 +
+
+Figure 1: Proceeding video frames are generated from a world model given the context of the robot's task.
+
+### Robotics Problem Statement
+Classical simulators such as Isaac Sim \[1\] and Mujoco \[2\] capture the physical dynamics necessary for training embodied agents, however the hardcoded dynamics used in such simulators is not practical for large-scale data generation of nuanced physical phenomena and realistic rendering.
+World models (also referred to as World Foundation Models or WFMs) offer an alternative, data-driven approach to simulation and future state prediction that can capture more nuanced physical phenomena and render realistic video/image outputs.
+World models are trained to capture the underlying spatial and temporal dynamics in images and video to predict future states of the environment.
+In this document, we will look at four prevalent world models: GAIA-1 \[3\], Genie \[4\], TesserAct \[5\], and Cosmos \[6\].
+
+### Model Highlights
+- **GAIA-1** (Wayve) \[3\]: A multimodal world model specifically tailored for **autonomous driving** scenarios.
+- **Genie** (Google Deepmind) \[4\]: Learning **interactive environments** and latent actions from unlabeled Internet video
+- **TesserAct** (UMass Amherst / et al.) \[5\]: A **4D embodied world model** that predicts geometry via RGB, depth, and normal maps.
+- **Cosmos** (NVIDIA) \[6\]: A unified platform for **Physical AI** supporting diffusion and autoregressive paradigms.
+
+## Architecture
+
+Each world model analyzed in this document fundamentally learns to predict the spatio-temporal dynamics of static frames.
+Each model follows the encoder-decoder formulation where an encoder $\mathcal{E}$ ingests input frames $x$ from time $t=0:T$ and encodes them into latent tokens $z_{0:T}$, a dynamics model $\text{DYN}$ predicts the next latent tokens $z_{T+1:T+K}$, and a decoder $\mathcal{D}$ reconstructs the frames at time $t>T$.
+
+$$\hat{x}_{T+1:T+K} = \mathcal{D}(\text{DYN}(\mathcal{E}(x_{0:T})))$$
+
+### Features
+
+
+
+
+Figure 1: Proceeding video frames are generated from a world model given the context of the robot's task.
+
+### Robotics Problem Statement
+Classical simulators such as Isaac Sim \[1\] and Mujoco \[2\] capture the physical dynamics necessary for training embodied agents, however the hardcoded dynamics used in such simulators is not practical for large-scale data generation of nuanced physical phenomena and realistic rendering.
+World models (also referred to as World Foundation Models or WFMs) offer an alternative, data-driven approach to simulation and future state prediction that can capture more nuanced physical phenomena and render realistic video/image outputs.
+World models are trained to capture the underlying spatial and temporal dynamics in images and video to predict future states of the environment.
+In this document, we will look at four prevalent world models: GAIA-1 \[3\], Genie \[4\], TesserAct \[5\], and Cosmos \[6\].
+
+### Model Highlights
+- **GAIA-1** (Wayve) \[3\]: A multimodal world model specifically tailored for **autonomous driving** scenarios.
+- **Genie** (Google Deepmind) \[4\]: Learning **interactive environments** and latent actions from unlabeled Internet video
+- **TesserAct** (UMass Amherst / et al.) \[5\]: A **4D embodied world model** that predicts geometry via RGB, depth, and normal maps.
+- **Cosmos** (NVIDIA) \[6\]: A unified platform for **Physical AI** supporting diffusion and autoregressive paradigms.
+
+## Architecture
+
+Each world model analyzed in this document fundamentally learns to predict the spatio-temporal dynamics of static frames.
+Each model follows the encoder-decoder formulation where an encoder $\mathcal{E}$ ingests input frames $x$ from time $t=0:T$ and encodes them into latent tokens $z_{0:T}$, a dynamics model $\text{DYN}$ predicts the next latent tokens $z_{T+1:T+K}$, and a decoder $\mathcal{D}$ reconstructs the frames at time $t>T$.
