You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: README.md
+43-15Lines changed: 43 additions & 15 deletions
Display the source diff
Display the rich diff
Original file line number
Diff line number
Diff line change
@@ -1,6 +1,6 @@
1
1
# optillm
2
2
3
-
optillm is an OpenAI API compatible optimizing inference proxy which implements several state-of-the-art techniques that can improve the accuracy and performance of LLMs. The current focus is on implementing techniques that improve reasoning over coding, logical and mathematical queries.
3
+
optillm is an OpenAI API compatible optimizing inference proxy which implements several state-of-the-art techniques that can improve the accuracy and performance of LLMs. The current focus is on implementing techniques that improve reasoning over coding, logical and mathematical queries.
4
4
5
5
It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time. A good example of how to combine such techniques together is the [CePO approach](optillm/cepo) from Cerebras.
6
6
@@ -14,7 +14,7 @@ It is possible to beat the frontier models using these techniques across diverse
14
14
15
15
```bash
16
16
pip install optillm
17
-
optillm
17
+
optillm
18
18
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
19
19
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
20
20
2024-10-22 07:45:06,293 - INFO - Starting server with approach: auto
@@ -52,7 +52,7 @@ We support all major LLM providers and models for inference. You need to set the
| OptiLLM |`OPTILLM_API_KEY`| Uses the inbuilt local server for inference, supports logprobs and decoding techniques like `cot_decoding` & `entropy_decoding`|
55
+
| OptiLLM |`OPTILLM_API_KEY`| Uses the inbuilt local server for inference, supports logprobs and decoding techniques like `cot_decoding` & `entropy_decoding`|
56
56
| OpenAI |`OPENAI_API_KEY`| You can use this with any OpenAI compatible endpoint (e.g. OpenRouter) by setting the `base_url`|
57
57
| Cerebras |`CEREBRAS_API_KEY`| You can use this for fast inference with supported models, see [docs for details](https://inference-docs.cerebras.ai/introduction)|
The code above applies to both OpenAI and Azure OpenAI, just remember to populate the `OPENAI_API_KEY` env variable with the proper key.
101
+
The code above applies to both OpenAI and Azure OpenAI, just remember to populate the `OPENAI_API_KEY` env variable with the proper key.
102
102
There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
103
103
104
104
- You can control the technique you use for optimization by prepending the slug to the model name `{slug}-model-name`. E.g. in the above code we are using `moa` or mixture of agents as the optimization approach. In the proxy logs you will see the following showing the `moa` is been used with the base model as `gpt-4o-mini`.
> You can also combine different techniques either by using symbols `&` and `|`. When you use `&` the techniques are processed in the order from left to right in a pipeline
136
136
> with response from previous stage used as request to the next. While, with `|` we run all the requests in parallel and generate multiple responses that are returned as a list.
137
137
138
-
Please note that the convention described above works only when the optillm server has been started with inference approach set to `auto`. Otherwise, the `model` attribute in the client request must be set with the model name only.
138
+
Please note that the convention described above works only when the optillm server has been started with inference approach set to `auto`. Otherwise, the `model` attribute in the client request must be set with the model name only.
139
139
140
140
We now suport all LLM providers (by wrapping around the [LiteLLM sdk](https://docs.litellm.ai/docs/#litellm-python-sdk)). E.g. you can use the Gemini Flash model with `moa` by setting passing the api key in the environment variable `os.environ['GEMINI_API_KEY']` and then calling the model `moa-gemini/gemini-1.5-flash-002`. In the output you will then see that LiteLLM is being used to call the base model.
> optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes
155
+
> optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes
156
156
the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use
157
157
doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use [LiteLLM proxy server](https://docs.litellm.ai/docs/proxy/quick_start) that supports most LLMs.
158
158
159
-
The following sequence diagram illustrates how the request and responses go through optillm.
159
+
The following sequence diagram illustrates how the request and responses go through optillm.
