![]()
![]()


A PyTorch module for vectorized and differentiable parametric curves with learnable coefficients, such as a B-Spline curve with learnable control points, for KANs, continuous embeddings, and shape constraints.
Use cases
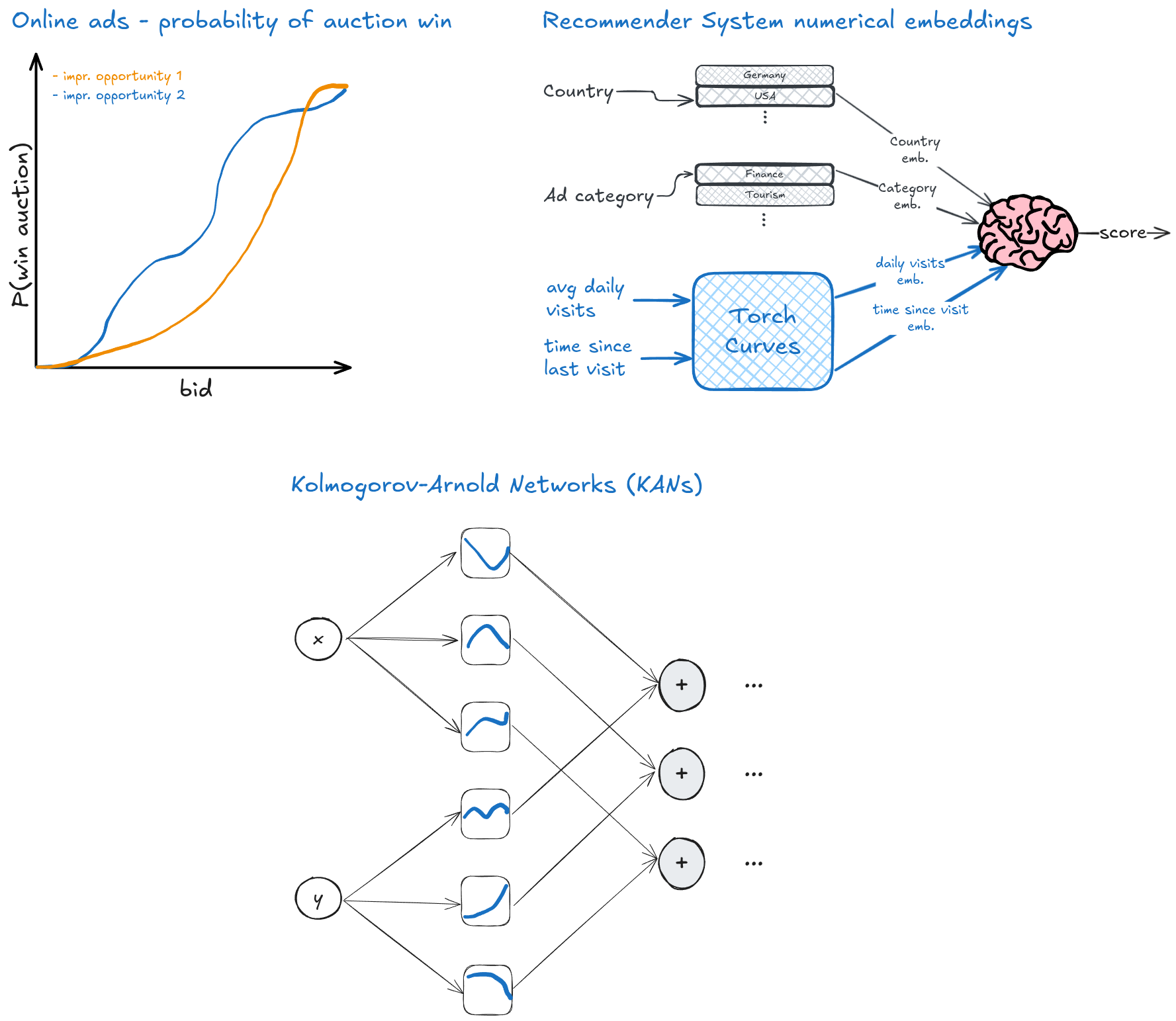
Turns out all the above use cases have one thing in common - they can all be expressed using learnable parametric curves, and this the tool this library provides.