+
+$$\hat{x}_{T+1:T+K} = \mathcal{D}(\text{DYN}(\mathcal{E}(x_{0:T})))$$
+
+### Features
+
+ +
+
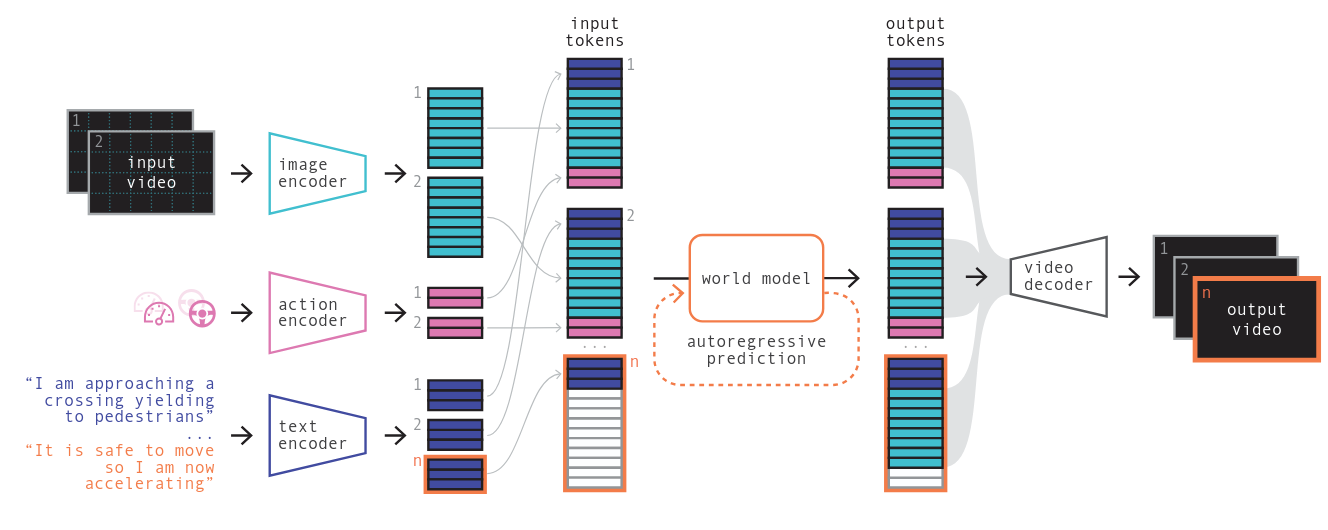
+The data flow proceeds as follows: (1) Input video frames are encoded into discrete image tokens via the tokenizer; (2) Text descriptions are embedded via frozen T5-Large [24]; (3) Actions (speed, curvature) are projected via learned linear layers; (4) All modalities are interleaved into a single sequence and processed by the autoregressive world model to predict future image tokens; (5) Predicted tokens are decoded into video frames via the diffusion decoder.
+
+### 2.2 Image Tokenizer (0.3B parameters)
+
+**Architecture**: Fully convolutional 2D U-Net encoder-decoder with vector quantization
+
+**Specifications**:
+- Input resolution: $H \times W = 288 \times 512$ (9:16 aspect ratio)
+- Downsampling factor: $D = 16$
+- Tokens per image: $n = \frac{H}{D} \times \frac{W}{D} = 18 \times 32 = 576$ tokens
+- Vocabulary size: $K = 8192$
+- Bit compression ratio: $\frac{288 \times 512 \times 3 \times 8}{18 \times 32 \times 13} \approx 470\times$
+
+**Key Innovation - DINO Distillation**:
+The tokenizer incorporates inductive biases from DINO [30] (self-supervised vision transformer) to ensure tokens are semantically meaningful rather than dominated by high-frequency signals.
+
+**Mathematical Formulation**:
+
+For input image $x_t$, the encoder produces discrete tokens:
+$$
+z_t = E_\theta(x_t) \in \lbrace 1, ..., K \rbrace^{n}
+$$
+
+where quantization uses nearest-neighbor lookup from learnable embedding table.
+
+**Training Losses**:
+
+$$
+\mathcal{L}_{\text{tokenizer}} = \lambda_{L_1} \mathcal{L}_{L_1} + \lambda_{L_2} \mathcal{L}_{L_2} + \lambda_{\text{perceptual}} \mathcal{L}_{\text{perceptual}} + \lambda_{\text{GAN}} \mathcal{L}_{\text{GAN}} + \lambda_{\text{codebook}} \mathcal{L}_{\text{codebook}} + \lambda_{\text{DINO}} \mathcal{L}_{\text{DINO}}
+$$
+
+With weights: $\lambda_{L_1} = 0.2$, $\lambda_{L_2} = 2.0$, $\lambda_{\text{perceptual}} = 0.1$, $\lambda_{\text{GAN}} = 1.0$, $\lambda_{\text{codebook}} = 1.0$, $\lambda_{\text{DINO}} = 0.1$
+
+### 2.3 World Model (6.5B parameters)
+
+**Architecture**: Autoregressive Transformer with causal masking
+
+**Token Interleaving**: The key design choice is how multimodal inputs are combined.
+Rather than using separate encoders with cross-attention, GAIA-1 interleaves all modalities into a single flat sequence processed with standard causal self-attention.
+For each timestep $t$, tokens are ordered as: **text to image to action**.
+
+```
+Sequence: [c₁ z₁ a₁] [c₂ z₂ a₂] ... [cₜ zₜ aₜ]
+ ↑ ↑ ↑
+ Frame 1 Frame 2 ... Frame T
+
+Where per frame:
+ c = 32 text tokens (from T5-Large embeddings)
+ z = 576 image tokens (from VQ-VAE discrete codes)
+ a = 2 action tokens (speed, curvature as continuous embeddings)
+```
+
+This interleaving enables the model to learn cross-modal dependencies: image tokens attend to preceding text (for conditional generation), and action tokens provide ego-motion context for predicting future frames.
