-For more details about model downloading, please refer to [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli) or [ModelScope](https://modelscope.cn/docs/models/download).
+For more details about model downloading, see [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli) or [ModelScope](https://modelscope.cn/docs/models/download).
@@ -215,35 +242,49 @@ huggingface-cli download {dataset_name} --repo-type dataset --local-dir $DATASET
modelscope download --dataset {dataset_name} --local_dir $DATASET_PATH/{dataset_name}
```
-For more details about dataset downloading, please refer to [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli#download-a-dataset-or-a-space) or [ModelScope](https://modelscope.cn/docs/datasets/download).
+For more details about dataset downloading, see [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli#download-a-dataset-or-a-space) or [ModelScope](https://modelscope.cn/docs/datasets/download).
### Step 3: configurations
-For convenience, Trinity-RFT provides a web interface for configuring your RFT process.
+Trinity-RFT provides a web interface for configuring your RFT process.
> [!NOTE]
> This is an experimental feature, and we will continue to improve it.
-To enable *minimal* features (mainly for trainer), you can run
+To enable minimal features (mainly for trainer), you can run
+
```bash
trinity studio --port 8080
```
+
Then you can configure your RFT process in the web page and generate a config file. You can save the config for later use or run it directly as described in the following section.
-Advanced users can also configure the RFT process by editing the config file directly.
-We provide a set of example config files in [`examples`](examples/).
+Advanced users can also edit the config file directly.
+We provide example config files in [`examples`](examples/).
+
+For complete GUI features, please refer to the monorepo for [Trinity-Studio](https://github.com/modelscope/Trinity-Studio).
+
+
+
+
+ Example: config manager GUI
+
+
+
+
+
+
-To enable *complete* visualization features, please refer to the monorepo for [Trinity-Studio](https://github.com/modelscope/Trinity-Studio).
### Step 4: run the RFT process
-First, start a ray cluster with the following command:
+Start a ray cluster:
```shell
# On master node
@@ -253,57 +294,73 @@ ray start --head
ray start --address=
```
-Optionally, we can login into [wandb](https://docs.wandb.ai/quickstart/) to better monitor the RFT process:
+(Optional) Log in to [wandb](https://docs.wandb.ai/quickstart/) for better monitoring:
```shell
export WANDB_API_KEY=
wandb login
```
-Then, for command-line users, run the RFT process with the following command:
+For command-line users, run the RFT process:
```shell
trinity run --config
```
-> For example, below is the command for fine-tuning Qwen2.5-1.5B-Instruct on GSM8k dataset using GRPO algorithm:
-> ```shell
-> trinity run --config examples/grpo_gsm8k/gsm8k.yaml
-> ```
+For example, below is the command for fine-tuning Qwen2.5-1.5B-Instruct on GSM8k with GRPO:
-For studio users, just click the "Run" button in the web page.
+```shell
+trinity run --config examples/grpo_gsm8k/gsm8k.yaml
+```
+For studio users, click "Run" in the web interface.
-For more detailed examples about how to use Trinity-RFT, please refer to the following tutorials:
-+ [A quick example with GSM8k](./docs/sphinx_doc/source/tutorial/example_reasoning_basic.md)
-+ [Off-policy mode of RFT](./docs/sphinx_doc/source/tutorial/example_reasoning_advanced.md)
-+ [Asynchronous mode of RFT](./docs/sphinx_doc/source/tutorial/example_async_mode.md)
-+ [Multi-turn tasks](./docs/sphinx_doc/source/tutorial/example_multi_turn.md)
+
+## Further tutorials
+
+
+Tutorials for running different RFT modes:
+
++ [Quick example: GRPO on GSM8k](./docs/sphinx_doc/source/tutorial/example_reasoning_basic.md)
++ [Off-policy RFT](./docs/sphinx_doc/source/tutorial/example_reasoning_advanced.md)
++ [Fully asynchronous RFT](./docs/sphinx_doc/source/tutorial/example_async_mode.md)
+ [Offline learning by DPO or SFT](./docs/sphinx_doc/source/tutorial/example_dpo.md)
-+ [Advanced data processing / human-in-the-loop](./docs/sphinx_doc/source/tutorial/example_data_functionalities.md)
-For some frequently asked questions, check [FAQ](./docs/sphinx_doc/source/tutorial/faq.md) for answers.