160
160
161
161
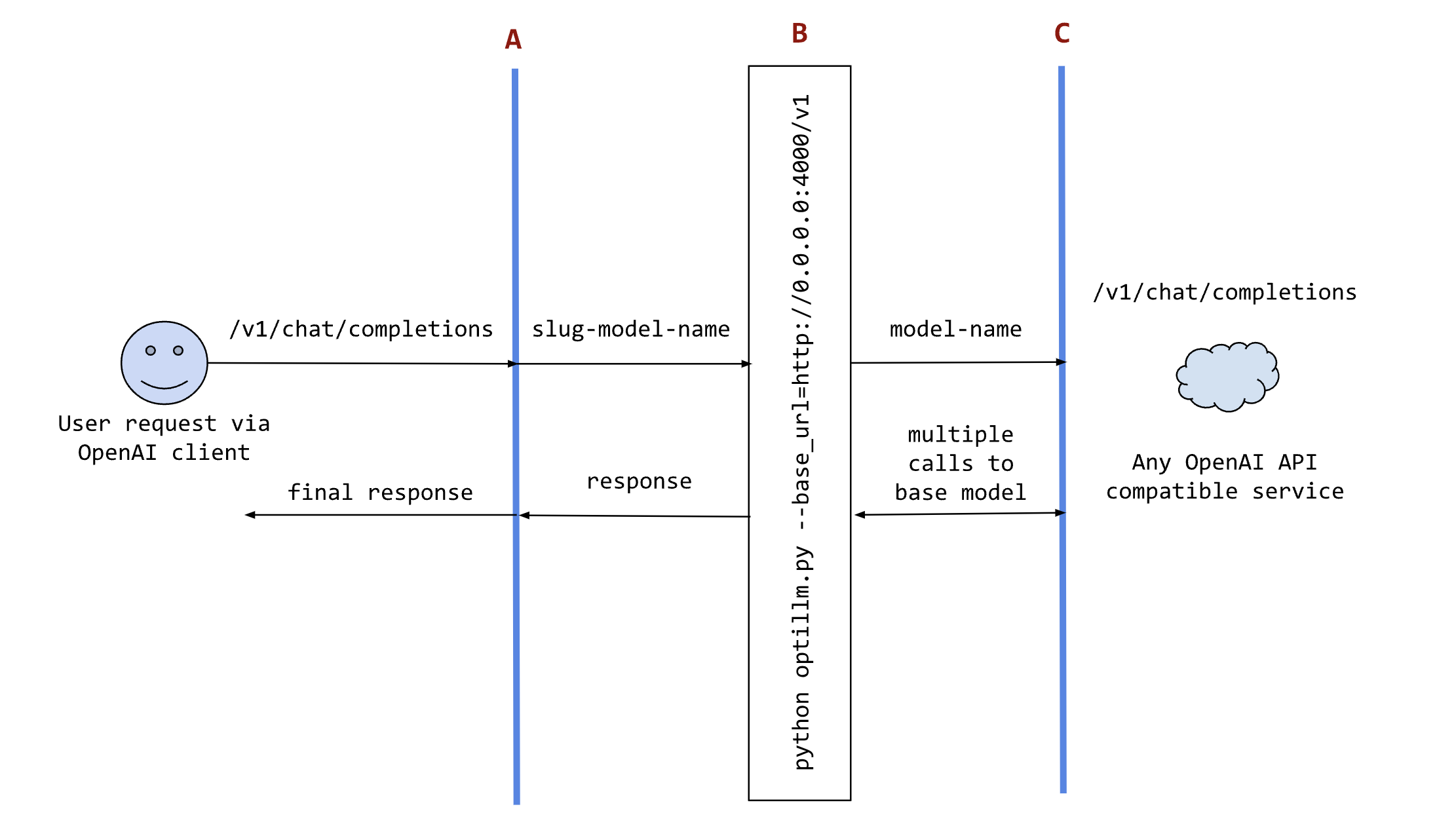
162
162
@@ -170,7 +170,7 @@ or your own code where you want to use the results from optillm. You can use it
170
170
171
171
We support loading any HuggingFace model or LoRA directly in optillm. To use the built-in inference server set the `OPTILLM_API_KEY` to any value (e.g. `export OPTILLM_API_KEY="optillm"`)
172
172
and then use the same in your OpenAI client. You can pass any HuggingFace model in model field. If it is a private model make sure you set the `HF_TOKEN` environment variable
173
-
with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the `+` separator.
173
+
with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the `+` separator.
174
174
175
175
E.g. The following code loads the base model `meta-llama/Llama-3.2-1B-Instruct` and then adds two LoRAs on top - `patched-codes/Llama-3.2-1B-FixVulns` and `patched-codes/Llama-3.2-1B-FastApply`.
176
176
You can specify which LoRA to use using the `active_adapter` param in `extra_args` field of OpenAI SDK client. By default we will load the last specified adapter.