+
+**Per-Modality Specifications**:
+- Text tokens: $c_t \in \mathbb{R}^{32 \times 4096}$ (T5-Large embeddings, frozen)
+- Image tokens: $z_t \in \lbrace 1,...,8192 \rbrace^{576}$ (discrete VQ codes, learned embedding)
+- Action tokens: $a_t \in \mathbb{R}^{2 \times 4096}$ (speed + curvature, linear projection)
+
+**Sequence Scale**:
+- Tokens per frame: $32 + 576 + 2 = 610$
+- Video length: $T = 26$ frames at 6.25 Hz (4 seconds)
+- **Total sequence length**: $26 \times 610 = 15{,}860$ tokens
+
+**Training Objective**: Standard next-token prediction over image tokens only (text and action are conditioning inputs):
+
+$$
+\mathcal{L}_{\text{world model}} = -\sum_{t=1}^{T} \sum_{i=1}^{n} \log p(z_{t,i} | z_{
+
+
+The data flow proceeds as follows: (1) Input video frames are encoded into discrete image tokens via the tokenizer; (2) Text descriptions are embedded via frozen T5-Large [24]; (3) Actions (speed, curvature) are projected via learned linear layers; (4) All modalities are interleaved into a single sequence and processed by the autoregressive world model to predict future image tokens; (5) Predicted tokens are decoded into video frames via the diffusion decoder.
+
+### 2.2 Image Tokenizer (0.3B parameters)
+
+**Architecture**: Fully convolutional 2D U-Net encoder-decoder with vector quantization
+
+**Specifications**:
+- Input resolution: $H \times W = 288 \times 512$ (9:16 aspect ratio)
+- Downsampling factor: $D = 16$
+- Tokens per image: $n = \frac{H}{D} \times \frac{W}{D} = 18 \times 32 = 576$ tokens
+- Vocabulary size: $K = 8192$
+- Bit compression ratio: $\frac{288 \times 512 \times 3 \times 8}{18 \times 32 \times 13} \approx 470\times$
+
+**Key Innovation - DINO Distillation**:
+The tokenizer incorporates inductive biases from DINO [30] (self-supervised vision transformer) to ensure tokens are semantically meaningful rather than dominated by high-frequency signals.
+
+**Mathematical Formulation**:
+
+For input image $x_t$, the encoder produces discrete tokens:
+$$
+z_t = E_\theta(x_t) \in \lbrace 1, ..., K \rbrace^{n}
+$$
+
+where quantization uses nearest-neighbor lookup from learnable embedding table.
+
+**Training Losses**:
+
+$$
+\mathcal{L}_{\text{tokenizer}} = \lambda_{L_1} \mathcal{L}_{L_1} + \lambda_{L_2} \mathcal{L}_{L_2} + \lambda_{\text{perceptual}} \mathcal{L}_{\text{perceptual}} + \lambda_{\text{GAN}} \mathcal{L}_{\text{GAN}} + \lambda_{\text{codebook}} \mathcal{L}_{\text{codebook}} + \lambda_{\text{DINO}} \mathcal{L}_{\text{DINO}}
+$$
+
+With weights: $\lambda_{L_1} = 0.2$, $\lambda_{L_2} = 2.0$, $\lambda_{\text{perceptual}} = 0.1$, $\lambda_{\text{GAN}} = 1.0$, $\lambda_{\text{codebook}} = 1.0$, $\lambda_{\text{DINO}} = 0.1$
+
+### 2.3 World Model (6.5B parameters)
+
+**Architecture**: Autoregressive Transformer with causal masking
+
+**Token Interleaving**: The key design choice is how multimodal inputs are combined.
+Rather than using separate encoders with cross-attention, GAIA-1 interleaves all modalities into a single flat sequence processed with standard causal self-attention.
+For each timestep $t$, tokens are ordered as: **text to image to action**.
+
+```
+Sequence: [c₁ z₁ a₁] [c₂ z₂ a₂] ... [cₜ zₜ aₜ]
+ ↑ ↑ ↑
+ Frame 1 Frame 2 ... Frame T
+
+Where per frame:
+ c = 32 text tokens (from T5-Large embeddings)
+ z = 576 image tokens (from VQ-VAE discrete codes)
+ a = 2 action tokens (speed, curvature as continuous embeddings)
+```
+
+This interleaving enables the model to learn cross-modal dependencies: image tokens attend to preceding text (for conditional generation), and action tokens provide ego-motion context for predicting future frames.