+Tutorials for adapting Trinity-RFT to a new multi-turn agentic scenario:
+
++ [Multi-turn tasks](./docs/sphinx_doc/source/tutorial/example_multi_turn.md)
+
+
+Tutorials for data-related functionalities:
+
++ [Advanced data processing & human-in-the-loop](./docs/sphinx_doc/source/tutorial/example_data_functionalities.md)
+
+
+Tutorials for RL algorithm development/research with Trinity-RFT:
++ [RL algorithm development with Trinity-RFT](./docs/sphinx_doc/source/tutorial/example_mix_algo.md)
-## Advanced usage and full configurations
+Guidelines for full configurations: see [this document](./docs/sphinx_doc/source/tutorial/trinity_configs.md)
-Please refer to [this document](./docs/sphinx_doc/source/tutorial/trinity_configs.md).
+Guidelines for developers and researchers:
++ [Build new RL scenarios](./docs/sphinx_doc/source/tutorial/trinity_programming_guide.md#workflows-for-rl-environment-developers)
++ [Implement new RL algorithms](./docs/sphinx_doc/source/tutorial/trinity_programming_guide.md#algorithms-for-rl-algorithm-developers)
-## Programming guide for developers
+
+For some frequently asked questions, see [FAQ](./docs/sphinx_doc/source/tutorial/faq.md).
-Please refer to [this document](./docs/sphinx_doc/source/tutorial/trinity_programming_guide.md).
## Upcoming features
-A tentative roadmap: https://github.com/modelscope/Trinity-RFT/issues/51
+A tentative roadmap: [#51](https://github.com/modelscope/Trinity-RFT/issues/51)
@@ -342,11 +399,9 @@ This project is built upon many excellent open-source projects, including:
+ we have also drawn inspirations from RL frameworks like [OpenRLHF](https://github.com/OpenRLHF/OpenRLHF), [TRL](https://github.com/huggingface/trl) and [ChatLearn](https://github.com/alibaba/ChatLearn);
+ ......
+## Citation
-
-
-## Citation
```plain
@misc{trinity-rft,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
diff --git a/docs/sphinx_doc/assets/config-manager.png b/docs/sphinx_doc/assets/config-manager.png
new file mode 100644
index 0000000000..fb1997e6c3
Binary files /dev/null and b/docs/sphinx_doc/assets/config-manager.png differ
diff --git a/docs/sphinx_doc/assets/trinity-architecture.pdf b/docs/sphinx_doc/assets/trinity-architecture.pdf
new file mode 100644
index 0000000000..533bc49a38
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-architecture.pdf differ
diff --git a/docs/sphinx_doc/assets/trinity-architecture.png b/docs/sphinx_doc/assets/trinity-architecture.png
new file mode 100644
index 0000000000..e44e8e9c1c
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-architecture.png differ
diff --git a/docs/sphinx_doc/assets/trinity-data-pipeline-buffer.png b/docs/sphinx_doc/assets/trinity-data-pipeline-buffer.png
new file mode 100644
index 0000000000..e0cfd6116d
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-data-pipeline-buffer.png differ
diff --git a/docs/sphinx_doc/assets/trinity-data-pipelines.png b/docs/sphinx_doc/assets/trinity-data-pipelines.png
new file mode 100644
index 0000000000..3ecdb06685
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-data-pipelines.png differ
diff --git a/docs/sphinx_doc/assets/trinity-mix.png b/docs/sphinx_doc/assets/trinity-mix.png
new file mode 100644
index 0000000000..d14962b125
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-mix.png differ
diff --git a/docs/sphinx_doc/assets/trinity-mode.png b/docs/sphinx_doc/assets/trinity-mode.png
new file mode 100644
index 0000000000..bf02135298
Binary files /dev/null and b/docs/sphinx_doc/assets/trinity-mode.png differ
diff --git a/docs/sphinx_doc/source/main.md b/docs/sphinx_doc/source/main.md
index c7d9f6385b..bdbf75eae8 100644
--- a/docs/sphinx_doc/source/main.md
+++ b/docs/sphinx_doc/source/main.md
@@ -1,104 +1,137 @@
-# Trinity-RFT
-
+
+# Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models
-Trinity-RFT is a general-purpose, flexible, scalable and user-friendly framework designed for reinforcement fine-tuning (RFT) of large language models (LLM).