@@ -343,7 +343,7 @@ Check this log file for connection issues, tool execution errors, and other diag
| Cerebras Planning and Optimimization|`cepo`| Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
346
+
| Cerebras Planning and Optimization|`cepo`| Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
347
347
| CoT with Reflection |`cot_reflection`| Implements chain-of-thought reasoning with \<thinking\>, \<reflection> and \<output\> sections |
348
348
| PlanSearch |`plansearch`| Implements a search algorithm over candidate plans for solving a problem in natural language |
349
349
| ReRead |`re2`| Implements rereading to improve reasoning by processing queries twice |
@@ -364,6 +364,7 @@ Check this log file for connection issues, tool execution errors, and other diag
| Long-Context Cerebras Planning and Optimization |`longcepo`| Combines planning and divide-and-conquer processing of long documents to enable infinite context |
367
368
| MCP Client |`mcp`| Implements the model context protocol (MCP) client, enabling you to use any LLM with any MCP Server |
368
369
| Router |`router`| Uses the [optillm-modernbert-large](https://huggingface.co/codelion/optillm-modernbert-large) model to route requests to different approaches based on the user prompt |
369
370
| Chain-of-Code |`coc`| Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
Since optillm is a drop-in replacement for OpenAI API you can easily integrate it with existing tools and frameworks using the OpenAI client. We used optillm with [patchwork](https://github.com/patched-codes/patchwork) which is an open-source framework that automates development gruntwork like PR reviews, bug fixing, security patching using workflows
522
-
called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
549
+
called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
523
550
524
551
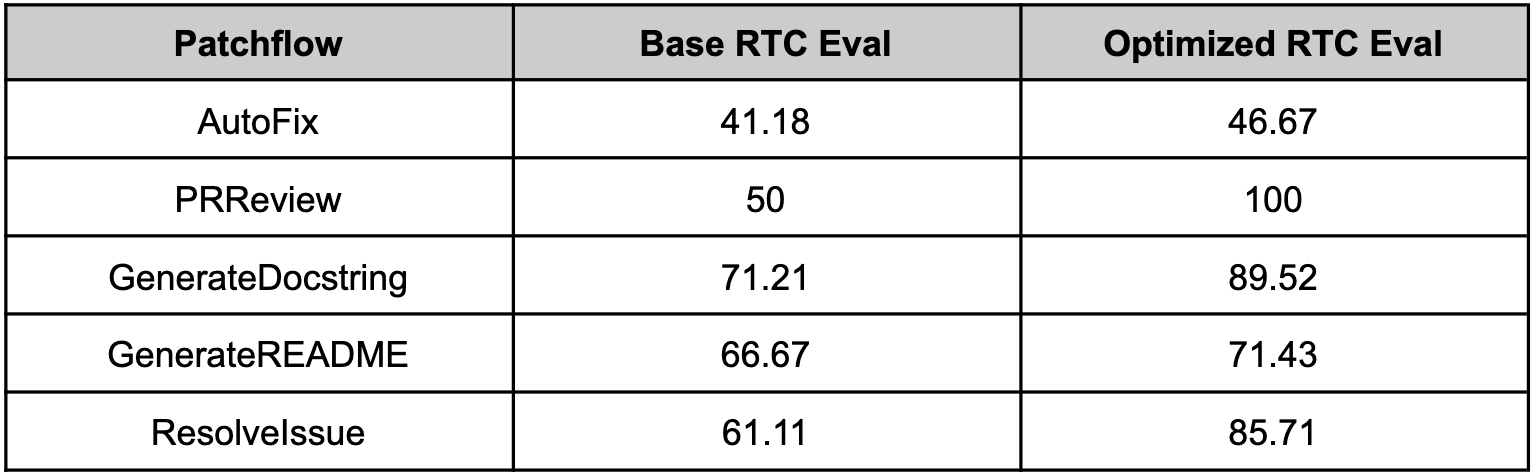
525
552
526
553
## References
527
554
-[CePO: Empowering Llama with Reasoning using Test-Time Compute](https://cerebras.ai/blog/cepo) - [Implementation](optillm/cepo)
555
+
-[LongCePO: Empowering LLMs to efficiently leverage infinite context](https://cerebras.ai/blog/longcepo) - [Implementation](optillm/plugins/longcepo/main.py)
528
556
-[Chain of Code: Reasoning with a Language Model-Augmented Code Emulator](https://arxiv.org/abs/2312.04474) - [Inspired the implementation of coc plugin](optillm/plugins/coc_plugin.py)
529
557
-[Entropy Based Sampling and Parallel CoT Decoding](https://github.com/xjdr-alt/entropix) - [Implementation](optillm/entropy_decoding.py)
530
558
-[Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation](https://arxiv.org/abs/2409.12941) - [Evaluation script](scripts/eval_frames_benchmark.py)
"""The Long-Context Cerebras Planning and Optimization (LongCePO) Method
2
+
3
+
LongCePO is an inference-time computation method designed to provide LLMs with the capability to work with infinite context such as external knowledge bases that can run into millions of tokens. We achieve this goal through a combination of multiple strategies including planning (query decomposition) and divide-and-conquer long-context processing. This approach enables to use a limited context window (e.g. 8K) and outperform full-context processing with the same base model in many question-answering tasks.
4
+
5
+
If you have any questions or want to contribute, please reach out to us on [cerebras.ai/discord](https://cerebras.ai/discord).
0 commit comments