+
+**Per-Modality Specifications**:
+- Text tokens: $c_t \in \mathbb{R}^{32 \times 4096}$ (T5-Large embeddings, frozen)
+- Image tokens: $z_t \in \lbrace 1,...,8192 \rbrace^{576}$ (discrete VQ codes, learned embedding)
+- Action tokens: $a_t \in \mathbb{R}^{2 \times 4096}$ (speed + curvature, linear projection)
+
+**Sequence Scale**:
+- Tokens per frame: $32 + 576 + 2 = 610$
+- Video length: $T = 26$ frames at 6.25 Hz (4 seconds)
+- **Total sequence length**: $26 \times 610 = 15{,}860$ tokens
+
+**Training Objective**: Standard next-token prediction over image tokens only (text and action are conditioning inputs):
+
+$$
+\mathcal{L}_{\text{world model}} = -\sum_{t=1}^{T} \sum_{i=1}^{n} \log p(z_{t,i} | z_{ +
+
+
+The data flow proceeds as follows: (1) RGB, depth, and normal videos are separately encoded by the frozen CogVideoX 3D VAE; (2) Three separate input projectors extract embeddings for each modality; (3) The DiT backbone processes the sum of embeddings conditioned on text instruction and diffusion timestep; (4) RGB output uses the original CogVideoX projector; (5) Depth and normal outputs use additional Conv3D + MLP projectors that combine hidden states with RGB predictions.
+
+### 2.2 RGB-DN Video Prediction
+
+**Core Innovation**: Rather than predicting explicit 3D representations (meshes, point clouds, NeRFs [44]), TesserAct predicts RGB-DN (RGB, Depth, Normal) videos as a compact 4D proxy.
+
+**Why RGB-DN?** This representation offers three advantages:
+- **Computational efficiency**: Same dimensionality as standard video, enabling use of pretrained video models
+- **Geometric completeness**: Depth provides metric distance; normals provide surface orientation - together sufficient for 3D reconstruction
+- **Temporal modeling**: Video diffusion naturally captures dynamics, unlike per-frame 3D estimation
+
+**Diffusion Formulation**: The model learns the joint distribution $p(v, d, n | v_0, d_0, n_0, T)$
+
+where:
+- $v, d, n$: Predicted RGB, depth, and normal video latents
+- $v_0, d_0, n_0$: First frame's RGB, depth, and normal latents
+- $T$: Text instruction
+
+**Training Objective**:
+
+$$
+\mathcal{L} = \mathbb{E}_{v_0, T, t, \epsilon} [ \| [\epsilon_v, \epsilon_d, \epsilon_n] - \epsilon_\theta(x_t, t, x_0, T) \|^2 ]
+$$
+
+where:
+- $v_0$: Ground truth RGB video latents
+- $T$: Text instruction
+- $t$: Diffusion timestep
+- $\epsilon$: Noise sampled from standard normal distribution
+- $\epsilon_v, \epsilon_d, \epsilon_n$: Noise components for RGB, depth, and normal modalities
+- $x_t$: Noisy latents at timestep $t$
+- $x_0$: Clean latents (first frame)
+- $\epsilon_\theta$: Denoising network parameterized by $\theta$
+
+### 2.3 Input/Output Architecture
+
+**Input Design**: Three separate projectors extract modality-specific embeddings that are summed before the DiT backbone:
+```
+f_z = InputProj(z_t, z_0) for z ∈ {v, d, n}
+h = DiT(Σ f_z, t, T)
+```
+
+where:
+- $f_z$: Modality-specific embedding for modality $z$
+- $z_t$: Noisy latents at timestep $t$ for modality $z$
+- $z_0$: Clean latents (first frame) for modality $z$
+- $z \in \lbrace v,d,n \rbrace$: Modalities (RGB, depth, normal)
+- $h$: Hidden states from DiT backbone
+- $t$: Diffusion timestep
+- $T$: Text instruction
+- $\text{InputProj}$: Input projection module
+- $\text{DiT}$: Diffusion Transformer backbone
+
+**Text Conditioning**: Instructions are formatted as `[action instruction] + [robot arm name]`, e.g., "pick up apple google robot".
+This enables cross-embodiment generalization.
+
+**Output Design**: RGB uses the original CogVideoX output projector. Depth and normal use additional modules:
+
+$\epsilon_{d,n} = \text{DNProj}(h, \text{Conv3D}(\epsilon_v, [z_t; z_0]_{z \in \{v,d,n\}}))$
+
+where:
+- $\epsilon^*_{d,n}$: Predicted noise for depth and normal modalities
+- $\epsilon^*_v$: Predicted noise for RGB modality
+- $h$: Hidden states from DiT backbone
+- $z_t$: Noisy latents at timestep $t$ for modality $z$
+- $z_0$: Clean latents (first frame) for modality $z$
+- $z \in \lbrace v,d,n \rbrace$: Modalities (RGB, depth, normal)
+- $\text{DNProj}$: Depth/Normal projection module
+- $\text{Conv3D}$: 3D convolutional layer
+
+**Zero Initialization**: All new modules are initialized with zeros, ensuring the model initially reproduces CogVideoX's RGB output before learning geometric predictions.
+This preserves pretrained knowledge.
+
+### 2.4 4D Scene Reconstruction
+
+After generating RGB-DN videos, TesserAct reconstructs temporally consistent 4D point clouds through a novel optimization procedure.
+
+**Normal Integration**: Raw depth predictions are often coarse with tilted planes.