-Built with a decoupled design, seamless integration for agent-environment interaction, and systematic data processing pipelines, Trinity-RFT can be easily adapted for diverse application scenarios, and serve as a unified platform for exploring advanced reinforcement learning (RL) paradigms.
+## 🚀 News
+* [2025-07] Trinity-RFT v0.2.0 is released.
+* [2025-07] We update the [technical report](https://arxiv.org/abs/2505.17826) (arXiv v2) with new features, examples, and experiments.
+* [2025-06] Trinity-RFT v0.1.1 is released.
+* [2025-05] We release Trinity-RFT v0.1.0 and a technical report.
+* [2025-04] The initial codebase of Trinity-RFT is open.
+## 💡 What is Trinity-RFT?
-**Vision of this project:**
+Trinity-RFT is a general-purpose, flexible and easy-to-use framework for reinforcement fine-tuning (RFT) of large language models (LLM).
+It is designed to support diverse application scenarios and serve as a unified platform for exploring advanced RL paradigms in the [era of experience](https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf).
-Current RFT approaches, such as RLHF (Reinforcement Learning from Human Feedback) with proxy reward models or training long-CoT reasoning models with rule-based rewards, are limited in their ability to handle dynamic, real-world, and continuous learning.
-Trinity-RFT envisions a future where AI agents learn by interacting directly with environments, collecting delayed or complex reward signals, and continuously refining their behavior through RL.
-For example, imagine an AI scientist that designs an experiment, executes it, waits for feedback (while working on other tasks concurrently), and iteratively updates itself based on true environmental rewards when the experiment is finally finished.
-Trinity-RFT offers a path into this future by providing various useful features.
+## ✨ Key Features
+* **Unified RFT Core:**
-**Key features of Trinity-RFT:**
+ Supports *synchronous/asynchronous*, *on-policy/off-policy*, and *online/offline* training. Rollout and training can run separately and scale independently on different devices.
+* **First-Class Agent-Environment Interaction:**
+ Handles lagged feedback, long-tailed latencies, and agent/env failures gracefully. Supports multi-turn agent-env interaction.
-+ **Unified RFT modes & algorithm support.**
-Trinity-RFT unifies and generalizes existing RFT methodologies into a flexible and configurable framework, supporting synchronous/asynchronous, on-policy/off-policy, and online/offline training, as well as hybrid modes that combine the above seamlessly into a single learning process (e.g., incorporating expert trajectories or high-quality SFT data to accelerate an online RL process).
+* **Optimized Data Pipelines:**
-+ **Agent-environment interaction as a first-class citizen.**
-Trinity-RFT natively models the challenges of RFT with real-world agent-environment interactions. It allows delayed rewards in multi-step and/or time-lagged feedback loops, handles long-tailed latencies and environment/agent failures gracefully, and supports distributed deployment where explorers (i.e., the rollout agents) and trainers (i.e., the policy model trained by RL) can operate across separate clusters or devices (e.g., explorers on edge devices, trainers in cloud clusters) and scale up independently.
+ Treats rollout tasks and experiences as dynamic assets, enabling active management (prioritization, cleaning, augmentation) throughout the RFT lifecycle.
-+ **Data processing pipelines optimized for RFT with diverse/messy data.**
-These include converting raw datasets to task sets for RL, cleaning/filtering/prioritizing experiences stored in the replay buffer, synthesizing data for tasks and experiences, offering user interfaces for RFT with human in the loop, among others.
+* **User-Friendly Design:**
+ Modular and decoupled architecture for easy adoption and development, plus rich graphical user interfaces for low-code usage.
+
-## The design of Trinity-RFT
+
+ Figure: The high-level design of Trinity-RFT
+
-
+
+Figure: The architecture of RFT-core
+
+
-The overall design of Trinity-RFT exhibits a trinity:
-+ RFT-core;
-+ agent-environment interaction;
-+ data processing pipelines.