A simple "hello world" example - evaluate three two-dimensional b-spline curves at four points:
import torch
import torchcurves as tc
u = torch.rand(4, 3) # (B, C)
curve = tc.BSplineCurve(
num_curves=3, # C
dim=2, # D
)
y = curve(u) # (B, C, D)
print(u.shape, "->", y.shape) # torch.Size([4, 3]) -> torch.Size([4, 3, 2])For more information:
- Documentation site.
- Example notebooks for you to try out.
- Differentiable: Custom autograd function ensures gradients flow properly through the curve evaluation.
- Vectorized: Vectorized operations for efficient batch and multi-curve evaluation.
- Efficient numerics: Clenshaw recursion for polynomials, Cox-DeBoor for splines.
With pip:
pip install torchcurvesWith uv:
uv add torchcurvesThere are examples in the doc/examples directory showing how to build models using
this library. Here we show some simple code snippets to appreciate the library.
import torchcurves as tc
from torch import nn
import torch
class Net(nn.Module):
def __init__(self, num_categorical, num_numerical, dim, num_knots=10):
super().__init__()
self.cat_emb = nn.Embedding(num_categorical, dim)
self.num_emb = tc.BSplineCurve(num_numerical, dim, knots_config=num_knots)
self.embedding_based_model = MySuperDuperModel() # <-- put your encoder model here
def forward(self, x_categorical, x_numerical):
embeddings = torch.cat([
self.cat_emb(x_categorical),
self.num_emb(x_numerical)
], dim=-2)
return self.embedding_based_model(embeddings)Working on online advertising, and want to model the probability of winning an ad auction given the bid? We know higher bids must result in a higher win probability - we need a monotone function. Turns out B-Splines are monotone if their coefficient vectors are monotone. Want an increasing function? Just make sure the increasing - so let's use it.
Below is an example with an auction encoder that encodes the auction into a vector, we then transform it to an increasing vector, and use it as the coefficient vector for a B-Spline curve.
import torch
from torch import nn
import torchcurves.functional as tcf
class AuctionWinModel(nn.Module):
def __init__(self, num_auction_features, num_bid_coefficients):
self.auction_encoder = make_auction_encoder( # example - an MLP, a transformer, etc.
input_features=num_auction_features,
output_features=num_bid_coefficients,
)
self.spline_knots = nn.Buffer(tcf.uniform_augmented_knots(
n_control_points=num_bid_coefficients,
degree=3,
k_min=0,
k_max=1
))
def forward(self, auction_features, bids):
# map auction features to increasing spline coefficients
spline_coeffs = self._make_increasing(self.auction_encoder(auction_features))
# map bids to [0, 1] using the arctan (or any other) normalization
mapped_bid = tcf.arctan(bids)
# evaluate the spline at the mapped bids, treating each
# mini-batch sample as a separate curve
return tcf.bspline_curves(
mapped_bid.unsqueeze(0), # 1 x B (B curves in 1 dimension)
spline_coeffs.unsqueeze(-1), # B x C x 1 (B curves with C coefs in 1 dimension)
self.spline_knots,
degree=3
)
def _make_increasing(self, x):
# transform a mini-batch of vectors to a mini-batch of increasing vectors
initial = x[..., :1]
increments = nn.functional.softplus(x[..., 1:])
concatenated = torch.concat((initial, increments), dim=-1)
return torch.cumsum(concatenated, dim=-1)Now we can train the model to predict the probability of winning auctions given auction features and bid:
import torch.nn.functional as F
for auction_features, bids, win_labels in train_loader:
win_logits = model(auction_features, bids)
loss = F.binary_cross_entropy_with_logits( # or any loss we desire
win_logits,
win_labels
)
optimizer.zero_grad()
loss.backward()
optimizer.step()A KAN [1] based on the B-Spline basis, along the lines of the original paper:
import torchcurves as tc
from torch import nn
input_dim = 2
intermediate_dim = 5
num_control_points = 10
kan = nn.Sequential(
# layer 1
tc.BSplineCurve(input_dim, intermediate_dim, knots_config=num_control_points),
tc.Sum(dim=-2),
# layer 2
tc.BSplineCurve(intermediate_dim, intermediate_dim, knots_config=num_control_points),
tc.Sum(dim=-2),
# layer 3
tc.BSplineCurve(intermediate_dim, 1, knots_config=num_control_points),
tc.Sum(dim=-2),
)Yes, we know the original KAN paper used a different curve parametrization, B-Spline + arcsinh, but the whole point of this repo is showing that KAN activations can be parametrized in arbitrary ways.