+Normal maps provide surface orientation constraints that refine depth via integration:
+
+$\min_{\tilde{d}} \iint_\Omega (\tilde{n}_z \partial_u \tilde{d} + n_x)^2 + (\tilde{n}_z \partial_v \tilde{d} + n_y)^2 \, du \, dv$
+
+where:
+- $\tilde{d}$: Optimized depth map
+- $\tilde{n}_z, n_x, n_y$: Normal map components (z-component and x, y components)
+- $\partial_u, \partial_v$: Partial derivatives with respect to image coordinates $u, v$
+- $\Omega$: Image domain
+
+This spatial consistency loss $L_s$ enforces that depth gradients align with normal predictions.
+
+**Temporal Consistency Loss**: Frame-by-frame optimization lacks temporal coherence.
+TesserAct uses optical flow (RAFT [59]) to enforce consistency:
+- **Static regions**: Pixels with small optical flow magnitude ($\|F^i\| \leq c$)
+- **Dynamic regions**: Moving pixels
+- **Background**: Static regions consistent across frames
+
+The consistency loss enforces depth agreement for corresponding pixels across frames:
+
+$L_c = \lambda_{cd} \left\| \tilde{D}^i \circ M^i_d - D^{i \to (i-1)} \circ M^i_d \right\|^2 + \lambda_{cb} \left\| \tilde{D}^i \circ M^i_b - D^{i \to (i-1)} \circ M^i_b \right\|^2$
+
+where:
+- $L_c$: Temporal consistency loss
+- $\tilde{D}^i$: Optimized depth map at frame $i$
+- $D^{i \to (i-1)}$: Depth map at frame $i$ warped to frame $i-1$ using optical flow
+- $M^i_d$: Mask for dynamic regions at frame $i$
+- $M^i_b$: Mask for background/static regions at frame $i$
+- $\lambda_{cd}, \lambda_{cb}$: Loss weights for dynamic and background regions
+- $\circ$: Element-wise multiplication (Hadamard product)
+
+**Regularization Loss**: Prevents optimized depth from deviating too far from the generated prediction:
+
+$L_r = \lambda_{rd} \left\| \tilde{D}^i \circ M^i_d - D^i \circ M^i_d \right\|^2 + \lambda_{rb} \left\| \tilde{D}^i \circ M^i_b - D^i \circ M^i_b \right\|^2$
+
+where:
+- $L_r$: Regularization loss
+- $\tilde{D}^i$: Optimized depth map at frame $i$
+- $D^i$: Generated depth prediction at frame $i$ (before optimization)
+- $M^i_d$: Mask for dynamic regions at frame $i$
+- $M^i_b$: Mask for background/static regions at frame $i$
+- $\lambda_{rd}, \lambda_{rb}$: Regularization weights for dynamic and background regions
+- $\circ$: Element-wise multiplication (Hadamard product)
+
+**Full Objective**: $\arg\min_{\tilde{D}} (L_s + L_c + L_r)$
+
+where:
+- $\tilde{D}$: Optimized depth maps across all frames
+- $L_s$: Spatial consistency loss (normal integration)
+- $L_c$: Temporal consistency loss
+- $L_r$: Regularization loss
+
+### 2.5 Key Architectural Trade-Offs
+
+**Joint vs. Separate Modality Prediction.** TesserAct predicts RGB, depth, and normal jointly through a shared backbone rather than using separate models for each.
+This enables cross-modal reasoning - depth predictions can leverage RGB texture cues, normals can condition on depth edges - but creates a more complex training objective.
+The alternative (separate estimators applied post-hoc) would lose temporal consistency and cross-modal coherence.
+
+**Pretrained Video Model vs. Training from Scratch.** With only ~285k training videos (far less than the billions used for CogVideoX), training from scratch is infeasible.
+Fine-tuning preserves video generation priors while adding geometric capability.
+The trade-off is inheriting CogVideoX's biases and architecture constraints.
+
+**RGB-DN vs. Full 3D Representation.** Point clouds, meshes, or NeRFs would provide more complete 3D information, but are computationally expensive to generate and lack mature pretrained models.
+RGB-DN is a middle ground: richer than 2D pixels, cheaper than full 3D, and compatible with video diffusion architectures.
+
+---
+
+## 3. Scaling
+
+### 3.1 Training Scale
+
+**4D Embodied Video Dataset**:
+
+
+
+
+
+The data flow proceeds as follows: (1) RGB, depth, and normal videos are separately encoded by the frozen CogVideoX 3D VAE; (2) Three separate input projectors extract embeddings for each modality; (3) The DiT backbone processes the sum of embeddings conditioned on text instruction and diffusion timestep; (4) RGB output uses the original CogVideoX projector; (5) Depth and normal outputs use additional Conv3D + MLP projectors that combine hidden states with RGB predictions.
+
+### 2.2 RGB-DN Video Prediction
+
+**Core Innovation**: Rather than predicting explicit 3D representations (meshes, point clouds, NeRFs [44]), TesserAct predicts RGB-DN (RGB, Depth, Normal) videos as a compact 4D proxy.