+
+Figure: Some RFT modes supported by Trinity-RFT
+
-In particular, the design of RFT-core also exhibits a trinity:
-+ explorer;
-+ trainer;
-+ buffer.
+
+
+Figure: The architecture of data processors
-The explorer, powered by the rollout model, interacts with the environment and generates rollout trajectories to be stored in the experience buffer.
-The trainer, powered by the policy model, samples batches of experiences from the buffer and updates the policy via RL algorithms.
-These two can be completely decoupled and act asynchronously on separate machines, except that they share the same experience buffer, and their model weights are synchronized once in a while (according to a schedule specified by user configurations).
+
+
-Such a decoupled design is crucial for making the aforementioned features of Trinity-RFT possible,
-e.g., flexible and configurable RFT modes (on-policy/off-policy, synchronous/asynchronous, immediate/lagged rewards),
-fault tolerance for failures of explorer (agent/environment) or trainer,
-high efficiency in the presence of long-tailed rollout latencies,
-data processing pipelines and human in the loop of RFT (e.g., via acting on the experience buffer, which is implemented as a persistent database),
-among others.
+
+Figure: The high-level design of data pipelines in Trinity-RFT
+
-Meanwhile, Trinity-RFT has done the dirty work for ensuring high efficiency in every component of the framework,
-e.g., utilizing NCCL (when feasible) for model weight synchronization, sequence concatenation with proper masking for multi-turn conversations and ReAct workflows, pipeline parallelism for the synchronous RFT mode, asynchronous and concurrent LLM inference for rollout, among many others.
+
-## Getting started
+## 🛠️ What can I use Trinity-RFT for?
-```{note}
-Note: This project is currently under active development; comments and suggestions are welcome!
-```
+* **Adaptation to New Scenarios:**
+ Implement agent-environment interaction logic in a single `Workflow` or `MultiTurnWorkflow` class. ([Example](./docs/sphinx_doc/source/tutorial/example_multi_turn.md))
-### Step 1: preparations
-Trinity-RFT requires
-Python version >= 3.10,
-CUDA version >= 12.4,
-and at least 2 GPUs.
+* **RL Algorithm Development:**
+
+ Develop custom RL algorithms (loss design, sampling, data processing) in compact, plug-and-play classes. ([Example](./docs/sphinx_doc/source/tutorial/example_mix_algo.md))
+
+
+* **Low-Code Usage:**
+ Use graphical interfaces for easy monitoring and tracking of the learning process.
-Installation from source (recommended):
+
+---
+
+## Table of contents
+
+
+- [Getting started](#getting-started)
+ - [Step 1: installation](#step-1-installation)
+ - [Step 2: prepare dataset and model](#step-2-prepare-dataset-and-model)
+ - [Step 3: configurations](#step-3-configurations)
+ - [Step 4: run the RFT process](#step-4-run-the-rft-process)
+- [Further tutorials](#further-tutorials)
+- [Upcoming features](#upcoming-features)
+- [Contribution guide](#contribution-guide)
+- [Acknowledgements](#acknowledgements)
+- [Citation](#citation)
+
+
+
+## Getting started
+
+
+```{note}
+Note: This project is currently under active development. Comments and suggestions are welcome!
+```
+
+### Step 1: installation
+
+
+Installation from source **(recommended)**:
```shell
# Pull the source code from GitHub
@@ -111,7 +144,7 @@ conda create -n trinity python=3.10
conda activate trinity
# Option 2: venv
-python3 -m venv .venv
+python3.10 -m venv .venv
source .venv/bin/activate
# Install the package in editable mode
@@ -122,15 +155,18 @@ pip install -e .\[dev\]
# Install flash-attn after all dependencies are installed
# Note: flash-attn will take a long time to compile, please be patient.
-pip install flash-attn -v
-# Try the following command if you encounter errors during installation
+# for bash
+pip install -e .[flash_attn]
+# for zsh
+pip install -e .\[flash_attn\]
+# Try the following command if you encounter errors during flash-attn installation
# pip install flash-attn -v --no-build-isolation
```
Installation using pip:
```shell
-pip install trinity-rft==0.1.1
+pip install trinity-rft==0.2.0
```
Installation from docker:
@@ -150,6 +186,12 @@ docker run -it --gpus all --shm-size="64g" --rm -v $PWD:/workspace -v = 3.10,
+CUDA version >= 12.4,
+and at least 2 GPUs.