For example, here is a KAN based on Legendre polynomials of degree 5:
import torchcurves as tc
from torch import nn
input_dim = 2
intermediate_dim = 5
degree = 5
kan = nn.Sequential(
# layer 1
tc.LegendreCurve(input_dim, intermediate_dim, degree=degree),
tc.Sum(dim=-2),
# layer 2
tc.LegendreCurve(intermediate_dim, intermediate_dim, degree=degree),
tc.Sum(dim=-2),
# layer 3
tc.LegendreCurve(intermediate_dim, 1, degree=degree),
tc.Sum(dim=-2),
)Since KANs are the primary use case for the tc.Sum() layer, we can omit the dim=-2 argument, but it is provided
here for clarity.
The curves we provide here typically rely on their inputs to lie in a compact interval, typically [-1, 1]. Arbitrary inputs need to be normalized to this interval. We provide two simple out-of-the-box normalization strategies described below.
This is the default strategy — this strategy computes
and is based on the paper
Wang, Z.Q. and Guo, B.Y., 2004. Modified Legendre rational spectral method for the whole line. Journal of Computational Mathematics, pp.457-474.
In Python it looks like this:
tc.BSplineCurve(num_curves, curve_dim, normalize_fn='rational', normalization_scale=s)This strategy computes
This kind of scaling function, up to constants, is the CDF of the Cauchy distribution. It is useful when our inputs are assumed to be heavy tailed.
In Python it looks like this:
tc.BSplineCurve(num_curves, curve_dim, normalize_fn='arctan', normalization_scale=s)The inputs are simply clipped to [-1, 1] after scaling, i.e.
In Python it looks like this:
tc.BSplineCurve(num_curves, curve_dim, normalize_fn='clamp', normalization_scale=s)Provide a custom function that maps its input to the designated range after scaling. Example:
def erf_clamp(x: Tensor, scale: float = 1, out_min: float = -1, out_max: float = 1) -> torch.Tensor:
mapped = torch.special.erf(x / scale)
return ((mapped + 1) * (out_max - out_min)) / 2 + out_min
tc.BSplineCurve(num_curves, curve_dim, normalize_fn=erf_clamp, normalization_scale=s)For large degrees, the backward pass can be memory-intensive. Use
checkpoint_segments to trade compute for memory. Larger values create more
segments (lower memory, higher compute). Set to None to disable. Checkpointing
is applied only when gradients are enabled.
# Functional API
tc.functional.legendre_curves(x, coeffs, checkpoint_segments=4)
# Module API
tc.LegendreCurve(num_curves, curve_dim, degree=degree, checkpoint_segments=4)A KAN based on rationally scaled B-Spline basis with the default scale of
import torchcurves as tc
from torch import nn
input_dim = 2
intermediate_dim = 5
num_control_points = 10
config = dict(knots_config=num_control_points, normalize_fn='clamp')
spline_kan = nn.Sequential(
# layer 1
tc.BSplineCurve(input_dim, intermediate_dim, **config),
tc.Sum(),
# layer 2
tc.BSplineCurve(intermediate_dim, intermediate_dim, **config),
tc.Sum(),
# layer 3
tc.BSplineCurve(intermediate_dim, 1, **config),
tc.Sum(),
)import torchcurves as tc
from torch import nn
input_dim = 2
intermediate_dim = 5
degree = 5
config = dict(degree=degree, normalize_fn="clamp")
kan = nn.Sequential(
# layer 1
tc.LegendreCurve(input_dim, intermediate_dim, **config),
tc.Sum(),
# layer 2
tc.LegendreCurve(intermediate_dim, intermediate_dim, **config),
tc.Sum(),
# layer 3
tc.LegendreCurve(intermediate_dim, 1, **config),
tc.Sum(),
)Using uv (recommended):
# Clone the repository
git clone https://github.com/alexshtf/torchcurves.git
cd torchcurves
# Create virtual environment and install
uv venv
uv sync --all-groups# Run all tests
uv run pytest
# Run with coverage
uv run pytest --cov=torchcurves
# Run specific test file
uv run pytest tests/test_bspline.py -vThis project includes opt-in performance benchmarks (forward and backward passes) using pytest-benchmark.