+
+**Why RGB-DN?** This representation offers three advantages:
+- **Computational efficiency**: Same dimensionality as standard video, enabling use of pretrained video models
+- **Geometric completeness**: Depth provides metric distance; normals provide surface orientation - together sufficient for 3D reconstruction
+- **Temporal modeling**: Video diffusion naturally captures dynamics, unlike per-frame 3D estimation
+
+**Diffusion Formulation**: The model learns the joint distribution $p(v, d, n | v_0, d_0, n_0, T)$
+
+where:
+- $v, d, n$: Predicted RGB, depth, and normal video latents
+- $v_0, d_0, n_0$: First frame's RGB, depth, and normal latents
+- $T$: Text instruction
+
+**Training Objective**:
+
+$$
+\mathcal{L} = \mathbb{E}_{v_0, T, t, \epsilon} [ \| [\epsilon_v, \epsilon_d, \epsilon_n] - \epsilon_\theta(x_t, t, x_0, T) \|^2 ]
+$$
+
+where:
+- $v_0$: Ground truth RGB video latents
+- $T$: Text instruction
+- $t$: Diffusion timestep
+- $\epsilon$: Noise sampled from standard normal distribution
+- $\epsilon_v, \epsilon_d, \epsilon_n$: Noise components for RGB, depth, and normal modalities
+- $x_t$: Noisy latents at timestep $t$
+- $x_0$: Clean latents (first frame)
+- $\epsilon_\theta$: Denoising network parameterized by $\theta$
+
+### 2.3 Input/Output Architecture
+
+**Input Design**: Three separate projectors extract modality-specific embeddings that are summed before the DiT backbone:
+```
+f_z = InputProj(z_t, z_0) for z ∈ {v, d, n}
+h = DiT(Σ f_z, t, T)
+```
+
+where:
+- $f_z$: Modality-specific embedding for modality $z$
+- $z_t$: Noisy latents at timestep $t$ for modality $z$
+- $z_0$: Clean latents (first frame) for modality $z$
+- $z \in \lbrace v,d,n \rbrace$: Modalities (RGB, depth, normal)
+- $h$: Hidden states from DiT backbone
+- $t$: Diffusion timestep
+- $T$: Text instruction
+- $\text{InputProj}$: Input projection module
+- $\text{DiT}$: Diffusion Transformer backbone
+
+**Text Conditioning**: Instructions are formatted as `[action instruction] + [robot arm name]`, e.g., "pick up apple google robot".
+This enables cross-embodiment generalization.
+
+**Output Design**: RGB uses the original CogVideoX output projector. Depth and normal use additional modules:
+
+$\epsilon_{d,n} = \text{DNProj}(h, \text{Conv3D}(\epsilon_v, [z_t; z_0]_{z \in \{v,d,n\}}))$
+
+where:
+- $\epsilon^*_{d,n}$: Predicted noise for depth and normal modalities
+- $\epsilon^*_v$: Predicted noise for RGB modality
+- $h$: Hidden states from DiT backbone
+- $z_t$: Noisy latents at timestep $t$ for modality $z$
+- $z_0$: Clean latents (first frame) for modality $z$
+- $z \in \lbrace v,d,n \rbrace$: Modalities (RGB, depth, normal)
+- $\text{DNProj}$: Depth/Normal projection module
+- $\text{Conv3D}$: 3D convolutional layer
+
+**Zero Initialization**: All new modules are initialized with zeros, ensuring the model initially reproduces CogVideoX's RGB output before learning geometric predictions.
+This preserves pretrained knowledge.
+
+### 2.4 4D Scene Reconstruction
+
+After generating RGB-DN videos, TesserAct reconstructs temporally consistent 4D point clouds through a novel optimization procedure.
+
+**Normal Integration**: Raw depth predictions are often coarse with tilted planes.
+Normal maps provide surface orientation constraints that refine depth via integration:
+
+$\min_{\tilde{d}} \iint_\Omega (\tilde{n}_z \partial_u \tilde{d} + n_x)^2 + (\tilde{n}_z \partial_v \tilde{d} + n_y)^2 \, du \, dv$
+
+where:
+- $\tilde{d}$: Optimized depth map
+- $\tilde{n}_z, n_x, n_y$: Normal map components (z-component and x, y components)
+- $\partial_u, \partial_v$: Partial derivatives with respect to image coordinates $u, v$
+- $\Omega$: Image domain
+
+This spatial consistency loss $L_s$ enforces that depth gradients align with normal predictions.
+
+**Temporal Consistency Loss**: Frame-by-frame optimization lacks temporal coherence.