+
+
### Step 2: prepare dataset and model
@@ -158,7 +200,7 @@ Trinity-RFT supports most datasets and models from Huggingface and ModelScope.
**Prepare the model** in the local directory `$MODEL_PATH/{model_name}`:
-```shell
+```bash
# Using Huggingface
huggingface-cli download {model_name} --local-dir $MODEL_PATH/{model_name}
@@ -166,13 +208,13 @@ huggingface-cli download {model_name} --local-dir $MODEL_PATH/{model_name}
modelscope download {model_name} --local_dir $MODEL_PATH/{model_name}
```
-For more details about model downloading, please refer to [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli) or [ModelScope](https://modelscope.cn/docs/models/download).
+For more details about model downloading, see [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli) or [ModelScope](https://modelscope.cn/docs/models/download).
**Prepare the dataset** in the local directory `$DATASET_PATH/{dataset_name}`:
-```shell
+```bash
# Using Huggingface
huggingface-cli download {dataset_name} --repo-type dataset --local-dir $DATASET_PATH/{dataset_name}
@@ -180,39 +222,49 @@ huggingface-cli download {dataset_name} --repo-type dataset --local-dir $DATASET
modelscope download --dataset {dataset_name} --local_dir $DATASET_PATH/{dataset_name}
```
-For more details about dataset downloading, please refer to [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli#download-a-dataset-or-a-space) or [ModelScope](https://modelscope.cn/docs/datasets/download).
+For more details about dataset downloading, see [Huggingface](https://huggingface.co/docs/huggingface_hub/main/en/guides/cli#download-a-dataset-or-a-space) or [ModelScope](https://modelscope.cn/docs/datasets/download).
### Step 3: configurations
-You may customize the configurations in [`examples`](https://github.com/modelscope/Trinity-RFT/tree/main/examples/). For example, the model and dataset are specified as:
+Trinity-RFT provides a web interface for configuring your RFT process.
-```yaml
-model:
- model_path: $MODEL_PATH/{model_name}
+```{note}
+Note: This is an experimental feature, and we will continue to improve it.
+```
-buffer:
- explorer_input:
- taskset:
- name: $TASKSET_NAME
- path: $DATASET_PATH/{dataset_name}
- format:
- prompt_key: 'question'
- response_key: 'answer'
- default_workflow_type: $WORKFLOW_NAME
- default_reward_fn_type: $REWARD_FN_NAME
+To enable minimal features (mainly for trainer), you can run
+
+```bash
+trinity studio --port 8080
```
-Please refer to [`examples`](https://github.com/modelscope/Trinity-RFT/tree/main/examples/) for more details.
+Then you can configure your RFT process in the web page and generate a config file. You can save the config for later use or run it directly as described in the following section.
+
+Advanced users can also edit the config file directly.
+We provide example config files in [`examples`](examples/).
+
+For complete GUI features, please refer to the monorepo for [Trinity-Studio](https://github.com/modelscope/Trinity-Studio).
+
+
+
+
+ Example: config manager GUI
+
+
+
+
+
+
### Step 4: run the RFT process
-First, start a ray cluster with the following command:
+Start a ray cluster:
```shell
# On master node
@@ -222,62 +274,73 @@ ray start --head
ray start --address=
```
-
-
-Optionally, we can login into wandb to monitor the RFT process. More details of wandb can be found in its [docs](https://docs.wandb.ai/quickstart/).
+(Optional) Log in to [wandb](https://docs.wandb.ai/quickstart/) for better monitoring:
```shell
export WANDB_API_KEY=
wandb login
```
-
-
-Then, run the RFT process with the following command:
+For command-line users, run the RFT process:
```shell
trinity run --config
```
-
-
-For example, below is the command for fine-tuning Qwen2.5-1.5B-Instruct on GSM8k dataset using GRPO algorithm:
+For example, below is the command for fine-tuning Qwen2.5-1.5B-Instruct on GSM8k with GRPO:
```shell
trinity run --config examples/grpo_gsm8k/gsm8k.yaml
```
+For studio users, click "Run" in the web interface.