Location: benchmarks/
Run benchmarks:
# Run all benchmarks
uv run pytest benchmarks -q
# Or select only perf-marked tests if you mix them into tests/
uv run pytest -m perf -qCUDA timing notes: We synchronize before/after timed regions for accurate GPU timings.
Compare runs and fail CI on regressions:
# Save a baseline
uv run pytest benchmarks --benchmark-save=legendre_baseline
# Compare current run to baseline (fail if mean slower by 10% or more)
uv run pytest benchmarks --benchmark-compare --benchmark-compare-fail=mean:10%Export results:
uv run pytest benchmarks --benchmark-json=bench.json# Prepare API docs
cd doc
make htmlIf you use this package in your research, please cite:
@software{torchcurves,
author = {Shtoff, Alex},
title = {torchcurves: Differentiable Parametric Curves in PyTorch},
year = {2025},
publisher = {GitHub},
url = {https://github.com/alexshtf/torchcurves}
}Several well-maintained PyTorch libraries use splines in practice. They mostly target interpolation/resampling or geometric warping rather than providing a generic, drop-in learnable parametric curve layer.
-
torch-interpol (also on PyPI) implements high-order spline interpolation for ND tensors (e.g., 2D/3D images), with TorchScript acceleration and explicit forward/backward implementations. It is primarily designed for resampling under a sampling grid / deformation-field workflows, including dimension-specific interpolation orders and boundary handling (
bound). Best suited for resampling tensor data on fixed grids. -
xitorch –
Interp1D(repo: xitorch/xitorch) provides differentiable 1D interpolation including cubic splines (method="cspline") for non-uniform sample locations with configurable boundary conditions and extrapolation options. This is an interpolation primitive: you provide(x, y)samples and query atxq. Designed as a functional primitive for data interpolation.
- torch-cubic-spline-grids (also on PyPI) provides learnable, continuous parametrisations of 1–4D spaces using uniform grids whose coordinate system spans
[0, 1]along each dimension. It supports both cubic B-spline grids (C2, not interpolating) and cubic Catmull–Rom grids (C1, interpolating), which are well suited to learning smooth spatial/temporal fields (e.g., deformation fields). Targets dense continuous fields rather than curve trajectories.
-
torch-tps (also on PyPI) implements generalized polyharmonic spline interpolation (thin-plate splines in 2D) for learning smooth mappings between Euclidean spaces from control point correspondences, with configurable spline order and regularization. Specializes in spatial warping and point-set registration.
-
Kornia includes TPS utilities such as
get_tps_transformandwarp_image_tps(see kornia.geometry.transform docs) as part of a larger differentiable computer vision and geometry toolkit, mainly targeting point/image warping operations. Focuses on image geometry transforms.
[1]: Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y. Hou, Max Tegmark. "KAN: Kolmogorov–Arnold Networks." ICLR (2025).
[2]: Juergen Schmidhuber. "Learning to control fast-weight memories: An alternative to dynamic recurrent networks." Neural Computation, 4(1), pp.131-139. (1992)
[3]: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[4]: Alex Shtoff, Elie Abboud, Rotem Stram, and Oren Somekh. "Function Basis Encoding of Numerical Features in Factorization Machines." Transactions on Machine Learning Research.
[5]: Rügamer, David. "Scalable Higher-Order Tensor Product Spline Models." In International Conference on Artificial Intelligence and Statistics, pp. 1-9. PMLR, 2024.
[6]: Steffen Rendle. "Factorization machines." In 2010 IEEE International conference on data mining, pp. 995-1000. IEEE, 2010.