+TesserAct uses optical flow (RAFT [59]) to enforce consistency:
+- **Static regions**: Pixels with small optical flow magnitude ($\|F^i\| \leq c$)
+- **Dynamic regions**: Moving pixels
+- **Background**: Static regions consistent across frames
+
+The consistency loss enforces depth agreement for corresponding pixels across frames:
+
+$L_c = \lambda_{cd} \left\| \tilde{D}^i \circ M^i_d - D^{i \to (i-1)} \circ M^i_d \right\|^2 + \lambda_{cb} \left\| \tilde{D}^i \circ M^i_b - D^{i \to (i-1)} \circ M^i_b \right\|^2$
+
+where:
+- $L_c$: Temporal consistency loss
+- $\tilde{D}^i$: Optimized depth map at frame $i$
+- $D^{i \to (i-1)}$: Depth map at frame $i$ warped to frame $i-1$ using optical flow
+- $M^i_d$: Mask for dynamic regions at frame $i$
+- $M^i_b$: Mask for background/static regions at frame $i$
+- $\lambda_{cd}, \lambda_{cb}$: Loss weights for dynamic and background regions
+- $\circ$: Element-wise multiplication (Hadamard product)
+
+**Regularization Loss**: Prevents optimized depth from deviating too far from the generated prediction:
+
+$L_r = \lambda_{rd} \left\| \tilde{D}^i \circ M^i_d - D^i \circ M^i_d \right\|^2 + \lambda_{rb} \left\| \tilde{D}^i \circ M^i_b - D^i \circ M^i_b \right\|^2$
+
+where:
+- $L_r$: Regularization loss
+- $\tilde{D}^i$: Optimized depth map at frame $i$
+- $D^i$: Generated depth prediction at frame $i$ (before optimization)
+- $M^i_d$: Mask for dynamic regions at frame $i$
+- $M^i_b$: Mask for background/static regions at frame $i$
+- $\lambda_{rd}, \lambda_{rb}$: Regularization weights for dynamic and background regions
+- $\circ$: Element-wise multiplication (Hadamard product)
+
+**Full Objective**: $\arg\min_{\tilde{D}} (L_s + L_c + L_r)$
+
+where:
+- $\tilde{D}$: Optimized depth maps across all frames
+- $L_s$: Spatial consistency loss (normal integration)
+- $L_c$: Temporal consistency loss
+- $L_r$: Regularization loss
+
+### 2.5 Key Architectural Trade-Offs
+
+**Joint vs. Separate Modality Prediction.** TesserAct predicts RGB, depth, and normal jointly through a shared backbone rather than using separate models for each.
+This enables cross-modal reasoning - depth predictions can leverage RGB texture cues, normals can condition on depth edges - but creates a more complex training objective.
+The alternative (separate estimators applied post-hoc) would lose temporal consistency and cross-modal coherence.
+
+**Pretrained Video Model vs. Training from Scratch.** With only ~285k training videos (far less than the billions used for CogVideoX), training from scratch is infeasible.
+Fine-tuning preserves video generation priors while adding geometric capability.
+The trade-off is inheriting CogVideoX's biases and architecture constraints.
+
+**RGB-DN vs. Full 3D Representation.** Point clouds, meshes, or NeRFs would provide more complete 3D information, but are computationally expensive to generate and lack mature pretrained models.
+RGB-DN is a middle ground: richer than 2D pixels, cheaper than full 3D, and compatible with video diffusion architectures.
+
+---
+
+## 3. Scaling
+
+### 3.1 Training Scale
+
+**4D Embodied Video Dataset**:
+
+| Dataset | +Domain | +Depth Source | +Normal Source | +Embodiment | +Videos | +
|---|---|---|---|---|---|
| RLBench | +Synthetic | +Simulator GT | +Depth2Normal | +Franka Panda | +80k | +
| RT1 Fractal | +Real | +RollingDepth | +Marigold | +Google Robot | +80k | +
| Bridge | +Real | +RollingDepth | +Marigold | +WidowX | +25k | +
| SomethingSomethingV2 | +Real | +RollingDepth | +Marigold | +Human Hand | +100k | +
| Total | +- | +- | +- | +- | +~285k | +
| Method | +close box | +open drawer | +open jar | +open microwave | +put knife | +sweep dustpan | +lid off | +weighing off | +water plants | +
|---|---|---|---|---|---|---|---|---|---|
| Image-BC | +53 | +4 | +0 | +5 | +0 | +0 | +12 | +21 | +0 | +
| UniPi* | +81 | +67 | +38 | +72 | +66 | +49 | +70 | +68 | +35 | +
| TesserAct | +88 | +80 | +44 | +70 | +70 | +56 | +73 | +62 | +41 | +
| Component | +Primary Functions and Parts | +
|---|---|
| Data Curation | +The video curation pipeline transforms raw video into high-quality training data through a five-step process: splitting videos into shots, filtering for rich dynamics, annotating via VLMs, performing semantic deduplication, and sharding clips for model consumption. | +
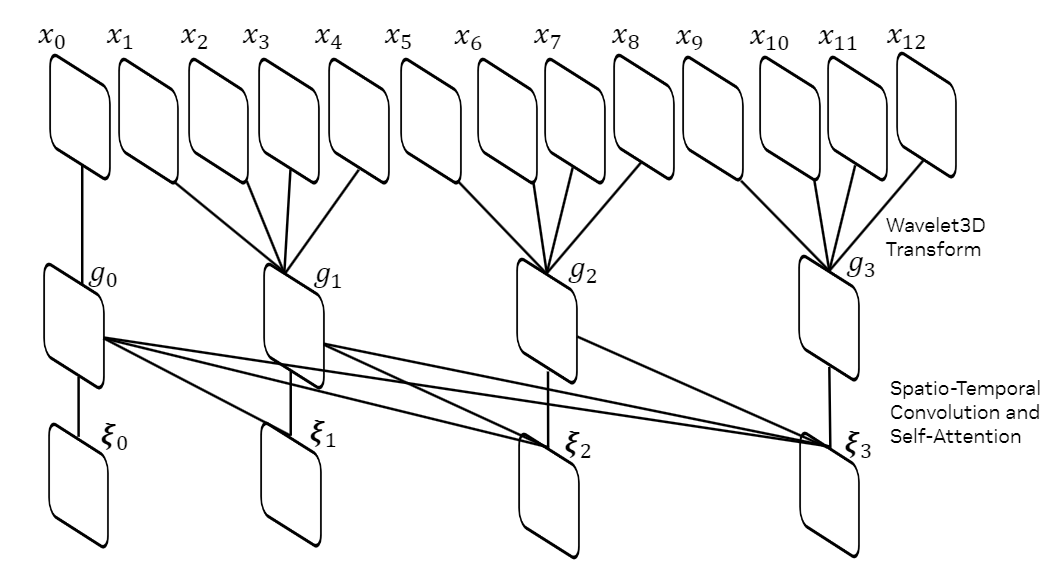
| Tokenization | +This suite of temporally causal tokenizers uses an attention-based encoder-decoder architecture in wavelet space to compress raw pixels into either continuous latent embeddings for diffusion models or discrete quantized tokens for autoregressive models. | +
| Pre-trained WFM | +These general-purpose simulators leverage scalable transformer architectures to perform Video2World generation, predicting future observations based on past sequences and perturbations using either diffusion denoising or autoregressive next-token prediction. | +
| Post-training Adapters | +Pre-trained generalist models are fine-tuned on specialized datasets to create specialized world models capable of task-specific behaviors like camera controllability, robotic instruction-following, and multi-view autonomous driving simulation. | +
| Guardrails and Safety | +The safety system provides a comprehensive defense through a pre-Guard stage that blocks harmful prompts using keyword lists and Aegis, and a post-Guard stage that filters unsafe visual outputs and applies face blurring. | +
 +
+The Cosmos-Tokenizer1 is trained using a two-stage training scheme, followed by a fine-tuning stage to capture the spatio-temporal information in the inputs.
+The following table summarizes the loss equations used during these stages:
+
+
+
+The Cosmos-Tokenizer1 is trained using a two-stage training scheme, followed by a fine-tuning stage to capture the spatio-temporal information in the inputs.
+The following table summarizes the loss equations used during these stages:
+
+| Loss Name | +Training Stage | +Equation | +Primary Purpose | +
|---|---|---|---|
| L1 Loss | +Stage 1 | +$\mathcal{L}_1 = \|\hat{x}_{0:T} - x_{0:T}\|_1$ | +Minimizes the pixel-wise RGB difference between the input and reconstructed video. | +
| Perceptual Loss | +Stage 1 | +$\mathcal{L}_{\text{Perceptual}} = \frac{1}{L} \sum_{l=1}^L \sum_{t} \alpha_l \|VGG_l(\hat{x}_t) - VGG_l(x_t)\|_1$ | +Uses VGG-19 network features \[2\] to ensure high-level semantic and visual information is preserved. | +
| Optical Flow (OF) Loss | +Stage 2 | +$\mathcal{L}_{\text{Flow}} = \frac{1}{T} \sum_{t=1}^T \|OF(\hat{x}_t, \hat{x}_{t-1}) - OF(x_t, x_{t-1})\|_1$ $+ \frac{1}{T} \sum_{t=0}^{T-1} \|OF(\hat{x}_t, \hat{x}_{t+1}) - OF(x_t, x_{t+1})\|_1$ | +Handles the temporal smoothness of reconstructed videos across adjacent frames. | +
| Gram-matrix (GM) Loss | +Stage 2 | +$\mathcal{L}_{\text{Gram}} = \frac{1}{L} \sum_{l=1}^L \sum_{t} \alpha_l \|GM_l(\hat{x}_t) - GM_l(x_t)\|_1$ | +Specifically designed to enhance the sharpness of the reconstructed images. | +
| Adversarial Loss | +Fine-tuning | +(Equation not explicitly provided in text) | +Applied during the fine-tuning stage to enhance reconstruction details, especially at high compression rates. | +
| Feature | +Diffusion WFMs | +Autoregressive WFMs | +
|---|---|---|
| Visual Fidelity | +High: Photorealistic outputs. | +Moderate: Prone to blur without a decoder. | +
| Generation Speed | +Slow: Iterative denoising. | +Fast: Real-time (10 FPS) via KV-caching \[5\]. | +
| Representations | +Continuous latents. | +Discrete quantized tokens. | +