+
+
+## Further tutorials
+
+
+Tutorials for running different RFT modes:
+
++ [Quick example: GRPO on GSM8k](./docs/sphinx_doc/source/tutorial/example_reasoning_basic.md)
++ [Off-policy RFT](./docs/sphinx_doc/source/tutorial/example_reasoning_advanced.md)
++ [Fully asynchronous RFT](./docs/sphinx_doc/source/tutorial/example_async_mode.md)
++ [Offline learning by DPO or SFT](./docs/sphinx_doc/source/tutorial/example_dpo.md)
+
+Tutorials for adapting Trinity-RFT to a new multi-turn agentic scenario:
-More example config files can be found in [`examples`](https://github.com/modelscope/Trinity-RFT/tree/main/examples/).
++ [Multi-turn tasks](./docs/sphinx_doc/source/tutorial/example_multi_turn.md)
+Tutorials for data-related functionalities:
-For more detailed examples about how to use Trinity-RFT, please refer to the following documents:
-+ [A quick example with GSM8k](tutorial/example_reasoning_basic.md)
-+ [Off-policy mode of RFT](tutorial/example_reasoning_advanced.md)
-+ [Asynchronous mode of RFT](tutorial/example_async_mode.md)
-+ [Multi-turn tasks](tutorial/example_multi_turn.md)
-+ [Offline learning by DPO or SFT](tutorial/example_dpo.md)
-+ [Advanced data processing / human-in-the-loop](tutorial/example_data_functionalities.md)
++ [Advanced data processing & human-in-the-loop](./docs/sphinx_doc/source/tutorial/example_data_functionalities.md)
+Tutorials for RL algorithm development/research with Trinity-RFT:
++ [RL algorithm development with Trinity-RFT](./docs/sphinx_doc/source/tutorial/example_mix_algo.md)
-## Advanced usage and full configurations
+Guidelines for full configurations: see [this document](./docs/sphinx_doc/source/tutorial/trinity_configs.md)
-Please refer to [this document](tutorial/trinity_configs.md).
+Guidelines for developers and researchers:
++ [Build new RL scenarios](./docs/sphinx_doc/source/tutorial/trinity_programming_guide.md#workflows-for-rl-environment-developers)
++ [Implement new RL algorithms](./docs/sphinx_doc/source/tutorial/trinity_programming_guide.md#algorithms-for-rl-algorithm-developers)
-## Programming guide for developers
+For some frequently asked questions, see [FAQ](./docs/sphinx_doc/source/tutorial/faq.md).
-Please refer to [this document](tutorial/trinity_programming_guide.md).
+
+
+## Upcoming features
+
+A tentative roadmap: [#51](https://github.com/modelscope/Trinity-RFT/issues/51)
@@ -316,12 +379,10 @@ This project is built upon many excellent open-source projects, including:
+ we have also drawn inspirations from RL frameworks like [OpenRLHF](https://github.com/OpenRLHF/OpenRLHF), [TRL](https://github.com/huggingface/trl) and [ChatLearn](https://github.com/alibaba/ChatLearn);
+ ......
+## Citation
-
-
-## Citation
-```
+```plain
@misc{trinity-rft,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
diff --git a/docs/sphinx_doc/source/tutorial/example_mix_algo.md b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
index 59f7036f46..e39d10f4dc 100644
--- a/docs/sphinx_doc/source/tutorial/example_mix_algo.md
+++ b/docs/sphinx_doc/source/tutorial/example_mix_algo.md
@@ -20,6 +20,11 @@ $$
The first term corresponds to the standard GRPO objective, which aims to maximize the expected reward. The last term is an auxiliary objective defined on expert data, encouraging the policy to imitate expert behavior. $\mu$ is a weighting factor that controls the relative importance of the two terms.
+
+A visualization of this pipeline is as follows:
+
+
+
## Step 0: Prepare the Expert Data
We prompt a powerful LLM to generate responses with the CoT process for some pre-defined questions. The collected dta are viewed as some experiences from an expert. We store them in a `jsonl` file `expert_data.jsonl` with the following format:
